IMSDB-セカンダリインデックス
セカンダリインデックスは、完全に連結されたキーを使用せずにデータベースにアクセスする場合、またはシーケンスのプライマリフィールドを使用しない場合に使用されます。
インデックスポインタセグメント
DL / Iは、インデックス付きデータベースのセグメントへのポインタを別のデータベースに格納します。インデックスポインタセグメントは、セカンダリインデックスの唯一のタイプです。それは2つの部分で構成されています-
- プレフィックス要素
- データ要素
プレフィックス要素
インデックスポインタセグメントのプレフィックス部分には、インデックスターゲットセグメントへのポインタが含まれています。インデックスターゲットセグメントは、セカンダリインデックスを使用してアクセスできるセグメントです。
データ要素
データ要素には、インデックスが作成されるインデックス付きデータベースのセグメントからのキー値が含まれます。これは、インデックスソースセグメントとも呼ばれます。
セカンダリインデックスについて注意すべき重要なポイントは次のとおりです-
インデックスソースセグメントとターゲットソースセグメントは同じである必要はありません。
セカンダリインデックスを設定すると、DL / Iによって自動的に維持されます。
DBAは、複数のアクセスパスに従って多くのセカンダリインデックスを定義します。これらのセカンダリインデックスは、別のインデックスデータベースに保存されます。
DL / Iに追加の処理オーバーヘッドがかかるため、セカンダリインデックスをこれ以上作成しないでください。
二次キー
注意点-
セカンダリインデックスが構築されるインデックスソースセグメントのフィールドは、セカンダリキーと呼ばれます。
任意のフィールドを2次キーとして使用できます。セグメントシーケンスフィールドである必要はありません。
セカンダリキーは、インデックスソースセグメント内の単一フィールドの任意の組み合わせにすることができます。
二次キー値は一意である必要はありません。
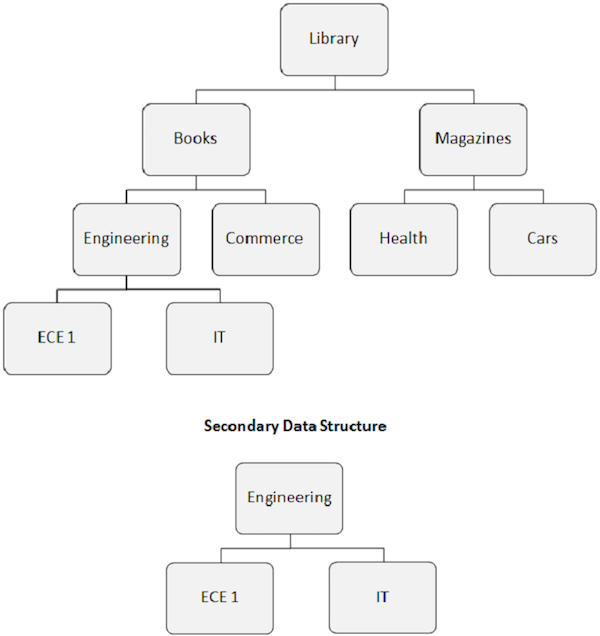
二次データ構造
注意点-
セカンダリインデックスを作成すると、データベースの見かけの階層構造も変更されます。
インデックスターゲットセグメントが見かけのルートセグメントになります。次の画像に示すように、エンジニアリングセグメントは、ルートセグメントでなくても、ルートセグメントになります。
セカンダリインデックスによって引き起こされるデータベース構造の再配置は、セカンダリデータ構造と呼ばれます。
セカンダリデータ構造は、ディスク上に存在するメインの物理データベース構造に変更を加えません。これは、アプリケーションプログラムの前でデータベース構造を変更する方法にすぎません。
独立したAND演算子
注意点-
AND(*または&)演算子がセカンダリインデックスで使用される場合、それは従属AND演算子と呼ばれます。
独立AND(#)を使用すると、従属ANDでは不可能な資格を指定できます。
この演算子は、インデックスソースセグメントがインデックスターゲットセグメントに依存しているセカンダリインデックスにのみ使用できます。
独立したANDを使用してSSAをコーディングし、2つ以上の依存するソースセグメントのフィールドに基づいてターゲットセグメントのオカレンスを処理するように指定できます。
01 ITEM-SELECTION-SSA.
05 FILLER PIC X(8).
05 FILLER PIC X(1) VALUE '('.
05 FILLER PIC X(10).
05 SSA-KEY-1 PIC X(8).
05 FILLER PIC X VALUE '#'.
05 FILLER PIC X(10).
05 SSA-KEY-2 PIC X(8).
05 FILLER PIC X VALUE ')'.スパースシーケンス
注意点-
スパースシーケンスは、スパースインデックスとも呼ばれます。セカンダリインデックスデータベースでスパースシーケンスを使用して、インデックスからインデックスソースセグメントの一部を削除できます。
スパースシーケンスは、パフォーマンスを向上させるために使用されます。インデックスソースセグメントの一部のオカレンスが使用されていない場合、それを削除できます。
DL / Iは、抑制値または抑制ルーチン、あるいはその両方を使用して、セグメントにインデックスを付ける必要があるかどうかを判断します。
インデックスソースセグメントのシーケンスフィールドの値が抑制値と一致する場合、インデックス関係は確立されません。
抑制ルーチンは、セグメントを評価し、インデックスを作成する必要があるかどうかを判断するユーザー作成プログラムです。
スパースインデックスが使用される場合、その関数はDL / Iによって処理されます。申請プログラムで特別な規定をする必要はありません。
DBDGEN要件
前のモジュールで説明したように、DBDGENはDBDの作成に使用されます。セカンダリインデックスを作成する場合、2つのデータベースが関係します。DBAは、インデックス付きデータベースとセカンダリインデックス付きデータベースの間の関係を作成するために、2つのDBDGENを使用して2つのDBDを作成する必要があります。
PSBGENの要件
データベースのセカンダリインデックスを作成した後、DBAはPSBを作成する必要があります。プログラムのPSBGENは、PSBマクロのPROCSEQパラメーターでデータベースの適切な処理シーケンスを指定します。PROCSEQパラメーターの場合、DBAは2次索引データベースのDBD名をコーディングします。