LISP-퀵 가이드
John McCarthy는 FORTRAN이 개발 된 직후 인 1958 년에 LISP를 발명했습니다. Steve Russell이 IBM 704 컴퓨터에서 처음 구현했습니다.
상징적 정보를 효과적으로 처리하기 때문에 인공 지능 프로그램에 특히 적합합니다.
Common Lisp는 1980 년대와 1990 년대에 ZetaLisp 및 NIL (New Implementation of Lisp) 등과 같이 Maclisp의 후계자 인 여러 구현 그룹의 작업을 통합하려는 시도에서 시작되었습니다.
특정 구현을 위해 쉽게 확장 할 수있는 공통 언어 역할을합니다.
Common LISP로 작성된 프로그램은 단어 길이 등과 같은 기계 별 특성에 의존하지 않습니다.
Common LISP의 특징
기계 독립적입니다.
반복적 인 설계 방법론과 쉬운 확장 성을 사용합니다.
프로그램을 동적으로 업데이트 할 수 있습니다.
높은 수준의 디버깅을 제공합니다.
고급 객체 지향 프로그래밍을 제공합니다.
편리한 매크로 시스템을 제공합니다.
객체, 구조, 목록, 벡터, 조정 가능한 배열, 해시 테이블 및 기호와 같은 광범위한 데이터 유형을 제공합니다.
표현 기반입니다.
객체 지향 조건 시스템을 제공합니다.
완전한 I / O 라이브러리를 제공합니다.
광범위한 제어 구조를 제공합니다.
LISP에 내장 된 애플리케이션
Lisp에 구축 된 대규모 성공적인 애플리케이션.
Emacs
G2
AutoCad
이고르 조각사
야후 스토어
지역 환경 설정
Lisp 프로그래밍 언어에 대한 환경을 설정하려는 경우 컴퓨터에서 사용할 수있는 다음 두 소프트웨어, (a) 텍스트 편집기 및 (b) Lisp Executer가 필요합니다.
텍스트 에디터
이것은 프로그램을 입력하는 데 사용됩니다. 몇 가지 편집기의 예로는 Windows 메모장, OS 편집 명령, Brief, Epsilon, EMACS 및 vim 또는 vi가 있습니다.
텍스트 편집기의 이름과 버전은 운영 체제에 따라 다를 수 있습니다. 예를 들어 메모장은 Windows에서 사용되며 vim 또는 vi는 Linux 또는 UNIX뿐만 아니라 Windows에서도 사용할 수 있습니다.
편집기로 만든 파일을 소스 파일이라고하며 프로그램 소스 코드를 포함합니다. Lisp 프로그램의 소스 파일 이름은 일반적으로 ".lisp".
프로그래밍을 시작하기 전에 하나의 텍스트 편집기가 있고 컴퓨터 프로그램을 작성하고 파일에 저장 한 다음 마지막으로 실행하기에 충분한 경험이 있는지 확인하십시오.
Lisp 실행자
소스 파일에 작성된 소스 코드는 프로그램의 사람이 읽을 수있는 소스입니다. CPU가 주어진 명령에 따라 실제로 프로그램을 실행할 수 있도록 기계어로 전환하려면 "실행"되어야합니다.
이 Lisp 프로그래밍 언어는 소스 코드를 최종 실행 프로그램으로 실행하는 데 사용됩니다. 프로그래밍 언어에 대한 기본 지식이 있다고 가정합니다.
CLISP는 Windows에서 LISP를 설정하는 데 사용되는 GNU Common LISP 다중 아키텍처 컴파일러입니다. Windows 버전은 Windows에서 MingW를 사용하여 유닉스 환경을 에뮬레이트합니다. 설치 프로그램이이를 처리하고 자동으로 Windows PATH 변수에 clisp를 추가합니다.
여기에서 Windows 용 최신 CLISP를 얻을 수 있습니다. https://sourceforge.net/projects/clisp/files/latest/download
줄 단위 인터프리터를 위해 기본적으로 시작 메뉴에 바로 가기를 만듭니다.
CLISP 사용 방법
설치하는 동안 clisp 옵션을 선택하면 PATH 변수에 자동으로 추가됩니다 (권장). 즉, 새 명령 프롬프트 창을 열고 "clisp"를 입력하여 컴파일러를 불러올 수 있습니다.
* .lisp 또는 * .lsp 파일을 실행하려면 간단히 −
clisp hello.lispLISP 표현식을 기호 표현식 또는 s- 표현이라고합니다. s- 표현식은 세 개의 유효한 객체, 원자, 목록 및 문자열로 구성됩니다.
모든 s-expression은 유효한 프로그램입니다.
LISP 프로그램은 interpreter 또는 compiled code.
인터프리터는 읽기-평가-인쇄 루프 (REPL)라고도하는 반복 루프에서 소스 코드를 확인합니다. 프로그램 코드를 읽고 평가 한 다음 프로그램에서 반환 한 값을 인쇄합니다.
간단한 프로그램
세 숫자 7, 9, 11의 합을 찾기 위해 s- 표현식을 작성해 보겠습니다.이를 위해 인터프리터 프롬프트에 입력 할 수 있습니다.
(+ 7 9 11)LISP는 결과를 반환합니다-
27컴파일 된 코드와 동일한 프로그램을 실행하려면 myprog.lisp라는 LISP 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write (+ 7 9 11))실행 버튼을 클릭하거나 Ctrl + E를 입력하면 LISP가 즉시 실행하고 반환 된 결과는 다음과 같습니다.
27LISP는 접두사 표기법을 사용합니다.
LISP가 prefix notation.
위의 프로그램에서 + 기호는 숫자 합산 프로세스의 함수 이름으로 작동합니다.
접두사 표기법에서 연산자는 피연산자 앞에 기록됩니다. 예를 들어, 식,
a * ( b + c ) / d다음과 같이 작성됩니다-
(/ (* a (+ b c) ) d)또 다른 예를 들어, 화씨 60 o F를 섭씨 눈금으로 변환하는 코드를 작성해 보겠습니다.
이 변환에 대한 수학적 표현은 다음과 같습니다.
(60 * 9 / 5) + 32main.lisp라는 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write(+ (* (/ 9 5) 60) 32))실행 버튼을 클릭하거나 Ctrl + E를 입력하면 LISP가 즉시 실행하고 반환 된 결과는 다음과 같습니다.
140LISP 프로그램 평가
LISP 프로그램의 평가는 두 부분으로 구성됩니다.
리더 프로그램에 의해 프로그램 텍스트를 Lisp 객체로 번역
평가자 프로그램에 의해 이러한 객체의 관점에서 언어의 의미론 구현
평가 프로세스는 다음 단계를 따릅니다.
판독기는 문자열을 LISP 객체 또는 s-expressions.
평가자는 Lisp의 구문을 정의합니다. formss- 표현식으로 만들어졌습니다. 이 두 번째 평가 수준은 다음을 결정하는 구문을 정의합니다.s-expressions LISP 양식입니다.
평가자는 유효한 LISP 형식을 인수로 사용하고 값을 반환하는 함수로 작동합니다. 이것이 LISP 표현식을 괄호 안에 넣은 이유입니다. 전체 표현식 / 양식을 평가자에게 인수로 전송하기 때문입니다.
'Hello World'프로그램
새로운 프로그래밍 언어를 배우는 것은 그 언어로 전 세계를 맞이하는 방법을 배울 때까지 실제로 시작되지 않습니다.
따라서 main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력하십시오.
(write-line "Hello World")
(write-line "I am at 'Tutorials Point'! Learning LISP")실행 버튼을 클릭하거나 Ctrl + E를 입력하면 LISP가 즉시 실행하고 반환 된 결과는 다음과 같습니다.
Hello World
I am at 'Tutorials Point'! Learning LISPLISP의 기본 빌딩 블록
LISP 프로그램은 세 가지 기본 구성 요소로 구성됩니다.
- atom
- list
- string
안 atom연속 문자의 숫자 또는 문자열입니다. 숫자와 특수 문자가 포함됩니다.
다음은 몇 가지 유효한 원자의 예입니다.
hello-from-tutorials-point
name
123008907
*hello*
Block#221
abc123ㅏ list 괄호로 묶인 원자 시퀀스 및 / 또는 기타 목록입니다.
다음은 몇 가지 유효한 목록의 예입니다.
( i am a list)
(a ( a b c) d e fgh)
(father tom ( susan bill joe))
(sun mon tue wed thur fri sat)
( )ㅏ string 큰 따옴표로 묶인 문자 그룹입니다.
다음은 몇 가지 유효한 문자열의 예입니다.
" I am a string"
"a ba c d efg #$%^&!"
"Please enter the following details :"
"Hello from 'Tutorials Point'! "댓글 추가
세미콜론 기호 (;)는 주석 행을 표시하는 데 사용됩니다.
예를 들어
(write-line "Hello World") ; greet the world
; tell them your whereabouts
(write-line "I am at 'Tutorials Point'! Learning LISP")실행 버튼을 클릭하거나 Ctrl + E를 입력하면 LISP가 즉시 실행하고 반환 된 결과는 다음과 같습니다.
Hello World
I am at 'Tutorials Point'! Learning LISP다음으로 이동하기 전에 몇 가지 주목할 점
다음은 주목해야 할 몇 가지 중요한 사항입니다.
LISP의 기본 숫자 연산은 +,-, * 및 /입니다.
LISP는 함수 호출 f (x)를 (fx)로 나타냅니다. 예를 들어 cos (45)는 cos 45로 작성됩니다.
LISP 표현식은 대소 문자를 구분하지 않으며 cos 45 또는 COS 45는 동일합니다.
LISP는 함수의 인수를 포함하여 모든 것을 평가하려고합니다. 세 가지 유형의 요소 만 상수이며 항상 자체 값을 반환합니다.
Numbers
그 편지 t, 그것은 논리적 진실을 의미합니다.
가치 nil, 논리적 거짓과 빈 목록을 의미합니다.
LISP 양식에 대한 추가 정보
이전 장에서 LISP 코드의 평가 과정은 다음과 같은 단계를 거친다고 언급했습니다.
판독기는 문자열을 LISP 객체 또는 s-expressions.
평가자는 Lisp의 구문을 정의합니다. formss- 표현식으로 만들어졌습니다. 이 두 번째 평가 수준은 어떤 s- 표현식이 LISP 형식인지 결정하는 구문을 정의합니다.
이제 LISP 양식이 될 수 있습니다.
- 원자
- 비어 있거나 목록이 아닌
- 첫 번째 요소로 기호가있는 모든 목록
평가자는 유효한 LISP 형식을 인수로 사용하고 값을 반환하는 함수로 작동합니다. 이것이 우리가LISP expression in parenthesis, 전체 표현식 / 양식을 평가자에게 인수로 전송하기 때문입니다.
LISP의 명명 규칙
이름 또는 기호는 공백, 여는 괄호, 큰 따옴표, 작은 따옴표, 백 슬래시, 쉼표, 콜론, 세미콜론 및 세로 막대를 제외한 모든 영숫자 문자로 구성 될 수 있습니다. 이러한 문자를 이름에 사용하려면 이스케이프 문자 (\)를 사용해야합니다.
이름은 숫자를 가질 수 있지만 완전히 숫자로 구성되지는 않습니다. 왜냐하면 숫자로 읽히기 때문입니다. 마찬가지로 이름에는 마침표가있을 수 있지만 완전히 마침표로 만들 수는 없습니다.
작은 따옴표 사용
LISP는 함수 인수와 목록 멤버를 포함한 모든 것을 평가합니다.
때때로 우리는 원 자나 목록을 문자 그대로 가져 와서 평가하거나 함수 호출로 취급하지 않도록해야합니다.
이렇게하려면 원자 또는 목록 앞에 작은 따옴표를 붙여야합니다.
다음 예제는이를 보여줍니다.
main.lisp라는 파일을 만들고 다음 코드를 입력합니다.
(write-line "single quote used, it inhibits evaluation")
(write '(* 2 3))
(write-line " ")
(write-line "single quote not used, so expression evaluated")
(write (* 2 3))실행 버튼을 클릭하거나 Ctrl + E를 입력하면 LISP가 즉시 실행하고 반환 된 결과는 다음과 같습니다.
single quote used, it inhibits evaluation
(* 2 3)
single quote not used, so expression evaluated
6LISP에서 변수는 형식화되지 않지만 데이터 개체는 형식화됩니다.
LISP 데이터 유형은 다음과 같이 분류 할 수 있습니다.
Scalar types − 예 : 숫자 유형, 문자, 기호 등
Data structures − 예를 들어, 목록, 벡터, 비트 벡터 및 문자열.
명시 적으로 선언하지 않는 한 모든 변수는 LISP 객체를 값으로 사용할 수 있습니다.
LISP 변수에 대한 데이터 유형을 지정할 필요는 없지만 특정 루프 확장, 메서드 선언 및 이후 장에서 논의 할 기타 상황에서 도움이됩니다.
데이터 유형은 계층 구조로 정렬됩니다. 데이터 유형은 LISP 개체의 집합이며 많은 개체가 이러한 집합에 속할 수 있습니다.
그만큼 typep 술어는 객체가 특정 유형에 속하는지 여부를 찾는 데 사용됩니다.
그만큼 type-of 함수는 주어진 객체의 데이터 유형을 반환합니다.
LISP의 유형 지정자
유형 지정자는 데이터 유형에 대한 시스템 정의 기호입니다.
| 정렬 | fixnum | 꾸러미 | 단순 문자열 |
| 원자 | 흙손 | 경로명 | 단순 벡터 |
| 빅넘 | 함수 | 무작위 상태 | 단일 플로트 |
| 비트 | 해시 테이블 | 비율 | 표준 문자 |
| 비트 벡터 | 정수 | 합리적인 | 흐름 |
| 캐릭터 | 예어 | 읽을 수있는 | 끈 |
| [흔한] | 명부 | 순서 | [문자열-문자] |
| 컴파일 된 함수 | long-float | 짧은 부동 | 상징 |
| 복잡한 | 무 | 부호있는 바이트 | 티 |
| 단점 | 없는 | 단순 배열 | 부호없는 바이트 |
| 이중 부동 | 번호 | 단순 비트 벡터 | 벡터 |
이러한 시스템 정의 유형 외에도 고유 한 데이터 유형을 만들 수 있습니다. 구조 유형이 다음을 사용하여 정의되는 경우defstruct 함수의 경우 구조 유형의 이름이 유효한 유형 기호가됩니다.
예 1
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(setq x 10)
(setq y 34.567)
(setq ch nil)
(setq n 123.78)
(setq bg 11.0e+4)
(setq r 124/2)
(print x)
(print y)
(print n)
(print ch)
(print bg)
(print r)실행 버튼을 클릭하거나 Ctrl + E를 입력하면 LISP가 즉시 실행하고 반환 된 결과는 다음과 같습니다.
10
34.567
123.78
NIL
110000.0
62예 2
다음으로 이전 예제에서 사용 된 변수의 유형을 확인하겠습니다. main이라는 새 소스 코드 파일을 만듭니다. lisp를 입력하고 다음 코드를 입력하십시오.
(defvar x 10)
(defvar y 34.567)
(defvar ch nil)
(defvar n 123.78)
(defvar bg 11.0e+4)
(defvar r 124/2)
(print (type-of x))
(print (type-of y))
(print (type-of n))
(print (type-of ch))
(print (type-of bg))
(print (type-of r))실행 버튼을 클릭하거나 Ctrl + E를 입력하면 LISP가 즉시 실행하고 반환 된 결과는 다음과 같습니다.
(INTEGER 0 281474976710655)
SINGLE-FLOAT
SINGLE-FLOAT
NULL
SINGLE-FLOAT
(INTEGER 0 281474976710655)매크로를 사용하면 표준 LISP의 구문을 확장 할 수 있습니다.
기술적으로 매크로는 s- 표현식을 인수로 사용하고 LISP 양식을 반환 한 다음 평가되는 함수입니다.
매크로 정의
LISP에서 명명 된 매크로는 명명 된 다른 매크로를 사용하여 정의됩니다. defmacro. 매크로를 정의하는 구문은 다음과 같습니다.
(defmacro macro-name (parameter-list))
"Optional documentation string."
body-form매크로 정의는 매크로 이름, 매개 변수 목록, 선택적 문서 문자열 및 매크로에서 수행 할 작업을 정의하는 Lisp 표현식의 본문으로 구성됩니다.
예
숫자를 가져와 값을 10으로 설정하는 setTo10이라는 간단한 매크로를 작성하겠습니다.
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(defmacro setTo10(num)
(setq num 10)(print num))
(setq x 25)
(print x)
(setTo10 x)실행 버튼을 클릭하거나 Ctrl + E를 입력하면 LISP가 즉시 실행하고 반환 된 결과는 다음과 같습니다.
25
10LISP에서 각 변수는 symbol. 변수의 이름은 심볼의 이름이며 심볼의 저장 셀에 저장됩니다.
글로벌 변수
전역 변수는 LISP 시스템 전체에서 영구적 인 값을 가지며 새 값이 지정 될 때까지 유효합니다.
전역 변수는 일반적으로 defvar 구성.
예를 들면
(defvar x 234)
(write x)실행 버튼을 클릭하거나 Ctrl + E를 입력하면 LISP가 즉시 실행하고 반환 된 결과는 다음과 같습니다.
234LISP에는 변수에 대한 유형 선언이 없으므로 다음을 사용하여 기호에 대한 값을 직접 지정합니다. setq 구성.
예를 들어
->(setq x 10)위의 식은 변수 x에 값 10을 할당합니다. 기호 자체를 표현식으로 사용하여 변수를 참조 할 수 있습니다.
그만큼 symbol-value 기능을 사용하면 심볼 저장 장소에 저장된 값을 추출 할 수 있습니다.
예를 들어
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(setq x 10)
(setq y 20)
(format t "x = ~2d y = ~2d ~%" x y)
(setq x 100)
(setq y 200)
(format t "x = ~2d y = ~2d" x y)실행 버튼을 클릭하거나 Ctrl + E를 입력하면 LISP가 즉시 실행하고 반환 된 결과는 다음과 같습니다.
x = 10 y = 20
x = 100 y = 200지역 변수
지역 변수는 주어진 프로 시저 내에서 정의됩니다. 함수 정의 내에서 인수로 명명 된 매개 변수도 지역 변수입니다. 지역 변수는 해당 함수 내에서만 액세스 할 수 있습니다.
전역 변수와 마찬가지로 지역 변수는 setq 구성.
다른 두 가지 구조가 있습니다. let 과 prog 지역 변수를 만들기 위해.
let 구조는 다음 구문을 갖습니다.
(let ((var1 val1) (var2 val2).. (varn valn))<s-expressions>)여기서 var1, var2, ..varn은 변수 이름이고 val1, val2, .. valn은 각 변수에 할당 된 초기 값입니다.
언제 let실행되면 각 변수에 해당 값이 할당되고 마지막으로 s- 표현식 이 평가됩니다. 마지막으로 평가 된 식의 값이 반환됩니다.
변수에 대한 초기 값을 포함하지 않으면 nil.
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(let ((x 'a) (y 'b)(z 'c))
(format t "x = ~a y = ~a z = ~a" x y z))실행 버튼을 클릭하거나 Ctrl + E를 입력하면 LISP가 즉시 실행하고 반환 된 결과는 다음과 같습니다.
x = A y = B z = C그만큼 prog 구문은 또한 첫 번째 인수로 지역 변수 목록을 가지며, 그 뒤에는 prog, 및 모든 s- 표현식.
그만큼 prog 함수는 s- 표현식 목록을 순서대로 실행하고 이름이 지정된 함수 호출을 만나지 않는 한 nil을 반환합니다. return. 그런 다음의 주장 return 함수가 평가되고 반환됩니다.
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(prog ((x '(a b c))(y '(1 2 3))(z '(p q 10)))
(format t "x = ~a y = ~a z = ~a" x y z))실행 버튼을 클릭하거나 Ctrl + E를 입력하면 LISP가 즉시 실행하고 반환 된 결과는 다음과 같습니다.
x = (A B C) y = (1 2 3) z = (P Q 10)LISP에서 상수는 프로그램 실행 중에 값을 변경하지 않는 변수입니다. 상수는defconstant 구성.
예
다음 예제는 전역 상수 PI를 선언하고 나중에 원 의 면적을 계산하는 area -circle 이라는 함수 내에서이 값을 사용하는 것을 보여줍니다 .
그만큼 defun 구문은 함수를 정의하는 데 사용됩니다. Functions 장.
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(defconstant PI 3.141592)
(defun area-circle(rad)
(terpri)
(format t "Radius: ~5f" rad)
(format t "~%Area: ~10f" (* PI rad rad)))
(area-circle 10)실행 버튼을 클릭하거나 Ctrl + E를 입력하면 LISP가 즉시 실행하고 반환 된 결과는 다음과 같습니다.
Radius: 10.0
Area: 314.1592연산자는 컴파일러에게 특정 수학적 또는 논리적 조작을 수행하도록 지시하는 기호입니다. LISP는 다양한 함수, 매크로 및 기타 구성에 의해 지원되는 데이터에 대한 수많은 작업을 허용합니다.
데이터에 허용되는 작업은 다음과 같이 분류 될 수 있습니다.
- 산술 연산
- 비교 작업
- 논리적 작업
- 비트 연산
산술 연산
다음 표는 LISP에서 지원하는 모든 산술 연산자를 보여줍니다. 변수 가정A 10 개와 가변 B 20을 보유하고-
Show Examples
| 운영자 | 기술 | 예 |
|---|---|---|
| + | 두 개의 피연산자를 더합니다. | (+ AB)는 30을 줄 것입니다 |
| - | 첫 번째에서 두 번째 피연산자를 뺍니다. | (-AB)는 -10을 줄 것입니다. |
| * | 두 피연산자를 곱합니다. | (* AB)는 200을 줄 것입니다 |
| / | 분자를 탈 분자로 나눕니다. | (/ BA)는 2를 줄 것입니다 |
| 모드, 렘 | 계수 연산자 및 정수 나누기 후의 나머지 | (mod BA)는 0을 줄 것입니다. |
| incf | 증가 연산자는 지정된 두 번째 인수만큼 정수 값을 증가시킵니다. | (incf A 3)는 13을 줄 것입니다 |
| decf | Decrements 연산자는 지정된 두 번째 인수만큼 정수 값을 줄입니다. | (decf A 4)는 9를 줄 것입니다 |
비교 작업
다음 표는 숫자를 비교하는 LISP에서 지원하는 모든 관계 연산자를 보여줍니다. 그러나 다른 언어의 관계 연산자와 달리 LISP 비교 연산자는 두 개 이상의 피연산자를 사용할 수 있으며 숫자에 대해서만 작동합니다.
변수 가정 A 10 개와 가변 B 20 개를 보유하면-
Show Examples
| 운영자 | 기술 | 예 |
|---|---|---|
| = | 피연산자의 값이 모두 같거나 같지 않은지 확인하고, 예이면 조건이 참이됩니다. | (= AB)는 사실이 아닙니다. |
| / = | 피연산자의 값이 모두 다른지 확인합니다. 값이 같지 않으면 조건이 참이됩니다. | (/ = AB)는 참입니다. |
| > | 피연산자의 값이 단조 감소하는지 확인합니다. | (> AB)는 사실이 아닙니다. |
| < | 피연산자의 값이 단조롭게 증가하는지 확인합니다. | (<AB)는 사실입니다. |
| > = | 왼쪽 피연산자의 값이 다음 오른쪽 피연산자의 값보다 크거나 같은지 확인합니다. 그렇다면 조건이 참이됩니다. | (> = AB)는 사실이 아닙니다. |
| <= | 왼쪽 피연산자의 값이 오른쪽 피연산자의 값보다 작거나 같은지 확인합니다. 그렇다면 조건이 참이됩니다. | (<= AB)는 참입니다. |
| 최대 | 둘 이상의 인수를 비교하고 최대 값을 반환합니다. | (최대 AB)는 20을 반환합니다. |
| 분 | 두 개 이상의 인수를 비교하고 최소값을 반환합니다. | (min AB)는 10을 반환합니다. |
부울 값에 대한 논리 연산
Common LISP는 세 가지 논리 연산자를 제공합니다. and, or, 과 not부울 값에서 작동합니다. 취하다A 값이 nil이고 B 값이 5이면-
Show Examples
| 운영자 | 기술 | 예 |
|---|---|---|
| 과 | 여러 인수를 사용합니다. 인수는 왼쪽에서 오른쪽으로 평가됩니다. 모든 인수가 nil이 아닌 것으로 평가되면 마지막 인수의 값이 반환됩니다. 그렇지 않으면 nil이 반환됩니다. | (및 AB)는 NIL을 반환합니다. |
| 또는 | 여러 인수를 사용합니다. 인수는 0이 아닌 값으로 평가 될 때까지 왼쪽에서 오른쪽으로 평가됩니다.이 경우 인수 값이 반환되고 그렇지 않으면 반환됩니다.nil. | (또는 AB)는 5를 반환합니다. |
| 아니 | 하나의 인수를 취하고 반환 t 인수가 다음과 같이 평가되면 nil. | (A가 아님)은 T를 반환합니다. |
숫자에 대한 비트 연산
비트 연산자는 비트에 대해 작업하고 비트 단위 연산을 수행합니다. 비트 및 또는 또는 xor 연산에 대한 진리표는 다음과 같습니다.
Show Examples
| 피 | 큐 | p와 q | p 또는 q | p xor q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
Assume if A = 60; and B = 13; now in binary format they will be as follows:
A = 0011 1100
B = 0000 1101
-----------------
A and B = 0000 1100
A or B = 0011 1101
A xor B = 0011 0001
not A = 1100 0011LISP에서 지원하는 비트 연산자는 다음 표에 나열되어 있습니다. 변수 가정A 60 개와 가변 B 13을 보유하면-
| 운영자 | 기술 | 예 |
|---|---|---|
| Logand | 인수의 비트 단위 논리 AND를 반환합니다. 인수가 제공되지 않으면 결과는이 작업의 ID 인 -1입니다. | (logand ab)) 12를 줄 것입니다 |
| Logior | 인수의 비트 단위 논리 INCLUSIVE OR을 반환합니다. 인수가 제공되지 않으면 결과는이 작업의 ID 인 0입니다. | (logior ab)는 61을 줄 것입니다. |
| logxor | 인수의 비트 단위 논리 EXCLUSIVE OR을 반환합니다. 인수가 제공되지 않으면 결과는이 작업의 ID 인 0입니다. | (logxor ab)는 49를 줄 것입니다. |
| Lognor | 이것은 인수의 비트 단위 NOT을 반환합니다. 인수가 제공되지 않으면 결과는이 작업의 ID 인 -1입니다. | (lognor ab)는 -62, |
| logeqv | 이것은 인수의 비트 단위 논리 EQUIVALENCE (배타적 또는 배타적이라고도 함)를 반환합니다. 인수가 제공되지 않으면 결과는이 작업의 ID 인 -1입니다. | (logeqv ab)는 -50을 제공합니다. |
의사 결정 구조에서는 프로그래머가 조건이 참인 경우 실행될 명령문 또는 명령문과 함께 프로그램에서 평가하거나 테스트 할 하나 이상의 조건을 지정하고, 조건이 충족되는 경우 실행될 다른 명령문을 선택적으로 지정해야합니다. 거짓으로 결정됩니다.
다음은 대부분의 프로그래밍 언어에서 발견되는 일반적인 의사 결정 구조의 일반적인 형태입니다.
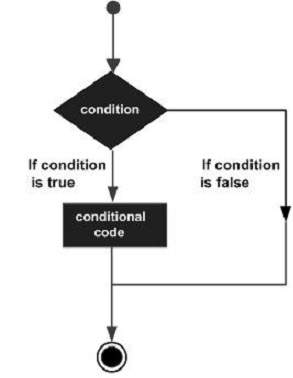
LISP는 다음 유형의 의사 결정 구조를 제공합니다. 세부 사항을 확인하려면 다음 링크를 클릭하십시오.
| Sr. 아니. | 구성 및 설명 |
|---|---|
| 1 | cond 이 구조는 여러 테스트 조치 절을 확인하는 데 사용됩니다. 다른 프로그래밍 언어의 중첩 된 if 문과 비교할 수 있습니다. |
| 2 | 만약 if 구문에는 다양한 형태가 있습니다. 가장 간단한 형태로 테스트 절, 테스트 작업 및 기타 결과 작업이 뒤 따릅니다. 테스트 절이 참으로 평가되면 테스트 작업이 실행되고 그렇지 않으면 결과 절이 평가됩니다. |
| 삼 | 언제 가장 간단한 형식으로 테스트 절과 테스트 조치가 뒤 따릅니다. 테스트 절이 참으로 평가되면 테스트 작업이 실행되고 그렇지 않으면 결과 절이 평가됩니다. |
| 4 | 케이스 이 구문은 cond 구문과 같은 여러 테스트 작업 절을 구현합니다. 그러나 키 양식을 평가하고 해당 키 양식의 평가를 기반으로 여러 작업 절을 허용합니다. |
코드 블록을 여러 번 실행해야하는 상황이있을 수 있습니다. 루프 문을 사용하면 문 또는 문 그룹을 여러 번 실행할 수 있으며 다음은 대부분의 프로그래밍 언어에서 루프 문의 일반적인 형식입니다.
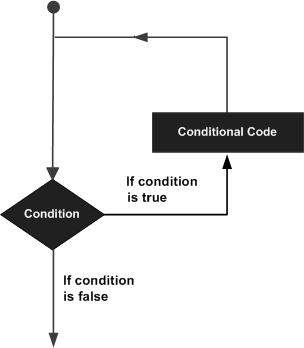
LISP는 루핑 요구 사항을 처리하기 위해 다음 유형의 구성을 제공합니다. 세부 사항을 확인하려면 다음 링크를 클릭하십시오.
| Sr. 아니. | 구성 및 설명 |
|---|---|
| 1 | 고리 그만큼 loop구성은 LISP에서 제공하는 가장 간단한 반복 형식입니다. 가장 간단한 형태로, 어떤 문장을 찾을 때까지 반복적으로 실행할 수 있습니다.return 성명서. |
| 2 | 루프 루프 for 구문을 사용하면 다른 언어에서 가장 일반적인 반복과 같은 for 루프를 구현할 수 있습니다. |
| 삼 | 하다 do 구문은 LISP를 사용하여 반복을 수행하는데도 사용됩니다. 구조화 된 형태의 반복을 제공합니다. |
| 4 | dotimes dotimes 구조는 고정 된 수의 반복에 대해 루핑을 허용합니다. |
| 5 | dolist dolist 구조를 사용하면 목록의 각 요소를 반복 할 수 있습니다. |
블록에서 정상적으로 나가기
그만큼 block 과 return-from 오류 발생시 중첩 된 블록에서 정상적으로 종료 할 수 있습니다.
그만큼 block함수를 사용하면 0 개 이상의 문으로 구성된 본문으로 명명 된 블록을 만들 수 있습니다. 구문은-
(block block-name(
...
...
))그만큼 return-from 함수는 블록 이름과 선택적 (기본값은 nil) 반환 값을받습니다.
다음 예제는 이것을 보여줍니다-
예
main.lisp라는 새 소스 코드 파일을 만들고 다음 코드를 입력합니다.
(defun demo-function (flag)
(print 'entering-outer-block)
(block outer-block
(print 'entering-inner-block)
(print (block inner-block
(if flag
(return-from outer-block 3)
(return-from inner-block 5)
)
(print 'This-wil--not-be-printed))
)
(print 'left-inner-block)
(print 'leaving-outer-block)
t)
)
(demo-function t)
(terpri)
(demo-function nil)실행 버튼을 클릭하거나 Ctrl + E를 입력하면 LISP가 즉시 실행하고 반환 된 결과는 다음과 같습니다.
ENTERING-OUTER-BLOCK
ENTERING-INNER-BLOCK
ENTERING-OUTER-BLOCK
ENTERING-INNER-BLOCK
5
LEFT-INNER-BLOCK
LEAVING-OUTER-BLOCK함수는 함께 작업을 수행하는 문 그룹입니다.
코드를 별도의 함수로 나눌 수 있습니다. 코드를 다른 함수로 나누는 방법은 사용자에게 달려 있지만 논리적으로 나누는 것은 일반적으로 각 함수가 특정 작업을 수행하는 것입니다.
LISP에서 함수 정의
명명 된 매크로 defun함수를 정의하는 데 사용됩니다. 그만큼defun 매크로에는 세 가지 인수가 필요합니다-
- 기능의 이름
- 기능의 매개 변수
- 기능의 본문
defun 구문은 −
(defun name (parameter-list) "Optional documentation string." body)간단한 예를 들어 개념을 설명하겠습니다.
예 1
네 숫자의 평균을 인쇄하는 averagenum 이라는 함수를 작성해 보겠습니다 . 이 숫자를 매개 변수로 보냅니다.
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(defun averagenum (n1 n2 n3 n4)
(/ ( + n1 n2 n3 n4) 4)
)
(write(averagenum 10 20 30 40))코드를 실행하면 다음 결과가 반환됩니다.
25예 2
원의 반경이 인자로 주어 졌을 때 원의 면적을 계산하는 함수를 정의하고 호출 해 봅시다.
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(defun area-circle(rad)
"Calculates area of a circle with given radius"
(terpri)
(format t "Radius: ~5f" rad)
(format t "~%Area: ~10f" (* 3.141592 rad rad))
)
(area-circle 10)코드를 실행하면 다음 결과가 반환됩니다.
Radius: 10.0
Area: 314.1592유의하십시오-
빈 목록을 매개 변수로 제공 할 수 있습니다. 즉, 함수가 인수를 취하지 않고 목록이 비어 있으며 ()로 작성됩니다.
LISP는 선택적, 다중 및 키워드 인수도 허용합니다.
문서 문자열은 함수의 목적을 설명합니다. 함수의 이름과 연관되며 다음을 사용하여 얻을 수 있습니다.documentation 함수.
함수의 본문은 여러 Lisp 표현식으로 구성 될 수 있습니다.
본문의 마지막 표현식 값이 함수 값으로 반환됩니다.
다음을 사용하여 함수에서 값을 반환 할 수도 있습니다. return-from 특수 연산자.
위의 개념을 간략하게 설명하겠습니다. 자세한 내용을 보려면 다음 링크를 클릭하십시오 −
선택적 매개 변수
나머지 매개 변수
키워드 매개 변수
함수에서 값 반환
Lambda 함수
매핑 기능
술어는 특정 조건에 대한 인수를 테스트하고 조건이 거짓 인 경우 nil을 반환하거나 조건이 참인 경우 nil이 아닌 값을 반환하는 함수입니다.
다음 표는 가장 일반적으로 사용되는 술어 중 일부를 보여줍니다-
| Sr. 아니. | 술어 및 설명 |
|---|---|
| 1 | atom 하나의 인수를 취하고 인수가 원자이면 t를 반환하고 그렇지 않으면 nil을 반환합니다. |
| 2 | equal 두 개의 인수를 취하고 t 구조적으로 동일하거나 nil 그렇지 않으면. |
| 삼 | eq 두 개의 인수를 취하고 t 동일한 객체 인 경우 동일한 메모리 위치를 공유하거나 nil 그렇지 않으면. |
| 4 | eql 두 개의 인수를 취하고 t 인수가 eq, 또는 동일한 값을 가진 동일한 유형의 숫자이거나 동일한 문자를 나타내는 문자 객체 인 경우 또는 nil 그렇지 않으면. |
| 5 | evenp 하나의 숫자 인수를 사용하여 t 인수가 짝수이거나 nil 그렇지 않으면. |
| 6 | oddp 하나의 숫자 인수를 사용하여 t 인수가 홀수이거나 nil 그렇지 않으면. |
| 7 | zerop 하나의 숫자 인수를 사용하여 t 인수가 0이거나 nil 그렇지 않으면. |
| 8 | null 하나의 인수를 취하고 반환 t 인수가 nil로 평가되면 nil. |
| 9 | listp 하나의 인수를 취하고 반환 t 인수가 목록으로 평가되면 그렇지 않으면 반환됩니다. nil. |
| 10 | greaterp 하나 이상의 인수를 취하고 t 단일 인수가 있거나 인수가 왼쪽에서 오른쪽으로 연속적으로 더 큰 경우 또는 nil 그렇지 않으면. |
| 11 | lessp 하나 이상의 인수를 취하고 t 단일 인수가 있거나 인수가 왼쪽에서 오른쪽으로 연속적으로 작은 경우, 또는 nil 그렇지 않으면. |
| 12 | numberp 하나의 인수를 취하고 반환 t 인수가 숫자이거나 nil 그렇지 않으면. |
| 13 | symbolp 하나의 인수를 취하고 반환 t 인수가 기호이면 그렇지 않으면 반환합니다. nil. |
| 14 | integerp 하나의 인수를 취하고 반환 t 인수가 정수이면 그렇지 않으면 반환합니다. nil. |
| 15 | rationalp 하나의 인수를 취하고 반환 t 인수가 유리수, 비율 또는 숫자이면 다음을 반환합니다. nil. |
| 16 | floatp 하나의 인수를 취하고 반환 t 인수가 부동 소수점 숫자이면 nil. |
| 17 | realp 하나의 인수를 취하고 반환 t 인수가 실수이면 그렇지 않으면 반환합니다. nil. |
| 18 | complexp 하나의 인수를 취하고 반환 t 인수가 복소수이면 반환합니다. nil. |
| 19 | characterp 하나의 인수를 취하고 반환 t 인수가 문자이면 그렇지 않으면 반환합니다. nil. |
| 20 | stringp 하나의 인수를 취하고 반환 t 인수가 문자열 객체이면 반환합니다. nil. |
| 21 | arrayp 하나의 인수를 취하고 반환 t 인수가 배열 객체이면 nil. |
| 22 | packagep 하나의 인수를 취하고 반환 t 인수가 패키지이면 그렇지 않으면 반환합니다. nil. |
예 1
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write (atom 'abcd))
(terpri)
(write (equal 'a 'b))
(terpri)
(write (evenp 10))
(terpri)
(write (evenp 7 ))
(terpri)
(write (oddp 7 ))
(terpri)
(write (zerop 0.0000000001))
(terpri)
(write (eq 3 3.0 ))
(terpri)
(write (equal 3 3.0 ))
(terpri)
(write (null nil ))코드를 실행하면 다음 결과가 반환됩니다.
T
NIL
T
NIL
T
NIL
NIL
NIL
T예 2
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(defun factorial (num)
(cond ((zerop num) 1)
(t ( * num (factorial (- num 1))))
)
)
(setq n 6)
(format t "~% Factorial ~d is: ~d" n (factorial n))코드를 실행하면 다음 결과가 반환됩니다.
Factorial 6 is: 720Common Lisp는 여러 종류의 숫자를 정의합니다. 그만큼number 데이터 유형에는 LISP에서 지원하는 다양한 종류의 숫자가 포함됩니다.
LISP에서 지원하는 숫자 유형은 다음과 같습니다.
- Integers
- Ratios
- 부동 소수점 숫자
- 복소수
다음 다이어그램은 LISP에서 사용할 수있는 숫자 계층 구조와 다양한 숫자 데이터 유형을 보여줍니다.
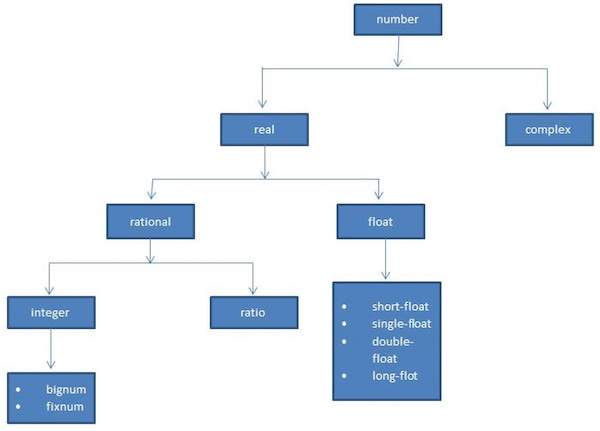
LISP의 다양한 숫자 유형
다음 표는 LISP에서 사용할 수있는 다양한 숫자 유형 데이터를 설명합니다.
| Sr. 아니. | 데이터 유형 및 설명 |
|---|---|
| 1 | fixnum 이 데이터 유형은 너무 크지 않고 대부분 -215에서 215-1 범위에있는 정수를 나타냅니다 (기계에 따라 다름). |
| 2 | bignum 이들은 LISP에 할당 된 메모리 양에 의해 크기가 제한되는 매우 큰 숫자이며 fixnum 숫자가 아닙니다. |
| 삼 | ratio 분자 / 분모 형식으로 두 숫자의 비율을 나타냅니다. / 함수는 인수가 정수인 경우 항상 비율로 결과를 생성합니다. |
| 4 | float 정수가 아닌 숫자를 나타냅니다. 정밀도가 증가하는 4 개의 float 데이터 유형이 있습니다. |
| 5 | complex #c로 표시되는 복소수를 나타냅니다. 실수 부분과 허수 부분은 모두 유리수이거나 부동 소수점 수일 수 있습니다. |
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write (/ 1 2))
(terpri)
(write ( + (/ 1 2) (/ 3 4)))
(terpri)
(write ( + #c( 1 2) #c( 3 -4)))코드를 실행하면 다음 결과가 반환됩니다.
1/2
5/4
#C(4 -2)숫자 함수
다음 표는 일반적으로 사용되는 몇 가지 숫자 함수를 설명합니다.
| Sr. 아니. | 기능 및 설명 |
|---|---|
| 1 | +, -, *, / 각 산술 연산 |
| 2 | sin, cos, tan, acos, asin, atan 각 삼각 함수. |
| 삼 | sinh, cosh, tanh, acosh, asinh, atanh 각 쌍곡선 함수. |
| 4 | exp 지수 함수. e x를 계산합니다. |
| 5 | expt 지수 함수는 밑과 거듭 제곱을 모두 취합니다. |
| 6 | sqrt 숫자의 제곱근을 계산합니다. |
| 7 | log 대수 함수. 하나의 매개 변수가 주어지면 자연 로그를 계산합니다. 그렇지 않으면 두 번째 매개 변수가 밑으로 사용됩니다. |
| 8 | conjugate 숫자의 켤레 복소수를 계산합니다. 실수의 경우 숫자 자체를 반환합니다. |
| 9 | abs 숫자의 절대 값 (또는 크기)을 반환합니다. |
| 10 | gcd 주어진 숫자의 최대 공약수를 계산합니다. |
| 11 | lcm 주어진 숫자의 최소 공배수를 계산합니다. |
| 12 | isqrt 주어진 자연수의 정확한 제곱근보다 작거나 같은 가장 큰 정수를 제공합니다. |
| 13 | floor, ceiling, truncate, round 이 모든 함수는 두 개의 인수를 숫자로 취하고 몫을 반환합니다. floor 비율보다 크지 않은 가장 큰 정수를 반환합니다. ceiling 비율보다 큰 작은 정수를 선택하고 truncate 비율의 절대 값보다 작은 절대 값이 가장 큰 비율과 동일한 부호의 정수를 선택합니다. round 비율에 가장 가까운 정수를 선택합니다. |
| 14 | ffloor, fceiling, ftruncate, fround 위와 동일하지만 몫을 부동 소수점 숫자로 반환합니다. |
| 15 | mod, rem 나누기 연산의 나머지를 반환합니다. |
| 16 | float 실수를 부동 소수점 숫자로 변환합니다. |
| 17 | rational, rationalize 실수를 유리수로 변환합니다. |
| 18 | numerator, denominator 유리수의 각 부분을 반환합니다. |
| 19 | realpart, imagpart 복소수의 실수 부와 허수 부를 반환합니다. |
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write (/ 45 78))
(terpri)
(write (floor 45 78))
(terpri)
(write (/ 3456 75))
(terpri)
(write (floor 3456 75))
(terpri)
(write (ceiling 3456 75))
(terpri)
(write (truncate 3456 75))
(terpri)
(write (round 3456 75))
(terpri)
(write (ffloor 3456 75))
(terpri)
(write (fceiling 3456 75))
(terpri)
(write (ftruncate 3456 75))
(terpri)
(write (fround 3456 75))
(terpri)
(write (mod 3456 75))
(terpri)
(setq c (complex 6 7))
(write c)
(terpri)
(write (complex 5 -9))
(terpri)
(write (realpart c))
(terpri)
(write (imagpart c))코드를 실행하면 다음 결과가 반환됩니다.
15/26
0
1152/25
46
47
46
46
46.0
47.0
46.0
46.0
6
#C(6 7)
#C(5 -9)
6
7LISP에서 문자는 유형의 데이터 오브젝트로 표시됩니다. character.
문자 앞에 # \ 앞의 문자 객체를 표시 할 수 있습니다. 예를 들어, # \ a는 문자 a를 의미합니다.
공백 및 기타 특수 문자는 문자 이름 앞에 # \를 선행하여 표시 할 수 있습니다. 예를 들어 # \ SPACE는 공백 문자를 나타냅니다.
다음 예제는 이것을 보여줍니다-
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write 'a)
(terpri)
(write #\a)
(terpri)
(write-char #\a)
(terpri)
(write-char 'a)코드를 실행하면 다음 결과가 반환됩니다.
A
#\a
a
*** - WRITE-CHAR: argument A is not a character특수 문자
Common LISP를 사용하면 코드에서 다음 특수 문자를 사용할 수 있습니다. 이를 준 표준 문자라고합니다.
- #\Backspace
- #\Tab
- #\Linefeed
- #\Page
- #\Return
- #\Rubout
문자 비교 기능
숫자 비교 함수 및 연산자 (예 : <및>)는 문자에서 작동하지 않습니다. Common LISP는 코드에서 문자를 비교하기위한 다른 두 가지 기능 세트를 제공합니다.
한 세트는 대소 문자를 구분하고 다른 세트는 대소 문자를 구분하지 않습니다.
다음 표는 기능을 제공합니다-
| 대소 문자 구분 함수 | 대소 문자를 구분하지 않는 함수 | 기술 |
|---|---|---|
| char = | char-equal | 피연산자의 값이 모두 같거나 같지 않은지 확인하고, 예이면 조건이 참이됩니다. |
| char / = | 같지 않은 문자 | 피연산자의 값이 모두 다른지 확인합니다. 값이 같지 않으면 조건이 참이됩니다. |
| char < | charlessp | 피연산자의 값이 단조 감소하는지 확인합니다. |
| char> | char-greaterp | 피연산자의 값이 단조롭게 증가하는지 확인합니다. |
| char <= | char-not-greaterp | 왼쪽 피연산자의 값이 다음 오른쪽 피연산자의 값보다 크거나 같은지 확인합니다. 그렇다면 조건이 참이됩니다. |
| char> = | char-not-lessp | 왼쪽 피연산자의 값이 오른쪽 피연산자의 값보다 작거나 같은지 확인합니다. 그렇다면 조건이 참이됩니다. |
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
; case-sensitive comparison
(write (char= #\a #\b))
(terpri)
(write (char= #\a #\a))
(terpri)
(write (char= #\a #\A))
(terpri)
;case-insensitive comparision
(write (char-equal #\a #\A))
(terpri)
(write (char-equal #\a #\b))
(terpri)
(write (char-lessp #\a #\b #\c))
(terpri)
(write (char-greaterp #\a #\b #\c))코드를 실행하면 다음 결과가 반환됩니다.
NIL
T
NIL
T
NIL
T
NILLISP를 사용하면 단일 또는 다중 차원 배열을 정의 할 수 있습니다. make-array함수. 배열은 모든 LISP 객체를 요소로 저장할 수 있습니다.
모든 어레이는 연속적인 메모리 위치로 구성됩니다. 가장 낮은 주소는 첫 번째 요소에 해당하고 가장 높은 주소는 마지막 요소에 해당합니다.
배열의 차원 수를 순위라고합니다.
LISP에서 배열 요소는 음이 아닌 정수 인덱스 시퀀스로 지정됩니다. 시퀀스의 길이는 배열의 순위와 같아야합니다. 인덱싱은 0부터 시작됩니다.
예를 들어, my-array라는 이름의 10 개 셀이있는 배열을 만들려면 다음과 같이 작성할 수 있습니다.
(setf my-array (make-array '(10)))aref 함수를 사용하면 셀의 내용에 액세스 할 수 있습니다. 두 개의 인수, 배열 이름과 인덱스 값을 사용합니다.
예를 들어, 열 번째 셀의 내용에 액세스하려면 다음과 같이 작성합니다.
(aref my-array 9)예 1
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write (setf my-array (make-array '(10))))
(terpri)
(setf (aref my-array 0) 25)
(setf (aref my-array 1) 23)
(setf (aref my-array 2) 45)
(setf (aref my-array 3) 10)
(setf (aref my-array 4) 20)
(setf (aref my-array 5) 17)
(setf (aref my-array 6) 25)
(setf (aref my-array 7) 19)
(setf (aref my-array 8) 67)
(setf (aref my-array 9) 30)
(write my-array)코드를 실행하면 다음 결과가 반환됩니다.
#(NIL NIL NIL NIL NIL NIL NIL NIL NIL NIL)
#(25 23 45 10 20 17 25 19 67 30)예 2
3x3 배열을 만들어 보겠습니다.
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(setf x (make-array '(3 3)
:initial-contents '((0 1 2 ) (3 4 5) (6 7 8)))
)
(write x)코드를 실행하면 다음 결과가 반환됩니다.
#2A((0 1 2) (3 4 5) (6 7 8))예제 3
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(setq a (make-array '(4 3)))
(dotimes (i 4)
(dotimes (j 3)
(setf (aref a i j) (list i 'x j '= (* i j)))
)
)
(dotimes (i 4)
(dotimes (j 3)
(print (aref a i j))
)
)코드를 실행하면 다음 결과가 반환됩니다.
(0 X 0 = 0)
(0 X 1 = 0)
(0 X 2 = 0)
(1 X 0 = 0)
(1 X 1 = 1)
(1 X 2 = 2)
(2 X 0 = 0)
(2 X 1 = 2)
(2 X 2 = 4)
(3 X 0 = 0)
(3 X 1 = 3)
(3 X 2 = 6)make-array 함수에 대한 완전한 구문
make-array 함수는 다른 많은 인수를 사용합니다. 이 함수의 전체 구문을 살펴 보겠습니다.
make-array dimensions :element-type :initial-element :initial-contents :adjustable :fill-pointer :displaced-to :displaced-index-offsetdimension 인수를 제외 하고 다른 모든 인수는 키워드입니다. 다음 표는 인수에 대한 간략한 설명을 제공합니다.
| Sr. 아니. | 인수 및 설명 |
|---|---|
| 1 | dimensions 배열의 차원을 제공합니다. 1 차원 배열의 경우 숫자이고 다차원 배열의 경우 목록입니다. |
| 2 | :element-type 유형 지정자이며 기본값은 T, 즉 모든 유형입니다. |
| 삼 | :initial-element 초기 요소 값. 모든 요소가 특정 값으로 초기화 된 배열을 만듭니다. |
| 4 | :initial-content 개체로서의 초기 콘텐츠. |
| 5 | :adjustable 기본 메모리의 크기를 조정할 수있는 크기 조정 가능 (또는 조정 가능) 벡터를 만드는 데 도움이됩니다. 인수는 배열을 조정할 수 있는지 여부를 나타내는 부울 값이며 기본값은 NIL입니다. |
| 6 | :fill-pointer 크기 조정이 가능한 벡터에 실제로 저장된 요소의 수를 추적합니다. |
| 7 | :displaced-to 지정된 배열과 내용을 공유하는 변위 된 배열 또는 공유 배열을 만드는 데 도움이됩니다. 두 배열 모두 동일한 요소 유형을 가져야합니다. : displaced-to 옵션은 : initial-element 또는 : initial-contents 옵션과 함께 사용할 수 없습니다. 이 인수의 기본값은 nil입니다. |
| 8 | :displaced-index-offset 생성 된 공유 배열의 인덱스 오프셋을 제공합니다. |
예 4
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(setq myarray (make-array '(3 2 3)
:initial-contents
'(((a b c) (1 2 3))
((d e f) (4 5 6))
((g h i) (7 8 9))
))
)
(setq array2 (make-array 4 :displaced-to myarray :displaced-index-offset 2))
(write myarray)
(terpri)
(write array2)코드를 실행하면 다음 결과가 반환됩니다.
#3A(((A B C) (1 2 3)) ((D E F) (4 5 6)) ((G H I) (7 8 9)))
#(C 1 2 3)변위 된 배열이 2 차원 인 경우-
(setq myarray (make-array '(3 2 3)
:initial-contents
'(((a b c) (1 2 3))
((d e f) (4 5 6))
((g h i) (7 8 9))
))
)
(setq array2 (make-array '(3 2) :displaced-to myarray :displaced-index-offset 2))
(write myarray)
(terpri)
(write array2)코드를 실행하면 다음 결과가 반환됩니다.
#3A(((A B C) (1 2 3)) ((D E F) (4 5 6)) ((G H I) (7 8 9)))
#2A((C 1) (2 3) (D E))변위 된 인덱스 오프셋을 5로 변경해 보겠습니다.
(setq myarray (make-array '(3 2 3)
:initial-contents
'(((a b c) (1 2 3))
((d e f) (4 5 6))
((g h i) (7 8 9))
))
)
(setq array2 (make-array '(3 2) :displaced-to myarray :displaced-index-offset 5))
(write myarray)
(terpri)
(write array2)코드를 실행하면 다음 결과가 반환됩니다.
#3A(((A B C) (1 2 3)) ((D E F) (4 5 6)) ((G H I) (7 8 9)))
#2A((3 D) (E F) (4 5))예 5
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
;a one dimensional array with 5 elements,
;initail value 5
(write (make-array 5 :initial-element 5))
(terpri)
;two dimensional array, with initial element a
(write (make-array '(2 3) :initial-element 'a))
(terpri)
;an array of capacity 14, but fill pointer 5, is 5
(write(length (make-array 14 :fill-pointer 5)))
(terpri)
;however its length is 14
(write (array-dimensions (make-array 14 :fill-pointer 5)))
(terpri)
; a bit array with all initial elements set to 1
(write(make-array 10 :element-type 'bit :initial-element 1))
(terpri)
; a character array with all initial elements set to a
; is a string actually
(write(make-array 10 :element-type 'character :initial-element #\a))
(terpri)
; a two dimensional array with initial values a
(setq myarray (make-array '(2 2) :initial-element 'a :adjustable t))
(write myarray)
(terpri)
;readjusting the array
(adjust-array myarray '(1 3) :initial-element 'b)
(write myarray)코드를 실행하면 다음 결과가 반환됩니다.
#(5 5 5 5 5)
#2A((A A A) (A A A))
5
(14)
#*1111111111
"aaaaaaaaaa"
#2A((A A) (A A))
#2A((A A B))Common Lisp의 문자열은 벡터, 즉 1 차원 문자 배열입니다.
문자열 리터럴은 큰 따옴표로 묶습니다. 큰 따옴표 문자 ( ") 및 이스케이프 문자 (\)를 제외하고 문자 집합에서 지원하는 모든 문자를 큰 따옴표로 묶어 문자열을 만들 수 있습니다. 그러나 백 슬래시 (\)로 이스케이프하여 포함 할 수 있습니다.
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write-line "Hello World")
(write-line "Welcome to Tutorials Point")
;escaping the double quote character
(write-line "Welcome to \"Tutorials Point\"")코드를 실행하면 다음 결과가 반환됩니다.
Hello World
Welcome to Tutorials Point
Welcome to "Tutorials Point"문자열 비교 함수
숫자 비교 함수 및 연산자 (예 : <및>)는 문자열에서 작동하지 않습니다. Common LISP는 코드에서 문자열을 비교하기위한 다른 두 가지 함수 세트를 제공합니다. 한 세트는 대소 문자를 구분하고 다른 세트는 대소 문자를 구분하지 않습니다.
다음 표는 기능을 제공합니다-
| 대소 문자 구분 함수 | 대소 문자를 구분하지 않는 함수 | 기술 |
|---|---|---|
| 문자열 = | 문자열 같음 | 피연산자의 값이 모두 같거나 같지 않은지 확인하고, 예이면 조건이 참이됩니다. |
| 문자열 / = | 같지 않은 문자열 | 피연산자의 값이 모두 다른지 확인합니다. 값이 같지 않으면 조건이 참이됩니다. |
| 문자열 < | 끈이없는 | 피연산자의 값이 단조 감소하는지 확인합니다. |
| 문자열> | string-greaterp | 피연산자의 값이 단조롭게 증가하는지 확인합니다. |
| 문자열 <= | 큰 문자열이 아닌 문자열 | 왼쪽 피연산자의 값이 다음 오른쪽 피연산자의 값보다 크거나 같은지 확인합니다. 그렇다면 조건이 참이됩니다. |
| 문자열> = | 끈이없는 | 왼쪽 피연산자의 값이 오른쪽 피연산자의 값보다 작거나 같은지 확인합니다. 그렇다면 조건이 참이됩니다. |
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
; case-sensitive comparison
(write (string= "this is test" "This is test"))
(terpri)
(write (string> "this is test" "This is test"))
(terpri)
(write (string< "this is test" "This is test"))
(terpri)
;case-insensitive comparision
(write (string-equal "this is test" "This is test"))
(terpri)
(write (string-greaterp "this is test" "This is test"))
(terpri)
(write (string-lessp "this is test" "This is test"))
(terpri)
;checking non-equal
(write (string/= "this is test" "this is Test"))
(terpri)
(write (string-not-equal "this is test" "This is test"))
(terpri)
(write (string/= "lisp" "lisping"))
(terpri)
(write (string/= "decent" "decency"))코드를 실행하면 다음 결과가 반환됩니다.
NIL
0
NIL
T
NIL
NIL
8
NIL
4
5케이스 제어 기능
다음 표는 케이스 제어 기능을 설명합니다.
| Sr. 아니. | 기능 및 설명 |
|---|---|
| 1 | string-upcase 문자열을 대문자로 변환합니다. |
| 2 | string-downcase 문자열을 소문자로 변환합니다. |
| 삼 | string-capitalize 문자열의 각 단어를 대문자로 표시 |
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write-line (string-upcase "a big hello from tutorials point"))
(write-line (string-capitalize "a big hello from tutorials point"))코드를 실행하면 다음 결과가 반환됩니다.
A BIG HELLO FROM TUTORIALS POINT
A Big Hello From Tutorials Point줄 자르기
다음 표는 문자열 트리밍 기능을 설명합니다.
| Sr. 아니. | 기능 및 설명 |
|---|---|
| 1 | string-trim 첫 번째 인수로 문자열을, 두 번째 인수로 문자열을 취하고 첫 번째 인수에있는 모든 문자가 인수 문자열에서 제거 된 부분 문자열을 리턴합니다. |
| 2 | String-left-trim 첫 번째 인수로 문자열을, 두 번째 인수로 문자열을 취하고 첫 번째 인수에있는 모든 문자가 인수 문자열의 시작 부분에서 제거되는 부분 문자열을 리턴합니다. |
| 삼 | String-right-trim 첫 번째 인수로 문자열 문자를, 두 번째 인수로 문자열을 취하고 첫 번째 인수에있는 모든 문자가 인수 문자열의 끝에서 제거 된 부분 문자열을 리턴합니다. |
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write-line (string-trim " " " a big hello from tutorials point "))
(write-line (string-left-trim " " " a big hello from tutorials point "))
(write-line (string-right-trim " " " a big hello from tutorials point "))
(write-line (string-trim " a" " a big hello from tutorials point "))코드를 실행하면 다음 결과가 반환됩니다.
a big hello from tutorials point
a big hello from tutorials point
a big hello from tutorials point
big hello from tutorials point기타 문자열 함수
LISP의 문자열은 배열이므로 시퀀스도 있습니다. 다음 튜토리얼에서 이러한 데이터 유형을 다룰 것입니다. 배열과 시퀀스에 적용 할 수있는 모든 함수는 문자열에도 적용됩니다. 그러나 다양한 예제를 사용하여 일반적으로 사용되는 몇 가지 기능을 보여줍니다.
길이 계산
그만큼 length 함수는 문자열의 길이를 계산합니다.
하위 문자열 추출
그만큼 subseq 함수는 특정 인덱스에서 시작하여 특정 끝 인덱스 또는 문자열의 끝까지 계속되는 하위 문자열 (문자열도 시퀀스이기 때문에)을 반환합니다.
문자열의 문자에 액세스
그만큼 char 함수를 사용하면 문자열의 개별 문자에 액세스 할 수 있습니다.
Example
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write (length "Hello World"))
(terpri)
(write-line (subseq "Hello World" 6))
(write (char "Hello World" 6))코드를 실행하면 다음 결과가 반환됩니다.
11
World
#\W문자열 정렬 및 병합
그만큼 sort함수는 문자열 정렬을 허용합니다. 시퀀스 (벡터 또는 문자열)와 두 인수 술어를 사용하여 정렬 된 시퀀스 버전을 반환합니다.
그만큼 merge 함수는 두 개의 시퀀스와 하나의 술어를 취하고 술어에 따라 두 시퀀스를 병합하여 생성 된 시퀀스를 리턴합니다.
Example
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
;sorting the strings
(write (sort (vector "Amal" "Akbar" "Anthony") #'string<))
(terpri)
;merging the strings
(write (merge 'vector (vector "Rishi" "Zara" "Priyanka")
(vector "Anju" "Anuj" "Avni") #'string<))코드를 실행하면 다음 결과가 반환됩니다.
#("Akbar" "Amal" "Anthony")
#("Anju" "Anuj" "Avni" "Rishi" "Zara" "Priyanka")문자열 반전
그만큼 reverse 함수는 문자열을 반전합니다.
예를 들어, main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write-line (reverse "Are we not drawn onward, we few, drawn onward to new era"))코드를 실행하면 다음 결과가 반환됩니다.
are wen ot drawno nward ,wef ew ,drawno nward ton ew erA문자열 연결
concatenate 함수는 두 문자열을 연결합니다. 이것은 일반 시퀀스 함수이며 결과 유형을 첫 번째 인수로 제공해야합니다.
예를 들어, main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write-line (concatenate 'string "Are we not drawn onward, " "we few, drawn onward to new era"))코드를 실행하면 다음 결과가 반환됩니다.
Are we not drawn onward, we few, drawn onward to new era시퀀스는 LISP의 추상 데이터 유형입니다. 벡터와 목록은이 데이터 유형의 두 가지 구체적인 하위 유형입니다. 시퀀스 데이터 유형에 정의 된 모든 기능은 실제로 모든 벡터 및 목록 유형에 적용됩니다.
이 섹션에서는 시퀀스에서 가장 일반적으로 사용되는 함수에 대해 설명합니다.
시퀀스 (즉, 벡터 및 목록)를 조작하는 다양한 방법을 시작하기 전에 사용 가능한 모든 함수 목록을 살펴 보겠습니다.
시퀀스 생성
make-sequence 함수를 사용하면 모든 유형의 시퀀스를 만들 수 있습니다. 이 함수의 구문은 다음과 같습니다.
make-sequence sqtype sqsize &key :initial-elementsqtype 유형 과 sqsize 길이 의 시퀀스를 생성합니다 .
선택적으로 : initial-element 인수를 사용하여 일부 값을 지정할 수 있습니다 . 그러면 각 요소가이 값으로 초기화됩니다.
예를 들어, main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write (make-sequence '(vector float)
10
:initial-element 1.0))코드를 실행하면 다음 결과가 반환됩니다.
#(1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0)시퀀스의 일반 함수
| Sr. 아니. | 기능 및 설명 |
|---|---|
| 1 | elt 정수 인덱스를 통해 개별 요소에 액세스 할 수 있습니다. |
| 2 | length 시퀀스의 길이를 반환합니다. |
| 삼 | subseq 특정 인덱스에서 시작하여 특정 종료 인덱스 또는 시퀀스의 끝까지 계속되는 하위 시퀀스를 추출하여 하위 시퀀스를 반환합니다. |
| 4 | copy-seq 인수와 동일한 요소를 포함하는 시퀀스를 반환합니다. |
| 5 | fill 시퀀스의 여러 요소를 단일 값으로 설정하는 데 사용됩니다. |
| 6 | replace 두 시퀀스를 취하고 첫 번째 인수 시퀀스는 두 번째 인수 시퀀스에서 연속 요소를 복사하여 파괴적으로 수정됩니다. |
| 7 | count 항목과 시퀀스를 취하고 항목이 시퀀스에 나타나는 횟수를 반환합니다. |
| 8 | reverse 인수의 동일한 요소를 포함하지만 역순으로 시퀀스를 반환합니다. |
| 9 | nreverse sequence와 동일한 요소를 포함하지만 역순으로 동일한 시퀀스를 반환합니다. |
| 10 | concatenate 여러 시퀀스의 연결을 포함하는 새 시퀀스를 만듭니다. |
| 11 | position 항목과 시퀀스를 취하고 시퀀스 또는 nil에서 항목의 인덱스를 반환합니다. |
| 12 | find 항목과 시퀀스가 필요합니다. 시퀀스에서 항목을 찾아 반환합니다. 찾을 수 없으면 nil을 반환합니다. |
| 13 | sort 시퀀스와 두 개의 인수 조건자를 취하고 정렬 된 시퀀스 버전을 반환합니다. |
| 14 | merge 두 시퀀스와 술어를 취하고 술어에 따라 두 시퀀스를 병합하여 생성 된 시퀀스를 리턴합니다. |
| 15 | map n- 인수 함수와 n 시퀀스를 취하고 시퀀스의 후속 요소에 함수를 적용한 결과를 포함하는 새 시퀀스를 반환합니다. |
| 16 | some 조건자를 인수로 사용하고 인수 시퀀스를 반복하고 조건자가 반환 한 NIL이 아닌 첫 번째 값을 반환하거나 조건자가 충족되지 않으면 false를 반환합니다. |
| 17 | every 술어를 인수로 취하고 인수 시퀀스를 반복하며 술어가 실패하자마자 종료되고 false를 리턴합니다. 술어가 항상 충족되면 true를 리턴합니다. |
| 18 | notany 술어를 인수로 취하고 인수 시퀀스를 반복하며 술어가 충족되는 즉시 false를 리턴하고 그렇지 않으면 true를 리턴합니다. |
| 19 | notevery 술어를 인수로 취하고 인수 시퀀스를 반복하며 술어가 실패하면 즉시 true를 리턴하고 술어가 항상 충족되면 false를 리턴합니다. |
| 20 | reduce 단일 시퀀스에 대해 매핑하여 시퀀스의 처음 두 요소에 먼저 두 인수 함수를 적용한 다음 함수 및 시퀀스의 후속 요소가 반환 한 값에 적용합니다. |
| 21 | search 시퀀스를 검색하여 일부 테스트를 만족하는 하나 이상의 요소를 찾습니다. |
| 22 | remove 항목과 시퀀스를 취하고 항목 인스턴스가 제거 된 시퀀스를 반환합니다. |
| 23 | delete 이것은 또한 항목과 시퀀스를 취하고 항목을 제외하고 동일한 요소를 갖는 인수 시퀀스와 동일한 종류의 시퀀스를 반환합니다. |
| 24 | substitute 새 항목, 기존 항목 및 시퀀스를 취하고 기존 항목의 인스턴스가 새 항목으로 대체 된 시퀀스를 반환합니다. |
| 25 | nsubstitute 새 항목, 기존 항목 및 시퀀스를 취하고 기존 항목의 인스턴스가 새 항목으로 대체 된 동일한 시퀀스를 반환합니다. |
| 26 | mismatch 두 개의 시퀀스를 취하고 일치하지 않는 첫 번째 요소 쌍의 인덱스를 반환합니다. |
표준 시퀀스 함수 키워드 인수
| 논의 | 의미 | 기본값 |
|---|---|---|
| :테스트 | 항목 (또는 : key 함수로 추출한 값)을 요소와 비교하는 데 사용되는 2 인수 함수입니다. | EQL |
| :키 | 실제 시퀀스 요소에서 키 값을 추출하는 단일 인수 함수입니다. NIL은 요소를 그대로 사용함을 의미합니다. | 무 |
| :스타트 | 하위 시퀀스의 시작 인덱스 (포함)입니다. | 0 |
| :종료 | 하위 시퀀스의 끝 인덱스 (배타적)입니다. NIL은 시퀀스의 끝을 나타냅니다. | 무 |
| : 끝부터 | 참이면 시퀀스가 끝에서 시작까지 역순으로 순회됩니다. | 무 |
| :카운트 | 제거하거나 대체 할 요소 수를 나타내는 숫자 또는 모두를 나타내는 NIL (REMOVE 및 SUBSTITUTE 만 해당). | 무 |
시퀀스에서 작동하는 이러한 함수에서 인수로 사용되는 다양한 함수와 키워드에 대해 방금 논의했습니다. 다음 섹션에서는 예제를 사용하여 이러한 함수를 사용하는 방법을 살펴 봅니다.
길이와 요소 찾기
그만큼 length 함수는 시퀀스의 길이를 반환하고 elt 함수를 사용하면 정수 인덱스를 사용하여 개별 요소에 액세스 할 수 있습니다.
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(setq x (vector 'a 'b 'c 'd 'e))
(write (length x))
(terpri)
(write (elt x 3))코드를 실행하면 다음 결과가 반환됩니다.
5
D시퀀스 수정
일부 시퀀스 함수는 시퀀스를 반복하고 명시적인 루프를 작성하지 않고 특정 요소를 검색, 제거, 계산 또는 필터링하는 것과 같은 일부 작업을 수행 할 수 있습니다.
다음 예제는 이것을 보여줍니다-
예 1
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write (count 7 '(1 5 6 7 8 9 2 7 3 4 5)))
(terpri)
(write (remove 5 '(1 5 6 7 8 9 2 7 3 4 5)))
(terpri)
(write (delete 5 '(1 5 6 7 8 9 2 7 3 4 5)))
(terpri)
(write (substitute 10 7 '(1 5 6 7 8 9 2 7 3 4 5)))
(terpri)
(write (find 7 '(1 5 6 7 8 9 2 7 3 4 5)))
(terpri)
(write (position 5 '(1 5 6 7 8 9 2 7 3 4 5)))코드를 실행하면 다음 결과가 반환됩니다.
2
(1 6 7 8 9 2 7 3 4)
(1 6 7 8 9 2 7 3 4)
(1 5 6 10 8 9 2 10 3 4 5)
7
1예 2
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write (delete-if #'oddp '(1 5 6 7 8 9 2 7 3 4 5)))
(terpri)
(write (delete-if #'evenp '(1 5 6 7 8 9 2 7 3 4 5)))
(terpri)
(write (remove-if #'evenp '(1 5 6 7 8 9 2 7 3 4 5) :count 1 :from-end t))
(terpri)
(setq x (vector 'a 'b 'c 'd 'e 'f 'g))
(fill x 'p :start 1 :end 4)
(write x)코드를 실행하면 다음 결과가 반환됩니다.
(6 8 2 4)
(1 5 7 9 7 3 5)
(1 5 6 7 8 9 2 7 3 5)
#(A P P P E F G)시퀀스 정렬 및 병합
정렬 함수는 시퀀스와 두 인수 조건자를 취하고 정렬 된 시퀀스 버전을 반환합니다.
예 1
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write (sort '(2 4 7 3 9 1 5 4 6 3 8) #'<))
(terpri)
(write (sort '(2 4 7 3 9 1 5 4 6 3 8) #'>))
(terpri)코드를 실행하면 다음 결과가 반환됩니다.
(1 2 3 3 4 4 5 6 7 8 9)
(9 8 7 6 5 4 4 3 3 2 1)예 2
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write (merge 'vector #(1 3 5) #(2 4 6) #'<))
(terpri)
(write (merge 'list #(1 3 5) #(2 4 6) #'<))
(terpri)코드를 실행하면 다음 결과가 반환됩니다.
#(1 2 3 4 5 6)
(1 2 3 4 5 6)시퀀스 술어
every, some, notany 및 notevery 함수를 시퀀스 술어라고합니다.
이러한 함수는 시퀀스를 반복하고 Boolean 술어를 테스트합니다.
이러한 모든 함수는 첫 번째 인수로 술어를 취하고 나머지 인수는 시퀀스입니다.
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write (every #'evenp #(2 4 6 8 10)))
(terpri)
(write (some #'evenp #(2 4 6 8 10 13 14)))
(terpri)
(write (every #'evenp #(2 4 6 8 10 13 14)))
(terpri)
(write (notany #'evenp #(2 4 6 8 10)))
(terpri)
(write (notevery #'evenp #(2 4 6 8 10 13 14)))
(terpri)코드를 실행하면 다음 결과가 반환됩니다.
T
T
NIL
NIL
T매핑 시퀀스
우리는 이미 매핑 기능에 대해 논의했습니다. 마찬가지로map 함수를 사용하면 하나 이상의 시퀀스의 후속 요소에 함수를 적용 할 수 있습니다.
그만큼 map 함수는 n- 인수 함수와 n 시퀀스를 취하고 시퀀스의 후속 요소에 함수를 적용한 후 새 시퀀스를 반환합니다.
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write (map 'vector #'* #(2 3 4 5) #(3 5 4 8)))코드를 실행하면 다음 결과가 반환됩니다.
#(6 15 16 40)목록은 기존 LISP에서 가장 중요하고 주요 복합 데이터 구조였습니다. 현재의 Common LISP는 벡터, 해시 테이블, 클래스 또는 구조와 같은 다른 데이터 구조를 제공합니다.
목록은 단일 연결 목록입니다. LISP에서 목록은 다음과 같은 간단한 레코드 구조의 체인으로 구성됩니다.cons 함께 연결됩니다.
단점 레코드 구조
ㅏ cons 두 개의 구성 요소를 포함하는 레코드 구조입니다. car 그리고 cdr.
단점 셀 또는 단점은 함수를 사용하여 생성 된 값의 쌍입니다. cons.
그만큼 cons함수는 두 개의 인수를 취하고 두 값을 포함하는 새로운 cons 셀을 반환합니다. 이러한 값은 모든 종류의 개체에 대한 참조가 될 수 있습니다.
두 번째 값이 nil이 아니거나 다른 cons 셀이면 값은 괄호로 묶인 점선 쌍으로 인쇄됩니다.
단점 셀의 두 값을 car 그리고 cdr. 그만큼 car 함수는 첫 번째 값에 액세스하는 데 사용되며 cdr 함수는 두 번째 값에 액세스하는 데 사용됩니다.
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write (cons 1 2))
(terpri)
(write (cons 'a 'b))
(terpri)
(write (cons 1 nil))
(terpri)
(write (cons 1 (cons 2 nil)))
(terpri)
(write (cons 1 (cons 2 (cons 3 nil))))
(terpri)
(write (cons 'a (cons 'b (cons 'c nil))))
(terpri)
(write ( car (cons 'a (cons 'b (cons 'c nil)))))
(terpri)
(write ( cdr (cons 'a (cons 'b (cons 'c nil)))))코드를 실행하면 다음 결과가 반환됩니다.
(1 . 2)
(A . B)
(1)
(1 2)
(1 2 3)
(A B C)
A
(B C)위의 예는 cons 구조를 사용하여 단일 연결 목록을 만드는 방법을 보여줍니다. 예를 들어 목록 (ABC)은 cdrs에 의해 함께 연결된 세 개의 cons 셀로 구성됩니다 .
도식적으로 표현하면-
LISP의 목록
그러나 cons 셀을 사용하여 목록을 만들 수 있지만 중첩 된 목록을 구성합니다. cons함수 호출은 최상의 솔루션이 될 수 없습니다. 그만큼list 함수는 오히려 LISP에서 목록을 만드는 데 사용됩니다.
목록 함수는 여러 인수를 사용할 수 있으며 함수이므로 인수를 평가합니다.
그만큼 first 과 rest함수는 목록의 첫 번째 요소와 나머지 부분을 제공합니다. 다음 예제는 개념을 보여줍니다.
예 1
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write (list 1 2))
(terpri)
(write (list 'a 'b))
(terpri)
(write (list 1 nil))
(terpri)
(write (list 1 2 3))
(terpri)
(write (list 'a 'b 'c))
(terpri)
(write (list 3 4 'a (car '(b . c)) (* 4 -2)))
(terpri)
(write (list (list 'a 'b) (list 'c 'd 'e)))코드를 실행하면 다음 결과가 반환됩니다.
(1 2)
(A B)
(1 NIL)
(1 2 3)
(A B C)
(3 4 A B -8)
((A B) (C D E))예 2
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(defun my-library (title author rating availability)
(list :title title :author author :rating rating :availabilty availability)
)
(write (getf (my-library "Hunger Game" "Collins" 9 t) :title))코드를 실행하면 다음 결과가 반환됩니다.
"Hunger Game"목록 조작 함수
다음 표는 일반적으로 사용되는 목록 조작 함수를 제공합니다.
| Sr. 아니. | 기능 및 설명 |
|---|---|
| 1 | car 목록을 인수로 취하고 첫 번째 요소를 반환합니다. |
| 2 | cdr 목록을 인수로 취하고 첫 번째 요소가없는 목록을 반환합니다. |
| 삼 | cons 두 개의 인수, 요소와 목록을 취하고 첫 번째 위치에 요소가 삽입 된 목록을 반환합니다. |
| 4 | list 임의의 수의 인수를 취하고 목록의 구성원 요소로 인수가있는 목록을 반환합니다. |
| 5 | append 둘 이상의 목록을 하나로 병합합니다. |
| 6 | last 목록을 받아 마지막 요소를 포함하는 목록을 반환합니다. |
| 7 | member 첫 번째 인수가 두 번째 인수의 구성원 인 경우 두 번째 인수는 목록이어야하며 첫 번째 인수로 시작하는 목록의 나머지를 반환합니다. |
| 8 | reverse 목록을 가져와 역순으로 최상위 요소가있는 목록을 반환합니다. |
모든 시퀀스 기능은 목록에 적용 가능합니다.
예제 3
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write (car '(a b c d e f)))
(terpri)
(write (cdr '(a b c d e f)))
(terpri)
(write (cons 'a '(b c)))
(terpri)
(write (list 'a '(b c) '(e f)))
(terpri)
(write (append '(b c) '(e f) '(p q) '() '(g)))
(terpri)
(write (last '(a b c d (e f))))
(terpri)
(write (reverse '(a b c d (e f))))코드를 실행하면 다음 결과가 반환됩니다.
A
(B C D E F)
(A B C)
(A (B C) (E F))
(B C E F P Q G)
((E F))
((E F) D C B A)자동차와 cdr 함수의 연결
그만큼 car 과 cdr 함수와 그 조합을 통해 목록의 특정 요소 / 구성원을 추출 할 수 있습니다.
그러나 car 및 cdr 함수의 시퀀스는 문자 c 및 r 내에서 car의 문자 a와 cdr의 d를 연결하여 축약 할 수 있습니다.
예를 들어 cadadr를 작성하여 함수 호출 순서를 축약 할 수 있습니다. car cdr car cdr.
따라서 (cadadr '(a (cd) (efg)))는 d를 반환합니다.
예 4
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write (cadadr '(a (c d) (e f g))))
(terpri)
(write (caar (list (list 'a 'b) 'c)))
(terpri)
(write (cadr (list (list 1 2) (list 3 4))))
(terpri)코드를 실행하면 다음 결과가 반환됩니다.
D
A
(3 4)LISP에서 심볼은 데이터 개체를 나타내는 이름이며 흥미롭게도 데이터 개체이기도합니다.
심볼을 특별하게 만드는 것은 property list, 또는 plist.
부동산 목록
LISP를 사용하면 기호에 특성을 지정할 수 있습니다. 예를 들어 '사람'개체가 있다고합시다. 이 '사람'개체가 이름, 성별, 키, 몸무게, 주소, 직업 등과 같은 속성을 갖기를 원합니다. 속성은 속성 이름과 같습니다.
속성 목록은 요소가 짝수 (0 일 수 있음) 인 목록으로 구현됩니다. 목록의 각 요소 쌍은 항목을 구성합니다. 첫 번째 항목은indicator, 두 번째는 value.
심볼이 생성되면 속성 목록은 처음에 비어 있습니다. 속성은 다음을 사용하여 생성됩니다.get 내 setf 형태.
예를 들어, 다음 문을 사용하면 (기호) 'book'이라는 개체에 제목, 저자 및 출판사 속성, 각 값을 할당 할 수 있습니다.
예 1
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write (setf (get 'books'title) '(Gone with the Wind)))
(terpri)
(write (setf (get 'books 'author) '(Margaret Michel)))
(terpri)
(write (setf (get 'books 'publisher) '(Warner Books)))코드를 실행하면 다음 결과가 반환됩니다.
(GONE WITH THE WIND)
(MARGARET MICHEL)
(WARNER BOOKS)다양한 속성 목록 기능을 사용하여 속성을 할당하고 심볼의 속성을 검색, 교체 또는 제거 할 수 있습니다.
그만큼 get함수는 주어진 인디케이터에 대한 심볼의 속성 목록을 반환합니다. 다음과 같은 구문이 있습니다.
get symbol indicator &optional default그만큼 get함수는 지정된 인디케이터에 대해 지정된 기호의 속성 목록을 찾습니다. 발견되면 해당 값을 반환합니다. 그렇지 않으면 기본값이 반환됩니다 (또는 기본값이 지정되지 않은 경우 nil).
예 2
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(setf (get 'books 'title) '(Gone with the Wind))
(setf (get 'books 'author) '(Margaret Micheal))
(setf (get 'books 'publisher) '(Warner Books))
(write (get 'books 'title))
(terpri)
(write (get 'books 'author))
(terpri)
(write (get 'books 'publisher))코드를 실행하면 다음 결과가 반환됩니다.
(GONE WITH THE WIND)
(MARGARET MICHEAL)
(WARNER BOOKS)그만큼 symbol-plist 기능을 사용하면 심볼의 모든 속성을 볼 수 있습니다.
예제 3
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(setf (get 'annie 'age) 43)
(setf (get 'annie 'job) 'accountant)
(setf (get 'annie 'sex) 'female)
(setf (get 'annie 'children) 3)
(terpri)
(write (symbol-plist 'annie))코드를 실행하면 다음 결과가 반환됩니다.
(CHILDREN 3 SEX FEMALE JOB ACCOUNTANT AGE 43)그만큼 remprop 함수는 기호에서 지정된 속성을 제거합니다.
예 4
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(setf (get 'annie 'age) 43)
(setf (get 'annie 'job) 'accountant)
(setf (get 'annie 'sex) 'female)
(setf (get 'annie 'children) 3)
(terpri)
(write (symbol-plist 'annie))
(remprop 'annie 'age)
(terpri)
(write (symbol-plist 'annie))코드를 실행하면 다음 결과가 반환됩니다.
(CHILDREN 3 SEX FEMALE JOB ACCOUNTANT AGE 43)
(CHILDREN 3 SEX FEMALE JOB ACCOUNTANT)벡터는 1 차원 배열이므로 배열의 하위 유형입니다. 벡터와 목록을 집합 적으로 시퀀스라고합니다. 따라서 지금까지 논의한 모든 시퀀스 일반 함수와 배열 함수는 벡터에서 작동합니다.
벡터 만들기
벡터 함수를 사용하면 특정 값으로 고정 크기 벡터를 만들 수 있습니다. 임의의 수의 인수를 취하고 해당 인수를 포함하는 벡터를 반환합니다.
예 1
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(setf v1 (vector 1 2 3 4 5))
(setf v2 #(a b c d e))
(setf v3 (vector 'p 'q 'r 's 't))
(write v1)
(terpri)
(write v2)
(terpri)
(write v3)코드를 실행하면 다음 결과가 반환됩니다.
#(1 2 3 4 5)
#(A B C D E)
#(P Q R S T)LISP는 # (...) 구문을 벡터의 리터럴 표기법으로 사용합니다. 이 # (...) 구문을 사용하여 코드에 리터럴 벡터를 만들고 포함 할 수 있습니다.
그러나 이들은 리터럴 벡터이므로 수정하는 것은 LISP에서 정의되지 않습니다. 따라서 프로그래밍을 위해 항상vector 기능 또는 더 일반적인 기능 make-array 수정하려는 벡터를 만듭니다.
그만큼 make-array함수는 벡터를 만드는보다 일반적인 방법입니다. 다음을 사용하여 벡터 요소에 액세스 할 수 있습니다.aref 함수.
예 2
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(setq a (make-array 5 :initial-element 0))
(setq b (make-array 5 :initial-element 2))
(dotimes (i 5)
(setf (aref a i) i))
(write a)
(terpri)
(write b)
(terpri)코드를 실행하면 다음 결과가 반환됩니다.
#(0 1 2 3 4)
#(2 2 2 2 2)포인터 채우기
그만큼 make-array 함수를 사용하면 크기를 조정할 수있는 벡터를 만들 수 있습니다.
그만큼 fill-pointer함수의 인수는 벡터에 실제로 저장된 요소의 수를 추적합니다. 벡터에 요소를 추가 할 때 채워질 다음 위치의 인덱스입니다.
그만큼 vector-push함수를 사용하면 크기를 조정할 수있는 벡터 끝에 요소를 추가 할 수 있습니다. 채우기 포인터를 1 씩 증가시킵니다.
그만큼 vector-pop 함수는 가장 최근에 푸시 된 항목을 반환하고 채우기 포인터를 1 씩 감소시킵니다.
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(setq a (make-array 5 :fill-pointer 0))
(write a)
(vector-push 'a a)
(vector-push 'b a)
(vector-push 'c a)
(terpri)
(write a)
(terpri)
(vector-push 'd a)
(vector-push 'e a)
;this will not be entered as the vector limit is 5
(vector-push 'f a)
(write a)
(terpri)
(vector-pop a)
(vector-pop a)
(vector-pop a)
(write a)코드를 실행하면 다음 결과가 반환됩니다.
#()
#(A B C)
#(A B C D E)
#(A B)벡터는 시퀀스이며 모든 시퀀스 함수는 벡터에 적용 할 수 있습니다. 벡터 함수에 대해서는 시퀀스 장을 참조하십시오.
Common Lisp는 집합 데이터 유형을 제공하지 않습니다. 그러나 목록에서 설정 작업을 수행 할 수있는 여러 기능을 제공합니다.
다양한 기준에 따라 목록에서 항목을 추가, 제거 및 검색 할 수 있습니다. 또한 합집합, 교차, 차이 집합과 같은 다양한 집합 작업을 수행 할 수 있습니다.
LISP에서 세트 구현
목록과 같은 집합은 일반적으로 단점 셀 측면에서 구현됩니다. 그러나 바로 이러한 이유로 집합 연산은 집합이 클수록 효율성이 떨어집니다.
그만큼 adjoin기능을 사용하면 세트를 만들 수 있습니다. 항목과 집합을 나타내는 목록을 가져 와서 원래 집합의 항목과 모든 항목을 포함하는 집합을 나타내는 목록을 반환합니다.
그만큼 adjoin함수는 먼저 주어진 목록에서 항목을 찾습니다. 발견되면 원래 목록을 반환합니다. 그렇지 않으면 새로운 단점 셀을 생성합니다.car 항목으로 cdr 원래 목록을 가리키고이 새 목록을 반환합니다.
그만큼 adjoin 기능도 걸립니다 :key 과 :test키워드 인수. 이러한 인수는 항목이 원래 목록에 있는지 확인하는 데 사용됩니다.
adjoin 함수는 원래 목록을 수정하지 않기 때문에 목록 자체를 변경하려면 adjoin에서 반환 한 값을 원래 목록에 할당하거나 매크로를 사용할 수 있습니다. pushnew 세트에 항목을 추가합니다.
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
; creating myset as an empty list
(defparameter *myset* ())
(adjoin 1 *myset*)
(adjoin 2 *myset*)
; adjoin did not change the original set
;so it remains same
(write *myset*)
(terpri)
(setf *myset* (adjoin 1 *myset*))
(setf *myset* (adjoin 2 *myset*))
;now the original set is changed
(write *myset*)
(terpri)
;adding an existing value
(pushnew 2 *myset*)
;no duplicate allowed
(write *myset*)
(terpri)
;pushing a new value
(pushnew 3 *myset*)
(write *myset*)
(terpri)코드를 실행하면 다음 결과가 반환됩니다.
NIL
(2 1)
(2 1)
(3 2 1)회원 확인
멤버 함수 그룹을 사용하면 요소가 집합의 멤버인지 여부를 확인할 수 있습니다.
다음은 이러한 함수의 구문입니다-
member item list &key :test :test-not :key
member-if predicate list &key :key
member-if-not predicate list &key :key이 함수는 주어진 목록에서 테스트를 만족하는 주어진 항목을 검색합니다. 그러한 항목이 없으면 함수는 다음을 반환합니다.nil. 그렇지 않으면 첫 번째 요소가 요소 인 목록의 꼬리가 반환됩니다.
검색은 최상위 수준에서만 수행됩니다.
이러한 함수는 술어로 사용할 수 있습니다.
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(write (member 'zara '(ayan abdul zara riyan nuha)))
(terpri)
(write (member-if #'evenp '(3 7 2 5/3 'a)))
(terpri)
(write (member-if-not #'numberp '(3 7 2 5/3 'a 'b 'c)))코드를 실행하면 다음 결과가 반환됩니다.
(ZARA RIYAN NUHA)
(2 5/3 'A)
('A 'B 'C)조합 설정
통합 함수 그룹을 사용하면 테스트를 기반으로 이러한 함수에 대한 인수로 제공된 두 목록에서 통합 집합을 수행 할 수 있습니다.
다음은 이러한 함수의 구문입니다-
union list1 list2 &key :test :test-not :key
nunion list1 list2 &key :test :test-not :key그만큼 union함수는 두 개의 목록을 취하고 목록 중 하나에있는 모든 요소를 포함하는 새 목록을 리턴합니다. 중복 된 항목이있는 경우 반환 된 목록에 구성원의 복사본 하나만 유지됩니다.
그만큼 nunion 함수는 동일한 작업을 수행하지만 인수 목록을 삭제할 수 있습니다.
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(setq set1 (union '(a b c) '(c d e)))
(setq set2 (union '(#(a b) #(5 6 7) #(f h))
'(#(5 6 7) #(a b) #(g h)) :test-not #'mismatch)
)
(setq set3 (union '(#(a b) #(5 6 7) #(f h))
'(#(5 6 7) #(a b) #(g h)))
)
(write set1)
(terpri)
(write set2)
(terpri)
(write set3)코드를 실행하면 다음 결과가 반환됩니다.
(A B C D E)
(#(F H) #(5 6 7) #(A B) #(G H))
(#(A B) #(5 6 7) #(F H) #(5 6 7) #(A B) #(G H))참고하십시오
통합 기능은 다음 없이는 예상대로 작동하지 않습니다. :test-not #'mismatch세 개의 벡터 목록에 대한 인수. 그 이유는 목록이 단점 셀로 구성되어 있고 값이 분명히 우리에게 동일하게 보이지만cdr셀의 일부가 일치하지 않으므로 LISP 인터프리터 / 컴파일러와 정확히 일치하지 않습니다. 이것이 이유 다; 목록을 사용하여 큰 집합을 구현하는 것은 권장되지 않습니다. 그래도 작은 세트에는 잘 작동합니다.
교차로 설정
교차 함수 그룹을 사용하면 테스트를 기반으로 이러한 함수에 대한 인수로 제공된 두 목록에서 교차를 수행 할 수 있습니다.
다음은 이러한 함수의 구문입니다-
intersection list1 list2 &key :test :test-not :key
nintersection list1 list2 &key :test :test-not :key이러한 함수는 두 개의 목록을 가져와 두 인수 목록에있는 모든 요소를 포함하는 새 목록을 반환합니다. 목록에 중복 항목이있는 경우 중복 항목이 결과에 표시되거나 표시되지 않을 수 있습니다.
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(setq set1 (intersection '(a b c) '(c d e)))
(setq set2 (intersection '(#(a b) #(5 6 7) #(f h))
'(#(5 6 7) #(a b) #(g h)) :test-not #'mismatch)
)
(setq set3 (intersection '(#(a b) #(5 6 7) #(f h))
'(#(5 6 7) #(a b) #(g h)))
)
(write set1)
(terpri)
(write set2)
(terpri)
(write set3)코드를 실행하면 다음 결과가 반환됩니다.
(C)
(#(A B) #(5 6 7))
NIL교차 기능은 교차의 파괴적인 버전입니다. 즉, 원래 목록을 파괴 할 수 있습니다.
차이 설정
set-difference 함수 그룹을 사용하면 테스트를 기반으로 이러한 함수에 대한 인수로 제공된 두 목록에서 차이 집합을 수행 할 수 있습니다.
다음은 이러한 함수의 구문입니다-
set-difference list1 list2 &key :test :test-not :key
nset-difference list1 list2 &key :test :test-not :keyset-difference 함수는 두 번째 목록에 나타나지 않는 첫 번째 목록의 요소 목록을 반환합니다.
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(setq set1 (set-difference '(a b c) '(c d e)))
(setq set2 (set-difference '(#(a b) #(5 6 7) #(f h))
'(#(5 6 7) #(a b) #(g h)) :test-not #'mismatch)
)
(setq set3 (set-difference '(#(a b) #(5 6 7) #(f h))
'(#(5 6 7) #(a b) #(g h)))
)
(write set1)
(terpri)
(write set2)
(terpri)
(write set3)코드를 실행하면 다음 결과가 반환됩니다.
(A B)
(#(F H))
(#(A B) #(5 6 7) #(F H))목록 목록으로 cons 셀에서 트리 데이터 구조를 작성할 수 있습니다.
트리 구조를 구현하려면 이진 트리에 대한 사전 주문, 순서 및 사후 주문과 같이 특정 순서로 cons 셀을 통과하는 기능을 설계해야합니다.
목록 목록으로 트리
다음 목록 목록을 형성하는 cons 셀로 구성된 트리 구조를 고려해 보겠습니다.
((1 2) (3 4) (5 6)).
도식적으로 표현하면-
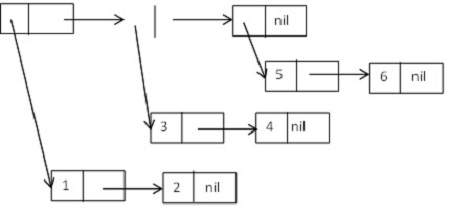
LISP의 트리 함수
대부분의 경우 특정 필요에 따라 자체 트리 기능을 작성해야하지만 LISP는 사용할 수있는 몇 가지 트리 기능을 제공합니다.
모든 목록 함수 외에도 다음 함수는 특히 트리 구조에서 작동합니다.
| Sr. 아니. | 기능 및 설명 |
|---|---|
| 1 | copy-tree x 및 선택적 vecp 죄수 셀 x의 트리 복사본을 반환합니다. 자동차와 cdr 방향을 모두 반복적으로 복사합니다. x가 단점 셀이 아니면 함수는 x를 변경하지 않고 반환합니다. 선택적 vecp 인수가 true이면이 함수는 벡터 (재귀 적으로)와 cons 셀을 복사합니다. |
| 2 | tree-equal xy & key : test : test-not : key 그것은 죄수 세포의 두 나무를 비교합니다. x와 y가 모두 단점 셀이면 자동차와 cdrs가 재귀 적으로 비교됩니다. x도 y도 cons 셀이 아니면 eql 또는 지정된 테스트에 따라 비교됩니다. : key 함수가 지정되면 두 트리의 요소에 적용됩니다. |
| 삼 | subst 새로운 오래된 트리 및 키 : test : test-not : key 그것은과 주어진 된 항목의 발생으로 대체 새 의 항목 트리 단점 세포의 나무입니다. |
| 4 | nsubst 새로운 오래된 트리 및 키 : test : test-not : key subst와 동일하게 작동하지만 원래 트리를 파괴합니다. |
| 5 | sublis alist tree & key : test : test-not : key 그것은 연관 목록 걸리는 것을 제외하고, SUBST처럼 작동 alist 된 새로운 쌍을. 트리의 각 요소 (: key 함수를 적용한 후)는 alist의 자동차와 비교됩니다. 일치하면 해당 cdr로 대체됩니다. |
| 6 | nsublis alist tree & key : test : test-not : key sublis와 동일하게 작동하지만 파괴적인 버전입니다. |
예 1
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(setq lst (list '(1 2) '(3 4) '(5 6)))
(setq mylst (copy-list lst))
(setq tr (copy-tree lst))
(write lst)
(terpri)
(write mylst)
(terpri)
(write tr)코드를 실행하면 다음 결과가 반환됩니다.
((1 2) (3 4) (5 6))
((1 2) (3 4) (5 6))
((1 2) (3 4) (5 6))예 2
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(setq tr '((1 2 (3 4 5) ((7 8) (7 8 9)))))
(write tr)
(setq trs (subst 7 1 tr))
(terpri)
(write trs)코드를 실행하면 다음 결과가 반환됩니다.
((1 2 (3 4 5) ((7 8) (7 8 9))))
((7 2 (3 4 5) ((7 8) (7 8 9))))나만의 나무 만들기
LISP에서 사용할 수있는 목록 함수를 사용하여 자체 트리를 구축해 보겠습니다.
먼저 데이터가 포함 된 새 노드를 생성하겠습니다.
(defun make-tree (item)
"it creates a new node with item."
(cons (cons item nil) nil)
)다음으로 트리에 자식 노드를 추가해 보겠습니다. 두 개의 트리 노드를 사용하고 두 번째 트리를 첫 번째 트리의 자식으로 추가합니다.
(defun add-child (tree child)
(setf (car tree) (append (car tree) child))
tree)이 함수는 주어진 트리의 첫 번째 자식을 반환합니다-트리 노드를 가져 와서 해당 노드의 첫 번째 자식을 반환하거나이 노드에 자식 노드가 없으면 nil을 반환합니다.
(defun first-child (tree)
(if (null tree)
nil
(cdr (car tree))
)
)이 함수는 주어진 노드의 다음 형제를 반환합니다-트리 노드를 인수로 취하고 다음 형제 노드에 대한 참조를 반환하거나 노드에없는 경우 nil을 반환합니다.
(defun next-sibling (tree)
(cdr tree)
)마지막으로 노드에서 정보를 반환하는 함수가 필요합니다.
(defun data (tree)
(car (car tree))
)예
이 예제는 위의 기능을 사용합니다-
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(defun make-tree (item)
"it creates a new node with item."
(cons (cons item nil) nil)
)
(defun first-child (tree)
(if (null tree)
nil
(cdr (car tree))
)
)
(defun next-sibling (tree)
(cdr tree)
)
(defun data (tree)
(car (car tree))
)
(defun add-child (tree child)
(setf (car tree) (append (car tree) child))
tree
)
(setq tr '((1 2 (3 4 5) ((7 8) (7 8 9)))))
(setq mytree (make-tree 10))
(write (data mytree))
(terpri)
(write (first-child tr))
(terpri)
(setq newtree (add-child tr mytree))
(terpri)
(write newtree)코드를 실행하면 다음 결과가 반환됩니다.
10
(2 (3 4 5) ((7 8) (7 8 9)))
((1 2 (3 4 5) ((7 8) (7 8 9)) (10)))해시 테이블 데이터 구조는 key-and-value키의 해시 코드를 기반으로 구성된 쌍입니다. 컬렉션의 요소에 액세스하기 위해 키를 사용합니다.
해시 테이블은 키를 사용하여 요소에 액세스해야 할 때 사용되며 유용한 키 값을 식별 할 수 있습니다. 해시 테이블의 각 항목에는 키 / 값 쌍이 있습니다. 키는 컬렉션의 항목에 액세스하는 데 사용됩니다.
LISP에서 해시 테이블 생성
Common LISP에서 해시 테이블은 범용 컬렉션입니다. 임의의 객체를 키 또는 인덱스로 사용할 수 있습니다.
해시 테이블에 값을 저장할 때 키-값 쌍을 만들고 해당 키 아래에 저장합니다. 나중에 동일한 키를 사용하여 해시 테이블에서 값을 검색 할 수 있습니다. 키에 새 값을 저장할 수 있지만 각 키는 단일 값에 매핑됩니다.
LISP의 해시 테이블은 키 비교 방법에 따라 eq, eql 또는 같음의 세 가지 유형으로 분류 할 수 있습니다. 해시 테이블이 LISP 객체에서 해시 된 경우 키는 eq 또는 eql과 비교됩니다. 해시 테이블이 트리 구조에 해시되면 equal을 사용하여 비교됩니다.
그만큼 make-hash-table함수는 해시 테이블을 만드는 데 사용됩니다. 이 함수의 구문은 다음과 같습니다.
make-hash-table &key :test :size :rehash-size :rehash-threshold어디-
그만큼 key 인수는 키를 제공합니다.
그만큼 :test인수는 키 비교 방법을 결정합니다. 세 개의 값 # 'eq, #'eql 또는 # 'equal 중 하나 또는 세 기호 eq, eql 또는 같음 중 하나가 있어야합니다. 지정하지 않으면 eql이 가정됩니다.
그만큼 :size인수는 해시 테이블의 초기 크기를 설정합니다. 0보다 큰 정수 여야합니다.
그만큼 :rehash-size인수는 해시 테이블이 가득 찰 때 해시 테이블의 크기를 얼마나 늘릴 것인지 지정합니다. 추가 할 항목 수인 0보다 큰 정수이거나 이전 크기에 대한 새 크기의 비율 인 1보다 큰 부동 소수점 숫자 일 수 있습니다. 이 인수의 기본값은 구현에 따라 다릅니다.
그만큼 :rehash-threshold인수는 해시 테이블이 커지기 전에 얼마나 꽉 찰 수 있는지 지정합니다. 이는 0보다 크고 : rehash-size보다 작은 정수 (이 경우 테이블이 커질 때마다 크기가 조정 됨)이거나 0과 1 사이의 부동 소수점 숫자 일 수 있습니다. 이에 대한 기본값 인수는 구현에 따라 다릅니다.
인수없이 make-hash-table 함수를 호출 할 수도 있습니다.
해시 테이블에서 항목 검색 및 항목 추가
그만큼 gethash함수는 키를 검색하여 해시 테이블에서 항목을 검색합니다. 키를 찾지 못하면 nil을 반환합니다.
다음과 같은 구문이 있습니다.
gethash key hash-table &optional default어디서-
key : 관련 키입니다.
hash-table : 검색 할 해시 테이블입니다.
default : 항목을 찾을 수없는 경우 반환되는 값이며 지정되지 않은 경우 nil입니다.
그만큼 gethash 함수는 실제로 두 개의 값을 리턴하는데, 두 번째는 항목이 발견되면 참인 술어 값이고 항목이 없으면 거짓입니다.
해시 테이블에 항목을 추가하려면 다음을 사용할 수 있습니다. setf 기능과 함께 gethash 함수.
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(setq empList (make-hash-table))
(setf (gethash '001 empList) '(Charlie Brown))
(setf (gethash '002 empList) '(Freddie Seal))
(write (gethash '001 empList))
(terpri)
(write (gethash '002 empList))코드를 실행하면 다음 결과가 반환됩니다.
(CHARLIE BROWN)
(FREDDIE SEAL)항목 제거
그만큼 remhash함수는 해시 테이블의 특정 키에 대한 항목을 제거합니다. 항목이 있으면 true이고 없으면 false 인 술어입니다.
이 함수의 구문은 다음과 같습니다.
remhash key hash-table예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(setq empList (make-hash-table))
(setf (gethash '001 empList) '(Charlie Brown))
(setf (gethash '002 empList) '(Freddie Seal))
(setf (gethash '003 empList) '(Mark Mongoose))
(write (gethash '001 empList))
(terpri)
(write (gethash '002 empList))
(terpri)
(write (gethash '003 empList))
(remhash '003 empList)
(terpri)
(write (gethash '003 empList))코드를 실행하면 다음 결과가 반환됩니다.
(CHARLIE BROWN)
(FREDDIE SEAL)
(MARK MONGOOSE)
NIL맵해시 함수
그만큼 maphash 함수를 사용하면 해시 테이블의 각 키-값 쌍에 지정된 함수를 적용 할 수 있습니다.
두 개의 인수 (함수와 해시 테이블)를 취하고 해시 테이블의 각 키 / 값 쌍에 대해 한 번씩 함수를 호출합니다.
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(setq empList (make-hash-table))
(setf (gethash '001 empList) '(Charlie Brown))
(setf (gethash '002 empList) '(Freddie Seal))
(setf (gethash '003 empList) '(Mark Mongoose))
(maphash #'(lambda (k v) (format t "~a => ~a~%" k v)) empList)코드를 실행하면 다음 결과가 반환됩니다.
3 => (MARK MONGOOSE)
2 => (FREDDIE SEAL)
1 => (CHARLIE BROWN)Common LISP는 다양한 입출력 기능을 제공합니다. 우리는 이미 출력을 위해 포맷 기능과 인쇄 기능을 사용했습니다. 이 섹션에서는 LISP에서 제공하는 가장 일반적으로 사용되는 입력-출력 함수 중 일부를 살펴 봅니다.
입력 기능
다음 표는 LISP에서 가장 일반적으로 사용되는 입력 함수를 제공합니다.
| Sr. 아니. | 기능 및 설명 |
|---|---|
| 1 | read& 선택적인 입력 스트림 eof-error-p eof-value recursive-p 입력 스트림에서 Lisp 객체의 인쇄 된 표현을 읽고 해당 Lisp 객체를 빌드 한 다음 객체를 반환합니다. |
| 2 | read-preserving-whitespace& 선택적 인스 트림 eof-error-p eof-value recursive-p 확장 토큰을 종료 한 문자를 정확하게 결정하는 것이 바람직한 일부 특수 상황에서 사용됩니다. |
| 삼 | read-line& 선택적인 입력 스트림 eof-error-p eof-value recursive-p 줄 바꿈으로 끝나는 텍스트 줄을 읽습니다. |
| 4 | read-char& 선택적인 입력 스트림 eof-error-p eof-value recursive-p 입력 스트림에서 한 문자를 가져와 문자 객체로 반환합니다. |
| 5 | unread-char 문자 및 선택적 입력 스트림 입력 스트림에서 가장 최근에 읽은 문자를 입력 스트림의 전면에 놓습니다. |
| 6 | peek-char& 선택적 peek-type 입력 스트림 eof-error-p eof-value recursive-p 입력 스트림에서 실제로 제거하지 않고 입력 스트림에서 읽을 다음 문자를 반환합니다. |
| 7 | listen및 선택적 입력 스트림 술어 listen 입력 스트림에서 즉시 사용할 수있는 문자가 있으면 true이고 그렇지 않으면 false입니다. |
| 8 | read-char-no-hang& 선택적인 입력 스트림 eof-error-p eof-value recursive-p 유사하다 read-char그러나 문자를 얻지 못하면 문자를 기다리지 않고 즉시 nil을 반환합니다. |
| 9 | clear-input및 선택적 입력 스트림 입력 스트림 과 관련된 버퍼링 된 입력을 지 웁니다 . |
| 10 | read-from-string 문자열 및 선택적 eof-error-p eof-value 및 키 : start : end : preserve-whitespace 연속적으로 문자열의 문자를 취하고 LISP 오브젝트를 빌드하고 오브젝트를 리턴합니다. 또한 읽지 않은 문자열에서 첫 번째 문자의 인덱스 또는 경우에 따라 문자열의 길이 (또는 길이 +1)를 반환합니다. |
| 11 | parse-integer 문자열 및 키 : 시작 : 종료 : radix : 정크 허용 : start 및 : end로 구분 된 문자열의 하위 문자열을 검사합니다 (기본값은 문자열의 시작과 끝). 공백 문자를 건너 뛰고 정수 구문 분석을 시도합니다. |
| 12 | read-byte 바이너리 입력 스트림 및 선택적 eof-error-p eof-value 바이너리 입력 스트림에서 1 바이트를 읽고이를 정수 형식으로 반환합니다. |
키보드에서 입력 읽기
그만큼 read기능은 키보드에서 입력을받는 데 사용됩니다. 어떤 논쟁도 할 수 없습니다.
예를 들어, 코드 스 니펫을 고려하십시오.
(write ( + 15.0 (read)))사용자가 STDIN 입력에서 10.2를 입력한다고 가정하면 다음이 반환됩니다.
25.2read 함수는 입력 스트림에서 문자를 읽고 Lisp 객체의 표현으로 구문 분석하여 해석합니다.
예
main.lisp라는 새 소스 코드 파일을 만들고 다음 코드를 입력합니다.
; the function AreaOfCircle
; calculates area of a circle
; when the radius is input from keyboard
(defun AreaOfCircle()
(terpri)
(princ "Enter Radius: ")
(setq radius (read))
(setq area (* 3.1416 radius radius))
(princ "Area: ")
(write area))
(AreaOfCircle)코드를 실행하면 다음 결과가 반환됩니다.
Enter Radius: 5 (STDIN Input)
Area: 78.53999예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(with-input-from-string (stream "Welcome to Tutorials Point!")
(print (read-char stream))
(print (read-char stream))
(print (read-char stream))
(print (read-char stream))
(print (read-char stream))
(print (read-char stream))
(print (read-char stream))
(print (read-char stream))
(print (read-char stream))
(print (read-char stream))
(print (peek-char nil stream nil 'the-end))
(values)
)코드를 실행하면 다음 결과가 반환됩니다.
#\W
#\e
#\l
#\c
#\o
#\m
#\e
#\Space
#\t
#\o
#\Space출력 기능
LISP의 모든 출력 함수 는 출력이 전송되는 output-stream 이라는 선택적 인수를 사용 합니다. 언급되지 않거나 nil 인 경우 output-stream은 기본적으로 변수 * standard-output * 값으로 설정됩니다.
다음 표는 LISP의 가장 일반적으로 사용되는 출력 함수를 제공합니다.
| Sr. 아니. | 기능 및 설명 |
|---|---|
| 1 | write 객체 및 키 : 스트림 : 탈출 : radix : base : circle : pretty : level : length : case : gensym : array write 객체 및 키 : 스트림 : 탈출 : radix : base : circle : pretty : level : length : case : gensym : array : readably : right-margin : miser-width : lines : pprint-dispatch 둘 다 : stream으로 지정된 출력 스트림에 객체를 씁니다. 기본값은 * standard-output *입니다. 다른 값은 기본적으로 인쇄를 위해 설정된 해당 전역 변수로 설정됩니다. |
| 2 | prin1 개체 및 선택적 출력 스트림 print 개체 및 선택적 출력 스트림 pprint 개체 및 선택적 출력 스트림 princ 개체 및 선택적 출력 스트림 이 모든 함수는 object의 인쇄 된 표현을 output-stream 에 출력합니다 . 그러나 다음과 같은 차이점이 있습니다.
|
| 삼 | write-to-string 객체 및 키 : 탈출 : radix : base : circle : pretty : level : length : case : gensym : array write-to-string 객체 및 키 : 탈출 : radix : base : circle : pretty : level : length : case : gensym : array : readably : right-margin : miser-width : lines : pprint-dispatch prin1-to-string 목적 princ-to-string 목적 객체가 효과적으로 인쇄되고 출력 문자가 문자열로 만들어져 반환됩니다. |
| 4 | write-char 문자 및 선택적 출력 스트림 문자를 출력 스트림에 출력하고 문자를 반환합니다. |
| 5 | write-string 문자열 및 선택적 출력 스트림 및 키 : start : end 그것은 지정된 문자열의 문자 기록 문자열을 받는 출력 스트림입니다. |
| 6 | write-line 문자열 및 선택적 출력 스트림 및 키 : start : end write-string과 동일한 방식으로 작동하지만 나중에 개행을 출력합니다. |
| 7 | terpri및 선택적 출력 스트림 출력 스트림에 개행을 출력합니다. |
| 8 | fresh-line및 선택적 출력 스트림 스트림이 이미 줄의 시작 부분에 있지 않은 경우에만 개행을 출력합니다. |
| 9 | finish-output및 선택적 출력 스트림 force-output및 선택적 출력 스트림 clear-output및 선택적 출력 스트림
|
| 10 | write-byte 정수 이진 출력 스트림 정수 값인 1 바이트를 씁니다 . |
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
; this program inputs a numbers and doubles it
(defun DoubleNumber()
(terpri)
(princ "Enter Number : ")
(setq n1 (read))
(setq doubled (* 2.0 n1))
(princ "The Number: ")
(write n1)
(terpri)
(princ "The Number Doubled: ")
(write doubled)
)
(DoubleNumber)코드를 실행하면 다음 결과가 반환됩니다.
Enter Number : 3456.78 (STDIN Input)
The Number: 3456.78
The Number Doubled: 6913.56형식화 된 출력
함수 format멋진 형식의 텍스트를 생성하는 데 사용됩니다. 다음과 같은 구문이 있습니다.
format destination control-string &rest arguments어디,
- 대상은 표준 출력입니다.
- control-string은 출력 할 문자와 인쇄 지시문을 보유합니다.
ㅏ format directive 물결표 (~), 쉼표로 구분 된 선택적 접 두부 매개 변수, 선택적 콜론 (:) 및 at- 기호 (@) 수정 자, 이것이 어떤 종류의 지시문인지 나타내는 단일 문자로 구성됩니다.
접두사 매개 변수는 일반적으로 정수이며 선택적으로 부호있는 십진수로 표시됩니다.
다음 표는 일반적으로 사용되는 지시문에 대한 간략한 설명을 제공합니다.
| Sr. 아니. | 지침 및 설명 |
|---|---|
| 1 | ~A ASCII 인수가 뒤에옵니다. |
| 2 | ~S S- 표현이 뒤 따릅니다. |
| 삼 | ~D 10 진수 인수의 경우. |
| 4 | ~B 이진 인수의 경우. |
| 5 | ~O 8 진 인수의 경우. |
| 6 | ~X 16 진 인수의 경우. |
| 7 | ~C 문자 인수 용. |
| 8 | ~F 고정 형식 부동 소수점 인수의 경우. |
| 9 | ~E 지수 부동 소수점 인수. |
| 10 | ~$ 달러 및 부동 소수점 인수. |
| 11 | ~% 새 줄이 인쇄됩니다. |
| 12 | ~* 다음 인수는 무시됩니다. |
| 13 | ~? 우회. 다음 인수는 문자열이어야하며 그 다음 인수는 목록이어야합니다. |
예
원의 면적을 계산하는 프로그램을 다시 작성해 보겠습니다.
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(defun AreaOfCircle()
(terpri)
(princ "Enter Radius: ")
(setq radius (read))
(setq area (* 3.1416 radius radius))
(format t "Radius: = ~F~% Area = ~F" radius area)
)
(AreaOfCircle)코드를 실행하면 다음 결과가 반환됩니다.
Enter Radius: 10.234 (STDIN Input)
Radius: = 10.234
Area = 329.03473일반적인 LISP에서 표준 입력 및 출력을 처리하는 방법에 대해 논의했습니다. 이러한 모든 함수는 텍스트 및 이진 파일을 읽고 쓰는데도 작동합니다. 이 경우 유일한 차이점은 우리가 사용하는 스트림은 표준 입력 또는 출력이 아니라 파일에 쓰거나 파일에서 읽는 특정 목적을 위해 만들어진 스트림입니다.
이 장에서는 LISP가 데이터 저장을 위해 텍스트 또는 바이너리 파일을 만들고, 열고, 닫는 방법을 알아 봅니다.
파일은 바이트 시퀀스를 나타내며 텍스트 파일이든 바이너리 파일이든 상관 없습니다. 이 장에서는 파일 관리를위한 중요한 기능 / 매크로에 대해 설명합니다.
파일 열기
사용할 수 있습니다 open새 파일을 만들거나 기존 파일을 여는 기능. 파일을 여는 가장 기본적인 기능입니다. 그러나, 그with-open-file 이 섹션의 뒷부분에서 볼 수 있듯이 일반적으로 더 편리하고 일반적으로 사용됩니다.
파일이 열리면 LISP 환경에서이를 나타 내기 위해 스트림 객체가 구성됩니다. 스트림에 대한 모든 작업은 기본적으로 파일에 대한 작업과 동일합니다.
구문 open 함수는-
open filename &key :direction :element-type :if-exists :if-does-not-exist :external-format어디,
파일 이름 인수는 파일의 이름을 열거 나 만들 수있다.
키워드 인수 스트림과 오류 처리 방법의 유형을 지정합니다.
그만큼 :direction 키워드는 스트림이 입력, 출력 또는 둘 다를 처리해야하는지 여부를 지정하며 다음 값을 사용합니다.
: input-입력 스트림 용 (기본값)
: output-출력 스트림 용
: io-양방향 스트림 용
: probe-파일 존재 여부를 확인합니다. 스트림이 열렸다가 닫힙니다.
그만큼 :element-type 스트림의 트랜잭션 단위 유형을 지정합니다.
그만큼 :if-exists인수는 : direction이 : output 또는 : io이고 지정된 이름의 파일이 이미있는 경우 취할 조치를 지정합니다. 방향이 : input 또는 : probe 인 경우이 인수는 무시됩니다. 다음 값을 취합니다-
: error-오류를 나타냅니다.
: new-version-이름은 같지만 버전 번호가 더 큰 새 파일을 만듭니다.
: rename-기존 파일의 이름을 바꿉니다.
: rename-and-delete-기존 파일의 이름을 바꾼 다음 삭제합니다.
: append-기존 파일에 추가합니다.
: supersede-기존 파일을 대체합니다.
nil-파일을 생성하지 않거나 심지어 스트림이 실패를 나타 내기 위해 nil을 반환합니다.
그만큼 :if-does-not-exist인수는 지정된 이름의 파일이 아직 존재하지 않는 경우 취할 조치를 지정합니다. 다음 값을 취합니다-
: error-오류를 나타냅니다.
: create-지정된 이름으로 빈 파일을 만든 다음 사용합니다.
nil-파일이나 스트림을 생성하지 않고 대신 단순히 nil을 반환하여 실패를 나타냅니다.
그만큼 :external-format 인수는 파일에서 문자를 표현하기위한 구현 인식 체계를 지정합니다.
예를 들어, 다음과 같이 / tmp 폴더에 저장된 myfile.txt라는 파일을 열 수 있습니다.
(open "/tmp/myfile.txt")파일 쓰기 및 읽기
그만큼 with-open-file읽기 / 쓰기 트랜잭션과 관련된 스트림 변수를 사용하여 파일을 읽거나 쓸 수 있습니다. 작업이 완료되면 파일이 자동으로 닫힙니다. 사용하기 매우 편리합니다.
다음과 같은 구문이 있습니다.
with-open-file (stream filename {options}*)
{declaration}* {form}*filename 은 열 파일의 이름입니다. 문자열, 경로 이름 또는 스트림 일 수 있습니다.
옵션은 함수 열려면 키워드 인자와 동일합니다.
예 1
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(with-open-file (stream "/tmp/myfile.txt" :direction :output)
(format stream "Welcome to Tutorials Point!")
(terpri stream)
(format stream "This is a tutorials database")
(terpri stream)
(format stream "Submit your Tutorials, White Papers and Articles into our Tutorials Directory.")
)terpri 및 format과 같은 이전 장에서 설명한 모든 입력-출력 함수는 여기서 만든 파일에 쓰기 위해 작동합니다.
코드를 실행하면 아무 것도 반환하지 않습니다. 그러나 우리의 데이터는 파일에 기록됩니다. 그만큼:direction :output 키워드를 사용하면이를 수행 할 수 있습니다.
그러나 우리는이 파일에서 read-line 함수.
예 2
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(let ((in (open "/tmp/myfile.txt" :if-does-not-exist nil)))
(when in
(loop for line = (read-line in nil)
while line do (format t "~a~%" line))
(close in)
)
)코드를 실행하면 다음 결과가 반환됩니다.
Welcome to Tutorials Point!
This is a tutorials database
Submit your Tutorials, White Papers and Articles into our Tutorials Directory.파일 닫기
그만큼 close 함수는 스트림을 닫습니다.
구조는 다양한 종류의 데이터 항목을 결합 할 수있는 사용자 정의 데이터 유형 중 하나입니다.
구조는 레코드를 나타내는 데 사용됩니다. 도서관에서 책을 추적하고 싶다고 가정 해 보겠습니다. 각 책에 대한 다음 속성을 추적 할 수 있습니다.
- Title
- Author
- Subject
- 도서 ID
구조 정의
그만큼 defstructLISP의 매크로를 사용하면 추상 레코드 구조를 정의 할 수 있습니다. 그만큼defstruct 문은 프로그램에 대해 둘 이상의 멤버로 새 데이터 유형을 정의합니다.
형식을 논의하려면 defstruct매크로, Book 구조의 정의를 작성하겠습니다. 책 구조를 다음과 같이 정의 할 수 있습니다.
(defstruct book
title
author
subject
book-id
)참고
위의 선언은 4 개의 책 구조를 만듭니다. named components. 따라서 만들어진 모든 책은이 구조의 대상이됩니다.
book-title, book-author, book-subject 및 book-book-id라는 4 개의 함수를 정의합니다.이 함수는 하나의 인수, 책 구조를 취하고 책의 제목, 저자, 주제 및 책 ID 필드를 반환합니다. 목적. 이러한 기능을access functions.
심볼 북은 데이터 형이되며 typep 술부.
또한라는 암시 적 함수가 있습니다. book-p, 이는 술어이며 인수가 책이면 참이고 그렇지 않으면 거짓입니다.
명명 된 또 다른 암시 적 함수 make-book 생성됩니다. constructor, 호출되면 액세스 기능과 함께 사용하기에 적합한 네 가지 구성 요소가있는 데이터 구조를 만듭니다.
그만큼 #S syntax 구조를 나타내며이를 사용하여 책의 인스턴스를 읽거나 인쇄 할 수 있습니다.
한 인수의 copy-book이라는 암시 적 함수도 정의됩니다. 책 개체를 가져 와서 첫 번째 책의 복사 본인 다른 책 개체를 만듭니다. 이 기능을copier function.
당신이 사용할 수있는 setf 예를 들어 책의 구성 요소를 변경하려면
(setf (book-book-id book3) 100)예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(defstruct book
title
author
subject
book-id
)
( setq book1 (make-book :title "C Programming"
:author "Nuha Ali"
:subject "C-Programming Tutorial"
:book-id "478")
)
( setq book2 (make-book :title "Telecom Billing"
:author "Zara Ali"
:subject "C-Programming Tutorial"
:book-id "501")
)
(write book1)
(terpri)
(write book2)
(setq book3( copy-book book1))
(setf (book-book-id book3) 100)
(terpri)
(write book3)코드를 실행하면 다음 결과가 반환됩니다.
#S(BOOK :TITLE "C Programming" :AUTHOR "Nuha Ali" :SUBJECT "C-Programming Tutorial" :BOOK-ID "478")
#S(BOOK :TITLE "Telecom Billing" :AUTHOR "Zara Ali" :SUBJECT "C-Programming Tutorial" :BOOK-ID "501")
#S(BOOK :TITLE "C Programming" :AUTHOR "Nuha Ali" :SUBJECT "C-Programming Tutorial" :BOOK-ID 100)프로그래밍 언어의 일반적인 용어로 패키지는 한 세트의 이름을 다른 세트와 분리하는 방법을 제공하도록 설계되었습니다. 한 패키지에서 선언 된 기호는 다른 패키지에서 선언 된 동일한 기호와 충돌하지 않습니다. 이런 식으로 패키지는 독립 코드 모듈 간의 이름 충돌을 줄입니다.
LISP 판독기는 발견 한 모든 기호의 표를 유지합니다. 새 문자 시퀀스를 찾으면 새 기호를 만들고 기호 테이블에 저장합니다. 이 테이블을 패키지라고합니다.
현재 패키지는 특수 변수 * package *에 의해 참조됩니다.
LISP에는 두 개의 미리 정의 된 패키지가 있습니다.
common-lisp − 정의 된 모든 기능과 변수에 대한 기호를 포함합니다.
common-lisp-user− 편집 및 디버깅 도구와 함께 common-lisp 패키지 및 기타 모든 패키지를 사용합니다. 간단히 cl-user라고합니다.
LISP의 패키지 기능
다음 표는 패키지 생성, 사용 및 조작에 가장 일반적으로 사용되는 함수를 제공합니다.
| Sr. 아니. | 기능 및 설명 |
|---|---|
| 1 | make-package 패키지 이름 및 키 : 닉네임 : 사용 지정된 패키지 이름으로 새 패키지를 만들고 반환합니다. |
| 2 | in-package 패키지 이름 및 키 : 닉네임 : 사용 패키지를 최신 상태로 만듭니다. |
| 삼 | in-package 이름 이 매크로를 사용하면 * package *가 기호 또는 문자열이어야하는 name 패키지로 설정됩니다. |
| 4 | find-package 이름 패키지를 검색합니다. 해당 이름 또는 별명이있는 패키지가 리턴됩니다. 그러한 패키지가 없으면 find-package는 nil을 반환합니다. |
| 5 | rename-package 패키지 새 이름 및 선택적 새 별명 패키지 이름을 바꿉니다. |
| 6 | list-all-packages 이 함수는 현재 Lisp 시스템에있는 모든 패키지 목록을 반환합니다. |
| 7 | delete-package 꾸러미 패키지를 삭제합니다. |
LISP 패키지 생성
그만큼 defpackage함수는 사용자 정의 패키지를 만드는 데 사용됩니다. 다음과 같은 구문이 있습니다.
(defpackage :package-name
(:use :common-lisp ...)
(:export :symbol1 :symbol2 ...)
)어디,
package-name은 패키지의 이름입니다.
: use 키워드는이 패키지에 필요한 패키지, 즉이 패키지의 코드에서 사용하는 함수를 정의하는 패키지를 지정합니다.
: export 키워드는이 패키지의 외부 기호를 지정합니다.
그만큼 make-package함수는 패키지 생성에도 사용됩니다. 이 함수의 구문은 다음과 같습니다.
make-package package-name &key :nicknames :use인수와 키워드는 이전과 동일한 의미를 갖습니다.
패키지 사용
패키지를 만든 후에는 현재 패키지로 만들어이 패키지의 코드를 사용할 수 있습니다. 그만큼in-package 매크로는 패키지를 환경에서 최신 상태로 만듭니다.
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(make-package :tom)
(make-package :dick)
(make-package :harry)
(in-package tom)
(defun hello ()
(write-line "Hello! This is Tom's Tutorials Point")
)
(hello)
(in-package dick)
(defun hello ()
(write-line "Hello! This is Dick's Tutorials Point")
)
(hello)
(in-package harry)
(defun hello ()
(write-line "Hello! This is Harry's Tutorials Point")
)
(hello)
(in-package tom)
(hello)
(in-package dick)
(hello)
(in-package harry)
(hello)코드를 실행하면 다음 결과가 반환됩니다.
Hello! This is Tom's Tutorials Point
Hello! This is Dick's Tutorials Point
Hello! This is Harry's Tutorials Point패키지 삭제
그만큼 delete-package매크로를 사용하면 패키지를 삭제할 수 있습니다. 다음 예제는 이것을 보여줍니다-
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(make-package :tom)
(make-package :dick)
(make-package :harry)
(in-package tom)
(defun hello ()
(write-line "Hello! This is Tom's Tutorials Point")
)
(in-package dick)
(defun hello ()
(write-line "Hello! This is Dick's Tutorials Point")
)
(in-package harry)
(defun hello ()
(write-line "Hello! This is Harry's Tutorials Point")
)
(in-package tom)
(hello)
(in-package dick)
(hello)
(in-package harry)
(hello)
(delete-package tom)
(in-package tom)
(hello)코드를 실행하면 다음 결과가 반환됩니다.
Hello! This is Tom's Tutorials Point
Hello! This is Dick's Tutorials Point
Hello! This is Harry's Tutorials Point
*** - EVAL: variable TOM has no value공통 LISP 용어에서는 예외를 조건이라고합니다.
사실 조건은 기존 프로그래밍 언어의 예외보다 더 일반적입니다. condition 다양한 수준의 함수 호출 스택에 영향을 미칠 수있는 발생, 오류 여부를 나타냅니다.
LISP의 조건 처리 메커니즘은 호출 스택의 상위 수준 코드가 작업을 계속할 수있는 동안 조건이 경고 신호 (예 : 경고 인쇄)에 사용되는 방식으로 이러한 상황을 처리합니다.
LISP의 상태 처리 시스템은 세 부분으로 구성됩니다.
- 조건 신호
- 조건 처리
- 프로세스 다시 시작
조건 처리
여기서 개념을 설명하기 위해 0으로 나누기 조건에서 발생하는 조건을 처리하는 예를 들어 보겠습니다.
조건을 처리하려면 다음 단계를 수행해야합니다.
Define the Condition − "조건은 해당 클래스가 조건의 일반적인 특성을 나타내고 해당 인스턴스 데이터가 조건을 신호로 이끄는 특정 상황의 세부 정보에 대한 정보를 전달하는 객체입니다."
조건 정의 매크로는 다음 구문을 갖는 조건을 정의하는 데 사용됩니다.
(define-condition condition-name (error) ((text :initarg :text :reader text)) )새로운 조건 개체는 MAKE-CONDITION 매크로를 사용하여 생성되며, 이는 다음을 기반으로 새 조건의 슬롯을 초기화합니다. :initargs 논의.
이 예에서 다음 코드는 조건을 정의합니다.
(define-condition on-division-by-zero (error) ((message :initarg :message :reader message)) )Writing the Handlers− 조건 핸들러는 신호를받은 조건을 처리하는 데 사용되는 코드입니다. 일반적으로 오류 함수를 호출하는 상위 수준 함수 중 하나로 작성됩니다. 조건이 시그널링되면 시그널링 메커니즘은 조건의 클래스를 기반으로 적절한 핸들러를 검색합니다.
각 핸들러는-
- 처리 할 수있는 조건의 유형을 나타내는 유형 지정자
- 단일 인수, 조건을 취하는 함수
조건이 시그널링되면 시그널링 메커니즘은 조건 유형과 호환되는 가장 최근에 설정된 핸들러를 찾아 해당 기능을 호출합니다.
매크로 handler-case조건 핸들러를 설정합니다. 핸들러 케이스의 기본 형태-
(handler-case expression error-clause*)여기서 각 오류 절은 다음과 같은 형식입니다.
condition-type ([var]) code)Restarting Phase
이것은 실제로 프로그램을 오류로부터 복구하는 코드이며, 조건 핸들러는 적절한 재시작을 호출하여 조건을 처리 할 수 있습니다. 재시작 코드는 일반적으로 중간 수준 또는 하위 수준 함수에 배치되고 조건 핸들러는 애플리케이션의 상위 수준에 배치됩니다.
그만큼 handler-bind매크로를 사용하면 다시 시작 기능을 제공 할 수 있으며 함수 호출 스택을 해제하지 않고도 하위 수준 기능을 계속할 수 있습니다. 즉, 제어 흐름은 여전히 하위 수준 기능에 있습니다.
기본 형태 handler-bind 다음과 같습니다-
(handler-bind (binding*) form*)각 바인딩은 다음 목록입니다.
- 조건 유형
- 한 인수의 핸들러 함수
그만큼 invoke-restart 매크로는 지정된 이름을 인수로 사용하여 가장 최근에 바인딩 된 재시작 함수를 찾아 호출합니다.
여러 번 다시 시작할 수 있습니다.
예
이 예에서는 divisor 인수가 0 인 경우 오류 조건을 생성하는 division-function이라는 함수를 작성하여 위의 개념을 설명합니다. 값 1을 반환하거나, 제수 2를 보내고 다시 계산하거나, 1을 반환하는 세 가지 방법을 제공하는 세 가지 익명 함수가 있습니다.
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(define-condition on-division-by-zero (error)
((message :initarg :message :reader message))
)
(defun handle-infinity ()
(restart-case
(let ((result 0))
(setf result (division-function 10 0))
(format t "Value: ~a~%" result)
)
(just-continue () nil)
)
)
(defun division-function (value1 value2)
(restart-case
(if (/= value2 0)
(/ value1 value2)
(error 'on-division-by-zero :message "denominator is zero")
)
(return-zero () 0)
(return-value (r) r)
(recalc-using (d) (division-function value1 d))
)
)
(defun high-level-code ()
(handler-bind
(
(on-division-by-zero
#'(lambda (c)
(format t "error signaled: ~a~%" (message c))
(invoke-restart 'return-zero)
)
)
(handle-infinity)
)
)
)
(handler-bind
(
(on-division-by-zero
#'(lambda (c)
(format t "error signaled: ~a~%" (message c))
(invoke-restart 'return-value 1)
)
)
)
(handle-infinity)
)
(handler-bind
(
(on-division-by-zero
#'(lambda (c)
(format t "error signaled: ~a~%" (message c))
(invoke-restart 'recalc-using 2)
)
)
)
(handle-infinity)
)
(handler-bind
(
(on-division-by-zero
#'(lambda (c)
(format t "error signaled: ~a~%" (message c))
(invoke-restart 'just-continue)
)
)
)
(handle-infinity)
)
(format t "Done."))코드를 실행하면 다음 결과가 반환됩니다.
error signaled: denominator is zero
Value: 1
error signaled: denominator is zero
Value: 5
error signaled: denominator is zero
Done.위에서 설명한 'Condition System'외에도 Common LISP는 오류 신호를 보내기 위해 호출 될 수있는 다양한 기능을 제공합니다. 그러나 신호를받을 때 오류 처리는 구현에 따라 다릅니다.
LISP의 오류 신호 기능
다음 표는 경고, 중단, 치명적이지 않은 오류 및 치명적 오류를 알리는 일반적으로 사용되는 기능을 제공합니다.
사용자 프로그램은 오류 메시지 (문자열)를 지정합니다. 함수는이 메시지를 처리하고 사용자에게 표시하거나 표시하지 않을 수 있습니다.
오류 메시지는 다음을 적용하여 구성해야합니다. format LISP 시스템이 선호하는 스타일에 따라 처리하므로 시작 또는 끝에 개행 문자를 포함하지 않아야하며 오류를 표시 할 필요가 없습니다.
| Sr. 아니. | 기능 및 설명 |
|---|---|
| 1 | error 형식 문자열 및 나머지 인수 치명적인 오류를 나타냅니다. 이런 종류의 오류에서 계속하는 것은 불가능합니다. 따라서 오류는 호출자에게 반환되지 않습니다. |
| 2 | cerror 계속 형식 문자열 오류 형식 문자열 및 나머지 인수 오류를 알리고 디버거로 들어갑니다. 그러나 오류를 해결 한 후 디버거에서 프로그램을 계속할 수 있습니다. |
| 삼 | warn 형식 문자열 및 나머지 인수 오류 메시지를 인쇄하지만 일반적으로 디버거로 이동하지 않습니다. |
| 4 | break& 옵션 형식 문자열 및 나머지 인수 프로그래밍 된 오류 처리 기능에 의한 가로 채기 가능성없이 메시지를 인쇄하고 디버거로 직접 이동합니다. |
예
이 예에서 factorial 함수는 숫자의 계승을 계산합니다. 그러나 인수가 음수이면 오류 조건이 발생합니다.
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(defun factorial (x)
(cond ((or (not (typep x 'integer)) (minusp x))
(error "~S is a negative number." x))
((zerop x) 1)
(t (* x (factorial (- x 1))))
)
)
(write(factorial 5))
(terpri)
(write(factorial -1))코드를 실행하면 다음 결과가 반환됩니다.
120
*** - -1 is a negative number.Common LISP는 객체 지향 프로그래밍의 발전을 수십 년 앞두고 있습니다. 그러나 객체 지향은 이후 단계에서 통합되었습니다.
클래스 정의
그만큼 defclass매크로를 사용하면 사용자 정의 클래스를 만들 수 있습니다. 클래스를 데이터 유형으로 설정합니다. 다음과 같은 구문이 있습니다.
(defclass class-name (superclass-name*)
(slot-description*)
class-option*))슬롯은 데이터 또는 필드를 저장하는 변수입니다.
슬롯 설명은 (slot-name slot-option *) 형식을 가지며, 여기서 각 옵션은 이름, 표현식 및 기타 옵션이 뒤 따르는 키워드입니다. 가장 일반적으로 사용되는 슬롯 옵션은 다음과 같습니다.
:accessor 기능 명
:initform 표현
:initarg 상징
예를 들어, 길이, 너비 및 높이가 3 개인 Box 클래스를 정의 해 보겠습니다.
(defclass Box ()
(length
breadth
height)
)슬롯에 대한 액세스 및 읽기 / 쓰기 제어 제공
슬롯에 액세스, 읽기 또는 쓰기가 가능한 값이 없으면 클래스는 거의 쓸모가 없습니다.
지정할 수 있습니다 accessors클래스를 정의 할 때 각 슬롯에 대해. 예를 들어, Box 클래스를 살펴 보겠습니다.
(defclass Box ()
((length :accessor length)
(breadth :accessor breadth)
(height :accessor height)
)
)별도로 지정할 수도 있습니다. accessor 슬롯을 읽고 쓰기위한 이름.
(defclass Box ()
((length :reader get-length :writer set-length)
(breadth :reader get-breadth :writer set-breadth)
(height :reader get-height :writer set-height)
)
)클래스의 인스턴스 생성
일반 기능 make-instance 클래스의 새 인스턴스를 만들고 반환합니다.
다음과 같은 구문이 있습니다.
(make-instance class {initarg value}*)예
길이, 너비 및 높이의 세 개의 슬롯이있는 Box 클래스를 만들어 보겠습니다. 세 개의 슬롯 접근자를 사용하여 이러한 필드의 값을 설정합니다.
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(defclass box ()
((length :accessor box-length)
(breadth :accessor box-breadth)
(height :accessor box-height)
)
)
(setf item (make-instance 'box))
(setf (box-length item) 10)
(setf (box-breadth item) 10)
(setf (box-height item) 5)
(format t "Length of the Box is ~d~%" (box-length item))
(format t "Breadth of the Box is ~d~%" (box-breadth item))
(format t "Height of the Box is ~d~%" (box-height item))코드를 실행하면 다음 결과가 반환됩니다.
Length of the Box is 10
Breadth of the Box is 10
Height of the Box is 5클래스 메서드 정의
그만큼 defmethod매크로를 사용하면 클래스 내부에 메서드를 정의 할 수 있습니다. 다음 예제는 volume이라는 메서드를 포함하도록 Box 클래스를 확장합니다.
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(defclass box ()
((length :accessor box-length)
(breadth :accessor box-breadth)
(height :accessor box-height)
(volume :reader volume)
)
)
; method calculating volume
(defmethod volume ((object box))
(* (box-length object) (box-breadth object)(box-height object))
)
;setting the values
(setf item (make-instance 'box))
(setf (box-length item) 10)
(setf (box-breadth item) 10)
(setf (box-height item) 5)
; displaying values
(format t "Length of the Box is ~d~%" (box-length item))
(format t "Breadth of the Box is ~d~%" (box-breadth item))
(format t "Height of the Box is ~d~%" (box-height item))
(format t "Volume of the Box is ~d~%" (volume item))코드를 실행하면 다음 결과가 반환됩니다.
Length of the Box is 10
Breadth of the Box is 10
Height of the Box is 5
Volume of the Box is 500계승
LISP를 사용하면 다른 개체의 관점에서 개체를 정의 할 수 있습니다. 이것은 ... 불리운다inheritance.새롭거나 다른 기능을 추가하여 파생 클래스를 만들 수 있습니다. 파생 클래스는 부모 클래스의 기능을 상속합니다.
다음 예제는 이것을 설명합니다-
예
main.lisp라는 새 소스 코드 파일을 만들고 그 안에 다음 코드를 입력합니다.
(defclass box ()
((length :accessor box-length)
(breadth :accessor box-breadth)
(height :accessor box-height)
(volume :reader volume)
)
)
; method calculating volume
(defmethod volume ((object box))
(* (box-length object) (box-breadth object)(box-height object))
)
;wooden-box class inherits the box class
(defclass wooden-box (box)
((price :accessor box-price)))
;setting the values
(setf item (make-instance 'wooden-box))
(setf (box-length item) 10)
(setf (box-breadth item) 10)
(setf (box-height item) 5)
(setf (box-price item) 1000)
; displaying values
(format t "Length of the Wooden Box is ~d~%" (box-length item))
(format t "Breadth of the Wooden Box is ~d~%" (box-breadth item))
(format t "Height of the Wooden Box is ~d~%" (box-height item))
(format t "Volume of the Wooden Box is ~d~%" (volume item))
(format t "Price of the Wooden Box is ~d~%" (box-price item))코드를 실행하면 다음 결과가 반환됩니다.
Length of the Wooden Box is 10
Breadth of the Wooden Box is 10
Height of the Wooden Box is 5
Volume of the Wooden Box is 500
Price of the Wooden Box is 1000