SparkSQL-はじめに
Sparkは、SparkSQLと呼ばれる構造化データ処理用のプログラミングモジュールを導入しています。DataFrameと呼ばれるプログラミングの抽象化を提供し、分散SQLクエリエンジンとして機能できます。
SparkSQLの機能
以下はSparkSQLの機能です-
Integrated−SQLクエリとSparkプログラムをシームレスに組み合わせる。Spark SQLを使用すると、Python、Scala、Javaの統合APIを使用して、構造化データをSparkの分散データセット(RDD)としてクエリできます。この緊密な統合により、複雑な分析アルゴリズムと一緒にSQLクエリを簡単に実行できます。
Unified Data Access−さまざまなソースからデータをロードしてクエリします。Schema-RDDは、Apache Hiveテーブル、寄木細工のファイル、JSONファイルなどの構造化データを効率的に操作するための単一のインターフェイスを提供します。
Hive Compatibility−既存のウェアハウスで変更されていないHiveクエリを実行します。Spark SQLはHiveフロントエンドとMetaStoreを再利用し、既存のHiveデータ、クエリ、およびUDFとの完全な互換性を提供します。Hiveと一緒にインストールするだけです。
Standard Connectivity−JDBCまたはODBCを介して接続します。Spark SQLには、業界標準のJDBCおよびODBC接続を備えたサーバーモードが含まれています。
Scalability−インタラクティブクエリと長いクエリの両方に同じエンジンを使用します。Spark SQLは、RDDモデルを利用してクエリ中のフォールトトレランスをサポートし、大規模なジョブにも拡張できるようにします。履歴データに別のエンジンを使用することを心配する必要はありません。
SparkSQLアーキテクチャ
次の図は、SparkSQLのアーキテクチャを説明しています-
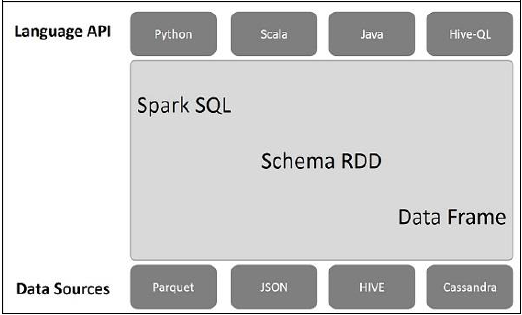
このアーキテクチャには、言語API、スキーマRDD、データソースの3つのレイヤーが含まれています。
Language API−Sparkはさまざまな言語およびSparkSQLと互換性があります。また、これらの言語-API(python、scala、java、HiveQL)でもサポートされています。
Schema RDD− Spark Coreは、RDDと呼ばれる特別なデータ構造で設計されています。通常、Spark SQLはスキーマ、テーブル、およびレコードで機能します。したがって、スキーマRDDを一時テーブルとして使用できます。このスキーマRDDをデータフレームと呼ぶことができます。
Data Sources−通常、spark-coreのデータソースはテキストファイル、Avroファイルなどです。ただし、SparkSQLのデータソースは異なります。それらは、Parquetファイル、JSONドキュメント、HIVEテーブル、およびCassandraデータベースです。
これらについては、次の章で詳しく説明します。