ハイブ-クイックガイド
「ビッグデータ」という用語は、膨大な量、高速、および日々増加しているさまざまなデータを含む大規模なデータセットのコレクションに使用されます。従来のデータ管理システムを使用すると、ビッグデータを処理することは困難です。そのため、Apache Software Foundationは、ビッグデータの管理と処理の課題を解決するためにHadoopと呼ばれるフレームワークを導入しました。
Hadoop
Hadoopは、分散環境でビッグデータを保存および処理するためのオープンソースフレームワークです。2つのモジュールが含まれています。1つはMapReduceで、もう1つはHadoop分散ファイルシステム(HDFS)です。
MapReduce: これは、コモディティハードウェアの大規模なクラスターで大量の構造化データ、半構造化データ、および非構造化データを処理するための並列プログラミングモデルです。
HDFS:Hadoop分散ファイルシステムはHadoopフレームワークの一部であり、データセットの保存と処理に使用されます。コモディティハードウェアで実行するフォールトトレラントファイルシステムを提供します。
Hadoopエコシステムには、Hadoopモジュールを支援するために使用されるSqoop、Pig、Hiveなどのさまざまなサブプロジェクト(ツール)が含まれています。
Sqoop: これは、HDFSとRDBMSの間でデータをインポートおよびエクスポートするために使用されます。
Pig: これは、MapReduce操作のスクリプトを開発するために使用される手続き型言語プラットフォームです。
Hive: これは、MapReduce操作を実行するSQLタイプのスクリプトを開発するために使用されるプラットフォームです。
Note: MapReduce操作を実行するにはさまざまな方法があります。
- 構造化データ、半構造化データ、および非構造化データにJavaMapReduceプログラムを使用する従来のアプローチ。
- Pigを使用して構造化データと半構造化データを処理するためのMapReduceのスクリプトアプローチ。
- Hiveを使用して構造化データを処理するためのMapReduce用のHiveクエリ言語(HiveQLまたはHQL)。
Hiveとは
Hiveは、Hadoopで構造化データを処理するためのデータウェアハウスインフラストラクチャツールです。ビッグデータを要約するためにHadoopの上にあり、クエリと分析を簡単にします。
当初、HiveはFacebookによって開発されましたが、後にApache Software Foundationがそれを採用し、ApacheHiveという名前でオープンソースとしてさらに開発しました。さまざまな会社で使用されています。たとえば、AmazonはAmazon ElasticMapReduceでそれを使用します。
ハイブはそうではありません
- リレーショナルデータベース
- オンライントランザクション処理(OLTP)の設計
- リアルタイムクエリと行レベルの更新のための言語
Hiveの機能
- スキーマをデータベースに保存し、データをHDFSに処理します。
- OLAP用に設計されています。
- HiveQLまたはHQLと呼ばれるクエリ用のSQL型言語を提供します。
- 使い慣れた、高速で、スケーラブルで、拡張可能です。
Hiveのアーキテクチャ
次のコンポーネント図は、Hiveのアーキテクチャを示しています。

このコンポーネント図には、さまざまな単位が含まれています。次の表で、各ユニットについて説明します。
| ユニット名 | 操作 |
|---|---|
| ユーザーインターフェース | Hiveは、ユーザーとHDFS間の相互作用を作成できるデータウェアハウスインフラストラクチャソフトウェアです。Hiveがサポートするユーザーインターフェイスは、Hive Web UI、Hiveコマンドライン、およびHive HD Insight(Windowsサーバー内)です。 |
| メタストア | Hiveは、それぞれのデータベースサーバーを選択して、テーブル、データベース、テーブル内の列、それらのデータ型、およびHDFSマッピングのスキーマまたはメタデータを格納します。 |
| HiveQLプロセスエンジン | HiveQLは、メタストアのスキーマ情報をクエリするためのSQLに似ています。これは、MapReduceプログラムの従来のアプローチに代わるものの1つです。JavaでMapReduceプログラムを作成する代わりに、MapReduceジョブのクエリを作成して処理することができます。 |
| 実行エンジン | HiveQLプロセスエンジンとMapReduceの結合部分は、Hive実行エンジンです。実行エンジンはクエリを処理し、MapReduceの結果と同じ結果を生成します。MapReduceのフレーバーを使用しています。 |
| HDFSまたはHBASE | Hadoop分散ファイルシステムまたはHBASEは、データをファイルシステムに保存するためのデータストレージ技術です。 |
Hiveの動作
次の図は、HiveとHadoop間のワークフローを示しています。
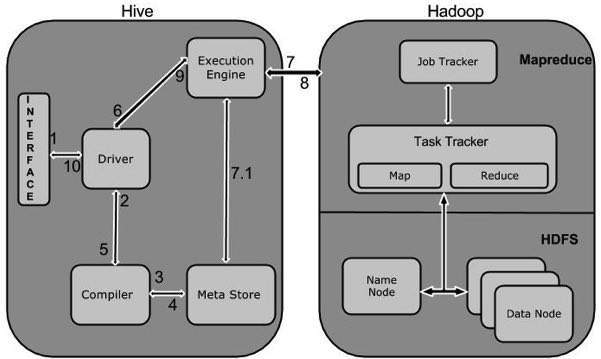
次の表は、HiveがHadoopフレームワークとどのように相互作用するかを定義しています。
| ステップ番号 | 操作 |
|---|---|
| 1 | Execute Query コマンドラインやWebUIなどのHiveインターフェイスは、クエリをドライバー(JDBC、ODBCなどのデータベースドライバー)に送信して実行します。 |
| 2 | Get Plan ドライバーは、クエリを解析して構文とクエリプラン、またはクエリの要件をチェックするクエリコンパイラの助けを借ります。 |
| 3 | Get Metadata コンパイラーはメタデータ要求をMetastore(任意のデータベース)に送信します。 |
| 4 | Send Metadata Metastoreは、コンパイラへの応答としてメタデータを送信します。 |
| 5 | Send Plan コンパイラーは要件をチェックし、プランをドライバーに再送信します。ここまでで、クエリの解析とコンパイルが完了しました。 |
| 6 | Execute Plan ドライバーは実行計画を実行エンジンに送信します。 |
| 7 | Execute Job 内部的には、実行ジョブのプロセスはMapReduceジョブです。実行エンジンは、ジョブをNameノードにあるJobTrackerに送信し、このジョブをDataノードにあるTaskTrackerに割り当てます。ここで、クエリはMapReduceジョブを実行します。 |
| 7.1 | Metadata Ops 一方、実行中、実行エンジンはMetastoreを使用してメタデータ操作を実行できます。 |
| 8 | Fetch Result 実行エンジンは、データノードから結果を受け取ります。 |
| 9 | Send Results 実行エンジンは、それらの結果の値をドライバーに送信します。 |
| 10 | Send Results ドライバーは結果をHiveInterfacesに送信します。 |
Hive、Pig、HBaseなどのすべてのHadoopサブプロジェクトは、Linuxオペレーティングシステムをサポートしています。したがって、LinuxフレーバーのOSをインストールする必要があります。Hiveのインストールでは、次の簡単な手順が実行されます。
ステップ1:JAVAインストールの確認
Hiveをインストールする前に、Javaをシステムにインストールする必要があります。次のコマンドを使用して、Javaのインストールを確認しましょう。
$ java –versionJavaがすでにシステムにインストールされている場合は、次の応答が表示されます。
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)システムにJavaがインストールされていない場合は、以下の手順に従ってJavaをインストールしてください。
Javaのインストール
ステップI:
次のリンクにアクセスして、Java(JDK <最新バージョン> -X64.tar.gz)をダウンロードします。 http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html。
次に、jdk-7u71-linux-x64.tar.gzがシステムにダウンロードされます。
ステップII:
通常、ダウンロードしたJavaファイルはDownloadsフォルダーにあります。それを確認し、次のコマンドを使用してjdk-7u71-linux-x64.gzファイルを抽出します。
$ cd Downloads/
$ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzステップIII:
すべてのユーザーがJavaを使用できるようにするには、Javaを「/ usr / local /」の場所に移動する必要があります。rootを開き、次のコマンドを入力します。
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitステップIV:
PATH変数とJAVA_HOME変数を設定するには、次のコマンドを〜/ .bashrcファイルに追加します。
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH=PATH:$JAVA_HOME/bin次に、上記で説明したように、ターミナルからコマンドjava-versionを使用してインストールを確認します。
ステップ2:Hadoopのインストールを確認する
Hiveをインストールする前に、Hadoopをシステムにインストールする必要があります。次のコマンドを使用して、Hadoopのインストールを確認しましょう。
$ hadoop versionHadoopがすでにシステムにインストールされている場合は、次の応答が返されます。
Hadoop 2.4.1 Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768
Compiled by hortonmu on 2013-10-07T06:28Z
Compiled with protoc 2.5.0
From source with checksum 79e53ce7994d1628b240f09af91e1af4Hadoopがシステムにインストールされていない場合は、次の手順に進みます。
Hadoopのダウンロード
次のコマンドを使用して、Apache SoftwareFoundationからHadoop2.4.1をダウンロードして抽出します。
$ su
password:
# cd /usr/local
# wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/
hadoop-2.4.1.tar.gz
# tar xzf hadoop-2.4.1.tar.gz
# mv hadoop-2.4.1/* to hadoop/
# exit疑似分散モードでのHadoopのインストール
次の手順は、Hadoop2.4.1を疑似分散モードでインストールするために使用されます。
ステップI:Hadoopのセットアップ
次のコマンドをに追加することで、Hadoop環境変数を設定できます。 ~/.bashrc ファイル。
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export
PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin次に、すべての変更を現在実行中のシステムに適用します。
$ source ~/.bashrcステップII:Hadoop構成
すべてのHadoop構成ファイルは、「$ HADOOP_HOME / etc / hadoop」の場所にあります。Hadoopインフラストラクチャに応じて、これらの構成ファイルに適切な変更を加える必要があります。
$ cd $HADOOP_HOME/etc/hadoopJavaを使用してHadoopプログラムを開発するには、Java環境変数をリセットする必要があります。 hadoop-env.sh 置き換えることによってファイル JAVA_HOME システム内のJavaの場所を含む値。
export JAVA_HOME=/usr/local/jdk1.7.0_71以下に、Hadoopを構成するために編集する必要のあるファイルのリストを示します。
core-site.xml
ザ・ core-site.xml fileには、Hadoopインスタンスに使用されるポート番号、ファイルシステムに割り当てられたメモリ、データを格納するためのメモリ制限、読み取り/書き込みバッファのサイズなどの情報が含まれています。
core-site.xmlを開き、<configuration>タグと</ configuration>タグの間に次のプロパティを追加します。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
ザ・ hdfs-site.xmlfileには、レプリケーションデータの値、namenodeパス、ローカルファイルシステムのdatanodeパスなどの情報が含まれています。これは、Hadoopインフラストラクチャを格納する場所を意味します。
以下のデータを想定します。
dfs.replication (data replication value) = 1
(In the following path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeこのファイルを開き、このファイルの<configuration>、</ configuration>タグの間に次のプロパティを追加します。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value >
</property>
</configuration>Note: 上記のファイルでは、すべてのプロパティ値がユーザー定義であり、Hadoopインフラストラクチャに応じて変更を加えることができます。
yarn-site.xml
このファイルは、Hadoopにyarnを構成するために使用されます。ヤーンサイト.xmlファイルを開き、このファイルの<configuration>、</ configuration>タグの間に次のプロパティを追加します。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
このファイルは、使用しているMapReduceフレームワークを指定するために使用されます。デフォルトでは、Hadoopにはyarn-site.xmlのテンプレートが含まれています。まず、次のコマンドを使用して、ファイルをmapred-site、xml.templateからmapred-site.xmlファイルにコピーする必要があります。
$ cp mapred-site.xml.template mapred-site.xml開いた mapred-site.xml ファイルを作成し、このファイルの<configuration>、</ configuration>タグの間に次のプロパティを追加します。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Hadoopのインストールの確認
次の手順は、Hadoopのインストールを確認するために使用されます。
ステップI:ノードのセットアップに名前を付ける
次のようにコマンド「hdfsnamenode-format」を使用してnamenodeを設定します。
$ cd ~ $ hdfs namenode -format期待される結果は以下のとおりです。
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/ステップII:Hadoopdfsの検証
次のコマンドは、dfsを開始するために使用されます。このコマンドを実行すると、Hadoopファイルシステムが起動します。
$ start-dfs.sh期待される出力は次のとおりです。
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]ステップIII:糸スクリプトの検証
次のコマンドを使用して、yarnスクリプトを開始します。このコマンドを実行すると、yarnデーモンが起動します。
$ start-yarn.sh期待される出力は次のとおりです。
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-2.4.1/logs/yarn-hadoop-nodemanager-localhost.outステップIV:ブラウザーでHadoopにアクセスする
Hadoopにアクセスするためのデフォルトのポート番号は50070です。ブラウザーでHadoopサービスを取得するには、次のURLを使用します。
http://localhost:50070/
ステップV:クラスターのすべてのアプリケーションを確認する
クラスタのすべてのアプリケーションにアクセスするためのデフォルトのポート番号は8088です。このサービスにアクセスするには、次のURLを使用してください。
http://localhost:8088/
ステップ3:ハイブをダウンロードする
このチュートリアルでは、hive-0.14.0を使用します。次のリンクからダウンロードできますhttp://apache.petsads.us/hive/hive-0.14.0/./ Downloadsディレクトリにダウンロードされると仮定します。ここでは、このチュートリアル用に「apache-hive-0.14.0-bin.tar.gz」という名前のHiveアーカイブをダウンロードします。次のコマンドを使用して、ダウンロードを確認します。
$ cd Downloads $ lsダウンロードが成功すると、次の応答が表示されます。
apache-hive-0.14.0-bin.tar.gzステップ4:Hiveをインストールする
システムにHiveをインストールするには、次の手順が必要です。Hiveアーカイブが/ Downloadsディレクトリにダウンロードされていると仮定します。
Hiveアーカイブの抽出と検証
次のコマンドを使用して、ダウンロードを確認し、ハイブアーカイブを抽出します。
$ tar zxvf apache-hive-0.14.0-bin.tar.gz $ lsダウンロードが成功すると、次の応答が表示されます。
apache-hive-0.14.0-bin apache-hive-0.14.0-bin.tar.gz/ usr / local / hiveディレクトリへのファイルのコピー
スーパーユーザー「su-」からファイルをコピーする必要があります。次のコマンドを使用して、抽出されたディレクトリから/ usr / local / hive」ディレクトリにファイルをコピーします。
$ su -
passwd:
# cd /home/user/Download
# mv apache-hive-0.14.0-bin /usr/local/hive
# exitHiveの環境をセットアップする
次の行をに追加することで、Hive環境をセットアップできます。 ~/.bashrc ファイル:
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:.
export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.次のコマンドは、〜/ .bashrcファイルを実行するために使用されます。
$ source ~/.bashrc手順5:Hiveを構成する
HadoopでHiveを構成するには、を編集する必要があります hive-env.sh ファイルは、に配置されます $HIVE_HOME/confディレクトリ。次のコマンドはHiveにリダイレクトしますconfig フォルダを作成し、テンプレートファイルをコピーします。
$ cd $HIVE_HOME/conf $ cp hive-env.sh.template hive-env.sh編集する hive-env.sh 次の行を追加してファイルを作成します。
export HADOOP_HOME=/usr/local/hadoopハイブのインストールが正常に完了しました。ここで、メタストアを構成するために外部データベースサーバーが必要です。ApacheDerbyデータベースを使用します。
ステップ6:ApacheDerbyのダウンロードとインストール
以下の手順に従って、ApacheDerbyをダウンロードしてインストールします。
ApacheDerbyのダウンロード
次のコマンドを使用して、ApacheDerbyをダウンロードします。ダウンロードには時間がかかります。
$ cd ~ $ wget http://archive.apache.org/dist/db/derby/db-derby-10.4.2.0/db-derby-10.4.2.0-bin.tar.gz次のコマンドを使用して、ダウンロードを確認します。
$ lsダウンロードが成功すると、次の応答が表示されます。
db-derby-10.4.2.0-bin.tar.gzDerbyアーカイブの抽出と検証
次のコマンドは、Derbyアーカイブの抽出と検証に使用されます。
$ tar zxvf db-derby-10.4.2.0-bin.tar.gz
$ lsダウンロードが成功すると、次の応答が表示されます。
db-derby-10.4.2.0-bin db-derby-10.4.2.0-bin.tar.gz/ usr / local / derbyディレクトリへのファイルのコピー
スーパーユーザー「su-」からコピーする必要があります。次のコマンドを使用して、抽出されたディレクトリから/ usr / local / derbyディレクトリにファイルをコピーします。
$ su -
passwd:
# cd /home/user
# mv db-derby-10.4.2.0-bin /usr/local/derby
# exitダービーの環境をセットアップする
次の行をに追加することで、ダービー環境をセットアップできます。 ~/.bashrc ファイル:
export DERBY_HOME=/usr/local/derby
export PATH=$PATH:$DERBY_HOME/bin
Apache Hive
18
export CLASSPATH=$CLASSPATH:$DERBY_HOME/lib/derby.jar:$DERBY_HOME/lib/derbytools.jar次のコマンドを使用して実行します ~/.bashrc ファイル:
$ source ~/.bashrcMetastoreを保存するディレクトリを作成します
$ DERBY_HOMEディレクトリにdataという名前のディレクトリを作成して、メタストアデータを保存します。
$ mkdir $DERBY_HOME/dataこれで、Derbyのインストールと環境のセットアップが完了しました。
ステップ7:Hiveのメタストアを構成する
Metastoreの構成とは、データベースが保存されている場所をHiveに指定することを意味します。これを行うには、$ HIVE_HOME / confディレクトリにあるhive-site.xmlファイルを編集します。まず、次のコマンドを使用してテンプレートファイルをコピーします。
$ cd $HIVE_HOME/conf
$ cp hive-default.xml.template hive-site.xml編集 hive-site.xml <configuration>タグと</ configuration>タグの間に次の行を追加します。
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby://localhost:1527/metastore_db;create=true </value>
<description>JDBC connect string for a JDBC metastore </description>
</property>jpox.propertiesという名前のファイルを作成し、そのファイルに次の行を追加します。
javax.jdo.PersistenceManagerFactoryClass =
org.jpox.PersistenceManagerFactoryImpl
org.jpox.autoCreateSchema = false
org.jpox.validateTables = false
org.jpox.validateColumns = false
org.jpox.validateConstraints = false
org.jpox.storeManagerType = rdbms
org.jpox.autoCreateSchema = true
org.jpox.autoStartMechanismMode = checked
org.jpox.transactionIsolation = read_committed
javax.jdo.option.DetachAllOnCommit = true
javax.jdo.option.NontransactionalRead = true
javax.jdo.option.ConnectionDriverName = org.apache.derby.jdbc.ClientDriver
javax.jdo.option.ConnectionURL = jdbc:derby://hadoop1:1527/metastore_db;create = true
javax.jdo.option.ConnectionUserName = APP
javax.jdo.option.ConnectionPassword = mine手順8:Hiveのインストールを確認する
Hiveを実行する前に、を作成する必要があります /tmpフォルダーとHDFSの個別のHiveフォルダー。ここでは、/user/hive/warehouseフォルダ。以下に示すように、これらの新しく作成されたフォルダーの書き込み権限を設定する必要があります。
chmod g+wHiveを検証する前に、HDFSでそれらを設定します。次のコマンドを使用します。
$ $HADOOP_HOME/bin/hadoop fs -mkdir /tmp $ $HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse $ $HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp $ $HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse次のコマンドは、Hiveのインストールを確認するために使用されます。
$ cd $HIVE_HOME $ bin/hiveHiveが正常にインストールされると、次の応答が表示されます。
Logging initialized using configuration in jar:file:/home/hadoop/hive-0.9.0/lib/hive-common-0.9.0.jar!/hive-log4j.properties
Hive history file=/tmp/hadoop/hive_job_log_hadoop_201312121621_1494929084.txt
………………….
hive>次のサンプルコマンドを実行して、すべてのテーブルを表示します。
hive> show tables;
OK
Time taken: 2.798 seconds
hive>この章では、テーブルの作成に関係するHiveのさまざまなデータ型について説明します。Hiveのすべてのデータ型は、次の4つの型に分類されます。
- 列タイプ
- Literals
- ヌル値
- 複雑なタイプ
列タイプ
列タイプは、Hiveの列データ型として使用されます。それらは次のとおりです。
整数型
整数型データは、整数型データ型INTを使用して指定できます。データ範囲がINTの範囲を超える場合は、BIGINTを使用する必要があり、データ範囲がINTよりも小さい場合は、SMALLINTを使用します。TINYINTはSMALLINTよりも小さいです。
次の表は、さまざまなINTデータ型を示しています。
| タイプ | Postfix | 例 |
|---|---|---|
| TINYINT | Y | 10年 |
| SMALLINT | S | 10S |
| INT | - | 10 |
| BIGINT | L | 10L |
文字列タイプ
文字列型のデータ型は、一重引用符( '')または二重引用符( "")を使用して指定できます。VARCHARとCHARの2つのデータ型が含まれています。ハイブはCタイプのエスケープ文字に従います。
次の表は、さまざまなCHARデータ型を示しています。
| データ・タイプ | 長さ |
|---|---|
| VARCHAR | 1から65355 |
| CHAR | 255 |
タイムスタンプ
オプションのナノ秒精度で従来のUNIXタイムスタンプをサポートします。java.sql.Timestamp形式「YYYY-MM-DDHH:MM:SS.fffffffff」および形式「yyyy-mm-ddhh:mm:ss.ffffffffff」をサポートします。
日付
DATE値は、{{YYYY-MM-DD}}の形式で年/月/日の形式で記述されます。
小数
HiveのDECIMAL型は、JavaのBigDecimal形式と同じです。これは、不変の任意精度を表すために使用されます。構文と例は次のとおりです。
DECIMAL(precision, scale)
decimal(10,0)共用体タイプ
Unionは、異種データ型のコレクションです。を使用してインスタンスを作成できますcreate union。構文と例は次のとおりです。
UNIONTYPE<int, double, array<string>, struct<a:int,b:string>>
{0:1}
{1:2.0}
{2:["three","four"]}
{3:{"a":5,"b":"five"}}
{2:["six","seven"]}
{3:{"a":8,"b":"eight"}}
{0:9}
{1:10.0}リテラル
次のリテラルがHiveで使用されます。
浮動小数点型
浮動小数点型は、小数点付きの数値に他なりません。通常、このタイプのデータはDOUBLEデータタイプで構成されます。
10進型
-308 308ヌル値
欠落している値は、特別な値NULLで表されます。
複雑なタイプ
Hiveの複雑なデータ型は次のとおりです。
配列
Hiveの配列は、Javaで使用されるのと同じ方法で使用されます。
構文:ARRAY <data_type>
マップ
HiveのマップはJavaマップに似ています。
構文:MAP <primitive_type、data_type>
構造体
Hiveの構造体は、コメント付きの複雑なデータを使用するのと似ています。
構文:STRUCT <col_name:data_type [COMMENT col_comment]、...>
Hiveは、構造化データを分析するためのデータベースとテーブルを定義できるデータベーステクノロジーです。構造化データ分析のテーマは、データを表形式で保存し、クエリを渡して分析することです。この章では、Hiveデータベースを作成する方法について説明します。Hiveには、という名前のデフォルトデータベースが含まれていますdefault。
データベースステートメントの作成
Create Databaseは、Hiveでデータベースを作成するために使用されるステートメントです。Hiveのデータベースはnamespaceまたはテーブルのコレクション。ザ・syntax このステートメントの場合は次のとおりです。
CREATE DATABASE|SCHEMA [IF NOT EXISTS] <database name>ここで、IF NOT EXISTSはオプションの句であり、同じ名前のデータベースがすでに存在することをユーザーに通知します。このコマンドでは、DATABASEの代わりにSCHEMAを使用できます。次のクエリを実行して、という名前のデータベースを作成します。userdb:
hive> CREATE DATABASE [IF NOT EXISTS] userdb;or
hive> CREATE SCHEMA userdb;次のクエリは、データベースリストを確認するために使用されます。
hive> SHOW DATABASES;
default
userdbJDBCプログラム
データベースを作成するためのJDBCプログラムを以下に示します。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet; 4. CREATE DATABASE
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveCreateDb {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/default", "", "");
Statement stmt = con.createStatement();
stmt.executeQuery("CREATE DATABASE userdb");
System.out.println(“Database userdb created successfully.”);
con.close();
}
}プログラムをHiveCreateDb.javaという名前のファイルに保存します。このプログラムをコンパイルして実行するには、次のコマンドを使用します。
$ javac HiveCreateDb.java $ java HiveCreateDb出力:
Database userdb created successfully.この章では、Hiveにデータベースをドロップする方法について説明します。SCHEMAとDATABASEの使用法は同じです。
データベースステートメントの削除
Drop Databaseは、すべてのテーブルを削除してデータベースを削除するステートメントです。その構文は次のとおりです。
DROP DATABASE StatementDROP (DATABASE|SCHEMA) [IF EXISTS] database_name
[RESTRICT|CASCADE];次のクエリは、データベースを削除するために使用されます。データベース名がであると仮定しましょうuserdb。
hive> DROP DATABASE IF EXISTS userdb;次のクエリは、を使用してデータベースを削除します CASCADE。これは、データベースを削除する前に、それぞれのテーブルを削除することを意味します。
hive> DROP DATABASE IF EXISTS userdb CASCADE;次のクエリは、を使用してデータベースを削除します SCHEMA。
hive> DROP SCHEMA userdb;この句はHive0.6で追加されました。
JDBCプログラム
データベースを削除するJDBCプログラムを以下に示します。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager; 5. DROP DATABASE
public class HiveDropDb {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/default", "", "");
Statement stmt = con.createStatement();
stmt.executeQuery("DROP DATABASE userdb");
System.out.println(“Drop userdb database successful.”);
con.close();
}
}プログラムをHiveDropDb.javaという名前のファイルに保存します。このプログラムをコンパイルして実行するためのコマンドを以下に示します。
$ javac HiveDropDb.java $ java HiveDropDb出力:
Drop userdb database successful.この章では、テーブルを作成する方法とテーブルにデータを挿入する方法について説明します。HIVEでテーブルを作成する規則は、SQLを使用してテーブルを作成するのと非常によく似ています。
テーブルステートメントの作成
Create Tableは、Hiveでテーブルを作成するために使用されるステートメントです。構文と例は次のとおりです。
構文
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[ROW FORMAT row_format]
[STORED AS file_format]例
次の名前のテーブルを作成する必要があると仮定します employee を使用して CREATE TABLEステートメント。次の表に、employeeテーブルのフィールドとそのデータ型を示します。
| シニア番号 | フィールド名 | データ・タイプ |
|---|---|---|
| 1 | イード | int |
| 2 | 名前 | ストリング |
| 3 | 給料 | 浮く |
| 4 | 指定 | ストリング |
次のデータは、コメント、フィールドターミネータ、ラインターミネータ、保存ファイルタイプなどの行形式のフィールドです。
COMMENT ‘Employee details’
FIELDS TERMINATED BY ‘\t’
LINES TERMINATED BY ‘\n’
STORED IN TEXT FILE次のクエリは、という名前のテーブルを作成します employee 上記のデータを使用します。
hive> CREATE TABLE IF NOT EXISTS employee ( eid int, name String,
> salary String, destination String)
> COMMENT ‘Employee details’
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ‘\t’
> LINES TERMINATED BY ‘\n’
> STORED AS TEXTFILE;オプションIFNOT EXISTSを追加すると、テーブルがすでに存在する場合、Hiveはステートメントを無視します。
テーブルが正常に作成されると、次の応答が表示されます。
OK
Time taken: 5.905 seconds
hive>JDBCプログラム
テーブルを作成するためのJDBCプログラムに例を示します。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveCreateTable {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("CREATE TABLE IF NOT EXISTS "
+" employee ( eid int, name String, "
+" salary String, destignation String)"
+" COMMENT ‘Employee details’"
+" ROW FORMAT DELIMITED"
+" FIELDS TERMINATED BY ‘\t’"
+" LINES TERMINATED BY ‘\n’"
+" STORED AS TEXTFILE;");
System.out.println(“ Table employee created.”);
con.close();
}
}プログラムをHiveCreateDb.javaという名前のファイルに保存します。このプログラムをコンパイルして実行するには、次のコマンドを使用します。
$ javac HiveCreateDb.java $ java HiveCreateDb出力
Table employee created.データステートメントのロード
通常、SQLでテーブルを作成した後、Insertステートメントを使用してデータを挿入できます。ただし、Hiveでは、LOADDATAステートメントを使用してデータを挿入できます。
Hiveにデータを挿入するときは、LOADDATAを使用してバルクレコードを保存することをお勧めします。データをロードする方法は2つあります。1つはローカルファイルシステムから、もう1つはHadoopファイルシステムからです。
Syntex
ロードデータの構文は次のとおりです。
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename
[PARTITION (partcol1=val1, partcol2=val2 ...)]- LOCALは、ローカルパスを指定するための識別子です。オプションです。
- OVERWRITEは、テーブル内のデータを上書きするためのオプションです。
- PARTITIONはオプションです。
例
以下のデータをテーブルに挿入します。これは、という名前のテキストファイルです。sample.txt に /home/user ディレクトリ。
1201 Gopal 45000 Technical manager
1202 Manisha 45000 Proof reader
1203 Masthanvali 40000 Technical writer
1204 Krian 40000 Hr Admin
1205 Kranthi 30000 Op Admin次のクエリは、指定されたテキストをテーブルにロードします。
hive> LOAD DATA LOCAL INPATH '/home/user/sample.txt'
> OVERWRITE INTO TABLE employee;ダウンロードが成功すると、次の応答が表示されます。
OK
Time taken: 15.905 seconds
hive>JDBCプログラム
以下に示すのは、指定されたデータをテーブルにロードするためのJDBCプログラムです。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveLoadData {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("LOAD DATA LOCAL INPATH '/home/user/sample.txt'"
+"OVERWRITE INTO TABLE employee;");
System.out.println("Load Data into employee successful");
con.close();
}
}プログラムをHiveLoadData.javaという名前のファイルに保存します。このプログラムをコンパイルして実行するには、次のコマンドを使用します。
$ javac HiveLoadData.java $ java HiveLoadData出力:
Load Data into employee successfulこの章では、テーブル名の変更、列名の変更、列の追加、列の削除または置換など、テーブルの属性を変更する方法について説明します。
テーブルステートメントの変更
これは、Hiveのテーブルを変更するために使用されます。
構文
このステートメントは、テーブルで変更する属性に基づいて、次の構文のいずれかを取ります。
ALTER TABLE name RENAME TO new_name
ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...])
ALTER TABLE name DROP [COLUMN] column_name
ALTER TABLE name CHANGE column_name new_name new_type
ALTER TABLE name REPLACE COLUMNS (col_spec[, col_spec ...])名前の変更…ステートメント
次のクエリは、テーブルの名前を employee に emp。
hive> ALTER TABLE employee RENAME TO emp;JDBCプログラム
テーブルの名前を変更するJDBCプログラムは次のとおりです。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveAlterRenameTo {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("ALTER TABLE employee RENAME TO emp;");
System.out.println("Table Renamed Successfully");
con.close();
}
}プログラムをHiveAlterRenameTo.javaという名前のファイルに保存します。このプログラムをコンパイルして実行するには、次のコマンドを使用します。
$ javac HiveAlterRenameTo.java $ java HiveAlterRenameTo出力:
Table renamed successfully.変更ステートメント
次の表には、 employee 表に、変更するフィールドが表示されます(太字)。
| フィールド名 | データ型から変換 | フィールド名を変更する | データ型に変換 |
|---|---|---|---|
| eid | int | eid | int |
| name | ストリング | ename | ストリング |
| 給料 | Float | 給料 | Double |
| 指定 | ストリング | 指定 | ストリング |
次のクエリは、上記のデータを使用して列名と列データ型の名前を変更します。
hive> ALTER TABLE employee CHANGE name ename String;
hive> ALTER TABLE employee CHANGE salary salary Double;JDBCプログラム
以下に示すのは、列を変更するためのJDBCプログラムです。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveAlterChangeColumn {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("ALTER TABLE employee CHANGE name ename String;");
stmt.executeQuery("ALTER TABLE employee CHANGE salary salary Double;");
System.out.println("Change column successful.");
con.close();
}
}プログラムをHiveAlterChangeColumn.javaという名前のファイルに保存します。このプログラムをコンパイルして実行するには、次のコマンドを使用します。
$ javac HiveAlterChangeColumn.java $ java HiveAlterChangeColumn出力:
Change column successful.列ステートメントの追加
次のクエリは、deptという名前の列をemployeeテーブルに追加します。
hive> ALTER TABLE employee ADD COLUMNS (
> dept STRING COMMENT 'Department name');JDBCプログラム
テーブルに列を追加するJDBCプログラムを以下に示します。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveAlterAddColumn {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("ALTER TABLE employee ADD COLUMNS "
+" (dept STRING COMMENT 'Department name');");
System.out.prinln("Add column successful.");
con.close();
}
}プログラムをHiveAlterAddColumn.javaという名前のファイルに保存します。このプログラムをコンパイルして実行するには、次のコマンドを使用します。
$ javac HiveAlterAddColumn.java $ java HiveAlterAddColumn出力:
Add column successful.ステートメントを置き換える
次のクエリは、からすべての列を削除します employee テーブルとそれを置き換えます emp そして name 列:
hive> ALTER TABLE employee REPLACE COLUMNS (
> eid INT empid Int,
> ename STRING name String);JDBCプログラム
以下に、置き換えるJDBCプログラムを示します。 eid との列 empid そして ename との列 name。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveAlterReplaceColumn {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("ALTER TABLE employee REPLACE COLUMNS "
+" (eid INT empid Int,"
+" ename STRING name String);");
System.out.println(" Replace column successful");
con.close();
}
}プログラムをHiveAlterReplaceColumn.javaという名前のファイルに保存します。このプログラムをコンパイルして実行するには、次のコマンドを使用します。
$ javac HiveAlterReplaceColumn.java $ java HiveAlterReplaceColumn出力:
Replace column successful.この章では、Hiveにテーブルをドロップする方法について説明します。Hive Metastoreからテーブルを削除すると、テーブル/列のデータとそのメタデータが削除されます。通常のテーブル(メタストアに格納されている)または外部テーブル(ローカルファイルシステムに格納されている)の場合があります。Hiveは、タイプに関係なく、両方を同じように扱います。
ドロップテーブルステートメント
構文は次のとおりです。
DROP TABLE [IF EXISTS] table_name;次のクエリは、という名前のテーブルを削除します employee:
hive> DROP TABLE IF EXISTS employee;クエリが正常に実行されると、次の応答が表示されます。
OK
Time taken: 5.3 seconds
hive>JDBCプログラム
次のJDBCプログラムは、employeeテーブルを削除します。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveDropTable {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("DROP TABLE IF EXISTS employee;");
System.out.println("Drop table successful.");
con.close();
}
}プログラムをHiveDropTable.javaという名前のファイルに保存します。このプログラムをコンパイルして実行するには、次のコマンドを使用します。
$ javac HiveDropTable.java $ java HiveDropTable出力:
Drop table successful次のクエリは、テーブルのリストを確認するために使用されます。
hive> SHOW TABLES;
emp
ok
Time taken: 2.1 seconds
hive>Hiveはテーブルをパーティションに編成します。これは、日付、都市、部門などの分割された列の値に基づいて、テーブルを関連する部分に分割する方法です。パーティションを使用すると、データの一部を簡単にクエリできます。
テーブルまたはパーティションはに細分されます buckets,より効率的なクエリに使用できるデータに追加の構造を提供するため。バケット化は、テーブルのある列のハッシュ関数の値に基づいて機能します。
たとえば、 Tab1id、name、dept、yoj(つまり、参加した年)などの従業員データが含まれます。2012年に参加したすべての従業員の詳細を取得する必要があるとします。クエリは、テーブル全体で必要な情報を検索します。ただし、従業員データを年で分割して別のファイルに保存すると、クエリの処理時間が短縮されます。次の例は、ファイルとそのデータをパーティション分割する方法を示しています。
次のファイルには、employeedataテーブルが含まれています。
/ tab1 / employeedata / file1
id、name、dept、yoj
1、gopal、TP、2012
2、キラン、HR、2012
3、サウスカロライナ州カリール、2013年
4、サウスカロライナ州プラシャーント、2013年
上記のデータは、年を使用して2つのファイルに分割されます。
/ tab1 / employeedata / 2012 / file2
1、gopal、TP、2012
2、キラン、HR、2012
/ tab1 / employeedata / 2013 / file3
3、サウスカロライナ州カリール、2013年
4、サウスカロライナ州プラシャーント、2013年
パーティションの追加
テーブルを変更することで、テーブルにパーティションを追加できます。と呼ばれるテーブルがあるとしましょうemployee Id、Name、Salary、Designation、Dept、yojなどのフィールドがあります。
構文:
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec
[LOCATION 'location1'] partition_spec [LOCATION 'location2'] ...;
partition_spec:
: (p_column = p_col_value, p_column = p_col_value, ...)次のクエリは、employeeテーブルにパーティションを追加するために使用されます。
hive> ALTER TABLE employee
> ADD PARTITION (year=’2012’)
> location '/2012/part2012';パーティションの名前を変更する
このコマンドの構文は次のとおりです。
ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;次のクエリは、パーティションの名前を変更するために使用されます。
hive> ALTER TABLE employee PARTITION (year=’1203’)
> RENAME TO PARTITION (Yoj=’1203’);パーティションの削除
次の構文は、パーティションを削除するために使用されます。
ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spec, PARTITION partition_spec,...;次のクエリは、パーティションを削除するために使用されます。
hive> ALTER TABLE employee DROP [IF EXISTS]
> PARTITION (year=’1203’);この章では、Hiveの組み込み演算子について説明します。Hiveには4つのタイプの演算子があります。
- 関係演算子
- 算術演算子
- 論理演算子
- 複雑な演算子
関係演算子
これらの演算子は、2つのオペランドを比較するために使用されます。次の表に、Hiveで使用できる関係演算子を示します。
| オペレーター | オペランド | 説明 |
|---|---|---|
| A = B | すべてのプリミティブ型 | 式Aが式Bと同等である場合はTRUE、それ以外の場合はFALSE。 |
| A!= B | すべてのプリミティブ型 | 式Aが式Bと同等でない場合はTRUE、それ以外の場合はFALSE。 |
| A <B | すべてのプリミティブ型 | 式Aが式Bよりも小さい場合はTRUE、それ以外の場合はFALSE。 |
| A <= B | すべてのプリミティブ型 | 式Aが式B以下の場合はTRUE、それ以外の場合はFALSE。 |
| A> B | すべてのプリミティブ型 | 式Aが式Bより大きい場合はTRUE、それ以外の場合はFALSE。 |
| A> = B | すべてのプリミティブ型 | 式Aが式B以上の場合はTRUE、それ以外の場合はFALSE。 |
| AはNULLです | いろんなタイプ | 式AがNULLと評価された場合はTRUE、それ以外の場合はFALSE。 |
| AはNULLではありません | いろんなタイプ | 式AがNULLと評価された場合はFALSE、それ以外の場合はTRUE。 |
| いいねB | 文字列 | 文字列パターンAがBと一致する場合はTRUE、それ以外の場合はFALSE。 |
| A RLIKE B | 文字列 | AまたはBがNULLの場合はNULL、Aの部分文字列がJava正規表現Bと一致する場合はTRUE、それ以外の場合はFALSE。 |
| 正規表現B | 文字列 | RLIKEと同じです。 |
例
仮定しましょう employeeテーブルは、以下に示すように、Id、Name、Salary、Designation、およびDeptという名前のフィールドで構成されています。IDが1205である従業員の詳細を取得するクエリを生成します。
+-----+--------------+--------+---------------------------+------+
| Id | Name | Salary | Designation | Dept |
+-----+--------------+------------------------------------+------+
|1201 | Gopal | 45000 | Technical manager | TP |
|1202 | Manisha | 45000 | Proofreader | PR |
|1203 | Masthanvali | 40000 | Technical writer | TP |
|1204 | Krian | 40000 | Hr Admin | HR |
|1205 | Kranthi | 30000 | Op Admin | Admin|
+-----+--------------+--------+---------------------------+------+上記の表を使用して従業員の詳細を取得するには、次のクエリが実行されます。
hive> SELECT * FROM employee WHERE Id=1205;クエリが正常に実行されると、次の応答が表示されます。
+-----+-----------+-----------+----------------------------------+
| ID | Name | Salary | Designation | Dept |
+-----+---------------+-------+----------------------------------+
|1205 | Kranthi | 30000 | Op Admin | Admin |
+-----+-----------+-----------+----------------------------------+次のクエリは、給与が40000ルピー以上の従業員の詳細を取得するために実行されます。
hive> SELECT * FROM employee WHERE Salary>=40000;クエリが正常に実行されると、次の応答が表示されます。
+-----+------------+--------+----------------------------+------+
| ID | Name | Salary | Designation | Dept |
+-----+------------+--------+----------------------------+------+
|1201 | Gopal | 45000 | Technical manager | TP |
|1202 | Manisha | 45000 | Proofreader | PR |
|1203 | Masthanvali| 40000 | Technical writer | TP |
|1204 | Krian | 40000 | Hr Admin | HR |
+-----+------------+--------+----------------------------+------+算術演算子
これらの演算子は、オペランドに対するさまざまな一般的な算術演算をサポートしています。それらはすべて数値タイプを返します。次の表に、Hiveで使用できる算術演算子を示します。
| 演算子 | オペランド | 説明 |
|---|---|---|
| A + B | すべての番号タイプ | AとBを加算した結果を示します。 |
| A-B | すべての番号タイプ | AからBを引いた結果を示します。 |
| A * B | すべての番号タイプ | AとBを掛けた結果を示します。 |
| A / B | すべての番号タイプ | BをAから除算した結果を示します。 |
| A%B | すべての番号タイプ | AをBで割った結果のリマインダーを表示します。 |
| A&B | すべての番号タイプ | AとBのビットごとのANDの結果を示します。 |
| A | B | すべての番号タイプ | AとBのビットごとのORの結果を示します。 |
| A ^ B | すべての番号タイプ | AとBのビット単位のXORの結果を示します。 |
| 〜A | すべての番号タイプ | Aのビット単位のNOTの結果を返します。 |
例
次のクエリは、20と30の2つの数値を追加します。
hive> SELECT 20+30 ADD FROM temp;クエリが正常に実行されると、次の応答が表示されます。
+--------+
| ADD |
+--------+
| 50 |
+--------+論理演算子
演算子は論理式です。それらはすべてTRUEまたはFALSEを返します。
| 演算子 | オペランド | 説明 |
|---|---|---|
| AとB | ブール値 | AとBの両方がTRUEの場合はTRUE、それ以外の場合はFALSE。 |
| A && B | ブール値 | A ANDBと同じです。 |
| AまたはB | ブール値 | AまたはB、あるいはその両方がTRUEの場合はTRUE、それ以外の場合はFALSE。 |
| A || B | ブール値 | AまたはBと同じです。 |
| ない | ブール値 | AがFALSEの場合はTRUE、それ以外の場合はFALSE。 |
| !A | ブール値 | NOTAと同じです。 |
例
次のクエリは、部門がTPで、給与が40000ルピーを超える従業員の詳細を取得するために使用されます。
hive> SELECT * FROM employee WHERE Salary>40000 && Dept=TP;クエリが正常に実行されると、次の応答が表示されます。
+------+--------------+-------------+-------------------+--------+
| ID | Name | Salary | Designation | Dept |
+------+--------------+-------------+-------------------+--------+
|1201 | Gopal | 45000 | Technical manager | TP |
+------+--------------+-------------+-------------------+--------+複雑な演算子
これらの演算子は、複合型の要素にアクセスするための式を提供します。
| オペレーター | オペランド | 説明 |
|---|---|---|
| A [n] | Aは配列で、nはintです。 | 配列Aのn番目の要素を返します。最初の要素のインデックスは0です。 |
| M [キー] | MはMap <K、V>であり、キーのタイプはKです。 | マップ内のキーに対応する値を返します。 |
| Sx | Sは構造体です | Sのxフィールドを返します。 |
Hiveクエリ言語(HiveQL)は、Hiveがメタストア内の構造化データを処理および分析するためのクエリ言語です。この章では、WHERE句でSELECTステートメントを使用する方法について説明します。
SELECTステートメントは、テーブルからデータを取得するために使用されます。WHERE句は、条件と同様に機能します。条件を使用してデータをフィルタリングし、有限の結果を提供します。組み込みの演算子と関数は、条件を満たす式を生成します。
構文
以下に、SELECTクエリの構文を示します。
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[HAVING having_condition]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list]]
[LIMIT number];例
SELECT…WHERE句の例を見てみましょう。以下に示すように、Id、Name、Salary、Designation、およびDeptという名前のフィールドを持つemployeeテーブルがあるとします。クエリを生成して、30000ルピーを超える給与を獲得した従業員の詳細を取得します。
+------+--------------+-------------+-------------------+--------+
| ID | Name | Salary | Designation | Dept |
+------+--------------+-------------+-------------------+--------+
|1201 | Gopal | 45000 | Technical manager | TP |
|1202 | Manisha | 45000 | Proofreader | PR |
|1203 | Masthanvali | 40000 | Technical writer | TP |
|1204 | Krian | 40000 | Hr Admin | HR |
|1205 | Kranthi | 30000 | Op Admin | Admin |
+------+--------------+-------------+-------------------+--------+次のクエリは、上記のシナリオを使用して従業員の詳細を取得します。
hive> SELECT * FROM employee WHERE salary>30000;クエリが正常に実行されると、次の応答が表示されます。
+------+--------------+-------------+-------------------+--------+
| ID | Name | Salary | Designation | Dept |
+------+--------------+-------------+-------------------+--------+
|1201 | Gopal | 45000 | Technical manager | TP |
|1202 | Manisha | 45000 | Proofreader | PR |
|1203 | Masthanvali | 40000 | Technical writer | TP |
|1204 | Krian | 40000 | Hr Admin | HR |
+------+--------------+-------------+-------------------+--------+JDBCプログラム
与えられた例のwhere句を適用するJDBCプログラムは次のとおりです。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveQLWhere {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
Resultset res = stmt.executeQuery("SELECT * FROM employee WHERE
salary>30000;");
System.out.println("Result:");
System.out.println(" ID \t Name \t Salary \t Designation \t Dept ");
while (res.next()) {
System.out.println(res.getInt(1)+" "+ res.getString(2)+" "+
res.getDouble(3)+" "+ res.getString(4)+" "+ res.getString(5));
}
con.close();
}
}プログラムをHiveQLWhere.javaという名前のファイルに保存します。このプログラムをコンパイルして実行するには、次のコマンドを使用します。
$ javac HiveQLWhere.java $ java HiveQLWhere出力:
ID Name Salary Designation Dept
1201 Gopal 45000 Technical manager TP
1202 Manisha 45000 Proofreader PR
1203 Masthanvali 40000 Technical writer TP
1204 Krian 40000 Hr Admin HRこの章では、SELECTステートメントでORDERBY句を使用する方法について説明します。ORDER BY句は、1つの列に基づいて詳細を取得し、結果セットを昇順または降順で並べ替えるために使用されます。
構文
以下に、ORDERBY句の構文を示します。
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[HAVING having_condition]
[ORDER BY col_list]]
[LIMIT number];例
SELECT ... ORDERBY句の例を見てみましょう。Id、Name、Salary、Designation、およびDeptという名前のフィールドを持つ以下の従業員テーブルを想定します。部門名を使用して従業員の詳細を順番に取得するクエリを生成します。
+------+--------------+-------------+-------------------+--------+
| ID | Name | Salary | Designation | Dept |
+------+--------------+-------------+-------------------+--------+
|1201 | Gopal | 45000 | Technical manager | TP |
|1202 | Manisha | 45000 | Proofreader | PR |
|1203 | Masthanvali | 40000 | Technical writer | TP |
|1204 | Krian | 40000 | Hr Admin | HR |
|1205 | Kranthi | 30000 | Op Admin | Admin |
+------+--------------+-------------+-------------------+--------+次のクエリは、上記のシナリオを使用して従業員の詳細を取得します。
hive> SELECT Id, Name, Dept FROM employee ORDER BY DEPT;クエリが正常に実行されると、次の応答が表示されます。
+------+--------------+-------------+-------------------+--------+
| ID | Name | Salary | Designation | Dept |
+------+--------------+-------------+-------------------+--------+
|1205 | Kranthi | 30000 | Op Admin | Admin |
|1204 | Krian | 40000 | Hr Admin | HR |
|1202 | Manisha | 45000 | Proofreader | PR |
|1201 | Gopal | 45000 | Technical manager | TP |
|1203 | Masthanvali | 40000 | Technical writer | TP |
+------+--------------+-------------+-------------------+--------+JDBCプログラム
与えられた例にOrderBy句を適用するJDBCプログラムを次に示します。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveQLOrderBy {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
Resultset res = stmt.executeQuery("SELECT * FROM employee ORDER BY
DEPT;");
System.out.println(" ID \t Name \t Salary \t Designation \t Dept ");
while (res.next()) {
System.out.println(res.getInt(1)+" "+ res.getString(2)+" "+
res.getDouble(3)+" "+ res.getString(4)+" "+ res.getString(5));
}
con.close();
}
}プログラムをHiveQLOrderBy.javaという名前のファイルに保存します。このプログラムをコンパイルして実行するには、次のコマンドを使用します。
$ javac HiveQLOrderBy.java $ java HiveQLOrderBy出力:
ID Name Salary Designation Dept
1205 Kranthi 30000 Op Admin Admin
1204 Krian 40000 Hr Admin HR
1202 Manisha 45000 Proofreader PR
1201 Gopal 45000 Technical manager TP
1203 Masthanvali 40000 Technical writer TP
1204 Krian 40000 Hr Admin HRこの章では、SELECTステートメントのGROUPBY句の詳細について説明します。GROUP BY句は、特定のコレクション列を使用して結果セット内のすべてのレコードをグループ化するために使用されます。これは、レコードのグループを照会するために使用されます。
構文
GROUPBY句の構文は次のとおりです。
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[HAVING having_condition]
[ORDER BY col_list]]
[LIMIT number];例
SELECT…GROUPBY句の例を見てみましょう。Id、Name、Salary、Designation、およびDeptフィールドを含む、以下に示す従業員テーブルを想定します。各部門の従業員数を取得するクエリを生成します。
+------+--------------+-------------+-------------------+--------+
| ID | Name | Salary | Designation | Dept |
+------+--------------+-------------+-------------------+--------+
|1201 | Gopal | 45000 | Technical manager | TP |
|1202 | Manisha | 45000 | Proofreader | PR |
|1203 | Masthanvali | 40000 | Technical writer | TP |
|1204 | Krian | 45000 | Proofreader | PR |
|1205 | Kranthi | 30000 | Op Admin | Admin |
+------+--------------+-------------+-------------------+--------+次のクエリは、上記のシナリオを使用して従業員の詳細を取得します。
hive> SELECT Dept,count(*) FROM employee GROUP BY DEPT;クエリが正常に実行されると、次の応答が表示されます。
+------+--------------+
| Dept | Count(*) |
+------+--------------+
|Admin | 1 |
|PR | 2 |
|TP | 3 |
+------+--------------+JDBCプログラム
以下に示すのは、特定の例にGroupBy句を適用するためのJDBCプログラムです。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveQLGroupBy {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
Resultset res = stmt.executeQuery(“SELECT Dept,count(*) ”
+“FROM employee GROUP BY DEPT; ”);
System.out.println(" Dept \t count(*)");
while (res.next()) {
System.out.println(res.getString(1)+" "+ res.getInt(2));
}
con.close();
}
}プログラムをHiveQLGroupBy.javaという名前のファイルに保存します。このプログラムをコンパイルして実行するには、次のコマンドを使用します。
$ javac HiveQLGroupBy.java $ java HiveQLGroupBy出力:
Dept Count(*)
Admin 1
PR 2
TP 3JOINSは、2つのテーブルの特定のフィールドを、それぞれに共通の値を使用して結合するために使用される句です。データベース内の2つ以上のテーブルのレコードを結合するために使用されます。
構文
join_table:
table_reference JOIN table_factor [join_condition]
| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference
join_condition
| table_reference LEFT SEMI JOIN table_reference join_condition
| table_reference CROSS JOIN table_reference [join_condition]例
この章では、次の2つの表を使用します。CUSTOMERSという名前の次のテーブルについて考えてみます。
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------+次のように別のテーブルORDERSを検討してください。
+-----+---------------------+-------------+--------+
|OID | DATE | CUSTOMER_ID | AMOUNT |
+-----+---------------------+-------------+--------+
| 102 | 2009-10-08 00:00:00 | 3 | 3000 |
| 100 | 2009-10-08 00:00:00 | 3 | 1500 |
| 101 | 2009-11-20 00:00:00 | 2 | 1560 |
| 103 | 2008-05-20 00:00:00 | 4 | 2060 |
+-----+---------------------+-------------+--------+次のように、さまざまなタイプの結合があります。
- JOIN
- 左外部結合
- 右外部結合
- 完全外部結合
参加する
JOIN句は、複数のテーブルからレコードを結合して取得するために使用されます。JOINは、SQLのOUTERJOINと同じです。JOIN条件は、テーブルの主キーと外部キーを使用して発生します。
次のクエリは、CUSTOMERテーブルとORDERテーブルでJOINを実行し、レコードを取得します。
hive> SELECT c.ID, c.NAME, c.AGE, o.AMOUNT
> FROM CUSTOMERS c JOIN ORDERS o
> ON (c.ID = o.CUSTOMER_ID);クエリが正常に実行されると、次の応答が表示されます。
+----+----------+-----+--------+
| ID | NAME | AGE | AMOUNT |
+----+----------+-----+--------+
| 3 | kaushik | 23 | 3000 |
| 3 | kaushik | 23 | 1500 |
| 2 | Khilan | 25 | 1560 |
| 4 | Chaitali | 25 | 2060 |
+----+----------+-----+--------+左外部結合
HiveQL LEFT OUTER JOINは、右側のテーブルに一致するものがない場合でも、左側のテーブルからすべての行を返します。つまり、ON句が右側のテーブルの0(ゼロ)レコードと一致する場合、JOINは結果に行を返しますが、右側のテーブルの各列にはNULLが含まれます。
LEFT JOINは、左側のテーブルのすべての値に加えて、右側のテーブルの一致した値を返します。一致するJOIN述語がない場合はNULLを返します。
次のクエリは、CUSTOMERテーブルとORDERテーブルの間のLEFT OUTERJOINを示しています。
hive> SELECT c.ID, c.NAME, o.AMOUNT, o.DATE
> FROM CUSTOMERS c
> LEFT OUTER JOIN ORDERS o
> ON (c.ID = o.CUSTOMER_ID);クエリが正常に実行されると、次の応答が表示されます。
+----+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+----+----------+--------+---------------------+
| 1 | Ramesh | NULL | NULL |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
| 5 | Hardik | NULL | NULL |
| 6 | Komal | NULL | NULL |
| 7 | Muffy | NULL | NULL |
+----+----------+--------+---------------------+右外部結合
HiveQL RIGHT OUTER JOINは、左側のテーブルに一致するものがない場合でも、右側のテーブルからすべての行を返します。ON句が左側のテーブルの0(ゼロ)レコードと一致する場合でも、JOINは結果に行を返しますが、左側のテーブルの各列にはNULLが含まれます。
RIGHT JOINは、右側のテーブルのすべての値に加えて、左側のテーブルの一致した値を返します。一致する結合述語がない場合はNULLを返します。
次のクエリは、CUSTOMERテーブルとORDERテーブルの間のRIGHT OUTERJOINを示しています。
hive> SELECT c.ID, c.NAME, o.AMOUNT, o.DATE
> FROM CUSTOMERS c
> RIGHT OUTER JOIN ORDERS o
> ON (c.ID = o.CUSTOMER_ID);クエリが正常に実行されると、次の応答が表示されます。
+------+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+------+----------+--------+---------------------+
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
+------+----------+--------+---------------------+完全外部結合
HiveQL FULL OUTER JOINは、JOIN条件を満たす左右の外部テーブルの両方のレコードを結合します。結合されたテーブルには、両方のテーブルのすべてのレコードが含まれるか、いずれかの側で一致が欠落している場合はNULL値が入力されます。
次のクエリは、CUSTOMERテーブルとORDERテーブルの間の完全外部結合を示しています。
hive> SELECT c.ID, c.NAME, o.AMOUNT, o.DATE
> FROM CUSTOMERS c
> FULL OUTER JOIN ORDERS o
> ON (c.ID = o.CUSTOMER_ID);クエリが正常に実行されると、次の応答が表示されます。
+------+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+------+----------+--------+---------------------+
| 1 | Ramesh | NULL | NULL |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
| 5 | Hardik | NULL | NULL |
| 6 | Komal | NULL | NULL |
| 7 | Muffy | NULL | NULL |
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
+------+----------+--------+---------------------+この章では、Hiveで使用できる組み込み関数について説明します。関数は、使用法を除いて、SQL関数と非常によく似ています。
組み込み関数
Hiveは、次の組み込み関数をサポートしています。
| 戻り値の型 | 署名 | 説明 |
|---|---|---|
| BIGINT | ラウンド(ダブルa) | doubleの丸められたBIGINT値を返します。 |
| BIGINT | フロア(ダブルa) | double以下の最大BIGINT値を返します。 |
| BIGINT | ceil(double a) | double以上の最小BIGINT値を返します。 |
| ダブル | rand()、rand(int seed) | 行ごとに変化する乱数を返します。 |
| ストリング | concat(文字列A、文字列B、...) | Aの後にBを連結した結果の文字列を返します。 |
| ストリング | substr(string A、int start) | 開始位置から文字列Aの終わりまでのAの部分文字列を返します。 |
| ストリング | substr(文字列A、int開始、int長) | 指定された長さの開始位置から始まるAの部分文字列を返します。 |
| ストリング | アッパー(文字列A) | Aのすべての文字を大文字に変換した結果の文字列を返します。 |
| ストリング | ucase(文字列A) | 同上。 |
| ストリング | lower(文字列A) | Bのすべての文字を小文字に変換した結果の文字列を返します。 |
| ストリング | lcase(文字列A) | 同上。 |
| ストリング | トリム(文字列A) | Aの両端からスペースをトリミングした結果の文字列を返します。 |
| ストリング | ltrim(文字列A) | Aの先頭(左側)からスペースをトリミングした結果の文字列を返します。 |
| ストリング | rtrim(文字列A) | rtrim(string A)Aの末尾(右側)からスペースをトリミングした結果の文字列を返します。 |
| ストリング | regexp_replace(文字列A、文字列B、文字列C) | これは、Java正規表現構文に一致するBのすべての部分文字列をCに置き換えた結果の文字列を返します。 |
| int | サイズ(マップ<KV>) | マップタイプの要素数を返します。 |
| int | size(Array <T>) | 配列型の要素数を返します。 |
| <type>の値 | cast(<expr> as <type>) | 式exprの結果を<type>に変換します。たとえば、cast( '1' as BIGINT)は、文字列 '1'を整数表現に変換します。変換が成功しなかった場合はNULLが返されます。 |
| ストリング | from_unixtime(int unixtime) | Unixエポック(1970-01-01 00:00:00 UTC)からの秒数を、現在のシステムタイムゾーンでのその瞬間のタイムスタンプを表す文字列に「1970-01-0100:00:」の形式で変換します。 00 " |
| ストリング | to_date(文字列タイムスタンプ) | タイムスタンプ文字列の日付部分を返します:to_date( "1970-01-01 00:00:00")= "1970-01-01" |
| int | 年(文字列の日付) | 日付またはタイムスタンプ文字列の年の部分を返します:year( "1970-01-01 00:00:00")= 1970、year( "1970-01-01")= 1970 |
| int | 月(文字列の日付) | 日付の月の部分またはタイムスタンプ文字列を返します:month( "1970-11-01 00:00:00")= 11、month( "1970-11-01")= 11 |
| int | 日(文字列の日付) | 日付またはタイムスタンプ文字列の日の部分を返します:day( "1970-11-01 00:00:00")= 1、day( "1970-11-01")= 1 |
| ストリング | get_json_object(string json_string、string path) | 指定されたjsonパスに基づいてjson文字列からjsonオブジェクトを抽出し、抽出されたjsonオブジェクトのjson文字列を返します。入力されたjson文字列が無効な場合はNULLを返します。 |
例
次のクエリは、いくつかの組み込み関数を示しています。
round()関数
hive> SELECT round(2.6) from temp;クエリが正常に実行されると、次の応答が表示されます。
3.0floor()関数
hive> SELECT floor(2.6) from temp;クエリが正常に実行されると、次の応答が表示されます。
2.0ceil()関数
hive> SELECT ceil(2.6) from temp;クエリが正常に実行されると、次の応答が表示されます。
3.0集計関数
Hiveは次の組み込みをサポートします aggregate functions。これらの関数の使用法は、SQL集計関数と同じです。
| 戻り値の型 | 署名 | 説明 |
|---|---|---|
| BIGINT | count(*)、count(expr)、 | count(*)-取得した行の総数を返します。 |
| ダブル | sum(col)、sum(DISTINCT col) | グループ内の要素の合計、またはグループ内の列の個別の値の合計を返します。 |
| ダブル | avg(col)、avg(DISTINCT col) | グループ内の要素の平均、またはグループ内の列の個別の値の平均を返します。 |
| ダブル | min(col) | グループ内の列の最小値を返します。 |
| ダブル | max(col) | グループ内の列の最大値を返します。 |
この章では、ビューを作成および管理する方法について説明します。ビューは、ユーザーの要件に基づいて生成されます。結果セットのデータはすべてビューとして保存できます。Hiveでのビューの使用法は、SQLでのビューの使用法と同じです。これは標準のRDBMSの概念です。ビューですべてのDML操作を実行できます。
ビューの作成
SELECTステートメントの実行時にビューを作成できます。構文は次のとおりです。
CREATE VIEW [IF NOT EXISTS] view_name [(column_name [COMMENT column_comment], ...) ]
[COMMENT table_comment]
AS SELECT ...例
例を見てみましょう。Id、Name、Salary、Designation、およびDeptのフィールドを持つ以下の従業員テーブルを想定します。クエリを生成して、30000ルピーを超える給与を獲得した従業員の詳細を取得します。結果を次の名前のビューに保存します。emp_30000.
+------+--------------+-------------+-------------------+--------+
| ID | Name | Salary | Designation | Dept |
+------+--------------+-------------+-------------------+--------+
|1201 | Gopal | 45000 | Technical manager | TP |
|1202 | Manisha | 45000 | Proofreader | PR |
|1203 | Masthanvali | 40000 | Technical writer | TP |
|1204 | Krian | 40000 | Hr Admin | HR |
|1205 | Kranthi | 30000 | Op Admin | Admin |
+------+--------------+-------------+-------------------+--------+次のクエリは、上記のシナリオを使用して従業員の詳細を取得します。
hive> CREATE VIEW emp_30000 AS
> SELECT * FROM employee
> WHERE salary>30000;ビューをドロップする
ビューを削除するには、次の構文を使用します。
DROP VIEW view_name次のクエリは、emp_30000という名前のビューを削除します。
hive> DROP VIEW emp_30000;インデックスの作成
インデックスは、テーブルの特定の列へのポインタに他なりません。インデックスの作成とは、テーブルの特定の列にポインタを作成することを意味します。その構文は次のとおりです。
CREATE INDEX index_name
ON TABLE base_table_name (col_name, ...)
AS 'index.handler.class.name'
[WITH DEFERRED REBUILD]
[IDXPROPERTIES (property_name=property_value, ...)]
[IN TABLE index_table_name]
[PARTITIONED BY (col_name, ...)]
[
[ ROW FORMAT ...] STORED AS ...
| STORED BY ...
]
[LOCATION hdfs_path]
[TBLPROPERTIES (...)]例
インデックスの例を見てみましょう。前に使用したのと同じemployeeテーブルを、フィールドId、Name、Salary、Designation、およびDeptで使用します。employeeテーブルのsalary列にindex_salaryという名前のインデックスを作成します。
次のクエリはインデックスを作成します。
hive> CREATE INDEX inedx_salary ON TABLE employee(salary)
> AS 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler';給与列へのポインタです。列が変更された場合、変更はインデックス値を使用して保存されます。
インデックスを削除する
次の構文は、インデックスを削除するために使用されます。
DROP INDEX <index_name> ON <table_name>次のクエリは、index_salaryという名前のインデックスを削除します。
hive> DROP INDEX index_salary ON employee;