OpenNLP-クイックガイド
NLPは、Webページやテキストドキュメントなどの自然言語ソースから意味のある有用な情報を引き出すために使用されるツールのセットです。
Open NLPとは何ですか?
Apache OpenNLP自然言語テキストの処理に使用されるオープンソースのJavaライブラリです。このライブラリを使用して、効率的なテキスト処理サービスを構築できます。
OpenNLPは、トークン化、文のセグメンテーション、品詞のタグ付け、名前付きエンティティの抽出、チャンク化、解析、共参照の解決などのサービスを提供します。
OpenNLPの機能
以下はOpenNLPの注目すべき機能です-
Named Entity Recognition (NER) − Open NLPはNERをサポートしており、クエリの処理中でも場所、人、物の名前を抽出できます。
Summarize −を使用して summarize 機能を使用すると、段落、記事、ドキュメント、またはそれらのコレクションをNLPで要約できます。
Searching − OpenNLPでは、特定の単語が変更されたりスペルが間違っていたりしても、特定の検索文字列またはその同義語を特定のテキストで識別できます。
Tagging (POS) − NLPのタグ付けは、テキストをさまざまな文法要素に分割してさらに分析するために使用されます。
Translation − NLPでは、翻訳はある言語を別の言語に翻訳するのに役立ちます。
Information grouping − NLPのこのオプションは、品詞と同様に、ドキュメントのコンテンツ内のテキスト情報をグループ化します。
Natural Language Generation −データベースから情報を生成し、気象分析や医療レポートなどの情報レポートを自動化するために使用されます。
Feedback Analysis −名前が示すように、NLPは製品に関して人々からさまざまな種類のフィードバックを収集し、製品がどれだけ彼らの心をつかむことに成功しているかを分析します。
Speech recognition −人間の発話を分析することは困難ですが、NLPにはこの要件に対応するいくつかの機能が組み込まれています。
NLPAPIを開く
Apache OpenNLPライブラリは、文の検出、トークン化、名前の検索、品詞のタグ付け、文のチャンク化、解析、相互参照の解決、ドキュメントの分類など、自然言語処理のさまざまなタスクを実行するためのクラスとインターフェイスを提供します。
これらのタスクに加えて、これらのタスクのいずれかについて独自のモデルをトレーニングおよび評価することもできます。
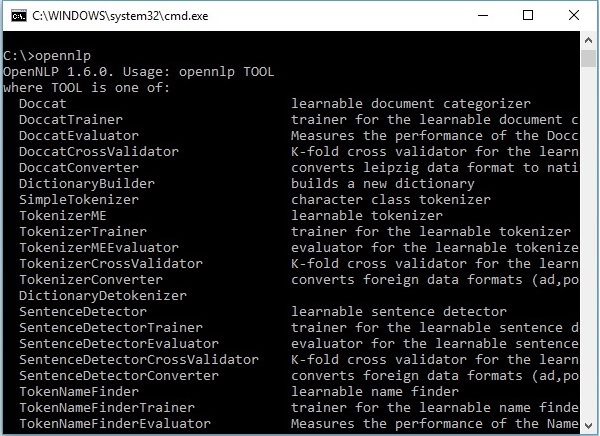
OpenNLP CLI
ライブラリに加えて、OpenNLPは、モデルをトレーニングおよび評価できるコマンドラインインターフェイス(CLI)も提供します。このトピックについては、このチュートリアルの最後の章で詳しく説明します。
NLPモデルを開く
さまざまなNLPタスクを実行するために、OpenNLPは事前定義されたモデルのセットを提供します。このセットには、さまざまな言語のモデルが含まれています。
モデルのダウンロード
以下の手順に従って、OpenNLPが提供する定義済みモデルをダウンロードできます。
Step 1 −次のリンクをクリックして、OpenNLPモデルのインデックスページを開きます。 http://opennlp.sourceforge.net/models-1.5/。

Step 2−所定のリンクにアクセスすると、さまざまな言語のコンポーネントのリストとそれらをダウンロードするためのリンクが表示されます。ここでは、OpenNLPによって提供されるすべての定義済みモデルのリストを取得できます。
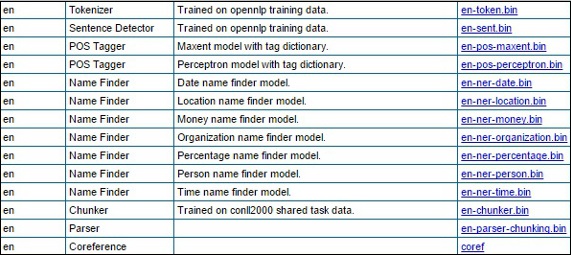
これらすべてのモデルをフォルダーにダウンロードします C:/OpenNLP_models/>、それぞれのリンクをクリックします。これらのモデルはすべて言語に依存しており、これらを使用するときは、モデルの言語が入力テキストの言語と一致していることを確認する必要があります。
OpenNLPの歴史
2010年、OpenNLPはApacheのインキュベーションに入りました。
2011年にApacheOpenNLP 1.5.2 Incubatingがリリースされ、同じ年にトップレベルのApacheプロジェクトとして卒業しました。
2015年、OpenNLPは1.6.0でリリースされました。
この章では、システムにOpenNLP環境をセットアップする方法について説明します。インストールプロセスから始めましょう。
OpenNLPのインストール
ダウンロードする手順は次のとおりです Apache OpenNLP library あなたのシステムで。
Step 1 −のホームページを開く Apache OpenNLP 次のリンクをクリックして- https://opennlp.apache.org/。
Step 2 −次に、をクリックします。 Downloadsリンク。クリックすると、Apache Software FoundationDistributionディレクトリにリダイレクトされるさまざまなミラーを見つけることができるページに移動します。
Step 3−このページには、さまざまなApacheディストリビューションをダウンロードするためのリンクがあります。それらを参照し、OpenNLPディストリビューションを見つけてクリックします。
Step 4 −クリックすると、以下に示すように、OpenNLPディストリビューションのインデックスを表示できるディレクトリにリダイレクトされます。
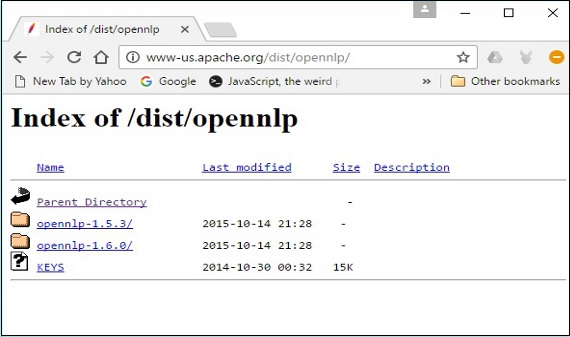
利用可能なディストリビューションから最新バージョンをクリックします。
Step 5−各ディストリビューションは、OpenNLPライブラリのソースファイルとバイナリファイルをさまざまな形式で提供します。ソースファイルとバイナリファイルをダウンロードし、apache-opennlp-1.6.0-bin.zip そして apache-opennlp1.6.0-src.zip (Windowsの場合)。

クラスパスの設定
OpenNLPライブラリをダウンロードした後、そのパスをに設定する必要があります。 binディレクトリ。OpenNLPライブラリをシステムのEドライブにダウンロードしたと仮定します。
次に、以下の手順に従います。
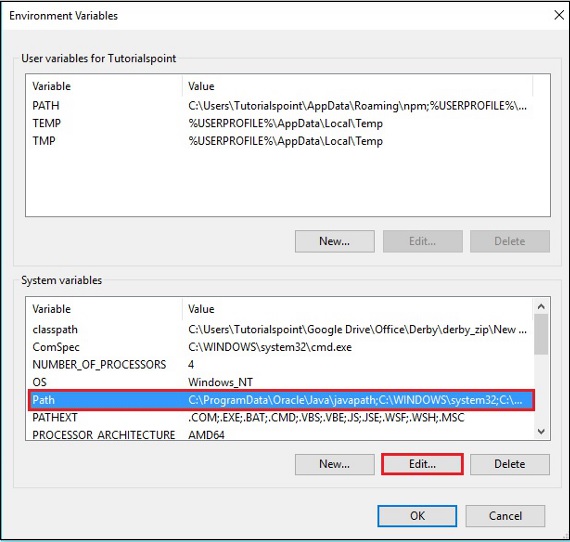
Step 1 −「マイコンピュータ」を右クリックして「プロパティ」を選択します。
Step 2 − [詳細設定]タブの下の[環境変数]ボタンをクリックします。
Step 3 −を選択します path 変数をクリックして、 Edit 次のスクリーンショットに示すように、ボタン。
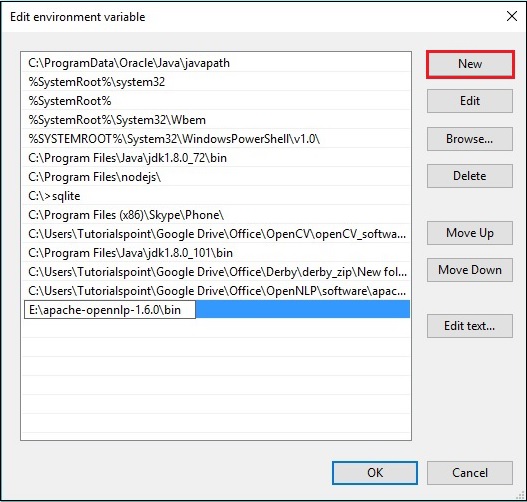
Step 4 − [環境変数の編集]ウィンドウで、[ New ボタンをクリックして、OpenNLPディレクトリのパスを追加します E:\apache-opennlp-1.6.0\bin をクリックします OK 次のスクリーンショットに示すように、ボタン。
Eclipseのインストール
OpenNLPライブラリのEclipse環境を設定するには、 Build path JARファイルに、またはを使用して pom.xml。
JARファイルへのビルドパスの設定
以下の手順に従って、EclipseにOpenNLPをインストールします-
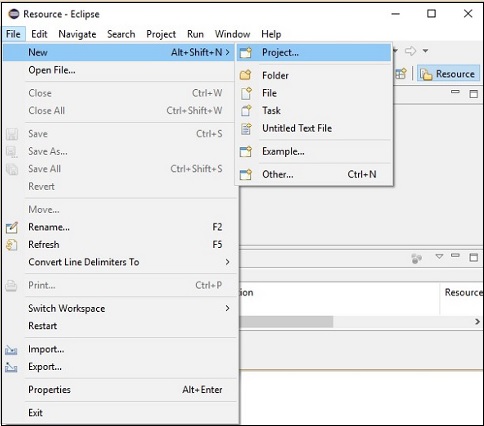
Step 1 −システムにEclipse環境がインストールされていることを確認してください。
Step 2−Eclipseを開きます。以下に示すように、「ファイル」→「新規」→「新規プロジェクトを開く」をクリックします。
Step 3 −あなたは New Projectウィザード。このウィザードで、Javaプロジェクトを選択し、[Next ボタン。
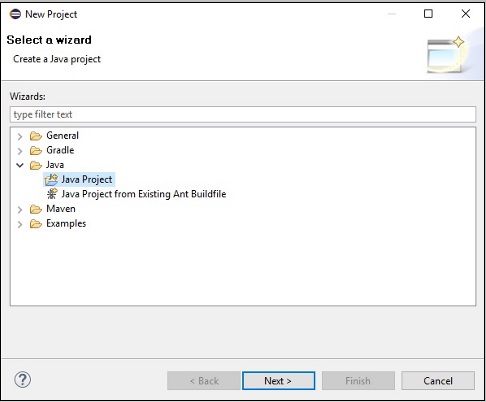
Step 4 −次に、 New Java Project wizard。ここで、新しいプロジェクトを作成し、をクリックする必要がありますNext 以下に示すように、ボタン。
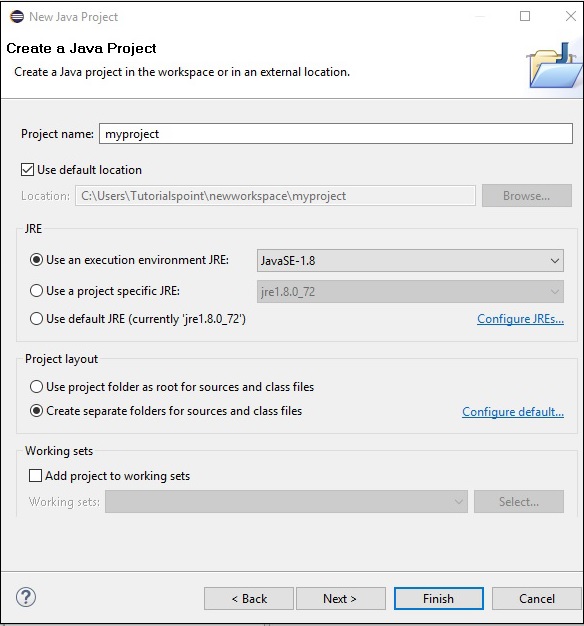
Step 5 −新しいプロジェクトを作成したら、それを右クリックして、 Build Path をクリックします Configure Build Path。
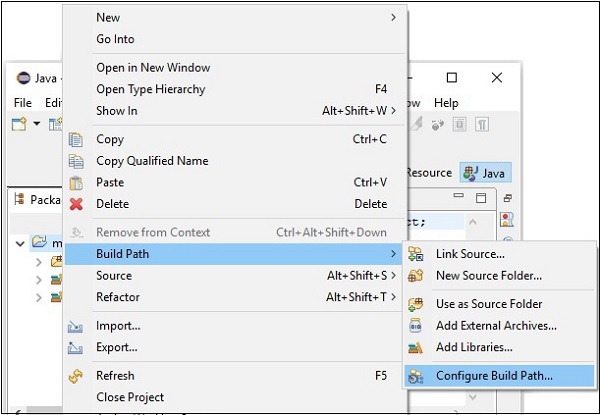
Step 6 −次に、 Java Build Pathウィザード。ここで、をクリックしますAdd External JARs 以下に示すように、ボタン。
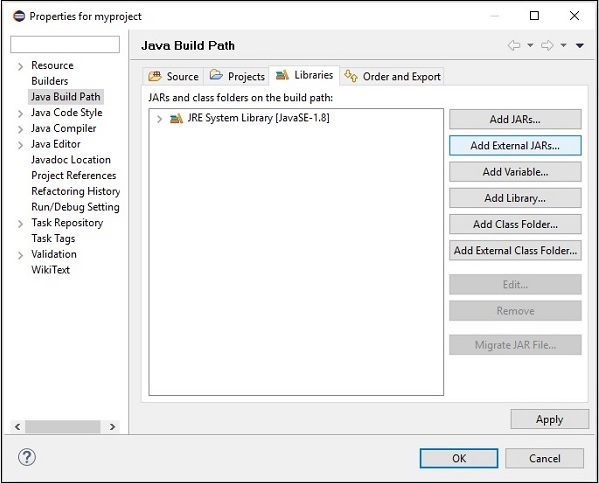
Step 7 −jarファイルを選択します opennlp-tools-1.6.0.jar そして opennlp-uima-1.6.0.jar にあります lib のフォルダ apache-opennlp-1.6.0 folder。
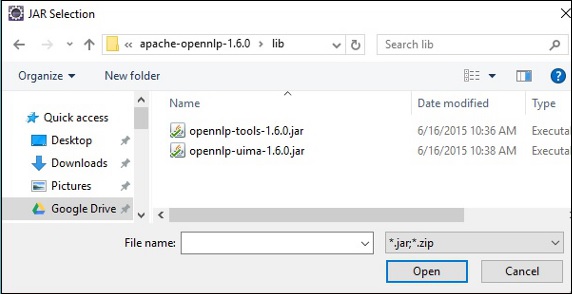
クリックすると Open 上の画面のボタンをクリックすると、選択したファイルがライブラリに追加されます。
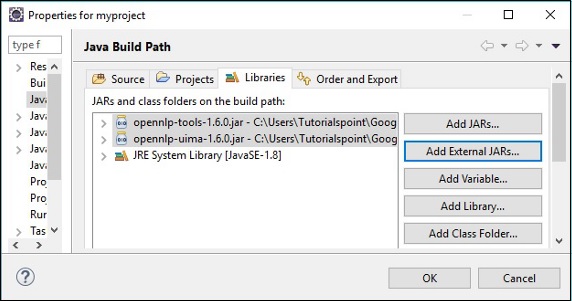
クリックすると OK、必要なJARファイルを現在のプロジェクトに正常に追加し、以下に示すように、参照ライブラリを展開することで、これらの追加されたライブラリを確認できます。

pom.xmlの使用
プロジェクトをMavenプロジェクトに変換し、次のコードをそのプロジェクトに追加します pom.xml。
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>myproject</groupId>
<artifactId>myproject</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.opennlp</groupId>
<artifactId>opennlp-tools</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.opennlp</groupId>
<artifactId>opennlp-uima</artifactId>
<version>1.6.0</version>
</dependency>
</dependencies>
</project>この章では、このチュートリアルの後続の章で使用するクラスとメソッドについて説明します。
文の検出
SentenceModelクラス
このクラスは、指定された生のテキスト内の文を検出するために使用される事前定義されたモデルを表します。このクラスはパッケージに属していますopennlp.tools.sentdetect。
このクラスのコンストラクターは、 InputStream 文検出器モデルファイル(en-sent.bin)の目的語。
SentenceDetectorMEクラス
このクラスはパッケージに属しています opennlp.tools.sentdetect生のテキストを文に分割するメソッドが含まれています。このクラスは、最大エントロピーモデルを使用して、文字列内の文末文字を評価し、それらが文の終わりを示しているかどうかを判断します。
このクラスの重要なメソッドは次のとおりです。
| S.No | メソッドと説明 |
|---|---|
| 1 | sentDetect() このメソッドは、渡された生のテキスト内の文を検出するために使用されます。String変数をパラメーターとして受け取り、指定された生のテキストからの文を保持するString配列を返します。 |
| 2 | sentPosDetect() このメソッドは、指定されたテキスト内の文の位置を検出するために使用されます。このメソッドは、文を表す文字列変数を受け入れ、タイプのオブジェクトの配列を返しますSpan。 名前の付いたクラス Span の opennlp.tools.util パッケージは、セットの開始整数と終了整数を格納するために使用されます。 |
| 3 | getSentenceProbabilities() このメソッドは、への最新の呼び出しに関連付けられた確率を返します sentDetect() 方法。 |
トークン化
TokenizerModelクラス
このクラスは、指定された文をトークン化するために使用される事前定義されたモデルを表します。このクラスはパッケージに属していますopennlp.tools.tokenizer。
このクラスのコンストラクターは、 InputStream トークナイザーモデルファイル(entoken.bin)のオブジェクト。
クラス
トークン化を実行するために、OpenNLPライブラリは3つの主要なクラスを提供します。3つのクラスはすべて、と呼ばれるインターフェイスを実装しますTokenizer。
| S.No | クラスと説明 |
|---|---|
| 1 | SimpleTokenizer このクラスは、文字クラスを使用して、指定された生のテキストをトークン化します。 |
| 2 | WhitespaceTokenizer このクラスは、空白を使用して、指定されたテキストをトークン化します。 |
| 3 | TokenizerME このクラスは、生のテキストを個別のトークンに変換します。最大エントロピーを使用して決定を下します。 |
これらのクラスには、次のメソッドが含まれています。
| S.No | メソッドと説明 |
|---|---|
| 1 | tokenize() このメソッドは、生のテキストをトークン化するために使用されます。このメソッドは、パラメーターとしてString変数を受け取り、String(トークン)の配列を返します。 |
| 2 | sentPosDetect() このメソッドは、トークンの位置またはスパンを取得するために使用されます。文字列の形式で文(または)生のテキストを受け入れ、タイプのオブジェクトの配列を返しますSpan。 |
上記の2つの方法に加えて、 TokenizerME クラスには getTokenProbabilities() 方法。
| S.No | メソッドと説明 |
|---|---|
| 1 | getTokenProbabilities() このメソッドは、への最新の呼び出しに関連付けられた確率を取得するために使用されます tokenizePos() 方法。 |
NameEntityRecognition
TokenNameFinderModelクラス
このクラスは、指定された文で名前付きエンティティを検索するために使用される事前定義されたモデルを表します。このクラスはパッケージに属していますopennlp.tools.namefind。
このクラスのコンストラクターは、 InputStream ネームファインダーモデルファイル(enner-person.bin)のオブジェクト。
NameFinderMEクラス
クラスはパッケージに属しています opennlp.tools.namefindまた、NERタスクを実行するためのメソッドが含まれています。このクラスは、最大エントロピーモデルを使用して、指定された生のテキスト内の名前付きエンティティを検索します。
| S.No | メソッドと説明 |
|---|---|
| 1 | find() このメソッドは、生のテキスト内の名前を検出するために使用されます。生のテキストを表すString変数をパラメーターとして受け取り、Span型のオブジェクトの配列を返します。 |
| 2 | probs() このメソッドは、最後にデコードされたシーケンスの確率を取得するために使用されます。 |
品詞を見つける
POSModelクラス
このクラスは、特定の文の品詞にタグを付けるために使用される事前定義されたモデルを表します。このクラスはパッケージに属していますopennlp.tools.postag。
このクラスのコンストラクターは、 InputStream pos-taggerモデルファイル(enpos-maxent.bin)のオブジェクト。
POSTaggerMEクラス
このクラスはパッケージに属しています opennlp.tools.postagまた、特定の生のテキストの品詞を予測するために使用されます。最大エントロピーを使用して決定を下します。
| S.No | メソッドと説明 |
|---|---|
| 1 | tag() このメソッドは、トークンPOSタグの文を割り当てるために使用されます。このメソッドは、トークンの配列(String)をパラメーターとして受け取り、タグ(array)を返します。 |
| 2 | getSentenceProbabilities() このメソッドは、最近タグ付けされた文の各タグの確率を取得するために使用されます。 |
文の解析
ParserModelクラス
このクラスは、指定された文を解析するために使用される事前定義されたモデルを表します。このクラスはパッケージに属していますopennlp.tools.parser。
このクラスのコンストラクターは、 InputStream パーサーモデルファイル(en-parserchunking.bin)のオブジェクト。
パーサーファクトリクラス
このクラスはパッケージに属しています opennlp.tools.parser パーサーを作成するために使用されます。
| S.No | メソッドと説明 |
|---|---|
| 1 | create() これは静的メソッドであり、パーサーオブジェクトを作成するために使用されます。このメソッドは、パーサーモデルファイルのFilestreamオブジェクトを受け入れます。 |
ParserToolクラス
このクラスはに属します opennlp.tools.cmdline.parser パッケージと、コンテンツを解析するために使用されます。
| S.No | メソッドと説明 |
|---|---|
| 1 | parseLine() この方法の ParserToolクラスは、OpenNLPの生のテキストを解析するために使用されます。このメソッドは次を受け入れます-
|
チャンキング
ChunkerModelクラス
このクラスは、文を小さなチャンクに分割するために使用される事前定義されたモデルを表します。このクラスはパッケージに属していますopennlp.tools.chunker。
このクラスのコンストラクターは、 InputStream のオブジェクト chunker モデルファイル(enchunker.bin)。
ChunkerMEクラス
このクラスは、という名前のパッケージに属しています opennlp.tools.chunker そしてそれは与えられた文をより小さなチャンクに分割するために使用されます。
| S.No | メソッドと説明 |
|---|---|
| 1 | chunk() このメソッドは、指定された文を小さなチャンクに分割するために使用されます。文のトークンを受け入れ、P芸術 Of Sパラメータとしてのピーチタグ。 |
| 2 | probs() このメソッドは、最後にデコードされたシーケンスの確率を返します。 |
自然言語を処理する際に、文の最初と最後を決定することは、対処すべき問題の1つです。このプロセスは、Sentence B境界 Disambiguation(SBD)または単に文を壊す。
特定のテキスト内の文を検出するために使用する手法は、テキストの言語によって異なります。
Javaを使用した文の検出
正規表現と一連の単純なルールを使用して、Javaで特定のテキスト内の文を検出できます。
たとえば、ピリオド、疑問符、または感嘆符が指定されたテキストの文を終了すると仮定すると、を使用して文を分割できます。 split() の方法 Stringクラス。ここでは、文字列形式で正規表現を渡す必要があります。
以下は、Java正規表現を使用して特定のテキストの文を決定するプログラムです。 (split method)。このプログラムを名前のファイルに保存しますSentenceDetection_RE.java。
public class SentenceDetection_RE {
public static void main(String args[]){
String sentence = " Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
String simple = "[.?!]";
String[] splitString = (sentence.split(simple));
for (String string : splitString)
System.out.println(string);
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します。
javac SentenceDetection_RE.java
java SentenceDetection_RE上記のプログラムを実行すると、次のメッセージを表示するPDFドキュメントが作成されます。
Hi
How are you
Welcome to Tutorialspoint
We provide free tutorials on various technologiesOpenNLPを使用した文の検出
文を検出するために、OpenNLPは事前定義されたモデルを使用します。 en-sent.bin。この事前定義されたモデルは、特定の生のテキスト内の文を検出するようにトレーニングされています。
ザ・ opennlp.tools.sentdetect パッケージには、文検出タスクを実行するために使用されるクラスとインターフェースが含まれています。
OpenNLPライブラリを使用して文を検出するには、次のことを行う必要があります。
をロードします en-sent.bin を使用したモデル SentenceModel クラス
インスタンス化する SentenceDetectorME クラス。
を使用して文を検出します sentDetect() このクラスのメソッド。
以下は、与えられた生のテキストから文を検出するプログラムを書くために従うべきステップです。
ステップ1:モデルをロードする
文検出のモデルは、という名前のクラスで表されます。 SentenceModel、パッケージに属します opennlp.tools.sentdetect。
文検出モデルをロードするには-
作成する InputStream モデルのオブジェクト(FileInputStreamをインスタンス化し、モデルのパスを文字列形式でコンストラクターに渡します)。
インスタンス化する SentenceModel クラスと合格 InputStream 次のコードブロックに示すように、コンストラクターへのパラメーターとしてのモデルの(オブジェクト)-
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/ensent.bin");
SentenceModel model = new SentenceModel(inputStream);ステップ2:SentenceDetectorMEクラスをインスタンス化する
ザ・ SentenceDetectorME パッケージのクラス opennlp.tools.sentdetect生のテキストを文に分割するメソッドが含まれています。このクラスは、最大エントロピーモデルを使用して、文字列内の文末文字を評価し、それらが文の終わりを示しているかどうかを判断します。
以下に示すように、このクラスをインスタンス化し、前の手順で作成したモデルオブジェクトを渡します。
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);ステップ3:文を検出する
ザ・ sentDetect() の方法 SentenceDetectorMEクラスは、渡された生のテキスト内の文を検出するために使用されます。このメソッドは、String変数をパラメーターとして受け入れます。
文の文字列形式をこのメソッドに渡して、このメソッドを呼び出します。
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);Example
以下は、与えられた生のテキストの文を検出するプログラムです。このプログラムをという名前のファイルに保存しますSentenceDetectionME.java。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
public class SentenceDetectionME {
public static void main(String args[]) throws Exception {
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);
//Printing the sentences
for(String sent : sentences)
System.out.println(sent);
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します-
javac SentenceDetectorME.java
java SentenceDetectorME実行時に、上記のプログラムは指定された文字列を読み取り、その中の文を検出して、次の出力を表示します。
Hi. How are you?
Welcome to Tutorialspoint.
We provide free tutorials on various technologies文の位置を検出する
また、sentPosDetect()メソッドを使用して文の位置を検出することもできます。 SentenceDetectorME class。
以下は、与えられた生のテキストから文の位置を検出するプログラムを書くために従うべきステップです。
ステップ1:モデルをロードする
文検出のモデルは、という名前のクラスで表されます。 SentenceModel、パッケージに属します opennlp.tools.sentdetect。
文検出モデルをロードするには-
作成する InputStream モデルのオブジェクト(FileInputStreamをインスタンス化し、モデルのパスを文字列形式でコンストラクターに渡します)。
インスタンス化する SentenceModel クラスと合格 InputStream 次のコードブロックに示すように、コンストラクターへのパラメーターとしてのモデルの(オブジェクト)。
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);ステップ2:SentenceDetectorMEクラスをインスタンス化する
ザ・ SentenceDetectorME パッケージのクラス opennlp.tools.sentdetect生のテキストを文に分割するメソッドが含まれています。このクラスは、最大エントロピーモデルを使用して、文字列内の文末文字を評価し、それらが文の終わりを示しているかどうかを判断します。
このクラスをインスタンス化し、前の手順で作成したモデルオブジェクトを渡します。
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);ステップ3:文の位置を検出する
ザ・ sentPosDetect() の方法 SentenceDetectorMEクラスは、渡された生のテキスト内の文の位置を検出するために使用されます。このメソッドは、String変数をパラメーターとして受け入れます。
文の文字列形式をパラメータとしてこのメソッドに渡すことにより、このメソッドを呼び出します。
//Detecting the position of the sentences in the paragraph
Span[] spans = detector.sentPosDetect(sentence);ステップ4:文のスパンを印刷する
ザ・ sentPosDetect() の方法 SentenceDetectorME クラスは、次のタイプのオブジェクトの配列を返します Span。Span oftheという名前のクラスopennlp.tools.util パッケージは、セットの開始整数と終了整数を格納するために使用されます。
によって返されたスパンを保存できます sentPosDetect() 次のコードブロックに示すように、Span配列のメソッドを取得して出力します。
//Printing the sentences and their spans of a sentence
for (Span span : spans)
System.out.println(paragraph.substring(span);Example
以下は、与えられた生のテキストの文を検出するプログラムです。このプログラムをという名前のファイルに保存しますSentenceDetectionME.java。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
import opennlp.tools.util.Span;
public class SentencePosDetection {
public static void main(String args[]) throws Exception {
String paragraph = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the position of the sentences in the raw text
Span spans[] = detector.sentPosDetect(paragraph);
//Printing the spans of the sentences in the paragraph
for (Span span : spans)
System.out.println(span);
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します-
javac SentencePosDetection.java
java SentencePosDetection実行時に、上記のプログラムは指定された文字列を読み取り、その中の文を検出して、次の出力を表示します。
[0..16)
[17..43)
[44..93)文とその位置
ザ・ substring() Stringクラスのメソッドは begin そしてその end offsetsそれぞれの文字列を返します。次のコードブロックに示すように、このメソッドを使用して、文とそのスパン(位置)を一緒に印刷できます。
for (Span span : spans)
System.out.println(sen.substring(span.getStart(), span.getEnd())+" "+ span);以下は、与えられた生のテキストから文を検出し、それらをそれらの位置とともに表示するプログラムです。このプログラムを名前の付いたファイルに保存しますSentencesAndPosDetection.java。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
import opennlp.tools.util.Span;
public class SentencesAndPosDetection {
public static void main(String args[]) throws Exception {
String sen = "Hi. How are you? Welcome to Tutorialspoint."
+ " We provide free tutorials on various technologies";
//Loading a sentence model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the position of the sentences in the paragraph
Span[] spans = detector.sentPosDetect(sen);
//Printing the sentences and their spans of a paragraph
for (Span span : spans)
System.out.println(sen.substring(span.getStart(), span.getEnd())+" "+ span);
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します-
javac SentencesAndPosDetection.java
java SentencesAndPosDetection実行時に、上記のプログラムは指定された文字列を読み取り、文とその位置を検出して、次の出力を表示します。
Hi. How are you? [0..16)
Welcome to Tutorialspoint. [17..43)
We provide free tutorials on various technologies [44..93)文の確率の検出
ザ・ getSentenceProbabilities() の方法 SentenceDetectorME クラスは、sentDetect()メソッドへの最新の呼び出しに関連付けられた確率を返します。
//Getting the probabilities of the last decoded sequence
double[] probs = detector.getSentenceProbabilities();以下は、sentDetect()メソッドの呼び出しに関連する確率を出力するプログラムです。このプログラムを名前のファイルに保存しますSentenceDetectionMEProbs.java。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
public class SentenceDetectionMEProbs {
public static void main(String args[]) throws Exception {
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);
//Printing the sentences
for(String sent : sentences)
System.out.println(sent);
//Getting the probabilities of the last decoded sequence
double[] probs = detector.getSentenceProbabilities();
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します-
javac SentenceDetectionMEProbs.java
java SentenceDetectionMEProbs実行時に、上記のプログラムは指定された文字列を読み取り、文を検出して出力します。さらに、以下に示すように、sentDetect()メソッドへの最新の呼び出しに関連付けられた確率も返します。
Hi. How are you?
Welcome to Tutorialspoint.
We provide free tutorials on various technologies
0.9240246995179983
0.9957680129995953
1.0与えられた文をより小さな部分(トークン)に切り刻むプロセスは、 tokenization。一般に、指定された生のテキストは、区切り文字のセット(主に空白)に基づいてトークン化されます。
トークン化は、スペルチェック、検索の処理、品詞の識別、文の検出、ドキュメントのドキュメント分類などのタスクで使用されます。
OpenNLPを使用したトークン化
ザ・ opennlp.tools.tokenize パッケージには、トークン化を実行するために使用されるクラスとインターフェースが含まれています。
与えられた文をより単純なフラグメントにトークン化するために、OpenNLPライブラリは3つの異なるクラスを提供します-
SimpleTokenizer −このクラスは、文字クラスを使用して、指定された生のテキストをトークン化します。
WhitespaceTokenizer −このクラスは、空白を使用して、指定されたテキストをトークン化します。
TokenizerME−このクラスは、生のテキストを個別のトークンに変換します。最大エントロピーを使用して決定を下します。
SimpleTokenizer
を使用して文をトークン化するには SimpleTokenizer クラス、あなたはする必要があります-
それぞれのクラスのオブジェクトを作成します。
を使用して文をトークン化します tokenize() 方法。
トークンを印刷します。
以下は、指定された生のテキストをトークン化するプログラムを作成するために従うべき手順です。
Step 1 −それぞれのクラスのインスタンス化
どちらのクラスにも、それらをインスタンス化するために使用できるコンストラクターはありません。したがって、静的変数を使用してこれらのクラスのオブジェクトを作成する必要がありますINSTANCE。
SimpleTokenizer tokenizer = SimpleTokenizer.INSTANCE;Step 2 −文をトークン化する
これらのクラスには両方とも、というメソッドが含まれています tokenize()。このメソッドは、文字列形式の生のテキストを受け入れます。呼び出すと、指定された文字列をトークン化し、文字列(トークン)の配列を返します。
を使用して文をトークン化します tokenizer() 以下に示す方法。
//Tokenizing the given sentence
String tokens[] = tokenizer.tokenize(sentence);Step 3 −トークンを印刷する
文をトークン化した後、を使用してトークンを印刷できます for loop、以下に示すように。
//Printing the tokens
for(String token : tokens)
System.out.println(token);Example
以下は、SimpleTokenizerクラスを使用して指定された文をトークン化するプログラムです。このプログラムを名前のファイルに保存しますSimpleTokenizerExample.java。
import opennlp.tools.tokenize.SimpleTokenizer;
public class SimpleTokenizerExample {
public static void main(String args[]){
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
SimpleTokenizer simpleTokenizer = SimpleTokenizer.INSTANCE;
//Tokenizing the given sentence
String tokens[] = simpleTokenizer.tokenize(sentence);
//Printing the tokens
for(String token : tokens) {
System.out.println(token);
}
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します-
javac SimpleTokenizerExample.java
java SimpleTokenizerExample実行時に、上記のプログラムは指定された文字列(生のテキスト)を読み取り、トークン化し、次の出力を表示します-
Hi
.
How
are
you
?
Welcome
to
Tutorialspoint
.
We
provide
free
tutorials
on
various
technologiesWhitespaceTokenizer
を使用して文をトークン化するには WhitespaceTokenizer クラス、あなたはする必要があります-
それぞれのクラスのオブジェクトを作成します。
を使用して文をトークン化します tokenize() 方法。
トークンを印刷します。
以下は、指定された生のテキストをトークン化するプログラムを作成するために従うべき手順です。
Step 1 −それぞれのクラスのインスタンス化
どちらのクラスにも、それらをインスタンス化するために使用できるコンストラクターはありません。したがって、静的変数を使用してこれらのクラスのオブジェクトを作成する必要がありますINSTANCE。
WhitespaceTokenizer tokenizer = WhitespaceTokenizer.INSTANCE;Step 2 −文をトークン化する
これらのクラスには両方とも、というメソッドが含まれています tokenize()。このメソッドは、文字列形式の生のテキストを受け入れます。呼び出すと、指定された文字列をトークン化し、文字列(トークン)の配列を返します。
を使用して文をトークン化します tokenizer() 以下に示す方法。
//Tokenizing the given sentence
String tokens[] = tokenizer.tokenize(sentence);Step 3 −トークンを印刷する
文をトークン化した後、を使用してトークンを印刷できます for loop、以下に示すように。
//Printing the tokens
for(String token : tokens)
System.out.println(token);Example
以下は、を使用して与えられた文をトークン化するプログラムです WhitespaceTokenizerクラス。このプログラムを名前のファイルに保存しますWhitespaceTokenizerExample.java。
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class WhitespaceTokenizerExample {
public static void main(String args[]){
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating whitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer = WhitespaceTokenizer.INSTANCE;
//Tokenizing the given paragraph
String tokens[] = whitespaceTokenizer.tokenize(sentence);
//Printing the tokens
for(String token : tokens)
System.out.println(token);
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します-
javac WhitespaceTokenizerExample.java
java WhitespaceTokenizerExample実行時に、上記のプログラムは指定された文字列(生のテキスト)を読み取り、トークン化し、次の出力を表示します。
Hi.
How
are
you?
Welcome
to
Tutorialspoint.
We
provide
free
tutorials
on
various
technologiesTokenizerMEクラス
OpenNLPは、事前定義されたモデルであるde-token.binという名前のファイルを使用して、文をトークン化します。与えられた生のテキストの文をトークン化するように訓練されています。
ザ・ TokenizerME のクラス opennlp.tools.tokenizerパッケージは、このモデルをロードし、OpenNLPライブラリを使用して指定された生のテキストをトークン化するために使用されます。そうするために、あなたはする必要があります-
をロードします en-token.bin を使用したモデル TokenizerModel クラス。
インスタンス化する TokenizerME クラス。
を使用して文をトークン化します tokenize() このクラスのメソッド。
以下は、を使用して、指定された生のテキストから文をトークン化するプログラムを作成するために従うべき手順です。 TokenizerME クラス。
Step 1 −モデルのロード
トークン化のモデルは、という名前のクラスで表されます。 TokenizerModel、パッケージに属します opennlp.tools.tokenize。
トークナイザーモデルをロードするには-
作成する InputStream モデルのオブジェクト(FileInputStreamをインスタンス化し、モデルのパスを文字列形式でコンストラクターに渡します)。
インスタンス化する TokenizerModel クラスと合格 InputStream 次のコードブロックに示すように、コンストラクターへのパラメーターとしてのモデルの(オブジェクト)。
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);Step 2 −TokenizerMEクラスのインスタンス化
ザ・ TokenizerME パッケージのクラス opennlp.tools.tokenize生のテキストを小さな部分(トークン)に切り刻むメソッドが含まれています。最大エントロピーを使用して決定を下します。
このクラスをインスタンス化し、以下に示すように、前の手順で作成したモデルオブジェクトを渡します。
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);Step 3 −文のトークン化
ザ・ tokenize() の方法 TokenizerMEクラスは、渡された生のテキストをトークン化するために使用されます。このメソッドは、パラメーターとしてString変数を受け取り、String(トークン)の配列を返します。
次のように、文の文字列形式をこのメソッドに渡して、このメソッドを呼び出します。
//Tokenizing the given raw text
String tokens[] = tokenizer.tokenize(paragraph);Example
以下は、指定された生のテキストをトークン化するプログラムです。このプログラムを名前のファイルに保存しますTokenizerMEExample.java。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
public class TokenizerMEExample {
public static void main(String args[]) throws Exception{
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Tokenizing the given raw text
String tokens[] = tokenizer.tokenize(sentence);
//Printing the tokens
for (String a : tokens)
System.out.println(a);
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します-
javac TokenizerMEExample.java
java TokenizerMEExample実行時に、上記のプログラムは指定された文字列を読み取り、その中の文を検出して、次の出力を表示します-
Hi
.
How
are
you
?
Welcome
to
Tutorialspoint
.
We
provide
free
tutorials
on
various
technologieトークンの位置の取得
ポジションを取得することもできます spans を使用してトークンの tokenizePos()方法。これは、パッケージのTokenizerインターフェースのメソッドです。opennlp.tools.tokenize。すべての(3つの)Tokenizerクラスがこのインターフェイスを実装しているため、このメソッドはすべてのクラスで見つけることができます。
このメソッドは、文字列の形式で文または生のテキストを受け入れ、タイプのオブジェクトの配列を返します Span。
を使用してトークンの位置を取得できます tokenizePos() 次のような方法-
//Retrieving the tokens
tokenizer.tokenizePos(sentence);位置(スパン)の印刷
名前の付いたクラス Span の opennlp.tools.util パッケージは、セットの開始整数と終了整数を格納するために使用されます。
によって返されたスパンを保存できます tokenizePos() 次のコードブロックに示すように、Span配列のメソッドを取得して出力します。
//Retrieving the tokens
Span[] tokens = tokenizer.tokenizePos(sentence);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token);トークンとその位置を一緒に印刷する
ザ・ substring() Stringクラスのメソッドは begin そしてその endそれぞれの文字列をオフセットして返します。次のコードブロックに示すように、このメソッドを使用して、トークンとそのスパン(位置)を一緒に出力できます。
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));Example(SimpleTokenizer)
以下は、を使用して生のテキストのトークンスパンを取得するプログラムです。 SimpleTokenizerクラス。また、トークンとその位置を出力します。このプログラムをという名前のファイルに保存しますSimpleTokenizerSpans.java。
import opennlp.tools.tokenize.SimpleTokenizer;
import opennlp.tools.util.Span;
public class SimpleTokenizerSpans {
public static void main(String args[]){
String sent = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
SimpleTokenizer simpleTokenizer = SimpleTokenizer.INSTANCE;
//Retrieving the boundaries of the tokens
Span[] tokens = simpleTokenizer.tokenizePos(sent);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します-
javac SimpleTokenizerSpans.java
java SimpleTokenizerSpans実行時に、上記のプログラムは指定された文字列(生のテキスト)を読み取り、トークン化し、次の出力を表示します-
[0..2) Hi
[2..3) .
[4..7) How
[8..11) are
[12..15) you
[15..16) ?
[17..24) Welcome
[25..27) to
[28..42) Tutorialspoint
[42..43) .
[44..46) We
[47..54) provide
[55..59) free
[60..69) tutorials
[70..72) on
[73..80) various
[81..93) technologiesExample (WhitespaceTokenizer)
以下は、を使用して生のテキストのトークンスパンを取得するプログラムです。 WhitespaceTokenizerクラス。また、トークンとその位置を出力します。このプログラムを名前のファイルに保存しますWhitespaceTokenizerSpans.java。
import opennlp.tools.tokenize.WhitespaceTokenizer;
import opennlp.tools.util.Span;
public class WhitespaceTokenizerSpans {
public static void main(String args[]){
String sent = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
WhitespaceTokenizer whitespaceTokenizer = WhitespaceTokenizer.INSTANCE;
//Retrieving the tokens
Span[] tokens = whitespaceTokenizer.tokenizePos(sent);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +"
"+sent.substring(token.getStart(), token.getEnd()));
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します
javac WhitespaceTokenizerSpans.java
java WhitespaceTokenizerSpans実行時に、上記のプログラムは指定された文字列(生のテキスト)を読み取り、トークン化し、次の出力を表示します。
[0..3) Hi.
[4..7) How
[8..11) are
[12..16) you?
[17..24) Welcome
[25..27) to
[28..43) Tutorialspoint.
[44..46) We
[47..54) provide
[55..59) free
[60..69) tutorials
[70..72) on
[73..80) various
[81..93) technologiesExample (TokenizerME)
以下は、を使用して生のテキストのトークンスパンを取得するプログラムです。 TokenizerMEクラス。また、トークンとその位置を出力します。このプログラムを名前のファイルに保存しますTokenizerMESpans.java。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMESpans {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します-
javac TokenizerMESpans.java
java TokenizerMESpans実行時に、上記のプログラムは指定された文字列(生のテキスト)を読み取り、トークン化し、次の出力を表示します-
[0..5) Hello
[6..10) John
[11..14) how
[15..18) are
[19..22) you
[23..30) welcome
[31..33) to
[34..48) Tutorialspointトークナイザーの確率
TokenizerMEクラスのgetTokenProbabilities()メソッドは、tokenizePos()メソッドへの最新の呼び出しに関連付けられた確率を取得するために使用されます。
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = detector.getSentenceProbabilities();以下は、tokenizePos()メソッドの呼び出しに関連する確率を出力するプログラムです。このプログラムを名前のファイルに保存しますTokenizerMEProbs.java。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMEProbs {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = tokenizer.getTokenProbabilities();
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します-
javac TokenizerMEProbs.java
java TokenizerMEProbs実行時に、上記のプログラムは指定された文字列を読み取り、文をトークン化して出力します。さらに、tokenizerPos()メソッドへの最新の呼び出しに関連付けられた確率も返します。
[0..5) Hello
[6..10) John
[11..14) how
[15..18) are
[19..22) you
[23..30) welcome
[31..33) to
[34..48) Tutorialspoint
1.0
1.0
1.0
1.0
1.0
1.0
1.0
1.0特定のテキストから名前、人、場所、その他のエンティティを見つけるプロセスは、次のように知られています。 Named Entity Rエコグニション(NER)。この章では、OpenNLPライブラリを使用してJavaプログラムを介してNERを実行する方法について説明します。
オープンNLPを使用した名前付きエンティティの認識
さまざまなNERタスクを実行するために、OpenNLPはさまざまな定義済みモデル、つまりen-nerdate.bn、en-ner-location.bin、en-ner-organization.bin、en-ner-person.bin、およびen-ner-timeを使用します。置き場。これらのファイルはすべて事前定義されたモデルであり、特定の生テキスト内のそれぞれのエンティティを検出するようにトレーニングされています。
ザ・ opennlp.tools.namefindパッケージには、NERタスクの実行に使用されるクラスとインターフェイスが含まれています。OpenNLPライブラリを使用してNERタスクを実行するには、次のことを行う必要があります。
を使用してそれぞれのモデルをロードします TokenNameFinderModel クラス。
インスタンス化する NameFinder クラス。
名前を見つけて印刷します。
以下は、指定された生のテキストから名前エンティティを検出するプログラムを作成するために従うべき手順です。
ステップ1:モデルをロードする
文検出のモデルは、という名前のクラスで表されます。 TokenNameFinderModel、パッケージに属します opennlp.tools.namefind。
NERモデルをロードするには-
作成する InputStream モデルのオブジェクト(FileInputStreamをインスタンス化し、適切なNERモデルのパスを文字列形式でコンストラクターに渡します)。
インスタンス化する TokenNameFinderModel クラスと合格 InputStream 次のコードブロックに示すように、コンストラクターへのパラメーターとしてのモデルの(オブジェクト)。
//Loading the NER-person model
InputStream inputStreamNameFinder = new FileInputStream(".../en-nerperson.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);ステップ2:NameFinderMEクラスをインスタンス化する
ザ・ NameFinderME パッケージのクラス opennlp.tools.namefindNERタスクを実行するためのメソッドが含まれています。このクラスは、最大エントロピーモデルを使用して、指定された生のテキスト内の名前付きエンティティを検索します。
このクラスをインスタンス化し、以下に示すように、前の手順で作成したモデルオブジェクトを渡します-
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);ステップ3:文の中の名前を見つける
ザ・ find() の方法 NameFinderMEクラスは、渡された生のテキスト内の名前を検出するために使用されます。このメソッドは、String変数をパラメーターとして受け入れます。
文の文字列形式をこのメソッドに渡して、このメソッドを呼び出します。
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(sentence);ステップ4:文中の名前のスパンを印刷する
ザ・ find() の方法 NameFinderMEclassは、Span型のオブジェクトの配列を返します。Span oftheという名前のクラスopennlp.tools.util パッケージは、 start そして end セットの整数。
によって返されたスパンを保存できます find() 次のコードブロックに示すように、Span配列のメソッドを取得して出力します。
//Printing the sentences and their spans of a sentence
for (Span span : spans)
System.out.println(paragraph.substring(span);NER Example
以下は、与えられた文を読み、その中の人の名前のスパンを認識するプログラムです。このプログラムを名前のファイルに保存しますNameFinderME_Example.java。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.util.Span;
public class NameFinderME_Example {
public static void main(String args[]) throws Exception{
/Loading the NER - Person model InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-ner-person.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStream);
//Instantiating the NameFinder class
NameFinderME nameFinder = new NameFinderME(model);
//Getting the sentence in the form of String array
String [] sentence = new String[]{
"Mike",
"and",
"Smith",
"are",
"good",
"friends"
};
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(sentence);
//Printing the spans of the names in the sentence
for(Span s: nameSpans)
System.out.println(s.toString());
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します-
javac NameFinderME_Example.java
java NameFinderME_Example上記のプログラムは、実行時に、指定された文字列(生のテキスト)を読み取り、その中の人物の名前を検出し、以下に示すようにその位置(スパン)を表示します。
[0..1) person
[2..3) person名前とその位置
ザ・ substring() Stringクラスのメソッドは begin そしてその end offsetsそれぞれの文字列を返します。次のコードブロックに示すように、このメソッドを使用して、名前とそのスパン(位置)を一緒に出力できます。
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);以下は、指定された生のテキストから名前を検出し、それらの位置とともに表示するプログラムです。このプログラムを名前のファイルに保存しますNameFinderSentences.java。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class NameFinderSentences {
public static void main(String args[]) throws Exception{
//Loading the tokenizer model
InputStream inputStreamTokenizer = new
FileInputStream("C:/OpenNLP_models/entoken.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStreamTokenizer);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Tokenizing the sentence in to a string array
String sentence = "Mike is senior programming
manager and Rama is a clerk both are working at
Tutorialspoint";
String tokens[] = tokenizer.tokenize(sentence);
//Loading the NER-person model
InputStream inputStreamNameFinder = new
FileInputStream("C:/OpenNLP_models/enner-person.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(tokens);
//Printing the names and their spans in a sentence
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します-
javac NameFinderSentences.java
java NameFinderSentences実行時に、上記のプログラムは指定された文字列(生のテキスト)を読み取り、その中の人物の名前を検出し、以下に示すようにその位置(スパン)を表示します。
[0..1) person Mike場所の名前を見つける
さまざまなモデルをロードすることで、さまざまな名前付きエンティティを検出できます。以下は、をロードするJavaプログラムです。en-ner-location.bin指定された文の場所の名前をモデル化して検出します。このプログラムを名前のファイルに保存しますLocationFinder.java。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class LocationFinder {
public static void main(String args[]) throws Exception{
InputStream inputStreamTokenizer = new
FileInputStream("C:/OpenNLP_models/entoken.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStreamTokenizer);
//String paragraph = "Mike and Smith are classmates";
String paragraph = "Tutorialspoint is located in Hyderabad";
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
String tokens[] = tokenizer.tokenize(paragraph);
//Loading the NER-location moodel
InputStream inputStreamNameFinder = new
FileInputStream("C:/OpenNLP_models/en- ner-location.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);
//Finding the names of a location
Span nameSpans[] = nameFinder.find(tokens);
//Printing the spans of the locations in the sentence
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します-
javac LocationFinder.java
java LocationFinder上記のプログラムは、実行時に、指定された文字列(生のテキスト)を読み取り、その中の人物の名前を検出し、以下に示すようにその位置(スパン)を表示します。
[4..5) location HyderabadNameFinderの確率
ザ・ probs()の方法 NameFinderME クラスは、最後にデコードされたシーケンスの確率を取得するために使用されます。
double[] probs = nameFinder.probs();以下は、確率を出力するプログラムです。このプログラムを名前のファイルに保存しますTokenizerMEProbs.java。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMEProbs {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = tokenizer.getTokenProbabilities();
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +"
"+sent.substring(token.getStart(), token.getEnd()));
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します-
javac TokenizerMEProbs.java
java TokenizerMEProbs実行時に、上記のプログラムは指定された文字列を読み取り、文をトークン化し、それらを出力します。さらに、以下に示すように、最後にデコードされたシーケンスの確率も返します。
[0..5) Hello
[6..10) John
[11..14) how
[15..18) are
[19..22) you
[23..30) welcome
[31..33) to
[34..48) Tutorialspoint
1.0
1.0
1.0
1.0
1.0
1.0
1.0
1.0OpenNLPを使用すると、特定の文の品詞を検出して印刷することもできます。OpenNLPは、品詞のフルネームの代わりに、各品詞の短い形式を使用します。次の表は、OpenNLPによって検出された音声のさまざまな部分とその意味を示しています。
| 品詞 | 品詞の意味 |
|---|---|
| NN | 名詞、単数または質量 |
| DT | 限定詞 |
| VB | 動詞、基本形 |
| VBD | 動詞、過去形 |
| VBZ | 動詞、三人称単数現在形 |
| に | 前置詞または従属接続詞 |
| NNP | 固有名詞、単数 |
| に | に |
| JJ | 形容詞 |
品詞のタグ付け
OpenNLPは、文の品詞にタグを付けるために、モデルという名前のファイルを使用します。 en-posmaxent.bin。これは、指定された生のテキストの品詞にタグを付けるようにトレーニングされた事前定義されたモデルです。
ザ・ POSTaggerME のクラス opennlp.tools.postagパッケージは、このモデルをロードし、OpenNLPライブラリを使用して指定された生のテキストの品詞にタグを付けるために使用されます。そうするために、あなたはする必要があります-
をロードします en-pos-maxent.bin を使用したモデル POSModel クラス。
インスタンス化する POSTaggerME クラス。
文をトークン化します。
を使用してタグを生成します tag() 方法。
を使用してトークンとタグを印刷します POSSample クラス。
以下は、を使用して、指定された生のテキストのスピーチの部分にタグを付けるプログラムを作成するために従うべき手順です。 POSTaggerME クラス。
ステップ1:モデルをロードする
POSタグ付けのモデルは、という名前のクラスで表されます。 POSModel、パッケージに属します opennlp.tools.postag。
トークナイザーモデルをロードするには-
作成する InputStream モデルのオブジェクト(FileInputStreamをインスタンス化し、モデルのパスを文字列形式でコンストラクターに渡します)。
インスタンス化する POSModel クラスと合格 InputStream 次のコードブロックに示すように、コンストラクターへのパラメーターとしてのモデルの(オブジェクト)-
//Loading Parts of speech-maxent model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);ステップ2:POSTaggerMEクラスをインスタンス化する
ザ・ POSTaggerME パッケージのクラス opennlp.tools.postag与えられた生のテキストの品詞を予測するために使用されます。最大エントロピーを使用して決定を下します。
以下に示すように、このクラスをインスタンス化し、前の手順で作成したモデルオブジェクトを渡します。
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);ステップ3:文をトークン化する
ザ・ tokenize() の方法 whitespaceTokenizerクラスは、渡された生のテキストをトークン化するために使用されます。このメソッドは、パラメーターとしてString変数を受け取り、String(トークン)の配列を返します。
インスタンス化する whitespaceTokenizer クラスと文の文字列形式をこのメソッドに渡すことにより、このメソッドを呼び出します。
//Tokenizing the sentence using WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);ステップ4:タグを生成する
ザ・ tag() の方法 whitespaceTokenizerクラスは、トークンの文にPOSタグを割り当てます。このメソッドは、トークンの配列(String)をパラメーターとして受け取り、タグ(array)を返します。
を呼び出す tag() 前のステップで生成されたトークンをそれに渡すことによるメソッド。
//Generating tags
String[] tags = tagger.tag(tokens);ステップ5:トークンとタグを印刷する
ザ・ POSSampleclassはPOSタグ付きの文を表します。このクラスをインスタンス化するには、(テキストの)トークンの配列とタグの配列が必要になります。
ザ・ toString()このクラスのメソッドは、タグ付けされた文を返します。前の手順で作成したトークンとタグ配列を渡してこのクラスをインスタンス化し、toString() 次のコードブロックに示すように、メソッド。
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());Example
以下は、特定の生のテキストの品詞にタグを付けるプログラムです。このプログラムを名前のファイルに保存しますPosTaggerExample.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTaggerExample {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
String sentence = "Hi welcome to Tutorialspoint";
//Tokenizing the sentence using WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します-
javac PosTaggerExample.java
java PosTaggerExample上記のプログラムは、実行時に、指定されたテキストを読み取り、これらの文の品詞を検出して、以下に示すように表示します。
Hi_NNP welcome_JJ to_TO Tutorialspoint_VBPOSタガーパフォーマンス
以下は、特定の生のテキストの品詞にタグを付けるプログラムです。また、パフォーマンスを監視し、タガーのパフォーマンスを表示します。このプログラムを名前のファイルに保存しますPosTagger_Performance.java。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.cmdline.PerformanceMonitor;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTagger_Performance {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Creating an object of WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
//Monitoring the performance of POS tagger
PerformanceMonitor perfMon = new PerformanceMonitor(System.err, "sent");
perfMon.start();
perfMon.incrementCounter();
perfMon.stopAndPrintFinalResult();
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します-
javac PosTaggerExample.java
java PosTaggerExample実行時に、上記のプログラムは指定されたテキストを読み取り、これらの文の品詞にタグを付けて表示します。さらに、POSタガーのパフォーマンスを監視して表示します。
Hi_NNP welcome_JJ to_TO Tutorialspoint_VB
Average: 0.0 sent/s
Total: 1 sent
Runtime: 0.0sPOSタガー確率
ザ・ probs() の方法 POSTaggerME クラスは、最近タグ付けされた文の各タグの確率を見つけるために使用されます。
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = detector.getSentenceProbabilities();以下は、最後にタグ付けされた文の各タグの確率を表示するプログラムです。このプログラムを名前のファイルに保存しますPosTaggerProbs.java。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTaggerProbs {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new FileInputStream("C:/OpenNLP_mdl/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Creating an object of WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
//Probabilities for each tag of the last tagged sentence.
double [] probs = tagger.probs();
System.out.println(" ");
//Printing the probabilities
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します-
javac TokenizerMEProbs.java
java TokenizerMEProbs上記のプログラムは、実行時に、指定された生のテキストを読み取り、その中の各トークンの品詞にタグを付けて表示します。さらに、以下に示すように、特定の文の各品詞の確率も表示されます。
Hi_NNP welcome_JJ to_TO Tutorialspoint_VB
0.6416834779738033
0.42983612874819177
0.8584513635863117
0.4394784478206072OpenNLP APIを使用すると、指定された文を解析できます。この章では、OpenNLPAPIを使用して生のテキストを解析する方法について説明します。
OpenNLPライブラリを使用した生のテキストの解析
文を検出するために、OpenNLPは事前定義されたモデル、という名前のファイルを使用します en-parserchunking.bin。これは、指定された生のテキストを解析するようにトレーニングされた事前定義されたモデルです。
ザ・ Parser のクラス opennlp.tools.Parser パッケージは、解析構成要素と ParserTool のクラス opennlp.tools.cmdline.parser パッケージはコンテンツの解析に使用されます。
以下は、を使用して指定された生のテキストを解析するプログラムを作成するために従うべき手順です。 ParserTool クラス。
ステップ1:モデルをロードする
テキストを解析するためのモデルは、という名前のクラスで表されます。 ParserModel、パッケージに属します opennlp.tools.parser。
トークナイザーモデルをロードするには-
作成する InputStream モデルのオブジェクト(FileInputStreamをインスタンス化し、モデルのパスを文字列形式でコンストラクターに渡します)。
インスタンス化する ParserModel クラスと合格 InputStream 次のコードブロックに示すように、コンストラクターへのパラメーターとしてのモデルの(オブジェクト)。
//Loading parser model
InputStream inputStream = new FileInputStream(".../en-parserchunking.bin");
ParserModel model = new ParserModel(inputStream);ステップ2:パーサークラスのオブジェクトを作成する
ザ・ Parser パッケージのクラス opennlp.tools.parser解析構成要素を保持するためのデータ構造を表します。静的を使用してこのクラスのオブジェクトを作成できますcreate() の方法 ParserFactory クラス。
を呼び出す create() の方法 ParserFactory 以下に示すように、前のステップで作成したモデルオブジェクトを渡すことによって-
//Creating a parser Parser parser = ParserFactory.create(model);ステップ3:文を解析する
ザ・ parseLine() の方法 ParserToolクラスは、OpenNLPの生のテキストを解析するために使用されます。このメソッドは次を受け入れます-
解析するテキストを表す文字列変数。
パーサーオブジェクト。
実行される解析の数を表す整数。
次のパラメーターを文に渡して、このメソッドを呼び出します。前の手順で作成した解析オブジェクト、および実行する必要のある解析の数を表す整数。
//Parsing the sentence
String sentence = "Tutorialspoint is the largest tutorial library.";
Parse topParses[] = ParserTool.parseLine(sentence, parser, 1);Example
以下は、指定された生のテキストを解析するプログラムです。このプログラムを名前のファイルに保存しますParserExample.java。
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.cmdline.parser.ParserTool;
import opennlp.tools.parser.Parse;
import opennlp.tools.parser.Parser;
import opennlp.tools.parser.ParserFactory;
import opennlp.tools.parser.ParserModel;
public class ParserExample {
public static void main(String args[]) throws Exception{
//Loading parser model
InputStream inputStream = new FileInputStream(".../en-parserchunking.bin");
ParserModel model = new ParserModel(inputStream);
//Creating a parser
Parser parser = ParserFactory.create(model);
//Parsing the sentence
String sentence = "Tutorialspoint is the largest tutorial library.";
Parse topParses[] = ParserTool.parseLine(sentence, parser, 1);
for (Parse p : topParses)
p.show();
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します-
javac ParserExample.java
java ParserExample実行時に、上記のプログラムは指定された生のテキストを読み取り、それを解析して、次の出力を表示します-
(TOP (S (NP (NN Tutorialspoint)) (VP (VBZ is) (NP (DT the) (JJS largest) (NN
tutorial) (NN library.)))))文のチャンクとは、文を単語グループや動詞グループなどの単語の一部に分割/分割することです。
OpenNLPを使用して文をチャンクする
文を検出するために、OpenNLPはモデル、という名前のファイルを使用します en-chunker.bin。これは、指定された生のテキストの文をチャンク化するようにトレーニングされた事前定義されたモデルです。
ザ・ opennlp.tools.chunker パッケージには、名詞句チャンクなどの非再帰的な構文アノテーションを検索するために使用されるクラスとインターフェースが含まれています。
メソッドを使用して文をチャンクできます chunk() の ChunkerMEクラス。このメソッドは、文のトークンとPOSタグをパラメーターとして受け入れます。したがって、チャンク化のプロセスを開始する前に、まず文をトークン化し、その品詞POSタグを生成する必要があります。
OpenNLPライブラリを使用して文をチャンクするには、次のことを行う必要があります。
文をトークン化します。
そのためのPOSタグを生成します。
をロードします en-chunker.bin を使用したモデル ChunkerModel クラス
インスタンス化する ChunkerME クラス。
を使用して文をチャンクします chunk() このクラスのメソッド。
以下は、与えられた生のテキストから文をチャンクするプログラムを書くために従うべきステップです。
ステップ1:文をトークン化する
を使用して文をトークン化します tokenize() の方法 whitespaceTokenizer 次のコードブロックに示すように、クラス。
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);ステップ2:POSタグを生成する
を使用して文のPOSタグを生成します tag() の方法 POSTaggerME 次のコードブロックに示すように、クラス。
//Generating the POS tags
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);ステップ3:モデルをロードする
文をチャンク化するためのモデルは、という名前のクラスで表されます。 ChunkerModel、パッケージに属します opennlp.tools.chunker。
文検出モデルをロードするには-
作成する InputStream モデルのオブジェクト(FileInputStreamをインスタンス化し、モデルのパスを文字列形式でコンストラクターに渡します)。
インスタンス化する ChunkerModel クラスと合格 InputStream 次のコードブロックに示すように、コンストラクターへのパラメーターとしてのモデルの(オブジェクト)-
//Loading the chunker model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);ステップ4:chunkerMEクラスをインスタンス化する
ザ・ chunkerME パッケージのクラス opennlp.tools.chunker文をチャンクするメソッドが含まれています。これは、最大エントロピーベースのチャンカーです。
このクラスをインスタンス化し、前の手順で作成したモデルオブジェクトを渡します。
//Instantiate the ChunkerME class
ChunkerME chunkerME = new ChunkerME(chunkerModel);ステップ5:文をチャンクする
ザ・ chunk() の方法 ChunkerMEクラスは、渡された生のテキストの文をチャンク化するために使用されます。このメソッドは、トークンとタグを表す2つの文字列配列をパラメーターとして受け入れます。
前の手順で作成したトークン配列とタグ配列をパラメーターとして渡して、このメソッドを呼び出します。
//Generating the chunks
String result[] = chunkerME.chunk(tokens, tags);Example
以下は、与えられた生のテキストの文をチャンクするプログラムです。このプログラムを名前のファイルに保存しますChunkerExample.java。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class ChunkerExample{
public static void main(String args[]) throws IOException {
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating the POS tags
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);
//Instantiate the ChunkerME class
ChunkerME chunkerME = new ChunkerME(chunkerModel);
//Generating the chunks
String result[] = chunkerME.chunk(tokens, tags);
for (String s : result)
System.out.println(s);
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します-
javac ChunkerExample.java
java ChunkerExample実行時に、上記のプログラムは指定された文字列を読み取り、その中の文をチャンクして、以下に示すように表示します。
Loading POS Tagger model ... done (1.040s)
B-NP
I-NP
B-VP
I-VPトークンの位置の検出
チャンクの位置またはスパンを使用して検出することもできます chunkAsSpans() の方法 ChunkerMEクラス。このメソッドは、Span型のオブジェクトの配列を返します。Span oftheという名前のクラスopennlp.tools.util パッケージは、 start そして end セットの整数。
によって返されたスパンを保存できます chunkAsSpans() 次のコードブロックに示すように、Span配列のメソッドを取得して出力します。
//Generating the tagged chunk spans
Span[] span = chunkerME.chunkAsSpans(tokens, tags);
for (Span s : span)
System.out.println(s.toString());Example
以下は、与えられた生のテキストの文を検出するプログラムです。このプログラムを名前のファイルに保存しますChunkerSpansEample.java。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
import opennlp.tools.util.Span;
public class ChunkerSpansEample{
public static void main(String args[]) throws IOException {
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);
ChunkerME chunkerME = new ChunkerME(chunkerModel);
//Generating the tagged chunk spans
Span[] span = chunkerME.chunkAsSpans(tokens, tags);
for (Span s : span)
System.out.println(s.toString());
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します-
javac ChunkerSpansEample.java
java ChunkerSpansEample実行時に、上記のプログラムは指定された文字列とその中のチャンクのスパンを読み取り、次の出力を表示します-
Loading POS Tagger model ... done (1.059s)
[0..2) NP
[2..4) VPチャンカー確率の検出
ザ・ probs() の方法 ChunkerME classは、最後にデコードされたシーケンスの確率を返します。
//Getting the probabilities of the last decoded sequence
double[] probs = chunkerME.probs();以下は、最後にデコードされたシーケンスの確率を印刷するプログラムです。 chunker。このプログラムを名前のファイルに保存しますChunkerProbsExample.java。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class ChunkerProbsExample{
public static void main(String args[]) throws IOException {
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel cModel = new ChunkerModel(inputStream);
ChunkerME chunkerME = new ChunkerME(cModel);
//Generating the chunk tags
chunkerME.chunk(tokens, tags);
//Getting the probabilities of the last decoded sequence
double[] probs = chunkerME.probs();
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}次のコマンドを使用して、コマンドプロンプトから保存したJavaファイルをコンパイルして実行します-
javac ChunkerProbsExample.java
java ChunkerProbsExample実行時に、上記のプログラムは指定された文字列を読み取り、チャンク化し、最後にデコードされたシーケンスの確率を出力します。
0.9592746040797778
0.6883933131241501
0.8830563473996004
0.8951150529746051OpenNLPは、コマンドラインを介してさまざまな操作を実行するためのコマンドラインインターフェイス(CLI)を提供します。この章では、OpenNLPコマンドラインインターフェイスの使用方法を示すいくつかの例を取り上げます。
トークン化
input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologies構文
> opennlp TokenizerME path_for_models../en-token.bin <inputfile..> outputfile..コマンド
C:\> opennlp TokenizerME C:\OpenNLP_models/en-token.bin <input.txt >output.txt出力
Loading Tokenizer model ... done (0.207s)
Average: 214.3 sent/s
Total: 3 sent
Runtime: 0.014soutput.txt
Hi . How are you ? Welcome to Tutorialspoint . We provide free tutorials on various technologies文の検出
input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologies構文
> opennlp SentenceDetector path_for_models../en-token.bin <inputfile..> outputfile..コマンド
C:\> opennlp SentenceDetector C:\OpenNLP_models/en-sent.bin <input.txt > output_sendet.txt出力
Loading Sentence Detector model ... done (0.067s)
Average: 750.0 sent/s
Total: 3 sent
Runtime: 0.004sOutput_sendet.txt
Hi. How are you?
Welcome to Tutorialspoint.
We provide free tutorials on various technologies固有表現抽出
input.txt
<START:person> <START:person> Mike <END> <END> is senior programming manager and
<START:person> Rama <END> is a clerk both are working at Tutorialspoint構文
> opennlp TokenNameFinder path_for_models../en-token.bin <inputfile..コマンド
C:\>opennlp TokenNameFinder C:\OpenNLP_models\en-ner-person.bin <input_namefinder.txt出力
Loading Token Name Finder model ... done (0.730s)
<START:person> <START:person> Mike <END> <END> is senior programming manager and
<START:person> Rama <END> is a clerk both are working at Tutorialspoint
Average: 55.6 sent/s
Total: 1 sent
Runtime: 0.018s品詞タグ付け
Input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologies構文
> opennlp POSTagger path_for_models../en-token.bin <inputfile..コマンド
C:\>opennlp POSTagger C:\OpenNLP_models/en-pos-maxent.bin < input.txt出力
Loading POS Tagger model ... done (1.315s)
Hi._NNP How_WRB are_VBP you?_JJ Welcome_NNP to_TO Tutorialspoint._NNP We_PRP
provide_VBP free_JJ tutorials_NNS on_IN various_JJ technologies_NNS
Average: 66.7 sent/s
Total: 1 sent
Runtime: 0.015s