マハウト-環境
この章では、mahoutの設定方法について説明します。JavaとHadoopはmahoutの前提条件です。以下に、Java、Hadoop、およびMahoutをダウンロードしてインストールする手順を示します。
インストール前のセットアップ
Linux環境にHadoopをインストールする前に、を使用してLinuxをセットアップする必要があります。 ssh(セキュアシェル)。Linux環境をセットアップするには、以下の手順に従ってください。
ユーザーの作成
HadoopファイルシステムをUnixファイルシステムから分離するために、Hadoop用に別のユーザーを作成することをお勧めします。以下の手順に従って、ユーザーを作成します。
コマンド「su」を使用してrootを開きます。
- コマンドを使用してrootアカウントからユーザーを作成します “useradd username”。
これで、コマンドを使用して既存のユーザーアカウントを開くことができます “su username”。
Linuxターミナルを開き、次のコマンドを入力してユーザーを作成します。
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwdSSHセットアップとキー生成
SSHセットアップは、開始、停止、分散デーモンシェル操作など、クラスターでさまざまな操作を実行するために必要です。Hadoopのさまざまなユーザーを認証するには、Hadoopユーザーに公開鍵と秘密鍵のペアを提供し、それをさまざまなユーザーと共有する必要があります。
次のコマンドは、SSHを使用してキーと値のペアを生成し、id_rsa.pubからauthorized_keysに公開キーをコピーし、authorized_keysファイルにそれぞれ所有者、読み取り、および書き込みのアクセス許可を与えるために使用されます。
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keyssshの検証
ssh localhostJavaのインストール
JavaはHadoopとHBaseの主な前提条件です。まず、「java-version」を使用してシステム内のJavaの存在を確認する必要があります。Javaバージョンコマンドの構文を以下に示します。
$ java -version次の出力が生成されます。
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)システムにJavaがインストールされていない場合は、以下の手順に従ってJavaをインストールしてください。
Step 1
次のリンクにアクセスして、Java(JDK <最新バージョン> -X64.tar.gz)をダウンロードします。Oracle
次に jdk-7u71-linux-x64.tar.gz is downloaded あなたのシステムに。
Step 2
通常、ダウンロードしたJavaファイルはDownloadsフォルダーにあります。それを確認し、抽出しますjdk-7u71-linux-x64.gz 次のコマンドを使用してファイルします。
$ cd Downloads/
$ ls
jdk-7u71-linux-x64.gz
$ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzStep 3
すべてのユーザーがJavaを使用できるようにするには、Javaを「/ usr / local /」の場所に移動する必要があります。rootを開き、次のコマンドを入力します。
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitStep 4
設定用 PATH そして JAVA_HOME 変数については、次のコマンドを追加してください ~/.bashrc file。
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH= $PATH:$JAVA_HOME/bin次に、 java -version 上で説明したように端末からのコマンド。
Hadoopのダウンロード
Javaをインストールした後、最初にHadoopをインストールする必要があります。以下に示すように、「Hadoopバージョン」コマンドを使用してHadoopの存在を確認します。
hadoop version次の出力が生成されます。
Hadoop 2.6.0
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using /home/hadoop/hadoop/share/hadoop/common/hadoopcommon-2.6.0.jarシステムがHadoopを見つけられない場合は、Hadoopをダウンロードして、システムにインストールしてください。これを行うには、以下のコマンドに従います。
次のコマンドを使用して、Apache SoftwareFoundationからhadoop-2.6.0をダウンロードして抽出します。
$ su
password:
# cd /usr/local
# wget http://mirrors.advancedhosters.com/apache/hadoop/common/hadoop-
2.6.0/hadoop-2.6.0-src.tar.gz
# tar xzf hadoop-2.6.0-src.tar.gz
# mv hadoop-2.6.0/* hadoop/
# exitHadoopのインストール
必要なモードのいずれかでHadoopをインストールします。ここでは、疑似分散モードでのHBase機能を示しているため、Hadoopを疑似分散モードでインストールします。
以下の手順に従ってインストールしてください Hadoop 2.4.1 システム上で。
ステップ1:Hadoopを設定する
次のコマンドをに追加することで、Hadoop環境変数を設定できます。 ~/.bashrc ファイル。
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOMEここで、現在実行中のシステムにすべての変更を適用します。
$ source ~/.bashrcステップ2:Hadoop構成
すべてのHadoop構成ファイルは、「$ HADOOP_HOME / etc / hadoop」の場所にあります。Hadoopインフラストラクチャに応じて、これらの構成ファイルを変更する必要があります。
$ cd $HADOOP_HOME/etc/hadoopJavaでHadoopプログラムを開発するには、Java環境変数をリセットする必要があります。 hadoop-env.sh 置き換えることによってファイル JAVA_HOME システム内のJavaの場所を含む値。
export JAVA_HOME=/usr/local/jdk1.7.0_71以下に、Hadoopを構成するために編集する必要のあるファイルのリストを示します。
core-site.xml
ザ・ core-site.xml fileには、Hadoopインスタンスに使用されるポート番号、ファイルシステムに割り当てられたメモリ、データを格納するためのメモリ制限、読み取り/書き込みバッファのサイズなどの情報が含まれています。
core-site.xmlを開き、<configuration>、</ configuration>タグの間に次のプロパティを追加します。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xm
ザ・ hdfs-site.xmlファイルには、ローカルファイルシステムのレプリケーションデータの値、ネームノードパス、データノードパスなどの情報が含まれています。これは、Hadoopインフラストラクチャを保存する場所を意味します。
次のデータを想定します。
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeこのファイルを開き、このファイルの<configuration>、</ configuration>タグの間に次のプロパティを追加します。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note:上記のファイルでは、すべてのプロパティ値はユーザー定義です。Hadoopインフラストラクチャに応じて変更を加えることができます。
mapred-site.xml
このファイルは、Hadoopにyarnを構成するために使用されます。mapred-site.xmlファイルを開き、このファイルの<configuration>、</ configuration>タグの間に次のプロパティを追加します。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
このファイルは、使用しているMapReduceフレームワークを指定するために使用されます。デフォルトでは、Hadoopにはmapred-site.xmlのテンプレートが含まれています。まず、ファイルをコピーする必要がありますmapred-site.xml.template に mapred-site.xml 次のコマンドを使用してファイルします。
$ cp mapred-site.xml.template mapred-site.xml開いた mapred-site.xml ファイルを作成し、このファイルの<configuration>、</ configuration>タグの間に次のプロパティを追加します。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Hadoopのインストールの確認
次の手順は、Hadoopのインストールを確認するために使用されます。
ステップ1:ノードのセットアップに名前を付ける
次のように、コマンド「hdfsnamenode-format」を使用してnamenodeを設定します。
$ cd ~
$ hdfs namenode -format期待される結果は次のとおりです。
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain
1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/ステップ2:Hadoopdfsを確認する
次のコマンドは、dfsを開始するために使用されます。このコマンドは、Hadoopファイルシステムを起動します。
$ start-dfs.sh期待される出力は次のとおりです。
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]ステップ3:糸スクリプトを確認する
次のコマンドは、yarnスクリプトを開始するために使用されます。このコマンドを実行すると、ヤーンデーモンが起動します。
$ start-yarn.sh期待される出力は次のとおりです。
starting yarn daemons
starting resource manager, logging to /home/hadoop/hadoop-2.4.1/logs/yarn-
hadoop-resourcemanager-localhost.out
localhost: starting node manager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-nodemanager-localhost.outステップ4:ブラウザーでHadoopにアクセスする
hadoopにアクセスするためのデフォルトのポート番号は50070です。ブラウザーでHadoopサービスを取得するには、次のURLを使用します。
http://localhost:50070/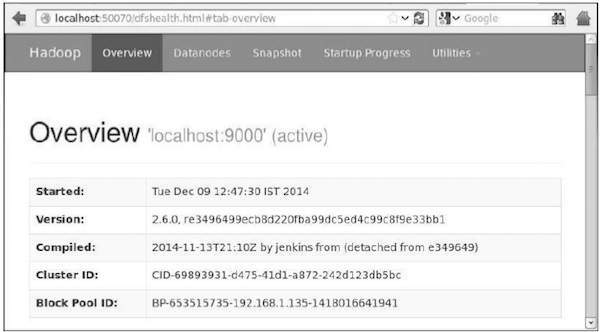
手順5:クラスターのすべてのアプリケーションを確認する
クラスタのすべてのアプリケーションにアクセスするためのデフォルトのポート番号は8088です。このサービスにアクセスするには、次のURLを使用してください。
http://localhost:8088/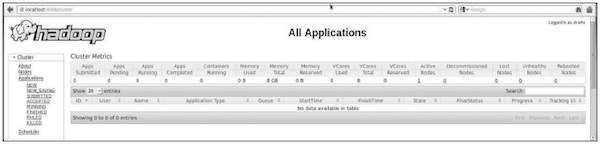
Mahoutのダウンロード
Mahoutは、MahoutのWebサイトで入手できます。Webサイトで提供されているリンクからMahoutをダウンロードします。これがウェブサイトのスクリーンショットです。

ステップ1
リンクからApachemahoutをダウンロードします http://mirror.nexcess.net/apache/mahout/ 次のコマンドを使用します。
[Hadoop@localhost ~]$ wget
http://mirror.nexcess.net/apache/mahout/0.9/mahout-distribution-0.9.tar.gz次に mahout-distribution-0.9.tar.gz システムにダウンロードされます。
ステップ2
フォルダーを参照します。 mahout-distribution-0.9.tar.gz を保存し、ダウンロードしたjarファイルを以下のように抽出します。
[Hadoop@localhost ~]$ tar zxvf mahout-distribution-0.9.tar.gzMavenリポジトリ
以下に示すのは、Eclipseを使用してApacheMahoutをビルドするためのpom.xmlです。
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-core</artifactId>
<version>0.9</version>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-math</artifactId>
<version>${mahout.version}</version>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-integration</artifactId>
<version>${mahout.version}</version>
</dependency>