Python 포렌식-기본 포렌식 애플리케이션
Forensic 지침에 따라 애플리케이션을 만들려면 명명 규칙과 패턴을 이해하고 따르는 것이 중요합니다.
명명 규칙
Python 포렌식 애플리케이션을 개발하는 동안 따라야 할 규칙과 규칙이 다음 표에 설명되어 있습니다.
| 상수 | 밑줄 구분이있는 대문자 | 높은 온도 |
| 지역 변수 이름 | 울퉁불퉁 한 대문자가있는 소문자 (밑줄은 선택 사항) | currentTemperature |
| 전역 변수 이름 | 울퉁불퉁 한 대문자가있는 접두사 gl 소문자 (밑줄은 선택 사항) | gl_maximumRecordedTemperature |
| 기능 명 | 울퉁불퉁 한 대문자가있는 대문자 (선택 사항) | ConvertFarenheitToCentigrade (...) |
| 개체 이름 | 울퉁불퉁 한 대문자로 접두사 ob_ 소문자 | ob_myTempRecorder |
| 기준 치수 | 밑줄 다음에 울퉁불퉁 한 대문자가있는 소문자 | _tempRecorder |
| 클래스 이름 | 접두사 class_ 다음 울퉁불퉁 한 대문자 및 간결하게 유지 | class_TempSystem |
Computational Forensics에서 명명 규칙의 중요성을 이해하는 시나리오를 살펴 보겠습니다. 일반적으로 데이터를 암호화하는 데 사용되는 해싱 알고리즘이 있다고 가정합니다. 단방향 해싱 알고리즘은 입력을 이진 데이터 스트림으로 사용합니다. 이것은 암호, 파일, 이진 데이터 또는 모든 디지털 데이터 일 수 있습니다. 해싱 알고리즘은 다음을 생성합니다.message digest (md) 입력에서 수신 된 데이터와 관련하여.
주어진 메시지 다이제스트를 생성 할 새로운 바이너리 입력을 만드는 것은 사실상 불가능합니다. 바이너리 입력 데이터의 단일 비트라도 변경되면 이전 메시지와 다른 고유 한 메시지를 생성합니다.
예
위에서 언급 한 규칙을 따르는 다음 샘플 프로그램을 살펴보십시오.
import sys, string, md5 # necessary libraries
print "Please enter your full name"
line = sys.stdin.readline()
line = line.rstrip()
md5_object = md5.new()
md5_object.update(line)
print md5_object.hexdigest() # Prints the output as per the hashing algorithm i.e. md5
exit위의 프로그램은 다음과 같은 출력을 생성합니다.
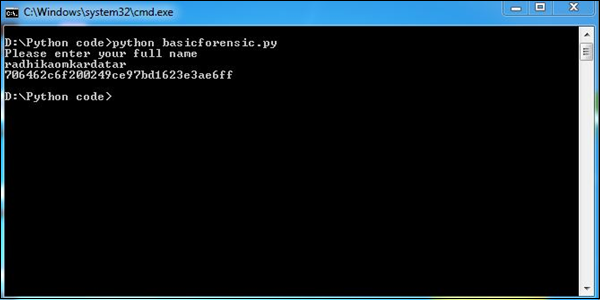
이 프로그램에서 Python 스크립트는 입력 (전체 이름)을 받아들이고 md5 해싱 알고리즘에 따라이를 변환합니다. 필요한 경우 데이터를 암호화하고 정보를 보호합니다. 법의학 지침에 따라 증거의 이름 또는 기타 증거를이 패턴으로 보호 할 수 있습니다.