PySpark-SparkContext
SparkContextは、Spark機能へのエントリポイントです。Sparkアプリケーションを実行すると、main関数を持つドライバープログラムが起動し、SparkContextがここで開始されます。次に、ドライバープログラムは、ワーカーノードのエグゼキューター内で操作を実行します。
SparkContextはPy4Jを使用して起動します JVM を作成します JavaSparkContext。デフォルトでは、PySparkにはSparkContextがあります。‘sc’そのため、新しいSparkContextの作成は機能しません。
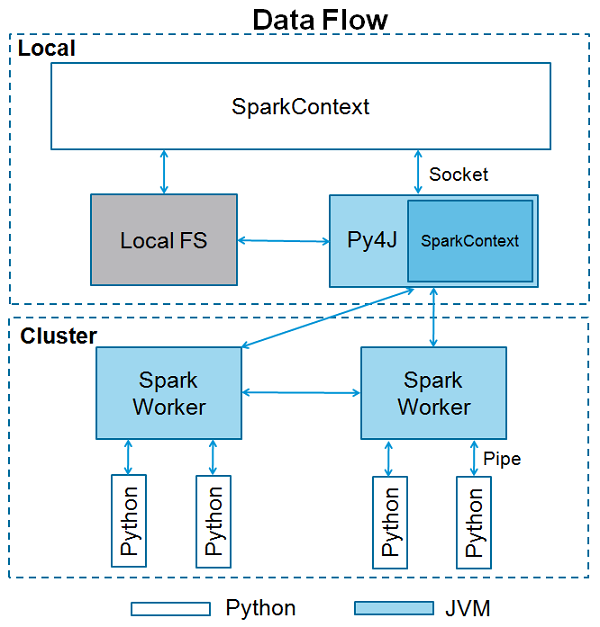
次のコードブロックには、SparkContextが取ることができるPySparkクラスとパラメーターの詳細が含まれています。
class pyspark.SparkContext (
master = None,
appName = None,
sparkHome = None,
pyFiles = None,
environment = None,
batchSize = 0,
serializer = PickleSerializer(),
conf = None,
gateway = None,
jsc = None,
profiler_cls = <class 'pyspark.profiler.BasicProfiler'>
)パラメーター
以下は、SparkContextのパラメーターです。
Master −接続先のクラスターのURLです。
appName −あなたの仕事の名前。
sparkHome −Sparkインストールディレクトリ。
pyFiles −クラスターに送信してPYTHONPATHに追加する.zipまたは.pyファイル。
Environment −ワーカーノードの環境変数。
batchSize−単一のJavaオブジェクトとして表されるPythonオブジェクトの数。バッチ処理を無効にするには1を設定し、オブジェクトサイズに基づいてバッチサイズを自動的に選択するには0を設定し、無制限のバッチサイズを使用するには-1を設定します。
Serializer −RDDシリアライザー。
Conf −すべてのSparkプロパティを設定するためのL {SparkConf}のオブジェクト。
Gateway −既存のゲートウェイとJVMを使用します。それ以外の場合は、新しいJVMを初期化します。
JSC −JavaSparkContextインスタンス。
profiler_cls −プロファイリングを行うために使用されるカスタムプロファイラーのクラス(デフォルトはpyspark.profiler.BasicProfilerです)。
上記のパラメータの中で、 master そして appname主に使用されます。PySparkプログラムの最初の2行は、次のようになります。
from pyspark import SparkContext
sc = SparkContext("local", "First App")SparkContextの例–PySparkシェル
SparkContextについて十分に理解したところで、PySparkシェルで簡単な例を実行してみましょう。この例では、文字「a」または「b」を含む行数をカウントします。README.mdファイル。したがって、ファイルに5行あり、3行に文字「a」が含まれている場合、出力は→になります。Line with a: 3。文字「b」についても同様です。
Note− PySparkシェルの起動時に、デフォルトでSparkがscという名前のSparkContextオブジェクトを自動的に作成するため、次の例ではSparkContextオブジェクトを作成していません。別のSparkContextオブジェクトを作成しようとすると、次のエラーが発生します–"ValueError: Cannot run multiple SparkContexts at once".

<<< logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md"
<<< logData = sc.textFile(logFile).cache()
<<< numAs = logData.filter(lambda s: 'a' in s).count()
<<< numBs = logData.filter(lambda s: 'b' in s).count()
<<< print "Lines with a: %i, lines with b: %i" % (numAs, numBs)
Lines with a: 62, lines with b: 30SparkContextの例-Pythonプログラム
Pythonプログラムを使用して同じ例を実行してみましょう。と呼ばれるPythonファイルを作成しますfirstapp.py そのファイルに次のコードを入力します。
----------------------------------------firstapp.py---------------------------------------
from pyspark import SparkContext
logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md"
sc = SparkContext("local", "first app")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
print "Lines with a: %i, lines with b: %i" % (numAs, numBs)
----------------------------------------firstapp.py---------------------------------------次に、ターミナルで次のコマンドを実行して、このPythonファイルを実行します。上記と同じ出力が得られます。
$SPARK_HOME/bin/spark-submit firstapp.py
Output: Lines with a: 62, lines with b: 30