CNTK-순환 신경망
이제 CNTK에서 RNN (Recurrent Neural Network)을 구성하는 방법을 이해하겠습니다.
소개
신경망을 사용하여 이미지를 분류하는 방법을 배웠으며 이는 딥 러닝의 상징적 인 작업 중 하나입니다. 그러나 신경망이 뛰어난 또 다른 분야는 RNN (Recurrent Neural Networks)입니다. 여기에서는 RNN이 무엇인지, 시계열 데이터를 처리해야하는 시나리오에서 RNN을 어떻게 사용할 수 있는지 알아 봅니다.
순환 신경망이란 무엇입니까?
RNN (Recurrent Neural Network)은 시간이 지남에 따라 추론 할 수있는 특별한 유형의 NN으로 정의 될 수 있습니다. RNN은 주로 시간에 따라 변하는 값, 즉 시계열 데이터를 처리해야하는 시나리오에서 사용됩니다. 더 나은 방법으로 이해하기 위해 일반 신경망과 반복 신경망을 약간 비교해 보겠습니다.
아시다시피 일반 신경망에서는 입력을 하나만 제공 할 수 있습니다. 결과적으로 하나의 예측으로 제한됩니다. 예를 들어, 일반 신경망을 사용하여 텍스트 번역 작업을 수행 할 수 있습니다.
반면, 반복 신경망에서는 단일 예측을 생성하는 일련의 샘플을 제공 할 수 있습니다. 즉, RNN을 사용하여 입력 시퀀스를 기반으로 출력 시퀀스를 예측할 수 있습니다. 예를 들어, 번역 작업에서 RNN을 사용한 성공적인 실험이 꽤 많이있었습니다.
순환 신경망 사용
RNN은 여러 가지 방법으로 사용할 수 있습니다. 그들 중 일부는 다음과 같습니다-
단일 출력 예측
RNN이 시퀀스를 기반으로 단일 출력을 예측할 수있는 방법에 대해 자세히 알아보기 전에 기본 RNN이 어떻게 생겼는지 살펴 보겠습니다.

위의 다이어그램에서 볼 수 있듯이 RNN은 입력에 대한 루프백 연결을 포함하며, 값 시퀀스를 공급할 때마다 시퀀스의 각 요소를 시간 단계로 처리합니다.
또한 루프백 연결로 인해 RNN은 생성 된 출력을 시퀀스의 다음 요소에 대한 입력과 결합 할 수 있습니다. 이런 식으로 RNN은 예측에 사용할 수있는 전체 시퀀스에 대한 메모리를 구축합니다.
RNN으로 예측하기 위해 다음 단계를 수행 할 수 있습니다.
먼저, 초기 은닉 상태를 생성하려면 입력 시퀀스의 첫 번째 요소를 공급해야합니다.
그 후 업데이트 된 은닉 상태를 생성하려면 초기 은닉 상태를 가져 와서 입력 시퀀스의 두 번째 요소와 결합해야합니다.
마지막으로 최종 은닉 상태를 생성하고 RNN에 대한 출력을 예측하려면 입력 시퀀스에서 최종 요소를 가져와야합니다.
이런 식으로 루프백 연결의 도움으로 RNN이 시간이 지남에 따라 발생하는 패턴을 인식하도록 가르 칠 수 있습니다.
시퀀스 예측
위에서 논의한 RNN의 기본 모델은 다른 사용 사례로도 확장 할 수 있습니다. 예를 들어 단일 입력을 기반으로 일련의 값을 예측하는 데 사용할 수 있습니다. 이 시나리오에서 RNN으로 예측하기 위해 다음 단계를 수행 할 수 있습니다.
먼저, 초기 은닉 상태를 생성하고 출력 시퀀스의 첫 번째 요소를 예측하려면 입력 샘플을 신경망에 공급해야합니다.
그 후 업데이트 된 은닉 상태와 출력 시퀀스의 두 번째 요소를 생성하려면 초기 은닉 상태를 동일한 샘플과 결합해야합니다.
마지막으로 숨겨진 상태를 한 번 더 업데이트하고 출력 시퀀스의 최종 요소를 예측하기 위해 샘플을 다시 공급합니다.
시퀀스 예측
시퀀스를 기반으로 단일 값을 예측하는 방법과 단일 값을 기반으로 시퀀스를 예측하는 방법을 살펴 보았습니다. 이제 시퀀스의 시퀀스를 예측하는 방법을 살펴 보겠습니다. 이 시나리오에서 RNN으로 예측하기 위해 다음 단계를 수행 할 수 있습니다.
먼저 초기 은닉 상태를 만들고 출력 시퀀스의 첫 번째 요소를 예측하려면 입력 시퀀스의 첫 번째 요소를 가져와야합니다.
그 후 히든 상태를 업데이트하고 출력 시퀀스의 두 번째 요소를 예측하려면 초기 히든 상태를 취해야합니다.
마지막으로 출력 시퀀스의 최종 요소를 예측하려면 업데이트 된 은닉 상태와 입력 시퀀스의 최종 요소를 가져와야합니다.
RNN의 작동
RNN (Recurrent Neural Network)의 작동을 이해하려면 먼저 네트워크의 반복 계층이 작동하는 방식을 이해해야합니다. 따라서 먼저 표준 반복 레이어를 사용하여 출력을 예측할 수있는 방법에 대해 논의하겠습니다.
표준 RNN 레이어로 출력 예측
앞서 논의했듯이 RNN의 기본 계층은 신경망의 일반 계층과 상당히 다릅니다. 이전 섹션에서는 다이어그램에서 RNN의 기본 아키텍처를 시연했습니다. 첫 번째 스텝 인 시퀀스의 숨겨진 상태를 업데이트하기 위해 다음 공식을 사용할 수 있습니다.

위의 방정식에서 초기 은닉 상태와 가중치 집합 사이의 내적을 계산하여 새로운 은닉 상태를 계산합니다.
이제 다음 단계에서 현재 시간 단계의 숨김 상태가 시퀀스의 다음 시간 단계에 대한 초기 숨김 상태로 사용됩니다. 그렇기 때문에 두 번째 시간 단계에서 숨겨진 상태를 업데이트하기 위해 다음과 같이 첫 번째 단계에서 수행 된 계산을 반복 할 수 있습니다.
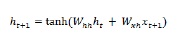
다음으로 다음과 같이 시퀀스의 세 번째 및 마지막 단계에서 숨겨진 상태를 업데이트하는 프로세스를 반복 할 수 있습니다.

위의 모든 단계를 순서대로 처리하면 다음과 같이 출력을 계산할 수 있습니다.

위 공식의 경우 마지막 시간 단계에서 세 번째 가중치 집합과 숨겨진 상태를 사용했습니다.
고급 반복 단위
기본 반복 레이어의 주요 문제는 그라디언트 문제가 사라지는 문제이며 이로 인해 장기 상관 관계를 학습하는 데별로 좋지 않습니다. 간단히 말해서 기본 반복 레이어는 긴 시퀀스를 잘 처리하지 못합니다. 이것이 긴 시퀀스 작업에 훨씬 더 적합한 다른 반복 레이어 유형이 다음과 같은 이유입니다.
장기 기억 (LSTM)

장기 기억 (LSTM) 네트워크는 Hochreiter & Schmidhuber에 의해 도입되었습니다. 오랫동안 사물을 기억하기 위해 기본 반복 레이어를 얻는 문제를 해결했습니다. LSTM의 아키텍처는 위의 다이어그램에 나와 있습니다. 보시다시피 입력 뉴런, 기억 세포 및 출력 뉴런이 있습니다. 소실 기울기 문제를 해결하기 위해 장기 단기 메모리 네트워크는 명시 적 메모리 셀 (이전 값 저장)과 다음 게이트를 사용합니다.
Forget gate− 이름에서 알 수 있듯이 이전 값을 잊어 버리도록 메모리 셀에 지시합니다. 메모리 셀은 게이트 즉 'forget gate'가 값을 잊으라고 지시 할 때까지 값을 저장합니다.
Input gate− 이름에서 알 수 있듯이 셀에 새로운 항목을 추가합니다.
Output gate− 이름에서 알 수 있듯이 출력 게이트는 벡터를 따라 셀에서 다음 은닉 상태로 전달할시기를 결정합니다.
GRU (Gated Recurrent Unit)

Gradient recurrent units(GRU)는 LSTM 네트워크의 약간 변형입니다. 게이트가 하나 적고 LSTM과 약간 다른 배선이되어 있습니다. 아키텍처는 위의 다이어그램에 나와 있습니다. 입력 뉴런, 게이트 메모리 셀 및 출력 뉴런이 있습니다. Gated Recurrent Units 네트워크에는 다음 두 개의 게이트가 있습니다.
Update gate− 다음 두 가지를 결정합니다 −
마지막 상태에서 얼마나 많은 정보를 보관해야합니까?
이전 레이어에서 어느 정도의 정보를 가져와야합니까?
Reset gate− 리셋 게이트의 기능은 LSTM 네트워크의 망각 게이트와 매우 유사합니다. 유일한 차이점은 위치가 약간 다르다는 것입니다.
장기 단기 메모리 네트워크와 달리 Gated Recurrent Unit 네트워크는 약간 더 빠르고 실행하기 쉽습니다.
RNN 구조 만들기
시작하기 전에 데이터 소스의 출력에 대한 예측을 수행하기 전에 먼저 RNN을 구성해야하며 RNN을 구성하는 것은 이전 섹션에서 일반 신경망을 구축 한 것과 매우 동일합니다. 다음은 하나를 빌드하는 코드입니다.
from cntk.losses import squared_error
from cntk.io import CTFDeserializer, MinibatchSource, INFINITELY_REPEAT, StreamDefs, StreamDef
from cntk.learners import adam
from cntk.logging import ProgressPrinter
from cntk.train import TestConfig
BATCH_SIZE = 14 * 10
EPOCH_SIZE = 12434
EPOCHS = 10여러 레이어 스테이 킹
CNTK에서 여러 반복 레이어를 쌓을 수도 있습니다. 예를 들어 다음과 같은 레이어 조합을 사용할 수 있습니다.
from cntk import sequence, default_options, input_variable
from cntk.layers import Recurrence, LSTM, Dropout, Dense, Sequential, Fold
features = sequence.input_variable(1)
with default_options(initial_state = 0.1):
model = Sequential([
Fold(LSTM(15)),
Dense(1)
])(features)
target = input_variable(1, dynamic_axes=model.dynamic_axes)위의 코드에서 볼 수 있듯이 CNTK에서 RNN을 모델링 할 수있는 다음 두 가지 방법이 있습니다.
첫째, 반복 레이어의 최종 출력 만 원하는 경우 다음을 사용할 수 있습니다. Fold GRU, LSTM 또는 RNNStep과 같은 반복 계층과 결합 된 계층.
둘째, 다른 방법으로 Recurrence 블록.
시계열 데이터로 RNN 학습
모델을 구축하고 나면 CNTK에서 RNN을 훈련하는 방법을 살펴 보겠습니다.
from cntk import Function
@Function
def criterion_factory(z, t):
loss = squared_error(z, t)
metric = squared_error(z, t)
return loss, metric
loss = criterion_factory(model, target)
learner = adam(model.parameters, lr=0.005, momentum=0.9)이제 훈련 프로세스에 데이터를로드하려면 일련의 CTF 파일에서 시퀀스를 역 직렬화해야합니다. 다음 코드는create_datasource 함수는 학습 및 테스트 데이터 소스를 모두 만드는 데 유용한 유틸리티 함수입니다.
target_stream = StreamDef(field='target', shape=1, is_sparse=False)
features_stream = StreamDef(field='features', shape=1, is_sparse=False)
deserializer = CTFDeserializer(filename, StreamDefs(features=features_stream, target=target_stream))
datasource = MinibatchSource(deserializer, randomize=True, max_sweeps=sweeps)
return datasource
train_datasource = create_datasource('Training data filename.ctf')#we need to provide the location of training file we created from our dataset.
test_datasource = create_datasource('Test filename.ctf', sweeps=1) #we need to provide the location of testing file we created from our dataset.이제 데이터 소스, 모델 및 손실 함수를 설정 했으므로 학습 프로세스를 시작할 수 있습니다. 기본 신경망에 대해 이전 섹션에서했던 것과 매우 유사합니다.
progress_writer = ProgressPrinter(0)
test_config = TestConfig(test_datasource)
input_map = {
features: train_datasource.streams.features,
target: train_datasource.streams.target
}
history = loss.train(
train_datasource,
epoch_size=EPOCH_SIZE,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer, test_config],
minibatch_size=BATCH_SIZE,
max_epochs=EPOCHS
)다음과 유사한 출력을 얻을 수 있습니다.
출력
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.005
0.4 0.4 0.4 0.4 19
0.4 0.4 0.4 0.4 59
0.452 0.495 0.452 0.495 129
[…]모델 검증
실제로 RNN으로 예측하는 것은 다른 CNK 모델로 예측하는 것과 매우 유사합니다. 유일한 차이점은 단일 샘플이 아닌 시퀀스를 제공해야한다는 것입니다.
이제 RNN이 마침내 훈련을 마쳤으므로 다음과 같이 몇 가지 샘플 시퀀스를 사용하여 모델을 테스트하여 모델을 검증 할 수 있습니다.
import pickle
with open('test_samples.pkl', 'rb') as test_file:
test_samples = pickle.load(test_file)
model(test_samples) * NORMALIZE출력
array([[ 8081.7905],
[16597.693 ],
[13335.17 ],
...,
[11275.804 ],
[15621.697 ],
[16875.555 ]], dtype=float32)