데이터웨어 하우징-시스템 프로세스
운영 데이터베이스에 적용 할 고정 된 수의 작업이 있으며 다음과 같은 잘 정의 된 기술이 있습니다. use normalized data, keep table small등. 이러한 기술은 솔루션을 제공하는 데 적합합니다. 그러나 의사 결정 지원 시스템의 경우 향후 어떤 쿼리와 작업을 수행해야하는지 알 수 없습니다. 따라서 운영 데이터베이스에 적용되는 기술은 데이터웨어 하우스에 적합하지 않습니다.
이 장에서는 Unix 및 관계형 데이터베이스와 같은 최고의 개방형 시스템 기술에 데이터웨어 하우징 솔루션을 구축하는 방법에 대해 설명합니다.
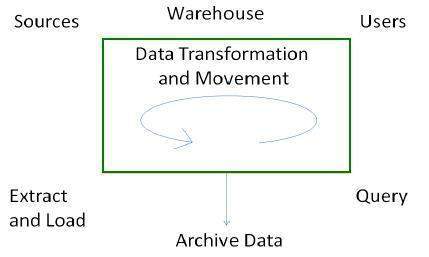
데이터웨어 하우스의 프로세스 흐름
데이터웨어 하우스에 기여하는 네 가지 주요 프로세스가 있습니다.
- 데이터를 추출하고로드합니다.
- 데이터 정리 및 변환.
- 데이터를 백업하고 보관합니다.
- 쿼리를 관리하고 적절한 데이터 소스로 보냅니다.
추출 및로드 프로세스
데이터 추출은 소스 시스템에서 데이터를 가져옵니다. 데이터로드는 추출 된 데이터를 가져 와서 데이터웨어 하우스에로드합니다.
Note − 데이터웨어 하우스에 데이터를로드하기 전에 외부 소스에서 추출한 정보를 재구성해야합니다.
프로세스 제어
프로세스 제어에는 데이터 추출 시작시기와 데이터에 대한 일관성 검사가 포함됩니다. 제어 프로세스는 도구, 논리 모듈 및 프로그램이 올바른 순서와 시간에 실행되도록합니다.
추출 시작시기
데이터는 추출 될 때 일관된 상태에 있어야합니다. 즉, 데이터웨어 하우스는 사용자에게 일관된 단일 버전의 정보를 표시해야합니다.
예를 들어, 통신 부문의 고객 프로파일 링 데이터웨어 하우스에서 수요일 오후 8시에 고객 데이터베이스의 고객 목록을 화요일 오후 8 시까 지의 고객 구독 이벤트와 병합하는 것은 비논리적입니다. 이는 연결된 구독이없는 고객을 찾고 있음을 의미합니다.
데이터로드
데이터를 추출한 후 임시 데이터 저장소에로드되어 정리되고 일관성을 유지합니다.
Note − 일관성 검사는 모든 데이터 소스가 임시 데이터 저장소에로드 된 경우에만 실행됩니다.
프로세스 정리 및 변환
데이터가 추출되어 임시 데이터 저장소에로드되면 정리 및 변환을 수행 할 차례입니다. 다음은 청소 및 변형과 관련된 단계 목록입니다.
- 로드 된 데이터를 정리하고 구조로 변환
- 데이터 분할
- Aggregation
로드 된 데이터를 정리하고 구조로 변환
로드 된 데이터를 정리하고 변환하면 쿼리 속도를 높일 수 있습니다. 데이터를 일관성있게 만들면 가능합니다.
- 그 자체로.
- 동일한 데이터 소스 내의 다른 데이터와 함께.
- 다른 소스 시스템의 데이터와 함께.
- 웨어 하우스에있는 기존 데이터로.
변환에는 소스 데이터를 구조로 변환하는 작업이 포함됩니다. 데이터를 구조화하면 쿼리 성능이 향상되고 운영 비용이 감소합니다. 데이터웨어 하우스에 포함 된 데이터는 성능 요구 사항을 지원하고 지속적인 운영 비용을 제어하기 위해 변환되어야합니다.
데이터 분할
하드웨어 성능을 최적화하고 데이터웨어 하우스 관리를 단순화합니다. 여기에서 각 팩트 테이블을 여러 개의 개별 파티션으로 분할합니다.
집합
일반적인 쿼리의 속도를 높이려면 집계가 필요합니다. 집계는 가장 일반적인 쿼리가 세부 데이터의 하위 집합 또는 집계를 분석한다는 사실에 의존합니다.
데이터 백업 및 아카이브
데이터 손실, 소프트웨어 장애 또는 하드웨어 장애가 발생한 경우 데이터를 복구하려면 정기적 인 백업을 유지해야합니다. 아카이브에는 필요할 때마다 신속하게 복원 할 수있는 형식으로 시스템에서 이전 데이터를 제거하는 작업이 포함됩니다.
예를 들어 소매 판매 분석 데이터웨어 하우스에서 최근 6 개월 데이터를 온라인으로 유지하면서 3 년 동안 데이터를 유지해야 할 수 있습니다. 이러한 시나리오에서는 종종 올해와 작년에 대한 월별 비교를 수행 할 수 있어야합니다. 이 경우 아카이브에서 일부 데이터를 복원해야합니다.
쿼리 관리 프로세스
이 프로세스는 다음 기능을 수행합니다.
쿼리를 관리합니다.
쿼리 실행 시간을 단축하는 데 도움이됩니다.
쿼리를 가장 효과적인 데이터 소스로 보냅니다.
모든 시스템 소스가 가장 효과적인 방법으로 사용되도록합니다.
실제 쿼리 프로필을 모니터링합니다.
이 프로세스에서 생성 된 정보는웨어 하우스 관리 프로세스에서 생성 할 집계를 결정하는 데 사용됩니다. 이 프로세스는 일반적으로 데이터웨어 하우스에 정보를 정기적으로로드하는 동안에는 작동하지 않습니다.