Zookeeper-ワークフロー
ZooKeeperアンサンブルが開始されると、クライアントが接続するのを待ちます。クライアントは、ZooKeeperアンサンブルのノードの1つに接続します。リーダーノードまたはフォロワーノードの場合があります。クライアントが接続されると、ノードはセッションIDを特定のクライアントに割り当て、確認応答をクライアントに送信します。クライアントが確認応答を受け取らない場合、クライアントは単にZooKeeperアンサンブル内の別のノードに接続しようとします。ノードに接続されると、クライアントは定期的にノードにハートビートを送信して、接続が失われないようにします。
If a client wants to read a particular znode, それは送信します read requestznodeパスを持つノードに、ノードは自身のデータベースから取得することにより、要求されたznodeを返します。このため、ZooKeeperアンサンブルでは読み取りが高速です。
If a client wants to store data in the ZooKeeper ensemble、znodeパスとデータをサーバーに送信します。接続されたサーバーはリクエストをリーダーに転送し、リーダーはすべてのフォロワーに書き込みリクエストを再発行します。大多数のノードのみが正常に応答した場合、書き込み要求は成功し、正常な戻りコードがクライアントに送信されます。そうしないと、書き込み要求は失敗します。ノードの厳密な大部分は次のように呼ばれますQuorum。
ZooKeeperアンサンブルのノード
ZooKeeperアンサンブルに異なる数のノードがある場合の影響を分析してみましょう。
私たちが持っている場合 a single nodeの場合、そのノードに障害が発生すると、ZooKeeperアンサンブルは失敗します。これは「単一障害点」の原因となるため、実稼働環境では推奨されません。
私たちが持っている場合 two nodes また、1つのノードに障害が発生した場合、2つのうち1つが過半数ではないため、過半数もありません。
私たちが持っている場合 three nodes1つのノードに障害が発生し、過半数を占めるため、これが最小要件です。ZooKeeperアンサンブルには、ライブ実稼働環境に少なくとも3つのノードが必要です。
私たちが持っている場合 four nodes2つのノードが失敗すると、再び失敗します。これは、3つのノードがあるのと似ています。追加のノードは目的を果たさないため、3、5、7などの奇数のノードを追加することをお勧めします。
すべてのノードがデータベースに同じデータを書き込む必要があるため、ZooKeeperアンサンブルの読み取りプロセスよりも書き込みプロセスの方がコストがかかることがわかっています。したがって、バランスの取れた環境では、ノードの数を多くするよりも、ノードの数を少なくする(3、5、または7)方が適切です。
次の図はZooKeeperワークフローを示し、次の表はそのさまざまなコンポーネントを説明しています。
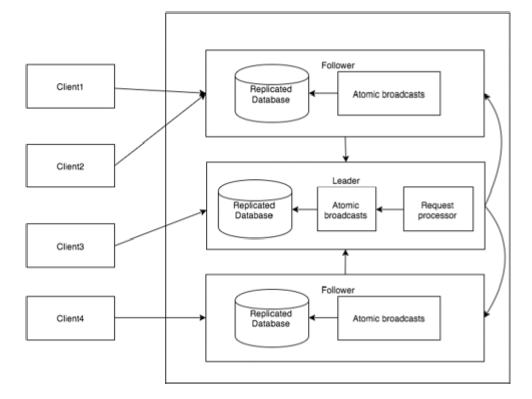
| 成分 | 説明 |
|---|---|
| 書く | 書き込みプロセスはリーダーノードによって処理されます。リーダーは書き込み要求をすべてのznodeに転送し、znodeからの応答を待ちます。znodeの半分が応答する場合、書き込みプロセスは完了しています。 |
| 読んだ | 読み取りは、接続された特定のznodeによって内部的に実行されるため、クラスターと対話する必要はありません。 |
| 複製されたデータベース | zookeeperにデータを保存するために使用されます。各znodeには独自のデータベースがあり、すべてのznodeには、一貫性の助けを借りて常に同じデータがあります。 |
| 盟主 | リーダーは、書き込み要求の処理を担当するZnodeです。 |
| フォロワー | フォロワーはクライアントから書き込み要求を受け取り、それらをリーダーznodeに転送します。 |
| リクエストプロセッサ | リーダーノードにのみ存在します。フォロワーノードからの書き込み要求を管理します。 |
| 原子放送 | リーダーノードからフォロワーノードへの変更をブロードキャストする責任があります。 |