PL / SQL-クイックガイド
PL / SQLプログラミング言語は、SQLおよびOracleリレーショナルデータベースの手続き型拡張言語として、1980年代後半にOracleCorporationによって開発されました。以下は、PL / SQLに関する特定の注目すべき事実です。
PL / SQLは、完全に移植可能な高性能のトランザクション処理言語です。
PL / SQLは、組み込みのインタープリタ型OSに依存しないプログラミング環境を提供します。
PL / SQLはコマンドラインから直接呼び出すこともできます SQL*Plus interface。
データベースへの外部プログラミング言語呼び出しから直接呼び出しを行うこともできます。
PL / SQLの一般的な構文は、ADAおよびPascalプログラミング言語の構文に基づいています。
Oracleとは別に、PL / SQLは TimesTen in-memory database そして IBM DB2。
PL / SQLの機能
PL / SQLには次の機能があります-
- PL / SQLはSQLと緊密に統合されています。
- 広範なエラーチェックを提供します。
- 多数のデータ型を提供します。
- さまざまなプログラミング構造を提供します。
- 関数とプロシージャを通じて構造化プログラミングをサポートします。
- オブジェクト指向プログラミングをサポートします。
- Webアプリケーションとサーバーページの開発をサポートします。
PL / SQLの利点
PL / SQLには次の利点があります-
SQLは標準のデータベース言語であり、PL / SQLはSQLと強力に統合されています。PL / SQLは、静的SQLと動的SQLの両方をサポートします。静的SQLは、PL / SQLブロックからのDML操作とトランザクション制御をサポートします。動的SQLでは、SQLを使用してDDL文をPL / SQLブロックに埋め込むことができます。
PL / SQLを使用すると、ステートメントのブロック全体を一度にデータベースに送信できます。これにより、ネットワークトラフィックが減少し、アプリケーションに高いパフォーマンスが提供されます。
PL / SQLは、データベース内のデータを照会、変換、および更新できるため、プログラマーに高い生産性を提供します。
PL / SQLは、例外処理、カプセル化、データ隠蔽、オブジェクト指向データ型などの強力な機能により、設計とデバッグの時間を節約します。
PL / SQLで記述されたアプリケーションは完全に移植可能です。
PL / SQLは高いセキュリティレベルを提供します。
PL / SQLは、事前定義されたSQLパッケージへのアクセスを提供します。
PL / SQLは、オブジェクト指向プログラミングのサポートを提供します。
PL / SQLは、Webアプリケーションとサーバーページの開発をサポートします。
この章では、PL / SQLの環境設定について説明します。PL / SQLはスタンドアロンのプログラミング言語ではありません。これは、Oracleプログラミング環境内のツールです。SQL* Plusは、コマンドプロンプトでSQLおよびPL / SQL文を入力できる対話型ツールです。これらのコマンドは、処理のためにデータベースに送信されます。ステートメントが処理されると、結果が返送され、画面に表示されます。
PL / SQLプログラムを実行するには、OracleRDBMSサーバーがマシンにインストールされている必要があります。これにより、SQLコマンドの実行が処理されます。OracleRDBMSの最新バージョンは11gです。Oracle 11gの試用版は、次のリンクからダウンロードできます。
Oracle 11g ExpressEditionをダウンロードする
オペレーティングシステムに応じて、32ビットバージョンまたは64ビットバージョンのインストールをダウンロードする必要があります。通常、2つのファイルがあります。64ビット版をダウンロードしました。LinuxでもSolarisでも、オペレーティングシステムで同様の手順を使用します。
win64_11gR2_database_1of2.zip
win64_11gR2_database_2of2.zip
上記の2つのファイルをダウンロードした後、それらを1つのディレクトリに解凍する必要があります database その下に次のサブディレクトリがあります-
ステップ1
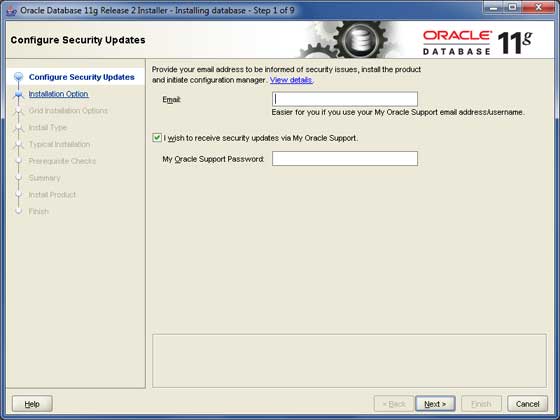
次に、セットアップファイルを使用してOracleDatabaseInstallerを起動します。以下は最初の画面です。次のスクリーンショットに示すように、メールIDを入力して、チェックボックスをオンにすることができます。クリックNext ボタン。
ステップ2
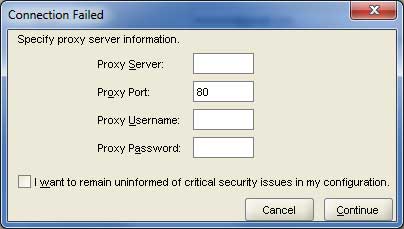
次の画面が表示されます。チェックボックスをオフにして、Continue ボタンをクリックして続行します。
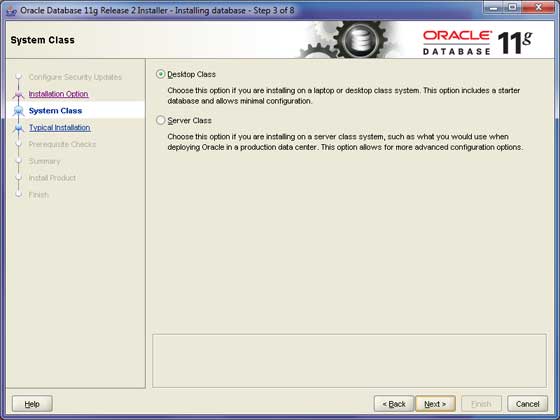
ステップ3
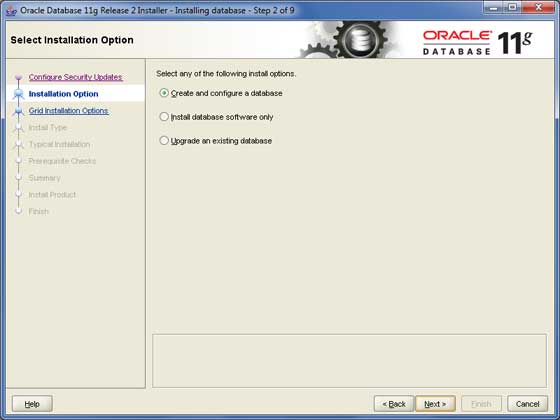
最初のオプションを選択するだけです Create and Configure Database ラジオボタンを使用して、 Next ボタンをクリックして続行します。
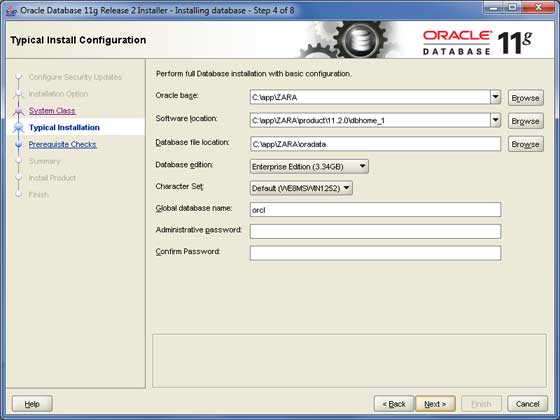
ステップ4
学習の基本的な目的でOracleをインストールし、PCまたはラップトップにインストールすることを前提としています。したがって、Desktop Class オプションをクリックし、 Next ボタンをクリックして続行します。
ステップ5
OracleServerをインストールする場所を指定します。変更するだけですOracle Base他の場所は自動的に設定されます。また、パスワードを入力する必要があります。これは、システムDBAによって使用されます。必要な情報を入力したら、をクリックしますNext ボタンをクリックして続行します。
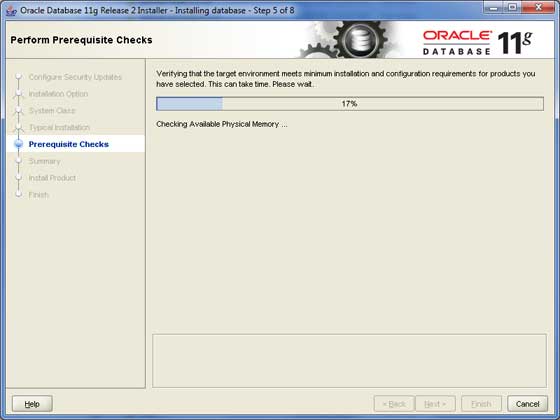
ステップ6
もう一度、 Next ボタンをクリックして続行します。
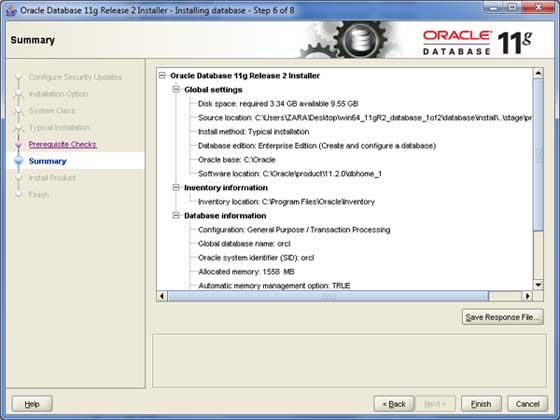
ステップ7
クリック Finish続行するボタン。これにより、実際のサーバーのインストールが開始されます。
ステップ8
Oracleが必要な構成の実行を開始するまで、これには少し時間がかかります。

ステップ9
ここで、Oracleのインストールにより、必要な構成ファイルがコピーされます。これには少し時間がかかります-
ステップ10
データベースファイルがコピーされると、次のダイアログボックスが表示されます。クリックするだけですOK ボタンを押して出てきます。
ステップ11
インストールすると、次の最終ウィンドウが表示されます。
最終段階
次に、インストールを確認します。Windowsを使用している場合は、コマンドプロンプトで次のコマンドを使用します-
sqlplus "/ as sysdba"PL / SQLコマンドとスクリプトを記述するSQLプロンプトが表示されます-

テキストエディタ
コマンドプロンプトから大きなプログラムを実行すると、不注意で作業の一部が失われる可能性があります。コマンドファイルを使用することを常にお勧めします。コマンドファイルを使用するには-
次のようなテキストエディタでコードを入力します Notepad, Notepad+, または EditPlus、など。
でファイルを保存します .sql ホームディレクトリの拡張子。
を起動します SQL*Plus command prompt PL / SQLファイルを作成したディレクトリから。
タイプ @file_name SQL * Plusコマンドプロンプトで、プログラムを実行します。
ファイルを使用してPL / SQLスクリプトを実行していない場合は、PL / SQLコードをコピーして、SQLプロンプトを表示する黒いウィンドウを右クリックします。使用pasteコマンドプロンプトで完全なコードを貼り付けるオプション。最後に、Enter コードがまだ実行されていない場合は、コードを実行します。
この章では、PL / SQLの基本構文について説明します。 block-structured言語; これは、PL / SQLプログラムが分割され、論理的なコードブロックで記述されることを意味します。各ブロックは3つのサブパートで構成されています-
| S.No | セクションと説明 |
|---|---|
| 1 | Declarations このセクションはキーワードで始まります DECLARE。これはオプションのセクションであり、プログラムで使用されるすべての変数、カーソル、サブプログラム、およびその他の要素を定義します。 |
| 2 | Executable Commands このセクションはキーワードで囲まれています BEGIN そして ENDそしてそれは必須のセクションです。これは、プログラムの実行可能なPL / SQL文で構成されています。少なくとも1行の実行可能コードが必要です。NULL command 何も実行しないことを示します。 |
| 3 | Exception Handling このセクションはキーワードで始まります EXCEPTION。このオプションのセクションには、exception(s) プログラムのエラーを処理します。 |
すべてのPL / SQL文はセミコロン(;)で終わります。PL / SQLブロックは、を使用して他のPL / SQLブロック内にネストできます。BEGIN そして END。PL / SQLブロックの基本構造は次のとおりです。
DECLARE
<declarations section>
BEGIN
<executable command(s)>
EXCEPTION
<exception handling>
END;「HelloWorld」の例
DECLARE
message varchar2(20):= 'Hello, World!';
BEGIN
dbms_output.put_line(message);
END;
/ザ・ end;lineは、PL / SQLブロックの終了を示します。SQLコマンドラインからコードを実行するには、コードの最後の行の後の最初の空白行の先頭に/を入力する必要がある場合があります。上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Hello World
PL/SQL procedure successfully completed.PL / SQL識別子
PL / SQL識別子は、定数、変数、例外、プロシージャ、カーソル、および予約語です。識別子は、オプションで文字とそれに続く文字、数字、ドル記号、アンダースコア、および番号記号で構成され、30文字を超えてはなりません。
デフォルトでは、 identifiers are not case-sensitive。だからあなたは使うことができますinteger または INTEGER数値を表します。予約済みのキーワードを識別子として使用することはできません。
PL / SQL区切り文字
区切り文字は、特別な意味を持つ記号です。以下は、PL / SQLの区切り文字のリストです。
| デリミタ | 説明 |
|---|---|
| +, -, *, / | 足し算、引き算/否定、掛け算、割り算 |
| % | 属性インジケーター |
| ' | 文字列区切り文字 |
| . | コンポーネントセレクター |
| (,) | 式またはリスト区切り文字 |
| : | ホスト変数インジケーター |
| , | アイテムセパレータ |
| " | 引用符で囲まれた識別子の区切り文字 |
| = | 関係演算子 |
| @ | リモートアクセスインジケーター |
| ; | ステートメントターミネータ |
| := | 代入演算子 |
| => | アソシエーション演算子 |
| || | 連結演算子 |
| ** | べき乗演算子 |
| <<, >> | ラベル区切り文字(開始と終了) |
| /*, */ | 複数行コメント区切り文字(開始と終了) |
| -- | 単一行コメントインジケータ |
| .. | 範囲演算子 |
| <, >, <=, >= | 関係演算子 |
| <>, '=, ~=, ^= | NOTEQUALの異なるバージョン |
PL / SQLコメント
プログラムコメントは、作成するPL / SQLコードに含めることができる説明文であり、ソースコードを読む人を支援します。すべてのプログラミング言語では、何らかの形式のコメントが許可されています。
PL / SQLは、単一行および複数行のコメントをサポートします。コメント内で使用可能なすべての文字は、PL / SQLコンパイラによって無視されます。PL / SQLの単一行コメントは区切り文字-(二重ハイフン)で始まり、複数行コメントは/ *および* /で囲まれます。
DECLARE
-- variable declaration
message varchar2(20):= 'Hello, World!';
BEGIN
/*
* PL/SQL executable statement(s)
*/
dbms_output.put_line(message);
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Hello World
PL/SQL procedure successfully completed.PL / SQLプログラムユニット
PL / SQLユニットは、次のいずれかです。
- PL / SQLブロック
- Function
- Package
- パッケージ本体
- Procedure
- Trigger
- Type
- タイプボディ
これらの各ユニットについては、次の章で説明します。
この章では、PL / SQLのデータ型について説明します。PL / SQL変数、定数、およびパラメータには、ストレージ形式、制約、および有効な値の範囲を指定する有効なデータ型が必要です。私たちは焦点を当てますSCALAR そしてその LOBこの章のデータ型。他の2つのデータ型については、他の章で説明します。
| S.No | カテゴリと説明 |
|---|---|
| 1 | Scalar 次のような内部コンポーネントのない単一の値 NUMBER, DATE, または BOOLEAN。 |
| 2 | Large Object (LOB) テキスト、グラフィックイメージ、ビデオクリップ、音声波形など、他のデータ項目とは別に保存される大きなオブジェクトへのポインタ。 |
| 3 | Composite 個別にアクセスできる内部コンポーネントを持つデータ項目。たとえば、コレクションやレコード。 |
| 4 | Reference 他のデータ項目へのポインタ。 |
PL / SQLスカラーのデータ型とサブタイプ
PL / SQLスカラーのデータ型とサブタイプは次のカテゴリに分類されます-
| S.No | 日付の種類と説明 |
|---|---|
| 1 | Numeric 算術演算が実行される数値。 |
| 2 | Character 単一文字または文字列を表す英数字の値。 |
| 3 | Boolean 論理演算が実行される論理値。 |
| 4 | Datetime 日付と時刻。 |
PL / SQLは、データ型のサブタイプを提供します。たとえば、データ型NUMBERには、INTEGERというサブタイプがあります。PL / SQLプログラムのサブタイプを使用して、Javaプログラムなどの別のプログラムにPL / SQLコードを埋め込みながら、データ型を他のプログラムのデータ型と互換性のあるものにすることができます。
PL / SQLの数値データ型とサブタイプ
次の表に、PL / SQLの事前定義された数値データ型とそのサブタイプを示します。
| S.No | データ型と説明 |
|---|---|
| 1 | PLS_INTEGER 32ビットで表される-2,147,483,648から2,147,483,647の範囲の符号付き整数 |
| 2 | BINARY_INTEGER 32ビットで表される-2,147,483,648から2,147,483,647の範囲の符号付き整数 |
| 3 | BINARY_FLOAT 単精度IEEE754形式の浮動小数点数 |
| 4 | BINARY_DOUBLE 倍精度IEEE754形式の浮動小数点数 |
| 5 | NUMBER(prec, scale) 絶対値が1E-130から1.0E126(ただし含まない)の範囲の固定小数点数または浮動小数点数。NUMBER変数は0を表すこともできます |
| 6 | DEC(prec, scale) 最大精度が10進数の38桁のANSI固有の固定小数点タイプ |
| 7 | DECIMAL(prec, scale) 最大精度が10進数の38桁のIBM固有の固定小数点タイプ |
| 8 | NUMERIC(pre, secale) 小数点以下38桁の最大精度のフローティングタイプ |
| 9 | DOUBLE PRECISION 最大精度が126の2進数(約38の10進数)のANSI固有の浮動小数点型 |
| 10 | FLOAT 最大精度が126の2進数(約38の10進数)のANSIおよびIBM固有の浮動小数点型 |
| 11 | INT 最大精度が10進数の38桁のANSI固有の整数型 |
| 12 | INTEGER 最大精度が10進数の38桁のANSIおよびIBM固有の整数型 |
| 13 | SMALLINT 最大精度が10進数の38桁のANSIおよびIBM固有の整数型 |
| 14 | REAL 最大精度63桁(10進数約18桁)の浮動小数点型 |
以下は有効な宣言です-
DECLARE
num1 INTEGER;
num2 REAL;
num3 DOUBLE PRECISION;
BEGIN
null;
END;
/上記のコードをコンパイルして実行すると、次の結果が得られます。
PL/SQL procedure successfully completedPL / SQL文字のデータ型とサブタイプ
以下は、PL / SQLの事前定義された文字データ型とそのサブタイプの詳細です。
| S.No | データ型と説明 |
|---|---|
| 1 | CHAR 最大サイズが32,767バイトの固定長文字ストリング |
| 2 | VARCHAR2 最大サイズが32,767バイトの可変長文字ストリング |
| 3 | RAW PL / SQLによって解釈されない最大サイズ32,767バイトの可変長バイナリまたはバイト文字列 |
| 4 | NCHAR 最大サイズが32,767バイトの固定長国別文字列 |
| 5 | NVARCHAR2 最大サイズが32,767バイトの可変長国別文字列 |
| 6 | LONG 最大サイズが32,760バイトの可変長文字ストリング |
| 7 | LONG RAW PL / SQLによって解釈されない最大サイズ32,760バイトの可変長バイナリまたはバイト文字列 |
| 8 | ROWID 物理行識別子、通常のテーブルの行のアドレス |
| 9 | UROWID ユニバーサル行識別子(物理、論理、または外部行識別子) |
PL / SQLブールデータ型
ザ・ BOOLEANデータ型は、論理演算で使用される論理値を格納します。論理値はブール値ですTRUE そして FALSE と値 NULL。
ただし、SQLにはBOOLEANに相当するデータ型はありません。したがって、ブール値は−では使用できません。
- SQLステートメント
- 組み込みSQL関数(など TO_CHAR)
- SQL文から呼び出されるPL / SQL関数
PL / SQLの日時タイプと間隔タイプ
ザ・ DATEデータ型は、午前0時からの秒単位の時刻を含む固定長の日時を格納するために使用されます。有効な日付の範囲は、紀元前4712年1月1日から西暦9999年12月31日までです。
デフォルトの日付形式は、Oracle初期化パラメータNLS_DATE_FORMATによって設定されます。たとえば、デフォルトは「DD-MON-YY」の場合があります。これには、月の日の2桁の数字、月名の省略形、および年の下2桁が含まれます。たとえば、01-OCT-12。
各DATEには、世紀、年、月、日、時、分、秒が含まれます。次の表は、各フィールドの有効な値を示しています-
| フィールド名 | 有効な日時値 | 有効な間隔値 |
|---|---|---|
| 年 | -4712から9999(0年を除く) | ゼロ以外の整数 |
| 月 | 01から12 | 0から11 |
| 日 | 01から31(ロケールのカレンダーの規則に従って、MONTHとYEARの値によって制限されます) | ゼロ以外の整数 |
| 時間 | 00から23 | 0から23 |
| 分 | 00から59 | 0から59 |
| 2番目 | 00〜59.9(n)、ここで9(n)は時間の小数秒の精度です | 0〜59.9(n)、ここで9(n)は間隔の小数秒の精度です |
| TIMEZONE_HOUR | -12〜14(範囲は夏時間の変更に対応) | 適用できません |
| TIMEZONE_MINUTE | 00から59 | 適用できません |
| TIMEZONE_REGION | 動的パフォーマンスビューにありますV $ TIMEZONE_NAMES | 適用できません |
| TIMEZONE_ABBR | 動的パフォーマンスビューにありますV $ TIMEZONE_NAMES | 適用できません |
PL / SQLラージ・オブジェクト(LOB)データ型
ラージオブジェクト(LOB)データ型は、テキスト、グラフィックイメージ、ビデオクリップ、サウンド波形などのラージデータアイテムを指します。LOBデータ型を使用すると、このデータに効率的、ランダム、区分的にアクセスできます。以下は、事前定義されたPL / SQLLOBデータ型です。
| データ・タイプ | 説明 | サイズ |
|---|---|---|
| BFILE | データベース外のオペレーティングシステムファイルに大きなバイナリオブジェクトを格納するために使用されます。 | システムに依存します。4ギガバイト(GB)を超えることはできません。 |
| BLOB | 大きなバイナリオブジェクトをデータベースに格納するために使用されます。 | 8〜128テラバイト(TB) |
| CLOB | データベースに文字データの大きなブロックを格納するために使用されます。 | 8〜128 TB |
| NCLOB | NCHARデータの大きなブロックをデータベースに格納するために使用されます。 | 8〜128 TB |
PL / SQLユーザー定義サブタイプ
サブタイプは、基本タイプと呼ばれる別のデータ型のサブセットです。サブタイプの有効な操作は基本タイプと同じですが、有効な値のサブセットのみです。
PL / SQLは、パッケージ内のいくつかのサブタイプを事前定義します STANDARD。たとえば、PL / SQLはサブタイプを事前定義しますCHARACTER そして INTEGER 次のように-
SUBTYPE CHARACTER IS CHAR;
SUBTYPE INTEGER IS NUMBER(38,0);独自のサブタイプを定義して使用できます。次のプログラムは、ユーザー定義のサブタイプの定義と使用を示しています。
DECLARE
SUBTYPE name IS char(20);
SUBTYPE message IS varchar2(100);
salutation name;
greetings message;
BEGIN
salutation := 'Reader ';
greetings := 'Welcome to the World of PL/SQL';
dbms_output.put_line('Hello ' || salutation || greetings);
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Hello Reader Welcome to the World of PL/SQL
PL/SQL procedure successfully completed.PL / SQLのNULL
PL / SQLNULL値は missing または unknown dataまた、整数、文字、またはその他の特定のデータ型ではありません。ご了承くださいNULL 空のデータ文字列またはヌル文字値と同じではありません '\0'。nullを割り当てることはできますが、それ自体を含むものと同一視することはできません。
この章では、Pl / SQLの変数について説明します。変数は、プログラムが操作できるストレージ領域に付けられた名前に他なりません。PL / SQLの各変数には、変数のメモリのサイズとレイアウトを決定する特定のデータ型があります。そのメモリ内に格納できる値の範囲と、変数に適用できる一連の操作。
PL / SQL変数の名前は、オプションでさらに文字、数字、ドル記号、アンダースコア、および番号記号が続く文字で構成され、30文字を超えてはなりません。デフォルトでは、変数名では大文字と小文字は区別されません。予約済みのPL / SQLキーワードを変数名として使用することはできません。
PL / SQLプログラミング言語を使用すると、日時データ型、レコード、コレクションなど、さまざまなタイプの変数を定義できます。これについては、以降の章で説明します。この章では、基本的な変数タイプのみを調べてみましょう。
PL / SQLでの変数宣言
PL / SQL変数は、宣言セクションまたはパッケージでグローバル変数として宣言する必要があります。変数を宣言すると、PL / SQLは変数の値にメモリを割り当て、格納場所は変数名で識別されます。
変数を宣言するための構文は次のとおりです。
variable_name [CONSTANT] datatype [NOT NULL] [:= | DEFAULT initial_value]ここで、variable_nameはPL / SQLの有効な識別子ですが、datatypeは、有効なPL / SQLデータ型、または前の章ですでに説明したユーザー定義のデータ型である必要があります。いくつかの有効な変数宣言とその定義を以下に示します-
sales number(10, 2);
pi CONSTANT double precision := 3.1415;
name varchar2(25);
address varchar2(100);データ型にサイズ、スケール、または精度の制限を指定すると、それは constrained declaration。制約付き宣言は、制約なし宣言よりも必要なメモリが少なくて済みます。例-
sales number(10, 2);
name varchar2(25);
address varchar2(100);PL / SQLでの変数の初期化
変数を宣言するたびに、PL / SQLはその変数にデフォルト値のNULLを割り当てます。NULL値以外の値で変数を初期化する場合は、宣言中に次のいずれかを使用して初期化できます。
ザ・ DEFAULT キーワード
ザ・ assignment オペレーター
例-
counter binary_integer := 0;
greetings varchar2(20) DEFAULT 'Have a Good Day';変数にを持たないように指定することもできます NULL を使用した値 NOT NULL制約。NOT NULL制約を使用する場合は、その変数に初期値を明示的に割り当てる必要があります。
変数を適切に初期化することは良いプログラミング手法です。そうしないと、プログラムが予期しない結果を生成することがあります。さまざまなタイプの変数を使用する次の例を試してください-
DECLARE
a integer := 10;
b integer := 20;
c integer;
f real;
BEGIN
c := a + b;
dbms_output.put_line('Value of c: ' || c);
f := 70.0/3.0;
dbms_output.put_line('Value of f: ' || f);
END;
/上記のコードを実行すると、次の結果が得られます。
Value of c: 30
Value of f: 23.333333333333333333
PL/SQL procedure successfully completed.PL / SQLの可変スコープ
PL / SQLでは、ブロックをネストできます。つまり、各プログラムブロックに別の内部ブロックを含めることができます。変数が内部ブロック内で宣言されている場合、外部ブロックからはアクセスできません。ただし、変数が宣言されて外部ブロックにアクセスできる場合は、ネストされたすべての内部ブロックにもアクセスできます。可変スコープには2つのタイプがあります-
Local variables −内側のブロックで宣言され、外側のブロックからアクセスできない変数。
Global variables −最も外側のブロックまたはパッケージで宣言された変数。
次の例は、の使用法を示しています Local そして Global 単純な形式の変数-
DECLARE
-- Global variables
num1 number := 95;
num2 number := 85;
BEGIN
dbms_output.put_line('Outer Variable num1: ' || num1);
dbms_output.put_line('Outer Variable num2: ' || num2);
DECLARE
-- Local variables
num1 number := 195;
num2 number := 185;
BEGIN
dbms_output.put_line('Inner Variable num1: ' || num1);
dbms_output.put_line('Inner Variable num2: ' || num2);
END;
END;
/上記のコードを実行すると、次の結果が得られます。
Outer Variable num1: 95
Outer Variable num2: 85
Inner Variable num1: 195
Inner Variable num2: 185
PL/SQL procedure successfully completed.PL / SQL変数へのSQLクエリ結果の割り当て
あなたは使用することができます SELECT INTOPL / SQL変数に値を割り当てるSQL文。の各アイテムについてSELECT list、に対応する型互換変数が必要です INTO list。次の例は、概念を示しています。CUSTOMERSという名前のテーブルを作成しましょう-
((For SQL statements, please refer to the SQL tutorial)
CREATE TABLE CUSTOMERS(
ID INT NOT NULL,
NAME VARCHAR (20) NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR (25),
SALARY DECIMAL (18, 2),
PRIMARY KEY (ID)
);
Table Createdここで、テーブルにいくつかの値を挿入しましょう-
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (1, 'Ramesh', 32, 'Ahmedabad', 2000.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (2, 'Khilan', 25, 'Delhi', 1500.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (3, 'kaushik', 23, 'Kota', 2000.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (4, 'Chaitali', 25, 'Mumbai', 6500.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (5, 'Hardik', 27, 'Bhopal', 8500.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (6, 'Komal', 22, 'MP', 4500.00 );次のプログラムは、を使用して上記の表の値をPL / SQL変数に割り当てます。 SELECT INTO clause SQLの-
DECLARE
c_id customers.id%type := 1;
c_name customers.name%type;
c_addr customers.address%type;
c_sal customers.salary%type;
BEGIN
SELECT name, address, salary INTO c_name, c_addr, c_sal
FROM customers
WHERE id = c_id;
dbms_output.put_line
('Customer ' ||c_name || ' from ' || c_addr || ' earns ' || c_sal);
END;
/上記のコードを実行すると、次の結果が得られます。
Customer Ramesh from Ahmedabad earns 2000
PL/SQL procedure completed successfullyこの章では、 constants そして literalsPL / SQLで。定数は、一度宣言されるとプログラム内で変更されない値を保持します。定数宣言は、その名前、データ型、および値を指定し、それにストレージを割り当てます。宣言はまた課すことができますNOT NULL constraint。
定数の宣言
定数は、を使用して宣言されます CONSTANTキーワード。初期値が必要であり、その値を変更することはできません。例-
PI CONSTANT NUMBER := 3.141592654;
DECLARE
-- constant declaration
pi constant number := 3.141592654;
-- other declarations
radius number(5,2);
dia number(5,2);
circumference number(7, 2);
area number (10, 2);
BEGIN
-- processing
radius := 9.5;
dia := radius * 2;
circumference := 2.0 * pi * radius;
area := pi * radius * radius;
-- output
dbms_output.put_line('Radius: ' || radius);
dbms_output.put_line('Diameter: ' || dia);
dbms_output.put_line('Circumference: ' || circumference);
dbms_output.put_line('Area: ' || area);
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Radius: 9.5
Diameter: 19
Circumference: 59.69
Area: 283.53
Pl/SQL procedure successfully completed.The PL/SQL Literals
A literal is an explicit numeric, character, string, or Boolean value not represented by an identifier. For example, TRUE, 786, NULL, 'tutorialspoint' are all literals of type Boolean, number, or string. PL/SQL, literals are case-sensitive. PL/SQL supports the following kinds of literals −
- Numeric Literals
- Character Literals
- String Literals
- BOOLEAN Literals
- Date and Time Literals
The following table provides examples from all these categories of literal values.
| S.No | Literal Type & Example |
|---|---|
| 1 | Numeric Literals 050 78 -14 0 +32767 6.6667 0.0 -12.0 3.14159 +7800.00 6E5 1.0E-8 3.14159e0 -1E38 -9.5e-3 |
| 2 | Character Literals 'A' '%' '9' ' ' 'z' '(' |
| 3 | String Literals 'Hello, world!' 'Tutorials Point' '19-NOV-12' |
| 4 | BOOLEAN Literals TRUE, FALSE, and NULL. |
| 5 | Date and Time Literals DATE '1978-12-25'; TIMESTAMP '2012-10-29 12:01:01'; |
To embed single quotes within a string literal, place two single quotes next to each other as shown in the following program −
DECLARE
message varchar2(30):= 'That''s tutorialspoint.com!';
BEGIN
dbms_output.put_line(message);
END;
/When the above code is executed at the SQL prompt, it produces the following result −
That's tutorialspoint.com!
PL/SQL procedure successfully completed.In this chapter, we will discuss operators in PL/SQL. An operator is a symbol that tells the compiler to perform specific mathematical or logical manipulation. PL/SQL language is rich in built-in operators and provides the following types of operators −
- Arithmetic operators
- Relational operators
- Comparison operators
- Logical operators
- String operators
Here, we will understand the arithmetic, relational, comparison and logical operators one by one. The String operators will be discussed in a later chapter − PL/SQL - Strings.
Arithmetic Operators
Following table shows all the arithmetic operators supported by PL/SQL. Let us assume variable A holds 10 and variable B holds 5, then −
Show Examples
| Operator | Description | Example |
|---|---|---|
| + | Adds two operands | A + B will give 15 |
| - | Subtracts second operand from the first | A - B will give 5 |
| * | Multiplies both operands | A * B will give 50 |
| / | Divides numerator by de-numerator | A / B will give 2 |
| ** | Exponentiation operator, raises one operand to the power of other | A ** B will give 100000 |
Relational Operators
Relational operators compare two expressions or values and return a Boolean result. Following table shows all the relational operators supported by PL/SQL. Let us assume variable A holds 10 and variable B holds 20, then −
Show Examples
| Operator | Description | Example |
|---|---|---|
| = | Checks if the values of two operands are equal or not, if yes then condition becomes true. | (A = B) is not true. |
!= <> ~= |
Checks if the values of two operands are equal or not, if values are not equal then condition becomes true. | (A != B) is true. |
| > | Checks if the value of left operand is greater than the value of right operand, if yes then condition becomes true. | (A > B) is not true. |
| < | Checks if the value of left operand is less than the value of right operand, if yes then condition becomes true. | (A < B) is true. |
| >= | Checks if the value of left operand is greater than or equal to the value of right operand, if yes then condition becomes true. | (A >= B) is not true. |
| <= | Checks if the value of left operand is less than or equal to the value of right operand, if yes then condition becomes true. | (A <= B) is true |
Comparison Operators
Comparison operators are used for comparing one expression to another. The result is always either TRUE, FALSE or NULL.
Show Examples
| Operator | Description | Example |
|---|---|---|
| LIKE | The LIKE operator compares a character, string, or CLOB value to a pattern and returns TRUE if the value matches the pattern and FALSE if it does not. | If 'Zara Ali' like 'Z% A_i' returns a Boolean true, whereas, 'Nuha Ali' like 'Z% A_i' returns a Boolean false. |
| BETWEEN | The BETWEEN operator tests whether a value lies in a specified range. x BETWEEN a AND b means that x >= a and x <= b. | If x = 10 then, x between 5 and 20 returns true, x between 5 and 10 returns true, but x between 11 and 20 returns false. |
| IN | The IN operator tests set membership. x IN (set) means that x is equal to any member of set. | If x = 'm' then, x in ('a', 'b', 'c') returns Boolean false but x in ('m', 'n', 'o') returns Boolean true. |
| IS NULL | The IS NULL operator returns the BOOLEAN value TRUE if its operand is NULL or FALSE if it is not NULL. Comparisons involving NULL values always yield NULL. | If x = 'm', then 'x is null' returns Boolean false. |
Logical Operators
Following table shows the Logical operators supported by PL/SQL. All these operators work on Boolean operands and produce Boolean results. Let us assume variable A holds true and variable B holds false, then −
Show Examples
| Operator | Description | Examples |
|---|---|---|
| and | Called the logical AND operator. If both the operands are true then condition becomes true. | (A and B) is false. |
| or | Called the logical OR Operator. If any of the two operands is true then condition becomes true. | (A or B) is true. |
| not | Called the logical NOT Operator. Used to reverse the logical state of its operand. If a condition is true then Logical NOT operator will make it false. | not (A and B) is true. |
PL/SQL Operator Precedence
Operator precedence determines the grouping of terms in an expression. This affects how an expression is evaluated. Certain operators have higher precedence than others; for example, the multiplication operator has higher precedence than the addition operator.
For example, x = 7 + 3 * 2; here, x is assigned 13, not 20 because operator * has higher precedence than +, so it first gets multiplied with 3*2 and then adds into 7.
Here, operators with the highest precedence appear at the top of the table, those with the lowest appear at the bottom. Within an expression, higher precedence operators will be evaluated first.
The precedence of operators goes as follows: =, <, >, <=, >=, <>, !=, ~=, ^=, IS NULL, LIKE, BETWEEN, IN.
Show Examples
| Operator | Operation |
|---|---|
| ** | exponentiation |
| +, - | identity, negation |
| *, / | multiplication, division |
| +, -, || | addition, subtraction, concatenation |
| comparison | |
| NOT | logical negation |
| AND | conjunction |
| OR | inclusion |
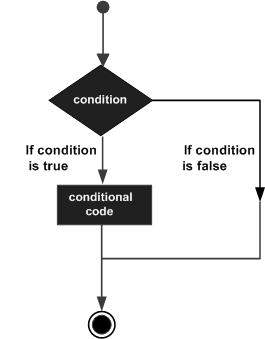
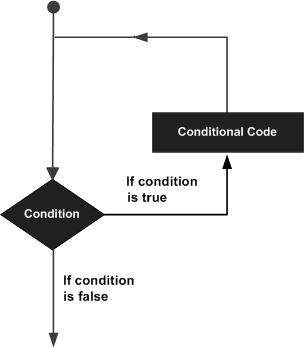
In this chapter, we will discuss conditions in PL/SQL. Decision-making structures require that the programmer specify one or more conditions to be evaluated or tested by the program, along with a statement or statements to be executed if the condition is determined to be true, and optionally, other statements to be executed if the condition is determined to be false.
Following is the general form of a typical conditional (i.e., decision making) structure found in most of the programming languages −
PL/SQL programming language provides following types of decision-making statements. Click the following links to check their detail.
| S.No | Statement & Description |
|---|---|
| 1 | IF - THEN statement The IF statement associates a condition with a sequence of statements enclosed by the keywords THEN and END IF. If the condition is true, the statements get executed and if the condition is false or NULL then the IF statement does nothing. |
| 2 | IF-THEN-ELSE statement IF statement adds the keyword ELSE followed by an alternative sequence of statement. If the condition is false or NULL, then only the alternative sequence of statements get executed. It ensures that either of the sequence of statements is executed. |
| 3 | IF-THEN-ELSIF statement It allows you to choose between several alternatives. |
| 4 | Case statement Like the IF statement, the CASE statement selects one sequence of statements to execute. However, to select the sequence, the CASE statement uses a selector rather than multiple Boolean expressions. A selector is an expression whose value is used to select one of several alternatives. |
| 5 | Searched CASE statement The searched CASE statement has no selector, and it's WHEN clauses contain search conditions that yield Boolean values. |
| 6 | nested IF-THEN-ELSE You can use one IF-THEN or IF-THEN-ELSIF statement inside another IF-THEN or IF-THEN-ELSIF statement(s). |
In this chapter, we will discuss Loops in PL/SQL. There may be a situation when you need to execute a block of code several number of times. In general, statements are executed sequentially: The first statement in a function is executed first, followed by the second, and so on.
Programming languages provide various control structures that allow for more complicated execution paths.
A loop statement allows us to execute a statement or group of statements multiple times and following is the general form of a loop statement in most of the programming languages −
PL/SQL provides the following types of loop to handle the looping requirements. Click the following links to check their detail.
| S.No | Loop Type & Description |
|---|---|
| 1 | PL/SQL Basic LOOP In this loop structure, sequence of statements is enclosed between the LOOP and the END LOOP statements. At each iteration, the sequence of statements is executed and then control resumes at the top of the loop. |
| 2 | PL/SQL WHILE LOOP Repeats a statement or group of statements while a given condition is true. It tests the condition before executing the loop body. |
| 3 | PL/SQL FOR LOOP Execute a sequence of statements multiple times and abbreviates the code that manages the loop variable. |
| 4 | Nested loops in PL/SQL You can use one or more loop inside any another basic loop, while, or for loop. |
Labeling a PL/SQL Loop
PL/SQL loops can be labeled. The label should be enclosed by double angle brackets (<< and >>) and appear at the beginning of the LOOP statement. The label name can also appear at the end of the LOOP statement. You may use the label in the EXIT statement to exit from the loop.
The following program illustrates the concept −
DECLARE
i number(1);
j number(1);
BEGIN
<< outer_loop >>
FOR i IN 1..3 LOOP
<< inner_loop >>
FOR j IN 1..3 LOOP
dbms_output.put_line('i is: '|| i || ' and j is: ' || j);
END loop inner_loop;
END loop outer_loop;
END;
/When the above code is executed at the SQL prompt, it produces the following result −
i is: 1 and j is: 1
i is: 1 and j is: 2
i is: 1 and j is: 3
i is: 2 and j is: 1
i is: 2 and j is: 2
i is: 2 and j is: 3
i is: 3 and j is: 1
i is: 3 and j is: 2
i is: 3 and j is: 3
PL/SQL procedure successfully completed.The Loop Control Statements
Loop control statements change execution from its normal sequence. When execution leaves a scope, all automatic objects that were created in that scope are destroyed.
PL/SQL supports the following control statements. Labeling loops also help in taking the control outside a loop. Click the following links to check their details.
| S.No | Control Statement & Description |
|---|---|
| 1 | EXIT statement The Exit statement completes the loop and control passes to the statement immediately after the END LOOP. |
| 2 | CONTINUE statement Causes the loop to skip the remainder of its body and immediately retest its condition prior to reiterating. |
| 3 | GOTO statement Transfers control to the labeled statement. Though it is not advised to use the GOTO statement in your program. |
The string in PL/SQL is actually a sequence of characters with an optional size specification. The characters could be numeric, letters, blank, special characters or a combination of all. PL/SQL offers three kinds of strings −
Fixed-length strings − In such strings, programmers specify the length while declaring the string. The string is right-padded with spaces to the length so specified.
Variable-length strings − In such strings, a maximum length up to 32,767, for the string is specified and no padding takes place.
Character large objects (CLOBs) − These are variable-length strings that can be up to 128 terabytes.
PL/SQL strings could be either variables or literals. A string literal is enclosed within quotation marks. For example,
'This is a string literal.' Or 'hello world'To include a single quote inside a string literal, you need to type two single quotes next to one another. For example,
'this isn''t what it looks like'Declaring String Variables
Oracle database provides numerous string datatypes, such as CHAR, NCHAR, VARCHAR2, NVARCHAR2, CLOB, and NCLOB. The datatypes prefixed with an 'N' are 'national character set' datatypes, that store Unicode character data.
If you need to declare a variable-length string, you must provide the maximum length of that string. For example, the VARCHAR2 data type. The following example illustrates declaring and using some string variables −
DECLARE
name varchar2(20);
company varchar2(30);
introduction clob;
choice char(1);
BEGIN
name := 'John Smith';
company := 'Infotech';
introduction := ' Hello! I''m John Smith from Infotech.';
choice := 'y';
IF choice = 'y' THEN
dbms_output.put_line(name);
dbms_output.put_line(company);
dbms_output.put_line(introduction);
END IF;
END;
/When the above code is executed at the SQL prompt, it produces the following result −
John Smith
Infotech
Hello! I'm John Smith from Infotech.
PL/SQL procedure successfully completedTo declare a fixed-length string, use the CHAR datatype. Here you do not have to specify a maximum length for a fixed-length variable. If you leave off the length constraint, Oracle Database automatically uses a maximum length required. The following two declarations are identical −
red_flag CHAR(1) := 'Y';
red_flag CHAR := 'Y';PL/SQL String Functions and Operators
PL/SQL offers the concatenation operator (||) for joining two strings. The following table provides the string functions provided by PL/SQL −
| S.No | Function & Purpose |
|---|---|
| 1 | ASCII(x); Returns the ASCII value of the character x. |
| 2 | CHR(x); Returns the character with the ASCII value of x. |
| 3 | CONCAT(x, y); Concatenates the strings x and y and returns the appended string. |
| 4 | INITCAP(x); Converts the initial letter of each word in x to uppercase and returns that string. |
| 5 | INSTR(x, find_string [, start] [, occurrence]); Searches for find_string in x and returns the position at which it occurs. |
| 6 | INSTRB(x); Returns the location of a string within another string, but returns the value in bytes. |
| 7 | LENGTH(x); Returns the number of characters in x. |
| 8 | LENGTHB(x); Returns the length of a character string in bytes for single byte character set. |
| 9 | LOWER(x); Converts the letters in x to lowercase and returns that string. |
| 10 | LPAD(x, width [, pad_string]) ; Pads x with spaces to the left, to bring the total length of the string up to width characters. |
| 11 | LTRIM(x [, trim_string]); Trims characters from the left of x. |
| 12 | NANVL(x, value); Returns value if x matches the NaN special value (not a number), otherwise x is returned. |
| 13 | NLS_INITCAP(x); Same as the INITCAP function except that it can use a different sort method as specified by NLSSORT. |
| 14 | NLS_LOWER(x) ; Same as the LOWER function except that it can use a different sort method as specified by NLSSORT. |
| 15 | NLS_UPPER(x); Same as the UPPER function except that it can use a different sort method as specified by NLSSORT. |
| 16 | NLSSORT(x); Changes the method of sorting the characters. Must be specified before any NLS function; otherwise, the default sort will be used. |
| 17 | NVL(x, value); Returns value if x is null; otherwise, x is returned. |
| 18 | NVL2(x, value1, value2); Returns value1 if x is not null; if x is null, value2 is returned. |
| 19 | REPLACE(x, search_string, replace_string); Searches x for search_string and replaces it with replace_string. |
| 20 | RPAD(x, width [, pad_string]); Pads x to the right. |
| 21 | RTRIM(x [, trim_string]); Trims x from the right. |
| 22 | SOUNDEX(x) ; Returns a string containing the phonetic representation of x. |
| 23 | SUBSTR(x, start [, length]); Returns a substring of x that begins at the position specified by start. An optional length for the substring may be supplied. |
| 24 | SUBSTRB(x); Same as SUBSTR except that the parameters are expressed in bytes instead of characters for the single-byte character systems. |
| 25 | TRIM([trim_char FROM) x); Trims characters from the left and right of x. |
| 26 | UPPER(x); Converts the letters in x to uppercase and returns that string. |
概念を理解するために、いくつかの例を考えてみましょう。
例1
DECLARE
greetings varchar2(11) := 'hello world';
BEGIN
dbms_output.put_line(UPPER(greetings));
dbms_output.put_line(LOWER(greetings));
dbms_output.put_line(INITCAP(greetings));
/* retrieve the first character in the string */
dbms_output.put_line ( SUBSTR (greetings, 1, 1));
/* retrieve the last character in the string */
dbms_output.put_line ( SUBSTR (greetings, -1, 1));
/* retrieve five characters,
starting from the seventh position. */
dbms_output.put_line ( SUBSTR (greetings, 7, 5));
/* retrieve the remainder of the string,
starting from the second position. */
dbms_output.put_line ( SUBSTR (greetings, 2));
/* find the location of the first "e" */
dbms_output.put_line ( INSTR (greetings, 'e'));
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
HELLO WORLD
hello world
Hello World
h
d
World
ello World
2
PL/SQL procedure successfully completed.例2
DECLARE
greetings varchar2(30) := '......Hello World.....';
BEGIN
dbms_output.put_line(RTRIM(greetings,'.'));
dbms_output.put_line(LTRIM(greetings, '.'));
dbms_output.put_line(TRIM( '.' from greetings));
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
......Hello World
Hello World.....
Hello World
PL/SQL procedure successfully completed.この章では、PL / SQLの配列について説明します。PL / SQLプログラミング言語は、と呼ばれるデータ構造を提供します。VARRAY、同じタイプの要素の固定サイズの順次コレクションを格納できます。配列はデータの順序付けられたコレクションを格納するために使用されますが、配列を同じタイプの変数のコレクションと考える方がよい場合がよくあります。
すべてのVARRAYは、連続したメモリ位置で構成されます。最小アドレスは最初の要素に対応し、最大アドレスは最後の要素に対応します。

配列はコレクション型データの一部であり、可変サイズ配列を表します。他のコレクションタイプについては、後の章で説明します。'PL/SQL Collections'。
の各要素 varrayインデックスが関連付けられています。また、動的に変更できる最大サイズもあります。
Varrayタイプの作成
VARRAYタイプは、 CREATE TYPEステートメント。VARRAYに格納される要素の最大サイズとタイプを指定する必要があります。
スキーマレベルでVARRAYタイプを作成するための基本的な構文は次のとおりです。
CREATE OR REPLACE TYPE varray_type_name IS VARRAY(n) of <element_type>どこ、
- varray_type_nameは有効な属性名であり、
- nは、VARRAY内の要素の数(最大)です。
- element_typeは、配列の要素のデータ型です。
VARRAYの最大サイズは、 ALTER TYPE ステートメント。
例えば、
CREATE Or REPLACE TYPE namearray AS VARRAY(3) OF VARCHAR2(10);
/
Type created.PL / SQLブロック内にVARRAYタイプを作成するための基本的な構文は次のとおりです。
TYPE varray_type_name IS VARRAY(n) of <element_type>例-
TYPE namearray IS VARRAY(5) OF VARCHAR2(10);
Type grades IS VARRAY(5) OF INTEGER;概念を理解するために、いくつかの例を考えてみましょう。
例1
次のプログラムは、VARRAYの使用法を示しています。
DECLARE
type namesarray IS VARRAY(5) OF VARCHAR2(10);
type grades IS VARRAY(5) OF INTEGER;
names namesarray;
marks grades;
total integer;
BEGIN
names := namesarray('Kavita', 'Pritam', 'Ayan', 'Rishav', 'Aziz');
marks:= grades(98, 97, 78, 87, 92);
total := names.count;
dbms_output.put_line('Total '|| total || ' Students');
FOR i in 1 .. total LOOP
dbms_output.put_line('Student: ' || names(i) || '
Marks: ' || marks(i));
END LOOP;
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Total 5 Students
Student: Kavita Marks: 98
Student: Pritam Marks: 97
Student: Ayan Marks: 78
Student: Rishav Marks: 87
Student: Aziz Marks: 92
PL/SQL procedure successfully completed.Please note −
Oracle環境では、VARRAYの開始インデックスは常に1です。
VARRAYと同じ名前のVARRAYタイプのコンストラクターメソッドを使用して、VARRAY要素を初期化できます。
Varrayは1次元配列です。
varrayは、宣言されると自動的にNULLになり、その要素を参照する前に初期化する必要があります。
例2
VARRAYの要素は、任意のデータベース表の%ROWTYPEまたは任意のデータベース表フィールドの%TYPEにすることもできます。次の例は、概念を示しています。
データベースに格納されているCUSTOMERSテーブルを-として使用します。
Select * from customers;
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
+----+----------+-----+-----------+----------+次の例では、 cursor、これについては別の章で詳しく学習します。
DECLARE
CURSOR c_customers is
SELECT name FROM customers;
type c_list is varray (6) of customers.name%type;
name_list c_list := c_list();
counter integer :=0;
BEGIN
FOR n IN c_customers LOOP
counter := counter + 1;
name_list.extend;
name_list(counter) := n.name;
dbms_output.put_line('Customer('||counter ||'):'||name_list(counter));
END LOOP;
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Customer(1): Ramesh
Customer(2): Khilan
Customer(3): kaushik
Customer(4): Chaitali
Customer(5): Hardik
Customer(6): Komal
PL/SQL procedure successfully completed.この章では、PL / SQLのプロシージャについて説明します。Asubprogram特定のタスクを実行するプログラムユニット/モジュールです。これらのサブプログラムを組み合わせて、より大きなプログラムを形成します。これは基本的に「モジュラーデザイン」と呼ばれます。サブプログラムは、別のサブプログラムまたはプログラムと呼ばれるプログラムによって呼び出すことができます。calling program。
サブプログラムを作成できます-
- スキーマレベルで
- パッケージ内
- PL / SQLブロック内
スキーマレベルでは、サブプログラムは standalone subprogram。これは、CREATEPROCEDUREまたはCREATEFUNCTIONステートメントで作成されます。これはデータベースに保管され、DROPPROCEDUREまたはDROPFUNCTIONステートメントで削除できます。
パッケージ内に作成されたサブプログラムは packaged subprogram。これはデータベースに保管されており、DROPPACKAGEステートメントでパッケージが削除された場合にのみ削除できます。この章でパッケージについて説明します'PL/SQL - Packages'。
PL / SQLサブプログラムは、パラメータのセットを使用して呼び出すことができるPL / SQLブロックと呼ばれます。PL / SQLは2種類のサブプログラムを提供します-
Functions−これらのサブプログラムは単一の値を返します。主に値を計算して返すために使用されます。
Procedures−これらのサブプログラムは値を直接返しません。主にアクションを実行するために使用されます。
この章では、の重要な側面について説明します。 PL/SQL procedure。私たちは議論する予定ですPL/SQL function 次の章で。
PL / SQLサブプログラムの一部
各PL / SQLサブプログラムには名前があり、パラメータリストがある場合もあります。匿名のPL / SQLブロックと同様に、名前付きブロックにも次の3つの部分があります。
| S.No | 部品と説明 |
|---|---|
| 1 | Declarative Part オプションパーツです。ただし、サブプログラムの宣言部分はDECLAREキーワードで始まりません。これには、型、カーソル、定数、変数、例外、およびネストされたサブプログラムの宣言が含まれています。これらの項目はサブプログラムに対してローカルであり、サブプログラムが実行を完了すると存在しなくなります。 |
| 2 | Executable Part これは必須の部分であり、指定されたアクションを実行するステートメントが含まれています。 |
| 3 | Exception-handling これもオプションパーツです。実行時エラーを処理するコードが含まれています。 |
プロシージャの作成
プロシージャは、 CREATE OR REPLACE PROCEDUREステートメント。CREATE OR REPLACEPROCEDUREステートメントの簡略化された構文は次のとおりです。
CREATE [OR REPLACE] PROCEDURE procedure_name
[(parameter_name [IN | OUT | IN OUT] type [, ...])]
{IS | AS}
BEGIN
< procedure_body >
END procedure_name;どこ、
procedure-nameは、プロシージャーの名前を指定します。
[OR REPLACE]オプションを使用すると、既存のプロシージャを変更できます。
オプションのパラメータリストには、パラメータの名前、モード、およびタイプが含まれています。 IN は外部から渡される値を表し、OUTはプロシージャの外部で値を返すために使用されるパラメータを表します。
procedure-bodyには、実行可能部分が含まれています。
スタンドアロンプロシージャを作成するために、ISキーワードの代わりにASキーワードが使用されます。
例
次の例では、文字列「HelloWorld!」を表示する簡単なプロシージャを作成します。実行時に画面に表示されます。
CREATE OR REPLACE PROCEDURE greetings
AS
BEGIN
dbms_output.put_line('Hello World!');
END;
/上記のコードをSQLプロンプトを使用して実行すると、次の結果が生成されます。
Procedure created.スタンドアロン手順の実行
スタンドアロンプロシージャは、2つの方法で呼び出すことができます-
を使用して EXECUTE キーワード
PL / SQLブロックからプロシージャの名前を呼び出す
上記の手順 'greetings' EXECUTEキーワードを使用して-として呼び出すことができます
EXECUTE greetings;上記の呼び出しは表示されます-
Hello World
PL/SQL procedure successfully completed.プロシージャは、別のPL / SQLブロックから呼び出すこともできます-
BEGIN
greetings;
END;
/上記の呼び出しは表示されます-
Hello World
PL/SQL procedure successfully completed.スタンドアロンプロシージャの削除
スタンドアロンプロシージャは、 DROP PROCEDUREステートメント。プロシージャを削除するための構文は次のとおりです。
DROP PROCEDURE procedure-name;次のステートメントを使用して、グリーティング手順を削除できます。
DROP PROCEDURE greetings;PL / SQLサブプログラムのパラメータモード
次の表に、PL / SQLサブプログラムのパラメータモードを示します。
| S.No | パラメータモードと説明 |
|---|---|
| 1 | IN INパラメーターを使用すると、サブプログラムに値を渡すことができます。 It is a read-only parameter。サブプログラム内では、INパラメーターは定数のように機能します。値を割り当てることはできません。定数、リテラル、初期化された変数、または式をINパラメーターとして渡すことができます。デフォルト値に初期化することもできます。ただし、その場合はサブプログラム呼び出しから省略されます。It is the default mode of parameter passing. Parameters are passed by reference。 |
| 2 | OUT OUTパラメータは、呼び出し元のプログラムに値を返します。サブプログラム内では、OUTパラメータは変数のように機能します。値を変更し、割り当てた後で値を参照できます。The actual parameter must be variable and it is passed by value。 |
| 3 | IN OUT アン IN OUTパラメータは初期値をサブプログラムに渡し、更新された値を呼び出し元に返します。値を割り当てたり、値を読み取ったりすることができます。 IN OUT仮パラメータに対応する実際のパラメータは、定数や式ではなく、変数である必要があります。正式なパラメータには値を割り当てる必要があります。Actual parameter is passed by value. |
IN&OUTモードの例1
このプログラムは、最小2つの値を見つけます。ここで、プロシージャはINモードを使用して2つの数値を取り、OUTパラメータを使用してそれらの最小値を返します。
DECLARE
a number;
b number;
c number;
PROCEDURE findMin(x IN number, y IN number, z OUT number) IS
BEGIN
IF x < y THEN
z:= x;
ELSE
z:= y;
END IF;
END;
BEGIN
a:= 23;
b:= 45;
findMin(a, b, c);
dbms_output.put_line(' Minimum of (23, 45) : ' || c);
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Minimum of (23, 45) : 23
PL/SQL procedure successfully completed.IN&OUTモードの例2
このプロシージャは、渡された値の値の2乗を計算します。この例は、同じパラメーターを使用して値を受け入れ、別の結果を返す方法を示しています。
DECLARE
a number;
PROCEDURE squareNum(x IN OUT number) IS
BEGIN
x := x * x;
END;
BEGIN
a:= 23;
squareNum(a);
dbms_output.put_line(' Square of (23): ' || a);
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Square of (23): 529
PL/SQL procedure successfully completed.パラメータを渡すためのメソッド
実際のパラメータは3つの方法で渡すことができます-
- 位置表記
- 名前付き表記
- 混合表記
位置表記
位置表記では、プロシージャを次のように呼び出すことができます。
findMin(a, b, c, d);位置表記では、最初の実パラメータが最初の仮パラメータに置き換えられます。2番目の実パラメータが2番目の仮パラメータに置き換えられ、以下同様に続きます。そう、a の代わりに x, b の代わりに y, c の代わりに z そして d の代わりに m。
名前付き表記
名前付き表記では、実際のパラメーターは、を使用して仮パラメーターに関連付けられます。 arrow symbol ( => )。プロシージャコールは次のようになります-
findMin(x => a, y => b, z => c, m => d);混合表記
混合表記では、プロシージャコールで両方の表記を混合できます。ただし、位置表記は名前付き表記の前に置く必要があります。
次の呼び出しは合法です-
findMin(a, b, c, m => d);ただし、これは合法ではありません。
findMin(x => a, b, c, d);この章では、PL / SQLの関数について説明します。関数は、値を返すことを除いて、プロシージャと同じです。したがって、前の章のすべての説明は関数にも当てはまります。
関数の作成
スタンドアロン関数は、を使用して作成されます CREATE FUNCTIONステートメント。の簡略化された構文CREATE OR REPLACE PROCEDURE ステートメントは次のとおりです-
CREATE [OR REPLACE] FUNCTION function_name
[(parameter_name [IN | OUT | IN OUT] type [, ...])]
RETURN return_datatype
{IS | AS}
BEGIN
< function_body >
END [function_name];どこ、
function-nameは、関数の名前を指定します。
[OR REPLACE]オプションを使用すると、既存の機能を変更できます。
オプションのパラメータリストには、パラメータの名前、モード、およびタイプが含まれています。INは外部から渡される値を表し、OUTはプロシージャの外部で値を返すために使用されるパラメータを表します。
関数には、 return ステートメント。
RETURNの句は、関数から戻るしようとしているデータのタイプを指定します。
function-bodyには、実行可能部分が含まれています。
スタンドアロン関数を作成するために、ISキーワードの代わりにASキーワードが使用されます。
例
次の例は、スタンドアロン関数を作成して呼び出す方法を示しています。この関数は、customersテーブル内のCUSTOMERSの総数を返します。
PL / SQL変数の章で作成したCUSTOMERS表を使用します。
Select * from customers;
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
+----+----------+-----+-----------+----------+CREATE OR REPLACE FUNCTION totalCustomers
RETURN number IS
total number(2) := 0;
BEGIN
SELECT count(*) into total
FROM customers;
RETURN total;
END;
/上記のコードをSQLプロンプトを使用して実行すると、次の結果が生成されます。
Function created.関数の呼び出し
関数を作成するときに、関数が何をしなければならないかを定義します。関数を使用するには、その関数を呼び出して定義されたタスクを実行する必要があります。プログラムが関数を呼び出すと、プログラム制御は呼び出された関数に移されます。
呼び出された関数は、定義されたタスクを実行し、そのreturnステートメントが実行されたとき、または last end statement に達すると、プログラム制御をメインプログラムに戻します。
関数を呼び出すには、必要なパラメーターを関数名と一緒に渡すだけで、関数が値を返す場合は、戻り値を保存できます。次のプログラムは関数を呼び出しますtotalCustomers 匿名ブロックから-
DECLARE
c number(2);
BEGIN
c := totalCustomers();
dbms_output.put_line('Total no. of Customers: ' || c);
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Total no. of Customers: 6
PL/SQL procedure successfully completed.例
次の例は、最大2つの値を計算して返す単純なPL / SQL関数の宣言、定義、および呼び出しを示しています。
DECLARE
a number;
b number;
c number;
FUNCTION findMax(x IN number, y IN number)
RETURN number
IS
z number;
BEGIN
IF x > y THEN
z:= x;
ELSE
Z:= y;
END IF;
RETURN z;
END;
BEGIN
a:= 23;
b:= 45;
c := findMax(a, b);
dbms_output.put_line(' Maximum of (23,45): ' || c);
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Maximum of (23,45): 45
PL/SQL procedure successfully completed.PL / SQL再帰関数
プログラムまたはサブプログラムが別のサブプログラムを呼び出す可能性があることを確認しました。サブプログラムがそれ自体を呼び出すとき、それは再帰呼び出しと呼ばれ、プロセスは次のように知られています。recursion。
概念を説明するために、数値の階乗を計算してみましょう。数nの階乗は次のように定義されます-
n! = n*(n-1)!
= n*(n-1)*(n-2)!
...
= n*(n-1)*(n-2)*(n-3)... 1次のプログラムは、それ自体を再帰的に呼び出すことによって、指定された数の階乗を計算します-
DECLARE
num number;
factorial number;
FUNCTION fact(x number)
RETURN number
IS
f number;
BEGIN
IF x=0 THEN
f := 1;
ELSE
f := x * fact(x-1);
END IF;
RETURN f;
END;
BEGIN
num:= 6;
factorial := fact(num);
dbms_output.put_line(' Factorial '|| num || ' is ' || factorial);
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Factorial 6 is 720
PL/SQL procedure successfully completed.この章では、PL / SQLのカーソルについて説明します。Oracleは、SQL文を処理するために、コンテキスト領域と呼ばれるメモリ領域を作成します。この領域には、文の処理に必要なすべての情報が含まれています。たとえば、処理された行数など。
A cursorこのコンテキスト領域へのポインタです。PL / SQLは、カーソルを介してコンテキスト領域を制御します。カーソルは、SQLステートメントによって返される行(1つ以上)を保持します。カーソルが保持する行のセットは、active set。
プログラムで参照できるようにカーソルに名前を付けて、SQLステートメントによって返された行を一度に1つずつフェッチして処理することができます。カーソルには2つのタイプがあります-
- 暗黙カーソル
- 明示カーソル
暗黙カーソル
暗黙カーソルは、SQLステートメントが実行されるたびに、ステートメントに明示カーソルがない場合にOracleによって自動的に作成されます。プログラマーは、暗黙カーソルとその中の情報を制御できません。
DMLステートメント(INSERT、UPDATE、およびDELETE)が発行されるたびに、暗黙カーソルがこのステートメントに関連付けられます。INSERT操作の場合、カーソルは挿入する必要のあるデータを保持します。UPDATEおよびDELETE操作の場合、カーソルは影響を受ける行を識別します。
PL / SQLでは、最新の暗黙カーソルを次のように参照できます。 SQL cursor、常に次のような属性があります %FOUND, %ISOPEN, %NOTFOUND、および %ROWCOUNT。SQLカーソルには追加の属性があります。%BULK_ROWCOUNT そして %BULK_EXCEPTIONS、で使用するために設計されています FORALLステートメント。次の表に、最もよく使用される属性の説明を示します-
| S.No | 属性と説明 |
|---|---|
| 1 | %FOUND INSERT、UPDATE、またはDELETEステートメントが1つ以上の行に影響を与えた場合、またはSELECT INTOステートメントが1つ以上の行を返した場合、TRUEを返します。それ以外の場合は、FALSEを返します。 |
| 2 | %NOTFOUND %FOUNDの論理的な反対。INSERT、UPDATE、またはDELETEステートメントが行に影響を与えなかった場合、またはSELECT INTOステートメントが行を返さなかった場合は、TRUEを返します。それ以外の場合は、FALSEを返します。 |
| 3 | %ISOPEN Oracleは関連するSQLステートメントの実行後にSQLカーソルを自動的に閉じるため、暗黙カーソルに対しては常にFALSEを返します。 |
| 4 | %ROWCOUNT INSERT、UPDATE、またはDELETEステートメントの影響を受ける行数、またはSELECTINTOステートメントによって返される行数を返します。 |
すべてのSQLカーソル属性は次のようにアクセスされます sql%attribute_name 以下の例に示すように。
例
前の章で作成して使用したCUSTOMERSテーブルを使用します。
Select * from customers;
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
+----+----------+-----+-----------+----------+次のプログラムは、テーブルを更新し、各顧客の給与を500増やし、 SQL%ROWCOUNT 影響を受ける行数を決定する属性-
DECLARE
total_rows number(2);
BEGIN
UPDATE customers
SET salary = salary + 500;
IF sql%notfound THEN
dbms_output.put_line('no customers selected');
ELSIF sql%found THEN
total_rows := sql%rowcount;
dbms_output.put_line( total_rows || ' customers selected ');
END IF;
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
6 customers selected
PL/SQL procedure successfully completed.Customersテーブルのレコードを確認すると、行が更新されていることがわかります-
Select * from customers;
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2500.00 |
| 2 | Khilan | 25 | Delhi | 2000.00 |
| 3 | kaushik | 23 | Kota | 2500.00 |
| 4 | Chaitali | 25 | Mumbai | 7000.00 |
| 5 | Hardik | 27 | Bhopal | 9000.00 |
| 6 | Komal | 22 | MP | 5000.00 |
+----+----------+-----+-----------+----------+明示カーソル
明示カーソルは、プログラマー定義のカーソルであり、 context area。PL / SQLブロックの宣言セクションで明示カーソルを定義する必要があります。これは、複数の行を返すSELECTステートメントで作成されます。
明示カーソルを作成するための構文は次のとおりです。
CURSOR cursor_name IS select_statement;明示カーソルの操作には、次の手順が含まれます-
- メモリを初期化するためのカーソルの宣言
- メモリを割り当てるためにカーソルを開く
- データを取得するためのカーソルの取得
- カーソルを閉じて、割り当てられたメモリを解放します
カーソルの宣言
カーソルを宣言すると、カーソルとそれに関連するSELECTステートメントが定義されます。例-
CURSOR c_customers IS
SELECT id, name, address FROM customers;カーソルを開く
カーソルを開くと、カーソルにメモリが割り当てられ、SQLステートメントによって返された行をカーソルにフェッチできるようになります。たとえば、上記で定義したカーソルを次のように開きます-
OPEN c_customers;カーソルのフェッチ
カーソルを取得するには、一度に1行にアクセスする必要があります。たとえば、上で開いたカーソルから次のように行をフェッチします-
FETCH c_customers INTO c_id, c_name, c_addr;カーソルを閉じる
カーソルを閉じるとは、割り当てられたメモリを解放することを意味します。たとえば、上で開いたカーソルを次のように閉じます-
CLOSE c_customers;例
以下は、明示カーソル&minua;の概念を説明するための完全な例です。
DECLARE
c_id customers.id%type;
c_name customer.name%type;
c_addr customers.address%type;
CURSOR c_customers is
SELECT id, name, address FROM customers;
BEGIN
OPEN c_customers;
LOOP
FETCH c_customers into c_id, c_name, c_addr;
EXIT WHEN c_customers%notfound;
dbms_output.put_line(c_id || ' ' || c_name || ' ' || c_addr);
END LOOP;
CLOSE c_customers;
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
1 Ramesh Ahmedabad
2 Khilan Delhi
3 kaushik Kota
4 Chaitali Mumbai
5 Hardik Bhopal
6 Komal MP
PL/SQL procedure successfully completed.この章では、PL / SQLのレコードについて説明します。Arecordは、さまざまな種類のデータ項目を保持できるデータ構造です。レコードは、データベーステーブルの行と同様に、さまざまなフィールドで構成されます。
たとえば、図書館で本を追跡したいとします。タイトル、著者、件名、本IDなど、各本に関する次の属性を追跡することをお勧めします。これらの各項目のフィールドを含むレコードを使用すると、BOOKを論理単位として扱うことができ、その情報をより適切に整理して表すことができます。
PL / SQLは、次のタイプのレコードを処理できます-
- Table-based
- カーソルベースのレコード
- ユーザー定義のレコード
テーブルベースのレコード
%ROWTYPE属性を使用すると、プログラマーは作成できます table-based そして cursorbased 記録。
次の例は、 table-based記録。前の章で作成して使用したCUSTOMERSテーブルを使用します-
DECLARE
customer_rec customers%rowtype;
BEGIN
SELECT * into customer_rec
FROM customers
WHERE id = 5;
dbms_output.put_line('Customer ID: ' || customer_rec.id);
dbms_output.put_line('Customer Name: ' || customer_rec.name);
dbms_output.put_line('Customer Address: ' || customer_rec.address);
dbms_output.put_line('Customer Salary: ' || customer_rec.salary);
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Customer ID: 5
Customer Name: Hardik
Customer Address: Bhopal
Customer Salary: 9000
PL/SQL procedure successfully completed.カーソルベースのレコード
次の例は、 cursor-based記録。前の章で作成して使用したCUSTOMERSテーブルを使用します-
DECLARE
CURSOR customer_cur is
SELECT id, name, address
FROM customers;
customer_rec customer_cur%rowtype;
BEGIN
OPEN customer_cur;
LOOP
FETCH customer_cur into customer_rec;
EXIT WHEN customer_cur%notfound;
DBMS_OUTPUT.put_line(customer_rec.id || ' ' || customer_rec.name);
END LOOP;
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
1 Ramesh
2 Khilan
3 kaushik
4 Chaitali
5 Hardik
6 Komal
PL/SQL procedure successfully completed.ユーザー定義のレコード
PL / SQLは、さまざまなレコード構造を定義できるユーザー定義のレコード型を提供します。これらのレコードは、さまざまなフィールドで構成されています。図書館で本を追跡したいとします。各本に関する次の属性を追跡することをお勧めします-
- Title
- Author
- Subject
- ブックID
レコードの定義
レコードタイプは次のように定義されます-
TYPE
type_name IS RECORD
( field_name1 datatype1 [NOT NULL] [:= DEFAULT EXPRESSION],
field_name2 datatype2 [NOT NULL] [:= DEFAULT EXPRESSION],
...
field_nameN datatypeN [NOT NULL] [:= DEFAULT EXPRESSION);
record-name type_name;ブックレコードは次のように宣言されます-
DECLARE
TYPE books IS RECORD
(title varchar(50),
author varchar(50),
subject varchar(100),
book_id number);
book1 books;
book2 books;フィールドへのアクセス
レコードの任意のフィールドにアクセスするには、ドットを使用します (.)オペレーター。メンバーアクセス演算子は、レコード変数名とアクセスするフィールドの間のピリオドとしてコード化されます。以下は、レコードの使用法を説明する例です。
DECLARE
type books is record
(title varchar(50),
author varchar(50),
subject varchar(100),
book_id number);
book1 books;
book2 books;
BEGIN
-- Book 1 specification
book1.title := 'C Programming';
book1.author := 'Nuha Ali ';
book1.subject := 'C Programming Tutorial';
book1.book_id := 6495407;
-- Book 2 specification
book2.title := 'Telecom Billing';
book2.author := 'Zara Ali';
book2.subject := 'Telecom Billing Tutorial';
book2.book_id := 6495700;
-- Print book 1 record
dbms_output.put_line('Book 1 title : '|| book1.title);
dbms_output.put_line('Book 1 author : '|| book1.author);
dbms_output.put_line('Book 1 subject : '|| book1.subject);
dbms_output.put_line('Book 1 book_id : ' || book1.book_id);
-- Print book 2 record
dbms_output.put_line('Book 2 title : '|| book2.title);
dbms_output.put_line('Book 2 author : '|| book2.author);
dbms_output.put_line('Book 2 subject : '|| book2.subject);
dbms_output.put_line('Book 2 book_id : '|| book2.book_id);
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Book 1 title : C Programming
Book 1 author : Nuha Ali
Book 1 subject : C Programming Tutorial
Book 1 book_id : 6495407
Book 2 title : Telecom Billing
Book 2 author : Zara Ali
Book 2 subject : Telecom Billing Tutorial
Book 2 book_id : 6495700
PL/SQL procedure successfully completed.サブプログラムパラメータとして記録
他の変数を渡すのと同じように、レコードをサブプログラムパラメータとして渡すことができます。上記の例でアクセスしたのと同じ方法でレコードフィールドにアクセスすることもできます-
DECLARE
type books is record
(title varchar(50),
author varchar(50),
subject varchar(100),
book_id number);
book1 books;
book2 books;
PROCEDURE printbook (book books) IS
BEGIN
dbms_output.put_line ('Book title : ' || book.title);
dbms_output.put_line('Book author : ' || book.author);
dbms_output.put_line( 'Book subject : ' || book.subject);
dbms_output.put_line( 'Book book_id : ' || book.book_id);
END;
BEGIN
-- Book 1 specification
book1.title := 'C Programming';
book1.author := 'Nuha Ali ';
book1.subject := 'C Programming Tutorial';
book1.book_id := 6495407;
-- Book 2 specification
book2.title := 'Telecom Billing';
book2.author := 'Zara Ali';
book2.subject := 'Telecom Billing Tutorial';
book2.book_id := 6495700;
-- Use procedure to print book info
printbook(book1);
printbook(book2);
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Book title : C Programming
Book author : Nuha Ali
Book subject : C Programming Tutorial
Book book_id : 6495407
Book title : Telecom Billing
Book author : Zara Ali
Book subject : Telecom Billing Tutorial
Book book_id : 6495700
PL/SQL procedure successfully completed.この章では、PL / SQLの例外について説明します。例外は、プログラム実行中のエラー状態です。PL / SQLは、プログラマがEXCEPTIONプログラムでブロックし、エラー状態に対して適切なアクションが実行されます。例外には2つのタイプがあります-
- システム定義の例外
- ユーザー定義の例外
例外処理の構文
例外処理の一般的な構文は次のとおりです。ここでは、処理できる限り多くの例外をリストできます。デフォルトの例外は、を使用して処理されますWHEN others THEN −
DECLARE
<declarations section>
BEGIN
<executable command(s)>
EXCEPTION
<exception handling goes here >
WHEN exception1 THEN
exception1-handling-statements
WHEN exception2 THEN
exception2-handling-statements
WHEN exception3 THEN
exception3-handling-statements
........
WHEN others THEN
exception3-handling-statements
END;例
概念を説明するコードを書いてみましょう。前の章で作成して使用したCUSTOMERSテーブルを使用します-
DECLARE
c_id customers.id%type := 8;
c_name customerS.Name%type;
c_addr customers.address%type;
BEGIN
SELECT name, address INTO c_name, c_addr
FROM customers
WHERE id = c_id;
DBMS_OUTPUT.PUT_LINE ('Name: '|| c_name);
DBMS_OUTPUT.PUT_LINE ('Address: ' || c_addr);
EXCEPTION
WHEN no_data_found THEN
dbms_output.put_line('No such customer!');
WHEN others THEN
dbms_output.put_line('Error!');
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
No such customer!
PL/SQL procedure successfully completed.上記のプログラムは、IDが与えられた顧客の名前と住所を表示します。データベースにID値8の顧客がいないため、プログラムは実行時例外を発生させますNO_DATA_FOUND、でキャプチャされます EXCEPTION block。
例外の発生
内部データベースエラーが発生すると、データベースサーバーによって例外が自動的に発生しますが、プログラマーはコマンドを使用して例外を明示的に発生させることができます。 RAISE。以下は、例外を発生させるための簡単な構文です-
DECLARE
exception_name EXCEPTION;
BEGIN
IF condition THEN
RAISE exception_name;
END IF;
EXCEPTION
WHEN exception_name THEN
statement;
END;上記の構文を使用して、Oracle標準例外または任意のユーザー定義例外を発生させることができます。次のセクションでは、ユーザー定義の例外を発生させる例を示します。同様の方法で、Oracle標準の例外を発生させることができます。
ユーザー定義の例外
PL / SQLを使用すると、プログラムの必要性に応じて独自の例外を定義できます。ユーザー定義の例外を宣言してから、RAISEステートメントまたはプロシージャを使用して明示的に発生させる必要があります。DBMS_STANDARD.RAISE_APPLICATION_ERROR。
例外を宣言するための構文は次のとおりです。
DECLARE
my-exception EXCEPTION;例
次の例は、概念を示しています。このプログラムは、ユーザーが無効なIDを入力すると、例外として顧客IDを要求します。invalid_id 上げられます。
DECLARE
c_id customers.id%type := &cc_id;
c_name customerS.Name%type;
c_addr customers.address%type;
-- user defined exception
ex_invalid_id EXCEPTION;
BEGIN
IF c_id <= 0 THEN
RAISE ex_invalid_id;
ELSE
SELECT name, address INTO c_name, c_addr
FROM customers
WHERE id = c_id;
DBMS_OUTPUT.PUT_LINE ('Name: '|| c_name);
DBMS_OUTPUT.PUT_LINE ('Address: ' || c_addr);
END IF;
EXCEPTION
WHEN ex_invalid_id THEN
dbms_output.put_line('ID must be greater than zero!');
WHEN no_data_found THEN
dbms_output.put_line('No such customer!');
WHEN others THEN
dbms_output.put_line('Error!');
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Enter value for cc_id: -6 (let's enter a value -6)
old 2: c_id customers.id%type := &cc_id;
new 2: c_id customers.id%type := -6;
ID must be greater than zero!
PL/SQL procedure successfully completed.事前定義された例外
PL / SQLには多くの事前定義された例外があり、プログラムがデータベースルールに違反した場合に実行されます。たとえば、SELECT INTOステートメントが行を返さない場合、事前定義された例外NO_DATA_FOUNDが発生します。次の表に、事前定義された重要な例外のいくつかを示します。
| 例外 | Oracleエラー | SQLCODE | 説明 |
|---|---|---|---|
| ACCESS_INTO_NULL | 06530 | -6530 | nullオブジェクトに値が自動的に割り当てられると発生します。 |
| CASE_NOT_FOUND | 06592 | -6592 | これは、CASEステートメントのWHEN句の選択肢がどれも選択されておらず、ELSE句がない場合に発生します。 |
| COLLECTION_IS_NULL | 06531 | -6531 | これは、プログラムがEXISTS以外の収集メソッドを初期化されていないネストされたテーブルまたはVARRAYに適用しようとした場合、またはプログラムが初期化されていないネストされたテーブルまたはVARRAYの要素に値を割り当てようとした場合に発生します。 |
| DUP_VAL_ON_INDEX | 00001 | -1 | 重複する値を一意のインデックスを持つ列に格納しようとすると発生します。 |
| INVALID_CURSOR | 01001 | -1001 | 開いていないカーソルを閉じるなど、許可されていないカーソル操作を行おうとすると発生します。 |
| 無効な番号 | 01722 | -1722 | 文字列が有効な数値を表していないために文字列の数値への変換が失敗した場合に発生します。 |
| LOGIN_DENIED | 01017 | -1017 | プログラムが無効なユーザー名またはパスワードでデータベースにログオンしようとすると発生します。 |
| 何もデータが見つかりませんでした | 01403 | +100 | SELECTINTOステートメントが行を返さない場合に発生します。 |
| NOT_LOGGED_ON | 01012 | -1012 | これは、データベースに接続せずにデータベース呼び出しが発行されたときに発生します。 |
| PROGRAM_ERROR | 06501 | -6501 | PL / SQLに内部問題がある場合に発生します。 |
| ROWTYPE_MISMATCH | 06504 | -6504 | カーソルが互換性のないデータ型を持つ変数の値をフェッチすると発生します。 |
| SELF_IS_NULL | 30625 | -30625 | メンバーメソッドが呼び出されたときに発生しますが、オブジェクトタイプのインスタンスは初期化されていません。 |
| STORAGE_ERROR | 06500 | -6500 | PL / SQLのメモリが不足した場合、またはメモリが破損した場合に発生します。 |
| TOO_MANY_ROWS | 01422 | -1422 | SELECTINTOステートメントが複数の行を返す場合に発生します。 |
| VALUE_ERROR | 06502 | -6502 | これは、算術、変換、切り捨て、またはサイズ制約エラーが発生したときに発生します。 |
| ZERO_DIVIDE | 01476 | 1476 | 数値をゼロで除算しようとすると発生します。 |
この章では、PL / SQLのトリガーについて説明します。トリガーはストアドプログラムであり、いくつかのイベントが発生すると自動的に実行または起動されます。実際、トリガーは、次のイベントのいずれかに応答して実行されるように記述されています。
A database manipulation (DML) ステートメント(DELETE、INSERT、またはUPDATE)
A database definition (DDL) ステートメント(CREATE、ALTER、またはDROP)。
A database operation (SERVERERROR、LOGON、LOGOFF、STARTUP、またはSHUTDOWN)。
トリガーは、イベントが関連付けられているテーブル、ビュー、スキーマ、またはデータベースで定義できます。
トリガーの利点
トリガーは次の目的で作成できます-
- 一部の派生列値を自動的に生成する
- 参照整合性の実施
- イベントログとテーブルアクセスに関する情報の保存
- Auditing
- テーブルの同期レプリケーション
- セキュリティ認証を課す
- 無効なトランザクションの防止
トリガーの作成
トリガーを作成するための構文は次のとおりです。
CREATE [OR REPLACE ] TRIGGER trigger_name
{BEFORE | AFTER | INSTEAD OF }
{INSERT [OR] | UPDATE [OR] | DELETE}
[OF col_name]
ON table_name
[REFERENCING OLD AS o NEW AS n]
[FOR EACH ROW]
WHEN (condition)
DECLARE
Declaration-statements
BEGIN
Executable-statements
EXCEPTION
Exception-handling-statements
END;どこ、
CREATE [OR REPLACE] TRIGGERtrigger_name-既存のトリガーを作成するか、trigger_nameで置き換えます。
{前| 後| INSTEAD OF}-これは、トリガーがいつ実行されるかを指定します。INSTEAD OF句は、ビューにトリガーを作成するために使用されます。
{INSERT [OR] | 更新[または] | DELETE}-これはDML操作を指定します。
[OF col_name] −これは更新される列名を指定します。
[ON table_name]-これは、トリガーに関連付けられたテーブルの名前を指定します。
[古いものを新しいものとして参照する]-これにより、INSERT、UPDATE、DELETEなどのさまざまなDMLステートメントの新しい値と古い値を参照できます。
[FOR EACH ROW]-これは、行レベルのトリガーを指定します。つまり、影響を受ける各行に対してトリガーが実行されます。それ以外の場合、トリガーはSQLステートメントの実行時に1回だけ実行されます。これは、テーブルレベルのトリガーと呼ばれます。
WHEN(条件)-これは、トリガーが起動する行の条件を提供します。この句は、行レベルのトリガーにのみ有効です。
例
まず、前の章で作成して使用したCUSTOMERSテーブルを使用します-
Select * from customers;
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
+----+----------+-----+-----------+----------+次のプログラムは、 row-levelCUSTOMERSテーブルで実行されたINSERT、UPDATE、またはDELETE操作に対して起動するcustomersテーブルのトリガー。このトリガーは、古い値と新しい値の給与の差を表示します-
CREATE OR REPLACE TRIGGER display_salary_changes
BEFORE DELETE OR INSERT OR UPDATE ON customers
FOR EACH ROW
WHEN (NEW.ID > 0)
DECLARE
sal_diff number;
BEGIN
sal_diff := :NEW.salary - :OLD.salary;
dbms_output.put_line('Old salary: ' || :OLD.salary);
dbms_output.put_line('New salary: ' || :NEW.salary);
dbms_output.put_line('Salary difference: ' || sal_diff);
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Trigger created.ここでは、以下の点を考慮する必要があります-
OLDおよびNEW参照は、テーブルレベルのトリガーには使用できませんが、レコードレベルのトリガーに使用できます。
同じトリガーでテーブルをクエリする場合は、AFTERキーワードを使用する必要があります。トリガーは、最初の変更が適用され、テーブルが一貫した状態に戻った後でのみ、テーブルをクエリしたり、テーブルを再度変更したりできるためです。
上記のトリガーは、テーブルに対するDELETE、INSERT、またはUPDATE操作の前に起動するように記述されていますが、たとえばBEFORE DELETEのように、単一または複数の操作でトリガーを書き込むことができます。テーブルのDELETE操作を使用して削除されます。
トリガーのトリガー
CUSTOMERSテーブルでいくつかのDML操作を実行してみましょう。これが1つのINSERTステートメントで、テーブルに新しいレコードを作成します-
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (7, 'Kriti', 22, 'HP', 7500.00 );CUSTOMERSテーブルにレコードが作成されると、上記の作成トリガー、 display_salary_changes が起動され、次の結果が表示されます-
Old salary:
New salary: 7500
Salary difference:これは新しいレコードであるため、古い給与は利用できず、上記の結果はnullになります。ここで、CUSTOMERSテーブルに対してもう1つのDML操作を実行してみましょう。UPDATEステートメントは、テーブル内の既存のレコードを更新します-
UPDATE customers
SET salary = salary + 500
WHERE id = 2;CUSTOMERSテーブルのレコードが更新されると、上記の作成トリガー、 display_salary_changes が起動され、次の結果が表示されます-
Old salary: 1500
New salary: 2000
Salary difference: 500この章では、PL / SQLのパッケージについて説明します。パッケージは、論理的に関連するPL / SQLタイプ、変数、およびサブプログラムをグループ化するスキーマ・オブジェクトです。
パッケージには2つの必須部分があります-
- パッケージ仕様
- パッケージ本体または定義
パッケージ仕様
仕様はパッケージへのインターフェースです。それだけDECLARESパッケージの外部から参照できるタイプ、変数、定数、例外、カーソル、およびサブプログラム。つまり、パッケージの内容に関するすべての情報が含まれていますが、サブプログラムのコードは除外されています。
仕様に配置されたすべてのオブジェクトは呼び出されます publicオブジェクト。パッケージ仕様に含まれていないがパッケージ本体にコーディングされているサブプログラムは、private オブジェクト。
次のコードスニペットは、単一のプロシージャを持つパッケージ仕様を示しています。パッケージ内に多くのグローバル変数を定義し、複数のプロシージャまたは関数を含めることができます。
CREATE PACKAGE cust_sal AS
PROCEDURE find_sal(c_id customers.id%type);
END cust_sal;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Package created.パッケージ本体
パッケージ本体には、パッケージ仕様で宣言されているさまざまなメソッドのコードやその他のプライベート宣言があり、パッケージ外のコードからは隠されています。
ザ・ CREATE PACKAGE BODYステートメントは、パッケージ本体の作成に使用されます。次のコードスニペットは、のパッケージ本体宣言を示しています。cust_sal上で作成したパッケージ。PL / SQL-変数の章で説明したように、データベースにはすでにCUSTOMERSテーブルが作成されていると想定しました。
CREATE OR REPLACE PACKAGE BODY cust_sal AS
PROCEDURE find_sal(c_id customers.id%TYPE) IS
c_sal customers.salary%TYPE;
BEGIN
SELECT salary INTO c_sal
FROM customers
WHERE id = c_id;
dbms_output.put_line('Salary: '|| c_sal);
END find_sal;
END cust_sal;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Package body created.パッケージ要素の使用
パッケージ要素(変数、プロシージャ、または関数)には、次の構文でアクセスします。
package_name.element_name;データベーススキーマに上記のパッケージをすでに作成していることを考慮してください。次のプログラムは find_sal の方法 cust_sal パッケージ-
DECLARE
code customers.id%type := &cc_id;
BEGIN
cust_sal.find_sal(code);
END;
/上記のコードをSQLプロンプトで実行すると、顧客IDの入力を求められ、IDを入力すると、対応する給与が次のように表示されます。
Enter value for cc_id: 1
Salary: 3000
PL/SQL procedure successfully completed.例
次のプログラムは、より完全なパッケージを提供します。データベースに保存されているCUSTOMERSテーブルを次のレコードとともに使用します-
Select * from customers;
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 3000.00 |
| 2 | Khilan | 25 | Delhi | 3000.00 |
| 3 | kaushik | 23 | Kota | 3000.00 |
| 4 | Chaitali | 25 | Mumbai | 7500.00 |
| 5 | Hardik | 27 | Bhopal | 9500.00 |
| 6 | Komal | 22 | MP | 5500.00 |
+----+----------+-----+-----------+----------+パッケージ仕様
CREATE OR REPLACE PACKAGE c_package AS
-- Adds a customer
PROCEDURE addCustomer(c_id customers.id%type,
c_name customerS.No.ame%type,
c_age customers.age%type,
c_addr customers.address%type,
c_sal customers.salary%type);
-- Removes a customer
PROCEDURE delCustomer(c_id customers.id%TYPE);
--Lists all customers
PROCEDURE listCustomer;
END c_package;
/上記のコードをSQLプロンプトで実行すると、上記のパッケージが作成され、次の結果が表示されます。
Package created.パッケージ本体の作成
CREATE OR REPLACE PACKAGE BODY c_package AS
PROCEDURE addCustomer(c_id customers.id%type,
c_name customerS.No.ame%type,
c_age customers.age%type,
c_addr customers.address%type,
c_sal customers.salary%type)
IS
BEGIN
INSERT INTO customers (id,name,age,address,salary)
VALUES(c_id, c_name, c_age, c_addr, c_sal);
END addCustomer;
PROCEDURE delCustomer(c_id customers.id%type) IS
BEGIN
DELETE FROM customers
WHERE id = c_id;
END delCustomer;
PROCEDURE listCustomer IS
CURSOR c_customers is
SELECT name FROM customers;
TYPE c_list is TABLE OF customers.Name%type;
name_list c_list := c_list();
counter integer :=0;
BEGIN
FOR n IN c_customers LOOP
counter := counter +1;
name_list.extend;
name_list(counter) := n.name;
dbms_output.put_line('Customer(' ||counter|| ')'||name_list(counter));
END LOOP;
END listCustomer;
END c_package;
/上記の例では、 nested table。次の章では、ネストされたテーブルの概念について説明します。
上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Package body created.パッケージの使用
次のプログラムは、パッケージc_packageで宣言および定義されたメソッドを使用します。
DECLARE
code customers.id%type:= 8;
BEGIN
c_package.addcustomer(7, 'Rajnish', 25, 'Chennai', 3500);
c_package.addcustomer(8, 'Subham', 32, 'Delhi', 7500);
c_package.listcustomer;
c_package.delcustomer(code);
c_package.listcustomer;
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Customer(1): Ramesh
Customer(2): Khilan
Customer(3): kaushik
Customer(4): Chaitali
Customer(5): Hardik
Customer(6): Komal
Customer(7): Rajnish
Customer(8): Subham
Customer(1): Ramesh
Customer(2): Khilan
Customer(3): kaushik
Customer(4): Chaitali
Customer(5): Hardik
Customer(6): Komal
Customer(7): Rajnish
PL/SQL procedure successfully completedこの章では、PL / SQLのコレクションについて説明します。コレクションは、同じデータ型を持つ要素の順序付けられたグループです。各要素は、コレクション内での位置を表す一意の添え字で識別されます。
PL / SQLは3つのコレクションタイプを提供します-
- インデックスバイテーブルまたは連想配列
- ネストされたテーブル
- 可変サイズ配列またはVarray
Oracleのドキュメントには、コレクションのタイプごとに次の特性が記載されています。
| コレクションタイプ | 要素の数 | 添え字タイプ | 密または疎 | 作成場所 | オブジェクトタイプ属性にすることができます |
|---|---|---|---|---|---|
| 連想配列(またはインデックスバイテーブル) | 無制限 | 文字列または整数 | どちらか | PL / SQLブロックのみ | 番号 |
| ネストされたテーブル | 無制限 | 整数 | 密集して始まり、疎になる可能性があります | PL / SQLブロックまたはスキーマレベルのいずれか | はい |
| 可変サイズ配列(Varray) | 跳ねる | 整数 | 常に密集 | PL / SQLブロックまたはスキーマレベルのいずれか | はい |
この章ではすでにvarrayについて説明しました 'PL/SQL arrays'。この章では、PL / SQL表について説明します。
両方のタイプのPL / SQL表、つまり、索引付け表とネストされた表は同じ構造を持ち、それらの行は添え字表記を使用してアクセスされます。ただし、これら2つのタイプのテーブルは1つの側面で異なります。ネストされたテーブルはデータベース列に格納できますが、index-byテーブルは格納できません。
インデックス-テーブル別
アン index-by テーブル(別名 associative array)はのセットです key-valueペア。各キーは一意であり、対応する値を見つけるために使用されます。キーは整数または文字列のいずれかです。
インデックスバイテーブルは、次の構文を使用して作成されます。ここでは、index-by 名前の付いたテーブル table_name、そのキーはsubscript_typeになり、関連する値はelement_typeになります
TYPE type_name IS TABLE OF element_type [NOT NULL] INDEX BY subscript_type;
table_name type_name;例
次の例は、名前とともに整数値を格納するテーブルを作成し、後で同じ名前のリストを出力する方法を示しています。
DECLARE
TYPE salary IS TABLE OF NUMBER INDEX BY VARCHAR2(20);
salary_list salary;
name VARCHAR2(20);
BEGIN
-- adding elements to the table
salary_list('Rajnish') := 62000;
salary_list('Minakshi') := 75000;
salary_list('Martin') := 100000;
salary_list('James') := 78000;
-- printing the table
name := salary_list.FIRST;
WHILE name IS NOT null LOOP
dbms_output.put_line
('Salary of ' || name || ' is ' || TO_CHAR(salary_list(name)));
name := salary_list.NEXT(name);
END LOOP;
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Salary of James is 78000
Salary of Martin is 100000
Salary of Minakshi is 75000
Salary of Rajnish is 62000
PL/SQL procedure successfully completed.例
index-byテーブルの要素は、 %ROWTYPE 任意のデータベーステーブルまたは %TYPE任意のデータベーステーブルフィールドの。次の例は、概念を示しています。を使用しますCUSTOMERS データベースに-として格納されているテーブル
Select * from customers;
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
+----+----------+-----+-----------+----------+DECLARE
CURSOR c_customers is
select name from customers;
TYPE c_list IS TABLE of customers.Name%type INDEX BY binary_integer;
name_list c_list;
counter integer :=0;
BEGIN
FOR n IN c_customers LOOP
counter := counter +1;
name_list(counter) := n.name;
dbms_output.put_line('Customer('||counter||'):'||name_lis t(counter));
END LOOP;
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Customer(1): Ramesh
Customer(2): Khilan
Customer(3): kaushik
Customer(4): Chaitali
Customer(5): Hardik
Customer(6): Komal
PL/SQL procedure successfully completedネストされたテーブル
A nested table任意の数の要素を持つ1次元配列のようなものです。ただし、ネストされたテーブルは、次の点で配列とは異なります。
配列には宣言された数の要素がありますが、ネストされたテーブルにはありません。ネストされたテーブルのサイズは動的に増加する可能性があります。
配列は常に密です。つまり、常に連続した添え字があります。ネストされた配列は最初は密ですが、要素が削除されると疎になる可能性があります。
ネストされたテーブルは、次の構文を使用して作成されます-
TYPE type_name IS TABLE OF element_type [NOT NULL];
table_name type_name;この宣言は、 index-by テーブルがありません INDEX BY 句。
ネストされたテーブルは、データベースの列に格納できます。さらに、単一列のテーブルをより大きなテーブルと結合するSQL操作を簡素化するために使用できます。連想配列をデータベースに保存することはできません。
例
次の例は、ネストされたテーブルの使用法を示しています。
DECLARE
TYPE names_table IS TABLE OF VARCHAR2(10);
TYPE grades IS TABLE OF INTEGER;
names names_table;
marks grades;
total integer;
BEGIN
names := names_table('Kavita', 'Pritam', 'Ayan', 'Rishav', 'Aziz');
marks:= grades(98, 97, 78, 87, 92);
total := names.count;
dbms_output.put_line('Total '|| total || ' Students');
FOR i IN 1 .. total LOOP
dbms_output.put_line('Student:'||names(i)||', Marks:' || marks(i));
end loop;
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Total 5 Students
Student:Kavita, Marks:98
Student:Pritam, Marks:97
Student:Ayan, Marks:78
Student:Rishav, Marks:87
Student:Aziz, Marks:92
PL/SQL procedure successfully completed.例
の要素 nested table することもできます %ROWTYPE任意のデータベーステーブルの、または任意のデータベーステーブルフィールドの%TYPE。次の例は、概念を示しています。データベースに格納されているCUSTOMERSテーブルを-として使用します。
Select * from customers;
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
+----+----------+-----+-----------+----------+DECLARE
CURSOR c_customers is
SELECT name FROM customers;
TYPE c_list IS TABLE of customerS.No.ame%type;
name_list c_list := c_list();
counter integer :=0;
BEGIN
FOR n IN c_customers LOOP
counter := counter +1;
name_list.extend;
name_list(counter) := n.name;
dbms_output.put_line('Customer('||counter||'):'||name_list(counter));
END LOOP;
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Customer(1): Ramesh
Customer(2): Khilan
Customer(3): kaushik
Customer(4): Chaitali
Customer(5): Hardik
Customer(6): Komal
PL/SQL procedure successfully completed.収集方法
PL / SQLには、コレクションを使いやすくする組み込みのコレクション・メソッドが用意されています。次の表に、メソッドとその目的を示します。
| S.No | メソッド名と目的 |
|---|---|
| 1 | EXISTS(n) コレクション内のn番目の要素が存在する場合はTRUEを返します。それ以外の場合はFALSEを返します。 |
| 2 | COUNT コレクションに現在含まれている要素の数を返します。 |
| 3 | LIMIT コレクションの最大サイズを確認します。 |
| 4 | FIRST 整数の添え字を使用するコレクションの最初の(最小の)インデックス番号を返します。 |
| 5 | LAST 整数の添え字を使用するコレクションの最後の(最大の)インデックス番号を返します。 |
| 6 | PRIOR(n) コレクション内のインデックスnの前にあるインデックス番号を返します。 |
| 7 | NEXT(n) インデックスnに続くインデックス番号を返します。 |
| 8 | EXTEND 1つのnull要素をコレクションに追加します。 |
| 9 | EXTEND(n) n個のnull要素をコレクションに追加します。 |
| 10 | EXTEND(n,i) 追加します ni番目の要素のコレクションへのコピー。 |
| 11 | TRIM コレクションの最後から1つの要素を削除します。 |
| 12 | TRIM(n) 削除します n コレクションの最後からの要素。 |
| 13 | DELETE コレクションからすべての要素を削除し、COUNTを0に設定します。 |
| 14 | DELETE(n) を削除します nth数値キーまたはネストされたテーブルを持つ連想配列の要素。連想配列に文字列キーがある場合、キー値に対応する要素が削除されます。場合n 無効である、 DELETE(n) 何もしません。 |
| 15 | DELETE(m,n) 範囲内のすべての要素を削除します m..n連想配列またはネストされたテーブルから。場合m より大きい n または m または n 無効である、 DELETE(m,n) 何もしません。 |
コレクションの例外
次の表に、コレクションの例外とそれらが発生した場合を示します。
| コレクションの例外 | 状況で発生 |
|---|---|
| COLLECTION_IS_NULL | アトミックにnullのコレクションを操作しようとしました。 |
| 何もデータが見つかりませんでした | 下付き文字は、削除された要素、または連想配列の存在しない要素を示します。 |
| SUBSCRIPT_BEYOND_COUNT | 添え字がコレクション内の要素の数を超えています。 |
| SUBSCRIPT_OUTSIDE_LIMIT | 添え字が許容範囲外です。 |
| VALUE_ERROR | 下付き文字がnullであるか、キータイプに変換できません。この例外は、キーが次のように定義されている場合に発生する可能性があります。PLS_INTEGER 範囲であり、添え字はこの範囲外です。 |
この章では、PL / SQLでのトランザクションについて説明します。データベースtransaction1つ以上の関連するSQLステートメントで構成される可能性のあるアトミックな作業単位です。トランザクションを構成するSQLステートメントによってもたらされるデータベースの変更は、まとめてコミットできる、つまりデータベースに永続的にするか、データベースからロールバック(元に戻す)できるため、アトミックと呼ばれます。
正常に実行されたSQLステートメントとコミットされたトランザクションは同じではありません。SQLステートメントが正常に実行された場合でも、ステートメントを含むトランザクションがコミットされない限り、SQLステートメントをロールバックして、ステートメントによって行われたすべての変更を元に戻すことができます。
トランザクションの開始と終了
トランザクションには beginning と end。次のいずれかのイベントが発生すると、トランザクションが開始されます-
最初のSQLステートメントは、データベースに接続した後に実行されます。
トランザクションの完了後に発行された新しいSQLステートメントごと。
次のいずれかのイベントが発生すると、トランザクションは終了します-
A COMMIT または ROLLBACK ステートメントが発行されます。
A DDL などのステートメント CREATE TABLEステートメントは、発行されます。その場合、COMMITが自動的に実行されるためです。
A DCL などのステートメント GRANTステートメントは、発行されます。その場合、COMMITが自動的に実行されるためです。
ユーザーがデータベースから切断します。
ユーザーはから終了します SQL*PLUS 発行することにより EXIT コマンドを実行すると、COMMITが自動的に実行されます。
SQL * Plusが異常終了します。 ROLLBACK 自動的に実行されます。
A DMLステートメントは失敗します。その場合、そのDMLステートメントを元に戻すためにROLLBACKが自動的に実行されます。
トランザクションのコミット
SQLコマンドCOMMITを発行すると、トランザクションが永続的になります。COMMITコマンドの一般的な構文は次のとおりです。
COMMIT;例えば、
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (1, 'Ramesh', 32, 'Ahmedabad', 2000.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (2, 'Khilan', 25, 'Delhi', 1500.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (3, 'kaushik', 23, 'Kota', 2000.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (4, 'Chaitali', 25, 'Mumbai', 6500.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (5, 'Hardik', 27, 'Bhopal', 8500.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (6, 'Komal', 22, 'MP', 4500.00 );
COMMIT;トランザクションのロールバック
COMMITを使用せずにデータベースに加えられた変更は、ROLLBACKコマンドを使用して元に戻すことができます。
ROLLBACKコマンドの一般的な構文は次のとおりです。
ROLLBACK [TO SAVEPOINT < savepoint_name>];システム障害などの前例のない状況が原因でトランザクションが中止された場合、コミット以降のトランザクション全体が自動的にロールバックされます。使用していない場合savepoint、次に、次のステートメントを使用して、すべての変更をロールバックします-
ROLLBACK;セーブポイント
セーブポイントは、いくつかのチェックポイントを設定することにより、長いトランザクションをより小さな単位に分割するのに役立つ一種のマーカーです。長いトランザクション内でセーブポイントを設定することにより、必要に応じてチェックポイントにロールバックできます。これは、を発行することによって行われますSAVEPOINT コマンド。
SAVEPOINTコマンドの一般的な構文は次のとおりです。
SAVEPOINT < savepoint_name >;例えば
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (7, 'Rajnish', 27, 'HP', 9500.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (8, 'Riddhi', 21, 'WB', 4500.00 );
SAVEPOINT sav1;
UPDATE CUSTOMERS
SET SALARY = SALARY + 1000;
ROLLBACK TO sav1;
UPDATE CUSTOMERS
SET SALARY = SALARY + 1000
WHERE ID = 7;
UPDATE CUSTOMERS
SET SALARY = SALARY + 1000
WHERE ID = 8;
COMMIT;ROLLBACK TO sav1 −このステートメントは、セーブポイントsav1をマークしたポイントまでのすべての変更をロールバックします。
その後、行った新しい変更が開始されます。
自動トランザクション制御
実行するには COMMIT いつでも自動的に INSERT, UPDATE または DELETE コマンドを実行すると、 AUTOCOMMIT −としての環境変数
SET AUTOCOMMIT ON;次のコマンドを使用して、自動コミットモードをオフにすることができます-
SET AUTOCOMMIT OFF;この章では、PL / SQLの日付と時刻について説明します。PL / SQLには、日付と時刻に関連するデータ型の2つのクラスがあります。
- 日時データ型
- 間隔データ型
日時のデータ型は次のとおりです。
- DATE
- TIMESTAMP
- タイムゾーン付きのタイムスタンプ
- ローカルタイムゾーンのタイムスタンプ
間隔のデータ型は次のとおりです。
- 年から月までの間隔
- 2番目の間隔日
日時および間隔データ型のフィールド値
どちらも datetime そして interval データ型は fields。これらのフィールドの値は、データ型の値を決定します。次の表に、フィールドと、日時および間隔の可能な値を示します。
| フィールド名 | 有効な日時値 | 有効な間隔値 |
|---|---|---|
| 年 | -4712から9999(0年を除く) | ゼロ以外の整数 |
| 月 | 01から12 | 0から11 |
| 日 | 01から31(ロケールのカレンダーの規則に従って、MONTHとYEARの値によって制限されます) | ゼロ以外の整数 |
| 時間 | 00から23 | 0から23 |
| 分 | 00から59 | 0から59 |
| 2番目 | 00〜59.9(n)、ここで9(n)は時間の小数秒の精度です 9(n)の部分はDATEには適用されません。 |
0〜59.9(n)、ここで9(n)は間隔の小数秒の精度です |
| TIMEZONE_HOUR | -12〜14(範囲は夏時間の変更に対応) DATEまたはTIMESTAMPには適用されません。 |
適用できません |
| TIMEZONE_MINUTE | 00から59 DATEまたはTIMESTAMPには適用されません。 |
適用できません |
| TIMEZONE_REGION | DATEまたはTIMESTAMPには適用されません。 | 適用できません |
| TIMEZONE_ABBR | DATEまたはTIMESTAMPには適用されません。 | 適用できません |
日時のデータ型と関数
日時のデータ型は次のとおりです-
日付
文字と数値の両方のデータ型で日付と時刻の情報を格納します。世紀、年、月、日付、時、分、秒の情報で構成されています。−として指定されます
タイムスタンプ
これは、DATEデータ型の拡張です。DATEデータ型の年、月、日を、時、分、秒の値とともに格納します。正確な時間値を保存するのに役立ちます。
タイムゾーン付きのタイムスタンプ
これは、タイムゾーン領域名またはタイムゾーンオフセットを値に含むTIMESTAMPのバリアントです。タイムゾーンオフセットは、現地時間とUTCの差(時間と分)です。このデータ型は、地理的地域全体の日付情報を収集および評価するのに役立ちます。
ローカルタイムゾーンのタイムスタンプ
これは、値にタイムゾーンオフセットを含むTIMESTAMPの別のバリアントです。
次の表に、日時関数を示します(ここで、xは日時値です)-
| S.No | 関数名と説明 |
|---|---|
| 1 | ADD_MONTHS(x, y); 追加します y に数ヶ月 x。 |
| 2 | LAST_DAY(x); 月の最後の日を返します。 |
| 3 | MONTHS_BETWEEN(x, y); 間の月数を返します x そして y。 |
| 4 | NEXT_DAY(x, day); 次の日時を返し日後にx。 |
| 5 | NEW_TIME; ユーザーが指定したタイムゾーンから時間/日の値を返します。 |
| 6 | ROUND(x [, unit]); ラウンド x。 |
| 7 | SYSDATE(); 現在の日時を返します。 |
| 8 | TRUNC(x [, unit]); 切り捨てる x。 |
タイムスタンプ関数(ここで、xはタイムスタンプ値を持ちます)-
| S.No | 関数名と説明 |
|---|---|
| 1 | CURRENT_TIMESTAMP(); 現在のセッション時間をセッションタイムゾーンとともに含むTIMESTAMPWITH TIMEZONEを返します。 |
| 2 | EXTRACT({ YEAR | MONTH | DAY | HOUR | MINUTE | SECOND } | { TIMEZONE_HOUR | TIMEZONE_MINUTE } | { TIMEZONE_REGION | } TIMEZONE_ABBR ) FROM x) 年、月、日、時、分、秒、またはタイムゾーンを抽出して返します。 x。 |
| 3 | FROM_TZ(x, time_zone); TIMESTAMPxとtime_zoneで指定されたタイムゾーンをTIMESTAMPWITHTIMEZONEに変換します。 |
| 4 | LOCALTIMESTAMP(); セッションタイムゾーンの現地時間を含むTIMESTAMPを返します。 |
| 5 | SYSTIMESTAMP(); 現在のデータベース時刻とデータベースタイムゾーンを含むTIMESTAMPWITH TIMEZONEを返します。 |
| 6 | SYS_EXTRACT_UTC(x); TIMESTAMP WITH TIMEZONE xを、UTCでの日付と時刻を含むTIMESTAMPに変換します。 |
| 7 | TO_TIMESTAMP(x, [format]); 文字列xをTIMESTAMPに変換します。 |
| 8 | TO_TIMESTAMP_TZ(x, [format]); 文字列xをTIMESTAMPWITHTIMEZONEに変換します。 |
例
次のコードスニペットは、上記の関数の使用法を示しています-
Example 1
SELECT SYSDATE FROM DUAL;Output −
08/31/2012 5:25:34 PMExample 2
SELECT TO_CHAR(CURRENT_DATE, 'DD-MM-YYYY HH:MI:SS') FROM DUAL;Output −
31-08-2012 05:26:14Example 3
SELECT ADD_MONTHS(SYSDATE, 5) FROM DUAL;Output −
01/31/2013 5:26:31 PMExample 4
SELECT LOCALTIMESTAMP FROM DUAL;Output −
8/31/2012 5:26:55.347000 PM区間データ型と関数
間隔のデータ型は次のとおりです-
IINTERVAL YEAR TOMONTH-YEARおよびMONTH日時フィールドを使用して期間を格納します。
INTERVAL DAY TO SECOND-日、時間、分、秒で期間を保存します。
区間関数
| S.No | 関数名と説明 |
|---|---|
| 1 | NUMTODSINTERVAL(x, interval_unit); 数値xをINTERVALDAY TOSECONDに変換します。 |
| 2 | NUMTOYMINTERVAL(x, interval_unit); 数値xをINTERVALYEAR TOMONTHに変換します。 |
| 3 | TO_DSINTERVAL(x); 文字列xをINTERVALDAY TOSECONDに変換します。 |
| 4 | TO_YMINTERVAL(x); 文字列xをINTERVALYEAR TOMONTHに変換します。 |
この章では、PL / SQLでのDBMS出力について説明します。ザ・DBMS_OUTPUTは、出力、デバッグ情報を表示し、PL / SQLブロック、サブプログラム、パッケージ、およびトリガーからメッセージを送信できるようにする組み込みパッケージです。チュートリアル全体でこのパッケージをすでに使用しています。
データベース内のすべてのユーザーテーブルを表示する小さなコードスニペットを見てみましょう。データベースで試して、すべてのテーブル名を一覧表示してください-
BEGIN
dbms_output.put_line (user || ' Tables in the database:');
FOR t IN (SELECT table_name FROM user_tables)
LOOP
dbms_output.put_line(t.table_name);
END LOOP;
END;
/DBMS_OUTPUTサブプログラム
DBMS_OUTPUTパッケージには、次のサブプログラムがあります-
| S.No | サブプログラムと目的 | |
|---|---|---|
| 1 | DBMS_OUTPUT.DISABLE; メッセージ出力を無効にします。 |
|
| 2 | DBMS_OUTPUT.ENABLE(buffer_size IN INTEGER DEFAULT 20000); メッセージ出力を有効にします。のNULL値buffer_size 無制限のバッファサイズを表します。 |
|
| 3 | DBMS_OUTPUT.GET_LINE (line OUT VARCHAR2, status OUT INTEGER); バッファリングされた情報の1行を取得します。 |
|
| 4 | DBMS_OUTPUT.GET_LINES (lines OUT CHARARR, numlines IN OUT INTEGER); バッファから行の配列を取得します。 |
|
| 5 | DBMS_OUTPUT.NEW_LINE; 行末マーカーを配置します。 |
|
| 6 | DBMS_OUTPUT.PUT(item IN VARCHAR2); バッファに部分的な行を配置します。 |
|
| 7 | DBMS_OUTPUT.PUT_LINE(item IN VARCHAR2); バッファに行を配置します。 |
例
DECLARE
lines dbms_output.chararr;
num_lines number;
BEGIN
-- enable the buffer with default size 20000
dbms_output.enable;
dbms_output.put_line('Hello Reader!');
dbms_output.put_line('Hope you have enjoyed the tutorials!');
dbms_output.put_line('Have a great time exploring pl/sql!');
num_lines := 3;
dbms_output.get_lines(lines, num_lines);
FOR i IN 1..num_lines LOOP
dbms_output.put_line(lines(i));
END LOOP;
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Hello Reader!
Hope you have enjoyed the tutorials!
Have a great time exploring pl/sql!
PL/SQL procedure successfully completed.この章では、オブジェクト指向PL / SQLについて説明します。PL / SQLを使用すると、オブジェクトタイプを定義できます。これは、Oracleでのオブジェクト指向データベースの設計に役立ちます。オブジェクトタイプを使用すると、複合タイプを作成できます。オブジェクトを使用すると、データの特定の構造とそれを操作するためのメソッドを使用して、実世界のオブジェクトを実装できます。オブジェクトには属性とメソッドがあります。属性はオブジェクトのプロパティであり、オブジェクトの状態を格納するために使用されます。とメソッドは、その動作をモデル化するために使用されます。
オブジェクトは、CREATE [OR REPLACE] TYPEステートメントを使用して作成されます。以下は、簡単なものを作成する例です。address いくつかの属性で構成されるオブジェクト-
CREATE OR REPLACE TYPE address AS OBJECT
(house_no varchar2(10),
street varchar2(30),
city varchar2(20),
state varchar2(10),
pincode varchar2(10)
);
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Type created.もう1つのオブジェクトを作成しましょう customer ラップする場所 attributes そして methods 一緒にオブジェクト指向の感覚を持つ-
CREATE OR REPLACE TYPE customer AS OBJECT
(code number(5),
name varchar2(30),
contact_no varchar2(12),
addr address,
member procedure display
);
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Type created.オブジェクトのインスタンス化
オブジェクトタイプを定義すると、オブジェクトの青写真が提供されます。このオブジェクトを使用するには、このオブジェクトのインスタンスを作成する必要があります。インスタンス名を使用してオブジェクトの属性とメソッドにアクセスでき、the access operator (.) 次のように-
DECLARE
residence address;
BEGIN
residence := address('103A', 'M.G.Road', 'Jaipur', 'Rajasthan','201301');
dbms_output.put_line('House No: '|| residence.house_no);
dbms_output.put_line('Street: '|| residence.street);
dbms_output.put_line('City: '|| residence.city);
dbms_output.put_line('State: '|| residence.state);
dbms_output.put_line('Pincode: '|| residence.pincode);
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
House No: 103A
Street: M.G.Road
City: Jaipur
State: Rajasthan
Pincode: 201301
PL/SQL procedure successfully completed.メンバーメソッド
Member methods を操作するために使用されます attributesオブジェクトの。オブジェクトタイプを宣言するときに、メンバーメソッドの宣言を提供します。オブジェクト本体は、メンバーメソッドのコードを定義します。オブジェクト本体は、CREATE TYPEBODYステートメントを使用して作成されます。
Constructors値として新しいオブジェクトを返す関数です。すべてのオブジェクトには、システム定義のコンストラクターメソッドがあります。コンストラクターの名前は、オブジェクトタイプと同じです。例-
residence := address('103A', 'M.G.Road', 'Jaipur', 'Rajasthan','201301');ザ・ comparison methodsオブジェクトを比較するために使用されます。オブジェクトを比較する方法は2つあります-
マップ方法
ザ・ Map methodは、その値が属性の値に依存するように実装された関数です。たとえば、顧客オブジェクトの場合、顧客コードが2人の顧客で同じである場合、両方の顧客が同じである可能性があります。したがって、これら2つのオブジェクト間の関係は、コードの値に依存します。
注文方法
ザ・ Order method2つのオブジェクトを比較するための内部ロジックを実装します。たとえば、長方形オブジェクトの場合、長方形の両側が大きいと、長方形は別の長方形よりも大きくなります。
Mapメソッドを使用する
次の長方形オブジェクトを使用して、上記の概念を理解してみましょう-
CREATE OR REPLACE TYPE rectangle AS OBJECT
(length number,
width number,
member function enlarge( inc number) return rectangle,
member procedure display,
map member function measure return number
);
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Type created.タイプ本体の作成-
CREATE OR REPLACE TYPE BODY rectangle AS
MEMBER FUNCTION enlarge(inc number) return rectangle IS
BEGIN
return rectangle(self.length + inc, self.width + inc);
END enlarge;
MEMBER PROCEDURE display IS
BEGIN
dbms_output.put_line('Length: '|| length);
dbms_output.put_line('Width: '|| width);
END display;
MAP MEMBER FUNCTION measure return number IS
BEGIN
return (sqrt(length*length + width*width));
END measure;
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Type body created.長方形オブジェクトとそのメンバー関数を使用するようになりました-
DECLARE
r1 rectangle;
r2 rectangle;
r3 rectangle;
inc_factor number := 5;
BEGIN
r1 := rectangle(3, 4);
r2 := rectangle(5, 7);
r3 := r1.enlarge(inc_factor);
r3.display;
IF (r1 > r2) THEN -- calling measure function
r1.display;
ELSE
r2.display;
END IF;
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Length: 8
Width: 9
Length: 5
Width: 7
PL/SQL procedure successfully completed.Orderメソッドを使用する
さて、 same effect could be achieved using an order method。orderメソッドを使用して長方形オブジェクトを再作成しましょう-
CREATE OR REPLACE TYPE rectangle AS OBJECT
(length number,
width number,
member procedure display,
order member function measure(r rectangle) return number
);
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Type created.タイプ本体の作成-
CREATE OR REPLACE TYPE BODY rectangle AS
MEMBER PROCEDURE display IS
BEGIN
dbms_output.put_line('Length: '|| length);
dbms_output.put_line('Width: '|| width);
END display;
ORDER MEMBER FUNCTION measure(r rectangle) return number IS
BEGIN
IF(sqrt(self.length*self.length + self.width*self.width)>
sqrt(r.length*r.length + r.width*r.width)) then
return(1);
ELSE
return(-1);
END IF;
END measure;
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Type body created.長方形オブジェクトとそのメンバー関数の使用-
DECLARE
r1 rectangle;
r2 rectangle;
BEGIN
r1 := rectangle(23, 44);
r2 := rectangle(15, 17);
r1.display;
r2.display;
IF (r1 > r2) THEN -- calling measure function
r1.display;
ELSE
r2.display;
END IF;
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Length: 23
Width: 44
Length: 15
Width: 17
Length: 23
Width: 44
PL/SQL procedure successfully completed.PL / SQLオブジェクトの継承
PL / SQLでは、既存の基本オブジェクトからオブジェクトを作成できます。継承を実装するには、基本オブジェクトを次のように宣言する必要があります。NOT FINAL。デフォルトはFINAL。
次のプログラムは、PL / SQLオブジェクトの継承を示しています。名前の付いた別のオブジェクトを作成しましょうTableTop、これはRectangleオブジェクトから継承されます。このために、ベース長方形オブジェクトを作成する必要があります-
CREATE OR REPLACE TYPE rectangle AS OBJECT
(length number,
width number,
member function enlarge( inc number) return rectangle,
NOT FINAL member procedure display) NOT FINAL
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Type created.ベースタイプのボディを作成する-
CREATE OR REPLACE TYPE BODY rectangle AS
MEMBER FUNCTION enlarge(inc number) return rectangle IS
BEGIN
return rectangle(self.length + inc, self.width + inc);
END enlarge;
MEMBER PROCEDURE display IS
BEGIN
dbms_output.put_line('Length: '|| length);
dbms_output.put_line('Width: '|| width);
END display;
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Type body created.子オブジェクトテーブルトップの作成-
CREATE OR REPLACE TYPE tabletop UNDER rectangle
(
material varchar2(20),
OVERRIDING member procedure display
)
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Type created.子オブジェクトテーブルトップの型本体の作成
CREATE OR REPLACE TYPE BODY tabletop AS
OVERRIDING MEMBER PROCEDURE display IS
BEGIN
dbms_output.put_line('Length: '|| length);
dbms_output.put_line('Width: '|| width);
dbms_output.put_line('Material: '|| material);
END display;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Type body created.使用する卓上型オブジェクトとそのメンバ関数を-
DECLARE
t1 tabletop;
t2 tabletop;
BEGIN
t1:= tabletop(20, 10, 'Wood');
t2 := tabletop(50, 30, 'Steel');
t1.display;
t2.display;
END;
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Length: 20
Width: 10
Material: Wood
Length: 50
Width: 30
Material: Steel
PL/SQL procedure successfully completed.PL / SQLの抽象オブジェクト
ザ・ NOT INSTANTIABLE句を使用すると、抽象オブジェクトを宣言できます。抽象オブジェクトをそのまま使用することはできません。その機能を使用するには、そのようなオブジェクトのサブタイプまたは子タイプを作成する必要があります。
例えば、
CREATE OR REPLACE TYPE rectangle AS OBJECT
(length number,
width number,
NOT INSTANTIABLE NOT FINAL MEMBER PROCEDURE display)
NOT INSTANTIABLE NOT FINAL
/上記のコードをSQLプロンプトで実行すると、次の結果が生成されます。
Type created.