시스템 및 메모리 아키텍처
프로그램 또는 동시 시스템을 설계 할 때 고려해야 할 다양한 시스템 및 메모리 아키텍처 스타일이 있습니다. 하나의 시스템 및 메모리 스타일이 하나의 작업에 적합 할 수 있지만 다른 작업에는 오류가 발생할 수 있기 때문에 매우 필요합니다.
동시성을 지원하는 컴퓨터 시스템 아키텍처
1972 년 Michael Flynn은 다양한 스타일의 컴퓨터 시스템 아키텍처를 분류하는 분류 체계를 제공했습니다. 이 분류는 다음과 같이 네 가지 스타일을 정의합니다.
- 단일 명령 스트림, 단일 데이터 스트림 (SISD)
- 단일 명령 스트림, 다중 데이터 스트림 (SIMD)
- 다중 명령 스트림, 단일 데이터 스트림 (MISD)
- 다중 명령 스트림, 다중 데이터 스트림 (MIMD).
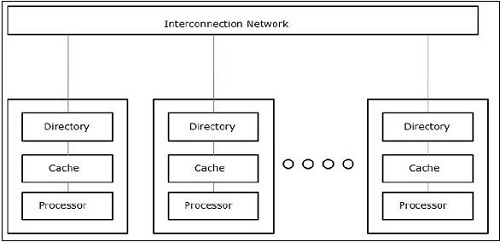
단일 명령 스트림, 단일 데이터 스트림 (SISD)
이름에서 알 수 있듯이 이러한 종류의 시스템은 하나의 순차적 수신 데이터 스트림과 데이터 스트림을 실행하기위한 하나의 단일 처리 장치를 갖습니다. 그들은 병렬 컴퓨팅 아키텍처를 갖는 단일 프로세서 시스템과 같습니다. 다음은 SISD의 아키텍처입니다-
SISD의 장점
SISD 아키텍처의 장점은 다음과 같습니다.
- 적은 전력이 필요합니다.
- 다중 코어간에 복잡한 통신 프로토콜 문제가 없습니다.
SISD의 단점
SISD 아키텍처의 단점은 다음과 같습니다.
- SISD 아키텍처의 속도는 단일 코어 프로세서와 마찬가지로 제한됩니다.
- 더 큰 용도에는 적합하지 않습니다.
단일 명령 스트림, 다중 데이터 스트림 (SIMD)
이름에서 알 수 있듯이 이러한 종류의 시스템에는 여러 수신 데이터 스트림과 주어진 시간에 단일 명령에 대해 작동 할 수있는 처리 장치 수가 있습니다. 병렬 컴퓨팅 아키텍처를 가진 다중 프로세서 시스템과 같습니다. 다음은 SIMD의 아키텍처입니다-
SIMD의 가장 좋은 예는 그래픽 카드입니다. 이 카드에는 수백 개의 개별 처리 장치가 있습니다. SISD와 SIMD의 계산 차이에 대해 이야기하면 배열 추가[5, 15, 20] 과 [15, 25, 10],SISD 아키텍처는 세 가지 다른 추가 작업을 수행해야합니다. 반면 SIMD 아키텍처를 사용하면 단일 추가 작업으로 추가 할 수 있습니다.
SIMD의 장점
SIMD 아키텍처의 장점은 다음과 같습니다.
여러 요소에 대해 동일한 작업을 하나의 명령으로 만 수행 할 수 있습니다.
프로세서의 코어 수를 늘려 시스템 처리량을 늘릴 수 있습니다.
처리 속도는 SISD 아키텍처보다 빠릅니다.
SIMD의 단점
SIMD 아키텍처의 단점은 다음과 같습니다.
- 프로세서 코어 수 사이에는 복잡한 통신이 있습니다.
- 비용은 SISD 아키텍처보다 높습니다.
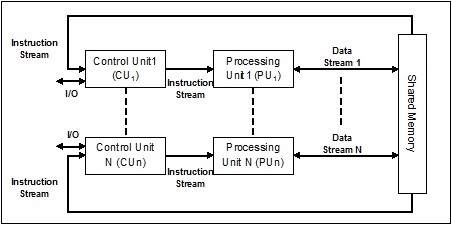
MISD (Multiple Instruction Single Data) 스트림
MISD 스트림이있는 시스템에는 동일한 데이터 세트에 대해 서로 다른 명령을 실행하여 서로 다른 작업을 수행하는 여러 처리 장치가 있습니다. 다음은 MISD의 아키텍처입니다-
MISD 아키텍처의 대표자는 아직 상업적으로 존재하지 않습니다.
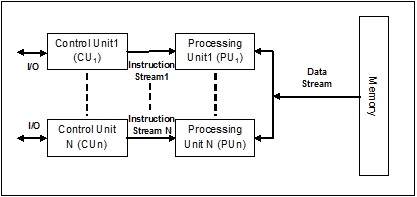
MIMD (Multiple Instruction Multiple Data) 스트림
MIMD 아키텍처를 사용하는 시스템에서 다중 프로세서 시스템의 각 프로세서는 병렬로 서로 다른 데이터 세트 세트에서 독립적으로 서로 다른 명령 세트를 실행할 수 있습니다. 단일 작업이 여러 데이터 세트에서 실행되는 SIMD 아키텍처와 반대입니다. 다음은 MIMD의 아키텍처입니다-
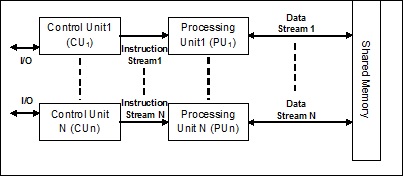
일반 멀티 프로세서는 MIMD 아키텍처를 사용합니다. 이러한 아키텍처는 기본적으로 컴퓨터 지원 설계 / 컴퓨터 지원 제조, 시뮬레이션, 모델링, 통신 스위치 등과 같은 여러 응용 분야에서 사용됩니다.
동시성을 지원하는 메모리 아키텍처
동시성 및 병렬성과 같은 개념으로 작업하는 동안 항상 프로그램 속도를 높일 필요가 있습니다. 컴퓨터 설계자가 찾은 한 가지 해결책은 공유 메모리 다중 컴퓨터를 만드는 것입니다. 즉, 단일 물리적 주소 공간을 가진 컴퓨터는 프로세서가 가지고있는 모든 코어에서 액세스합니다. 이 시나리오에서는 여러 가지 아키텍처 스타일이있을 수 있지만 다음은 세 가지 중요한 아키텍처 스타일입니다.
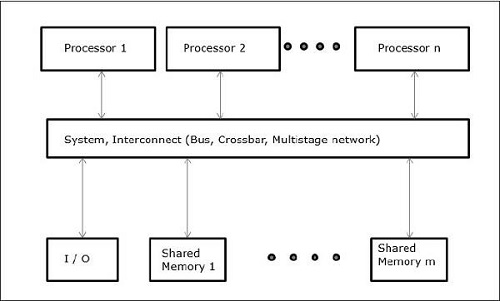
UMA (Uniform Memory Access)
이 모델에서 모든 프로세서는 물리적 메모리를 균일하게 공유합니다. 모든 프로세서는 모든 메모리 단어에 대해 동일한 액세스 시간을 갖습니다. 각 프로세서에는 개인 캐시 메모리가있을 수 있습니다. 주변 장치는 일련의 규칙을 따릅니다.
모든 프로세서가 모든 주변 장치에 동등하게 액세스 할 수있는 경우 시스템을 symmetric multiprocessor. 하나 또는 몇 개의 프로세서 만 주변 장치에 액세스 할 수있는 경우 시스템을asymmetric multiprocessor.
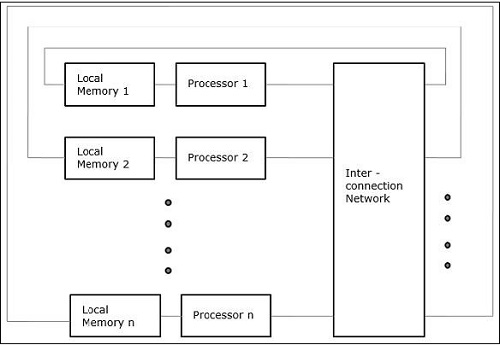
NUMA (Non-Uniform Memory Access)
NUMA 멀티 프로세서 모델에서 액세스 시간은 메모리 워드의 위치에 따라 다릅니다. 여기서 공유 메모리는 로컬 메모리라고하는 모든 프로세서에 물리적으로 분산됩니다. 모든 로컬 메모리의 모음은 모든 프로세서가 액세스 할 수있는 전역 주소 공간을 형성합니다.
캐시 전용 메모리 아키텍처 (COMA)
COMA 모델은 NUMA 모델의 특수 버전입니다. 여기서 분산 된 모든 메인 메모리는 캐시 메모리로 변환됩니다.