分度器-クイックガイド
この章では、分度器の概要を説明します。ここでは、このテストフレームワークの起源と、これを選択する必要がある理由、このツールの動作と制限について学習します。
分度器とは何ですか?
Protractorは、AngularおよびAngularJSアプリケーション向けのオープンソースのエンドツーエンドのテストフレームワークです。これは、GoogleがWebDriverの上に構築したものです。また、「AngularScenarioRunner」と呼ばれる既存のAngularJSE2Eテストフレームワークの代わりとしても機能します。
また、NodeJS、Selenium、Jasmine、WebDriver、Cucumber、Mochaなどの強力なテクノロジーを組み合わせたソリューションインテグレーターとしても機能します。AngularJSアプリケーションのテストに加えて、通常のWebアプリケーションの自動回帰テストも作成します。実際のブラウザを使用してテストを実行するため、実際のユーザーと同じようにアプリケーションをテストできます。
次の図は、分度器の概要を示しています。
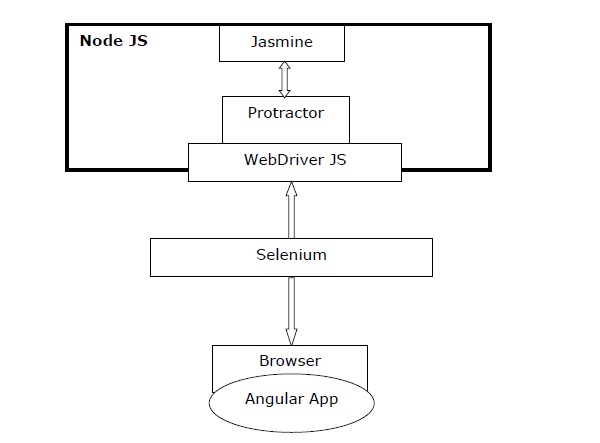
上の図では、次のようになっていることに注意してください。
Protractor −前述のように、これは特にAngularアプリ用に設計されたWebDriverJSのラッパーです。
Jasmine−これは基本的に、JavaScriptコードをテストするためのビヘイビア駆動開発フレームワークです。Jasmineで簡単にテストを書くことができます。
WebDriver JS −これはSelenium 2.0 / WebDriverのノードJSバインディングの実装です。
Selenium −ブラウザを自動化するだけです。
原点
前述のように、分度器は「AngularScenarioRunner」と呼ばれる既存のAngularJSE2Eテストフレームワークに代わるものです。基本的に、分度器の起源はシナリオランナーの終わりから始まります。ここで発生する質問は、なぜ分度器を構築する必要があるのかということです。これを理解するには、最初にその前身であるシナリオランナーについて確認する必要があります。
分度器の始まり
Protractorの開発に大きく貢献したJulieRalphは、Google内の他のプロジェクトでAngularシナリオランナーを使用して次のような経験をしました。これはさらに、特にギャップを埋めるために分度器を構築する動機になりました-
「ScenarioRunnerを使用してみましたが、テストに必要なことを実際に実行できないことがわかりました。ログインなどをテストする必要がありました。ログインページはAngularページではなく、ScenarioRunnerはそれを処理できませんでした。また、ポップアップや複数のウィンドウ、ブラウザの履歴のナビゲートなどを処理することはできませんでした。」
分度器の最大の利点は、Seleniumプロジェクトの成熟度であり、Angularプロジェクトで簡単に使用できるようにメソッドをまとめています。Protractorの設計は、アプリケーションのWeb UI、バックエンドサービス、永続層などのすべての層をテストするように構築されています。
なぜ分度器?
私たちが知っているように、ほとんどすべてのアプリケーションが開発にJavaScriptを使用しています。JavaScriptのサイズが大きくなり、アプリケーション自体の数が増えるためにアプリケーションが複雑になると、テスターのタスクは難しくなります。ほとんどの場合、AngularJSアプリケーションでWeb要素をキャプチャすることは非常に困難になり、拡張HTML構文を使用して、JUnitまたはSeleniumWebDriverを使用してWebアプリケーションコンポーネントを表現します。
ここでの問題は、Selenium WebDriverがAngularJSWeb要素を見つけられない理由です。その理由は、AngularJSアプリケーションには、Seleniumロケーターに含まれていないng-repeater、ng-controller、ng-modelなどの拡張HTML属性があるためです。
ここで、Seleniumの上部にあるProtractorがAngularJS Webアプリケーションでこれらの拡張HTML要素を処理および制御できるため、Protractorの重要性が生まれます。そのため、ほとんどのフレームワークは、アプリケーションの実際の機能のテストを行うために使用されていたAngularJSアプリケーションの単体テストの実行に焦点を合わせていると言えます。
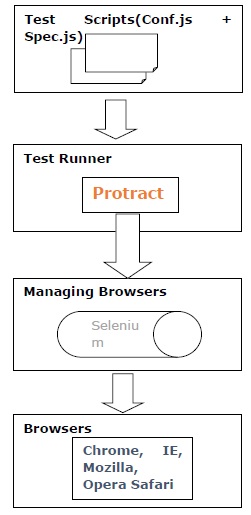
分度器の働き
テストフレームワークであるProtractorは、Seleniumと連携して動作し、ブラウザーまたはモバイルデバイスで実行されているAngularJSアプリケーションとのユーザーの対話をシミュレートするための自動テストインフラストラクチャを提供します。
分度器の動作は、次の手順の助けを借りて理解することができます-
Step 1−最初のステップでは、テストを作成する必要があります。それはジャスミンまたはモカまたはキュウリの助けを借りて行うことができます。
Step 2−次に、分度器を使用して実行できるテストを実行する必要があります。テストランナーとも呼ばれます。
Step 3 −このステップでは、Seleniumサーバーがブラウザーの管理に役立ちます。
Step 4 −最後に、ブラウザAPIはSeleniumWebDriverの助けを借りて呼び出されます。
利点
このオープンソースのエンドツーエンドのテストフレームワークには、次の利点があります。
オープンソースツールである分度器は、インストールとセットアップが非常に簡単です。
Jasmineフレームワークとうまく連携してテストを作成します。
テスト駆動開発(TDD)をサポートします。
自動待機が含まれているため、テストに待機とスリープを明示的に追加する必要はありません。
SeleniumWebDriverのすべての利点を提供します。
複数のブラウザによる並列テストをサポートします。
自動同期の利点を提供します。
優れたテスト速度を備えています。
制限事項
このオープンソースのエンドツーエンドのテストフレームワークには、次の制限があります。
WebDriver JSのラッパーであるため、ブラウザーの自動化の業種は明らかになりません。
JavaScriptの知識は、JavaScriptでのみ使用できるため、ユーザーにとって不可欠です。
UI駆動型のテストツールであるため、フロントエンドテストのみを提供します。
分度器を操作するにはJavaScriptの知識が不可欠なので、この章では、JavaScriptテストの概念を詳しく理解しましょう。
JavaScriptのテストと自動化
JavaScriptは、動的に型付けされ解釈される最も一般的なスクリプト言語ですが、最も困難なタスクはコードをテストすることです。これは、JAVAやC ++などの他のコンパイル言語とは異なり、JavaScriptには、テスターがエラーを把握するのに役立つコンパイル手順がないためです。さらに、ブラウザベースのテストには非常に時間がかかります。したがって、JavaScriptの自動テストをサポートするツールが必要です。
自動テストの概念
コードが改善されるため、テストを作成することは常に良い習慣です。手動テストの問題は、少し時間がかかり、エラーが発生しやすいことです。手動テストのプロセスは、プログラマーにとっても非常に退屈です。プログラマーは、プロセスを繰り返し、テスト仕様を記述し、コードを変更し、ブラウザーを数回更新する必要があるためです。さらに、手動テストも開発プロセスを遅くします。
上記の理由により、これらのテストを自動化し、プログラマーがこれらの反復的で退屈な手順を取り除くのに役立ついくつかのツールがあると常に役立ちます。テストプロセスを自動化するには、開発者は何をすべきですか?
基本的に、開発者はCLI(コマンドラインインタープリター)または開発IDE(統合開発環境)でツールセットを実装できます。その後、これらのテストは、開発者からの入力がなくても、別のプロセスで継続的に実行されます。JavaScriptの自動テストも新しいものではなく、Karma、Protractor、CasperJSなどの多くのツールが開発されています。
JavaScriptのテストの種類
目的ごとに異なるテストが存在する可能性があります。たとえば、プログラム内の関数の動作をチェックするために作成されたテストもあれば、モジュールまたは機能のフローをテストするために作成されたテストもあります。したがって、次の2種類のテストがあります。
ユニットテスト
テストは、ユニットと呼ばれるプログラムのテスト可能な最小部分で実行されます。ユニットは基本的に、そのユニットが他の部品に依存することなく、単独でテストされます。JavaScriptの場合、特定の動作をする個々のメソッドまたは関数はコードの単位である可能性があり、これらのコードの単位は分離された方法でテストする必要があります。
ユニットテストの利点の1つは、ユニットが互いに独立しているため、ユニットのテストを任意の順序で実行できることです。本当に重要な単体テストのもう1つの利点は、次のようにいつでもテストを実行できることです。
- 開発プロセスの最初から。
- モジュール/機能の開発が完了した後。
- モジュール/機能を変更した後。
- 既存のアプリケーションに新しい機能を追加した後。
JavaScriptアプリケーションの自動化された単体テストでは、Mocha、Jasmine、QUnitなどの多くのテストツールとフレームワークから選択できます。
エンドツーエンドのテスト
これは、アプリケーションの最初から最後まで(一方の端からもう一方の端まで)のフローが設計どおりに正常に機能しているかどうかをテストするために使用されるテスト方法として定義できます。
エンドツーエンドのテストは、関数/フローテストとも呼ばれます。単体テストとは異なり、エンドツーエンドのテストでは、個々のコンポーネントがアプリケーションとしてどのように連携するかをテストします。これが、単体テストとエンドツーエンドテストの主な違いです。
たとえば、ユーザーが登録を完了するためにいくつかの有効な情報を提供する必要がある登録モジュールがある場合、その特定のモジュールのE2Eテストは、次の手順に従ってテストを完了します。
- まず、フォームまたはモジュールをロード/コンパイルします。
- これで、フォームの要素のDOM(ドキュメントオブジェクトモデル)が取得されます。
- 次に、送信ボタンのクリックイベントをトリガーして、機能しているかどうかを確認します。
- ここで、検証の目的で、入力フィールドから値を収集します。
- 次に、入力フィールドを検証する必要があります。
- テストの目的で、偽のAPIを呼び出してデータを保存します。
すべてのステップで独自の結果が得られ、期待される結果セットと比較されます。
さて、この種のE2Eまたは機能テストは手動でも実行できますが、なぜこれを自動化する必要があるのでしょうか。主な理由は、自動化によってこのテストプロセスが簡単になるためです。この目的のために、任意のアプリケーションと簡単に統合できる利用可能なツールには、Selenium、PhantomJS、およびProtractorがあります。
テストツールとフレームワーク
Angularテスト用のさまざまなテストツールとフレームワークがあります。以下は、よく知られているツールとフレームワークの一部です-
カルマ
Vojta Jinaによって作成されたKarmaは、テストランナーです。もともとこのプロジェクトはTestacularと呼ばれていました。これはテストフレームワークではありません。つまり、実際のブラウザーでJavaScript単体テストを簡単かつ自動的に実行することができます。KarmaはAngularJS用に構築されました。これは、Karmaの前には、WebベースのJavaScript開発者向けの自動テストツールがなかったためです。一方、Karmaが提供する自動化により、開発者は単純な1つのコマンドを実行して、テストスイート全体が合格したか失敗したかを判断できます。
カルマを使用することの長所
以下は、手動プロセスと比較したカルマの使用のいくつかの長所です-
- 複数のブラウザとデバイスでのテストを自動化します。
- ファイルのエラーを監視して修正します。
- オンラインサポートとドキュメントを提供します。
- 継続的インテグレーションサーバーとの統合を容易にします。
カルマを使用することの短所
以下は、カルマを使用することのいくつかの短所です-
Karmaを使用する主な欠点は、構成と保守に追加のツールが必要になることです。
JasmineでKarmaテストランナーを使用している場合、1つの要素に複数のIDがある場合に、CSSの設定に関する情報を見つけるために利用できるドキュメントが少なくなります。
ジャスミン
JavaScriptコードをテストするためのビヘイビア駆動開発フレームワークであるJasmineは、PivotalLabsで開発されています。Jasmineフレームワークが積極的に開発される前に、JsUnitという名前の同様のユニットテストフレームワークも、テストランナーが組み込まれているPivotalLabsによって開発されました。ブラウザのテストは、SpecRunner.htmlファイルを含めるか、コマンドラインテストランナーとして使用することで、Jasmineテストを実行できます。カルマの有無にかかわらず使用することもできます。
ジャスミン使用の長所
以下は、ジャスミンを使用することのいくつかの長所です-
ブラウザ、プラットフォーム、言語に依存しないフレームワーク。
ビヘイビア駆動開発とともにテスト駆動開発(TDD)をサポートします。
Karmaとのデフォルトの統合があります。
構文がわかりやすい。
追加機能としてテストを支援するテストスパイ、偽物、パススルー機能を提供します。
ジャスミンを使用することの短所
以下はジャスミンを使用することの短所です-
テストの実行中にJasmineで使用できるファイル監視機能がないため、テストは変更されたときにユーザーが返す必要があります。
モカ
Node.jsアプリケーション用に作成されたMochaはテストフレームワークですが、ブラウザーテストもサポートしています。Jasmineと非常に似ていますが、両者の主な違いは、Mochaはテストフレームワークとしてスタンドアロンで実行できないため、プラグインとライブラリが必要なことです。一方、ジャスミンはスタンドアロンです。ただし、モカはジャスミンよりも柔軟に使用できます。
モカ使用の長所
以下は、Mochaを使用することのいくつかの長所です-
- Mochaはインストールと構成が非常に簡単です。
- ユーザーフレンドリーでシンプルなドキュメント。
- いくつかのノードプロジェクトを持つプラグインが含まれています。
モカを使用することの短所
以下は、Mochaを使用することのいくつかの短所です-
- アサーション、スパイなどのために個別のモジュールが必要です。
- また、Karmaで使用するには追加の構成が必要です。
QUnit
QUintは、もともとjQueryの一部として2008年にJohn Resigによって開発されたもので、強力でありながら使いやすいJavaScriptユニットテストスイートです。一般的なJavaScriptコードのテストに使用できます。ブラウザでのJavaScriptのテストに重点を置いていますが、開発者が使用すると非常に便利です。
QUnitを使用する長所
以下は、QUnitを使用することのいくつかの長所です-
- インストールと構成が簡単です。
- ユーザーフレンドリーでシンプルなドキュメント。
QUnitを使用することの短所
以下はQUnitを使用することの短所です-
- これは主にjQuery用に開発されたため、他のフレームワークでの使用にはあまり適していません。
セレン
Seleniumは、2004年にThoughtWorksの内部ツールとしてJason Hugginsによって開発されたもので、オープンソースのテスト自動化ツールです。Seleniumは、「Seleniumはブラウザを自動化します。それでおしまい!"。ブラウザの自動化は、開発者がブラウザと非常に簡単に対話できることを意味します。
Seleniumを使用する長所
以下は、Seleniumを使用することのいくつかの長所です-
- 大規模な機能セットが含まれています。
- 分散テストをサポートします。
- SauceLabsなどのサービスを通じてSaaSをサポートしています。
- シンプルなドキュメントと豊富なリソースを利用して簡単に使用できます。
Seleniumを使用することの短所
以下は、Seleniumを使用することのいくつかの短所です-
- Seleniumを使用する主な欠点は、別のプロセスとして実行する必要があることです。
- 開発者はいくつかの手順を実行する必要があるため、構成は少し面倒です。
前の章では、分度器の基本を学びました。この章では、インストールと構成の方法を学びましょう。
前提条件
コンピュータに分度器をインストールする前に、次の前提条件を満たしている必要があります-
Node.js
分度器はNode.jsモジュールであるため、非常に重要な前提条件は、コンピューターにNode.jsをインストールする必要があることです。Node.jsに付属のnpm(JavaScriptパッケージマネージャー)を使用してProtractorパッケージをインストールします。
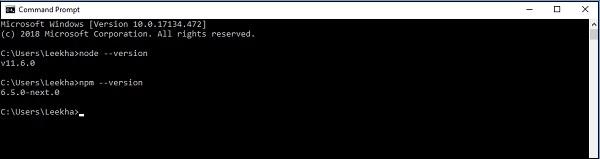
Node.jsをインストールするには、公式リンクをたどってください- https://nodejs.org/en/download/。Node.jsをインストールした後、コマンドを記述してNode.jsとnpmのバージョンを確認できます。node --version そして npm --version 以下に示すようにコマンドプロンプトで-
クロム
Googleが構築したウェブブラウザであるGoogleChromeは、Seleniumサーバーを必要とせずに、分度器でエンドツーエンドのテストを実行するために使用されます。リンクをクリックしてChromeをダウンロードできます-https://www.google.com/chrome/。
Chrome用SeleniumWebDriver
このツールは分度器npmモジュールに付属しており、Webアプリケーションと対話することができます。
分度器のインストール
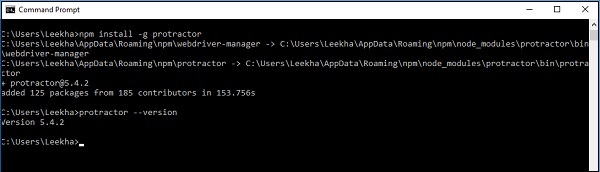
コンピューターにNode.jsをインストールした後、次のコマンドを使用して分度器をインストールできます-
npm install -g protractor分度器が正常にインストールされたら、次のように記述してバージョンを確認できます。 protractor --version 以下に示すように、コマンドプロンプトでコマンドを実行します-
Chrome用WebDriverのインストール
Protractorをインストールした後、Chrome用のSeleniumWebDriverをインストールする必要があります。次のコマンドを使用してインストールできます-
webdriver-manager update上記のコマンドは、プロジェクトで使用される必要なChromeドライバーを含むSeleniumディレクトリを作成します。
インストールと構成の確認
Protractorのインストール後に、例で提供されているconf.jsを少し変更することで、Protractorのインストールと構成を確認できます。このconf.jsファイルはルートディレクトリにありますnode_modules/Protractor/example。
このために、最初に同じディレクトリにtestingconfig.jsという名前の新しいファイルを作成します。 node_modules/Protractor/example。
ここで、conf.jsファイルのソースファイル宣言パラメーターの下に、testingconfig.jsと記述します。
次に、すべてのファイルを保存して閉じ、コマンドプロンプトを開きます。以下のスクリーンショットに示すように、conf.jsファイルを実行します。
以下に示す出力が得られれば、分度器の構成とインストールは成功します。
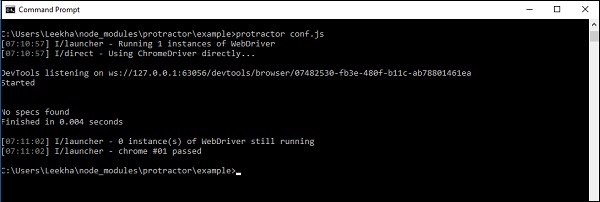
上記の出力は、conf.jsファイルのソースファイル宣言パラメーターに空のファイルを指定したため、指定がないことを示しています。しかし、上記の出力から、分度器とWebDriverの両方が正常に実行されていることがわかります。
インストールと構成の問題
分度器とWebDriverのインストールと構成中に、次の一般的な問題が発生する可能性があります-
セレンが正しくインストールされていません
これは、WebDriverのインストール中に最も一般的な問題です。この問題は、WebDriverを更新しない場合に発生します。WebDriverを更新する必要があることに注意してください。更新しないと、Protractorのインストールを参照できません。
テストが見つかりません
もう1つの一般的な問題は、分度器を実行した後、テストが見つからないことを示していることです。このためには、相対パス、ファイル名、または拡張子が正しいことを確認する必要があります。また、conf.jsファイルは構成ファイル自体から始まるため、慎重に作成する必要があります。
前に説明したように、Protractorは、AngularおよびAngularJSアプリケーション向けのオープンソースのエンドツーエンドのテストフレームワークです。Node.jsプログラムです。一方、Seleniumは、Seleniumサーバー、WebDriver API、およびWebDriverブラウザードライバーを含むブラウザー自動化フレームワークです。
Seleniumを使用した分度器
ProtractorとSeleniumの組み合わせについて説明すると、ProtractorはSeleniumサーバーと連携して、自動テストインフラストラクチャを提供できます。インフラストラクチャは、ブラウザーまたはモバイルデバイスで実行されているAngularアプリケーションとのユーザーの対話をシミュレートできます。次の図に示すように、分度器とSeleniumの接続詞は、テスト、サーバー、ブラウザーの3つのパーティションに分割できます。

SeleniumWebDriverプロセス
上の図で見たように、Selenium WebDriverを使用したテストには、次の3つのプロセスが含まれます。
- テストスクリプト
- サーバー
- ブラウザ
このセクションでは、これら3つのプロセス間の通信について説明します。
テストスクリプトとサーバー間の通信
最初の2つのプロセス(テストスクリプトとサーバー)間の通信は、Seleniumサーバーの動作に依存します。言い換えれば、Seleniumサーバーの実行方法によって、テストスクリプトとサーバー間の通信プロセスが形作られると言えます。
Seleniumサーバーは、スタンドアロンのSeleniumサーバー(selenium-server-standalone.jar)としてマシン上でローカルに実行することも、サービス(Sauce Labs)を介してリモートで実行することもできます。スタンドアロンのSeleniumサーバーの場合、Node.jsとseleniumサーバーの間にhttp通信があります。
サーバーとブラウザ間の通信
サーバーは、テストスクリプトからコマンドを解釈した後、ブラウザにコマンドを転送する責任があることを知っています。そのため、サーバーとブラウザにも通信媒体が必要であり、ここでは通信はJSON WebDriver Wire Protocol。コマンドの解釈に使用されるブラウザードライバーで拡張されたブラウザー。
Selenium WebDriverプロセスとその通信に関する上記の概念は、次の図を使用して理解できます。

Protractorの操作中、最初のプロセスであるテストスクリプトはNode.jsを使用して実行されますが、ブラウザーでアクションを実行する前に、テスト対象のアプリケーションが安定していることを確認するための追加のコマンドを送信します。
Seleniumサーバーのセットアップ
Selenium Serverは、テストスクリプトとブラウザードライバーの間のプロキシサーバーのように機能します。基本的に、コマンドをテストスクリプトからWebDriverに転送し、WebDriverからの応答をテストスクリプトに返します。Seleniumサーバーをセットアップするための以下のオプションが含まれています。conf.js テストスクリプトのファイル-
スタンドアロンSeleniumサーバー
ローカルマシンでサーバーを実行する場合は、スタンドアロンのセレンサーバーをインストールする必要があります。スタンドアロンのSeleniumサーバーをインストールするための前提条件は、JDK(Java Development Kit)です。ローカルマシンにJDKをインストールする必要があります。コマンドラインから次のコマンドを実行することで確認できます-
java -versionこれで、SeleniumServerを手動またはテストスクリプトからインストールして起動するオプションがあります。
Seleniumサーバーを手動でインストールして起動する
Seleniumサーバーを手動でインストールして起動するには、Protractorに付属のWebDriver-Managerコマンドラインツールを使用する必要があります。Seleniumサーバーをインストールして起動する手順は次のとおりです。
Step 1−最初のステップは、SeleniumサーバーとChromeDriverをインストールすることです。次のコマンドを実行することで実行できます-
webdriver-manager updateStep 2−次に、サーバーを起動する必要があります。次のコマンドを実行することで実行できます-
webdriver-manager startStep 3−最後に、構成ファイルのseleniumAddressを実行中のサーバーのアドレスに設定する必要があります。デフォルトのアドレスはhttp://localhost:4444/wd/hub。
テストスクリプトからSeleniumサーバーを起動する
テストスクリプトからSeleniumサーバーを起動するには、構成ファイルで次のオプションを設定する必要があります-
Location of jar file − seleniumServerJarを設定して、構成ファイルでスタンドアロンSeleniumサーバーのjarファイルの場所を設定する必要があります。
Specifying the port−スタンドアロンのSeleniumサーバーを起動するために使用するポートも指定する必要があります。seleniumPortを設定することで設定ファイルで指定できます。デフォルトのポートは4444です。
Array of command line options−サーバーに渡すコマンドラインオプションの配列も設定する必要があります。seleniumArgsを設定することで設定ファイルで指定できます。コマンドの配列の完全なリストが必要な場合は、次のコマンドでサーバーを起動します。-help 国旗。
リモートSeleniumサーバーの操作
テストを実行するためのもう1つのオプションは、Seleniumサーバーをリモートで使用することです。サーバーをリモートで使用するための前提条件は、サーバーをホストするサービスのアカウントを持っている必要があることです。分度器を使用している間、サーバーをホストする次のサービスのサポートが組み込まれています-
TestObject
TestObjectをリモートSeleniumサーバーとして使用するには、TestObjectアカウントのユーザー名であるtestobjectUserと、TestObjectアカウントのAPIキーであるtestobjectKeyを設定する必要があります。
BrowserStack
BrowserStackをリモートSeleniumサーバーとして使用するには、BrowserStackアカウントのユーザー名であるbrowserstackUserと、BrowserStackアカウントのAPIキーであるbrowserstackKeyを設定する必要があります。
ソースラボ
SauceLabsをリモートSeleniumServerとして使用するには、Sauce Labsアカウントのユーザー名であるsauceUserと、SauceLabsアカウントのAPIキーであるSauceKeyを設定する必要があります。
コビトン
KobitonをリモートSeleniumサーバーとして使用するには、Kobitonアカウントのユーザー名であるkobitonUserと、KobitonアカウントのAPIキーであるkobitonKeyを設定する必要があります。
Seleniumサーバーを使用せずにブラウザードライバーに直接接続する
テストを実行するためのもう1つのオプションは、Seleniumサーバーを使用せずにブラウザードライバーに直接接続することです。分度器は、構成ファイルでdirectConnect:trueを設定することにより、Selenium Serverを使用せずに、ChromeおよびFirefoxに対して直接テストできます。
ブラウザの設定
ブラウザを設定および設定する前に、Protractorでサポートされているブラウザを確認する必要があります。以下は、分度器でサポートされているブラウザのリストです。
- ChromeDriver
- FirefoxDriver
- SafariDriver
- IEDriver
- Appium-iOS/Safari
- Appium-Android/Chrome
- Selendroid
- PhantomJS
ブラウザの設定は設定ファイルの機能オブジェクト内で行われるため、ブラウザの設定と設定は分度器の設定ファイルに移動する必要があります。
Chromeの設定
Chromeブラウザを設定するには、機能オブジェクトを次のように設定する必要があります
capabilities: {
'browserName': 'chrome'
}chromeOptionsにネストされているChrome固有のオプションを追加することもでき、その完全なリストは次のURLで確認できます。 https://sites.google.com/a/chromium.org/chromedriver/capabilities。
たとえば、右上にFPSカウンターを追加する場合は、構成ファイルで次のように実行できます。
capabilities: {
'browserName': 'chrome',
'chromeOptions': {
'args': ['show-fps-counter=true']
}
},Firefoxのセットアップ
Firefoxブラウザを設定するには、機能オブジェクトを次のように設定する必要があります-
capabilities: {
'browserName': 'firefox'
}moz:firefoxOptionsオブジェクトにネストされているFirefox固有のオプションを追加することもでき、その完全なリストは次の場所で確認できます。 https://github.com/mozilla/geckodriver#firefox-capabilities。
たとえば、Firefoxでセーフモードでテストを実行する場合は、構成ファイルで次のように実行できます。
capabilities: {
'browserName': 'firefox',
'moz:firefoxOptions': {
'args': ['—safe-mode']
}
},他のブラウザの設定
ChromeまたはFirefox以外のブラウザを設定するには、から別のバイナリをインストールする必要があります。 https://docs.seleniumhq.org/download/。
PhantonJSの設定
実際、PhantomJSはクラッシュの問題があるため、サポートされなくなりました。その代わりに、ヘッドレスChromeまたはヘッドレスFirefoxを使用することをお勧めします。これらは次のように設定できます-
ヘッドレスChromeを設定するには、次のように–headlessフラグを使用してChromeを起動する必要があります。
capabilities: {
'browserName': 'chrome',
'chromeOptions': {
'args': [“--headless”, “--disable-gpu”, “--window-size=800,600”]
}
},ヘッドレスFirefoxをセットアップするには、Firefoxを次のコマンドで起動する必要があります。 –headless 次のようにフラグを立てます-
capabilities: {
'browserName': 'firefox',
'moz:firefoxOptions': {
'args': [“--headless”]
}
},テスト用に複数のブラウザを設定する
複数のブラウザに対してテストすることもできます。このために、次のようにmultiCapabilities構成オプションを使用する必要があります-
multiCapabilities: [{
'browserName': 'chrome'
},{
'browserName': 'firefox'
}]どのフレームワーク?
2つのBDD(ビヘイビア駆動開発)テストフレームワーク、JasmineとMochaがProtractorによってサポートされています。どちらのフレームワークもJavaScriptとNode.jsに基づいています。テストの作成と管理に必要な構文、レポート、およびスキャフォールディングは、これらのフレームワークによって提供されます。
次に、さまざまなフレームワークをインストールする方法を確認します-
ジャスミンフレームワーク
これは、分度器のデフォルトのテストフレームワークです。分度器をインストールすると、Jasmine2.xバージョンが付属します。個別にインストールする必要はありません。
モカフレームワーク
Mochaは、基本的にNode.jsで実行されるもう1つのJavaScriptテストフレームワークです。テストフレームワークとしてMochaを使用するには、BDD(ビヘイビア駆動開発)インターフェイスとChai AsPromisedでのChaiアサーションを使用する必要があります。インストールは、次のコマンドを使用して実行できます-
npm install -g mocha
npm install chai
npm install chai-as-promisedご覧のとおり、mochaのインストール時に-gオプションが使用されます。これは、-gオプションを使用してProtractorをグローバルにインストールしたためです。インストール後、テストファイル内にChaiを要求して設定する必要があります。それは次のように行うことができます-
var chai = require('chai');
var chaiAsPromised = require('chai-as-promised');
chai.use(chaiAsPromised);
var expect = chai.expect;この後、Chai AsPromisedをそのまま使用できます-
expect(myElement.getText()).to.eventually.equal('some text');ここで、framework: 'mocha'を追加して、frameworkプロパティを構成ファイルのmochaに設定する必要があります。mochaの「reporter」や「slow」などのオプションは、次のように設定ファイルに追加できます-
mochaOpts: {
reporter: "spec", slow: 3000
}キュウリフレームワーク
Cucumberをテストフレームワークとして使用するには、フレームワークオプションを使用して分度器と統合する必要があります custom。インストールは、次のコマンドの助けを借りて行うことができます
npm install -g cucumber
npm install --save-dev protractor-cucumber-frameworkご覧のとおり、Cucumberのインストール中に-gオプションが使用されます。これは、Protractorをグローバルにインストールしたためです。つまり-gオプションを使用します。次に、フレームワークプロパティをに設定する必要がありますcustom フレームワーク: 'custom'およびframeworkPath: 'Protractor-cucumber-framework'をcucumberConf.jsという名前の構成ファイルに追加することによる構成ファイルの作成。
以下に示すサンプルコードは、分度器でキュウリの機能ファイルを実行するために使用できる基本的なcucumberConf.jsファイルです。
exports.config = {
seleniumAddress: 'http://localhost:4444/wd/hub',
baseUrl: 'https://angularjs.org/',
capabilities: {
browserName:'Firefox'
},
framework: 'custom',
frameworkPath: require.resolve('protractor-cucumber-framework'),
specs: [
'./cucumber/*.feature'
],
// cucumber command line options
cucumberOpts: {
require: ['./cucumber/*.js'],
tags: [],
strict: true,
format: ["pretty"],
'dry-run': false,
compiler: []
},
onPrepare: function () {
browser.manage().window().maximize();
}
};この章では、分度器で最初のテストを作成する方法を理解しましょう。
分度器に必要なファイル
分度器を実行するには、次の2つのファイルが必要です-
仕様またはテストファイル
分度器を実行するための重要なファイルの1つです。このファイルには、実際のテストコードを記述します。テストコードは、テストフレームワークの構文を使用して記述されています。
たとえば、使用している場合 Jasmine フレームワークの場合、テストコードは次の構文を使用して記述されます。 Jasmine。このファイルには、テストのすべての機能フローとアサーションが含まれます。
簡単に言うと、このファイルには、アプリケーションと対話するためのロジックとロケーターが含まれていると言えます。
例
以下は、URLに移動してページタイトルを確認するためのテストケースを備えた単純なスクリプトTestSpecification.jsです。
//TestSpecification.js
describe('Protractor Demo', function() {
it('to check the page title', function() {
browser.ignoreSynchronization = true;
browser.get('https://www.tutorialspoint.com/tutorialslibrary.htm');
browser.driver.getTitle().then(function(pageTitle) {
expect(pageTitle).toEqual('Free Online Tutorials and Courses');
});
});
});コードの説明
上記仕様ファイルのコードは次のように説明できます-
ブラウザ
これは、すべてのブラウザレベルのコマンドを処理するために分度器によって作成されたグローバル変数です。これは基本的に、WebDriverのインスタンスのラッパーです。browser.get()は、Protractorに特定のページをロードするように指示する単純なSeleniumメソッドです。
describe そして it−どちらもJasmineテストフレームワークの構文です。ザ・’Describe’ テストケースのエンドツーエンドのフローを含めるために使用されますが、 ‘it’いくつかのテストシナリオが含まれています。私たちは複数を持つことができます‘it’ テストケースプログラムのブロック。
Expect −これは、Webページのタイトルをいくつかの事前定義されたデータと比較しているアサーションです。
ignoreSynchronization−角度のないWebサイトをテストするときに使用されるブラウザのタグです。分度器は角度のあるWebサイトのみを操作することを想定していますが、角度のないWebサイトを操作する場合は、このタグを次のように設定する必要があります。“true”。
構成ファイル
名前が示すように、このファイルはすべての分度器構成オプションの説明を提供します。それは基本的に分度器に次のことを伝えます-
- テストファイルまたは仕様ファイルの場所
- どのブラウザを選択するか
- 使用するテストフレームワーク
- Seleniumサーバーと話す場所
例
以下は、テストを行う単純なスクリプトconfig.jsです。
// config.js
exports.config = {
directConnect: true,
// Capabilities to be passed to the webdriver instance.
capabilities: {
'browserName': 'chrome'
},
// Framework to use. Jasmine is recommended.
framework: 'jasmine',
// Spec patterns are relative to the current working directory when
// protractor is called.
specs: ['TestSpecification.js'],コードの説明
3つの基本的なパラメータを持つ上記の設定ファイルのコードは次のように説明できます-
機能パラメータ
このパラメーターは、ブラウザーの名前を指定するために使用されます。これは、conf.jsファイルの次のコードブロックで確認できます-
exports.config = {
directConnect: true,
// Capabilities to be passed to the webdriver instance.
capabilities: {
'browserName': 'chrome'
},上で見たように、ここで与えられたブラウザの名前は「chrome」であり、これはデフォルトで分度器のブラウザです。ブラウザの名前を変更することもできます。
フレームワークパラメータ
このパラメーターは、テストフレームワークの名前を指定するために使用されます。これは、config.jsファイルの次のコードブロックで確認できます-
exports.config = {
directConnect: true,
// Framework to use. Jasmine is recommended.
framework: 'jasmine',ここでは、「ジャスミン」テストフレームワークを使用しています。
ソースファイル宣言パラメータ
このパラメーターは、ソースファイル宣言の名前を指定するために使用されます。これは、conf.jsファイルの次のコードブロックで確認できます-
exports.config = {
directConnect: true,
// Spec patterns are relative to the current working
directory when protractor is called.
specs: ['TsetSpecification.js'],上で見たように、ここで与えられたソースファイル宣言の名前は ‘TestSpecification.js’。これは、この例では、名前を使用して仕様ファイルを作成したためです。TestSpecification.js。
コードの実行
分度器を実行するために必要なファイルとそのコーディングについての基本的な理解が得られたので、例を実行してみましょう。次の手順に従って、この例を実行できます。
Step 1 −まず、コマンドプロンプトを開きます。
Step 2 −次に、ファイルを保存したディレクトリ、つまりconfig.jsに移動する必要があります。 TestSpecification.js。
Step 3 −ここで、コマンドProtrcator config.jsを実行して、config.jsファイルを実行します。
以下に示すスクリーンショットは、例を実行するための上記の手順を説明しています。

スクリーンショットでは、テストに合格したことがわかります。
ここで、角度のないWebサイトをテストしていて、ignoreSynchronizationタグをtrueに設定していない場合、コードを実行した後、「Angularがページに見つかりませんでした」というエラーが発生するとします。
次のスクリーンショットで見ることができます-

レポートの生成
これまで、テストケースを実行するために必要なファイルとそのコーディングについて説明してきました。分度器は、テストケースのレポートを生成することもできます。この目的のために、それはジャスミンをサポートします。JunitXMLReporterを使用して、テスト実行レポートを自動的に生成できます。
ただし、その前に、次のコマンドを使用してJasmineレポーターをインストールする必要があります-
npm install -g jasmine-reportersご覧のとおり、Jasmine Reportersのインストール中に-gオプションが使用されます。これは、-gオプションを使用してProtractorをグローバルにインストールしたためです。
jasmine-reportersを正常にインストールした後、以前に使用したconfig.jsファイルに次のコードを追加する必要があります-
onPrepare: function(){ //configure junit xml report
var jasmineReporters = require('jasmine-reporters');
jasmine.getEnv().addReporter(new jasmineReporters.JUnitXmlReporter({
consolidateAll: true,
filePrefix: 'guitest-xmloutput',
savePath: 'test/reports'
}));これで、新しいconfig.jsファイルは次のようになります-
// An example configuration file.
exports.config = {
directConnect: true,
// Capabilities to be passed to the webdriver instance.
capabilities: {
'browserName': 'chrome'
},
// Framework to use. Jasmine is recommended.
framework: 'jasmine',
// Spec patterns are relative to the current working directory when
// protractor is called.
specs: ['TestSpecification.js'],
//framework: "jasmine2", //must set it if you use JUnitXmlReporter
onPrepare: function(){ //configure junit xml report
var jasmineReporters = require('jasmine-reporters');
jasmine.getEnv().addReporter(new jasmineReporters.JUnitXmlReporter({
consolidateAll: true,
filePrefix: 'guitest-xmloutput',
savePath: 'reports'
}));
},
};上記の設定ファイルを同じ方法で実行した後、以前に実行しました。ルートディレクトリの下にレポートを含むXMLファイルが生成されます。 reportsフォルダ。テストが成功した場合、レポートは次のようになります-
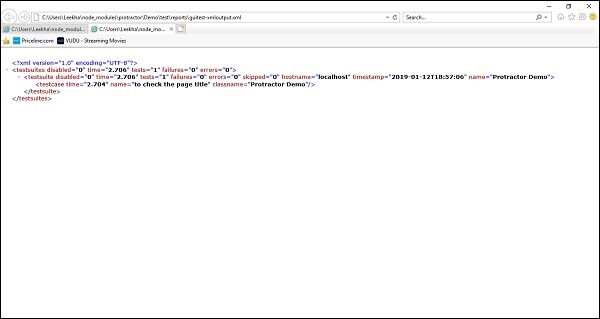
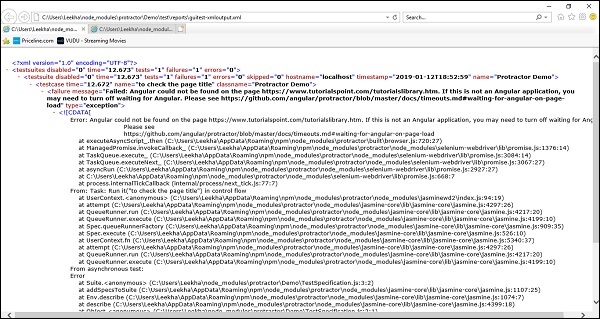
ただし、テストが失敗した場合、レポートは次のようになります-
分度器-コアAPI
この章では、分度器の機能の鍵となるさまざまなコアAPIを理解できます。
分度器APIの重要性
分度器は、ウェブサイトの現在の状態を取得するために次のアクションを実行するために非常に重要なさまざまなAPIを提供します-
- テストするWebページのDOM要素を取得します。
- DOM要素との相互作用。
- それらにアクションを割り当てます。
- 彼らに情報を共有する。
上記のタスクを実行するには、分度器APIを理解することが非常に重要です。
さまざまな分度器API
Protractorは、Node.jsのWebDriverバインディングであるSelenium-WebDriverのラッパーであることがわかっています。分度器には次のAPIがあります-
ブラウザ
これは、ナビゲーション、ページ全体の情報などのブラウザーレベルのコマンドを処理するために使用されるWebDriverのインスタンスのラッパーです。たとえば、browser.getメソッドはページをロードします。
素子
これは、テストしているページのDOM要素を検索して操作するために使用されます。この目的のために、要素を見つけるための1つのパラメーターが必要です。
ロケーター(by)
これは、要素ロケーター戦略のコレクションです。たとえば、要素は、CSSセレクター、ID、またはng-modelでバインドされているその他の属性によって見つけることができます。
次に、これらのAPIとその機能について詳しく説明します。
ブラウザAPI
上で説明したように、これはブラウザレベルのコマンドを処理するためのWebDriverのインスタンスのラッパーです。次のようにさまざまな機能を実行します-
関数とその説明
ProtractorBrowserAPIの機能は次のとおりです-
browser.angularAppRoot
Browser APIのこの関数は、Angularを検索する要素のCSSセレクターを設定します。通常、この関数は「body」にありますが、ng-appの場合は、ページのサブセクションにあります。サブ要素の場合もあります。
browser.waitForAngularEnabled
Browser APIのこの関数は、trueまたはfalseに設定できます。名前が示すように、この関数がfalseに設定されている場合、分度器はAngularを待機しません$http and $ブラウザと対話する前に完了するタイムアウトタスク。値を渡さずにwaitForAngularEnabled()を呼び出すことで、現在の状態を変更せずに読み取ることもできます。
browser.getProcessedConfig
このブラウザAPI関数の助けを借りて、現在実行されている仕様と機能を含む、処理された構成オブジェクトを取得できます。
browser.forkNewDriverInstance
名前が示すように、この関数は、対話型テストで使用されるブラウザーの別のインスタンスをフォークします。制御フローを有効または無効にして実行できます。両方の場合の例を以下に示します-
Example 1
ランニング browser.forkNewDriverInstance() 制御フローを有効にした場合-
var fork = browser.forkNewDriverInstance();
fork.get(‘page1’);Example 2
ランニング browser.forkNewDriverInstance() 制御フローを無効にした場合-
var fork = await browser.forkNewDriverInstance().ready;
await forked.get(‘page1’);browser.restart
名前が示すように、ブラウザインスタンスを閉じて新しいインスタンスを作成することにより、ブラウザを再起動します。また、制御フローを有効または無効にして実行することもできます。両方の場合の例を以下に示します-
Example 1 −ランニング browser.restart() 制御フローを有効にした場合-
browser.get(‘page1’);
browser.restart();
browser.get(‘page2’);Example 2 −ランニング browser.forkNewDriverInstance() 制御フローを無効にした場合-
await browser.get(‘page1’);
await browser.restart();
await browser.get(‘page2’);browser.restartSync
これはbrowser.restart()関数に似ています。唯一の違いは、新しいブラウザインスタンスに解決するpromiseを返すのではなく、新しいブラウザインスタンスを直接返すことです。制御フローが有効になっている場合にのみ実行できます。
Example −ランニング browser.restartSync() 制御フローを有効にした場合-
browser.get(‘page1’);
browser.restartSync();
browser.get(‘page2’);browser.useAllAngular2AppRoots
名前が示すように、Angular2とのみ互換性があります。要素を見つけたり、安定性を待ったりしながら、ページで利用可能なすべての角度のあるアプリを検索します。
browser.waitForAngular
このブラウザーAPI関数は、Angularがレンダリングを終了し、未処理のものがなくなるまで待機するようにWebDriverに指示します。 $http or $続行する前に呼び出しをタイムアウトします。
browser.findElement
名前が示すように、このブラウザーAPI関数は、要素を検索する前にAngularがレンダリングを終了するのを待ちます。
browser.isElementPresent
名前が示すように、このブラウザAPI関数は、要素がページに存在するかどうかをテストします。
browser.addMockModule
Protractor.getメソッドが呼び出されるたびに、Angularの前にロードするモジュールが追加されます。
Example
browser.addMockModule('modName', function() {
angular.module('modName', []).value('foo', 'bar');
});browser.clearMockModules
browser.addMockModuleとは異なり、登録されているモックモジュールのリストをクリアします。
browser.removeMockModule
名前が示すように、レジスタモックモジュールを削除します。例:browser.removeMockModule( 'modName');
browser.getRegisteredMockModules
browser.clearMockModuleの反対側で、登録されているモックモジュールのリストを取得します。
browser.get
browser.get()を使用して、ブラウザーを特定のWebアドレスにナビゲートし、Angularをロードする前にそのページのモックモジュールをロードできます。
Example
browser.get(url);
browser.get('http://localhost:3000');
// This will navigate to the localhost:3000 and will load mock module if neededbrowser.refresh
名前が示すように、これは現在のページをリロードし、Angularの前にモックモジュールをロードします。
browser.navigate
名前が示すように、以前と同じように呼び出されるように、ナビゲーションメソッドをナビゲーションオブジェクトに戻すために使用されます。例:driver.navigate()。refresh()。
browser.setLocation
ページ内ナビゲーションを使用して別のページを参照するために使用されます。
Example
browser.get('url/ABC');
browser.setLocation('DEF');
expect(browser.getCurrentUrl())
.toBe('url/DEF');ABCからDEFページに移動します。
browser.debugger
名前が示すように、これは分度器のデバッグで使用する必要があります。この関数は基本的に、制御フローにタスクを追加して、テストを一時停止し、ヘルパー関数をブラウザーに挿入して、ブラウザーコンソールでデバッグを実行できるようにします。
browser.pause
WebDriverテストのデバッグに使用されます。使用できますbrowser.pause() テストでは、制御フローのそのポイントから分度器デバッガーに入ります。
Example
element(by.id('foo')).click();
browser.pause();
// Execution will stop before the next click action.
element(by.id('bar')).click();browser.controlFlowEnabled
制御フローが有効かどうかを判断するために使用されます。
分度器-コアAPI(CONTD…)
この章では、分度器のコアAPIについてさらに学びましょう。
ElementsAPI
要素は、分度器によって公開されるグローバル関数の1つです。この関数はロケーターを受け取り、次を返します-
- ElementFinder。ロケーターに基づいて単一の要素を検索します。
- ElementArrayFinder。ロケーターに基づいて要素の配列を検索します。
上記の両方は、以下で説明するようにチェーン方式をサポートします。
ElementArrayFinderのチェーン関数とその説明
ElementArrayFinderの機能は以下のとおりです。
element.all(locator).clone
名前が示すように、この関数は要素の配列の浅いコピー、つまりElementArrayFinderを作成します。
element.all(locator).all(locator)
この関数は基本的に、空または子要素を含む可能性のある新しいElementArrayFinderを返します。次のように、複数の要素を配列として選択するために使用できます。
Example
element.all(locator).all(locator)
elementArr.all(by.css(‘.childselector’));
// it will return another ElementFindArray as child element based on child locator.element.all(locator).filter(filterFn)
名前が示すように、ElementArrayFinder内の各要素にフィルター関数を適用した後、フィルター関数を渡すすべての要素を含む新しいElementArrayFinderを返します。基本的に2つの引数があります。1つはElementFinderで、もう1つはインデックスです。ページオブジェクトでも使用できます。
Example
View
<ul class = "items">
<li class = "one">First</li>
<li class = "two">Second</li>
<li class = "three">Third</li>
</ul>Code
element.all(by.css('.items li')).filter(function(elem, index) {
return elem.getText().then(function(text) {
return text === 'Third';
});
}).first().click();element.all(locator).get(index)
これを利用して、ElementArrayFinder内の要素をインデックスで取得できます。インデックスは0から始まり、負のインデックスはラップされることに注意してください。
Example
View
<ul class = "items">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>Code
let list = element.all(by.css('.items li'));
expect(list.get(0).getText()).toBe('First');
expect(list.get(1).getText()).toBe('Second');element.all(locator).first()
名前が示すように、これはElementArrayFinderの最初の要素を取得します。基になる要素は取得されません。
Example
View
<ul class = "items">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>Code
let first = element.all(by.css('.items li')).first();
expect(first.getText()).toBe('First');element.all(locator).last()
名前が示すように、これはElementArrayFinderの最後の要素を取得します。基になる要素は取得されません。
Example
View
<ul class = "items">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>Code
let first = element.all(by.css('.items li')).last();
expect(last.getText()).toBe('Third');element.all(locator).all(selector)
$$の呼び出しが連鎖する可能性がある場合に、親内の要素の配列を見つけるために使用されます。
Example
View
<div class = "parent">
<ul>
<li class = "one">First</li>
<li class = "two">Second</li>
<li class = "three">Third</li>
</ul>
</div>Code
let items = element(by.css('.parent')).$$('li');element.all(locator).count()
名前が示すように、これはElementArrayFinderによって表される要素の数をカウントします。基になる要素は取得されません。
Example
View
<ul class = "items">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>Code
let list = element.all(by.css('.items li'));
expect(list.count()).toBe(3);element.all(locator).isPresent()
要素をファインダーと一致させます。trueまたはfalseを返すことができます。ファインダーに一致する要素が存在する場合はTrue、それ以外の場合はFalse。
Example
expect($('.item').isPresent()).toBeTruthy();element.all(locator).locator
名前が示すように、最も関連性の高いロケーターを返します。
Example
$('#ID1').locator();
// returns by.css('#ID1')
$('#ID1').$('#ID2').locator();
// returns by.css('#ID2')
$$('#ID1').filter(filterFn).get(0).click().locator();
// returns by.css('#ID1')element.all(locator).then(thenFunction)
ElementArrayFinderによって表される要素を取得します。
Example
View
<ul class = "items">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>Code
element.all(by.css('.items li')).then(function(arr) {
expect(arr.length).toEqual(3);
});element.all(locator).each(eachFunction)
名前が示すように、ElementArrayFinderで表される各ElementFinderで入力関数を呼び出します。
Example
View
<ul class = "items">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>Code
element.all(by.css('.items li')).each(function(element, index) {
// It will print First 0, Second 1 and Third 2.
element.getText().then(function (text) {
console.log(index, text);
});
});element.all(locator).map(mapFunction)
名前が示すように、ElementArrayFinder内の各要素にマップ関数を適用します。それは2つの議論を持っています。1つ目はElementFinderで、2つ目はインデックスです。
Example
View
<ul class = "items">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>Code
let items = element.all(by.css('.items li')).map(function(elm, index) {
return {
index: index,
text: elm.getText(),
class: elm.getAttribute('class')
};
});
expect(items).toEqual([
{index: 0, text: 'First', class: 'one'},
{index: 1, text: 'Second', class: 'two'},
{index: 2, text: 'Third', class: 'three'}
]);element.all(locator).reduce(reduceFn)
名前が示すように、アキュムレータおよびロケータを使用して検出されたすべての要素に対してreduce関数を適用します。この関数は、すべての要素を1つの値に減らします。
Example
View
<ul class = "items">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>Code
let value = element.all(by.css('.items li')).reduce(function(acc, elem) {
return elem.getText().then(function(text) {
return acc + text + ' ';
});
}, '');
expect(value).toEqual('First Second Third ');element.all(locator).evaluate
名前が示すように、入力が現在の基になる要素のスコープ内にあるかどうかを評価します。
Example
View
<span class = "foo">{{letiableInScope}}</span>Code
let value =
element.all(by.css('.foo')).evaluate('letiableInScope');element.all(locator).allowAnimations
名前が示すように、アニメーションが現在の基になる要素で許可されるかどうかを決定します。
Example
element(by.css('body')).allowAnimations(false);ElementFinderのチェーン機能とその説明
ElementFinderのチェーン機能とその説明-
element(locator).clone
名前が示すように、この関数はElementFinderの浅いコピーを作成します。
element(locator).getWebElement()
このElementFinderによって表されるWebElementを返し、要素が存在しない場合はWebDriverエラーがスローされます。
Example
View
<div class="parent">
some text
</div>Code
// All the four following expressions are equivalent.
$('.parent').getWebElement();
element(by.css('.parent')).getWebElement();
browser.driver.findElement(by.css('.parent'));
browser.findElement(by.css('.parent'));element(locator).all(locator)
親内の要素の配列を検索します。
Example
View
<div class = "parent">
<ul>
<li class = "one">First</li>
<li class = "two">Second</li>
<li class = "three">Third</li>
</ul>
</div>Code
let items = element(by.css('.parent')).all(by.tagName('li'));element(locator).element(locator)
親内の要素を検索します。
Example
View
<div class = "parent">
<div class = "child">
Child text
<div>{{person.phone}}</div>
</div>
</div>Code
// Calls Chain 2 element.
let child = element(by.css('.parent')).
element(by.css('.child'));
expect(child.getText()).toBe('Child text\n981-000-568');
// Calls Chain 3 element.
let triple = element(by.css('.parent')).
element(by.css('.child')).
element(by.binding('person.phone'));
expect(triple.getText()).toBe('981-000-568');element(locator).all(selector)
$$の呼び出しが連鎖している可能性がある場合、親内の要素の配列を検索します。
Example
View
<div class = "parent">
<ul>
<li class = "one">First</li>
<li class = "two">Second</li>
<li class = "three">Third</li>
</ul>
</div>Code
let items = element(by.css('.parent')).$$('li'));element(locator).$(locator)
$の呼び出しが連鎖する可能性がある場合、親内の要素を検索します。
Example
View
<div class = "parent">
<div class = "child">
Child text
<div>{{person.phone}}</div>
</div>
</div>Code
// Calls Chain 2 element.
let child = element(by.css('.parent')).
$('.child')); expect(child.getText()).toBe('Child text\n981-000-568'); // Calls Chain 3 element. let triple = element(by.css('.parent')). $('.child')).
element(by.binding('person.phone'));
expect(triple.getText()).toBe('981-000-568');element(locator).isPresent()
要素がページに表示されるかどうかを決定します。
Example
View
<span>{{person.name}}</span>Code
expect(element(by.binding('person.name')).isPresent()).toBe(true);
// will check for the existence of element
expect(element(by.binding('notPresent')).isPresent()).toBe(false);
// will check for the non-existence of elementelement(locator).isElementPresent()
element(locator).isPresent()と同じです。唯一の違いは、現在の要素ファインダーではなく、サブロケーターによって識別された要素が存在するかどうかをチェックすることです。
element.all(locator).evaluate
名前が示すように、入力が現在の基になる要素のスコープ内にあるかどうかを評価します。
Example
View
<span id = "foo">{{letiableInScope}}</span>Code
let value = element(by.id('.foo')).evaluate('letiableInScope');element(locator).allowAnimations
名前が示すように、アニメーションが現在の基になる要素で許可されるかどうかを決定します。
Example
element(by.css('body')).allowAnimations(false);element(locator).equals
名前が示すように、要素が等しいかどうかを比較します。
Locators(by)API
これは基本的に、バインディング、モデルなどによってAngularアプリケーションで要素を見つける方法を提供する要素ロケーター戦略のコレクションです。
Functions and their descriptions
ProtractorLocatorsAPIの機能は次のとおりです-
by.addLocator(locatorName,fuctionOrScript)
ProtrcatorByのこのインスタンスにロケーターを追加し、element(by.locatorName(args))でさらに使用できるようにします。
Example
View
<button ng-click = "doAddition()">Go!</button>Code
// Adding the custom locator.
by.addLocator('buttonTextSimple',
function(buttonText, opt_parentElement, opt_rootSelector) {
var using = opt_parentElement || document,
buttons = using.querySelectorAll('button');
return Array.prototype.filter.call(buttons, function(button) {
return button.textContent === buttonText;
});
});
element(by.buttonTextSimple('Go!')).click();// Using the custom locator.by.binding
名前が示すように、テキストバインディングによって要素を検索します。入力文字列を含む変数にバインドされた要素が返されるように、部分一致が行われます。
Example
View
<span>{{person.name}}</span>
<span ng-bind = "person.email"></span>Code
var span1 = element(by.binding('person.name'));
expect(span1.getText()).toBe('Foo');
var span2 = element(by.binding('person.email'));
expect(span2.getText()).toBe('[email protected]');by.exactbinding
名前が示すように、それは正確なバインディングによって要素を見つけます。
Example
View
<spangt;{{ person.name }}</spangt;
<span ng-bind = "person-email"gt;</spangt;
<spangt;{{person_phone|uppercase}}</span>Code
expect(element(by.exactBinding('person.name')).isPresent()).toBe(true);
expect(element(by.exactBinding('person-email')).isPresent()).toBe(true);
expect(element(by.exactBinding('person')).isPresent()).toBe(false);
expect(element(by.exactBinding('person_phone')).isPresent()).toBe(true);
expect(element(by.exactBinding('person_phone|uppercase')).isPresent()).toBe(true);
expect(element(by.exactBinding('phone')).isPresent()).toBe(false);by.model(modelName)
名前が示すように、ng-model式によって要素を検索します。
Example
View
<input type = "text" ng-model = "person.name">Code
var input = element(by.model('person.name'));
input.sendKeys('123');
expect(input.getAttribute('value')).toBe('Foo123');by.buttonText
名前が示すように、テキストでボタンが見つかります。
Example
View
<button>Save</button>Code
element(by.buttonText('Save'));by.partialButtonText
名前が示すように、部分的なテキストでボタンが見つかります。
Example
View
<button>Save my file</button>Code
element(by.partialButtonText('Save'));by.repeater
名前が示すように、ng-repeat内に要素が見つかります。
Example
View
<div ng-repeat = "cat in pets">
<span>{{cat.name}}</span>
<span>{{cat.age}}</span>
<</div>
<div class = "book-img" ng-repeat-start="book in library">
<span>{{$index}}</span>
</div>
<div class = "book-info" ng-repeat-end>
<h4>{{book.name}}</h4>
<p>{{book.blurb}}</p>
</div>Code
var secondCat = element(by.repeater('cat in
pets').row(1)); // It will return the DIV for the second cat.
var firstCatName = element(by.repeater('cat in pets').
row(0).column('cat.name')); // It will return the SPAN for the first cat's name.by.exactRepeater
名前が示すように、それは正確なリピーターによって要素を見つけます。
Example
View
<li ng-repeat = "person in peopleWithRedHair"></li>
<li ng-repeat = "car in cars | orderBy:year"></li>Code
expect(element(by.exactRepeater('person in
peopleWithRedHair')).isPresent())
.toBe(true);
expect(element(by.exactRepeater('person in
people')).isPresent()).toBe(false);
expect(element(by.exactRepeater('car in cars')).isPresent()).toBe(true);by.cssContainingText
名前が示すように、CSSによって正確な文字列を含む要素が検索されます
Example
View
<ul>
<li class = "pet">Dog</li>
<li class = "pet">Cat</li>
</ul>Code
var dog = element(by.cssContainingText('.pet', 'Dog'));
// It will return the li for the dog, but not for the cat.by.options(optionsDescriptor)
名前が示すように、ng-options式で要素を検索します。
Example
View
<select ng-model = "color" ng-options = "c for c in colors">
<option value = "0" selected = "selected">red</option>
<option value = "1">green</option>
</select>Code
var allOptions = element.all(by.options('c for c in colors'));
expect(allOptions.count()).toEqual(2);
var firstOption = allOptions.first();
expect(firstOption.getText()).toEqual('red');by.deepCSS(selector)
名前が示すように、シャドウDOM内のCSSセレクターによって要素を検索します。
Example
View
<div>
<span id = "outerspan">
<"shadow tree">
<span id = "span1"></span>
<"shadow tree">
<span id = "span2"></span>
</>
</>
</div>Code
var spans = element.all(by.deepCss('span'));
expect(spans.count()).toEqual(3);分度器-オブジェクト
この章では、分度器のオブジェクトについて詳しく説明します。
ページオブジェクトとは何ですか?
ページオブジェクトは、テストのメンテナンスを強化し、コードの重複を減らすためにe2eテストを作成するために一般的になっているデザインパターンです。これは、AUT(テスト中のアプリケーション)のページへのインターフェイスとして機能するオブジェクト指向クラスとして定義できます。ただし、ページオブジェクトを深く掘り下げる前に、自動UIテストの課題とその処理方法を理解する必要があります。
自動UIテストの課題
以下は、UIテストの自動化に関するいくつかの一般的な課題です-
UIの変更
UIテストでの作業中によくある問題は、UIで変更が発生することです。たとえば、ボタンやテキストボックスなどが通常変更され、UIテストの問題が発生することがほとんどです。
DSL(ドメイン固有言語)サポートの欠如
UIテストのもう1つの問題は、DSLサポートの欠如です。この問題により、何がテストされているのかを理解するのが非常に難しくなります。
繰り返し/コードの重複が多い
UIテストの次の一般的な問題は、繰り返しやコードの重複が多いことです。次のコード行の助けを借りて理解することができます-
element(by.model(‘event.name’)).sendKeys(‘An Event’);
element(by.model(‘event.name’)).sendKeys(‘Module 3’);
element(by.model(‘event.name’));厳しいメンテナンス
上記の課題により、メンテナンスの頭痛の種になります。これは、すべてのインスタンスを検索し、新しい名前、セレクター、その他のコードに置き換える必要があるためです。また、テストをリファクタリングに合わせるために多くの時間を費やす必要があります。
壊れたテスト
UIテストのもう1つの課題は、テストで多くの失敗が発生することです。
課題に対処する方法
UIテストのいくつかの一般的な課題を見てきました。このような課題に対処する方法のいくつかは次のとおりです-
参照を手動で更新する
上記の課題を処理するための最初のオプションは、参照を手動で更新することです。このオプションの問題は、テストだけでなくコードも手動で変更する必要があることです。これは、1つまたは2つのテストファイルがある場合に実行できますが、プロジェクトに数百のテストファイルがある場合はどうなりますか?
ページオブジェクトの使用
上記の課題を処理するための別のオプションは、ページオブジェクトを使用することです。ページオブジェクトは基本的に、Angularテンプレートのプロパティをカプセル化するプレーンなJavaScriptです。たとえば、次の仕様ファイルは、違いを理解するためにページオブジェクトなしとページオブジェクトありで記述されています。
Without Page Objects
describe('angularjs homepage', function() {
it('should greet the named user', function() {
browser.get('http://www.angularjs.org');
element(by.model('yourName')).sendKeys('Julie');
var greeting = element(by.binding('yourName'));
expect(greeting.getText()).toEqual('Hello Julie!');
});
});With Page Objects
ページオブジェクトを使用してコードを作成する場合、最初に行う必要があるのは、ページオブジェクトを作成することです。したがって、上記の例のページオブジェクトは次のようになります-
var AngularHomepage = function() {
var nameInput = element(by.model('yourName'));
var greeting = element(by.binding('yourName'));
this.get = function() {
browser.get('http://www.angularjs.org');
};
this.setName = function(name) {
nameInput.sendKeys(name);
};
this.getGreetingText = function() {
return greeting.getText();
};
};
module.exports = new AngularHomepage();ページオブジェクトを使用したテストの整理
上記の例では、UIテストの課題を処理するためにページオブジェクトを使用することを確認しました。次に、それらを使用してテストを整理する方法について説明します。このため、テストスクリプトの機能を変更せずにテストスクリプトを変更する必要があります。
例
この概念を理解するために、ページオブジェクトを含む上記の構成ファイルを使用しています。テストスクリプトを次のように変更する必要があります-
var angularHomepage = require('./AngularHomepage');
describe('angularjs homepage', function() {
it('should greet the named user', function() {
angularHomepage.get();
angularHomepage.setName('Julie');
expect(angularHomepage.getGreetingText()).toEqual
('Hello Julie!');
});
});ここで、ページオブジェクトへのパスは仕様に関連していることに注意してください。
同じように、テストスイートをさまざまなテストスイートに分割することもできます。その後、構成ファイルを次のように変更できます。
exports.config = {
// The address of a running selenium server.
seleniumAddress: 'http://localhost:4444/wd/hub',
// Capabilities to be passed to the webdriver instance.
capabilities: {
'browserName': 'chrome'
},
// Spec patterns are relative to the location of the spec file. They may
// include glob patterns.
suites: {
homepage: 'tests/e2e/homepage/**/*Spec.js',
search: ['tests/e2e/contact_search/**/*Spec.js',
'tests/e2e/venue_search/**/*Spec.js']
},
// Options to be passed to Jasmine-node.
jasmineNodeOpts: {
showColors: true, // Use colors in the command line report.
}
};これで、テストスイートの実行を簡単に切り替えることができます。次のコマンドは、テストのホームページセクションのみを実行します-
protractor protractor.conf.js --suite homepage同様に、次のコマンドを使用して特定のテストスイートを実行できます。
protractor protractor.conf.js --suite homepage,search分度器-デバッグ
前の章で分度器のすべての概念を確認したので、この章でデバッグの概念を詳しく理解しましょう。
前書き
エンドツーエンド(e2e)テストは、そのアプリケーションのエコシステム全体に依存するため、デバッグが非常に困難です。それらはさまざまなアクションに依存していることがわかりました。特に、ログインなどの以前のアクションに依存しており、場合によっては権限に依存していると言えます。e2eテストのデバッグにおけるもう1つの問題は、オペレーティングシステムやブラウザーによって動作が異なるため、WebDriverに依存していることです。最後に、e2eテストのデバッグも長いエラーメッセージを生成し、ブラウザ関連の問題とテストプロセスエラーを分離することを困難にします。
失敗の種類
テストスイートの失敗にはさまざまな理由が考えられます。よく知られている失敗の種類は次のとおりです。
WebDriverの失敗
コマンドを完了できない場合、WebDriverによってエラーがスローされます。たとえば、ブラウザが定義されたアドレスを取得できない、または要素が期待どおりに見つからないなどです。
WebDriverの予期しない障害
Webドライバーマネージャーの更新に失敗すると、予期しないブラウザーおよびOS関連の障害が発生します。
Angularの分度器の故障
Protractor for Angularの失敗は、ProtractorがライブラリでAngularを期待どおりに見つけられなかった場合に発生します。
分度器Angular2の障害
この種の失敗では、useAllAngular2AppRootsパラメーターが構成に見つからない場合、分度器は失敗します。これがないと、テストプロセスは、プロセス内に複数の要素を予期しながら、単一のルート要素を確認するために発生します。
タイムアウトによる分度器の故障
この種の失敗は、テスト仕様がループまたは長いプールにヒットし、時間内にデータを返さない場合に発生します。
期待の失敗
通常の期待の失敗がどのように見えるかを示す最も一般的なテストの失敗の1つ。
分度器でデバッグが重要なのはなぜですか?
テストケースを作成して失敗した場合、エラーが発生した正確な場所を見つけるのは非常に難しいため、それらのテストケースをデバッグする方法を知ることが非常に重要であるとします。分度器を使用していると、コマンドラインで赤色のフォントに長いエラーが発生します。
テストの一時停止とデバッグ
分度器でデバッグする方法はここで説明されています&miuns;
一時停止方法
分度器でテストケースをデバッグするためにpauseメソッドを使用することは、最も簡単な方法の1つです。テストコードを一時停止する場所で次のコマンドを入力できます&miuns;
browser.pause();実行中のコードが上記のコマンドにヒットすると、その時点で実行中のプログラムが一時停止します。その後、好みに応じて次のコマンドを実行できます-
前進するためのタイプC
コマンドが使い果たされるたびに、先に進むにはCと入力する必要があります。Cを入力しない場合、テストは完全なコードを実行せず、Jasmineタイムアウトエラーのために失敗します。
インタラクティブモードに入るためにreplと入力します
インタラクティブモードの利点は、WebDriverコマンドをブラウザに送信できることです。インタラクティブモードに入る場合は、次のように入力しますrepl。
Ctrl-Cを入力して、テストを終了して続行します
一時停止状態からテストを終了し、停止した場所からテストを続行するには、Ctrl-Cを入力する必要があります。
例
この例では、次の名前の仕様ファイルがあります。 example_debug.js、分度器はロケーターで要素を識別しようとします by.binding( 'mmmm')しかしURL(https://angularjs.org/ ページには、指定されたロケーターを持つ要素がありません。
describe('Suite for protractor debugger',function(){
it('Failing spec',function(){
browser.get("http://angularjs.org");
element(by.model('yourName')).sendKeys('Vijay');
//Element doesn't exist
var welcomeText =
element(by.binding('mmmm')).getText();
expect('Hello '+welcomeText+'!').toEqual('Hello Ram!')
});
});ここで、上記のテストを実行するには、テストを一時停止する場所に、上記の仕様ファイルにbrowser.pause()コードを追加する必要があります。次のようになります-
describe('Suite for protractor debugger',function(){
it('Failing spec',function(){
browser.get("http://angularjs.org");
browser.pause();
element(by.model('yourName')).sendKeys('Vijay');
//Element doesn't exist
var welcomeText =
element(by.binding('mmmm')).getText();
expect('Hello '+welcomeText+'!').toEqual('Hello Ram!')
});
});ただし、実行する前に、構成ファイルにもいくつかの変更を加える必要があります。以前に使用した構成ファイルで、次の名前の変更を行っています。example_configuration.js 前の章で-
// An example configuration file.
exports.config = {
directConnect: true,
// Capabilities to be passed to the webdriver instance.
capabilities: {
'browserName': 'chrome'
},
// Framework to use. Jasmine is recommended.
framework: 'jasmine',
// Spec patterns are relative to the current working directory when
// protractor is called.
specs: ['example_debug.js'],
allScriptsTimeout: 999999,
jasmineNodeOpts: {
defaultTimeoutInterval: 999999
},
onPrepare: function () {
browser.manage().window().maximize();
browser.manage().timeouts().implicitlyWait(5000);
}
};ここで、次のコマンドを実行します-
protractor example_configuration.js上記のコマンドの後にデバッガが起動します。
デバッガーメソッド
一時停止メソッドを使用して分度器のテストケースをデバッグするのは、少し高度な方法です。テストコードを壊したい場所で次のコマンドを入力できます-
browser.debugger();ノードデバッガーを使用してテストコードをデバッグします。上記のコマンドを実行するには、テストプロジェクトの場所から開いた別のコマンドプロンプトに次のコマンドを入力する必要があります-
protractor debug protractor.conf.jsこの方法では、テストコードを続行するために、ターミナルにCを入力する必要もあります。ただし、pauseメソッドとは逆に、このメソッドでは1回だけ入力します。
例
この例では、bという名前の同じ仕様ファイルを使用しています。example_debug.js、上記で使用。唯一の違いは、browser.pause()、使用する必要があります browser.debugger()テストコードを壊したいところ。次のようになります-
describe('Suite for protractor debugger',function(){
it('Failing spec',function(){
browser.get("http://angularjs.org");
browser.debugger();
element(by.model('yourName')).sendKeys('Vijay');
//Element doesn't exist
var welcomeText = element(by.binding('mmmm')).getText();
expect('Hello '+welcomeText+'!').toEqual('Hello Ram!')
});
});同じ構成ファイルを使用していますが、 example_configuration.js、上記の例で使用されています。
次に、次のデバッグコマンドラインオプションを使用して分度器テストを実行します
protractor debug example_configuration.js上記のコマンドの後にデバッガが起動します。
分度器-分度器のスタイルガイド
この章では、分度器のスタイルガイドについて詳しく学びましょう。
前書き
スタイルガイドは、2人のソフトウェアエンジニアによって作成されました。 Carmen Popoviciu、INGのフロントエンドエンジニアおよび Andres Dominguez、Googleのソフトウェアエンジニア。したがって、このスタイルガイドはCarmenPopoviciuおよびGoogleの分度器用スタイルガイドとも呼ばれます。
このスタイルガイドは、次の5つのキーポイントに分けることができます-
- 一般的なルール
- プロジェクト構造
- ロケーター戦略
- ページオブジェクト
- テストスイート
一般的なルール
以下は、テストに分度器を使用する際に注意しなければならないいくつかの一般的なルールです。
すでに単体テストされているものをエンドツーエンドでテストしないでください
これは、カルメンとアンドレスによって与えられた最初の一般的なルールです。彼らは、すでに単体テストされたコードに対してe2eテストを実行してはならないことを提案しました。その背後にある主な理由は、ユニットテストがe2eテストよりもはるかに高速であるということです。もう1つの理由は、時間を節約するために、重複テストを回避する必要があることです(ユニットテストとe2eテストの両方を実行しないでください)。
構成ファイルを1つだけ使用する
推奨されるもう1つの重要な点は、1つの構成ファイルのみを使用する必要があるということです。テストする環境ごとに構成ファイルを作成しないでください。使用できますgrunt-protractor-coverage さまざまな環境をセットアップするために。
テストにロジックを使用しないでください
テストケースでIFステートメントまたはFORループを使用しないようにする必要があります。そうすると、何もテストせずにテストに合格したり、実行速度が非常に遅くなったりする可能性があるためです。
テストをファイルレベルで独立させる
共有が有効になっている場合、分度器はテストを並行して実行できます。これらのファイルは、利用可能になったときに、さまざまなブラウザで実行されます。カルメンとアンドレスは、分度器によって実行される順序が不確実であり、さらにテストを単独で実行するのが非常に簡単であるため、少なくともファイルレベルでテストを独立させることを推奨しました。
プロジェクト構造
分度器のスタイルガイドに関するもう1つの重要なポイントは、プロジェクトの構造です。以下は、プロジェクト構造に関する推奨事項です。
賢明な構造でのe2eテストの模索
CarmenとAndresは、e2eテストをプロジェクトの構造に適した構造にグループ化する必要があることを推奨しました。この推奨事項の背後にある理由は、ファイルの検索が容易になり、フォルダー構造が読みやすくなるためです。このステップでは、e2eテストを単体テストから分離します。彼らは、次のような構造は避けるべきであると推奨しました-
|-- project-folder
|-- app
|-- css
|-- img
|-- partials
home.html
profile.html
contacts.html
|-- js
|-- controllers
|-- directives
|-- services
app.js
...
index.html
|-- test
|-- unit
|-- e2e
home-page.js
home-spec.js
profile-page.js
profile-spec.js
contacts-page.js
contacts-spec.js一方、彼らは次のような構造を推奨しました-
|-- project-folder
|-- app
|-- css
|-- img
|-- partials
home.html
profile.html
contacts.html
|-- js
|-- controllers
|-- directives
|-- services
app.js
...
index.html
|-- test
|-- unit
|-- e2e
|-- page-objects
home-page.js
profile-page.js
contacts-page.js
home-spec.js
profile-spec.js
contacts-spec.jsロケーター戦略
以下は、テストに分度器を使用する際に注意しなければならないロケーター戦略です。
XPATHは絶対に使用しないでください
これは、分度器スタイルガイドで推奨されている最初のロケーター戦略です。同じ理由は、マークアップは非常に簡単に変更される可能性があるため、XPathには多くのメンテナンスが必要なためです。さらに、XPath式は最も遅く、デバッグが非常に困難です。
by.modelやby.bindingなどの分度器固有のロケーターを常に優先する
by.modelやby.bindingなどの分度器固有のロケーターは短く、具体的で読みやすいです。それらの助けを借りて、私たちのロケーターを書くことも非常に簡単です。
例
View
<ul class = "red">
<li>{{color.name}}</li>
<li>{{color.shade}}</li>
<li>{{color.code}}</li>
</ul>
<div class = "details">
<div class = "personal">
<input ng-model = "person.name">
</div>
</div>上記のコードでは、次のことを避けることをお勧めします-
var nameElement = element.all(by.css('.red li')).get(0);
var personName = element(by.css('.details .personal input'));一方、以下の使用をお勧めします-
var nameElement = element.all(by.css('.red li')).get(0);
var personName = element(by.css('.details .personal input'));var nameElement = element(by.binding('color.name'));
var personName = element(by.model('person.name'));分度器ロケーターが利用できない場合は、by.idとby.cssを優先することをお勧めします。
頻繁に変更されるテキストのテキストロケーターは常に避けてください
ボタン、リンク、ラベルのテキストは時間の経過とともに頻繁に変化するため、by.linkText、by.buttonText、by.cssContaningTextなどのテキストベースのロケーターは避ける必要があります。
ページオブジェクト
前に説明したように、ページオブジェクトは、アプリケーションページの要素に関する情報をカプセル化します。これにより、よりクリーンなテストケースを作成できます。ページオブジェクトの非常に便利な利点は、複数のテストで再利用できることです。アプリケーションのテンプレートが変更された場合は、ページオブジェクトを更新するだけで済みます。以下は、テストに分度器を使用する際に注意が必要なページオブジェクトに関するいくつかの推奨事項です。
テスト対象のページを操作するには、ページオブジェクトを使用します
ページオブジェクトを使用して、テスト対象のページと対話することをお勧めします。これは、テスト対象のページの要素に関する情報をカプセル化でき、再利用もできるためです。
ファイルごとに常に1ページのオブジェクトを宣言する
コードをクリーンに保ち、物事の検索が容易になるため、各ページオブジェクトを独自のファイルで定義する必要があります。
ページの終わりに、オブジェクトファイルは常に単一のmodule.exportsを使用します
1つのクラスのみをエクスポートする必要があるように、各ページオブジェクトで1つのクラスを宣言することをお勧めします。たとえば、次のオブジェクトファイルの使用は避ける必要があります-
var UserProfilePage = function() {};
var UserSettingsPage = function() {};
module.exports = UserPropertiesPage;
module.exports = UserSettingsPage;ただし、その一方で、以下を使用することをお勧めします-
/** @constructor */
var UserPropertiesPage = function() {};
module.exports = UserPropertiesPage;必要なすべてのモジュールを上部で宣言します
モジュールの依存関係が明確になり、見つけやすくなるため、必要なすべてのモジュールをページオブジェクトの上部で宣言する必要があります。
テストスイートの開始時にすべてのページオブジェクトをインスタンス化します
テストスイートの最初にすべてのページオブジェクトをインスタンス化することをお勧めします。これにより、依存関係がテストコードから分離され、スイートのすべての仕様で依存関係を利用できるようになります。
ページオブジェクトでexpect()を使用しないでください
すべてのアサーションはテストケースで実行する必要があるため、ページオブジェクトでexpect()を使用しないでください。つまり、ページオブジェクトでアサーションを作成しないでください。
もう1つの理由は、テストの読者がテストケースのみを読むことでアプリケーションの動作を理解できる必要があることです。