Keras-퀵 가이드
Keras-소개
딥 러닝은 머신 러닝 프레임 워크의 주요 하위 분야 중 하나입니다. 기계 학습은 인간 두뇌 모델에서 영감을 얻은 알고리즘 설계 연구입니다. 딥 러닝은 로봇 공학, 인공 지능 (AI), 오디오 및 비디오 인식 및 이미지 인식과 같은 데이터 과학 분야에서 더욱 인기를 얻고 있습니다. 인공 신경망은 딥 러닝 방법론의 핵심입니다. 딥 러닝은 Theano, TensorFlow, Caffe, Mxnet 등과 같은 다양한 라이브러리에서 지원되며 Keras는 TensorFlow, Theano 등과 같은 인기있는 딥 러닝 라이브러리를 기반으로 구축 된 가장 강력하고 사용하기 쉬운 Python 라이브러리 중 하나입니다. , 딥 러닝 모델을 생성합니다.
Keras 개요
Keras는 TensorFlow, Theano 또는 Cognitive Toolkit (CNTK)과 같은 오픈 소스 머신 라이브러리 위에서 실행됩니다. Theano는 빠른 수치 계산 작업에 사용되는 Python 라이브러리입니다. TensorFlow는 신경망 및 딥 러닝 모델을 생성하는 데 사용되는 가장 유명한 기호 수학 라이브러리입니다. TensorFlow는 매우 유연하며 주요 이점은 분산 컴퓨팅입니다. CNTK는 Microsoft에서 개발 한 딥 러닝 프레임 워크입니다. Python, C #, C ++ 또는 독립형 기계 학습 툴킷과 같은 라이브러리를 사용합니다. Theano와 TensorFlow는 매우 강력한 라이브러리이지만 신경망을 만드는 데는 이해하기 어렵습니다.
Keras는 TensorFlow 또는 Theano를 기반으로 딥 러닝 모델을 생성하는 깔끔하고 쉬운 방법을 제공하는 최소 구조를 기반으로합니다. Keras는 딥 러닝 모델을 빠르게 정의하도록 설계되었습니다. Keras는 딥 러닝 애플리케이션을위한 최적의 선택입니다.
풍모
Keras는 다양한 최적화 기술을 활용하여 높은 수준의 신경망 API를보다 쉽고 성능있게 만듭니다. 다음 기능을 지원합니다-
일관되고 간단하며 확장 가능한 API.
최소한의 구조-주름없이 쉽게 결과를 얻을 수 있습니다.
여러 플랫폼과 백엔드를 지원합니다.
CPU와 GPU 모두에서 실행되는 사용자 친화적 인 프레임 워크입니다.
계산의 높은 확장 성.
혜택
Keras는 매우 강력하고 동적 인 프레임 워크이며 다음과 같은 장점이 있습니다.
더 큰 커뮤니티 지원.
테스트하기 쉽습니다.
Keras 신경망은 Python으로 작성되어 더 간단합니다.
Keras는 컨볼 루션 및 순환 네트워크를 모두 지원합니다.
딥 러닝 모델은 이산 구성 요소이므로 여러 방법으로 결합 할 수 있습니다.
Keras-설치
이 장에서는 컴퓨터에 Keras를 설치하는 방법에 대해 설명합니다. 설치로 이동하기 전에 Keras의 기본 요구 사항을 살펴 보겠습니다.
전제 조건
다음 요구 사항을 충족해야합니다.
- 모든 종류의 OS (Windows, Linux 또는 Mac)
- Python 버전 3.5 이상.
파이썬
Keras는 Python 기반의 신경망 라이브러리이므로 Python을 컴퓨터에 설치해야합니다. python이 컴퓨터에 제대로 설치되어 있으면 터미널을 열고 python을 입력하면 아래와 비슷한 응답을 볼 수 있습니다.
Python 3.6.5 (v3.6.5:f59c0932b4, Mar 28 2018, 17:00:18)
[MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>현재 최신 버전은 '3.7.2'입니다. Python이 설치되지 않은 경우 공식 Python 링크 ( www.python.org) 를 방문 하여 OS에 따라 최신 버전을 다운로드하고 시스템에 즉시 설치하십시오.
Keras 설치 단계
Keras 설치는 아주 쉽습니다. 시스템에 Keras를 올바르게 설치하려면 아래 단계를 따르십시오.
1 단계 : 가상 환경 생성
Virtualenv다른 프로젝트의 Python 패키지를 관리하는 데 사용됩니다. 이것은 다른 환경에 설치된 패키지가 깨지는 것을 방지하는 데 도움이됩니다. 따라서 Python 애플리케이션을 개발하는 동안 항상 가상 환경을 사용하는 것이 좋습니다.
Linux/Mac OS
Linux 또는 Mac OS 사용자는 프로젝트 루트 디렉토리로 이동하여 아래 명령을 입력하여 가상 환경을 만듭니다.
python3 -m venv kerasenv위 명령을 실행하면 "kerasenv"디렉토리가 생성됩니다. bin,lib and include folders 설치 위치에서.
Windows
Windows 사용자는 아래 명령을 사용할 수 있습니다.
py -m venv keras2 단계 : 환경 활성화
이 단계는 셸 경로에 python 및 pip 실행 파일을 구성합니다.
Linux/Mac OS
이제 "kerasvenv"라는 가상 환경을 만들었습니다. 폴더로 이동하여 아래 명령을 입력하십시오.
$ cd kerasvenv kerasvenv $ source bin/activateWindows
Windows 사용자는 "kerasenv"폴더로 이동하여 아래 명령을 입력합니다.
.\env\Scripts\activate3 단계 : Python 라이브러리
Keras는 다음 Python 라이브러리에 의존합니다.
- Numpy
- Pandas
- Scikit-learn
- Matplotlib
- Scipy
- Seaborn
위의 모든 라이브러리를 시스템에 설치했으면합니다. 이러한 라이브러리가 설치되지 않은 경우 아래 명령을 사용하여 하나씩 설치하십시오.
numpy
pip install numpy다음과 같은 응답을 볼 수 있습니다.
Collecting numpy
Downloading
https://files.pythonhosted.org/packages/cf/a4/d5387a74204542a60ad1baa84cd2d3353c330e59be8cf2d47c0b11d3cde8/
numpy-3.1.1-cp36-cp36m-macosx_10_6_intel.
macosx_10_9_intel.macosx_10_9_x86_64.
macosx_10_10_intel.macosx_10_10_x86_64.whl (14.4MB)
|████████████████████████████████| 14.4MB 2.8MB/spandas
pip install pandas다음과 같은 응답을 볼 수 있습니다.
Collecting pandas
Downloading
https://files.pythonhosted.org/packages/cf/a4/d5387a74204542a60ad1baa84cd2d3353c330e59be8cf2d47c0b11d3cde8/
pandas-3.1.1-cp36-cp36m-macosx_10_6_intel.
macosx_10_9_intel.macosx_10_9_x86_64.
macosx_10_10_intel.macosx_10_10_x86_64.whl (14.4MB)
|████████████████████████████████| 14.4MB 2.8MB/smatplotlib
pip install matplotlib다음과 같은 응답을 볼 수 있습니다.
Collecting matplotlib
Downloading
https://files.pythonhosted.org/packages/cf/a4/d5387a74204542a60ad1baa84cd2d3353c330e59be8cf2d47c0b11d3cde8/
matplotlib-3.1.1-cp36-cp36m-macosx_10_6_intel.
macosx_10_9_intel.macosx_10_9_x86_64.
macosx_10_10_intel.macosx_10_10_x86_64.whl (14.4MB)
|████████████████████████████████| 14.4MB 2.8MB/sscipy
pip install scipy다음과 같은 응답을 볼 수 있습니다.
Collecting scipy
Downloading
https://files.pythonhosted.org/packages/cf/a4/d5387a74204542a60ad1baa84cd2d3353c330e59be8cf2d47c0b11d3cde8
/scipy-3.1.1-cp36-cp36m-macosx_10_6_intel.
macosx_10_9_intel.macosx_10_9_x86_64.
macosx_10_10_intel.macosx_10_10_x86_64.whl (14.4MB)
|████████████████████████████████| 14.4MB 2.8MB/sscikit-learn
오픈 소스 기계 학습 라이브러리입니다. 분류, 회귀 및 클러스터링 알고리즘에 사용됩니다. 설치로 이동하기 전에 다음이 필요합니다.
- Python 버전 3.5 이상
- NumPy 버전 1.11.0 이상
- SciPy 버전 0.17.0 이상
- joblib 0.11 이상.
이제 아래 명령을 사용하여 scikit-learn을 설치합니다.
pip install -U scikit-learnSeaborn
Seaborn은 데이터를 쉽게 시각화 할 수있는 놀라운 라이브러리입니다. 아래 명령을 사용하여 설치하십시오-
pip pip install seaborninstall -U scikit-learn아래에 지정된 것과 유사한 메시지를 볼 수 있습니다.
Collecting seaborn
Downloading
https://files.pythonhosted.org/packages/a8/76/220ba4420459d9c4c9c9587c6ce607bf56c25b3d3d2de62056efe482dadc
/seaborn-0.9.0-py3-none-any.whl (208kB) 100%
|████████████████████████████████| 215kB 4.0MB/s
Requirement already satisfied: numpy> = 1.9.3 in
./lib/python3.7/site-packages (from seaborn) (1.17.0)
Collecting pandas> = 0.15.2 (from seaborn)
Downloading
https://files.pythonhosted.org/packages/39/b7/441375a152f3f9929ff8bc2915218ff1a063a59d7137ae0546db616749f9/
pandas-0.25.0-cp37-cp37m-macosx_10_9_x86_64.
macosx_10_10_x86_64.whl (10.1MB) 100%
|████████████████████████████████| 10.1MB 1.8MB/s
Requirement already satisfied: scipy>=0.14.0 in
./lib/python3.7/site-packages (from seaborn) (1.3.0)
Collecting matplotlib> = 1.4.3 (from seaborn)
Downloading
https://files.pythonhosted.org/packages/c3/8b/af9e0984f
5c0df06d3fab0bf396eb09cbf05f8452de4e9502b182f59c33b/
matplotlib-3.1.1-cp37-cp37m-macosx_10_6_intel.
macosx_10_9_intel.macosx_10_9_x86_64
.macosx_10_10_intel.macosx_10_10_x86_64.whl (14.4MB) 100%
|████████████████████████████████| 14.4MB 1.4MB/s
......................................
......................................
Successfully installed cycler-0.10.0 kiwisolver-1.1.0
matplotlib-3.1.1 pandas-0.25.0 pyparsing-2.4.2
python-dateutil-2.8.0 pytz-2019.2 seaborn-0.9.0Python을 사용한 Keras 설치
현재 Kera 설치를위한 기본 요구 사항을 완료했습니다. 이제 아래 지정된 것과 동일한 절차를 사용하여 Keras를 설치하십시오.
pip install keras가상 환경 종료
프로젝트의 모든 변경 사항을 마친 후 아래 명령을 실행하여 환경을 종료하십시오.
deactivate아나콘다 클라우드
컴퓨터에 아나콘다 클라우드를 설치했다고 믿습니다. anaconda가 설치되지 않은 경우 공식 링크 www.anaconda.com/distribution 을 방문 하여 OS에 따라 다운로드를 선택하십시오.
새로운 conda 환경 만들기
아나콘다 프롬프트를 시작하면 기본 Anaconda 환경이 열립니다. 새로운 conda 환경을 만들어 보겠습니다. 이 프로세스는 virtualenv와 유사합니다. 콘다 터미널에 아래 명령을 입력하십시오-
conda create --name PythonCPU원하는 경우 GPU를 사용하여 모듈을 만들고 설치할 수도 있습니다. 이 자습서에서는 CPU 지침을 따릅니다.
conda 환경 활성화
환경을 활성화하려면 아래 명령을 사용하십시오-
activate PythonCPU스파이더 설치
Spyder는 파이썬 애플리케이션을 실행하기위한 IDE입니다. 아래 명령을 사용하여 conda 환경에이 IDE를 설치하겠습니다.
conda install spyderPython 라이브러리 설치
우리는 keras에 필요한 파이썬 라이브러리 numpy, pandas 등을 이미 알고 있습니다. 아래 구문을 사용하여 모든 모듈을 설치할 수 있습니다.
Syntax
conda install -c anaconda <module-name>예를 들어, pandas를 설치하고 싶습니다.
conda install -c anaconda pandas같은 방법으로 나머지 모듈을 직접 설치해보십시오.
Keras 설치
이제 모든 것이 좋아 보이므로 아래 명령을 사용하여 keras 설치를 시작할 수 있습니다.
conda install -c anaconda keras스파이더 시작
마지막으로 아래 명령을 사용하여 conda 터미널에서 spyder를 시작하십시오.
spyder모든 것이 올바르게 설치되었는지 확인하기 위해 모든 모듈을 가져 오면 모든 것이 추가되고 문제가 발생하면 module not found 에러 메시지.
Keras-백엔드 구성
이 장에서는 Keras 백엔드 구현 TensorFlow 및 Theano에 대해 자세히 설명합니다. 각 구현을 하나씩 살펴 보겠습니다.
TensorFlow
TensorFlow는 Google에서 개발 한 수치 계산 작업에 사용되는 오픈 소스 머신 러닝 라이브러리입니다. Keras는 TensorFlow 또는 Theano를 기반으로 구축 된 고수준 API입니다. 우리는 이미 pip를 사용하여 TensorFlow를 설치하는 방법을 알고 있습니다.
설치되어 있지 않은 경우 아래 명령을 사용하여 설치할 수 있습니다.
pip install TensorFlowkeras를 실행하면 구성 파일이 홈 디렉토리 내부에 있고 .keras / keras.json으로 이동하는 것을 볼 수 있습니다.
keras.json
{
"image_data_format": "channels_last",
"epsilon": 1e-07, "floatx": "float32", "backend": "tensorflow"
}여기,
image_data_format 데이터 형식을 나타냅니다.
epsilon숫자 상수를 나타냅니다. 피하는 데 사용됩니다.DivideByZero 오류.
floatx는 기본 데이터 유형을 나타냅니다. float32. 다음으로 변경할 수도 있습니다.float16 또는 float64 사용 set_floatx() 방법.
image_data_format 데이터 형식을 나타냅니다.
파일이 생성되지 않은 경우 해당 위치로 이동하여 아래 단계를 사용하여 생성한다고 가정합니다.
> cd home
> mkdir .keras
> vi keras.json.keras를 폴더 이름으로 지정하고 keras.json 파일에 위의 구성을 추가해야합니다. 백엔드 기능을 알기 위해 사전 정의 된 작업을 수행 할 수 있습니다.
테 아노
Theano는 다차원 배열을 효과적으로 평가할 수있는 오픈 소스 딥 러닝 라이브러리입니다. 아래 명령을 사용하여 쉽게 설치할 수 있습니다.
pip install theano기본적으로 keras는 TensorFlow 백엔드를 사용합니다. 백엔드 구성을 TensorFlow에서 Theano로 변경하려면 keras.json 파일에서 backend = theano를 변경하면됩니다. 아래에 설명되어 있습니다-
keras.json
{
"image_data_format": "channels_last",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "theano"
}이제 파일을 저장하고 터미널을 다시 시작하고 keras를 시작하면 백엔드가 변경됩니다.
>>> import keras as k
using theano backend.Keras-딥 러닝 개요
딥 러닝은 기계 학습의 진화하는 하위 분야입니다. 딥 러닝은 입력을 레이어별로 분석하는 것을 포함하며, 각 레이어는 입력에 대한 더 높은 수준의 정보를 점진적으로 추출합니다.
이미지를 분석하는 간단한 시나리오를 살펴 보겠습니다. 입력 이미지가 픽셀의 직사각형 격자로 나뉘어져 있다고 가정 해 보겠습니다. 이제 첫 번째 레이어는 픽셀을 추상화합니다. 두 번째 레이어는 이미지의 가장자리를 이해합니다. 다음 레이어는 가장자리에서 노드를 구성합니다. 그런 다음 다음 노드는 노드에서 분기를 찾습니다. 마지막으로 출력 레이어는 전체 개체를 감지합니다. 여기서 특징 추출 프로세스는 한 레이어의 출력에서 다음 후속 레이어의 입력으로 이동합니다.
이 접근 방식을 사용하면 엄청난 양의 기능을 처리 할 수 있으므로 딥 러닝이 매우 강력한 도구가됩니다. 딥 러닝 알고리즘은 비정형 데이터 분석에도 유용합니다. 이 장에서 딥 러닝의 기초를 살펴 보겠습니다.
인공 신경망
딥 러닝의 가장 널리 사용되는 기본 접근 방식은 "인공 신경망"(ANN)을 사용하는 것입니다. 그들은 우리 몸의 가장 복잡한 기관인 인간의 뇌 모델에서 영감을 받았습니다. 인간의 뇌는 "뉴런"이라고 불리는 900 억 개 이상의 작은 세포로 구성되어 있습니다. 뉴런은 "축선"과 "수상 돌기"라고하는 신경 섬유를 통해 상호 연결됩니다. 축삭의 주요 역할은 한 뉴런에서 연결된 다른 뉴런으로 정보를 전송하는 것입니다.
마찬가지로 수상 돌기의 주요 역할은 연결된 다른 뉴런의 축삭에 의해 전달되는 정보를 수신하는 것입니다. 각 뉴런은 작은 정보를 처리 한 다음 결과를 다른 뉴런으로 전달하고이 과정은 계속됩니다. 이것은 인간의 두뇌가 음성, 시각 등과 같은 방대한 정보를 처리하고 유용한 정보를 추출하는 데 사용하는 기본 방법입니다.
이 모델을 기반으로 심리학자에 의해 최초의 인공 신경망 (ANN)이 발명되었습니다. Frank Rosenblatt, 1958 년. ANN은 뉴런과 유사한 여러 노드로 구성됩니다. 노드는 밀접하게 상호 연결되어 있으며 서로 다른 숨겨진 레이어로 구성됩니다. 입력 계층은 입력 데이터를 수신하고 데이터는 하나 이상의 숨겨진 계층을 순차적으로 통과하고 마지막으로 출력 계층은 입력 데이터에 대해 유용한 것을 예측합니다. 예를 들어, 입력은 이미지 일 수 있고 출력은 이미지에서 식별 된 것, 즉 "고양이"일 수 있습니다.
단일 뉴런 (ANN에서 퍼셉트론이라고 함)은 다음과 같이 나타낼 수 있습니다.
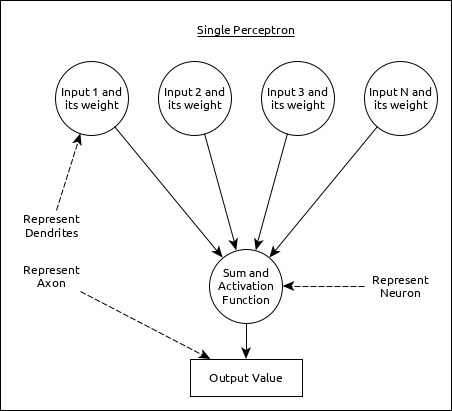
여기,
무게와 함께 다중 입력은 수상 돌기를 나타냅니다.
활성화 함수와 함께 입력의 합계는 뉴런을 나타냅니다. Sum 실제로 모든 입력의 계산 된 값을 의미하고 활성화 함수는 함수를 나타냅니다. Sum 값을 0, 1 또는 0에서 1로
실제 출력은 축삭을 나타내며 출력은 다음 레이어의 뉴런에 의해 수신됩니다.
이 섹션에서 다양한 유형의 인공 신경망을 이해하겠습니다.
다층 퍼셉트론
다층 퍼셉트론은 ANN의 가장 간단한 형태입니다. 단일 입력 레이어, 하나 이상의 은닉 레이어 및 마지막으로 출력 레이어로 구성됩니다. 레이어는 퍼셉트론 모음으로 구성됩니다. 입력 계층은 기본적으로 입력 데이터의 하나 이상의 기능입니다. 모든 히든 레이어는 하나 이상의 뉴런으로 구성되어 있으며 기능의 특정 측면을 처리하고 처리 된 정보를 다음 히든 레이어로 보냅니다. 출력 레이어 프로세스는 마지막 은닉 레이어에서 데이터를 수신하고 최종적으로 결과를 출력합니다.

컨볼 루션 신경망 (CNN)
컨볼 루션 신경망은 가장 인기있는 ANN 중 하나입니다. 이미지 및 비디오 인식 분야에서 널리 사용됩니다. 그것은 수학적 개념 인 컨볼 루션의 개념을 기반으로합니다. 완전히 연결된 은닉 뉴런 레이어 이전에 일련의 컨볼 루션 레이어와 풀링 레이어를 포함한다는 점을 제외하면 다층 퍼셉트론과 거의 유사합니다. 세 가지 중요한 레이어가 있습니다.
Convolution layer − 기본 빌딩 블록이며 convolution 함수를 기반으로 계산 작업을 수행합니다.
Pooling layer − convolution layer 옆에 배치되며 불필요한 정보를 제거하여 입력 크기를 줄여 계산이 더 빠르게 수행 될 수 있도록합니다.
Fully connected layer − 일련의 convolution 및 pooling 레이어 옆에 배치되어 입력을 다양한 카테고리로 분류합니다.
간단한 CNN은 다음과 같이 나타낼 수 있습니다.

여기,
2 시리즈의 Convolution과 pooling layer가 사용되며 입력 (예 : 이미지)을 받아 처리합니다.
완전히 연결된 단일 레이어가 사용되며 데이터를 출력하는 데 사용됩니다 (예 : 이미지 분류).
RNN (Recurrent Neural Network)
RNN (Recurrent Neural Networks)은 다른 ANN 모델의 결함을 해결하는 데 유용합니다. 글쎄요, 대부분의 ANN은 이전 상황의 단계를 기억하지 못하고 훈련의 맥락을 기반으로 결정을 내리는 법을 배웠습니다. 한편 RNN은 과거 정보를 저장하고 모든 결정은 과거로부터 배운 것에서 취합니다.
이 접근 방식은 주로 이미지 분류에 유용합니다. 때때로 우리는 과거를 고치기 위해 미래를 들여다 봐야 할 수도 있습니다. 이 경우 양방향 RNN은 과거로부터 배우고 미래를 예측하는 데 도움이됩니다. 예를 들어, 여러 입력에 손으로 쓴 샘플이 있습니다. 한 입력에 혼동이있는 경우 다른 입력을 다시 확인하여 과거로부터 결정을 내리는 올바른 컨텍스트를 인식해야한다고 가정합니다.
ANN의 워크 플로우
먼저 딥 러닝의 여러 단계를 이해 한 다음 Keras가 딥 러닝 과정에서 어떻게 도움이되는지 알아 보겠습니다.
필요한 데이터 수집
딥 러닝은 결과를 성공적으로 학습하고 예측하기 위해 많은 입력 데이터가 필요합니다. 따라서 먼저 가능한 한 많은 데이터를 수집하십시오.
데이터 분석
데이터를 분석하고 데이터를 잘 이해합니다. 올바른 ANN 알고리즘을 선택하려면 데이터를 더 잘 이해해야합니다.
알고리즘 (모델) 선택
학습 프로세스 유형 (예 : 이미지 분류, 텍스트 처리 등) 및 사용 가능한 입력 데이터에 가장 적합한 알고리즘을 선택합니다. 알고리즘은 다음과 같이 표현됩니다.ModelKeras에서. 알고리즘은 하나 이상의 레이어를 포함합니다. ANN의 각 레이어는 다음과 같이 나타낼 수 있습니다.Keras Layer Keras에서.
Prepare data − 데이터에서 필요한 정보 만 처리, 필터링 및 선택합니다.
Split data− 데이터를 훈련 및 테스트 데이터 세트로 분할합니다. 테스트 데이터는 알고리즘 / 모델 (머신 러닝 후)의 예측을 평가하고 학습 프로세스의 효율성을 교차 확인하는 데 사용됩니다.
Compile the model− 알고리즘 / 모델을 컴파일하여 학습을 통해 학습하고 마지막으로 예측에 사용할 수 있도록합니다. 이 단계에서는 손실 함수와 Optimizer를 선택해야합니다. 손실 함수와 Optimizer는 학습 단계에서 오류 (실제 출력과의 편차)를 찾고 최적화하여 오류가 최소화되도록합니다.
Fit the model − 실제 학습 과정은 훈련 데이터 세트를 사용하여이 단계에서 수행됩니다.
Predict result for unknown value − 알려지지 않은 입력 데이터 (기존 교육 및 테스트 데이터 제외)에 대한 출력 예측
Evaluate model − 테스트 데이터의 출력을 예측하고 예측을 테스트 데이터의 실제 결과와 교차 비교하여 모델을 평가합니다.
Freeze, Modify or choose new algorithm− 모델 평가가 성공했는지 확인합니다. 그렇다면 향후 예측을 위해 알고리즘을 저장하십시오. 그렇지 않은 경우 새 알고리즘 / 모델을 수정하거나 선택하고 마지막으로 모델을 다시 학습, 예측 및 평가합니다. 최상의 알고리즘 (모델)을 찾을 때까지 프로세스를 반복하십시오.
위의 단계는 아래 순서도를 사용하여 나타낼 수 있습니다.

Keras-딥 러닝
Keras는 모든 유형의 신경망을 생성 할 수있는 완벽한 프레임 워크를 제공합니다. Keras는 혁신적이고 배우기 매우 쉽습니다. 단순한 신경망부터 매우 크고 복잡한 신경망 모델까지 지원합니다. Keras 프레임 워크의 아키텍처와이 장에서 Keras가 딥 러닝에 어떻게 도움이되는지 이해하겠습니다.
Keras의 아키텍처
Keras API는 세 가지 주요 범주로 나눌 수 있습니다.
- Model
- Layer
- 핵심 모듈
Keras에서 모든 ANN은 Keras Models. 차례로 모든 Keras 모델은Keras Layers 입력, 히든 레이어, 출력 레이어, 컨볼 루션 레이어, 풀링 레이어 등과 같은 ANN 레이어, Keras 모델 및 레이어 액세스를 나타냅니다. Keras modules 활성화 함수, 손실 함수, 정규화 함수 등의 경우 Keras 모델, Keras Layer 및 Keras 모듈을 사용하여 모든 ANN 알고리즘 (CNN, RNN 등)을 간단하고 효율적으로 표현할 수 있습니다.
다음 다이어그램은 모델, 계층 및 핵심 모듈 간의 관계를 보여줍니다.

Keras 모델, Keras 레이어 및 Keras 모듈의 개요를 살펴 보겠습니다.
모델
Keras 모델은 다음과 같이 두 가지 유형이 있습니다.
Sequential Model− 순차 모델은 기본적으로 Keras 레이어의 선형 구성입니다. 순차 모델은 간단하고 간단 할뿐만 아니라 거의 모든 사용 가능한 신경망을 나타낼 수 있습니다.
간단한 순차 모델은 다음과 같습니다.
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,)))어디,
Line 1 수입품 Sequential Keras 모델의 모델
Line 2 수입품 Dense 레이어 및 Activation 기준 치수
Line 4 다음을 사용하여 새 순차 모델 생성 Sequential API
Line 5 고밀도 레이어 (Dense API)를 추가합니다. relu 활성화 (활성화 모듈 사용) 기능.
Sequential 모델 노출 Model맞춤 모델을 만들 수도 있습니다. 하위 분류 개념을 사용하여 복잡한 모델을 만들 수 있습니다.
Functional API − Functional API는 기본적으로 복잡한 모델을 생성하는 데 사용됩니다.
층
Keras 모델의 각 Keras 레이어는 실제 제안 된 신경망 모델에서 해당 레이어 (입력 레이어, 히든 레이어 및 출력 레이어)를 나타냅니다. Keras는 복잡한 신경망을 쉽게 만들 수 있도록 많은 사전 빌드 레이어를 제공합니다. 중요한 Keras 레이어 중 일부는 아래에 지정되어 있습니다.
- 코어 레이어
- 컨볼 루션 레이어
- 풀링 레이어
- 반복 레이어
다음을 사용하여 신경망 모델을 나타내는 간단한 파이썬 코드 sequential 모델은 다음과 같습니다-
from keras.models import Sequential
from keras.layers import Dense, Activation, Dropout model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation = 'relu')) model.add(Dropout(0.2))
model.add(Dense(num_classes, activation = 'softmax'))어디,
Line 1 수입품 Sequential Keras 모델의 모델
Line 2 수입품 Dense 레이어 및 Activation 기준 치수
Line 4 다음을 사용하여 새 순차 모델 생성 Sequential API
Line 5 고밀도 레이어 (Dense API)를 추가합니다. relu 활성화 (활성화 모듈 사용) 기능.
Line 6 오 버핏을 처리하기 위해 드롭 아웃 레이어 (Dropout API)를 추가합니다.
Line 7 다른 고밀도 레이어 (Dense API)를 추가합니다. relu 활성화 (활성화 모듈 사용) 기능.
Line 8 과적 합을 처리하기 위해 다른 드롭 아웃 레이어 (Dropout API)를 추가합니다.
Line 9 최종 고밀도 레이어 (Dense API)를 추가합니다. softmax 활성화 (활성화 모듈 사용) 기능.
Keras는 사용자 정의 레이어를 생성하는 옵션도 제공합니다. 사용자 정의 레이어는 하위 분류하여 만들 수 있습니다.Keras.Layer 클래스이며 Keras 모델의 하위 클래스 화와 유사합니다.
핵심 모듈
Keras는 또한 Keras 모델과 Keras 레이어를 올바르게 생성하기 위해 많은 내장 신경망 관련 기능을 제공합니다. 일부 기능은 다음과 같습니다.
Activations module − 활성화 기능은 ANN에서 중요한 개념이며 활성화 모듈은 softmax, relu 등과 같은 많은 활성화 기능을 제공합니다.
Loss module − Loss 모듈은 mean_squared_error, mean_absolute_error, poisson 등과 같은 손실 함수를 제공합니다.
Optimizer module − Optimizer 모듈은 adam, sgd 등과 같은 최적화 기능을 제공합니다.
Regularizers − 정규화 모듈은 L1 정규화, L2 정규화 등의 기능을 제공합니다.
다음 장에서 Keras 모듈에 대해 자세히 알아 보겠습니다.
Keras-모듈
앞서 배운 것처럼 Keras 모듈에는 딥 러닝 알고리즘에 유용한 사전 정의 된 클래스, 함수 및 변수가 포함되어 있습니다. 이 장에서 Keras가 제공하는 모듈에 대해 알아 보겠습니다.
사용 가능한 모듈
먼저 Keras에서 사용할 수있는 모듈 목록을 살펴 보겠습니다.
Initializers− 이니셜 라이저 기능 목록을 제공합니다. Keras 레이어 장 에서 자세히 배울 수 있습니다 . 머신 러닝의 모델 생성 단계에서
Regularizers− 정규화 함수 목록을 제공합니다. Keras Layers 장 에서 자세히 배울 수 있습니다 .
Constraints− 제약 기능 목록을 제공합니다. Keras Layers 장 에서 자세히 배울 수 있습니다 .
Activations− 활성기 기능 목록을 제공합니다. Keras Layers 장 에서 자세히 배울 수 있습니다 .
Losses− 손실 기능 목록을 제공합니다. Model Training 장 에서 자세히 배울 수 있습니다 .
Metrics− 메트릭 기능 목록을 제공합니다. Model Training 장 에서 자세히 배울 수 있습니다 .
Optimizers− 최적화 기능 목록을 제공합니다. Model Training 장 에서 자세히 배울 수 있습니다 .
Callback− 콜백 기능 목록을 제공합니다. 훈련 과정에서 중간 데이터를 인쇄하고 훈련 자체를 중지하는 데 사용할 수 있습니다 (EarlyStopping 방법) 일부 조건에 따라.
Text processing− 텍스트를 머신 러닝에 적합한 NumPy 배열로 변환하는 기능을 제공합니다. 머신 러닝의 데이터 준비 단계에서 사용할 수 있습니다.
Image processing− 머신 러닝에 적합한 NumPy 배열로 이미지를 변환하는 기능을 제공합니다. 머신 러닝의 데이터 준비 단계에서 사용할 수 있습니다.
Sequence processing− 주어진 입력 데이터에서 시간 기반 데이터를 생성하는 기능을 제공합니다. 머신 러닝의 데이터 준비 단계에서 사용할 수 있습니다.
Backend− TensorFlow 및 Theano 와 같은 백엔드 라이브러리의 기능을 제공합니다 .
Utilities − 딥 러닝에 유용한 다양한 기능을 제공합니다.
우리에게 보여줘 backend 모듈 및 utils 이 장의 모델.
백엔드 모듈
backend modulekeras 백엔드 작업에 사용됩니다. 기본적으로 keras는 TensorFlow 백엔드에서 실행됩니다. 원하는 경우 Theano 또는 CNTK와 같은 다른 백엔드로 전환 할 수 있습니다. 기본 백엔드 구성은 .keras / keras.json 파일의 루트 디렉토리 내에 정의됩니다.
Keras 백엔드 모듈은 아래 코드를 사용하여 가져올 수 있습니다.
>>> from keras import backend as k기본 백엔드 TensorFlow 를 사용하는 경우 아래 함수는 아래 지정된대로 TensorFlow 기반 정보를 반환합니다.
>>> k.backend()
'tensorflow'
>>> k.epsilon()
1e-07
>>> k.image_data_format()
'channels_last'
>>> k.floatx()
'float32'데이터 분석에 사용되는 몇 가지 중요한 백엔드 기능을 간략하게 이해하겠습니다.
get_uid ()
기본 그래프의 식별자입니다. 아래에 정의되어 있습니다-
>>> k.get_uid(prefix='')
1
>>> k.get_uid(prefix='') 2reset_uids
uid 값을 재설정하는 데 사용됩니다.
>>> k.reset_uids()이제 다시 get_uid ()를 실행합니다 . 이것은 재설정되고 다시 1로 변경됩니다.
>>> k.get_uid(prefix='')
1자리 표시 자
자리 표시 자 텐서를 인스턴스화하는 데 사용됩니다. 3D 모양을 유지하는 간단한 자리 표시자는 다음과 같습니다.
>>> data = k.placeholder(shape = (1,3,3))
>>> data
<tf.Tensor 'Placeholder_9:0' shape = (1, 3, 3) dtype = float32>
If you use int_shape(), it will show the shape.
>>> k.int_shape(data) (1, 3, 3)점
두 개의 텐서를 곱하는 데 사용됩니다. a와 b는 두 개의 텐서이고 c는 ab의 곱셈 결과라고 가정합니다. 모양이 (4,2)이고 b 모양이 (2,3)이라고 가정합니다. 아래에 정의되어 있습니다.
>>> a = k.placeholder(shape = (4,2))
>>> b = k.placeholder(shape = (2,3))
>>> c = k.dot(a,b)
>>> c
<tf.Tensor 'MatMul_3:0' shape = (4, 3) dtype = float32>
>>>하나
모두 초기화하는 데 사용됩니다. one 값.
>>> res = k.ones(shape = (2,2))
#print the value
>>> k.eval(res)
array([[1., 1.], [1., 1.]], dtype = float32)batch_dot
두 데이터의 곱을 일괄 적으로 수행하는 데 사용됩니다. 입력 치수는 2 이상이어야합니다. 아래에 나와 있습니다-
>>> a_batch = k.ones(shape = (2,3))
>>> b_batch = k.ones(shape = (3,2))
>>> c_batch = k.batch_dot(a_batch,b_batch)
>>> c_batch
<tf.Tensor 'ExpandDims:0' shape = (2, 1) dtype = float32>변하기 쉬운
변수를 초기화하는 데 사용됩니다. 이 변수에서 간단한 전치 연산을 수행해 보겠습니다.
>>> data = k.variable([[10,20,30,40],[50,60,70,80]])
#variable initialized here
>>> result = k.transpose(data)
>>> print(result)
Tensor("transpose_6:0", shape = (4, 2), dtype = float32)
>>> print(k.eval(result))
[[10. 50.]
[20. 60.]
[30. 70.]
[40. 80.]]numpy에서 액세스하려면-
>>> data = np.array([[10,20,30,40],[50,60,70,80]])
>>> print(np.transpose(data))
[[10 50]
[20 60]
[30 70]
[40 80]]
>>> res = k.variable(value = data)
>>> print(res)
<tf.Variable 'Variable_7:0' shape = (2, 4) dtype = float32_ref>is_sparse (텐서)
텐서가 희소 여부를 확인하는 데 사용됩니다.
>>> a = k.placeholder((2, 2), sparse=True)
>>> print(a) SparseTensor(indices =
Tensor("Placeholder_8:0",
shape = (?, 2), dtype = int64),
values = Tensor("Placeholder_7:0", shape = (?,),
dtype = float32), dense_shape = Tensor("Const:0", shape = (2,), dtype = int64))
>>> print(k.is_sparse(a)) Trueto_dense ()
희소를 조밀로 변환하는 데 사용됩니다.
>>> b = k.to_dense(a)
>>> print(b) Tensor("SparseToDense:0", shape = (2, 2), dtype = float32)
>>> print(k.is_sparse(b)) Falserandom_uniform_variable
사용하여 초기화하는 데 사용됩니다. uniform distribution 개념.
k.random_uniform_variable(shape, mean, scale)여기,
shape − 튜플 형식의 행과 열을 나타냅니다.
mean − 균등 분포의 평균.
scale − 균일 분포의 표준 편차.
아래의 사용 예를 살펴 보겠습니다.
>>> a = k.random_uniform_variable(shape = (2, 3), low=0, high = 1)
>>> b = k. random_uniform_variable(shape = (3,2), low = 0, high = 1)
>>> c = k.dot(a, b)
>>> k.int_shape(c)
(2, 2)유틸리티 모듈
utils딥 러닝에 유용한 유틸리티 기능을 제공합니다. 제공하는 방법 중 일부는utils 모듈은 다음과 같습니다-
HDF5Matrix
입력 데이터를 HDF5 형식으로 표현하는 데 사용됩니다.
from keras.utils import HDF5Matrix data = HDF5Matrix('data.hdf5', 'data')to_categorical
클래스 벡터를 이진 클래스 행렬로 변환하는 데 사용됩니다.
>>> from keras.utils import to_categorical
>>> labels = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> to_categorical(labels)
array([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]], dtype = float32)
>>> from keras.utils import normalize
>>> normalize([1, 2, 3, 4, 5])
array([[0.13483997, 0.26967994, 0.40451992, 0.53935989, 0.67419986]])print_summary
모델 요약을 인쇄하는 데 사용됩니다.
from keras.utils import print_summary print_summary(model)plot_model
모델 표현을 도트 형식으로 생성하고 파일에 저장하는 데 사용됩니다.
from keras.utils import plot_model
plot_model(model,to_file = 'image.png')이 plot_model 모델의 성능을 이해하기 위해 이미지를 생성합니다.
Keras-레이어
앞서 배운 것처럼 Keras 레이어는 Keras 모델의 기본 구성 요소입니다. 각 계층은 입력 정보를 수신하고 일부 계산을 수행 한 다음 최종적으로 변환 된 정보를 출력합니다. 한 레이어의 출력은 입력으로 다음 레이어로 흐릅니다. 이 장에서 레이어에 대한 자세한 내용을 알아 보겠습니다.
소개
Keras 레이어에는 shape of the input (input_shape) 입력 데이터의 구조를 이해하려면 initializer각 입력에 대한 가중치를 설정하고 마지막으로 활성기를 설정하여 출력을 비선형으로 변환합니다. 그 사이에 제약 조건은 생성 할 입력 데이터의 가중치 범위를 제한하고 지정하며 정규화는 최적화 프로세스 중에 가중치에 대한 패널티를 동적으로 적용하여 계층 (및 모델)을 최적화하려고 시도합니다.
요약하자면, Keras 레이어는 완전한 레이어를 생성하기 위해 최소한의 세부 사항 이하를 요구합니다.
- 입력 데이터의 형태
- 레이어의 뉴런 수 / 단위
- Initializers
- Regularizers
- Constraints
- Activations
다음 장에서 기본 개념을 이해합시다. 기본 개념을 이해하기 전에 Sequential 모델 API를 사용하여 간단한 Keras 레이어를 만들어 Keras 모델 및 레이어가 작동하는 방식에 대한 아이디어를 얻습니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
from keras import regularizers
from keras import constraints
model = Sequential()
model.add(Dense(32, input_shape=(16,), kernel_initializer = 'he_uniform',
kernel_regularizer = None, kernel_constraint = 'MaxNorm', activation = 'relu'))
model.add(Dense(16, activation = 'relu'))
model.add(Dense(8))어디,
Line 1-5 필요한 모듈을 가져옵니다.
Line 7 Sequential API를 사용하여 새 모델을 생성합니다.
Line 9 새로운 창조 Dense 레이어를 만들고 모델에 추가합니다. DenseKeras에서 제공하는 엔트리 레벨 계층으로, 필수 매개 변수로 뉴런 또는 단위 수 (32)를 허용합니다. 레이어가 첫 번째 레이어 인 경우 제공해야합니다.Input Shape, (16,)게다가. 그렇지 않으면 이전 레이어의 출력이 다음 레이어의 입력으로 사용됩니다. 다른 모든 매개 변수는 선택 사항입니다.
첫 번째 매개 변수는 단위 (뉴런)의 수를 나타냅니다.
input_shape 입력 데이터의 모양을 나타냅니다.
kernel_initializer 사용할 이니셜 라이저를 나타냅니다. he_uniform 기능이 값으로 설정됩니다.
kernel_regularizer 말하다 regularizer사용될. 없음이 값으로 설정됩니다.
kernel_constraint 사용할 제약을 나타냅니다. MaxNorm 기능이 값으로 설정됩니다.
activation사용할 활성화를 나타냅니다. relu 함수가 값으로 설정됩니다.
Line 10 두 번째 생성 Dense 16 개 단위와 세트를 가진 층 relu 활성화 기능으로.
Line 11 8 개 단위로 최종 Dense 레이어를 만듭니다.
레이어의 기본 개념
레이어의 기본 개념과 Keras가 각 개념을 어떻게 지원하는지 이해합시다.
입력 형태
기계 학습에서 텍스트, 이미지 또는 비디오와 같은 모든 유형의 입력 데이터는 먼저 숫자 배열로 변환 된 다음 알고리즘에 공급됩니다. 입력 숫자는 1 차원 배열, 2 차원 배열 (행렬) 또는 다차원 배열 일 수 있습니다. 다음을 사용하여 차원 정보를 지정할 수 있습니다.shape, 정수의 튜플. 예를 들면(4,2) 4 개의 행과 2 개의 열이있는 행렬을 나타냅니다.
>>> import numpy as np
>>> shape = (4, 2)
>>> input = np.zeros(shape)
>>> print(input)
[
[0. 0.]
[0. 0.]
[0. 0.]
[0. 0.]
]
>>>비슷하게, (3,4,2) 3 개의 4x2 행렬 모음 (2 행 4 열)이있는 3 차원 행렬.
>>> import numpy as np
>>> shape = (3, 4, 2)
>>> input = np.zeros(shape)
>>> print(input)
[
[[0. 0.] [0. 0.] [0. 0.] [0. 0.]]
[[0. 0.] [0. 0.] [0. 0.] [0. 0.]]
[[0. 0.] [0. 0.] [0. 0.] [0. 0.]]
]
>>>모델의 첫 번째 레이어 (또는 모델의 입력 레이어)를 만들려면 입력 데이터의 모양을 지정해야합니다.
이니셜 라이저
머신 러닝에서는 모든 입력 데이터에 가중치가 할당됩니다. Initializers모듈은 이러한 초기 무게를 설정하는 다양한 기능을 제공합니다. 일부Keras Initializer 기능은 다음과 같습니다-
제로
생성 0 모든 입력 데이터에 대해.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.Zeros()
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))어디, kernel_initializer 모델 커널의 이니셜 라이저를 나타냅니다.
하나
생성 1 모든 입력 데이터에 대해.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.Ones()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))일정한
상수 값을 생성합니다 (예 : 5) 모든 입력 데이터에 대해 사용자가 지정합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.Constant(value = 0) model.add(
Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init)
)어디, value 상수 값을 나타냄
RandomNormal
입력 데이터의 정규 분포를 사용하여 값을 생성합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.RandomNormal(mean=0.0,
stddev = 0.05, seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))어디,
mean 생성 할 임의 값의 평균을 나타냅니다.
stddev 생성 할 임의 값의 표준 편차를 나타냅니다.
seed 난수를 생성하는 값을 나타냅니다.
RandomUniform
입력 데이터의 균일 한 분포를 사용하여 값을 생성합니다.
from keras import initializers
my_init = initializers.RandomUniform(minval = -0.05, maxval = 0.05, seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))어디,
minval 생성 할 임의 값의 하한을 나타냅니다.
maxval 생성 할 임의 값의 상한을 나타냅니다.
잘림 정상
입력 데이터의 잘린 정규 분포를 사용하여 값을 생성합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.TruncatedNormal(mean = 0.0, stddev = 0.05, seed = None
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))VarianceScaling
지정된 배율과 함께 레이어의 입력 모양 및 출력 모양을 기반으로 값을 생성합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.VarianceScaling(
scale = 1.0, mode = 'fan_in', distribution = 'normal', seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
skernel_initializer = my_init))어디,
scale 스케일링 계수를 나타냅니다.
mode 다음 중 하나를 나타내 다 fan_in, fan_out 과 fan_avg 가치
distribution 다음 중 하나를 나타내 다 normal 또는 uniform
VarianceScaling
그것은 stddev 아래 공식을 사용하여 정규 분포 값을 지정한 다음 정규 분포를 사용하여 가중치를 찾습니다.
stddev = sqrt(scale / n)어디 n 말하다,
모드 입력 장치 수 = fan_in
모드의 출력 장치 수 = fan_out
모드의 평균 입력 및 출력 장치 수 = fan_avg
마찬가지로, 아래 공식을 사용하여 균일 분포 의 한계 를 찾은 다음 균일 분포를 사용하여 가중치를 찾습니다.
limit = sqrt(3 * scale / n)lecun_normal
입력 데이터의 lecun 정규 분포를 사용하여 값을 생성합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.RandomUniform(minval = -0.05, maxval = 0.05, seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))그것은 stddev 아래 공식을 사용하여 정규 분포를 적용
stddev = sqrt(1 / fan_in)어디, fan_in 입력 단위의 수를 나타냅니다.
lecun_uniform
입력 데이터의 lecun 균일 분포를 사용하여 값을 생성합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.lecun_uniform(seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))그것은 limit 아래 공식을 사용하여 균일 분포를 적용
limit = sqrt(3 / fan_in)어디,
fan_in 입력 단위의 수를 나타냅니다.
fan_out 출력 단위의 수를 나타냅니다.
glorot_normal
입력 데이터의 glorot 정규 분포를 사용하여 값을 생성합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.glorot_normal(seed=None) model.add(
Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init)
)그것은 stddev 아래 공식을 사용하여 정규 분포를 적용
stddev = sqrt(2 / (fan_in + fan_out))어디,
fan_in 입력 단위의 수를 나타냅니다.
fan_out 출력 단위의 수를 나타냅니다.
glorot_uniform
입력 데이터의 glorot 균일 분포를 사용하여 값을 생성합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.glorot_uniform(seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))그것은 limit 아래 공식을 사용하여 균일 분포를 적용
limit = sqrt(6 / (fan_in + fan_out))어디,
fan_in 입력 단위의 수를 나타냅니다.
fan_out 출력 단위의 수를 나타냅니다.
he_normal
입력 데이터의 정규 분포를 사용하여 값을 생성합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.RandomUniform(minval = -0.05, maxval = 0.05, seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))아래 공식을 사용 하여 stddev 를 찾은 다음 정규 분포를 적용합니다.
stddev = sqrt(2 / fan_in)어디, fan_in 입력 단위의 수를 나타냅니다.
he_uniform
입력 데이터의 균일 한 분포를 사용하여 값을 생성합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.he_normal(seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))그것은 limit 아래 공식을 사용하여 균일 한 분포를 적용합니다.
limit = sqrt(6 / fan_in)어디, fan_in 입력 단위의 수를 나타냅니다.
직교
임의의 직교 행렬을 생성합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.Orthogonal(gain = 1.0, seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))어디, gain 행렬의 곱셈 계수를 나타냅니다.
정체
단위 행렬을 생성합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.Identity(gain = 1.0) model.add(
Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init)
)제약
머신 러닝에서는 최적화 단계에서 매개 변수 (가중치)에 제약 조건이 설정됩니다. <> Constraints 모듈은 레이어에 대한 제약을 설정하는 다양한 기능을 제공합니다. 제약 함수 중 일부는 다음과 같습니다.
NonNeg
가중치를 음수가 아니도록 제한합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.Identity(gain = 1.0) model.add(
Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init)
)어디, kernel_constraint 레이어에서 사용할 제약 조건을 나타냅니다.
UnitNorm
가중치를 단위 표준으로 제한합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import constraints
my_constrain = constraints.UnitNorm(axis = 0)
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_constraint = my_constrain))MaxNorm
가중치를 주어진 값보다 작거나 같은 표준으로 제한합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import constraints
my_constrain = constraints.MaxNorm(max_value = 2, axis = 0)
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_constraint = my_constrain))어디,
max_value 상한을 나타내 다
축은 구속 조건이 적용될 치수를 나타냅니다. 예를 들어 Shape (2,3,4) 축에서 0은 첫 번째 차원, 1은 두 번째 차원, 2는 세 번째 차원을 나타냅니다.
MinMaxNorm
가중치가 지정된 최소값과 최대 값 사이의 표준이되도록 제한합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import constraints
my_constrain = constraints.MinMaxNorm(min_value = 0.0, max_value = 1.0, rate = 1.0, axis = 0)
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_constraint = my_constrain))어디, rate 무게 제한이 적용되는 비율을 나타냅니다.
정규화
기계 학습에서 정규화는 최적화 단계에서 사용됩니다. 최적화 중에 레이어 매개 변수에 몇 가지 패널티를 적용합니다. Keras 정규화 모듈은 레이어에 페널티를 설정하는 아래 기능을 제공합니다. 정규화는 레이어 단위로만 적용됩니다.
L1 정규화
L1 기반 정규화를 제공합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import regularizers
my_regularizer = regularizers.l1(0.)
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_regularizer = my_regularizer))어디, kernel_regularizer 무게 제한이 적용되는 비율을 나타냅니다.
L2 정규화
L2 기반 정규화를 제공합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import regularizers
my_regularizer = regularizers.l2(0.)
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_regularizer = my_regularizer))L1 및 L2 정규화
L1 및 L2 기반 정규화를 모두 제공합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import regularizers
my_regularizer = regularizers.l2(0.)
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_regularizer = my_regularizer))활성화
기계 학습에서 활성화 기능은 특정 뉴런이 활성화되었는지 여부를 확인하는 데 사용되는 특수 기능입니다. 기본적으로 활성화 함수는 입력 데이터의 비선형 변환을 수행하므로 뉴런이 더 잘 학습 할 수 있습니다. 뉴런의 출력은 활성화 기능에 따라 다릅니다.
단일 지각의 개념을 떠 올릴 때 퍼셉트론 (뉴런)의 출력은 활성화 함수의 결과 일 뿐이며, 해당 가중치와 전체 편향 (있는 경우)을 곱한 모든 입력의 합계를 받아들입니다.
result = Activation(SUMOF(input * weight) + bias)따라서 활성화 기능은 모델의 성공적인 학습에 중요한 역할을합니다. Keras는 활성화 모듈에서 많은 활성화 기능을 제공합니다. 모듈에서 사용 가능한 모든 활성화에 대해 알아 보겠습니다.
선의
선형 함수를 적용합니다. 아무것도하지 않습니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'linear', input_shape = (784,)))어디, activation레이어의 활성화 기능을 나타냅니다. 함수의 이름으로 간단히 지정할 수 있으며 레이어는 해당 활성자를 사용합니다.
elu
지수 선형 단위를 적용합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'elu', input_shape = (784,)))셀루
스케일링 된 지수 선형 단위를 적용합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'selu', input_shape = (784,)))Relu
정류 된 선형 단위를 적용합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,)))소프트 맥스
Softmax 기능을 적용합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'softmax', input_shape = (784,)))소프트 플러스
Softplus 기능을 적용합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'softplus', input_shape = (784,)))소프트 사인
Softsign 기능을 적용합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'softsign', input_shape = (784,)))탄
쌍곡 탄젠트 함수를 적용합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'tanh', input_shape = (784,)))시그 모이 드
Sigmoid 함수를 적용합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'sigmoid', input_shape = (784,)))hard_sigmoid
Hard Sigmoid 기능을 적용합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'hard_sigmoid', input_shape = (784,)))지수
지수 함수를 적용합니다.
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'exponential', input_shape = (784,)))| Sr. 아니요 | 레이어 및 설명 |
|---|---|
| 1 | 고밀도 레이어 Dense layer 규칙적으로 깊이 연결된 신경망 계층입니다. |
| 2 | 드롭 아웃 레이어 Dropout 기계 학습에서 중요한 개념 중 하나입니다. |
| 삼 | 레이어 병합 Flatten 입력을 평면화하는 데 사용됩니다. |
| 4 | 레이어 모양 변경 Reshape 입력의 모양을 변경하는 데 사용됩니다. |
| 5 | 퍼 뮤트 레이어 Permute 패턴을 사용하여 입력의 모양을 변경하는데도 사용됩니다. |
| 6 | 반복 벡터 레이어 RepeatVector 입력을 설정 횟수 n 회 반복하는 데 사용됩니다. |
| 7 | Lambda 계층 Lambda 표현식 또는 함수를 사용하여 입력 데이터를 변환하는 데 사용됩니다. |
| 8 | 컨볼 루션 레이어 Keras에는 일반적으로 Convolution Neural Network (CNN) 라고하는 Convolution 기반 ANN을 만들기위한 많은 레이어가 포함되어 있습니다 . |
| 9 | 풀링 레이어 시간 데이터에 대해 최대 풀링 작업을 수행하는 데 사용됩니다. |
| 10 | 로컬로 연결된 레이어 로컬로 연결된 레이어는 Conv1D 레이어와 유사하지만 차이점은 Conv1D 레이어 가중치는 공유되지만 여기서 가중치는 공유되지 않는다는 것입니다. |
| 11 | 레이어 병합 입력 목록을 병합하는 데 사용됩니다. |
| 12 | 포함 레이어 입력 레이어에서 임베딩 작업을 수행합니다. |
Keras-맞춤형 레이어
Keras를 사용하면 사용자 정의 레이어를 만들 수 있습니다. 새 레이어가 생성되면 제한없이 모든 모델에서 사용할 수 있습니다. 이 장에서는 새 레이어를 만드는 방법을 알아 보겠습니다.
Keras는 기초를 제공합니다 layerclass, Layer는 우리 자신의 맞춤형 레이어를 만들기 위해 하위 클래스화할 수 있습니다. 정규 분포를 기반으로 가중치를 찾는 간단한 계층을 만든 다음 훈련 중에 입력과 가중치의 곱을 찾는 기본 계산을 수행하겠습니다.
1 단계 : 필요한 모듈 가져 오기
먼저 필요한 모듈을 가져 오겠습니다.
from keras import backend as K
from keras.layers import Layer여기,
backend 액세스하는 데 사용됩니다 dot 함수.
Layer 기본 클래스이며 레이어를 생성하기 위해 하위 클래스 화합니다.
2 단계 : 레이어 클래스 정의
새 클래스를 만들고 MyCustomLayer 하위 분류로 Layer class −
class MyCustomLayer(Layer):
...3 단계 : 레이어 클래스 초기화
아래에 지정된대로 새 클래스를 초기화하겠습니다.
def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(MyCustomLayer, self).__init__(**kwargs)여기,
Line 2 출력 치수를 설정합니다.
Line 3 기본 또는 수퍼 레이어를 호출합니다. init 함수.
4 단계 : 빌드 방법 구현
build주요 방법이며 유일한 목적은 레이어를 올바르게 구축하는 것입니다. 레이어의 내부 작업과 관련된 모든 작업을 수행 할 수 있습니다. 사용자 지정 기능이 완료되면 기본 클래스를 호출 할 수 있습니다.build함수. 우리의 관습build 기능은 다음과 같습니다-
def build(self, input_shape):
self.kernel = self.add_weight(name = 'kernel',
shape = (input_shape[1], self.output_dim),
initializer = 'normal', trainable = True)
super(MyCustomLayer, self).build(input_shape)여기,
Line 1 정의 build 인수가 하나 인 메서드, input_shape. 입력 데이터의 모양은 input_shape에 의해 참조됩니다.
Line 2입력 모양에 해당하는 가중치를 생성하고 커널에 설정합니다. 레이어의 사용자 지정 기능입니다. 'normal'이니셜 라이저를 사용하여 가중치를 생성합니다.
Line 6 기본 클래스를 호출하고 build 방법.
5 단계 : 호출 메서드 구현
call 방법은 훈련 과정에서 레이어의 정확한 작업을 수행합니다.
우리의 관습 call 방법은 다음과 같습니다
def call(self, input_data):
return K.dot(input_data, self.kernel)여기,
Line 1 정의 call 인수가 하나 인 메서드, input_data. input_data는 레이어의 입력 데이터입니다.
Line 2 입력 데이터의 내적을 반환하고, input_data 레이어의 커널, self.kernel
6 단계 : compute_output_shape 메서드 구현
def compute_output_shape(self, input_shape): return (input_shape[0], self.output_dim)여기,
Line 1 정의 compute_output_shape 인수가 하나 인 메서드 input_shape
Line 2 레이어를 초기화하는 동안 입력 데이터의 모양과 출력 차원 설정을 사용하여 출력 모양을 계산합니다.
구현 build, call 과 compute_output_shape사용자 지정 레이어 만들기를 완료합니다. 최종적이고 완전한 코드는 다음과 같습니다.
from keras import backend as K from keras.layers import Layer
class MyCustomLayer(Layer):
def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(MyCustomLayer, self).__init__(**kwargs)
def build(self, input_shape): self.kernel =
self.add_weight(name = 'kernel',
shape = (input_shape[1], self.output_dim),
initializer = 'normal', trainable = True)
super(MyCustomLayer, self).build(input_shape) #
Be sure to call this at the end
def call(self, input_data): return K.dot(input_data, self.kernel)
def compute_output_shape(self, input_shape): return (input_shape[0], self.output_dim)맞춤형 레이어 사용
아래에 지정된대로 사용자 정의 된 레이어를 사용하여 간단한 모델을 생성 해 보겠습니다.
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(MyCustomLayer(32, input_shape = (16,)))
model.add(Dense(8, activation = 'softmax')) model.summary()여기,
우리의 MyCustomLayer 32 개 단위를 사용하여 모델에 추가되고 (16,) 입력 형태로
응용 프로그램을 실행하면 아래와 같이 모델 요약이 인쇄됩니다.
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param
#================================================================
my_custom_layer_1 (MyCustomL (None, 32) 512
_________________________________________________________________
dense_1 (Dense) (None, 8) 264
=================================================================
Total params: 776
Trainable params: 776
Non-trainable params: 0
_________________________________________________________________Keras-모델
앞서 배운 것처럼 Keras 모델은 실제 신경망 모델을 나타냅니다. Keras는 모델을 생성하기위한 두 가지 모드를 제공합니다. 간단하고 사용하기 쉬운 Sequential API 는 물론 더 유연하고 고급 기능적인 API 입니다. 이제이 장에서 Sequential 및 Functional API 를 모두 사용하여 모델을 생성하는 방법을 알아 보겠습니다 .
잇달아 일어나는
핵심 아이디어 Sequential API단순히 Keras 레이어를 순차적으로 배열하는 것이므로 Sequential API 라고 합니다 . 대부분의 ANN에는 또한 순차적 인 레이어가 있으며 데이터가 최종적으로 출력 레이어에 도달 할 때까지 주어진 순서로 한 레이어에서 다른 레이어로 데이터가 흐릅니다.
ANN 모델은 간단히 호출하여 만들 수 있습니다. Sequential() 아래 지정된 API-
from keras.models import Sequential
model = Sequential()레이어 추가
레이어를 추가하려면 Keras 레이어 API를 사용하여 레이어를 생성 한 다음 아래 지정된대로 add () 함수를 통해 레이어를 전달하면됩니다.
from keras.models import Sequential
model = Sequential()
input_layer = Dense(32, input_shape=(8,)) model.add(input_layer)
hidden_layer = Dense(64, activation='relu'); model.add(hidden_layer)
output_layer = Dense(8)
model.add(output_layer)여기에서는 하나의 입력 계층, 하나의 숨겨진 계층 및 하나의 출력 계층을 만들었습니다.
모델에 액세스
Keras는 레이어, 입력 데이터 및 출력 데이터와 같은 모델 정보를 얻는 몇 가지 방법을 제공합니다. 그들은 다음과 같습니다-
model.layers − 모델의 모든 레이어를 목록으로 반환합니다.
>>> layers = model.layers
>>> layers
[
<keras.layers.core.Dense object at 0x000002C8C888B8D0>,
<keras.layers.core.Dense object at 0x000002C8C888B7B8>
<keras.layers.core.Dense object at 0x 000002C8C888B898>
]model.inputs − 모델의 모든 입력 텐서를 목록으로 반환합니다.
>>> inputs = model.inputs
>>> inputs
[<tf.Tensor 'dense_13_input:0' shape=(?, 8) dtype=float32>]model.outputs − 모델의 모든 출력 텐서를 목록으로 반환합니다.
>>> outputs = model.outputs
>>> outputs
<tf.Tensor 'dense_15/BiasAdd:0' shape=(?, 8) dtype=float32>]model.get_weights − 모든 가중치를 NumPy 배열로 반환합니다.
model.set_weights(weight_numpy_array) − 모델의 가중치를 설정합니다.
모델 직렬화
Keras는 모델을 json뿐만 아니라 객체로 직렬화하고 나중에 다시로드하는 방법을 제공합니다. 그들은 다음과 같습니다-
get_config() − I 모델을 객체로 반환합니다.
config = model.get_config()from_config() − 모델 구성 객체를 인수로 받아들이고 그에 따라 모델을 생성합니다.
new_model = Sequential.from_config(config)to_json() − 모델을 json 객체로 반환합니다.
>>> json_string = model.to_json()
>>> json_string '{"class_name": "Sequential", "config":
{"name": "sequential_10", "layers":
[{"class_name": "Dense", "config":
{"name": "dense_13", "trainable": true, "batch_input_shape":
[null, 8], "dtype": "float32", "units": 32, "activation": "linear",
"use_bias": true, "kernel_initializer":
{"class_name": "Vari anceScaling", "config":
{"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}},
"bias_initializer": {"class_name": "Zeros", "conf
ig": {}}, "kernel_regularizer": null, "bias_regularizer": null,
"activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}},
{" class_name": "Dense", "config": {"name": "dense_14", "trainable": true,
"dtype": "float32", "units": 64, "activation": "relu", "use_bias": true,
"kern el_initializer": {"class_name": "VarianceScaling", "config":
{"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}},
"bias_initia lizer": {"class_name": "Zeros",
"config": {}}, "kernel_regularizer": null, "bias_regularizer": null,
"activity_regularizer": null, "kernel_constraint" : null, "bias_constraint": null}},
{"class_name": "Dense", "config": {"name": "dense_15", "trainable": true,
"dtype": "float32", "units": 8, "activation": "linear", "use_bias": true,
"kernel_initializer": {"class_name": "VarianceScaling", "config":
{"scale": 1.0, "mode": "fan_avg", "distribution": " uniform", "seed": null}},
"bias_initializer": {"class_name": "Zeros", "config": {}},
"kernel_regularizer": null, "bias_regularizer": null, "activity_r egularizer":
null, "kernel_constraint": null, "bias_constraint":
null}}]}, "keras_version": "2.2.5", "backend": "tensorflow"}'
>>>model_from_json() − 모델의 json 표현을 받아들이고 새 모델을 생성합니다.
from keras.models import model_from_json
new_model = model_from_json(json_string)to_yaml() − 모델을 yaml 문자열로 반환합니다.
>>> yaml_string = model.to_yaml()
>>> yaml_string 'backend: tensorflow\nclass_name:
Sequential\nconfig:\n layers:\n - class_name: Dense\n config:\n
activation: linear\n activity_regular izer: null\n batch_input_shape:
!!python/tuple\n - null\n - 8\n bias_constraint: null\n bias_initializer:\n
class_name : Zeros\n config: {}\n bias_regularizer: null\n dtype:
float32\n kernel_constraint: null\n
kernel_initializer:\n cla ss_name: VarianceScaling\n config:\n
distribution: uniform\n mode: fan_avg\n
scale: 1.0\n seed: null\n kernel_regularizer: null\n name: dense_13\n
trainable: true\n units: 32\n
use_bias: true\n - class_name: Dense\n config:\n activation: relu\n activity_regularizer: null\n
bias_constraint: null\n bias_initializer:\n class_name: Zeros\n
config : {}\n bias_regularizer: null\n dtype: float32\n
kernel_constraint: null\n kernel_initializer:\n class_name: VarianceScalin g\n
config:\n distribution: uniform\n mode: fan_avg\n scale: 1.0\n
seed: null\n kernel_regularizer: nu ll\n name: dense_14\n trainable: true\n
units: 64\n use_bias: true\n - class_name: Dense\n config:\n
activation: linear\n activity_regularizer: null\n
bias_constraint: null\n bias_initializer:\n
class_name: Zeros\n config: {}\n bias_regu larizer: null\n
dtype: float32\n kernel_constraint: null\n
kernel_initializer:\n class_name: VarianceScaling\n config:\n
distribution: uniform\n mode: fan_avg\n
scale: 1.0\n seed: null\n kernel_regularizer: null\n name: dense _15\n
trainable: true\n units: 8\n
use_bias: true\n name: sequential_10\nkeras_version: 2.2.5\n'
>>>model_from_yaml() − 모델의 yaml 표현을 수락하고 새 모델을 생성합니다.
from keras.models import model_from_yaml
new_model = model_from_yaml(yaml_string)모델 요약
모델을 이해하는 것은 학습 및 예측 목적으로 적절하게 사용하기위한 매우 중요한 단계입니다. Keras는 모델 및 해당 계층에 대한 전체 정보를 얻을 수있는 간단한 방법, 요약을 제공합니다.
이전 섹션에서 생성 된 모델의 요약은 다음과 같습니다.
>>> model.summary() Model: "sequential_10"
_________________________________________________________________
Layer (type) Output Shape Param
#================================================================
dense_13 (Dense) (None, 32) 288
_________________________________________________________________
dense_14 (Dense) (None, 64) 2112
_________________________________________________________________
dense_15 (Dense) (None, 8) 520
=================================================================
Total params: 2,920
Trainable params: 2,920
Non-trainable params: 0
_________________________________________________________________
>>>모델 훈련 및 예측
모델은 학습, 평가 및 예측 프로세스를위한 기능을 제공합니다. 그들은 다음과 같습니다-
compile − 모델의 학습 과정 구성
fit − 훈련 데이터를 사용하여 모델 훈련
evaluate − 테스트 데이터를 사용하여 모델 평가
predict − 새로운 입력에 대한 결과를 예측합니다.
기능성 API
Sequential API는 모델을 레이어별로 생성하는 데 사용됩니다. Functional API는 더 복잡한 모델을 생성하는 대체 접근 방식입니다. 기능적 모델, 레이어를 공유하는 여러 입력 또는 출력을 정의 할 수 있습니다. 먼저 모델에 대한 인스턴스를 만들고 레이어에 연결하여 모델에 대한 입력 및 출력에 액세스합니다. 이 섹션에서는 기능 모델에 대해 간략하게 설명합니다.
모델 생성
아래 모듈을 사용하여 입력 레이어 가져 오기-
>>> from keras.layers import Input이제 아래 코드를 사용하여 모델의 입력 치수 모양을 지정하는 입력 레이어를 만듭니다.
>>> data = Input(shape=(2,3))아래 모듈을 사용하여 입력 레이어를 정의하십시오-
>>> from keras.layers import Dense아래 코드 줄을 사용하여 입력에 Dense 레이어를 추가하십시오-
>>> layer = Dense(2)(data)
>>> print(layer)
Tensor("dense_1/add:0", shape =(?, 2, 2), dtype = float32)아래 모듈을 사용하여 모델 정의-
from keras.models import Model입력 및 출력 레이어를 모두 지정하여 기능적인 방식으로 모델 생성-
model = Model(inputs = data, outputs = layer)간단한 모델을 만드는 전체 코드는 다음과 같습니다.
from keras.layers import Input
from keras.models import Model
from keras.layers import Dense
data = Input(shape=(2,3))
layer = Dense(2)(data) model =
Model(inputs=data,outputs=layer) model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, 2, 3) 0
_________________________________________________________________
dense_2 (Dense) (None, 2, 2) 8
=================================================================
Total params: 8
Trainable params: 8
Non-trainable params: 0
_________________________________________________________________Keras-모델 편집
이전에는 Sequential 및 Functional API를 사용하여 모델을 만드는 방법에 대한 기본 사항을 공부했습니다. 이 장에서는 모델을 컴파일하는 방법에 대해 설명합니다. 컴파일은 모델 생성의 마지막 단계입니다. 컴파일이 완료되면 훈련 단계로 넘어갈 수 있습니다.
컴파일 과정을 더 잘 이해하는 데 필요한 몇 가지 개념을 배우겠습니다.
손실
머신 러닝에서 Loss함수는 학습 과정에서 오류 또는 편차를 찾는 데 사용됩니다. Keras는 모델 컴파일 과정에서 손실 기능이 필요합니다.
Keras는 losses 모듈과 그들은 다음과 같습니다-
- mean_squared_error
- mean_absolute_error
- mean_absolute_percentage_error
- mean_squared_logarithmic_error
- squared_hinge
- hinge
- categorical_hinge
- logcosh
- huber_loss
- categorical_crossentropy
- sparse_categorical_crossentropy
- binary_crossentropy
- kullback_leibler_divergence
- poisson
- cosine_proximity
- is_categorical_crossentropy
위의 모든 손실 함수는 두 가지 인수를 허용합니다.
y_true − 텐서로서의 진정한 레이블
y_pred − 같은 형태의 예측 y_true
아래 명시된 손실 기능을 사용하기 전에 손실 모듈을 가져옵니다.
from keras import losses옵티 마이저
머신 러닝에서 Optimization예측과 손실 함수를 비교하여 입력 가중치를 최적화하는 중요한 프로세스입니다. Keras는 몇 가지 최적화 프로그램을 모듈, 최적화 프로그램으로 제공 하며 다음과 같습니다.
SGD − 확률 적 경사 하강 법 최적화 프로그램.
keras.optimizers.SGD(learning_rate = 0.01, momentum = 0.0, nesterov = False)RMSprop − RMSProp 최적화 프로그램.
keras.optimizers.RMSprop(learning_rate = 0.001, rho = 0.9)Adagrad − Adagrad 최적화 프로그램.
keras.optimizers.Adagrad(learning_rate = 0.01)Adadelta − Adadelta 최적화 프로그램.
keras.optimizers.Adadelta(learning_rate = 1.0, rho = 0.95)Adam − Adam 최적화 프로그램.
keras.optimizers.Adam(
learning_rate = 0.001, beta_1 = 0.9, beta_2 = 0.999, amsgrad = False
)Adamax − Adam의 Adamax 최적화 프로그램.
keras.optimizers.Adamax(learning_rate = 0.002, beta_1 = 0.9, beta_2 = 0.999)Nadam − Nesterov Adam 최적화 프로그램.
keras.optimizers.Nadam(learning_rate = 0.002, beta_1 = 0.9, beta_2 = 0.999)아래에 지정된 최적화 프로그램을 사용하기 전에 최적화 모듈을 가져옵니다.
from keras import optimizers메트릭
머신 러닝에서 Metrics모델의 성능을 평가하는 데 사용됩니다. 손실 함수와 유사하지만 훈련 과정에서는 사용되지 않습니다. Keras는 모듈로 몇 가지 메트릭을 제공합니다.metrics 그리고 그들은 다음과 같습니다
- accuracy
- binary_accuracy
- categorical_accuracy
- sparse_categorical_accuracy
- top_k_categorical_accuracy
- sparse_top_k_categorical_accuracy
- cosine_proximity
- clone_metric
손실 함수와 유사하게, 메트릭은 아래의 두 인수도 허용합니다.
y_true − 텐서로서의 진정한 레이블
y_pred − 같은 형태의 예측 y_true
아래 지정된대로 메트릭을 사용하기 전에 메트릭 모듈을 가져옵니다.
from keras import metrics모델 컴파일
Keras 모델은 방법을 제공합니다. compile()모델을 컴파일합니다. 인수 및 기본값compile() 방법은 다음과 같습니다
compile(
optimizer,
loss = None,
metrics = None,
loss_weights = None,
sample_weight_mode = None,
weighted_metrics = None,
target_tensors = None
)중요한 인수는 다음과 같습니다-
- 손실 함수
- Optimizer
- metrics
모드를 컴파일하는 샘플 코드는 다음과 같습니다.
from keras import losses
from keras import optimizers
from keras import metrics
model.compile(loss = 'mean_squared_error',
optimizer = 'sgd', metrics = [metrics.categorical_accuracy])어디,
손실 기능은 다음과 같이 설정됩니다. mean_squared_error
최적화 프로그램은 다음과 같이 설정됩니다. sgd
메트릭은 다음과 같이 설정됩니다. metrics.categorical_accuracy
모델 훈련
모델은 다음을 사용하여 NumPy 배열로 학습됩니다. fit(). 이 적합 함수의 주요 목적은 훈련에서 모델을 평가하는 데 사용됩니다. 모델 성능을 그래프로 표시하는데도 사용할 수 있습니다. 다음과 같은 구문이 있습니다.
model.fit(X, y, epochs = , batch_size = )여기,
X, y − 데이터를 평가하는 튜플입니다.
epochs − 훈련 중에 모델을 평가할 필요가 없습니다.
batch_size − 훈련 인스턴스.
이 개념을 사용하기 위해 numpy random data의 간단한 예를 들어 보겠습니다.
데이터 생성
아래에 언급 된 명령을 사용하여 x와 y에 대해 numpy를 사용하여 임의의 데이터를 생성 해 보겠습니다.
import numpy as np
x_train = np.random.random((100,4,8))
y_train = np.random.random((100,10))이제 임의의 유효성 검사 데이터를 만들고
x_val = np.random.random((100,4,8))
y_val = np.random.random((100,10))모델 생성
간단한 순차 모델을 만들어 보겠습니다.
from keras.models import Sequential model = Sequential()레이어 추가
모델을 추가 할 레이어 만들기-
from keras.layers import LSTM, Dense
# add a sequence of vectors of dimension 16
model.add(LSTM(16, return_sequences = True))
model.add(Dense(10, activation = 'softmax'))모델 컴파일
이제 모델이 정의되었습니다. 아래 명령을 사용하여 컴파일 할 수 있습니다.
model.compile(
loss = 'categorical_crossentropy', optimizer = 'sgd', metrics = ['accuracy']
)fit () 적용
이제 데이터를 훈련하기 위해 fit () 함수를 적용합니다.
model.fit(x_train, y_train, batch_size = 32, epochs = 5, validation_data = (x_val, y_val))다층 퍼셉트론 ANN 생성
우리는 Keras 모델을 생성, 컴파일 및 훈련하는 방법을 배웠습니다.
학습 한 내용을 적용하고 간단한 MPL 기반 ANN을 만들어 보겠습니다.
데이터 세트 모듈
모델을 만들기 전에 문제를 선택하고 필요한 데이터를 수집하고 데이터를 NumPy 배열로 변환해야합니다. 데이터가 수집되면 수집 된 데이터를 사용하여 모델을 준비하고 훈련 할 수 있습니다. 데이터 수집은 기계 학습에서 가장 어려운 단계 중 하나입니다. Keras는 교육 목적으로 온라인 기계 학습 데이터를 다운로드 할 수있는 특수 모듈, 데이터 세트를 제공합니다. 온라인 서버에서 데이터를 가져 와서 데이터를 처리하고 학습 및 테스트 세트로 데이터를 반환합니다. Keras 데이터 셋 모듈에서 제공하는 데이터를 확인해 보겠습니다. 모듈에서 사용 가능한 데이터는 다음과 같습니다.
- CIFAR10 작은 이미지 분류
- CIFAR100 작은 이미지 분류
- IMDB 영화 리뷰 감정 분류
- Reuters Newswire 주제 분류
- 손으로 쓴 숫자의 MNIST 데이터베이스
- Fashion-MNIST 패션 기사 데이터베이스
- 보스턴 주택 가격 회귀 데이터 세트
사용하자 MNIST database of handwritten digits(또는 minst)를 입력합니다. minst는 60,000, 28x28 그레이 스케일 이미지 모음입니다. 10 자리 숫자입니다. 또한 10,000 개의 테스트 이미지가 포함되어 있습니다.
아래 코드는 데이터 세트를로드하는 데 사용할 수 있습니다-
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()어디
Line 1 수입품 minst keras 데이터 세트 모듈에서.
Line 3 전화 load_data 온라인 서버에서 데이터를 가져와 데이터를 2 개의 튜플, First tuple, (x_train, y_train) 훈련 데이터를 형태로 표현하고, (number_sample, 28, 28) 모양이있는 숫자 라벨, (number_samples, ). 두 번째 튜플,(x_test, y_test) 동일한 모양의 테스트 데이터를 나타냅니다.
다른 데이터 세트도 유사한 API를 사용하여 가져올 수 있으며 모든 API는 데이터의 모양을 제외하고 유사한 데이터도 반환합니다. 데이터의 모양은 데이터 유형에 따라 다릅니다.
모델 생성
아래와 같이 간단한 다중 레이어 퍼셉트론 (MLP)을 선택하고 Keras를 사용하여 모델을 생성 해 봅니다.

모델의 핵심 기능은 다음과 같습니다.
입력 계층은 784 개의 값 (28 x 28 = 784)으로 구성됩니다.
첫 번째 숨겨진 레이어, Dense 512 개의 뉴런과 'relu'활성화 기능으로 구성됩니다.
두 번째 숨겨진 레이어, Dropout 값은 0.2입니다.
세 번째 은닉층, 다시 Dense는 512 개의 뉴런과 'relu'활성화 함수로 구성됩니다.
네 번째 은닉층, Dropout 값은 0.2입니다.
다섯 번째 및 마지막 레이어는 10 개의 뉴런과 'softmax'활성화 함수로 구성됩니다.
사용하다 categorical_crossentropy 손실 함수로.
사용하다 RMSprop() Optimizer로.
사용하다 accuracy 메트릭으로.
128을 배치 크기로 사용하십시오.
20을 시대로 사용하십시오.
Step 1 − Import the modules
필요한 모듈을 가져 오겠습니다.
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
import numpy as npStep 2 − Load data
mnist 데이터 세트를 가져 오겠습니다.
(x_train, y_train), (x_test, y_test) = mnist.load_data()Step 3 − Process the data
모델에 따라 데이터 세트를 변경하여 모델에 피드 할 수 있도록하겠습니다.
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)어디
reshape 입력을 (28, 28) 튜플에서 (784,)로 변경하는 데 사용됩니다.
to_categorical 벡터를 이진 행렬로 변환하는 데 사용됩니다.
Step 4 − Create the model
실제 모델을 만들어 보겠습니다.
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation = 'relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation = 'softmax'))Step 5 − Compile the model
선택한 손실 함수, 최적화 프로그램 및 메트릭을 사용하여 모델을 컴파일 해 보겠습니다.
model.compile(loss = 'categorical_crossentropy',
optimizer = RMSprop(),
metrics = ['accuracy'])Step 6 − Train the model
다음을 사용하여 모델을 학습 시키십시오. fit() 방법.
history = model.fit(
x_train, y_train,
batch_size = 128,
epochs = 20,
verbose = 1,
validation_data = (x_test, y_test)
)마지막 생각들
모델을 생성하고 데이터를로드하고 모델에 데이터를 훈련 시켰습니다. 우리는 여전히 모델을 평가하고 알려지지 않은 입력에 대한 출력을 예측해야합니다. 다음 장에서 배울 것입니다.
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
import numpy as np
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
model = Sequential()
model.add(Dense(512, activation='relu', input_shape = (784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation = 'relu')) model.add(Dropout(0.2))
model.add(Dense(10, activation = 'softmax'))
model.compile(loss = 'categorical_crossentropy',
optimizer = RMSprop(),
metrics = ['accuracy'])
history = model.fit(x_train, y_train,
batch_size = 128, epochs = 20, verbose = 1, validation_data = (x_test, y_test))응용 프로그램을 실행하면 아래 내용이 출력으로 제공됩니다.
Train on 60000 samples, validate on 10000 samples Epoch 1/20
60000/60000 [==============================] - 7s 118us/step - loss: 0.2453
- acc: 0.9236 - val_loss: 0.1004 - val_acc: 0.9675 Epoch 2/20
60000/60000 [==============================] - 7s 110us/step - loss: 0.1023
- acc: 0.9693 - val_loss: 0.0797 - val_acc: 0.9761 Epoch 3/20
60000/60000 [==============================] - 7s 110us/step - loss: 0.0744
- acc: 0.9770 - val_loss: 0.0727 - val_acc: 0.9791 Epoch 4/20
60000/60000 [==============================] - 7s 110us/step - loss: 0.0599
- acc: 0.9823 - val_loss: 0.0704 - val_acc: 0.9801 Epoch 5/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0504
- acc: 0.9853 - val_loss: 0.0714 - val_acc: 0.9817 Epoch 6/20
60000/60000 [==============================] - 7s 111us/step - loss: 0.0438
- acc: 0.9868 - val_loss: 0.0845 - val_acc: 0.9809 Epoch 7/20
60000/60000 [==============================] - 7s 114us/step - loss: 0.0391
- acc: 0.9887 - val_loss: 0.0823 - val_acc: 0.9802 Epoch 8/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0364
- acc: 0.9892 - val_loss: 0.0818 - val_acc: 0.9830 Epoch 9/20
60000/60000 [==============================] - 7s 113us/step - loss: 0.0308
- acc: 0.9905 - val_loss: 0.0833 - val_acc: 0.9829 Epoch 10/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0289
- acc: 0.9917 - val_loss: 0.0947 - val_acc: 0.9815 Epoch 11/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0279
- acc: 0.9921 - val_loss: 0.0818 - val_acc: 0.9831 Epoch 12/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0260
- acc: 0.9927 - val_loss: 0.0945 - val_acc: 0.9819 Epoch 13/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0257
- acc: 0.9931 - val_loss: 0.0952 - val_acc: 0.9836 Epoch 14/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0229
- acc: 0.9937 - val_loss: 0.0924 - val_acc: 0.9832 Epoch 15/20
60000/60000 [==============================] - 7s 115us/step - loss: 0.0235
- acc: 0.9937 - val_loss: 0.1004 - val_acc: 0.9823 Epoch 16/20
60000/60000 [==============================] - 7s 113us/step - loss: 0.0214
- acc: 0.9941 - val_loss: 0.0991 - val_acc: 0.9847 Epoch 17/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0219
- acc: 0.9943 - val_loss: 0.1044 - val_acc: 0.9837 Epoch 18/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0190
- acc: 0.9952 - val_loss: 0.1129 - val_acc: 0.9836 Epoch 19/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0197
- acc: 0.9953 - val_loss: 0.0981 - val_acc: 0.9841 Epoch 20/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0198
- acc: 0.9950 - val_loss: 0.1215 - val_acc: 0.9828Keras-모델 평가 및 모델 예측
이 장에서는 Keras의 모델 평가 및 모델 예측을 다룹니다.
모델 평가를 이해하는 것으로 시작하겠습니다.
모델 평가
평가는 모델이 주어진 문제와 해당 데이터에 가장 적합한 지 확인하기위한 모델 개발 과정입니다. Keras 모델은 모델을 평가하는 기능을 제공합니다. 세 가지 주요 주장이 있습니다.
- 테스트 데이터
- 테스트 데이터 레이블
- verbose-참 또는 거짓
테스트 데이터를 사용하여 이전 장에서 만든 모델을 평가 해 보겠습니다.
score = model.evaluate(x_test, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])위 코드를 실행하면 아래와 같은 정보가 출력됩니다.
0테스트 정확도는 98.28 %입니다. 우리는 손글씨 숫자를 식별하는 최고의 모델을 만들었습니다. 긍정적 인 측면에서 우리는 여전히 모델을 개선 할 수 있습니다.
모델 예측
Prediction모델 생성의 최종 단계이자 예상되는 결과입니다. Keras는 방법을 제공 예측 훈련 모델의 예측을 얻을. 예측 방법 의 서명은 다음과 같습니다.
predict(
x,
batch_size = None,
verbose = 0,
steps = None,
callbacks = None,
max_queue_size = 10,
workers = 1,
use_multiprocessing = False
)여기서 알 수없는 입력 데이터를 참조하는 첫 번째 인수를 제외한 모든 인수는 선택 사항입니다. 적절한 예측을 얻으려면 모양을 유지해야합니다.
아래 코드를 사용하여 이전 장에서 만든 MPL 모델에 대한 예측을 수행해 보겠습니다.
pred = model.predict(x_test)
pred = np.argmax(pred, axis = 1)[:5]
label = np.argmax(y_test,axis = 1)[:5]
print(pred)
print(label)여기,
Line 1 테스트 데이터를 사용하여 예측 함수를 호출합니다.
Line 2 처음 5 개의 예측을 얻습니다.
Line 3 테스트 데이터의 처음 5 개 레이블을 가져옵니다.
Line 5 - 6 예측 및 실제 레이블을 인쇄합니다.
위 응용 프로그램의 출력은 다음과 같습니다.
[7 2 1 0 4]
[7 2 1 0 4]두 배열의 출력은 동일하며 모델이 처음 5 개의 이미지를 올바르게 예측 함을 나타냅니다.
Keras-컨볼 루션 신경망
MPL에서 다음으로 모델을 수정 해 보겠습니다. Convolution Neural Network (CNN) 우리의 이전 숫자 식별 문제에 대해.
CNN은 아래와 같이 표현할 수 있습니다.
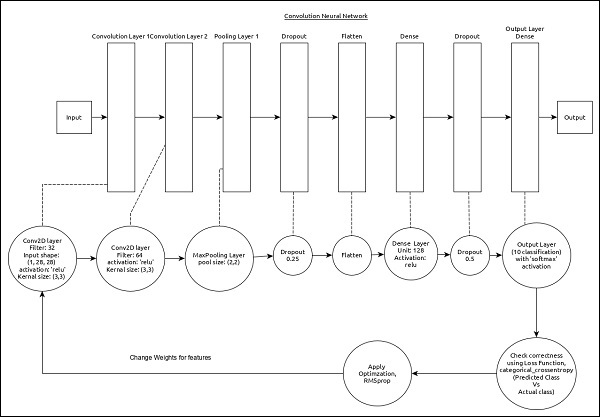
모델의 핵심 기능은 다음과 같습니다.
입력 레이어는 (1, 8, 28) 값으로 구성됩니다.
첫 번째 레이어, Conv2D 32 개의 필터와 커널 크기 (3,3)의 'relu'활성화 함수로 구성됩니다.
두 번째 레이어, Conv2D 64 개의 필터와 커널 크기 (3,3)의 'relu'활성화 함수로 구성됩니다.
Thrid 레이어, MaxPooling 풀 크기는 (2, 2)입니다.
다섯 번째 레이어, Flatten 모든 입력을 단일 차원으로 평면화하는 데 사용됩니다.
여섯 번째 레이어, Dense 128 개의 뉴런과 'relu'활성화 기능으로 구성됩니다.
일곱 번째 층, Dropout 값으로 0.5가 있습니다.
여덟 번째 및 마지막 층은 10 개의 뉴런과 'softmax'활성화 함수로 구성됩니다.
사용하다 categorical_crossentropy 손실 함수로.
사용하다 Adadelta() Optimizer로.
사용하다 accuracy 메트릭으로.
128을 배치 크기로 사용하십시오.
20을 시대로 사용하십시오.
Step 1 − Import the modules
필요한 모듈을 가져 오겠습니다.
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
import numpy as npStep 2 − Load data
mnist 데이터 세트를 가져 오겠습니다.
(x_train, y_train), (x_test, y_test) = mnist.load_data()Step 3 − Process the data
모델에 따라 데이터 세트를 변경하여 모델에 피드 할 수 있도록하겠습니다.
img_rows, img_cols = 28, 28
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)데이터 처리는 입력 데이터의 모양과 이미지 형식 구성을 제외하고 MPL 모델과 유사합니다.
Step 4 − Create the model
실제 모델을 만들어 보겠습니다.
model = Sequential()
model.add(Conv2D(32, kernel_size = (3, 3),
activation = 'relu', input_shape = input_shape))
model.add(Conv2D(64, (3, 3), activation = 'relu'))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Dropout(0.25)) model.add(Flatten())
model.add(Dense(128, activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation = 'softmax'))Step 5 − Compile the model
선택한 손실 함수, 최적화 프로그램 및 메트릭을 사용하여 모델을 컴파일 해 보겠습니다.
model.compile(loss = keras.losses.categorical_crossentropy,
optimizer = keras.optimizers.Adadelta(), metrics = ['accuracy'])Step 6 − Train the model
다음을 사용하여 모델을 학습 시키십시오. fit() 방법.
model.fit(
x_train, y_train,
batch_size = 128,
epochs = 12,
verbose = 1,
validation_data = (x_test, y_test)
)응용 프로그램을 실행하면 아래 정보가 출력됩니다.
Train on 60000 samples, validate on 10000 samples Epoch 1/12
60000/60000 [==============================] - 84s 1ms/step - loss: 0.2687
- acc: 0.9173 - val_loss: 0.0549 - val_acc: 0.9827 Epoch 2/12
60000/60000 [==============================] - 86s 1ms/step - loss: 0.0899
- acc: 0.9737 - val_loss: 0.0452 - val_acc: 0.9845 Epoch 3/12
60000/60000 [==============================] - 83s 1ms/step - loss: 0.0666
- acc: 0.9804 - val_loss: 0.0362 - val_acc: 0.9879 Epoch 4/12
60000/60000 [==============================] - 81s 1ms/step - loss: 0.0564
- acc: 0.9830 - val_loss: 0.0336 - val_acc: 0.9890 Epoch 5/12
60000/60000 [==============================] - 86s 1ms/step - loss: 0.0472
- acc: 0.9861 - val_loss: 0.0312 - val_acc: 0.9901 Epoch 6/12
60000/60000 [==============================] - 83s 1ms/step - loss: 0.0414
- acc: 0.9877 - val_loss: 0.0306 - val_acc: 0.9902 Epoch 7/12
60000/60000 [==============================] - 89s 1ms/step - loss: 0.0375
-acc: 0.9883 - val_loss: 0.0281 - val_acc: 0.9906 Epoch 8/12
60000/60000 [==============================] - 91s 2ms/step - loss: 0.0339
- acc: 0.9893 - val_loss: 0.0280 - val_acc: 0.9912 Epoch 9/12
60000/60000 [==============================] - 89s 1ms/step - loss: 0.0325
- acc: 0.9901 - val_loss: 0.0260 - val_acc: 0.9909 Epoch 10/12
60000/60000 [==============================] - 89s 1ms/step - loss: 0.0284
- acc: 0.9910 - val_loss: 0.0250 - val_acc: 0.9919 Epoch 11/12
60000/60000 [==============================] - 86s 1ms/step - loss: 0.0287
- acc: 0.9907 - val_loss: 0.0264 - val_acc: 0.9916 Epoch 12/12
60000/60000 [==============================] - 86s 1ms/step - loss: 0.0265
- acc: 0.9920 - val_loss: 0.0249 - val_acc: 0.9922Step 7 − Evaluate the model
테스트 데이터를 사용하여 모델을 평가 해 보겠습니다.
score = model.evaluate(x_test, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])위의 코드를 실행하면 아래 정보가 출력됩니다.
Test loss: 0.024936060590433316
Test accuracy: 0.9922테스트 정확도는 99.22 %입니다. 우리는 손글씨 숫자를 식별하는 최고의 모델을 만들었습니다.
Step 8 − Predict
마지막으로 다음과 같이 이미지에서 숫자를 예측하십시오.
pred = model.predict(x_test)
pred = np.argmax(pred, axis = 1)[:5]
label = np.argmax(y_test,axis = 1)[:5]
print(pred)
print(label)위 응용 프로그램의 출력은 다음과 같습니다.
[7 2 1 0 4]
[7 2 1 0 4]두 배열의 출력은 동일하며 모델이 처음 5 개의 이미지를 올바르게 예측 함을 나타냅니다.
Keras-MPL을 사용한 회귀 예측
이 장에서는 회귀 예측을 수행하기 위해 간단한 MPL 기반 ANN을 작성해 보겠습니다. 지금까지는 분류 기반 예측 만 수행했습니다. 이제 이전 (연속) 값과 그 영향 요인을 분석하여 다음 가능한 값을 예측하려고합니다.
회귀 MPL은 다음과 같이 나타낼 수 있습니다.

모델의 핵심 기능은 다음과 같습니다.
입력 레이어는 (13,) 값으로 구성됩니다.
첫 번째 계층 인 Dense 는 64 개의 유닛과 'normal'커널 이니셜 라이저가있는 'relu'활성화 함수로 구성됩니다.
두 번째 레이어 인 Dense 는 64 개의 유닛과 'relu'활성화 기능으로 구성됩니다.
출력 레이어, Dense 는 1 개의 단위로 구성됩니다.
사용하다 mse 손실 함수로.
사용하다 RMSprop Optimizer로.
사용하다 accuracy 메트릭으로.
128을 배치 크기로 사용하십시오.
Epoch로 500을 사용합니다.
Step 1 − Import the modules
필요한 모듈을 가져 오겠습니다.
import keras
from keras.datasets import boston_housing
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import RMSprop
from keras.callbacks import EarlyStopping
from sklearn import preprocessing
from sklearn.preprocessing import scaleStep 2 − Load data
보스턴 주택 데이터 셋을 가져 오겠습니다.
(x_train, y_train), (x_test, y_test) = boston_housing.load_data()여기,
boston_housingKeras에서 제공하는 데이터 세트입니다. 보스턴 지역의 주택 정보 모음을 나타내며 각각 13 개의 기능이 있습니다.
Step 3 − Process the data
모델에 따라 데이터 세트를 변경하여 모델에 입력 할 수 있습니다. 데이터는 아래 코드를 사용하여 변경할 수 있습니다-
x_train_scaled = preprocessing.scale(x_train)
scaler = preprocessing.StandardScaler().fit(x_train)
x_test_scaled = scaler.transform(x_test)여기에서는 다음을 사용하여 훈련 데이터를 정규화했습니다. sklearn.preprocessing.scale 함수. preprocessing.StandardScaler().fit 함수는 훈련 데이터의 정규화 된 평균과 표준 편차가있는 스칼라를 반환합니다.이를 사용하여 테스트 데이터에 적용 할 수 있습니다. scalar.transform함수. 이렇게하면 학습 데이터와 동일한 설정으로 테스트 데이터도 정규화됩니다.
Step 4 − Create the model
실제 모델을 만들어 보겠습니다.
model = Sequential()
model.add(Dense(64, kernel_initializer = 'normal', activation = 'relu',
input_shape = (13,)))
model.add(Dense(64, activation = 'relu')) model.add(Dense(1))Step 5 − Compile the model
선택한 손실 함수, 최적화 프로그램 및 메트릭을 사용하여 모델을 컴파일 해 보겠습니다.
model.compile(
loss = 'mse',
optimizer = RMSprop(),
metrics = ['mean_absolute_error']
)Step 6 − Train the model
다음을 사용하여 모델을 학습 시키십시오. fit() 방법.
history = model.fit(
x_train_scaled, y_train,
batch_size=128,
epochs = 500,
verbose = 1,
validation_split = 0.2,
callbacks = [EarlyStopping(monitor = 'val_loss', patience = 20)]
)여기에서는 콜백 함수를 사용했습니다. EarlyStopping. 이 콜백의 목적은 각 Epoch 동안 손실 값을 모니터링하고 이전 Epoch 손실 값과 비교하여 훈련의 개선점을 찾는 것입니다. 개선이없는 경우patience 시간이 지나면 전체 프로세스가 중지됩니다.
응용 프로그램을 실행하면 아래 정보가 출력으로 제공됩니다.
Train on 323 samples, validate on 81 samples Epoch 1/500 2019-09-24 01:07:03.889046: I
tensorflow/core/platform/cpu_feature_guard.cc:142]
Your CPU supports instructions that this
TensorFlow binary was not co mpiled to use: AVX2 323/323
[==============================] - 0s 515us/step - loss: 562.3129
- mean_absolute_error: 21.8575 - val_loss: 621.6523 - val_mean_absolute_erro
r: 23.1730 Epoch 2/500
323/323 [==============================] - 0s 11us/step - loss: 545.1666
- mean_absolute_error: 21.4887 - val_loss: 605.1341 - val_mean_absolute_error
: 22.8293 Epoch 3/500
323/323 [==============================] - 0s 12us/step - loss: 528.9944
- mean_absolute_error: 21.1328 - val_loss: 588.6594 - val_mean_absolute_error
: 22.4799 Epoch 4/500
323/323 [==============================] - 0s 12us/step - loss: 512.2739
- mean_absolute_error: 20.7658 - val_loss: 570.3772 - val_mean_absolute_error
: 22.0853 Epoch 5/500
323/323 [==============================] - 0s 9us/step - loss: 493.9775
- mean_absolute_error: 20.3506 - val_loss: 550.9548 - val_mean_absolute_error: 21.6547
..........
..........
..........
Epoch 143/500
323/323 [==============================] - 0s 15us/step - loss: 8.1004
- mean_absolute_error: 2.0002 - val_loss: 14.6286 - val_mean_absolute_error:
2. 5904 Epoch 144/500
323/323 [==============================] - 0s 19us/step - loss: 8.0300
- mean_absolute_error: 1.9683 - val_loss: 14.5949 - val_mean_absolute_error:
2. 5843 Epoch 145/500
323/323 [==============================] - 0s 12us/step - loss: 7.8704
- mean_absolute_error: 1.9313 - val_loss: 14.3770 - val_mean_absolute_error: 2. 4996Step 7 − Evaluate the model
테스트 데이터를 사용하여 모델을 평가 해 보겠습니다.
score = model.evaluate(x_test_scaled, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])위의 코드를 실행하면 아래 정보가 출력됩니다.
Test loss: 21.928471583946077 Test accuracy: 2.9599233234629914Step 8 − Predict
마지막으로 다음과 같이 테스트 데이터를 사용하여 예측하십시오.
prediction = model.predict(x_test_scaled)
print(prediction.flatten())
print(y_test)위 응용 프로그램의 출력은 다음과 같습니다.
[ 7.5612316 17.583357 21.09344 31.859276 25.055613 18.673872 26.600405 22.403967 19.060272 22.264952
17.4191 17.00466 15.58924 41.624374 20.220217 18.985565 26.419338 19.837091 19.946192 36.43445
12.278508 16.330965 20.701359 14.345301 21.741161 25.050423 31.046402 27.738455 9.959419 20.93039
20.069063 14.518344 33.20235 24.735163 18.7274 9.148898 15.781284 18.556862 18.692865 26.045074
27.954073 28.106823 15.272034 40.879818 29.33896 23.714525 26.427515 16.483374 22.518442 22.425386
33.94826 18.831465 13.2501955 15.537227 34.639984 27.468002 13.474407 48.134598 34.39617
22.8503124.042334 17.747198 14.7837715 18.187277 23.655672 22.364983 13.858193 22.710032 14.371148
7.1272087 35.960033 28.247292 25.3014 14.477208 25.306196 17.891165 20.193708 23.585173 34.690193
12.200583 20.102983 38.45882 14.741723 14.408362 17.67158 18.418497 21.151712 21.157492 22.693687
29.809034 19.366991 20.072294 25.880817 40.814568 34.64087 19.43741 36.2591 50.73806 26.968863 43.91787
32.54908 20.248306 ] [ 7.2 18.8 19. 27. 22.2 24.5 31.2 22.9 20.5 23.2 18.6 14.5 17.8 50. 20.8 24.3 24.2
19.8 19.1 22.7 12. 10.2 20. 18.5 20.9 23. 27.5 30.1 9.5 22. 21.2 14.1 33.1 23.4 20.1 7.4 15.4 23.8 20.1
24.5 33. 28.4 14.1 46.7 32.5 29.6 28.4 19.8 20.2 25. 35.4 20.3 9.7 14.5 34.9 26.6 7.2 50. 32.4 21.6 29.8
13.1 27.5 21.2 23.1 21.9 13. 23.2 8.1 5.6 21.7 29.6 19.6 7. 26.4 18.9 20.9 28.1 35.4 10.2 24.3 43.1 17.6
15.4 16.2 27.1 21.4 21.5 22.4 25. 16.6 18.6 22. 42.8 35.1 21.5 36. 21.9 24.1 50. 26.7 25. ]두 배열의 출력은 약 10-30 %의 차이가 있으며 모델이 합리적인 범위로 예측 함을 나타냅니다.
Keras-LSTM RNN을 사용한 시계열 예측
이 장에서는 시퀀스 분석을 수행하기 위해 간단한 LSTM (Long Short Term Memory) 기반 RNN을 작성해 보겠습니다. 시퀀스는 각 값이 특정 시간 인스턴스에 해당하는 값 집합입니다. 문장을 읽는 간단한 예를 살펴 보겠습니다. 문장을 읽고 이해하는 것은 주어진 순서대로 단어를 읽고 주어진 문맥에서 각 단어와 그 의미를 이해하고 마지막으로 긍정적 또는 부정적인 감정으로 문장을 이해하는 것을 포함합니다.
여기서는 단어를 값으로 간주하고 첫 번째 값은 첫 번째 단어에 해당하고 두 번째 값은 두 번째 단어에 해당하며 순서는 엄격하게 유지됩니다. Sequence Analysis 주어진 텍스트의 감정 분석을 찾기 위해 자연어 처리에서 자주 사용됩니다.
IMDB 영화 리뷰를 분석하고 긍정적 / 부정적 감정을 찾기위한 LSTM 모델을 만들어 보겠습니다.
시퀀스 분석을위한 모델은 다음과 같이 표현할 수 있습니다.
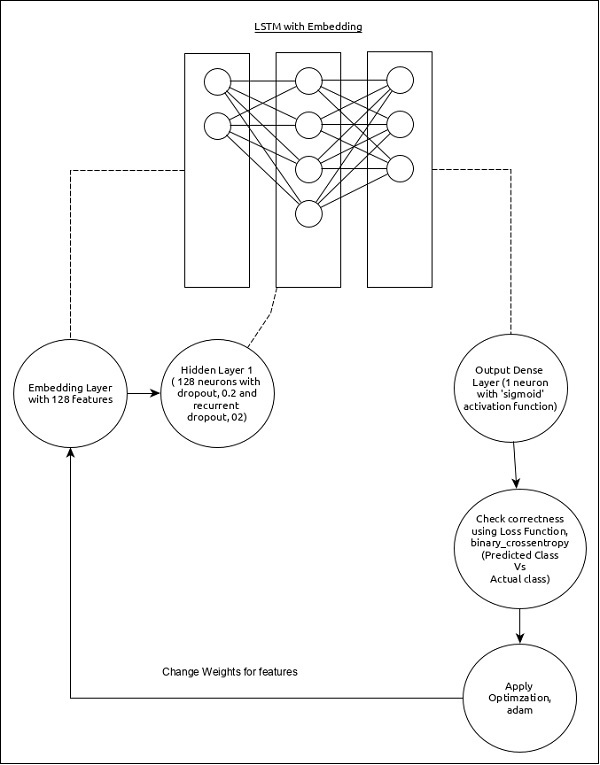
모델의 핵심 기능은 다음과 같습니다.
128 개의 피처가있는 Embedding 레이어를 사용하는 입력 레이어.
첫 번째 레이어 인 Dense는 일반 드롭 아웃 및 반복 드롭 아웃이 0.2로 설정된 128 개 단위로 구성됩니다.
출력 레이어, Dense 는 1 개의 단위와 '시그 모이 드'활성화 기능으로 구성됩니다.
사용하다 binary_crossentropy 손실 함수로.
사용하다 adam Optimizer로.
사용하다 accuracy 메트릭으로.
배치 크기로 32를 사용합니다.
15를 시대로 사용하십시오.
단어의 최대 길이로 80을 사용하십시오.
주어진 문장의 최대 단어 수로 2000을 사용하십시오.
1 단계 : 모듈 가져 오기
필요한 모듈을 가져 오겠습니다.
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Embedding
from keras.layers import LSTM
from keras.datasets import imdb2 단계 : 데이터로드
imdb 데이터 세트를 가져 오겠습니다.
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words = 2000)여기,
imdbKeras에서 제공하는 데이터 세트입니다. 그것은 영화 모음과 그 리뷰를 나타냅니다.
num_words 리뷰의 최대 단어 수를 나타냅니다.
3 단계 : 데이터 처리
모델에 따라 데이터 세트를 변경하여 모델에 입력 할 수 있도록하겠습니다. 데이터는 아래 코드를 사용하여 변경할 수 있습니다-
x_train = sequence.pad_sequences(x_train, maxlen=80)
x_test = sequence.pad_sequences(x_test, maxlen=80)여기,
sequence.pad_sequences 입력 데이터 목록을 모양으로 변환하고, (data) 모양의 2D NumPy 배열로 (data, timesteps). 기본적으로 주어진 데이터에 시간 단계 개념을 추가합니다. 길이의 시간 단계를 생성합니다.maxlen.
4 단계 : 모델 생성
실제 모델을 만들어 보겠습니다.
model = Sequential()
model.add(Embedding(2000, 128))
model.add(LSTM(128, dropout = 0.2, recurrent_dropout = 0.2))
model.add(Dense(1, activation = 'sigmoid'))여기,
우리는 사용했습니다 Embedding layer입력 레이어로 추가 한 다음 LSTM 레이어를 추가했습니다. 마지막으로Dense layer 출력 레이어로 사용됩니다.
5 단계 : 모델 컴파일
선택한 손실 함수, 최적화 프로그램 및 메트릭을 사용하여 모델을 컴파일 해 보겠습니다.
model.compile(loss = 'binary_crossentropy',
optimizer = 'adam', metrics = ['accuracy'])6 단계 : 모델 학습
다음을 사용하여 모델을 훈련 시키십시오. fit() 방법.
model.fit(
x_train, y_train,
batch_size = 32,
epochs = 15,
validation_data = (x_test, y_test)
)응용 프로그램을 실행하면 아래 정보가 출력됩니다.
Epoch 1/15 2019-09-24 01:19:01.151247: I
tensorflow/core/platform/cpu_feature_guard.cc:142]
Your CPU supports instructions that this
TensorFlow binary was not co mpiled to use: AVX2
25000/25000 [==============================] - 101s 4ms/step - loss: 0.4707
- acc: 0.7716 - val_loss: 0.3769 - val_acc: 0.8349 Epoch 2/15
25000/25000 [==============================] - 95s 4ms/step - loss: 0.3058
- acc: 0.8756 - val_loss: 0.3763 - val_acc: 0.8350 Epoch 3/15
25000/25000 [==============================] - 91s 4ms/step - loss: 0.2100
- acc: 0.9178 - val_loss: 0.5065 - val_acc: 0.8110 Epoch 4/15
25000/25000 [==============================] - 90s 4ms/step - loss: 0.1394
- acc: 0.9495 - val_loss: 0.6046 - val_acc: 0.8146 Epoch 5/15
25000/25000 [==============================] - 90s 4ms/step - loss: 0.0973
- acc: 0.9652 - val_loss: 0.5969 - val_acc: 0.8147 Epoch 6/15
25000/25000 [==============================] - 98s 4ms/step - loss: 0.0759
- acc: 0.9730 - val_loss: 0.6368 - val_acc: 0.8208 Epoch 7/15
25000/25000 [==============================] - 95s 4ms/step - loss: 0.0578
- acc: 0.9811 - val_loss: 0.6657 - val_acc: 0.8184 Epoch 8/15
25000/25000 [==============================] - 97s 4ms/step - loss: 0.0448
- acc: 0.9850 - val_loss: 0.7452 - val_acc: 0.8136 Epoch 9/15
25000/25000 [==============================] - 95s 4ms/step - loss: 0.0324
- acc: 0.9894 - val_loss: 0.7616 - val_acc: 0.8162Epoch 10/15
25000/25000 [==============================] - 100s 4ms/step - loss: 0.0247
- acc: 0.9922 - val_loss: 0.9654 - val_acc: 0.8148 Epoch 11/15
25000/25000 [==============================] - 99s 4ms/step - loss: 0.0169
- acc: 0.9946 - val_loss: 1.0013 - val_acc: 0.8104 Epoch 12/15
25000/25000 [==============================] - 90s 4ms/step - loss: 0.0154
- acc: 0.9948 - val_loss: 1.0316 - val_acc: 0.8100 Epoch 13/15
25000/25000 [==============================] - 89s 4ms/step - loss: 0.0113
- acc: 0.9963 - val_loss: 1.1138 - val_acc: 0.8108 Epoch 14/15
25000/25000 [==============================] - 89s 4ms/step - loss: 0.0106
- acc: 0.9971 - val_loss: 1.0538 - val_acc: 0.8102 Epoch 15/15
25000/25000 [==============================] - 89s 4ms/step - loss: 0.0090
- acc: 0.9972 - val_loss: 1.1453 - val_acc: 0.8129
25000/25000 [==============================] - 10s 390us/step7 단계-모델 평가
테스트 데이터를 사용하여 모델을 평가 해 보겠습니다.
score, acc = model.evaluate(x_test, y_test, batch_size = 32)
print('Test score:', score)
print('Test accuracy:', acc)위의 코드를 실행하면 아래 정보가 출력됩니다.
Test score: 1.145306069601178
Test accuracy: 0.81292Keras-애플리케이션
Keras 애플리케이션 모듈은 심층 신경망을위한 사전 학습 된 모델을 제공하는 데 사용됩니다. Keras 모델은 예측, 특징 추출 및 미세 조정에 사용됩니다. 이 장에서는 Keras 응용 프로그램에 대해 자세히 설명합니다.
사전 훈련 된 모델
학습 된 모델은 아키텍처와 모델 가중치의 두 부분으로 구성됩니다. 모델 가중치는 대용량 파일이므로 ImageNet 데이터베이스에서 기능을 다운로드하고 추출해야합니다. 인기있는 사전 학습 된 모델 중 일부는 다음과 같습니다.
- ResNet
- VGG16
- MobileNet
- InceptionResNetV2
- InceptionV3
모델로드
Keras 사전 훈련 된 모델은 아래 지정된대로 쉽게로드 할 수 있습니다.
import keras
import numpy as np
from keras.applications import vgg16, inception_v3, resnet50, mobilenet
#Load the VGG model
vgg_model = vgg16.VGG16(weights = 'imagenet')
#Load the Inception_V3 model
inception_model = inception_v3.InceptionV3(weights = 'imagenet')
#Load the ResNet50 model
resnet_model = resnet50.ResNet50(weights = 'imagenet')
#Load the MobileNet model mobilenet_model = mobilenet.MobileNet(weights = 'imagenet')모델이로드되면 즉시 예측 목적으로 사용할 수 있습니다. 다음 장에서 사전 훈련 된 각 모델을 확인하겠습니다.
ResNet 모델을 사용한 실시간 예측
ResNet 은 사전 훈련 된 모델입니다. ImageNet을 사용하여 훈련 되었습니다 . ImageNet 에서 사전 학습 된 ResNet 모델 가중치 . 다음과 같은 구문이 있습니다.
keras.applications.resnet.ResNet50 (
include_top = True,
weights = 'imagenet',
input_tensor = None,
input_shape = None,
pooling = None,
classes = 1000
)여기,
include_top 네트워크 상단에있는 완전 연결 계층을 나타냅니다.
weights ImageNet에 대한 사전 교육을 참조하십시오.
input_tensor 모델의 이미지 입력으로 사용할 선택적 Keras 텐서를 참조합니다.
input_shape선택적 모양 튜플을 나타냅니다. 이 모델의 기본 입력 크기는 224x224입니다.
classes 이미지를 분류하기 위해 선택적 클래스 수를 참조하십시오.
간단한 예제를 작성하여 모델을 이해합시다.
1 단계 : 모듈 가져 오기
아래에 지정된대로 필요한 모듈을로드하겠습니다.
>>> import PIL
>>> from keras.preprocessing.image import load_img
>>> from keras.preprocessing.image import img_to_array
>>> from keras.applications.imagenet_utils import decode_predictions
>>> import matplotlib.pyplot as plt
>>> import numpy as np
>>> from keras.applications.resnet50 import ResNet50
>>> from keras.applications import resnet502 단계 : 입력 선택
입력 이미지를 선택하겠습니다. Lotus 아래에 명시된대로-
>>> filename = 'banana.jpg'
>>> ## load an image in PIL format
>>> original = load_img(filename, target_size = (224, 224))
>>> print('PIL image size',original.size)
PIL image size (224, 224)
>>> plt.imshow(original)
<matplotlib.image.AxesImage object at 0x1304756d8>
>>> plt.show()여기에 이미지를로드했습니다. (banana.jpg) 그리고 그것을 표시했습니다.
3 단계 : 이미지를 NumPy 배열로 변환
입력을 변환 해 보겠습니다. Banana 예측을 위해 모델에 전달할 수 있도록 NumPy 배열에 넣습니다.
>>> #convert the PIL image to a numpy array
>>> numpy_image = img_to_array(original)
>>> plt.imshow(np.uint8(numpy_image))
<matplotlib.image.AxesImage object at 0x130475ac8>
>>> print('numpy array size',numpy_image.shape)
numpy array size (224, 224, 3)
>>> # Convert the image / images into batch format
>>> image_batch = np.expand_dims(numpy_image, axis = 0)
>>> print('image batch size', image_batch.shape)
image batch size (1, 224, 224, 3)
>>>4 단계 : 모델 예측
예측을 얻기 위해 모델에 입력을 입력하겠습니다.
>>> prepare the image for the resnet50 model >>>
>>> processed_image = resnet50.preprocess_input(image_batch.copy())
>>> # create resnet model
>>>resnet_model = resnet50.ResNet50(weights = 'imagenet')
>>> Downloavding data from https://github.com/fchollet/deep-learning-models/releas
es/download/v0.2/resnet50_weights_tf_dim_ordering_tf_kernels.h5
102858752/102853048 [==============================] - 33s 0us/step
>>> # get the predicted probabilities for each class
>>> predictions = resnet_model.predict(processed_image)
>>> # convert the probabilities to class labels
>>> label = decode_predictions(predictions)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/
data/imagenet_class_index.json
40960/35363 [==================================] - 0s 0us/step
>>> print(label)산출
[
[
('n07753592', 'banana', 0.99229723),
('n03532672', 'hook', 0.0014551596),
('n03970156', 'plunger', 0.0010738898),
('n07753113', 'fig', 0.0009359837) ,
('n03109150', 'corkscrew', 0.00028538404)
]
]여기서 모델은 이미지를 바나나로 올바르게 예측했습니다.
Keras-사전 훈련 된 모델
이 장에서는 Keras의 사전 훈련 된 모델에 대해 알아 봅니다. VGG16부터 시작하겠습니다.
VGG16
VGG16사전 훈련 된 또 다른 모델입니다. 또한 ImageNet을 사용하여 훈련됩니다. 모델을로드하는 구문은 다음과 같습니다.
keras.applications.vgg16.VGG16(
include_top = True,
weights = 'imagenet',
input_tensor = None,
input_shape = None,
pooling = None,
classes = 1000
)이 모델의 기본 입력 크기는 224x224입니다.
MobileNetV2
MobileNetV2사전 훈련 된 또 다른 모델입니다. 그것은 또한 훈련 된 uing입니다ImageNet.
모델을로드하는 구문은 다음과 같습니다.
keras.applications.mobilenet_v2.MobileNetV2 (
input_shape = None,
alpha = 1.0,
include_top = True,
weights = 'imagenet',
input_tensor = None,
pooling = None,
classes = 1000
)여기,
alpha네트워크의 너비를 제어합니다. 값이 1 미만이면 각 레이어의 필터 수를 줄입니다. 값이 1보다 크면 각 레이어의 필터 수를 늘립니다. alpha = 1이면 용지의 기본 필터 수가 각 레이어에 사용됩니다.
이 모델의 기본 입력 크기는 다음과 같습니다. 224x224.
InceptionResNetV2
InceptionResNetV2사전 훈련 된 또 다른 모델입니다. 또한 다음을 사용하여 훈련됩니다.ImageNet. 모델을로드하는 구문은 다음과 같습니다.
keras.applications.inception_resnet_v2.InceptionResNetV2 (
include_top = True,
weights = 'imagenet',
input_tensor = None,
input_shape = None,
pooling = None,
classes = 1000)이 모델은 'channels_first'데이터 형식 (채널, 높이, 너비) 또는 'channels_last'데이터 형식 (높이, 너비, 채널)으로 구축 할 수 있습니다.
이 모델의 기본 입력 크기는 다음과 같습니다. 299x299.
InceptionV3
InceptionV3사전 훈련 된 또 다른 모델입니다. 그것은 또한 훈련 된 uing입니다ImageNet. 모델을로드하는 구문은 다음과 같습니다.
keras.applications.inception_v3.InceptionV3 (
include_top = True,
weights = 'imagenet',
input_tensor = None,
input_shape = None,
pooling = None,
classes = 1000
)여기,
이 모델의 기본 입력 크기는 다음과 같습니다. 299x299.
결론
Keras는 매우 간단하고 확장 가능하며 구현하기 쉬운 신경망 API로, 높은 수준의 추상화로 딥 러닝 애플리케이션을 구축하는 데 사용할 수 있습니다. Keras는 깊숙한 모델을위한 최적의 선택입니다.