HBase-개요
1970 년부터 RDBMS는 데이터 저장 및 유지 관리 관련 문제에 대한 솔루션입니다. 빅 데이터의 출현 이후 기업들은 빅 데이터 처리의 이점을 깨닫고 Hadoop과 같은 솔루션을 선택하기 시작했습니다.
Hadoop은 분산 파일 시스템을 사용하여 빅 데이터를 저장하고 MapReduce를 사용하여 처리합니다. Hadoop은 임의, 반 또는 비정형과 같은 다양한 형식의 방대한 데이터를 저장하고 처리하는 데 탁월합니다.
Hadoop의 한계
Hadoop은 일괄 처리 만 수행 할 수 있으며 데이터는 순차적 인 방식으로 만 액세스됩니다. 즉, 가장 간단한 작업이라도 전체 데이터 세트를 검색해야합니다.
처리 될 때 거대한 데이터 세트는 또 다른 거대한 데이터 세트를 생성하며 이는 또한 순차적으로 처리되어야합니다. 이 시점에서 단일 시간 단위 (랜덤 액세스)로 모든 데이터 지점에 액세스하려면 새로운 솔루션이 필요합니다.
Hadoop 랜덤 액세스 데이터베이스
HBase, Cassandra, couchDB, Dynamo 및 MongoDB와 같은 애플리케이션은 엄청난 양의 데이터를 저장하고 임의의 방식으로 데이터에 액세스하는 데이터베이스 중 일부입니다.
HBase는 무엇입니까?
HBase는 Hadoop 파일 시스템 위에 구축 된 분산 열 지향 데이터베이스입니다. 오픈 소스 프로젝트이며 수평 확장이 가능합니다.
HBase는 방대한 양의 구조화 된 데이터에 대한 빠른 임의 액세스를 제공하도록 설계된 Google의 빅 테이블과 유사한 데이터 모델입니다. HDFS (Hadoop File System)에서 제공하는 내결함성을 활용합니다.
Hadoop 파일 시스템의 데이터에 대한 임의의 실시간 읽기 / 쓰기 액세스를 제공하는 Hadoop 에코 시스템의 일부입니다.
하나는 직접 또는 HBase를 통해 HDFS에 데이터를 저장할 수 있습니다. 데이터 소비자는 HBase를 사용하여 HDFS의 데이터를 임의로 읽고 액세스합니다. HBase는 Hadoop 파일 시스템의 맨 위에 있으며 읽기 및 쓰기 액세스를 제공합니다.

HBase 및 HDFS
| HDFS | HBase |
|---|---|
| HDFS는 대용량 파일 저장에 적합한 분산 파일 시스템입니다. | HBase는 HDFS 위에 구축 된 데이터베이스입니다. |
| HDFS는 빠른 개별 레코드 조회를 지원하지 않습니다. | HBase는 더 큰 테이블에 대한 빠른 조회를 제공합니다. |
| 대기 시간이 긴 일괄 처리를 제공합니다. 일괄 처리의 개념이 없습니다. | 수십억 개의 레코드에서 단일 행에 대한 짧은 대기 시간 액세스를 제공합니다 (랜덤 액세스). |
| 데이터의 순차 액세스 만 제공합니다. | HBase는 내부적으로 해시 테이블을 사용하고 임의 액세스를 제공하며 더 빠른 조회를 위해 데이터를 인덱싱 된 HDFS 파일에 저장합니다. |
HBase의 스토리지 메커니즘
HBase는 column-oriented database그 안에있는 테이블은 행별로 정렬됩니다. 테이블 스키마는 키 값 쌍인 column family 만 정의합니다. 테이블에는 여러 column family가 있고 각 column family에는 여러 열이있을 수 있습니다. 후속 열 값은 디스크에 연속적으로 저장됩니다. 테이블의 각 셀 값에는 타임 스탬프가 있습니다. 간단히 말해서 HBase에서 :
- 테이블은 행의 모음입니다.
- 행은 column family의 모음입니다.
- Column family는 열 모음입니다.
- 열은 키 값 쌍의 모음입니다.
다음은 HBase의 테이블 스키마 예입니다.
| Rowid | 컬럼 패밀리 | 컬럼 패밀리 | 컬럼 패밀리 | 컬럼 패밀리 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | |
| 1 | ||||||||||||
| 2 | ||||||||||||
| 삼 | ||||||||||||
열 지향 및 행 지향
열 지향 데이터베이스는 데이터 테이블을 데이터 행이 아닌 데이터 열 섹션으로 저장하는 데이터베이스입니다. 곧 그들은 column family를 갖게 될 것입니다.
| 행 지향 데이터베이스 | 열 지향 데이터베이스 |
|---|---|
| OLTP (Online Transaction Process)에 적합합니다. | OLAP (Online Analytical Processing)에 적합합니다. |
| 이러한 데이터베이스는 적은 수의 행과 열을 위해 설계되었습니다. | 열 지향 데이터베이스는 거대한 테이블을 위해 설계되었습니다. |
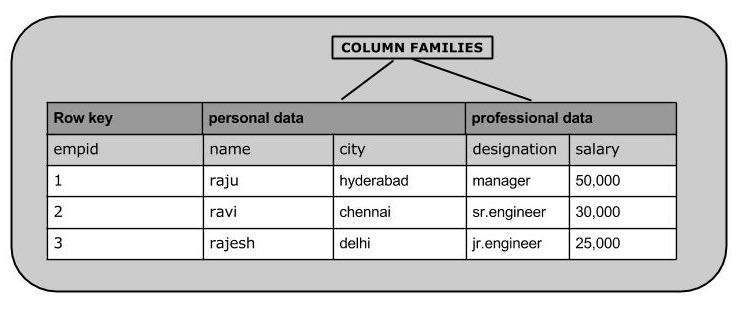
다음 이미지는 열 기반 데이터베이스의 열 패밀리를 보여줍니다.
HBase 및 RDBMS
| HBase | RDBMS |
|---|---|
| HBase는 스키마가 없으며 고정 열 스키마의 개념이 없습니다. column family 만 정의합니다. | RDBMS는 테이블의 전체 구조를 설명하는 스키마에 의해 관리됩니다. |
| 넓은 테이블 용으로 제작되었습니다. HBase는 수평 확장이 가능합니다. | 얇고 작은 테이블 용으로 제작되었습니다. 확장하기 어렵습니다. |
| HBase에는 트랜잭션이 없습니다. | RDBMS는 트랜잭션입니다. |
| 비정규 화 된 데이터가 있습니다. | 정규화 된 데이터를 갖게됩니다. |
| 반 구조화 된 데이터와 구조화 된 데이터에 적합합니다. | 구조화 된 데이터에 적합합니다. |
HBase의 특징
- HBase는 선형 적으로 확장 가능합니다.
- 자동 실패 지원이 있습니다.
- 일관된 읽기 및 쓰기를 제공합니다.
- 소스 및 대상 모두에서 Hadoop과 통합됩니다.
- 클라이언트를위한 쉬운 자바 API가 있습니다.
- 클러스터간에 데이터 복제를 제공합니다.
HBase를 사용하는 곳
Apache HBase는 빅 데이터에 대한 임의의 실시간 읽기 / 쓰기 액세스 권한을 갖는 데 사용됩니다.
상용 하드웨어 클러스터 위에 매우 큰 테이블을 호스팅합니다.
Apache HBase는 Google의 Bigtable을 모델로 한 비 관계형 데이터베이스입니다. Bigtable은 Google 파일 시스템에서 작동하며 Apache HBase는 Hadoop 및 HDFS에서 작동합니다.
HBase의 응용
- 무거운 애플리케이션을 작성해야 할 때마다 사용됩니다.
- HBase는 사용 가능한 데이터에 대한 빠른 임의 액세스를 제공해야 할 때마다 사용됩니다.
- Facebook, Twitter, Yahoo 및 Adobe와 같은 회사는 내부적으로 HBase를 사용합니다.
HBase 역사
| 년 | 행사 |
|---|---|
| 2006 년 11 월 | Google은 BigTable에 대한 논문을 발표했습니다. |
| 2007 년 2 월 | 초기 HBase 프로토 타입은 Hadoop 기여로 생성되었습니다. |
| 2007 년 10 월 | Hadoop 0.15.0과 함께 사용 가능한 최초의 HBase가 출시되었습니다. |
| 2008 년 1 월 | HBase는 Hadoop의 하위 프로젝트가되었습니다. |
| 2008 년 10 월 | HBase 0.18.1이 출시되었습니다. |
| 2009 년 1 월 | HBase 0.19.0이 출시되었습니다. |
| 2009 년 9 월 | HBase 0.20.0이 출시되었습니다. |
| 2010 년 5 월 | HBase는 Apache 최상위 프로젝트가되었습니다. |