Ruby-クイックガイド
Rubyは純粋なオブジェクト指向プログラミング言語です。1993年に日本のまつもとゆきひろによって作成されました。
まつもとゆきひろという名前は、www.ruby-lang.orgのRubyメーリングリストにあります。松本は、RubyコミュニティではMatzとしても知られています。
Ruby is "A Programmer's Best Friend".
Rubyには、Smalltalk、Perl、Pythonと同様の機能があります。Perl、Python、およびSmalltalkはスクリプト言語です。Smalltalkは真のオブジェクト指向言語です。Smalltalkと同様に、Rubyは完璧なオブジェクト指向言語です。Ruby構文の使用は、Smalltalk構文の使用よりもはるかに簡単です。
Rubyの機能
Rubyはオープンソースであり、Webで無料で入手できますが、ライセンスが必要です。
Rubyは、汎用のインタープリター型プログラミング言語です。
Rubyは真のオブジェクト指向プログラミング言語です。
Rubyは、PythonやPERLに似たサーバーサイドスクリプト言語です。
Rubyを使用して、Common Gateway Interface(CGI)スクリプトを作成できます。
Rubyはハイパーテキストマークアップ言語(HTML)に埋め込むことができます。
Rubyにはクリーンで簡単な構文があり、新しい開発者は非常にすばやく簡単に学習できます。
Rubyの構文は、C ++やPerlなどの多くのプログラミング言語の構文と似ています。
Rubyは非常にスケーラブルであり、Rubyで記述された大きなプログラムは簡単に保守できます。
Rubyは、インターネットおよびイントラネットアプリケーションの開発に使用できます。
RubyはWindowsおよびPOSIX環境にインストールできます。
Rubyは、Tcl / Tk、GTK、OpenGLなどの多くのGUIツールをサポートしています。
Rubyは、DB2、MySQL、Oracle、Sybaseに簡単に接続できます。
Rubyには、Rubyスクリプトに直接使用できる豊富な組み込み関数のセットがあります。
必要なツール
このチュートリアルで説明する例を実行するには、2GB以上のRAM(4GBのRAMを推奨)を搭載したIntel Corei3またはi5などの最新のコンピューターが必要です。また、次のソフトウェアが必要になります-
LinuxまたはWindows95 / 98/2000 / NTまたはWindows7オペレーティングシステム。
Apache 1.3.19-5Webサーバー。
Internet Explorer5.0以降のWebブラウザ。
Ruby 1.8.5
このチュートリアルでは、Rubyを使用してGUI、ネットワーキング、およびWebアプリケーションを作成するために必要なスキルを提供します。また、Rubyアプリケーションの拡張と埋め込みについても説明します。
次は何ですか?
次の章では、Rubyとそのドキュメントを入手できる場所について説明します。最後に、Rubyをインストールし、Rubyアプリケーションを開発するための環境を準備する方法について説明します。
ローカル環境のセットアップ
それでもRubyプログラミング言語用の環境をセットアップする意思がある場合は、先に進みましょう。このチュートリアルでは、環境設定に関連するすべての重要なトピックについて説明します。最初に次のトピックを実行してから、さらに進むことをお勧めします-
Linux / UnixでのRubyのインストール-Linux / Unixマシンで開発環境を構築することを計画している場合は、この章を実行してください。
WindowsへのRubyのインストール-Windowsマシンに開発環境を構築することを計画している場合は、この章を実行してください。
Rubyコマンドラインオプション-この章では、Rubyインタープリターと一緒に使用できるすべてのコマンドラインオプションをリストします。
Ruby環境変数-この章には、Rubyインタープリターを機能させるために設定するすべての重要な環境変数のリストがあります。
人気のRubyエディター
Rubyプログラムを作成するには、エディターが必要です-
Windowsマシンで作業している場合は、メモ帳やEditplusなどの単純なテキストエディターを使用できます。
VIM(Vi IMproved)は非常にシンプルなテキストエディターです。これは、ほぼすべてのUnixマシンで利用でき、現在はWindowsでも利用できます。それ以外の場合は、お気に入りのviエディターを使用してRubyプログラムを作成できます。
RubyWinは、Windows用のRuby統合開発環境(IDE)です。
Ruby開発環境(RDE)も、Windowsユーザーにとって非常に優れたIDEです。
インタラクティブRuby(IRb)
Interactive Ruby(IRb)は、実験用のシェルを提供します。IRbシェル内で、式の結果を1行ずつすぐに表示できます。
このツールはRubyのインストールに付属しているため、IRbを機能させるために特別なことをする必要はありません。
入力するだけです irb コマンドプロンプトで、インタラクティブRubyセッションが以下のように開始されます-
$irb
irb 0.6.1(99/09/16)
irb(main):001:0> def hello
irb(main):002:1> out = "Hello World"
irb(main):003:1> puts out
irb(main):004:1> end
nil
irb(main):005:0> hello
Hello World
nil
irb(main):006:0>ここで何をしたか心配しないでください。これらのすべての手順については、以降の章で学習します。
次は何ですか?
これで、Ruby環境が機能し、最初のRubyプログラムを作成する準備ができたと想定します。次の章では、Rubyプログラムの書き方を説明します。
Rubyで簡単なプログラムを書いてみましょう。すべてのrubyファイルの拡張子は.rb。したがって、次のソースコードをtest.rbファイルに入れます。
#!/usr/bin/ruby -w
puts "Hello, Ruby!";ここでは、Rubyインタープリターが/ usr / binディレクトリーにあると想定しています。ここで、このプログラムを次のように実行してみてください-
$ ruby test.rbこれにより、次の結果が生成されます-
Hello, Ruby!簡単なRubyプログラムを見てきましたが、Ruby構文に関連するいくつかの基本的な概念を見てみましょう。
Rubyプログラムの空白
スペースやタブなどの空白文字は、文字列で表示される場合を除いて、Rubyコードでは通常無視されます。ただし、あいまいなステートメントを解釈するために使用されることもあります。この種の解釈は、-wオプションが有効になっている場合に警告を生成します。
例
a + b is interpreted as a+b ( Here a is a local variable)
a +b is interpreted as a(+b) ( Here a is a method call)Rubyプログラムの行末
Rubyは、セミコロンと改行文字をステートメントの終わりとして解釈します。ただし、Rubyが行の終わりで+、-、バックスラッシュなどの演算子を検出した場合、それらはステートメントの継続を示します。
Ruby識別子
識別子は、変数、定数、およびメソッドの名前です。Ruby識別子では大文字と小文字が区別されます。これは、RamとRAMがRubyの2つの異なる識別子であることを意味します。
Ruby識別子名は、英数字と下線文字(_)で構成されます。
予約語
次のリストは、Rubyで予約されている単語を示しています。これらの予約語は、定数名または変数名として使用することはできません。ただし、メソッド名として使用することはできます。
| ベギン | 行う | 次 | その後 |
| 終わり | そうしないと | なし | true |
| エイリアス | elsif | ない | undef |
| そして | 終わり | または | そうでなければ |
| ベギン | 確認する | やり直し | まで |
| ブレーク | false | 救援 | いつ |
| 場合 | にとって | リトライ | 一方 |
| クラス | もし | 戻る | 一方 |
| def | に | 自己 | __ファイル__ |
| 定義されていますか? | モジュール | 素晴らしい | __ライン__ |
Rubyのヒアドキュメント
「ヒアドキュメント」とは、複数行から文字列を作成することを指します。<<に続いて、文字列または識別子を指定して文字列リテラルを終了できます。現在の行からターミネータまでのすべての行が文字列の値になります。
ターミネータが引用符で囲まれている場合、引用符のタイプによって、行指向の文字列リテラルのタイプが決まります。<<とターミネータの間にスペースがあってはならないことに注意してください。
ここにさまざまな例があります-
#!/usr/bin/ruby -w
print <<EOF
This is the first way of creating
here document ie. multiple line string.
EOF
print <<"EOF"; # same as above
This is the second way of creating
here document ie. multiple line string.
EOF
print <<`EOC` # execute commands
echo hi there
echo lo there
EOC
print <<"foo", <<"bar" # you can stack them
I said foo.
foo
I said bar.
barこれにより、次の結果が生成されます-
This is the first way of creating
her document ie. multiple line string.
This is the second way of creating
her document ie. multiple line string.
hi there
lo there
I said foo.
I said bar.RubyBEGINステートメント
構文
BEGIN {
code
}プログラムが実行される前に呼び出されるコードを宣言します。
例
#!/usr/bin/ruby
puts "This is main Ruby Program"
BEGIN {
puts "Initializing Ruby Program"
}これにより、次の結果が生成されます-
Initializing Ruby Program
This is main Ruby ProgramRubyENDステートメント
構文
END {
code
}プログラムの最後に呼び出されるコードを宣言します。
例
#!/usr/bin/ruby
puts "This is main Ruby Program"
END {
puts "Terminating Ruby Program"
}
BEGIN {
puts "Initializing Ruby Program"
}これにより、次の結果が生成されます-
Initializing Ruby Program
This is main Ruby Program
Terminating Ruby ProgramRubyコメント
コメントは、Rubyインタープリターから1行、1行の一部、または複数行を非表示にします。行の先頭にハッシュ文字(#)を使用できます-
# I am a comment. Just ignore me.または、コメントがステートメントまたは式の後の同じ行にある場合があります-
name = "Madisetti" # This is again comment次のように複数行にコメントを付けることができます-
# This is a comment.
# This is a comment, too.
# This is a comment, too.
# I said that already.これが別の形式です。このブロックコメントは、= begin / = end −を使用してインタプリタから数行を隠します。
=begin
This is a comment.
This is a comment, too.
This is a comment, too.
I said that already.
=endRubyは完璧なオブジェクト指向プログラミング言語です。オブジェクト指向プログラミング言語の機能は次のとおりです。
- データのカプセル化
- データの抽象化
- Polymorphism
- Inheritance
これらの機能については、オブジェクト指向Rubyの章で説明しています。
オブジェクト指向プログラムには、クラスとオブジェクトが含まれます。クラスは、個々のオブジェクトが作成される青写真です。オブジェクト指向の用語では、あなたの自転車は自転車として知られているオブジェクトのクラスのインスタンスであると言います。
あらゆる車両を例にとってみましょう。これは、車輪、馬力、および燃料またはガスタンクの容量で構成されます。これらの特性は、クラスVehicleのデータメンバーを形成します。これらの特性を利用して、1台の車両を他の車両と区別することができます。
車両には、停止、運転、スピード違反などの特定の機能もあります。これらの関数でさえ、Vehicleクラスのデータメンバーを形成します。したがって、クラスを特性と機能の組み合わせとして定義することができます。
クラスVehicleは次のように定義できます-
Class Vehicle {
Number no_of_wheels
Number horsepower
Characters type_of_tank
Number Capacity
Function speeding {
}
Function driving {
}
Function halting {
}
}これらのデータメンバーに異なる値を割り当てることにより、クラスVehicleの複数のインスタンスを形成できます。たとえば、飛行機には3つの車輪があり、馬力は1,000、タンクの種類は燃料、容量は100リットルです。同様に、車は4つの車輪、200の馬力、タンクのタイプとしてのガス、および25リットルの容量を備えています。
Rubyでクラスを定義する
Rubyを使用してオブジェクト指向プログラミングを実装するには、最初にRubyでオブジェクトとクラスを作成する方法を学ぶ必要があります。
Rubyのクラスは、常にキーワードclassで始まり、その後にクラスの名前が続きます。名前は常に頭文字である必要があります。クラスCustomerは次のように表示できます-
class Customer
endキーワードendを使用してクラスを終了します。クラス内のすべてのデータメンバーは、クラス定義とendキーワードの間にあります。
Rubyクラスの変数
Rubyは4種類の変数を提供します-
Local Variables−ローカル変数は、メソッドで定義される変数です。ローカル変数はメソッドの外部では使用できません。メソッドの詳細については、次の章で説明します。ローカル変数は小文字または_で始まります。
Instance Variables−インスタンス変数は、特定のインスタンスまたはオブジェクトのメソッド間で使用できます。これは、インスタンス変数がオブジェクトごとに変わることを意味します。インスタンス変数の前にはアットマーク(@)があり、その後に変数名が続きます。
Class Variables−クラス変数はさまざまなオブジェクトで使用できます。クラス変数はクラスに属し、クラスの特性です。それらの前には記号@@があり、その後に変数名が続きます。
Global Variables−クラス変数はクラス間で使用できません。クラス間で使用できる単一の変数が必要な場合は、グローバル変数を定義する必要があります。グローバル変数の前には常にドル記号($)が付きます。
例
クラス変数@@ no_of_customersを使用して、作成されているオブジェクトの数を判別できます。これにより、顧客数を導き出すことができます。
class Customer
@@no_of_customers = 0
end新しいメソッドを使用してRubyでオブジェクトを作成する
オブジェクトはクラスのインスタンスです。ここでは、Rubyでクラスのオブジェクトを作成する方法を学習します。クラスのnewメソッドを使用して、Rubyでオブジェクトを作成できます。
この方法は、新しいRubyのライブラリであらかじめ定義された方法、のユニークなタイプです。新しいメソッドはクラスメソッドに属しています。
これは、Customer-クラスの2つのオブジェクトcust1とcust2を作成する例です。
cust1 = Customer. new
cust2 = Customer. newここで、cust1とcust2は2つのオブジェクトの名前です。オブジェクト名の後に等号(=)を記述し、その後にクラス名を記述します。次に、ドット演算子とキーワードnewが続きます。
Rubyオブジェクトを作成するためのカスタムメソッド
新しいメソッドにパラメーターを渡すことができ、それらのパラメーターを使用してクラス変数を初期化できます。
パラメータを使用して新しいメソッドを宣言する場合は、クラスの作成時にメソッドの初期化を宣言する必要があります。
初期化メソッドは、ときに実行されるメソッドの特殊なタイプであり、新クラスのメソッドは、パラメータと呼ばれています。
初期化メソッドを作成する例を次に示します-
class Customer
@@no_of_customers = 0
def initialize(id, name, addr)
@cust_id = id
@cust_name = name
@cust_addr = addr
end
endこの例では、initializeメソッドを次のように宣言します。id, name、および addrローカル変数として。ここで、defとendは、Rubyメソッドinitializeを定義するために使用されます。メソッドについては、次の章で詳しく説明します。
で初期化方法、あなたは@cust_name、および@cust_addr、@cust_idインスタンス変数にこれらのローカル変数の値を渡します。ここで、ローカル変数は、新しいメソッドとともに渡される値を保持します。
これで、次のようにオブジェクトを作成できます-
cust1 = Customer.new("1", "John", "Wisdom Apartments, Ludhiya")
cust2 = Customer.new("2", "Poul", "New Empire road, Khandala")Rubyクラスのメンバー関数
Rubyでは、関数はメソッドと呼ばれます。クラス内の各メソッドは、キーワードdefで始まり、その後にメソッド名が続きます。
で常に優先されるメソッド名 lowercase letters。キーワードendを使用して、Rubyでメソッドを終了します。
これがRubyメソッドを定義する例です-
class Sample
def function
statement 1
statement 2
end
endここで、ステートメント1とステートメント2は、クラスSample内のメソッド関数の本体の一部です。これらのステートメントは、任意の有効なRubyステートメントである可能性があります。たとえば、私たちは、メソッドに置くことができプットを印刷するこんにちはルビーを次のように-
class Sample
def hello
puts "Hello Ruby!"
end
end次の例では、Sampleクラスのオブジェクトを1つ作成し、helloメソッドを呼び出して、結果を確認します。
#!/usr/bin/ruby
class Sample
def hello
puts "Hello Ruby!"
end
end
# Now using above class to create objects
object = Sample. new
object.helloこれにより、次の結果が生成されます-
Hello Ruby!簡単なケーススタディ
クラスとオブジェクトをさらに練習したい場合のケーススタディを次に示します。
Rubyクラスのケーススタディ
変数は、任意のプログラムで使用される任意のデータを保持するメモリ位置です。
Rubyでサポートされている変数には5つのタイプがあります。前の章でも、これらの変数について簡単に説明しました。この章では、これら5種類の変数について説明します。
Rubyグローバル変数
グローバル変数は$で始まります。初期化されていないグローバル変数の値はnilであり、-wオプションを使用すると警告が生成されます。
グローバル変数に割り当てると、グローバルステータスが変更されます。グローバル変数の使用はお勧めしません。彼らはプログラムを不可解にします。
これは、グローバル変数の使用法を示す例です。
#!/usr/bin/ruby
$global_variable = 10 class Class1 def print_global puts "Global variable in Class1 is #$global_variable"
end
end
class Class2
def print_global
puts "Global variable in Class2 is #$global_variable"
end
end
class1obj = Class1.new
class1obj.print_global
class2obj = Class2.new
class2obj.print_globalここで、$ global_variableはグローバル変数です。これにより、次の結果が生成されます-
NOTE − Rubyでは、変数または定数の直前にハッシュ(#)文字を置くことで、任意の変数または定数の値にアクセスできます。
Global variable in Class1 is 10
Global variable in Class2 is 10Rubyインスタンス変数
インスタンス変数は@で始まります。初期化されていないインスタンス変数の値はnilであり、-wオプションを使用すると警告が生成されます。
これは、インスタンス変数の使用法を示す例です。
#!/usr/bin/ruby
class Customer
def initialize(id, name, addr)
@cust_id = id
@cust_name = name
@cust_addr = addr
end
def display_details()
puts "Customer id #@cust_id"
puts "Customer name #@cust_name"
puts "Customer address #@cust_addr"
end
end
# Create Objects
cust1 = Customer.new("1", "John", "Wisdom Apartments, Ludhiya")
cust2 = Customer.new("2", "Poul", "New Empire road, Khandala")
# Call Methods
cust1.display_details()
cust2.display_details()ここで、@ cust_id、@ cust_name、および@cust_addrはインスタンス変数です。これにより、次の結果が生成されます-
Customer id 1
Customer name John
Customer address Wisdom Apartments, Ludhiya
Customer id 2
Customer name Poul
Customer address New Empire road, KhandalaRubyクラス変数
クラス変数は@@で始まり、メソッド定義で使用する前に初期化する必要があります。
初期化されていないクラス変数を参照すると、エラーが発生します。クラス変数は、クラス変数が定義されているクラスまたはモジュールの子孫間で共有されます。
クラス変数をオーバーライドすると、-wオプションを使用して警告が生成されます。
これはクラス変数の使用法を示す例です-
#!/usr/bin/ruby
class Customer
@@no_of_customers = 0
def initialize(id, name, addr)
@cust_id = id
@cust_name = name
@cust_addr = addr
end
def display_details()
puts "Customer id #@cust_id"
puts "Customer name #@cust_name"
puts "Customer address #@cust_addr"
end
def total_no_of_customers()
@@no_of_customers += 1
puts "Total number of customers: #@@no_of_customers"
end
end
# Create Objects
cust1 = Customer.new("1", "John", "Wisdom Apartments, Ludhiya")
cust2 = Customer.new("2", "Poul", "New Empire road, Khandala")
# Call Methods
cust1.total_no_of_customers()
cust2.total_no_of_customers()ここで、@@ no_of_customersはクラス変数です。これにより、次の結果が生成されます-
Total number of customers: 1
Total number of customers: 2Rubyローカル変数
ローカル変数は小文字または_で始まります。ローカル変数のスコープは、class、module、def、doから対応する端まで、またはブロックの開始中括弧からその終了中括弧{}までの範囲です。
初期化されていないローカル変数が参照されると、引数のないメソッドの呼び出しとして解釈されます。
初期化されていないローカル変数への割り当ては、変数宣言としても機能します。変数は、現在のスコープの終わりに達するまで存在し始めます。ローカル変数の有効期間は、Rubyがプログラムを解析するときに決定されます。
上記の例では、ローカル変数はid、name、およびaddrです。
Ruby定数
定数は大文字で始まります。クラスまたはモジュール内で定義された定数は、そのクラスまたはモジュール内からアクセスでき、クラスまたはモジュール外で定義された定数は、グローバルにアクセスできます。
メソッド内で定数を定義することはできません。初期化されていない定数を参照すると、エラーが発生します。すでに初期化されている定数に割り当てると、警告が生成されます。
#!/usr/bin/ruby
class Example
VAR1 = 100
VAR2 = 200
def show
puts "Value of first Constant is #{VAR1}"
puts "Value of second Constant is #{VAR2}"
end
end
# Create Objects
object = Example.new()
object.showここで、VAR1とVAR2は定数です。これにより、次の結果が生成されます-
Value of first Constant is 100
Value of second Constant is 200Ruby疑似変数
これらは、ローカル変数のように見えますが、定数のように動作する特別な変数です。これらの変数に値を割り当てることはできません。
self −現在のメソッドのレシーバーオブジェクト。
true −真を表す値。
false −falseを表す値。
nil −未定義を表す値。
__FILE__ −現在のソースファイルの名前。
__LINE__ −ソースファイルの現在の行番号。
Ruby基本リテラル
Rubyがリテラルに使用するルールはシンプルで直感的です。このセクションでは、すべての基本的なRubyリテラルについて説明します。
整数
Rubyは整数をサポートしています。整数から-2の範囲とすることができる30〜2 30-1または-2 62 2 62-1。この範囲内の整数はクラスFixnumのオブジェクトであり、この範囲外の整数はクラスBignumのオブジェクトに格納されます。
オプションの先行記号、オプションの基数標識(8進数の場合は0、16進数の場合は0x、または2進数の場合は0b)を使用して整数を記述し、その後に適切な基数の数字列を続けます。数字列ではアンダースコア文字は無視されます。
ASCII文字に対応する整数値を取得したり、疑問符を前に付けてシーケンスをエスケープしたりすることもできます。
例
123 # Fixnum decimal
1_234 # Fixnum decimal with underline
-500 # Negative Fixnum
0377 # octal
0xff # hexadecimal
0b1011 # binary
?a # character code for 'a'
?\n # code for a newline (0x0a)
12345678901234567890 # BignumNOTE −クラスとオブジェクトについては、このチュートリアルの別の章で説明しています。
浮動小数点数
Rubyは浮動小数点をサポートしています。それらも数字ですが、小数が付いています。浮動小数点数はFloatクラスのオブジェクトであり、次のいずれかになります。
例
123.4 # floating point value
1.0e6 # scientific notation
4E20 # dot not required
4e+20 # sign before exponential文字列リテラル
Ruby文字列は、単に8ビットバイトのシーケンスであり、Stringクラスのオブジェクトです。二重引用符で囲まれた文字列では置換と円記号の表記が可能ですが、一重引用符で囲まれた文字列では置換ができず、\\と\ 'に対してのみ円記号表記が許可されます
例
#!/usr/bin/ruby -w
puts 'escape using "\\"';
puts 'That\'s right';これにより、次の結果が生成されます-
escape using "\"
That's rightシーケンスを使用して、任意のRuby式の値を文字列に置き換えることができます #{ expr }。ここで、exprは任意のルビー式にすることができます。
#!/usr/bin/ruby -w
puts "Multiplication Value : #{24*60*60}";これにより、次の結果が生成されます-
Multiplication Value : 86400バックスラッシュ表記
以下は、Rubyでサポートされているバックスラッシュ表記のリストです。
| 表記 | 表現された文字 |
|---|---|
| \ n | 改行(0x0a) |
| \ r | キャリッジリターン(0x0d) |
| \ f | 改ページ(0x0c) |
| \ b | バックスペース(0x08) |
| \ a | ベル(0x07) |
| \ e | エスケープ(0x1b) |
| \ s | スペース(0x20) |
| \ nnn | 8進表記(nは0〜7) |
| \ xnn | 16進表記(nは0-9、af、またはAF) |
| \ cx、\ Cx | Control-x |
| \ Mx | Meta-x(c | 0x80) |
| \ M- \ Cx | Meta-Control-x |
| \バツ | 文字x |
Ruby文字列の詳細については、Ruby文字列を参照してください。
Ruby配列
Ruby配列のリテラルは、角括弧の間にコンマで区切られた一連のオブジェクト参照を配置することによって作成されます。末尾のコンマは無視されます。
例
#!/usr/bin/ruby
ary = [ "fred", 10, 3.14, "This is a string", "last element", ]
ary.each do |i|
puts i
endこれにより、次の結果が生成されます-
fred
10
3.14
This is a string
last elementRuby配列の詳細については、Ruby配列を参照してください。
Rubyハッシュ
リテラルのRubyハッシュは、キーと値のペアのリストを中括弧の間に配置し、キーと値の間にコンマまたはシーケンス=>を使用して作成されます。末尾のコンマは無視されます。
例
#!/usr/bin/ruby
hsh = colors = { "red" => 0xf00, "green" => 0x0f0, "blue" => 0x00f }
hsh.each do |key, value|
print key, " is ", value, "\n"
endこれにより、次の結果が生成されます-
red is 3840
green is 240
blue is 15Rubyハッシュの詳細については、Rubyハッシュを参照してください。
Rubyの範囲
範囲は、開始と終了の値のセットである間隔を表します。範囲は、s..eおよびs ... eリテラルを使用するか、Range.newを使用して作成できます。
..を使用して構築された範囲は、最初から最後まで包括的に実行されます。...を使用して作成されたものは、最終値を除外します。イテレータとして使用する場合、範囲はシーケンス内の各値を返します。
範囲(1..5)は、1、2、3、4、5の値を含むことを意味し、範囲(1 ... 5)は、1、2、3、4の値を含むことを意味します。
例
#!/usr/bin/ruby
(10..15).each do |n|
print n, ' '
endこれにより、次の結果が生成されます-
10 11 12 13 14 15Ruby Rangesの詳細については、RubyRangesを参照してください。
Rubyは、現代語に期待されるように、豊富な演算子のセットをサポートしています。ほとんどの演算子は実際にはメソッド呼び出しです。たとえば、a + bはa。+(b)として解釈されます。ここで、変数aによって参照されるオブジェクトの+メソッドは、bを引数として呼び出されます。
各演算子(+-* /%**&| ^ << >> && ||)には、対応する形式の省略代入演算子(+ =-=など)があります。
Ruby算術演算子
変数aが10を保持し、変数bが20を保持すると仮定すると、−
| オペレーター | 説明 | 例 |
|---|---|---|
| + | 加算-演算子のいずれかの側に値を加算します。 | a + bは30を与えます |
| − | 減算-左側のオペランドから右側のオペランドを減算します。 | a-bは-10を与えます |
| * | 乗算-演算子のいずれかの側で値を乗算します。 | a * bは200を与えます |
| / | 除算-左側のオペランドを右側のオペランドで除算します。 | b / aは2を与えます |
| % | モジュラス-左側のオペランドを右側のオペランドで除算し、余りを返します。 | b%aは0を与えます |
| **** | 指数-演算子に対して指数(累乗)計算を実行します。 | a ** bは10の累乗20を与えます |
Ruby比較演算子
変数aが10を保持し、変数bが20を保持すると仮定すると、−
| オペレーター | 説明 | 例 |
|---|---|---|
| == | 2つのオペランドの値が等しいかどうかをチェックし、等しい場合は条件が真になります。 | (a == b)は真ではありません。 |
| != | 2つのオペランドの値が等しいかどうかをチェックし、値が等しくない場合は条件が真になります。 | (a!= b)は真です。 |
| >> | 左のオペランドの値が右のオペランドの値より大きいかどうかを確認します。大きい場合は、条件が真になります。 | (a> b)は正しくありません。 |
| < | 左のオペランドの値が右のオペランドの値よりも小さいかどうかを確認します。小さい場合は、条件が真になります。 | (a <b)は真です。 |
| > = | 左のオペランドの値が右のオペランドの値以上であるかどうかをチェックします。はいの場合、条件は真になります。 | (a> = b)は正しくありません。 |
| <= | 左のオペランドの値が右のオペランドの値以下であるかどうかをチェックします。はいの場合、条件は真になります。 | (a <= b)は真です。 |
| <=> | 結合された比較演算子。最初のオペランドが2番目に等しい場合は0を返し、最初のオペランドが2番目よりも大きい場合は1を返し、最初のオペランドが2番目よりも小さい場合は-1を返します。 | (a <=> b)は-1を返します。 |
| === | caseステートメントのwhen句内の同等性をテストするために使用されます。 | (1 ... 10)=== 5はtrueを返します。 |
| .eql? | レシーバーと引数のタイプが同じで値が等しい場合はTrue。 | 1 == 1.0はtrueを返しますが、1.eql?(1.0)はfalseです。 |
| 等しい? | レシーバーと引数のオブジェクトIDが同じ場合はTrue。 | aObjがbObjと重複している場合、aObj == bObjは真、a.equal?bObjは偽、a.equal?aObjは真です。 |
Ruby代入演算子
変数aが10を保持し、変数bが20を保持すると仮定すると、−
| オペレーター | 説明 | 例 |
|---|---|---|
| = | 単純な代入演算子。右側のオペランドから左側のオペランドに値を代入します。 | c = a + bは、a + bの値をcに割り当てます |
| + = | AND代入演算子を追加し、右のオペランドを左のオペランドに追加し、結果を左のオペランドに割り当てます。 | c + = aはc = c + aと同等です |
| -= | AND代入演算子を減算し、左オペランドから右オペランドを減算し、結果を左オペランドに割り当てます。 | c- = aはc = c-aと同等です |
| * = | AND代入演算子を乗算し、右のオペランドと左のオペランドを乗算して、その結果を左のオペランドに代入します。 | c * = aはc = c * aと同等です |
| / = | AND代入演算子を除算し、左オペランドを右オペランドで除算し、結果を左オペランドに代入します。 | c / = aはc = c / aと同等です |
| %= | モジュラスAND代入演算子。2つのオペランドを使用してモジュラスを取り、その結果を左側のオペランドに割り当てます。 | c%= aはc = c%aと同等です |
| ** = | 指数AND代入演算子。演算子に対して指数(累乗)計算を実行し、左側のオペランドに値を代入します。 | c ** = aはc = c ** aと同等です |
Ruby並列代入
Rubyは、変数の並列割り当てもサポートしています。これにより、1行のRubyコードで複数の変数を初期化できます。例-
a = 10
b = 20
c = 30これは、並列割り当てを使用してより迅速に宣言できます-
a, b, c = 10, 20, 30並列代入は、2つの変数に保持されている値を交換する場合にも役立ちます-
a, b = b, cRubyビット演算子
ビット単位の演算子はビットを処理し、ビットごとの演算を実行します。
a = 60の場合を想定します。およびb = 13; 現在、バイナリ形式では次のようになります-
a = 0011 1100
b = 0000 1101
------------------
a&b = 0000 1100
a|b = 0011 1101
a^b = 0011 0001
~a = 1100 0011次のビット演算子はRuby言語でサポートされています。
| オペレーター | 説明 | 例 |
|---|---|---|
| & | バイナリAND演算子は、両方のオペランドに存在する場合、結果にビットをコピーします。 | (a&b)は12、つまり00001100を与えます |
| | | バイナリOR演算子は、いずれかのオペランドに存在する場合、ビットをコピーします。 | (a | b)は61を返します。これは00111101です。 |
| ^ | バイナリXOR演算子は、ビットが両方ではなく一方のオペランドに設定されている場合、そのビットをコピーします。 | (a ^ b)は49を返します。これは00110001です。 |
| 〜 | Binary Ones Complement Operatorは単項であり、ビットを「反転」させる効果があります。 | (〜a)は-61を返します。これは、符号付き2進数のため、2の補数形式の11000011です。 |
| << | バイナリ左シフト演算子。左のオペランドの値は、右のオペランドで指定されたビット数だけ左に移動します。 | << 2は240、つまり11110000になります |
| >> | バイナリ右シフト演算子。左のオペランドの値は、右のオペランドで指定されたビット数だけ右に移動します。 | a >> 2は15、つまり00001111になります |
Ruby論理演算子
以下の論理演算子はRuby言語でサポートされています
変数aが10を保持し、変数bが20を保持すると仮定すると、−
| オペレーター | 説明 | 例 |
|---|---|---|
| そして | 論理AND演算子と呼ばれます。両方のオペランドが真の場合、条件は真になります。 | (aとb)は真です。 |
| または | 論理OR演算子と呼ばれます。2つのオペランドのいずれかがゼロ以外の場合、条件は真になります。 | (aまたはb)は真です。 |
| && | 論理AND演算子と呼ばれます。両方のオペランドがゼロ以外の場合、条件は真になります。 | (a && b)は真です。 |
| || | 論理OR演算子と呼ばれます。2つのオペランドのいずれかがゼロ以外の場合、条件は真になります。 | (a || b)は真です。 |
| ! | 論理NOT演算子と呼ばれます。オペランドの論理状態を逆にするために使用します。条件がtrueの場合、LogicalNOT演算子はfalseになります。 | !(a && b)はfalseです。 |
| ない | 論理NOT演算子と呼ばれます。オペランドの論理状態を逆にするために使用します。条件がtrueの場合、LogicalNOT演算子はfalseになります。 | not(a && b)はfalseです。 |
Ruby三項演算子
三項演算子と呼ばれるもう1つの演算子があります。最初に式の真または偽の値を評価し、次に評価の結果に応じて、指定された2つのステートメントのいずれかを実行します。条件演算子の構文は次のとおりです-
| オペレーター | 説明 | 例 |
|---|---|---|
| ?: | 条件式 | 条件が真の場合?次に値X:それ以外の場合は値Y |
Ruby範囲演算子
Rubyのシーケンス範囲は、開始値、終了値、およびその間の値の範囲で構成される、連続する値の範囲を作成するために使用されます。
Rubyでは、これらのシーケンスは「..」および「...」範囲演算子を使用して作成されます。2ドット形式は包括的範囲を作成し、3ドット形式は指定された高い値を除外する範囲を作成します。
| オペレーター | 説明 | 例 |
|---|---|---|
| .. | 始点から終点までの範囲を作成します。 | 1..101から10までの範囲を作成します。 |
| ..。 | 始点から終点までの範囲を排他的に作成します。 | 1 ... 101から9までの範囲を作成します。 |
Rubyは定義されていますか?演算子
定義されていますか?は、渡された式が定義されているかどうかを判別するためのメソッド呼び出しの形式をとる特別な演算子です。式の説明文字列を返します。式が定義されていない場合はnilを返します。
定義されたのさまざまな使用法がありますか?オペレーター
使用法1
defined? variable # True if variable is initializedFor Example
foo = 42
defined? foo # => "local-variable"
defined? $_ # => "global-variable"
defined? bar # => nil (undefined)使用法2
defined? method_call # True if a method is definedFor Example
defined? puts # => "method"
defined? puts(bar) # => nil (bar is not defined here)
defined? unpack # => nil (not defined here)使用法3
# True if a method exists that can be called with super user
defined? superFor Example
defined? super # => "super" (if it can be called)
defined? super # => nil (if it cannot be)使用法4
defined? yield # True if a code block has been passedFor Example
defined? yield # => "yield" (if there is a block passed)
defined? yield # => nil (if there is no block)ルビードット「。」およびダブルコロン "::"演算子
モジュールの名前の前にモジュールの名前とピリオドを付けてモジュールメソッドを呼び出し、モジュール名と2つのコロンを使用して定数を参照します。
ザ・ :: は、クラスまたはモジュール内で定義された定数、インスタンスメソッド、およびクラスメソッドを、クラスまたはモジュールの外部のどこからでもアクセスできるようにする単項演算子です。
Remember Rubyでは、クラスとメソッドも定数と見なされる場合があります。
プレフィックスを付ける必要があります :: 適切なクラスまたはモジュールオブジェクトを返す式を持つConst_name。
プレフィックス式が使用されていない場合、デフォルトでメインのObjectクラスが使用されます。
ここに2つの例があります-
MR_COUNT = 0 # constant defined on main Object class
module Foo
MR_COUNT = 0
::MR_COUNT = 1 # set global count to 1
MR_COUNT = 2 # set local count to 2
end
puts MR_COUNT # this is the global constant
puts Foo::MR_COUNT # this is the local "Foo" constantSecond Example
CONST = ' out there'
class Inside_one
CONST = proc {' in there'}
def where_is_my_CONST
::CONST + ' inside one'
end
end
class Inside_two
CONST = ' inside two'
def where_is_my_CONST
CONST
end
end
puts Inside_one.new.where_is_my_CONST
puts Inside_two.new.where_is_my_CONST
puts Object::CONST + Inside_two::CONST
puts Inside_two::CONST + CONST
puts Inside_one::CONST
puts Inside_one::CONST.call + Inside_two::CONSTRuby演算子の優先順位
次の表に、すべての演算子を優先順位の高いものから低いものの順に示します。
| 方法 | オペレーター | 説明 |
|---|---|---|
| はい | ::: | 一定の解像度の演算子 |
| はい | [] [] = | 要素参照、要素セット |
| はい | **** | べき乗(累乗) |
| はい | !〜+- | Not、complement、unary plus andminus(最後の2つのメソッド名は+ @と-@です) |
| はい | * /% | 乗算、除算、モジュロ |
| はい | +- | 足し算と引き算 |
| はい | >> << | 左右のビット単位のシフト |
| はい | & | ビット単位の「AND」 |
| はい | ^ | | ビット単位の排他的論理和と通常の論理和 |
| はい | <= <>> = | 比較演算子 |
| はい | <=> == ===!= =〜!〜 | 等式およびパターン一致演算子(!=および!〜はメソッドとして定義されない場合があります) |
| && | 論理積「AND」 | |
| || | 論理「OR」 | |
| ....。 | 範囲(包括的および排他的) | |
| ?: | 三項if-then-else | |
| =%= {/ =-= + = | =&= >> = << = * = && = || = ** = | 割り当て | |
| 定義されていますか? | 指定されたシンボルが定義されているかどうかを確認してください | |
| ない | 論理否定 | |
| または | 論理構成 |
NOTE−メソッド列に「はい」が付いている演算子は実際にはメソッドであるため、オーバーライドされる場合があります。
コメントは、実行時に無視されるRubyコード内の注釈行です。1行のコメントは#文字で始まり、次のように#から行の終わりまで続きます-
#!/usr/bin/ruby -w
# This is a single line comment.
puts "Hello, Ruby!"上記のプログラムを実行すると、次の結果が得られます。
Hello, Ruby!Rubyマルチラインコメント
を使用して複数行にコメントを付けることができます =begin そして =end 次のような構文-
#!/usr/bin/ruby -w
puts "Hello, Ruby!"
=begin
This is a multiline comment and con spwan as many lines as you
like. But =begin and =end should come in the first line only.
=end上記のプログラムを実行すると、次の結果が得られます。
Hello, Ruby!末尾のコメントがコードから十分に離れていて、簡単に区別できることを確認してください。ブロック内に複数の末尾のコメントが存在する場合は、それらを揃えます。例-
@counter # keeps track times page has been hit
@siteCounter # keeps track of times all pages have been hitRubyは、現代語にかなり一般的な条件構造を提供します。ここでは、Rubyで使用できるすべての条件ステートメントと修飾子について説明します。
Ruby if ... elseステートメント
構文
if conditional [then]
code...
[elsif conditional [then]
code...]...
[else
code...]
end式が条件付き実行に使用される場合。値falseとnilはfalseであり、他のすべてはtrueです。Rubyはelsifを使用し、elseifもelifも使用しないことに注意してください。
条件が真の場合にコードを実行します。場合は、条件が真ではありません、コードelse節で指定が実行されます。
if式の条件は、予約語then、改行、またはセミコロンによってコードから分離されています。
例
#!/usr/bin/ruby
x = 1
if x > 2
puts "x is greater than 2"
elsif x <= 2 and x!=0
puts "x is 1"
else
puts "I can't guess the number"
endx is 1Rubyif修飾子
構文
code if condition条件が真の場合にコードを実行します。
例
#!/usr/bin/ruby
$debug = 1
print "debug\n" if $debugこれにより、次の結果が生成されます-
debugステートメントでない限りRuby
構文
unless conditional [then]
code
[else
code ]
end条件がfalseの場合、コードを実行します。条件が真の場合、else句で指定されたコードが実行されます。
例
#!/usr/bin/ruby
x = 1
unless x>=2
puts "x is less than 2"
else
puts "x is greater than 2"
endこれにより、次の結果が生成されます-
x is less than 2Ruby unless modifier
Syntax
code unless conditionalExecutes code if conditional is false.
Example
#!/usr/bin/ruby
$var = 1
print "1 -- Value is set\n" if $var print "2 -- Value is set\n" unless $var
$var = false print "3 -- Value is set\n" unless $varThis will produce the following result −
1 -- Value is set
3 -- Value is setRuby case Statement
Syntax
case expression
[when expression [, expression ...] [then]
code ]...
[else
code ]
endCompares the expression specified by case and that specified by when using the === operator and executes the code of the when clause that matches.
The expression specified by the when clause is evaluated as the left operand. If no when clauses match, case executes the code of the else clause.
A when statement's expression is separated from code by the reserved word then, a newline, or a semicolon. Thus −
case expr0
when expr1, expr2
stmt1
when expr3, expr4
stmt2
else
stmt3
endis basically similar to the following −
_tmp = expr0
if expr1 === _tmp || expr2 === _tmp
stmt1
elsif expr3 === _tmp || expr4 === _tmp
stmt2
else
stmt3
end例
#!/usr/bin/ruby
$age = 5 case $age
when 0 .. 2
puts "baby"
when 3 .. 6
puts "little child"
when 7 .. 12
puts "child"
when 13 .. 18
puts "youth"
else
puts "adult"
endこれにより、次の結果が生成されます-
little childRubyのループは、同じコードブロックを指定された回数実行するために使用されます。この章では、Rubyでサポートされているすべてのループステートメントについて詳しく説明します。
Rubywhileステートメント
構文
while conditional [do]
code
end条件が真のときにコードを実行します。一方、ループの条件をから分離されているコード予約語行い、改行、バックスラッシュ\、またはセミコロン;。
例
#!/usr/bin/ruby
$i = 0
$num = 5
while $i < $num do
puts("Inside the loop i = #$i" )
$i +=1
endこれにより、次の結果が生成されます-
Inside the loop i = 0
Inside the loop i = 1
Inside the loop i = 2
Inside the loop i = 3
Inside the loop i = 4Rubywhile修飾子
構文
code while condition
OR
begin
code
end while conditional条件が真のときにコードを実行します。
while修飾子がrescueまたはensure句のないbeginステートメントの後に続く場合、条件が評価される前にコードが1回実行されます。
例
#!/usr/bin/ruby
$i = 0
$num = 5
begin
puts("Inside the loop i = #$i" )
$i +=1
end while $i < $numこれにより、次の結果が生成されます-
Inside the loop i = 0
Inside the loop i = 1
Inside the loop i = 2
Inside the loop i = 3
Inside the loop i = 4Rubyuntilステートメント
until conditional [do]
code
end条件がfalseのときにコードを実行します。まで文の条件は以下から分離されているコード予約語で行い、改行、またはセミコロン。
例
#!/usr/bin/ruby
$i = 0
$num = 5
until $i > $num do
puts("Inside the loop i = #$i" )
$i +=1;
endこれにより、次の結果が生成されます-
Inside the loop i = 0
Inside the loop i = 1
Inside the loop i = 2
Inside the loop i = 3
Inside the loop i = 4
Inside the loop i = 5修飾子までのRuby
構文
code until conditional
OR
begin
code
end until conditional条件がfalseのときにコードを実行します。
until修飾子がrescueまたはensure句のないbeginステートメントの後に続く場合、条件が評価される前にコードが1回実行されます。
例
#!/usr/bin/ruby
$i = 0
$num = 5
begin
puts("Inside the loop i = #$i" )
$i +=1;
end until $i > $numこれにより、次の結果が生成されます-
Inside the loop i = 0
Inside the loop i = 1
Inside the loop i = 2
Inside the loop i = 3
Inside the loop i = 4
Inside the loop i = 5RubyforStatement
構文
for variable [, variable ...] in expression [do]
code
end式の要素ごとに1回コードを実行します。
例
#!/usr/bin/ruby
for i in 0..5
puts "Value of local variable is #{i}"
endここでは、範囲0..5を定義しました。以下のための声明私0..5ではできるようになります私は(5を含む)、0から5までの範囲の値を取ること。これにより、次の結果が生成されます-
Value of local variable is 0
Value of local variable is 1
Value of local variable is 2
Value of local variable is 3
Value of local variable is 4
Value of local variable is 5以下のために...でループほぼ正確に以下と等価です-
(expression).each do |variable[, variable...]| code endただし、forループはローカル変数の新しいスコープを作成しません。用ループの発現がから分離されているコード予約語行い、改行、またはセミコロン。
例
#!/usr/bin/ruby
(0..5).each do |i|
puts "Value of local variable is #{i}"
endこれにより、次の結果が生成されます-
Value of local variable is 0
Value of local variable is 1
Value of local variable is 2
Value of local variable is 3
Value of local variable is 4
Value of local variable is 5Rubybreakステートメント
構文
break最も内部のループを終了します。ブロック内で呼び出された場合、関連付けられたブロックでメソッドを終了します(メソッドはnilを返します)。
例
#!/usr/bin/ruby
for i in 0..5
if i > 2 then
break
end
puts "Value of local variable is #{i}"
endこれにより、次の結果が生成されます-
Value of local variable is 0
Value of local variable is 1
Value of local variable is 2Rubyの次のステートメント
構文
next最も内部のループの次の反復にジャンプします。ブロック内で呼び出された場合(yieldまたはcallがnilを返す場合)、ブロックの実行を終了します。
例
#!/usr/bin/ruby
for i in 0..5
if i < 2 then
next
end
puts "Value of local variable is #{i}"
endこれにより、次の結果が生成されます-
Value of local variable is 2
Value of local variable is 3
Value of local variable is 4
Value of local variable is 5RubyREDOステートメント
構文
redoループの状態をチェックせずに、最も内部のループのこの反復を再開します。ブロック内で呼び出された場合、yieldまたはcallを再開します。
例
#!/usr/bin/ruby
for i in 0..5
if i < 2 then
puts "Value of local variable is #{i}"
redo
end
endこれにより、次の結果が生成され、無限ループになります-
Value of local variable is 0
Value of local variable is 0
............................Ruby再試行ステートメント
構文
retrybegin式のrescue句に再試行が表示された場合は、begin本体の先頭から再起動してください。
begin
do_something # exception raised
rescue
# handles error
retry # restart from beginning
endイテレータ、ブロック、またはfor式の本体に再試行が表示された場合、イテレータ呼び出しの呼び出しが再開されます。イテレータへの引数が再評価されます。
for i in 1..5
retry if some_condition # restart from i == 1
end例
#!/usr/bin/ruby
for i in 0..5
retry if i > 2
puts "Value of local variable is #{i}"
endこれにより、次の結果が生成され、無限ループになります-
Value of local variable is 1
Value of local variable is 2
Value of local variable is 1
Value of local variable is 2
Value of local variable is 1
Value of local variable is 2
............................Rubyメソッドは、他のプログラミング言語の関数と非常によく似ています。Rubyメソッドは、1つ以上の繰り返し可能なステートメントを1つのユニットにバンドルするために使用されます。
メソッド名は小文字で始める必要があります。メソッド名を大文字で始めると、Rubyはそれが定数であると見なす可能性があるため、呼び出しを誤って解析する可能性があります。
メソッドは、呼び出す前に定義する必要があります。そうしないと、Rubyは未定義のメソッド呼び出しの例外を発生させます。
構文
def method_name [( [arg [= default]]...[, * arg [, &expr ]])]
expr..
endしたがって、次のように簡単なメソッドを定義できます。
def method_name
expr..
endこのようなパラメータを受け入れるメソッドを表すことができます-
def method_name (var1, var2)
expr..
endパラメータのデフォルト値を設定できます。これは、必要なパラメータを渡さずにメソッドが呼び出された場合に使用されます-
def method_name (var1 = value1, var2 = value2)
expr..
end単純なメソッドを呼び出すときは常に、次のようにメソッド名のみを記述します。
method_nameただし、パラメータを使用してメソッドを呼び出す場合は、メソッド名をパラメータとともに記述します。たとえば、-
method_name 25, 30パラメータ付きのメソッドを使用することの最も重要な欠点は、そのようなメソッドを呼び出すたびにパラメータの数を覚えておく必要があることです。たとえば、メソッドが3つのパラメーターを受け入れ、2つだけを渡すと、Rubyはエラーを表示します。
例
#!/usr/bin/ruby
def test(a1 = "Ruby", a2 = "Perl")
puts "The programming language is #{a1}"
puts "The programming language is #{a2}"
end
test "C", "C++"
testこれにより、次の結果が生成されます-
The programming language is C
The programming language is C++
The programming language is Ruby
The programming language is Perlメソッドからの戻り値
Rubyのすべてのメソッドは、デフォルトで値を返します。この戻り値は、最後のステートメントの値になります。例-
def test
i = 100
j = 10
k = 0
endこのメソッドが呼び出されると、最後に宣言された変数kが返されます。
Rubyのreturnステートメント
Rubyのreturnステートメントは、Rubyメソッドから1つ以上の値を返すために使用されます。
構文
return [expr[`,' expr...]]3つ以上の式が指定されている場合、これらの値を含む配列が戻り値になります。式が指定されていない場合、nilが戻り値になります。
例
return
OR
return 12
OR
return 1,2,3この例を見てください-
#!/usr/bin/ruby
def test
i = 100
j = 200
k = 300
return i, j, k
end
var = test
puts varこれにより、次の結果が生成されます-
100
200
300可変数のパラメーター
2つのパラメーターを受け取るメソッドを宣言するとします。このメソッドを呼び出すときは常に、2つのパラメーターを一緒に渡す必要があります。
ただし、Rubyでは、可変数のパラメーターで機能するメソッドを宣言できます。これのサンプルを調べてみましょう-
#!/usr/bin/ruby
def sample (*test)
puts "The number of parameters is #{test.length}"
for i in 0...test.length
puts "The parameters are #{test[i]}"
end
end
sample "Zara", "6", "F"
sample "Mac", "36", "M", "MCA"このコードでは、1つのパラメーターテストを受け入れるメソッドサンプルを宣言しました。ただし、このパラメーターは可変パラメーターです。これは、このパラメーターが任意の数の変数を取り込むことができることを意味します。したがって、上記のコードは次の結果を生成します-
The number of parameters is 3
The parameters are Zara
The parameters are 6
The parameters are F
The number of parameters is 4
The parameters are Mac
The parameters are 36
The parameters are M
The parameters are MCAクラスメソッド
メソッドがクラス定義の外部で定義されている場合、そのメソッドはデフォルトでプライベートとしてマークされます。一方、クラス定義で定義されたメソッドは、デフォルトでパブリックとしてマークされています。メソッドのデフォルトの可視性とプライベートマークは、モジュールのパブリックまたはプライベートによって変更できます。
クラスのメソッドにアクセスするときはいつでも、最初にクラスをインスタンス化する必要があります。次に、オブジェクトを使用して、クラスの任意のメンバーにアクセスできます。
Rubyは、クラスをインスタンス化せずにメソッドにアクセスする方法を提供します。クラスメソッドがどのように宣言され、アクセスされるかを見てみましょう-
class Accounts
def reading_charge
end
def Accounts.return_date
end
endメソッドreturn_dateがどのように宣言されているかを確認してください。クラス名の後にピリオドが続き、その後にメソッドの名前が続くことで宣言されます。このクラスメソッドには、次のように直接アクセスできます。
Accounts.return_dateこのメソッドにアクセスするために、クラスAccountsのオブジェクトを作成する必要はありません。
Rubyエイリアスステートメント
これにより、メソッドまたはグローバル変数にエイリアスが与えられます。メソッド本体内でエイリアスを定義することはできません。メソッドのエイリアスは、メソッドがオーバーライドされた場合でも、メソッドの現在の定義を保持します。
番号付きグローバル変数($ 1、$ 2、...)のエイリアスを作成することは禁止されています。組み込みのグローバル変数をオーバーライドすると、深刻な問題が発生する可能性があります。
構文
alias method-name method-name
alias global-variable-name global-variable-name例
alias foo bar
alias $MATCH $&ここでは、barのfooエイリアスを定義しました。$ MATCHは$&のエイリアスです。
Rubyundefステートメント
これにより、メソッド定義がキャンセルされます。undefがメソッド本体に表示することはできません。
undefとaliasを使用することで、クラスのインターフェースをスーパークラスとは独立して変更できますが、selfへの内部メソッド呼び出しによってプログラムが壊れている可能性があることに注意してください。
構文
undef method-name例
barと呼ばれるメソッドの定義を解除するには、次のようにします。
undef bar多数のステートメントを配置できるメソッドをRubyがどのように定義し、そのメソッドを呼び出すかを見てきました。同様に、Rubyにはブロックの概念があります。
ブロックはコードのチャンクで構成されます。
ブロックに名前を割り当てます。
ブロック内のコードは常に中括弧({})で囲まれています。
ブロックは常に、ブロックと同じ名前の関数から呼び出されます。これは、testという名前のブロックがある場合、関数testを使用してこのブロックを呼び出すことを意味します。
イールドステートメントを使用してブロックを呼び出します。
構文
block_name {
statement1
statement2
..........
}ここでは、簡単なyieldステートメントを使用してブロックを呼び出す方法を学習します。また、ブロックを呼び出すためのパラメーターを指定して、yieldステートメントを使用する方法も学習します。両方のタイプのyieldステートメントを使用してサンプルコードを確認します。
利回りステートメント
歩留まりステートメントの例を見てみましょう-
#!/usr/bin/ruby
def test
puts "You are in the method"
yield
puts "You are again back to the method"
yield
end
test {puts "You are in the block"}これにより、次の結果が生成されます-
You are in the method
You are in the block
You are again back to the method
You are in the blockまた、yieldステートメントを使用してパラメーターを渡すこともできます。ここに例があります-
#!/usr/bin/ruby
def test
yield 5
puts "You are in the method test"
yield 100
end
test {|i| puts "You are in the block #{i}"}これにより、次の結果が生成されます-
You are in the block 5
You are in the method test
You are in the block 100ここでは、yieldステートメントの後にパラメーターが記述されています。複数のパラメーターを渡すこともできます。ブロック内で、2本の垂直線(||)の間に変数を配置して、パラメーターを受け入れます。したがって、上記のコードでは、yield5ステートメントは値5をパラメーターとしてテストブロックに渡します。
さて、次のステートメントを見てください-
test {|i| puts "You are in the block #{i}"}ここで、値5は変数iで受け取られます。ここで、次のputsステートメントを観察します-
puts "You are in the block #{i}"このputsステートメントの出力は次のとおりです。
You are in the block 5複数のパラメーターを渡したい場合、yieldステートメントは次のようになります。
yield a, bそしてブロックは-です
test {|a, b| statement}パラメータはコンマで区切られます。
ブロックとメソッド
ブロックとメソッドを相互に関連付ける方法を見てきました。通常、ブロックと同じ名前のメソッドからyieldステートメントを使用してブロックを呼び出します。したがって、あなたは書く-
#!/usr/bin/ruby
def test
yield
end
test{ puts "Hello world"}この例は、ブロックを実装する最も簡単な方法です。イールドステートメントを使用してテストブロックを呼び出します。
ただし、メソッドの最後の引数の前に&が付いている場合は、このメソッドにブロックを渡すことができ、このブロックは最後のパラメーターに割り当てられます。*と&の両方が引数リストに存在する場合、&は後で来る必要があります。
#!/usr/bin/ruby
def test(&block)
block.call
end
test { puts "Hello World!"}これにより、次の結果が生成されます-
Hello World!BEGINブロックとENDブロック
すべてのRubyソースファイルは、ファイルのロード中(BEGINブロック)およびプログラムの実行終了後(ENDブロック)に実行されるコードのブロックを宣言できます。
#!/usr/bin/ruby
BEGIN {
# BEGIN block code
puts "BEGIN code block"
}
END {
# END block code
puts "END code block"
}
# MAIN block code
puts "MAIN code block"プログラムには、複数のBEGINブロックとENDブロックが含まれる場合があります。BEGINブロックは、検出された順序で実行されます。ENDブロックは逆の順序で実行されます。上記のプログラムを実行すると、次の結果が得られます。
BEGIN code block
MAIN code block
END code blockモジュールは、メソッド、クラス、および定数をグループ化する方法です。モジュールには2つの大きな利点があります。
モジュールは名前空間を提供し、名前の衝突を防ぎます。
モジュールはミックスイン機能を実装します。
モジュールは名前空間を定義します。これは、他のメソッドや定数に踏まれることを心配することなく、メソッドや定数を再生できるサンドボックスです。
構文
module Identifier
statement1
statement2
...........
endモジュール定数は、クラス定数と同じように名前が付けられ、最初に大文字が付けられます。メソッド定義も同様に見えます。モジュールメソッドは、クラスメソッドと同じように定義されます。
クラスメソッドと同様に、モジュールメソッドの名前の前にモジュールの名前とピリオドを付けてモジュールメソッドを呼び出し、モジュール名と2つのコロンを使用して定数を参照します。
例
#!/usr/bin/ruby
# Module defined in trig.rb file
module Trig
PI = 3.141592654
def Trig.sin(x)
# ..
end
def Trig.cos(x)
# ..
end
end同じ関数名で機能が異なるモジュールをもう1つ定義できます-
#!/usr/bin/ruby
# Module defined in moral.rb file
module Moral
VERY_BAD = 0
BAD = 1
def Moral.sin(badness)
# ...
end
endクラスメソッドと同様に、モジュールでメソッドを定義するときは常に、モジュール名、ドット、メソッド名の順に指定します。
Rubyrequireステートメント
requireステートメントは、CおよびC ++のincludeステートメントとJavaのimportステートメントに似ています。3番目のプログラムが定義済みのモジュールを使用する場合は、Rubyrequireステートメントを使用してモジュールファイルをロードするだけです。
構文
require filenameここでは、与える必要はありません .rb ファイル名と一緒に拡張子。
例
$LOAD_PATH << '.'
require 'trig.rb'
require 'moral'
y = Trig.sin(Trig::PI/4)
wrongdoing = Moral.sin(Moral::VERY_BAD)ここでは使用しています $LOAD_PATH << '.'含まれているファイルを現在のディレクトリで検索する必要があることをRubyに認識させるため。$ LOAD_PATHを使用したくない場合は、次を使用できます。require_relative 相対ディレクトリのファイルを含める。
IMPORTANT−ここでは、両方のファイルに同じ関数名が含まれています。したがって、これにより、プログラムの呼び出しに含めるときにコードのあいまいさが生じますが、モジュールはこのコードのあいまいさを回避し、モジュール名を使用して適切な関数を呼び出すことができます。
Rubyincludeステートメント
モジュールをクラスに埋め込むことができます。モジュールをクラスに埋め込むには、クラスでincludeステートメントを使用します-
構文
include modulenameモジュールが別のファイルで定義されている場合は、モジュールをクラスに埋め込む前に、requireステートメントを使用してそのファイルを含める必要があります。
例
support.rbファイルに記述されている次のモジュールについて考えてみます。
module Week
FIRST_DAY = "Sunday"
def Week.weeks_in_month
puts "You have four weeks in a month"
end
def Week.weeks_in_year
puts "You have 52 weeks in a year"
end
endこれで、次のようにこのモジュールをクラスに含めることができます-
#!/usr/bin/ruby
$LOAD_PATH << '.'
require "support"
class Decade
include Week
no_of_yrs = 10
def no_of_months
puts Week::FIRST_DAY
number = 10*12
puts number
end
end
d1 = Decade.new
puts Week::FIRST_DAY
Week.weeks_in_month
Week.weeks_in_year
d1.no_of_monthsこれにより、次の結果が生成されます-
Sunday
You have four weeks in a month
You have 52 weeks in a year
Sunday
120Rubyのミックスイン
このセクションを通過する前に、オブジェクト指向の概念についての知識があることを前提としています。
クラスが複数の親クラスから機能を継承できる場合、そのクラスは多重継承を示すことになっています。
Rubyは多重継承を直接サポートしていませんが、Rubyモジュールには別の素晴らしい用途があります。一気に、それらは多重継承の必要性をほとんど排除し、ミックスインと呼ばれる機能を提供します。
Mixinは、クラスに機能を追加するための見事に制御された方法を提供します。ただし、ミックスイン内のコードがそれを使用するクラス内のコードと相互作用し始めると、それらの真の力が発揮されます。
次のサンプルコードを調べて、mixinを理解しましょう。
module A
def a1
end
def a2
end
end
module B
def b1
end
def b2
end
end
class Sample
include A
include B
def s1
end
end
samp = Sample.new
samp.a1
samp.a2
samp.b1
samp.b2
samp.s1モジュールAは、メソッドa1とa2で構成されています。モジュールBは、メソッドb1とb2で構成されています。クラスSampleには、モジュールAとBの両方が含まれます。クラスSampleは、4つのメソッドすべて、つまりa1、a2、b1、およびb2にアクセスできます。したがって、クラスSampleが両方のモジュールから継承していることがわかります。したがって、クラスSampleは多重継承またはミックスインを示していると言えます。
RubyのStringオブジェクトは、通常、人間の言語を表す文字を表す1バイト以上の任意のシーケンスを保持および操作します。
最も単純な文字列リテラルは一重引用符(アポストロフィ文字)で囲まれています。引用符内のテキストは文字列の値です-
'This is a simple Ruby string literal'一重引用符で囲まれた文字列リテラル内にアポストロフィを配置する必要がある場合は、その前にバックスラッシュを付けて、Rubyインタプリタが文字列を終了したと見なさないようにします。
'Won\'t you read O\'Reilly\'s book?'バックスラッシュは別のバックスラッシュをエスケープするためにも機能するため、2番目のバックスラッシュ自体はエスケープ文字として解釈されません。
以下は、Rubyの文字列関連の機能です。
式の置換
式の置換は、#{および} −を使用してRuby式の値を文字列に埋め込む手段です。
#!/usr/bin/ruby
x, y, z = 12, 36, 72
puts "The value of x is #{ x }."
puts "The sum of x and y is #{ x + y }."
puts "The average was #{ (x + y + z)/3 }."これにより、次の結果が生成されます-
The value of x is 12.
The sum of x and y is 48.
The average was 40.一般的な区切り文字列
一般的な区切り文字列を使用すると、任意の区切り文字を使用して、一致するペア内に文字列を作成できます。たとえば、!、(、{、<など、先頭にパーセント文字(%)が付きます。Q、q、およびxには特別な意味があります。 。一般的な区切り文字列は次のようになります-
%{Ruby is fun.} equivalent to "Ruby is fun."
%Q{ Ruby is fun. } equivalent to " Ruby is fun. "
%q[Ruby is fun.] equivalent to a single-quoted string
%x!ls! equivalent to back tick command output `ls`エスケープ文字
NOTE−二重引用符で囲まれた文字列では、エスケープ文字が解釈されます。一重引用符で囲まれた文字列では、エスケープ文字が保持されます。
| バックスラッシュ表記 | 16進文字 | 説明 |
|---|---|---|
| \ a | 0x07 | ベルまたはアラート |
| \ b | 0x08 | バックスペース |
| \ cx | Control-x | |
| \ Cx | Control-x | |
| \ e | 0x1b | 逃れる |
| \ f | 0x0c | フォームフィード |
| \ M- \ Cx | Meta-Control-x | |
| \ n | 0x0a | 改行 |
| \ nnn | nが0.7の範囲にある8進表記 | |
| \ r | 0x0d | キャリッジリターン |
| \ s | 0x20 | スペース |
| \ t | 0x09 | タブ |
| \ v | 0x0b | 垂直タブ |
| \バツ | 文字x | |
| \ xnn | nが0.9、af、またはAFの範囲にある16進表記 |
文字コード
Rubyのデフォルトの文字セットはASCIIであり、その文字は1バイトで表すことができます。UTF-8または別の最新の文字セットを使用する場合、文字は1〜4バイトで表される場合があります。
プログラムの開始時に$ KCODEを使用して、次のように文字セットを変更できます。
$KCODE = 'u'| シニア番号 | コードと説明 |
|---|---|
| 1 | a ASCII(なしと同じ)。これがデフォルトです。 |
| 2 | e EUC。 |
| 3 | n なし(ASCIIと同じ)。 |
| 4 | u UTF-8。 |
文字列組み込みメソッド
Stringメソッドを呼び出すには、Stringオブジェクトのインスタンスが必要です。以下は、Stringオブジェクトのインスタンスを作成する方法です-
new [String.new(str = "")]これにより、strのコピーを含む新しい文字列オブジェクトが返されます。これで、strオブジェクトを使用して、使用可能なインスタンスメソッドをすべて使用できます。例-
#!/usr/bin/ruby
myStr = String.new("THIS IS TEST")
foo = myStr.downcase
puts "#{foo}"これにより、次の結果が生成されます-
this is test| シニア番号 | 方法と説明 |
|---|---|
| 1 | str % arg フォーマット仕様を使用して文字列をフォーマットします。複数の置換が含まれている場合、argは配列である必要があります。フォーマット仕様については、「カーネルモジュール」のsprintfを参照してください。 |
| 2 | str * integer strの整数倍を含む新しい文字列を返します。言い換えれば、strは繰り返される整数imesです。 |
| 3 | str + other_str other_strをstrに連結します。 |
| 4 | str << obj オブジェクトをstrに連結します。オブジェクトが0.255の範囲のFixnumである場合、文字に変換されます。concatと比較してください。 |
| 5 | str <=> other_str strをother_strと比較し、-1(より小さい)、0(等しい)、または1(より大きい)を返します。比較では大文字と小文字が区別されます。 |
| 6 | str == obj strとobjが等しいかどうかをテストします。objが文字列でない場合、falseを返します。str <=> objが0を返す場合はtrueを返します。 |
| 7 | str =~ obj strを正規表現パターンobjと照合します。試合が始まる位置を返します。それ以外の場合はfalse。 |
| 8 | str.capitalize 文字列を大文字にします。 |
| 9 | str.capitalize! 大文字と同じですが、変更が加えられます。 |
| 10 | str.casecmp 文字列の大文字と小文字を区別しない比較を行います。 |
| 11 | str.center 文字列を中央揃えにします。 |
| 12 | str.chomp 文字列の末尾からレコード区切り文字($ /)(通常は\ n)を削除します。レコード区切り文字が存在しない場合、何もしません。 |
| 13 | str.chomp! chompと同じですが、変更が加えられています。 |
| 14 | str.chop strの最後の文字を削除します。 |
| 15 | str.chop! チョップと同じですが、変更が加えられています。 |
| 16 | str.concat(other_str) other_strをstrに連結します。 |
| 17 | str.count(str, ...) 1つ以上の文字セットをカウントします。文字のセットが複数ある場合は、それらのセットの共通部分をカウントします |
| 18 | str.crypt(other_str) 一方向の暗号化ハッシュをstrに適用します。引数はソルト文字列で、長さは2文字で、各文字はaz、AZ、0.9、の範囲にあります。または/。 |
| 19 | str.delete(other_str, ...) 引数の交点にあるすべての文字が削除されたstrのコピーを返します。 |
| 20 | str.delete!(other_str, ...) 削除と同じですが、変更が加えられます。 |
| 21 | str.downcase すべて大文字を小文字に置き換えたstrのコピーを返します。 |
| 22 | str.downcase! ダウンケースと同じですが、変更が加えられます。 |
| 23 | str.dump 印刷されないすべての文字が\ nnn表記に置き換えられ、すべての特殊文字がエスケープされたバージョンのstrを返します。 |
| 24 | str.each(separator = $/) { |substr| block } 引数をレコード区切り文字(デフォルトでは$ /)として使用してstrを分割し、各部分文字列を指定されたブロックに渡します。 |
| 25 | str.each_byte { |fixnum| block } strからブロックに各バイトを渡し、各バイトをバイトの10進表現として返します。 |
| 26 | str.each_line(separator=$/) { |substr| block } 引数をレコード区切り文字(デフォルトでは$ /)として使用してstrを分割し、各部分文字列を指定されたブロックに渡します。 |
| 27 | str.empty? strが空の場合(長さがゼロの場合)はtrueを返します。 |
| 28 | str.eql?(other) 2つの文字列は、長さと内容が同じであれば同じです。 |
| 29 | str.gsub(pattern, replacement) [or] str.gsub(pattern) { |match| block } パターンのすべての出現が置換またはブロックの値のいずれかで置き換えられたstrのコピーを返します。パターンは通常、正規表現になります。文字列の場合、正規表現のメタ文字は解釈されません(つまり、/ \ d /は数字と一致しますが、 '\ d'は円記号とそれに続く 'd'と一致します) |
| 30 | str[fixnum] [or] str[fixnum,fixnum] [or] str[range] [or] str[regexp] [or] str[regexp, fixnum] [or] str[other_str] 次の引数を使用してstrを参照します。1つのFixnumは、fixnumで文字コードを返します。2つのFixnum、オフセット(最初のfixnum)から長さ(2番目のfixnum)までの部分文字列を返します。range、範囲内の部分文字列を返します。正規表現は、一致した文字列の一部を返します。fixnumを使用した正規表現。fixnumで一致したデータを返します。other_strは、other_strに一致する部分文字列を返します。負のFixnumは、文字列の末尾の-1から始まります。 |
| 31 | str[fixnum] = fixnum [or] str[fixnum] = new_str [or] str[fixnum, fixnum] = new_str [or] str[range] = aString [or] str[regexp] = new_str [or] str[regexp, fixnum] = new_str [or] str[other_str] = new_str ] 文字列の全部または一部を置換(割り当て)します。スライスの同義語! |
| 32 | str.gsub!(pattern, replacement) [or] str.gsub!(pattern) { |match|block } String#gsubの置換を実行し、置換が実行されなかった場合はstrまたはnilを返します。 |
| 33 | str.hash 文字列の長さと内容に基づいてハッシュを返します。 |
| 34 | str.hex strの先頭の文字を16進数の文字列(オプションの記号とオプションの0xを含む)として扱い、対応する数値を返します。エラーの場合はゼロが返されます。 |
| 35 | str.include? other_str [or] str.include? fixnum strに指定された文字列または文字が含まれている場合、trueを返します。 |
| 36 | str.index(substring [, offset]) [or] str.index(fixnum [, offset]) [or] str.index(regexp [, offset]) strで指定された部分文字列、文字(fixnum)、またはパターン(regexp)が最初に出現するインデックスを返します。見つからない場合はnilを返します。2番目のパラメーターが存在する場合は、検索を開始する文字列内の位置を指定します。 |
| 37 | str.insert(index, other_str) 指定されたインデックスの文字の前にother_strを挿入し、strを変更します。負のインデックスは文字列の末尾から数え、指定された文字の後に挿入します。目的は、指定されたインデックスから始まるように文字列を挿入することです。 |
| 38 | str.inspect 特殊文字をエスケープした、印刷可能なバージョンのstrを返します。 |
| 39 | str.intern [or] str.to_sym strに対応するシンボルを返し、以前に存在していなかった場合はシンボルを作成します。 |
| 40 | str.length strの長さを返します。サイズを比較します。 |
| 41 | str.ljust(integer, padstr = ' ') integerがstrの長さより大きい場合、strが左寄せされ、padstrが埋め込まれた長さintegerの新しい文字列を返します。それ以外の場合は、strを返します。 |
| 42 | str.lstrip 先頭の空白を削除したstrのコピーを返します。 |
| 43 | str.lstrip! strから先頭の空白を削除し、変更が行われなかった場合はnilを返します。 |
| 44 | str.match(pattern) パターンを正規表現に変換し(まだ正規表現になっていない場合)、strでそのmatchメソッドを呼び出します。 |
| 45 | str.oct strの先頭文字を8進数の文字列(オプションの記号付き)として扱い、対応する数値を返します。変換が失敗した場合は0を返します。 |
| 46 | str.replace(other_str) strの内容と汚染をother_strの対応する値に置き換えます。 |
| 47 | str.reverse strの文字を逆の順序で含む新しい文字列を返します。 |
| 48 | str.reverse! strを所定の位置に戻します。 |
| 49 | str.rindex(substring [, fixnum]) [or] str.rindex(fixnum [, fixnum]) [or] str.rindex(regexp [, fixnum]) str内の指定された部分文字列、文字(fixnum)、またはパターン(regexp)の最後の出現のインデックスを返します。見つからない場合はnilを返します。2番目のパラメーターが存在する場合、検索を終了する文字列内の位置を指定します。このポイントを超える文字は考慮されません。 |
| 50。 | str.rjust(integer, padstr = ' ') 整数がstrの長さより大きい場合、strが右寄せされ、padstrが埋め込まれた長さ整数の新しい文字列を返します。それ以外の場合は、strを返します。 |
| 51 | str.rstrip 末尾の空白が削除されたstrのコピーを返します。 |
| 52 | str.rstrip! strから末尾の空白を削除し、変更が行われなかった場合はnilを返します。 |
| 53 | str.scan(pattern) [or] str.scan(pattern) { |match, ...| block } どちらのフォームもstrを反復処理し、パターン(RegexpまたはStringの場合があります)に一致します。一致するたびに、結果が生成され、結果配列に追加されるか、ブロックに渡されます。パターンにグループが含まれていない場合、個々の結果は一致した文字列$&で構成されます。パターンにグループが含まれている場合、個々の結果はそれ自体がグループごとに1つのエントリを含む配列になります。 |
| 54 | str.slice(fixnum) [or] str.slice(fixnum, fixnum) [or] str.slice(range) [or] str.slice(regexp) [or] str.slice(regexp, fixnum) [or] str.slice(other_str) See str[fixnum], etc. str.slice!(fixnum) [or] str.slice!(fixnum, fixnum) [or] str.slice!(range) [or] str.slice!(regexp) [or] str.slice!(other_str) 指定した部分をstrから削除し、削除した部分を返します。Fixnumをとるフォームは、値が範囲外の場合にIndexErrorを発生させます。RangeフォームはRangeErrorを発生させ、RegexpフォームとStringフォームはサイレントに割り当てを無視します。 |
| 55 | str.split(pattern = $, [limit]) strを区切り文字に基づいて部分文字列に分割し、これらの部分文字列の配列を返します。 patternがStringの場合、strを分割するときにその内容が区切り文字として使用されます。パターンが単一のスペースの場合、strは空白で分割され、先頭の空白と連続する空白文字の実行は無視されます。 patternがRegexpの場合、strはパターンが一致する場所で分割されます。パターンが長さゼロの文字列に一致する場合は常に、strは個々の文字に分割されます。 場合はパターンが省略されている、の値$; is used. If $; はnil(デフォルト)であり、strは ``が指定されたかのように空白で分割されます。 場合限界パラメータが省略され、末尾のヌルフィールドが抑制されます。limitが正の数の場合、最大でその数のフィールドが返されます(limitが1の場合、文字列全体が配列内の唯一のエントリとして返されます)。負の場合、返されるフィールドの数に制限はなく、末尾のnullフィールドは抑制されません。 |
| 56 | str.squeeze([other_str]*) String#countで説明されている手順を使用して、other_strパラメーターから文字のセットを作成します。このセットで発生する同じ文字の実行が単一の文字に置き換えられた新しい文字列を返します。引数が指定されていない場合、同一文字のすべての実行は単一の文字に置き換えられます。 |
| 57 | str.squeeze!([other_str]*) strを所定の位置に押し込み、strを返すか、変更が加えられていない場合はnilを返します。 |
| 58 | str.strip 先頭と末尾の空白が削除されたstrのコピーを返します。 |
| 59 | str.strip! strから先頭と末尾の空白を削除します。strが変更されていない場合は、nilを返します。 |
| 60 | str.sub(pattern, replacement) [or] str.sub(pattern) { |match| block } パターンの最初の出現が置換またはブロックの値のいずれかで置き換えられたstrのコピーを返します。パターンは通常、正規表現になります。文字列の場合、正規表現のメタ文字は解釈されません。 |
| 61 | str.sub!(pattern, replacement) [or] str.sub!(pattern) { |match| block } String#subの置換を実行し、置換が実行されなかった場合はstrまたはnilを返します。 |
| 62 | str.succ [or] str.next 後続をstrに返します。 |
| 63 | str.succ! [or] str.next! String#succと同等ですが、レシーバーを適切に変更します。 |
| 64 | str.sum(n = 16) str内の文字の基本的なnビットチェックサムを返します。nはオプションのFixnumパラメーターで、デフォルトは16です。結果は単純にstrを法とする各文字のバイナリ値の合計です。これは特にありません。良いチェックサム。 |
| 65 | str.swapcase 大文字の英字を小文字に変換し、小文字を大文字に変換したstrのコピーを返します。 |
| 66 | str.swapcase! String#swapcaseと同等ですが、レシーバーを所定の位置に変更し、変更が行われなかった場合はstrまたはnilを返します。 |
| 67 | str.to_f > strの先頭文字を浮動小数点数として解釈した結果を返します。有効な数値の終わりを超える無関係な文字は無視されます。strの先頭に有効な数値がない場合は、0.0が返されます。このメソッドで例外が発生することはありません。 |
| 68 | str.to_i(base = 10) strの先頭文字を整数ベース(基数2、8、10、または16)として解釈した結果を返します。有効な数値の終わりを超える無関係な文字は無視されます。strの先頭に有効な数値がない場合は、0が返されます。このメソッドで例外が発生することはありません。 |
| 69 | str.to_s [or] str.to_str 受信者を返します。 |
| 70 | str.tr(from_str, to_str) from_strの文字がto_strの対応する文字に置き換えられたstrのコピーを返します。to_strがfrom_strより短い場合は、最後の文字が埋め込まれます。どちらの文字列もc1.c2表記を使用して文字の範囲を示し、from_strは^で始まる場合があります。これは、リストされている文字を除くすべての文字を示します。 |
| 71 | str.tr!(from_str, to_str) String#trと同じルールを使用して、strをインプレースで変換します。strを返します。変更が加えられていない場合はnilを返します。 |
| 72 | str.tr_s(from_str, to_str) String#trで説明されているようにstrのコピーを処理してから、変換の影響を受けた領域で重複する文字を削除します。 |
| 73 | str.tr_s!(from_str, to_str) strに対してString#tr_s処理を実行し、strを返します。変更が行われなかった場合は、nilを返します。 |
| 74 | str.unpack(format) >フォーマット文字列に従ってstr(バイナリデータを含む場合があります)をデコードし、抽出された各値の配列を返します。フォーマット文字列は、表18に要約されている、一連の1文字のディレクティブで構成されます。各ディレクティブの後には、このディレクティブで繰り返す回数を示す数字を続けることができます。アスタリスク(*)は、残りのすべての要素を使い果たします。ディレクティブsSiIlLの後には、それぞれアンダースコア(_)を付けて、指定されたタイプの基になるプラットフォームのネイティブサイズを使用できます。それ以外の場合は、プラットフォームに依存しない一貫したサイズを使用します。フォーマット文字列ではスペースは無視されます。 |
| 75 | str.upcase すべての小文字が対応する大文字に置き換えられたstrのコピーを返します。操作はロケールに依存しません。影響を受けるのは文字aからzのみです。 |
| 76 | str.upcase! strの内容を大文字に変更し、変更がない場合はnilを返します。 |
| 77 | str.upto(other_str) { |s| block } strで始まりother_strで終わる連続する値を繰り返し、各値を順番にブロックに渡します。String#succメソッドは、各値を生成するために使用されます。 |
文字列アンパックディレクティブ
| 指令 | 戻り値 | 説明 |
|---|---|---|
| A | ストリング | 末尾のヌルとスペースが削除されています。 |
| a | ストリング | ストリング。 |
| B | ストリング | 各文字からビットを抽出します(最上位ビットが最初)。 |
| b | ストリング | 各文字からビットを抽出します(最下位ビットが最初)。 |
| C | Fixnum | 文字を符号なし整数として抽出します。 |
| c | Fixnum | 文字を整数として抽出します。 |
| D、d | 浮く | sizeof(double)文字をネイティブdoubleとして扱います。 |
| E | 浮く | sizeof(double)文字をリトルエンディアンバイト順のdoubleとして扱います。 |
| e | 浮く | sizeof(float)文字をリトルエンディアンバイト順のfloatとして扱います。 |
| F、f | 浮く | sizeof(float)文字をネイティブfloatとして扱います。 |
| G | 浮く | sizeof(double)文字をネットワークバイトオーダーのdoubleとして扱います。 |
| g | ストリング | sizeof(float)文字をネットワークバイトオーダーのfloatとして扱います。 |
| H | ストリング | 各文字から16進ニブルを抽出します(最上位ビットが最初) |
| h | ストリング | 各文字から16進ニブルを抽出します(最下位ビットが最初)。 |
| 私 | 整数 | sizeof(int)(_で変更)の連続する文字を符号なしネイティブ整数として扱います。 |
| 私 | 整数 | sizeof(int)(_で変更)の連続する文字を符号付きネイティブ整数として扱います。 |
| L | 整数 | 4つの(_で変更された)連続する文字を符号なしのネイティブ長整数として扱います。 |
| l | 整数 | 4つの(_で変更された)連続する文字を符号付きのネイティブ長整数として扱います。 |
| M | ストリング | 引用-印刷可能。 |
| m | ストリング | Base64でエンコードされています。 |
| N | 整数 | 4文字をネットワークバイトオーダーのunsignedlongとして扱います。 |
| n | Fixnum | 2文字をネットワークバイトオーダーのunsignedshortとして扱います。 |
| P | ストリング | sizeof(char *)文字をポインタとして扱い、参照された場所から\ emph {len}文字を返します。 |
| p | ストリング | sizeof(char *)文字をnullで終了する文字列へのポインタとして扱います。 |
| Q | 整数 | 8文字を符号なしクワッドワード(64ビット)として扱います。 |
| q | 整数 | 8文字を符号付きクワッドワード(64ビット)として扱います。 |
| S | Fixnum | 2つの(_が使用されている場合は異なります)連続する文字を、ネイティブバイト順の符号なしショートとして扱います。 |
| s | Fixnum | 2つの(_が使用されている場合は異なります)連続する文字を、ネイティブバイト順の符号付きショートとして扱います。 |
| U | 整数 | 符号なし整数としてのUTF-8文字。 |
| u | ストリング | UUエンコード。 |
| V | Fixnum | 4文字をリトルエンディアンのバイト順でunsignedlongとして扱います。 |
| v | Fixnum | 2文字をリトルエンディアンのバイト順でunsignedshortとして扱います。 |
| w | 整数 | BER圧縮された整数。 |
| バツ | 1文字後方にスキップします。 | |
| バツ | 1文字前にスキップします。 | |
| Z | ストリング | 末尾のnullを*で最初のnullまで削除します。 |
| @ | length引数で指定されたオフセットにスキップします。 |
例
次の例を試して、さまざまなデータを解凍してください。
"abc \0\0abc \0\0".unpack('A6Z6') #=> ["abc", "abc "]
"abc \0\0".unpack('a3a3') #=> ["abc", " \000\000"]
"abc \0abc \0".unpack('Z*Z*') #=> ["abc ", "abc "]
"aa".unpack('b8B8') #=> ["10000110", "01100001"]
"aaa".unpack('h2H2c') #=> ["16", "61", 97]
"\xfe\xff\xfe\xff".unpack('sS') #=> [-2, 65534]
"now = 20is".unpack('M*') #=> ["now is"]
"whole".unpack('xax2aX2aX1aX2a') #=> ["h", "e", "l", "l", "o"]Ruby配列は、任意のオブジェクトの順序付けられた整数インデックス付きのコレクションです。配列内の各要素は、インデックスに関連付けられ、インデックスによって参照されます。
CやJavaの場合と同様に、配列のインデックス作成は0から始まります。配列の終わりに対して負のインデックスが想定されます。つまり、インデックス-1は配列の最後の要素を示し、-2は配列の最後の要素の次の要素を示します。
Ruby配列は、String、Integer、Fixnum、Hash、Symbol、さらには他のArrayオブジェクトなどのオブジェクトを保持できます。Ruby配列は、他の言語の配列ほど厳密ではありません。Ruby配列は、要素を追加するときに自動的に大きくなります。
配列の作成
配列を作成または初期化する方法はたくさんあります。1つの方法は、新しいクラスメソッドを使用することです。
names = Array.new配列の作成時に配列のサイズを設定できます-
names = Array.new(20)配列名のサイズまたは長さは20要素になりました。sizeまたはlengthメソッドのいずれかを使用して配列のサイズを返すことができます-
#!/usr/bin/ruby
names = Array.new(20)
puts names.size # This returns 20
puts names.length # This also returns 20これにより、次の結果が生成されます-
20
20次のように、配列の各要素に値を割り当てることができます。
#!/usr/bin/ruby
names = Array.new(4, "mac")
puts "#{names}"これにより、次の結果が生成されます-
["mac", "mac", "mac", "mac"]また、新しいブロックを使用して、各要素にブロックの評価値を入力することもできます。
#!/usr/bin/ruby
nums = Array.new(10) { |e| e = e * 2 }
puts "#{nums}"これにより、次の結果が生成されます-
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]配列には別の方法[]があります。このように動作します-
nums = Array.[](1, 2, 3, 4,5)配列作成のもう1つの形式は、次のとおりです。
nums = Array[1, 2, 3, 4,5]カーネルコアRubyで使用可能なモジュールは、単一の引数を受け入れアレイ法を有しています。ここで、このメソッドは、数字の配列を作成するための引数として範囲を取ります-
#!/usr/bin/ruby
digits = Array(0..9)
puts "#{digits}"これにより、次の結果が生成されます-
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]配列組み込みメソッド
Arrayメソッドを呼び出すには、Arrayオブジェクトのインスタンスが必要です。これまで見てきたように、以下はArrayオブジェクトのインスタンスを作成する方法です-
Array.[](...) [or] Array[...] [or] [...]これにより、指定されたオブジェクトが入力された新しい配列が返されます。これで、作成されたオブジェクトを使用して、使用可能な任意のインスタンスメソッドを呼び出すことができます。例-
#!/usr/bin/ruby
digits = Array(0..9)
num = digits.at(6)
puts "#{num}"これにより、次の結果が生成されます-
6| シニア番号 | 方法と説明 |
|---|---|
| 1 | array & other_array 2つの配列に共通の要素を含み、重複のない新しい配列を返します。 |
| 2 | array * int [or] array * str selfのintコピーを連結して作成された新しい配列を返します。文字列引数を使用すると、self.join(str)と同等になります。 |
| 3 | array + other_array 2つの配列を連結して3番目の配列を生成することによって構築された新しい配列を返します。 |
| 4 | array - other_array 元の配列のコピーである新しい配列を返し、other_arrayにも表示されるアイテムをすべて削除します。 |
| 5 | array <=> other_array strをother_strと比較し、-1(より小さい)、0(等しい)、または1(より大きい)を返します。比較では大文字と小文字が区別されます。 |
| 6 | array | other_array 配列をother_arrayと結合し、重複を削除して、新しい配列を返します。 |
| 7 | array << obj 指定されたオブジェクトを配列の最後にプッシュします。この式は配列自体を返すため、複数の追加をチェーン化できます。 |
| 8 | array <=> other_array この配列がother_arrayより小さい、等しい、または大きい場合、整数(-1、0、または+1)を返します。 |
| 9 | array == other_array 2つの配列が同じ数の要素を含み、各要素が(Object。==に従って)他の配列の対応する要素と等しい場合、2つの配列は等しくなります。 |
| 10 | array[index] [or] array[start, length] [or] array[range] [or] array.slice(index) [or] array.slice(start, length) [or] array.slice(range) インデックスの要素を返すか、開始から始まり長さの要素まで続くサブ配列を返すか、範囲で指定されたサブ配列を返します。負のインデックスは、配列の最後から逆方向にカウントされます(-1は最後の要素です)。インデックス(または開始インデックス)が範囲外の場合はnilを返します。 |
| 11 | array[index] = obj [or] array[start, length] = obj or an_array or nil [or] array[range] = obj or an_array or nil 要素をインデックスに設定するか、開始から始まり長さ要素まで続くサブ配列を置き換えるか、範囲で指定されたサブ配列を置き換えます。インデックスが配列の現在の容量よりも大きい場合、配列は自動的に大きくなります。負のインデックスは、配列の末尾から逆方向にカウントされます。長さがゼロの場合に要素を挿入します。2番目と3番目の形式でnilが使用されている場合、selfから要素を削除します。 |
| 12 | array.abbrev(pattern = nil) self内の文字列の明確な略語のセットを計算します。パターンまたは文字列が渡された場合、パターンに一致するか、文字列で始まる文字列のみが考慮されます。 |
| 13 | array.assoc(obj) obj。==を使用して、要素が含まれている各配列の最初の要素とobjを比較する配列でもある配列を検索します。一致する最初に含まれる配列を返します。一致するものが見つからない場合はnilを返します。 |
| 14 | array.at(index) インデックスの要素を返します。負のインデックスは、自己の終わりから数えます。インデックスが範囲外の場合はnilを返します。 |
| 15 | array.clear 配列からすべての要素を削除します。 |
| 16 | array.collect { |item| block } [or] array.map { |item| block } selfの要素ごとに1回ブロックを呼び出します。ブロックによって返される値を含む新しい配列を作成します。 |
| 17 | array.collect! { |item| block } [or] array.map! { |item| block } selfの要素ごとに1回ブロックを呼び出し、要素をblockによって返される値に置き換えます。 |
| 18 | array.compact すべてのnil要素が削除されたselfのコピーを返します。 |
| 19 | array.compact! 配列からnil要素を削除します。変更が加えられていない場合はnilを返します。 |
| 20 | array.concat(other_array) other_arrayの要素を追加し、自己。 |
| 21 | array.delete(obj) [or] array.delete(obj) { block } objに等しいアイテムをselfから削除します。アイテムが見つからない場合は、nilを返します。オプションのコードブロックが指定されている場合、アイテムが見つからない場合はブロックの結果を返します。 |
| 22 | array.delete_at(index) 指定されたインデックスの要素を削除してその要素を返します。インデックスが範囲外の場合はnilを返します。 |
| 23 | array.delete_if { |item| block } すべての要素を削除し、自己いるブロックが真と評価します。 |
| 24 | array.each { |item| block } self内の要素ごとに1回ブロックを呼び出し、その要素をパラメーターとして渡します。 |
| 25 | array.each_index { |index| block } Array#eachと同じですが、要素自体ではなく要素のインデックスを渡します。 |
| 26 | array.empty? 自己配列に要素が含まれていない場合はtrueを返します。 |
| 27 | array.eql?(other) arrayとotherが同じオブジェクトであるか、両方が同じ内容の配列である場合、trueを返します。 |
| 28 | array.fetch(index) [or] array.fetch(index, default) [or] array.fetch(index) { |index| block } 位置インデックスの要素を返そうとします。インデックスが配列の外側にある場合、最初のフォームはIndexError例外をスローし、2番目のフォームはデフォルトを返し、3番目のフォームは呼び出しブロックの値を返し、インデックスを渡します。配列の末尾からのインデックスカウントの負の値。 |
| 29 | array.fill(obj) [or] array.fill(obj, start [, length]) [or] array.fill(obj, range) [or] array.fill { |index| block } [or] array.fill(start [, length] ) { |index| block } [or] array.fill(range) { |index| block } 最初の3つのフォームは、selfの選択された要素をobjに設定します。nilの開始は、ゼロと同等です。nilの長さは、self.lengthと同等です。最後の3つの形式が埋めるブロックの値を持つ配列を。ブロックが充填される各要素の絶対インデックスに渡されます。 |
| 30 | array.first [or] array.first(n) 配列の最初の要素、または最初のn個の要素を返します。配列が空の場合、最初の形式はnilを返し、2番目の形式は空の配列を返します。 |
| 31 | array.flatten この配列を(再帰的に)1次元で平坦化した新しい配列を返します。 |
| 32 | array.flatten! アレイを所定の位置に平坦化します。変更が行われなかった場合はnilを返します。(配列にはサブ配列は含まれていません。) |
| 33 | array.frozen? 配列がフリーズしている(またはソート中に一時的にフリーズしている)場合はtrueを返します。 |
| 34 | array.hash 配列のハッシュコードを計算します。同じ内容の2つの配列は、同じハッシュコードを持ちます。 |
| 35 | array.include?(obj) objがselfに存在する場合はtrueを返し、それ以外の場合はfalseを返します。 |
| 36 | array.index(obj) 自己の最初のオブジェクトのインデックス、つまり==からobjを返します。一致するものが見つからない場合はnilを返します。 |
| 37 | array.indexes(i1, i2, ... iN) [or] array.indices(i1, i2, ... iN) このメソッドは最新バージョンのRubyで非推奨になっているため、Array#values_atを使用してください。 |
| 38 | array.indices(i1, i2, ... iN) [or] array.indexes(i1, i2, ... iN) このメソッドは最新バージョンのRubyで非推奨になっているため、Array#values_atを使用してください。 |
| 39 | array.insert(index, obj...) 指定されたインデックス(負の場合があります)を持つ要素の前に指定された値を挿入します。 |
| 40 | array.inspect 印刷可能なバージョンの配列を作成します。 |
| 41 | array.join(sep = $,) 配列の各要素をsepで区切られた文字列に変換して作成された文字列を返します。 |
| 42 | array.last [or] array.last(n) selfの最後の要素を返します。配列が空の場合、最初の形式はnilを返します。 |
| 43 | array.length self内の要素の数を返します。ゼロの可能性があります。 |
| 44 | array.map { |item| block } [or] array.collect { |item| block } selfの要素ごとに1回ブロックを呼び出します。ブロックによって返される値を含む新しい配列を作成します。 |
| 45 | array.map! { |item| block } [or] array.collect! { |item| block } 配列の要素ごとに1回ブロックを呼び出し、要素をブロックによって返される値に置き換えます。 |
| 46 | array.nitems self内のnil以外の要素の数を返します。ゼロの可能性があります。 |
| 47 | array.pack(aTemplateString) TemplateStringのディレクティブに従って、配列の内容をバイナリシーケンスにパックします。ディレクティブA、a、およびZの後にカウントを続けることができます。これにより、結果のフィールドの幅がわかります。残りのディレクティブもカウントを取り、変換する配列要素の数を示します。カウントがアスタリスク(*)の場合、残りのすべての配列要素が変換されます。指定されたタイプの基になるプラットフォームのネイティブサイズを使用するために、ディレクティブの後にアンダースコア(_)を付けることができます。それ以外の場合は、プラットフォームに依存しないサイズを使用します。テンプレート文字列ではスペースは無視されます。 |
| 48 | array.pop 配列から最後の要素を削除して返します。配列が空の場合はnilを返します。 |
| 49 | array.push(obj, ...) 指定されたobjをこの配列の最後にプッシュ(追加)します。この式は配列自体を返すため、複数の追加をチェーン化できます。 |
| 50 | array.rassoc(key) 要素が配列でもある配列を検索します。==を使用して、含まれている各配列の2番目の要素とキーを比較します。一致する最初に含まれる配列を返します。 |
| 51 | array.reject { |item| block } ブロックがtrueではないitems配列を含む新しい配列を返します。 |
| 52 | array.reject! { |item| block } ブロックがtrueと評価される配列から要素を削除しますが、変更が行われなかった場合はnilを返します。Array#delete_ifと同等です。 |
| 53 | array.replace(other_array) 内容置き換えアレイの内容other_array切り詰めるか、必要に応じて拡大し、。 |
| 54 | array.reverse 配列の要素を逆の順序で含む新しい配列を返します。 |
| 55 | array.reverse! アレイを元の位置に戻します。 |
| 56 | array.reverse_each {|item| block } Array#eachと同じですが、逆の順序で配列をトラバースします。 |
| 57 | array.rindex(obj) 配列==の最後のオブジェクトのインデックスをobjに返します。一致するものが見つからない場合はnilを返します。 |
| 58 | array.select {|item| block } 配列から連続する要素を渡すブロックを呼び出し、ブロックが真の値を返す要素を含む配列を返します。 |
| 59 | array.shift selfの最初の要素を返し、それを削除します(他のすべての要素を1つ下にシフトします)。配列が空の場合はnilを返します。 |
| 60 | array.size 配列の長さ(要素の数)を返します。長さのエイリアス。 |
| 61 | array.slice(index) [or] array.slice(start, length) [or] array.slice(range) [or] array[index] [or] array[start, length] [or] array[range] インデックスの要素を返すか、開始から始まり長さの要素まで続くサブ配列を返すか、範囲で指定されたサブ配列を返します。負のインデックスは、配列の最後から逆方向にカウントされます(-1は最後の要素です)。インデックス(または開始インデックス)が範囲外の場合はnilを返します。 |
| 62 | array.slice!(index) [or] array.slice!(start, length) [or] array.slice!(range) インデックス(オプションで長さ)または範囲で指定された要素を削除します。削除されたオブジェクト、サブ配列、またはインデックスが範囲外の場合はnilを返します。 |
| 63 | array.sort [or] array.sort { | a,b | block } selfをソートして作成された新しい配列を返します。 |
| 64 | array.sort! [or] array.sort! { | a,b | block } 自己をソートします。 |
| 65 | array.to_a selfを返します。Arrayのサブクラスで呼び出された場合、レシーバーをArrayオブジェクトに変換します。 |
| 66 | array.to_ary 自己を返します。 |
| 67 | array.to_s self.joinを返します。 |
| 68 | array.transpose selfは配列の配列であると想定し、行と列を転置します。 |
| 69 | array.uniq で重複する値を削除して、新しい配列を返します配列。 |
| 70 | array.uniq! 自己から重複要素を削除します。変更が加えられていない場合(つまり、重複が見つからない場合)はnilを返します。 |
| 71 | array.unshift(obj, ...) オブジェクトを配列の前に、他の要素を1つ上に追加します。 |
| 72 | array.values_at(selector,...) 指定されたセレクター(1つ以上)に対応するself内の要素を含む配列を返します。セレクターは、整数のインデックスまたは範囲のいずれかです。 |
| 73 | array.zip(arg, ...) [or] array.zip(arg, ...){ | arr | block } アレイへの引数を変換し、その後の要素マージ配列を各引数の対応する要素を有します。 |
アレイパックディレクティブ
| シニア番号 | 指令と説明 |
|---|---|
| 1 | @ 絶対位置に移動します。 |
| 2 | A ASCII文字列(スペースが埋め込まれ、カウントは幅です)。 |
| 3 | a ASCII文字列(nullが埋め込まれ、カウントは幅です)。 |
| 4 | B 文字列(ビット順の降順)。 |
| 5 | b ビット文字列(ビットの昇順)。 |
| 6 | C unsignedchar。 |
| 7 | c チャー |
| 8 | D, d 倍精度浮動小数点、ネイティブ形式。 |
| 9 | E 倍精度浮動小数点、リトルエンディアンのバイト順序。 |
| 10 | e 単精度浮動小数点、リトルエンディアンのバイト順序。 |
| 11 | F, f 単精度浮動小数点、ネイティブ形式。 |
| 12 | G 倍精度浮動小数点数、ネットワーク(ビッグエンディアン)バイトオーダー。 |
| 13 | g 単精度浮動小数点、ネットワーク(ビッグエンディアン)バイトオーダー。 |
| 14 | H 16進文字列(最初に高ニブル)。 |
| 15 | h 16進文字列(最初に低いニブル)。 |
| 16 | I 符号なし整数。 |
| 17 | i 整数。 |
| 18 | L 署名されていない長い。 |
| 19 | l 長いです。 |
| 20 | M 引用された印刷可能なMIMEエンコーディング(RFC 2045を参照)。 |
| 21 | m Base64でエンコードされた文字列。 |
| 22 | N 長いネットワーク(ビッグエンディアン)バイトオーダー。 |
| 23 | n 短いネットワーク(ビッグエンディアン)バイトオーダー。 |
| 24 | P 構造体へのポインター(固定長文字列)。 |
| 25 | p nullで終了する文字列へのポインタ。 |
| 26 | Q, q 64ビットの数値。 |
| 27 | S 符号なしショート。 |
| 28 | s ショート。 |
| 29 | U UTF-8。 |
| 30 | u UUでエンコードされた文字列。 |
| 31 | V 長いリトルエンディアンのバイトオーダー。 |
| 32 | v 短いリトルエンディアンのバイトオーダー。 |
| 33 | w BER圧縮された整数\ fnm。 |
| 34 | X バイトをバックアップします。 |
| 35 | x ヌルバイト。 |
| 36 | Z nullが*で追加されることを除いて、aと同じです。 |
例
次の例を試して、さまざまなデータをパックしてください。
a = [ "a", "b", "c" ]
n = [ 65, 66, 67 ]
puts a.pack("A3A3A3") #=> "a b c "
puts a.pack("a3a3a3") #=> "a\000\000b\000\000c\000\000"
puts n.pack("ccc") #=> "ABC"これにより、次の結果が生成されます-
a b c
abc
ABCハッシュは、次のようなキーと値のペアのコレクションです: "employee" => "salary"。インデックス付けが整数インデックスではなく、任意のオブジェクトタイプの任意のキーを介して行われることを除いて、配列に似ています。
キーまたは値のいずれかでハッシュをトラバースする順序は任意に見える場合があり、通常は挿入順序ではありません。存在しないキーを使用してハッシュにアクセスしようとすると、メソッドはnilを返します。
ハッシュの作成
配列と同様に、ハッシュを作成するにはさまざまな方法があります。新しいクラスメソッドで空のハッシュを作成できます-
months = Hash.newnewを使用して、デフォルト値でハッシュを作成することもできます。それ以外の場合はnil −です。
months = Hash.new( "month" )
or
months = Hash.new "month"デフォルト値を持つハッシュ内のキーにアクセスするときに、キーまたは値が存在しない場合、ハッシュにアクセスするとデフォルト値が返されます-
#!/usr/bin/ruby
months = Hash.new( "month" )
puts "#{months[0]}"
puts "#{months[72]}"これにより、次の結果が生成されます-
month
month#!/usr/bin/ruby
H = Hash["a" => 100, "b" => 200]
puts "#{H['a']}"
puts "#{H['b']}"これにより、次の結果が生成されます-
100
200配列であっても、任意のRubyオブジェクトをキーまたは値として使用できるため、次の例は有効な例です。
[1,"jan"] => "January"ハッシュ組み込みメソッド
Hashメソッドを呼び出すには、Hashオブジェクトのインスタンスが必要です。これまで見てきたように、以下はハッシュオブジェクトのインスタンスを作成する方法です-
Hash[[key =>|, value]* ] or
Hash.new [or] Hash.new(obj) [or]
Hash.new { |hash, key| block }これにより、指定されたオブジェクトが入力された新しいハッシュが返されます。作成したオブジェクトを使用して、使用可能なインスタンスメソッドを呼び出すことができます。例-
#!/usr/bin/ruby
$, = ", "
months = Hash.new( "month" )
months = {"1" => "January", "2" => "February"}
keys = months.keys
puts "#{keys}"これにより、次の結果が生成されます-
["1", "2"]以下はパブリックハッシュメソッドです(ハッシュが配列オブジェクトであると仮定)-
| シニア番号 | 方法と説明 |
|---|---|
| 1 | hash == other_hash 2つのハッシュが等しいかどうか、キーと値のペアの数が同じかどうか、およびキーと値のペアが各ハッシュの対応するペアと一致するかどうかをテストします。 |
| 2 | hash.[key] キーを使用して、ハッシュから値を参照します。キーが見つからない場合は、デフォルト値を返します。 |
| 3 | hash.[key] = value valueで指定された値をkeyで指定されたキーに関連付けます。 |
| 4 | hash.clear すべてのキーと値のペアをハッシュから削除します。 |
| 5 | hash.default(key = nil) hashのデフォルト値を返します。default=で設定されていない場合はnilを返します。([]は、キーがハッシュに存在しない場合、デフォルト値を返します。) |
| 6 | hash.default = obj hashのデフォルト値を設定します。 |
| 7 | hash.default_proc ハッシュがブロックによって作成された場合、ブロックを返します。 |
| 8 | hash.delete(key) [or] array.delete(key) { |key| block } キーごとのハッシュからキーと値のペアを削除します。ブロックが使用されている場合、ペアが見つからない場合はブロックの結果を返します。delete_ifを比較します。 |
| 9 | hash.delete_if { |key,value| block } ブロックがtrueと評価するすべてのペアのハッシュからキーと値のペアを削除します。 |
| 10 | hash.each { |key,value| block } ハッシュを反復処理し、キーごとに1回ブロックを呼び出し、キー値を2要素配列として渡します。 |
| 11 | hash.each_key { |key| block } ハッシュを反復処理し、キーごとに1回ブロックを呼び出し、キーをパラメーターとして渡します。 |
| 12 | hash.each_key { |key_value_array| block } で反復ハッシュ、それぞれに一度ブロックを呼び出すキー渡して、キーと値のパラメータとしてを。 |
| 13 | hash.each_key { |value| block } ハッシュを反復処理し、キーごとに1回ブロックを呼び出し、値をパラメーターとして渡します。 |
| 14 | hash.empty? ハッシュが空(キーと値のペアを含まない)であるかどうかをテストし、trueまたはfalseを返します。 |
| 15 | hash.fetch(key [, default] ) [or] hash.fetch(key) { | key | block } 指定されたキーのハッシュから値を返します。場合は、キーを見つけることができず、他の引数がない、それが提起はIndexError例外を。デフォルトが指定されている場合は、それが返されます。オプションのブロックが指定されている場合、その結果が返されます。 |
| 16 | hash.has_key?(key) [or] hash.include?(key) [or] hash.key?(key) [or] hash.member?(key) 指定されたキーがハッシュに存在するかどうかをテストし、trueまたはfalseを返します。 |
| 17 | hash.has_value?(value) ハッシュに指定された値が含まれているかどうかをテストします。 |
| 18 | hash.index(value) 戻り値のキー与えられたため値のハッシュでは、nilに一致する値が見つからない場合。 |
| 19 | hash.indexes(keys) 指定されたキーの値で構成される新しい配列を返します。見つからないキーのデフォルト値を挿入します。このメソッドは非推奨です。selectを使用します。 |
| 20 | hash.indices(keys) 指定されたキーの値で構成される新しい配列を返します。見つからないキーのデフォルト値を挿入します。このメソッドは非推奨です。selectを使用します。 |
| 21 | hash.inspect ハッシュのプリティプリント文字列バージョンを返します。 |
| 22 | hash.invert 新しい作成ハッシュ反転、キーと値のハッシュは、つまり、新しいハッシュでは、ハッシュのキーが値になり、値がキーになります。 |
| 23 | hash.keys hashからのキーを使用して新しい配列を作成します。 |
| 24 | hash.length ハッシュのサイズまたは長さを整数として返します。 |
| 25 | hash.merge(other_hash) [or] hash.merge(other_hash) { |key, oldval, newval| block } 内容を含む新しいハッシュを返しますハッシュとother_hashをからのものと重複したキーを持つハッシュでペアを上書きし、other_hash。 |
| 26 | hash.merge!(other_hash) [or] hash.merge!(other_hash) { |key, oldval, newval| block } マージと同じですが、変更はその場で行われます。 |
| 27 | hash.rehash 各キーの現在の値に基づいてハッシュを再構築します。挿入後に値が変更された場合、このメソッドはハッシュのインデックスを再作成します。 |
| 28 | hash.reject { |key, value| block } ブロックがtrueと評価するすべてのペアに対して新しいハッシュを作成します |
| 29 | hash.reject! { |key, value| block } 拒否と同じですが、変更が加えられます。 |
| 30 | hash.replace(other_hash) hashの内容をother_hashの内容に置き換えます。 |
| 31 | hash.select { |key, value| block } 戻り値からキーと値のペアからなる新しい配列ハッシュ対象のブロックが返さ真。 |
| 32 | hash.shift キーと値のペアをハッシュから削除し、2要素の配列として返します。 |
| 33 | hash.size ハッシュのサイズまたは長さを整数として返します。 |
| 34 | hash.sort ハッシュをキーと値のペアの配列を含む2次元配列に変換し、それを配列として並べ替えます。 |
| 35 | hash.store(key, value) キーと値のペアをハッシュに格納します。 |
| 36 | hash.to_a ハッシュから2次元配列を作成します。各キーと値のペアは配列に変換され、これらの配列はすべて、含まれている配列に格納されます。 |
| 37 | hash.to_hash ハッシュ(自己)を返します。 |
| 38 | hash.to_s 変換のハッシュ配列には、その文字列にその配列を変換します。 |
| 39 | hash.update(other_hash) [or] hash.update(other_hash) {|key, oldval, newval| block} 内容を含む新しいハッシュを返しますハッシュとother_hashで、上書きペアをハッシュからのものと重複キーでother_hashを。 |
| 40 | hash.value?(value) ハッシュに指定された値が含まれているかどうかをテストします。 |
| 41 | hash.values hashのすべての値を含む新しい配列を返します。 |
| 42 | hash.values_at(obj, ...) 指定された1つまたは複数のキーに関連付けられているハッシュからの値を含む新しい配列を返します。 |
ザ・ TimeクラスはRubyの日付と時刻を表します。これは、オペレーティングシステムによって提供されるシステムの日付と時刻の機能を覆う薄い層です。このクラスは、システム上で1970年より前または2038年以降の日付を表すことができない場合があります。
この章では、最も必要とされる日付と時刻の概念をすべて理解します。
現在の日付と時刻を取得する
以下は、現在の日付と時刻を取得する簡単な例です。
#!/usr/bin/ruby -w
time1 = Time.new
puts "Current Time : " + time1.inspect
# Time.now is a synonym:
time2 = Time.now
puts "Current Time : " + time2.inspectこれにより、次の結果が生成されます-
Current Time : Mon Jun 02 12:02:39 -0700 2008
Current Time : Mon Jun 02 12:02:39 -0700 2008日付と時刻のコンポーネントの取得
Timeオブジェクトを使用して、日付と時刻のさまざまなコンポーネントを取得できます。以下は同じを示す例です-
#!/usr/bin/ruby -w
time = Time.new
# Components of a Time
puts "Current Time : " + time.inspect
puts time.year # => Year of the date
puts time.month # => Month of the date (1 to 12)
puts time.day # => Day of the date (1 to 31 )
puts time.wday # => 0: Day of week: 0 is Sunday
puts time.yday # => 365: Day of year
puts time.hour # => 23: 24-hour clock
puts time.min # => 59
puts time.sec # => 59
puts time.usec # => 999999: microseconds
puts time.zone # => "UTC": timezone nameこれにより、次の結果が生成されます-
Current Time : Mon Jun 02 12:03:08 -0700 2008
2008
6
2
1
154
12
3
8
247476
UTCTime.utc、Time.gmおよびTime.local関数
これらの2つの関数を使用して、次のように標準形式で日付をフォーマットできます。
# July 8, 2008
Time.local(2008, 7, 8)
# July 8, 2008, 09:10am, local time
Time.local(2008, 7, 8, 9, 10)
# July 8, 2008, 09:10 UTC
Time.utc(2008, 7, 8, 9, 10)
# July 8, 2008, 09:10:11 GMT (same as UTC)
Time.gm(2008, 7, 8, 9, 10, 11)以下は、配列内のすべてのコンポーネントを次の形式で取得する例です。
[sec,min,hour,day,month,year,wday,yday,isdst,zone]次のことを試してください-
#!/usr/bin/ruby -w
time = Time.new
values = time.to_a
p valuesこれにより、次の結果が生成されます-
[26, 10, 12, 2, 6, 2008, 1, 154, false, "MST"]この配列はに渡すことができTime.utcまたはTime.local次のように日付の異なるフォーマットを取得する機能-
#!/usr/bin/ruby -w
time = Time.new
values = time.to_a
puts Time.utc(*values)これにより、次の結果が生成されます-
Mon Jun 02 12:15:36 UTC 2008以下は、(プラットフォームに依存する)エポックからの秒数として内部的に表される時間を取得する方法です。
# Returns number of seconds since epoch
time = Time.now.to_i
# Convert number of seconds into Time object.
Time.at(time)
# Returns second since epoch which includes microseconds
time = Time.now.to_fタイムゾーンと夏時間
次のように、Timeオブジェクトを使用して、タイムゾーンと夏時間に関連するすべての情報を取得できます。
time = Time.new
# Here is the interpretation
time.zone # => "UTC": return the timezone
time.utc_offset # => 0: UTC is 0 seconds offset from UTC
time.zone # => "PST" (or whatever your timezone is)
time.isdst # => false: If UTC does not have DST.
time.utc? # => true: if t is in UTC time zone
time.localtime # Convert to local timezone.
time.gmtime # Convert back to UTC.
time.getlocal # Return a new Time object in local zone
time.getutc # Return a new Time object in UTC時間と日付のフォーマット
日付と時刻をフォーマットするには、さまざまな方法があります。これはいくつかを示す一例です-
#!/usr/bin/ruby -w
time = Time.new
puts time.to_s
puts time.ctime
puts time.localtime
puts time.strftime("%Y-%m-%d %H:%M:%S")これにより、次の結果が生成されます-
Mon Jun 02 12:35:19 -0700 2008
Mon Jun 2 12:35:19 2008
Mon Jun 02 12:35:19 -0700 2008
2008-06-02 12:35:19時間フォーマットディレクティブ
次の表のこれらのディレクティブは、Time.strftimeメソッドで使用されます。
| シニア番号 | 指令と説明 |
|---|---|
| 1 | %a 平日の略称(日)。 |
| 2 | %A 完全な平日の名前(日曜日)。 |
| 3 | %b 月の省略名(1月)。 |
| 4 | %B 完全な月の名前(1月)。 |
| 5 | %c 推奨されるローカルの日付と時刻の表現。 |
| 6 | %d 月の日(01から31)。 |
| 7 | %H 1日の時間、24時間制(00から23)。 |
| 8 | %I 1日の時間、12時間制(01から12)。 |
| 9 | %j 年間通算日(001から366)。 |
| 10 | %m 年の月(01から12)。 |
| 11 | %M 時間の分(00から59)。 |
| 12 | %p 子午線インジケーター(AMまたはPM)。 |
| 13 | %S 分の秒(00から60)。 |
| 14 | %U 今年の週番号。最初の週の最初の日(00から53)として最初の日曜日から始まります。 |
| 15 | %W 今年の週番号。最初の週の最初の日として最初の月曜日から始まります(00から53)。 |
| 16 | %w 曜日(日曜日は0、0から6)。 |
| 17 | %x 日付のみ、時間なしの優先表現。 |
| 18 | %X 日付なしで、時間のみの優先表現。 |
| 19 | %y 世紀のない年(00から99)。 |
| 20 | %Y 世紀のある年。 |
| 21 | %Z タイムゾーン名。 |
| 22 | %% リテラル%文字。 |
時間演算
次のように、時間とともに簡単な算術演算を実行できます。
now = Time.now # Current time
puts now
past = now - 10 # 10 seconds ago. Time - number => Time
puts past
future = now + 10 # 10 seconds from now Time + number => Time
puts future
diff = future - past # => 10 Time - Time => number of seconds
puts diffこれにより、次の結果が生成されます-
Thu Aug 01 20:57:05 -0700 2013
Thu Aug 01 20:56:55 -0700 2013
Thu Aug 01 20:57:15 -0700 2013
20.0範囲はどこでも発生します:1月から12月、0から9、50行から67行など。Rubyは範囲をサポートし、さまざまな方法で範囲を使用できるようにします-
- シーケンスとしての範囲
- 条件としての範囲
- 間隔としての範囲
シーケンスとしての範囲
範囲の最初の、そしておそらく最も自然な使用法は、シーケンスを表現することです。シーケンスには、開始点、終了点、およびシーケンス内で連続する値を生成する方法があります。
Rubyはこれらのシーケンスを使用して作成します ''..'' そして ''...''範囲演算子。2ドット形式は包括的範囲を作成し、3ドット形式は指定された高い値を除外する範囲を作成します。
(1..5) #==> 1, 2, 3, 4, 5
(1...5) #==> 1, 2, 3, 4
('a'..'d') #==> 'a', 'b', 'c', 'd'シーケンス1..100は、2つのFixnumオブジェクトへの参照を含むRangeオブジェクトとして保持されます。必要に応じて、to_aメソッドを使用して範囲をリストに変換できます。次の例を試してください-
#!/usr/bin/ruby
$, =", " # Array value separator
range1 = (1..10).to_a
range2 = ('bar'..'bat').to_a
puts "#{range1}"
puts "#{range2}"これにより、次の結果が生成されます-
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
["bar", "bas", "bat"]Ranges implement methods that let you iterate over them and test their contents in a variety of ways −
#!/usr/bin/ruby
# Assume a range
digits = 0..9
puts digits.include?(5)
ret = digits.min
puts "Min value is #{ret}"
ret = digits.max
puts "Max value is #{ret}"
ret = digits.reject {|i| i < 5 }
puts "Rejected values are #{ret}"
digits.each do |digit|
puts "In Loop #{digit}"
endThis will produce the following result −
true
Min value is 0
Max value is 9
Rejected values are 5, 6, 7, 8, 9
In Loop 0
In Loop 1
In Loop 2
In Loop 3
In Loop 4
In Loop 5
In Loop 6
In Loop 7
In Loop 8
In Loop 9Ranges as Conditions
Ranges may also be used as conditional expressions. For example, the following code fragment prints sets of lines from the standard input, where the first line in each set contains the word start and the last line the word ends −
while gets
print if /start/../end/
endRanges can be used in case statements −
#!/usr/bin/ruby
score = 70
result = case score
when 0..40 then "Fail"
when 41..60 then "Pass"
when 61..70 then "Pass with Merit"
when 71..100 then "Pass with Distinction"
else "Invalid Score"
end
puts resultThis will produce the following result −
Pass with MeritRanges as Intervals
A final use of the versatile range is as an interval test: seeing if some value falls within the interval represented by the range. This is done using ===, the case equality operator.
#!/usr/bin/ruby
if ((1..10) === 5)
puts "5 lies in (1..10)"
end
if (('a'..'j') === 'c')
puts "c lies in ('a'..'j')"
end
if (('a'..'j') === 'z')
puts "z lies in ('a'..'j')"
endThis will produce the following result −
5 lies in (1..10)
c lies in ('a'..'j')Iterators are nothing but methods supported by collections. Objects that store a group of data members are called collections. In Ruby, arrays and hashes can be termed collections.
Iterators return all the elements of a collection, one after the other. We will be discussing two iterators here, each and collect. Let's look at these in detail.
Ruby each Iterator
The each iterator returns all the elements of an array or a hash.
Syntax
collection.each do |variable|
code
endExecutes code for each element in collection. Here, collection could be an array or a ruby hash.
Example
#!/usr/bin/ruby
ary = [1,2,3,4,5]
ary.each do |i|
puts i
endThis will produce the following result −
1
2
3
4
5You always associate the each iterator with a block. It returns each value of the array, one by one, to the block. The value is stored in the variable i and then displayed on the screen.
Ruby collect Iterator
The collect iterator returns all the elements of a collection.
Syntax
collection = collection.collectThe collect method need not always be associated with a block. The collect method returns the entire collection, regardless of whether it is an array or a hash.
Example
#!/usr/bin/ruby
a = [1,2,3,4,5]
b = Array.new
b = a.collect
puts bThis will produce the following result −
1
2
3
4
5NOTE − The collect method is not the right way to do copying between arrays. There is another method called a clone, which should be used to copy one array into another array.
You normally use the collect method when you want to do something with each of the values to get the new array. For example, this code produces an array b containing 10 times each value in a.
#!/usr/bin/ruby
a = [1,2,3,4,5]
b = a.collect{|x| 10*x}
puts bThis will produce the following result −
10
20
30
40
50Ruby provides a whole set of I/O-related methods implemented in the Kernel module. All the I/O methods are derived from the class IO.
The class IO provides all the basic methods, such as read, write, gets, puts, readline, getc, and printf.
This chapter will cover all the basic I/O functions available in Ruby. For more functions, please refer to Ruby Class IO.
The puts Statement
In the previous chapters, you have assigned values to variables and then printed the output using puts statement.
The puts statement instructs the program to display the value stored in the variable. This will add a new line at the end of each line it writes.
Example
#!/usr/bin/ruby
val1 = "This is variable one"
val2 = "This is variable two"
puts val1
puts val2This will produce the following result −
This is variable one
This is variable twoThe gets Statement
The gets statement can be used to take any input from the user from standard screen called STDIN.
Example
The following code shows you how to use the gets statement. This code will prompt the user to enter a value, which will be stored in a variable val and finally will be printed on STDOUT.
#!/usr/bin/ruby
puts "Enter a value :"
val = gets
puts valThis will produce the following result −
Enter a value :
This is entered value
This is entered valueThe putc Statement
Unlike the puts statement, which outputs the entire string onto the screen, the putc statement can be used to output one character at a time.
Example
The output of the following code is just the character H −
#!/usr/bin/ruby
str = "Hello Ruby!"
putc strThis will produce the following result −
HThe print Statement
The print statement is similar to the puts statement. The only difference is that the puts statement goes to the next line after printing the contents, whereas with the print statement the cursor is positioned on the same line.
Example
#!/usr/bin/ruby
print "Hello World"
print "Good Morning"This will produce the following result −
Hello WorldGood MorningOpening and Closing Files
Until now, you have been reading and writing to the standard input and output. Now, we will see how to play with actual data files.
The File.new Method
You can create a File object using File.new method for reading, writing, or both, according to the mode string. Finally, you can use File.close method to close that file.
Syntax
aFile = File.new("filename", "mode")
# ... process the file
aFile.closeThe File.open Method
You can use File.open method to create a new file object and assign that file object to a file. However, there is one difference in between File.open and File.new methods. The difference is that the File.open method can be associated with a block, whereas you cannot do the same using the File.new method.
File.open("filename", "mode") do |aFile|
# ... process the file
end| Sr.No. | Modes & Description |
|---|---|
| 1 | r Read-only mode. The file pointer is placed at the beginning of the file. This is the default mode. |
| 2 | r+ Read-write mode. The file pointer will be at the beginning of the file. |
| 3 | w Write-only mode. Overwrites the file if the file exists. If the file does not exist, creates a new file for writing. |
| 4 | w+ Read-write mode. Overwrites the existing file if the file exists. If the file does not exist, creates a new file for reading and writing. |
| 5 | a Write-only mode. The file pointer is at the end of the file if the file exists. That is, the file is in the append mode. If the file does not exist, it creates a new file for writing. |
| 6 | a+ Read and write mode. The file pointer is at the end of the file if the file exists. The file opens in the append mode. If the file does not exist, it creates a new file for reading and writing. |
Reading and Writing Files
The same methods that we've been using for 'simple' I/O are available for all file objects. So, gets reads a line from standard input, and aFile.gets reads a line from the file object aFile.
However, I/O objects provides additional set of access methods to make our lives easier.
The sysread Method
You can use the method sysread to read the contents of a file. You can open the file in any of the modes when using the method sysread. For example −
Following is the input text file −
This is a simple text file for testing purpose.Now let's try to read this file −
#!/usr/bin/ruby
aFile = File.new("input.txt", "r")
if aFile
content = aFile.sysread(20)
puts content
else
puts "Unable to open file!"
endThis statement will output the first 20 characters of the file. The file pointer will now be placed at the 21st character in the file.
The syswrite Method
You can use the method syswrite to write the contents into a file. You need to open the file in write mode when using the method syswrite. For example −
#!/usr/bin/ruby
aFile = File.new("input.txt", "r+")
if aFile
aFile.syswrite("ABCDEF")
else
puts "Unable to open file!"
endThis statement will write "ABCDEF" into the file.
The each_byte Method
This method belongs to the class File. The method each_byte is always associated with a block. Consider the following code sample −
#!/usr/bin/ruby
aFile = File.new("input.txt", "r+")
if aFile
aFile.syswrite("ABCDEF")
aFile.each_byte {|ch| putc ch; putc ?. }
else
puts "Unable to open file!"
endCharacters are passed one by one to the variable ch and then displayed on the screen as follows −
s. .a. .s.i.m.p.l.e. .t.e.x.t. .f.i.l.e. .f.o.r. .t.e.s.t.i.n.g. .p.u.r.p.o.s.e...
.
.The IO.readlines Method
The class File is a subclass of the class IO. The class IO also has some methods, which can be used to manipulate files.
One of the IO class methods is IO.readlines. This method returns the contents of the file line by line. The following code displays the use of the method IO.readlines −
#!/usr/bin/ruby
arr = IO.readlines("input.txt")
puts arr[0]
puts arr[1]In this code, the variable arr is an array. Each line of the file input.txt will be an element in the array arr. Therefore, arr[0] will contain the first line, whereas arr[1] will contain the second line of the file.
The IO.foreach Method
このメソッドは、出力を1行ずつ返します。メソッドforeachとメソッドreadlinesの違いは、メソッドforeachがブロックに関連付けられていることです。しかし、メソッドとは異なりreadlines、メソッドのforeachは、配列を返しません。例-
#!/usr/bin/ruby
IO.foreach("input.txt"){|block| puts block}このコードは、ファイルテストの内容を1行ずつ変数ブロックに渡し、出力が画面に表示されます。
ファイルの名前変更と削除
名前の変更と削除のメソッドを使用して、Rubyを使用してプログラムでファイルの名前を変更および削除できます。
以下は、既存のファイルの名前を変更する例であるtest1.txtというの-
#!/usr/bin/ruby
# Rename a file from test1.txt to test2.txt
File.rename( "test1.txt", "test2.txt" )以下は、既存のファイルを削除する例ですtest2.txtという名前を-
#!/usr/bin/ruby
# Delete file test2.txt
File.delete("test2.txt")ファイルモードと所有権
マスクを指定したchmodメソッドを使用して、ファイルのモードまたはアクセス許可/アクセスリストを変更します-
以下は、既存のファイルtest.txtのモードをマスク値に変更する例です-
#!/usr/bin/ruby
file = File.new( "test.txt", "w" )
file.chmod( 0755 )| シニア番号 | マスクと説明 |
|---|---|
| 1 | 0700 所有者のためのrwxマスク |
| 2 | 0400 所有者のr |
| 3 | 0200 オーナーはw |
| 4 | 0100 所有者の場合はx |
| 5 | 0070 グループのrwxマスク |
| 6 | 0040 グループのr |
| 7 | 0020 グループの場合はw |
| 8 | 0010 グループの場合はx |
| 9 | 0007 その他のrwxマスク |
| 10 | 0004 その他のr |
| 11 | 0002 その他はw |
| 12 | 0001 その他の場合はx |
| 13 | 4000 実行時にユーザーIDを設定する |
| 14 | 2000 実行時にグループIDを設定する |
| 15 | 1000 使用後もスワップされたテキストを保存する |
ファイルのお問い合わせ
次のコマンドは、ファイルを開く前にファイルが存在するかどうかをテストします-
#!/usr/bin/ruby
File.open("file.rb") if File::exists?( "file.rb" )次のコマンドは、ファイルが本当にファイルであるかどうかを問い合わせます-
#!/usr/bin/ruby
# This returns either true or false
File.file?( "text.txt" )次のコマンドは、指定されたファイル名がディレクトリであるかどうかを確認します-
#!/usr/bin/ruby
# a directory
File::directory?( "/usr/local/bin" ) # => true
# a file
File::directory?( "file.rb" ) # => false次のコマンドは、ファイルが読み取り可能、書き込み可能、または実行可能かどうかを検出します-
#!/usr/bin/ruby
File.readable?( "test.txt" ) # => true
File.writable?( "test.txt" ) # => true
File.executable?( "test.txt" ) # => false次のコマンドは、ファイルのサイズがゼロかどうかを検出します-
#!/usr/bin/ruby
File.zero?( "test.txt" ) # => true次のコマンドはファイルのサイズを返します-
#!/usr/bin/ruby
File.size?( "text.txt" ) # => 1002次のコマンドを使用して、ファイルのタイプを見つけることができます-
#!/usr/bin/ruby
File::ftype( "test.txt" ) # => fileftypeメソッドは、file、directory、characterSpecial、blockSpecial、fifo、link、socket、unknownのいずれかを返すことによってファイルのタイプを識別します。
次のコマンドを使用して、ファイルがいつ作成、変更、または最後にアクセスされたかを確認できます-
#!/usr/bin/ruby
File::ctime( "test.txt" ) # => Fri May 09 10:06:37 -0700 2008
File::mtime( "text.txt" ) # => Fri May 09 10:44:44 -0700 2008
File::atime( "text.txt" ) # => Fri May 09 10:45:01 -0700 2008Rubyのディレクトリ
すべてのファイルはさまざまなディレクトリに含まれており、Rubyもこれらを問題なく処理できます。一方、ファイルのクラスハンドルファイル、ディレクトリがで扱われるのDirクラス。
ディレクトリをナビゲートする
Rubyプログラム内のディレクトリを変更するには、次のようにDir.chdirを使用します。この例では、現在のディレクトリを/ usr / binに変更します。
Dir.chdir("/usr/bin")Dir.pwd −を使用して、現在のディレクトリが何であるかを確認できます。
puts Dir.pwd # This will return something like /usr/binDir.entries −を使用して、特定のディレクトリ内のファイルとディレクトリのリストを取得できます。
puts Dir.entries("/usr/bin").join(' ')Dir.entriesは、指定されたディレクトリ内のすべてのエントリを含む配列を返します。Dir.foreachは同じ機能を提供します-
Dir.foreach("/usr/bin") do |entry|
puts entry
endディレクトリリストを取得するさらに簡潔な方法は、Dirのクラス配列メソッドを使用することです。
Dir["/usr/bin/*"]ディレクトリの作成
Dir.mkdirは、ディレクトリを作成するために使用することができます-
Dir.mkdir("mynewdir")mkdir −を使用して、新しいディレクトリ(既存のディレクトリではない)にアクセス許可を設定することもできます。
NOTE −マスク755は、パーミッションの所有者、グループ、ワールド[誰でも]をrwxr-xr-xに設定します。ここで、r =読み取り、w =書き込み、x =実行です。
Dir.mkdir( "mynewdir", 755 )ディレクトリの削除
Dir.deleteは、ディレクトリを削除するために使用することができます。Dir.unlinkとDir.rmdirはまったく同じ機能を実行し、便宜のために提供されます。
Dir.delete("testdir")ファイルと一時ディレクトリの作成
一時ファイルとは、プログラムの実行中に一時的に作成される可能性があるが、情報の永続的な保存ではないファイルです。
Dir.tmpdirは、現在のシステムの一時ディレクトリへのパスを提供しますが、このメソッドはデフォルトでは使用できません。Dir.tmpdirを使用可能にするには、require'tmpdir 'を使用する必要があります。
あなたは使用することができますDir.tmpdirをしてFile.joinプラットフォームに依存しない一時ファイルを作成するために-
require 'tmpdir'
tempfilename = File.join(Dir.tmpdir, "tingtong")
tempfile = File.new(tempfilename, "w")
tempfile.puts "This is a temporary file"
tempfile.close
File.delete(tempfilename)このコードは、一時ファイルを作成し、それにデータを書き込み、削除します。Rubyの標準ライブラリには、一時ファイルを作成できるTempfileというライブラリも含まれています。
require 'tempfile'
f = Tempfile.new('tingtong')
f.puts "Hello"
puts f.path
f.close組み込み関数
ファイルとディレクトリを処理するためのruby組み込み関数は次のとおりです-
ファイルクラスとメソッド。
Dirクラスとメソッド。
実行と例外は常に一緒に行われます。存在しないファイルを開いている場合、この状況を適切に処理しなかった場合、プログラムの品質が悪いと見なされます。
例外が発生すると、プログラムは停止します。そのため、例外は、プログラムの実行中に発生する可能性のあるさまざまなタイプのエラーを処理し、プログラムを完全に停止する代わりに適切なアクションを実行するために使用されます。
Rubyは、例外を処理するための優れたメカニズムを提供します。例外を発生させる可能性のあるコードをbegin / endブロックで囲み、rescue句を使用して、処理する例外のタイプをRubyに通知します。
構文
begin
# -
rescue OneTypeOfException
# -
rescue AnotherTypeOfException
# -
else
# Other exceptions
ensure
# Always will be executed
end開始から救助まですべてが保護されます。このコードブロックの実行中に例外が発生した場合、レスキューと終了の間のブロックに制御が渡されます。
開始ブロックの各レスキュー句について、Rubyは発生した例外を各パラメーターと順番に比較します。レスキュー句で指定された例外が現在スローされている例外のタイプと同じであるか、その例外のスーパークラスである場合、一致は成功します。
例外が指定されたエラータイプのいずれにも一致しない場合、すべてのレスキュー句の後にelse句を使用できます。
例
#!/usr/bin/ruby
begin
file = open("/unexistant_file")
if file
puts "File opened successfully"
end
rescue
file = STDIN
end
print file, "==", STDIN, "\n"これにより、次の結果が得られます。開くことができなかったため、STDINがファイルに置き換えられていることがわかります。
#<IO:0xb7d16f84>==#<IO:0xb7d16f84>再試行ステートメントの使用
レスキューブロックを使用して例外をキャプチャしてから、retryステートメントを使用してbeginブロックを最初から実行できます。
構文
begin
# Exceptions raised by this code will
# be caught by the following rescue clause
rescue
# This block will capture all types of exceptions
retry # This will move control to the beginning of begin
end例
#!/usr/bin/ruby
begin
file = open("/unexistant_file")
if file
puts "File opened successfully"
end
rescue
fname = "existant_file"
retry
endプロセスの流れは次のとおりです。
- オープン時に例外が発生しました。
- 救助に行きました。fnameが再割り当てされました。
- 再試行により、開始の最初に行きました。
- この時間ファイルは正常に開きます。
- 本質的なプロセスを続けた。
NOTE−再置換された名前のファイルが存在しない場合、このサンプルコードは無限に再試行することに注意してください。例外プロセスに再試行を使用する場合は注意してください。
raiseステートメントの使用
raiseステートメントを使用して例外を発生させることができます。次のメソッドは、呼び出されるたびに例外を発生させます。2番目のメッセージが印刷されます。
構文
raise
OR
raise "Error Message"
OR
raise ExceptionType, "Error Message"
OR
raise ExceptionType, "Error Message" condition最初の形式は、現在の例外(または、現在の例外がない場合はRuntimeError)を再発生させるだけです。これは、例外を渡す前にインターセプトする必要がある例外ハンドラーで使用されます。
2番目の形式は、新しいRuntimeError例外を作成し、そのメッセージを指定された文字列に設定します。この例外は、コールスタックで発生します。
3番目の形式は、最初の引数を使用して例外を作成し、関連するメッセージを2番目の引数に設定します。
4番目の形式は3番目の形式に似ていますが、例外を発生させない限り、のような任意の条件ステートメントを追加できます。
例
#!/usr/bin/ruby
begin
puts 'I am before the raise.'
raise 'An error has occurred.'
puts 'I am after the raise.'
rescue
puts 'I am rescued.'
end
puts 'I am after the begin block.'これにより、次の結果が生成されます-
I am before the raise.
I am rescued.
I am after the begin block.レイズの使用法を示すもう1つの例-
#!/usr/bin/ruby
begin
raise 'A test exception.'
rescue Exception => e
puts e.message
puts e.backtrace.inspect
endこれにより、次の結果が生成されます-
A test exception.
["main.rb:4"]sureステートメントの使用
例外が発生したかどうかに関係なく、コードのブロックの最後で何らかの処理が行われることを保証する必要がある場合があります。たとえば、ブロックへのエントリ時にファイルを開いていて、ブロックの終了時にファイルが閉じていることを確認する必要がある場合があります。
確実句はちょうどこれを行います。sureは最後のレスキュー句の後にあり、ブロックの終了時に常に実行されるコードのチャンクを含みます。通常、ブロックが終了した場合、それが上昇し、救出する例外を、またはそれがキャッチされない例外によって終了した場合、かどうかは、問題ではないことを確認のブロックが実行されます。
構文
begin
#.. process
#..raise exception
rescue
#.. handle error
ensure
#.. finally ensure execution
#.. This will always execute.
end例
begin
raise 'A test exception.'
rescue Exception => e
puts e.message
puts e.backtrace.inspect
ensure
puts "Ensuring execution"
endこれにより、次の結果が生成されます-
A test exception.
["main.rb:4"]
Ensuring executionelseステートメントの使用
else句が存在する場合は、rescue句の後、ensureの前に配置されます。
ボディ他の句は、例外がコードの本体によって提起されていない場合にのみ実行されます。
構文
begin
#.. process
#..raise exception
rescue
# .. handle error
else
#.. executes if there is no exception
ensure
#.. finally ensure execution
#.. This will always execute.
end例
begin
# raise 'A test exception.'
puts "I'm not raising exception"
rescue Exception => e
puts e.message
puts e.backtrace.inspect
else
puts "Congratulations-- no errors!"
ensure
puts "Ensuring execution"
endこれにより、次の結果が生成されます-
I'm not raising exception
Congratulations-- no errors!
Ensuring execution発生したエラーメッセージは$を使用してキャプチャできます!変数。
キャッチアンドスロー
レイズとレスキューの例外メカニズムは、問題が発生したときに実行を中止するのに最適ですが、通常の処理中に、深くネストされた構造から飛び出すことができると便利な場合があります。ここでキャッチアンドスローが役に立ちます。
キャッチ(記号又は文字列であってもよい)指定された名前でラベル付けされたブロックを定義します。ブロックは、スローが発生するまで通常どおり実行されます。
構文
throw :lablename
#.. this will not be executed
catch :lablename do
#.. matching catch will be executed after a throw is encountered.
end
OR
throw :lablename condition
#.. this will not be executed
catch :lablename do
#.. matching catch will be executed after a throw is encountered.
end例
次の例では、throwを使用して、「!」の場合にユーザーとの対話を終了します。プロンプトに応答して入力されます。
def promptAndGet(prompt)
print prompt
res = readline.chomp
throw :quitRequested if res == "!"
return res
end
catch :quitRequested do
name = promptAndGet("Name: ")
age = promptAndGet("Age: ")
sex = promptAndGet("Sex: ")
# ..
# process information
end
promptAndGet("Name:")上記のプログラムは手動で操作する必要があるため、マシンで試してみてください。これにより、次の結果が生成されます-
Name: Ruby on Rails
Age: 3
Sex: !
Name:Just Rubyクラス例外
Rubyの標準クラスとモジュールは例外を発生させます。すべての例外クラスは階層を形成し、クラスExceptionが最上位にあります。次のレベルには7つの異なるタイプが含まれています-
- Interrupt
- NoMemoryError
- SignalException
- ScriptError
- StandardError
- SystemExit
このレベルにはもう1つの例外があります。 Fatal、ただし、Rubyインタープリターはこれを内部でのみ使用します。
ScriptErrorとStandardErrorの両方にいくつかのサブクラスがありますが、ここで詳細を説明する必要はありません。重要なことは、独自の例外クラスを作成する場合、それらはクラスExceptionまたはその子孫の1つのサブクラスである必要があるということです。
例を見てみましょう-
class FileSaveError < StandardError
attr_reader :reason
def initialize(reason)
@reason = reason
end
endここで、この例外を使用する次の例を見てください-
File.open(path, "w") do |file|
begin
# Write out the data ...
rescue
# Something went wrong!
raise FileSaveError.new($!)
end
endここで重要な行は、fileSaveError.new($!)を発生させることです。例外が発生したことを通知するためにraiseを呼び出し、FileSaveErrorの新しいインスタンスを渡します。これは、特定の例外が原因でデータの書き込みが失敗したためです。
Rubyは純粋なオブジェクト指向言語であり、すべてがオブジェクトとしてRubyに表示されます。Rubyのすべての値はオブジェクトであり、最も原始的なものでさえ、文字列、数値、さらにはtrueとfalseです。クラス自体でさえ、Classクラスのインスタンスであるオブジェクトです。この章では、オブジェクト指向Rubyに関連するすべての主要な機能について説明します。
クラスはオブジェクトの形式を指定するために使用され、データ表現とそのデータを操作するためのメソッドを1つのきちんとしたパッケージに結合します。クラス内のデータとメソッドは、クラスのメンバーと呼ばれます。
Rubyクラスの定義
クラスを定義するときは、データ型の青写真を定義します。これは実際にはデータを定義しませんが、クラス名の意味、つまり、クラスのオブジェクトが何で構成され、そのようなオブジェクトに対してどのような操作を実行できるかを定義します。
クラス定義はキーワードで始まります class 続いて class name で区切られています end。たとえば、キーワードクラスを使用してBoxクラスを次のように定義しました-
class Box
code
end名前は大文字で始まる必要があり、慣例により、複数の単語を含む名前は、大文字で区切られた各単語と一緒に実行され、区切り文字は使用されません(CamelCase)。
Rubyオブジェクトを定義する
クラスはオブジェクトの青写真を提供するため、基本的にオブジェクトはクラスから作成されます。を使用してクラスのオブジェクトを宣言しますnewキーワード。次のステートメントは、クラスBox −の2つのオブジェクトを宣言します。
box1 = Box.new
box2 = Box.new初期化メソッド
ザ・ initialize method は標準のRubyクラスメソッドであり、とほぼ同じように機能します。 constructor他のオブジェクト指向プログラミング言語で動作します。initializeメソッドは、オブジェクトの作成時にいくつかのクラス変数を初期化する場合に役立ちます。このメソッドはパラメータのリストを取得する場合があり、他のrubyメソッドと同様に、その前にdef 以下に示すキーワード-
class Box
def initialize(w,h)
@width, @height = w, h
end
endインスタンス変数
ザ・ instance variablesは一種のクラス属性であり、クラスを使用してオブジェクトが作成されると、オブジェクトのプロパティになります。すべてのオブジェクトの属性は個別に割り当てられ、他のオブジェクトと値を共有しません。これらはクラス内で@演算子を使用してアクセスされますが、クラス外でアクセスするために使用しますpublic と呼ばれるメソッド accessor methods。上記で定義されたクラスを取る場合Box その場合、@ widthと@heightはクラスBoxのインスタンス変数です。
class Box
def initialize(w,h)
# assign instance variables
@width, @height = w, h
end
endアクセサーとセッターのメソッド
クラスの外部から変数を使用できるようにするには、変数をクラス内で定義する必要があります。 accessor methods、これらのアクセサメソッドはゲッターメソッドとも呼ばれます。次の例は、アクセサメソッドの使用法を示しています-
#!/usr/bin/ruby -w
# define a class
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# accessor methods
def printWidth
@width
end
def printHeight
@height
end
end
# create an object
box = Box.new(10, 20)
# use accessor methods
x = box.printWidth()
y = box.printHeight()
puts "Width of the box is : #{x}"
puts "Height of the box is : #{y}"上記のコードを実行すると、次の結果が得られます。
Width of the box is : 10
Height of the box is : 20変数の値にアクセスするために使用されるアクセサメソッドと同様に、Rubyは、クラスの外部からこれらの変数の値を設定する方法を提供します。 setter methods、以下のように定義されます-
#!/usr/bin/ruby -w
# define a class
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# accessor methods
def getWidth
@width
end
def getHeight
@height
end
# setter methods
def setWidth=(value)
@width = value
end
def setHeight=(value)
@height = value
end
end
# create an object
box = Box.new(10, 20)
# use setter methods
box.setWidth = 30
box.setHeight = 50
# use accessor methods
x = box.getWidth()
y = box.getHeight()
puts "Width of the box is : #{x}"
puts "Height of the box is : #{y}"上記のコードを実行すると、次の結果が得られます。
Width of the box is : 30
Height of the box is : 50インスタンスメソッド
ザ・ instance methods を使用して他のメソッドを定義するのと同じ方法で定義されます defキーワードであり、以下に示すように、クラスインスタンスを使用してのみ使用できます。それらの機能は、インスタンス変数へのアクセスに限定されていませんが、要件に応じてさらに多くのことを実行できます。
#!/usr/bin/ruby -w
# define a class
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# instance method
def getArea
@width * @height
end
end
# create an object
box = Box.new(10, 20)
# call instance methods
a = box.getArea()
puts "Area of the box is : #{a}"上記のコードを実行すると、次の結果が得られます。
Area of the box is : 200クラスメソッドと変数
ザ・ class variablesは変数であり、クラスのすべてのインスタンス間で共有されます。つまり、変数のインスタンスが1つあり、オブジェクトインスタンスからアクセスされます。クラス変数の前には2つの@文字(@@)が付いています。以下に示すように、クラス変数はクラス定義内で初期化する必要があります。
クラスメソッドは、を使用して定義されます def self.methodname()、終了区切り文字で終わり、クラス名を使用して呼び出されます。 classname.methodname 次の例に示すように-
#!/usr/bin/ruby -w
class Box
# Initialize our class variables
@@count = 0
def initialize(w,h)
# assign instance avriables
@width, @height = w, h
@@count += 1
end
def self.printCount()
puts "Box count is : #@@count"
end
end
# create two object
box1 = Box.new(10, 20)
box2 = Box.new(30, 100)
# call class method to print box count
Box.printCount()上記のコードを実行すると、次の結果が得られます。
Box count is : 2to_sメソッド
定義するクラスには、 to_sオブジェクトの文字列表現を返すインスタンスメソッド。以下は、幅と高さの観点からBoxオブジェクトを表す簡単な例です。
#!/usr/bin/ruby -w
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# define to_s method
def to_s
"(w:#@width,h:#@height)" # string formatting of the object.
end
end
# create an object
box = Box.new(10, 20)
# to_s method will be called in reference of string automatically.
puts "String representation of box is : #{box}"上記のコードを実行すると、次の結果が得られます。
String representation of box is : (w:10,h:20)アクセス制御
Rubyは、インスタンスメソッドレベルで3つのレベルの保護を提供します。 public, private, or protected。Rubyは、インスタンス変数とクラス変数にアクセス制御を適用しません。
Public Methods−パブリックメソッドは誰でも呼び出すことができます。メソッドは、常にプライベートである初期化を除いて、デフォルトでパブリックです。
Private Methods−プライベートメソッドにアクセスしたり、クラスの外部から表示したりすることはできません。クラスメソッドのみがプライベートメンバーにアクセスできます。
Protected Methods−保護されたメソッドは、定義するクラスとそのサブクラスのオブジェクトによってのみ呼び出すことができます。アクセスは家族内で維持されます。
以下は、3つのアクセス修飾子すべての構文を示す簡単な例です-
#!/usr/bin/ruby -w
# define a class
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# instance method by default it is public
def getArea
getWidth() * getHeight
end
# define private accessor methods
def getWidth
@width
end
def getHeight
@height
end
# make them private
private :getWidth, :getHeight
# instance method to print area
def printArea
@area = getWidth() * getHeight
puts "Big box area is : #@area"
end
# make it protected
protected :printArea
end
# create an object
box = Box.new(10, 20)
# call instance methods
a = box.getArea()
puts "Area of the box is : #{a}"
# try to call protected or methods
box.printArea()上記のコードを実行すると、次のような結果になります。ここでは、最初のメソッドが正常に呼び出されましたが、2番目のメソッドで問題が発生しました。
Area of the box is : 200
test.rb:42: protected method `printArea' called for #
<Box:0xb7f11280 @height = 20, @width = 10> (NoMethodError)クラスの継承
オブジェクト指向プログラミングで最も重要な概念の1つは、継承の概念です。継承により、別のクラスの観点からクラスを定義できるため、アプリケーションの作成と保守が容易になります。
継承は、コード機能と迅速な実装時間を再利用する機会も提供しますが、残念ながら、Rubyは複数レベルの継承をサポートしていませんが、Rubyはサポートしています。 mixins。ミックスインは、インターフェイス部分のみが継承される多重継承の特殊な実装のようなものです。
クラスを作成するとき、プログラマーは、完全に新しいデータメンバーとメンバー関数を作成する代わりに、新しいクラスが既存のクラスのメンバーを継承するように指定できます。この既存のクラスは、base class or superclass、および新しいクラスは、 derived class or sub-class。
Rubyは、サブクラス化の概念、つまり継承もサポートしています。次の例で概念を説明します。クラスを拡張するための構文は単純です。<文字とスーパークラスの名前をクラスステートメントに追加するだけです。たとえば、以下では、クラスBigBoxをBox −のサブクラスとして定義します。
#!/usr/bin/ruby -w
# define a class
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# instance method
def getArea
@width * @height
end
end
# define a subclass
class BigBox < Box
# add a new instance method
def printArea
@area = @width * @height
puts "Big box area is : #@area"
end
end
# create an object
box = BigBox.new(10, 20)
# print the area
box.printArea()上記のコードを実行すると、次の結果が得られます。
Big box area is : 200メソッドのオーバーライド
派生クラスに新しい機能を追加することはできますが、親クラスですでに定義されているメソッドの動作を変更したい場合があります。以下の例に示すように、メソッド名を同じに保ち、メソッドの機能をオーバーライドするだけで、これを行うことができます。
#!/usr/bin/ruby -w
# define a class
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# instance method
def getArea
@width * @height
end
end
# define a subclass
class BigBox < Box
# change existing getArea method as follows
def getArea
@area = @width * @height
puts "Big box area is : #@area"
end
end
# create an object
box = BigBox.new(10, 20)
# print the area using overriden method.
box.getArea()演算子のオーバーロード
+演算子で+を使用して2つのBoxオブジェクトのベクトル加算を実行し、*演算子でボックスの幅と高さをスカラーで乗算し、単項-演算子でボックスの幅と高さを無効にします。これは、数学演算子が定義されたBoxクラスのバージョンです-
class Box
def initialize(w,h) # Initialize the width and height
@width,@height = w, h
end
def +(other) # Define + to do vector addition
Box.new(@width + other.width, @height + other.height)
end
def -@ # Define unary minus to negate width and height
Box.new(-@width, -@height)
end
def *(scalar) # To perform scalar multiplication
Box.new(@width*scalar, @height*scalar)
end
endオブジェクトの凍結
オブジェクトが変更されないようにしたい場合があります。Objectのfreezeメソッドを使用すると、これを実行して、オブジェクトを効果的に定数に変換できます。を呼び出すことで、任意のオブジェクトをフリーズできますObject.freeze。フリーズされたオブジェクトは変更できません。インスタンス変数を変更することはできません。
特定のオブジェクトがすでにフリーズされているかどうか、または使用していないかどうかを確認できます Object.frozen?メソッド。オブジェクトがフリーズした場合はtrueを返し、それ以外の場合はfalse値を返します。次の例は概念をクリアします-
#!/usr/bin/ruby -w
# define a class
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# accessor methods
def getWidth
@width
end
def getHeight
@height
end
# setter methods
def setWidth=(value)
@width = value
end
def setHeight=(value)
@height = value
end
end
# create an object
box = Box.new(10, 20)
# let us freez this object
box.freeze
if( box.frozen? )
puts "Box object is frozen object"
else
puts "Box object is normal object"
end
# now try using setter methods
box.setWidth = 30
box.setHeight = 50
# use accessor methods
x = box.getWidth()
y = box.getHeight()
puts "Width of the box is : #{x}"
puts "Height of the box is : #{y}"上記のコードを実行すると、次の結果が得られます。
Box object is frozen object
test.rb:20:in `setWidth=': can't modify frozen object (TypeError)
from test.rb:39クラス定数
@または@@を使用せずに定義された変数に直接数値または文字列値を割り当てることにより、クラス内で定数を定義できます。慣例により、定数名は大文字のままにします。
定数を定義すると、その値を変更することはできませんが、変数のようにクラス内で直接定数にアクセスできますが、クラス外の定数にアクセスする場合は、を使用する必要があります。 classname::constant 以下の例に示すように。
#!/usr/bin/ruby -w
# define a class
class Box
BOX_COMPANY = "TATA Inc"
BOXWEIGHT = 10
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# instance method
def getArea
@width * @height
end
end
# create an object
box = Box.new(10, 20)
# call instance methods
a = box.getArea()
puts "Area of the box is : #{a}"
puts Box::BOX_COMPANY
puts "Box weight is: #{Box::BOXWEIGHT}"上記のコードを実行すると、次の結果が得られます。
Area of the box is : 200
TATA Inc
Box weight is: 10クラス定数は継承され、インスタンスメソッドのようにオーバーライドできます。
Allocateを使用してオブジェクトを作成する
コンストラクターを呼び出さずにオブジェクトを作成したい場合があります initializeつまり、新しいメソッドを使用します。このような場合、allocateを呼び出すことができます。これにより、次の例のように、初期化されていないオブジェクトが作成されます。
#!/usr/bin/ruby -w
# define a class
class Box
attr_accessor :width, :height
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# instance method
def getArea
@width * @height
end
end
# create an object using new
box1 = Box.new(10, 20)
# create another object using allocate
box2 = Box.allocate
# call instance method using box1
a = box1.getArea()
puts "Area of the box is : #{a}"
# call instance method using box2
a = box2.getArea()
puts "Area of the box is : #{a}"上記のコードを実行すると、次の結果が得られます。
Area of the box is : 200
test.rb:14: warning: instance variable @width not initialized
test.rb:14: warning: instance variable @height not initialized
test.rb:14:in `getArea': undefined method `*'
for nil:NilClass (NoMethodError) from test.rb:29クラス情報
クラス定義が実行可能コードである場合、これは、それらが何らかのオブジェクトのコンテキストで実行されることを意味します。selfは何かを参照する必要があります。それが何であるかを調べましょう。
#!/usr/bin/ruby -w
class Box
# print class information
puts "Type of self = #{self.type}"
puts "Name of self = #{self.name}"
end上記のコードを実行すると、次の結果が得られます。
Type of self = Class
Name of self = Boxこれは、クラス定義がそのクラスを現在のオブジェクトとして実行されることを意味します。これは、メタクラスとそのスーパークラスのメソッドが、メソッド定義の実行中に使用可能になることを意味します。
正規表現は、あなたが一致するかのパターンで開催された専門の構文を使用して文字列の他の文字列またはセットを見つけることができます文字の特別なシーケンスです。
正規表現リテラルは、スラッシュの間、または次のように%のR、続いて任意の区切り文字の間のパターンであります-
構文
/pattern/
/pattern/im # option can be specified
%r!/usr/local! # general delimited regular expression例
#!/usr/bin/ruby
line1 = "Cats are smarter than dogs";
line2 = "Dogs also like meat";
if ( line1 =~ /Cats(.*)/ )
puts "Line1 contains Cats"
end
if ( line2 =~ /Cats(.*)/ )
puts "Line2 contains Dogs"
endこれにより、次の結果が生成されます-
Line1 contains Cats正規表現修飾子
正規表現リテラルには、マッチングのさまざまな側面を制御するためのオプションの修飾子が含まれる場合があります。前に示したように、修飾子は2番目のスラッシュ文字の後に指定され、これらの文字の1つで表すことができます-
| シニア番号 | 修飾子と説明 |
|---|---|
| 1 | i テキストを照合するときに大文字と小文字を区別しません。 |
| 2 | o #{}補間は、regexpリテラルが最初に評価されるときに1回だけ実行されます。 |
| 3 | x 空白を無視し、正規表現でのコメントを許可します。 |
| 4 | m 複数の行に一致し、改行を通常の文字として認識します。 |
| 5 | u,e,s,n 正規表現をUnicode(UTF-8)、EUC、SJIS、またはASCIIとして解釈します。これらの修飾子のいずれも指定されていない場合、正規表現はソースエンコーディングを使用すると見なされます。 |
%Qで区切られた文字列リテラルと同様に、Rubyでは、正規表現を%rで開始し、その後に任意の区切り文字を続けることができます。これは、説明しているパターンに、エスケープしたくないスラッシュ文字が多数含まれている場合に役立ちます。
# Following matches a single slash character, no escape required
%r|/|
# Flag characters are allowed with this syntax, too
%r[</(.*)>]i正規表現パターン
制御文字を除いて、 (+ ? . * ^ $ ( ) [ ] { } | \)、すべての文字が一致します。制御文字の前に円記号を付けると、制御文字をエスケープできます。
| シニア番号 | パターンと説明 |
|---|---|
| 1 | ^ 行頭に一致します。 |
| 2 | $ 行末に一致します。 |
| 3 | . 改行以外の任意の1文字に一致します。mオプションを使用すると、改行にも一致させることができます。 |
| 4 | [...] 角かっこ内の任意の1文字に一致します。 |
| 5 | [^...] 角かっこで囲まれていない任意の1文字に一致します |
| 6 | re* Matches 0 or more occurrences of preceding expression. |
| 7 | re+ Matches 1 or more occurrence of preceding expression. |
| 8 | re? Matches 0 or 1 occurrence of preceding expression. |
| 9 | re{ n} Matches exactly n number of occurrences of preceding expression. |
| 10 | re{ n,} Matches n or more occurrences of preceding expression. |
| 11 | re{ n, m} Matches at least n and at most m occurrences of preceding expression. |
| 12 | a| b Matches either a or b. |
| 13 | (re) Groups regular expressions and remembers matched text. |
| 14 | (?imx) Temporarily toggles on i, m, or x options within a regular expression. If in parentheses, only that area is affected. |
| 15 | (?-imx) Temporarily toggles off i, m, or x options within a regular expression. If in parentheses, only that area is affected. |
| 16 | (?: re) Groups regular expressions without remembering matched text. |
| 17 | (?imx: re) Temporarily toggles on i, m, or x options within parentheses. |
| 18 | (?-imx: re) Temporarily toggles off i, m, or x options within parentheses. |
| 19 | (?#...) Comment. |
| 20 | (?= re) Specifies position using a pattern. Doesn't have a range. |
| 21 | (?! re) Specifies position using pattern negation. Doesn't have a range. |
| 22 | (?> re) Matches independent pattern without backtracking. |
| 23 | \w Matches word characters. |
| 24 | \W Matches nonword characters. |
| 25 | \s Matches whitespace. Equivalent to [\t\n\r\f]. |
| 26 | \S Matches nonwhitespace. |
| 27 | \d Matches digits. Equivalent to [0-9]. |
| 28 | \D Matches nondigits. |
| 29 | \A Matches beginning of string. |
| 30 | \Z Matches end of string. If a newline exists, it matches just before newline. |
| 31 | \z Matches end of string. |
| 32 | \G Matches point where last match finished. |
| 33 | \b Matches word boundaries when outside brackets. Matches backspace (0x08) when inside brackets. |
| 34 | \B Matches non-word boundaries. |
| 35 | \n, \t, etc. Matches newlines, carriage returns, tabs, etc. |
| 36 | \1...\9 Matches nth grouped subexpression. |
| 37 | \10 Matches nth grouped subexpression if it matched already. Otherwise refers to the octal representation of a character code. |
Regular-Expression Examples
| Sr.No. | Example & Description |
|---|---|
| 1 | /ruby/ Matches "ruby". |
| 2 | ¥ Matches Yen sign. Multibyte characters are supported in Ruby 1.9 and Ruby 1.8. |
| Sr.No. | Example & Description |
|---|---|
| 1 | /[Rr]uby/ Matches "Ruby" or "ruby". |
| 2 | /rub[ye]/ Matches "ruby" or "rube". |
| 3 | /[aeiou]/ Matches any one lowercase vowel. |
| 4 | /[0-9]/ Matches any digit; same as /[0123456789]/. |
| 5 | /[a-z]/ Matches any lowercase ASCII letter. |
| 6 | /[A-Z]/ Matches any uppercase ASCII letter. |
| 7 | /[a-zA-Z0-9]/ Matches any of the above. |
| 8 | /[^aeiou]/ Matches anything other than a lowercase vowel. |
| 9 | /[^0-9]/ Matches anything other than a digit. |
| Sr.No. | Example & Description |
|---|---|
| 1 | /./ Matches any character except newline. |
| 2 | /./m In multi-line mode, matches newline, too. |
| 3 | /\d/ Matches a digit: /[0-9]/. |
| 4 | /\D/ Matches a non-digit: /[^0-9]/. |
| 5 | /\s/ Matches a whitespace character: /[ \t\r\n\f]/. |
| 6 | /\S/ Matches non-whitespace: /[^ \t\r\n\f]/. |
| 7 | /\w/ Matches a single word character: /[A-Za-z0-9_]/. |
| 8 | /\W/ Matches a non-word character: /[^A-Za-z0-9_]/. |
| Sr.No. | Example & Description |
|---|---|
| 1 | /ruby?/ Matches "rub" or "ruby": the y is optional. |
| 2 | /ruby*/ Matches "rub" plus 0 or more ys. |
| 3 | /ruby+/ Matches "rub" plus 1 or more ys. |
| 4 | /\d{3}/ Matches exactly 3 digits. |
| 5 | /\d{3,}/ Matches 3 or more digits. |
| 6 | /\d{3,5}/ Matches 3, 4, or 5 digits. |
This matches the smallest number of repetitions −
| Sr.No. | Example & Description |
|---|---|
| 1 | /<.*>/ Greedy repetition: matches "<ruby>perl>". |
| 2 | /<.*?>/ Non-greedy: matches "<ruby>" in "<ruby>perl>". |
| Sr.No. | Example & Description |
|---|---|
| 1 | /\D\d+/ No group: + repeats \d |
| 2 | /(\D\d)+/ Grouped: + repeats \D\d pair |
| 3 | /([Rr]uby(, )?)+/ Match "Ruby", "Ruby, ruby, ruby", etc. |
This matches a previously matched group again −
| Sr.No. | Example & Description |
|---|---|
| 1 | /([Rr])uby&\1ails/ Matches ruby&rails or Ruby&Rails. |
| 2 | /(['"])(?:(?!\1).)*\1/ Single or double-quoted string. \1 matches whatever the 1st group matched . \2 matches whatever the 2nd group matched, etc. |
| Sr.No. | Example & Description |
|---|---|
| 1 | /ruby|rube/ Matches "ruby" or "rube". |
| 2 | /rub(y|le))/ Matches "ruby" or "ruble". |
| 3 | /ruby(!+|\?)/ "ruby" followed by one or more ! or one ? |
It needs to specify match position.
| Sr.No. | Example & Description |
|---|---|
| 1 | /^Ruby/ Matches "Ruby" at the start of a string or internal line. |
| 2 | /Ruby$/ Matches "Ruby" at the end of a string or line. |
| 3 | /\ARuby/ Matches "Ruby" at the start of a string. |
| 4 | /Ruby\Z/ Matches "Ruby" at the end of a string. |
| 5 | /\bRuby\b/ Matches "Ruby" at a word boundary. |
| 6 | /\brub\B/ \B is non-word boundary: matches "rub" in "rube" and "ruby" but not alone. |
| 7 | /Ruby(?=!)/ Matches "Ruby", if followed by an exclamation point. |
| 8 | /Ruby(?!!)/ Matches "Ruby", if not followed by an exclamation point. |
| Sr.No. | Example & Description |
|---|---|
| 1 | /R(?#comment)/ Matches "R". All the rest is a comment. |
| 2 | /R(?i)uby/ Case-insensitive while matching "uby". |
| 3 | /R(?i:uby)/ Same as above. |
| 4 | /rub(?:y|le))/ Group only without creating \1 backreference. |
Search and Replace
Some of the most important String methods that use regular expressions are sub and gsub, and their in-place variants sub! and gsub!.
All of these methods perform a search-and-replace operation using a Regexp pattern. The sub & sub! replaces the first occurrence of the pattern and gsub & gsub! replaces all occurrences.
The sub and gsub returns a new string, leaving the original unmodified where as sub! and gsub! modify the string on which they are called.
Following is the example −
#!/usr/bin/ruby
phone = "2004-959-559 #This is Phone Number"
# Delete Ruby-style comments
phone = phone.sub!(/#.*$/, "")
puts "Phone Num : #{phone}"
# Remove anything other than digits
phone = phone.gsub!(/\D/, "")
puts "Phone Num : #{phone}"This will produce the following result −
Phone Num : 2004-959-559
Phone Num : 2004959559Following is another example −
#!/usr/bin/ruby
text = "rails are rails, really good Ruby on Rails"
# Change "rails" to "Rails" throughout
text.gsub!("rails", "Rails")
# Capitalize the word "Rails" throughout
text.gsub!(/\brails\b/, "Rails")
puts "#{text}"これにより、次の結果が生成されます-
Rails are Rails, really good Ruby on Railsこの章では、Rubyを使用してデータベースにアクセスする方法について説明します。ルビーDBIのモジュールは、Perl DBIモジュールと同様のRubyスクリプトのデータベースに依存しないインタフェースを提供します。
DBIはRubyのDatabaseIndependent Interfaceの略で、DBIはRubyコードと基盤となるデータベースの間に抽象化レイヤーを提供し、データベースの実装を非常に簡単に切り替えることができることを意味します。これは、使用されている実際のデータベースに関係なく、一貫したデータベースインターフェイスを提供する一連のメソッド、変数、および規則を定義します。
DBIは次のものとインターフェースできます-
- ADO(ActiveXデータオブジェクト)
- DB2
- Frontbase
- mSQL
- MySQL
- ODBC
- Oracle
- OCI8(Oracle)
- PostgreSQL
- Proxy/Server
- SQLite
- SQLRelay
DBIアプリケーションのアーキテクチャ
DBIは、バックエンドで使用可能なデータベースから独立しています。Oracle、MySQL、Informixなどを使用している場合でも、DBIを使用できます。これは次のアーキテクチャ図から明らかです。

Ruby DBIの一般的なアーキテクチャは、2つのレイヤーを使用します-
データベースインターフェイス(DBI)層。このレイヤーはデータベースに依存せず、通信しているデータベースサーバーのタイプに関係なく同じ方法で使用される一連の一般的なアクセス方法を提供します。
データベースドライバー(DBD)レイヤー。このレイヤーはデータベースに依存します。さまざまなドライバーがさまざまなデータベースエンジンへのアクセスを提供します。MySQL用、PostgreSQL用、InterBase用、Oracle用などのドライバーがあります。各ドライバーは、DBIレイヤーからの要求を解釈し、それらを特定のタイプのデータベースサーバーに適した要求にマップします。
前提条件
MySQLデータベースにアクセスするためのRubyスクリプトを作成する場合は、RubyMySQLモジュールをインストールする必要があります。
このモジュールは、上記で説明したようにDBDとして機能し、からダウンロードできます。 https://www.tmtm.org/en/mysql/ruby/
Ruby / DBIの入手とインストール
次の場所からRubyDBIモジュールをダウンロードしてインストールできます-
https://imgur.com/NFEuWe4/embed
このインストールを開始する前に、root権限を持っていることを確認してください。次に、以下の手順に従います-
ステップ1
$ tar zxf dbi-0.2.0.tar.gzステップ2
配布ディレクトリdbi-0.2.0に移動し、そのディレクトリのsetup.rbスクリプトを使用して構成します。最も一般的な構成コマンドは次のようになり、config引数の後に引数はありません。このコマンドは、デフォルトですべてのドライバーをインストールするようにディストリビューションを構成します。
$ ruby setup.rb config具体的には、使用するディストリビューションの特定の部分を一覧表示する--withオプションを指定します。たとえば、メインDBIモジュールとMySQL DBDレベルのドライバーのみを構成するには、次のコマンドを発行します。
$ ruby setup.rb config --with = dbi,dbd_mysqlステップ3
最後のステップは、ドライバーをビルドし、次のコマンドを使用してインストールすることです-
$ ruby setup.rb setup $ ruby setup.rb installデータベース接続
MySQLデータベースを使用する場合、データベースに接続する前に、次のことを確認してください。
データベースTESTDBを作成しました。
TESTDBでEMPLOYEEを作成しました。
このテーブルには、FIRST_NAME、LAST_NAME、AGE、SEX、およびINCOMEのフィールドがあります。
TESTDBにアクセスするためのユーザーID「testuser」とパスワード「test123」が設定されています。
RubyモジュールDBIがマシンに正しくインストールされています。
MySQLの基本を理解するためにMySQLチュートリアルを完了しました。
以下は、MySQLデータベース「TESTDB」との接続例です。
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
# get server version string and display it
row = dbh.select_one("SELECT VERSION()")
puts "Server version: " + row[0]
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
ensure
# disconnect from server
dbh.disconnect if dbh
endこのスクリプトを実行すると、Linuxマシンで次の結果が生成されます。
Server version: 5.0.45データソースとの接続が確立されると、データベースハンドルが返され、に保存されます。 dbh それ以外の場合はさらに使用する dbhはnil値に設定され、e.errとe :: errstrはそれぞれエラーコードとエラー文字列を返します。
最後に、それを出す前に、データベース接続が閉じられ、リソースが解放されていることを確認してください。
INSERT操作
レコードをデータベーステーブルに作成する場合は、INSERT操作が必要です。
データベース接続が確立されると、を使用してデータベーステーブルにテーブルまたはレコードを作成する準備が整います。 do メソッドまたは prepare そして execute 方法。
doステートメントの使用
行を返さないステートメントは、を呼び出すことによって発行できます。 doデータベースハンドルメソッド。このメソッドは、ステートメント文字列引数を取り、ステートメントの影響を受ける行数のカウントを返します。
dbh.do("DROP TABLE IF EXISTS EMPLOYEE")
dbh.do("CREATE TABLE EMPLOYEE (
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT )" );同様に、SQL INSERTステートメントを実行して、EMPLOYEEテーブルにレコードを作成できます。
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
dbh.do( "INSERT INTO EMPLOYEE(FIRST_NAME, LAST_NAME, AGE, SEX, INCOME)
VALUES ('Mac', 'Mohan', 20, 'M', 2000)" )
puts "Record has been created"
dbh.commit
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
dbh.rollback
ensure
# disconnect from server
dbh.disconnect if dbh
end準備と実行の使用
DBIクラスのprepareメソッドとexecuteメソッドを使用して、Rubyコードを介してSQLステートメントを実行できます。
レコードの作成には次の手順があります-
INSERTステートメントを使用したSQLステートメントの準備。これは、を使用して行われますprepare 方法。
SQLクエリを実行して、データベースからすべての結果を選択します。これは、を使用して行われますexecute 方法。
ステートメントハンドルを解放します。これはを使用して行われますfinish API
すべてがうまくいけば、 commit この操作以外の場合はできます rollback 完全なトランザクション。
以下は、これら2つの方法を使用するための構文です-
sth = dbh.prepare(statement)
sth.execute
... zero or more SQL operations ...
sth.finishこれらの2つの方法を使用して合格することができます bindSQLステートメントへの値。入力する値が事前に指定されていない場合があります。このような場合、バインディング値が使用されます。疑問符(?)は実際の値の代わりに使用され、実際の値はexecute()APIを介して渡されます。
以下は、EMPLOYEEテーブルに2つのレコードを作成する例です。
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
sth = dbh.prepare( "INSERT INTO EMPLOYEE(FIRST_NAME, LAST_NAME, AGE, SEX, INCOME)
VALUES (?, ?, ?, ?, ?)" )
sth.execute('John', 'Poul', 25, 'M', 2300)
sth.execute('Zara', 'Ali', 17, 'F', 1000)
sth.finish
dbh.commit
puts "Record has been created"
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
dbh.rollback
ensure
# disconnect from server
dbh.disconnect if dbh
end一度に複数のINSERTがある場合は、最初にステートメントを準備してから、ループ内で複数回実行する方が、ループを介して毎回doを呼び出すよりも効率的です。
READ操作
任意のデータベースでのREAD操作は、データベースからいくつかの有用な情報をフェッチすることを意味します。
データベース接続が確立されると、このデータベースにクエリを実行する準備が整います。どちらでも使用できますdo メソッドまたは prepare そして execute データベーステーブルから値をフェッチするメソッド。
レコードのフェッチは次の手順で実行されます-
必要な条件に基づいてSQLクエリを準備します。これは、を使用して行われますprepare 方法。
SQLクエリを実行して、データベースからすべての結果を選択します。これは、を使用して行われますexecute 方法。
すべての結果を1つずつフェッチし、それらの結果を印刷します。これは、を使用して行われますfetch 方法。
ステートメントハンドルを解放します。これは、を使用して行われますfinish 方法。
以下は、給与が1000を超えるEMPLOYEEテーブルからすべてのレコードをクエリする手順です。
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
sth = dbh.prepare("SELECT * FROM EMPLOYEE WHERE INCOME > ?")
sth.execute(1000)
sth.fetch do |row|
printf "First Name: %s, Last Name : %s\n", row[0], row[1]
printf "Age: %d, Sex : %s\n", row[2], row[3]
printf "Salary :%d \n\n", row[4]
end
sth.finish
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
ensure
# disconnect from server
dbh.disconnect if dbh
endこれにより、次の結果が生成されます-
First Name: Mac, Last Name : Mohan
Age: 20, Sex : M
Salary :2000
First Name: John, Last Name : Poul
Age: 25, Sex : M
Salary :2300データベースからレコードをフェッチするためのショートカットメソッドは他にもあります。興味がある場合は、結果のフェッチを実行してください。それ以外の場合は、次のセクションに進んでください。
更新操作
UPDATE任意のデータベースでの操作とは、データベースですでに使用可能な1つ以上のレコードを更新することを意味します。以下は、SEXが「M」であるすべてのレコードを更新する手順です。ここでは、すべての男性の年齢を1年増やします。これには3つのステップが必要です-
必要な条件に基づいてSQLクエリを準備します。これは、を使用して行われますprepare 方法。
SQLクエリを実行して、データベースからすべての結果を選択します。これは、を使用して行われますexecute 方法。
ステートメントハンドルを解放します。これは、を使用して行われますfinish 方法。
すべてがうまくいけば、 commit この操作以外の場合はできます rollback 完全なトランザクション。
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
sth = dbh.prepare("UPDATE EMPLOYEE SET AGE = AGE + 1 WHERE SEX = ?")
sth.execute('M')
sth.finish
dbh.commit
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
dbh.rollback
ensure
# disconnect from server
dbh.disconnect if dbh
endDELETE操作
データベースから一部のレコードを削除する場合は、DELETE操作が必要です。以下は、AGEが20を超えるEMPLOYEEからすべてのレコードを削除する手順です。この操作は次の手順を実行します。
必要な条件に基づいてSQLクエリを準備します。これは、を使用して行われますprepare 方法。
SQLクエリを実行して、データベースから必要なレコードを削除します。これは、を使用して行われますexecute 方法。
ステートメントハンドルを解放します。これは、を使用して行われますfinish 方法。
すべてがうまくいけば、 commit この操作以外の場合はできます rollback 完全なトランザクション。
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
sth = dbh.prepare("DELETE FROM EMPLOYEE WHERE AGE > ?")
sth.execute(20)
sth.finish
dbh.commit
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
dbh.rollback
ensure
# disconnect from server
dbh.disconnect if dbh
endトランザクションの実行
トランザクションは、データの整合性を保証するメカニズムです。トランザクションには、次の4つのプロパティが必要です-
Atomicity −トランザクションが完了するか、まったく何も起こりません。
Consistency −トランザクションは一貫性のある状態で開始し、システムを一貫性のある状態のままにする必要があります。
Isolation −トランザクションの中間結果は、現在のトランザクションの外部には表示されません。
Durability −トランザクションがコミットされると、システム障害が発生した後でも、影響は持続します。
DBIは、トランザクションをコミットまたはロールバックするための2つの方法を提供します。トランザクションを実装するために使用できるtransactionと呼ばれるもう1つのメソッドがあります。トランザクションを実装するための2つの簡単なアプローチがあります-
アプローチI
最初のアプローチでは、DBIのcommitメソッドとrollbackメソッドを使用して、トランザクションを明示的にコミットまたはキャンセルします-
dbh['AutoCommit'] = false # Set auto commit to false.
begin
dbh.do("UPDATE EMPLOYEE SET AGE = AGE+1 WHERE FIRST_NAME = 'John'")
dbh.do("UPDATE EMPLOYEE SET AGE = AGE+1 WHERE FIRST_NAME = 'Zara'")
dbh.commit
rescue
puts "transaction failed"
dbh.rollback
end
dbh['AutoCommit'] = trueアプローチII
2番目のアプローチは、トランザクション方式を使用します。トランザクションを構成するステートメントを含むコードブロックを使用するため、これはより簡単です。取引方法は、次に呼び出すには、ブロックを実行コミットやロールバックブロックが成功したか失敗したかどうかに応じて、自動的に-
dbh['AutoCommit'] = false # Set auto commit to false.
dbh.transaction do |dbh|
dbh.do("UPDATE EMPLOYEE SET AGE = AGE+1 WHERE FIRST_NAME = 'John'")
dbh.do("UPDATE EMPLOYEE SET AGE = AGE+1 WHERE FIRST_NAME = 'Zara'")
end
dbh['AutoCommit'] = trueCOMMIT操作
コミットは、変更を確定するためにデータベースに緑色の信号を与える操作であり、この操作の後、変更を元に戻すことはできません。
これは、を呼び出す簡単な例です。 commit 方法。
dbh.commitロールバック操作
1つ以上の変更に満足できず、それらの変更を完全に元に戻したい場合は、 rollback 方法。
これは、を呼び出す簡単な例です。 rollback 方法。
dbh.rollbackデータベースの切断
データベース接続を切断するには、disconnectAPIを使用します。
dbh.disconnectユーザーが切断方式でデータベースへの接続を閉じた場合、未処理のトランザクションはDBIによってロールバックされます。ただし、DBIの実装の詳細に依存する代わりに、アプリケーションはコミットまたはロールバックを明示的に呼び出す方がよいでしょう。
エラーの処理
エラーの原因はたくさんあります。いくつかの例は、実行されたSQLステートメントの構文エラー、接続の失敗、またはすでにキャンセルまたは終了したステートメントハンドルのフェッチメソッドの呼び出しです。
DBIメソッドが失敗すると、DBIは例外を発生させます。DBIメソッドは、いくつかのタイプの例外のいずれかを発生させる可能性がありますが、2つの最も重要な例外クラスはDBI :: InterfaceErrorとDBI :: DatabaseErrorです。
これらのクラスの例外オブジェクトには、エラー番号、説明的なエラー文字列、および標準エラーコードを表すerr、errstr、およびstateという名前の3つの属性があります。属性について以下に説明します-
err−発生したエラーの整数表現を返します。DBDでサポートされていない場合はnilを返します。たとえば、Oracle DBDは、ORA-XXXXエラーメッセージの数値部分を返します。
errstr −発生したエラーの文字列表現を返します。
state−発生したエラーのSQLSTATEコードを返します。SQLSTATEは5文字の長さの文字列です。ほとんどのDBDはこれをサポートしておらず、代わりにnilを返します。
ほとんどの例で上記のコードを見てきました-
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
dbh.rollback
ensure
# disconnect from server
dbh.disconnect if dbh
endスクリプトの実行時にスクリプトが実行していることに関するデバッグ情報を取得するには、トレースを有効にします。これを行うには、最初にdbi / traceモジュールをロードしてから、トレースモードと出力先を制御するtraceメソッドを呼び出す必要があります。
require "dbi/trace"
..............
trace(mode, destination)モード値は0(オフ)、1、2、または3であり、宛先はIOオブジェクトである必要があります。デフォルト値は、それぞれ2とSTDERRです。
メソッドを使用したコードブロック
ハンドルを作成するメソッドがいくつかあります。これらのメソッドは、コードブロックを使用して呼び出すことができます。メソッドと一緒にコードブロックを使用する利点は、コードブロックへのハンドルをパラメーターとして提供し、ブロックが終了したときにハンドルを自動的にクリーンアップすることです。概念を理解するためのいくつかの例があります。
DBI.connect−このメソッドはデータベースハンドルを生成します。データベースを切断するには、ブロックの最後でdisconnectを呼び出すことをお勧めします。
dbh.prepare-このメソッドは、ステートメント・ハンドルを生成し、それをすることが推奨され仕上げブロックの最後に。ブロック内で、ステートメントを実行するには、executeメソッドを呼び出す必要があります。
dbh.execute−このメソッドは、ブロック内でexecuteを呼び出す必要がないことを除いて同様です。ステートメントハンドルは自動的に実行されます。
例1
DBI.connect 次のように、コードブロックを取得し、データベースハンドルを渡し、ブロックの最後でハンドルを自動的に切断します。
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123") do |dbh|例2
dbh.prepare コードブロックを受け取り、ステートメントハンドルをそれに渡し、次のようにブロックの最後で自動的にfinishを呼び出します。
dbh.prepare("SHOW DATABASES") do |sth|
sth.execute
puts "Databases: " + sth.fetch_all.join(", ")
end例3
dbh.execute コードブロックを取得し、それにステートメントハンドルを渡し、次のようにブロックの最後で自動的にfinishを呼び出すことができます-
dbh.execute("SHOW DATABASES") do |sth|
puts "Databases: " + sth.fetch_all.join(", ")
endDBIトランザクションメソッドも、上記で説明したコードブロックを取ります。
ドライバー固有の機能と属性
DBIを使用すると、データベースドライバーは、Handleオブジェクトのfuncメソッドを介してユーザーが呼び出すことができる追加のデータベース固有の関数を提供できます。
ドライバー固有の属性がサポートされており、を使用して設定または取得できます。 []= または [] メソッド。
| シニア番号 | 機能と説明 |
|---|---|
| 1 | dbh.func(:createdb, db_name) 新しいデータベースを作成します。 |
| 2 | dbh.func(:dropdb, db_name) データベースを削除します。 |
| 3 | dbh.func(:reload) リロード操作を実行します。 |
| 4 | dbh.func(:shutdown) サーバーをシャットダウンします。 |
| 5 | dbh.func(:insert_id) => Fixnum 接続の最新のAUTO_INCREMENT値を返します。 |
| 6 | dbh.func(:client_info) => String バージョンの観点からMySQLクライアント情報を返します。 |
| 7 | dbh.func(:client_version) => Fixnum バージョンの観点からクライアント情報を返します。:client_infoに似ていますが、stingの代わりにfixnumを返します。 |
| 8 | dbh.func(:host_info) => String ホスト情報を返します。 |
| 9 | dbh.func(:proto_info) => Fixnum 通信に使用されているプロトコルを返します。 |
| 10 | dbh.func(:server_info) => String バージョンの観点からMySQLサーバー情報を返します。 |
| 11 | dbh.func(:stat) => String データベースの現在の状態を返します。 |
| 12 | dbh.func(:thread_id) => Fixnum 現在のスレッドIDを返します。 |
例
#!/usr/bin/ruby
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
puts dbh.func(:client_info)
puts dbh.func(:client_version)
puts dbh.func(:host_info)
puts dbh.func(:proto_info)
puts dbh.func(:server_info)
puts dbh.func(:thread_id)
puts dbh.func(:stat)
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
ensure
dbh.disconnect if dbh
endこれにより、次の結果が生成されます-
5.0.45
50045
Localhost via UNIX socket
10
5.0.45
150621
Uptime: 384981 Threads: 1 Questions: 1101078 Slow queries: 4 \
Opens: 324 Flush tables: 1 Open tables: 64 \
Queries per second avg: 2.860Rubyは汎用言語です。Web言語とはまったく呼べません。それでも、一般的にWebアプリケーションとWebツールはRubyの最も一般的な使用法の1つです。
Rubyで独自のSMTPサーバー、FTPデーモン、またはWebサーバーを作成できるだけでなく、CGIプログラミングなどのより一般的なタスクやPHPの代わりにRubyを使用することもできます。
CGIプログラミングの詳細については、CGIプログラミングチュートリアルで数分を費やしてください。
CGIスクリプトの作成
最も基本的なRubyCGIスクリプトは次のようになります-
#!/usr/bin/ruby
puts "HTTP/1.0 200 OK"
puts "Content-type: text/html\n\n"
puts "<html><body>This is a test</body></html>"このスクリプトtest.cgiを呼び出して、適切なアクセス許可を持つUnixベースのWebホスティングプロバイダーにアップロードすると、CGIスクリプトとして使用できます。
たとえば、Webサイトがある場合 https://www.example.com/Linux Webホスティングプロバイダーでホストされており、test.cgiをメインディレクトリにアップロードして実行権限を付与してから、https://www.example.com/test.cgi 次のようなHTMLページを返す必要があります This is a test。
ここで、Webブラウザーからtest.cgiが要求されると、WebサーバーはWebサイトでtest.cgiを探し、Rubyインタープリターを使用してそれを実行します。Rubyスクリプトは、基本HTTPヘッダーを返し、次に基本HTMLドキュメントを返します。
cgi.rbの使用
Rubyには、という特別なライブラリが付属しています cgi これにより、前述のCGIスクリプトを使用した場合よりも高度な対話が可能になります。
cgiを使用する基本的なCGIスクリプトを作成しましょう−
#!/usr/bin/ruby
require 'cgi'
cgi = CGI.new
puts cgi.header
puts "<html><body>This is a test</body></html>"ここでは、CGIオブジェクトを作成し、それを使用してヘッダー行を印刷しました。
フォーム処理
クラスCGIを使用すると、2つの方法でHTMLクエリパラメータにアクセスできます。/cgi-bin/test.cgi?FirstName = Zara&LastName = AliのURLが与えられたとします。
次のように、CGI#[]を使用してパラメータFirstNameおよびLastNameに直接アクセスできます。
#!/usr/bin/ruby
require 'cgi'
cgi = CGI.new
cgi['FirstName'] # => ["Zara"]
cgi['LastName'] # => ["Ali"]これらのフォーム変数にアクセスする別の方法があります。このコードは、すべてのキーと値のハッシュを提供します-
#!/usr/bin/ruby
require 'cgi'
cgi = CGI.new
h = cgi.params # => {"FirstName"=>["Zara"],"LastName"=>["Ali"]}
h['FirstName'] # => ["Zara"]
h['LastName'] # => ["Ali"]以下は、すべてのキーを取得するためのコードです-
#!/usr/bin/ruby
require 'cgi'
cgi = CGI.new
cgi.keys # => ["FirstName", "LastName"]フォームに同じ名前の複数のフィールドが含まれている場合、対応する値が配列としてスクリプトに返されます。[]アクセサーは、これらすべてを取得するために、これらの最初の.indexをparamsメソッドの結果として返します。
この例では、フォームに「name」という3つのフィールドがあり、「Zara」、「Huma」、「Nuha」の3つの名前を入力したとします。
#!/usr/bin/ruby
require 'cgi'
cgi = CGI.new
cgi['name'] # => "Zara"
cgi.params['name'] # => ["Zara", "Huma", "Nuha"]
cgi.keys # => ["name"]
cgi.params # => {"name"=>["Zara", "Huma", "Nuha"]}Note−RubyはGETメソッドとPOSTメソッドを自動的に処理します。これらの2つの異なる方法に別々の治療法はありません。
正しいデータを送信できる、関連付けられているが基本的なフォームには、次のようなHTMLコードが含まれます。
<html>
<body>
<form method = "POST" action = "http://www.example.com/test.cgi">
First Name :<input type = "text" name = "FirstName" value = "" />
<br />
Last Name :<input type = "text" name = "LastName" value = "" />
<input type = "submit" value = "Submit Data" />
</form>
</body>
</html>フォームとHTMLの作成
CGIには、HTMLの作成に使用される膨大な数のメソッドが含まれています。タグごとに1つのメソッドがあります。これらのメソッドを有効にするには、CGI.newを呼び出してCGIオブジェクトを作成する必要があります。
タグのネストを容易にするために、これらのメソッドはコンテンツをコードブロックとして受け取ります。コードブロックは、タグのコンテンツとして使用される文字列を返す必要があります。例-
#!/usr/bin/ruby
require "cgi"
cgi = CGI.new("html4")
cgi.out {
cgi.html {
cgi.head { "\n"+cgi.title{"This Is a Test"} } +
cgi.body { "\n"+
cgi.form {"\n"+
cgi.hr +
cgi.h1 { "A Form: " } + "\n"+
cgi.textarea("get_text") +"\n"+
cgi.br +
cgi.submit
}
}
}
}NOTE− CGIクラスのformメソッドは、フォーム送信で使用されるHTTPメソッド(GET、POSTなど)を設定するメソッドパラメーターを受け入れることができます。この例で使用されるデフォルトはPOSTです。
これにより、次の結果が生成されます-
Content-Type: text/html
Content-Length: 302
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Final//EN">
<HTML>
<HEAD>
<TITLE>This Is a Test</TITLE>
</HEAD>
<BODY>
<FORM METHOD = "post" ENCTYPE = "application/x-www-form-urlencoded">
<HR>
<H1>A Form: </H1>
<TEXTAREA COLS = "70" NAME = "get_text" ROWS = "10"></TEXTAREA>
<BR>
<INPUT TYPE = "submit">
</FORM>
</BODY>
</HTML>文字列の引用
URLやHTMLコードを扱うときは、特定の文字を引用するように注意する必要があります。たとえば、スラッシュ文字(/)はURLで特別な意味を持つため、次のようにする必要があります。escaped パス名の一部でない場合。
たとえば、URLのクエリ部分の/は文字列%2Fに変換され、使用するには/に戻す必要があります。スペースとアンパサンドも特殊文字です。これを処理するために、CGIはルーチンを提供しますCGI.escape そして CGI.unescape。
#!/usr/bin/ruby
require 'cgi'
puts CGI.escape(Zara Ali/A Sweet & Sour Girl")これにより、次の結果が生成されます-
Zara+Ali%2FA Sweet+%26+Sour+Girl")#!/usr/bin/ruby
require 'cgi'
puts CGI.escapeHTML('<h1>Zara Ali/A Sweet & Sour Girl</h1>')これにより、次の結果が生成されます-
<h1>Zara Ali/A Sweet & Sour Girl</h1>'CGIクラスの便利なメソッド
これがCGIクラスに関連するメソッドのリストです-
RubyのCGI -標準CGIライブラリーに関連するメソッド。
クッキーとセッション
これらの2つの概念については、さまざまなセクションで説明しました。セクションに従ってください-
RubyのCGIクッキー- CGIクッキーを処理する方法。
RubyのCGIセッション- CGIセッションを管理する方法。
Webホスティングサーバー
インターネットで次のトピックをチェックして、UnixベースのサーバーでWebサイトをホストできます。
UnixベースのWebホスティング
Simple Mail Transfer Protocol(SMTP)は、電子メールの送信とメールサーバー間の電子メールのルーティングを処理するプロトコルです。
Rubyは、SMTP(Simple Mail Transfer Protocol)クライアント側接続用のNet :: SMTPクラスを提供し、newとstartの2つのクラスメソッドを提供します。
ザ・ new 2つのパラメータを取ります-
サーバ名はlocalhostをデフォルト。
デフォルトのポート番号は、既知のポート25です。
ザ・ start メソッドはこれらのパラメータを取ります-
サーバー- SMTPサーバーのIP名、localhostに不履行。
ポート- 25をデフォルトのポート番号、。
ドメインENV [「HOSTNAME」]をデフォルトメール送信者のドメイン、 - 。
アカウント-ユーザー名、デフォルトはnilです。
パスワード-ユーザーのパスワード、nilに不履行。
authType -認証タイプ、をデフォルトCRAM_MD5。
SMTPオブジェクトには、sendmailと呼ばれるインスタンスメソッドがあります。これは通常、メッセージをメールで送信する作業を行うために使用されます。それは3つのパラメータを取ります-
ソース-の文字列又はアレイ又は何か各イテレータは、一度に1つの文字列を返します。
送信者-に表示される文字列からの電子メールのフィールド。
受信者-文字列または受信者の宛先(複数可)を表す文字列の配列。
例
これは、Rubyスクリプトを使用して1つの電子メールを送信する簡単な方法です。一度試してみてください-
require 'net/smtp'
message = <<MESSAGE_END
From: Private Person <[email protected]>
To: A Test User <[email protected]>
Subject: SMTP e-mail test
This is a test e-mail message.
MESSAGE_END
Net::SMTP.start('localhost') do |smtp|
smtp.send_message message, '[email protected]', '[email protected]'
endここでは、ヘッダーを正しくフォーマットするように注意しながら、ドキュメントを使用して基本的な電子メールをメッセージに配置しました。電子メールにはFrom、 To、および Subject 電子メールの本文から空白行で区切られたヘッダー。
メールを送信するには、Net :: SMTPを使用してローカルマシンのSMTPサーバーに接続し、send_messageメソッドをメッセージ、差出人アドレス、および宛先アドレスとともにパラメーターとして使用します(差出人アドレスと宛先アドレスは電子メール自体の中で、これらは常にメールのルーティングに使用されるとは限りません)。
マシンでSMTPサーバーを実行していない場合は、Net :: SMTPを使用してリモートSMTPサーバーと通信できます。Webメールサービス(HotmailやYahoo! Mailなど)を使用している場合を除き、次のように、電子メールプロバイダーからNet :: SMTPに提供できる送信メールサーバーの詳細が提供されます。
Net::SMTP.start('mail.your-domain.com')このコード行は、ユーザー名やパスワードを使用せずに、mail.your-domain.comのポート25でSMTPサーバーに接続します。ただし、必要に応じて、ポート番号やその他の詳細を指定できます。例-
Net::SMTP.start('mail.your-domain.com',
25,
'localhost',
'username', 'password' :plain)この例では、プレーンテキスト形式のユーザー名とパスワードを使用して、mail.your-domain.comのSMTPサーバーに接続します。クライアントのホスト名をlocalhostとして識別します。
Rubyを使用してHTMLメールを送信する
Rubyを使用してテキストメッセージを送信すると、すべてのコンテンツが単純なテキストとして扱われます。テキストメッセージにHTMLタグを含めても、単純なテキストとして表示され、HTMLタグはHTML構文に従ってフォーマットされません。ただし、Ruby Net :: SMTPには、HTMLメッセージを実際のHTMLメッセージとして送信するオプションがあります。
電子メールメッセージの送信中に、HTML電子メールを送信するためのMimeバージョン、コンテンツタイプ、および文字セットを指定できます。
例
以下は、HTMLコンテンツを電子メールとして送信する例です。一度試してみてください-
require 'net/smtp'
message = <<MESSAGE_END
From: Private Person <[email protected]>
To: A Test User <[email protected]>
MIME-Version: 1.0
Content-type: text/html
Subject: SMTP e-mail test
This is an e-mail message to be sent in HTML format
<b>This is HTML message.</b>
<h1>This is headline.</h1>
MESSAGE_END
Net::SMTP.start('localhost') do |smtp|
smtp.send_message message, '[email protected]', '[email protected]'
end添付ファイルを電子メールで送信する
混合コンテンツを含むメールを送信するには、設定する必要があります Content-type へのヘッダー multipart/mixed。次に、テキストと添付ファイルのセクションを内で指定できますboundaries。
境界は2つのハイフンで始まり、その後に一意の番号が続きます。これは、電子メールのメッセージ部分には表示できません。電子メールの最後のセクションを示す最後の境界も、2つのハイフンで終わる必要があります。
添付ファイルは、 pack("m") 送信前にbase64エンコーディングを行う関数。
例
以下は、ファイルを送信する例です。 /tmp/test.txt 添付ファイルとして。
require 'net/smtp'
filename = "/tmp/test.txt"
# Read a file and encode it into base64 format
filecontent = File.read(filename)
encodedcontent = [filecontent].pack("m") # base64
marker = "AUNIQUEMARKER"
body = <<EOF
This is a test email to send an attachement.
EOF
# Define the main headers.
part1 = <<EOF
From: Private Person <[email protected]>
To: A Test User <[email protected]>
Subject: Sending Attachement
MIME-Version: 1.0
Content-Type: multipart/mixed; boundary = #{marker}
--#{marker}
EOF
# Define the message action
part2 = <<EOF
Content-Type: text/plain
Content-Transfer-Encoding:8bit
#{body}
--#{marker}
EOF
# Define the attachment section
part3 = <<EOF
Content-Type: multipart/mixed; name = \"#{filename}\"
Content-Transfer-Encoding:base64
Content-Disposition: attachment; filename = "#{filename}"
#{encodedcontent}
--#{marker}--
EOF
mailtext = part1 + part2 + part3
# Let's put our code in safe area
begin
Net::SMTP.start('localhost') do |smtp|
smtp.sendmail(mailtext, '[email protected]', ['[email protected]'])
end
rescue Exception => e
print "Exception occured: " + e
endNOTE −配列内で複数の宛先を指定できますが、それらはコンマで区切る必要があります。
Rubyは、ネットワークサービスへの2つのレベルのアクセスを提供します。低レベルでは、基盤となるオペレーティングシステムの基本的なソケットサポートにアクセスできます。これにより、コネクション型プロトコルとコネクションレス型プロトコルの両方のクライアントとサーバーを実装できます。
Rubyには、FTP、HTTPなどの特定のアプリケーションレベルのネットワークプロトコルへの高レベルのアクセスを提供するライブラリもあります。
この章では、ネットワーキング-ソケットプログラミングの最も有名な概念について理解します。
ソケットとは何ですか?
ソケットは、双方向通信チャネルのエンドポイントです。ソケットは、プロセス内、同じマシン上のプロセス間、または異なる大陸のプロセス間で通信できます。
ソケットは、Unixドメインソケット、TCP、UDPなどのさまざまなチャネルタイプで実装できます。ソケットは共通トランスポートだけでなく、残りの部分を処理するための汎用インタフェースを処理するための特定のクラスを提供します。
ソケットには独自の語彙があります-
| シニア番号 | 用語と説明 |
|---|---|
| 1 | domain トランスポートメカニズムとして使用されるプロトコルのファミリー。これらの値は、PF_INET、PF_UNIX、PF_X25などの定数です。 |
| 2 | type 2つのエンドポイント間の通信のタイプ。通常、コネクション型プロトコルの場合はSOCK_STREAM、コネクションレス型プロトコルの場合はSOCK_DGRAMです。 |
| 3 | protocol 通常はゼロです。これは、ドメインおよびタイプ内のプロトコルのバリアントを識別するために使用できます。 |
| 4 | hostname ネットワークインターフェースの識別子- 文字列。ホスト名、ドット付きクワッドアドレス、またはコロン(場合によってはドット)表記のIPV6アドレスにすることができます。 INADDR_BROADCASTアドレスを指定する文字列「<broadcast>」。 INADDR_ANYを指定する長さゼロの文字列、または ホストバイト順のバイナリアドレスとして解釈される整数。 |
| 5 | port 各サーバーは、1つ以上のポートで呼び出すクライアントをリッスンします。ポートは、Fixnumポート番号、ポート番号を含む文字列、またはサービスの名前です。 |
シンプルなクライアント
ここでは、特定のポートと特定のホストへの接続を開く非常に単純なクライアントプログラムを作成します。RubyクラスTCPSocketそのようなソケットを開くためのopen機能を提供します。
ザ・ TCPSocket.open(hosname, port )TCP接続が開き、ホスト名のポートを。
ソケットを開いたら、他のIOオブジェクトと同じようにソケットから読み取ることができます。完了したら、ファイルを閉じるのと同じように、忘れずに閉じてください。
次のコードは、特定のホストとポートに接続し、ソケットから使用可能なデータを読み取り、終了する非常に単純なクライアントです。
require 'socket' # Sockets are in standard library
hostname = 'localhost'
port = 2000
s = TCPSocket.open(hostname, port)
while line = s.gets # Read lines from the socket
puts line.chop # And print with platform line terminator
end
s.close # Close the socket when doneシンプルなサーバー
インターネットサーバーを作成するには、 TCPServerクラス。TCPServerオブジェクトは、TCPSocketオブジェクトのファクトリです。
今すぐ電話 TCPServer.open(hostname, portサービスのポートを指定して作成する関数TCPServer オブジェクト。
次に、返されたTCPServerオブジェクトのacceptメソッドを呼び出します。このメソッドは、クライアントが指定されたポートに接続するまで待機してから、そのクライアントへの接続を表すTCPSocketオブジェクトを返します。
require 'socket' # Get sockets from stdlib
server = TCPServer.open(2000) # Socket to listen on port 2000
loop { # Servers run forever
client = server.accept # Wait for a client to connect
client.puts(Time.now.ctime) # Send the time to the client
client.puts "Closing the connection. Bye!"
client.close # Disconnect from the client
}ここで、このサーバーをバックグラウンドで実行してから、上記のクライアントを実行して結果を確認します。
マルチクライアントTCPサーバー
インターネット上のほとんどのサーバーは、一度に多数のクライアントを処理するように設計されています。
RubyのThreadクラスを使用すると、マルチスレッドサーバーを簡単に作成できます。サーバーは、要求を受け入れ、すぐに新しい実行スレッドを作成して接続を処理し、メインプログラムがさらに接続を待機できるようにします。
require 'socket' # Get sockets from stdlib
server = TCPServer.open(2000) # Socket to listen on port 2000
loop { # Servers run forever
Thread.start(server.accept) do |client|
client.puts(Time.now.ctime) # Send the time to the client
client.puts "Closing the connection. Bye!"
client.close # Disconnect from the client
end
}この例では、永続的なループがあり、server.acceptが応答すると、新しいスレッドが作成され、スレッドに渡された接続オブジェクトを使用して、受け入れられたばかりの接続を処理するためにすぐに開始されます。ただし、メインプログラムはすぐにループバックし、新しい接続を待ちます。
このようにRubyスレッドを使用すると、コードが移植可能になり、Linux、OS X、およびWindowsで同じように実行されます。
小さなWebブラウザ
ソケットライブラリを使用して、任意のインターネットプロトコルを実装できます。ここに、例えば、ウェブページのコンテンツをフェッチするためのコードがあります-
require 'socket'
host = 'www.tutorialspoint.com' # The web server
port = 80 # Default HTTP port
path = "/index.htm" # The file we want
# This is the HTTP request we send to fetch a file
request = "GET #{path} HTTP/1.0\r\n\r\n"
socket = TCPSocket.open(host,port) # Connect to server
socket.print(request) # Send request
response = socket.read # Read complete response
# Split response at first blank line into headers and body
headers,body = response.split("\r\n\r\n", 2)
print body # And display it同様のWebクライアントを実装するには、次のようなビルド済みのライブラリを使用できます。 Net::HTTPHTTPを使用するため。これが前のコードと同等のコードです-
require 'net/http' # The library we need
host = 'www.tutorialspoint.com' # The web server
path = '/index.htm' # The file we want
http = Net::HTTP.new(host) # Create a connection
headers, body = http.get(path) # Request the file
if headers.code == "200" # Check the status code
print body
else
puts "#{headers.code} #{headers.message}"
endFTP、SMTP、POP、およびIMAPプロトコルで動作するには、同様のライブラリを確認してください。
さらなる読み物
ソケットプログラミングのクイックスタートを提供しました。これは大きなテーマなので、Rubyソケットライブラリとクラスメソッドを調べて詳細を確認することをお勧めします。
XMLとは何ですか?
Extensible Markup Language(XML)は、HTMLやSGMLによく似たマークアップ言語です。これは、World Wide Web Consortiumによって推奨されており、オープンスタンダードとして利用できます。
XMLは、オペレーティングシステムや開発言語に関係なく、プログラマーが他のアプリケーションで読み取ることができるアプリケーションを開発できるようにする、移植可能なオープンソース言語です。
XMLは、SQLベースのバックボーンを必要とせずに、少量から中量のデータを追跡するのに非常に役立ちます。
XMLパーサーのアーキテクチャとAPI
XMLパーサーで使用できる2つの異なるフレーバーがあります-
SAX-like (Stream interfaces)−ここでは、対象のイベントのコールバックを登録してから、パーサーにドキュメントを進めさせます。これは、ドキュメントが大きい場合やメモリに制限がある場合に便利です。ファイルをディスクから読み取るときにファイルを解析し、ファイル全体がメモリに保存されることはありません。
DOM-like (Object tree interfaces) −これはWorld Wide Web Consortiumの推奨事項であり、ファイル全体がメモリに読み込まれ、階層(ツリーベース)形式で格納されて、XMLドキュメントのすべての機能を表します。
SAXは、大きなファイルを処理する場合、DOMほど高速に情報を処理できないことは明らかです。一方、DOMを排他的に使用すると、特に多くの小さなファイルで使用する場合、リソースが実際に停止する可能性があります。
SAXは読み取り専用ですが、DOMではXMLファイルへの変更が許可されています。これらの2つの異なるAPIは文字通り互いに補完し合うため、大規模なプロジェクトで両方を使用できない理由はありません。
Rubyを使用したXMLの解析と作成
XMLを操作する最も一般的な方法は、SeanRussellによるREXMLライブラリを使用することです。2002年以来、REXMLは標準のRubyディストリビューションの一部となっています。
REXMLは、XML1.0標準に準拠した純粋なRubyXMLプロセッサです。これは非検証プロセッサであり、すべてのOASIS非検証適合性テストに合格しています。
REXMLパーサーには、他の利用可能なパーサーに比べて次の利点があります。
- それはRubyで100パーセント書かれています。
- SAXとDOMの両方の解析に使用できます。
- 軽量で、2000行未満のコードです。
- メソッドとクラスは本当に理解しやすいです。
- SAX2ベースのAPIと完全なXPathサポート。
- Rubyインストールで出荷され、個別のインストールは必要ありません。
すべてのXMLコード例について、単純なXMLファイルを入力として使用しましょう-
<collection shelf = "New Arrivals">
<movie title = "Enemy Behind">
<type>War, Thriller</type>
<format>DVD</format>
<year>2003</year>
<rating>PG</rating>
<stars>10</stars>
<description>Talk about a US-Japan war</description>
</movie>
<movie title = "Transformers">
<type>Anime, Science Fiction</type>
<format>DVD</format>
<year>1989</year>
<rating>R</rating>
<stars>8</stars>
<description>A schientific fiction</description>
</movie>
<movie title = "Trigun">
<type>Anime, Action</type>
<format>DVD</format>
<episodes>4</episodes>
<rating>PG</rating>
<stars>10</stars>
<description>Vash the Stampede!</description>
</movie>
<movie title = "Ishtar">
<type>Comedy</type>
<format>VHS</format>
<rating>PG</rating>
<stars>2</stars>
<description>Viewable boredom</description>
</movie>
</collection>DOMのような構文解析
まず、XMLデータをツリー形式で解析しましょう。まず、rexml/document図書館; 多くの場合、便宜上、インクルードREXMLを実行してトップレベルの名前空間にインポートします。
#!/usr/bin/ruby -w
require 'rexml/document'
include REXML
xmlfile = File.new("movies.xml")
xmldoc = Document.new(xmlfile)
# Now get the root element
root = xmldoc.root
puts "Root element : " + root.attributes["shelf"]
# This will output all the movie titles.
xmldoc.elements.each("collection/movie"){
|e| puts "Movie Title : " + e.attributes["title"]
}
# This will output all the movie types.
xmldoc.elements.each("collection/movie/type") {
|e| puts "Movie Type : " + e.text
}
# This will output all the movie description.
xmldoc.elements.each("collection/movie/description") {
|e| puts "Movie Description : " + e.text
}これにより、次の結果が生成されます-
Root element : New Arrivals
Movie Title : Enemy Behind
Movie Title : Transformers
Movie Title : Trigun
Movie Title : Ishtar
Movie Type : War, Thriller
Movie Type : Anime, Science Fiction
Movie Type : Anime, Action
Movie Type : Comedy
Movie Description : Talk about a US-Japan war
Movie Description : A schientific fiction
Movie Description : Vash the Stampede!
Movie Description : Viewable boredomSAXのような構文解析
同じデータ、movies.xml、ファイルをストリーム指向の方法で処理するために、パーサーからのコールバックのターゲットとなるメソッドを持つリスナークラスを定義します。
NOTE −小さなファイルにSAXのような解析を使用することはお勧めしません。これは、デモの例にすぎません。
#!/usr/bin/ruby -w
require 'rexml/document'
require 'rexml/streamlistener'
include REXML
class MyListener
include REXML::StreamListener
def tag_start(*args)
puts "tag_start: #{args.map {|x| x.inspect}.join(', ')}"
end
def text(data)
return if data =~ /^\w*$/ # whitespace only
abbrev = data[0..40] + (data.length > 40 ? "..." : "")
puts " text : #{abbrev.inspect}"
end
end
list = MyListener.new
xmlfile = File.new("movies.xml")
Document.parse_stream(xmlfile, list)これにより、次の結果が生成されます-
tag_start: "collection", {"shelf"=>"New Arrivals"}
tag_start: "movie", {"title"=>"Enemy Behind"}
tag_start: "type", {}
text : "War, Thriller"
tag_start: "format", {}
tag_start: "year", {}
tag_start: "rating", {}
tag_start: "stars", {}
tag_start: "description", {}
text : "Talk about a US-Japan war"
tag_start: "movie", {"title"=>"Transformers"}
tag_start: "type", {}
text : "Anime, Science Fiction"
tag_start: "format", {}
tag_start: "year", {}
tag_start: "rating", {}
tag_start: "stars", {}
tag_start: "description", {}
text : "A schientific fiction"
tag_start: "movie", {"title"=>"Trigun"}
tag_start: "type", {}
text : "Anime, Action"
tag_start: "format", {}
tag_start: "episodes", {}
tag_start: "rating", {}
tag_start: "stars", {}
tag_start: "description", {}
text : "Vash the Stampede!"
tag_start: "movie", {"title"=>"Ishtar"}
tag_start: "type", {}
tag_start: "format", {}
tag_start: "rating", {}
tag_start: "stars", {}
tag_start: "description", {}
text : "Viewable boredom"XPathとRuby
XMLを表示する別の方法はXPathです。これは、XMLドキュメント内の特定の要素と属性を検索し、そのドキュメントを論理的に順序付けられたツリーとして扱う方法を説明する一種の疑似言語です。
REXMLは、XPathクラスを介してXPathをサポートしています。上で見たように、ツリーベースの解析(ドキュメントオブジェクトモデル)を想定しています。
#!/usr/bin/ruby -w
require 'rexml/document'
include REXML
xmlfile = File.new("movies.xml")
xmldoc = Document.new(xmlfile)
# Info for the first movie found
movie = XPath.first(xmldoc, "//movie")
p movie
# Print out all the movie types
XPath.each(xmldoc, "//type") { |e| puts e.text }
# Get an array of all of the movie formats.
names = XPath.match(xmldoc, "//format").map {|x| x.text }
p namesこれにより、次の結果が生成されます-
<movie title = 'Enemy Behind'> ... </>
War, Thriller
Anime, Science Fiction
Anime, Action
Comedy
["DVD", "DVD", "DVD", "VHS"]XSLTとRuby
Rubyで使用できるXSLTパーサーは2つあります。それぞれの簡単な説明をここに示します。
ルビー-サブロトロン
このパーサーは、高橋正義によって作成および保守されています。これは主にLinuxOS用に書かれており、次のライブラリが必要です-
- Sablot
- Iconv
- Expat
このモジュールは次の場所にあります。 Ruby-Sablotron。
XSLT4R
XSLT4RはMichaelNeumannによって作成され、RAAのライブラリセクションのXMLの下にあります。XSLT4Rは単純なコマンドラインインターフェイスを使用しますが、代わりにサードパーティアプリケーション内で使用してXMLドキュメントを変換することもできます。
XSLT4Rが動作するにはXMLScanが必要です。これはXSLT4Rアーカイブに含まれており、100%Rubyモジュールでもあります。これらのモジュールは、標準のRubyインストール方法(つまり、ruby install.rb)を使用してインストールできます。
XSLT4Rの構文は次のとおりです-
ruby xslt.rb stylesheet.xsl document.xml [arguments]アプリケーション内からXSLT4Rを使用する場合は、XSLTを含めて、必要なパラメーターを入力できます。これが例です-
require "xslt"
stylesheet = File.readlines("stylesheet.xsl").to_s
xml_doc = File.readlines("document.xml").to_s
arguments = { 'image_dir' => '/....' }
sheet = XSLT::Stylesheet.new( stylesheet, arguments )
# output to StdOut
sheet.apply( xml_doc )
# output to 'str'
str = ""
sheet.output = [ str ]
sheet.apply( xml_doc )参考文献
REXMLパーサーの詳細については、REXMLパーサーのドキュメントの標準ドキュメントを参照してください。
XSLT4RはRAAリポジトリからダウンロードできます。
SOAPとは何ですか?
Simple Object Access Protocol(SOAP)は、クロスプラットフォームで言語に依存しないRPCプロトコルであり、XMLと、通常は(必ずしもそうとは限りませんが)HTTPに基づいています。
XMLを使用してリモートプロシージャコールを行う情報をエンコードし、HTTPを使用してその情報をネットワーク経由でクライアントからサーバーに(またはその逆に)転送します。
SOAPには、COM、CORBAなどの他のテクノロジに比べていくつかの利点があります。たとえば、比較的安価な展開とデバッグのコスト、拡張性と使いやすさ、さまざまな言語とプラットフォーム用のいくつかの実装の存在などです。
詳細については、簡単なチュートリアルSOAPを参照してください。
この章では、RubyのSOAP実装(SOAP4R)について理解します。これは基本的なチュートリアルであるため、詳細が必要な場合は、他のリソースを参照する必要があります。
SOAP4Rのインストール
SOAP4Rは、中村宏によって開発されたRuby用のSOAP実装であり、-からダウンロードできます。
NOTE −このコンポーネントをすでにインストールしている可能性が高いです。
Download SOAPあなたが知っているなら gem ユーティリティの場合、次のコマンドを使用して、SOAP4Rおよび関連パッケージをインストールできます。
$ gem install soap4r --include-dependenciesあなたがWindows上で作業している場合は、上記の場所と実行することで、標準的なインストール方法を使用してインストールする必要性から、ZIPファイルをダウンロードする必要がルビーinstall.rbを。
SOAP4Rサーバーの作成
SOAP4Rは、2つの異なるタイプのサーバーをサポートします-
- CGI / FastCGIベース(SOAP :: RPC :: CGIStub)
- スタンドアロン(SOAP :: RPC:StandaloneServer)
この章では、スタンドアロンサーバーの作成について詳しく説明します。以下のステップは、SOAPサーバーの作成に関係しています。
ステップ1-SOAP :: RPC :: StandaloneServerクラスを継承する
独自のスタンドアロンサーバーを実装するには、SOAP :: StandaloneServerの子となる新しいクラスを次のように作成する必要があります。
class MyServer < SOAP::RPC::StandaloneServer
...............
endNOTE− FastCGIベースのサーバーを作成する場合は、SOAP :: RPC :: CGIStubを親クラスとして使用する必要があります。残りの手順は、同じままです。
ステップ2-ハンドラーメソッドを定義する
2番目のステップは、外部に公開したいWebサービスメソッドを作成することです。
それらは単純なRubyメソッドとして書くことができます。たとえば、2つの数値を加算し、2つの数値を除算する2つのメソッドを記述してみましょう-
class MyServer < SOAP::RPC::StandaloneServer
...............
# Handler methods
def add(a, b)
return a + b
end
def div(a, b)
return a / b
end
endステップ3-ハンドラメソッドを公開する
次のステップは、定義したメソッドをサーバーに追加することです。初期化方法は、次の二つの方法のいずれかでサービスメソッドを公開するために使用されます-
class MyServer < SOAP::RPC::StandaloneServer
def initialize(*args)
add_method(receiver, methodName, *paramArg)
end
endパラメータの説明は次のとおりです-
| シニア番号 | パラメータと説明 |
|---|---|
| 1 | receiver methodNameメソッドを含むオブジェクト。methodDefメソッドと同じクラスでサービスメソッドを定義します。このパラメーターはselfです。 |
| 2 | methodName RPC要求のために呼び出されるメソッドの名前。 |
| 3 | paramArg 指定されている場合は、パラメーター名とパラメーターモードを指定します。 |
inoutまたはoutパラメーターの使用法を理解するために、2つのパラメーター(inParamおよびinoutParam)を取り、1つの通常の戻り値(retVal)と2つの追加パラメーターを返す次のサービスメソッドを検討してください:inoutParamおよびoutParam −
def aMeth(inParam, inoutParam)
retVal = inParam + inoutParam
outParam = inParam . inoutParam
inoutParam = inParam * inoutParam
return retVal, inoutParam, outParam
endこれで、このメソッドを次のように公開できます。
add_method(self, 'aMeth', [
%w(in inParam),
%w(inout inoutParam),
%w(out outParam),
%w(retval return)
])ステップ4-サーバーを起動します
最後のステップは、派生クラスの1つのインスタンスをインスタンス化し、を呼び出すことによってサーバーを起動することです。 start 方法。
myServer = MyServer.new('ServerName', 'urn:ruby:ServiceName', hostname, port)
myServer.start必要なパラメータの説明は次のとおりです-
| シニア番号 | パラメータと説明 |
|---|---|
| 1 | ServerName サーバー名、あなたはあなたが最も好きなものを与えることができます。 |
| 2 | urn:ruby:ServiceName ここでurn:rubyは定数ですが、このサーバーに一意のServiceName名を付けることができます。 |
| 3 | hostname このサーバーがリッスンするホスト名を指定します。 |
| 4 | port Webサービスに使用できる使用可能なポート番号。 |
例
ここで、上記の手順を使用して、1つのスタンドアロンサーバーを作成しましょう-
require "soap/rpc/standaloneserver"
begin
class MyServer < SOAP::RPC::StandaloneServer
# Expose our services
def initialize(*args)
add_method(self, 'add', 'a', 'b')
add_method(self, 'div', 'a', 'b')
end
# Handler methods
def add(a, b)
return a + b
end
def div(a, b)
return a / b
end
end
server = MyServer.new("MyServer",
'urn:ruby:calculation', 'localhost', 8080)
trap('INT){
server.shutdown
}
server.start
rescue => err
puts err.message
end実行されると、このサーバーアプリケーションはローカルホストでスタンドアロンSOAPサーバーを起動し、ポート8080で要求をリッスンします。2つのパラメーターを取り、結果を返す1つのサービスメソッドaddとdivを公開します。
これで、次のようにこのサーバーをバックグラウンドで実行できます。
$ ruby MyServer.rb&SOAP4Rクライアントの作成
SOAP :: RPC ::ドライバー・クラスは、SOAPクライアントアプリケーションを記述するためのサポートを提供します。この章では、このクラスについて説明し、アプリケーションに基づいてその使用法を示します。
以下は、SOAPサービスを呼び出すために必要な最低限の情報です。
- SOAPサービスのURL(SOAPエンドポイントURL)。
- サービスメソッドの名前空間(メソッド名前空間URI)。
- サービスメソッドの名前とそのパラメータ。
ここで、上記の例で定義されたaddおよびdivという名前のサービスメソッドを呼び出すSOAPクライアントを作成します。
SOAPクライアントを作成する主な手順は次のとおりです。
ステップ1-SOAPドライバーインスタンスを作成する
次のように新しいメソッドを呼び出すことにより、SOAP :: RPC :: Driverのインスタンスを作成します-
SOAP::RPC::Driver.new(endPoint, nameSpace, soapAction)必要なパラメータの説明は次のとおりです-
| シニア番号 | パラメータと説明 |
|---|---|
| 1 | endPoint 接続するSOAPサーバーのURL。 |
| 2 | nameSpace このSOAP :: RPC :: Driverオブジェクトで実行されるすべてのRPCに使用する名前空間。 |
| 3 | soapAction HTTPヘッダーのSOAPActionフィールドの値。nilの場合、これはデフォルトで空の文字列 ""になります。 |
ステップ2-サービスメソッドを追加する
SOAPサービスメソッドをSOAP :: RPC :: Driverに追加するには、SOAP :: RPC :: Driverインスタンスを使用して次のメソッドを呼び出すことができます。
driver.add_method(name, *paramArg)パラメータの説明は次のとおりです-
| シニア番号 | パラメータと説明 |
|---|---|
| 1 | name リモートWebサービスメソッドの名前。 |
| 2 | paramArg リモートプロシージャのパラメータの名前を指定します。 |
ステップ3-SOAPサービスを呼び出す
最後のステップは、SOAP :: RPC :: Driverインスタンスを使用してSOAPサービスに次のように請求することです。
result = driver.serviceMethod(paramArg...)ここで、serviceMethodは実際のWebサービスメソッドであり、paramArg ...はサービスメソッドを渡すために必要なリストパラメーターです。
Example
上記の手順に基づいて、SOAPクライアントを次のように記述します-
#!/usr/bin/ruby -w
require 'soap/rpc/driver'
NAMESPACE = 'urn:ruby:calculation'
URL = 'http://localhost:8080/'
begin
driver = SOAP::RPC::Driver.new(URL, NAMESPACE)
# Add remote sevice methods
driver.add_method('add', 'a', 'b')
# Call remote service methods
puts driver.add(20, 30)
rescue => err
puts err.message
endさらなる読み物
Rubyを使用したWebサービスの非常に基本的な概念について説明しました。さらにドリルダウンしたい場合は、Rubyを使用したWebサービスの詳細を見つけるための次のリンクがあります。
前書き
Rubyの標準のグラフィカルユーザーインターフェイス(GUI)はTkです。Tkは、JohnOusterhoutによって開発されたTclスクリプト言語のGUIとして始まりました。
Tkには、唯一のクロスプラットフォームGUIであるという独自の特徴があります。TkはWindows、Mac、およびLinuxで実行され、各オペレーティングシステムでネイティブのルックアンドフィールを提供します。
Tkベースのアプリケーションの基本コンポーネントはウィジェットと呼ばれます。Tkでは、「ウィンドウ」と「ウィジェット」が同じ意味で使用されることが多いため、コンポーネントはウィンドウと呼ばれることもあります。
Tkアプリケーションはウィジェット階層に従い、ウィジェットは別のウィジェット内にいくつでも配置でき、それらのウィジェットは別のウィジェット内に無限に配置できます。Tkプログラムのメインウィジェットはルートウィジェットと呼ばれ、TkRootクラスの新しいインスタンスを作成することで作成できます。
ほとんどのTkベースのアプリケーションは同じサイクルに従います。ウィジェットを作成し、それらをインターフェイスに配置し、最後に、各ウィジェットに関連付けられたイベントをメソッドにバインドします。
3つのジオメトリマネージャがあります。インターフェイス内の各ウィジェットのサイズと場所を制御する役割を担う場所、グリッド、およびパック。
インストール
Ruby TkバインディングはRubyとともに配布されますが、Tkは別のインストールです。Windowsユーザーは、ActiveStateのActiveTclからシングルクリックのTkインストールをダウンロードできます。
MacおよびLinuxユーザーは、OSと一緒にすでにインストールされている可能性が高いため、インストールする必要がない場合がありますが、インストールされていない場合は、ビルド済みパッケージをダウンロードするか、Tcl DeveloperXchangeからソースを入手できます。
シンプルなTkアプリケーション
Ruby / Tkプログラムの一般的な構造は、メインまたは root ウィンドウ(TkRootのインスタンス)にウィジェットを追加してユーザーインターフェイスを構築し、を呼び出してメインイベントループを開始します Tk.mainloop。
伝統的なHello、World!Ruby / Tkの例は次のようになります-
require 'tk'
root = TkRoot.new { title "Hello, World!" }
TkLabel.new(root) do
text 'Hello, World!'
pack { padx 15 ; pady 15; side 'left' }
end
Tk.mainloopここでは、tk拡張モジュールをロードした後、TkRoot.newを使用してルートレベルのフレームを作成します。次に、ルートフレームの子としてTkLabelウィジェットを作成し、ラベルにいくつかのオプションを設定します。最後に、ルートフレームをパックし、メインGUIイベントループに入ります。
このスクリプトを実行すると、次の結果が生成されます-
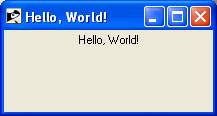
Ruby / Tkウィジェットクラス
Ruby / Tkを使用して目的のGUIを作成するために使用できるさまざまなRuby / Tkクラスのリストがあります。
TkFrameフレームウィジェットを作成および操作します。
TkButtonボタンウィジェットを作成および操作します。
TkLabelラベルウィジェットを作成および操作します。
TkEntryエントリウィジェットを作成および操作します。
TkCheckButtonチェックボタンウィジェットを作成および操作します。
TkRadioButtonラジオボタンウィジェットを作成および操作します。
TkListboxリストボックスウィジェットを作成および操作します。
TkComboBoxリストボックスウィジェットを作成および操作します。
TkMenuメニューウィジェットを作成および操作します。
TkMenubuttonメニューボタンウィジェットを作成および操作します。
Tk.messageBoxメッセージダイアログを作成および操作します。
TkScrollbarスクロールバーウィジェットを作成および操作します。
TkCanvasキャンバスウィジェットを作成および操作します。
TkScaleスケールウィジェットを作成および操作します。
TkTextテキストウィジェットを作成および操作します。
TkToplevelトップレベルウィジェットを作成および操作します。
TkSpinboxSpinboxウィジェットを作成および操作します。
TkProgressBarプログレスバーウィジェットを作成および操作します。
ダイアログボックスダイアログボックスウィジェットを作成および操作します。
Tk :: Tile :: Notebookノートブックの比喩で限られたスペースにいくつかのウィンドウを表示します。
Tk :: Tile :: Paned垂直または水平に積み重ねられた多数のサブウィンドウを表示します。
Tk :: Tile :: Separator水平または垂直のセパレータバーを表示します。
Ruby / Tkフォント、色、画像Ruby / Tkフォント、色、画像を理解する
標準構成オプション
すべてのウィジェットには、さまざまな構成オプションがあり、通常、ウィジェットの表示方法や動作を制御します。もちろん、使用できるオプションはウィジェットクラスによって異なります。
これは、すべてのRuby / Tkウィジェットに適用できるすべての標準構成オプションのリストです。
| シニア番号 | オプションと説明 |
|---|---|
| 1 | activebackground =>文字列 アクティブな要素を描画するときに使用する背景色を指定します。マウスカーソルが要素の上に置かれ、マウスボタンを押すと何らかのアクションが発生する場合、要素はアクティブです。「赤」、「青」、「ピンク」、「黄色」などの色の名前を使用できます。 |
| 2 | activeborderwidth =>整数 アクティブな要素の周囲に描画される3D境界線の幅を示す負でない値を指定します。 |
| 3 | activeforeground =>文字列 アクティブな要素を描画するときに使用する前景色を指定します。 |
| 4 | anchor =>文字列 ウィジェット内の情報(テキストやビットマップなど)をウィジェットに表示する方法を指定します。値の1つである必要がありますn、 ne、 e、 se、 s、 sw、 w、 nw、または center。例えば、nw 左上隅がウィジェットの左上隅になるように情報を表示することを意味します。 |
| 5 | background or bg =>文字列 ウィジェットを表示するときに使用する通常の背景色を指定します。 |
| 6 | bitmap =>ビットマップ ウィジェットに表示するビットマップを指定します。ビットマップが表示される正確な方法は、アンカーや位置揃えなどの他のオプションの影響を受ける可能性があります。 |
| 7 | borderwidth or bd =>整数 ウィジェットの外側に描画する3D境界線の幅を示す負でない値を指定します。 |
| 8 | compound =>文字列 ウィジェットがテキストとビットマップ/画像を同時に表示するかどうかを指定し、表示する場合は、ビットマップ/画像をテキストに対してどこに配置するかを指定します。値の1つである必要がありますnone、 bottom、 top、 left、 right、または center。 |
| 9 | cursor =>文字列 ウィジェットに使用するマウスカーソルを指定します。可能な値は、「watch」、「arrow」などです。 |
| 10 | disabledforeground =>文字列 無効な要素を描画するときに使用する前景色を指定します。 |
| 11 | exportselection =>ブール値 ウィジェット内の選択がX選択でもあるかどうかを指定します。値には、true、 false、 0、 1、 yes、または no。選択範囲がエクスポートされる場合、ウィジェット内で選択すると現在のX選択範囲の選択が解除され、ウィジェットの外側を選択するとウィジェット選択範囲の選択が解除され、ウィジェットは選択範囲がある場合に選択取得要求に応答します。 |
| 12 | font =>文字列 ウィジェット内にテキストを描画するときに使用するフォントを指定します。 |
| 13 | foreground or fg =>文字列 ウィジェットを表示するときに使用する通常の前景色を指定します。 |
| 14 | highlightbackground =>文字列 ウィジェットに入力フォーカスがない場合にトラバーサルハイライト領域に表示する色を指定します。 |
| 15 | highlightcolor =>文字列 入力フォーカスがあるときにウィジェットの周囲に描画されるトラバーサルハイライト長方形に使用する色を指定します。 |
| 16 | highlightthickness =>整数 入力フォーカスがあるときにウィジェットの外側に描画するハイライト長方形の幅を示す負でない値を指定します。 |
| 17 | image =>画像 ウィジェットに表示する画像を指定します。画像の作成で作成されている必要があります。通常、imageオプションが指定されている場合、ウィジェットに表示するビットマップまたはテキスト値を指定する他のオプションをオーバーライドします。画像オプションを空の文字列にリセットして、ビットマップまたはテキスト表示を再度有効にすることができます。 |
| 18 | jump =>文字列 スクロールバーやスケールなど、ドラッグして値を調整できるスライダーを備えたウィジェットの場合、このオプションは、値の変更について通知が行われるタイミングを決定します。オプションの値はブール値でなければなりません。値がfalseの場合、スライダーをドラッグすると更新が継続的に行われます。値がtrueの場合、マウスボタンを離してドラッグを終了するまで更新が遅延されます。その時点で、単一の通知が行われます。 |
| 19 | justify =>文字列 ウィジェットに複数行のテキストが表示されている場合、このオプションは、行が互いにどのように整列するかを決定します。のいずれかである必要がありますleft、 center、または right。 Left 線の左端がすべて整列することを意味します。 center 線の中心が整列していることを意味し、 right 線の右端が揃うことを意味します。 |
| 20 | offset =>文字列 タイルのオフセットを指定します(「 tileオプション)。それは2つの異なるフォーマットを持つことができますoffset x,y または offset side、サイドができる場所 n、 ne、 e、 se、 s、 sw、 w、 nw、または center。 |
| 21 | orient =>文字列 スクロールバーなど、水平方向または垂直方向のいずれかでレイアウトできるウィジェットの場合、このオプションは使用する方向を指定します。どちらかでなければなりませんhorizontal または vertical またはこれらのいずれかの略語。 |
| 22 | padx =>整数 X方向にウィジェットに要求する追加スペースの量を示す負でない値を指定します。 |
| 23 | pady =>整数 Y方向にウィジェットに要求する追加スペースの量を示す負でない値を指定します。 |
| 24 | relief =>整数 ウィジェットに必要な3D効果を指定します。許容値はraised、 sunken、 flat、 ridge、および groove。 |
| 25 | repeatdelay =>整数 自動リピートを開始する前にボタンまたはキーを押し続ける必要があるミリ秒数を指定します。たとえば、スクロールバーの上矢印と下矢印に使用されます。 |
| 26 | repeatinterval =>整数 と組み合わせて使用 repeatdelay:自動リピートが開始されると、このオプションは自動リピート間のミリ秒数を決定します |
| 27 | selectbackground =>文字列 選択したアイテムを表示するときに使用する背景色を指定します。 |
| 28 | selectborderwidth =>整数 選択したアイテムの周囲に描画する3D境界線の幅を示す負でない値を指定します。 |
| 29 | selectforeground =>文字列 選択したアイテムを表示するときに使用する前景色を指定します。 |
| 30 | setgrid =>ブール値 このウィジェットがトップレベルウィンドウのサイズ変更グリッドを制御するかどうかを決定するブール値を指定します。このオプションは通常、テキストウィジェットで使用されます。ウィジェット内の情報は自然なサイズ(文字のサイズ)であり、ウィンドウのサイズがこれらの単位の整数であることが理にかなっています。 |
| 31 | takefocus =>整数 キーボードトラバーサル(TabやShift-Tabなど)を介してウィンドウからウィンドウにフォーカスを移動するときに使用される情報を提供します。ウィンドウにフォーカスを設定する前に、トラバーサルスクリプトは、最初にウィンドウが表示可能かどうかを確認します(ウィンドウとそのすべての祖先がマップされます)。そうでない場合、ウィンドウはスキップされます。値0は、キーボードトラバーサル中にこのウィンドウを完全にスキップする必要があることを意味します。1は、このウィンドウが常に入力フォーカスを受け取る必要があることを意味します。 |
| 32 | text =>文字列 ウィジェット内に表示する文字列を指定します。文字列の表示方法は特定のウィジェットによって異なり、次のような他のオプションによって決定される場合があります。anchor または justify。 |
| 33 | textvariable =>変数 変数の名前を指定します。変数の値は、ウィジェット内に表示されるテキスト文字列です。変数値が変更されると、ウィジェットは自動的に更新されて新しい値を反映します。文字列がウィジェットに表示される方法は、特定のウィジェットによって異なり、次のような他のオプションによって決定される場合があります。anchor または justify。 |
| 34 | tile =>画像 ウィジェットの表示に使用する画像を指定します。画像が空の文字列の場合、通常の背景色が表示されます。 |
| 35 | troughcolor =>文字列 スクロールバーやスケールなどのウィジェットの長方形のトラフ領域に使用する色を指定します。 |
| 36 | troughtile =>画像 スクロールバーやスケールなどのウィジェットの長方形のトラフ領域に表示するために使用される画像を指定します。 |
| 37 | underline =>整数 ウィジェットで下線を引く文字の整数インデックスを指定します。このオプションは、メニューボタンとメニューエントリのキーボードトラバーサルを実装するためにデフォルトのバインディングで使用されます。0はウィジェットに表示されるテキストの最初の文字に対応し、1は次の文字に対応します。 |
| 38 | wraplength =>整数 ワードラップを実行できるウィジェットの場合、このオプションは最大行長を指定します。 |
| 39 | xscrollcommand =>関数 水平スクロールバーとの通信に使用されるコールバックを指定します。 |
| 40 | yscrollcommand =>関数 垂直スクロールバーとの通信に使用されるコールバックを指定します。 |
Ruby / Tkジオメトリ管理
ジオメトリ管理では、要件に応じてさまざまなウィジェットを配置します。Tkのジオメトリ管理は、マスターウィジェットとスレーブウィジェットの概念に依存しています。
マスターはウィジェットであり、通常はトップレベルのウィンドウまたはフレームであり、スレーブと呼ばれる他のウィジェットが含まれます。ジオメトリマネージャーは、マスターウィジェットを制御し、その中に何を表示するかを決定するものと考えることができます。
ジオメトリマネージャは、各スレーブウィジェットに、その自然なサイズ、または理想的に表示するサイズを尋ねます。次に、その情報を取得し、ジオメトリマネージャーにその特定のスレーブウィジェットを管理するように要求するときに、プログラムによって提供されるパラメーターと組み合わせます。
インターフェイス内の各ウィジェットのサイズと場所を制御する3つのジオメトリマネージャーの配置、グリッド、およびパックがあります。
ウィジェットをグリッドに配置するグリッドジオメトリマネージャー。
キャビティのエッジの周りにパックするジオメトリマネージャをパックします。
場所の固定またはゴムシート配置のためのジオメトリマネージャ。
Ruby / Tkイベント処理
Ruby / Tkは、オペレーティングシステムからイベントを受信するイベントループをサポートしています。これらは、ボタンの押下、キーストローク、マウスの動き、ウィンドウのサイズ変更などです。
Ruby / Tkが、このイベントループの管理を担当します。イベントが適用されるウィジェットを特定し(ユーザーがこのボタンをクリックしたかどうか、キーが押された場合、どのテキストボックスにフォーカスがあったか)、それに応じてディスパッチします。個々のウィジェットはイベントへの応答方法を知っているため、たとえば、マウスがボタンの上に移動するとボタンの色が変わり、マウスが離れると元に戻る場合があります。
より高いレベルでは、Ruby / Tkはプログラムでコールバックを呼び出して、ウィジェットに何か重要なことが起こったことを示します。どちらの場合でも、アプリケーションがイベントまたはコールバックにどのように応答するかを指定するコードブロックまたはRubyProcオブジェクトを提供できます。
bindメソッドを使用して、基本的なウィンドウシステムイベントをそれらを処理するRubyプロシージャに関連付ける方法を見てみましょう。最も単純な形式のバインドは、入力として、イベント名を示す文字列と、Tkがイベントを処理するために使用するコードブロックを取ります。
たとえば、ウィジェットの最初のマウスボタンのButtonReleaseイベントをキャッチするには、次のように記述します。
someWidget.bind('ButtonRelease-1') {
....code block to handle this event...
}イベント名には、追加の修飾子と詳細を含めることができます。修飾子は、Shift、Control、Altなどの文字列であり、修飾子キーの1つが押されたことを示します。
したがって、たとえば、ユーザーがCtrlキーを押しながらマウスの右ボタンをクリックしたときに生成されるイベントをキャッチします。
someWidget.bind('Control-ButtonPress-3', proc { puts "Ouch!" })多くのRuby / Tkウィジェットは、ユーザーがウィジェットをアクティブ化したときにコールバックをトリガーできます。コマンドコールバックを使用して、特定のコードブロックまたはプロシージャが発生したときに呼び出されるように指定できます。前に見たように、ウィジェットを作成するときにコマンドコールバックプロシージャを指定できます-
helpButton = TkButton.new(buttonFrame) {
text "Help"
command proc { showHelp }
}または、ウィジェットのコマンドメソッドを使用して後で割り当てることができます-
helpButton.command proc { showHelp }コマンドメソッドはプロシージャまたはコードブロックのいずれかを受け入れるため、前のコード例を次のように記述することもできます。
helpButton = TkButton.new(buttonFrame) {
text "Help"
command { showHelp }
}| シニア番号 | タグとイベントの説明 |
|---|---|
| 1 | "1" (one) マウスの左ボタンをクリックしました。 |
| 2 | "ButtonPress-1" マウスの左ボタンをクリックしました。 |
| 3 | "Enter" マウスを内側に移動しました。 |
| 4 | "Leave" マウスを外側に移動しました。 |
| 5 | "Double-1" ダブルクリックしました。 |
| 6 | "B3-Motion" 右ボタンをある位置から別の位置にドラッグします。 |
| 7 | Control-ButtonPress-3 Ctrlキーとともに右ボタンを押します。 |
| 8 | Alt-ButtonPress-1 Altキーと一緒にボタンを押します。 |
configureメソッド
configureメソッドを設定するために使用し、任意のウィジェットの設定値を取得することができます。たとえば、ボタンの幅を変更するには、次のようにいつでもconfigureメソッドを呼び出すことができます。
require "tk"
button = TkButton.new {
text 'Hello World!'
pack
}
button.configure('activebackground', 'blue')
Tk.mainloop現在のウィジェットの値を取得するには、次のように値なしでウィジェットを指定するだけです。
color = button.configure('activebackground')オプションをまったく使用せずにconfigureを呼び出すこともできます。これにより、すべてのオプションとその値のリストが表示されます。
cgetメソッド
オプションの値を単純に取得するために、configureは通常必要な情報よりも多くの情報を返します。cgetメソッドは、現在の値のみを返します。
color = button.cget('activebackground')Ruby / LDAPはRubyの拡張ライブラリです。OpenLDAP、UMich LDAP、Netscape SDK、ActiveDirectoryなどの一部のLDAPライブラリへのインターフェイスを提供します。
アプリケーション開発用の一般的なAPIはRFC1823で説明されており、Ruby / LDAPでサポートされています。
Ruby / LDAPのインストール
完全なRuby / LDAPパッケージをSOURCEFORGE.NETからダウンロードしてインストールできます。
Ruby / LDAPをインストールする前に、次のコンポーネントがあることを確認してください-
- Ruby 1.8.x(ldap / controlを使用する場合は少なくとも1.8.2)。
- OpenLDAP、Netscape SDK、Windows2003またはWindowsXP。
これで、標準のRubyインストール方法を使用できます。開始する前に、extconf.rbで使用可能なオプションを確認したい場合は、「-help」オプションを指定して実行してください。
$ ruby extconf.rb [--with-openldap1|--with-openldap2| \
--with-netscape|--with-wldap32]
$ make $ make installNOTE− Windowsでソフトウェアをビルドしている場合は、makeの代わりにnmakeを使用する必要がある場合があります。
LDAP接続を確立する
これは2段階のプロセスです-
ステップ1-接続オブジェクトを作成する
LDAPディレクトリへの接続を作成するための構文は次のとおりです。
LDAP::Conn.new(host = 'localhost', port = LDAP_PORT)host−これはLDAPディレクトリを実行しているホストIDです。私たちは、としてそれを取るだろうlocalhostを。
port−これはLDAPサービスに使用されているポートです。標準のLDAPポートは636と389です。サーバーで使用されているポートを確認してください。使用されていない場合は、LDAP :: LDAP_PORTを使用できます。
この呼び出しは、ポートポート上のサーバー、ホストへの新しいLDAP :: Conn接続を返します。
ステップ2-バインディング
これは通常、セッションの残りの部分で使用するユーザー名とパスワードを指定する場所です。
以下は、DNを使用してLDAP接続をバインドするための構文です。 dn、資格情報、 pwd、およびバインドメソッド、 method −
conn.bind(dn = nil, password = nil, method = LDAP::LDAP_AUTH_SIMPLE)do
....
endコードブロックなしで同じ方法を使用できます。この場合、次のように明示的に接続のバインドを解除する必要があります-
conn.bind(dn = nil, password = nil, method = LDAP::LDAP_AUTH_SIMPLE)
....
conn.unbindコードブロックが与えられた場合、自己はブロックに譲られます。
適切な権限があれば、bindメソッドのブロック内(bindとunbindの間)で検索、追加、変更、または削除操作を実行できるようになりました。
Example
ローカルサーバーで作業していると仮定して、適切なホスト、ドメイン、ユーザーID、パスワードなどを組み合わせてみましょう。
#/usr/bin/ruby -w
require 'ldap'
$HOST = 'localhost' $PORT = LDAP::LDAP_PORT
$SSLPORT = LDAP::LDAPS_PORT conn = LDAP::Conn.new($HOST, $PORT)
conn.bind('cn = root, dc = localhost, dc = localdomain','secret')
....
conn.unbindLDAPエントリの追加
LDPAエントリの追加は2段階のプロセスです-
ステップ1- LDAP :: Modオブジェクトを作成する
エントリを作成するには、conn.addメソッドにLDAP :: Modオブジェクトを渡す必要があります。LDAP :: Modオブジェクトを作成するための簡単な構文を次に示します-
Mod.new(mod_type, attr, vals)mod_type − 1つ以上のオプションLDAP_MOD_ADD、LDAP_MOD_REPLACE、またはLDAP_MOD_DELETE。
attr −操作する属性の名前である必要があります。
vals−はattrに関連する値の配列です。valsにバイナリデータが含まれている場合、mod_typeはLDAP_MOD_BVALUESと論理的にOR(|)する必要があります。
この呼び出しはLDAP :: Modオブジェクトを返します。これは、LDAP :: Connクラスのメソッド(Conn#add、Conn#add_ext、Conn#modify、Conn#modify_extなど)に渡すことができます。
ステップ2- conn.addメソッドを呼び出す
LDAP :: Modオブジェクトの準備ができたら、conn.addメソッドを呼び出してエントリを作成できます。このメソッドを呼び出す構文は次のとおりです-
conn.add(dn, attrs)このメソッドは、DN、dn、および属性attrsを持つエントリを追加します。ここで、attrsは、LDAP :: Modオブジェクトの配列、または属性と値の配列ペアのハッシュのいずれかである必要があります。
Example
これは完全な例で、2つのディレクトリエントリを作成します-
#/usr/bin/ruby -w
require 'ldap'
$HOST = 'localhost'
$PORT = LDAP::LDAP_PORT $SSLPORT = LDAP::LDAPS_PORT
conn = LDAP::Conn.new($HOST, $PORT)
conn.bind('cn = root, dc = localhost, dc = localdomain','secret')
conn.perror("bind")
entry1 = [
LDAP.mod(LDAP::LDAP_MOD_ADD,'objectclass',['top','domain']),
LDAP.mod(LDAP::LDAP_MOD_ADD,'o',['TTSKY.NET']),
LDAP.mod(LDAP::LDAP_MOD_ADD,'dc',['localhost']),
]
entry2 = [
LDAP.mod(LDAP::LDAP_MOD_ADD,'objectclass',['top','person']),
LDAP.mod(LDAP::LDAP_MOD_ADD, 'cn', ['Zara Ali']),
LDAP.mod(LDAP::LDAP_MOD_ADD | LDAP::LDAP_MOD_BVALUES, 'sn',
['ttate','ALI', "zero\000zero"]),
]
begin
conn.add("dc = localhost, dc = localdomain", entry1)
conn.add("cn = Zara Ali, dc = localhost, dc = localdomain", entry2)
rescue LDAP::ResultError
conn.perror("add")
exit
end
conn.perror("add")
conn.unbindLDAPエントリの変更
エントリの変更は、エントリの追加に似ています。変更する属性を追加する代わりに、modifyメソッドを呼び出すだけです。これはmodifyメソッドの簡単な構文です。
conn.modify(dn, mods)このメソッドは、DN、dn、および属性modsを使用してエントリを変更します。ここで、改造はの配列のいずれかでなければなりませんLDAP :: modはオブジェクトまたは属性/値配列のペアのハッシュ。
例
前のセクションで追加したエントリの姓を変更するには、次のように記述します。
#/usr/bin/ruby -w
require 'ldap'
$HOST = 'localhost' $PORT = LDAP::LDAP_PORT
$SSLPORT = LDAP::LDAPS_PORT conn = LDAP::Conn.new($HOST, $PORT)
conn.bind('cn = root, dc = localhost, dc = localdomain','secret')
conn.perror("bind")
entry1 = [
LDAP.mod(LDAP::LDAP_MOD_REPLACE, 'sn', ['Mohtashim']),
]
begin
conn.modify("cn = Zara Ali, dc = localhost, dc = localdomain", entry1)
rescue LDAP::ResultError
conn.perror("modify")
exit
end
conn.perror("modify")
conn.unbindLDAPエントリの削除
エントリを削除するには、識別名をパラメータとしてdeleteメソッドを呼び出します。これがdeleteメソッドの簡単な構文です。
conn.delete(dn)このメソッドは、DN、dnを持つエントリを削除します。
例
前のセクションで追加したZaraMohtashimエントリを削除するには、次のように記述します。
#/usr/bin/ruby -w
require 'ldap'
$HOST = 'localhost'
$PORT = LDAP::LDAP_PORT $SSLPORT = LDAP::LDAPS_PORT
conn = LDAP::Conn.new($HOST, $PORT)
conn.bind('cn = root, dc = localhost, dc = localdomain','secret')
conn.perror("bind")
begin
conn.delete("cn = Zara-Mohtashim, dc = localhost, dc = localdomain")
rescue LDAP::ResultError
conn.perror("delete")
exit
end
conn.perror("delete")
conn.unbind識別名の変更
エントリの識別名をmodifyメソッドで変更することはできません。代わりに、modrdnメソッドを使用してください。modrdnメソッドの簡単な構文は次のとおりです-
conn.modrdn(dn, new_rdn, delete_old_rdn)このメソッドは、エントリのRDNをDN、dnで変更し、新しいRDN、new_rdnを与えます。場合delete_old_rdnがある真、古いRDN値を項目から削除されます。
例
次のエントリがあるとします-
dn: cn = Zara Ali,dc = localhost,dc = localdomain
cn: Zara Ali
sn: Ali
objectclass: person次に、その識別名を次のコードで変更できます-
#/usr/bin/ruby -w
require 'ldap'
$HOST = 'localhost' $PORT = LDAP::LDAP_PORT
$SSLPORT = LDAP::LDAPS_PORT conn = LDAP::Conn.new($HOST, $PORT)
conn.bind('cn = root, dc = localhost, dc = localdomain','secret')
conn.perror("bind")
begin
conn.modrdn("cn = Zara Ali, dc = localhost, dc = localdomain", "cn = Zara Mohtashim", true)
rescue LDAP::ResultError
conn.perror("modrdn")
exit
end
conn.perror("modrdn")
conn.unbind検索の実行
LDAPディレクトリで検索を実行するには、3つの異なる検索モードのいずれかで検索方法を使用します-
LDAP_SCOPE_BASEM −ベースノードのみを検索します。
LDAP_SCOPE_ONELEVEL −ベースノードのすべての子を検索します。
LDAP_SCOPE_SUBTREE −ベースノードを含むサブツリー全体を検索します。
例
ここでは、エントリdc = localhost、dc = localdomainのサブツリー全体で人物オブジェクトを検索します-
#/usr/bin/ruby -w
require 'ldap'
$HOST = 'localhost'
$PORT = LDAP::LDAP_PORT $SSLPORT = LDAP::LDAPS_PORT
base = 'dc = localhost,dc = localdomain'
scope = LDAP::LDAP_SCOPE_SUBTREE
filter = '(objectclass = person)'
attrs = ['sn', 'cn']
conn = LDAP::Conn.new($HOST, $PORT)
conn.bind('cn = root, dc = localhost, dc = localdomain','secret')
conn.perror("bind")
begin
conn.search(base, scope, filter, attrs) { |entry|
# print distinguished name
p entry.dn
# print all attribute names
p entry.attrs
# print values of attribute 'sn'
p entry.vals('sn')
# print entry as Hash
p entry.to_hash
}
rescue LDAP::ResultError
conn.perror("search")
exit
end
conn.perror("search")
conn.unbindこれにより、一致するエントリごとに指定されたコードブロックが呼び出され、LDAPエントリはLDAP :: Entryクラスのインスタンスによって表されます。検索の最後のパラメーターを使用して、他のすべてを省略して、関心のある属性を指定できます。ここでnilを渡すと、すべての属性がリレーショナルデータベースの「SELECT *」と同じように返されます。
LDAP :: Entryクラスのdnメソッド(get_dnのエイリアス)は、エントリの識別名を返します。to_hashメソッドを使用すると、その属性(識別名を含む)のハッシュ表現を取得できます。エントリの属性のリストを取得するには、attrsメソッド(get_attributesのエイリアス)を使用します。また、1つの特定の属性の値のリストを取得するには、valsメソッド(get_valuesのエイリアス)を使用します。
エラーの処理
Ruby / LDAPは2つの異なる例外クラスを定義します-
エラーが発生した場合、new、bind、またはunbindメソッドはLDAP :: Error例外を発生させます。
LDAPディレクトリを追加、変更、削除、または検索すると、LDAP :: ResultErrorが発生します。
参考文献
LDAP方法の詳細については、のための標準的なドキュメントを参照してくださいLDAPのドキュメント。
従来のプログラムには単一の実行スレッドがあり、プログラムを構成するステートメントまたは命令は、プログラムが終了するまで順番に実行されます。
マルチスレッドプログラムには、複数の実行スレッドがあります。各スレッド内では、ステートメントは順番に実行されますが、スレッド自体は、たとえばマルチコアCPUで並列に実行される場合があります。多くの場合、単一のCPUマシンでは、複数のスレッドが実際には並列に実行されませんが、並列処理はスレッドの実行をインターリーブすることによってシミュレートされます。
Rubyを使用すると、Threadクラスを使用してマルチスレッドプログラムを簡単に作成できます。Rubyスレッドは、コードの並行性を実現するための軽量で効率的な方法です。
Rubyスレッドの作成
新しいスレッドを開始するには、ブロックをThread.newの呼び出しに関連付けるだけです。ブロック内のコードを実行するために新しいスレッドが作成され、元のスレッドはThread.newからすぐに戻り、次のステートメントで実行を再開します-
# Thread #1 is running here
Thread.new {
# Thread #2 runs this code
}
# Thread #1 runs this code例
これは、マルチスレッドのRubyプログラムを使用する方法を示す例です。
#!/usr/bin/ruby
def func1
i = 0
while i<=2
puts "func1 at: #{Time.now}"
sleep(2)
i = i+1
end
end
def func2
j = 0
while j<=2
puts "func2 at: #{Time.now}"
sleep(1)
j = j+1
end
end
puts "Started At #{Time.now}"
t1 = Thread.new{func1()}
t2 = Thread.new{func2()}
t1.join
t2.join
puts "End at #{Time.now}"これにより、次の結果が生成されます-
Started At Wed May 14 08:21:54 -0700 2008
func1 at: Wed May 14 08:21:54 -0700 2008
func2 at: Wed May 14 08:21:54 -0700 2008
func2 at: Wed May 14 08:21:55 -0700 2008
func1 at: Wed May 14 08:21:56 -0700 2008
func2 at: Wed May 14 08:21:56 -0700 2008
func1 at: Wed May 14 08:21:58 -0700 2008
End at Wed May 14 08:22:00 -0700 2008スレッドのライフサイクル
Thread.newを使用して新しいスレッドが作成されます。同義語のThread.startとThread.forkを使用することもできます。
スレッドの作成後にスレッドを開始する必要はありません。CPUリソースが使用可能になると、スレッドは自動的に実行を開始します。
Threadクラスは、実行中にスレッドを照会および操作するためのいくつかのメソッドを定義します。スレッドは、Thread.newの呼び出しに関連付けられたブロック内のコードを実行してから、実行を停止します。
そのブロックの最後の式の値はスレッドの値であり、Threadオブジェクトのvalueメソッドを呼び出すことで取得できます。スレッドが完了するまで実行された場合、値はスレッドの値をすぐに返します。それ以外の場合、valueメソッドはブロックされ、スレッドが完了するまで戻りません。
クラスメソッドThread.currentは、現在のスレッドを表すThreadオブジェクトを返します。これにより、スレッドは自分自身を操作できます。クラスメソッドThread.mainは、メインスレッドを表すThreadオブジェクトを返します。これは、Rubyプログラムが開始されたときに開始された最初の実行スレッドです。
特定のスレッドのThread.joinメソッドを呼び出すことにより、そのスレッドが終了するのを待つことができます。呼び出し元のスレッドは、指定されたスレッドが終了するまでブロックします。
スレッドと例外
メインスレッドで例外が発生し、どこでも処理されない場合、Rubyインタープリターはメッセージを出力して終了します。メインスレッド以外のスレッドでは、未処理の例外によりスレッドの実行が停止します。
スレッドの場合 t 未処理の例外と別のスレッドが原因で終了します st.joinまたはt.valueを呼び出してから、で発生した例外t スレッドで発生します s。
Thread.abort_on_exceptionがデフォルトの条件であるfalseの場合、未処理の例外は単に現在のスレッドを強制終了し、残りはすべて実行を継続します。
スレッド内の未処理の例外によってインタープリターが終了するようにする場合は、クラスメソッドThread.abort_on_exceptionをtrueに設定します。
t = Thread.new { ... }
t.abort_on_exception = trueスレッド変数
スレッドは通常、スレッドの作成時にスコープ内にあるすべての変数にアクセスできます。スレッドのブロックにローカルな変数はスレッドにローカルであり、共有されません。
スレッドクラスは、スレッドローカル変数を作成して名前でアクセスできるようにする特別な機能を備えています。スレッドオブジェクトをハッシュであるかのように扱い、[] =を使用して要素に書き込み、[]を使用して要素を読み戻します。
この例では、各スレッドは、変数countの現在の値をキーmycountを使用してthreadlocal変数に記録します。
#!/usr/bin/ruby
count = 0
arr = []
10.times do |i|
arr[i] = Thread.new {
sleep(rand(0)/10.0)
Thread.current["mycount"] = count
count += 1
}
end
arr.each {|t| t.join; print t["mycount"], ", " }
puts "count = #{count}"これにより、次の結果が生成されます-
8, 0, 3, 7, 2, 1, 6, 5, 4, 9, count = 10メインスレッドはサブスレッドが終了するのを待ってから、それぞれがキャプチャしたカウントの値を出力します。
スレッドの優先順位
スレッドのスケジューリングに影響を与える最初の要因は、スレッドの優先度です。優先度の高いスレッドは、優先度の低いスレッドの前にスケジュールされます。より正確には、実行を待機している優先度の高いスレッドがない場合にのみ、スレッドはCPU時間を取得します。
優先度=および優先度を使用して、Rubyスレッドオブジェクトの優先度を設定およびクエリできます。新しく作成されたスレッドは、それを作成したスレッドと同じ優先度で開始されます。メインスレッドは優先度0から始まります。
実行を開始する前にスレッドの優先度を設定する方法はありません。ただし、スレッドは、最初に実行するアクションとして、スレッド自体の優先度を上げたり下げたりすることができます。
スレッドの除外
2つのスレッドが同じデータへのアクセスを共有し、少なくとも1つのスレッドがそのデータを変更する場合は、スレッドが一貫性のない状態でデータを参照できないように特別な注意を払う必要があります。これはスレッド除外と呼ばれます。
Mutexは、共有リソースへの相互に排他的なアクセスのための単純なセマフォロックを実装するクラスです。つまり、一度に1つのスレッドだけがロックを保持できます。他のスレッドは、ロックが使用可能になるまで順番に待機することを選択する場合もあれば、ロックが使用できないことを示す即時エラーを取得することを選択する場合もあります。
共有データへのすべてのアクセスをミューテックスの制御下に置くことにより、一貫性とアトミック操作を保証します。例を試してみましょう。最初の例はmutaxなしで、2番目の例はmutaxありです-
Mutaxを使用しない例
#!/usr/bin/ruby
require 'thread'
count1 = count2 = 0
difference = 0
counter = Thread.new do
loop do
count1 += 1
count2 += 1
end
end
spy = Thread.new do
loop do
difference += (count1 - count2).abs
end
end
sleep 1
puts "count1 : #{count1}"
puts "count2 : #{count2}"
puts "difference : #{difference}"これにより、次の結果が生成されます-
count1 : 1583766
count2 : 1583766
difference : 0#!/usr/bin/ruby
require 'thread'
mutex = Mutex.new
count1 = count2 = 0
difference = 0
counter = Thread.new do
loop do
mutex.synchronize do
count1 += 1
count2 += 1
end
end
end
spy = Thread.new do
loop do
mutex.synchronize do
difference += (count1 - count2).abs
end
end
end
sleep 1
mutex.lock
puts "count1 : #{count1}"
puts "count2 : #{count2}"
puts "difference : #{difference}"これにより、次の結果が生成されます-
count1 : 696591
count2 : 696591
difference : 0デッドロックの処理
スレッドの除外にミューテックスオブジェクトを使用し始めるときは、デッドロックを回避するように注意する必要があります。デッドロックは、すべてのスレッドが別のスレッドによって保持されているリソースの取得を待機しているときに発生する状態です。すべてのスレッドがブロックされているため、保持しているロックを解放することはできません。また、ロックを解放できないため、他のスレッドはそれらのロックを取得できません。
ここで、条件変数が明らかになります。条件変数は、単にリソースに関連付けられている特定の保護範囲内で使用されているセマフォであるミューテックス。利用できないリソースが必要な場合は、条件変数を待ちます。このアクションにより、対応するミューテックスのロックが解除されます。他のスレッドがリソースが使用可能であることを通知すると、元のスレッドは待機を解除し、同時にクリティカル領域のロックを回復します。
例
#!/usr/bin/ruby
require 'thread'
mutex = Mutex.new
cv = ConditionVariable.new
a = Thread.new {
mutex.synchronize {
puts "A: I have critical section, but will wait for cv"
cv.wait(mutex)
puts "A: I have critical section again! I rule!"
}
}
puts "(Later, back at the ranch...)"
b = Thread.new {
mutex.synchronize {
puts "B: Now I am critical, but am done with cv"
cv.signal
puts "B: I am still critical, finishing up"
}
}
a.join
b.joinこれにより、次の結果が生成されます-
A: I have critical section, but will wait for cv
(Later, back at the ranch...)
B: Now I am critical, but am done with cv
B: I am still critical, finishing up
A: I have critical section again! I rule!スレッドの状態
次の表に示すように、5つの可能な状態に対応する5つの可能な戻り値があります。ステータスメソッドは、スレッドの状態を返します。
| スレッドの状態 | 戻り値 |
|---|---|
| 実行可能 | 実行 |
| 睡眠 | 睡眠 |
| 中絶 | 中絶 |
| 正常に終了 | false |
| 例外を除いて終了 | なし |
スレッドクラスメソッド
以下のメソッドはThreadクラスによって提供され、プログラムで使用可能なすべてのスレッドに適用できます。これらのメソッドは、次のようにThreadクラス名を使用して呼び出されます-
Thread.abort_on_exception = true| シニア番号 | 方法と説明 |
|---|---|
| 1 | Thread.abort_on_exception 例外条件でグローバルアボートのステータスを返します。デフォルトはfalseです。trueに設定すると、いずれかのスレッドで例外が発生した場合、すべてのスレッドが中止されます(プロセスはexit(0)になります)。 |
| 2 | Thread.abort_on_exception= trueに設定すると、例外が発生した場合にすべてのスレッドが中止されます。新しい状態を返します。 |
| 3 | Thread.critical グローバルスレッドのクリティカル状態のステータスを返します。 |
| 4 | Thread.critical= グローバルスレッドのクリティカル状態のステータスを設定し、それを返します。trueに設定すると、既存のスレッドのスケジューリングを禁止します。新しいスレッドの作成と実行をブロックしません。特定のスレッド操作(スレッドの停止または強制終了、現在のスレッドでのスリープ、例外の発生など)により、クリティカルセクションにある場合でもスレッドがスケジュールされる場合があります。 |
| 5 | Thread.current 現在実行中のスレッドを返します。 |
| 6 | Thread.exit 現在実行中のスレッドを終了し、別のスレッドを実行するようにスケジュールします。このスレッドがすでに強制終了としてマークされている場合、exitはスレッドを返します。これがメインスレッドまたは最後のスレッドである場合は、プロセスを終了します。 |
| 7 | Thread.fork { block } Thread.newの同義語。 |
| 8 | Thread.kill( aThread ) 指定されたスレッドを終了させます |
| 9 | Thread.list 実行可能または停止中のすべてのスレッドのThreadオブジェクトの配列を返します。糸。 |
| 10 | Thread.main プロセスのメインスレッドを返します。 |
| 11 | Thread.new( [ arg ]* ) {| args | block } ブロックで指定された命令を実行するための新しいスレッドを作成し、実行を開始します。Thread.newに渡された引数はすべて、ブロックに渡されます。 |
| 12 | Thread.pass スレッドスケジューラを呼び出して、実行を別のスレッドに渡します。 |
| 13 | Thread.start( [ args ]* ) {| args | block } 基本的にThread.newと同じです。ただし、クラスThreadがサブクラス化されている場合、そのサブクラスでstartを呼び出しても、サブクラスのinitializeメソッドは呼び出されません。 |
| 14 | Thread.stop 現在のスレッドの実行を停止してスリープ状態にし、別のスレッドの実行をスケジュールします。クリティカル状態をfalseにリセットします。 |
スレッドインスタンスメソッド
これらのメソッドは、スレッドのインスタンスに適用できます。これらのメソッドは、次のようにスレッドのインスタンスを使用して呼び出されます-
#!/usr/bin/ruby
thr = Thread.new do # Calling a class method new
puts "In second thread"
raise "Raise exception"
end
thr.join # Calling an instance method join| シニア番号 | 方法と説明 |
|---|---|
| 1 | thr[ aSymbol ] 属性リファレンス-シンボルまたはaSymbol名のいずれかを使用して、スレッドローカル変数の値を返します。指定された変数が存在しない場合、nilを返します。 |
| 2 | thr[ aSymbol ] = 属性の割り当て-シンボルまたは文字列のいずれかを使用して、スレッドローカル変数の値を設定または作成します。 |
| 3 | thr.abort_on_exception thrの例外条件での中止のステータスを返します。デフォルトはfalseです。 |
| 4 | thr.abort_on_exception= trueに設定すると、thrで例外が発生した場合に、すべてのスレッド(メインプログラムを含む)が中止されます。プロセスは事実上exit(0)になります。 |
| 5 | thr.alive? thrが実行中またはスリープ中の場合はtrueを返します。 |
| 6 | thr.exit thrを終了し、実行する別のスレッドをスケジュールします。このスレッドがすでに強制終了としてマークされている場合、exitはスレッドを返します。これがメインスレッドまたは最後のスレッドである場合、プロセスを終了します。 |
| 7 | thr.join 呼び出し元のスレッドは実行を一時停止し、thrを実行します。thrが終了するまで戻りません。参加していないスレッドは、メインプログラムが終了すると強制終了されます。 |
| 8 | thr.key? 指定された文字列(またはシンボル)がスレッドローカル変数として存在する場合、trueを返します。 |
| 9 | thr.kill 同義語Thread.exit。 |
| 10 | thr.priority thrの優先度を返します。デフォルトはゼロです。優先度の高いスレッドは、優先度の低いスレッドの前に実行されます。 |
| 11 | thr.priority= thrの優先度を整数に設定します。優先度の高いスレッドは、優先度の低いスレッドの前に実行されます。 |
| 12 | thr.raise( anException ) thrから例外を発生させます。発信者はthrである必要はありません。 |
| 13 | thr.run thrを起動し、スケジューリングの対象にします。クリティカルセクションにない場合は、スケジューラを呼び出します。 |
| 14 | thr.safe_level thrに対して有効な安全レベルを返します。 |
| 15 | thr.status 戻り値の状態THR:睡眠場合THRは寝たり、I / O上で待機している実行する場合はTHRがあれば、偽を実行しているTHRが正常に終了し、nilの場合THRは例外で終了。 |
| 16 | thr.stop? thrが死んでいるか眠っている場合はtrueを返します。 |
| 17 | thr.value thrがThread.joinを介して完了するのを待ち、その値を返します。 |
| 18 | thr.wakeup thrをスケジューリングの対象としてマークしますが、I / Oでブロックされたままになる可能性があります。 |
カーネルモジュールはObjectクラスに含まれているため、そのメソッドはRubyプログラムのどこからでも使用できます。受信機なしで呼び出すことができます(関数形式)。したがって、それらはしばしば関数と呼ばれます。
| シニア番号 | 方法と説明 |
|---|---|
| 1 | abort プログラムを終了します。例外が発生した場合(つまり、$!がnilでない場合)、そのエラーメッセージが表示されます。 |
| 2 | Array( obj) to_aryまたはto_aを使用して配列に変換した後、objを返します。 |
| 3 | at_exit {...} プログラムの終了時に実行するブロックを登録します。ENDステートメントに似ていますが、ENDステートメントはブロックを1回だけ登録します。 |
| 4 | autoload( classname, file) 初めて使用するときにファイルからロードするクラスクラス名を登録します。クラス名は文字列または記号です。 |
| 5 | binding 現在の変数とメソッドのバインディングを返します。結合返されたオブジェクトが渡されてもよいevalの第2引数の方法。 |
| 6 | block_given? メソッドがブロックで呼び出された場合はtrueを返します。 |
| 7 | callcc {| c|...} 通過継続ブロックにオブジェクトCを、ブロックを実行します。callccは、グローバル出口またはループ構造に使用できます。 |
| 8 | caller([ n]) file:line形式の文字列の配列で現在の実行スタックを返します。nが指定されている場合、n番目のレベルから下のスタックエントリを返します。 |
| 9 | catch( tag) {...} ブロックの実行中に呼び出されたスローによって非ローカル出口をキャッチします。 |
| 10 | chomp([ rs = $/]) 変数の値を返します $_ with the ending newline removed, assigning the result back to $_。改行文字列の値はrsで指定できます。 |
| 11 | chomp!([ rs = $/]) $ _から改行を削除し、その場で文字列を変更します。 |
| 12 | chop の値を返します $_ with its last character (one byte) removed, assigning the result back to $_。 |
| 13 | chop! $ _から最後の文字を削除し、その場で文字列を変更します。 |
| 14 | eval( str[, scope[, file, line]]) strをRubyコードとして実行します。評価を実行するバインディングは、スコープで指定できます。コンパイルするコードのファイル名と行番号は、ファイルと行を使用して指定できます。 |
| 15 | exec( cmd[, arg...]) コマンドcmdを実行して、現在のプロセスを置き換えます。複数の引数が指定されている場合、コマンドはシェル展開なしで実行されます。 |
| 16 | exit([ result = 0]) 終了したプログラムでは、との結果ステータスコードが返されます。 |
| 17 | exit!([ result = 0]) 確認などの出口処理をバイパスしてプログラムを強制終了します。 |
| 18 | fail(...) raise(...)を参照してください |
| 19 | Float( obj) floatに変換した後にobjを返します。数値オブジェクトは直接変換されます。nilは0.0に変換されます。文字列は、0x、0bの基数プレフィックスを考慮して変換されます。残りはobj.to_fを使用して変換されます。 |
| 20 | fork fork {...} 子プロセスを作成します。nilは子プロセスで返され、子プロセスのID(整数)は親プロセスで返されます。ブロックが指定されている場合、そのブロックは子プロセスで実行されます。 |
| 21 | format( fmt[, arg...]) sprintfを参照してください。 |
| 22 | gets([ rs = $/]) コマンドラインまたは標準入力から1行で指定されたファイル名を読み取ります。レコード区切り文字列は、rsを使用して明示的に指定できます。 |
| 23 | global_variables グローバル変数名の配列を返します。 |
| 24 | gsub( x, y) gsub( x) {...} のxに一致するすべての文字列を置き換えます $_ with y. If a block is specified, matched strings are replaced with the result of the block. The modified result is assigned to $_。 |
| 25 | gsub!( x, y) gsub!( x) {...} 文字列がその場で変更されることを除いて、gsubと同じ置換を実行します。 |
| 26 | Integer( obj) 整数に変換した後、objを返します。数値オブジェクトは直接変換されます。nilは0に変換されます。文字列は、0x、0bの基数プレフィックスを考慮して変換されます。残りはobj.to_iを使用して変換されます。 |
| 27 | lambda {| x|...} proc {| x|...} lambda proc ブロックをProcオブジェクトに変換します。ブロックが指定されていない場合、呼び出し元のメソッドに関連付けられているブロックが変換されます。 |
| 28 | load( file[, private = false]) ファイルからRubyプログラムをロードします。requireとは異なり、拡張ライブラリはロードされません。場合は、民間である真、プログラムは、このように呼び出しプログラムの名前空間を保護し、匿名のモジュールにロードされます。 |
| 29 | local_variables ローカル変数名の配列を返します。 |
| 30 | loop {...} コードのブロックを繰り返します。 |
| 31 | open( path[, mode = "r"]) open( path[, mode = "r"]) {| f|...} ファイルを開きます。ブロックが指定されている場合、ブロックは、開かれたストリームを引数として渡して実行されます。ブロックが終了すると、ファイルは自動的に閉じられます。パスがパイプ|で始まる場合、次の文字列がコマンドとして実行され、そのプロセスに関連付けられたストリームが返されます。 |
| 32 | p( obj) inspectメソッドを使用してobjを表示します(多くの場合、デバッグに使用されます)。 |
| 33 | print([ arg...]) argを$ defoutに出力します。引数が指定されていない場合、$ _の値が出力されます。 |
| 34 | printf( fmt[, arg...]) sprintfを使用してfmtに従ってargをフォーマットし、結果を$ defoutに出力します。フォーマットの仕様については、sprintfを参照してください。 |
| 35 | proc {| x|...} proc lamdaを参照してください。 |
| 36 | putc( c) デフォルトの出力($ defout)に1文字を出力します。 |
| 37 | puts([ str]) 文字列をデフォルトの出力($ defout)に出力します。文字列が改行で終わっていない場合は、文字列に改行が追加されます。 |
| 38 | raise(...) fail(...) 例外を発生させます。例外クラスが指定されていない場合、RuntimeErrorを想定します。レスキュー句で引数なしでraiseを呼び出すと、例外が再発生します。レスキュー句の外でこれを行うと、メッセージのないRuntimeErrorが発生します。fail レイズの廃止された名前です。 |
| 39 | rand([ max = 0]) 0以上max未満の疑似乱数を生成します。maxが指定されていないか、0に設定されている場合、乱数は0以上1未満の浮動小数点数として返されます。srandを使用して疑似乱数ストリームを初期化できます。 |
| 40 | readline([ rs = $/]) EOFの読み取り時にEOFError例外が発生することを除いて、getsと同等です。 |
| 41 | readlines([ rs = $/]) コマンドライン引数として指定されたファイル名または標準入力の内容のいずれかを保持する文字列の配列を返します。 |
| 42 | require( lib) 最初に呼び出されたときにライブラリ(拡張ライブラリを含む)libをロードします。requireは同じライブラリを複数回ロードしません。libに拡張子が指定されていない場合、requireはそれに.rb、.soなどを追加しようとします。 |
| 43 | scan( re) scan( re) {|x|...} $ _。scanに相当します。 |
| 44 | select( reads[, writes = nil[, excepts = nil[, timeout = nil]]]) IOオブジェクトの配列として渡される、入力、出力、および例外の3つのタイプのIOオブジェクトのステータスの変化をチェックします。チェックする必要のない引数にはnilが渡されます。ステータスが変更されたIOオブジェクトの配列を含む3要素の配列が返されます。nilはタイムアウト時に返されます。 |
| 45 | set_trace_func( proc) トレース用のハンドラーを設定します。procは、文字列またはprocオブジェクトの場合があります。set_trace_funcは、デバッガーとプロファイラーによって使用されます。 |
| 46 | sleep([ sec]) プログラムの実行を秒秒間中断します。secが指定されていない場合、プログラムは永久に中断されます。 |
| 47 | split([ sep[, max]]) $ _。splitに相当します。 |
| 48 | sprintf( fmt[, arg...]) format( fmt[, arg...]) argがfmtに従ってフォーマットされた文字列を返します。フォーマット仕様は、基本的にCプログラミング言語のsprintfの仕様と同じです。fmtの変換指定子(%の後に変換フィールド指定子が続く)は、対応する引数のフォーマットされた文字列に置き換えられます。提出された変換のリストは、次のセクションで以下に示されています。 |
| 49 | srand([ seed]) 乱数の配列を初期化します。シードが指定されていない場合、初期化はシードの時間およびその他のシステム情報を使用して実行されます。 |
| 50 | String( obj) obj.to_sを使用して文字列に変換した後、objを返します。 |
| 51 | syscall( sys[, arg...]) 番号sysで指定されたオペレーティングシステムコール関数を呼び出します。sysの数と意味はシステムに依存します。 |
| 52 | system( cmd[, arg...]) コマンドラインへの呼び出しとしてcmdを実行します。複数の引数が指定されている場合、コマンドはシェル拡張なしで直接実行されます。戻りステータスが0(成功)の場合、trueを返します。 |
| 53 | sub( x, y) sub( x) {...} $ _のxに一致する最初の文字列をyに置き換えます。ブロックが指定されている場合、一致した文字列はブロックの結果に置き換えられます。変更された結果は$ _に割り当てられます。 |
| 54 | sub!( x, y) sub!( x) {...} 文字列がその場で変更されることを除いて、subと同じ置換を実行します。 |
| 55 | test( test, f1[, f2]) 文字テストで指定されたさまざまなファイルテストを実行します。読みやすさを向上させるには、この関数ではなく、Fileクラスのメソッド(たとえば、File ::読み取り可能?)を使用する必要があります。引数のリストは、次のセクションで以下に示されています。 |
| 56 | throw( tag[, value = nil]) シンボルまたは文字列タグで待機しているcatch関数にジャンプします。valueは、catchによって使用される戻り値です。 |
| 57 | trace_var( var, cmd) trace_var( var) {...} グローバル変数のトレースを設定します。変数名はシンボルとして指定されます。cmdは文字列またはProcオブジェクトです。 |
| 58 | trap( sig, cmd) trap( sig) {...} シグナルハンドラーを設定します。sigは、文字列(SIGUSR1など)または整数です。信号名からSIGを省略できます。EXITシグナルまたはシグナル番号0のシグナルハンドラーは、プロセス終了の直前に呼び出されます。 |
| 59 | untrace_var( var[, cmd]) グローバル変数のトレースを削除します。cmdが指定されている場合、そのコマンドのみが削除されます。 |
数字の関数
数値に関連する組み込み関数のリストは次のとおりです。それらは次のように使用する必要があります-
#!/usr/bin/ruby
num = 12.40
puts num.floor # 12
puts num + 10 # 22.40
puts num.integer? # false as num is a float.これにより、次の結果が生成されます-
12
22.4
false| シニア番号 | 方法と説明 |
|---|---|
| 1 | n + num n - num n * num n / num 算術演算(加算、減算、乗算、除算)を実行します。 |
| 2 | n % num nのモジュラスを返します。 |
| 3 | n ** num べき乗。 |
| 4 | n.abs nの絶対値を返します。 |
| 5 | n.ceil n以上の最小の整数を返します。 |
| 6 | n.coerce( num) numとnを含む配列を返します。両方とも、相互に操作できるタイプに変換される可能性があります。数値演算子の自動型変換で使用されます。 |
| 7 | n.divmod( num) nをnumで割った商とモジュラスを含む配列を返します。 |
| 8 | n.floor n以下の最大の整数を返します。 |
| 9 | n.integer? nが整数の場合はtrueを返します。 |
| 10 | n.modulo( num) nをnumで除算し、商を床で丸めて得られたモジュラスを返します |
| 11 | n.nonzero? ゼロでない場合はnを返し、そうでない場合はnilを返します。 |
| 12 | n.remainder( num) 除算して得られた余りを返します n 沿って num商から小数を削除します。ザ・result そして n 常に同じ符号を持っています。 |
| 13 | n.round 最も近い整数に丸められたnを返します。 |
| 14 | n.truncate nを小数を削除した整数として返します。 |
| 15 | n.zero? nが0の場合、ゼロを返します。 |
| 16 | n & num n | num n ^ num ビット演算:AND、OR、XOR、および反転。 |
| 17 | n << num n >> num ビット単位の左シフトと右シフト。 |
| 18 | n[num] の値を返します num最下位ビットからのthビット、つまりn [0]。 |
| 19 | n.chr 文字コードの文字を含む文字列を返します n。 |
| 20 | n.next n.succ nに続く次の整数を返します。n +1に相当します。 |
| 21 | n.size のマシン表現のバイト数を返します n。 |
| 22 | n.step( upto, step) {|n| ...} からブロックを繰り返します n に upto、増分 step 毎回。 |
| 23 | n.times {|n| ...} ブロックを繰り返します n 回。 |
| 24 | n.to_f 変換します n浮動小数点数に。フロート変換は、正確な情報を失う可能性があります。 |
| 25 | n.to_int 戻り値 n 整数に変換した後。 |
フロートの関数
| シニア番号 | 方法と説明 |
|---|---|
| 1 | Float::induced_from(num) numを浮動小数点数に変換した結果を返します。 |
| 2 | f.finite? fが無限ではなく、f.nanがfalseの場合、trueを返します。 |
| 3 | f.infinite? fが正の無限大の場合は1を返し、負の無限大の場合は-1を返し、それ以外の場合はnilを返します。 |
| 4 | f.nan? fが有効なIEEE浮動小数点数でない場合はtrueを返します。 |
数学の関数
| シニア番号 | 方法と説明 |
|---|---|
| 1 | atan2( x, y) アークタンジェントを計算します。 |
| 2 | cos( x) xのコサインを計算します。 |
| 3 | exp( x) 指数関数(eをxの累乗)を計算します。 |
| 4 | frexp( x) xの名詞化された分数と指数を含む2要素配列を返します。 |
| 5 | ldexp( x, exp) xの2の値をexpの累乗で返します。 |
| 6 | log( x) xの自然対数を計算します。 |
| 7 | log10( x) xの常用対数を計算します。 |
| 8 | sin( x) xの正弦を計算します。 |
| 9 | sqrt( x) xの平方根を返します。xは正でなければなりません。 |
| 10 | tan( x) xの接線を計算します。 |
変換フィールド指定子
関数sprintf(fmt [、arg ...])およびformat(fmt [、arg ...])は、argがfmtに従ってフォーマットされた文字列を返します。フォーマット仕様は、基本的にCプログラミング言語のsprintfの仕様と同じです。fmtの変換指定子(%の後に変換フィールド指定子が続く)は、対応する引数のフォーマットされた文字列に置き換えられます。
| シニア番号 | 指定子と説明 |
|---|---|
| 1 | b 2進整数 |
| 2 | c 1文字 |
| 3 | d,i 10進整数 |
| 4 | e 指数表記(例:2.44e6) |
| 5 | E 指数表記(例:2.44E6) |
| 6 | f 浮動小数点数(例:2.44) |
| 7 | g 指数が-4未満の場合は%eを使用し、それ以外の場合は%fを使用します。 |
| 8 | G 指数が-4未満の場合は%Eを使用し、それ以外の場合は%fを使用します。 |
| 9 | o 8進整数 |
| 10 | s to_sを使用して変換された文字列またはオブジェクト |
| 11 | u 符号なし10進整数 |
| 12.12。 | x 16進整数(例、39ff) |
| 13 | X 16進整数(例、39FF) |
以下は使用例です-
#!/usr/bin/ruby
str = sprintf("%s\n", "abc") # => "abc\n" (simplest form)
puts str
str = sprintf("d=%d", 42) # => "d=42" (decimal output)
puts str
str = sprintf("%04x", 255) # => "00ff" (width 4, zero padded)
puts str
str = sprintf("%8s", "hello") # => " hello" (space padded)
puts str
str = sprintf("%.2s", "hello") # => "he" (trimmed by precision)
puts strこれにより、次の結果が生成されます-
abc
d = 42
00ff
hello
heテスト関数の引数
関数test(test、f1 [、f2])は、文字テストで指定された次のファイルテストのいずれかを実行します。読みやすさを向上させるには、この関数ではなくFileクラスのメソッド(たとえば、File :: readable?)を使用する必要があります。
| シニア番号 | 引数と説明 |
|---|---|
| 1 | ?r f1は発信者の有効なuidで読み取り可能ですか? |
| 2 | ?w f1は発信者の有効なuidによって書き込み可能ですか? |
| 3 | ?x f1は呼び出し元の有効なuidによって実行可能ですか? |
| 4 | ?o f1は発信者の有効なuidによって所有されていますか? |
| 5 | ?R f1は発信者の実際のuidで読み取り可能ですか? |
| 6 | ?W f1は発信者の実際のuidで書き込み可能ですか? |
| 7 | ?X f1は呼び出し元の実際のuidで実行可能ですか? |
| 8 | ?O f1は発信者の実際のuidによって所有されていますか? |
| 9 | ?e f1は存在しますか? |
| 10 | ?z f1の長さはゼロですか? |
| 11 | ?s f1のファイルサイズ(0の場合はnil) |
| 12 | ?f f1は通常のファイルですか? |
| 13 | ?d f1はディレクトリですか? |
| 14 | ?l f1はシンボリックリンクですか? |
| 15 | ?p f1は名前付きパイプ(FIFO)ですか? |
| 16 | ?S f1はソケットですか? |
| 17 | ?b f1はブロックデバイスですか? |
| 18 | ?c f1はキャラクターデバイスですか? |
| 19 | ?u f1にはsetuidビットが設定されていますか? |
| 20 | ?g f1にはsetgidビットが設定されていますか? |
| 21 | ?k f1にはスティッキービットが設定されていますか? |
| 22 | ?M f1の最終変更時刻。 |
| 23 | ?A f1の最終アクセス時間。 |
| 24 | ?C f1の最後のiノード変更時間。 |
| シニア番号 | 引数と説明 |
|---|---|
| 1 | ?= f1とf2の変更時間は等しいですか? |
| 2 | ?> f1の変更時刻はf2よりも新しいですか? |
| 3 | ?< f1の修正時間はf2よりも古いですか? |
| 4 | ?- f1はf2へのハードリンクですか? |
以下は使用例です。main.rbが読み取り、書き込み、実行権限なしで存在すると仮定します-
#!/usr/bin/ruby
puts test(?r, "main.rb" ) # => true
puts test(?w, "main.rb" ) # => true
puts test(?x, "main.rb" ) # => falseこれにより、次の結果が生成されます-
true
false
falseRuby-事前定義された変数
Rubyの事前定義された変数はプログラム全体の動作に影響を与えるため、ライブラリでの使用はお勧めしません。
ほとんどの事前定義された変数の値には、別の方法でアクセスできます。
次の表に、Rubyの事前定義されたすべての変数を示します。
| シニア番号 | 変数名と説明 |
|---|---|
| 1 | $! 発生した最後の例外オブジェクト。例外オブジェクトには、rescue句で=>を使用してアクセスすることもできます。 |
| 2 | $@ 発生した最後の例外のスタックバックトレース。スタックバックトレース情報は、最後の例外のException#backtraceメソッドによって取得できます。 |
| 3 | $/ 入力レコード区切り文字(デフォルトでは改行)。get、readlineなどは、オプションの引数として入力レコード区切り文字を取ります。 |
| 4 | $\ 出力レコード区切り文字(デフォルトではnil)。 |
| 5 | $, printする引数とArray#join(デフォルトではnil)の間の出力区切り文字。Array#joinに明示的に区切り文字を指定できます。 |
| 6 | $; 分割のデフォルトの区切り文字(デフォルトではnil)。String#splitには明示的に区切り文字を指定できます。 |
| 7 | $. 現在の入力ファイルから読み取られた最後の行の番号。ARGF.linenoと同等です。 |
| 8 | $< ARGFの同義語。 |
| 9 | $> $ defoutの同義語。 |
| 10 | $0 実行中の現在のRubyプログラムの名前。 |
| 11 | $$ 実行中の現在のRubyプログラムのプロセスpid。 |
| 12 | $? 最後のプロセスの終了ステータスが終了しました。 |
| 13 | $: $ LOAD_PATHの同義語。 |
| 14 | $DEBUG -dまたは--debugコマンドラインオプションが指定されている場合はTrue。 |
| 15 | $defout printおよびprintfの宛先出力(デフォルトでは$ stdout)。 |
| 16 | $F -aが指定されている場合にsplitから出力を受け取る変数。この変数は、-pまたは-nオプションとともに-aコマンドラインオプションが指定されている場合に設定されます。 |
| 17 | $FILENAME ARGFから現在読み取られているファイルの名前。ARGF.filenameと同等です。 |
| 18 | $LOAD_PATH loadメソッドとrequireメソッドを使用してファイルをロードするときに検索されるディレクトリを保持する配列。 |
| 19 | $SAFE セキュリティレベル 0→外部から提供された(汚染された)データに対してチェックは実行されません。(デフォルト) 1→汚染されたデータを使用した潜在的に危険な操作は禁止されています。 2→プロセスおよびファイルに対する潜在的に危険な操作は禁止されています。 3→新しく作成されたすべてのオブジェクトは汚染されていると見なされます。 4→グローバルデータの変更は禁止されています。 |
| 20 | $stdin 標準入力(デフォルトではSTDIN)。 |
| 21 | $stdout 標準出力(デフォルトではSTDOUT)。 |
| 22 | $stderr 標準エラー(デフォルトではSTDERR)。 |
| 23 | $VERBOSE -v、-w、または--verboseコマンドラインオプションが指定されている場合はTrue。 |
| 24 | $- x The value of interpreter option -x (x=0, a, d, F, i, K, l, p, v). These options are listed below |
| 25 | $-0 The value of interpreter option -x and alias of $/. |
| 26 | $-a The value of interpreter option -x and true if option -a is set. Read-only. |
| 27 | $-d The value of interpreter option -x and alias of $DEBUG |
| 28 | $-F The value of interpreter option -x and alias of $;. |
| 29 | $-i The value of interpreter option -x and in in-place-edit mode, holds the extension, otherwise nil. Can enable or disable in-place-edit mode. |
| 30 | $-I The value of interpreter option -x and alias of $:. |
| 31 | $-l The value of interpreter option -x and true if option -lis set. Read-only. |
| 32 | $-p The value of interpreter option -x and true if option -pis set. Read-only. |
| 33 | $_ The local variable, last string read by gets or readline in the current scope. |
| 34 | $~ The local variable, MatchData relating to the last match. Regex#match method returns the last match information. |
| 35 | $ n ($1, $2, $3...) The string matched in the nth group of the last pattern match. Equivalent to m[n], where m is a MatchData object. |
| 36 | $& The string matched in the last pattern match. Equivalent to m[0], where m is a MatchData object. |
| 37 | $` The string preceding the match in the last pattern match. Equivalent to m.pre_match, where m is a MatchData object. |
| 38 | $' The string following the match in the last pattern match. Equivalent to m.post_match, where m is a MatchData object. |
| 39 | $+ The string corresponding to the last successfully matched group in the last pattern match. |
Ruby - Predefined Constants
The following table lists all the Ruby's Predefined Constants −
NOTE − TRUE, FALSE, and NIL are backward-compatible. It's preferable to use true, false, and nil.
| Sr.No. | Constant Name & Description |
|---|---|
| 1 | TRUE Synonym for true. |
| 2 | FALSE Synonym for false. |
| 3 | NIL Synonym for nil. |
| 4 | ARGF An object providing access to virtual concatenation of files passed as command-line arguments or standard input if there are no command-line arguments. A synonym for $<. |
| 5 | ARGV An array containing the command-line arguments passed to the program. A synonym for $*. |
| 6 | DATA An input stream for reading the lines of code following the __END__ directive. Not defined if __END__ isn't present in code. |
| 7 | ENV A hash-like object containing the program's environment variables. ENV can be handled as a hash. |
| 8 | RUBY_PLATFORM A string indicating the platform of the Ruby interpreter. |
| 9 | RUBY_RELEASE_DATE A string indicating the release date of the Ruby interpreter |
| 10 | RUBY_VERSION A string indicating the version of the Ruby interpreter. |
| 11 | STDERR Standard error output stream. Default value of $stderr. |
| 12 | STDIN Standard input stream. Default value of $stdin. |
| 13 | STDOUT Standard output stream. Default value of $stdout. |
| 14 | TOPLEVEL_BINDING A binding object at Ruby's top level. |
Ruby - Associated Tools
Standard Ruby Tools
The standard Ruby distribution contains useful tools along with the interpreter and standard libraries −
These tools help you debug and improve your Ruby programs without spending much effort. This tutorial will give you a very good start with these tools.
RubyGems −
RubyGems is a package utility for Ruby, which installs Ruby software packages and keeps them up-to-date.
Ruby Debugger −
To help deal with bugs, the standard distribution of Ruby includes a debugger. This is very similar to gdb utility, which can be used to debug complex programs.
Interactive Ruby (irb) −
irb (Interactive Ruby) was developed by Keiju Ishitsuka. It allows you to enter commands at the prompt and have the interpreter respond as if you were executing a program. irb is useful to experiment with or to explore Ruby.
Ruby Profiler −
Ruby profiler helps you to improve the performance of a slow program by finding the bottleneck.
Additional Ruby Tools
There are other useful tools that don't come bundled with the Ruby standard distribution. However, you do need to install them yourself.
eRuby: Embeded Ruby −
eRuby stands for embedded Ruby. It's a tool that embeds fragments of Ruby code in other files, such as HTML files similar to ASP, JSP and PHP.
ri: Ruby Interactive Reference −
When you have a question about the behavior of a certain method, you can invoke ri to read the brief explanation of the method.
For more information on Ruby tool and resources, have a look at Ruby Useful Resources.