Apache Storm-빠른 가이드
Apache Storm이란 무엇입니까?
Apache Storm은 분산 된 실시간 빅 데이터 처리 시스템입니다. Storm은 내결함성 및 수평 확장 가능한 방법으로 방대한 양의 데이터를 처리하도록 설계되었습니다. 가장 높은 수집 속도 기능을 가진 스트리밍 데이터 프레임 워크입니다. Storm은 상태 비 저장이지만 Apache ZooKeeper를 통해 분산 환경 및 클러스터 상태를 관리합니다. 간단하고 실시간 데이터에 대한 모든 종류의 조작을 병렬로 실행할 수 있습니다.
Apache Storm은 지속적으로 실시간 데이터 분석의 선두 주자입니다. Storm은 설정, 작동이 쉬우 며 모든 메시지가 토폴로지를 통해 적어도 한 번 처리되도록 보장합니다.
Apache Storm과 Hadoop
기본적으로 Hadoop 및 Storm 프레임 워크는 빅 데이터 분석에 사용됩니다. 둘 다 서로를 보완하고 일부 측면에서 다릅니다. Apache Storm은 지속성을 제외한 모든 작업을 수행하는 반면 Hadoop은 모든 작업에 능숙하지만 실시간 계산이 지연됩니다. 다음 표는 Storm과 Hadoop의 속성을 비교합니다.
| 폭풍 | 하둡 |
|---|---|
| 실시간 스트림 처리 | 일괄 처리 |
| 무국적 | 상태 저장 |
| ZooKeeper 기반 조정 기능이있는 마스터 / 슬레이브 아키텍처. 마스터 노드는 다음과 같이 호출됩니다.nimbus 그리고 노예는 supervisors. | ZooKeeper 기반 조정이 있거나없는 마스터-슬레이브 아키텍처. 마스터 노드는job tracker 슬레이브 노드는 task tracker. |
| Storm 스트리밍 프로세스는 클러스터에서 초당 수만 개의 메시지에 액세스 할 수 있습니다. | Hadoop 분산 파일 시스템 (HDFS)은 MapReduce 프레임 워크를 사용하여 몇 분 또는 몇 시간이 걸리는 방대한 양의 데이터를 처리합니다. |
| Storm 토폴로지는 사용자가 종료하거나 예기치 않은 복구 불가능한 오류가 발생할 때까지 실행됩니다. | MapReduce 작업은 순차적으로 실행되고 결국 완료됩니다. |
| Both are distributed and fault-tolerant | |
| nimbus / supervisor가 죽으면 다시 시작하면 중지 된 위치에서 계속 진행되므로 아무런 영향을받지 않습니다. | JobTracker가 종료되면 실행중인 모든 작업이 손실됩니다. |
Apache Storm의 사용 사례
Apache Storm은 실시간 빅 데이터 스트림 처리로 매우 유명합니다. 이러한 이유로 대부분의 회사는 시스템의 필수 부분으로 Storm을 사용하고 있습니다. 몇 가지 주목할만한 예는 다음과 같습니다.
Twitter− Twitter는 다양한 "Publisher Analytics 제품"에 Apache Storm을 사용하고 있습니다. "게시자 분석 제품"은 Twitter 플랫폼에서 모든 트윗과 클릭을 처리합니다. Apache Storm은 Twitter 인프라와 긴밀하게 통합됩니다.
NaviSite− NaviSite는 이벤트 로그 모니터링 / 감사 시스템을 위해 Storm을 사용하고 있습니다. 시스템에서 생성 된 모든 로그는 Storm을 통과합니다. Storm은 구성된 정규식 집합에 대해 메시지를 확인하고 일치하는 항목이 있으면 해당 특정 메시지가 데이터베이스에 저장됩니다.
Wego− Wego는 싱가포르에 위치한 여행 메타 검색 엔진입니다. 여행 관련 데이터는 시간이 다른 전 세계 여러 출처에서 제공됩니다. Storm은 Wego가 실시간 데이터를 검색하고 동시성 문제를 해결하며 최종 사용자에게 가장 적합한 것을 찾을 수 있도록 도와줍니다.
Apache Storm의 이점
다음은 Apache Storm이 제공하는 이점 목록입니다.
Storm은 오픈 소스이며 강력하며 사용자 친화적입니다. 대기업뿐만 아니라 중소기업에서도 활용할 수 있습니다.
Storm은 내결함성, 유연성, 안정성 및 모든 프로그래밍 언어를 지원합니다.
실시간 스트림 처리를 허용합니다.
Storm은 엄청난 데이터 처리 능력을 가지고 있기 때문에 믿을 수 없을 정도로 빠릅니다.
Storm은 리소스를 선형으로 추가하여 부하가 증가하더라도 성능을 유지할 수 있습니다. 확장 성이 뛰어납니다.
Storm은 데이터 새로 고침을 수행하고 문제에 따라 몇 초 또는 몇 분 안에 종단 간 전달 응답을 수행합니다. 대기 시간이 매우 짧습니다.
Storm에는 운영 인텔리전스가 있습니다.
Storm은 클러스터의 연결된 노드가 죽거나 메시지가 손실 된 경우에도 보장 된 데이터 처리를 제공합니다.
Apache Storm은 한쪽 끝에서 실시간 데이터의 원시 스트림을 읽고이를 일련의 작은 처리 장치를 통해 전달하고 다른 쪽 끝에서 처리 된 / 유용한 정보를 출력합니다.
다음 다이어그램은 Apache Storm의 핵심 개념을 보여줍니다.

이제 Apache Storm의 구성 요소를 자세히 살펴 보겠습니다.
| 구성품 | 기술 |
|---|---|
| 튜플 | 튜플은 Storm의 주요 데이터 구조입니다. 정렬 된 요소의 목록입니다. 기본적으로 튜플은 모든 데이터 유형을 지원합니다. 일반적으로 쉼표로 구분 된 값 세트로 모델링되고 Storm 클러스터에 전달됩니다. |
| 흐름 | 스트림은 순서가 지정되지 않은 튜플 시퀀스입니다. |
| 스파우트 | 스트림 소스. 일반적으로 Storm은 Twitter Streaming API, Apache Kafka 대기열, Kestrel 대기열 등과 같은 원시 데이터 소스의 입력 데이터를받습니다. 그렇지 않으면 스파우트를 작성하여 데이터 소스에서 데이터를 읽을 수 있습니다. "ISpout"은 스파우트 구현을위한 핵심 인터페이스입니다. 특정 인터페이스 중 일부는 IRichSpout, BaseRichSpout, KafkaSpout 등입니다. |
| 볼트 | 볼트는 논리적 처리 장치입니다. 스파우트는 데이터를 볼트 및 볼트 프로세스로 전달하고 새로운 출력 스트림을 생성합니다. Bolts는 데이터 소스 및 데이터베이스와의 필터링, 집계, 결합, 상호 작용 작업을 수행 할 수 있습니다. 볼트는 데이터를 받아 하나 이상의 볼트로 방출합니다. “IBolt”는 볼트 구현을위한 핵심 인터페이스입니다. 일반적인 인터페이스 중 일부는 IRichBolt, IBasicBolt 등입니다. |
"Twitter Analysis"의 실시간 예를 들어 Apache Storm에서 어떻게 모델링 할 수 있는지 살펴 보겠습니다. 다음 다이어그램은 구조를 보여줍니다.

"Twitter Analysis"에 대한 입력은 Twitter Streaming API에서 제공됩니다. Spout는 Twitter Streaming API를 사용하여 사용자의 트윗을 읽고 튜플 스트림으로 출력합니다. 스파우트의 단일 튜플은 트위터 사용자 이름과 단일 트윗을 쉼표로 구분 된 값으로 갖습니다. 그런 다음이 튜플 증기가 Bolt로 전달되고 Bolt는 트윗을 개별 단어로 분할하고 단어 수를 계산하며 구성된 데이터 소스에 정보를 유지합니다. 이제 데이터 소스를 쿼리하여 결과를 쉽게 얻을 수 있습니다.
토폴로지
스파우트와 볼트는 함께 연결되어 토폴로지를 형성합니다. 실시간 애플리케이션 로직은 Storm 토폴로지 내에 지정됩니다. 간단히 말해서 토폴로지는 정점이 계산이고 가장자리가 데이터 스트림 인 방향성 그래프입니다.
간단한 토폴로지는 스파우트로 시작됩니다. 주둥이는 하나 이상의 볼트로 데이터를 내 보냅니다. Bolt는 가장 작은 처리 로직을 갖는 토폴로지의 노드를 나타내며 볼트의 출력은 입력으로 다른 볼트로 방출 될 수 있습니다.
Storm은 토폴로지를 종료 할 때까지 토폴로지를 항상 실행합니다. Apache Storm의 주요 작업은 토폴로지를 실행하는 것이며 주어진 시간에 여러 토폴로지를 실행합니다.
과제
이제 스파우트와 볼트에 대한 기본적인 아이디어를 얻었습니다. 이들은 토폴로지의 가장 작은 논리적 단위이며 토폴로지는 단일 스파우트와 볼트 배열을 사용하여 구축됩니다. 토폴로지가 성공적으로 실행 되려면 특정 순서로 제대로 실행되어야합니다. Storm에 의한 각각의 모든 주둥이와 볼트의 실행을 "작업"이라고합니다. 간단히 말해서, 작업은 주둥이 또는 볼트의 실행입니다. 주어진 시간에 각 스파우트와 볼트는 여러 개의 개별 스레드에서 실행되는 여러 인스턴스를 가질 수 있습니다.
노동자
토폴로지는 여러 작업자 노드에서 분산 방식으로 실행됩니다. Storm은 모든 작업자 노드에서 작업을 균등하게 분산합니다. 작업자 노드의 역할은 작업을 수신하고 새 작업이 도착할 때마다 프로세스를 시작하거나 중지하는 것입니다.
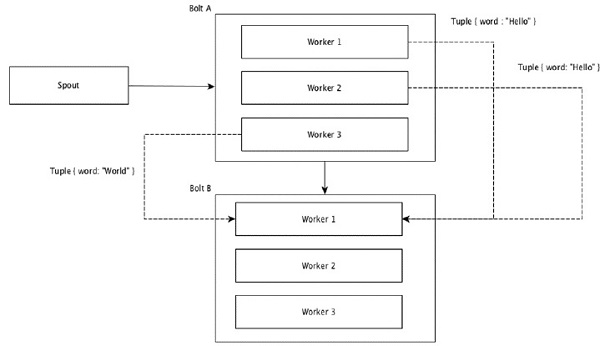
스트림 그룹화
데이터 스트림은 스파우트에서 볼트로 또는 한 볼트에서 다른 볼트로 흐릅니다. 스트림 그룹화는 토폴로지에서 튜플이 라우팅되는 방식을 제어하고 토폴로지에서 튜플 흐름을 이해하는 데 도움이됩니다. 아래에 설명 된대로 4 개의 내장 된 그룹이 있습니다.
셔플 그룹화
셔플 그룹화에서는 볼트를 실행하는 모든 워커에 동일한 수의 튜플이 무작위로 배포됩니다. 다음 다이어그램은 구조를 보여줍니다.

필드 그룹화
튜플에서 동일한 값을 가진 필드는 함께 그룹화되고 나머지 튜플은 외부에 유지됩니다. 그런 다음 동일한 필드 값을 가진 튜플이 볼트를 실행하는 동일한 작업자에게 전달됩니다. 예를 들어 스트림이 "word"필드로 그룹화 된 경우 동일한 문자열 "Hello"를 가진 튜플이 동일한 작업자로 이동합니다. 다음 다이어그램은 필드 그룹화의 작동 방식을 보여줍니다.

글로벌 그룹화
모든 스트림을 그룹화하여 하나의 볼트로 전달할 수 있습니다. 이 그룹화는 소스의 모든 인스턴스에서 생성 된 튜플을 단일 대상 인스턴스로 보냅니다 (특히 ID가 가장 낮은 작업자 선택).
모든 그룹화
모든 그룹화는 각 튜플의 단일 복사본을 수신 볼트의 모든 인스턴스로 보냅니다. 이러한 종류의 그룹화는 신호를 볼트로 보내는 데 사용됩니다. 모든 그룹화는 조인 작업에 유용합니다.

Apache Storm의 주요 특징 중 하나는 "단일 실패 지점"(SPOF) 분산 응용 프로그램이없는 빠르며 내결함성이 있다는 것입니다. 애플리케이션 용량을 늘리기 위해 필요한만큼 많은 시스템에 Apache Storm을 설치할 수 있습니다.
Apache Storm 클러스터의 설계 방식과 내부 아키텍처를 살펴 보겠습니다. 다음 다이어그램은 클러스터 설계를 보여줍니다.

Apache Storm에는 두 가지 유형의 노드가 있습니다. Nimbus (마스터 노드) 및 Supervisor(작업자 노드). Nimbus는 Apache Storm의 핵심 구성 요소입니다. Nimbus의 주요 작업은 Storm 토폴로지를 실행하는 것입니다. Nimbus는 토폴로지를 분석하고 실행할 작업을 수집합니다. 그런 다음 사용 가능한 감독자에게 작업을 배포합니다.
감독자는 하나 이상의 작업자 프로세스를 갖게됩니다. 감독자는 작업을 작업자 프로세스에 위임합니다. 작업자 프로세스는 필요한만큼의 실행기를 생성하고 작업을 실행합니다. Apache Storm은 nimbus와 감독자 간의 통신을 위해 내부 분산 메시징 시스템을 사용합니다.
| 구성품 | 기술 |
|---|---|
| 후광 | Nimbus는 Storm 클러스터의 마스터 노드입니다. 클러스터의 다른 모든 노드는 다음과 같이 호출됩니다.worker nodes. 마스터 노드는 모든 작업자 노드에 데이터를 분배하고 작업자 노드에 작업을 할당하며 실패를 모니터링합니다. |
| 감독자 | nimbus가 제공하는 지시를 따르는 노드를 Supervisor라고합니다. ㅏsupervisor 여러 작업자 프로세스가 있으며 작업자 프로세스를 관리하여 nimbus가 할당 한 작업을 완료합니다. |
| 작업자 프로세스 | 작업자 프로세스는 특정 토폴로지와 관련된 작업을 실행합니다. 작업자 프로세스는 자체적으로 작업을 실행하지 않고 대신executors특정 작업을 수행하도록 요청합니다. 작업자 프로세스에는 여러 실행자가 있습니다. |
| 집행자 | 실행기는 작업자 프로세스에 의해 생성되는 단일 스레드에 불과합니다. 실행자는 특정 스파우트 또는 볼트에 대해서만 하나 이상의 작업을 실행합니다. |
| 직무 | 작업은 실제 데이터 처리를 수행합니다. 그래서 그것은 주둥이 또는 볼트입니다. |
| ZooKeeper 프레임 워크 | Apache ZooKeeper는 클러스터 (노드 그룹)에서 강력한 동기화 기술을 사용하여 자신을 조정하고 공유 데이터를 유지하는 데 사용하는 서비스입니다. Nimbus는 상태 비 저장이므로 ZooKeeper에 의존하여 작업 노드 상태를 모니터링합니다. ZooKeeper는 감독자가 후광과 상호 작용하도록 도와줍니다. 후광 및 감독자의 상태를 유지하는 책임이 있습니다. |
폭풍은 본질적으로 무국적 상태입니다. 상태 비 저장 특성에는 자체 단점이 있지만 실제로 Storm이 실시간 데이터를 가장 빠르고 가장 빠른 방법으로 처리하는 데 도움이됩니다.
폭풍은 완전히 무국적 상태 가 아닙니다 . 상태를 Apache ZooKeeper에 저장합니다. 상태는 Apache ZooKeeper에서 사용할 수 있으므로 실패한 nimbus를 다시 시작하고 남은 위치에서 작동하도록 만들 수 있습니다. 일반적으로 다음과 같은 서비스 모니터링 도구monit Nimbus를 모니터링하고 오류가 발생하면 다시 시작합니다.
Apache Storm에는 다음과 같은 고급 토폴로지도 있습니다. Trident Topology상태 유지 관리와 함께 Pig와 같은 고급 API도 제공합니다. 다음 장에서 이러한 모든 기능에 대해 설명합니다.
작동중인 Storm 클러스터에는 하나의 nimbus와 하나 이상의 감독자가 있어야합니다. 또 다른 중요한 노드는 Apache ZooKeeper로, nimbus와 감독자 간의 조정에 사용됩니다.
이제 Apache Storm의 워크 플로우를 자세히 살펴 보겠습니다.
처음에 후광은 "Storm 토폴로지"가 제출 될 때까지 기다립니다.
토폴로지가 제출되면 토폴로지를 처리하고 수행 할 모든 작업과 작업이 실행되는 순서를 수집합니다.
그런 다음 후광은 사용 가능한 모든 감독자에게 작업을 고르게 분배합니다.
특정 시간 간격으로 모든 감독자는 후광에게 하트 비트를 보내 아직 살아 있음을 알립니다.
감독자가 죽고 후광에게 하트 비트를 보내지 않으면 후광은 작업을 다른 감독자에게 할당합니다.
후광 자체가 죽으면 감독자는 문제없이 이미 할당 된 작업을 수행합니다.
모든 작업이 완료되면 감독자는 새로운 작업이 들어올 때까지 기다립니다.
그동안 데드 님 버스는 서비스 모니터링 도구에 의해 자동으로 다시 시작됩니다.
다시 시작된 후광은 중지 된 위치에서 계속됩니다. 마찬가지로 데드 수퍼바이저도 자동으로 다시 시작할 수 있습니다. nimbus와 수퍼바이저 모두 자동으로 다시 시작할 수 있고 둘 다 이전과 같이 계속되므로 Storm은 모든 작업을 적어도 한 번은 처리 할 수 있습니다.
모든 토폴로지가 처리되면 nimbus는 새 토폴로지가 도착할 때까지 기다립니다. 마찬가지로 감독자는 새 작업을 기다립니다.
기본적으로 Storm 클러스터에는 두 가지 모드가 있습니다.
Local mode−이 모드는 함께 작동하는 모든 토폴로지 구성 요소를 확인하는 가장 쉬운 방법이기 때문에 개발, 테스트 및 디버깅에 사용됩니다. 이 모드에서는 다른 Storm 구성 환경에서 토폴로지가 어떻게 실행되는지 확인할 수 있도록 매개 변수를 조정할 수 있습니다. 로컬 모드에서 스톰 토폴로지는 단일 JVM의 로컬 시스템에서 실행됩니다.
Production mode−이 모드에서는 일반적으로 서로 다른 시스템에서 실행되는 많은 프로세스로 구성된 작업 폭풍 클러스터에 토폴로지를 제출합니다. Storm의 워크 플로에서 설명한 것처럼 작동중인 클러스터는 종료 될 때까지 무기한 실행됩니다.
Apache Storm은 실시간 데이터를 처리하고 입력은 일반적으로 메시지 대기열 시스템에서 제공됩니다. 외부 분산 메시징 시스템은 실시간 계산에 필요한 입력을 제공합니다. Spout는 메시징 시스템에서 데이터를 읽고이를 튜플로 변환하고 Apache Storm에 입력합니다. 흥미로운 사실은 Apache Storm이 nimbus와 감독자 간의 통신을 위해 내부적으로 자체 분산 메시징 시스템을 사용한다는 것입니다.
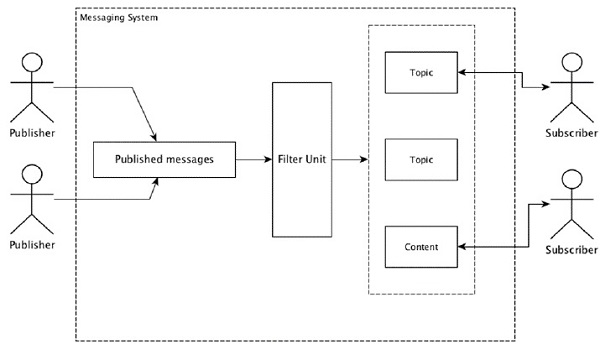
분산 메시징 시스템이란 무엇입니까?
분산 메시징은 신뢰할 수있는 메시지 대기열 개념을 기반으로합니다. 메시지는 클라이언트 응용 프로그램과 메시징 시스템간에 비동기식으로 대기합니다. 분산 메시징 시스템은 안정성, 확장 성 및 지속성의 이점을 제공합니다.
대부분의 메시징 패턴은 publish-subscribe 모델 (간단히 Pub-Sub) 메시지 발신자가 호출되는 위치 publishers 메시지를 받고 싶은 사람이 subscribers.
보낸 사람이 메시지를 게시하면 구독자는 필터링 옵션을 사용하여 선택한 메시지를받을 수 있습니다. 일반적으로 두 가지 유형의 필터링이 있습니다. 하나는topic-based filtering 그리고 또 하나는 content-based filtering.
pub-sub 모델은 메시지를 통해서만 통신 할 수 있습니다. 이것은 매우 느슨하게 결합 된 아키텍처입니다. 발신자조차도 구독자가 누구인지 모릅니다. 많은 메시지 패턴을 통해 메시지 브로커를 통해 많은 구독자가 적시에 액세스 할 수 있도록 게시 메시지를 교환 할 수 있습니다. 실제 예는 스포츠, 영화, 음악 등과 같은 다양한 채널을 게시하는 Dish TV이며 누구나 자신의 채널 세트를 구독하고 구독 한 채널을 사용할 수있을 때마다받을 수 있습니다.
다음 표는 인기있는 고 처리량 메시징 시스템 중 일부를 설명합니다.
| 분산 메시징 시스템 | 기술 |
|---|---|
| Apache Kafka | Kafka는 LinkedIn 회사에서 개발되었으며 나중에 Apache의 하위 프로젝트가되었습니다. Apache Kafka는 브로커 지원, 영구 분산 게시-구독 모델을 기반으로합니다. Kafka는 빠르고 확장 가능하며 매우 효율적입니다. |
| RabbitMQ | RabbitMQ는 오픈 소스 분산 형 강력한 메시징 애플리케이션입니다. 사용하기 쉽고 모든 플랫폼에서 실행됩니다. |
| JMS (Java Message Service) | JMS는 한 애플리케이션에서 다른 애플리케이션으로 메시지 작성, 읽기 및 전송을 지원하는 오픈 소스 API입니다. 보장 된 메시지 전달을 제공하고 게시-구독 모델을 따릅니다. |
| ActiveMQ | ActiveMQ 메시징 시스템은 JMS의 오픈 소스 API입니다. |
| ZeroMQ | ZeroMQ는 브로커가없는 피어-피어 메시지 처리입니다. 푸시-풀, 라우터-딜러 메시지 패턴을 제공합니다. |
| 황조롱이 | Kestrel은 빠르고 안정적이며 간단한 분산 메시지 대기열입니다. |
중고품 프로토콜
Thrift는 다국어 서비스 개발 및 RPC (원격 프로 시저 호출)를 위해 Facebook에서 구축되었습니다. 나중에 오픈 소스 Apache 프로젝트가되었습니다. Apache Thrift는Interface Definition Language 정의 된 데이터 유형 위에 새로운 데이터 유형 및 서비스 구현을 쉽게 정의 할 수 있습니다.
Apache Thrift는 또한 임베디드 시스템, 모바일 애플리케이션, 웹 애플리케이션 및 기타 여러 프로그래밍 언어를 지원하는 통신 프레임 워크입니다. Apache Thrift와 관련된 주요 기능 중 일부는 모듈성, 유연성 및 고성능입니다. 또한 분산 응용 프로그램에서 스트리밍, 메시징 및 RPC를 수행 할 수 있습니다.
Storm은 내부 통신 및 데이터 정의를 위해 Thrift 프로토콜을 광범위하게 사용합니다. Storm 토폴로지는 간단합니다.Thrift Structs. Apache Storm에서 토폴로지를 실행하는 Storm Nimbus는Thrift service.
이제 컴퓨터에 Apache Storm 프레임 워크를 설치하는 방법을 살펴 보겠습니다. 여기에는 세 가지 마조 단계가 있습니다.
- 아직 Java가없는 경우 시스템에 Java를 설치하십시오.
- ZooKeeper 프레임 워크를 설치합니다.
- Apache Storm 프레임 워크를 설치합니다.
1 단계-Java 설치 확인
다음 명령을 사용하여 시스템에 Java가 이미 설치되어 있는지 확인하십시오.
$ java -versionJava가 이미있는 경우 버전 번호가 표시됩니다. 그렇지 않으면 최신 버전의 JDK를 다운로드하십시오.
1.1 단계-JDK 다운로드
다음 링크를 사용하여 최신 버전의 JDK를 다운로드하십시오. www.oracle.com
최신 버전은 JDK 8u 60이고 파일은 “jdk-8u60-linux-x64.tar.gz”. 컴퓨터에 파일을 다운로드합니다.
1.2 단계-파일 추출
일반적으로 파일은 downloads폴더. 다음 명령을 사용하여 tar 설정을 추출하십시오.
$ cd /go/to/download/path
$ tar -zxf jdk-8u60-linux-x64.gz1.3 단계-opt 디렉토리로 이동
모든 사용자가 Java를 사용할 수 있도록하려면 추출 된 Java 컨텐츠를 "/ usr / local / java"폴더로 이동하십시오.
$ su
password: (type password of root user)
$ mkdir /opt/jdk $ mv jdk-1.8.0_60 /opt/jdk/1.4 단계-경로 설정
경로 및 JAVA_HOME 변수를 설정하려면 ~ / .bashrc 파일에 다음 명령을 추가하십시오.
export JAVA_HOME =/usr/jdk/jdk-1.8.0_60
export PATH=$PATH:$JAVA_HOME/bin이제 모든 변경 사항을 현재 실행중인 시스템에 적용합니다.
$ source ~/.bashrc1.5 단계-자바 대안
다음 명령을 사용하여 Java 대안을 변경하십시오.
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 1001.6 단계
이제 확인 명령을 사용하여 Java 설치를 확인하십시오. (java -version) 1 단계에서 설명합니다.
2 단계-ZooKeeper 프레임 워크 설치
2.1 단계 − ZooKeeper 다운로드
컴퓨터에 ZooKeeper 프레임 워크를 설치하려면 다음 링크를 방문하여 최신 버전의 ZooKeeper를 다운로드하십시오. http://zookeeper.apache.org/releases.html
현재 ZooKeeper의 최신 버전은 3.4.6 (ZooKeeper-3.4.6.tar.gz)입니다.
2.2 단계-tar 파일 추출
다음 명령을 사용하여 tar 파일을 추출하십시오.
$ cd opt/
$ tar -zxf zookeeper-3.4.6.tar.gz $ cd zookeeper-3.4.6
$ mkdir data2.3 단계-구성 파일 생성
"vi conf / zoo.cfg"명령을 사용하여 "conf / zoo.cfg"라는 구성 파일을 열고 다음 매개 변수를 모두 시작점으로 설정합니다.
$ vi conf/zoo.cfg
tickTime=2000
dataDir=/path/to/zookeeper/data
clientPort=2181
initLimit=5
syncLimit=2구성 파일이 성공적으로 저장되면 ZooKeeper 서버를 시작할 수 있습니다.
2.4 단계-ZooKeeper 서버 시작
다음 명령을 사용하여 ZooKeeper 서버를 시작합니다.
$ bin/zkServer.sh start이 명령을 실행하면 다음과 같은 응답을 받게됩니다.
$ JMX enabled by default
$ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg $ Starting zookeeper ... STARTED2.5 단계-CLI 시작
다음 명령을 사용하여 CLI를 시작하십시오.
$ bin/zkCli.sh위의 명령을 실행하면 ZooKeeper 서버에 연결되고 다음과 같은 응답이 나타납니다.
Connecting to localhost:2181
................
................
................
Welcome to ZooKeeper!
................
................
WATCHER::
WatchedEvent state:SyncConnected type: None path:null
[zk: localhost:2181(CONNECTED) 0]2.6 단계-ZooKeeper 서버 중지
서버를 연결하고 모든 작업을 수행 한 후 다음 명령을 사용하여 ZooKeeper 서버를 중지 할 수 있습니다.
bin/zkServer.sh stop컴퓨터에 Java 및 ZooKeeper를 성공적으로 설치했습니다. 이제 Apache Storm 프레임 워크를 설치하는 단계를 살펴 보겠습니다.
3 단계-Apache Storm Framework 설치
3.1 단계 Storm 다운로드
컴퓨터에 Storm 프레임 워크를 설치하려면 다음 링크를 방문하여 최신 버전의 Storm을 다운로드하십시오. http://storm.apache.org/downloads.html
현재 Storm의 최신 버전은“apache-storm-0.9.5.tar.gz”입니다.
3.2 단계-tar 파일 추출
다음 명령을 사용하여 tar 파일을 추출하십시오.
$ cd opt/
$ tar -zxf apache-storm-0.9.5.tar.gz $ cd apache-storm-0.9.5
$ mkdir data3.3 단계-구성 파일 열기
현재 Storm 릴리스에는 Storm 데몬을 구성하는 "conf / storm.yaml"파일이 있습니다. 해당 파일에 다음 정보를 추가하십시오.
$ vi conf/storm.yaml
storm.zookeeper.servers:
- "localhost"
storm.local.dir: “/path/to/storm/data(any path)”
nimbus.host: "localhost"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703모든 변경 사항을 적용한 후 저장하고 터미널로 돌아갑니다.
3.4 단계-Nimbus 시작
$ bin/storm nimbus3.5 단계-감독자 시작
$ bin/storm supervisor3.6 단계 UI 시작
$ bin/storm uiStorm 사용자 인터페이스 애플리케이션을 시작한 후 URL을 입력하십시오. http://localhost:8080즐겨 찾는 브라우저에서 Storm 클러스터 정보와 실행중인 토폴로지를 볼 수 있습니다. 페이지는 다음 스크린 샷과 유사해야합니다.

Apache Storm의 핵심 기술 세부 사항을 살펴 보았으므로 이제 몇 가지 간단한 시나리오를 코딩 할 차례입니다.
시나리오 – 모바일 통화 로그 분석기
모바일 통화 및 통화 시간은 Apache Storm에 대한 입력으로 제공되며 Storm은 동일한 발신자와 수신자 간의 통화 및 총 통화 수를 처리하고 그룹화합니다.
주둥이 만들기
Spout는 데이터 생성에 사용되는 구성 요소입니다. 기본적으로 스파우트는 IRichSpout 인터페이스를 구현합니다. “IRichSpout”인터페이스에는 다음과 같은 중요한 방법이 있습니다.
open− 스파우트에 실행할 환경을 제공합니다. 실행자는이 메서드를 실행하여 스파우트를 초기화합니다.
nextTuple − 생성 된 데이터를 수집기를 통해 방출합니다.
close −이 메서드는 스파우트가 종료 될 때 호출됩니다.
declareOutputFields − 튜플의 출력 스키마를 선언합니다.
ack − 특정 튜플이 처리되었음을 확인
fail − 특정 튜플이 처리되지 않고 재 처리되지 않도록 지정합니다.
열다
의 서명 open 방법은 다음과 같습니다-
open(Map conf, TopologyContext context, SpoutOutputCollector collector)conf −이 스파우트에 대한 스톰 구성을 제공합니다.
context − 토폴로지 내 스파우트 위치, 작업 ID, 입력 및 출력 정보에 대한 완전한 정보를 제공합니다.
collector − 볼트에 의해 처리 될 튜플을 방출 할 수 있습니다.
nextTuple
의 서명 nextTuple 방법은 다음과 같습니다-
nextTuple()nextTuple ()은 ack () 및 fail () 메서드와 동일한 루프에서 주기적으로 호출됩니다. 수행 할 작업이 없을 때 스레드의 제어를 해제해야 다른 메서드가 호출 될 수 있습니다. 따라서 nextTuple의 첫 번째 줄은 처리가 완료되었는지 확인합니다. 그렇다면 반환하기 전에 프로세서의 부하를 줄이기 위해 최소 1 밀리 초 동안 절전 모드를 유지해야합니다.
닫기
의 서명 close 방법은 다음과 같습니다-
close()declareOutputFields
의 서명 declareOutputFields 방법은 다음과 같습니다-
declareOutputFields(OutputFieldsDeclarer declarer)declarer − 출력 스트림 ID, 출력 필드 등을 선언하는 데 사용됩니다.
이 메서드는 튜플의 출력 스키마를 지정하는 데 사용됩니다.
확인
의 서명 ack 방법은 다음과 같습니다-
ack(Object msgId)이 메서드는 특정 튜플이 처리되었음을 확인합니다.
불합격
의 서명 nextTuple 방법은 다음과 같습니다-
ack(Object msgId)이 메서드는 특정 튜플이 완전히 처리되지 않았 음을 알려줍니다. Storm은 특정 튜플을 다시 처리합니다.
FakeCallLogReaderSpout
이 시나리오에서는 통화 기록 세부 정보를 수집해야합니다. 통화 기록의 정보가 포함됩니다.
- 발신자 번호
- 수신자 번호
- duration
실시간 통화 기록 정보가 없기 때문에 가짜 통화 기록을 생성합니다. 가짜 정보는 Random 클래스를 사용하여 생성됩니다. 전체 프로그램 코드는 다음과 같습니다.
코딩-FakeCallLogReaderSpout.java
import java.util.*;
//import storm tuple packages
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
//import Spout interface packages
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
//Create a class FakeLogReaderSpout which implement IRichSpout interface
to access functionalities
public class FakeCallLogReaderSpout implements IRichSpout {
//Create instance for SpoutOutputCollector which passes tuples to bolt.
private SpoutOutputCollector collector;
private boolean completed = false;
//Create instance for TopologyContext which contains topology data.
private TopologyContext context;
//Create instance for Random class.
private Random randomGenerator = new Random();
private Integer idx = 0;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
if(this.idx <= 1000) {
List<String> mobileNumbers = new ArrayList<String>();
mobileNumbers.add("1234123401");
mobileNumbers.add("1234123402");
mobileNumbers.add("1234123403");
mobileNumbers.add("1234123404");
Integer localIdx = 0;
while(localIdx++ < 100 && this.idx++ < 1000) {
String fromMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
String toMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
while(fromMobileNumber == toMobileNumber) {
toMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
}
Integer duration = randomGenerator.nextInt(60);
this.collector.emit(new Values(fromMobileNumber, toMobileNumber, duration));
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("from", "to", "duration"));
}
//Override all the interface methods
@Override
public void close() {}
public boolean isDistributed() {
return false;
}
@Override
public void activate() {}
@Override
public void deactivate() {}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}볼트 생성
Bolt는 튜플을 입력으로 사용하고 튜플을 처리하고 새 튜플을 출력으로 생성하는 구성 요소입니다. 볼트는IRichBolt상호 작용. 이 프로그램에서 두 개의 볼트 클래스CallLogCreatorBolt 과 CallLogCounterBolt 작업을 수행하는 데 사용됩니다.
IRichBolt 인터페이스에는 다음과 같은 방법이 있습니다.
prepare− 볼트에 실행할 환경을 제공합니다. 실행자는이 메서드를 실행하여 스파우트를 초기화합니다.
execute − 단일 튜플 입력을 처리합니다.
cleanup − 볼트가 셧다운 될 때 호출됩니다.
declareOutputFields − 튜플의 출력 스키마를 선언합니다.
준비
의 서명 prepare 방법은 다음과 같습니다-
prepare(Map conf, TopologyContext context, OutputCollector collector)conf −이 볼트에 대한 Storm 구성을 제공합니다.
context − 토폴로지 내 볼트 위치, 작업 ID, 입력 및 출력 정보 등에 대한 완전한 정보를 제공합니다.
collector − 처리 된 튜플을 방출 할 수 있습니다.
실행하다
의 서명 execute 방법은 다음과 같습니다-
execute(Tuple tuple)여기 tuple 처리 할 입력 튜플입니다.
그만큼 execute메서드는 한 번에 하나의 튜플을 처리합니다. 튜플 데이터는 Tuple 클래스의 getValue 메서드를 통해 액세스 할 수 있습니다. 입력 튜플을 즉시 처리 할 필요는 없습니다. 여러 튜플을 처리하고 단일 출력 튜플로 출력 할 수 있습니다. 처리 된 튜플은 OutputCollector 클래스를 사용하여 내보낼 수 있습니다.
대청소
의 서명 cleanup 방법은 다음과 같습니다-
cleanup()declareOutputFields
의 서명 declareOutputFields 방법은 다음과 같습니다-
declareOutputFields(OutputFieldsDeclarer declarer)여기에 매개 변수 declarer 출력 스트림 ID, 출력 필드 등을 선언하는 데 사용됩니다.
이 메서드는 튜플의 출력 스키마를 지정하는 데 사용됩니다.
콜 로그 Creator Bolt
콜 로그 생성자 볼트는 콜 로그 튜플을 수신합니다. 통화 기록 튜플에는 발신자 번호, 수신자 번호 및 통화 시간이 있습니다. 이 볼트는 단순히 발신자 번호와 수신자 번호를 결합하여 새로운 값을 생성합니다. 새 값의 형식은 "발신자 번호 – 수신자 번호"이며 새 필드 "통화"로 이름이 지정됩니다. 전체 코드는 다음과 같습니다.
코딩-CallLogCreatorBolt.java
//import util packages
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
//import Storm IRichBolt package
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
//Create a class CallLogCreatorBolt which implement IRichBolt interface
public class CallLogCreatorBolt implements IRichBolt {
//Create instance for OutputCollector which collects and emits tuples to produce output
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String from = tuple.getString(0);
String to = tuple.getString(1);
Integer duration = tuple.getInteger(2);
collector.emit(new Values(from + " - " + to, duration));
}
@Override
public void cleanup() {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("call", "duration"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}콜 로그 카운터 볼트
콜 로그 카운터 볼트는 콜과 그 기간을 튜플로받습니다. 이 볼트는 prepare 메소드에서 사전 (Map) 객체를 초기화합니다. 에execute메소드는 튜플을 확인하고 튜플의 모든 새로운 "호출"값에 대해 사전 객체에 새 항목을 만들고 사전 객체에 값 1을 설정합니다. 사전에서 이미 사용 가능한 항목의 경우 값을 증가시킵니다. 간단히 말해서,이 볼트는 사전 개체에 호출 및 해당 개수를 저장합니다. 사전에 호출 및 해당 개수를 저장하는 대신 데이터 소스에 저장할 수도 있습니다. 전체 프로그램 코드는 다음과 같습니다.
코딩-CallLogCounterBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class CallLogCounterBolt implements IRichBolt {
Map<String, Integer> counterMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.counterMap = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String call = tuple.getString(0);
Integer duration = tuple.getInteger(1);
if(!counterMap.containsKey(call)){
counterMap.put(call, 1);
}else{
Integer c = counterMap.get(call) + 1;
counterMap.put(call, c);
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counterMap.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("call"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}토폴로지 생성
Storm 토폴로지는 기본적으로 Thrift 구조입니다. TopologyBuilder 클래스는 복잡한 토폴로지를 만드는 간단하고 쉬운 방법을 제공합니다. TopologyBuilder 클래스에는 스파우트를 설정하는 메서드가 있습니다.(setSpout) 볼트를 설정하려면 (setBolt). 마지막으로 TopologyBuilder에는 토폴로지를 생성하는 createTopology가 있습니다. 다음 코드 조각을 사용하여 토폴로지를 만듭니다.
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("call-log-reader-spout", new FakeCallLogReaderSpout());
builder.setBolt("call-log-creator-bolt", new CallLogCreatorBolt())
.shuffleGrouping("call-log-reader-spout");
builder.setBolt("call-log-counter-bolt", new CallLogCounterBolt())
.fieldsGrouping("call-log-creator-bolt", new Fields("call"));shuffleGrouping 과 fieldsGrouping 메서드는 주둥이와 볼트에 대한 스트림 그룹화를 설정하는 데 도움이됩니다.
로컬 클러스터
개발 목적으로 "LocalCluster"개체를 사용하여 로컬 클러스터를 만든 다음 "LocalCluster"클래스의 "submitTopology"메서드를 사용하여 토폴로지를 제출할 수 있습니다. "submitTopology"에 대한 인수 중 하나는 "Config"클래스의 인스턴스입니다. "Config"클래스는 토폴로지를 제출하기 전에 구성 옵션을 설정하는 데 사용됩니다. 이 구성 옵션은 런타임에 클러스터 구성과 병합되고 준비 방법을 사용하여 모든 작업 (spout 및 bolt)으로 전송됩니다. 토폴로지가 클러스터에 제출되면 클러스터가 제출 된 토폴로지를 계산할 때까지 10 초간 기다린 다음 "LocalCluster"의 "종료"방법을 사용하여 클러스터를 종료합니다. 전체 프로그램 코드는 다음과 같습니다.
코딩-LogAnalyserStorm.java
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
//import storm configuration packages
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
//Create main class LogAnalyserStorm submit topology.
public class LogAnalyserStorm {
public static void main(String[] args) throws Exception{
//Create Config instance for cluster configuration
Config config = new Config();
config.setDebug(true);
//
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("call-log-reader-spout", new FakeCallLogReaderSpout());
builder.setBolt("call-log-creator-bolt", new CallLogCreatorBolt())
.shuffleGrouping("call-log-reader-spout");
builder.setBolt("call-log-counter-bolt", new CallLogCounterBolt())
.fieldsGrouping("call-log-creator-bolt", new Fields("call"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LogAnalyserStorm", config, builder.createTopology());
Thread.sleep(10000);
//Stop the topology
cluster.shutdown();
}
}응용 프로그램 빌드 및 실행
완전한 애플리케이션에는 4 개의 Java 코드가 있습니다. 그들은-
- FakeCallLogReaderSpout.java
- CallLogCreaterBolt.java
- CallLogCounterBolt.java
- LogAnalyerStorm.java
응용 프로그램은 다음 명령을 사용하여 구축 할 수 있습니다-
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*” *.java응용 프로그램은 다음 명령을 사용하여 실행할 수 있습니다-
java -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:. LogAnalyserStorm산출
응용 프로그램이 시작되면 클러스터 시작 프로세스, 스파우트 및 볼트 처리, 마지막으로 클러스터 종료 프로세스에 대한 전체 세부 정보가 출력됩니다. "CallLogCounterBolt"에서 호출 및 카운트 세부 정보를 인쇄했습니다. 이 정보는 다음과 같이 콘솔에 표시됩니다.
1234123402 - 1234123401 : 78
1234123402 - 1234123404 : 88
1234123402 - 1234123403 : 105
1234123401 - 1234123404 : 74
1234123401 - 1234123403 : 81
1234123401 - 1234123402 : 81
1234123403 - 1234123404 : 86
1234123404 - 1234123401 : 63
1234123404 - 1234123402 : 82
1234123403 - 1234123402 : 83
1234123404 - 1234123403 : 86
1234123403 - 1234123401 : 93비 JVM 언어
Storm 토폴로지는 Thrift 인터페이스로 구현되어 모든 언어로 토폴로지를 쉽게 제출할 수 있습니다. Storm은 Ruby, Python 및 기타 여러 언어를 지원합니다. 파이썬 바인딩을 살펴 보겠습니다.
파이썬 바인딩
Python은 범용 해석, 대화 형, 객체 지향 및 고급 프로그래밍 언어입니다. Storm은 Python을 지원하여 토폴로지를 구현합니다. Python은 방출, 고정, 접근 및 로깅 작업을 지원합니다.
아시다시피 볼트는 모든 언어로 정의 할 수 있습니다. 다른 언어로 작성된 Bolt는 하위 프로세스로 실행되고 Storm은 stdin / stdout을 통해 JSON 메시지를 사용하여 해당 하위 프로세스와 통신합니다. 먼저 파이썬 바인딩을 지원하는 샘플 볼트 WordCount를 가져옵니다.
public static class WordCount implements IRichBolt {
public WordSplit() {
super("python", "splitword.py");
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}여기 수업 WordCount 구현 IRichBolt인터페이스 및 파이썬 구현에 지정된 수퍼 메소드 인수 "splitword.py"로 실행됩니다. 이제 "splitword.py"라는 파이썬 구현을 만듭니다.
import storm
class WordCountBolt(storm.BasicBolt):
def process(self, tup):
words = tup.values[0].split(" ")
for word in words:
storm.emit([word])
WordCountBolt().run()이것은 주어진 문장에서 단어를 세는 Python의 샘플 구현입니다. 마찬가지로 다른 지원 언어와도 바인딩 할 수 있습니다.
Trident는 Storm의 확장입니다. Storm과 마찬가지로 Trident도 Twitter에서 개발했습니다. Trident를 개발하는 주된 이유는 상태 저장 스트림 처리 및 낮은 대기 시간 분산 쿼리와 함께 Storm 위에 높은 수준의 추상화를 제공하는 것입니다.
Trident는 주둥이와 볼트를 사용하지만 이러한 하위 수준 구성 요소는 실행 전에 Trident에 의해 자동 생성됩니다. Trident에는 함수, 필터, 조인, 그룹화 및 집계가 있습니다.
Trident는 스트림을 트랜잭션이라고하는 일련의 배치로 처리합니다. 일반적으로 이러한 작은 배치의 크기는 입력 스트림에 따라 수천 또는 수백만 개의 튜플 정도입니다. 이런 식으로 Trident는 튜플 단위 처리를 수행하는 Storm과 다릅니다.
일괄 처리 개념은 데이터베이스 트랜잭션과 매우 유사합니다. 모든 거래에는 거래 ID가 할당됩니다. 모든 처리가 완료되면 트랜잭션이 성공한 것으로 간주됩니다. 그러나 트랜잭션의 튜플 중 하나를 처리하는 데 실패하면 전체 트랜잭션이 다시 전송됩니다. 각 배치에 대해 Trident는 트랜잭션이 시작될 때 beginCommit을 호출하고 트랜잭션이 끝날 때 커밋합니다.
트라이던트 토폴로지
Trident API는 "TridentTopology"클래스를 사용하여 Trident 토폴로지를 만드는 쉬운 옵션을 제공합니다. 기본적으로 Trident 토폴로지는 spout에서 입력 스트림을 수신하고 스트림에서 순서가 지정된 작업 순서 (필터, 집계, 그룹화 등)를 수행합니다. Storm Tuple은 Trident Tuple로 대체되고 Bolts는 작업으로 대체됩니다. 간단한 Trident 토폴로지는 다음과 같이 만들 수 있습니다.
TridentTopology topology = new TridentTopology();트라이던트 튜플
Trident 튜플은 명명 된 값 목록입니다. TridentTuple 인터페이스는 Trident 토폴로지의 데이터 모델입니다. TridentTuple 인터페이스는 Trident 토폴로지에서 처리 할 수있는 데이터의 기본 단위입니다.
트라이던트 스파우트
트라이던트 스파우트는 스톰 스파우트와 유사하며 트라이던트의 기능을 사용할 수있는 추가 옵션이 있습니다. 실제로 우리는 Storm 토폴로지에서 사용한 IRichSpout을 계속 사용할 수 있지만 본질적으로 트랜잭션이 아니며 Trident가 제공하는 이점을 사용할 수 없습니다.
Trident의 기능을 사용하기위한 모든 기능을 갖춘 기본 스파우트는 "ITridentSpout"입니다. 트랜잭션 및 불투명 트랜잭션 의미를 모두 지원합니다. 다른 스파우트는 IBatchSpout, IPartitionedTridentSpout 및 IOpaquePartitionedTridentSpout입니다.
이러한 일반 스파우트 외에도 Trident에는 트라이던트 스파우트의 많은 샘플 구현이 있습니다. 그중 하나는 FeederBatchSpout spout로, 일괄 처리, 병렬 처리 등에 대한 걱정없이 쉽게 트라이던트 튜플 목록을 보내는 데 사용할 수 있습니다.
FeederBatchSpout 생성 및 데이터 공급은 다음과 같이 수행 할 수 있습니다.
TridentTopology topology = new TridentTopology();
FeederBatchSpout testSpout = new FeederBatchSpout(
ImmutableList.of("fromMobileNumber", "toMobileNumber", “duration”));
topology.newStream("fixed-batch-spout", testSpout)
testSpout.feed(ImmutableList.of(new Values("1234123401", "1234123402", 20)));트라이던트 작업
Trident는“Trident Operation”에 의존하여 삼지창 튜플의 입력 스트림을 처리합니다. Trident API에는 간단하고 복잡한 스트림 처리를 처리하기위한 여러 가지 내장 작업이 있습니다. 이러한 작업은 간단한 유효성 검사에서 복잡한 그룹화 및 트라이던트 튜플 집계에 이르기까지 다양합니다. 가장 중요하고 자주 사용되는 작업을 살펴 보겠습니다.
필터
필터는 입력 유효성 검사 작업을 수행하는 데 사용되는 개체입니다. 트라이던트 필터는 트라이던트 튜플 필드의 하위 집합을 입력으로 가져오고 특정 조건이 충족되는지 여부에 따라 true 또는 false를 반환합니다. true가 반환되면 튜플은 출력 스트림에 유지됩니다. 그렇지 않으면 튜플이 스트림에서 제거됩니다. 필터는 기본적으로BaseFilter 클래스 및 구현 isKeep방법. 다음은 필터 연산의 샘플 구현입니다.
public class MyFilter extends BaseFilter {
public boolean isKeep(TridentTuple tuple) {
return tuple.getInteger(1) % 2 == 0;
}
}
input
[1, 2]
[1, 3]
[1, 4]
output
[1, 2]
[1, 4]필터 기능은 "각"방법을 사용하여 토폴로지에서 호출 할 수 있습니다. "Fields"클래스는 입력 (삼지창 튜플의 하위 집합)을 지정하는 데 사용할 수 있습니다. 샘플 코드는 다음과 같습니다.
TridentTopology topology = new TridentTopology();
topology.newStream("spout", spout)
.each(new Fields("a", "b"), new MyFilter())함수
Function단일 트라이던트 튜플에 대해 간단한 작업을 수행하는 데 사용되는 객체입니다. 트라이던트 튜플 필드의 하위 집합을 취하고 0 개 이상의 새로운 트라이던트 튜플 필드를 내 보냅니다.
Function 기본적으로 BaseFunction 클래스 및 구현 execute방법. 샘플 구현은 다음과 같습니다.
public class MyFunction extends BaseFunction {
public void execute(TridentTuple tuple, TridentCollector collector) {
int a = tuple.getInteger(0);
int b = tuple.getInteger(1);
collector.emit(new Values(a + b));
}
}
input
[1, 2]
[1, 3]
[1, 4]
output
[1, 2, 3]
[1, 3, 4]
[1, 4, 5]필터 연산과 마찬가지로 기능 연산은 다음을 사용하여 토폴로지에서 호출 할 수 있습니다. each방법. 샘플 코드는 다음과 같습니다.
TridentTopology topology = new TridentTopology();
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d")));집합
집계는 입력 배치, 파티션 또는 스트림에서 집계 작업을 수행하는 데 사용되는 개체입니다. Trident에는 세 가지 유형의 집계가 있습니다. 그들은 다음과 같습니다-
aggregate− 트라이던트 튜플의 각 배치를 분리하여 집계합니다. 집계 프로세스 중에 튜플은 처음에 전역 그룹화를 사용하여 다시 분할되어 동일한 일괄 처리의 모든 파티션을 단일 파티션으로 결합합니다.
partitionAggregate− 트라이던트 튜플의 전체 배치 대신 각 파티션을 집계합니다. 파티션 집계의 출력은 입력 튜플을 완전히 대체합니다. 파티션 집계의 출력에는 단일 필드 튜플이 포함됩니다.
persistentaggregate − 모든 배치에 걸쳐 모든 트라이던트 튜플을 집계하고 그 결과를 메모리 또는 데이터베이스에 저장합니다.
TridentTopology topology = new TridentTopology();
// aggregate operation
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.aggregate(new Count(), new Fields(“count”))
// partitionAggregate operation
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.partitionAggregate(new Count(), new Fields(“count"))
// persistentAggregate - saving the count to memory
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));CombinerAggregator, ReducerAggregator 또는 일반 Aggregator 인터페이스를 사용하여 집계 작업을 생성 할 수 있습니다. 위의 예에서 사용 된 "count"어 그리 게이터는 빌트인 어 그리 게이터 중 하나이며 "CombinerAggregator"를 사용하여 구현됩니다. 구현은 다음과 같습니다.
public class Count implements CombinerAggregator<Long> {
@Override
public Long init(TridentTuple tuple) {
return 1L;
}
@Override
public Long combine(Long val1, Long val2) {
return val1 + val2;
}
@Override
public Long zero() {
return 0L;
}
}그룹화
그룹화 작업은 내장 된 작업이며 groupBy방법. groupBy 메서드는 지정된 필드에서 partitionBy를 수행하여 스트림을 다시 분할 한 다음 각 파티션 내에서 그룹 필드가 동일한 튜플을 함께 그룹화합니다. 일반적으로 그룹화 된 집계를 가져 오기 위해 "persistentAggregate"와 함께 "groupBy"를 사용합니다. 샘플 코드는 다음과 같습니다.
TridentTopology topology = new TridentTopology();
// persistentAggregate - saving the count to memory
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.groupBy(new Fields(“d”)
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));병합 및 결합
병합 및 결합은 각각 "병합"및 "결합"방법을 사용하여 수행 할 수 있습니다. 병합은 하나 이상의 스트림을 결합합니다. 조인은 두 스트림을 확인하고 조인하기 위해 양쪽에서 트라이던트 튜플 필드를 사용한다는 점을 제외하면 병합과 유사합니다. 또한 결합은 배치 수준에서만 작동합니다. 샘플 코드는 다음과 같습니다.
TridentTopology topology = new TridentTopology();
topology.merge(stream1, stream2, stream3);
topology.join(stream1, new Fields("key"), stream2, new Fields("x"),
new Fields("key", "a", "b", "c"));상태 유지
Trident는 상태 유지를위한 메커니즘을 제공합니다. 상태 정보는 토폴로지 자체에 저장 될 수 있습니다. 그렇지 않으면 별도의 데이터베이스에도 저장할 수 있습니다. 그 이유는 처리 중에 튜플이 실패하면 실패한 튜플을 다시 시도하는 상태를 유지하기 위함입니다. 이 튜플의 상태가 이전에 업데이트되었는지 여부가 확실하지 않기 때문에 상태를 업데이트하는 동안 문제가 발생합니다. 상태를 업데이트하기 전에 튜플이 실패한 경우 튜플을 다시 시도하면 상태가 안정됩니다. 그러나 상태를 업데이트 한 후 튜플이 실패한 경우 동일한 튜플을 다시 시도하면 데이터베이스의 개수가 다시 증가하고 상태가 불안정 해집니다. 메시지가 한 번만 처리되도록하려면 다음 단계를 수행해야합니다.
작은 배치로 튜플을 처리합니다.
각 배치에 고유 한 ID를 할당합니다. 일괄 처리를 다시 시도하면 동일한 고유 ID가 부여됩니다.
상태 업데이트는 배치간에 정렬됩니다. 예를 들어 두 번째 배치의 상태 업데이트는 첫 번째 배치의 상태 업데이트가 완료 될 때까지 가능하지 않습니다.
분산 RPC
분산 RPC는 Trident 토폴로지에서 결과를 쿼리하고 검색하는 데 사용됩니다. Storm에는 내장 된 분산 RPC 서버가 있습니다. 분산 RPC 서버는 클라이언트로부터 RPC 요청을 수신하여 토폴로지에 전달합니다. 토폴로지는 요청을 처리하고 결과를 분산 RPC 서버로 전송하며, 분산 RPC 서버는 분산 RPC 서버에서 클라이언트로 리디렉션합니다. Trident의 분산 RPC 쿼리는 이러한 쿼리가 병렬로 실행된다는 사실을 제외하고는 일반 RPC 쿼리처럼 실행됩니다.
Trident는 언제 사용합니까?
많은 사용 사례에서와 같이 쿼리를 한 번만 처리해야하는 경우 Trident에서 토폴로지를 작성하여이를 달성 할 수 있습니다. 반면에 Storm의 경우 정확히 한 번 처리하는 것은 어려울 것입니다. 따라서 Trident는 정확히 한 번 처리해야하는 사용 사례에 유용합니다. Trident는 Storm에 복잡성을 추가하고 상태를 관리하기 때문에 모든 사용 사례, 특히 고성능 사용 사례를위한 것은 아닙니다.
Trident의 작동 예
이전 섹션에서 작업 한 콜 로그 분석기 애플리케이션을 Trident 프레임 워크로 변환 할 것입니다. Trident 응용 프로그램은 높은 수준의 API 덕분에 일반 폭풍에 비해 상대적으로 쉽습니다. Storm은 기본적으로 Trident에서 Function, Filter, Aggregate, GroupBy, Join 및 Merge 작업 중 하나를 수행하는 데 필요합니다. 마지막으로 다음을 사용하여 DRPC 서버를 시작합니다.LocalDRPC 클래스를 사용하여 키워드를 검색하고 execute LocalDRPC 클래스의 메서드.
통화 정보 포맷
FormatCall 클래스의 목적은 "발신자 번호"와 "수신자 번호"로 구성된 통화 정보의 형식을 지정하는 것입니다. 전체 프로그램 코드는 다음과 같습니다.
코딩 : FormatCall.java
import backtype.storm.tuple.Values;
import storm.trident.operation.BaseFunction;
import storm.trident.operation.TridentCollector;
import storm.trident.tuple.TridentTuple;
public class FormatCall extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
String fromMobileNumber = tuple.getString(0);
String toMobileNumber = tuple.getString(1);
collector.emit(new Values(fromMobileNumber + " - " + toMobileNumber));
}
}CSVSplit
CSVSplit 클래스의 목적은 "쉼표 (,)"를 기준으로 입력 문자열을 분할하고 문자열의 모든 단어를 내보내는 것입니다. 이 함수는 분산 쿼리의 입력 인수를 구문 분석하는 데 사용됩니다. 완전한 코드는 다음과 같습니다.
코딩 : CSVSplit.java
import backtype.storm.tuple.Values;
import storm.trident.operation.BaseFunction;
import storm.trident.operation.TridentCollector;
import storm.trident.tuple.TridentTuple;
public class CSVSplit extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
for(String word: tuple.getString(0).split(",")) {
if(word.length() > 0) {
collector.emit(new Values(word));
}
}
}
}로그 분석기
이것이 주요 응용 프로그램입니다. 처음에 응용 프로그램은 TridentTopology를 초기화하고 다음을 사용하여 발신자 정보를 제공합니다.FeederBatchSpout. Trident 토폴로지 스트림은newStreamTridentTopology 클래스의 메서드. 마찬가지로 Trident 토폴로지 DRPC 스트림은newDRCPStreamTridentTopology 클래스의 메서드. LocalDRPC 클래스를 사용하여 간단한 DRCP 서버를 만들 수 있습니다.LocalDRPC일부 키워드를 검색하는 실행 메소드가 있습니다. 전체 코드는 다음과 같습니다.
코딩 : LogAnalyserTrident.java
import java.util.*;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.LocalDRPC;
import backtype.storm.utils.DRPCClient;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import storm.trident.TridentState;
import storm.trident.TridentTopology;
import storm.trident.tuple.TridentTuple;
import storm.trident.operation.builtin.FilterNull;
import storm.trident.operation.builtin.Count;
import storm.trident.operation.builtin.Sum;
import storm.trident.operation.builtin.MapGet;
import storm.trident.operation.builtin.Debug;
import storm.trident.operation.BaseFilter;
import storm.trident.testing.FixedBatchSpout;
import storm.trident.testing.FeederBatchSpout;
import storm.trident.testing.Split;
import storm.trident.testing.MemoryMapState;
import com.google.common.collect.ImmutableList;
public class LogAnalyserTrident {
public static void main(String[] args) throws Exception {
System.out.println("Log Analyser Trident");
TridentTopology topology = new TridentTopology();
FeederBatchSpout testSpout = new FeederBatchSpout(ImmutableList.of("fromMobileNumber",
"toMobileNumber", "duration"));
TridentState callCounts = topology
.newStream("fixed-batch-spout", testSpout)
.each(new Fields("fromMobileNumber", "toMobileNumber"),
new FormatCall(), new Fields("call"))
.groupBy(new Fields("call"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(),
new Fields("count"));
LocalDRPC drpc = new LocalDRPC();
topology.newDRPCStream("call_count", drpc)
.stateQuery(callCounts, new Fields("args"), new MapGet(), new Fields("count"));
topology.newDRPCStream("multiple_call_count", drpc)
.each(new Fields("args"), new CSVSplit(), new Fields("call"))
.groupBy(new Fields("call"))
.stateQuery(callCounts, new Fields("call"), new MapGet(),
new Fields("count"))
.each(new Fields("call", "count"), new Debug())
.each(new Fields("count"), new FilterNull())
.aggregate(new Fields("count"), new Sum(), new Fields("sum"));
Config conf = new Config();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("trident", conf, topology.build());
Random randomGenerator = new Random();
int idx = 0;
while(idx < 10) {
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123402", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123403", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123404", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123402",
"1234123403", randomGenerator.nextInt(60))));
idx = idx + 1;
}
System.out.println("DRPC : Query starts");
System.out.println(drpc.execute("call_count","1234123401 - 1234123402"));
System.out.println(drpc.execute("multiple_call_count", "1234123401 -
1234123402,1234123401 - 1234123403"));
System.out.println("DRPC : Query ends");
cluster.shutdown();
drpc.shutdown();
// DRPCClient client = new DRPCClient("drpc.server.location", 3772);
}
}응용 프로그램 빌드 및 실행
완전한 애플리케이션에는 세 개의 Java 코드가 있습니다. 그들은 다음과 같습니다-
- FormatCall.java
- CSVSplit.java
- LogAnalyerTrident.java
응용 프로그램은 다음 명령을 사용하여 구축 할 수 있습니다-
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*” *.java응용 프로그램은 다음 명령을 사용하여 실행할 수 있습니다-
java -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:. LogAnalyserTrident산출
응용 프로그램이 시작되면 응용 프로그램은 클러스터 시작 프로세스, 작업 처리, DRPC 서버 및 클라이언트 정보, 마지막으로 클러스터 종료 프로세스에 대한 전체 세부 정보를 출력합니다. 이 출력은 아래와 같이 콘솔에 표시됩니다.
DRPC : Query starts
[["1234123401 - 1234123402",10]]
DEBUG: [1234123401 - 1234123402, 10]
DEBUG: [1234123401 - 1234123403, 10]
[[20]]
DRPC : Query ends이 장에서는 Apache Storm의 실시간 애플리케이션에 대해 설명합니다. Twitter에서 Storm이 어떻게 사용되는지 살펴 보겠습니다.
트위터
Twitter는 사용자 트윗을주고받을 수있는 플랫폼을 제공하는 온라인 소셜 네트워킹 서비스입니다. 등록 된 사용자는 트윗을 읽고 게시 할 수 있지만 등록되지 않은 사용자는 트윗을 읽을 수만 있습니다. 해시 태그는 관련 키워드 앞에 #을 추가하여 키워드별로 트윗을 분류하는 데 사용됩니다. 이제 주제별로 가장 많이 사용되는 해시 태그를 찾는 실시간 시나리오를 살펴 보겠습니다.
주둥이 만들기
spout의 목적은 가능한 한 빨리 사람들이 제출 한 트윗을 얻는 것입니다. 트위터는 사람들이 제출 한 트윗을 실시간으로 검색 할 수있는 웹 서비스 기반 도구 인 "Twitter Streaming API"를 제공합니다. Twitter Streaming API는 모든 프로그래밍 언어로 액세스 할 수 있습니다.
twitter4j Twitter Streaming API에 쉽게 액세스 할 수있는 Java 기반 모듈을 제공하는 오픈 소스 비공식 Java 라이브러리입니다. twitter4j트윗에 액세스 할 수있는 리스너 기반 프레임 워크를 제공합니다. Twitter Streaming API에 액세스하려면 Twitter 개발자 계정에 로그인해야하며 다음 OAuth 인증 세부 정보를 가져와야합니다.
- Customerkey
- CustomerSecret
- AccessToken
- AccessTookenSecret
Storm은 트위터 스파우트를 제공합니다. TwitterSampleSpout,시작 키트에서. 우리는 그것을 사용하여 트윗을 검색 할 것입니다. 스파우트에는 OAuth 인증 세부 정보와 최소한 키워드가 필요합니다. 스파우트는 키워드를 기반으로 실시간 트윗을 내 보냅니다. 전체 프로그램 코드는 다음과 같습니다.
코딩 : TwitterSampleSpout.java
import java.util.Map;
import java.util.concurrent.LinkedBlockingQueue;
import twitter4j.FilterQuery;
import twitter4j.StallWarning;
import twitter4j.Status;
import twitter4j.StatusDeletionNotice;
import twitter4j.StatusListener;
import twitter4j.TwitterStream;
import twitter4j.TwitterStreamFactory;
import twitter4j.auth.AccessToken;
import twitter4j.conf.ConfigurationBuilder;
import backtype.storm.Config;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
@SuppressWarnings("serial")
public class TwitterSampleSpout extends BaseRichSpout {
SpoutOutputCollector _collector;
LinkedBlockingQueue<Status> queue = null;
TwitterStream _twitterStream;
String consumerKey;
String consumerSecret;
String accessToken;
String accessTokenSecret;
String[] keyWords;
public TwitterSampleSpout(String consumerKey, String consumerSecret,
String accessToken, String accessTokenSecret, String[] keyWords) {
this.consumerKey = consumerKey;
this.consumerSecret = consumerSecret;
this.accessToken = accessToken;
this.accessTokenSecret = accessTokenSecret;
this.keyWords = keyWords;
}
public TwitterSampleSpout() {
// TODO Auto-generated constructor stub
}
@Override
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
queue = new LinkedBlockingQueue<Status>(1000);
_collector = collector;
StatusListener listener = new StatusListener() {
@Override
public void onStatus(Status status) {
queue.offer(status);
}
@Override
public void onDeletionNotice(StatusDeletionNotice sdn) {}
@Override
public void onTrackLimitationNotice(int i) {}
@Override
public void onScrubGeo(long l, long l1) {}
@Override
public void onException(Exception ex) {}
@Override
public void onStallWarning(StallWarning arg0) {
// TODO Auto-generated method stub
}
};
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setDebugEnabled(true)
.setOAuthConsumerKey(consumerKey)
.setOAuthConsumerSecret(consumerSecret)
.setOAuthAccessToken(accessToken)
.setOAuthAccessTokenSecret(accessTokenSecret);
_twitterStream = new TwitterStreamFactory(cb.build()).getInstance();
_twitterStream.addListener(listener);
if (keyWords.length == 0) {
_twitterStream.sample();
}else {
FilterQuery query = new FilterQuery().track(keyWords);
_twitterStream.filter(query);
}
}
@Override
public void nextTuple() {
Status ret = queue.poll();
if (ret == null) {
Utils.sleep(50);
} else {
_collector.emit(new Values(ret));
}
}
@Override
public void close() {
_twitterStream.shutdown();
}
@Override
public Map<String, Object> getComponentConfiguration() {
Config ret = new Config();
ret.setMaxTaskParallelism(1);
return ret;
}
@Override
public void ack(Object id) {}
@Override
public void fail(Object id) {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("tweet"));
}
}해시 태그 리더 볼트
spout에서 내 보낸 트윗은 다음으로 전달됩니다. HashtagReaderBolt, 트윗을 처리하고 사용 가능한 모든 해시 태그를 내 보냅니다. HashtagReaderBolt 사용getHashTagEntitiestwitter4j에서 제공하는 메소드입니다. getHashTagEntities는 트윗을 읽고 해시 태그 목록을 반환합니다. 전체 프로그램 코드는 다음과 같습니다.
코딩 : HashtagReaderBolt.java
import java.util.HashMap;
import java.util.Map;
import twitter4j.*;
import twitter4j.conf.*;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class HashtagReaderBolt implements IRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
Status tweet = (Status) tuple.getValueByField("tweet");
for(HashtagEntity hashtage : tweet.getHashtagEntities()) {
System.out.println("Hashtag: " + hashtage.getText());
this.collector.emit(new Values(hashtage.getText()));
}
}
@Override
public void cleanup() {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("hashtag"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}해시 태그 카운터 볼트
내 보낸 해시 태그는 HashtagCounterBolt. 이 볼트는 모든 해시 태그를 처리하고 Java Map 객체를 사용하여 각 해시 태그와 해당 개수를 메모리에 저장합니다. 전체 프로그램 코드는 다음과 같습니다.
코딩 : HashtagCounterBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class HashtagCounterBolt implements IRichBolt {
Map<String, Integer> counterMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.counterMap = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String key = tuple.getString(0);
if(!counterMap.containsKey(key)){
counterMap.put(key, 1);
}else{
Integer c = counterMap.get(key) + 1;
counterMap.put(key, c);
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counterMap.entrySet()){
System.out.println("Result: " + entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("hashtag"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}토폴로지 제출
토폴로지 제출이 주요 응용 프로그램입니다. Twitter 토폴로지는 다음으로 구성됩니다.TwitterSampleSpout, HashtagReaderBolt, 및 HashtagCounterBolt. 다음 프로그램 코드는 토폴로지를 제출하는 방법을 보여줍니다.
코딩 : TwitterHashtagStorm.java
import java.util.*;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
public class TwitterHashtagStorm {
public static void main(String[] args) throws Exception{
String consumerKey = args[0];
String consumerSecret = args[1];
String accessToken = args[2];
String accessTokenSecret = args[3];
String[] arguments = args.clone();
String[] keyWords = Arrays.copyOfRange(arguments, 4, arguments.length);
Config config = new Config();
config.setDebug(true);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("twitter-spout", new TwitterSampleSpout(consumerKey,
consumerSecret, accessToken, accessTokenSecret, keyWords));
builder.setBolt("twitter-hashtag-reader-bolt", new HashtagReaderBolt())
.shuffleGrouping("twitter-spout");
builder.setBolt("twitter-hashtag-counter-bolt", new HashtagCounterBolt())
.fieldsGrouping("twitter-hashtag-reader-bolt", new Fields("hashtag"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("TwitterHashtagStorm", config,
builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}응용 프로그램 빌드 및 실행
완전한 애플리케이션에는 4 개의 Java 코드가 있습니다. 그들은 다음과 같습니다-
- TwitterSampleSpout.java
- HashtagReaderBolt.java
- HashtagCounterBolt.java
- TwitterHashtagStorm.java
다음 명령을 사용하여 응용 프로그램을 컴파일 할 수 있습니다-
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/twitter4j/lib/*” *.java다음 명령을 사용하여 응용 프로그램을 실행하십시오-
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/twitter4j/lib/*”:.
TwitterHashtagStorm <customerkey> <customersecret> <accesstoken> <accesstokensecret>
<keyword1> <keyword2> … <keywordN>산출
응용 프로그램은 현재 사용 가능한 해시 태그와 개수를 인쇄합니다. 출력은 다음과 유사해야합니다.
Result: jazztastic : 1
Result: foodie : 1
Result: Redskins : 1
Result: Recipe : 1
Result: cook : 1
Result: android : 1
Result: food : 2
Result: NoToxicHorseMeat : 1
Result: Purrs4Peace : 1
Result: livemusic : 1
Result: VIPremium : 1
Result: Frome : 1
Result: SundayRoast : 1
Result: Millennials : 1
Result: HealthWithKier : 1
Result: LPs30DaysofGratitude : 1
Result: cooking : 1
Result: gameinsight : 1
Result: Countryfile : 1
Result: androidgames : 1야후! 금융은 인터넷을 선도하는 비즈니스 뉴스 및 금융 데이터 웹 사이트입니다. Yahoo!의 일부입니다. 금융 뉴스, 시장 통계, 국제 시장 데이터 및 누구나 액세스 할 수있는 금융 자원에 대한 기타 정보를 제공합니다.
등록 된 Yahoo! 사용자는 Yahoo! 특정 서비스를 활용하기위한 금융. 야후! Finance API는 Yahoo!에서 재무 데이터를 쿼리하는 데 사용됩니다.
이 API는 실시간에서 15 분 지연된 데이터를 표시하고 1 분마다 데이터베이스를 업데이트하여 현재 주식 관련 정보에 액세스합니다. 이제 회사의 실시간 시나리오를 살펴보고 주식 가치가 100 아래로 떨어질 때 경고를 발생시키는 방법을 살펴 보겠습니다.
주둥이 만들기
주둥이의 목적은 회사의 세부 정보를 얻고 가격을 볼트로 내보내는 것입니다. 다음 프로그램 코드를 사용하여 주둥이를 만들 수 있습니다.
코딩 : YahooFinanceSpout.java
import java.util.*;
import java.io.*;
import java.math.BigDecimal;
//import yahoofinace packages
import yahoofinance.YahooFinance;
import yahoofinance.Stock;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
public class YahooFinanceSpout implements IRichSpout {
private SpoutOutputCollector collector;
private boolean completed = false;
private TopologyContext context;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector){
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
try {
Stock stock = YahooFinance.get("INTC");
BigDecimal price = stock.getQuote().getPrice();
this.collector.emit(new Values("INTC", price.doubleValue()));
stock = YahooFinance.get("GOOGL");
price = stock.getQuote().getPrice();
this.collector.emit(new Values("GOOGL", price.doubleValue()));
stock = YahooFinance.get("AAPL");
price = stock.getQuote().getPrice();
this.collector.emit(new Values("AAPL", price.doubleValue()));
} catch(Exception e) {}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("company", "price"));
}
@Override
public void close() {}
public boolean isDistributed() {
return false;
}
@Override
public void activate() {}
@Override
public void deactivate() {}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}볼트 생성
여기서 bolt의 목적은 가격이 100 이하로 떨어질 때 주어진 회사의 가격을 처리하는 것입니다. Java Map 객체를 사용하여 마감 가격 제한 경고를 다음과 같이 설정합니다. true주가가 100 이하로 떨어질 때; 그렇지 않으면 거짓입니다. 전체 프로그램 코드는 다음과 같습니다.
코딩 : PriceCutOffBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class PriceCutOffBolt implements IRichBolt {
Map<String, Integer> cutOffMap;
Map<String, Boolean> resultMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.cutOffMap = new HashMap <String, Integer>();
this.cutOffMap.put("INTC", 100);
this.cutOffMap.put("AAPL", 100);
this.cutOffMap.put("GOOGL", 100);
this.resultMap = new HashMap<String, Boolean>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String company = tuple.getString(0);
Double price = tuple.getDouble(1);
if(this.cutOffMap.containsKey(company)){
Integer cutOffPrice = this.cutOffMap.get(company);
if(price < cutOffPrice) {
this.resultMap.put(company, true);
} else {
this.resultMap.put(company, false);
}
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Boolean> entry:resultMap.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("cut_off_price"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}토폴로지 제출
YahooFinanceSpout.java와 PriceCutOffBolt.java가 함께 연결되어 토폴로지를 생성하는 메인 애플리케이션입니다. 다음 프로그램 코드는 토폴로지를 제출하는 방법을 보여줍니다.
코딩 : YahooFinanceStorm.java
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
public class YahooFinanceStorm {
public static void main(String[] args) throws Exception{
Config config = new Config();
config.setDebug(true);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("yahoo-finance-spout", new YahooFinanceSpout());
builder.setBolt("price-cutoff-bolt", new PriceCutOffBolt())
.fieldsGrouping("yahoo-finance-spout", new Fields("company"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("YahooFinanceStorm", config, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}응용 프로그램 빌드 및 실행
완전한 애플리케이션에는 세 개의 Java 코드가 있습니다. 그들은 다음과 같습니다-
- YahooFinanceSpout.java
- PriceCutOffBolt.java
- YahooFinanceStorm.java
응용 프로그램은 다음 명령을 사용하여 구축 할 수 있습니다-
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/yahoofinance/lib/*” *.java응용 프로그램은 다음 명령을 사용하여 실행할 수 있습니다-
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/yahoofinance/lib/*”:.
YahooFinanceStorm산출
출력은 다음과 유사합니다.
GOOGL : false
AAPL : false
INTC : trueApache Storm 프레임 워크는 오늘날 최고의 산업용 애플리케이션을 많이 지원합니다. 이 장에서는 Storm의 가장 주목할만한 몇 가지 응용 프로그램에 대한 간략한 개요를 제공합니다.
Klout
Klout은 소셜 미디어 분석을 사용하여 온라인 소셜 영향력을 기반으로 사용자 순위를 매기는 애플리케이션입니다. Klout Score, 이는 1에서 100 사이의 숫자 값입니다. Klout은 Apache Storm의 내장 된 Trident 추상화를 사용하여 데이터를 스트리밍하는 복잡한 토폴로지를 만듭니다.
날씨 채널
Weather Channel은 Storm 토폴로지를 사용하여 날씨 데이터를 수집합니다. 트위터와 모바일 애플리케이션에서 날씨 정보를 제공하는 광고를 활성화하기 위해 트위터와 제휴했습니다.OpenSignal 무선 커버리지 매핑을 전문으로하는 회사입니다. StormTag 과 WeatherSignalOpenSignal에서 만든 날씨 기반 프로젝트입니다. StormTag는 키 체인에 연결되는 Bluetooth 기상 관측소입니다. 기기에서 수집 한 날씨 데이터는 WeatherSignal 앱 및 OpenSignal 서버로 전송됩니다.
통신 산업
통신 제공 업체는 초당 수백만 건의 전화 통화를 처리합니다. 통화가 끊기고 음질이 좋지 않으면 포렌식을 수행합니다. 통화 정보 레코드는 초당 수백만의 속도로 유입되며 Apache Storm은이를 실시간으로 처리하고 문제가되는 패턴을 식별합니다. 스톰 분석을 사용하여 통화 품질을 지속적으로 개선 할 수 있습니다.