HSQLDB-クイックガイド
HyperSQLデータベース(HSQLDB)は、SQL:2011標準およびJDBC4仕様に厳密に準拠する最新のリレーショナルデータベースマネージャーです。すべてのコア機能とRDBMSをサポートします。HSQLDBは、データベースアプリケーションの開発、テスト、および展開に使用されます。
HSQLDBの主でユニークな機能は、標準コンプライアンスです。ユーザーのアプリケーションプロセス内、アプリケーションサーバー内、または個別のサーバープロセスとしてデータベースアクセスを提供できます。
HSQLDBの機能
HSQLDBは、DBサーバーに対する高速操作のためにメモリ内構造を使用します。ユーザーの柔軟性に応じてディスクの永続性を使用し、信頼性の高いクラッシュリカバリを提供します。
HSQLDBは、ビジネスインテリジェンス、ETL、および大規模なデータセットを処理するその他のアプリケーションにも適しています。
HSQLDBには、XAトランザクション、接続プールデータソース、リモート認証など、さまざまなエンタープライズ展開オプションがあります。
HSQLDBはJavaプログラミング言語で記述されており、Java仮想マシン(JVM)で実行されます。データベースアクセス用のJDBCインターフェイスをサポートします。
HSQLDBのコンポーネント
HSQLDBjarパッケージには3つの異なるコンポーネントがあります。
HyperSQL RDBMSエンジン(HSQLDB)
HyperSQLJDBCドライバー
データベースマネージャー(GUIデータベースアクセスツール、SwingおよびAWTバージョン付き)
HyperSQLRDBMSとJDBCドライバーがコア機能を提供します。データベースマネージャは、JDBCドライバを備えた任意のデータベースエンジンで使用できる汎用データベースアクセスツールです。
sqltool.jarと呼ばれる追加のjarには、コマンドラインデータベースアクセスツールであるSQLツールが含まれています。これは汎用コマンドです。他のデータベースエンジンでも使用できるラインデータベースアクセスツール。
HSQLDBは、純粋なJavaで実装されたリレーショナルデータベース管理システムです。JDBCを使用して、このデータベースをアプリケーションに簡単に埋め込むことができます。または、操作を個別に使用することもできます。
前提条件
HSQLDBの前提条件となるソフトウェアのインストールに従います。
Javaのインストールを確認する
HSQLDBは純粋なJavaで実装されたリレーショナルデータベース管理システムであるため、HSQLDBをインストールする前にJDK(Java Development Kit)ソフトウェアをインストールする必要があります。システムにすでにJDKがインストールされている場合は、次のコマンドを試してJavaのバージョンを確認してください。
java –versionJDKがシステムに正常にインストールされると、次の出力が得られます。
java version "1.8.0_91"
Java(TM) SE Runtime Environment (build 1.8.0_91-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)システムにJDKがインストールされていない場合は、次のリンクにアクセスしてJDKをインストールしてください。
HSQLDBのインストール
HSQLDBをインストールする手順は次のとおりです。
Step 1 − Download HSQLDB bundle
次のリンクからHSQLDBデータベースの最新バージョンをダウンロードします https://sourceforge.net/projects/hsqldb/files/. リンクをクリックすると、次のスクリーンショットが表示されます。

HSQLDBをクリックすると、ダウンロードがすぐに開始されます。最後に、という名前のzipファイルを取得しますhsqldb-2.3.4.zip。
Step 2 − Extract the HSQLDB zip file
zipファイルを抽出して、 C:\ディレクトリ。抽出後、次のスクリーンショットに示すようなファイル構造が得られます。
Step 3 − Create a default database
HSQLDBのデフォルトのデータベースはないため、HSQLDBのデータベースを作成する必要があります。という名前のプロパティファイルを作成しましょうserver.properties これは、という名前の新しいデータベースを定義します demodb。次のデータベースサーバーのプロパティを確認してください。
server.database.0 = file:hsqldb/demodb
server.dbname.0 = testdbこのserver.propertiesファイルをHSQLDBホームディレクトリに配置します。 C:\hsqldb- 2.3.4\hsqldb\。
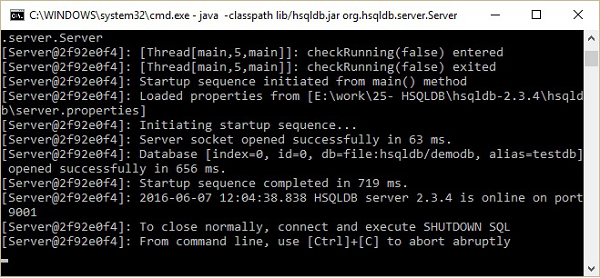
コマンドプロンプトで次のコマンドを実行します。
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server上記のコマンドを実行すると、次のスクリーンショットに示すようなサーバーステータスが表示されます。
後で、HSQLDBホームディレクトリにあるhsqldbディレクトリの次のフォルダ構造を見つけることができます。 C:\hsqldb-2.3.4\hsqldb。これらのファイルは、HSQLDBデータベースサーバーによって作成されたdemodbデータベースの一時ファイル、lckファイル、ログファイル、プロパティファイル、およびスクリプトファイルです。
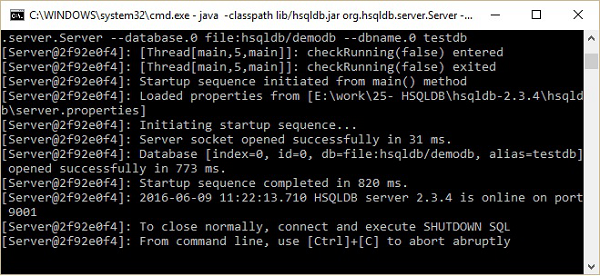
Step 4 − Start the database server
データベースの作成が完了したら、次のコマンドを使用してデータベースを起動する必要があります。
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0
file:hsqldb/demodb --dbname.0 testdb上記のコマンドを実行すると、次のステータスになります。
これで、データベースのホーム画面を開くことができます。 runManagerSwing.bat から C:\hsqldb-2.3.4\hsqldb\binロケーション。このbatファイルは、HSQLDBデータベースのGUIファイルを開きます。その前に、ダイアログボックスからデータベース設定を求められます。次のスクリーンショットを見てください。このダイアログボックスで、上記のように設定名、URLを入力し、[OK]をクリックします。
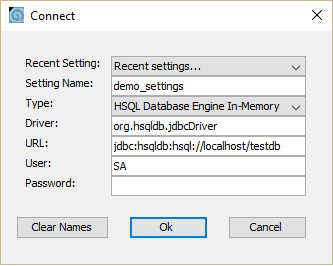
次のスクリーンショットに示すように、HSQLDBデータベースのGUI画面が表示されます。
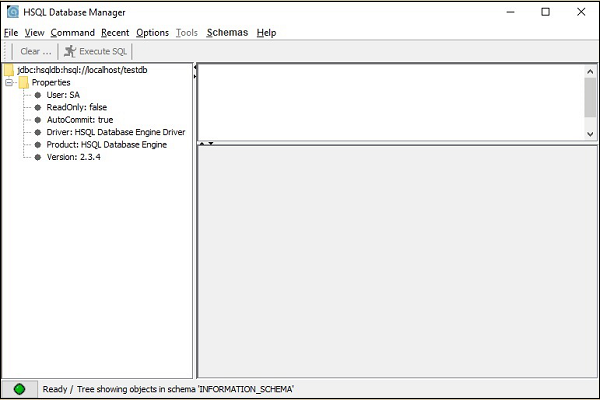
インストールの章では、データベースを手動で接続する方法について説明しました。この章では、データベースをプログラムで接続する方法(Javaプログラミングを使用)について説明します。
サーバーを起動し、Javaアプリケーションとデータベース間の接続を作成する次のプログラムを見てください。
例
import java.sql.Connection;
import java.sql.DriverManager;
public class ConnectDatabase {
public static void main(String[] args) {
Connection con = null;
try {
//Registering the HSQLDB JDBC driver
Class.forName("org.hsqldb.jdbc.JDBCDriver");
//Creating the connection with HSQLDB
con = DriverManager.getConnection("jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
if (con!= null){
System.out.println("Connection created successfully");
}else{
System.out.println("Problem with creating connection");
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}このコードをに保存します ConnectDatabase.javaファイル。次のコマンドを使用してデータベースを起動する必要があります。
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0
file:hsqldb/demodb --dbname.0 testdb次のコマンドを使用して、コードをコンパイルおよび実行できます。
\>javac ConnectDatabase.java
\>java ConnectDatabase上記のコマンドを実行すると、次の出力が表示されます-
Connection created successfullyこの章では、HSQLDBのさまざまなデータ型について説明します。HSQLDBサーバーは、6つのカテゴリーのデータ型を提供します。
正確な数値データ型
| データ・タイプ | から | に |
|---|---|---|
| bigint | -9,223,372,036,854,775,808 | 9,223,372,036,854,775,807 |
| int | -2,147,483,648 | 2,147,483,647 |
| smallint | -32,768 | 32,767 |
| tinyint | 0 | 255 |
| ビット | 0 | 1 |
| 10進数 | -10 ^ 38 +1 | 10 ^ 38 -1 |
| 数値 | -10 ^ 38 +1 | 10 ^ 38 -1 |
| お金 | -922,337,203,685,477.5808 | +922,337,203,685,477.5807 |
| smallmoney | -214,748.3648 | +214,748.3647 |
おおよその数値データ型
| データ・タイプ | から | に |
|---|---|---|
| 浮く | -1.79E + 308 | 1.79E + 308 |
| リアル | -3.40E + 38 | 3.40E + 38 |
日付と時刻のデータ型
| データ・タイプ | から | に |
|---|---|---|
| 日付時刻 | 1753年1月1日 | 9999年12月31日 |
| smalldatetime | 1900年1月1日 | 2079年6月6日 |
| 日付 | 1991年6月30日のような日付を格納します | |
| 時間 | 午後12時30分などの時刻を保存します | |
Note −ここで、日時の精度は3.33ミリ秒ですが、小さい日時の精度は1分です。
文字列データ型
| データ・タイプ | 説明 |
|---|---|
| char | 最大長8,000文字(固定長の非Unicode文字) |
| varchar | 最大8,000文字(可変長の非Unicodeデータ) |
| varchar(max) | 最大長231文字、可変長の非Unicodeデータ(SQL Server 2005のみ) |
| テキスト | 最大長が2,147,483,647文字の可変長の非Unicodeデータ |
Unicode文字列データ型
| データ・タイプ | 説明 |
|---|---|
| nchar | 最大長4,000文字(固定長Unicode) |
| nvarchar | 最大長4,000文字(可変長Unicode) |
| nvarchar(max) | 最大長231文字(SQL Server 2005のみ)、(可変長Unicode) |
| ntext | 最大長1,073,741,823文字(可変長Unicode) |
バイナリデータ型
| データ・タイプ | 説明 |
|---|---|
| バイナリ | 最大長8,000バイト(固定長のバイナリデータ) |
| バイナリ | 最大長8,000バイト(可変長バイナリデータ) |
| varbinary(max) | 最大長231バイト(SQL Server 2005のみ)、(可変長バイナリデータ) |
| 画像 | 最大長2,147,483,647バイト(可変長バイナリデータ) |
その他のデータ型
| データ・タイプ | 説明 |
|---|---|
| sql_variant | テキスト、ntext、タイムスタンプを除く、SQLServerでサポートされているさまざまなデータ型の値を格納します |
| タイムスタンプ | 行が更新されるたびに更新されるデータベース全体の一意の番号を格納します |
| 一意の識別子 | グローバル一意識別子(GUID)を格納します |
| xml | XMLデータを格納します。xmlインスタンスを列または変数に格納できます(SQL Server 2005のみ) |
| カーソル | カーソルオブジェクトへの参照 |
| テーブル | 後で処理するために結果セットを保存します |
テーブルを作成するための基本的な必須要件は、テーブル名、フィールド名、およびそれらのフィールドのデータ型です。オプションで、テーブルに主要な制約を指定することもできます。
構文
次の構文を見てください。
CREATE TABLE table_name (column_name column_type);例
id、title、author、submission_dateなどのフィールド名を使用してtutorials_tblという名前のテーブルを作成しましょう。次のクエリを見てください。
CREATE TABLE tutorials_tbl (
id INT NOT NULL,
title VARCHAR(50) NOT NULL,
author VARCHAR(20) NOT NULL,
submission_date DATE,
PRIMARY KEY (id)
);上記のクエリの実行後、次の出力が表示されます-
(0) rows effectedHSQLDB –JDBCプログラム
以下は、tutorials_tblという名前のテーブルをHSQLDBデータベースに作成するために使用されるJDBCプログラムです。プログラムをに保存しますCreateTable.java ファイル。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class CreateTable {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection("jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate("CREATE TABLE tutorials_tbl (
id INT NOT NULL, title VARCHAR(50) NOT NULL,
author VARCHAR(20) NOT NULL, submission_date DATE,
PRIMARY KEY (id));
");
} catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println("Table created successfully");
}
}次のコマンドを使用してデータベースを起動できます。
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0
file:hsqldb/demodb --dbname.0 testdb次のコマンドを使用して、上記のプログラムをコンパイルして実行します。
\>javac CreateTable.java
\>java CreateTable上記のコマンドを実行すると、次の出力が表示されます-
Table created successfully既存のHSQLDBテーブルを削除するのは非常に簡単です。ただし、テーブルを削除した後、失われたデータは回復されないため、既存のテーブルを削除するときは十分に注意する必要があります。
構文
以下は、HSQLDBテーブルを削除するための一般的なSQL構文です。
DROP TABLE table_name;例
HSQLDBサーバーからemployeeという名前のテーブルを削除する例を考えてみましょう。以下は、employeeという名前のテーブルを削除するためのクエリです。
DROP TABLE employee;上記のクエリの実行後、次の出力が表示されます-
(0) rows effectedHSQLDB –JDBCプログラム
以下は、HSQLDBサーバーからテーブルemployeeを削除するために使用されるJDBCプログラムです。
次のコードをに保存します DropTable.java ファイル。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class DropTable {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection("jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate("DROP TABLE employee");
}catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println("Table dropped successfully");
}
}次のコマンドを使用してデータベースを起動できます。
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0
file:hsqldb/demodb --dbname.0 testdb次のコマンドを使用して、上記のプログラムをコンパイルして実行します。
\>javac DropTable.java
\>java DropTable上記のコマンドを実行すると、次の出力が表示されます-
Table dropped successfullyINSERT INTOコマンドを使用して、HSQLDBでInsertqueryステートメントを実行できます。テーブルの列フィールドの順序に従って、ユーザー定義データを提供する必要があります。
構文
以下は、次の一般的な構文です。 INSERT クエリ。
INSERT INTO table_name (field1, field2,...fieldN)
VALUES (value1, value2,...valueN );文字列型のデータをテーブルに挿入するには、二重引用符または一重引用符を使用して、文字列値を挿入クエリステートメントに指定する必要があります。
例
次の名前のテーブルにレコードを挿入する例を考えてみましょう。 tutorials_tbl 値はid = 100、title = Learn PHP、Author = John Poulで、送信日は現在の日付です。
以下は、与えられた例のクエリです。
INSERT INTO tutorials_tbl VALUES (100,'Learn PHP', 'John Poul', NOW());上記のクエリの実行後、次の出力が表示されます-
1 row effectedHSQLDB –JDBCプログラム
これは、指定された値、id = 100、title = Learn PHP、Author = John Poul、および送信日が現在の日付であるレコードをテーブルに挿入するJDBCプログラムです。与えられたプログラムを見てください。コードをに保存しますInserQuery.java ファイル。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class InsertQuery {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate("INSERT INTO tutorials_tbl
VALUES (100,'Learn PHP', 'John Poul', NOW())");
con.commit();
}catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println(result+" rows effected");
System.out.println("Rows inserted successfully");
}
}次のコマンドを使用してデータベースを起動できます。
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0
file:hsqldb/demodb --dbname.0 testdb次のコマンドを使用して、上記のプログラムをコンパイルして実行します。
\>javac InsertQuery.java
\>java InsertQuery上記のコマンドを実行すると、次の出力が表示されます-
1 rows effected
Rows inserted successfully次のレコードをに挿入してみてください tutorials_tbl を使用してテーブル INSERT INTO コマンド。
| Id | 題名 | 著者 | 提出日 |
|---|---|---|---|
| 101 | Cを学ぶ | ヤスワント | Now() |
| 102 | MySQLを学ぶ | アブドゥルS | Now() |
| 103 | Excellを学ぶ | バヴィアカンナ | Now() |
| 104 | JDBを学ぶ | アジット・クマール | Now() |
| 105 | JUnitを学ぶ | Sathya Murthi | Now() |
SELECTコマンドは、HSQLDBデータベースからレコードデータをフェッチするために使用されます。ここでは、Selectステートメントで必須フィールドのリストを指定する必要があります。
構文
Selectクエリの一般的な構文は次のとおりです。
SELECT field1, field2,...fieldN table_name1, table_name2...
[WHERE Clause]
[OFFSET M ][LIMIT N]1つのSELECTコマンドで1つ以上のフィールドをフェッチできます。
フィールドの代わりにスター(*)を指定できます。この場合、SELECTはすべてのフィールドを返します。
WHERE句を使用して任意の条件を指定できます。
SELECTがレコードの戻りを開始するOFFSETを使用して、オフセットを指定できます。デフォルトでは、オフセットはゼロです。
LIMIT属性を使用して、返品の数を制限できます。
例
これは、すべてのレコードのid、title、およびauthorフィールドをからフェッチする例です。 tutorials_tblテーブル。これは、SELECTステートメントを使用して実現できます。以下は、例のクエリです。
SELECT id, title, author FROM tutorials_tbl上記のクエリを実行すると、次の出力が表示されます。
+------+----------------+-----------------+
| id | title | author |
+------+----------------+-----------------+
| 100 | Learn PHP | John Poul |
| 101 | Learn C | Yaswanth |
| 102 | Learn MySQL | Abdul S |
| 103 | Learn Excell | Bavya kanna |
| 104 | Learn JDB | Ajith kumar |
| 105 | Learn Junit | Sathya Murthi |
+------+----------------+-----------------+HSQLDB –JDBCプログラム
これは、すべてのレコードのID、タイトル、および作成者フィールドをからフェッチするJDBCプログラムです。 tutorials_tblテーブル。次のコードをに保存しますSelectQuery.java ファイル。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class SelectQuery {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeQuery(
"SELECT id, title, author FROM tutorials_tbl");
while(result.next()){
System.out.println(result.getInt("id")+" | "+
result.getString("title")+" | "+
result.getString("author"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}次のコマンドを使用してデータベースを起動できます。
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0
file:hsqldb/demodb --dbname.0 testdb次のコマンドを使用して、上記のコードをコンパイルして実行します。
\>javac SelectQuery.java
\>java SelectQuery上記のコマンドを実行すると、次の出力が表示されます-
100 | Learn PHP | John Poul
101 | Learn C | Yaswanth
102 | Learn MySQL | Abdul S
103 | Learn Excell | Bavya Kanna
104 | Learn JDB | Ajith kumar
105 | Learn Junit | Sathya Murthi通常、SELECTコマンドを使用してHSQLDBテーブルからデータをフェッチします。WHERE条件節を使用して、結果のデータをフィルタリングできます。WHEREを使用すると、選択基準を指定して、テーブルから必要なレコードを選択できます。
構文
以下は、HSQLDBテーブルからデータをフェッチするためのSELECTコマンドWHERE句の構文です。
SELECT field1, field2,...fieldN table_name1, table_name2...
[WHERE condition1 [AND [OR]] condition2.....カンマで区切られた1つ以上のテーブルを使用して、WHERE句を使用してさまざまな条件を含めることができますが、WHERE句はSELECTコマンドのオプション部分です。
WHERE句を使用して任意の条件を指定できます。
ANDまたはOR演算子を使用して、複数の条件を指定できます。
WHERE句をDELETEまたはUPDATESQLコマンドと一緒に使用して、条件を指定することもできます。
条件を使用してレコードデータをフィルタリングできます。条件付きWHERE句でさまざまな演算子を使用しています。WHERE句で使用できる演算子のリストを次に示します。
| オペレーター | 説明 | 例 |
|---|---|---|
| = | 2つのオペランドの値が等しいかどうかをチェックし、等しい場合は条件が真になります。 | (A = B)は真ではありません |
| != | 2つのオペランドの値が等しいかどうかをチェックし、値が等しくない場合は条件が真になります。 | (A!= B)は真です |
| >> | 左側のオペランドの値が右側のオペランドの値より大きいかどうかを確認します。大きい場合は、条件が真になります。 | (A> B)は正しくありません |
| < | 左側のオペランドの値が右側のオペランドの値よりも小さいかどうかを確認します。小さい場合は、条件が真になります。 | (A <B)は真です |
| > = | 左のオペランドの値が右のオペランドの値以上であるかどうかをチェックし、そうである場合は条件が真になります。 | (A> = B)は真ではありません |
| <= | 左のオペランドの値が右のオペランドの値以下であるかどうかをチェックし、そうである場合は条件が真になります。 | (A <= B)は真です |
例
これは、id、title、「LearnC」というタイトルの本の著者などの詳細を取得する例です。SELECTコマンドでWHERE句を使用することで可能です。以下は同じもののクエリです。
SELECT id, title, author FROM tutorials_tbl WHERE title = 'Learn C';上記のクエリを実行すると、次の出力が表示されます。
+------+----------------+-----------------+
| id | title | author |
+------+----------------+-----------------+
| 101 | Learn C | Yaswanth |
+------+----------------+-----------------+HSQLDB –JDBCプログラム
これは、タイトルを持つtutorials_tblテーブルからレコードデータを取得するJDBCプログラムです。 Learn C。次のコードをに保存しますWhereClause.java。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class WhereClause {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeQuery(
"SELECT id, title, author FROM tutorials_tbl
WHERE title = 'Learn C'");
while(result.next()){
System.out.println(result.getInt("id")+" |
"+result.getString("title")+" |
"+result.getString("author"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}次のコマンドを使用してデータベースを起動できます。
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0
file:hsqldb/demodb --dbname.0 testdb次のコマンドを使用して、上記のコードをコンパイルして実行します。
\>javac WhereClause.java
\>java WhereClause上記のコマンドを実行すると、次の出力が表示されます。
101 | Learn C | Yaswanthテーブルの値を変更するときはいつでも、UPDATEコマンドを使用できます。これにより、HSQLDBテーブルのフィールド値が変更されます。
構文
UPDATEコマンドの一般的な構文は次のとおりです。
UPDATE table_name SET field1 = new-value1, field2 = new-value2 [WHERE Clause]- 1つ以上のフィールドを完全に更新できます。
- WHERE句を使用して任意の条件を指定できます。
- 一度に1つのテーブルの値を更新できます。
例
チュートリアルのタイトルを「LearnC」からIDが「101」の「CandDataStructures」に更新する例を考えてみましょう。以下は、更新のクエリです。
UPDATE tutorials_tbl SET title = 'C and Data Structures' WHERE id = 101;上記のクエリを実行すると、次の出力が表示されます。
(1) Rows effectedHSQLDB –JDBCプログラム
これは、チュートリアルのタイトルを更新するJDBCプログラムです。 Learn C に C and Data Structures IDを持っている 101。次のプログラムをに保存しますUpdateQuery.java ファイル。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class UpdateQuery {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate(
"UPDATE tutorials_tbl SET title = 'C and Data Structures' WHERE id = 101");
} catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println(result+" Rows effected");
}
}次のコマンドを使用してデータベースを起動できます。
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0
file:hsqldb/demodb --dbname.0 testdb次のコマンドを使用して、上記のプログラムをコンパイルして実行します。
\>javac UpdateQuery.java
\>java UpdateQuery上記のコマンドを実行すると、次の出力が表示されます-
1 Rows effectedHSQLDBテーブルからレコードを削除する場合はいつでも、DELETEFROMコマンドを使用できます。
構文
HSQLDBテーブルからデータを削除するDELETEコマンドの一般的な構文は次のとおりです。
DELETE FROM table_name [WHERE Clause]WHERE句が指定されていない場合、すべてのレコードが指定されたMySQLテーブルから削除されます。
WHERE句を使用して任意の条件を指定できます。
一度に1つのテーブルのレコードを削除できます。
例
名前の付いたテーブルからレコードデータを削除する例を考えてみましょう。 tutorials_tbl IDを持っている 105。以下は、与えられた例を実装するクエリです。
DELETE FROM tutorials_tbl WHERE id = 105;上記のクエリの実行後、次の出力が表示されます-
(1) rows effectedHSQLDB –JDBCプログラム
これは、与えられた例を実装するJDBCプログラムです。次のプログラムをに保存しますDeleteQuery.java。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class DeleteQuery {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate(
"DELETE FROM tutorials_tbl WHERE id=105");
} catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println(result+" Rows effected");
}
}次のコマンドを使用してデータベースを起動できます。
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0
file:hsqldb/demodb --dbname.0 testdb次のコマンドを使用して、上記のプログラムをコンパイルして実行します。
\>javac DeleteQuery.java
\>java DeleteQuery上記のコマンドを実行すると、次の出力が表示されます-
1 Rows effectedRDBMS構造にはWHERE句があります。完全一致を実行する場合は、等号(=)を指定してWHERE句を使用できます。ただし、作成者名に「john」を含める必要があるすべての結果を除外する必要がある場合があります。これは、WHERE句とともにSQLLIKE句を使用して処理できます。
SQL LIKE句を%文字とともに使用すると、コマンドプロンプトですべてのファイルまたはディレクトリを一覧表示しながら、UNIXではメタ文字(*)のように機能します。
構文
以下は、LIKE句の一般的なSQL構文です。
SELECT field1, field2,...fieldN table_name1, table_name2...
WHERE field1 LIKE condition1 [AND [OR]] filed2 = 'somevalue'WHERE句を使用して任意の条件を指定できます。
LIKE句をWHERE句と一緒に使用できます。
等号の代わりにLIKE句を使用できます。
LIKE句を%記号と一緒に使用すると、メタ文字検索のように機能します。
ANDまたはOR演算子を使用して、複数の条件を指定できます。
WHERE ... LIKE句をDELETEまたはUPDATESQLコマンドと一緒に使用して、条件を指定できます。
例
著者名がで始まるチュートリアルデータのリストを取得する例を考えてみましょう。 John。以下は、特定の例のHSQLDBクエリです。
SELECT * from tutorials_tbl WHERE author LIKE 'John%';上記のクエリを実行すると、次の出力が表示されます。
+-----+----------------+-----------+-----------------+
| id | title | author | submission_date |
+-----+----------------+-----------+-----------------+
| 100 | Learn PHP | John Poul | 2016-06-20 |
+-----+----------------+-----------+-----------------+HSQLDB –JDBCプログラム
以下は、作成者名がで始まるチュートリアルデータのリストを取得するJDBCプログラムです。 John。コードをに保存しますLikeClause.java。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class LikeClause {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeQuery(
"SELECT * from tutorials_tbl WHERE author LIKE 'John%';");
while(result.next()){
System.out.println(result.getInt("id")+" |
"+result.getString("title")+" |
"+result.getString("author")+" |
"+result.getDate("submission_date"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}次のコマンドを使用してデータベースを起動できます。
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0
file:hsqldb/demodb --dbname.0 testdb次のコマンドを使用して、上記のコードをコンパイルして実行します。
\>javac LikeClause.java
\>java LikeClause次のコマンドを実行すると、次の出力が表示されます。
100 | Learn PHP | John Poul | 2016-06-20SQL SELECTコマンドは、レコードの取得および表示中に特定の順序に従う要件がある場合は常に、HSQLDBテーブルからデータをフェッチします。その場合、ORDER BY 句。
構文
これは、HSQLDBからデータをソートするためのSELECTコマンドとORDERBY句の構文です。
SELECT field1, field2,...fieldN table_name1, table_name2...
ORDER BY field1, [field2...] [ASC [DESC]]フィールドがリストされている場合は、返された結果を任意のフィールドで並べ替えることができます。
結果は複数のフィールドで並べ替えることができます。
キーワードASCまたはDESCを使用して、結果を昇順または降順で取得できます。デフォルトでは、昇順です。
通常の方法でWHERE ... LIKE句を使用して、条件を設定できます。
例
のレコードをフェッチしてソートする例を考えてみましょう。 tutorials_tbl著者名を昇順で並べた表。以下は同じもののクエリです。
SELECT id, title, author from tutorials_tbl ORDER BY author ASC;上記のクエリを実行すると、次の出力が表示されます。
+------+----------------+-----------------+
| id | title | author |
+------+----------------+-----------------+
| 102 | Learn MySQL | Abdul S |
| 104 | Learn JDB | Ajith kumar |
| 103 | Learn Excell | Bavya kanna |
| 100 | Learn PHP | John Poul |
| 105 | Learn Junit | Sathya Murthi |
| 101 | Learn C | Yaswanth |
+------+----------------+-----------------+HSQLDB –JDBCプログラム
これは、のレコードをフェッチしてソートするJDBCプログラムです。 tutorials_tbl著者名を昇順で並べた表。次のプログラムをに保存しますOrderBy.java。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class OrderBy {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeQuery(
"SELECT id, title, author from tutorials_tbl
ORDER BY author ASC");
while(result.next()){
System.out.println(result.getInt("id")+" |
"+result.getString("title")+" |
"+result.getString("author"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}次のコマンドを使用してデータベースを起動できます。
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0
file:hsqldb/demodb --dbname.0 testdb次のコマンドを使用して、上記のプログラムをコンパイルして実行します。
\>javac OrderBy.java
\>java OrderBy上記のコマンドを実行すると、次の出力が表示されます。
102 | Learn MySQL | Abdul S
104 | Learn JDB | Ajith kumar
103 | Learn Excell | Bavya Kanna
100 | Learn PHP | John Poul
105 | Learn Junit | Sathya Murthi
101 | C and Data Structures | Yaswanth単一のクエリを使用して複数のテーブルからデータを取得する必要がある場合はいつでも、RDBMSからJOINSを使用できます。1つのSQLクエリで複数のテーブルを使用できます。HSQLDBに参加するという行為は、2つ以上のテーブルを1つのテーブルに粉砕することを意味します。
次のCustomersテーブルとOrdersテーブルについて考えてみます。
Customer:
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------+
Orders:
+-----+---------------------+-------------+--------+
|OID | DATE | CUSTOMER_ID | AMOUNT |
+-----+---------------------+-------------+--------+
| 102 | 2009-10-08 00:00:00 | 3 | 3000 |
| 100 | 2009-10-08 00:00:00 | 3 | 1500 |
| 101 | 2009-11-20 00:00:00 | 2 | 1560 |
| 103 | 2008-05-20 00:00:00 | 4 | 2060 |
+-----+---------------------+-------------+--------+それでは、顧客のデータと、それぞれの顧客が出した注文金額を取得してみましょう。これは、顧客と注文テーブルの両方からレコードデータを取得していることを意味します。これは、HSQLDBのJOINSコンセプトを使用して実現できます。以下は、同じものに対するJOINクエリです。
SELECT ID, NAME, AGE, AMOUNT FROM CUSTOMERS, ORDERS WHERE CUSTOMERS.ID =
ORDERS.CUSTOMER_ID;上記のクエリを実行すると、次の出力が表示されます。
+----+----------+-----+--------+
| ID | NAME | AGE | AMOUNT |
+----+----------+-----+--------+
| 3 | kaushik | 23 | 3000 |
| 3 | kaushik | 23 | 1500 |
| 2 | Khilan | 25 | 1560 |
| 4 | Chaitali | 25 | 2060 |
+----+----------+-----+--------+JOINタイプ
HSQLDBで使用できる結合にはさまざまなタイプがあります。
INNER JOIN −両方のテーブルに一致する場合に行を返します。
LEFT JOIN −右側のテーブルに一致するものがない場合でも、左側のテーブルからすべての行を返します。
RIGHT JOIN −左側のテーブルに一致するものがない場合でも、右側のテーブルからすべての行を返します。
FULL JOIN −テーブルの1つに一致する場合、行を返します。
SELF JOIN −テーブルが2つのテーブルであるかのようにテーブルをそれ自体に結合するために使用され、SQLステートメントの少なくとも1つのテーブルの名前を一時的に変更します。
内部結合
結合の中で最も頻繁に使用され、重要なのは、内部結合です。EQUIJOINとも呼ばれます。
INNER JOINは、結合述語に基づいて2つのテーブル(table1とtable2)の列値を組み合わせることにより、新しい結果テーブルを作成します。クエリは、table1の各行をtable2の各行と比較して、結合述語を満たすすべての行のペアを見つけます。結合述語が満たされると、一致した行AとBの各ペアの列値が結合されて結果行になります。
構文
INNERJOINの基本的な構文は次のとおりです。
SELECT table1.column1, table2.column2...
FROM table1
INNER JOIN table2
ON table1.common_field = table2.common_field;例
次の2つのテーブルについて考えてみます。1つはCUSTOMERSテーブル、もう1つはORDERSテーブルというタイトルです。
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------++-----+---------------------+-------------+--------+
| OID | DATE | CUSTOMER_ID | AMOUNT |
+-----+---------------------+-------------+--------+
| 102 | 2009-10-08 00:00:00 | 3 | 3000 |
| 100 | 2009-10-08 00:00:00 | 3 | 1500 |
| 101 | 2009-11-20 00:00:00 | 2 | 1560 |
| 103 | 2008-05-20 00:00:00 | 4 | 2060 |
+-----+---------------------+-------------+--------+ここで、次のようにINNERJOINクエリを使用してこれら2つのテーブルを結合しましょう。
SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS
INNER JOIN ORDERS
ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;上記のクエリを実行すると、次の出力が表示されます。
+----+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+----+----------+--------+---------------------+
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
+----+----------+--------+---------------------+左結合
HSQLDB LEFT JOINは、右側のテーブルに一致するものがない場合でも、左側のテーブルからすべての行を返します。これは、ON句が右側のテーブルの0(ゼロ)レコードと一致する場合でも、結合は結果に行を返しますが、右側のテーブルの各列にはNULLが含まれることを意味します。
これは、左結合が左テーブルのすべての値に加えて、右テーブルの一致した値を返すか、一致する結合述語がない場合はNULLを返すことを意味します。
構文
LEFTJOINの基本的な構文は次のとおりです。
SELECT table1.column1, table2.column2...
FROM table1
LEFT JOIN table2
ON table1.common_field = table2.common_field;ここで、指定された条件は、要件に基づいた任意の式にすることができます。
例
次の2つのテーブルについて考えてみます。1つはCUSTOMERSテーブル、もう1つはORDERSテーブルというタイトルです。
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------++-----+---------------------+-------------+--------+
| OID | DATE | CUSTOMER_ID | AMOUNT |
+-----+---------------------+-------------+--------+
| 102 | 2009-10-08 00:00:00 | 3 | 3000 |
| 100 | 2009-10-08 00:00:00 | 3 | 1500 |
| 101 | 2009-11-20 00:00:00 | 2 | 1560 |
| 103 | 2008-05-20 00:00:00 | 4 | 2060 |
+-----+---------------------+-------------+--------+ここで、LEFT JOINクエリを使用してこれら2つのテーブルを次のように結合しましょう-
SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS
LEFT JOIN ORDERS
ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;上記のクエリの実行後、次の出力が表示されます-
+----+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+----+----------+--------+---------------------+
| 1 | Ramesh | NULL | NULL |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
| 5 | Hardik | NULL | NULL |
| 6 | Komal | NULL | NULL |
| 7 | Muffy | NULL | NULL |
+----+----------+--------+---------------------+右結合
HSQLDB RIGHT JOINは、左側のテーブルに一致するものがない場合でも、右側のテーブルからすべての行を返します。これは、ON句が左側のテーブルの0(ゼロ)レコードと一致する場合でも、結合は結果に行を返しますが、左側のテーブルの各列にはNULLが含まれることを意味します。
これは、右結合が右テーブルのすべての値に加えて、左テーブルの一致した値を返すか、一致する結合述語がない場合はNULLを返すことを意味します。
構文
の基本構文 RIGHT JOIN 次のとおりです-
SELECT table1.column1, table2.column2...
FROM table1
RIGHT JOIN table2
ON table1.common_field = table2.common_field;例
次の2つのテーブルについて考えてみます。1つはCUSTOMERSテーブル、もう1つはORDERSテーブルというタイトルです。
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------++-----+---------------------+-------------+--------+
| OID | DATE | CUSTOMER_ID | AMOUNT |
+-----+---------------------+-------------+--------+
| 102 | 2009-10-08 00:00:00 | 3 | 3000 |
| 100 | 2009-10-08 00:00:00 | 3 | 1500 |
| 101 | 2009-11-20 00:00:00 | 2 | 1560 |
| 103 | 2008-05-20 00:00:00 | 4 | 2060 |
+-----+---------------------+-------------+--------+ここで、次のようにRIGHTJOINクエリを使用してこれら2つのテーブルを結合しましょう。
SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS
RIGHT JOIN ORDERS
ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;上記のクエリを実行すると、次の結果が表示されます。
+------+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+------+----------+--------+---------------------+
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
+------+----------+--------+---------------------+完全結合
HSQLDB FULL JOINは、左右両方の外部結合の結果を結合します。
結合されたテーブルには、両方のテーブルのすべてのレコードが含まれ、いずれかの側で欠落している一致についてNULLを入力します。
構文
FULLJOINの基本的な構文は次のとおりです。
SELECT table1.column1, table2.column2...
FROM table1
FULL JOIN table2
ON table1.common_field = table2.common_field;ここで、指定された条件は、要件に基づいた任意の式にすることができます。
例
次の2つのテーブルについて考えてみます。1つはCUSTOMERSテーブル、もう1つはORDERSテーブルというタイトルです。
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------++-----+---------------------+-------------+--------+
| OID | DATE | CUSTOMER_ID | AMOUNT |
+-----+---------------------+-------------+--------+
| 102 | 2009-10-08 00:00:00 | 3 | 3000 |
| 100 | 2009-10-08 00:00:00 | 3 | 1500 |
| 101 | 2009-11-20 00:00:00 | 2 | 1560 |
| 103 | 2008-05-20 00:00:00 | 4 | 2060 |
+-----+---------------------+-------------+--------+ここで、次のようにFULLJOINクエリを使用してこれら2つのテーブルを結合しましょう。
SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS
FULL JOIN ORDERS
ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;上記のクエリを実行すると、次の結果が表示されます。
+------+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+------+----------+--------+---------------------+
| 1 | Ramesh | NULL | NULL |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
| 5 | Hardik | NULL | NULL |
| 6 | Komal | NULL | NULL |
| 7 | Muffy | NULL | NULL |
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
+------+----------+--------+---------------------+自己結合
SQL SELF JOINは、テーブルが2つのテーブルであるかのようにテーブルをそれ自体に結合するために使用され、SQLステートメント内の少なくとも1つのテーブルの名前を一時的に変更します。
構文
SELFJOINの基本的な構文は次のとおりです。
SELECT a.column_name, b.column_name...
FROM table1 a, table1 b
WHERE a.common_field = b.common_field;ここで、WHERE句は、要件に基づいて任意の式にすることができます。
例
次の2つのテーブルについて考えてみます。1つはCUSTOMERSテーブル、もう1つはORDERSテーブルというタイトルです。
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------+ここで、SELFJOINクエリを使用して次のようにこのテーブルを結合しましょう-
SELECT a.ID, b.NAME, a.SALARY FROM CUSTOMERS a, CUSTOMERS b
WHERE a.SALARY > b.SALARY;上記のクエリの実行後、次の出力が表示されます-
+----+----------+---------+
| ID | NAME | SALARY |
+----+----------+---------+
| 2 | Ramesh | 1500.00 |
| 2 | kaushik | 1500.00 |
| 1 | Chaitali | 2000.00 |
| 2 | Chaitali | 1500.00 |
| 3 | Chaitali | 2000.00 |
| 6 | Chaitali | 4500.00 |
| 1 | Hardik | 2000.00 |
| 2 | Hardik | 1500.00 |
| 3 | Hardik | 2000.00 |
| 4 | Hardik | 6500.00 |
| 6 | Hardik | 4500.00 |
| 1 | Komal | 2000.00 |
| 2 | Komal | 1500.00 |
| 3 | Komal | 2000.00 |
| 1 | Muffy | 2000.00 |
| 2 | Muffy | 1500.00 |
| 3 | Muffy | 2000.00 |
| 4 | Muffy | 6500.00 |
| 5 | Muffy | 8500.00 |
| 6 | Muffy | 4500.00 |
+----+----------+---------+SQL NULLは、欠落している値を表すために使用される用語です。テーブルのNULL値は、空白のように見えるフィールドの値です。フィールドまたは列の値をNULLと比較する条件を指定しようとすると、正しく機能しません。
3つのことを使用してNULL値を処理できます。
IS NULL −列の値がNULLの場合、演算子はtrueを返します。
IS NOT NULL −列の値がNULLでない場合、演算子はtrueを返します。
<=> −演算子は値を比較します。これは、(=演算子とは異なり)2つのNULL値に対しても当てはまります。
NULLまたはNOTNULLの列を探すには、それぞれISNULLまたはISNOTNULLを使用します。
例
テーブルがある例を考えてみましょう tcount_tblこれには、authorとtutorial_countの2つの列が含まれています。tutorial_countにNULL値を指定できます。これは、作成者がチュートリアルを1つも公開していないことを示します。したがって、それぞれの作成者のtutorial_count値はNULLです。
以下のクエリを実行します。
create table tcount_tbl(author varchar(40) NOT NULL, tutorial_count INT);
INSERT INTO tcount_tbl values ('Abdul S', 20);
INSERT INTO tcount_tbl values ('Ajith kumar', 5);
INSERT INTO tcount_tbl values ('Jen', NULL);
INSERT INTO tcount_tbl values ('Bavya kanna', 8);
INSERT INTO tcount_tbl values ('mahran', NULL);
INSERT INTO tcount_tbl values ('John Poul', 10);
INSERT INTO tcount_tbl values ('Sathya Murthi', 6);次のコマンドを使用して、からのすべてのレコードを表示します。 tcount_tbl テーブル。
select * from tcount_tbl;上記のコマンドを実行すると、次の出力が表示されます。
+-----------------+----------------+
| author | tutorial_count |
+-----------------+----------------+
| Abdul S | 20 |
| Ajith kumar | 5 |
| Jen | NULL |
| Bavya kanna | 8 |
| mahran | NULL |
| John Poul | 10 |
| Sathya Murthi | 6 |
+-----------------+----------------+tutorial_count列がNULLであるレコードを見つけるためのクエリは、次のとおりです。
SELECT * FROM tcount_tbl WHERE tutorial_count IS NULL;クエリの実行後、次の出力が表示されます。
+-----------------+----------------+
| author | tutorial_count |
+-----------------+----------------+
| Jen | NULL |
| mahran | NULL |
+-----------------+----------------+tutorial_count列がNULLでないレコードを見つけるためのクエリは、次のとおりです。
SELECT * FROM tcount_tbl WHERE tutorial_count IS NOT NULL;クエリの実行後、次の出力が表示されます。
+-----------------+----------------+
| author | tutorial_count |
+-----------------+----------------+
| Abdul S | 20 |
| Ajith kumar | 5 |
| Bavya kanna | 8 |
| John Poul | 10 |
| Sathya Murthi | 6 |
+-----------------+----------------+HSQLDB –JDBCプログラム
これは、tutorial_countがNULLでtutorial_countがNOTNULLであるテーブルtcount_tblとは別にレコードを取得するJDBCプログラムです。次のプログラムをに保存しますNullValues.java。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class NullValues {
public static void main(String[] args) {
Connection con = null;
Statement stmt_is_null = null;
Statement stmt_is_not_null = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt_is_null = con.createStatement();
stmt_is_not_null = con.createStatement();
result = stmt_is_null.executeQuery(
"SELECT * FROM tcount_tbl WHERE tutorial_count IS NULL;");
System.out.println("Records where the tutorial_count is NULL");
while(result.next()){
System.out.println(result.getString("author")+" |
"+result.getInt("tutorial_count"));
}
result = stmt_is_not_null.executeQuery(
"SELECT * FROM tcount_tbl WHERE tutorial_count IS NOT NULL;");
System.out.println("Records where the tutorial_count is NOT NULL");
while(result.next()){
System.out.println(result.getString("author")+" |
"+result.getInt("tutorial_count"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}次のコマンドを使用して、上記のプログラムをコンパイルして実行します。
\>javac NullValues.java
\>Java NullValues上記のコマンドを実行すると、次の出力が表示されます。
Records where the tutorial_count is NULL
Jen | 0
mahran | 0
Records where the tutorial_count is NOT NULL
Abdul S | 20
Ajith kumar | 5
Bavya kanna | 8
John Poul | 10
Sathya Murthi | 6HSQLDBは、正規表現とREGEXP演算子に基づくパターンマッチング操作のためのいくつかの特別なシンボルをサポートしています。
以下は、REGEXP演算子と一緒に使用できるパターンの表です。
| パターン | パターンが一致するもの |
|---|---|
| ^ | 文字列の始まり |
| $ | 文字列の終わり |
| 。 | 任意の1文字 |
| [...] | 角括弧の間にリストされている文字 |
| [^ ...] | 角括弧の間にリストされていない文字 |
| p1 | p2 | p3 | 交替; パターンp1、p2、またはp3のいずれかに一致します |
| * | 前の要素の0個以上のインスタンス |
| + | 前の要素の1つ以上のインスタンス |
| {n} | 前の要素のn個のインスタンス |
| {m、n} | 前の要素のmからn個のインスタンス |
例
要件を満たすために、さまざまなクエリ例を試してみましょう。次のクエリを見てください。
このクエリを試して、名前が「^ A」で始まるすべての作成者を検索してください。
SELECT author FROM tcount_tbl WHERE REGEXP_MATCHES(author,'^A.*');上記のクエリを実行すると、次の出力が表示されます。
+-----------------+
| author |
+-----------------+
| Abdul S |
| Ajith kumar |
+-----------------+このクエリを試して、名前が「ul $」で終わるすべての作成者を見つけてください。
SELECT author FROM tcount_tbl WHERE REGEXP_MATCHES(author,'.*ul$');上記のクエリを実行すると、次の出力が表示されます。
+-----------------+
| author |
+-----------------+
| John Poul |
+-----------------+このクエリを試して、名前に「th」が含まれているすべての作成者を検索してください。
SELECT author FROM tcount_tbl WHERE REGEXP_MATCHES(author,'.*th.*');上記のクエリを実行すると、次の出力が表示されます。
+-----------------+
| author |
+-----------------+
| Ajith kumar |
| Abdul S |
+-----------------+このクエリを試して、名前が母音(a、e、i、o、u)で始まるすべての著者を見つけてください。
SELECT author FROM tcount_tbl WHERE REGEXP_MATCHES(author,'^[AEIOU].*');上記のクエリを実行すると、次の出力が表示されます。
+-----------------+
| author |
+-----------------+
| Abdul S |
| Ajith kumar |
+-----------------+A Transactionは、データベース操作操作の順次グループであり、実行され、単一の作業単位と見なされます。つまり、すべての操作が正常に実行されると、トランザクション全体が完了します。トランザクション内のいずれかの操作が失敗すると、トランザクション全体が失敗します。
トランザクションのプロパティ
基本的に、トランザクションは4つの標準プロパティをサポートします。それらはACIDプロパティと呼ばれることがあります。
Atomicity −トランザクション内のすべての操作は正常に実行されます。それ以外の場合、トランザクションは失敗した時点で中止され、前の操作は前の位置にロールバックされます。
Consistency −データベースは、トランザクションが正常にコミットされると、状態を適切に変更します。
Isolation −トランザクションが独立して動作し、相互に透過的になることを可能にします。
Durability −システム障害が発生した場合でも、コミットされたトランザクションの結果または効果は持続します。
コミット、ロールバック、およびセーブポイント
これらのキーワードは、主にHSQLDBトランザクションに使用されます。
Commit−常に、COMMITコマンドを実行してトランザクションを成功させる必要があります。
Rollback −トランザクションで障害が発生した場合は、ROLLBACKコマンドを実行して、トランザクションで参照されているすべてのテーブルを以前の状態に戻す必要があります。
Savepoint −ロールバックするトランザクションのグループ内にポイントを作成します。
例
次の例では、トランザクションの概念と、コミット、ロールバック、およびセーブポイントについて説明します。id、name、age、address、salaryの各列を持つCustomersテーブルについて考えてみましょう。
| Id | 名前 | 年齢 | 住所 | 給料 |
|---|---|---|---|---|
| 1 | ラメッシュ | 32 | アーメダバード | 2000.00 |
| 2 | カルン | 25 | デリー | 1500.00 |
| 3 | カウシク | 23 | コタ | 2000.00 |
| 4 | チャイタンヤ | 25 | ムンバイ | 6500.00 |
| 5 | ハリッシュ | 27 | ボパール | 8500.00 |
| 6 | カメシュ | 22 | MP | 1500.00 |
| 7 | ムラリ | 24 | インドール | 10000.00 |
次のコマンドを使用して、上記のデータに沿って顧客テーブルを作成します。
CREATE TABLE Customer (id INT NOT NULL, name VARCHAR(100) NOT NULL, age INT NOT
NULL, address VARCHAR(20), Salary INT, PRIMARY KEY (id));
Insert into Customer values (1, "Ramesh", 32, "Ahmedabad", 2000);
Insert into Customer values (2, "Karun", 25, "Delhi", 1500);
Insert into Customer values (3, "Kaushik", 23, "Kota", 2000);
Insert into Customer values (4, "Chaitanya", 25, "Mumbai", 6500);
Insert into Customer values (5, "Harish", 27, "Bhopal", 8500);
Insert into Customer values (6, "Kamesh", 22, "MP", 1500);
Insert into Customer values (7, "Murali", 24, "Indore", 10000);COMMITの例
次のクエリは、age = 25のテーブルから行を削除し、COMMITコマンドを使用してそれらの変更をデータベースに適用します。
DELETE FROM CUSTOMERS WHERE AGE = 25;
COMMIT;上記のクエリを実行すると、次の出力が表示されます。
2 rows effected上記のコマンドを正常に実行した後、以下のコマンドを実行して、customerテーブルのレコードを確認します。
Select * from Customer;上記のクエリを実行すると、次の出力が表示されます。
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000 |
| 3 | kaushik | 23 | Kota | 2000 |
| 5 | Harish | 27 | Bhopal | 8500 |
| 6 | Kamesh | 22 | MP | 4500 |
| 7 | Murali | 24 | Indore | 10000 |
+----+----------+-----+-----------+----------+ロールバックの例
入力と同じCustomerテーブルを考えてみましょう。
| Id | 名前 | 年齢 | 住所 | 給料 |
|---|---|---|---|---|
| 1 | ラメッシュ | 32 | アーメダバード | 2000.00 |
| 2 | カルン | 25 | デリー | 1500.00 |
| 3 | カウシク | 23 | コタ | 2000.00 |
| 4 | チャイタンヤ | 25 | ムンバイ | 6500.00 |
| 5 | ハリッシュ | 27 | ボパール | 8500.00 |
| 6 | カメシュ | 22 | MP | 1500.00 |
| 7 | ムラリ | 24 | インドール | 10000.00 |
これは、age = 25のテーブルからレコードを削除してから、データベース内の変更をロールバックすることにより、ロールバック機能について説明するクエリの例です。
DELETE FROM CUSTOMERS WHERE AGE = 25;
ROLLBACK;上記の2つのクエリが正常に実行された後、次のコマンドを使用してCustomerテーブルのレコードデータを表示できます。
Select * from Customer;上記のコマンドを実行すると、次の出力が表示されます。
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000 |
| 2 | Karun | 25 | Delhi | 1500 |
| 3 | Kaushik | 23 | Kota | 2000 |
| 4 | Chaitanya| 25 | Mumbai | 6500 |
| 5 | Harish | 27 | Bhopal | 8500 |
| 6 | Kamesh | 22 | MP | 4500 |
| 7 | Murali | 24 | Indore | 10000 |
+----+----------+-----+-----------+----------+削除クエリは、年齢= 25の顧客のレコードデータを削除します。ロールバックコマンドは、Customerテーブルでそれらの変更をロールバックします。
セーブポイントの例
セーブポイントは、トランザクション全体をロールバックせずにトランザクションを特定のポイントにロールバックできるトランザクション内のポイントです。
入力と同じCustomerテーブルを考えてみましょう。
| Id | 名前 | 年齢 | 住所 | 給料 |
|---|---|---|---|---|
| 1 | ラメッシュ | 32 | アーメダバード | 2000.00 |
| 2 | カルン | 25 | デリー | 1500.00 |
| 3 | カウシク | 23 | コタ | 2000.00 |
| 4 | チャイタンヤ | 25 | ムンバイ | 6500.00 |
| 5 | ハリッシュ | 27 | ボパール | 8500.00 |
| 6 | カメシュ | 22 | MP | 1500.00 |
| 7 | ムラリ | 24 | インドール | 10000.00 |
この例では、Customersテーブルから3つの異なるレコードを削除することを計画していると考えてみましょう。削除するたびにセーブポイントを作成して、いつでも任意のセーブポイントにロールバックして、適切なデータを元の状態に戻すことができるようにします。
これが一連の操作です。
SAVEPOINT SP1;
DELETE FROM CUSTOMERS WHERE ID = 1;
SAVEPOINT SP2;
DELETE FROM CUSTOMERS WHERE ID = 2;
SAVEPOINT SP3;
DELETE FROM CUSTOMERS WHERE ID = 3;これで、3つのセーブポイントが作成され、3つのレコードが削除されました。この状況で、ID 2および3のレコードをロールバックする場合は、次のロールバックコマンドを使用します。
ROLLBACK TO SP2;SP2にロールバックしてから、最初の削除のみが行われたことに注意してください。次のクエリを使用して、顧客のすべてのレコードを表示します。
Select * from Customer;上記のクエリを実行すると、次の出力が表示されます。
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 2 | Karun | 25 | Delhi | 1500 |
| 3 | Kaushik | 23 | Kota | 2000 |
| 4 | Chaitanya| 25 | Mumbai | 6500 |
| 5 | Harish | 27 | Bhopal | 8500 |
| 6 | Kamesh | 22 | MP | 4500 |
| 7 | Murali | 24 | Indore | 10000 |
+----+----------+-----+-----------+----------+セーブポイントを解放する
RELEASEコマンドを使用してセーブポイントを解放できます。以下は一般的な構文です。
RELEASE SAVEPOINT SAVEPOINT_NAME;テーブルまたはフィールドの名前の変更、フィールドの順序の変更、フィールドのデータ型の変更、または任意のテーブル構造が必要な場合はいつでも、ALTERコマンドを使用して同じことを実現できます。
例
さまざまなシナリオを使用してALTERコマンドを説明する例を考えてみましょう。
次のクエリを使用して、という名前のテーブルを作成します testalter_tbl フィールドで」 id そして name。
//below given query is to create a table testalter_tbl table.
create table testalter_tbl(id INT, name VARCHAR(10));
//below given query is to verify the table structure testalter_tbl.
Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM =
'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';上記のクエリを実行すると、次の出力が表示されます。
+------------+-------------+------------+-----------+-----------+------------+
|TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE|
+------------+-------------+------------+-----------+-----------+------------+
| PUBLIC |TESTALTER_TBL| ID | 4 | INTEGER | 4 |
| PUBLIC |TESTALTER_TBL| NAME | 12 | VARCHAR | 10 |
+------------+-------------+------------+-----------+-----------+------------+列の削除または追加
HSQLDBテーブルから既存の列をDROPする場合はいつでも、ALTERコマンドとともにDROP句を使用できます。
次のクエリを使用して列を削除します(name)テーブルtestalter_tblから。
ALTER TABLE testalter_tbl DROP name;上記のクエリが正常に実行された後、次のコマンドを使用して、名前フィールドがテーブルtestalter_tblから削除されているかどうかを確認できます。
Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM =
'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';上記のコマンドを実行すると、次の出力が表示されます。
+------------+-------------+------------+-----------+-----------+------------+
|TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE|
+------------+-------------+------------+-----------+-----------+------------+
| PUBLIC |TESTALTER_TBL| ID | 4 | INTEGER | 4 |
+------------+-------------+------------+-----------+-----------+------------+HSQLDBテーブルに列を追加するときはいつでも、ALTERコマンドと一緒にADD句を使用できます。
次のクエリを使用して、という名前の列を追加します NAME テーブルに testalter_tbl。
ALTER TABLE testalter_tbl ADD name VARCHAR(10);上記のクエリが正常に実行された後、名前フィールドがテーブルに追加されているかどうかを知ることができます testalter_tbl 次のコマンドを使用します。
Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM =
'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';上記のクエリを実行すると、次の出力が表示されます。
+------------+-------------+------------+-----------+-----------+------------+
|TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE|
+------------+-------------+------------+-----------+-----------+------------+
| PUBLIC |TESTALTER_TBL| ID | 4 | INTEGER | 4 |
| PUBLIC |TESTALTER_TBL| NAME | 12 | VARCHAR | 10 |
+------------+-------------+------------+-----------+-----------+------------+列の定義または名前の変更
列定義を変更する必要がある場合は常に、 MODIFY または CHANGE と一緒に条項 ALTER コマンド。
CHANGE句の使用方法を説明する例を考えてみましょう。テーブルtestalter_tblデータ型がそれぞれintとvarcharの2つのフィールド(idとname)が含まれています。ここで、idのデータ型をINTからBIGINTに変更してみましょう。以下は、変更を加えるためのクエリです。
ALTER TABLE testalter_tbl CHANGE id id BIGINT;上記のクエリが正常に実行された後、次のコマンドを使用してテーブル構造を確認できます。
Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM =
'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';上記のコマンドを実行すると、次の出力が表示されます。
+------------+-------------+------------+-----------+-----------+------------+
|TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE|
+------------+-------------+------------+-----------+-----------+------------+
| PUBLIC |TESTALTER_TBL| ID | 4 | BIGINT | 4 |
| PUBLIC |TESTALTER_TBL| NAME | 12 | VARCHAR | 10 |
+------------+-------------+------------+-----------+-----------+------------+次に、列NAMEのサイズを10から20に増やしてみましょう。 testalter_tblテーブル。以下は、ALTERコマンドとともにMODIFY句を使用してこれを実現するためのクエリです。
ALTER TABLE testalter_tbl MODIFY name VARCHAR(20);上記のクエリが正常に実行された後、次のコマンドを使用してテーブル構造を確認できます。
Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM =
'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';上記のコマンドを実行すると、次の出力が表示されます。
+------------+-------------+------------+-----------+-----------+------------+
|TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE|
+------------+-------------+------------+-----------+-----------+------------+
| PUBLIC |TESTALTER_TBL| ID | 4 | BIGINT | 4 |
| PUBLIC |TESTALTER_TBL| NAME | 12 | VARCHAR | 20 |
+------------+-------------+------------+-----------+-----------+------------+A database indexテーブル内の操作の速度を向上させるデータ構造です。インデックスは、1つ以上の列を使用して作成でき、迅速なランダムルックアップとレコードへのアクセスの効率的な順序付けの両方の基礎を提供します。
インデックスを作成するときは、SQLクエリを作成するために使用される列を考慮し、それらの列に1つ以上のインデックスを作成する必要があります。
実際には、インデックスはテーブルのタイプでもあり、主キーまたはインデックスフィールドと、各レコードへのポインタを実際のテーブルに保持します。
ユーザーはインデックスを見ることができません。これらはクエリを高速化するために使用され、データベース検索エンジンがレコードをすばやく見つけるために使用されます。
INSERTステートメントとUPDATEステートメントは、インデックスを持つテーブルでは時間がかかりますが、SELECTステートメントはこれらのテーブルでより高速に実行されます。その理由は、挿入または更新中に、データベースがインデックス値も挿入または更新する必要があるためです。
シンプルでユニークなインデックス
テーブルに一意のインデックスを作成できます。Aunique index2つの行が同じインデックス値を持つことができないことを意味します。以下は、テーブルにインデックスを作成するための構文です。
CREATE UNIQUE INDEX index_name
ON table_name (column1, column2,...);1つ以上の列を使用してインデックスを作成できます。たとえば、tutorial_authorを使用してtutorials_tblにインデックスを作成します。
CREATE UNIQUE INDEX AUTHOR_INDEX
ON tutorials_tbl (tutorial_author)テーブルに簡単なインデックスを作成できます。クエリからUNIQUEキーワードを省略するだけで、単純なインデックスが作成されます。Asimple index テーブル内の重複値を許可します。
列の値に降順でインデックスを付ける場合は、列名の後に予約語DESCを追加できます。
CREATE UNIQUE INDEX AUTHOR_INDEX
ON tutorials_tbl (tutorial_author DESC)INDEXを追加および削除するALTERコマンド
テーブルにインデックスを追加するためのステートメントには4つのタイプがあります-
ALTER TABLE tbl_name ADD PRIMARY KEY (column_list) −このステートメントは、PRIMARY KEYを追加します。これは、インデックス付きの値が一意である必要があり、NULLであってはならないことを意味します。
ALTER TABLE tbl_name ADD UNIQUE index_name (column_list) −このステートメントは、値が一意でなければならないインデックスを作成します(NULL値は複数回表示される場合があります)。
ALTER TABLE tbl_name ADD INDEX index_name (column_list) −これにより、任意の値が複数回表示される可能性のある通常のインデックスが追加されます。
ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list) −これにより、テキスト検索の目的で使用される特別なFULLTEXTインデックスが作成されます。
以下は、既存のテーブルにインデックスを追加するためのクエリです。
ALTER TABLE testalter_tbl ADD INDEX (c);DROP句をALTERコマンドと一緒に使用すると、任意のINDEXを削除できます。以下は、上記で作成したインデックスを削除するためのクエリです。
ALTER TABLE testalter_tbl DROP INDEX (c);INDEX情報の表示
SHOW INDEXコマンドを使用して、テーブルに関連付けられているすべてのインデックスを一覧表示できます。垂直形式の出力(\ Gで指定)は、長い行の折り返しを避けるために、このステートメントで役立つことがよくあります。
以下は、テーブルに関するインデックス情報を表示するための一般的な構文です。
SHOW INDEX FROM table_name\G