Python 웹 스크래핑-소개
웹 스크래핑은 웹에서 정보를 추출하는 자동 프로세스입니다. 이 장에서는 웹 스크래핑에 대한 심층적 인 아이디어, 웹 크롤링과의 비교 및 웹 스크래핑을 선택해야하는 이유에 대해 설명합니다. 또한 웹 스크레이퍼의 구성 요소 및 작동에 대해 배웁니다.
웹 스크래핑이란 무엇입니까?
'스크래핑'이라는 단어의 사전 적 의미는 웹에서 무언가를 얻는 것을 의미합니다. 여기에서 두 가지 질문이 생깁니다. 웹에서 얻을 수있는 것과 그것을 얻는 방법입니다.
첫 번째 질문에 대한 답은 ‘data’. 데이터는 모든 프로그래머에게 필수 불가결하며 모든 프로그래밍 프로젝트의 기본 요구 사항은 많은 양의 유용한 데이터입니다.
두 번째 질문에 대한 답은 데이터를 얻는 방법이 많기 때문에 약간 까다 롭습니다. 일반적으로 데이터베이스 나 데이터 파일 및 기타 소스에서 데이터를 가져올 수 있습니다. 그러나 온라인에서 사용할 수있는 많은 양의 데이터가 필요하면 어떻게해야합니까? 이러한 종류의 데이터를 가져 오는 한 가지 방법은 필요한 데이터를 수동으로 검색 (웹 브라우저에서 클릭)하고 저장 (스프레드 시트 또는 파일에 복사-붙여 넣기)하는 것입니다. 이 방법은 매우 지루하고 시간이 많이 걸립니다. 이러한 데이터를 얻는 또 다른 방법은web scraping.
Web scraping라고도 함 web data mining 또는 web harvesting, 웹에서 유용한 정보를 자동으로 추출, 파싱, 다운로드 및 정리할 수있는 에이전트를 구축하는 과정입니다. 즉, 웹 사이트의 데이터를 수동으로 저장하는 대신 웹 스크래핑 소프트웨어가 요구 사항에 따라 여러 웹 사이트에서 데이터를 자동으로로드하고 추출한다고 말할 수 있습니다.
웹 스크래핑의 기원
웹 스크래핑의 기원은 웹 기반이 아닌 응용 프로그램이나 기본 Windows 응용 프로그램을 통합하는 데 사용 된 화면 스크랩입니다. 원래는 WWW (World Wide Web)가 널리 사용되기 전에 화면 스크래핑이 사용되었지만 확장 된 WWW를 확장 할 수 없었습니다. 이로 인해 화면 스크래핑 접근 방식과라는 기술을 자동화해야했습니다.‘Web Scraping’ 존재하게되었습니다.
웹 크롤링 대 웹 스크래핑
웹 크롤링 및 스크래핑이라는 용어는 기본 개념이 데이터를 추출하는 것이므로 종종 같은 의미로 사용됩니다. 그러나 그들은 서로 다릅니다. 우리는 그들의 정의와 기본적인 차이점을 이해할 수 있습니다.
웹 크롤링은 기본적으로 크롤러라고하는 봇을 사용하여 페이지의 정보를 색인화하는 데 사용됩니다. 그것은 또한 불린다indexing. 한편, 웹 스크래핑은 스크레이퍼라고하는 봇을 사용하여 정보를 추출하는 자동화 된 방법입니다. 그것은 또한 불린다data extraction.
이 두 용어의 차이점을 이해하기 위해 아래에 제공된 비교 테이블을 살펴 보겠습니다.
| 웹 크롤링 | 웹 스크래핑 |
|---|---|
| 다수의 웹 사이트 콘텐츠를 다운로드하고 저장하는 것을 말합니다. | 사이트 별 구조를 사용하여 웹 사이트에서 개별 데이터 요소를 추출하는 것을 말합니다. |
| 대부분 대규모로 수행됩니다. | 모든 규모로 구현할 수 있습니다. |
| 일반 정보를 제공합니다. | 특정 정보를 제공합니다. |
| Google, Bing, Yahoo와 같은 주요 검색 엔진에서 사용됩니다. Googlebot 웹 크롤러의 예입니다. | 웹 스크래핑을 사용하여 추출 된 정보는 다른 웹 사이트에서 복제하거나 데이터 분석을 수행하는 데 사용할 수 있습니다. 예를 들어 데이터 요소는 이름, 주소, 가격 등이 될 수 있습니다. |
웹 스크래핑 사용
웹 스크래핑을 사용하는 용도와 이유는 World Wide Web의 사용만큼이나 끝이 없습니다. 웹 스크레이퍼는 사람이 할 수있는 것처럼 온라인 음식 주문, 온라인 쇼핑 웹 사이트 스캔, 경기 티켓 구매 등 무엇이든 할 수 있습니다. 여기서는 웹 스크래핑의 중요한 용도에 대해 설명합니다.
E-commerce Websites − 웹 스크레이퍼는 비교를 위해 다양한 전자 상거래 웹 사이트에서 특정 제품의 가격과 관련된 데이터를 수집 할 수 있습니다.
Content Aggregators − 웹 스크래핑은 업데이트 된 데이터를 사용자에게 제공하기 위해 뉴스 애그리 게이터 및 작업 애그리 게이터와 같은 콘텐츠 애그리 게이터가 널리 사용합니다.
Marketing and Sales Campaigns − 웹 스크레이퍼를 사용하여 영업 및 마케팅 캠페인을위한 이메일, 전화 번호 등과 같은 데이터를 얻을 수 있습니다.
Search Engine Optimization (SEO) − 웹 스크래핑은 SEMRush, Majestic 등과 같은 SEO 도구에서 널리 사용되어 중요한 검색 키워드의 순위를 비즈니스에 알려줍니다.
Data for Machine Learning Projects − 기계 학습 프로젝트를위한 데이터 검색은 웹 스크래핑에 따라 다릅니다.
Data for Research − 연구원은이 자동화 된 프로세스를 통해 시간을 절약함으로써 연구 작업 목적으로 유용한 데이터를 수집 할 수 있습니다.
웹 스크레이퍼의 구성 요소
웹 스크레이퍼는 다음 구성 요소로 구성됩니다.
웹 크롤러 모듈
웹 스크레이퍼의 매우 필요한 구성 요소 인 웹 크롤러 모듈은 URL에 대한 HTTP 또는 HTTPS 요청을 만들어 대상 웹 사이트를 탐색하는 데 사용됩니다. 크롤러는 구조화되지 않은 데이터 (HTML 콘텐츠)를 다운로드하여 다음 모듈 인 추출기에 전달합니다.
추출기
추출기는 가져온 HTML 콘텐츠를 처리하고 데이터를 반 구조화 된 형식으로 추출합니다. 이것은 파서 모듈이라고도하며 정규 표현식, HTML 파싱, DOM 파싱 또는 인공 지능과 같은 다양한 파싱 기술을 사용합니다.
데이터 변환 및 정리 모듈
위에서 추출한 데이터는 즉시 사용하기에 적합하지 않습니다. 우리가 사용할 수 있도록 청소 모듈을 통과해야합니다. 이를 위해 문자열 조작 또는 정규식과 같은 메서드를 사용할 수 있습니다. 추출 및 변환은 단일 단계에서도 수행 할 수 있습니다.
스토리지 모듈
데이터를 추출한 후 요구 사항에 따라 데이터를 저장해야합니다. 스토리지 모듈은 데이터베이스 또는 JSON 또는 CSV 형식으로 저장할 수있는 표준 형식으로 데이터를 출력합니다.
웹 스크레이퍼의 작동
웹 스크레이퍼는 여러 웹 페이지의 콘텐츠를 다운로드하고 여기에서 데이터를 추출하는 데 사용되는 소프트웨어 또는 스크립트로 정의 될 수 있습니다.
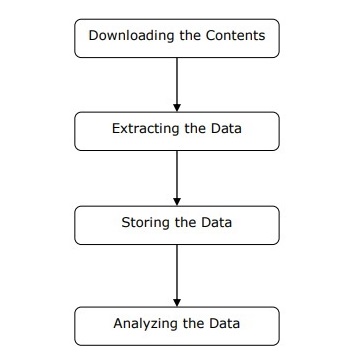
위의 다이어그램에 표시된 것처럼 간단한 단계로 웹 스크레이퍼의 작동을 이해할 수 있습니다.
1 단계 : 웹 페이지에서 콘텐츠 다운로드
이 단계에서 웹 스크레이퍼는 여러 웹 페이지에서 요청 된 콘텐츠를 다운로드합니다.
2 단계 : 데이터 추출
웹 사이트의 데이터는 HTML이며 대부분 구조화되지 않았습니다. 따라서이 단계에서 웹 스크레이퍼는 다운로드 한 콘텐츠에서 구조화 된 데이터를 구문 분석하고 추출합니다.
3 단계 : 데이터 저장
여기에서 웹 스크레이퍼는 추출 된 데이터를 CSV, JSON 또는 데이터베이스와 같은 형식으로 저장하고 저장합니다.
4 단계 : 데이터 분석
이 모든 단계가 성공적으로 완료되면 웹 스크레이퍼가 얻은 데이터를 분석합니다.