MapReduce-소개
MapReduce는 여러 노드에서 병렬로 빅 데이터를 처리 할 수있는 애플리케이션을 작성하기위한 프로그래밍 모델입니다. MapReduce는 방대한 양의 복잡한 데이터를 분석하기위한 분석 기능을 제공합니다.
빅 데이터 란?
빅 데이터는 기존 컴퓨팅 기술을 사용하여 처리 할 수없는 대규모 데이터 세트의 모음입니다. 예를 들어 Facebook 또는 Youtube에서 매일 수집하고 관리하는 데 필요한 데이터의 양은 빅 데이터 범주에 속할 수 있습니다. 그러나 빅 데이터는 규모와 양에 관한 것이 아니라 속도, 다양성, 양 및 복잡성과 같은 측면 중 하나 이상을 포함합니다.
왜 MapReduce인가?
기존 엔터프라이즈 시스템에는 일반적으로 데이터를 저장하고 처리하는 중앙 집중식 서버가 있습니다. 다음 그림은 기존 엔터프라이즈 시스템의 개략도를 보여줍니다. 기존 모델은 확장 가능한 대량의 데이터를 처리하는 데 적합하지 않으며 표준 데이터베이스 서버에서 수용 할 수 없습니다. 더욱이 중앙 집중식 시스템은 여러 파일을 동시에 처리하는 동안 너무 많은 병목 현상을 만듭니다.

Google은 MapReduce라는 알고리즘을 사용하여이 병목 문제를 해결했습니다. MapReduce는 작업을 작은 부분으로 나누어 여러 컴퓨터에 할당합니다. 나중에 결과는 한곳에서 수집되고 통합되어 결과 데이터 세트를 형성합니다.

MapReduce는 어떻게 작동합니까?
MapReduce 알고리즘에는 Map 및 Reduce라는 두 가지 중요한 작업이 포함됩니다.
Map 태스크는 데이터 세트를 가져 와서 개별 요소가 튜플 (키-값 쌍)로 분할되는 다른 데이터 세트로 변환합니다.
축소 작업은 맵의 출력을 입력으로 가져와 해당 데이터 튜플 (키-값 쌍)을 더 작은 튜플 집합으로 결합합니다.
축소 작업은 항상 맵 작업 후에 수행됩니다.
이제 각 단계를 자세히 살펴보고 그 중요성을 이해해 보겠습니다.
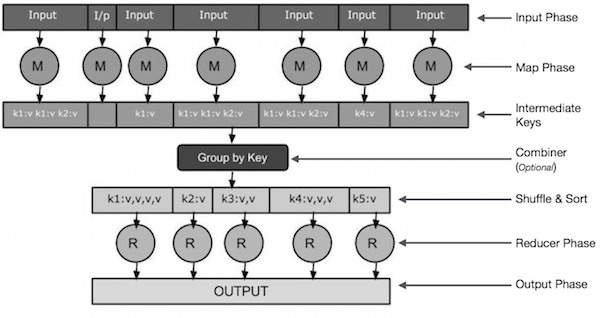
Input Phase − 여기에는 입력 파일의 각 레코드를 번역하고 구문 분석 된 데이터를 키-값 쌍의 형태로 매퍼에게 보내는 레코드 리더가 있습니다.
Map − Map은 일련의 키-값 쌍을 가져와 각각을 처리하여 0 개 이상의 키-값 쌍을 생성하는 사용자 정의 함수입니다.
Intermediate Keys − 매퍼에 의해 생성 된 키-값 쌍을 중간 키라고합니다.
Combiner− 결합기는 맵 단계의 유사한 데이터를 식별 가능한 집합으로 그룹화하는 로컬 감속기 유형입니다. 매퍼에서 중간 키를 입력으로 사용하고 사용자 정의 코드를 적용하여 한 매퍼의 작은 범위에서 값을 집계합니다. 이것은 주요 MapReduce 알고리즘의 일부가 아닙니다. 선택 사항입니다.
Shuffle and Sort− Reducer 작업은 Shuffle 및 Sort 단계로 시작됩니다. 그룹화 된 키-값 쌍을 Reducer가 실행중인 로컬 머신에 다운로드합니다. 개별 키-값 쌍은 키별로 더 큰 데이터 목록으로 정렬됩니다. 데이터 목록은 동일한 키를 그룹화하여 Reducer 작업에서 해당 값을 쉽게 반복 할 수 있도록합니다.
Reducer− Reducer는 그룹화 된 키-값 쌍 데이터를 입력으로 취하고 각각에 대해 Reducer 기능을 실행합니다. 여기에서 데이터는 여러 가지 방법으로 집계, 필터링 및 결합 될 수 있으며 광범위한 처리가 필요합니다. 실행이 끝나면 최종 단계에 0 개 이상의 키-값 쌍을 제공합니다.
Output Phase − 출력 단계에는 Reducer 함수에서 최종 키-값 쌍을 변환하고 레코드 작성기를 사용하여 파일에 쓰는 출력 포맷터가 있습니다.
작은 다이어그램의 도움으로 Map & f Reduce의 두 가지 작업을 이해해 보겠습니다.

MapReduce- 예제
MapReduce의 힘을 이해하기 위해 실제 사례를 살펴 보겠습니다. Twitter는 하루에 약 5 억 개의 트윗을 수신하며 이는 초당 거의 3000 개의 트윗입니다. 다음 그림은 Tweeter가 MapReduce를 사용하여 트윗을 관리하는 방법을 보여줍니다.
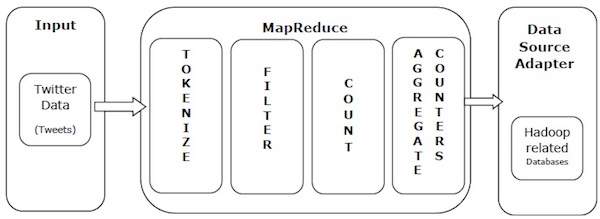
그림과 같이 MapReduce 알고리즘은 다음 작업을 수행합니다.
Tokenize − 트윗을 토큰 맵으로 토큰 화하고 키-값 쌍으로 작성합니다.
Filter − 토큰 맵에서 원하지 않는 단어를 필터링하고 필터링 된 맵을 키-값 쌍으로 작성합니다.
Count − 단어 당 토큰 카운터를 생성합니다.
Aggregate Counters − 유사한 카운터 값의 집계를 관리 가능한 작은 단위로 준비합니다.