KDB +アーキテクチャ
Kdb +は、膨大な量のデータを処理するために最初から設計された高性能で大量のデータベースです。完全に64ビットであり、マルチコア処理とマルチスレッドが組み込まれています。同じアーキテクチャがリアルタイムデータと履歴データに使用されます。データベースには、独自の強力なクエリ言語が組み込まれています。q, そのため、分析はデータに対して直接実行できます。
kdb+tick は、リアルタイムおよび履歴データのキャプチャ、処理、およびクエリを可能にするアーキテクチャです。
Kdb + /ティックアーキテクチャ
次の図は、典型的なKdb + / tickアーキテクチャの一般的な概要を示し、その後にさまざまなコンポーネントとデータのスルーフローについて簡単に説明しています。
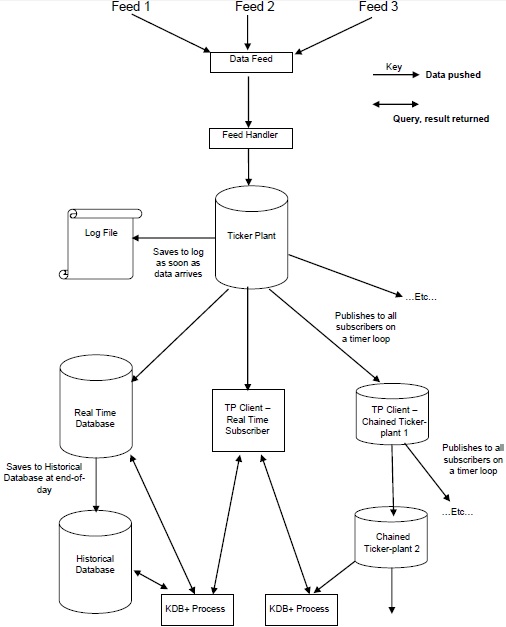
ザ・ Data Feeds は、ロイター、ブルームバーグなどのデータフィードプロバイダーによって、または取引所から直接提供される時系列データです。
関連するデータを取得するために、データフィードからのデータはによって解析されます feed handler。
データがフィードハンドラーによって解析されると、データは ticker-plant。
障害からデータを回復するために、ticker-plantは最初に新しいデータを更新/ログファイルに保存してから、独自のテーブルを更新します。
内部テーブルとログファイルを更新した後、オンタイムループデータは、リアルタイムデータベースと、データを要求したすべてのチェーンサブスクライバーに継続的に送信/公開されます。
営業日の終わりに、ログファイルが削除され、新しいログファイルが作成され、リアルタイムデータベースが履歴データベースに保存されます。すべてのデータが履歴データベースに保存されると、リアルタイムデータベースはそのテーブルを削除します。
Kdb + Tickアーキテクチャのコンポーネント
データフィード
データフィードは、任意の市場またはその他の時系列データにすることができます。データフィードをフィードハンドラーへの生の入力と見なします。フィードは、取引所(ライブストリーミングデータ)、トムソンロイター、ブルームバーグなどのニュース/データプロバイダー、またはその他の外部機関から直接送信できます。
フィードハンドラー
フィードハンドラーは、データストリームをkdb +への書き込みに適した形式に変換します。データフィードに接続され、データを取得してフィード固有の形式からKdb +メッセージに変換し、ティッカープラントプロセスに公開します。通常、フィードハンドラは、次の操作を実行するために使用されます-
- 一連のルールに従ってデータをキャプチャします。
- そのデータをある形式から別の形式に変換(/強化)します。
- 最新の値をキャッチします。
ティッカープラント
Ticker Plantは、KDB +アーキテクチャの最も重要なコンポーネントです。これは、リアルタイムデータベースまたは直接サブスクライバー(クライアント)が財務データにアクセスするために接続されるティッカープラントです。それはで動作しますpublish and subscribe機構。サブスクリプション(ライセンス)を取得すると、発行者(ティッカープラント)からのティック(定期的)パブリケーションが定義されます。以下の操作を行います-
フィードハンドラーからデータを受信します。
ティッカープラントはデータを受信するとすぐに、コピーをログファイルとして保存し、ティッカープラントが更新を取得すると更新するため、障害が発生した場合でもデータが失われることはありません。
クライアント(リアルタイムサブスクライバー)は、ティッカープラントに直接サブスクライブできます。
各営業日の終わりに、つまり、リアルタイムデータベースが最後のメッセージを受信すると、今日のすべてのデータを履歴データベースに保存し、今日のデータをサブスクライブしたすべてのサブスクライバーに同じものをプッシュします。次に、すべてのテーブルをリセットします。データが履歴データベースまたはリアルタイムデータベース(rtdb)に直接リンクされた他のサブスクライバーに保存されると、ログファイルも削除されます。
その結果、ティッカープラント、リアルタイムデータベース、および履歴データベースは24時間年中無休で運用されています。
ティッカープラントはKdb +アプリケーションであるため、そのテーブルは次を使用してクエリできます。 q他のKdb +データベースと同じように。すべてのティッカープラントクライアントは、サブスクライバーとしてのみデータベースにアクセスできる必要があります。
リアルタイムデータベース
リアルタイムデータベース(rdb)は、今日のデータを格納します。ティッカープラントに直接接続されています。通常、市場時間(1日)にメモリに保存され、1日の終わりに履歴データベース(hdb)に書き出されます。データ(rdbデータ)はメモリに保存されるため、処理は非常に高速です。
kdb +は1日あたりのデータの予想サイズの4倍以上のRAMサイズを推奨しているため、rdbで実行されるクエリは非常に高速で、優れたパフォーマンスを提供します。リアルタイムデータベースには今日のデータのみが含まれているため、日付列(パラメーター)は必要ありません。
たとえば、次のようなrdbクエリを作成できます。
select from trade where sym = `ibm
OR
select from trade where sym = `ibm, price > 100履歴データベース
会社の見積もりを計算する必要がある場合は、その履歴データを利用できるようにする必要があります。履歴データベース(hdb)は、過去に行われたトランザクションのデータを保持します。新しい日のレコードは、1日の終わりにhdbに追加されます。hdb内の大きなテーブルは、分散して保存されるか(各列は独自のファイルに保存されます)、一時データによってパーティション分割されて保存されます。また、一部の非常に大規模なデータベースは、par.txt (ファイル)。
これらのストレージ戦略(分散、パーティション化など)は、大きなテーブルからデータを検索またはアクセスするときに効率的です。
履歴データベースは、内部および外部のレポート目的、つまり分析にも使用できます。たとえば、特定の日のIBMの会社の取引を取引(または任意の)テーブル名から取得したい場合、次のようにクエリを作成する必要があります。
thisday: 2014.10.12
select from trade where date = thisday, sym =`ibmNote −概要がわかり次第、このようなクエリをすべて記述します。 q 言語。