Apache Spark-빠른 가이드
업계에서는 데이터 세트를 분석하기 위해 Hadoop을 광범위하게 사용하고 있습니다. 그 이유는 Hadoop 프레임 워크가 단순 프로그래밍 모델 (MapReduce)을 기반으로하며 확장 가능하고 유연하며 내결함성이 있으며 비용 효율적인 컴퓨팅 솔루션을 가능하게하기 때문입니다. 여기서 주요 관심사는 쿼리 간 대기 시간과 프로그램 실행 대기 시간 측면에서 대용량 데이터 세트 처리 속도를 유지하는 것입니다.
Spark는 Hadoop 컴퓨팅 컴퓨팅 소프트웨어 프로세스의 속도를 높이기 위해 Apache Software Foundation에서 도입했습니다.
일반적인 믿음과는 반대로 Spark is not a modified version of Hadoop자체 클러스터 관리 기능이 있기 때문에 실제로 Hadoop에 의존하지 않습니다. Hadoop은 Spark를 구현하는 방법 중 하나 일뿐입니다.
Spark는 두 가지 방식으로 Hadoop을 사용합니다. storage 두 번째는 processing. Spark에는 자체 클러스터 관리 계산이 있으므로 저장 용도로만 Hadoop을 사용합니다.
Apache Spark
Apache Spark는 빠른 계산을 위해 설계된 초고속 클러스터 컴퓨팅 기술입니다. Hadoop MapReduce를 기반으로하며 MapReduce 모델을 확장하여 대화 형 쿼리 및 스트림 처리를 포함하는 더 많은 유형의 계산에 효율적으로 사용합니다. Spark의 주요 기능은in-memory cluster computing 이는 애플리케이션의 처리 속도를 증가시킵니다.
Spark는 배치 애플리케이션, 반복 알고리즘, 대화 형 쿼리 및 스트리밍과 같은 광범위한 워크로드를 처리하도록 설계되었습니다. 각 시스템에서 이러한 모든 워크로드를 지원하는 것 외에도 별도의 도구를 유지 관리하는 관리 부담이 줄어 듭니다.
Apache Spark의 진화
Spark는 Matei Zaharia가 UC Berkeley의 AMPLab에서 2009 년에 개발 한 Hadoop의 하위 프로젝트 중 하나입니다. BSD 라이선스에 따라 2010 년에 오픈 소스되었습니다. 2013 년에 Apache 소프트웨어 재단에 기부되었으며 이제 Apache Spark는 2014 년 2 월부터 최상위 수준의 Apache 프로젝트가되었습니다.
Apache Spark의 기능
Apache Spark에는 다음과 같은 기능이 있습니다.
Speed− Spark는 Hadoop 클러스터에서 애플리케이션을 실행하는 데 도움이됩니다. 메모리에서 최대 100 배, 디스크에서 실행할 때 10 배 더 빠릅니다. 이는 디스크에 대한 읽기 / 쓰기 작업 수를 줄임으로써 가능합니다. 중간 처리 데이터를 메모리에 저장합니다.
Supports multiple languages− Spark는 Java, Scala 또는 Python으로 내장 된 API를 제공합니다. 따라서 다른 언어로 응용 프로그램을 작성할 수 있습니다. Spark는 대화 형 쿼리를위한 80 개의 고급 연산자를 제공합니다.
Advanced Analytics− Spark는 'Map'및 'reduce'만 지원하지 않습니다. 또한 SQL 쿼리, 스트리밍 데이터, 기계 학습 (ML) 및 그래프 알고리즘을 지원합니다.
Hadoop에 구축 된 Spark
다음 다이어그램은 Hadoop 구성 요소로 Spark를 빌드 할 수있는 세 가지 방법을 보여줍니다.

아래에 설명 된대로 Spark 배포에는 세 가지 방법이 있습니다.
Standalone− Spark Standalone 배포는 Spark가 HDFS (Hadoop Distributed File System)의 최상위 위치를 차지하고 HDFS를위한 공간이 명시 적으로 할당됨을 의미합니다. 여기서 Spark와 MapReduce는 클러스터의 모든 Spark 작업을 처리하기 위해 나란히 실행됩니다.
Hadoop Yarn− Hadoop Yarn 배포는 간단히 말해 사전 설치 나 루트 액세스없이 Yarn에서 스파크가 실행됨을 의미합니다. Spark를 Hadoop 에코 시스템 또는 Hadoop 스택에 통합하는 데 도움이됩니다. 다른 구성 요소가 스택 위에서 실행될 수 있습니다.
Spark in MapReduce (SIMR)− MapReduce의 Spark는 독립 실행 형 배포 외에 Spark 작업을 시작하는 데 사용됩니다. SIMR을 통해 사용자는 Spark를 시작하고 관리 액세스없이 셸을 사용할 수 있습니다.
Spark의 구성 요소
다음 그림은 Spark의 다양한 구성 요소를 보여줍니다.

Apache Spark 코어
Spark Core는 다른 모든 기능을 기반으로하는 Spark 플랫폼의 기본 일반 실행 엔진입니다. 메모리 내 컴퓨팅을 제공하고 외부 스토리지 시스템의 데이터 세트를 참조합니다.
Spark SQL
Spark SQL은 정형 및 반 정형 데이터를 지원하는 SchemaRDD라는 새로운 데이터 추상화를 도입하는 Spark Core의 상위 구성 요소입니다.
스파크 스트리밍
Spark Streaming은 Spark Core의 빠른 스케줄링 기능을 활용하여 스트리밍 분석을 수행합니다. 미니 배치로 데이터를 수집하고 해당 미니 배치 데이터에 대해 RDD (Resilient Distributed Datasets) 변환을 수행합니다.
MLlib (머신 러닝 라이브러리)
MLlib는 분산 메모리 기반 Spark 아키텍처로 인해 Spark 위의 분산 기계 학습 프레임 워크입니다. 벤치 마크에 따르면 MLlib 개발자가 ALS (Alternating Least Squares) 구현에 대해 수행합니다. Spark MLlib는 Hadoop 디스크 기반 버전보다 9 배 빠릅니다.Apache Mahout (Mahout이 Spark 인터페이스를 획득하기 전).
GraphX
GraphX는 Spark 기반의 분산 그래프 처리 프레임 워크입니다. Pregel abstraction API를 이용하여 사용자 정의 그래프를 모델링 할 수있는 그래프 연산 표현을위한 API를 제공합니다. 또한이 추상화를 위해 최적화 된 런타임을 제공합니다.
탄력적 인 분산 데이터 세트
RDD (Resilient Distributed Dataset)는 Spark의 기본 데이터 구조입니다. 불변의 분산 된 객체 모음입니다. RDD의 각 데이터 세트는 클러스터의 다른 노드에서 계산 될 수있는 논리 파티션으로 나뉩니다. RDD는 사용자 정의 클래스를 포함하여 모든 유형의 Python, Java 또는 Scala 객체를 포함 할 수 있습니다.
공식적으로 RDD는 읽기 전용으로 분할 된 레코드 모음입니다. RDD는 안정적인 스토리지 또는 다른 RDD의 데이터에 대한 결정적 작업을 통해 생성 될 수 있습니다. RDD는 병렬로 작동 할 수있는 내결함성 요소 모음입니다.
RDD를 생성하는 방법에는 두 가지가 있습니다. parallelizing 드라이버 프로그램의 기존 컬렉션 또는 referencing a dataset 공유 파일 시스템, HDFS, HBase 또는 Hadoop 입력 형식을 제공하는 모든 데이터 소스와 같은 외부 스토리지 시스템
Spark는 RDD 개념을 사용하여 더 빠르고 효율적인 MapReduce 작업을 수행합니다. 먼저 MapReduce 작업이 수행되는 방식과 그다지 효율적이지 않은 이유에 대해 논의하겠습니다.
MapReduce에서 데이터 공유가 느립니다.
MapReduce는 클러스터에서 병렬 분산 알고리즘을 사용하여 대규모 데이터 세트를 처리하고 생성하는 데 널리 채택됩니다. 이를 통해 사용자는 작업 분배 및 내결함성에 대해 걱정할 필요없이 일련의 고급 연산자를 사용하여 병렬 계산을 작성할 수 있습니다.
안타깝게도 대부분의 현재 프레임 워크에서 계산 사이 (Ex-두 MapReduce 작업 사이) 사이에 데이터를 재사용하는 유일한 방법은 외부 안정 저장 시스템 (Ex-HDFS)에 데이터를 쓰는 것입니다. 이 프레임 워크는 클러스터의 계산 리소스에 액세스하기위한 수많은 추상화를 제공하지만 사용자는 여전히 더 많은 것을 원합니다.
양자 모두 Iterative 과 Interactive애플리케이션은 병렬 작업에서 더 빠른 데이터 공유가 필요합니다. MapReduce에서 데이터 공유가 느립니다.replication, serialization, 및 disk IO. 스토리지 시스템과 관련하여 대부분의 Hadoop 애플리케이션은 HDFS 읽기-쓰기 작업에 90 % 이상의 시간을 소비합니다.
MapReduce에 대한 반복 작업
다단계 응용 프로그램의 여러 계산에서 중간 결과를 재사용합니다. 다음 그림은 MapReduce에서 반복 작업을 수행하는 동안 현재 프레임 워크가 작동하는 방식을 설명합니다. 이로 인해 데이터 복제, 디스크 I / O 및 직렬화로 인해 상당한 오버 헤드가 발생하여 시스템 속도가 느려집니다.
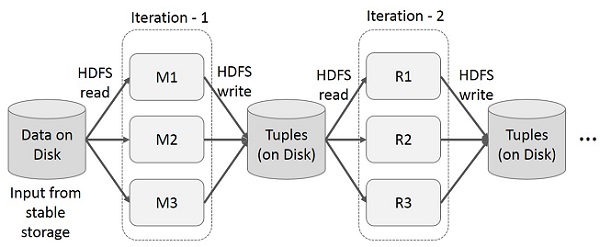
MapReduce의 대화 형 작업
사용자는 동일한 데이터 하위 집합에 대해 임시 쿼리를 실행합니다. 각 쿼리는 안정적인 스토리지에서 디스크 I / O를 수행하므로 애플리케이션 실행 시간을 지배 할 수 있습니다.
다음 그림은 MapReduce에서 대화 형 쿼리를 수행하는 동안 현재 프레임 워크가 작동하는 방식을 설명합니다.
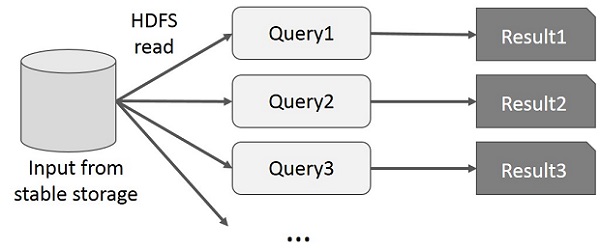
Spark RDD를 사용한 데이터 공유
MapReduce에서 데이터 공유가 느립니다. replication, serialization, 및 disk IO. 대부분의 Hadoop 애플리케이션은 HDFS 읽기-쓰기 작업에 90 % 이상의 시간을 소비합니다.
이 문제를 인식 한 연구원들은 Apache Spark라는 특수 프레임 워크를 개발했습니다. 스파크의 핵심 아이디어는R탄력이있는 D분배 D아타 세트 (RDD); 메모리 내 처리 계산을 지원합니다. 즉, 메모리 상태를 작업 전반에 걸쳐 객체로 저장하고 객체를 해당 작업간에 공유 할 수 있습니다. 메모리의 데이터 공유는 네트워크 및 디스크보다 10 ~ 100 배 빠릅니다.
이제 Spark RDD에서 반복 및 대화 형 작업이 어떻게 발생하는지 알아 보겠습니다.
Spark RDD에 대한 반복 작업
아래 그림은 Spark RDD의 반복 작업을 보여줍니다. 중간 결과를 안정적인 스토리지 (디스크) 대신 분산 메모리에 저장하고 시스템을 더 빠르게 만듭니다.
Note − 분산 메모리 (RAM)가 중간 결과 (Job 상태)를 저장하기에 충분하면 해당 결과를 디스크에 저장합니다.

Spark RDD에서 대화 형 작업
이 그림은 Spark RDD의 대화 형 작업을 보여줍니다. 동일한 데이터 세트에 대해 다른 쿼리가 반복적으로 실행되는 경우이 특정 데이터는 더 나은 실행 시간을 위해 메모리에 보관 될 수 있습니다.

기본적으로 변환 된 각 RDD는 작업을 실행할 때마다 다시 계산 될 수 있습니다. 그러나persist메모리의 RDD.이 경우 Spark는 다음에 쿼리 할 때 훨씬 빠른 액세스를 위해 클러스터에 요소를 유지합니다. 또한 디스크에 RDD를 유지하거나 여러 노드에 복제되는 지원도 있습니다.
Spark는 Hadoop의 하위 프로젝트입니다. 따라서 Linux 기반 시스템에 Spark를 설치하는 것이 좋습니다. 다음 단계는 Apache Spark를 설치하는 방법을 보여줍니다.
1 단계 : Java 설치 확인
Java 설치는 Spark 설치의 필수 사항 중 하나입니다. JAVA 버전을 확인하려면 다음 명령을 시도하십시오.
$java -versionJava가 이미 시스템에 설치되어 있으면 다음과 같은 응답을 볼 수 있습니다.
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)시스템에 Java가 설치되어 있지 않은 경우 다음 단계로 진행하기 전에 Java를 설치하십시오.
2 단계 : Scala 설치 확인
Spark를 구현하려면 Scala 언어를 사용해야합니다. 따라서 다음 명령을 사용하여 Scala 설치를 확인하겠습니다.
$scala -versionScala가 이미 시스템에 설치되어 있으면 다음과 같은 응답을 볼 수 있습니다.
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFL시스템에 Scala가 설치되어 있지 않은 경우 Scala 설치를 위해 다음 단계로 진행하십시오.
3 단계 : Scala 다운로드
Scala 다운로드 링크를 방문하여 최신 버전의 Scala를 다운로드 하십시오 . 이 튜토리얼에서는 scala-2.11.6 버전을 사용합니다. 다운로드 후 다운로드 폴더에서 Scala tar 파일을 찾을 수 있습니다.
4 단계 : Scala 설치
Scala를 설치하려면 아래 단계를 따르십시오.
Scala tar 파일 추출
Scala tar 파일을 추출하려면 다음 명령을 입력하십시오.
$ tar xvf scala-2.11.6.tgzScala 소프트웨어 파일 이동
Scala 소프트웨어 파일을 각 디렉토리로 이동하려면 다음 명령을 사용하십시오. (/usr/local/scala).
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv scala-2.11.6 /usr/local/scala
# exitScala에 대한 PATH 설정
Scala에 대한 PATH를 설정하려면 다음 명령을 사용하십시오.
$ export PATH = $PATH:/usr/local/scala/binScala 설치 확인
설치 후 확인하는 것이 좋습니다. Scala 설치를 확인하려면 다음 명령을 사용하십시오.
$scala -versionScala가 이미 시스템에 설치되어 있으면 다음과 같은 응답을 볼 수 있습니다.
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFL5 단계 : Apache Spark 다운로드
다음 링크를 방문하여 최신 버전의 Spark를 다운로드하십시오 . 이 튜토리얼에서는spark-1.3.1-bin-hadoop2.6버전. 다운로드 후 다운로드 폴더에서 Spark tar 파일을 찾을 수 있습니다.
6 단계 : Spark 설치
Spark를 설치하려면 아래 단계를 따르십시오.
Spark tar 추출
다음은 Spark tar 파일을 추출하는 명령입니다.
$ tar xvf spark-1.3.1-bin-hadoop2.6.tgzSpark 소프트웨어 파일 이동
Spark 소프트웨어 파일을 각 디렉터리로 이동하기위한 다음 명령 (/usr/local/spark).
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv spark-1.3.1-bin-hadoop2.6 /usr/local/spark
# exitSpark를위한 환경 설정
~에 다음 줄을 추가하십시오./.bashrc파일. 이는 스파크 소프트웨어 파일이있는 위치를 PATH 변수에 추가하는 것을 의미합니다.
export PATH=$PATH:/usr/local/spark/bin~ / .bashrc 파일을 소싱하려면 다음 명령을 사용하십시오.
$ source ~/.bashrc7 단계 : Spark 설치 확인
Spark 셸을 열기 위해 다음 명령을 작성합니다.
$spark-shell스파크가 성공적으로 설치되면 다음 출력을 찾을 수 있습니다.
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>Spark Core는 전체 프로젝트의 기반입니다. 분산 작업 디스패치, 스케줄링 및 기본 I / O 기능을 제공합니다. Spark는 시스템간에 분할 된 데이터의 논리적 모음 인 RDD (Resilient Distributed Datasets)라는 특수한 기본 데이터 구조를 사용합니다. RDD는 두 가지 방법으로 만들 수 있습니다. 하나는 외부 스토리지 시스템의 데이터 세트를 참조하는 것이고 두 번째는 기존 RDD에 변환 (예 : 맵, 필터, 리듀서, 조인)을 적용하는 것입니다.
RDD 추상화는 언어 통합 API를 통해 노출됩니다. 이는 애플리케이션이 RDD를 조작하는 방식이 로컬 데이터 콜렉션을 조작하는 것과 유사하기 때문에 프로그래밍 복잡성을 단순화합니다.
스파크 쉘
Spark는 대화식으로 데이터를 분석 할 수있는 강력한 도구 인 대화 형 셸을 제공합니다. Scala 또는 Python 언어로 제공됩니다. Spark의 기본 추상화는 RDD (Resilient Distributed Dataset)라고하는 분산 된 항목 모음입니다. RDD는 Hadoop 입력 형식 (예 : HDFS 파일)에서 만들거나 다른 RDD를 변환하여 만들 수 있습니다.
Spark Shell 열기
다음 명령은 Spark 셸을 여는 데 사용됩니다.
$ spark-shell간단한 RDD 만들기
텍스트 파일에서 간단한 RDD를 생성 해 보겠습니다. 다음 명령을 사용하여 간단한 RDD를 만듭니다.
scala> val inputfile = sc.textFile(“input.txt”)위 명령의 출력은 다음과 같습니다.
inputfile: org.apache.spark.rdd.RDD[String] = input.txt MappedRDD[1] at textFile at <console>:12Spark RDD API는 Transformations 그리고 거의 Actions RDD를 조작합니다.
RDD 변환
RDD 변환은 새 RDD에 대한 포인터를 반환하고 RDD간에 종속성을 만들 수 있습니다. 종속성 체인 (종속성 문자열)의 각 RDD에는 데이터를 계산하는 함수가 있으며 부모 RDD에 대한 포인터 (종속성)가 있습니다.
Spark는 게으 르기 때문에 작업 생성 및 실행을 트리거하는 일부 변환 또는 작업을 호출하지 않는 한 아무것도 실행되지 않습니다. 단어 개수 예제의 다음 스 니펫을보십시오.
따라서 RDD 변환은 데이터 집합이 아니라 Spark에 데이터를 가져 오는 방법과 데이터로 수행 할 작업을 알려주는 프로그램의 한 단계입니다 (유일한 단계 일 수 있음).
| S. 아니 | 변환 및 의미 |
|---|---|
| 1 | map(func) 함수를 통해 소스의 각 요소를 전달하여 형성된 새로운 분산 데이터 세트를 반환합니다. func. |
| 2 | filter(func) 소스의 해당 요소를 선택하여 형성된 새 데이터 세트를 반환합니다. func true를 반환합니다. |
| 삼 | flatMap(func) map과 유사하지만 각 입력 항목은 0 개 이상의 출력 항목에 매핑 될 수 있습니다 (따라서 func 는 단일 항목이 아닌 Seq를 반환해야 함). |
| 4 | mapPartitions(func) map과 유사하지만 RDD의 각 파티션 (블록)에서 개별적으로 실행되므로 func 유형 T의 RDD에서 실행중인 경우 Iterator <T> ⇒ Iterator <U> 유형이어야합니다. |
| 5 | mapPartitionsWithIndex(func) 맵 파티션과 유사하지만 func 파티션의 인덱스를 나타내는 정수 값으로 func 유형 T의 RDD에서 실행중인 경우 (Int, Iterator <T>) ⇒ Iterator <U> 유형이어야합니다. |
| 6 | sample(withReplacement, fraction, seed) 샘플 A fraction 주어진 난수 생성기 시드를 사용하여 대체 여부에 관계없이 데이터의 |
| 7 | union(otherDataset) 소스 데이터 세트의 요소와 인수의 합집합을 포함하는 새 데이터 세트를 반환합니다. |
| 8 | intersection(otherDataset) 소스 데이터 세트의 요소와 인수의 교차를 포함하는 새 RDD를 반환합니다. |
| 9 | distinct([numTasks]) 소스 데이터 세트의 고유 한 요소가 포함 된 새 데이터 세트를 반환합니다. |
| 10 | groupByKey([numTasks]) (K, V) 쌍의 데이터 세트에서 호출되면 (K, Iterable <V>) 쌍의 데이터 세트를 반환합니다. Note − 각 키에 대해 집계 (예 : 합계 또는 평균)를 수행하기 위해 그룹화하는 경우 reduceByKey 또는 aggregateByKey를 사용하면 훨씬 더 나은 성능을 얻을 수 있습니다. |
| 11 | reduceByKey(func, [numTasks]) (K, V) 쌍의 데이터 세트에서 호출되면 (K, V) 쌍의 데이터 세트를 반환합니다. 여기서 각 키의 값은 주어진 reduce 함수 func를 사용하여 집계되며 (V, V) ⇒ V 유형이어야합니다. groupByKey에서와 같이 축소 작업의 수는 선택적 두 번째 인수를 통해 구성 할 수 있습니다. |
| 12 | aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) (K, V) 쌍의 데이터 세트에서 호출되면 주어진 결합 함수와 중립 "0"값을 사용하여 각 키의 값이 집계되는 (K, U) 쌍의 데이터 세트를 반환합니다. 불필요한 할당을 피하면서 입력 값 유형과 다른 집계 값 유형을 허용합니다. groupByKey와 마찬가지로 감소 작업의 수는 선택적 두 번째 인수를 통해 구성 할 수 있습니다. |
| 13 | sortByKey([ascending], [numTasks]) K가 Ordered를 구현하는 (K, V) 쌍의 데이터 세트에서 호출되면 부울 오름차순 인수에 지정된대로 오름차순 또는 내림차순으로 키별로 정렬 된 (K, V) 쌍의 데이터 세트를 반환합니다. |
| 14 | join(otherDataset, [numTasks]) (K, V) 및 (K, W) 유형의 데이터 세트에서 호출되면 각 키에 대한 모든 요소 쌍과 함께 (K, (V, W)) 쌍의 데이터 세트를 반환합니다. 외부 조인은 leftOuterJoin, rightOuterJoin 및 fullOuterJoin을 통해 지원됩니다. |
| 15 | cogroup(otherDataset, [numTasks]) (K, V) 및 (K, W) 유형의 데이터 세트에서 호출되면 (K, (Iterable <V>, Iterable <W>)) 튜플의 데이터 세트를 반환합니다. 이 작업을 그룹 포함이라고도합니다. |
| 16 | cartesian(otherDataset) T 및 U 유형의 데이터 세트에서 호출되면 (T, U) 쌍 (모든 요소 쌍)의 데이터 세트를 반환합니다. |
| 17 | pipe(command, [envVars]) Perl 또는 bash 스크립트와 같은 쉘 명령을 통해 RDD의 각 파티션을 파이프하십시오. RDD 요소는 프로세스의 stdin에 기록되고 해당 stdout에 출력되는 라인은 문자열의 RDD로 반환됩니다. |
| 18 | coalesce(numPartitions) RDD의 파티션 수를 numPartitions로 줄이십시오. 대규모 데이터 세트를 필터링 한 후 작업을보다 효율적으로 실행하는 데 유용합니다. |
| 19 | repartition(numPartitions) RDD의 데이터를 무작위로 재편성하여 더 많거나 적은 파티션을 생성하고 이들간에 균형을 맞 춥니 다. 이것은 항상 네트워크를 통해 모든 데이터를 섞습니다. |
| 20 | repartitionAndSortWithinPartitions(partitioner) 주어진 파티 셔너에 따라 RDD를 다시 파티셔닝하고 각 결과 파티션 내에서 키별로 레코드를 정렬합니다. 이는 재분할을 호출 한 다음 각 파티션 내에서 정렬하는 것보다 효율적입니다. 정렬을 셔플 기계로 밀어 넣을 수 있기 때문입니다. |
행위
| S. 아니 | 행동 및 의미 |
|---|---|
| 1 | reduce(func) 함수를 사용하여 데이터 세트의 요소 집계 func(두 개의 인수를 취하고 하나를 반환합니다). 함수는 병렬로 올바르게 계산 될 수 있도록 교환 및 연관이어야합니다. |
| 2 | collect() 드라이버 프로그램에서 데이터 셋의 모든 요소를 배열로 반환합니다. 이는 일반적으로 충분히 작은 데이터 하위 집합을 반환하는 필터 또는 기타 작업 후에 유용합니다. |
| 삼 | count() 데이터 세트의 요소 수를 반환합니다. |
| 4 | first() 데이터 세트의 첫 번째 요소를 반환합니다 (take (1)과 유사). |
| 5 | take(n) 첫 번째 배열을 반환합니다. n 데이터 세트의 요소. |
| 6 | takeSample (withReplacement,num, [seed]) 무작위 샘플이있는 배열을 반환합니다. num 대체가 있거나없는 데이터 세트의 요소. 선택적으로 난수 생성기 시드를 미리 지정합니다. |
| 7 | takeOrdered(n, [ordering]) 첫 번째를 반환합니다. n 자연 순서 또는 사용자 지정 비교기를 사용하여 RDD의 요소. |
| 8 | saveAsTextFile(path) 로컬 파일 시스템, HDFS 또는 기타 Hadoop 지원 파일 시스템의 지정된 디렉토리에 데이터 세트의 요소를 텍스트 파일 (또는 텍스트 파일 세트)로 씁니다. Spark는 각 요소에서 toString을 호출하여 파일의 텍스트 행으로 변환합니다. |
| 9 | saveAsSequenceFile(path) (Java and Scala) 데이터 세트의 요소를 로컬 파일 시스템, HDFS 또는 기타 Hadoop 지원 파일 시스템의 지정된 경로에 Hadoop SequenceFile로 씁니다. 이는 Hadoop의 쓰기 가능한 인터페이스를 구현하는 키-값 쌍의 RDD에서 사용할 수 있습니다. Scala에서는 암시 적으로 쓰기 가능으로 변환 할 수있는 유형에서도 사용할 수 있습니다 (Spark에는 Int, Double, String 등과 같은 기본 유형에 대한 변환이 포함됨). |
| 10 | saveAsObjectFile(path) (Java and Scala) Java 직렬화를 사용하여 데이터 세트의 요소를 간단한 형식으로 작성한 다음 SparkContext.objectFile ()을 사용하여로드 할 수 있습니다. |
| 11 | countByKey() 유형 (K, V)의 RDD에서만 사용할 수 있습니다. 각 키의 개수와 함께 (K, Int) 쌍의 해시 맵을 반환합니다. |
| 12 | foreach(func) 함수 실행 func데이터 세트의 각 요소에 대해 이는 일반적으로 Accumulator 업데이트 또는 외부 스토리지 시스템과의 상호 작용과 같은 부작용에 대해 수행됩니다. Note− foreach () 외부에서 Accumulators 이외의 변수를 수정하면 정의되지 않은 동작이 발생할 수 있습니다. 자세한 내용은 폐쇄 이해를 참조하세요. |
RDD로 프로그래밍
예제를 통해 RDD 프로그래밍에서 몇 가지 RDD 변환 및 작업의 구현을 살펴 보겠습니다.
예
단어 수의 예를 고려하십시오-문서에 나타나는 각 단어를 계산합니다. 다음 텍스트를 입력으로 고려하고input.txt 홈 디렉토리의 파일.
input.txt − 입력 파일.
people are not as beautiful as they look,
as they walk or as they talk.
they are only as beautiful as they love,
as they care as they share.아래의 절차에 따라 주어진 예제를 실행하십시오.
Spark-Shell 열기
다음 명령은 스파크 셸을 여는 데 사용됩니다. 일반적으로 Spark는 Scala를 사용하여 빌드됩니다. 따라서 Spark 프로그램은 Scala 환경에서 실행됩니다.
$ spark-shellSpark 셸이 성공적으로 열리면 다음 출력을 찾을 수 있습니다. "Spark context available as sc"출력의 마지막 줄을 보면 Spark 컨테이너가 이름을 가진 Spark 컨텍스트 개체가 자동으로 생성됨을 의미합니다.sc. 프로그램의 첫 번째 단계를 시작하기 전에 SparkContext 개체를 만들어야합니다.
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>RDD 생성
먼저 Spark-Scala API를 사용하여 입력 파일을 읽고 RDD를 만들어야합니다.
다음 명령은 지정된 위치에서 파일을 읽는 데 사용됩니다. 여기서는 inputfile의 이름으로 새로운 RDD가 생성됩니다. textFile (“”) 메서드에서 인수로 주어진 문자열은 입력 파일 이름의 절대 경로입니다. 그러나 파일 이름 만 제공되면 입력 파일이 현재 위치에 있음을 의미합니다.
scala> val inputfile = sc.textFile("input.txt")단어 수 변환 실행
우리의 목표는 파일의 단어 수를 세는 것입니다. 각 줄을 단어로 분할하기위한 평면지도를 만듭니다 (flatMap(line ⇒ line.split(“ ”)).
다음으로 각 단어를 값이있는 키로 읽습니다. ‘1’ (<key, value> = <word, 1>)지도 기능 사용 (map(word ⇒ (word, 1)).
마지막으로 유사한 키의 값을 추가하여 해당 키를 줄입니다 (reduceByKey(_+_)).
다음 명령은 워드 카운트 로직을 실행하는 데 사용됩니다. 이 작업을 실행 한 후에는 작업이 아니기 때문에 출력을 찾을 수 없습니다. 이것은 변환입니다. 새로운 RDD를 가리 키거나 주어진 데이터로 무엇을해야하는지 스파크에게 지시)
scala> val counts = inputfile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_);현재 RDD
RDD로 작업하는 동안 현재 RDD에 대해 알고 싶다면 다음 명령을 사용하십시오. 현재 RDD에 대한 설명과 디버깅을위한 종속성을 보여줍니다.
scala> counts.toDebugString변환 캐싱
persist () 또는 cache () 메소드를 사용하여 RDD를 지속되도록 표시 할 수 있습니다. 작업에서 처음 계산 될 때 노드의 메모리에 보관됩니다. 다음 명령을 사용하여 중간 변환을 메모리에 저장합니다.
scala> counts.cache()액션 적용
모든 변환 저장과 같은 동작을 적용하면 텍스트 파일이 생성됩니다. saveAsTextFile (“”) 메서드의 String 인수는 출력 폴더의 절대 경로입니다. 출력을 텍스트 파일로 저장하려면 다음 명령을 시도하십시오. 다음 예에서 'output'폴더는 현재 위치에 있습니다.
scala> counts.saveAsTextFile("output")출력 확인
다른 터미널을 열어 홈 디렉터리로 이동합니다 (다른 터미널에서 스파크가 실행 됨). 출력 디렉토리를 확인하려면 다음 명령을 사용하십시오.
[hadoop@localhost ~]$ cd output/ [hadoop@localhost output]$ ls -1
part-00000
part-00001
_SUCCESS다음 명령은 다음에서 출력을 보는 데 사용됩니다. Part-00000 파일.
[hadoop@localhost output]$ cat part-00000산출
(people,1)
(are,2)
(not,1)
(as,8)
(beautiful,2)
(they, 7)
(look,1)다음 명령은 다음에서 출력을 보는 데 사용됩니다. Part-00001 파일.
[hadoop@localhost output]$ cat part-00001산출
(walk, 1)
(or, 1)
(talk, 1)
(only, 1)
(love, 1)
(care, 1)
(share, 1)UN Persist the Storage
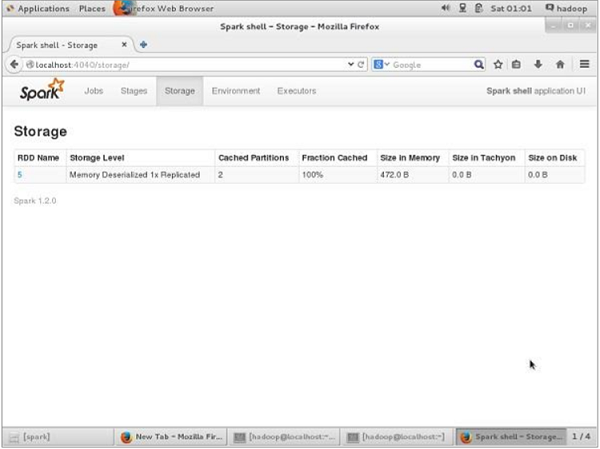
UN-persisting 전에이 애플리케이션에 사용되는 저장 공간을 확인하려면 브라우저에서 다음 URL을 사용하십시오.
http://localhost:4040Spark 셸에서 실행중인 애플리케이션에 사용 된 저장 공간을 보여주는 다음 화면이 표시됩니다.

특정 RDD의 저장 공간을 유지 해제하려면 다음 명령을 사용하십시오.
Scala> counts.unpersist()다음과 같이 출력이 표시됩니다.
15/06/27 00:57:33 INFO ShuffledRDD: Removing RDD 9 from persistence list
15/06/27 00:57:33 INFO BlockManager: Removing RDD 9
15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_1
15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_1 of size 480 dropped from memory (free 280061810)
15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_0
15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_0 of size 296 dropped from memory (free 280062106)
res7: cou.type = ShuffledRDD[9] at reduceByKey at <console>:14브라우저의 저장 공간을 확인하려면 다음 URL을 사용하십시오.
http://localhost:4040/다음 화면이 표시됩니다. Spark 셸에서 실행중인 애플리케이션에 사용 된 저장 공간을 보여줍니다.
spark-submit을 사용하는 Spark 애플리케이션은 Spark 애플리케이션을 클러스터에 배포하는 데 사용되는 셸 명령입니다. 균일 한 인터페이스를 통해 모든 클러스터 관리자를 사용합니다. 따라서 각각에 대해 응용 프로그램을 구성 할 필요가 없습니다.
예
쉘 명령을 사용하여 이전에 사용한 단어 수의 동일한 예를 살펴 보겠습니다. 여기서는 스파크 애플리케이션과 동일한 예를 고려합니다.
샘플 입력
다음 텍스트는 입력 데이터이며 이름이 지정된 파일은 in.txt.
people are not as beautiful as they look,
as they walk or as they talk.
they are only as beautiful as they love,
as they care as they share.다음 프로그램을보십시오-
SparkWordCount.scala
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark._
object SparkWordCount {
def main(args: Array[String]) {
val sc = new SparkContext( "local", "Word Count", "/usr/local/spark", Nil, Map(), Map())
/* local = master URL; Word Count = application name; */
/* /usr/local/spark = Spark Home; Nil = jars; Map = environment */
/* Map = variables to work nodes */
/*creating an inputRDD to read text file (in.txt) through Spark context*/
val input = sc.textFile("in.txt")
/* Transform the inputRDD into countRDD */
val count = input.flatMap(line ⇒ line.split(" "))
.map(word ⇒ (word, 1))
.reduceByKey(_ + _)
/* saveAsTextFile method is an action that effects on the RDD */
count.saveAsTextFile("outfile")
System.out.println("OK");
}
}위 프로그램을 SparkWordCount.scala 이름이 지정된 사용자 정의 디렉토리에 배치합니다. spark-application.
Note − inputRDD를 countRDD로 변환하는 동안, 우리는 줄 (텍스트 파일에서)을 단어로 토큰 화하기 위해 flatMap ()을 사용하고, 단어 빈도를 계산하기위한 map () 메소드와 각 단어 반복을 계산하기 위해 reduceByKey () 메소드를 사용합니다.
이 신청서를 제출하려면 다음 단계를 따르십시오. 모든 단계를spark-application 터미널을 통해 디렉토리.
1 단계 : Spark Ja 다운로드
컴파일에는 Spark core jar가 필요하므로 다음 링크 Spark core jar 에서 spark-core_2.10-1.3.0.jar 을 다운로드하고 jar 파일을 다운로드 디렉토리에서 다음으로 이동합니다.spark-application 예배 규칙서.
2 단계 : 프로그램 컴파일
아래 명령을 사용하여 위 프로그램을 컴파일하십시오. 이 명령은 spark-application 디렉토리에서 실행해야합니다. 여기,/usr/local/spark/lib/spark-assembly-1.4.0-hadoop2.6.0.jar Spark 라이브러리에서 가져온 Hadoop 지원 jar입니다.
$ scalac -classpath "spark-core_2.10-1.3.0.jar:/usr/local/spark/lib/spark-assembly-1.4.0-hadoop2.6.0.jar" SparkPi.scala3 단계 : JAR 생성
다음 명령을 사용하여 Spark 애플리케이션의 jar 파일을 만듭니다. 여기,wordcount jar 파일의 파일 이름입니다.
jar -cvf wordcount.jar SparkWordCount*.class spark-core_2.10-1.3.0.jar/usr/local/spark/lib/spark-assembly-1.4.0-hadoop2.6.0.jar4 단계 : Spark 신청서 제출
다음 명령을 사용하여 Spark 응용 프로그램을 제출하십시오-
spark-submit --class SparkWordCount --master local wordcount.jar성공적으로 실행되면 아래에 주어진 출력을 찾을 수 있습니다. 그만큼OK다음 출력은 사용자 식별을위한 것이며 이는 프로그램의 마지막 줄입니다. 다음 출력을주의 깊게 읽으면 다음과 같은 다른 것을 찾을 수 있습니다.
- 포트 42954에서 서비스 'sparkDriver'를 성공적으로 시작했습니다.
- MemoryStore는 267.3MB 용량으로 시작되었습니다.
- http://192.168.1.217:4040에서 SparkUI 시작
- 추가 된 JAR 파일 : /home/hadoop/piapplication/count.jar
- ResultStage 1 (SparkPi.scala : 11의 saveAsTextFile)이 0.566 초 안에 완료되었습니다.
- http://192.168.1.217:4040에서 Spark 웹 UI를 중지했습니다.
- MemoryStore가 지워졌습니다.
15/07/08 13:56:04 INFO Slf4jLogger: Slf4jLogger started
15/07/08 13:56:04 INFO Utils: Successfully started service 'sparkDriver' on port 42954.
15/07/08 13:56:04 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://[email protected]:42954]
15/07/08 13:56:04 INFO MemoryStore: MemoryStore started with capacity 267.3 MB
15/07/08 13:56:05 INFO HttpServer: Starting HTTP Server
15/07/08 13:56:05 INFO Utils: Successfully started service 'HTTP file server' on port 56707.
15/07/08 13:56:06 INFO SparkUI: Started SparkUI at http://192.168.1.217:4040
15/07/08 13:56:07 INFO SparkContext: Added JAR file:/home/hadoop/piapplication/count.jar at http://192.168.1.217:56707/jars/count.jar with timestamp 1436343967029
15/07/08 13:56:11 INFO Executor: Adding file:/tmp/spark-45a07b83-42ed-42b3b2c2-823d8d99c5af/userFiles-df4f4c20-a368-4cdd-a2a7-39ed45eb30cf/count.jar to class loader
15/07/08 13:56:11 INFO HadoopRDD: Input split: file:/home/hadoop/piapplication/in.txt:0+54
15/07/08 13:56:12 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 2001 bytes result sent to driver
(MapPartitionsRDD[5] at saveAsTextFile at SparkPi.scala:11), which is now runnable
15/07/08 13:56:12 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (MapPartitionsRDD[5] at saveAsTextFile at SparkPi.scala:11)
15/07/08 13:56:13 INFO DAGScheduler: ResultStage 1 (saveAsTextFile at SparkPi.scala:11) finished in 0.566 s
15/07/08 13:56:13 INFO DAGScheduler: Job 0 finished: saveAsTextFile at SparkPi.scala:11, took 2.892996 s
OK
15/07/08 13:56:13 INFO SparkContext: Invoking stop() from shutdown hook
15/07/08 13:56:13 INFO SparkUI: Stopped Spark web UI at http://192.168.1.217:4040
15/07/08 13:56:13 INFO DAGScheduler: Stopping DAGScheduler
15/07/08 13:56:14 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
15/07/08 13:56:14 INFO Utils: path = /tmp/spark-45a07b83-42ed-42b3-b2c2823d8d99c5af/blockmgr-ccdda9e3-24f6-491b-b509-3d15a9e05818, already present as root for deletion.
15/07/08 13:56:14 INFO MemoryStore: MemoryStore cleared
15/07/08 13:56:14 INFO BlockManager: BlockManager stopped
15/07/08 13:56:14 INFO BlockManagerMaster: BlockManagerMaster stopped
15/07/08 13:56:14 INFO SparkContext: Successfully stopped SparkContext
15/07/08 13:56:14 INFO Utils: Shutdown hook called
15/07/08 13:56:14 INFO Utils: Deleting directory /tmp/spark-45a07b83-42ed-42b3b2c2-823d8d99c5af
15/07/08 13:56:14 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!5 단계 : 출력 확인
프로그램을 성공적으로 실행하면 다음과 같은 디렉토리를 찾을 수 있습니다. outfile spark-application 디렉토리에 있습니다.
다음 명령은 outfile 디렉토리에있는 파일 목록을 열고 확인하는 데 사용됩니다.
$ cd outfile $ ls
Part-00000 part-00001 _SUCCESS출력 확인을위한 명령 part-00000 파일은-
$ cat part-00000
(people,1)
(are,2)
(not,1)
(as,8)
(beautiful,2)
(they, 7)
(look,1)part-00001 파일에서 출력을 확인하는 명령은 다음과 같습니다.
$ cat part-00001
(walk, 1)
(or, 1)
(talk, 1)
(only, 1)
(love, 1)
(care, 1)
(share, 1)'spark-submit'명령에 대해 자세히 알아 보려면 다음 섹션을 참조하십시오.
Spark-submit 구문
spark-submit [options] <app jar | python file> [app arguments]옵션
| S. 아니 | 선택권 | 기술 |
|---|---|---|
| 1 | --석사 | spark : // host : port, mesos : // host : port, yarn 또는 local. |
| 2 | -배포 모드 | 드라이버 프로그램을 로컬 ( "클라이언트") 또는 클러스터 내부의 작업자 머신 ( "클러스터") 중 하나에서 시작할지 여부 (기본값 : 클라이언트). |
| 삼 | --수업 | 애플리케이션의 기본 클래스 (Java / Scala 앱용). |
| 4 | --이름 | 응용 프로그램의 이름입니다. |
| 5 | -항아리 | 드라이버 및 실행기 클래스 경로에 포함 할 쉼표로 구분 된 로컬 jar 목록입니다. |
| 6 | -패키지 | 드라이버 및 실행기 클래스 경로에 포함 할 jar의 maven 좌표의 쉼표로 구분 된 목록입니다. |
| 7 | -저장소 | --packages로 제공된 Maven 좌표를 검색하기위한 추가 원격 저장소의 쉼표로 구분 된 목록입니다. |
| 8 | --py 파일 | Python 앱용 PYTHON PATH에 배치 할 .zip, .egg 또는 .py 파일의 쉼표로 구분 된 목록입니다. |
| 9 | -파일 | 각 실행기의 작업 디렉토리에 배치 할 파일의 쉼표로 구분 된 목록입니다. |
| 10 | --conf (prop = val) | 임의의 Spark 구성 속성. |
| 11 | -속성 파일 | 추가 속성을로드 할 파일의 경로입니다. 지정하지 않으면 conf / spark-defaults를 찾습니다. |
| 12 | -드라이버 메모리 | 드라이버 용 메모리 (예 : 1000M, 2G) (기본값 : 512M). |
| 13 | -드라이버-자바-옵션 | 드라이버에 전달할 추가 Java 옵션. |
| 14 | -드라이버 라이브러리 경로 | 드라이버에 전달할 추가 라이브러리 경로 항목입니다. |
| 15 | -드라이버 클래스 경로 | 드라이버에 전달할 추가 클래스 경로 항목입니다. --jars로 추가 된 jar는 자동으로 클래스 경로에 포함됩니다. |
| 16 | -실행자 메모리 | 실행기 당 메모리 (예 : 1000M, 2G) (기본값 : 1G). |
| 17 | --proxy-user | 신청서를 제출할 때 가장 할 사용자입니다. |
| 18 | -도움말, -h | 이 도움말 메시지를 표시하고 종료하십시오. |
| 19 | --verbose, -v | 추가 디버그 출력을 인쇄합니다. |
| 20 | --버전 | 현재 Spark 버전을 인쇄합니다. |
| 21 | -드라이버 코어 NUM | 드라이버 용 코어 (기본값 : 1). |
| 22 | -감독 | 주어진 경우 실패시 드라이버를 다시 시작합니다. |
| 23 | --죽임 | 주어진 경우 지정된 드라이버를 종료합니다. |
| 24 | --상태 | 주어진 경우 지정된 드라이버의 상태를 요청합니다. |
| 25 | -총 집행자 코어 | 모든 실행기에 대한 총 코어. |
| 26 | -실행자 코어 | 실행기 당 코어 수. (기본값 : YARN 모드의 경우 1 또는 독립 실행 형 모드의 작업자에서 사용 가능한 모든 코어). |
Spark에는 두 가지 유형의 공유 변수가 있습니다. broadcast variables 두 번째는 accumulators.
Broadcast variables − 큰 값을 효율적으로 배포하는 데 사용됩니다.
Accumulators − 특정 수집 정보를 집계하는 데 사용됩니다.
방송 변수
브로드 캐스트 변수를 사용하면 프로그래머가 작업과 함께 복사본을 제공하지 않고 각 시스템에 캐시 된 읽기 전용 변수를 유지할 수 있습니다. 예를 들어 모든 노드에 대규모 입력 데이터 세트의 사본을 효율적인 방식으로 제공하는 데 사용할 수 있습니다. Spark는 또한 통신 비용을 줄이기 위해 효율적인 방송 알고리즘을 사용하여 방송 변수를 배포하려고합니다.
Spark 작업은 분산 된 "셔플"작업으로 구분 된 일련의 단계를 통해 실행됩니다. Spark는 각 단계 내의 작업에 필요한 공통 데이터를 자동으로 브로드 캐스트합니다.
이러한 방식으로 브로드 캐스트 된 데이터는 직렬화 된 형식으로 캐시되고 각 작업을 실행하기 전에 역 직렬화됩니다. 즉, 명시 적으로 브로드 캐스트 변수를 만드는 것은 여러 단계의 작업에 동일한 데이터가 필요하거나 역 직렬화 된 형식의 데이터 캐싱이 중요한 경우에만 유용합니다.
방송 변수는 변수에서 생성됩니다. v 전화로 SparkContext.broadcast(v). 브로드 캐스트 변수는v, 그 값은 value방법. 아래에 주어진 코드는 이것을 보여줍니다-
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))Output −
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)브로드 캐스트 변수가 생성 된 후에는 값 대신 사용해야합니다. v 클러스터에서 실행되는 모든 기능에서 v노드에 두 번 이상 제공되지 않습니다. 또한 개체v 모든 노드가 브로드 캐스트 변수의 동일한 값을 갖도록하기 위해 브로드 캐스트 후에 수정해서는 안됩니다.
어큐뮬레이터
누산기는 연관 연산을 통해서만 "추가"되는 변수이므로 병렬로 효율적으로 지원할 수 있습니다. 카운터 (MapReduce에서와 같이) 또는 합계를 구현하는 데 사용할 수 있습니다. Spark는 기본적으로 숫자 유형의 누산기를 지원하며 프로그래머는 새로운 유형에 대한 지원을 추가 할 수 있습니다. 누산기가 이름으로 생성되면 다음 위치에 표시됩니다.Spark’s UI. 이것은 실행 단계의 진행 상황을 이해하는 데 유용 할 수 있습니다 (참고-Python에서는 아직 지원되지 않음).
누산기는 초기 값에서 생성됩니다. v 전화로 SparkContext.accumulator(v). 클러스터에서 실행중인 작업은 다음을 사용하여 클러스터에 추가 할 수 있습니다.add메서드 또는 + = 연산자 (Scala 및 Python). 그러나 그들은 그 값을 읽을 수 없습니다. 드라이버 프로그램 만이 그 사용하여 누산기의 값을 읽을 수 있습니다.value 방법.
아래에 주어진 코드는 배열의 요소를 더하는 데 사용되는 누산기를 보여줍니다.
scala> val accum = sc.accumulator(0)
scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)위 코드의 출력을 보려면 다음 명령을 사용하십시오.
scala> accum.value산출
res2: Int = 10숫자 RDD 연산
Spark를 사용하면 미리 정의 된 API 메서드 중 하나를 사용하여 숫자 데이터에 대해 다양한 작업을 수행 할 수 있습니다. Spark의 숫자 연산은 한 번에 한 요소 씩 모델을 빌드 할 수있는 스트리밍 알고리즘으로 구현됩니다.
이러한 작업은 계산되어 StatusCounter 호출하여 객체 status() 방법.
| S. 아니 | 방법 및 의미 |
|---|---|
| 1 | count() RDD의 요소 수입니다. |
| 2 | Mean() RDD의 요소 평균입니다. |
| 삼 | Sum() RDD에있는 요소의 총 가치. |
| 4 | Max() RDD의 모든 요소 중 최대 값입니다. |
| 5 | Min() RDD의 모든 요소 중 최소값입니다. |
| 6 | Variance() 요소의 차이. |
| 7 | Stdev() 표준 편차. |
이러한 메소드 중 하나만 사용하려면 RDD에서 직접 해당 메소드를 호출 할 수 있습니다.