プログラミング方法論-クイックガイド
在庫管理、給与処理、学生の入学、試験結果の処理などの実際の問題を解決するためにプログラムが開発されると、それらは巨大で複雑になる傾向があります。このような複雑な問題を分析し、ソフトウェア開発を計画し、開発プロセスを制御するアプローチは、programming methodology。
プログラミング方法論の種類
ソフトウェア開発者の間で普及しているプログラミング方法論には多くの種類があります-
手続き型プログラミング
問題は、プロシージャ、またはそれぞれ1つのタスクを実行するコードのブロックに分解されます。一緒に取られたすべての手順は、プログラム全体を形成します。複雑さのレベルが低い小さなプログラムにのみ適しています。
Example−加算、減算、乗算、除算、平方根、および比較を行う計算機プログラムの場合、これらの各操作は個別の手順として開発できます。メインプログラムでは、各プロシージャはユーザーの選択に基づいて呼び出されます。
オブジェクト指向プログラミング
ここでの解決策は、問題の一部であるエンティティまたはオブジェクトを中心に展開します。このソリューションは、エンティティに関連するデータを保存する方法、エンティティがどのように動作するか、およびエンティティが互いにどのように相互作用してまとまりのあるソリューションを提供するかを扱います。
Example −給与管理システムを開発する必要がある場合は、従業員、給与体系、休暇規則などのエンティティがあり、その周りにソリューションを構築する必要があります。
関数型プログラミング
ここで、問題または望ましい解決策は、機能単位に分解されます。各ユニットは独自のタスクを実行し、自給自足です。次に、これらのユニットをつなぎ合わせて、完全なソリューションを形成します。
Example −給与処理には、従業員データの保守、基本給の計算、総給与の計算、休暇処理、ローン返済処理などの機能単位を含めることができます。
論理プログラミング
ここで、問題は機能単位ではなく論理単位に分解されます。 Example:学校の管理システムでは、ユーザーはクラスティーチャー、サブジェクトティーチャー、ラボアシスタント、コーディネーター、アカデミック担当など、非常に明確な役割を持っています。したがって、ソフトウェアはユーザーの役割に応じてユニットに分割できます。各ユーザーは、異なるインターフェース、権限などを持つことができます。
ソフトウェア開発者は、ソフトウェアを開発するために、これらの方法論の1つまたは複数の組み合わせを選択できます。説明した各方法論では、問題をより小さな単位に分割する必要があることに注意してください。これを行うために、開発者は次の2つのアプローチのいずれかを使用します-
- トップダウンアプローチ
- ボトムアップアプローチ
トップダウンまたはモジュラーアプローチ
問題はより小さな単位に分解され、さらに小さな単位に分解される可能性があります。各ユニットは、module。各モジュールは、そのタスクを実行するために必要なすべてを備えた自給自足のユニットです。
次の図は、給与処理プログラムの開発中に、モジュラーアプローチに従ってさまざまなモジュールを作成する方法の例を示しています。
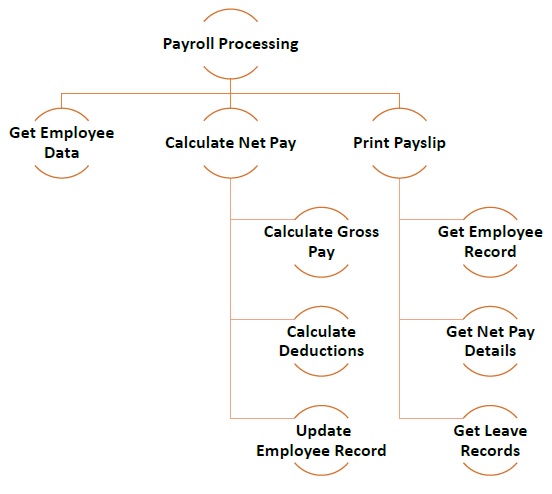
ボトムアップアプローチ
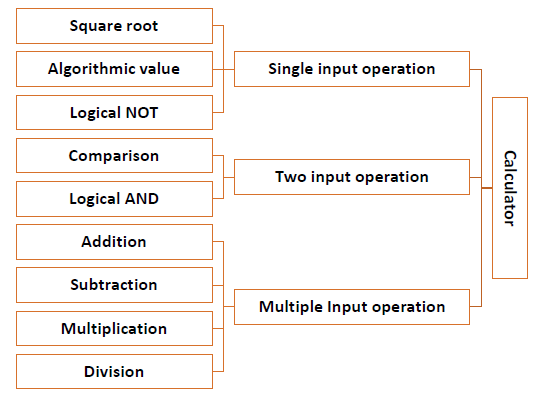
ボトムアップアプローチでは、システム設計は最低レベルのコンポーネントから始まり、次に相互接続されてより高いレベルのコンポーネントを取得します。このプロセスは、すべてのシステムコンポーネントの階層が生成されるまで続きます。ただし、実際のシナリオでは、最初にすべての最低レベルのコンポーネントを知ることは非常に困難です。したがって、ボトムアップアプローチは非常に単純な問題にのみ使用されます。
電卓プログラムのコンポーネントを見てみましょう。
典型的なソフトウェア開発プロセスは、次の手順に従います。
- 要件の収集
- 問題の定義
- システムデザイン
- Implementation
- Testing
- Documentation
- トレーニングとサポート
- Maintenance
最初の2つのステップは、チームが問題を理解するのに役立ちます。これは、解決策を得るための最も重要な最初のステップです。要件の収集、問題の定義、およびシステムの設計を担当する担当者は、system analyst。
要件の収集
通常、クライアントまたはユーザーは、問題や要件を明確に定義することはできません。彼らは彼らが何を望んでいるかについて漠然とした考えを持っています。したがって、システム開発者は、解決する必要のある問題、または提供する必要のある問題を理解するために、クライアントの要件を収集する必要があります。問題の詳細な理解は、最初にソリューションが開発されている事業領域を理解することによってのみ可能です。ビジネスを理解するのに役立ついくつかの重要な質問は次のとおりです。
- 何が行われていますか?
- それはどのように行われていますか?
- タスクの頻度はどれくらいですか?
- 決定またはトランザクションの量はどれくらいですか?
- 発生している問題は何ですか?
この情報を収集するのに役立ついくつかのテクニックは次のとおりです。
- Interviews
- Questionnaires
- 既存のシステムドキュメントの調査
- ビジネスデータの分析
システムアナリストは、SMART(具体的、測定可能、合意済み、現実的、時間ベース)の要件を特定するために、明確で簡潔でありながら徹底的な要件ドキュメントを作成する必要があります。そうしないと、次のようになります。
- 不完全な問題定義
- プログラムの目標が正しくない
- クライアントに必要な結果を提供するためにやり直します
- コストの増加
- 配達の遅れ
必要な情報の深さのため、要件の収集は、 detailed investigation。
問題の定義
要件を収集して分析した後、問題の説明を明確に記載する必要があります。問題の定義では、どの問題を解決する必要があるかを明確に示す必要があります。明確な問題ステートメントを持っていることが必要です-
- プロジェクトスコープを定義する
- チームの集中力を維持する
- プロジェクトを軌道に乗せる
- プロジェクトの終了時に望ましい結果が達成されたことを検証します
多くの場合、コーディングはソフトウェア開発プロセスの最も重要な部分であると考えられています。ただし、コーディングはプロセスの一部にすぎず、システムが正しく設計されていれば、実際には最小限の時間がかかる場合があります。システムを設計する前に、目前の問題の解決策を特定する必要があります。
システムの設計について最初に注意すべきことは、最初にシステムアナリストが複数のソリューションを考え出す可能性があるということです。しかし、最終的な解決策または製品は1つだけにすることができます。要件収集フェーズで収集されたデータの詳細な分析は、独自のソリューションを実現するのに役立ちます。問題を正しく定義することも、解決策を見つけるために重要です。
複数のソリューションの問題に直面した場合、アナリストはフローチャート、データフロー図、エンティティ関係図などの視覚的な支援を利用して、各ソリューションを詳細に理解します。
フローチャート
フローチャートは、システム内のワークフローとデータフローを記号と図で示すプロセスです。これは、システムアナリストが問題の解決策を特定するのを支援する重要なツールです。システムのコンポーネントを視覚的に表現します。
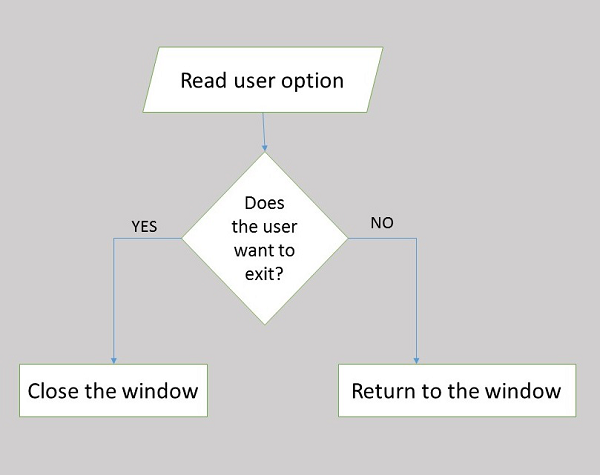
これらはフローチャートの利点です-
視覚的表現は、プログラムロジックの理解に役立ちます
それらは実際のプログラムコーディングの青写真として機能します
フローチャートはプログラムの文書化にとって重要です
フローチャートは、プログラムのメンテナンス中の重要な支援です
これらはフローチャートの欠点です-
フローチャートを使用して複雑なロジックを表現することはできません
ロジックまたはデータ/ワークフローに変更があった場合は、フローチャートを完全に再描画する必要があります
データフロー図
データフロー図またはDFDは、システムまたはサブシステムを通過するデータフローをグラフィカルに表現したものです。各プロセスには独自のデータフローがあり、データフロー図のレベルがあります。レベル0は、システム全体の入力データと出力データを示します。次に、システムはモジュールに分割され、レベル1DFDは各モジュールのデータフローを個別に表示します。モジュールは、必要に応じてさらにサブモジュールに分割され、レベル2のDFDが描画されます。
擬似コード
システムが設計された後、実装、つまりコーディングのためにプロジェクトマネージャーに渡されます。プログラムの実際のコーディングはプログラミング言語で行われ、その言語で訓練されたプログラマーだけが理解できます。ただし、実際のコーディングが行われる前に、プログラムの基本的な動作原理、ワークフロー、およびデータフローは、使用されるプログラミング言語と同様の表記法を使用して記述されます。このような表記はと呼ばれますpseudocode。
これは、C ++での擬似コードの例です。プログラマーは、プログラムコードを取得するために、各ステートメントをC ++構文に変換する必要があります。

数学演算の識別
コンピュータへのすべての命令は、最終的にマシンレベルでの算術演算および論理演算として実装されます。これらの操作は重要です。
- メモリスペースを占有する
- 実行に時間がかかる
- ソフトウェアの効率を判断する
- ソフトウェア全体のパフォーマンスに影響を与える
システムアナリストは、目前の問題に対する独自の解決策を特定しながら、すべての主要な数学演算を特定しようとします。
現実の問題は複雑で大きなものです。モノリシックソリューションが開発された場合、これらの問題が発生します-
1つの大きなプログラムを作成、テスト、および実装するのが難しい
最終製品が納品された後の変更はほぼ不可能です
プログラムのメンテナンスが非常に難しい
1つのエラーにより、システム全体が停止する可能性があります
これらの問題を克服するには、ソリューションを次のような小さな部分に分割する必要があります。 modules。開発、実装、変更、および保守を容易にするために、1つの大きなソリューションをより小さなモジュールに分割する手法は次のように呼ばれます。modular technique プログラミングまたはソフトウェア開発の。
モジュラープログラミングの利点
モジュラープログラミングにはこれらの利点があります-
各モジュールを並行して開発できるため、開発を迅速化できます
モジュールは再利用できます
各モジュールは個別にテストされるため、テストはより高速で堅牢です
プログラム全体のデバッグとメンテナンスが簡単
モジュールはより小さく、複雑さのレベルが低いため、理解しやすいです。
モジュールの識別
ソフトウェア内のモジュールを特定することは、正しい方法が1つではないため、気が遠くなるような作業です。モジュールを識別するためのいくつかのポインタがあります-
データがシステムの最も重要な要素である場合は、関連データを処理するモジュールを作成します。
システムが提供するサービスが多様である場合は、システムを機能モジュールに分割します。
他のすべてが失敗した場合は、要件収集フェーズでのシステムの理解に従って、システムを論理モジュールに分割します。
コーディングの場合、プログラミングを容易にするために、各モジュールを再び小さなモジュールに分割する必要があります。これも、特定のプログラミングルールと組み合わせて、上記で共有した3つのヒントを使用して実行できます。たとえば、C ++やJavaなどのオブジェクト指向プログラミング言語の場合、データとメソッドを持つ各クラスが1つのモジュールを形成できます。
ステップバイステップのソリューション
モジュールを実装するには、各モジュールのプロセスフローを段階的に説明する必要があります。ステップバイステップのソリューションは、を使用して開発できますalgorithms または pseudocodes。ステップバイステップのソリューションを提供することは、これらの利点を提供します-
解決策を読んでいる人は誰でも、問題と解決策の両方を理解できます。
これは、プログラマーと非プログラマーが等しく理解できます。
コーディング中に、各ステートメントをプログラムステートメントに変換する必要があります。
これはドキュメントの一部であり、プログラムのメンテナンスを支援します。
識別子名、必要な操作などのミクロレベルの詳細が自動的に処理されます
例を見てみましょう。

制御構造
上記の例でわかるように、プログラムロジックを実行する必要はありません。 sequentially。プログラミング言語では、control structures与えられたパラメータに基づいてプログラムフローについて決定を下します。これらはソフトウェアの非常に重要な要素であり、コーディングを開始する前に特定する必要があります。
アルゴリズムと pseudocodes アナリストとプログラマーが制御構造が必要な場所を特定するのに役立ちます。
制御構造には次の3つのタイプがあります-
意思決定制御構造
決定制御構造は、実行される次のステップが基準に依存する場合に使用されます。この基準は通常、評価する必要のある1つ以上のブール式です。ブール式は常に「true」または「false」に評価されます。基準が「true」の場合に1セットのステートメントが実行され、基準が「false」と評価された場合に別のセットのステートメントが実行されます。たとえば、ifステートメント
選択制御構造
プログラムシーケンスが特定の質問への回答に依存する場合、選択制御構造が使用されます。たとえば、プログラムにはユーザー向けの多くのオプションがあります。次に実行されるステートメントは、選択したオプションによって異なります。例えば、switch ステートメント、 case ステートメント。
繰り返し/ループ制御構造
繰り返し制御構造は、一連のステートメントが何度も繰り返される場合に使用されます。繰り返しの数は、開始する前にわかっている場合もあれば、式の値に依存する場合もあります。例えば、for ステートメント、 while ステートメント、 do while ステートメントなど。
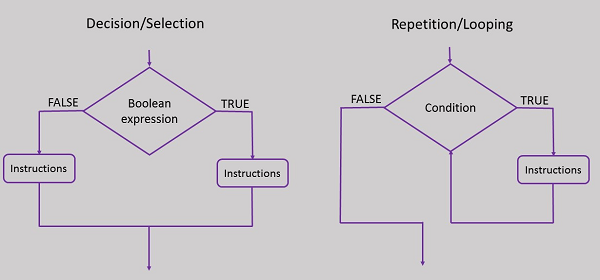
上の画像でわかるように、選択構造と決定構造の両方がフローチャートで同様に実装されています。選択制御は、順番に行われる一連の決定ステートメントに他なりません。
これらのステートメントがどのように機能するかを示すプログラムの例を次に示します。

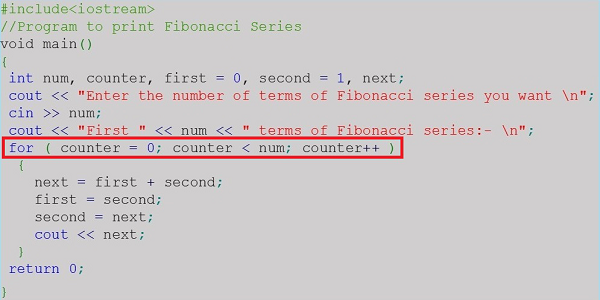
問題を解決するために従わなければならない一連の有限のステップは、 algorithm。アルゴリズムは通常、実際のコーディングが行われる前に開発されます。プログラマーでなくてもわかりやすいように、英語のような言語で書かれています。
アルゴリズムは、 pseudocodes、つまり、使用するプログラミング言語に類似した言語。問題を解決するためのアルゴリズムを書くことはこれらの利点を提供します-
チームメンバー間の効果的なコミュニケーションを促進します
手元の問題の分析を可能にします
コーディングの青写真として機能します
デバッグを支援します
メンテナンスフェーズで将来参照できるように、ソフトウェアドキュメントの一部になります
これらは、優れた正しいアルゴリズムの特徴です。
入力のセットがあります
ステップは一意に定義されます
ステップ数に限りがあります
必要な出力を生成します
アルゴリズムの例
まず、アルゴリズムを作成するための実際の状況の例を見てみましょう。ペンを購入するために市場に行くためのアルゴリズムは次のとおりです。

このアルゴリズムのステップ4は、それ自体が完全なタスクであり、個別のアルゴリズムを作成できます。ここで、数値が正か負かを確認するアルゴリズムを作成しましょう。

Flowchartプログラムの論理ステップのシーケンスを図で表したものです。フローチャートは、単純な幾何学的形状を使用してプロセスを示し、矢印を使用して関係とプロセス/データフローを示します。
フローチャート記号
これは、フローチャートの描画に使用されるいくつかの一般的な記号のチャートです。
| シンボル | シンボル名 | 目的 |
|---|---|---|

|
起動停止 | プログラムの開始と終了を示すために、アルゴリズムの開始と終了で使用されます。 |

|
処理する | 数学演算などのプロセスを示します。 |

|
入出力 | プログラムの入力と出力を示すために使用されます。 |

|
決定 | プログラム内の決定ステートメントを表します。通常、回答は「はい」または「いいえ」です。 |
|
|
矢印 | 異なる形状間の関係を示します。 |

|
オンページコネクタ | 同じページにあるフローチャートの2つ以上の部分を接続します。 |

|
オフページコネクタ | 異なるページにまたがるフローチャートの2つの部分を接続します。 |
フローチャートを作成するためのガイドライン
これらは、フローチャートを作成する際に留意すべきいくつかのポイントです-
フローチャートには、開始記号と停止記号を1つだけ含めることができます
ページ上のコネクタは番号を使用して参照されます
オフページコネクタはアルファベットを使用して参照されます
プロセスの一般的な流れは上から下または左から右です
矢印は互いに交差してはいけません
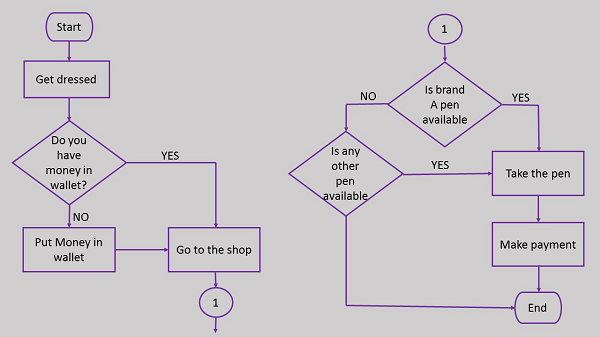
フローチャートの例
これがペンを購入するために市場に行くためのフローチャートです。
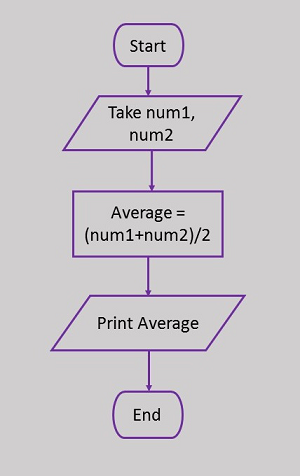
これは、2つの数値の平均を計算するためのフローチャートです。
ご存知のように、コンピューターには独自のインテリジェンスがありません。それは単に従うinstructions ユーザーによって与えられます。 Instructionsコンピュータプログラムの構成要素であり、したがってソフトウェアです。プログラムを成功させるには、明確な指示を与えることが重要です。プログラマーまたはソフトウェア開発者として、明確な指示を書く習慣を身につける必要があります。これを行うには2つの方法があります。
表現の明瞭さ
プログラム内の式は、算術計算または論理計算を行うための一連の演算子とオペランドです。有効な式の例を次に示します-
- 2つの値の比較
- 変数、オブジェクト、またはクラスの定義
- 1つ以上の変数を使用した算術計算
- データベースからのデータの取得
- データベースの値を更新しています
明確な表現を書くことは、すべてのプログラマーが開発しなければならないスキルです。このような表現を書く際に留意すべき点がいくつかあります-
明確な結果
式の評価は、1つの明確な結果を与える必要があります。たとえば、単項演算子は注意して使用する必要があります。
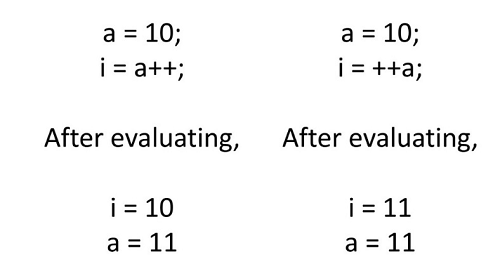
複雑な式を避ける
1つの表現で多くのことを達成しようとしないでください。物事が複雑になり始めた瞬間に、2つ以上の表現に分割します。
指示の単純さ
明確な指示を書く必要があるのは、コンピューターだけではありません。後でプログラムを読む人は誰でも(あなた自身も!!)、命令が何を達成しようとしているのかを理解できるはずです。プログラマーがしばらくしてから再訪したときに、自分のプログラムのコツをつかまないことは非常に一般的です。これは、そのようなプログラムの保守と変更が非常に難しいことを示しています。
簡単な指示を書くことは、この問題を回避するのに役立ちます。ここに簡単な指示を書くためのいくつかのヒントがあります-
Avoid clever instructions −賢い指示は、だれもそれを正しく理解できなければ、後でそれほど賢く見えないかもしれません。
One instruction per task −一度に複数のことを行おうとすると、指示が複雑になります。
Use standards−すべての言語には独自の基準があり、それに従ってください。プロジェクトで一人で作業しているのではないことを忘れないでください。コーディングについては、プロジェクトの標準とガイドラインに従ってください。
この章では、優れたプログラムの作成方法について説明します。しかし、その前に、優れたプログラムの特徴を見てみましょう。
Portable−プログラムまたはソフトウェアは、同じタイプのすべてのコンピューターで実行する必要があります。同じタイプとは、パーソナルコンピュータ用に開発されたソフトウェアがすべてのPCで実行される必要があることを意味します。または、タブレット用に作成されたソフトウェアは、適切な仕様を持つすべてのタブレットで実行する必要があります。
Efficient−割り当てられたタスクを迅速に実行するソフトウェアは効率的であると言われています。コードの最適化とメモリの最適化は、プログラムの効率を上げる方法のいくつかです。

Effective−ソフトウェアは、目前の問題の解決を支援する必要があります。それを行うソフトウェアは効果的だと言われています。
Reliable −プログラムは、同じ入力セットが与えられるたびに同じ出力を与える必要があります。
User friendly −プログラムインターフェイス、クリック可能なリンクやアイコンなどは、ユーザーフレンドリーである必要があります。
Self-documenting −明示的な名前を使用しているため、識別子名、モジュール名などがそれ自体を記述できるプログラムまたはソフトウェア。
ここに良いプログラムを書くことができるいくつかの方法があります。
適切な識別子名
変数、オブジェクト、関数、クラス、またはメソッドを識別する名前は、 identifier。適切な識別子名を付けると、プログラムは自己文書化されます。これは、オブジェクトの名前が、オブジェクトの機能や保存する情報を示していることを意味します。このSQL命令の例を見てみましょう。
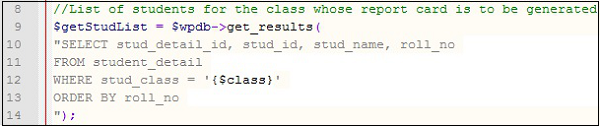
10行目を見てください。プログラムを読んでいる人には、学生のID、名前、ロール番号を選択するように指示されています。変数の名前はこれを自明にします。これらは、適切な識別子名を作成するためのいくつかのヒントです-
言語ガイドラインを使用する
明確さを維持するために長い名前を付けることを躊躇しないでください
大文字と小文字を使用する
言語で許可されている場合でも、2つの識別子に同じ名前を付けないでください
相互に排他的なスコープがある場合でも、複数の識別子に同じ名前を付けないでください
コメント
上の画像の8行目を見てください。次の数行のコードで、レポートカードが生成される学生のリストが取得されることがわかります。この行はコードの一部ではありませんが、プログラムをよりユーザーフレンドリーにするためにのみ提供されています。
コンパイルされていないが、プログラマーへのメモまたは説明として書かれているこのような式は、 comment。次のプログラムセグメントのコメントを見てください。コメントは//で始まります。

コメントは次のように挿入できます-
その目的を説明するためのプログラムのプロローグ
論理ブロックまたは機能ブロックの最初および/または最後
特別なシナリオや例外についてメモしてください
読みながらコードの流れを壊して逆効果になる可能性があるため、余分なコメントを追加することは避けてください。コンパイラはコメントとインデントを無視するかもしれませんが、読者はそれらのそれぞれを読む傾向があります。
インデント
左または右の余白からのテキストの距離は indent。プログラムでは、インデントは論理的に分離されたコードのブロックを分離するために使用されます。インデントされたプログラムセグメントの例を次に示します。
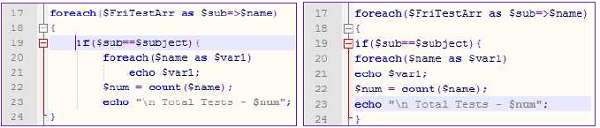
ご覧のとおり、インデントされたプログラムの方が理解しやすいです。からの制御の流れfor loop に if に戻る for非常に明確です。インデントは、制御構造の場合に特に役立ちます。
空白や行を挿入することもインデントの一部です。インデントを使用できる、または使用する必要があるいくつかの状況があります-
プログラム内のコードの論理ブロックまたは機能ブロック間の空白行
オペレーターの周りの空白
新しい制御構造の先頭にあるタブ
プログラムまたはソフトウェアからエラーを識別して削除することは、 debugging。デバッグは理想的にはテストプロセスの一部ですが、実際にはプログラミングのすべてのステップで実行されます。コーダーは、先に進む前に、最小のモジュールをデバッグする必要があります。これにより、テストフェーズ中に発生するエラーの数が減り、テストの時間と労力が大幅に削減されます。プログラムで発生する可能性のあるエラーの種類を見てみましょう。
構文エラー
Syntax errorsプログラムの文法エラーです。すべての言語には、プログラムを作成するための識別子の作成、式の作成など、独自のルールセットがあります。これらのルールに違反すると、エラーが呼び出されますsyntax errors。多くの現代integrated development environmentsプログラムを入力するときに構文エラーを識別できます。それ以外の場合は、プログラムをコンパイルすると表示されます。例を見てみましょう-
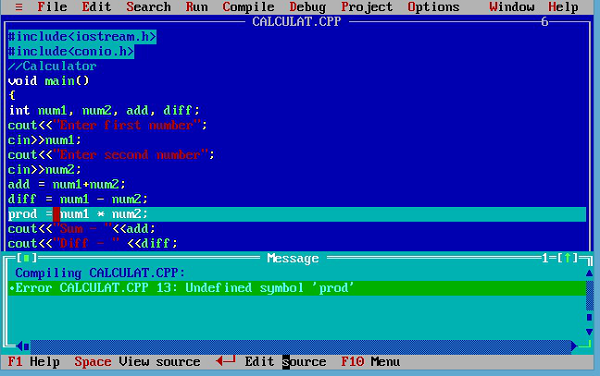
このプログラムでは、変数prodは宣言されていません。これは、コンパイラーによってスローされます。
セマンティックエラー
Semantic errors とも呼ばれます logical errors。このステートメントには構文エラーがないため、正しくコンパイルおよび実行されます。ただし、ロジックが正しくないため、目的の出力は得られません。例を見てみましょう。
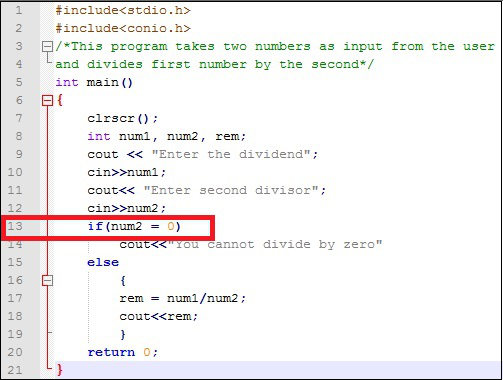
13行目を見てください。ここでプログラマーは、0による除算を避けるために、除数が0であるかどうかを確認したいと考えています。ただし、比較演算子==を使用する代わりに、代入演算子=を使用しています。これで、「if式」がtrueと評価され、プログラムが「0で除算することはできません」として出力を返すたびに。意図したものではありません!!
論理エラーはどのプログラムでも検出できません。目的の出力が得られない場合は、プログラマー自身がそれらを識別する必要があります。
ランタイムエラー
ランタイムエラーは、プログラムの実行中に発生するエラーです。これは、プログラムに構文エラーがないことを意味します。プログラムで発生する可能性のある最も一般的な実行時エラーのいくつかは次のとおりです。
- 無限ループ
- 「0」による除算
- ユーザーが間違った値を入力しました(たとえば、整数ではなく文字列)
コードの最適化
コードの品質と効率を向上させるためにコードを変更する方法は、 code optimization. Code qualityコードの寿命を決定します。コードを製品から製品へと引き継いで長期間使用および維持できる場合、その品質は高いと見なされ、寿命が長くなります。逆に、あるバージョンが有効になるまでなど、コードの一部を短期間しか使用および保守できない場合、そのコードは低品質であり、寿命が短いと見なされます。
コードの信頼性と速度が決定します code efficiency。コードの効率は、ソフトウェアの高性能を確保する上で重要な要素です。
コードの最適化には2つのアプローチがあります-
Intuition based optimization (IBO)−ここで、プログラマーは自分のスキルと経験に基づいてプログラムを最適化しようとします。これは小さなプログラムでは機能するかもしれませんが、プログラムの複雑さが増すにつれて惨めに失敗します。
Evidence based optimization (EBO)−ここでは、自動化されたツールを使用してパフォーマンスのボトルネックを見つけ、それに応じて関連する部分を最適化します。すべてのプログラミング言語には、独自のコード最適化ツールのセットがあります。たとえば、PMD、FindBug、CloverはJavaコードを最適化するために使用されます。
時間は少なく、メモリは高価であるため、コードは実行時間とメモリ消費に対して最適化されています。2つの間にバランスがなければなりません。場合time optimization メモリの負荷を増やす、または memory optimization コードが遅くなり、最適化の目的が失われます。

実行時間の最適化
ユーザーに高速サービスを提供するには、実行時間に合わせてコードを最適化する必要があります。実行時間の最適化に関するヒントを次に示します-
実行時間の最適化が組み込まれているコマンドを使用する
if条件の代わりにスイッチを使用する
ループ構造内の関数呼び出しを最小限に抑える
プログラムで使用されるデータ構造を最適化する
メモリの最適化
ご存知のように、データと命令はメモリを消費します。データとは、式の結果である中間データも指します。また、最適化しようとしているプログラムまたはモジュールを構成している命令の数を追跡する必要があります。ここにいくつかのヒントがありますmemory optimization −
メモリ最適化が組み込まれているコマンドを使用する
レジスタに格納する必要のある変数の使用を最小限に抑える
何度も実行されるループ内でグローバル変数を宣言することは避けてください
sqrt()のようなCPUを集中的に使用する関数の使用は避けてください
ソフトウェアまたはプログラムをユーザーに説明するテキスト、イラスト、またはビデオはすべて、 program or software document。ユーザーは、プログラマー、システムアナリスト、管理者からエンドユーザーまで、誰でもかまいません。開発のさまざまな段階で、さまざまなユーザー向けに複数のドキュメントが作成される場合があります。実際には、software documentation は、ソフトウェア開発プロセス全体の重要なプロセスです。
モジュラープログラミングでは、ソフトウェアのさまざまなモジュールがさまざまなチームによって開発されているため、ドキュメントはさらに重要になります。開発チーム以外の誰かがモジュールを理解したい、または理解する必要がある場合は、適切で詳細なドキュメントを使用すると、タスクが簡単になります。
これらは、ドキュメントを作成するためのいくつかのガイドラインです-
ドキュメントは読者の視点からのものでなければなりません
ドキュメントは明確である必要があります
繰り返しがあってはいけません
業界標準を使用する必要があります
ドキュメントは常に更新する必要があります
古いドキュメントは、段階的廃止を適切に記録した後、段階的に廃止する必要があります
ドキュメントの利点
これらは、プログラムのドキュメントを提供することの利点のいくつかです-
ソフトウェアまたはプログラムのすべての部分を追跡します
メンテナンスが簡単
開発者以外のプログラマーは、ソフトウェアのすべての側面を理解できます
ソフトウェアの全体的な品質を向上させます
ユーザートレーニングを支援します
知識の分散化を保証し、人々が突然システムを離れた場合のコストと労力を削減します
サンプルドキュメント
ソフトウェアには、さまざまな種類のドキュメントを関連付けることができます。重要なもののいくつかは次のとおりです。
User manual −エンドユーザーがソフトウェアのさまざまな機能を使用するための手順と手順について説明します。
Operational manual −実行されているすべての操作と、それらの相互依存関係をリストして説明します。
Design Document−ソフトウェアの概要を示し、設計要素を詳細に説明します。それは次のような詳細を文書化しますdata flow diagrams, entity relationship diagrams、など。
Requirements Document−システムのすべての要件のリストと、要件の実行可能性の分析があります。ユーザーケース、実際のシナリオなどが含まれる場合があります。
Technical Documentation −アルゴリズム、フローチャート、プログラムコード、機能モジュールなどの実際のプログラミングコンポーネントのドキュメントです。
Testing Document −テスト計画、テストケース、検証計画、検証計画、テスト結果などを記録します。テストは、集中的なドキュメントを必要とするソフトウェア開発の1つのフェーズです。
List of Known Bugs−すべてのソフトウェアにはバグやエラーがあり、発見が非常に遅いか無害であるか、修正に必要以上の労力と時間がかかるため、削除できません。これらのバグは、後日削除できるように、プログラムのドキュメントに記載されています。また、バグがアクティブ化された場合、ユーザー、実装者、および保守担当者を支援します。
Program maintenance これらの結果のいずれかを達成するために、配信後にソフトウェアまたはプログラムを変更するプロセスです。
- エラーを修正する
- 性能を上げる
- 機能を追加する
- 廃止された部分を削除します
ソフトウェアの稼働後に発生するエラーを修正するにはメンテナンスが必要であるという一般的な認識にもかかわらず、実際には、メンテナンス作業のほとんどは、既存のモジュールにマイナーまたはメジャー機能を追加することを伴います。たとえば、いくつかの新しいデータがレポートに追加され、新しいフィールドが入力フォームに追加され、変更された政府法を組み込むために変更されるコードなどがあります。
メンテナンスの種類
メンテナンス活動は4つの見出しに分類できます-
Corrective maintenance−ここでは、オンサイト実装後に発生するエラーが修正されています。エラーは、ユーザー自身が指摘する場合があります。
Preventive maintenance −将来のエラーを回避するために行われる変更は、予防保守と呼ばれます。
Adaptive maintenance−作業環境の変更により、ソフトウェアの変更が必要になる場合があります。これは適応型メンテナンスと呼ばれます。たとえば、政府の教育方針が変更された場合、学校管理ソフトウェアの生徒の結果処理モジュールに対応する変更を加える必要があります。
Perfective maintenance−クライアントからの新しい要件を組み込むために既存のソフトウェアで行われた変更は、完全保守と呼ばれます。ここでの目標は、常に最新のテクノロジーを使用することです。
メンテナンスツール
ソフトウェア開発者とプログラマーは、ソフトウェアのメンテナンスを支援するために多くのツールを使用しています。最も広く使用されているもののいくつかを次に示します-
Program slicer −変更の影響を受けるプログラムの一部を選択します
Data flow analyzer −ソフトウェア内のすべての可能なデータフローを追跡します
Dynamic analyzer −プログラム実行パスをトレースします
Static analyzer −プログラムの一般的な表示と要約を可能にします
Dependency analyzer −プログラムのさまざまな部分の相互依存性の理解と分析を支援します