분산 DBMS-퀵 가이드
조직이 제대로 작동하려면 잘 관리 된 데이터베이스가 필요합니다. 최근에는 데이터베이스가 본질적으로 중앙 집중화되었습니다. 그러나 세계화가 증가함에 따라 조직은 전 세계적으로 다양 해지는 경향이 있습니다. 중앙 데이터베이스 대신 로컬 서버를 통해 데이터를 배포하도록 선택할 수 있습니다. 따라서 개념에 도달했습니다.Distributed Databases.
이 장에서는 데이터베이스 및 데이터베이스 관리 시스템 (DBMS)에 대한 개요를 제공합니다. 데이터베이스는 관련 데이터의 정렬 된 모음입니다. DBMS는 데이터베이스에서 작동하는 소프트웨어 패키지입니다. DBMS에 대한 자세한 연구는“Learn DBMS”라는 자습서에서 확인할 수 있습니다. 이 장에서는 DDBMS를 쉽게 공부할 수 있도록 주요 개념을 수정합니다. 다루는 세 가지 주제는 데이터베이스 스키마, 데이터베이스 유형 및 데이터베이스 작업입니다.
데이터베이스 및 데이터베이스 관리 시스템
ㅏ database특정 목적을 위해 구축 된 관련 데이터의 정렬 된 모음입니다. 데이터베이스는 여러 테이블의 모음으로 구성 될 수 있으며 테이블은 실제 요소 또는 엔티티를 나타냅니다. 각 테이블에는 엔터티의 특징을 나타내는 여러 필드가 있습니다.
예를 들어, 회사 데이터베이스에는 프로젝트, 직원, 부서, 제품 및 재무 기록에 대한 테이블이 포함될 수 있습니다. Employee 테이블의 필드는 Name, Company_Id, Date_of_Joining 등이 될 수 있습니다.
ㅏ database management system데이터베이스 생성 및 유지 관리를 가능하게하는 프로그램 모음입니다. DBMS는 데이터베이스에서 데이터의 정의, 구성, 조작 및 공유를 용이하게하는 소프트웨어 패키지로 제공됩니다. 데이터베이스 정의에는 데이터베이스 구조에 대한 설명이 포함됩니다. 데이터베이스 구성에는 모든 저장 매체에 데이터를 실제로 저장하는 작업이 포함됩니다. 조작은 데이터베이스에서 정보를 검색하고 데이터베이스를 업데이트하며 보고서를 생성하는 것을 말합니다. 데이터를 공유하면 다른 사용자 나 프로그램이 데이터에 쉽게 액세스 할 수 있습니다.
DBMS 응용 분야의 예
- 자동 입출금기
- 열차 예약 시스템
- 직원 관리 시스템
- 학생 정보 시스템
DBMS 패키지의 예
- MySQL
- Oracle
- SQL 서버
- dBASE
- FoxPro
- PostgreSQL 등
데이터베이스 스키마
데이터베이스 스키마는 데이터베이스 설계 중에 지정되고 자주 변경되지 않는 데이터베이스에 대한 설명입니다. 데이터의 구성, 데이터 간의 관계 및 관련 제약 조건을 정의합니다.
데이터베이스는 종종 three-schema architecture 또는 ANSISPARC architecture. 이 아키텍처의 목표는 실제 데이터베이스에서 사용자 애플리케이션을 분리하는 것입니다. 세 가지 수준은-
Internal Level having Internal Schema − 물리적 구조, 내부 저장소의 세부 사항 및 데이터베이스의 접근 경로를 설명합니다.
Conceptual Level having Conceptual Schema− 데이터의 물리적 저장에 대한 세부 사항을 숨기면서 전체 데이터베이스의 구조를 설명합니다. 이것은 엔터티, 데이터 유형 및 제약 조건이있는 속성, 사용자 작업 및 관계를 보여줍니다.
External or View Level having External Schemas or Views − 데이터베이스의 나머지 부분을 숨기면서 특정 사용자 또는 사용자 그룹과 관련된 데이터베이스 부분을 설명합니다.
DBMS의 유형
DBMS에는 4 가지 유형이 있습니다.
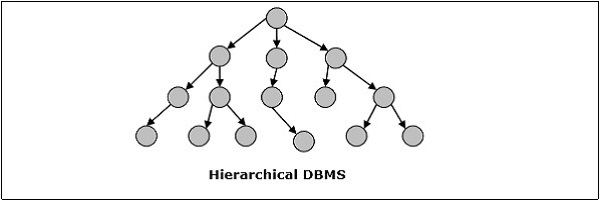
계층 적 DBMS
계층 적 DBMS에서는 한 데이터 요소가 다른 데이터 요소의 하위 요소로 존재하도록 데이터베이스의 데이터 간의 관계가 설정됩니다. 데이터 요소는 상위-하위 관계를 가지며 "트리"데이터 구조를 사용하여 모델링됩니다. 이것은 매우 빠르고 간단합니다.
네트워크 DBMS
데이터베이스의 데이터 간의 관계가 네트워크 형태의 다 대다 유형 인 네트워크 DBMS. 구조는 일반적으로 수많은 다 대다 관계의 존재로 인해 복잡합니다. 네트워크 DBMS는 "그래프"데이터 구조를 사용하여 모델링됩니다.

관계형 DBMS
관계형 데이터베이스에서 데이터베이스는 관계 형식으로 표시됩니다. 각 관계는 항목을 모델링하며 값 테이블로 표시됩니다. 관계 또는 테이블에서 행은 튜플이라고하며 단일 레코드를 나타냅니다. 열은 필드 또는 특성이라고하며 엔터티의 특성 속성을 나타냅니다. RDBMS는 가장 널리 사용되는 데이터베이스 관리 시스템입니다.
예를 들면-학생 관계-

객체 지향 DBMS
객체 지향 DBMS는 객체 지향 프로그래밍 패러다임의 모델에서 파생됩니다. 데이터베이스에 저장된 일관된 데이터와 프로그램 실행에서 발견되는 일시적인 데이터를 모두 나타내는 데 유용합니다. 개체라고하는 작고 재사용 가능한 요소를 사용합니다. 각 개체에는 데이터 부분과 데이터에 대해 작동하는 일련의 작업이 포함됩니다. 객체와 그 속성은 관계형 테이블 모델에 저장되는 대신 포인터를 통해 액세스됩니다.
예를 들면-단순화 된 은행 계좌 객체 지향 데이터베이스-

분산 DBMS
분산 데이터베이스는 컴퓨터 네트워크 또는 인터넷을 통해 분산되는 상호 연결된 데이터베이스 집합입니다. 분산 데이터베이스 관리 시스템 (DDBMS)은 분산 데이터베이스를 관리하고 데이터베이스를 사용자에게 투명하게 만들기위한 메커니즘을 제공합니다. 이러한 시스템에서는 조직의 모든 컴퓨팅 리소스를 최적으로 사용할 수 있도록 데이터가 여러 노드에 의도적으로 분산됩니다.
DBMS 운영
데이터베이스에 대한 네 가지 기본 작업은 만들기, 검색, 업데이트 및 삭제입니다.
CREATE 데이터베이스 구조 및 데이터로 채우기-데이터베이스 관계 생성에는 데이터 구조, 데이터 유형 및 저장할 데이터의 제약 조건을 지정하는 것이 포함됩니다.
Example − 학생 테이블을 생성하는 SQL 명령 −
CREATE TABLE STUDENT (
ROLL INTEGER PRIMARY KEY,
NAME VARCHAR2(25),
YEAR INTEGER,
STREAM VARCHAR2(10)
);데이터 형식이 정의되면 실제 데이터는 형식에 따라 일부 저장 매체에 저장됩니다.
Example 학생 테이블에 단일 튜플을 삽입하는 SQL 명령-
INSERT INTO STUDENT ( ROLL, NAME, YEAR, STREAM)
VALUES ( 1, 'ANKIT JHA', 1, 'COMPUTER SCIENCE');RETRIEVE데이터베이스의 정보 – 정보 검색에는 일반적으로 일부 계산이 완료된 후 테이블의 하위 집합을 선택하거나 테이블에서 데이터를 표시하는 작업이 포함됩니다. 테이블에 대한 쿼리를 통해 수행됩니다.
Example − Computer Science 스트림의 모든 학생 이름을 검색하려면 다음 SQL 쿼리를 실행해야합니다. −
SELECT NAME FROM STUDENT
WHERE STREAM = 'COMPUTER SCIENCE';UPDATE 정보 저장 및 데이터베이스 구조 수정 – 테이블 업데이트에는 기존 테이블 행의 이전 값을 새 값으로 변경하는 작업이 포함됩니다.
Example − 전자에서 전자 및 통신으로 스트림을 변경하는 SQL 명령 −
UPDATE STUDENT
SET STREAM = 'ELECTRONICS AND COMMUNICATIONS'
WHERE STREAM = 'ELECTRONICS';데이터베이스 수정은 테이블의 구조를 변경하는 것을 의미합니다. 그러나 테이블 수정에는 여러 제한 사항이 적용됩니다.
Example − 새 필드 또는 열을 추가하려면 Student 테이블에 주소라고 말하고 다음 SQL 명령을 사용합니다. −
ALTER TABLE STUDENT
ADD ( ADDRESS VARCHAR2(50) );DELETE 정보 저장 또는 테이블 전체 삭제 – 특정 정보 삭제에는 특정 조건을 충족하는 테이블에서 선택된 행이 제거됩니다.
Example- 4에있는 모든 학생들을 삭제하려면 일 우리는 SQL 명령을 사용하여, 그들은 기절 할 때 현재 년 -
DELETE FROM STUDENT
WHERE YEAR = 4;또는 데이터베이스에서 전체 테이블을 제거 할 수 있습니다.
Example − 학생 테이블을 완전히 제거하기 위해 사용되는 SQL 명령은 −
DROP TABLE STUDENT;이 장에서는 DDBMS의 개념을 소개합니다. 분산 데이터베이스에는 전 세계에 지리적으로 분산되어있을 수있는 여러 데이터베이스가 있습니다. 분산 DBMS는 사용자에게 하나의 단일 데이터베이스로 보이도록 분산 데이터베이스를 관리합니다. 이 장의 후반부에서는 분산 데이터베이스로 이어지는 요인, 장점 및 단점을 계속 연구합니다.
ㅏ distributed database 컴퓨터 네트워크를 통해 통신하는 다양한 위치에 물리적으로 분산 된 여러 상호 연결된 데이터베이스의 모음입니다.
풍모
컬렉션의 데이터베이스는 서로 논리적으로 상호 연관되어 있습니다. 종종 단일 논리 데이터베이스를 나타냅니다.
데이터는 여러 사이트에 물리적으로 저장됩니다. 각 사이트의 데이터는 다른 사이트와 독립적 인 DBMS로 관리 할 수 있습니다.
사이트의 프로세서는 네트워크를 통해 연결됩니다. 다중 프로세서 구성이 없습니다.
분산 데이터베이스는 느슨하게 연결된 파일 시스템이 아닙니다.
분산 데이터베이스는 트랜잭션 처리를 통합하지만 트랜잭션 처리 시스템과 동의어는 아닙니다.
분산 데이터베이스 관리 시스템
분산 데이터베이스 관리 시스템 (DDBMS)은 분산 데이터베이스를 모두 단일 위치에 저장 한 것처럼 관리하는 중앙 집중식 소프트웨어 시스템입니다.
풍모
분산 데이터베이스를 생성, 검색, 업데이트 및 삭제하는 데 사용됩니다.
데이터베이스를 주기적으로 동기화하고 배포가 사용자에게 투명 해 지도록 액세스 메커니즘을 제공합니다.
모든 사이트에서 수정 된 데이터가 보편적으로 업데이트되도록합니다.
많은 양의 데이터가 동시에 처리되고 많은 사용자가 액세스하는 응용 분야에서 사용됩니다.
이기종 데이터베이스 플랫폼 용으로 설계되었습니다.
데이터베이스의 기밀성과 데이터 무결성을 유지합니다.
DDBMS를 장려하는 요인
다음 요인은 DDBMS로 이동하도록 권장합니다.
Distributed Nature of Organizational Units− 현재 대부분의 조직은 전 세계에 물리적으로 분산 된 여러 단위로 세분화됩니다. 각 장치에는 자체 로컬 데이터 세트가 필요합니다. 따라서 조직의 전체 데이터베이스가 분산됩니다.
Need for Sharing of Data− 여러 조직 단위는 종종 서로 통신하고 데이터와 리소스를 공유해야합니다. 이를 위해서는 동기화 된 방식으로 사용해야하는 공통 데이터베이스 또는 복제 된 데이터베이스가 필요합니다.
Support for Both OLTP and OLAP− OLTP (온라인 트랜잭션 처리) 및 OLAP (온라인 분석 처리)는 공통 데이터를 가질 수있는 다양한 시스템에서 작동합니다. 분산 데이터베이스 시스템은 동기화 된 데이터를 제공하여 이러한 처리를 모두 지원합니다.
Database Recovery− DDBMS에서 사용되는 일반적인 기술 중 하나는 여러 사이트에서 데이터를 복제하는 것입니다. 데이터 복제는 사이트의 데이터베이스가 손상된 경우 데이터 복구에 자동으로 도움이됩니다. 사용자는 손상된 사이트가 재구성되는 동안 다른 사이트의 데이터에 액세스 할 수 있습니다. 따라서 데이터베이스 오류는 사용자에게 거의 눈에 띄지 않게 될 수 있습니다.
Support for Multiple Application Software− 대부분의 조직은 특정 데이터베이스를 지원하는 다양한 애플리케이션 소프트웨어를 사용합니다. DDBMS는 서로 다른 플랫폼간에 동일한 데이터를 사용하기위한 일관된 기능을 제공합니다.
분산 데이터베이스의 장점
다음은 중앙 집중식 데이터베이스에 비해 분산 데이터베이스의 장점입니다.
Modular Development− 중앙 집중식 데이터베이스 시스템에서 시스템을 새로운 위치 또는 새로운 단위로 확장해야하는 경우, 조치에는 기존 기능에 상당한 노력과 중단이 필요합니다. 그러나 분산 데이터베이스에서 작업은 단순히 새 컴퓨터와 로컬 데이터를 새 사이트에 추가하고 마지막으로 현재 기능을 중단하지 않고 분산 시스템에 연결하면됩니다.
More Reliable− 데이터베이스 장애 발생시 중앙 집중식 데이터베이스의 전체 시스템이 중단됩니다. 그러나 분산 시스템에서 구성 요소가 실패하면 시스템의 기능이 계속 저하 될 수 있습니다. 따라서 DDBMS가 더 안정적입니다.
Better Response− 데이터가 효율적으로 배포되면 로컬 데이터 자체에서 사용자 요청을 충족 할 수있어보다 빠른 응답이 가능합니다. 반면 중앙 집중식 시스템에서는 모든 쿼리가 처리를 위해 중앙 컴퓨터를 통과해야하므로 응답 시간이 늘어납니다.
Lower Communication Cost− 분산 데이터베이스 시스템에서 데이터가 주로 사용되는 로컬에 위치하면 데이터 조작에 대한 통신 비용을 최소화 할 수 있습니다. 이것은 중앙 집중식 시스템에서는 가능하지 않습니다.
분산 데이터베이스의 역경
다음은 분산 데이터베이스와 관련된 몇 가지 역경입니다.
Need for complex and expensive software − DDBMS는 여러 사이트에서 데이터 투명성과 조정을 제공하기 위해 복잡하고 종종 값 비싼 소프트웨어를 요구합니다.
Processing overhead − 간단한 작업이라도 사이트 전체에 걸쳐 데이터의 균일 성을 제공하기 위해 많은 통신과 추가 계산이 필요할 수 있습니다.
Data integrity − 여러 사이트에서 데이터를 업데이트해야하는 경우 데이터 무결성 문제가 발생합니다.
Overheads for improper data distribution− 쿼리 응답 성은 적절한 데이터 배포에 크게 좌우됩니다. 부적절한 데이터 배포는 종종 사용자 요청에 대한 매우 느린 응답으로 이어집니다.
자습서의이 부분에서는 분산 데이터베이스 환경을 설계하는 데 도움이되는 다양한 측면을 연구합니다. 이 장은 분산 데이터베이스 유형으로 시작합니다. 분산 데이터베이스는 추가로 구분 된 동종 데이터베이스와 이기종 데이터베이스로 분류 할 수 있습니다. 이 장의 다음 섹션에서는 클라이언트 – 서버, 피어 – 투 – 피어 및 다중 – DBMS라는 분산 아키텍처에 대해 설명합니다. 마지막으로 복제 및 조각화와 같은 다양한 디자인 대안이 소개됩니다.
분산 데이터베이스의 유형
분산 데이터베이스는 다음 그림과 같이 더 세분화 된 하위 구분이있는 동종 및 이기종 분산 데이터베이스 환경으로 광범위하게 분류 할 수 있습니다.

동종 분산 데이터베이스
동종 분산 데이터베이스에서 모든 사이트는 동일한 DBMS 및 운영 체제를 사용합니다. 그 속성은-
사이트는 매우 유사한 소프트웨어를 사용합니다.
사이트는 동일한 공급 업체의 동일한 DBMS 또는 DBMS를 사용합니다.
각 사이트는 다른 모든 사이트를 인식하고 다른 사이트와 협력하여 사용자 요청을 처리합니다.
데이터베이스는 마치 단일 데이터베이스 인 것처럼 단일 인터페이스를 통해 액세스됩니다.
동종 분산 데이터베이스의 유형
동종 분산 데이터베이스에는 두 가지 유형이 있습니다.
Autonomous− 각 데이터베이스는 독립적으로 작동하며 자체적으로 작동합니다. 제어 애플리케이션에 의해 통합되며 메시지 전달을 사용하여 데이터 업데이트를 공유합니다.
Non-autonomous − 데이터는 동종 노드에 분산되고 중앙 또는 마스터 DBMS가 사이트 전체의 데이터 업데이트를 조정합니다.
이기종 분산 데이터베이스
이기종 분산 데이터베이스에서 사이트마다 운영 체제, DBMS 제품 및 데이터 모델이 다릅니다. 그 속성은-
사이트마다 다른 스키마와 소프트웨어를 사용합니다.
시스템은 관계형, 네트워크, 계층 적 또는 객체 지향과 같은 다양한 DBMS로 구성 될 수 있습니다.
스키마가 다르기 때문에 쿼리 처리가 복잡합니다.
서로 다른 소프트웨어로 인해 트랜잭션 처리가 복잡합니다.
사이트는 다른 사이트를 인식하지 못할 수 있으므로 사용자 요청을 처리하는 데 제한적인 협력이 있습니다.
이기종 분산 데이터베이스의 유형
Federated − 이기종 데이터베이스 시스템은 본질적으로 독립적이며 함께 통합되어 단일 데이터베이스 시스템으로 작동합니다.
Un-federated − 데이터베이스 시스템은 데이터베이스에 액세스하는 중앙 조정 모듈을 사용합니다.
분산 DBMS 아키텍처
DDBMS 아키텍처는 일반적으로 세 가지 매개 변수에 따라 개발됩니다.
Distribution − 여러 사이트에 걸친 데이터의 물리적 분포를 나타냅니다.
Autonomy − 데이터베이스 시스템의 제어 분포와 각 구성 DBMS가 독립적으로 운영 할 수있는 정도를 나타냅니다.
Heterogeneity − 데이터 모델, 시스템 구성 요소 및 데이터베이스의 균일 성 또는 비 유사성을 나타냅니다.
건축 모델
일반적인 아키텍처 모델 중 일부는 다음과 같습니다.
- 클라이언트-DDBMS 용 서버 아키텍처
- DDBMS를위한 피어 투 피어 아키텍처
- 다중-DBMS 아키텍처
클라이언트-DDBMS 용 서버 아키텍처
이는 기능이 서버와 클라이언트로 구분되는 2 단계 아키텍처입니다. 서버 기능은 주로 데이터 관리, 쿼리 처리, 최적화 및 트랜잭션 관리를 포함합니다. 클라이언트 기능에는 주로 사용자 인터페이스가 포함됩니다. 그러나 일관성 검사 및 트랜잭션 관리와 같은 일부 기능이 있습니다.
두 개의 다른 클라이언트-서버 아키텍처는-
- 단일 서버 다중 클라이언트
- 다중 서버 다중 클라이언트 (다음 다이어그램에 표시됨)

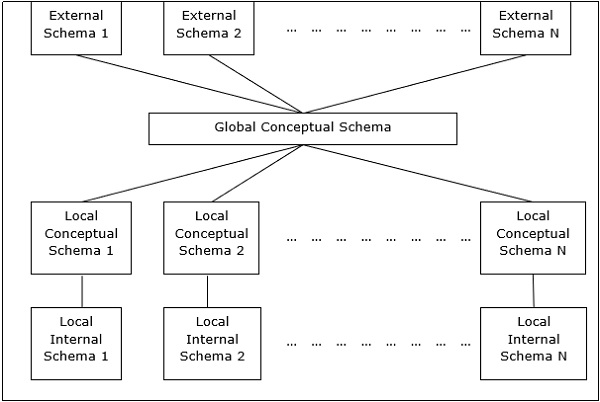
DDBMS를위한 피어 투 피어 아키텍처
이러한 시스템에서 각 피어는 데이터베이스 서비스를 제공하기 위해 클라이언트와 서버 역할을 모두 수행합니다. 동료는 다른 동료와 자원을 공유하고 활동을 조정합니다.
이 아키텍처에는 일반적으로 4 가지 수준의 스키마가 있습니다.
Global Conceptual Schema − 데이터의 글로벌 논리적보기를 나타냅니다.
Local Conceptual Schema − 각 사이트의 논리적 데이터 구성을 나타냅니다.
Local Internal Schema − 각 사이트의 물리적 데이터 구성을 나타냅니다.
External Schema − 데이터의 사용자보기를 나타냅니다.
다중-DBMS 아키텍처
이것은 두 개 이상의 자율 데이터베이스 시스템 모음으로 구성된 통합 데이터베이스 시스템입니다.
다중 DBMS는 6 단계의 스키마를 통해 표현할 수 있습니다.
Multi-database View Level − 통합 분산 데이터베이스의 하위 집합으로 구성된 여러 사용자보기를 나타냅니다.
Multi-database Conceptual Level − 글로벌 논리적 다중 데이터베이스 구조 정의로 구성된 통합 다중 데이터베이스를 설명합니다.
Multi-database Internal Level − 여러 사이트 및 다중 데이터베이스에서 로컬 데이터 매핑에 걸친 데이터 분포를 나타냅니다.
Local database View Level − 로컬 데이터의 공개보기를 나타냅니다.
Local database Conceptual Level − 각 사이트의 로컬 데이터 구성을 나타냅니다.
Local database Internal Level − 각 사이트의 물리적 데이터 구성을 나타냅니다.
다중 DBMS에는 두 가지 설계 대안이 있습니다.
- 다중 데이터베이스 개념 수준의 모델.
- 다중 데이터베이스 개념 수준이없는 모델입니다.


디자인 대안
DDBMS의 테이블에 대한 배포 설계 대안은 다음과 같습니다.
- 복제되지 않고 단편화되지 않음
- 완전히 복제 됨
- 부분적으로 복제 됨
- Fragmented
- Mixed
복제되지 않음 및 단편화되지 않음
이 디자인 대안에서는 다른 테이블이 다른 사이트에 배치됩니다. 데이터는 가장 많이 사용되는 사이트와 가까운 곳에 배치됩니다. 서로 다른 사이트에있는 테이블의 정보를 조인하는 데 필요한 쿼리 비율이 낮은 데이터베이스 시스템에 가장 적합합니다. 적절한 배포 전략이 채택되면이 설계 대안은 데이터 처리 중 통신 비용을 줄이는 데 도움이됩니다.
완전히 복제 됨
이 디자인 대안에서는 각 사이트에 모든 데이터베이스 테이블의 복사본 하나가 저장됩니다. 각 사이트에는 전체 데이터베이스의 자체 복사본이 있기 때문에 쿼리는 매우 빠르며 통신 비용이 거의 들지 않습니다. 반대로 데이터의 대규모 중복은 업데이트 작업에 막대한 비용이 필요합니다. 따라서 이것은 데이터베이스 업데이트 수가 적은 반면 많은 쿼리를 처리해야하는 시스템에 적합합니다.
부분적으로 복제 됨
테이블의 사본 또는 테이블의 일부는 다른 사이트에 저장됩니다. 테이블 배포는 액세스 빈도에 따라 수행됩니다. 이것은 테이블에 액세스하는 빈도가 사이트마다 상당히 다르다는 사실을 고려합니다. 테이블 (또는 부분)의 복사본 수는 액세스 쿼리가 실행되는 빈도와 액세스 쿼리를 생성하는 사이트에 따라 다릅니다.
조각난
이 디자인에서 테이블은 조각 또는 파티션이라고하는 둘 이상의 조각으로 나뉘며 각 조각은 서로 다른 사이트에 저장 될 수 있습니다. 이는 테이블에 저장된 모든 데이터가 주어진 사이트에서 필요한 경우가 거의 없다는 사실을 고려합니다. 또한 조각화는 병렬 처리를 증가시키고 더 나은 재해 복구를 제공합니다. 여기서 시스템에는 각 조각의 복사본이 하나만 있습니다. 즉, 중복 데이터가 없습니다.
세 가지 단편화 기술은 다음과 같습니다.
- 수직 분열
- 수평 조각화
- 하이브리드 단편화
혼합 분포
이것은 단편화와 부분 복제의 조합입니다. 여기서 테이블은 처음에 임의의 형태 (수평 또는 수직)로 조각난 다음 조각에 액세스하는 빈도에 따라 이러한 조각이 다른 사이트에 부분적으로 복제됩니다.
지난 장에서 우리는 다른 디자인 대안을 소개했습니다. 이 장에서는 디자인 채택에 도움이되는 전략을 연구합니다. 전략은 크게 복제와 조각화로 나눌 수 있습니다. 그러나 대부분의 경우 두 가지의 조합이 사용됩니다.
데이터 복제
데이터 복제는 두 개 이상의 사이트에 별도의 데이터베이스 복사본을 저장하는 프로세스입니다. 분산 데이터베이스에서 널리 사용되는 내결함성 기술입니다.
데이터 복제의 장점
Reliability − 사이트에 장애가 발생하더라도 다른 사이트에서 복사본을 사용할 수 있으므로 데이터베이스 시스템은 계속 작동합니다.
Reduction in Network Load− 데이터의 로컬 사본을 사용할 수 있기 때문에 특히 프라임 시간대에 네트워크 사용량을 줄이면서 쿼리 처리를 수행 할 수 있습니다. 데이터 업데이트는 프라임이 아닌 시간에 수행 할 수 있습니다.
Quicker Response − 데이터의 로컬 사본을 사용할 수 있으므로 쿼리 처리가 빠르고 결과적으로 빠른 응답 시간이 보장됩니다.
Simpler Transactions− 트랜잭션에는 서로 다른 사이트에있는 테이블의 조인 수가 적고 네트워크에서 최소한의 조정이 필요합니다. 따라서 그들은 본질적으로 더 단순 해집니다.
데이터 복제의 단점
Increased Storage Requirements− 데이터의 여러 사본을 유지하면 스토리지 비용이 증가합니다. 필요한 스토리지 공간은 중앙 집중식 시스템에 필요한 스토리지의 배수입니다.
Increased Cost and Complexity of Data Updating− 데이터 항목이 업데이트 될 때마다 다른 사이트에있는 모든 데이터 사본에 업데이트가 반영되어야합니다. 이를 위해서는 복잡한 동기화 기술과 프로토콜이 필요합니다.
Undesirable Application – Database coupling− 복잡한 업데이트 메커니즘을 사용하지 않는 경우 데이터 불일치를 제거하려면 애플리케이션 수준에서 복잡한 조정이 필요합니다. 그 결과 바람직하지 않은 애플리케이션 – 데이터베이스 커플 링이 발생합니다.
일반적으로 사용되는 복제 기술은 다음과 같습니다.
- 스냅 샷 복제
- 거의 실시간 복제
- 풀 복제
분열
조각화는 테이블을 더 작은 테이블 집합으로 나누는 작업입니다. 테이블의 하위 집합이 호출됩니다.fragments. 조각화는 수평, 수직 및 하이브리드 (수평 및 수직 조합)의 세 가지 유형이 될 수 있습니다. 수평 조각화는 기본 수평 조각화와 파생 된 수평 조각화의 두 가지 기술로 더 분류 될 수 있습니다.
조각화는 원본 테이블이 조각에서 재구성 될 수 있도록 수행되어야합니다. 이는 필요할 때마다 조각에서 원본 테이블을 재구성 할 수 있도록하기 위해 필요합니다. 이 요구 사항을 "재건 성"이라고합니다.
조각화의 장점
데이터가 사용 현장에 가깝게 저장되기 때문에 데이터베이스 시스템의 효율성이 향상됩니다.
로컬 쿼리 최적화 기술은 데이터를 로컬에서 사용할 수 있으므로 대부분의 쿼리에 충분합니다.
사이트에서 관련없는 데이터를 사용할 수 없으므로 데이터베이스 시스템의 보안 및 개인 정보를 유지할 수 있습니다.
단편화의 단점
다른 조각의 데이터가 필요한 경우 액세스 속도가 매우 빠를 수 있습니다.
재귀 적 조각화의 경우 재구성 작업에는 값 비싼 기술이 필요합니다.
다른 사이트에 데이터의 백업 복사본이 없으면 사이트에 장애가 발생할 경우 데이터베이스를 비효율적으로 만들 수 있습니다.
수직 조각화
수직 조각화에서는 테이블의 필드 또는 열이 조각으로 그룹화됩니다. 재구성을 유지하려면 각 조각에 테이블의 기본 키 필드가 있어야합니다. 수직 조각화를 사용하여 데이터의 개인 정보를 보호 할 수 있습니다.
예를 들어 University 데이터베이스가 등록 된 모든 학생의 레코드를 다음 스키마를 갖는 Student 테이블에 보관한다고 가정 해 보겠습니다.
학생
| Regd_No | 이름 | 강좌 | 주소 | 학기 | 수수료 | 점수 |
이제 수수료 세부 정보는 계정 섹션에서 유지됩니다. 이 경우 디자이너는 다음과 같이 데이터베이스를 조각화합니다.
CREATE TABLE STD_FEES AS
SELECT Regd_No, Fees
FROM STUDENT;수평 조각화
수평 조각화는 하나 이상의 필드 값에 따라 테이블의 튜플을 그룹화합니다. 수평 적 조각화는 또한 재건의 규칙을 확인해야합니다. 각 수평 조각에는 원래 기본 테이블의 모든 열이 있어야합니다.
예를 들어, 학생 스키마에서 컴퓨터 과학 과정의 모든 학생의 세부 정보를 컴퓨터 과학 학교에서 유지해야하는 경우 디자이너는 다음과 같이 데이터베이스를 수평으로 분할합니다.
CREATE COMP_STD AS
SELECT * FROM STUDENT
WHERE COURSE = "Computer Science";하이브리드 조각화
하이브리드 조각화에서는 수평 및 수직 조각화 기술의 조합이 사용됩니다. 이것은 최소한의 외부 정보로 조각을 생성하기 때문에 가장 유연한 조각화 기술입니다. 그러나 원래 테이블의 재구성은 종종 비용이 많이 드는 작업입니다.
하이브리드 단편화는 두 가지 다른 방법으로 수행 할 수 있습니다.
먼저 수평 조각 세트를 생성하십시오. 그런 다음 하나 이상의 수평 조각에서 수직 조각을 생성합니다.
먼저 수직 조각 세트를 생성하십시오. 그런 다음 하나 이상의 수직 조각에서 수평 조각을 생성합니다.
배포 투명성은 배포의 내부 세부 정보가 사용자에게 보이지 않는 분산 데이터베이스의 속성입니다. DDBMS 디자이너는 테이블을 조각화하고 조각을 복제하여 다른 사이트에 저장할 수 있습니다. 그러나 사용자는 이러한 세부 사항을 모르기 때문에 분산 데이터베이스를 중앙 집중식 데이터베이스처럼 사용하기 쉽습니다.
유통 투명성의 세 가지 차원은-
- 위치 투명성
- 조각화 투명성
- 복제 투명성
위치 투명성
위치 투명성은 사용자가 마치 사용자의 사이트에 로컬로 저장된 것처럼 테이블의 모든 테이블 또는 조각에 대해 쿼리 할 수 있도록합니다. 테이블 또는 해당 조각이 분산 데이터베이스 시스템의 원격 사이트에 저장된다는 사실은 최종 사용자가 완전히 알 수 없습니다. 원격 사이트의 주소와 액세스 메커니즘은 완전히 숨겨져 있습니다.
위치 투명성을 통합하기 위해 DDBMS는 업데이트되고 정확한 데이터 사전 및 데이터 위치의 세부 정보가 포함 된 DDBMS 디렉토리에 액세스 할 수 있어야합니다.
조각화 투명성
조각화 투명성을 통해 사용자는 조각화되지 않은 것처럼 테이블을 쿼리 할 수 있습니다. 따라서 사용자가 쿼리하는 테이블이 실제로 일부 조각의 조각 또는 결합이라는 사실을 숨 깁니다. 또한 파편이 다양한 위치에 있다는 사실을 은폐합니다.
이는 사용자가 테이블 자체 대신 테이블의보기를 사용하고 있다는 사실을 모를 수있는 SQL보기 사용자와 다소 유사합니다.
복제 투명성
복제 투명성은 데이터베이스 복제가 사용자에게 보이지 않도록합니다. 이를 통해 사용자는 테이블의 복사본이 하나만있는 것처럼 테이블을 쿼리 할 수 있습니다.
복제 투명성은 동시성 투명성 및 실패 투명성과 관련이 있습니다. 사용자가 데이터 항목을 업데이트 할 때마다 업데이트 내용이 테이블의 모든 복사본에 반영됩니다. 그러나이 작업은 사용자가 알 수 없습니다. 이것은 동시성 투명성입니다. 또한 사이트에 장애가 발생한 경우에도 사용자는 장애에 대한 지식없이 복제 된 복사본을 사용하여 쿼리를 계속 진행할 수 있습니다. 이것이 실패 투명성입니다.
투명 필름의 조합
모든 분산 데이터베이스 시스템에서 설계자는 명시된 모든 투명성이 상당한 정도로 유지되는지 확인해야합니다. 디자이너는 테이블을 조각화하고 복제하여 다른 사이트에 저장할 수 있습니다. 모두 최종 사용자가 알지 못합니다. 그러나 완전한 유통 투명성은 어려운 작업이며 상당한 설계 노력이 필요합니다.
데이터베이스 제어는 데이터베이스의 실제 사용자와 애플리케이션에 올바른 데이터를 제공하기 위해 규정을 시행하는 작업을 의미합니다. 사용자가 올바른 데이터를 사용할 수 있도록 모든 데이터는 데이터베이스에 정의 된 무결성 제약 조건을 준수해야합니다. 또한 데이터베이스의 보안과 프라이버시를 유지하기 위해 권한이없는 사용자로부터 데이터를 차단해야합니다. 데이터베이스 제어는 데이터베이스 관리자 (DBA)의 기본 작업 중 하나입니다.
데이터베이스 제어의 세 가지 차원은-
- Authentication
- 액세스 권한
- 무결성 제약
입증
분산 데이터베이스 시스템에서 인증은 합법적 인 사용자 만 데이터 리소스에 액세스 할 수있는 프로세스입니다.
인증은 두 가지 수준으로 시행 할 수 있습니다-
Controlling Access to Client Computer−이 수준에서는 데이터베이스 서버에 사용자 인터페이스를 제공하는 클라이언트 컴퓨터에 로그인하는 동안 사용자 액세스가 제한됩니다. 가장 일반적인 방법은 사용자 이름 / 암호 조합입니다. 그러나 높은 보안 데이터에는 생체 인증과 같은보다 정교한 방법이 사용될 수 있습니다.
Controlling Access to the Database Software−이 수준에서 데이터베이스 소프트웨어 / 관리자는 사용자에게 일부 자격 증명을 할당합니다. 사용자는 이러한 자격 증명을 사용하여 데이터베이스에 액세스 할 수 있습니다. 방법 중 하나는 데이터베이스 서버 내에 로그인 계정을 만드는 것입니다.
액세스 권한
사용자의 접근 권한은 테이블 생성, 테이블 삭제, 테이블에 튜플 추가 / 삭제 / 업데이트, 테이블 쿼리 등 DBMS 작업과 관련하여 사용자에게 부여되는 권한을 의미합니다.
분산 환경에서는 테이블이 많지만 사용자 수가 많기 때문에 개별 액세스 권한을 사용자에게 할당하는 것이 불가능합니다. 따라서 DDBMS는 특정 역할을 정의합니다. 역할은 데이터베이스 시스템 내에서 특정 권한이있는 구성입니다. 다른 역할이 정의되면 개별 사용자에게 이러한 역할 중 하나가 할당됩니다. 종종 역할 계층은 조직의 권한 및 책임 계층에 따라 정의됩니다.
예를 들어, 다음 SQL 문은 "Accountant"역할을 만든 다음이 역할을 "ABC"사용자에게 할당합니다.
CREATE ROLE ACCOUNTANT;
GRANT SELECT, INSERT, UPDATE ON EMP_SAL TO ACCOUNTANT;
GRANT INSERT, UPDATE, DELETE ON TENDER TO ACCOUNTANT;
GRANT INSERT, SELECT ON EXPENSE TO ACCOUNTANT;
COMMIT;
GRANT ACCOUNTANT TO ABC;
COMMIT;시맨틱 무결성 제어
의미 론적 무결성 제어는 데이터베이스 시스템의 무결성 제약을 정의하고 시행합니다.
무결성 제약은 다음과 같습니다-
- 데이터 유형 무결성 제약
- 엔티티 무결성 제약
- 참조 무결성 제약
데이터 유형 무결성 제약
데이터 유형 제약 조건은 지정된 데이터 유형을 사용하여 필드에 적용 할 수있는 값의 범위와 작업 유형을 제한합니다.
예를 들어 "HOSTEL"테이블에 호스텔 번호, 호스텔 이름 및 수용 인원의 세 필드가 있다고 가정 해 보겠습니다. 호스텔 번호는 대문자 "H"로 시작해야하며 NULL이 될 수 없으며 용량은 150을 초과 할 수 없습니다. 다음 SQL 명령을 데이터 정의에 사용할 수 있습니다.
CREATE TABLE HOSTEL (
H_NO VARCHAR2(5) NOT NULL,
H_NAME VARCHAR2(15),
CAPACITY INTEGER,
CHECK ( H_NO LIKE 'H%'),
CHECK ( CAPACITY <= 150)
);엔티티 무결성 제어
엔티티 무결성 제어는 각 튜플을 다른 튜플과 고유하게 식별 할 수 있도록 규칙을 적용합니다. 이를 위해 기본 키가 정의됩니다. 기본 키는 튜플을 고유하게 식별 할 수있는 최소 필드 집합입니다. 엔티티 무결성 제약 조건은 테이블의 두 튜플이 기본 키에 대해 동일한 값을 가질 수 없으며 기본 키의 일부인 필드가 NULL 값을 가질 수 없음을 나타냅니다.
예를 들어, 위의 호스텔 테이블에서 호스텔 번호는 다음 SQL 문 (수표 무시)을 통해 기본 키로 할당 될 수 있습니다.
CREATE TABLE HOSTEL (
H_NO VARCHAR2(5) PRIMARY KEY,
H_NAME VARCHAR2(15),
CAPACITY INTEGER
);참조 무결성 제약
참조 무결성 제약 조건은 외래 키 규칙을 설정합니다. 외래 키는 관련 테이블의 기본 키인 데이터 테이블의 필드입니다. 참조 무결성 제약 조건은 외래 키 필드의 값이 참조 된 테이블의 기본 키 값 중 하나이거나 완전히 NULL이어야한다는 규칙을 정합니다.
예를 들어, 학생이 호스텔에 살기를 선택할 수있는 학생 테이블을 생각해 봅시다. 이를 포함하려면 호스텔 테이블의 기본 키가 학생 테이블에 외래 키로 포함되어야합니다. 다음 SQL 문은 이것을 통합합니다-
CREATE TABLE STUDENT (
S_ROLL INTEGER PRIMARY KEY,
S_NAME VARCHAR2(25) NOT NULL,
S_COURSE VARCHAR2(10),
S_HOSTEL VARCHAR2(5) REFERENCES HOSTEL
);쿼리가 배치되면 처음에 검색, 구문 분석 및 유효성 검사가 수행됩니다. 그런 다음 쿼리 트리 또는 쿼리 그래프와 같은 쿼리의 내부 표현이 생성됩니다. 그런 다음 데이터베이스 테이블에서 결과를 검색하기위한 대체 실행 전략이 고 안됩니다. 쿼리 처리에 가장 적합한 실행 전략을 선택하는 프로세스를 쿼리 최적화라고합니다.
DDBMS의 쿼리 최적화 문제
DDBMS에서 쿼리 최적화는 중요한 작업입니다. 다음 요인으로 인해 대체 전략의 수가 기하 급수적으로 증가 할 수 있으므로 복잡성이 높습니다.
- 여러 조각이 있습니다.
- 다양한 사이트에 조각 또는 테이블 배포.
- 통신 링크의 속도.
- 로컬 처리 능력의 차이.
따라서 분산 시스템에서 대상은 쿼리 처리를위한 최상의 실행 전략을 찾는 것입니다. 쿼리를 실행하는 시간은 다음의 합계입니다.
- 데이터베이스에 쿼리를 전달할 시간입니다.
- 로컬 쿼리 조각을 실행할 시간입니다.
- 다른 사이트에서 데이터를 수집 할 시간입니다.
- 애플리케이션에 결과를 표시 할 시간입니다.
쿼리 처리
쿼리 처리는 쿼리 배치부터 쿼리 결과 표시까지 모든 활동의 집합입니다. 단계는 다음 다이어그램과 같습니다.

관계형 대수
관계형 대수는 관계형 데이터베이스 모델의 기본 연산 집합을 정의합니다. 일련의 관계형 대수 연산은 관계형 대수 표현식을 형성합니다. 이 식의 결과는 데이터베이스 쿼리의 결과를 나타냅니다.
기본 작업은-
- Projection
- Selection
- Union
- Intersection
- Minus
- Join
투사
프로젝션 작업은 테이블 필드의 하위 집합을 표시합니다. 이것은 테이블의 수직 분할을 제공합니다.
Syntax in Relational Algebra
$$ \ pi _ {<{AttributeList}>} {(<{테이블 이름}>)} $$
예를 들어, 다음 Student 데이터베이스를 고려해 보겠습니다.
|
|
||||
| Roll_No | Name | Course | Semester | Gender |
| 2 | 아밋 프라 사드 | BCA | 1 | 남성 |
| 4 | 바르샤 티 와리 | BCA | 1 | 여자 |
| 5 | 아시프 알리 | MCA | 2 | 남성 |
| 6 | 조 월리스 | MCA | 1 | 남성 |
| 8 | Shivani Iyengar | BCA | 1 | 여자 |
모든 학생의 이름과 코스를 표시하려면 다음 관계형 대수 표현식을 사용합니다.
$$\pi_{Name,Course}{(STUDENT)}$$
선택
선택 작업은 특정 조건을 충족하는 테이블의 튜플 하위 집합을 표시합니다. 이것은 테이블의 수평 분할을 제공합니다.
Syntax in Relational Algebra
$$ \ sigma _ {<{조건}>} {(<{테이블 이름}>)} $$
예를 들어, 학생 테이블에서 MCA 과정을 선택한 모든 학생의 세부 정보를 표시하려면 다음 관계형 대수 표현식을 사용합니다.
$$\sigma_{Course} = {\small "BCA"}^{(STUDENT)}$$
프로젝션 및 선택 작업의 조합
대부분의 쿼리에는 프로젝션 및 선택 작업의 조합이 필요합니다. 이 표현을 쓰는 데는 두 가지 방법이 있습니다.
- 일련의 투영 및 선택 작업 사용.
- 이름 바꾸기 작업을 사용하여 중간 결과를 생성합니다.
예를 들어, BCA 과정의 모든 여학생의 이름을 표시하려면-
- 일련의 투영 및 선택 연산을 사용한 관계형 대수 표현
$$\pi_{Name}(\sigma_{Gender = \small "Female" AND \: Course = \small "BCA"}{(STUDENT)})$$
- 이름 변경 작업을 사용하여 중간 결과를 생성하는 관계형 대수 표현식
$$FemaleBCAStudent \leftarrow \sigma_{Gender = \small "Female" AND \: Course = \small "BCA"} {(STUDENT)}$$
$$Result \leftarrow \pi_{Name}{(FemaleBCAStudent)}$$
노동 조합
P가 연산의 결과이고 Q가 다른 연산의 결과이면 P와 Q의 합집합 ($p \cup Q$)는 P 또는 Q 또는 둘 다에있는 모든 튜플의 집합입니다.
예를 들어, 1 학기 또는 BCA 과정에있는 모든 학생을 표시하려면-
$$Sem1Student \leftarrow \sigma_{Semester = 1}{(STUDENT)}$$
$$BCAStudent \leftarrow \sigma_{Course = \small "BCA"}{(STUDENT)}$$
$$Result \leftarrow Sem1Student \cup BCAStudent$$
교차로
P가 연산의 결과이고 Q가 다른 연산의 결과이면 P와 Q의 교차점 ( $p \cap Q$ )는 P와 Q 모두에있는 모든 튜플의 집합입니다.
예를 들어, 다음 두 스키마가 주어지면-
EMPLOYEE
| EmpID | 이름 | 시티 | 학과 | 봉급 |
PROJECT
| PId | 시티 | 학과 | 상태 |
프로젝트가 있고 직원이 거주하는 모든 도시의 이름을 표시하려면-
$$CityEmp \leftarrow \pi_{City}{(EMPLOYEE)}$$
$$CityProject \leftarrow \pi_{City}{(PROJECT)}$$
$$Result \leftarrow CityEmp \cap CityProject$$
마이너스
P가 작업의 결과이고 Q가 다른 작업의 결과 인 경우 P-Q는 Q가 아닌 P에있는 모든 튜플의 집합입니다.
예를 들어 진행중인 프로젝트가없는 모든 부서를 나열하려면 (상태 = 진행중인 프로젝트)-
$$AllDept \leftarrow \pi_{Department}{(EMPLOYEE)}$$
$$ProjectDept \leftarrow \pi_{Department} (\sigma_{Status = \small "ongoing"}{(PROJECT)})$$
$$Result \leftarrow AllDept - ProjectDept$$
어울리다
조인 작업은 두 개의 서로 다른 테이블 (쿼리 결과)의 관련 튜플을 단일 테이블로 결합합니다.
예를 들어, 다음과 같이 Bank 데이터베이스의 두 스키마, Customer 및 Branch를 고려하십시오.
CUSTOMER
| CustID | AccNo | TypeOfAc | BranchID | 개점 일 |
BRANCH
| BranchID | 지점명 | IFSCcode | 주소 |
지점 세부 정보와 함께 직원 세부 정보를 나열하려면-
$$Result \leftarrow CUSTOMER \bowtie_{Customer.BranchID=Branch.BranchID}{BRANCH}$$
SQL 쿼리를 관계형 대수로 변환
SQL 쿼리는 최적화 전에 동등한 관계형 대수 표현식으로 변환됩니다. 쿼리는 처음에 더 작은 쿼리 블록으로 분해됩니다. 이러한 블록은 동등한 관계형 대수 표현식으로 변환됩니다. 최적화에는 각 블록의 최적화와 쿼리 전체의 최적화가 포함됩니다.
예
다음 스키마를 고려해 보겠습니다.
종업원
| EmpID | 이름 | 시티 | 학과 | 봉급 |
계획
| PId | 시티 | 학과 | 상태 |
공장
| EmpID | PID | 시간 |
예 1
평균 급여보다 적은 급여를받는 모든 직원의 세부 정보를 표시하기 위해 SQL 쿼리를 작성합니다.
SELECT * FROM EMPLOYEE
WHERE SALARY < ( SELECT AVERAGE(SALARY) FROM EMPLOYEE ) ;이 쿼리에는 하나의 중첩 된 하위 쿼리가 포함됩니다. 따라서 이것은 두 블록으로 나눌 수 있습니다.
내부 블록은-
SELECT AVERAGE(SALARY)FROM EMPLOYEE ;이 쿼리의 결과가 AvgSal이면 외부 블록은-
SELECT * FROM EMPLOYEE WHERE SALARY < AvgSal;내부 블록에 대한 관계형 대수식 −
$$AvgSal \leftarrow \Im_{AVERAGE(Salary)}{EMPLOYEE}$$
외부 블록에 대한 관계형 대수식-
$$ \ sigma_ {급여 <{AvgSal}>} {EMPLOYEE} $$
예 2
직원 'Arun Kumar'의 모든 프로젝트의 프로젝트 ID와 상태를 표시하기 위해 SQL 쿼리를 작성합니다.
SELECT PID, STATUS FROM PROJECT
WHERE PID = ( SELECT FROM WORKS WHERE EMPID = ( SELECT EMPID FROM EMPLOYEE
WHERE NAME = 'ARUN KUMAR'));이 쿼리에는 두 개의 중첩 된 하위 쿼리가 포함됩니다. 따라서 다음과 같이 세 블록으로 나눌 수 있습니다.
SELECT EMPID FROM EMPLOYEE WHERE NAME = 'ARUN KUMAR';
SELECT PID FROM WORKS WHERE EMPID = ArunEmpID;
SELECT PID, STATUS FROM PROJECT WHERE PID = ArunPID;(여기서 ArunEmpID 및 ArunPID는 내부 쿼리의 결과입니다.)
세 블록에 대한 관계형 대수식은 다음과 같습니다.
$$ArunEmpID \leftarrow \pi_{EmpID}(\sigma_{Name = \small "Arun Kumar"} {(EMPLOYEE)})$$
$$ArunPID \leftarrow \pi_{PID}(\sigma_{EmpID = \small "ArunEmpID"} {(WORKS)})$$
$$Result \leftarrow \pi_{PID, Status}(\sigma_{PID = \small "ArunPID"} {(PROJECT)})$$
관계형 대수 연산자의 계산
관계형 대수 연산자의 계산은 다양한 방법으로 수행 할 수 있으며 각 대안을 access path.
계산 대안은 세 가지 주요 요인에 따라 달라집니다.
- 연산자 유형
- 사용 가능한 메모리
- 디스크 구조
관계형 대수 연산을 실행하는 데 걸리는 시간은 다음의 합계입니다.
- 튜플을 처리 할 시간입니다.
- 디스크에서 메모리로 테이블의 튜플을 가져올 시간입니다.
튜플을 처리하는 시간은 스토리지, 특히 분산 시스템에서 튜플을 가져 오는 시간보다 훨씬 적기 때문에 디스크 액세스는 관계식 비용을 계산하는 척도로 간주되는 경우가 많습니다.
선택 계산
선택 연산의 계산은 선택 조건의 복잡성과 테이블 속성의 인덱스 가용성에 따라 달라집니다.
다음은 인덱스에 따른 계산 대안입니다.
No Index− 테이블이 정렬되지 않고 인덱스가없는 경우 선택 프로세스에는 테이블의 모든 디스크 블록을 스캔하는 작업이 포함됩니다. 각 블록을 메모리로 가져오고 블록의 각 튜플을 검사하여 선택 조건을 충족하는지 확인합니다. 조건이 만족되면 출력으로 표시됩니다. 이것은 각 튜플이 메모리로 가져오고 각 튜플이 처리되기 때문에 가장 비용이 많이 드는 접근 방식입니다.
B+ Tree Index− 대부분의 데이터베이스 시스템은 B + 트리 인덱스를 기반으로합니다. 선택 조건이이 B + 트리 인덱스의 키인 필드를 기반으로하는 경우이 인덱스는 결과 검색에 사용됩니다. 그러나 복잡한 조건이있는 선택 문을 처리하려면 더 많은 디스크 블록 액세스가 필요하고 경우에 따라 테이블을 완전히 검색해야합니다.
Hash Index− 해시 인덱스를 사용하고 해당 키 필드를 선택 조건에서 사용하는 경우 해시 인덱스를 사용하여 튜플을 검색하는 것은 간단한 프로세스가됩니다. 해시 인덱스는 해시 함수를 사용하여 해시 값에 해당하는 키 값이 저장된 버킷의 주소를 찾습니다. 인덱스에서 키 값을 찾기 위해 해시 함수를 실행하고 버킷 주소를 찾습니다. 버킷의 키 값이 검색됩니다. 일치하는 것이 발견되면 실제 튜플을 디스크 블록에서 메모리로 가져옵니다.
조인 계산
두 테이블 (예 : P와 Q)을 조인하려면 P의 각 튜플을 Q의 각 튜플과 비교하여 조인 조건이 충족되는지 테스트해야합니다. 조건이 충족되면 해당 튜플이 연결되어 중복 필드를 제거하고 결과 관계에 추가됩니다. 결과적으로 이것은 가장 비용이 많이 드는 작업입니다.
조인을 계산하는 일반적인 접근 방식은 다음과 같습니다.
중첩 루프 접근법
이것은 일반적인 조인 접근 방식입니다. 다음 의사 코드를 통해 설명 할 수 있습니다 (테이블 P 및 Q, tuple_p 및 tuple_q 및 결합 속성 a)-
For each tuple_p in P
For each tuple_q in Q
If tuple_p.a = tuple_q.a Then
Concatenate tuple_p and tuple_q and append to Result
End If
Next tuple_q
Next tuple-p정렬-병합 접근법
이 접근 방식에서 두 테이블은 조인 속성에 따라 개별적으로 정렬 된 다음 정렬 된 테이블이 병합됩니다. 레코드 수가 매우 많고 메모리에 수용 할 수 없기 때문에 외부 정렬 기술이 채택되었습니다. 개별 테이블이 정렬되면 정렬 된 각 테이블이 메모리로 가져와 결합 속성에 따라 병합되고 결합 된 튜플이 기록됩니다.
해시 조인 방식
이 접근 방식은 분할 단계와 프로빙 단계의 두 단계로 구성됩니다. 분할 단계에서 테이블 P와 Q는 두 세트의 분리 된 분할로 나뉩니다. 공통 해시 함수가 결정됩니다. 이 해시 함수는 파티션에 튜플을 할당하는 데 사용됩니다. 프로빙 단계에서 P의 파티션에있는 튜플은 Q의 해당 파티션에있는 튜플과 비교됩니다. 일치하면 기록됩니다.
관계형 대수식 계산을위한 대체 액세스 경로가 파생되면 최적의 액세스 경로가 결정됩니다. 이 장에서는 중앙 집중식 시스템에서 쿼리 최적화를 살펴보고 다음 장에서는 분산 시스템에서 쿼리 최적화를 살펴 보겠습니다.
중앙 집중식 시스템에서 쿼리 처리는 다음과 같은 목적으로 수행됩니다.
질의 응답 시간 최소화 (사용자 질의에 대한 결과 생성에 소요되는 시간)
시스템 처리량 (주어진 시간 동안 처리되는 요청 수)을 최대화합니다.
처리에 필요한 메모리 및 스토리지 양을 줄이십시오.
병렬 처리를 늘리십시오.
쿼리 구문 분석 및 번역
처음에는 SQL 쿼리가 스캔됩니다. 그런 다음 구문 오류 및 데이터 유형의 정확성을 찾기 위해 구문 분석됩니다. 쿼리가이 단계를 통과하면 쿼리가 더 작은 쿼리 블록으로 분해됩니다. 그런 다음 각 블록은 동등한 관계형 대수식으로 변환됩니다.
쿼리 최적화를위한 단계
쿼리 최적화에는 쿼리 트리 생성, 계획 생성 및 쿼리 계획 코드 생성의 세 단계가 포함됩니다.
Step 1 − Query Tree Generation
쿼리 트리는 관계형 대수 표현식을 나타내는 트리 데이터 구조입니다. 쿼리 테이블은 리프 노드로 표시됩니다. 관계형 대수 연산은 내부 노드로 표시됩니다. 루트는 쿼리 전체를 나타냅니다.
실행 중에 내부 노드는 피연산자 테이블을 사용할 수있을 때마다 실행됩니다. 그런 다음 노드는 결과 테이블로 대체됩니다. 이 프로세스는 루트 노드가 실행되고 결과 테이블로 대체 될 때까지 모든 내부 노드에 대해 계속됩니다.
예를 들어, 다음 스키마를 고려해 보겠습니다.
종업원
| EmpID | EName | 봉급 | 부서 번호 | DateOfJoining |
학과
| D 아니 | DName | 위치 |
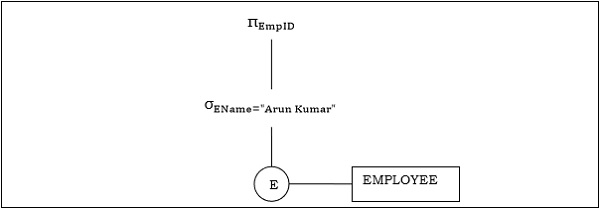
예 1
쿼리를 다음과 같이 생각해 봅시다.
$$\pi_{EmpID} (\sigma_{EName = \small "ArunKumar"} {(EMPLOYEE)})$$
해당 쿼리 트리는-
예 2
조인과 관련된 다른 쿼리를 고려해 보겠습니다.
$\pi_{EName, Salary} (\sigma_{DName = \small "Marketing"} {(DEPARTMENT)}) \bowtie_{DNo=DeptNo}{(EMPLOYEE)}$
다음은 위 쿼리에 대한 쿼리 트리입니다.

Step 2 − Query Plan Generation
쿼리 트리가 생성 된 후 쿼리 계획이 작성됩니다. 쿼리 계획은 쿼리 트리의 모든 작업에 대한 액세스 경로를 포함하는 확장 쿼리 트리입니다. 액세스 경로는 트리에서 관계형 작업을 수행하는 방법을 지정합니다. 예를 들어, 선택 작업에는 선택을위한 B + 트리 인덱스 사용에 대한 세부 정보를 제공하는 액세스 경로가있을 수 있습니다.
또한 쿼리 계획에는 한 연산자에서 다음 연산자로 중간 테이블을 전달하는 방법, 임시 테이블을 사용하는 방법 및 작업을 파이프 라인 / 결합하는 방법도 나와 있습니다.
Step 3− Code Generation
코드 생성은 쿼리 최적화의 마지막 단계입니다. 쿼리의 실행 가능한 형식이며, 그 형식은 기본 운영 체제의 유형에 따라 다릅니다. 쿼리 코드가 생성되면 Execution Manager가이를 실행하고 결과를 생성합니다.
쿼리 최적화에 대한 접근 방식
쿼리 최적화를위한 접근 방식 중 대부분은 철저한 검색 및 휴리스틱 기반 알고리즘이 사용됩니다.
철저한 검색 최적화
이러한 기술에서는 쿼리에 대해 가능한 모든 쿼리 계획이 처음에 생성 된 다음 최상의 계획이 선택됩니다. 이러한 기술이 최상의 솔루션을 제공하지만 솔루션 공간이 크기 때문에 시간과 공간이 기하 급수적으로 복잡해집니다. 예를 들어, 동적 프로그래밍 기술입니다.
휴리스틱 기반 최적화
휴리스틱 기반 최적화는 쿼리 최적화를 위해 규칙 기반 최적화 접근 방식을 사용합니다. 이러한 알고리즘은 다항식 시간 및 공간 복잡도를 가지며 이는 철저한 검색 기반 알고리즘의 지수 복잡도보다 낮습니다. 그러나 이러한 알고리즘이 반드시 최상의 쿼리 계획을 생성하는 것은 아닙니다.
일반적인 휴리스틱 규칙 중 일부는 다음과 같습니다.
조인 작업 전에 선택 및 프로젝트 작업을 수행합니다. 이 작업은 선택 및 프로젝트 작업을 쿼리 트리 아래로 이동하여 수행됩니다. 이렇게하면 조인에 사용할 수있는 튜플 수가 줄어 듭니다.
다른 작업보다 먼저 가장 제한적인 선택 / 프로젝트 작업을 수행합니다.
중간 테이블 크기가 매우 커지므로 교차 제품 작업을 피하십시오.
이 장에서는 분산 데이터베이스 시스템의 쿼리 최적화에 대해 설명합니다.
분산 쿼리 처리 아키텍처
분산 데이터베이스 시스템에서 쿼리 처리는 글로벌 및 로컬 수준 모두에서 최적화로 구성됩니다. 쿼리는 클라이언트 또는 제어 사이트의 데이터베이스 시스템에 입력됩니다. 여기에서 사용자의 유효성이 검사되고 쿼리가 글로벌 수준에서 확인, 번역 및 최적화됩니다.
아키텍처는 다음과 같이 나타낼 수 있습니다.
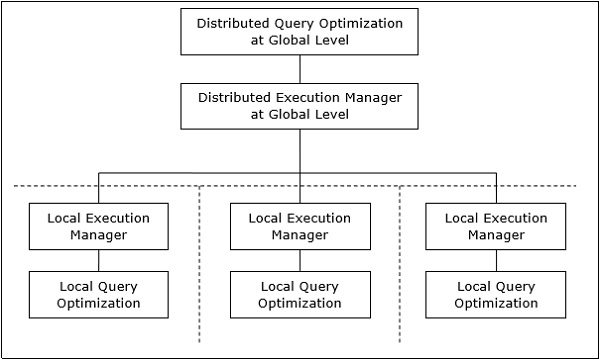
글로벌 쿼리를 로컬 쿼리에 매핑
전역 쿼리를 로컬 쿼리에 매핑하는 프로세스는 다음과 같이 실현할 수 있습니다.
전역 쿼리에 필요한 테이블에는 여러 사이트에 분산 된 조각이 있습니다. 로컬 데이터베이스에는 로컬 데이터에 대한 정보 만 있습니다. 제어 사이트는 전역 데이터 사전을 사용하여 배포에 대한 정보를 수집하고 조각에서 전역보기를 재구성합니다.
복제가없는 경우 글로벌 최적화 프로그램은 조각이 저장된 사이트에서 로컬 쿼리를 실행합니다. 복제가있는 경우 글로벌 최적화 프로그램은 통신 비용, 워크로드 및 서버 속도에 따라 사이트를 선택합니다.
글로벌 옵티마이 저는 사이트에서 최소한의 데이터 전송이 발생하도록 분산 실행 계획을 생성합니다. 계획은 조각의 위치, 쿼리 단계를 실행해야하는 순서 및 중간 결과 전송과 관련된 프로세스를 명시합니다.
로컬 쿼리는 로컬 데이터베이스 서버에 의해 최적화됩니다. 마지막으로 로컬 쿼리 결과는 수평 조각의 경우 유니온 연산, 수직 조각의 경우 조인 연산을 통해 병합됩니다.
예를 들어, 다음 프로젝트 스키마는 도시에 따라 수평으로 분할되어 있으며, 도시는 뉴 델리, 콜카타 및 하이데라바드입니다.
계획
| PId | 시티 | 학과 | 상태 |
상태가 "진행 중"인 모든 프로젝트의 세부 정보를 검색하는 쿼리가 있다고 가정합니다.
글로벌 쿼리는 & inus;
$$\sigma_{status} = {\small "ongoing"}^{(PROJECT)}$$
뉴 델리 서버의 쿼리는-
$$\sigma_{status} = {\small "ongoing"}^{({NewD}_-{PROJECT})}$$
콜카타 서버의 쿼리는-
$$\sigma_{status} = {\small "ongoing"}^{({Kol}_-{PROJECT})}$$
Hyderabad 서버의 쿼리는 다음과 같습니다.
$$\sigma_{status} = {\small "ongoing"}^{({Hyd}_-{PROJECT})}$$
전체 결과를 얻으려면 다음과 같이 세 가지 쿼리의 결과를 통합해야합니다.
$\sigma_{status} = {\small "ongoing"}^{({NewD}_-{PROJECT})} \cup \sigma_{status} = {\small "ongoing"}^{({kol}_-{PROJECT})} \cup \sigma_{status} = {\small "ongoing"}^{({Hyd}_-{PROJECT})}$
분산 쿼리 최적화
분산 쿼리 최적화를 위해서는 각각 필요한 쿼리 결과를 생성하는 많은 쿼리 트리를 평가해야합니다. 이는 주로 많은 양의 복제 및 조각화 된 데이터가 있기 때문입니다. 따라서 목표는 최상의 솔루션 대신 최적의 솔루션을 찾는 것입니다.
분산 쿼리 최적화의 주요 문제는 다음과 같습니다.
- 분산 시스템에서 리소스를 최적으로 활용합니다.
- 쿼리 거래.
- 쿼리의 솔루션 공간 감소.
분산 시스템에서 자원의 최적 활용
분산 시스템에는 쿼리와 관련된 작업을 수행하기 위해 다양한 사이트에 여러 데이터베이스 서버가 있습니다. 다음은 최적의 리소스 활용을위한 접근 방식입니다.
Operation Shipping− 작업 출하시 작업은 클라이언트 사이트가 아닌 데이터가 저장된 사이트에서 실행됩니다. 그런 다음 결과가 클라이언트 사이트로 전송됩니다. 동일한 사이트에서 피연산자를 사용할 수있는 작업에 적합합니다. 예 : 선택 및 프로젝트 작업.
Data Shipping− 데이터 전달에서 데이터 조각은 작업이 실행되는 데이터베이스 서버로 전송됩니다. 피연산자가 서로 다른 사이트에 배포되는 작업에 사용됩니다. 이는 통신 비용이 낮고 로컬 프로세서가 클라이언트 서버보다 훨씬 느린 시스템에서도 적합합니다.
Hybrid Shipping− 이것은 데이터와 운영 배송의 조합입니다. 여기서 데이터 조각은 작업이 실행되는 고속 프로세서로 전송됩니다. 결과는 클라이언트 사이트로 전송됩니다.

쿼리 거래
분산 데이터베이스 시스템의 쿼리 거래 알고리즘에서 분산 쿼리를위한 제어 / 클라이언트 사이트를 구매자라고하고 로컬 쿼리가 실행되는 사이트를 판매자라고합니다. 구매자는 판매자를 선택하고 글로벌 결과를 재구성하기위한 여러 대안을 공식화합니다. 구매자의 목표는 최적의 비용을 달성하는 것입니다.
알고리즘은 구매자가 판매자 사이트에 하위 쿼리를 할당하는 것으로 시작됩니다. 최종 결과를 재구성하기위한 통신 비용과 결합 된 판매자가 제안한 지역 최적화 된 쿼리 계획에서 최적의 계획이 생성됩니다. 글로벌 최적 계획이 수립되면 쿼리가 실행됩니다.
쿼리의 솔루션 공간 감소
최적의 솔루션은 일반적으로 솔루션 공간을 줄여 쿼리 및 데이터 전송 비용을 줄이는 것입니다. 이는 중앙 집중식 시스템의 휴리스틱과 마찬가지로 일련의 휴리스틱 규칙을 통해 달성 할 수 있습니다.
다음은 몇 가지 규칙입니다.
가능한 한 빨리 선택 및 투영 작업을 수행하십시오. 이것은 통신 네트워크를 통한 데이터 흐름을 줄입니다.
특정 사이트와 관련이없는 선택 조건을 제거하여 수평 조각에 대한 작업을 단순화합니다.
여러 사이트에 위치한 Fragment로 구성된 Join 및 Union 작업의 경우, 대부분의 데이터가 존재하는 사이트로 단편화 된 데이터를 전송하고 그곳에서 작업을 수행합니다.
세미 조인 작업을 사용하여 조인 할 튜플을 한정합니다. 이는 데이터 전송량을 줄여 통신 비용을 줄여줍니다.
분산 쿼리 트리에서 일반적인 잎과 하위 트리를 병합합니다.
이 장에서는 트랜잭션 처리의 다양한 측면에 대해 설명합니다. 또한 트랜잭션에 포함 된 저수준 작업, 트랜잭션 상태 및 트랜잭션 속성을 연구합니다. 마지막 부분에서는 일정과 일정의 직렬화 가능성에 대해 살펴 보겠습니다.
업무
트랜잭션은 데이터 처리의 논리적 단위로 실행되는 데이터베이스 작업 모음을 포함하는 프로그램입니다. 트랜잭션에서 수행되는 작업에는 데이터 삽입, 삭제, 업데이트 또는 검색과 같은 하나 이상의 데이터베이스 작업이 포함됩니다. 완전히 완료되거나 전혀 수행되지 않는 원자 프로세스입니다. 데이터 업데이트없이 데이터 검색 만 포함하는 트랜잭션을 읽기 전용 트랜잭션이라고합니다.
각 상위 수준 작업은 여러 하위 수준 작업 또는 작업으로 나눌 수 있습니다. 예를 들어, 데이터 업데이트 작업은 세 가지 작업으로 나눌 수 있습니다.
read_item() − 스토리지에서 메인 메모리로 데이터 항목을 읽습니다.
modify_item() − 메인 메모리의 항목 값을 변경합니다.
write_item() − 수정 된 값을 메인 메모리에서 저장 장치로 씁니다.
데이터베이스 액세스는 read_item () 및 write_item () 작업으로 제한됩니다. 마찬가지로 모든 트랜잭션에 대해 읽기 및 쓰기가 기본 데이터베이스 작업을 구성합니다.
거래 운영
트랜잭션에서 수행되는 낮은 수준의 작업은 다음과 같습니다.
begin_transaction − 트랜잭션 실행 시작을 지정하는 마커.
read_item or write_item − 트랜잭션의 일부로 주 메모리 작업과 인터리브 될 수있는 데이터베이스 작업.
end_transaction − 거래 종료를 지정하는 마커.
commit − 거래가 완전히 성공적으로 완료되었으며 취소되지 않을 것임을 지정하는 신호.
rollback− 트랜잭션이 실패하여 데이터베이스의 모든 임시 변경이 취소되었음을 지정하는 신호. 커밋 된 트랜잭션은 롤백 할 수 없습니다.
거래 상태
트랜잭션은 활성, 부분 커밋, 커밋, 실패 및 중단의 다섯 가지 상태의 하위 집합을 통과 할 수 있습니다.
Active− 트랜잭션이 시작되는 초기 상태가 활성 상태입니다. 트랜잭션은 읽기, 쓰기 또는 기타 작업을 실행하는 동안이 상태로 유지됩니다.
Partially Committed − 트랜잭션의 마지막 명령문이 실행 된 후 트랜잭션이이 상태로 들어갑니다.
Committed − 트랜잭션이 성공적으로 완료되고 시스템 검사가 커밋 신호를 발행 한 후 트랜잭션이이 상태로 들어갑니다.
Failed − 트랜잭션은 정상적인 실행이 더 이상 진행되지 않거나 시스템 검사가 실패한 경우 부분적으로 커밋 된 상태 또는 활성 상태에서 실패한 상태로 바뀝니다.
Aborted − 트랜잭션이 실패 후 롤백되고 데이터베이스가 트랜잭션이 시작되기 전의 상태로 복원 된 후의 상태입니다.
다음 상태 전환 다이어그램은 트랜잭션의 상태와 상태 변경을 유발하는 저수준 트랜잭션 작업을 보여줍니다.
거래의 바람직한 속성
모든 트랜잭션은 ACID 속성을 유지해야합니다. 원 자성, 일관성, 격리 및 내구성.
Atomicity−이 속성은 트랜잭션이 처리의 원자 단위, 즉 전체적으로 수행되거나 전혀 수행되지 않음을 나타냅니다. 부분 업데이트가 없어야합니다.
Consistency− 트랜잭션은 하나의 일관된 상태에서 다른 일관된 상태로 데이터베이스를 가져와야합니다. 데이터베이스의 데이터 항목에 부정적인 영향을주지 않아야합니다.
Isolation− 트랜잭션은 시스템에서 유일한 트랜잭션 인 것처럼 실행되어야합니다. 동시에 실행되는 다른 동시 트랜잭션의 간섭이 없어야합니다.
Durability − 커밋 된 트랜잭션으로 인해 변경이 발생하는 경우 해당 변경은 데이터베이스에서 지속되어야하며 오류가 발생하더라도 손실되지 않아야합니다.
일정 및 충돌
다수의 동시 트랜잭션이있는 시스템에서 schedule작업 실행의 총 순서입니다. n 개의 트랜잭션으로 구성된 스케줄 S가 주어지면, T1, T2, T3 ……… ..Tn이라고 말하십시오; 모든 트랜잭션 Ti에 대해 Ti의 작업은 일정 S에 명시된대로 실행되어야합니다.
일정 유형
두 가지 유형의 일정이 있습니다-
Serial Schedules− 연속 일정에서는 어느 시점에서든 하나의 트랜잭션 만 활성화됩니다. 즉, 트랜잭션이 겹치지 않습니다. 이것은 다음 그래프에 묘사되어 있습니다-

Parallel Schedules− 병렬 일정에서 둘 이상의 트랜잭션이 동시에 활성화됩니다. 즉, 트랜잭션에는 시간에 겹치는 작업이 포함됩니다. 이것은 다음 그래프에 묘사되어 있습니다-

일정의 충돌
여러 트랜잭션으로 구성된 일정에서 conflict두 개의 활성 트랜잭션이 호환되지 않는 작업을 수행 할 때 발생합니다. 다음 세 가지 조건이 모두 동시에 존재하는 경우 두 작업이 충돌한다고합니다.
두 작업은 서로 다른 트랜잭션의 일부입니다.
두 작업 모두 동일한 데이터 항목에 액세스합니다.
작업 중 적어도 하나는 write_item () 작업입니다. 즉, 데이터 항목을 수정하려고합니다.
직렬화 가능성
ㅏ serializable scheduleof 'n'트랜잭션은 동일한 'n'트랜잭션으로 구성된 직렬 일정과 동일한 병렬 일정입니다. 직렬화 가능한 일정에는 병렬 일정의 CPU 사용률을 높이는 동시에 직렬 일정의 정확성이 포함됩니다.
일정의 동등성
두 일정의 동등성은 다음 유형이 될 수 있습니다.
Result equivalence − 동일한 결과를 생성하는 두 개의 스케줄은 결과가 동등하다고합니다.
View equivalence − 유사한 방식으로 유사한 작업을 수행하는 두 개의 일정을 동등한 뷰라고합니다.
Conflict equivalence − 두 일정이 모두 동일한 트랜잭션 집합을 포함하고 충돌하는 작업 쌍의 순서가 같으면 두 일정이 충돌하는 것으로 간주됩니다.
동시성 제어 기술은 트랜잭션의 ACID 속성과 일정의 직렬 성을 유지하면서 여러 트랜잭션이 동시에 실행되도록합니다.
이 장에서는 동시성 제어에 대한 다양한 접근 방식을 연구합니다.
잠금 기반 동시성 제어 프로토콜
잠금 기반 동시성 제어 프로토콜은 데이터 항목 잠금 개념을 사용합니다. ㅏlock데이터 항목에 대해 읽기 / 쓰기 작업을 수행 할 수 있는지 여부를 결정하는 데이터 항목과 관련된 변수입니다. 일반적으로 데이터 항목이 동시에 두 트랜잭션에 의해 잠길 수 있는지 여부를 나타내는 잠금 호환성 매트릭스가 사용됩니다.
잠금 기반 동시성 제어 시스템은 1 단계 또는 2 단계 잠금 프로토콜을 사용할 수 있습니다.
단상 잠금 프로토콜
이 방법에서 각 트랜잭션은 사용하기 전에 항목을 잠그고 사용이 완료되는 즉시 잠금을 해제합니다. 이 잠금 방법은 최대 동시성을 제공하지만 항상 직렬 성을 적용하지는 않습니다.
2 단계 잠금 프로토콜
이 방법에서는 모든 잠금 작업이 첫 번째 잠금 해제 또는 잠금 해제 작업보다 우선합니다. 거래는 두 단계로 구성됩니다. 첫 번째 단계에서 트랜잭션은 필요한 모든 잠금 만 획득하고 잠금을 해제하지 않습니다. 이를 확장 또는growing phase. 두 번째 단계에서 트랜잭션은 잠금을 해제하고 새 잠금을 요청할 수 없습니다. 이것은shrinking phase.
2 단계 잠금 프로토콜을 따르는 모든 트랜잭션은 직렬화 할 수 있습니다. 그러나이 접근 방식은 충돌하는 두 트랜잭션간에 낮은 병렬성을 제공합니다.
타임 스탬프 동시성 제어 알고리즘
타임 스탬프 기반 동시성 제어 알고리즘은 트랜잭션의 타임 스탬프를 사용하여 데이터 항목에 대한 동시 액세스를 조정하여 직렬 성을 보장합니다. 타임 스탬프는 DBMS가 트랜잭션의 시작 시간을 나타내는 트랜잭션에 제공하는 고유 식별자입니다.
이러한 알고리즘은 트랜잭션이 타임 스탬프에 지정된 순서대로 커밋되도록합니다. 오래된 트랜잭션이 더 젊은 트랜잭션보다 먼저 시스템에 들어가기 때문에 더 오래된 트랜잭션이 더 젊은 트랜잭션보다 먼저 커밋되어야합니다.
타임 스탬프 기반 동시성 제어 기술은 동일한 직렬 일정이 참여하는 트랜잭션의 나이 순서대로 정렬되도록 직렬화 가능한 일정을 생성합니다.
타임 스탬프 기반 동시성 제어 알고리즘 중 일부는 다음과 같습니다.
- 기본 타임 스탬프 순서 알고리즘.
- 보수적 인 타임 스탬프 순서 알고리즘.
- 타임 스탬프 순서를 기반으로하는 다중 버전 알고리즘.
타임 스탬프 기반 순서는 직렬 성을 적용하기 위해 세 가지 규칙을 따릅니다.
Access Rule− 두 트랜잭션이 동일한 데이터 항목에 동시에 액세스하려고 할 때 충돌하는 작업에 대해 이전 트랜잭션에 우선 순위가 부여됩니다. 이로 인해 더 젊은 트랜잭션은 이전 트랜잭션이 먼저 커밋 될 때까지 기다립니다.
Late Transaction Rule− 더 젊은 트랜잭션이 데이터 항목을 쓴 경우 이전 트랜잭션은 해당 데이터 항목을 읽거나 쓸 수 없습니다. 이 규칙은 더 젊은 트랜잭션이 이미 커밋 된 후 이전 트랜잭션이 커밋되지 않도록합니다.
Younger Transaction Rule − 젊은 트랜잭션은 이전 트랜잭션에 의해 이미 작성된 데이터 항목을 읽거나 쓸 수 있습니다.
낙관적 동시성 제어 알고리즘
충돌 률이 낮은 시스템에서는 모든 트랜잭션의 직렬 성을 확인하는 작업이 성능을 저하시킬 수 있습니다. 이 경우 직렬 성 테스트는 커밋 직전에 연기됩니다. 충돌 률이 낮기 때문에 직렬화 할 수없는 트랜잭션을 중단 할 가능성도 낮습니다. 이 접근 방식을 낙관적 동시성 제어 기술이라고합니다.
이 접근 방식에서 트랜잭션의 수명주기는 다음 세 단계로 나뉩니다.
Execution Phase − 트랜잭션은 데이터 항목을 메모리로 가져 와서 작업을 수행합니다.
Validation Phase − 트랜잭션은 데이터베이스에 대한 변경 사항 커밋이 직렬 성 테스트를 통과하는지 확인하기 위해 검사를 수행합니다.
Commit Phase − 트랜잭션은 메모리의 수정 된 데이터 항목을 디스크에 다시 기록합니다.
이 알고리즘은 유효성 검사 단계에서 직렬 성을 적용하기 위해 세 가지 규칙을 사용합니다.
Rule 1- 두 개의 트랜잭션 T 주어 I 및 T의 j는 T 경우 나 T의 데이터 항목 읽고 J가 작성된다 후 T I 의 실행 단계 수없는 오버랩 T를 가진 J 의 위상을 저지한다. T j 는 T i 가 실행을 마친 후에 만 커밋 할 수 있습니다 .
Rule 2- 두 개의 트랜잭션 T 주어 I 및 T의 j는 T 경우 나 T에있는 데이터 항목을 작성한다 J가 판독되어, 다음 T I 's는 T하지 오버랩 위상 수 커밋 J 의 실행 단계'. T j 는 T i 가 이미 커밋 된 후에 만 실행을 시작할 수 있습니다 .
Rule 3- 두 개의 트랜잭션 T 주어 I 및 T의 j는 T 경우 나 T의 데이터 항목을 작성한다 j는 또한 기록된다 후 T I 'S는 T에하지 오버랩 위상 수 커밋 J 의 위상 커밋'. T j 는 T i 가 이미 커밋 한 후에 만 커밋을 시작할 수 있습니다 .
분산 시스템의 동시성 제어
이 섹션에서는 위의 기술이 분산 데이터베이스 시스템에서 어떻게 구현되는지 살펴 보겠습니다.
분산 2 단계 잠금 알고리즘
분산 2 단계 잠금의 기본 원리는 기본 2 단계 잠금 프로토콜과 동일합니다. 그러나 분산 시스템에는 잠금 관리자로 지정된 사이트가 있습니다. 잠금 관리자는 트랜잭션 모니터의 잠금 획득 요청을 제어합니다. 다양한 사이트에서 잠금 관리자 간의 조정을 시행하기 위해 적어도 하나의 사이트에 모든 트랜잭션을보고 잠금 충돌을 감지 할 수있는 권한이 부여됩니다.
잠금 충돌을 감지 할 수있는 사이트의 수에 따라 분산 2 단계 잠금 방식은 세 가지 유형이 있습니다.
Centralized two-phase locking−이 접근 방식에서는 한 사이트가 중앙 잠금 관리자로 지정됩니다. 환경의 모든 사이트는 중앙 잠금 관리자의 위치를 알고 트랜잭션 중에 잠금을 얻습니다.
Primary copy two-phase locking−이 접근 방식에서는 여러 사이트가 잠금 제어 센터로 지정됩니다. 이러한 각 사이트는 정의 된 잠금 집합을 관리 할 책임이 있습니다. 모든 사이트는 어떤 잠금 제어 센터가 어떤 데이터 테이블 / 조각 항목의 잠금을 관리 할 책임이 있는지 알고 있습니다.
Distributed two-phase locking−이 접근 방식에는 여러 잠금 관리자가 있으며 각 잠금 관리자는 로컬 사이트에 저장된 데이터 항목의 잠금을 제어합니다. 잠금 관리자의 위치는 데이터 분배 및 복제를 기반으로합니다.
분산 된 타임 스탬프 동시성 제어
중앙 집중식 시스템에서 모든 트랜잭션의 타임 스탬프는 물리적 클록 판독에 의해 결정됩니다. 그러나 분산 시스템에서는 사이트의 로컬 물리적 / 논리적 시계 판독 값이 전역 적으로 고유하지 않기 때문에 전역 타임 스탬프로 사용할 수 없습니다. 따라서 타임 스탬프는 사이트 ID와 해당 사이트의 시계 판독 값의 조합으로 구성됩니다.
타임 스탬프 순서 알고리즘을 구현하기 위해 각 사이트에는 각 트랜잭션 관리자에 대해 별도의 대기열을 유지하는 스케줄러가 있습니다. 트랜잭션 중에 트랜잭션 관리자는 사이트의 스케줄러에 잠금 요청을 보냅니다. 스케줄러는 증가하는 타임 스탬프 순서로 해당 큐에 요청을 넣습니다. 요청은 타임 스탬프 순서 (가장 오래된 것 먼저)에 따라 대기열의 앞부분에서 처리됩니다.
충돌 그래프
또 다른 방법은 충돌 그래프를 만드는 것입니다. 이 트랜잭션 클래스에 대해 정의됩니다. 트랜잭션 클래스에는 읽기 세트 및 쓰기 세트라는 두 개의 데이터 항목 세트가 포함됩니다. 트랜잭션의 읽기 세트가 클래스의 읽기 세트의 서브 세트이고 트랜잭션의 쓰기 세트가 클래스의 쓰기 세트의 서브 세트 인 경우 트랜잭션은 특정 클래스에 속합니다. 읽기 단계에서 각 트랜잭션은 읽기 세트의 데이터 항목에 대한 읽기 요청을 발행합니다. 쓰기 단계에서 각 트랜잭션은 쓰기 요청을 발행합니다.
활성 트랜잭션이 속한 클래스에 대해 충돌 그래프가 생성됩니다. 여기에는 수직, 수평 및 대각선 모서리 세트가 포함됩니다. 수직 가장자리는 클래스 내의 두 노드를 연결하고 클래스 내의 충돌을 나타냅니다. 수평 에지는 두 클래스에 걸쳐 두 노드를 연결하고 서로 다른 클래스 간의 쓰기-쓰기 충돌을 나타냅니다. 대각선 에지는 두 클래스에 걸쳐 두 노드를 연결하고 두 클래스 간의 쓰기-읽기 또는 읽기-쓰기 충돌을 나타냅니다.
충돌 그래프는 동일한 클래스 내에서 또는 두 개의 다른 클래스에 걸쳐 두 트랜잭션이 병렬로 실행될 수 있는지 확인하기 위해 분석됩니다.
분산 된 낙관적 동시성 제어 알고리즘
분산 낙관적 동시성 제어 알고리즘은 낙관적 동시성 제어 알고리즘을 확장합니다. 이 확장에는 두 가지 규칙이 적용됩니다.
Rule 1−이 규칙에 따라 트랜잭션이 실행될 때 모든 사이트에서 로컬로 검증되어야합니다. 트랜잭션이 사이트에서 유효하지 않은 것으로 확인되면 중단됩니다. 로컬 유효성 검사는 트랜잭션이 실행 된 사이트에서 직렬 성을 유지하도록 보장합니다. 트랜잭션이 로컬 유효성 검사를 통과하면 전역 적으로 유효성이 검사됩니다.
Rule 2−이 규칙에 따라 트랜잭션이 로컬 유효성 검사를 통과 한 후 전체적으로 유효성을 검사해야합니다. 전역 유효성 검사는 두 개의 충돌 트랜잭션이 둘 이상의 사이트에서 함께 실행되는 경우 함께 실행되는 모든 사이트에서 동일한 상대 순서로 커밋되어야합니다. 이를 위해 트랜잭션은 커밋 전에 유효성 검사 후 다른 충돌 트랜잭션을 기다려야 할 수 있습니다. 이 요구 사항은 트랜잭션이 사이트에서 확인되는 즉시 커밋하지 못할 수 있으므로 알고리즘의 낙관적이지 않게 만듭니다.
이 장에서는 데이터베이스 시스템의 교착 상태 처리 메커니즘에 대해 설명합니다. 중앙 집중식 및 분산 데이터베이스 시스템에서 교착 상태 처리 메커니즘을 연구 할 것입니다.
교착 상태는 무엇입니까?
교착 상태는 각 트랜잭션이 다른 트랜잭션에 의해 잠긴 데이터 항목을 기다리고있을 때 두 개 이상의 트랜잭션이있는 데이터베이스 시스템의 상태입니다. 교착 상태는 그래프 대기의 주기로 표시 될 수 있습니다. 정점이 트랜잭션을 나타내고 가장자리가 데이터 항목을 기다리는 것을 나타내는 방향 그래프입니다.
예를 들어, 다음 그래프 대기에서 트랜잭션 T1은 T3에 의해 잠긴 데이터 항목 X를 기다리고 있습니다. T3은 T2에 의해 잠긴 Y를 기다리고 있고 T2는 T1에 의해 잠긴 Z를 기다리고 있습니다. 따라서 대기주기가 형성되고 어떤 트랜잭션도 실행을 계속할 수 없습니다.

중앙 집중식 시스템의 교착 상태 처리
교착 상태 처리에 대한 세 가지 고전적인 접근 방식이 있습니다.
- 교착 상태 방지.
- 교착 상태 방지.
- 교착 상태 감지 및 제거.
세 가지 접근 방식은 모두 중앙 집중식 및 분산 데이터베이스 시스템에 통합 될 수 있습니다.
교착 상태 방지
교착 상태 방지 접근 방식에서는 어떤 트랜잭션도 교착 상태로 이어지는 잠금을 획득 할 수 없습니다. 규칙은 둘 이상의 트랜잭션이 동일한 데이터 항목을 잠그도록 요청하면 그중 하나만 잠금을 부여 받는다는 것입니다.
가장 널리 사용되는 교착 상태 방지 방법 중 하나는 모든 잠금을 사전 획득하는 것입니다. 이 방법에서 트랜잭션은 실행을 시작하기 전에 모든 잠금을 획득하고 전체 트랜잭션 기간 동안 잠금을 유지합니다. 다른 트랜잭션에 이미 획득 한 잠금이 필요한 경우 필요한 모든 잠금을 사용할 수있을 때까지 기다려야합니다. 이 접근 방식을 사용하면 대기중인 트랜잭션이 잠금을 보유하고 있지 않기 때문에 시스템이 교착 상태가되는 것을 방지합니다.
교착 상태 방지
교착 상태 방지 방법은 교착 상태가 발생하기 전에 처리합니다. 트랜잭션과 잠금을 분석하여 대기로 인해 교착 상태가 발생하는지 여부를 판별합니다.
이 방법은 다음과 같이 간략하게 설명 할 수 있습니다. 트랜잭션은 실행을 시작하고 잠그는 데 필요한 데이터 항목을 요청합니다. 잠금 관리자는 잠금이 사용 가능한지 확인합니다. 사용 가능한 경우 잠금 관리자가 데이터 항목을 할당하고 트랜잭션이 잠금을 획득합니다. 그러나 항목이 호환되지 않는 모드에서 다른 트랜잭션에 의해 잠긴 경우 잠금 관리자는 트랜잭션을 대기 상태로 유지하면 교착 상태가 발생하는지 여부를 테스트하는 알고리즘을 실행합니다. 따라서 알고리즘은 트랜잭션이 대기 할 수 있는지 또는 트랜잭션 중 하나가 중단되어야하는지 여부를 결정합니다.
이를 위해 두 가지 알고리즘이 있습니다. wait-die 과 wound-wait. 두 개의 트랜잭션 T1과 T2가 있다고 가정 해 보겠습니다. 여기서 T1은 이미 T2에 의해 잠긴 데이터 항목을 잠그려고합니다. 알고리즘은 다음과 같습니다-
Wait-Die− T1이 T2보다 오래된 경우 T1은 대기 할 수 있습니다. 그렇지 않고 T1이 T2보다 어린 경우 T1이 중단되고 나중에 다시 시작됩니다.
Wound-Wait− T1이 T2보다 오래된 경우 T2가 중단되고 나중에 다시 시작됩니다. 그렇지 않고 T1이 T2보다 어린 경우 T1은 대기 할 수 있습니다.
교착 상태 감지 및 제거
교착 상태 감지 및 제거 방법은 교착 상태 감지 알고리즘을 주기적으로 실행하고 교착 상태가있는 경우이를 제거합니다. 트랜잭션이 잠금 요청을 할 때 교착 상태를 확인하지 않습니다. 트랜잭션이 잠금을 요청하면 잠금 관리자는 잠금이 사용 가능한지 확인합니다. 사용 가능한 경우 트랜잭션은 데이터 항목을 잠글 수 있습니다. 그렇지 않으면 트랜잭션이 대기 할 수 있습니다.
잠금 요청을 허용하는 동안 예방 조치가 없기 때문에 일부 트랜잭션이 교착 상태가 될 수 있습니다. 교착 상태를 감지하기 위해 잠금 관리자는 주기적으로 wait-forgraph에주기가 있는지 확인합니다. 시스템이 교착 상태 인 경우 잠금 관리자는 각주기에서 희생 트랜잭션을 선택합니다. 피해자는 중단되고 롤백됩니다. 나중에 다시 시작했습니다. 피해자 선택에 사용되는 방법 중 일부는 다음과 같습니다.
- 가장 어린 거래를 선택하십시오.
- 데이터 항목이 가장 적은 트랜잭션을 선택하십시오.
- Choose the transaction that has performed least number of updates.
- Choose the transaction having least restart overhead.
- Choose the transaction which is common to two or more cycles.
This approach is primarily suited for systems having transactions low and where fast response to lock requests is needed.
Deadlock Handling in Distributed Systems
Transaction processing in a distributed database system is also distributed, i.e. the same transaction may be processing at more than one site. The two main deadlock handling concerns in a distributed database system that are not present in a centralized system are transaction location and transaction control. Once these concerns are addressed, deadlocks are handled through any of deadlock prevention, deadlock avoidance or deadlock detection and removal.
Transaction Location
Transactions in a distributed database system are processed in multiple sites and use data items in multiple sites. The amount of data processing is not uniformly distributed among these sites. The time period of processing also varies. Thus the same transaction may be active at some sites and inactive at others. When two conflicting transactions are located in a site, it may happen that one of them is in inactive state. This condition does not arise in a centralized system. This concern is called transaction location issue.
This concern may be addressed by Daisy Chain model. In this model, a transaction carries certain details when it moves from one site to another. Some of the details are the list of tables required, the list of sites required, the list of visited tables and sites, the list of tables and sites that are yet to be visited and the list of acquired locks with types. After a transaction terminates by either commit or abort, the information should be sent to all the concerned sites.
Transaction Control
Transaction control is concerned with designating and controlling the sites required for processing a transaction in a distributed database system. There are many options regarding the choice of where to process the transaction and how to designate the center of control, like −
- One server may be selected as the center of control.
- The center of control may travel from one server to another.
- The responsibility of controlling may be shared by a number of servers.
Distributed Deadlock Prevention
Just like in centralized deadlock prevention, in distributed deadlock prevention approach, a transaction should acquire all the locks before starting to execute. This prevents deadlocks.
The site where the transaction enters is designated as the controlling site. The controlling site sends messages to the sites where the data items are located to lock the items. Then it waits for confirmation. When all the sites have confirmed that they have locked the data items, transaction starts. If any site or communication link fails, the transaction has to wait until they have been repaired.
Though the implementation is simple, this approach has some drawbacks −
Pre-acquisition of locks requires a long time for communication delays. This increases the time required for transaction.
In case of site or link failure, a transaction has to wait for a long time so that the sites recover. Meanwhile, in the running sites, the items are locked. This may prevent other transactions from executing.
If the controlling site fails, it cannot communicate with the other sites. These sites continue to keep the locked data items in their locked state, thus resulting in blocking.
Distributed Deadlock Avoidance
As in centralized system, distributed deadlock avoidance handles deadlock prior to occurrence. Additionally, in distributed systems, transaction location and transaction control issues needs to be addressed. Due to the distributed nature of the transaction, the following conflicts may occur −
- Conflict between two transactions in the same site.
- Conflict between two transactions in different sites.
In case of conflict, one of the transactions may be aborted or allowed to wait as per distributed wait-die or distributed wound-wait algorithms.
Let us assume that there are two transactions, T1 and T2. T1 arrives at Site P and tries to lock a data item which is already locked by T2 at that site. Hence, there is a conflict at Site P. The algorithms are as follows −
Distributed Wound-Die
If T1 is older than T2, T1 is allowed to wait. T1 can resume execution after Site P receives a message that T2 has either committed or aborted successfully at all sites.
If T1 is younger than T2, T1 is aborted. The concurrency control at Site P sends a message to all sites where T1 has visited to abort T1. The controlling site notifies the user when T1 has been successfully aborted in all the sites.
Distributed Wait-Wait
If T1 is older than T2, T2 needs to be aborted. If T2 is active at Site P, Site P aborts and rolls back T2 and then broadcasts this message to other relevant sites. If T2 has left Site P but is active at Site Q, Site P broadcasts that T2 has been aborted; Site L then aborts and rolls back T2 and sends this message to all sites.
If T1 is younger than T1, T1 is allowed to wait. T1 can resume execution after Site P receives a message that T2 has completed processing.
Distributed Deadlock Detection
Just like centralized deadlock detection approach, deadlocks are allowed to occur and are removed if detected. The system does not perform any checks when a transaction places a lock request. For implementation, global wait-for-graphs are created. Existence of a cycle in the global wait-for-graph indicates deadlocks. However, it is difficult to spot deadlocks since transaction waits for resources across the network.
Alternatively, deadlock detection algorithms can use timers. Each transaction is associated with a timer which is set to a time period in which a transaction is expected to finish. If a transaction does not finish within this time period, the timer goes off, indicating a possible deadlock.
Another tool used for deadlock handling is a deadlock detector. In a centralized system, there is one deadlock detector. In a distributed system, there can be more than one deadlock detectors. A deadlock detector can find deadlocks for the sites under its control. There are three alternatives for deadlock detection in a distributed system, namely.
Centralized Deadlock Detector − One site is designated as the central deadlock detector.
Hierarchical Deadlock Detector − A number of deadlock detectors are arranged in hierarchy.
Distributed Deadlock Detector − All the sites participate in detecting deadlocks and removing them.
This chapter looks into replication control, which is required to maintain consistent data in all sites. We will study the replication control techniques and the algorithms required for replication control.
As discussed earlier, replication is a technique used in distributed databases to store multiple copies of a data table at different sites. The problem with having multiple copies in multiple sites is the overhead of maintaining data consistency, particularly during update operations.
In order to maintain mutually consistent data in all sites, replication control techniques need to be adopted. There are two approaches for replication control, namely −
- Synchronous Replication Control
- Asynchronous Replication Control
Synchronous Replication Control
In synchronous replication approach, the database is synchronized so that all the replications always have the same value. A transaction requesting a data item will have access to the same value in all the sites. To ensure this uniformity, a transaction that updates a data item is expanded so that it makes the update in all the copies of the data item. Generally, two-phase commit protocol is used for the purpose.
For example, let us consider a data table PROJECT(PId, PName, PLocation). We need to run a transaction T1 that updates PLocation to ‘Mumbai’, if PLocation is ‘Bombay’. If no replications are there, the operations in transaction T1 will be −
Begin T1:
Update PROJECT Set PLocation = 'Mumbai'
Where PLocation = 'Bombay';
End T1;If the data table has two replicas in Site A and Site B, T1 needs to spawn two children T1A and T1B corresponding to the two sites. The expanded transaction T1 will be −
Begin T1:
Begin T1A :
Update PROJECT Set PLocation = 'Mumbai'
Where PLocation = 'Bombay';
End T1A;
Begin T2A :
Update PROJECT Set PLocation = 'Mumbai'
Where PLocation = 'Bombay';
End T2A;
End T1;Asynchronous Replication Control
In asynchronous replication approach, the replicas do not always maintain the same value. One or more replicas may store an outdated value, and a transaction can see the different values. The process of bringing all the replicas to the current value is called synchronization.
A popular method of synchronization is store and forward method. In this method, one site is designated as the primary site and the other sites are secondary sites. The primary site always contains updated values. All the transactions first enter the primary site. These transactions are then queued for application in the secondary sites. The secondary sites are updated using rollout method only when a transaction is scheduled to execute on it.
Replication Control Algorithms
Some of the replication control algorithms are −
- Master-slave replication control algorithm.
- Distributed voting algorithm.
- Majority consensus algorithm.
- Circulating token algorithm.
Master-Slave Replication Control Algorithm
There is one master site and ‘N’ slave sites. A master algorithm runs at the master site to detect conflicts. A copy of slave algorithm runs at each slave site. The overall algorithm executes in the following two phases −
Transaction acceptance/rejection phase − When a transaction enters the transaction monitor of a slave site, the slave site sends a request to the master site. The master site checks for conflicts. If there aren’t any conflicts, the master sends an “ACK+” message to the slave site which then starts the transaction application phase. Otherwise, the master sends an “ACK-” message to the slave which then rejects the transaction.
Transaction application phase − Upon entering this phase, the slave site where transaction has entered broadcasts a request to all slaves for executing the transaction. On receiving the requests, the peer slaves execute the transaction and send an “ACK” to the requesting slave on completion. After the requesting slave has received “ACK” messages from all its peers, it sends a “DONE” message to the master site. The master understands that the transaction has been completed and removes it from the pending queue.
Distributed Voting Algorithm
This comprises of ‘N’ peer sites, all of whom must “OK” a transaction before it starts executing. Following are the two phases of this algorithm −
Distributed transaction acceptance phase − When a transaction enters the transaction manager of a site, it sends a transaction request to all other sites. On receiving a request, a peer site resolves conflicts using priority based voting rules. If all the peer sites are “OK” with the transaction, the requesting site starts application phase. If any of the peer sites does not “OK” a transaction, the requesting site rejects the transaction.
Distributed transaction application phase − Upon entering this phase, the site where the transaction has entered, broadcasts a request to all slaves for executing the transaction. On receiving the requests, the peer slaves execute the transaction and send an “ACK” message to the requesting slave on completion. After the requesting slave has received “ACK” messages from all its peers, it lets the transaction manager know that the transaction has been completed.
Majority Consensus Algorithm
This is a variation from the distributed voting algorithm, where a transaction is allowed to execute when a majority of the peers “OK” a transaction. This is divided into three phases −
Voting phase − When a transaction enters the transaction manager of a site, it sends a transaction request to all other sites. On receiving a request, a peer site tests for conflicts using voting rules and keeps the conflicting transactions, if any, in pending queue. Then, it sends either an “OK” or a “NOT OK” message.
Transaction acceptance/rejection phase − If the requesting site receives a majority “OK” on the transaction, it accepts the transaction and broadcasts “ACCEPT” to all the sites. Otherwise, it broadcasts “REJECT” to all the sites and rejects the transaction.
Transaction application phase − When a peer site receives a “REJECT” message, it removes this transaction from its pending list and reconsiders all deferred transactions. When a peer site receives an “ACCEPT” message, it applies the transaction and rejects all the deferred transactions in the pending queue which are in conflict with this transaction. It sends an “ACK” to the requesting slave on completion.
Circulating Token Algorithm
In this approach the transactions in the system are serialized using a circulating token and executed accordingly against every replica of the database. Thus, all the transactions are accepted, i.e. none is rejected. This has two phases −
Transaction serialization phase − In this phase, all transactions are scheduled to run in a serialization order. Each transaction in each site is assigned a unique ticket from a sequential series, indicating the order of transaction. Once a transaction has been assigned a ticket, it is broadcasted to all the sites.
Transaction application phase − When a site receives a transaction along with its ticket, it places the transaction for execution according to its ticket. After the transaction has finished execution, this site broadcasts an appropriate message. A transaction ends when it has completed execution in all the sites.
A database management system is susceptible to a number of failures. In this chapter we will study the failure types and commit protocols. In a distributed database system, failures can be broadly categorized into soft failures, hard failures and network failures.
Soft Failure
Soft failure is the type of failure that causes the loss in volatile memory of the computer and not in the persistent storage. Here, the information stored in the non-persistent storage like main memory, buffers, caches or registers, is lost. They are also known as system crash. The various types of soft failures are as follows −
- Operating system failure.
- Main memory crash.
- Transaction failure or abortion.
- System generated error like integer overflow or divide-by-zero error.
- Failure of supporting software.
- Power failure.
Hard Failure
A hard failure is the type of failure that causes loss of data in the persistent or non-volatile storage like disk. Disk failure may cause corruption of data in some disk blocks or failure of the total disk. The causes of a hard failure are −
- Power failure.
- Faults in media.
- Read-write malfunction.
- Corruption of information on the disk.
- Read/write head crash of disk.
Recovery from disk failures can be short, if there is a new, formatted, and ready-to-use disk on reserve. Otherwise, duration includes the time it takes to get a purchase order, buy the disk, and prepare it.
Network Failure
Network failures are prevalent in distributed or network databases. These comprises of the errors induced in the database system due to the distributed nature of the data and transferring data over the network. The causes of network failure are as follows −
- Communication link failure.
- Network congestion.
- Information corruption during transfer.
- Site failures.
- Network partitioning.
Commit Protocols
Any database system should guarantee that the desirable properties of a transaction are maintained even after failures. If a failure occurs during the execution of a transaction, it may happen that all the changes brought about by the transaction are not committed. This makes the database inconsistent. Commit protocols prevent this scenario using either transaction undo (rollback) or transaction redo (roll forward).
Commit Point
The point of time at which the decision is made whether to commit or abort a transaction, is known as commit point. Following are the properties of a commit point.
It is a point of time when the database is consistent.
At this point, the modifications brought about by the database can be seen by the other transactions. All transactions can have a consistent view of the database.
At this point, all the operations of transaction have been successfully executed and their effects have been recorded in transaction log.
At this point, a transaction can be safely undone, if required.
At this point, a transaction releases all the locks held by it.
Transaction Undo
The process of undoing all the changes made to a database by a transaction is called transaction undo or transaction rollback. This is mostly applied in case of soft failure.
Transaction Redo
The process of reapplying the changes made to a database by a transaction is called transaction redo or transaction roll forward. This is mostly applied for recovery from a hard failure.
Transaction Log
A transaction log is a sequential file that keeps track of transaction operations on database items. As the log is sequential in nature, it is processed sequentially either from the beginning or from the end.
Purposes of a transaction log −
- To support commit protocols to commit or support transactions.
- To aid database recovery after failure.
A transaction log is usually kept on the disk, so that it is not affected by soft failures. Additionally, the log is periodically backed up to an archival storage like magnetic tape to protect it from disk failures as well.
Lists in Transaction Logs
The transaction log maintains five types of lists depending upon the status of the transaction. This list aids the recovery manager to ascertain the status of a transaction. The status and the corresponding lists are as follows −
A transaction that has a transaction start record and a transaction commit record, is a committed transaction – maintained in commit list.
A transaction that has a transaction start record and a transaction failed record but not a transaction abort record, is a failed transaction – maintained in failed list.
A transaction that has a transaction start record and a transaction abort record is an aborted transaction – maintained in abort list.
A transaction that has a transaction start record and a transaction before-commit record is a before-commit transaction, i.e. a transaction where all the operations have been executed but not committed – maintained in before-commit list.
A transaction that has a transaction start record but no records of before-commit, commit, abort or failed, is an active transaction – maintained in active list.
Immediate Update and Deferred Update
Immediate Update and Deferred Update are two methods for maintaining transaction logs.
In immediate update mode, when a transaction executes, the updates made by the transaction are written directly onto the disk. The old values and the updates values are written onto the log before writing to the database in disk. On commit, the changes made to the disk are made permanent. On rollback, changes made by the transaction in the database are discarded and the old values are restored into the database from the old values stored in the log.
In deferred update mode, when a transaction executes, the updates made to the database by the transaction are recorded in the log file. On commit, the changes in the log are written onto the disk. On rollback, the changes in the log are discarded and no changes are applied to the database.
In order to recuperate from database failure, database management systems resort to a number of recovery management techniques. In this chapter, we will study the different approaches for database recovery.
The typical strategies for database recovery are −
In case of soft failures that result in inconsistency of database, recovery strategy includes transaction undo or rollback. However, sometimes, transaction redo may also be adopted to recover to a consistent state of the transaction.
In case of hard failures resulting in extensive damage to database, recovery strategies encompass restoring a past copy of the database from archival backup. A more current state of the database is obtained through redoing operations of committed transactions from transaction log.
Recovery from Power Failure
Power failure causes loss of information in the non-persistent memory. When power is restored, the operating system and the database management system restart. Recovery manager initiates recovery from the transaction logs.
In case of immediate update mode, the recovery manager takes the following actions −
Transactions which are in active list and failed list are undone and written on the abort list.
Transactions which are in before-commit list are redone.
No action is taken for transactions in commit or abort lists.
In case of deferred update mode, the recovery manager takes the following actions −
Transactions which are in the active list and failed list are written onto the abort list. No undo operations are required since the changes have not been written to the disk yet.
Transactions which are in before-commit list are redone.
No action is taken for transactions in commit or abort lists.
Recovery from Disk Failure
A disk failure or hard crash causes a total database loss. To recover from this hard crash, a new disk is prepared, then the operating system is restored, and finally the database is recovered using the database backup and transaction log. The recovery method is same for both immediate and deferred update modes.
The recovery manager takes the following actions −
The transactions in the commit list and before-commit list are redone and written onto the commit list in the transaction log.
The transactions in the active list and failed list are undone and written onto the abort list in the transaction log.
Checkpointing
Checkpoint is a point of time at which a record is written onto the database from the buffers. As a consequence, in case of a system crash, the recovery manager does not have to redo the transactions that have been committed before checkpoint. Periodical checkpointing shortens the recovery process.
The two types of checkpointing techniques are −
- Consistent checkpointing
- Fuzzy checkpointing
Consistent Checkpointing
Consistent checkpointing creates a consistent image of the database at checkpoint. During recovery, only those transactions which are on the right side of the last checkpoint are undone or redone. The transactions to the left side of the last consistent checkpoint are already committed and needn’t be processed again. The actions taken for checkpointing are −
- The active transactions are suspended temporarily.
- All changes in main-memory buffers are written onto the disk.
- A “checkpoint” record is written in the transaction log.
- The transaction log is written to the disk.
- The suspended transactions are resumed.
If in step 4, the transaction log is archived as well, then this checkpointing aids in recovery from disk failures and power failures, otherwise it aids recovery from only power failures.
Fuzzy Checkpointing
In fuzzy checkpointing, at the time of checkpoint, all the active transactions are written in the log. In case of power failure, the recovery manager processes only those transactions that were active during checkpoint and later. The transactions that have been committed before checkpoint are written to the disk and hence need not be redone.
Example of Checkpointing
Let us consider that in system the time of checkpointing is tcheck and the time of system crash is tfail. Let there be four transactions Ta, Tb, Tc and Td such that −
Ta commits before checkpoint.
Tb starts before checkpoint and commits before system crash.
Tc starts after checkpoint and commits before system crash.
Td starts after checkpoint and was active at the time of system crash.
The situation is depicted in the following diagram −
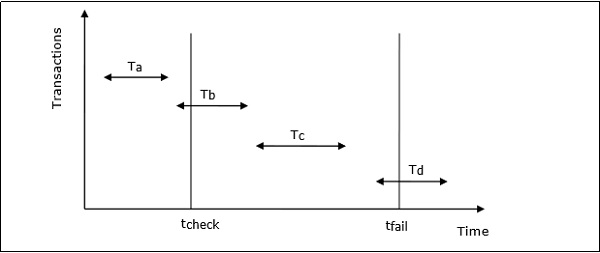
The actions that are taken by the recovery manager are −
- Nothing is done with Ta.
- Transaction redo is performed for Tb and Tc.
- Transaction undo is performed for Td.
Transaction Recovery Using UNDO / REDO
Transaction recovery is done to eliminate the adverse effects of faulty transactions rather than to recover from a failure. Faulty transactions include all transactions that have changed the database into undesired state and the transactions that have used values written by the faulty transactions.
Transaction recovery in these cases is a two-step process −
UNDO all faulty transactions and transactions that may be affected by the faulty transactions.
REDO all transactions that are not faulty but have been undone due to the faulty transactions.
Steps for the UNDO operation are −
If the faulty transaction has done INSERT, the recovery manager deletes the data item(s) inserted.
If the faulty transaction has done DELETE, the recovery manager inserts the deleted data item(s) from the log.
If the faulty transaction has done UPDATE, the recovery manager eliminates the value by writing the before-update value from the log.
Steps for the REDO operation are −
If the transaction has done INSERT, the recovery manager generates an insert from the log.
If the transaction has done DELETE, the recovery manager generates a delete from the log.
If the transaction has done UPDATE, the recovery manager generates an update from the log.
In a local database system, for committing a transaction, the transaction manager has to only convey the decision to commit to the recovery manager. However, in a distributed system, the transaction manager should convey the decision to commit to all the servers in the various sites where the transaction is being executed and uniformly enforce the decision. When processing is complete at each site, it reaches the partially committed transaction state and waits for all other transactions to reach their partially committed states. When it receives the message that all the sites are ready to commit, it starts to commit. In a distributed system, either all sites commit or none of them does.
The different distributed commit protocols are −
- One-phase commit
- Two-phase commit
- Three-phase commit
Distributed One-phase Commit
Distributed one-phase commit is the simplest commit protocol. Let us consider that there is a controlling site and a number of slave sites where the transaction is being executed. The steps in distributed commit are −
After each slave has locally completed its transaction, it sends a “DONE” message to the controlling site.
The slaves wait for “Commit” or “Abort” message from the controlling site. This waiting time is called window of vulnerability.
When the controlling site receives “DONE” message from each slave, it makes a decision to commit or abort. This is called the commit point. Then, it sends this message to all the slaves.
On receiving this message, a slave either commits or aborts and then sends an acknowledgement message to the controlling site.
Distributed Two-phase Commit
Distributed two-phase commit reduces the vulnerability of one-phase commit protocols. The steps performed in the two phases are as follows −
Phase 1: Prepare Phase
After each slave has locally completed its transaction, it sends a “DONE” message to the controlling site. When the controlling site has received “DONE” message from all slaves, it sends a “Prepare” message to the slaves.
The slaves vote on whether they still want to commit or not. If a slave wants to commit, it sends a “Ready” message.
A slave that does not want to commit sends a “Not Ready” message. This may happen when the slave has conflicting concurrent transactions or there is a timeout.
Phase 2: Commit/Abort Phase
After the controlling site has received “Ready” message from all the slaves −
The controlling site sends a “Global Commit” message to the slaves.
The slaves apply the transaction and send a “Commit ACK” message to the controlling site.
When the controlling site receives “Commit ACK” message from all the slaves, it considers the transaction as committed.
After the controlling site has received the first “Not Ready” message from any slave −
The controlling site sends a “Global Abort” message to the slaves.
The slaves abort the transaction and send a “Abort ACK” message to the controlling site.
When the controlling site receives “Abort ACK” message from all the slaves, it considers the transaction as aborted.
Distributed Three-phase Commit
The steps in distributed three-phase commit are as follows −
Phase 1: Prepare Phase
The steps are same as in distributed two-phase commit.
Phase 2: Prepare to Commit Phase
- The controlling site issues an “Enter Prepared State” broadcast message.
- The slave sites vote “OK” in response.
Phase 3: Commit / Abort Phase
The steps are same as two-phase commit except that “Commit ACK”/”Abort ACK” message is not required.
In this chapter, we will look into the threats that a database system faces and the measures of control. We will also study cryptography as a security tool.
Database Security and Threats
Data security is an imperative aspect of any database system. It is of particular importance in distributed systems because of large number of users, fragmented and replicated data, multiple sites and distributed control.
Threats in a Database
Availability loss − Availability loss refers to non-availability of database objects by legitimate users.
Integrity loss − Integrity loss occurs when unacceptable operations are performed upon the database either accidentally or maliciously. This may happen while creating, inserting, updating or deleting data. It results in corrupted data leading to incorrect decisions.
Confidentiality loss − Confidentiality loss occurs due to unauthorized or unintentional disclosure of confidential information. It may result in illegal actions, security threats and loss in public confidence.
Measures of Control
The measures of control can be broadly divided into the following categories −
Access Control − Access control includes security mechanisms in a database management system to protect against unauthorized access. A user can gain access to the database after clearing the login process through only valid user accounts. Each user account is password protected.
Flow Control − Distributed systems encompass a lot of data flow from one site to another and also within a site. Flow control prevents data from being transferred in such a way that it can be accessed by unauthorized agents. A flow policy lists out the channels through which information can flow. It also defines security classes for data as well as transactions.
Data Encryption − Data encryption refers to coding data when sensitive data is to be communicated over public channels. Even if an unauthorized agent gains access of the data, he cannot understand it since it is in an incomprehensible format.
What is Cryptography?
Cryptography is the science of encoding information before sending via unreliable communication paths so that only an authorized receiver can decode and use it.
The coded message is called cipher text and the original message is called plain text. The process of converting plain text to cipher text by the sender is called encoding or encryption. The process of converting cipher text to plain text by the receiver is called decoding or decryption.
The entire procedure of communicating using cryptography can be illustrated through the following diagram −

Conventional Encryption Methods
In conventional cryptography, the encryption and decryption is done using the same secret key. Here, the sender encrypts the message with an encryption algorithm using a copy of the secret key. The encrypted message is then send over public communication channels. On receiving the encrypted message, the receiver decrypts it with a corresponding decryption algorithm using the same secret key.
Security in conventional cryptography depends on two factors −
A sound algorithm which is known to all.
A randomly generated, preferably long secret key known only by the sender and the receiver.
The most famous conventional cryptography algorithm is Data Encryption Standard or DES.
The advantage of this method is its easy applicability. However, the greatest problem of conventional cryptography is sharing the secret key between the communicating parties. The ways to send the key are cumbersome and highly susceptible to eavesdropping.
Public Key Cryptography
In contrast to conventional cryptography, public key cryptography uses two different keys, referred to as public key and the private key. Each user generates the pair of public key and private key. The user then puts the public key in an accessible place. When a sender wants to sends a message, he encrypts it using the public key of the receiver. On receiving the encrypted message, the receiver decrypts it using his private key. Since the private key is not known to anyone but the receiver, no other person who receives the message can decrypt it.
The most popular public key cryptography algorithms are RSA algorithm and Diffie– Hellman algorithm. This method is very secure to send private messages. However, the problem is, it involves a lot of computations and so proves to be inefficient for long messages.
The solution is to use a combination of conventional and public key cryptography. The secret key is encrypted using public key cryptography before sharing between the communicating parties. Then, the message is send using conventional cryptography with the aid of the shared secret key.
Digital Signatures
A Digital Signature (DS) is an authentication technique based on public key cryptography used in e-commerce applications. It associates a unique mark to an individual within the body of his message. This helps others to authenticate valid senders of messages.
Typically, a user’s digital signature varies from message to message in order to provide security against counterfeiting. The method is as follows −
The sender takes a message, calculates the message digest of the message and signs it digest with a private key.
The sender then appends the signed digest along with the plaintext message.
The message is sent over communication channel.
The receiver removes the appended signed digest and verifies the digest using the corresponding public key.
The receiver then takes the plaintext message and runs it through the same message digest algorithm.
If the results of step 4 and step 5 match, then the receiver knows that the message has integrity and authentic.
A distributed system needs additional security measures than centralized system, since there are many users, diversified data, multiple sites and distributed control. In this chapter, we will look into the various facets of distributed database security.
In distributed communication systems, there are two types of intruders −
Passive eavesdroppers − They monitor the messages and get hold of private information.
Active attackers − They not only monitor the messages but also corrupt data by inserting new data or modifying existing data.
Security measures encompass security in communications, security in data and data auditing.
Communications Security
In a distributed database, a lot of data communication takes place owing to the diversified location of data, users and transactions. So, it demands secure communication between users and databases and between the different database environments.
Security in communication encompasses the following −
Data should not be corrupt during transfer.
The communication channel should be protected against both passive eavesdroppers and active attackers.
In order to achieve the above stated requirements, well-defined security algorithms and protocols should be adopted.
Two popular, consistent technologies for achieving end-to-end secure communications are −
- Secure Socket Layer Protocol or Transport Layer Security Protocol.
- Virtual Private Networks (VPN).
Data Security
In distributed systems, it is imperative to adopt measure to secure data apart from communications. The data security measures are −
Authentication and authorization − These are the access control measures adopted to ensure that only authentic users can use the database. To provide authentication digital certificates are used. Besides, login is restricted through username/password combination.
Data encryption − The two approaches for data encryption in distributed systems are −
Internal to distributed database approach: The user applications encrypt the data and then store the encrypted data in the database. For using the stored data, the applications fetch the encrypted data from the database and then decrypt it.
External to distributed database: The distributed database system has its own encryption capabilities. The user applications store data and retrieve them without realizing that the data is stored in an encrypted form in the database.
Validated input − In this security measure, the user application checks for each input before it can be used for updating the database. An un-validated input can cause a wide range of exploits like buffer overrun, command injection, cross-site scripting and corruption in data.
Data Auditing
A database security system needs to detect and monitor security violations, in order to ascertain the security measures it should adopt. It is often very difficult to detect breach of security at the time of occurrences. One method to identify security violations is to examine audit logs. Audit logs contain information such as −
- Date, time and site of failed access attempts.
- Details of successful access attempts.
- Vital modifications in the database system.
- Access of huge amounts of data, particularly from databases in multiple sites.
All the above information gives an insight of the activities in the database. A periodical analysis of the log helps to identify any unnatural activity along with its site and time of occurrence. This log is ideally stored in a separate server so that it is inaccessible to attackers.