빠른 가이드
시스템의 아키텍처는 주요 구성 요소, 관계 (구조) 및 서로 상호 작용하는 방식을 설명합니다. 소프트웨어 아키텍처 및 디자인에는 비즈니스 전략, 품질 속성, 인간 역학, 디자인 및 IT 환경과 같은 여러 기여 요소가 포함됩니다.

소프트웨어 아키텍처와 디자인을 소프트웨어 아키텍처와 소프트웨어 디자인의 두 단계로 분리 할 수 있습니다. 에Architecture, 비 기능적 결정은 기능적 요구 사항에 따라 캐스팅되고 분리됩니다. 디자인에서는 기능 요구 사항이 충족됩니다.
소프트웨어 아키텍처
아키텍처는 blueprint for a system. 시스템 복잡성을 관리하고 구성 요소 간의 통신 및 조정 메커니즘을 설정하기위한 추상화를 제공합니다.
그것은 structured solution 모든 기술 및 운영 요구 사항을 충족하는 동시에 성능 및 보안과 같은 공통 품질 속성을 최적화합니다.
또한 소프트웨어 개발과 관련된 조직에 대한 일련의 중요한 결정이 포함되며 이러한 각 결정은 최종 제품의 품질, 유지 관리 성, 성능 및 전반적인 성공에 상당한 영향을 미칠 수 있습니다. 이러한 결정은 다음으로 구성됩니다.
시스템을 구성하는 데 사용되는 구조 요소 및 인터페이스 선택.
이러한 요소 간의 공동 작업에 지정된 동작입니다.
이러한 구조 및 행동 요소를 대규모 하위 시스템으로 구성합니다.
아키텍처 결정은 비즈니스 목표와 일치합니다.
아키텍처 스타일은 조직을 안내합니다.
소프트웨어 디자인
소프트웨어 디자인은 design plan그것은 시스템의 요소, 그것들이 어떻게 적합하고 시스템의 요구 사항을 충족시키기 위해 함께 작동 하는지를 설명합니다. 설계 계획을 갖는 목적은 다음과 같습니다.
시스템 요구 사항을 협상하고 고객, 마케팅 및 관리 담당자와 기대치를 설정합니다.
개발 과정에서 청사진 역할을합니다.
세부 설계, 코딩, 통합 및 테스트를 포함한 구현 작업을 안내합니다.
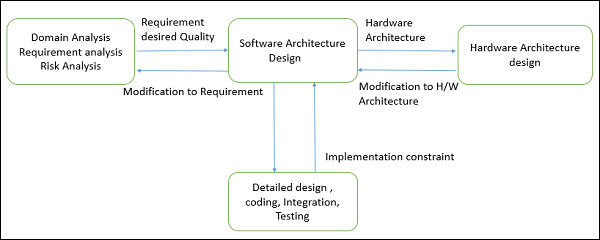
세부 설계, 코딩, 통합 및 테스트 전과 도메인 분석, 요구 사항 분석 및 위험 분석 후에 발생합니다.
건축의 목표
아키텍처의 주요 목표는 애플리케이션 구조에 영향을 미치는 요구 사항을 식별하는 것입니다. 잘 구성된 아키텍처는 기술 솔루션 구축과 관련된 비즈니스 위험을 줄이고 비즈니스와 기술 요구 사항을 연결합니다.
다른 목표 중 일부는 다음과 같습니다.
시스템 구조를 노출하되 구현 세부 정보를 숨 깁니다.
모든 사용 사례 및 시나리오를 실현하십시오.
다양한 이해 관계자의 요구 사항을 해결하십시오.
기능 및 품질 요구 사항을 모두 처리합니다.
소유권 목표를 줄이고 조직의 시장 지위를 개선합니다.
시스템에서 제공하는 품질과 기능을 개선합니다.
조직 또는 시스템에 대한 외부 신뢰를 향상시킵니다.
한계
소프트웨어 아키텍처는 여전히 소프트웨어 엔지니어링 분야에서 떠오르는 분야입니다. 다음과 같은 제한이 있습니다.
아키텍처를 표현하는 도구와 표준화 된 방법이 부족합니다.
아키텍처가 요구 사항을 충족하는 구현으로 이어질지 예측할 수있는 분석 방법이 없습니다.
소프트웨어 개발에 대한 건축 설계의 중요성에 대한 인식 부족.
소프트웨어 설계자의 역할에 대한 이해 부족 및 이해 관계자 간의 의사 소통 부족
디자인 프로세스, 디자인 경험 및 디자인 평가에 대한 이해 부족.
소프트웨어 설계자의 역할
소프트웨어 아키텍트는 기술 팀이 전체 애플리케이션을 만들고 설계 할 수있는 솔루션을 제공합니다. 소프트웨어 아키텍트는 다음 영역에 대한 전문 지식이 있어야합니다.
디자인 전문성
객체 지향 설계, 이벤트 중심 설계 등과 같은 다양한 방법과 접근 방식을 포함한 소프트웨어 설계 전문가
디자인의 무결성을 위해 개발 팀을 이끌고 개발 노력을 조정합니다.
설계 제안을 검토하고 그들 사이의 균형을 맞출 수 있어야합니다.
도메인 전문성
개발중인 시스템에 대한 전문가이며 소프트웨어 진화를 계획합니다.
요구 사항 조사 프로세스를 지원하여 완전성과 일관성을 보장합니다.
개발중인 시스템의 도메인 모델 정의를 조정합니다.
기술 전문성
시스템 구현에 도움이되는 사용 가능한 기술에 대한 전문가.
프로그래밍 언어, 프레임 워크, 플랫폼, 데이터베이스 등의 선택을 조정합니다.
방법 론적 전문성
SDLC (Software Development Life Cycle) 동안 채택 할 수있는 소프트웨어 개발 방법론에 대한 전문가입니다.
전체 팀에 도움이되는 적절한 개발 방식을 선택하십시오.
소프트웨어 아키텍트의 숨겨진 역할
팀 구성원 간의 기술 작업을 촉진하고 팀의 신뢰 관계를 강화합니다.
지식을 공유하고 풍부한 경험을 가진 정보 전문가.
팀원을 산만하게하고 프로젝트의 가치를 낮추는 외부 요인으로부터 팀원을 보호합니다.
건축가의 결과물
명확하고 완전하며 일관되며 달성 가능한 일련의 기능적 목표
적어도 두 개의 분해 계층이있는 시스템의 기능적 설명
시스템 개념
적어도 두 개의 분해 레이어가있는 시스템 형태의 디자인
타이밍, 운영자 속성, 구현 및 운영 계획에 대한 개념
기능적 분해를 보장하는 문서 또는 프로세스를 따르고 인터페이스 형식을 제어합니다.
품질 속성
품질은 우수성의 척도 또는 결함이나 결함이없는 상태입니다. 품질 속성은 시스템의 기능과는 별 개인 시스템 속성입니다.
품질 속성을 구현하면 좋은 시스템과 나쁜 시스템을 쉽게 구별 할 수 있습니다. 속성은 런타임 동작, 시스템 설계 및 사용자 경험에 영향을 미치는 전반적인 요소입니다.
그들은 다음과 같이 분류 될 수 있습니다-
정적 품질 속성
아키텍처, 디자인 및 소스 코드와 직접 관련된 시스템 및 조직의 구조를 반영합니다. 최종 사용자에게는 보이지 않지만 개발 및 유지 관리 비용 (예 : 모듈성, 테스트 가능성, 유지 관리 가능성 등)에 영향을줍니다.
동적 품질 속성
실행 중 시스템의 동작을 반영합니다. 이들은 시스템의 아키텍처, 디자인, 소스 코드, 구성, 배포 매개 변수, 환경 및 플랫폼과 직접 관련됩니다.
최종 사용자가 볼 수 있고 런타임에 존재합니다 (예 : 처리량, 견고성, 확장 성 등).
품질 시나리오
품질 시나리오는 오류가 실패하는 것을 방지하는 방법을 지정합니다. 속성 사양에 따라 여섯 부분으로 나눌 수 있습니다.
Source − 자극을 생성하는 사람, 하드웨어, 소프트웨어 또는 물리적 인프라와 같은 내부 또는 외부 개체.
Stimulus − 시스템에 도착했을 때 고려해야 할 조건.
Environment − 자극은 특정 조건 내에서 발생합니다.
Artifact − 전체 시스템 또는 프로세서, 통신 채널, 영구 저장소, 프로세스 등과 같은 일부 시스템
Response − 오류 감지, 오류 복구, 이벤트 소스 비활성화 등과 같은 자극 도착 후 수행되는 활동.
Response measure − 요구 사항을 테스트 할 수 있도록 발생한 응답을 측정해야합니다.
일반적인 품질 속성
다음 표는 소프트웨어 아키텍처가 가져야하는 일반적인 품질 속성을 나열합니다.
| 범주 | 품질 속성 | 기술 |
|---|---|---|
| 디자인 품질 | 개념적 무결성 | 전체 디자인의 일관성과 일관성을 정의합니다. 여기에는 구성 요소 또는 모듈이 설계되는 방식이 포함됩니다. |
| 유지 보수성 | 시스템이 어느 정도 쉽게 변경 될 수있는 능력. | |
| 재사용 성 | 다른 애플리케이션에서 사용하기에 적합한 구성 요소 및 하위 시스템의 기능을 정의합니다. | |
| 런타임 품질 | 상호 운용성 | 외부 당사자가 작성하고 실행하는 다른 외부 시스템과 통신하고 정보를 교환하여 시스템 또는 다른 시스템이 성공적으로 작동 할 수있는 능력. |
| 관리 용이성 | 시스템 관리자가 애플리케이션을 얼마나 쉽게 관리 할 수 있는지 정의합니다. | |
| 신뢰할 수 있음 | 시간이 지나도 계속 작동 할 수있는 시스템의 능력. | |
| 확장 성 | 시스템의 성능에 영향을주지 않고로드 증가를 처리 할 수있는 시스템의 능력 또는 쉽게 확장 할 수있는 능력. | |
| 보안 | 설계된 용도를 벗어난 악의적이거나 우발적 인 행동을 방지하는 시스템의 기능. | |
| 공연 | 주어진 시간 간격 내에 작업을 실행하기위한 시스템의 응답 성을 나타냅니다. | |
| 유효성 | 시스템이 작동하고 작동하는 시간의 비율을 정의합니다. 사전 정의 된 기간 동안 전체 시스템 다운 타임의 백분율로 측정 할 수 있습니다. | |
| 시스템 품질 | 지원 가능성 | 올바르게 작동하지 않을 때 문제를 식별하고 해결하는 데 도움이되는 정보를 제공하는 시스템의 능력. |
| 테스트 가능성 | 시스템 및 해당 구성 요소에 대한 테스트 기준을 만드는 것이 얼마나 쉬운 지 측정합니다. | |
| 사용자 자질 | 유용성 | 응용 프로그램이 직관적으로 사용자와 소비자의 요구 사항을 얼마나 잘 충족하는지 정의합니다. |
| 아키텍처 품질 | 단정 | 시스템의 모든 요구 사항을 충족하기위한 책임. |
| 비 런타임 품질 | 휴대 성 | 다른 컴퓨팅 환경에서 실행되는 시스템의 능력. |
| 완전 | 시스템의 별도로 개발 된 구성 요소가 함께 올바르게 작동하도록하는 기능. | |
| 수정 가능성 | 각 소프트웨어 시스템이 소프트웨어 변경 사항을 쉽게 수용 할 수 있습니다. | |
| 비즈니스 품질 속성 | 비용 및 일정 | 시장 출시 시간, 예상 프로젝트 수명 및 레거시 활용과 관련된 시스템 비용. |
| 시장성 | 시장 경쟁과 관련하여 시스템 사용. |
소프트웨어 아키텍처는 시스템의 구성으로 설명되며, 여기서 시스템은 정의 된 기능을 수행하는 구성 요소 집합을 나타냅니다.
건축 스타일
그만큼 architectural style라고도 함 architectural pattern는 애플리케이션을 형성하는 일련의 원칙입니다. 구조적 조직의 패턴 측면에서 시스템 제품군에 대한 추상 프레임 워크를 정의합니다.
건축 스타일은-
결합 방법에 대한 규칙과 함께 구성 요소 및 커넥터의 사전을 제공합니다.
자주 발생하는 문제에 대한 솔루션을 제공하여 파티셔닝을 개선하고 설계를 재사용 할 수 있습니다.
구성 요소 모음 (잘 정의 된 인터페이스, 재사용 및 교체 가능한 모듈) 및 커넥터 (모듈 간의 통신 링크)를 구성하는 특정 방법을 설명합니다.
컴퓨터 기반 시스템 용으로 구축 된 소프트웨어는 여러 아키텍처 스타일 중 하나를 나타냅니다. 각 스타일은 다음을 포함하는 시스템 범주를 설명합니다.
시스템에서 필요한 기능을 수행하는 구성 요소 유형 집합입니다.
서로 다른 구성 요소 간의 통신, 조정 및 협력을 가능하게하는 커넥터 세트 (서브 루틴 호출, 원격 프로 시저 호출, 데이터 스트림 및 소켓)입니다.
시스템을 형성하기 위해 구성 요소를 통합하는 방법을 정의하는 의미 적 제약.
런타임 상호 관계를 나타내는 구성 요소의 토폴로지 레이아웃입니다.
일반적인 건축 설계
다음 표는 주요 초점 영역별로 구성 할 수있는 건축 스타일을 나열합니다.
| 범주 | 건축 설계 | 기술 |
|---|---|---|
| 통신 | 메시지 버스 | 하나 이상의 통신 채널을 사용하여 메시지를 송수신 할 수있는 소프트웨어 시스템 사용을 규정합니다. |
| 서비스 지향 아키텍처 (SOA) | 계약 및 메시지를 사용하여 기능을 서비스로 노출하고 사용하는 애플리케이션을 정의합니다. | |
| 전개 | 클라이언트 서버 | 클라이언트가 서버에 요청하는 두 개의 애플리케이션으로 시스템을 분리합니다. |
| 3 계층 또는 N 계층 | 기능을 별도의 세그먼트로 분리하고 각 세그먼트는 물리적으로 분리 된 컴퓨터에있는 계층입니다. | |
| 도메인 | 도메인 중심 설계 | 비즈니스 도메인 모델링 및 비즈니스 도메인 내의 엔터티를 기반으로 비즈니스 개체를 정의하는 데 중점을 둡니다. |
| 구조 | 구성 요소 기반 | 애플리케이션 설계를 잘 정의 된 통신 인터페이스를 노출하는 재사용 가능한 기능 또는 논리적 구성 요소로 분류합니다. |
| 계층화 | 애플리케이션의 관심사를 스택 그룹 (레이어)으로 나눕니다. | |
| 객체 지향 | 응용 프로그램 또는 시스템의 책임을 개체로 나누는 것을 기반으로하며, 각각 개체와 관련된 데이터 및 동작을 포함합니다. |
건축 유형
기업의 관점에서 보면 4 가지 유형의 아키텍처가 있으며 총체적으로 이러한 아키텍처를 enterprise architecture.
Business architecture − 기업 내 비즈니스, 거버넌스, 조직 및 주요 비즈니스 프로세스의 전략을 정의하고 비즈니스 프로세스의 분석 및 설계에 중점을 둡니다.
Application (software) architecture − 개별 애플리케이션 시스템, 상호 작용 및 조직의 비즈니스 프로세스와의 관계에 대한 청사진 역할을합니다.
Information architecture − 논리적 및 물리적 데이터 자산과 데이터 관리 리소스를 정의합니다.
Information technology (IT) architecture − 조직의 전체 정보 시스템을 구성하는 하드웨어 및 소프트웨어 빌딩 블록을 정의합니다.
아키텍처 디자인 프로세스
아키텍처 설계 프로세스는 기능적 및 비 기능적 요구 사항을 충족하기 위해 시스템을 여러 구성 요소와 상호 작용으로 분해하는 데 중점을 둡니다. 소프트웨어 아키텍처 설계에 대한 주요 입력은 다음과 같습니다.
분석 작업에 의해 생성 된 요구 사항입니다.
하드웨어 아키텍처 (소프트웨어 아키텍트는 하드웨어 아키텍처를 구성하는 시스템 아키텍트에게 요구 사항을 제공합니다).
아키텍처 설계 프로세스의 결과 또는 출력은 architectural description. 기본 아키텍처 설계 프로세스는 다음 단계로 구성됩니다.
문제 이해
이것은 다음 디자인의 품질에 영향을 미치기 때문에 가장 중요한 단계입니다.
문제에 대한 명확한 이해 없이는 효과적인 솔루션을 만들 수 없습니다.
많은 소프트웨어 프로젝트와 제품은 실제로 유효한 비즈니스 문제를 해결하지 못했거나 인식 할 수있는 투자 수익 (ROI)이 없기 때문에 실패로 간주됩니다.
디자인 요소와 그 관계 식별
이 단계에서는 시스템의 경계와 컨텍스트를 정의하기위한 기준을 구축합니다.
기능 요구 사항에 따라 시스템을 주요 구성 요소로 분해합니다. 분해는 요소의 세분성을 지정하지 않고 디자인 요소 간의 종속성을 보여주는 DSM (Design Structure Matrix)을 사용하여 모델링 할 수 있습니다.
이 단계에서 아키텍처의 첫 번째 유효성 검사는 여러 시스템 인스턴스를 설명하여 수행되며이 단계를 기능 기반 아키텍처 설계라고합니다.
아키텍처 디자인 평가
각 품질 속성에는 추정치가 제공되므로 정 성적 측정 또는 정량적 데이터를 수집하기 위해 설계가 평가됩니다.
여기에는 아키텍처 품질 속성 요구 사항을 준수하기위한 아키텍처 평가가 포함됩니다.
모든 예상 품질 속성이 필수 표준에 부합하면 건축 설계 프로세스가 완료됩니다.
그렇지 않은 경우 소프트웨어 아키텍처 설계의 세 번째 단계 인 아키텍처 변환이 시작됩니다. 관찰 된 품질 속성이 요구 사항을 충족하지 않으면 새 디자인을 만들어야합니다.
아키텍처 디자인 혁신
이 단계는 건축 설계를 평가 한 후에 수행됩니다. 품질 속성 요구 사항을 완전히 충족 할 때까지 아키텍처 디자인을 변경해야합니다.
도메인 기능을 유지하면서 품질 속성을 개선하기 위해 디자인 솔루션을 선택하는 것과 관련이 있습니다.
디자인 연산자, 스타일 또는 패턴을 적용하여 디자인을 변형합니다. 변환을 위해 기존 설계를 취하고 분해, 복제, 압축, 추상화 및 리소스 공유와 같은 설계 연산자를 적용합니다.
디자인을 다시 평가하고 필요한 경우 동일한 프로세스를 여러 번 반복하고 심지어 재귀 적으로 수행합니다.
변환 (즉, 품질 속성 최적화 솔루션)은 일반적으로 하나 또는 일부 품질 속성을 개선하고 다른 항목에는 부정적인 영향을 미칩니다.
주요 아키텍처 원칙
다음은 아키텍처를 설계 할 때 고려해야 할 핵심 원칙입니다.
오래도록 구축하는 대신 변경하도록 구축
새로운 요구 사항과 과제를 해결하기 위해 시간이 지남에 따라 애플리케이션이 어떻게 변경되어야하는지 고려하고이를 지원할 수있는 유연성을 구축하십시오.
분석 할 위험 및 모델 감소
디자인 도구, 시각화, UML과 같은 모델링 시스템을 사용하여 요구 사항 및 디자인 결정을 캡처합니다. 영향도 분석 할 수 있습니다. 설계를 쉽게 반복하고 적용 할 수있는 기능을 억제 할 정도로 모델을 공식화하지 마십시오.
모델 및 시각화를 커뮤니케이션 및 협업 도구로 사용
설계, 결정 및 설계에 대한 지속적인 변경에 대한 효율적인 커뮤니케이션은 좋은 아키텍처에 매우 중요합니다. 아키텍처의 모델,보기 및 기타 시각화를 사용하여 모든 이해 관계자와 효율적으로 설계를 전달하고 공유합니다. 이를 통해 설계 변경 사항을 신속하게 전달할 수 있습니다.
주요 엔지니어링 결정과 실수가 가장 자주 발생하는 영역을 식별하고 이해합니다. 설계를보다 유연하게 만들고 변경으로 인해 손상 될 가능성을 줄이기 위해 처음에 주요 결정을 올바르게 내리는 데 투자하십시오.
점진적이고 반복적 인 접근 방식 사용
기본 아키텍처로 시작한 다음 반복 테스트를 통해 후보 아키텍처를 발전시켜 아키텍처를 개선합니다. 여러 번에 걸쳐 디자인에 세부 사항을 반복적으로 추가하여 크고 정확한 그림을 얻은 다음 세부 사항에 집중하십시오.
주요 설계 원칙
다음은 비용, 유지 보수 요구 사항을 최소화하고 아키텍처의 확장 성, 유용성을 최대화하기 위해 고려해야 할 설계 원칙입니다.
우려 사항 분리
시스템의 구성 요소를 특정 기능으로 분할하여 구성 요소 기능이 겹치지 않도록합니다. 이것은 높은 응집력과 낮은 결합을 제공합니다. 이 접근 방식은 시스템을 쉽게 유지하는 데 도움이되는 시스템 구성 요소 간의 상호 의존성을 방지합니다.
단일 책임 원칙
시스템의 모든 모듈에는 하나의 특정 책임이 있어야 사용자가 시스템을 명확하게 이해할 수 있습니다. 또한 구성 요소를 다른 구성 요소와 통합하는데도 도움이됩니다.
최소 지식의 원리
모든 구성 요소 또는 개체는 다른 구성 요소의 내부 세부 정보에 대한 지식이 없어야합니다. 이 접근 방식은 상호 의존성을 방지하고 유지 관리에 도움이됩니다.
대규모 설계를 사전에 최소화
응용 프로그램의 요구 사항이 명확하지 않은 경우 큰 디자인을 미리 최소화하십시오. 요구 사항을 수정할 가능성이있는 경우 전체 시스템에 대해 대규모 설계를하지 마십시오.
기능을 반복하지 마십시오
반복 금지 기능은 구성 요소의 기능이 반복되지 않도록 지정하므로 한 구성 요소에서만 코드를 구현해야합니다. 응용 프로그램 내에서 기능이 중복되면 변경 사항을 구현하기 어렵고 명확성이 떨어지며 잠재적 인 불일치가 발생할 수 있습니다.
기능을 재사용하면서 상속보다 구성 선호
상속은 하위 클래스와 상위 클래스간에 종속성을 생성하므로 하위 클래스의 무료 사용을 차단합니다. 반대로 컴포지션은 높은 수준의 자유를 제공하고 상속 계층 구조를 줄입니다.
구성 요소를 식별하고 논리적 계층으로 그룹화
요구 사항을 충족하기 위해 시스템에 필요한 식별 구성 요소 및 관심 영역. 그런 다음 이러한 관련 구성 요소를 논리적 계층으로 그룹화하면 사용자가 높은 수준에서 시스템의 구조를 이해하는 데 도움이됩니다. 동일한 레이어에서 다른 유형의 문제의 구성 요소를 혼합하지 마십시오.
계층 간 통신 프로토콜 정의
배포 시나리오 및 프로덕션 환경에 대한 완전한 지식이 필요한 구성 요소가 서로 통신하는 방법을 이해합니다.
레이어에 대한 데이터 형식 정의
다양한 구성 요소가 데이터 형식을 통해 서로 상호 작용합니다. 응용 프로그램을 쉽게 구현, 확장 및 유지 관리 할 수 있도록 데이터 형식을 혼합하지 마십시오. 여러 구성 요소가 서로 통신하는 동안 데이터를 코딩 / 디코딩 할 필요가 없도록 레이어의 데이터 형식을 동일하게 유지하십시오. 처리 오버 헤드를 줄입니다.
시스템 서비스 구성 요소는 추상적이어야합니다.
보안, 통신 또는 로깅, 프로파일 링 및 구성과 같은 시스템 서비스와 관련된 코드는 별도의 구성 요소에서 추상화해야합니다. 디자인을 확장하고 유지 관리하는 것이 쉽기 때문에이 코드를 비즈니스 로직과 혼합하지 마십시오.
설계 예외 및 예외 처리 메커니즘
미리 예외를 정의하면 구성 요소가 오류나 원치 않는 상황을 우아하게 관리 할 수 있습니다. 예외 관리는 시스템 전체에서 동일합니다.
명명 규칙
명명 규칙은 미리 정의해야합니다. 사용자가 시스템을 쉽게 이해할 수 있도록 일관된 모델을 제공합니다. 팀 구성원이 다른 사람이 작성한 코드의 유효성을 검사하는 것이 더 쉬우므로 유지 관리 가능성이 높아집니다.
소프트웨어 아키텍처는 아키텍처 스타일 및 품질 속성과 함께 분해 및 구성을 사용하여 소프트웨어 시스템 추상화의 높은 수준의 구조를 포함합니다. 소프트웨어 아키텍처 설계는 시스템의 주요 기능 및 성능 요구 사항을 준수하고 안정성, 확장 성, 이식성 및 가용성과 같은 비 기능적 요구 사항을 충족해야합니다.
소프트웨어 아키텍처는 구성 요소 그룹, 연결, 상호 작용 및 모든 구성 요소의 배포 구성을 설명해야합니다.
소프트웨어 아키텍처는 다양한 방법으로 정의 할 수 있습니다.
UML (Unified Modeling Language) − UML은 소프트웨어 모델링 및 설계에 사용되는 객체 지향 솔루션 중 하나입니다.
Architecture View Model (4+1 view model) − 아키텍처보기 모델은 소프트웨어 응용 프로그램의 기능 및 비 기능적 요구 사항을 나타냅니다.
ADL (Architecture Description Language) − ADL은 소프트웨어 아키텍처를 공식적이고 의미 적으로 정의합니다.
UML
UML은 Unified Modeling Language의 약자입니다. 소프트웨어 청사진을 만드는 데 사용되는 그림 언어입니다. UML은 OMG (Object Management Group)에서 생성되었습니다. UML 1.0 사양 초안은 1997 년 1 월 OMG에 제안되었습니다. 이는 소프트웨어 개발의 기초가되는 소프트웨어 요구 사항 분석 및 설계 문서의 표준 역할을합니다.
UML은 소프트웨어 시스템을 시각화, 지정, 구성 및 문서화하는 범용 시각적 모델링 언어로 설명 될 수 있습니다. UML은 일반적으로 소프트웨어 시스템을 모델링하는 데 사용되지만이 경계 내에서 제한되지 않습니다. 또한 제조 단위의 프로세스 흐름과 같은 비 소프트웨어 시스템을 모델링하는 데 사용됩니다.
요소는 완전한 UML 그림을 만들기 위해 다양한 방식으로 연관 될 수있는 구성 요소와 같습니다. diagram. 따라서 실제 시스템에서 지식을 구현하려면 다양한 다이어그램을 이해하는 것이 매우 중요합니다. 우리는 두 개의 광범위한 다이어그램 범주를 가지고 있으며 하위 범주 즉,Structural Diagrams 과 Behavioral Diagrams.
구조 다이어그램
구조 다이어그램은 시스템의 정적 측면을 나타냅니다. 이러한 정적 측면은 주요 구조를 형성하고 따라서 안정적인 다이어그램 부분을 나타냅니다.
이러한 정적 부분은 클래스, 인터페이스, 개체, 구성 요소 및 노드로 표시됩니다. 구조 다이어그램은 다음과 같이 세분화 할 수 있습니다.
- 클래스 다이어그램
- 개체 다이어그램
- 구성 요소 다이어그램
- 배포 다이어그램
- 패키지 다이어그램
- 복합 구조
다음 표는 이러한 다이어그램에 대한 간략한 설명을 제공합니다.
| Sr. 아니. | 다이어그램 및 설명 |
|---|---|
| 1 | Class 시스템의 개체 방향을 나타냅니다. 클래스가 정적으로 관련되는 방식을 보여줍니다. |
| 2 | Object 런타임시 개체 집합 및 해당 관계를 나타내며 시스템의 정적보기를 나타냅니다. |
| 삼 | Component 시스템의 모든 구성 요소, 상호 관계, 상호 작용 및 인터페이스를 설명합니다. |
| 4 | Composite structure 모든 클래스, 컴포넌트의 인터페이스 등 컴포넌트의 내부 구조를 설명합니다. |
| 5 | Package 패키지 구조 및 구성을 설명합니다. 패키지의 클래스와 다른 패키지의 패키지를 다룹니다. |
| 6 | Deployment 배포 다이어그램은 노드와 그 관계의 집합입니다. 이러한 노드는 구성 요소가 배포되는 물리적 엔터티입니다. |
행동 다이어그램
행동 다이어그램은 기본적으로 시스템의 동적 측면을 포착합니다. 동적 측면은 기본적으로 시스템의 변경 / 이동 부분입니다. UML에는 다음과 같은 유형의 행동 다이어그램이 있습니다.
- 사용 사례 다이어그램
- 시퀀스 다이어그램
- 커뮤니케이션 다이어그램
- 상태 차트 다이어그램
- 활동 다이어그램
- 상호 작용 개요
- 시간 순서도
다음 표는 이러한 다이어그램에 대한 간략한 설명을 제공합니다.
| Sr. 아니. | 다이어그램 및 설명 |
|---|---|
| 1 | Use case 기능과 내부 / 외부 컨트롤러 간의 관계를 설명합니다. 이러한 컨트롤러를 액터라고합니다. |
| 2 | Activity 시스템의 제어 흐름을 설명합니다. 활동과 링크로 구성됩니다. 흐름은 순차, 동시 또는 분기 일 수 있습니다. |
| 삼 | State Machine/state chart 시스템의 이벤트 기반 상태 변경을 나타냅니다. 기본적으로 클래스, 인터페이스 등의 상태 변화를 설명합니다. 시스템의 내 / 외부 요인에 의한 반응을 시각화하는 데 사용됩니다. |
| 4 | Sequence 특정 기능을 수행하기 위해 시스템에서 호출 순서를 시각화합니다. |
| 5 | Interaction Overview 활동 및 시퀀스 다이어그램을 결합하여 시스템 및 비즈니스 프로세스에 대한 제어 흐름 개요를 제공합니다. |
| 6 | Communication 오브젝트의 역할에 초점을 맞춘다는 점을 제외하면 시퀀스 다이어그램과 동일합니다. 각 통신은 시퀀스 순서, 번호 및 과거 메시지와 연관됩니다. |
| 7 | Time Sequenced 상태, 조건 및 이벤트의 메시지 별 변경 사항을 설명합니다. |
아키텍처보기 모델
모델은 특정 관점 또는 관점에서 여러보기로 구성된 소프트웨어 아키텍처에 대한 완전하고 기본적이며 단순화 된 설명입니다.
뷰는 관련된 관심 사항의 관점에서 전체 시스템을 표현한 것입니다. 최종 사용자, 개발자, 프로젝트 관리자 및 테스터와 같은 다양한 이해 관계자의 관점에서 시스템을 설명하는 데 사용됩니다.
4 + 1보기 모델
4 + 1보기 모델은 Philippe Kruchten이 다중 및 동시보기 사용을 기반으로하는 소프트웨어 집약적 시스템의 아키텍처를 설명하기 위해 설계되었습니다. 이것은multiple view시스템의 다양한 기능과 문제를 해결하는 모델입니다. 소프트웨어 설계 문서를 표준화하고 모든 이해 관계자가 설계를 쉽게 이해할 수 있도록합니다.
소프트웨어 아키텍처 설계를 연구하고 문서화하기위한 아키텍처 검증 방법이며 모든 이해 관계자를위한 소프트웨어 아키텍처의 모든 측면을 다룹니다. 네 가지 필수 뷰를 제공합니다.
The logical view or conceptual view − 디자인의 객체 모델을 설명합니다.
The process view − 시스템의 활동을 설명하고 설계의 동시성 및 동기화 측면을 포착합니다.
The physical view − 하드웨어에 대한 소프트웨어 매핑을 설명하고 분산 된 측면을 반영합니다.
The development view − 환경 개발에서 소프트웨어의 정적 조직 또는 구조를 설명합니다.
이 뷰 모델은라는 뷰를 하나 더 추가하여 확장 할 수 있습니다. scenario view 또는 use case view소프트웨어 시스템의 최종 사용자 또는 고객을 위해. 다른 4 개의 뷰와 일관성이 있으며 "플러스 원"뷰, (4 + 1) 뷰 모델로 제공되는 아키텍처를 설명하는 데 사용됩니다. 다음 그림은 5 개의 동시보기 (4 + 1) 모델을 사용하는 소프트웨어 아키텍처를 설명합니다.

5 대신 4 + 1이라고하는 이유는 무엇입니까?
그만큼 use case view시스템의 높은 수준의 요구 사항을 자세히 설명하는 반면 다른 사용자는 이러한 요구 사항이 어떻게 실현되는지 자세히보기 때문에 특별한 의미가 있습니다. 다른 네 가지보기가 모두 완료되면 사실상 중복됩니다. 그러나 다른 모든 견해는 그것 없이는 불가능합니다. 다음 이미지와 표는 4 + 1보기를 자세히 보여줍니다.
| 논리적 | 방법 | 개발 | 물리적 인 | 대본 | |
|---|---|---|---|---|---|
| 기술 | 시스템의 구성 요소 (Object)와 상호 작용을 보여줍니다. | 시스템의 프로세스 / 워크 플로 규칙 및 해당 프로세스가 통신하는 방법을 보여 주며 시스템의 동적보기에 중점을 둡니다. | 시스템의 빌딩 블록보기를 제공하고 시스템 모듈의 정적 구성을 설명합니다. | 소프트웨어 응용 프로그램의 설치, 구성 및 배포를 보여줍니다. | 검증 및 일러스트레이션을 수행하여 설계가 완료되었음을 보여줍니다. |
| 뷰어 / 스테이크 보유자 | 최종 사용자, 분석가 및 설계자 | 통합 자 및 개발자 | 프로그래머 및 소프트웨어 프로젝트 관리자 | 시스템 엔지니어, 운영자, 시스템 관리자 및 시스템 설치자 | 그들의 견해와 평가자의 모든 견해 |
| 중히 여기다 | 기능 요구 사항 | 비 기능적 요구 사항 | 소프트웨어 모듈 구성 (소프트웨어 관리 재사용, 도구 제약) | 기본 하드웨어와 관련된 비 기능적 요구 사항 | 시스템 일관성 및 유효성 |
| UML – 다이어그램 | 클래스, 상태, 개체, 시퀀스, 통신 다이어그램 | 활동 다이어그램 | 구성 요소, 패키지 다이어그램 | 배포 다이어그램 | 사용 사례 다이어그램 |
아키텍처 설명 언어 (ADL)
ADL은 소프트웨어 아키텍처를 정의하기위한 구문과 의미를 제공하는 언어입니다. 시스템의 구현과 구별되는 소프트웨어 시스템의 개념적 아키텍처를 모델링하기위한 기능을 제공하는 표기법 사양입니다.
ADL은 아키텍처 설명의 빌딩 블록 인 아키텍처 구성 요소, 연결, 인터페이스 및 구성을 지원해야합니다. 아키텍처 설명에 사용되는 표현의 한 형태이며 구성 요소를 분해하고, 구성 요소를 결합하고, 구성 요소의 인터페이스를 정의하는 기능을 제공합니다.
아키텍처 설명 언어는 프로세서, 장치, 버스 및 메모리와 같은 하드웨어 구성 요소뿐만 아니라 프로세스, 스레드, 데이터 및 하위 프로그램과 같은 소프트웨어 기능을 설명하는 공식 사양 언어입니다.
ADL과 프로그래밍 언어 또는 모델링 언어를 분류하거나 구별하기가 어렵습니다. 그러나 ADL로 분류되는 언어에는 다음과 같은 요구 사항이 있습니다.
모든 관련 당사자에게 아키텍처를 전달하는 데 적합해야합니다.
아키텍처 생성, 개선 및 검증 작업에 적합해야합니다.
추가 구현을위한 기반을 제공해야하므로 최종 시스템 사양이 ADL에서 파생 될 수 있도록 ADL 사양에 정보를 추가 할 수 있어야합니다.
대부분의 일반적인 건축 스타일을 표현할 수 있어야합니다.
분석 기능을 지원하거나 빠른 생성 프로토 타입 구현을 제공해야합니다.
객체 지향 (OO) 패러다임은 새로운 프로그래밍 접근 방식의 초기 개념에서 형태를 띠고 설계 및 분석 방법에 대한 관심은 훨씬 늦게 나타났습니다. OO 분석 및 디자인 패러다임은 OO 프로그래밍 언어가 널리 채택 된 논리적 결과입니다.
첫 번째 객체 지향 언어는 Simula (실제 시스템 시뮬레이션) 노르웨이 컴퓨팅 센터의 연구원이 1960 년에 개발했습니다.
1970 년 Alan Kay Xerox PARC의 그의 연구 그룹은 개인용 컴퓨터를 만들었습니다. Dynabook 그리고 Dynabook을 프로그래밍하기위한 최초의 순수 객체 지향 프로그래밍 언어 (OOPL)-Smalltalk.
1980 년대에 Grady Booch주로 프로그래밍 언어 인 Ada를위한 디자인을 제시 한 Object Oriented Design이라는 논문을 발표했습니다. 이어지는 에디션에서 그는 자신의 아이디어를 완전한 객체 지향 디자인 방법으로 확장했습니다.
1990 년대에 Coad 객체 지향 방법에 행동 아이디어를 통합했습니다.
다른 중요한 혁신은 다음과 같은 OMT (Object Modeling Techniques)였습니다. James Rum Baugh 및 OOSE (Object-Oriented Software Engineering) Ivar Jacobson.
OO 패러다임 소개
OO 패러다임은 모든 소프트웨어 개발을위한 중요한 방법론입니다. 파이프 및 필터, 데이터 저장소 및 구성 요소 기반과 같은 대부분의 아키텍처 스타일 또는 패턴은이 패러다임을 사용하여 구현할 수 있습니다.
객체 지향 시스템의 기본 개념과 용어-
목적
객체는 물리적 또는 개념적 존재를 가질 수있는 객체 지향 환경의 실제 요소입니다. 각 개체는-
시스템의 다른 개체와 구별하는 ID입니다.
개체의 특성 속성과 개체가 보유하는 속성 값을 결정하는 상태입니다.
상태 변경 측면에서 개체가 수행 한 외부에서 볼 수있는 활동을 나타내는 동작입니다.
응용 프로그램의 필요에 따라 개체를 모델링 할 수 있습니다. 객체는 고객, 자동차 등과 같은 물리적 존재를 가질 수 있습니다. 또는 프로젝트, 프로세스 등과 같은 무형의 개념적 존재.
수업
클래스는 일반적인 동작을 나타내는 동일한 특성 속성을 가진 개체 모음을 나타냅니다. 청사진 또는 생성 할 수있는 개체에 대한 설명을 제공합니다. 개체를 클래스의 구성원으로 만드는 것을 인스턴스화라고합니다. 따라서 객체는instance 수업의.
클래스의 구성 요소는 다음과 같습니다.
클래스에서 인스턴스화 할 개체에 대한 속성 집합입니다. 일반적으로 클래스의 다른 객체는 속성 값에 약간의 차이가 있습니다. 속성은 종종 클래스 데이터라고합니다.
클래스 객체의 동작을 나타내는 일련의 작업입니다. 작업은 기능 또는 방법이라고도합니다.
Example
2 차원 공간에서 기하학적 도형 원을 나타내는 간단한 클래스 Circle을 고려해 보겠습니다. 이 클래스의 속성은 다음과 같이 식별 할 수 있습니다.
- x 좌표, 중심의 x 좌표를 나타냅니다.
- y 좌표, 중심의 y 좌표를 나타냅니다.
- a, 원의 반경을 나타냅니다.
일부 작업은 다음과 같이 정의 할 수 있습니다.
- findArea (), 면적 계산 방법
- findCircumference (), 둘레를 계산하는 메서드
- scale (), 반경을 늘리거나 줄이는 방법
캡슐화
캡슐화는 클래스 내에서 속성과 메서드를 함께 바인딩하는 프로세스입니다. 캡슐화를 통해 클래스의 내부 세부 정보를 외부에서 숨길 수 있습니다. 클래스가 제공하는 인터페이스를 통해서만 외부에서 클래스의 요소에 액세스 할 수 있습니다.
다형성
다형성은 원래 여러 형태를 취할 수있는 능력을 의미하는 그리스어 단어입니다. 객체 지향 패러다임에서 다형성은 작동하는 인스턴스에 따라 다른 방식으로 작업을 사용하는 것을 의미합니다. 다형성은 내부 구조가 다른 객체가 공통 외부 인터페이스를 갖도록합니다. 다형성은 상속을 구현하는 동안 특히 효과적입니다.
Example
각각 findArea () 메소드가있는 Circle과 Square의 두 클래스를 고려해 보겠습니다. 클래스에 포함 된 메서드의 이름과 목적은 동일하지만 내부 구현, 즉 면적 계산 절차는 클래스마다 다릅니다. Circle 클래스의 객체가 findArea () 메서드를 호출하면 작업은 Square 클래스의 findArea () 메서드와 충돌하지 않고 원의 영역을 찾습니다.
Relationships
시스템을 설명하기 위해서는 시스템의 동적 (동작) 및 정적 (논리) 사양을 모두 제공해야합니다. 동적 사양은 메시지 전달과 같은 객체 간의 관계를 설명합니다. 그리고 정적 사양은 예를 들어 집계, 연관 및 상속과 같은 클래스 간의 관계를 설명합니다.
메시지 전달
모든 응용 프로그램에는 조화로운 방식으로 상호 작용하는 여러 개체가 필요합니다. 시스템의 개체는 메시지 전달을 사용하여 서로 통신 할 수 있습니다. 시스템에 obj1과 obj2라는 두 개의 객체가 있다고 가정합니다. obj1이 obj2가 메서드 중 하나를 실행하도록하려는 경우 개체 obj1은 개체 obj2에 메시지를 보냅니다.
구성 또는 집계
집계 또는 구성은 클래스가 다른 클래스의 개체 조합으로 구성 될 수있는 클래스 간의 관계입니다. 객체를 다른 클래스의 본문 내에 직접 배치 할 수 있습니다. 집계는 전체에서 부분으로 이동할 수있는 기능과 함께 "일부"또는 "가 있음"관계라고합니다. 집계 개체는 하나 이상의 다른 개체로 구성된 개체입니다.
협회
연관은 공통 구조와 공통 동작을 갖는 링크 그룹입니다. 연관은 하나 이상의 클래스 개체 간의 관계를 나타냅니다. 링크는 연관의 인스턴스로 정의 될 수 있습니다. 연관 정도는 연결에 관련된 클래스의 수를 나타냅니다. 차수는 단항, 이진 또는 삼항 일 수 있습니다.
- 단항 관계는 동일한 클래스의 개체를 연결합니다.
- 이진 관계는 두 클래스의 개체를 연결합니다.
- 삼항 관계는 세 개 이상의 클래스의 개체를 연결합니다.
계승
기능을 확장하고 개선하여 기존 클래스에서 새 클래스를 만들 수있는 메커니즘입니다. 기존 클래스를 기본 클래스 / 부모 클래스 / 수퍼 클래스라고하고 새 클래스를 파생 클래스 / 자식 클래스 / 하위 클래스라고합니다.
하위 클래스는 수퍼 클래스가 허용하는 경우 수퍼 클래스의 속성 및 메서드를 상속하거나 파생 할 수 있습니다. 게다가, 서브 클래스는 자체 속성과 메소드를 추가 할 수 있으며 수퍼 클래스 메소드를 수정할 수 있습니다. 상속은 "is – a"관계를 정의합니다.
Example
Mammal 클래스에서 Human, Cat, Dog, Cow 등과 같은 여러 클래스가 파생 될 수 있습니다. 인간, 고양이, 개 및 소는 모두 포유류의 고유 한 특성을 가지고 있습니다. 또한 각각 고유 한 특성이 있습니다. 소는 포유류라고 할 수 있습니다.
OO 분석
소프트웨어 개발의 객체 지향 분석 단계에서 시스템 요구 사항이 결정되고 클래스가 식별되며 클래스 간의 관계가 인식됩니다. OO 분석의 목적은 애플리케이션 도메인과 시스템의 특정 요구 사항을 이해하는 것입니다. 이 단계의 결과는 시스템의 논리적 구조 및 실행 가능성에 대한 요구 사항 사양 및 초기 분석입니다.
객체 지향 분석을 위해 서로 함께 사용되는 세 가지 분석 기술은 객체 모델링, 동적 모델링 및 기능 모델링입니다.
개체 모델링
객체 모델링은 객체 측면에서 소프트웨어 시스템의 정적 구조를 개발합니다. 개체, 개체를 그룹화 할 수있는 클래스 및 개체 간의 관계를 식별합니다. 또한 각 클래스를 특성화하는 주요 속성 및 작업을 식별합니다.
객체 모델링 프로세스는 다음 단계로 시각화 할 수 있습니다.
- 개체를 식별하고 클래스로 그룹화
- 클래스 간의 관계 식별
- 사용자 개체 모델 다이어그램 만들기
- 사용자 개체 속성 정의
- 클래스에서 수행해야하는 작업 정의
동적 모델링
시스템의 정적 동작을 분석 한 후 시간 및 외부 변화에 대한 동작을 조사해야합니다. 이것이 동적 모델링의 목적입니다.
동적 모델링은 "다른 개체에 의해 트리거 된 내부 이벤트 또는 외부 세계에 의해 트리거 된 외부 이벤트에 대해 개별 개체가 이벤트에 어떻게 반응하는지 설명하는 방법"으로 정의 할 수 있습니다.
동적 모델링 프로세스는 다음 단계로 시각화 할 수 있습니다.
- 각 개체의 상태 식별
- 이벤트 식별 및 조치의 적용 가능성 분석
- 상태 전이 다이어그램으로 구성된 동적 모델 다이어그램 구성
- 객체 속성으로 각 상태 표현
- 그려진 상태 전환 다이어그램 유효성 검사
기능적 모델링
기능적 모델링은 객체 지향 분석의 마지막 구성 요소입니다. 기능 모델은 개체 내에서 수행되는 프로세스와 메서드간에 이동하는 데이터 변경 방식을 보여줍니다. 객체 모델링 작업의 의미와 동적 모델링 작업을 지정합니다. 기능 모델은 전통적인 구조화 분석의 데이터 흐름 다이어그램에 해당합니다.
기능 모델링 과정은 다음 단계로 시각화 할 수 있습니다.
- 모든 입력 및 출력 식별
- 기능적 종속성을 보여주는 데이터 흐름 다이어그램 구성
- 각 기능의 목적 설명
- 제약 사항 파악
- 최적화 기준 지정
객체 지향 디자인
분석 단계 후 개념 모델은 객체 지향 설계 (OOD)를 사용하여 객체 지향 모델로 더욱 발전됩니다. OOD에서는 분석 모델의 기술 독립적 개념이 구현 클래스에 매핑되고 제약 조건이 식별되고 인터페이스가 설계되어 솔루션 도메인에 대한 모델이 생성됩니다. OO 디자인의 주요 목적은 시스템의 구조적 아키텍처를 개발하는 것입니다.
객체 지향 설계의 단계는 다음과 같이 식별 할 수 있습니다.
- 시스템의 컨텍스트 정의
- 시스템 아키텍처 설계
- 시스템의 개체 식별
- 디자인 모델 구축
- 개체 인터페이스 사양
OO 디자인은 개념 디자인과 세부 디자인의 두 단계로 나눌 수 있습니다.
Conceptual design
이 단계에서는 시스템 구축에 필요한 모든 클래스가 식별됩니다. 또한 각 클래스에는 특정 책임이 할당됩니다. 클래스 다이어그램은 클래스 간의 관계를 명확히하는 데 사용되며 상호 작용 다이어그램은 이벤트의 흐름을 보여주는 데 사용됩니다. 그것은 또한 알려져 있습니다high-level design.
Detailed design
이 단계에서는 상호 작용 다이어그램을 기반으로 각 클래스에 속성과 작업이 할당됩니다. 상태 머신 다이어그램은 디자인의 세부 사항을 설명하기 위해 개발되었습니다. 그것은 또한 알려져 있습니다low-level design.
설계 원칙
다음은 주요 설계 원칙입니다-
Principle of Decoupling
한 클래스를 수정하면 다른 클래스가 연속적으로 업데이트 될 수 있으므로 상호 의존성이 높은 클래스 세트로 시스템을 유지 관리하는 것은 어렵습니다. OO 디자인에서는 새로운 클래스 또는 상속을 도입하여 긴밀한 결합을 제거 할 수 있습니다.
Ensuring Cohesion
응집력있는 클래스는 밀접하게 관련된 일련의 기능을 수행합니다. 응집력이 없다는 것은 전체 시스템의 작동에 영향을주지 않지만 클래스가 관련없는 기능을 수행한다는 것을 의미합니다. 이는 소프트웨어의 전체 구조를 관리, 확장, 유지 및 변경하기 어렵게 만듭니다.
Open-closed Principle
이 원칙에 따라 시스템은 새로운 요구 사항을 충족하도록 확장 할 수 있어야합니다. 시스템 확장의 결과로 시스템의 기존 구현 및 코드를 수정해서는 안됩니다. 또한 다음 지침은 개방형 폐쇄 원칙에 따라야합니다.
각각의 구체적인 클래스에 대해 별도의 인터페이스와 구현을 유지해야합니다.
다중 스레드 환경에서는 속성을 비공개로 유지합니다.
전역 변수와 클래스 변수의 사용을 최소화합니다.
데이터 흐름 아키텍처에서 전체 소프트웨어 시스템은 데이터와 작업이 서로 독립적 인 연속적인 부분 또는 입력 데이터 집합에 대한 일련의 변환으로 간주됩니다. 이 접근 방식에서는 데이터가 시스템에 입력 된 다음 최종 대상 (출력 또는 데이터 저장소)에 할당 될 때까지 한 번에 하나씩 모듈을 통과합니다.
구성 요소 또는 모듈 간의 연결은 I / O 스트림, I / O 버퍼, 파이프 또는 기타 유형의 연결로 구현 될 수 있습니다. 데이터는주기가있는 그래프 토폴로지,주기가없는 선형 구조 또는 트리 유형 구조로 비행 할 수 있습니다.
이 접근 방식의 주요 목적은 재사용 및 수정 가능성의 품질을 달성하는 것입니다. 컴파일러 및 비즈니스 데이터 처리 응용 프로그램과 같이 순서대로 정의 된 입력 및 출력에 대한 잘 정의 된 일련의 독립적 인 데이터 변환 또는 계산을 포함하는 응용 프로그램에 적합합니다. 모듈 사이에는 세 가지 유형의 실행 시퀀스가 있습니다.
- 배치 순차
- 파이프 및 필터 또는 비 순차 파이프 라인 모드
- 공정 제어
배치 순차
배치 순차는 데이터 변환 하위 시스템이 이전 하위 시스템이 완전히 완료된 후에 만 프로세스를 시작할 수있는 고전적인 데이터 처리 모델입니다.
데이터 흐름은 한 하위 시스템에서 다른 하위 시스템으로 전체 데이터 배치를 전달합니다.
모듈 간의 통신은 연속적인 하위 시스템에서 제거 할 수있는 임시 중간 파일을 통해 수행됩니다.
데이터가 일괄 처리되고 각 하위 시스템이 관련 입력 파일을 읽고 출력 파일을 쓰는 애플리케이션에 적용됩니다.
이 아키텍처의 일반적인 애플리케이션에는 은행 및 유틸리티 청구와 같은 비즈니스 데이터 처리가 포함됩니다.

장점
하위 시스템에서 더 간단한 분할을 제공합니다.
각 하위 시스템은 입력 데이터에 대해 작업하고 출력 데이터를 생성하는 독립적 인 프로그램이 될 수 있습니다.
단점
높은 지연 시간과 낮은 처리량을 제공합니다.
동시성 및 대화 형 인터페이스를 제공하지 않습니다.
구현을 위해 외부 제어가 필요합니다.
파이프 및 필터 아키텍처
이 접근 방식은 연속적인 구성 요소에 의한 데이터의 점진적 변환에 중점을 둡니다. 이 접근 방식에서 데이터 흐름은 데이터에 의해 주도되고 전체 시스템은 데이터 소스, 필터, 파이프 및 데이터 싱크의 구성 요소로 분해됩니다.
모듈 간의 연결은 바이트, 문자 또는 다른 유형의 다른 유형이 될 수있는 선입 선출 버퍼 인 데이터 스트림입니다. 이 아키텍처의 주요 기능은 동시 및 증분 실행입니다.
필터
필터는 독립적 인 데이터 스트림 변환기 또는 스트림 변환기입니다. 입력 데이터 스트림의 데이터를 변환하고 처리하며 다음 필터가 처리 할 수 있도록 파이프를 통해 변환 된 데이터 스트림을 작성합니다. 증분 모드에서 작동하며 연결된 파이프를 통해 데이터가 도착하자마자 작동을 시작합니다. 두 가지 유형의 필터가 있습니다.active filter 과 passive filter.
Active filter
능동 필터를 사용하면 연결된 파이프가 데이터를 가져오고 변환 된 데이터를 내보낼 수 있습니다. 그것은 당기고 밀기위한 읽기 / 쓰기 메커니즘을 제공하는 패시브 파이프로 작동합니다. 이 모드는 UNIX 파이프 및 필터 메커니즘에서 사용됩니다.
Passive filter
패시브 필터를 사용하면 연결된 파이프가 데이터를 입력 및 추출 할 수 있습니다. 필터에서 데이터를 가져와 다음 필터로 푸시하는 활성 파이프로 작동합니다. 읽기 / 쓰기 메커니즘을 제공해야합니다.

장점
과도한 데이터 처리를 위해 동시성과 높은 처리량을 제공합니다.
재사용 성을 제공하고 시스템 유지 관리를 단순화합니다.
필터 간 수정 가능성 및 낮은 결합을 제공합니다.
파이프로 연결된 두 필터간에 명확한 구분을 제공하여 단순성을 제공합니다.
순차 및 병렬 실행을 모두 지원하여 유연성을 제공합니다.
단점
동적 상호 작용에는 적합하지 않습니다.
ASCII 형식으로 데이터를 전송하려면 낮은 공통 분모가 필요합니다.
필터 간 데이터 변환의 오버 헤드.
필터가 협력하여 문제를 해결하는 방법을 제공하지 않습니다.
이 아키텍처를 동적으로 구성하기가 어렵습니다.
파이프
파이프는 상태 비 저장이며 두 필터 사이에 존재하는 이진 또는 문자 스트림을 전달합니다. 한 필터에서 다른 필터로 데이터 스트림을 이동할 수 있습니다. 파이프는 약간의 컨텍스트 정보를 사용하고 인스턴스화 사이에 상태 정보를 유지하지 않습니다.
공정 제어 아키텍처
데이터가 일괄 처리 된 순차 또는 파이프 라인 스트림이 아닌 데이터 흐름 아키텍처 유형입니다. 데이터 흐름은 프로세스 실행을 제어하는 변수 집합에서 비롯됩니다. 전체 시스템을 하위 시스템 또는 모듈로 분해하여 연결합니다.
하위 시스템 유형
프로세스 제어 아키텍처는 processing unit 공정 제어 변수 변경 및 controller unit 변화량을 계산합니다.
컨트롤러 장치에는 다음 요소가 있어야합니다.
Controlled Variable− 제어 변수는 기본 시스템에 대한 값을 제공하며 센서로 측정해야합니다. 예를 들어, 크루즈 컨트롤 시스템의 속도.
Input Variable− 프로세스에 대한 입력을 측정합니다. 예를 들어, 온도 제어 시스템의 환기 온도
Manipulated Variable − 조작 된 변수 값은 컨트롤러에 의해 조정 또는 변경됩니다.
Process Definition − 일부 프로세스 변수를 조작하기위한 메커니즘이 포함되어 있습니다.
Sensor − 제어와 관련된 공정 변수의 값을 얻고 조작 된 변수를 재 계산하기위한 피드백 참조로 사용할 수 있습니다.
Set Point − 제어 변수에 대한 원하는 값입니다.
Control Algorithm − 공정 변수를 조작하는 방법을 결정하는 데 사용됩니다.
응용 분야
프로세스 제어 아키텍처는 다음 영역에 적합합니다.
프로세스 제어 변수 데이터에 의해 시스템이 조작되는 임베디드 시스템 소프트웨어 설계.
주어진 참조 값에서 프로세스 출력의 지정된 속성을 유지하는 것을 목표로하는 애플리케이션.
자동차 크루즈 제어 및 건물 온도 제어 시스템에 적용 가능합니다.
자동차 잠금 방지 브레이크, 원자력 발전소 등을 제어하는 실시간 시스템 소프트웨어
데이터 중심 아키텍처에서 데이터는 데이터를 수정하는 다른 구성 요소에 의해 중앙 집중화되고 자주 액세스됩니다. 이 스타일의 주요 목적은 데이터의 통합 성을 달성하는 것입니다. 데이터 중심 아키텍처는 공유 데이터 저장소를 통해 통신하는 다양한 구성 요소로 구성됩니다. 구성 요소는 공유 데이터 구조에 액세스하고 데이터 저장소를 통해서만 상호 작용한다는 점에서 상대적으로 독립적입니다.
데이터 중심 아키텍처의 가장 잘 알려진 예는 데이터 정의 프로토콜을 사용하여 공통 데이터베이스 스키마가 생성되는 데이터베이스 아키텍처입니다 (예 : RDBMS의 필드 및 데이터 유형이있는 관련 테이블 집합).
데이터 중심 아키텍처의 또 다른 예는 공통 데이터 스키마 (예 : 웹의 메타 구조)를 갖고 하이퍼 미디어 데이터 모델을 따르고 공유 웹 기반 데이터 서비스를 사용하여 통신하는 프로세스가있는 웹 아키텍처입니다.

구성 요소 유형
두 가지 유형의 구성 요소가 있습니다.
ㅏ central data영구 데이터 저장소를 제공하는 구조 또는 데이터 저장소 또는 데이터 저장소. 현재 상태를 나타냅니다.
ㅏ data accessor 또는 중앙 데이터 저장소에서 작동하고, 계산을 수행하고, 결과를 되돌릴 수있는 독립적 인 구성 요소 모음입니다.
데이터 접근 자 간의 상호 작용 또는 통신은 데이터 저장소를 통해서만 이루어집니다. 데이터는 클라이언트 간의 유일한 통신 수단입니다. 제어 흐름은 아키텍처를 두 가지 범주로 구분합니다.
- 리포지토리 아키텍처 스타일
- 칠판 아키텍처 스타일
리포지토리 아키텍처 스타일
리포지토리 아키텍처 스타일에서 데이터 저장소는 수동적이며 데이터 저장소의 클라이언트 (소프트웨어 구성 요소 또는 에이전트)는 활성화되어 논리 흐름을 제어합니다. 참여하는 구성 요소는 데이터 저장소에서 변경 사항을 확인합니다.
클라이언트는 작업 (예 : 데이터 삽입)을 수행하기 위해 시스템에 요청을 보냅니다.
계산 프로세스는 독립적이며 들어오는 요청에 의해 트리거됩니다.
트랜잭션 입력 스트림의 트랜잭션 유형이 실행할 프로세스 선택을 트리거하는 경우 기존 데이터베이스 또는 저장소 아키텍처 또는 수동 저장소입니다.
이 접근 방식은 DBMS, 라이브러리 정보 시스템, CORBA의 인터페이스 저장소, 컴파일러 및 CASE (컴퓨터 지원 소프트웨어 엔지니어링) 환경에서 널리 사용됩니다.

장점
데이터 무결성, 백업 및 복원 기능을 제공합니다.
에이전트가 서로 직접 통신하지 않으므로 확장 성과 재사용 성을 제공합니다.
소프트웨어 구성 요소 간 일시적인 데이터의 오버 헤드를 줄입니다.
단점
장애에 더 취약하고 데이터 복제 또는 복제가 가능합니다.
데이터 저장소의 데이터 구조와 에이전트 간의 높은 종속성.
데이터 구조의 변경은 클라이언트에 큰 영향을 미칩니다.
데이터의 진화는 어렵고 비용이 많이 듭니다.
분산 데이터를 위해 네트워크에서 데이터를 이동하는 비용.
칠판 아키텍처 스타일
Blackboard Architecture Style에서 데이터 저장소는 활성이고 클라이언트는 수동입니다. 따라서 논리적 흐름은 데이터 저장소의 현재 데이터 상태에 의해 결정됩니다. 중앙 데이터 저장소 역할을하는 블랙 보드 구성 요소가 있으며 내부 표현은 다른 계산 요소에 의해 구축되고 작동됩니다.
공통 데이터 구조에서 독립적으로 작동하는 여러 구성 요소가 블랙 보드에 저장됩니다.
이 스타일에서 구성 요소는 칠판을 통해서만 상호 작용합니다. 데이터 저장소는 데이터 저장소가 변경 될 때마다 클라이언트에게 경고합니다.
솔루션의 현재 상태는 칠판에 저장되고 칠판의 상태에 따라 처리가 시작됩니다.
시스템은 다음과 같은 알림을 보냅니다. trigger 데이터가 변경되면 클라이언트에 데이터를 보냅니다.
이 접근 방식은 음성 인식, 이미지 인식, 보안 시스템 및 비즈니스 리소스 관리 시스템 등과 같은 특정 AI 애플리케이션 및 복잡한 애플리케이션에서 발견됩니다.
중앙 데이터 구조의 현재 상태가 실행할 프로세스를 선택하는 주요 트리거 인 경우 저장소는 블랙 보드가 될 수 있으며이 공유 데이터 소스는 활성 에이전트입니다.
기존 데이터베이스 시스템과의 주요 차이점은 블랙 보드 아키텍처에서 계산 요소의 호출이 외부 입력이 아닌 블랙 보드의 현재 상태에 의해 트리거된다는 것입니다.
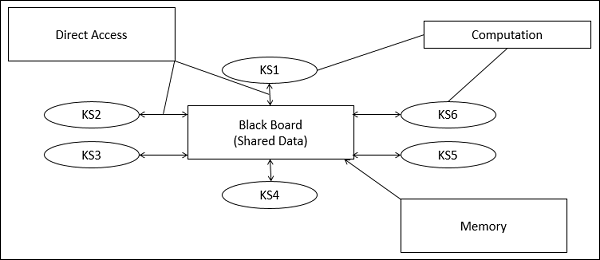
Blackboard 모델의 일부
칠판 모델은 일반적으로 세 가지 주요 부분으로 표시됩니다.
Knowledge Sources (KS)
라고도하는 지식 소스 Listeners 또는 Subscribers구별되고 독립적 인 단위입니다. 문제의 일부를 해결하고 부분적인 결과를 집계합니다. 지식 소스 간의 상호 작용은 칠판을 통해 고유하게 이루어집니다.
Blackboard Data Structure
문제 해결 상태 데이터는 애플리케이션 종속 계층으로 구성됩니다. 지식 소스는 문제에 대한 해결책으로 점진적으로 이어지는 칠판을 변경합니다.
Control
Control은 작업을 관리하고 작업 상태를 확인합니다.
장점
지식 소스를 쉽게 추가하거나 업데이트 할 수있는 확장 성을 제공합니다.
모든 지식 소스가 서로 독립적이므로 병렬로 작업 할 수 있도록 동시성을 제공합니다.
가설에 대한 실험을 지원합니다.
지식 소스 에이전트의 재사용을 지원합니다.
단점
칠판의 구조 변경은 칠판과 지식 소스간에 밀접한 종속성이 존재하기 때문에 모든 에이전트에 중대한 영향을 미칠 수 있습니다.
대략적인 솔루션 만 예상되므로 추론을 종료 할시기를 결정하기가 어려울 수 있습니다.
여러 에이전트의 동기화에 문제가 있습니다.
시스템 설계 및 테스트의 주요 과제.
계층 구조는 전체 시스템을 계층 구조로 간주하며 소프트웨어 시스템은 계층 구조의 여러 수준에서 논리 모듈 또는 하위 시스템으로 분해됩니다. 이 접근 방식은 일반적으로 네트워크 프로토콜 및 운영 체제와 같은 시스템 소프트웨어를 설계하는 데 사용됩니다.
시스템 소프트웨어 계층 설계에서 하위 수준 하위 시스템은 하위 수준의 메서드를 호출하는 인접한 상위 하위 하위 시스템에 서비스를 제공합니다. 하위 계층은 I / O 서비스, 트랜잭션, 스케줄링, 보안 서비스 등과 같은보다 구체적인 기능을 제공합니다. 중간 계층은 비즈니스 로직 및 핵심 처리 서비스와 같은 더 많은 도메인 종속 기능을 제공합니다. 그리고 상위 계층은 GUI, 쉘 프로그래밍 기능 등과 같은 사용자 인터페이스 형태로 더 추상적 인 기능을 제공합니다.
또한 네임 스페이스 계층 구조의 .NET 클래스 라이브러리와 같은 클래스 라이브러리의 구성에도 사용됩니다. 모든 디자인 유형은이 계층 적 아키텍처를 구현할 수 있으며 종종 다른 아키텍처 스타일과 결합됩니다.
계층 적 건축 스타일은 다음과 같이 나뉩니다.
- Main-subroutine
- Master-slave
- 가상 기기
메인 서브 루틴
이 스타일의 목적은 모듈을 재사용하고 개별 모듈 또는 서브 루틴을 자유롭게 개발하는 것입니다. 이 스타일에서 소프트웨어 시스템은 시스템의 원하는 기능에 따라 하향식 세분화를 사용하여 서브 루틴으로 나뉩니다.
이러한 개선은 분해 된 모듈이 배타적 인 독립 책임을 가질 수있을만큼 단순해질 때까지 수직으로 이어집니다. 기능은 상위 계층의 여러 호출자가 재사용하고 공유 할 수 있습니다.
데이터가 서브 루틴에 매개 변수로 전달되는 두 가지 방법이 있습니다.
Pass by Value − 서브 루틴은 과거 데이터 만 사용하며 수정할 수 없습니다.
Pass by Reference − 서브 루틴은 매개 변수가 참조하는 데이터의 값을 사용하고 변경합니다.

장점
계층 개선을 기반으로 시스템을 분해하기 쉽습니다.
객체 지향 디자인의 하위 시스템에서 사용할 수 있습니다.
단점
전 세계적으로 공유되는 데이터가 포함되어있어 취약합니다.
긴밀한 결합은 변화의 더 많은 파급 효과를 유발할 수 있습니다.
주인 노예
이 접근 방식은 '분할 및 정복'원칙을 적용하고 오류 계산 및 계산 정확도를 지원합니다. 시스템의 신뢰성과 내결함성을 제공하는 메인 서브 루틴 아키텍처의 수정입니다.
이 아키텍처에서 슬레이브는 마스터에게 중복 서비스를 제공하고 마스터는 특정 선택 전략에 따라 슬레이브 중에서 특정 결과를 선택합니다. 슬레이브는 서로 다른 알고리즘 및 방법 또는 완전히 다른 기능에 의해 동일한 기능 작업을 수행 할 수 있습니다. 여기에는 모든 슬레이브가 병렬로 실행될 수있는 병렬 컴퓨팅이 포함됩니다.

마스터-슬레이브 패턴의 구현은 5 단계를 따릅니다.
작업 계산을 동일한 하위 작업 집합으로 나눌 수있는 방법을 지정하고 하위 작업을 처리하는 데 필요한 하위 서비스를 식별합니다.
개별 하위 작업을 처리하여 얻은 결과를 사용하여 전체 서비스의 최종 결과를 계산하는 방법을 지정합니다.
1 단계에서 식별 한 하위 서비스에 대한 인터페이스를 정의합니다.이 인터페이스는 슬레이브에 의해 구현되고 마스터가 개별 하위 작업의 처리를 위임하는 데 사용됩니다.
이전 단계에서 개발 한 사양에 따라 슬레이브 구성 요소를 구현합니다.
1 ~ 3 단계에서 개발 한 사양에 따라 마스터를 구현합니다.
응용
소프트웨어의 신뢰성이 중요한 문제인 애플리케이션에 적합합니다.
병렬 및 분산 컴퓨팅 영역에 널리 적용됩니다.
장점
더 빠른 계산과 쉬운 확장 성.
슬레이브를 복제 할 수 있으므로 견고 함을 제공합니다.
슬레이브는 의미 오류를 최소화하기 위해 다르게 구현할 수 있습니다.
단점
통신 오버 헤드.
모든 문제를 나눌 수있는 것은 아닙니다.
구현하기 어렵고 이식성 문제.
가상 머신 아키텍처
가상 머신 아키텍처는 구현 된 하드웨어 및 / 또는 소프트웨어에 고유하지 않은 일부 기능을 가장합니다. 가상 머신은 기존 시스템을 기반으로 구축되며 가상 추상화, 속성 집합 및 작업을 제공합니다.
가상 머신 아키텍처에서 마스터는 슬레이브의 '동일한'하위 서비스를 사용하고 작업 분할, 슬레이브 호출 및 결과 결합과 같은 기능을 수행합니다. 이를 통해 개발자는 아직 구축되지 않은 플랫폼을 시뮬레이션 및 테스트하고 실제 시스템으로 테스트하기에는 너무 복잡하거나 비용이 많이 들거나 위험한 "재해"모드를 시뮬레이션 할 수 있습니다.
대부분의 경우 가상 머신은 실행 플랫폼에서 프로그래밍 언어 또는 애플리케이션 환경을 분리합니다. 주요 목표는portability. 가상 머신을 통한 특정 모듈의 해석은 다음과 같이 인식 될 수 있습니다.
해석 엔진은 해석되는 모듈에서 명령을 선택합니다.
명령에 따라 엔진은 가상 머신의 내부 상태를 업데이트하고 위의 프로세스를 반복합니다.
다음 그림은 단일 물리적 시스템의 표준 VM 인프라 아키텍처를 보여줍니다.

그만큼 hypervisor, 또한 virtual machine monitor, 호스트 OS에서 실행되고 일치하는 리소스를 각 게스트 OS에 할당합니다. 게스트가 시스템 호출을 할 때 하이퍼 바이저는이를 가로 채서 호스트 OS에서 지원하는 해당 시스템 호출로 변환합니다. 하이퍼 바이저는 CPU, 메모리, 영구 스토리지, I / O 장치 및 네트워크에 대한 각 가상 머신 액세스를 제어합니다.
응용
가상 머신 아키텍처는 다음 도메인에 적합합니다.
직접적인 해결책이없는 경우 시뮬레이션 또는 번역으로 문제를 해결하는 데 적합합니다.
샘플 응용 프로그램에는 마이크로 프로그래밍, XML 처리, 스크립트 명령 언어 실행, 규칙 기반 시스템 실행, Smalltalk 및 Java 인터프리터 유형 프로그래밍 언어의 인터프리터가 포함됩니다.
가상 머신의 일반적인 예로는 인터프리터, 규칙 기반 시스템, 구문 셸 및 명령 언어 프로세서가 있습니다.
장점
이식성 및 기계 플랫폼 독립성.
소프트웨어 개발의 단순성.
프로그램을 중단하고 쿼리하는 기능을 통해 유연성을 제공합니다.
재난 작업 모델을위한 시뮬레이션.
런타임에 수정 사항을 도입하십시오.
단점
인터프리터 특성으로 인해 인터프리터 실행이 느립니다.
실행과 관련된 추가 계산으로 인해 성능 비용이 발생합니다.
레이어드 스타일
이 접근 방식에서 시스템은 계층 구조에서 여러 상위 및 하위 계층으로 분해되며 각 계층은 시스템에서 고유 한 책임을 갖습니다.
각 계층은 패키지, 배포 된 구성 요소 또는 메서드 라이브러리 또는 헤더 파일 형식의 서브 루틴 그룹으로 캡슐화 된 관련 클래스 그룹으로 구성됩니다.
각 계층은 그 위에있는 계층에 서비스를 제공하고 아래 계층에 대한 클라이언트 역할을합니다. 즉, 계층 i +1에 대한 요청은 계층 i의 인터페이스를 통해 계층 i에서 제공하는 서비스를 호출합니다. 작업이 완료되면 응답은 레이어 i +1로 돌아갈 수 있습니다. 그렇지 않으면 계층 i가 아래 계층 i-1에서 서비스를 계속 호출합니다.
응용
레이어드 스타일은 다음 영역에 적합합니다.
계층 적으로 구성 할 수있는 고유 한 서비스 클래스를 포함하는 응용 프로그램입니다.
애플리케이션 별 및 플랫폼 별 부분으로 분해 할 수있는 모든 애플리케이션.
핵심 서비스, 중요 서비스 및 사용자 인터페이스 서비스 등을 명확하게 구분하는 애플리케이션
장점
점진적인 추상화 수준을 기반으로 디자인합니다.
한 레이어의 기능에 대한 변경 사항이 최대 두 개의 다른 레이어에 영향을 미치므로 향상된 독립성을 제공합니다.
표준 인터페이스와 그 구현의 분리.
새로운 구성 요소의 플러그 앤 플레이를 허용하는 시스템을 훨씬 쉽게 만드는 구성 요소 기반 기술을 사용하여 구현됩니다.
각 레이어는 이식성을 지원하는 독립적으로 배포 된 추상 머신이 될 수 있습니다.
하향식 세분화 방식으로 작업 정의를 기반으로 시스템 분해 용이
동일한 레이어의 서로 다른 구현 (동일한 인터페이스 포함)을 서로 바꿔서 사용할 수 있습니다.
단점
많은 응용 프로그램 또는 시스템이 계층화 된 방식으로 쉽게 구성되지 않습니다.
클라이언트의 요청 또는 클라이언트에 대한 응답이 잠재적으로 여러 계층을 거쳐야하므로 런타임 성능이 저하됩니다.
또한 각 계층의 데이터 마샬링 및 버퍼링에 대한 오버 헤드에 대한 성능 문제도 있습니다.
계층 간 통신을 열면 교착 상태가 발생할 수 있으며 "브리징"은 긴밀한 결합을 유발할 수 있습니다.
예외 및 오류 처리는 계층화 된 아키텍처에서 문제입니다. 한 계층의 오류가 모든 호출 계층으로 확산되어야하기 때문입니다.
상호 작용 지향 아키텍처의 주요 목표는 데이터 추상화 및 비즈니스 데이터 처리와 사용자 상호 작용을 분리하는 것입니다. 상호 작용 지향 소프트웨어 아키텍처는 시스템을 세 개의 주요 파티션으로 분해합니다.
Data module − 데이터 모듈은 데이터 추상화 및 모든 비즈니스 로직을 제공합니다.
Control module − 제어 모듈은 제어 및 시스템 구성 작업의 흐름을 식별합니다.
View presentation module − View presentation 모듈은 데이터 출력의 시각적 또는 오디오 프레젠테이션을 담당하며 사용자 입력을위한 인터페이스도 제공합니다.
상호 작용 지향 아키텍처에는 두 가지 주요 스타일이 있습니다. Model-View-Controller (MVC) 및 Presentation-Abstraction-Control(PAC). MVC와 PAC는 모두 세 가지 구성 요소 분해를 제안하며 다중 대화 및 사용자 상호 작용이있는 웹 응용 프로그램과 같은 대화 형 응용 프로그램에 사용됩니다. 제어 및 조직의 흐름이 다릅니다. PAC는 에이전트 기반 계층 구조이지만 MVC에는 명확한 계층 구조가 없습니다.
모델-뷰-컨트롤러 (MVC)
MVC는 주어진 소프트웨어 응용 프로그램을 상호 연결된 세 부분으로 분해하여 정보의 내부 표현을 사용자에게 제공하거나 사용자로부터받은 정보에서 분리하는 데 도움을줍니다.
| 기준 치수 | 함수 |
|---|---|
| 모델 | 기본 데이터 및 비즈니스 로직 캡슐화 |
| 제어 장치 | 사용자 작업에 응답하고 애플리케이션 흐름을 지시합니다. |
| 전망 | 모델에서 사용자에게 데이터를 형식화하고 표시합니다. |
모델
모델은 애플리케이션의 데이터, 논리 및 제약 조건을 직접 관리하는 MVC의 핵심 구성 요소입니다. 이는 원시 애플리케이션 데이터와 인터페이스를위한 애플리케이션 로직을 유지하는 데이터 구성 요소로 구성됩니다.
독립적 인 사용자 인터페이스이며 애플리케이션 문제 도메인의 동작을 캡처합니다.
도메인 별 소프트웨어 시뮬레이션 또는 애플리케이션의 중앙 구조 구현입니다.
상태가 변경되면 연결된보기에 알림을 제공하여 업데이트 된 출력을 생성하고 컨트롤러는 사용 가능한 명령 집합을 변경합니다.
전망
보기는 다이어그램 또는 차트와 같은 그래픽 형식의 정보 출력을 나타내는 데 사용할 수 있습니다. 데이터의 시각적 표현을 제공하는 프레젠테이션 구성 요소로 구성됩니다.
모델의 요청 정보를보고 사용자에게 출력 표현을 생성합니다.
관리를위한 막대 차트 및 회계사를위한 표보기와 같이 동일한 정보에 대한 여러보기가 가능합니다.
제어 장치
컨트롤러는 입력을 받아 모델 또는 뷰에 대한 명령으로 변환합니다. 모델을 수정하여 사용자의 입력을 처리하는 입력 처리 구성 요소로 구성됩니다.
연결된 모델과보기 및 입력 장치 간의 인터페이스 역할을합니다.
모델에 대한 명령을 보내 모델의 상태를 업데이트하고 연관된보기로 모델의보기 표시를 변경할 수 있습니다.

MVC-나
시스템이 두 개의 하위 시스템으로 나누어 진 MVC 아키텍처의 간단한 버전입니다.
The Controller-View − 컨트롤러 뷰는 입력 / 출력 인터페이스 역할을하며 처리가 완료됩니다.
The Model − 모델은 모든 데이터 및 도메인 서비스를 제공합니다.
MVC-I Architecture
모델 모듈은 데이터 변경 사항을 컨트롤러보기 모듈에 알려 그래픽 데이터 디스플레이가 그에 따라 변경되도록합니다. 컨트롤러는 또한 변경시 적절한 조치를 취합니다.

컨트롤러-뷰와 모델 간의 연결은 컨트롤러-뷰가 모델을 구독하고 모델이 변경 사항을 컨트롤러-뷰에 알리는 subscribe-notify의 패턴 (위 그림 참조)으로 설계 될 수 있습니다.
MVC-II
MVC–II는 뷰 모듈과 컨트롤러 모듈이 분리 된 MVC-I 아키텍처의 향상된 기능입니다. 모델 모듈은 데이터베이스에서 지원하는 모든 핵심 기능과 데이터를 제공하여 MVC-I에서와 같이 적극적인 역할을합니다.
보기 모듈은 데이터를 제공하는 반면 컨트롤러 모듈은 입력 요청을 수락하고 입력 데이터의 유효성을 검사하고 모델,보기, 연결을 시작하고 작업을 디스패치합니다.
MVC-II Architecture

MVC 애플리케이션
MVC 애플리케이션은 단일 데이터 모델에 여러보기가 필요하고 새로운 인터페이스보기를 플러그인하거나 변경하기 쉬운 대화 형 애플리케이션에 효과적입니다.
MVC 응용 프로그램은 모듈간에 명확한 구분이있는 응용 프로그램에 적합하므로 다른 전문가를 할당하여 해당 응용 프로그램의 다른 측면을 동시에 작업 할 수 있습니다.
Advantages
사용 가능한 많은 MVC 공급 업체 프레임 워크 툴킷이 있습니다.
동일한 데이터 모델로 동기화 된 여러보기.
새로운 플러그인 또는 인터페이스보기 교체가 쉽습니다.
그래픽 전문 전문가, 프로그래밍 전문가 및 데이터베이스 개발 전문가가 설계된 프로젝트 팀에서 작업하는 애플리케이션 개발에 사용됩니다.
Disadvantages
대화 형 모바일 및 로봇 응용 프로그램과 같은 에이전트 지향 응용 프로그램에는 적합하지 않습니다.
동일한 데이터 모델을 기반으로하는 여러 쌍의 컨트롤러와 뷰는 모든 데이터 모델 변경을 비용이 많이 듭니다.
뷰와 컨트롤러의 구분이 명확하지 않은 경우도 있습니다.
PAC (Presentation-Abstraction-Control)
PAC에서 시스템은 많은 협력 에이전트 (트라이어드)의 계층 구조로 배열됩니다. 상호 작용 요구 사항 외에도 여러 에이전트의 응용 프로그램 요구 사항을 지원하기 위해 MVC에서 개발되었습니다.
각 에이전트에는 세 가지 구성 요소가 있습니다.
The presentation component − 데이터의 시각적 및 오디오 프레젠테이션 형식을 지정합니다.
The abstraction component − 데이터를 검색하고 처리합니다.
The control component − 다른 두 구성 요소 간의 제어 흐름 및 통신과 같은 작업을 처리합니다.
PAC 아키텍처는 프레젠테이션 모듈이 MVC의 뷰 모듈과 같다는 점에서 MVC와 유사합니다. 추상화 모듈은 MVC의 모델 모듈처럼 보이고 제어 모듈은 MVC의 컨트롤러 모듈과 비슷하지만 제어 흐름과 구성이 다릅니다.
각 에이전트의 추상화 구성 요소와 프레젠테이션 구성 요소 간에는 직접적인 연결이 없습니다. 각 에이전트의 제어 구성 요소는 다른 에이전트와의 통신을 담당합니다.
다음 그림은 PAC 디자인의 단일 에이전트에 대한 블록 다이어그램을 보여줍니다.

여러 에이전트가있는 PAC
여러 에이전트로 구성된 PAC에서 최상위 에이전트는 핵심 데이터 및 비즈니스 논리를 제공합니다. 최하위 에이전트는 자세한 특정 데이터와 프레젠테이션을 정의합니다. 중급 또는 중급 상담원은 저급 상담원의 코디네이터 역할을합니다.
각 에이전트에는 고유 한 할당 된 작업이 있습니다.
일부 중급 상담원의 경우 대화 형 프레젠테이션이 필요하지 않으므로 프레젠테이션 구성 요소가 없습니다.
제어 구성 요소는 모든 에이전트가 서로 통신하는 모든 에이전트에 필요합니다.
다음 그림은 PAC에 참여하는 여러 에이전트를 보여줍니다.

Applications
시스템이 계층 적 방식으로 많은 협력 에이전트로 분해 될 수있는 대화 형 시스템에 효과적입니다.
에이전트 간의 결합이 느슨하여 에이전트의 변경이 다른 에이전트에 영향을 미치지 않을 것으로 예상되는 경우 효과적입니다.
모든 에이전트가 먼 거리에 분산되어 있고 각 에이전트가 데이터 및 대화 형 인터페이스를 통해 고유 한 기능을 가진 분산 시스템에 효과적입니다.
각각의 현재 데이터와 대화 형 인터페이스를 유지하고 다른 구성 요소와 통신해야하는 풍부한 GUI 구성 요소가있는 응용 프로그램에 적합합니다.
장점
멀티 태스킹 및 멀티 뷰 지원
에이전트 재사용 및 확장 성 지원
새 에이전트를 쉽게 플러그인하거나 기존 에이전트를 변경
여러 에이전트가 서로 다른 스레드 또는 서로 다른 장치 또는 컴퓨터에서 병렬로 실행되는 동시성 지원
단점
표현과 추상화 사이의 제어 브리지와 에이전트 간의 제어 통신으로 인한 오버 헤드.
느슨한 결합과 에이전트 간의 높은 독립성으로 인해 올바른 에이전트 수를 결정하기가 어렵습니다.
각 에이전트의 제어에 의한 프리젠 테이션과 추상화의 완전한 분리는 에이전트 간의 통신이 에이전트의 제어간에 만 발생하므로 개발 복잡성을 유발합니다.
분산 아키텍처에서 구성 요소는 서로 다른 플랫폼에 제공되며 여러 구성 요소가 특정 목표 또는 목표를 달성하기 위해 통신 네트워크를 통해 서로 협력 할 수 있습니다.
이 아키텍처에서 정보 처리는 단일 시스템에 국한되지 않고 여러 독립 컴퓨터에 분산됩니다.
분산 시스템은 다중 계층 아키텍처의 기반을 형성하는 클라이언트-서버 아키텍처에 의해 입증 될 수 있습니다. 대안은 CORBA와 같은 브로커 아키텍처 및 SOA (Service-Oriented Architecture)입니다.
.NET, J2EE, CORBA, .NET 웹 서비스, AXIS Java 웹 서비스 및 Globus Grid 서비스를 포함하여 분산 아키텍처를 지원하는 여러 기술 프레임 워크가 있습니다.
미들웨어는 분산 애플리케이션의 개발 및 실행을 적절하게 지원하는 인프라입니다. 애플리케이션과 네트워크 사이에 버퍼를 제공합니다.
시스템 중간에 위치하며 분산 시스템의 다양한 구성 요소를 관리하거나 지원합니다. 예로는 트랜잭션 처리 모니터, 데이터 변환기 및 통신 컨트롤러 등이 있습니다.
분산 시스템을위한 인프라로서의 미들웨어

분산 아키텍처의 기본은 투명성, 안정성 및 가용성입니다.
다음 표는 분산 시스템에서 다양한 형태의 투명성을 나열합니다.
| Sr. 아니. | 투명성 및 설명 |
|---|---|
| 1 | Access 리소스에 액세스하는 방식과 데이터 플랫폼의 차이점을 숨 깁니다. |
| 2 | Location 리소스가있는 위치를 숨 깁니다. |
| 삼 | Technology 프로그래밍 언어 및 OS와 같은 다양한 기술을 사용자로부터 숨 깁니다. |
| 4 | Migration / Relocation 사용중인 다른 위치로 이동할 수있는 리소스를 숨 깁니다. |
| 5 | Replication 여러 위치에 복사 할 수있는 리소스를 숨 깁니다. |
| 6 | Concurrency 다른 사용자와 공유 할 수있는 리소스를 숨 깁니다. |
| 7 | Failure 사용자로부터 자원의 실패 및 복구를 숨 깁니다. |
| 8 | Persistence 리소스 (소프트웨어)가 메모리 또는 디스크에 있는지 여부를 숨 깁니다. |
장점
Resource sharing − 하드웨어 및 소프트웨어 리소스 공유.
Openness − 다른 공급 업체의 하드웨어 및 소프트웨어를 사용할 수있는 유연성.
Concurrency − 성능 향상을위한 동시 처리.
Scalability − 새로운 리소스를 추가하여 처리량을 늘 렸습니다.
Fault tolerance − 오류가 발생한 후에도 계속 작동 할 수있는 기능.
단점
Complexity − 중앙 집중식 시스템보다 더 복잡합니다.
Security − 외부 공격에 더 취약합니다.
Manageability − 시스템 관리에 더 많은 노력이 필요합니다.
Unpredictability − 시스템 구성 및 네트워크 부하에 따라 예측할 수없는 응답.
중앙 집중식 시스템 vs. 분산 시스템
| 기준 | 중앙 집중식 시스템 | 분산 시스템 |
|---|---|---|
| 경제학 | 낮은 | 높은 |
| 유효성 | 낮은 | 높은 |
| 복잡성 | 낮은 | 높은 |
| 일관성 | 단순한 | 높은 |
| 확장 성 | 가난한 | 좋은 |
| 과학 기술 | 동종의 | 이기종 |
| 보안 | 높은 | 낮은 |
클라이언트-서버 아키텍처
클라이언트-서버 아키텍처는 시스템을 두 개의 주요 하위 시스템 또는 논리적 프로세스로 분해하는 가장 일반적인 분산 시스템 아키텍처입니다.
Client − 두 번째 프로세스, 즉 서버에 요청을 보내는 첫 번째 프로세스입니다.
Server − 요청을 수신하여 수행하고 클라이언트에 응답을 보내는 두 번째 프로세스입니다.
이 아키텍처에서 응용 프로그램은 서버에서 제공하는 서비스 집합과 이러한 서비스를 사용하는 클라이언트 집합으로 모델링됩니다. 서버는 클라이언트에 대해 알 필요가 없지만 클라이언트는 서버의 ID를 알아야하며 프로세서와 프로세스의 매핑이 반드시 1 : 1은 아닙니다.

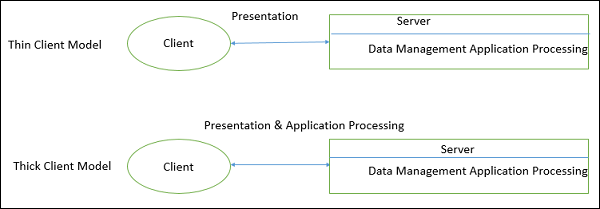
클라이언트-서버 아키텍처는 클라이언트의 기능에 따라 두 가지 모델로 분류 할 수 있습니다.
씬 클라이언트 모델
씬 클라이언트 모델에서는 모든 애플리케이션 처리 및 데이터 관리가 서버에서 수행됩니다. 클라이언트는 단순히 프레젠테이션 소프트웨어를 실행하는 책임이 있습니다.
레거시 시스템이 클라이언트에 구현 된 그래픽 인터페이스를 사용하여 레거시 시스템이 자체적으로 서버 역할을하는 클라이언트 서버 아키텍처로 마이그레이션 될 때 사용됩니다.
주요 단점은 서버와 네트워크 모두에 과도한 처리 부하를가한다는 것입니다.
씩 / 뚱뚱한 클라이언트 모델
씩 클라이언트 모델에서 서버는 데이터 관리 만 담당합니다. 클라이언트의 소프트웨어는 응용 프로그램 논리 및 시스템 사용자와의 상호 작용을 구현합니다.
클라이언트 시스템의 기능을 미리 알고있는 새로운 C / S 시스템에 가장 적합
특히 관리를 위해 씬 클라이언트 모델보다 더 복잡합니다. 모든 클라이언트에 새 버전의 응용 프로그램을 설치해야합니다.
장점
사용자 인터페이스 프레젠테이션 및 비즈니스 로직 처리와 같은 책임 분리.
서버 구성 요소의 재사용 가능성 및 동시성 가능성
분산 응용 프로그램의 설계 및 개발을 단순화합니다.
기존 애플리케이션을 분산 환경으로 쉽게 마이그레이션하거나 통합 할 수 있습니다.
또한 많은 클라이언트가 고성능 서버에 액세스 할 때 리소스를 효과적으로 사용합니다.
단점
요구 사항 변경을 처리 할 이기종 인프라가 부족합니다.
보안 문제.
제한된 서버 가용성 및 안정성.
제한된 테스트 가능성 및 확장 성.
프레젠테이션과 비즈니스 로직이 함께있는 팻 클라이언트.
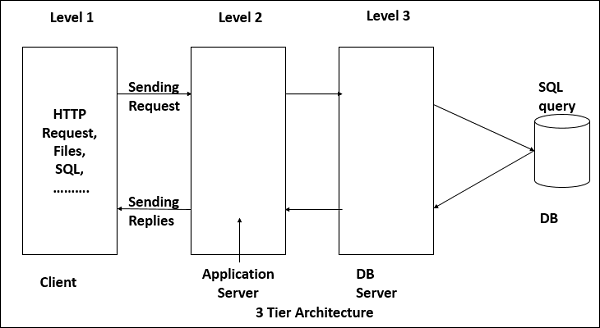
다중 계층 아키텍처 (n 계층 아키텍처)
다중 계층 아키텍처는 프레젠테이션, 응용 프로그램 처리 및 데이터 관리와 같은 기능이 물리적으로 분리 된 클라이언트-서버 아키텍처입니다. 애플리케이션을 계층으로 분리함으로써 개발자는 전체 애플리케이션을 재 작업하는 대신 특정 계층을 변경하거나 추가하는 옵션을 얻을 수 있습니다. 개발자가 유연하고 재사용 가능한 애플리케이션을 만들 수있는 모델을 제공합니다.

다 계층 아키텍처의 가장 일반적인 용도는 3 계층 아키텍처입니다. 3 계층 아키텍처는 일반적으로 프레젠테이션 계층, 애플리케이션 계층 및 데이터 스토리지 계층으로 구성되며 별도의 프로세서에서 실행될 수 있습니다.
프레젠테이션 계층
프리젠 테이션 계층은 사용자가 웹 페이지 또는 운영 체제 GUI (그래픽 사용자 인터페이스)와 같이 직접 액세스 할 수있는 애플리케이션의 최상위 레벨입니다. 이 계층의 주요 기능은 작업과 결과를 사용자가 이해할 수있는 것으로 변환하는 것입니다. 다른 계층과 통신하여 결과를 브라우저 / 클라이언트 계층 및 네트워크의 다른 모든 계층에 배치합니다.
애플리케이션 계층 (비즈니스 논리, 논리 계층 또는 중간 계층)
애플리케이션 계층은 애플리케이션을 조정하고, 명령을 처리하고, 논리적 결정을 내리고, 평가하고, 계산을 수행합니다. 세부 처리를 수행하여 응용 프로그램의 기능을 제어합니다. 또한 두 개의 주변 레이어간에 데이터를 이동하고 처리합니다.
데이터 계층
이 계층에서 정보는 데이터베이스 또는 파일 시스템에서 저장되고 검색됩니다. 그런 다음 정보는 처리를 위해 다시 전달 된 다음 사용자에게 다시 전달됩니다. 여기에는 데이터 지속성 메커니즘 (데이터베이스 서버, 파일 공유 등)이 포함되며 저장된 데이터를 관리하는 방법을 제공하는 API (Application Programming Interface)를 애플리케이션 계층에 제공합니다.
Advantages
씬 클라이언트 접근 방식보다 성능이 우수하고 씩 클라이언트 접근 방식보다 관리가 더 간단합니다.
재사용 성과 확장 성을 향상시킵니다. 수요가 증가하면 추가 서버를 추가 할 수 있습니다.
멀티 스레딩 지원을 제공하고 네트워크 트래픽도 줄입니다.
유지 관리 및 유연성 제공
Disadvantages
테스트 도구 부족으로 인해 만족스럽지 못한 테스트 가능성.
더 중요한 서버 안정성 및 가용성.
브로커 아키텍처 스타일
브로커 아키텍처 스타일은 등록 된 서버와 클라이언트 간의 통신을 조정하고 활성화하기 위해 분산 컴퓨팅에 사용되는 미들웨어 아키텍처입니다. 여기서 객체 통신은 객체 요청 브로커 (소프트웨어 버스)라는 미들웨어 시스템을 통해 이루어집니다.
클라이언트와 서버는 서로 직접 상호 작용하지 않습니다. 클라이언트와 서버는 중개자 브로커와 통신하는 프록시에 직접 연결됩니다.
서버는 브로커에 인터페이스를 등록하고 게시하여 서비스를 제공하고 클라이언트는 조회를 통해 브로커에 정적으로 또는 동적으로 서비스를 요청할 수 있습니다.
CORBA (Common Object Request Broker Architecture)는 브로커 아키텍처의 좋은 구현 예입니다.
브로커 아키텍처 스타일의 구성 요소
브로커 아키텍처 스타일의 구성 요소는 다음 헤드를 통해 논의됩니다.
Broker
브로커는 결과 및 예외 전달 및 발송과 같은 통신 조정을 담당합니다. 클라이언트가 메시지를 보내는 호출 지향 서비스, 문서 또는 메시지 지향 브로커 일 수 있습니다.
서비스 요청을 중개하고, 적절한 서버를 찾고, 요청을 전송하고, 클라이언트에 응답을 보내는 일을 담당합니다.
기능 및 서비스는 물론 위치 정보를 포함한 서버의 등록 정보를 유지합니다.
클라이언트가 요청할 API, 응답 할 서버, 서버 구성 요소 등록 또는 등록 취소, 메시지 전송 및 서버 찾기를 제공합니다.
Stub
스텁은 정적 컴파일 시간에 생성 된 다음 클라이언트에 대한 프록시로 사용되는 클라이언트 측에 배포됩니다. 클라이언트 측 프록시는 클라이언트와 브로커 사이의 중재자 역할을하며 클라이언트와 클라이언트 사이에 추가적인 투명성을 제공합니다. 원격 개체는 로컬 개체처럼 나타납니다.
프록시는 프로토콜 수준에서 IPC (프로세스 간 통신)를 숨기고 매개 변수 값을 마샬링하고 서버에서 결과를 마샬링 해제합니다.
Skeleton
스켈레톤은 서비스 인터페이스 컴파일에 의해 생성 된 다음 서버에 대한 프록시로 사용되는 서버 측에 배포됩니다. 서버 측 프록시는 낮은 수준의 시스템 특정 네트워킹 기능을 캡슐화하고 서버와 브로커 사이를 중재하기위한 높은 수준의 API를 제공합니다.
요청을 받고, 요청을 압축 해제하고, 메서드 인수를 마샬링하고, 적절한 서비스를 호출하고, 결과를 다시 클라이언트로 보내기 전에 마샬링합니다.
Bridge
브리지는 서로 다른 통신 프로토콜을 기반으로 두 개의 서로 다른 네트워크를 연결할 수 있습니다. DCOM, .NET 원격 및 Java CORBA 브로커를 포함한 다양한 브로커를 중재합니다.
브리지는 선택적 구성 요소로, 두 브로커가 상호 운용 될 때 구현 세부 정보를 숨기고 하나의 형식으로 요청과 매개 변수를 가져 와서 다른 형식으로 변환합니다.

Broker implementation in CORBA
CORBA는 OMG (객체 관리 그룹)에서 정의한 분산 객체 간의 통신을 관리하는 미들웨어 인 Object Request Broker의 국제 표준입니다.

서비스 지향 아키텍처 (SOA)
서비스는 잘 정의되고, 독립적이고, 독립적이며, 게시되고, 표준 프로그래밍 인터페이스를 통해 사용할 수있는 비즈니스 기능의 구성 요소입니다. 서비스 간의 연결은 서비스간에 요청과 응답을 느슨하게 전달할 수있는 SOAP 웹 서비스 프로토콜과 같은 공통 및 범용 메시지 지향 프로토콜에 의해 수행됩니다.
서비스 지향 아키텍처는 애플리케이션이 소프트웨어 서비스와 소프트웨어 서비스 소비자 (클라이언트 또는 서비스 요청 자라고도 함)로 구성된 비즈니스 중심 IT 접근 방식을 지원하는 클라이언트 / 서버 설계입니다.
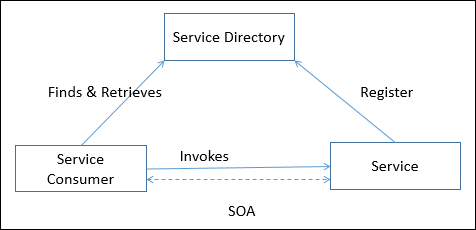
SOA의 특징
서비스 지향 아키텍처는 다음과 같은 기능을 제공합니다.
Distributed Deployment − 엔터프라이즈 데이터와 비즈니스 로직을 서비스라고하는 느슨하고, 결합되고, 검색 가능하고, 구조화되고, 표준 기반이며, 거칠고, 상태 비 저장 기능 단위로 노출됩니다.
Composability − 잘 정의되고 게시 된 표준 불만 인터페이스를 통해 원하는 세분화로 노출 된 기존 서비스에서 새로운 프로세스를 조립합니다.
Interoperability − 기본 프로토콜 또는 구현 기술에 관계없이 네트워크에서 기능을 공유하고 공유 서비스를 재사용합니다.
Reusability − 서비스 제공자를 선택하고 서비스로 노출 된 기존 리소스에 액세스합니다.
SOA 운영
다음 그림은 SOA가 어떻게 작동하는지 보여줍니다.

Advantages
서비스 지향의 느슨한 결합은 기업이 플랫폼 및 기술 제한에 관계없이 사용 가능한 모든 서비스 자원을 사용할 수있는 뛰어난 유연성을 제공합니다.
각 서비스 구성 요소는 상태 비 저장 서비스 기능으로 인해 다른 서비스와 독립적입니다.
서비스 구현은 노출 된 인터페이스가 변경되지 않는 한 서비스 응용 프로그램에 영향을주지 않습니다.
클라이언트 또는 모든 서비스는 플랫폼, 기술, 공급 업체 또는 언어 구현에 관계없이 다른 서비스에 액세스 할 수 있습니다.
서비스 클라이언트는 공용 인터페이스, 서비스 구성 만 알면되기 때문에 자산 및 서비스의 재사용 가능성.
SOA 기반 비즈니스 애플리케이션 개발은 시간과 비용면에서 훨씬 더 효율적입니다.
확장 성을 향상시키고 시스템 간의 표준 연결을 제공합니다.
'비즈니스 서비스'의 효율적이고 효과적인 사용.
통합이 훨씬 쉬워지고 본질적인 상호 운용성이 향상됩니다.
개발자를위한 복잡성을 추상화하고 최종 사용자에게 더 가까운 비즈니스 프로세스를 활성화합니다.
구성 요소 기반 아키텍처는 설계를 메서드, 이벤트 및 속성을 포함하는 잘 정의 된 통신 인터페이스를 나타내는 개별 기능 또는 논리적 구성 요소로 분해하는 데 중점을 둡니다. 더 높은 수준의 추상화를 제공하고 문제를 구성 요소 파티션과 관련된 하위 문제로 나눕니다.
구성 요소 기반 아키텍처의 주요 목표는 component reusability. 구성 요소는 소프트웨어 요소의 기능과 동작을 재사용 가능하고 자체 배포 가능한 바이너리 단위로 캡슐화합니다. COM / DCOM, JavaBean, EJB, CORBA, .NET, 웹 서비스 및 그리드 서비스와 같은 많은 표준 구성 요소 프레임 워크가 있습니다. 이러한 기술은 단순히 끌어서 놓기 작업으로 재사용 할 수있는 그래픽 JavaBean 구성 요소, MS ActiveX 구성 요소 및 COM 구성 요소와 같은 로컬 데스크톱 GUI 응용 프로그램 디자인에 널리 사용됩니다.
구성 요소 지향 소프트웨어 설계는 다음과 같은 전통적인 객체 지향 접근 방식에 비해 많은 장점이 있습니다.
기존 구성 요소를 재사용하여 시장 출시 시간과 개발 비용을 줄입니다.
기존 구성 요소를 재사용하여 안정성이 향상되었습니다.
구성 요소 란?
구성 요소는 구현을 캡슐화하고 상위 수준 인터페이스로 내보내는 잘 정의 된 기능의 모듈 식, 이식 가능, 교체 및 재사용 가능 집합입니다.
구성 요소는 특정 기능 또는 기능 집합을 캡슐화하여 다른 구성 요소와 상호 작용하기위한 소프트웨어 개체입니다. 명확하게 정의 된 인터페이스가 있으며 아키텍처 내의 모든 구성 요소에 공통적 인 권장 동작을 따릅니다.
소프트웨어 구성 요소는 계약 상 지정된 인터페이스와 명시 적 컨텍스트 종속성 만있는 구성 단위로 정의 할 수 있습니다. 즉, 소프트웨어 구성 요소는 독립적으로 배포 할 수 있으며 타사에서 구성 할 수 있습니다.
구성 요소보기
컴포넌트는 객체 지향보기, 기존보기 및 프로세스 관련보기의 세 가지보기를 가질 수 있습니다.
Object-oriented view
구성 요소는 하나 이상의 협력 클래스 집합으로 간주됩니다. 각 문제 도메인 클래스 (분석) 및 인프라 클래스 (설계)는 구현에 적용되는 모든 속성과 작업을 식별하기 위해 설명됩니다. 또한 클래스가 통신하고 협력 할 수 있도록 인터페이스를 정의하는 것도 포함됩니다.
Conventional view
이는 처리 논리, 처리 논리를 구현하는 데 필요한 내부 데이터 구조 및 구성 요소를 호출하고 데이터를 전달할 수있는 인터페이스를 통합하는 프로그램의 기능 요소 또는 모듈로 간주됩니다.
Process-related view
이보기에서 시스템은 처음부터 각 구성 요소를 만드는 대신 라이브러리에서 유지 관리되는 기존 구성 요소에서 빌드합니다. 소프트웨어 아키텍처가 공식화되면 라이브러리에서 구성 요소가 선택되어 아키텍처를 채우는 데 사용됩니다.
UI (사용자 인터페이스) 구성 요소에는 그리드, 컨트롤이라고하는 단추가 포함되며 유틸리티 구성 요소는 다른 구성 요소에서 사용되는 특정 기능 하위 집합을 표시합니다.
다른 일반적인 유형의 구성 요소는 리소스를 많이 사용하고 자주 액세스하지 않으며 JIT (Just-In-Time) 접근 방식을 사용하여 활성화해야하는 구성 요소입니다.
EJB (Enterprise JavaBean), .NET 구성 요소 및 CORBA 구성 요소와 같은 엔터프라이즈 비즈니스 응용 프로그램 및 인터넷 웹 응용 프로그램에 배포되는 많은 구성 요소가 보이지 않습니다.
구성 요소의 특성
Reusability− 구성 요소는 일반적으로 다른 응용 프로그램의 다른 상황에서 재사용되도록 설계되었습니다. 그러나 일부 구성 요소는 특정 작업을 위해 설계 될 수 있습니다.
Replaceable − 구성품은 다른 유사한 구성품으로 자유롭게 대체 할 수 있습니다.
Not context specific − 구성 요소는 다양한 환경과 상황에서 작동하도록 설계되었습니다.
Extensible − 기존 구성 요소에서 구성 요소를 확장하여 새로운 동작을 제공 할 수 있습니다.
Encapsulated − AA 구성 요소는 호출자가 기능을 사용할 수 있도록하는 인터페이스를 나타내며 내부 프로세스 나 내부 변수 또는 상태에 대한 세부 정보를 노출하지 않습니다.
Independent − 구성 요소는 다른 구성 요소에 대한 종속성을 최소화하도록 설계되었습니다.
구성 요소 기반 설계의 원리
구성 요소 수준 디자인은 소스 코드로 번역 할 수있는 일부 중간 표현 (예 : 그래픽, 표 또는 텍스트 기반)을 사용하여 표현할 수 있습니다. 데이터 구조, 인터페이스 및 알고리즘의 설계는 오류 발생을 방지 할 수 있도록 잘 확립 된 지침을 따라야합니다.
소프트웨어 시스템은 재사용 가능하고 응집력이 있으며 캡슐화 된 구성 요소 단위로 분해됩니다.
각 구성 요소에는 필요한 포트와 제공된 포트를 지정하는 자체 인터페이스가 있습니다. 각 구성 요소는 세부 구현을 숨 깁니다.
구성 요소는 구성 요소의 기존 부분에 대한 내부 코드 나 디자인 수정없이 확장되어야합니다.
추상화에 의존하는 구성 요소는 다른 구체적인 구성 요소에 의존하지 않으므로 확장성에 어려움이 있습니다.
커넥터는 구성 요소를 연결하여 구성 요소 간의 상호 작용을 지정하고 결정합니다. 상호 작용 유형은 구성 요소의 인터페이스에 의해 지정됩니다.
구성 요소 상호 작용은 메서드 호출, 비동기 호출, 브로드 캐스트, 메시지 기반 상호 작용, 데이터 스트림 통신 및 기타 프로토콜 특정 상호 작용의 형태를 취할 수 있습니다.
서버 클래스의 경우 주요 클라이언트 범주에 서비스를 제공하기 위해 특수 인터페이스를 만들어야합니다. 특정 범주의 클라이언트와 관련된 작업 만 인터페이스에 지정해야합니다.
구성 요소는 다른 구성 요소로 확장 될 수 있으며 여전히 자체 확장 점을 제공합니다. 플러그인 기반 아키텍처의 개념입니다. 이를 통해 플러그인이 다른 플러그인 API를 제공 할 수 있습니다.

구성 요소 수준 설계 지침
아키텍처 모델의 일부로 지정된 구성 요소에 대한 명명 규칙을 만든 다음 구성 요소 수준 모델의 일부로 구체화하거나 정교화합니다.
문제 도메인에서 아키텍처 구성 요소 이름을 얻고 아키텍처 모델을 보는 모든 이해 관계자에게 의미가 있는지 확인합니다.
다른 엔터티에 대한 관련 종속성없이 독립적으로 존재할 수있는 비즈니스 프로세스 엔터티를 추출합니다.
이러한 독립 엔티티를 새로운 구성 요소로 인식하고 발견합니다.
구현 별 의미를 반영하는 인프라 구성 요소 이름을 사용합니다.
왼쪽에서 오른쪽으로 종속성을 모델링하고 상위 (기본 클래스)에서 하위 (파생 클래스)로 상속을 모델링합니다.
구성 요소 종속성을 직접 구성 요소 간 종속성으로 나타내지 않고 인터페이스로 모델링합니다.
구성 요소 수준 설계 수행
해석 모델 및 아키텍처 모델에 정의 된대로 문제 도메인에 해당하는 모든 설계 클래스를 인식합니다.
인프라 도메인에 해당하는 모든 디자인 클래스를 인식합니다.
재사용 가능한 구성 요소로 획득되지 않은 모든 디자인 클래스를 설명하고 메시지 세부 정보를 지정합니다.
각 구성 요소에 대한 적절한 인터페이스를 식별하고 속성을 정교화하고이를 구현하는 데 필요한 데이터 유형 및 데이터 구조를 정의합니다.
의사 코드 또는 UML 활동 다이어그램을 통해 각 작업 내의 처리 흐름을 자세히 설명합니다.
영구 데이터 원본 (데이터베이스 및 파일)을 설명하고이를 관리하는 데 필요한 클래스를 식별합니다.
클래스 또는 구성 요소에 대한 동작 표현을 개발하고 정교하게 만듭니다. 이는 분석 모델에 대해 생성 된 UML 상태 다이어그램을 정교화하고 디자인 클래스와 관련된 모든 사용 사례를 검토하여 수행 할 수 있습니다.
추가 구현 세부 사항을 제공하기 위해 배치 다이어그램을 정교하게 작성합니다.
클래스 인스턴스를 사용하고 특정 하드웨어 및 운영 체제 환경을 지정하여 시스템에서 주요 패키지 또는 구성 요소 클래스의 위치를 보여줍니다.
최종 결정은 확립 된 설계 원칙과 지침을 사용하여 내릴 수 있습니다. 숙련 된 디자이너는 최종 디자인 모델을 결정하기 전에 모든 (또는 대부분의) 대체 디자인 솔루션을 고려합니다.
장점
Ease of deployment − 새로운 호환 버전을 사용할 수있게되면 다른 구성 요소 나 시스템 전체에 영향을주지 않고 기존 버전을 쉽게 교체 할 수 있습니다.
Reduced cost − 타사 구성 요소를 사용하면 개발 및 유지 관리 비용을 분산시킬 수 있습니다.
Ease of development − 구성 요소는 잘 알려진 인터페이스를 구현하여 정의 된 기능을 제공하므로 시스템의 다른 부분에 영향을주지 않고 개발할 수 있습니다.
Reusable − 재사용 가능한 구성 요소를 사용하면 여러 응용 프로그램 또는 시스템에 걸쳐 개발 및 유지 관리 비용을 분산하는 데 사용할 수 있습니다.
Modification of technical complexity − 컴포넌트는 컴포넌트 컨테이너와 그 서비스를 사용하여 복잡성을 수정합니다.
Reliability − 각 개별 부품의 신뢰성이 재사용을 통해 전체 시스템의 신뢰성을 향상시키기 때문에 전체 시스템 신뢰성이 증가합니다.
System maintenance and evolution − 시스템의 나머지 부분에 영향을주지 않고 구현을 변경하고 업데이트하기 쉽습니다.
Independent− 구성 요소의 독립성과 유연한 연결성. 병렬로 다른 그룹에 의한 구성 요소의 독립적 개발. 소프트웨어 개발 및 향후 소프트웨어 개발을위한 생산성.
사용자 인터페이스는 사용자 관점에서 본 소프트웨어 시스템의 첫인상입니다. 따라서 모든 소프트웨어 시스템은 사용자의 요구 사항을 충족해야합니다. UI는 주로 두 가지 기능을 수행합니다.
사용자 입력 수락
출력 표시
사용자 인터페이스는 모든 소프트웨어 시스템에서 중요한 역할을합니다. 그것은 아마도 소프트웨어 시스템의 유일한 가시적 측면 일 것입니다.
사용자는 처음에 내부 아키텍처를 고려하지 않고 소프트웨어 시스템의 외부 사용자 인터페이스 아키텍처를 보게됩니다.
좋은 사용자 인터페이스는 사용자가 실수없이 소프트웨어 시스템을 사용하도록 유도해야합니다. 사용자가 잘못된 정보없이 소프트웨어 시스템을 쉽게 이해할 수 있도록 도와야합니다. 잘못된 UI는 소프트웨어 시스템 경쟁에 대한 시장 실패를 유발할 수 있습니다.
UI에는 구문과 의미가 있습니다. 구문은 텍스트, 아이콘, 버튼 등과 같은 구성 요소 유형으로 구성되며 사용성은 UI의 의미를 요약합니다. UI의 품질은 모양과 느낌 (구문) 및 유용성 (의미론)이 특징입니다.
기본적으로 두 종류의 사용자 인터페이스가 있습니다. a) 텍스트 b) 그래픽.
다른 도메인의 소프트웨어는 다른 스타일의 사용자 인터페이스를 필요로 할 수 있습니다. 예를 들어 계산기는 숫자를 표시하기 위해 작은 영역 만 필요하지만 명령을위한 큰 영역, 웹 페이지에는 양식, 링크, 탭 등이 필요합니다.
그래픽 사용자 인터페이스
그래픽 사용자 인터페이스는 오늘날 사용 가능한 가장 일반적인 유형의 사용자 인터페이스입니다. 그림, 그래픽 및 아이콘을 사용하기 때문에 매우 사용자 친화적입니다. 따라서 '그래픽'이라고합니다.
또한 WIMP interface 사용하기 때문에-
Windows − 일반적으로 사용되는 응용 프로그램이 실행되는 화면의 직사각형 영역.
Icons − 소프트웨어 응용 프로그램 또는 하드웨어 장치를 나타내는 데 사용되는 그림 또는 기호.
Menus − 사용자가 필요한 것을 선택할 수있는 옵션 목록.
Pointers− 사용자가 마우스를 움직일 때 화면 주위를 움직이는 화살표와 같은 기호. 사용자가 개체를 선택하는 데 도움이됩니다.
사용자 인터페이스 디자인
사용자의 주요 작업과 문제 영역을 이해하는 작업 분석으로 시작됩니다. 프로그래머가 아닌 사용자의 용어와 사용자의 업무 시작에 따라 설계되어야합니다.
사용자 인터페이스 분석을 수행하려면 실무자는 네 가지 요소를 연구하고 이해해야합니다.
그만큼 users 인터페이스를 통해 시스템과 상호 작용할 사람
그만큼 tasks 최종 사용자가 작업을 수행하기 위해 수행해야하는
그만큼 content 인터페이스의 일부로 표시됩니다.
그만큼 work environment 이러한 작업이 수행 될
적절하거나 좋은 UI 디자인은 기계가 아닌 사용자의 능력과 한계에서 작동합니다. UI를 디자인하는 동안 사용자 작업 및 환경의 특성에 대한 지식도 중요합니다.
수행 할 작업은 각각의 기능과 제한 사항에 대한 지식을 기반으로 사용자 또는 컴퓨터에 할당 된 작업을 나눌 수 있습니다. 사용자 인터페이스의 디자인은 종종 네 가지 레벨로 나뉩니다.
The conceptual level − 시스템에 대한 사용자의 관점과 이에 대해 가능한 조치를 고려한 기본 엔티티를 설명합니다.
The semantic level − 시스템이 수행하는 기능, 즉 시스템의 기능적 요구 사항에 대한 설명을 설명하지만 사용자가 기능을 호출하는 방법은 설명하지 않습니다.
The syntactic level − 설명 된 함수를 호출하는 데 필요한 입력 및 출력 시퀀스를 설명합니다.
The lexical level − 입력과 출력이 실제로 원시 하드웨어 작업에서 어떻게 형성되는지를 결정합니다.
사용자 인터페이스 디자인은 모든 반복이 이전 단계에서 개발 된 정보를 설명하고 개선하는 반복적 인 프로세스입니다. 사용자 인터페이스 디자인을위한 일반적인 단계
사용자 인터페이스 개체 및 작업 (작업)을 정의합니다.
사용자 인터페이스의 상태를 변경하는 이벤트 (사용자 작업)를 정의합니다.
사용자가 인터페이스를 통해 제공된 정보에서 시스템 상태를 해석하는 방법을 나타냅니다.
최종 사용자가 실제로 보게 될 각 인터페이스 상태를 설명하십시오.
사용자 또는 소프트웨어 엔지니어가 생성하며 연령, 성별, 신체적 능력, 교육, 동기 부여, 목표 및 성격을 기반으로 시스템의 최종 사용자 프로필을 설정합니다.
사용자의 구문 및 의미 론적 지식을 고려하고 사용자를 초보자, 지식이있는 간헐적, 지식이있는 빈번한 사용자로 분류합니다.
소프트웨어의 데이터, 아키텍처, 인터페이스 및 절차 적 표현을 통합하는 소프트웨어 엔지니어가 만듭니다.
요구 사항의 분석 모델에서 파생되고 시스템 사용자를 정의하는 데 도움이되는 요구 사항 사양의 정보에 의해 제어됩니다.
시스템 구문 및 의미를 설명하는 모든 지원 정보 (책, 비디오, 도움말 파일)와 결합 된 인터페이스의 모양과 느낌에 대해 작업하는 소프트웨어 구현자가 작성합니다.
디자인 모델의 번역 역할을하고 사용자의 멘탈 모델에 동의하여 사용자가 소프트웨어에 익숙해지고 효과적으로 사용할 수 있도록합니다.
애플리케이션과 상호 작용할 때 사용자가 생성합니다. 사용자가 머릿속에 들고 다니는 시스템의 이미지가 포함되어 있습니다.
종종 사용자의 시스템 인식과 설명의 정확성은 사용자의 프로필과 응용 프로그램 도메인의 소프트웨어에 대한 전반적인 친숙도에 따라 달라집니다.
- 처음에 아키텍처 목표를 식별하십시오.
- 우리 아키텍처의 소비자를 식별하십시오.
- 제약 사항을 식별하십시오.
주요 프로젝트 이정표에서 그리고 기타 중요한 아키텍처 변경에 대응하여 아키텍처를 자주 검토합니다.
아키텍처 검토의 주요 목적은 아키텍처를 올바르게 검증하는 기준 및 후보 아키텍처의 실행 가능성을 결정하는 것입니다.
기능 요구 사항 및 품질 속성을 제안 된 기술 솔루션과 연결합니다. 또한 문제를 식별하고 개선 할 영역을 인식하는 데 도움이됩니다.
사용자 인터페이스 개발 프로세스
다음 다이어그램과 같이 나선형 프로세스를 따릅니다.

Interface analysis
시스템과 상호 작용할 사용자, 작업, 콘텐츠 및 작업 환경에 집중하거나 집중합니다. 시스템 기능을 달성하는 데 필요한 인간 및 컴퓨터 지향 작업을 정의합니다.
Interface design
사용자가 시스템에 대해 정의 된 모든 사용성 목표를 충족하는 방식으로 정의 된 모든 작업을 수행 할 수 있도록 인터페이스 개체, 작업 및 해당 화면 표현 세트를 정의합니다.
Interface construction
사용 시나리오를 평가할 수있는 프로토 타입으로 시작하여 구축을 완료하기위한 개발 도구로 계속됩니다.
Interface validation
모든 사용자 작업을 올바르게 구현하고, 모든 작업 변형을 수용하고, 모든 일반 사용자 요구 사항을 달성하고, 인터페이스가 사용하기 쉽고 배우기 쉬운 정도를 달성하는 인터페이스의 기능에 중점을 둡니다.
User Interface Models
다음과 같은 4 가지 모델을 사용하여 사용자 인터페이스를 분석하고 설계하면-
User profile model
Design model
Implementation model
User's mental model
사용자 인터페이스의 디자인 고려 사항
사용자 중심
사용자 인터페이스는 제품 개발 라이프 사이클 전체에 걸쳐 사용자를 포함하는 사용자 중심 제품이어야합니다. 사용자 인터페이스의 프로토 타입은 사용자가 사용할 수 있어야하며 사용자의 피드백은 최종 제품에 통합되어야합니다.
간단하고 직관적
UI는 단순성과 직관성을 제공하므로 지침 없이도 빠르고 효과적으로 사용할 수 있습니다. GUI는 메뉴, 창, 버튼으로 구성되어 있고 마우스만으로 동작하므로 텍스트 UI보다 낫습니다.
사용자 제어
사용자가 미리 정의 된 시퀀스를 완료하도록 강요하지 마십시오. 취소하거나 저장하고 중단 한 부분으로 돌아가는 옵션을 제공합니다. 시스템 또는 개발자 용어보다는 사용자가 이해할 수있는 용어를 인터페이스 전체에서 사용하십시오.
사용자에게 작업의 결과를 보여 주거나 작업이 성공적으로 수행되었음을 확인하여 작업이 수행되었음을 나타내는 몇 가지 표시를 제공합니다.
투명도
UI는 사용자가 컴퓨터를 통해 바로 접근하고 작업중인 개체를 직접 조작하는 것처럼 느낄 수 있도록 투명해야합니다. 사용자에게 시스템 개체가 아닌 작업 개체를 제공하여 인터페이스를 투명하게 만들 수 있습니다. 예를 들어, 사용자는 자신의 시스템 암호가 암호가 저장되어야하는 바이트 수가 아니라 6 자 이상이어야한다는 것을 이해해야합니다.
점진적 공개 사용
항상 일반적인 기능과 자주 사용하는 작업에 쉽게 액세스 할 수 있습니다. 덜 일반적인 기능과 작업을 숨기고 사용자가 탐색 할 수 있도록합니다. 모든 정보를 하나의 기본 창에 넣으려고하지 마십시오. 주요 정보가 아닌 정보는 보조 창을 사용하십시오.
일관성
UI는 제품 내 및 제품간에 일관성을 유지하고 상호 작용 결과를 동일하게 유지하며 UI 명령과 메뉴는 동일한 형식을 가져야하며 명령 구두점은 유사해야하며 매개 변수는 동일한 방식으로 모든 명령에 전달되어야합니다. UI에는 사용자를 놀라게 할 수있는 동작이 없어야하며 사용자가 실수에서 복구 할 수있는 메커니즘을 포함해야합니다.
완성
소프트웨어 시스템은 MS 메모장 및 MS-Office와 같은 다른 응용 프로그램과 원활하게 통합되어야합니다. 클립 보드 명령을 직접 사용하여 데이터 교환을 수행 할 수 있습니다.
구성 요소 지향
UI 디자인은 모듈 식이어야하며 구성 요소 지향 아키텍처를 통합해야 UI 디자인이 소프트웨어 시스템의 본체 디자인과 동일한 요구 사항을 갖습니다. 모듈은 시스템의 다른 부분에 영향을주지 않고 쉽게 수정 및 교체 할 수 있습니다.
맞춤형
전체 소프트웨어 시스템의 아키텍처에는 플러그인 모듈이 통합되어있어 여러 사람이 독립적으로 소프트웨어를 확장 할 수 있습니다. 개별 사용자는 개인 취향과 필요에 맞게 다양한 양식 중에서 선택할 수 있습니다.
사용자의 메모리 부하 감소
사용자가 컴퓨터가해야 할 일을 기억하고 반복하도록 강요하지 마십시오. 예를 들어 온라인 양식을 작성할 때 사용자가 입력하거나 고객 레코드가 열리면 시스템에서 고객 이름, 주소 및 전화 번호를 기억해야합니다.
사용자 인터페이스는 사용자가 정보를 기억할 필요없이 인식 할 수있는 항목을 제공하여 장기적인 기억 검색을 지원합니다.
분리
UI는 재사용 성과 유지 보수성을 높이기위한 구현을 통해 시스템의 로직과 분리되어야합니다.
반복적이고 점진적인 접근
후보 솔루션을 생성하는 데 도움이되는 5 가지 주요 단계로 구성된 반복적이고 점진적인 접근 방식입니다. 이 후보 솔루션은 이러한 단계를 반복하여 더욱 세분화 할 수 있으며 마지막으로 애플리케이션에 가장 적합한 아키텍처 디자인을 만들 수 있습니다. 프로세스가 끝나면 아키텍처를 검토하고 모든 이해 당사자에게 전달할 수 있습니다.
가능한 한 가지 접근 방식입니다. 아키텍처를 정의, 검토 및 전달하는 더 많은 공식적인 접근 방식이 있습니다.
아키텍처 목표 확인
아키텍처 및 디자인 프로세스를 형성하는 아키텍처 목표를 식별합니다. 완벽하고 정의 된 목표는 아키텍처를 강조하고 설계의 올바른 문제를 해결하며 현재 단계가 완료되고 다음 단계로 이동할 준비가되었는지 결정하는 데 도움이됩니다.
이 단계에는 다음 활동이 포함됩니다.
아키텍처 활동의 예로는 웹 애플리케이션의 주문 처리 UI에 대한 피드백을 얻기위한 프로토 타입 빌드, 고객 주문 추적 애플리케이션 빌드, 인증 설계, 보안 검토를 수행하기위한 애플리케이션의 권한 부여 아키텍처 등이 있습니다.
주요 시나리오
이 단계는 가장 중요한 디자인에 중점을 둡니다. 시나리오는 시스템과 사용자의 상호 작용에 대한 광범위한 설명입니다.
주요 시나리오는 응용 프로그램의 성공을 위해 가장 중요한 시나리오로 간주되는 시나리오입니다. 아키텍처에 대한 결정을 내리는 데 도움이됩니다. 목표는 사용자, 비즈니스 및 시스템 목표 간의 균형을 이루는 것입니다. 예를 들어, 사용자 인증은 중요한 기능 (사용자가 시스템에 로그인하는 방법)과 품질 속성 (보안)의 교차점이기 때문에 핵심 시나리오입니다.
응용 프로그램 개요
애플리케이션의 개요를 작성하여 아키텍처를보다 쉽게 만질 수있게 만들고 실제 제약 조건 및 결정에 연결합니다. 다음 활동으로 구성됩니다.
애플리케이션 유형 식별
모바일 애플리케이션, 리치 클라이언트, 리치 인터넷 애플리케이션, 서비스, 웹 애플리케이션 또는 이러한 유형의 일부 조합인지 여부에 관계없이 애플리케이션 유형을 식별하십시오.
배포 제한 사항 식별
적절한 배포 토폴로지를 선택하고 애플리케이션과 대상 인프라 간의 충돌을 해결합니다.
중요한 아키텍처 디자인 스타일 식별
클라이언트 / 서버, 계층 형, 메시지 버스, 도메인 중심 설계 등과 같은 중요한 아키텍처 설계 스타일을 식별하여 파티셔닝을 개선하고 자주 반복되는 문제에 대한 솔루션을 제공하여 설계 재사용을 촉진합니다. 응용 프로그램은 종종 스타일 조합을 사용합니다.
관련 기술 식별
개발중인 응용 프로그램 유형, 응용 프로그램 배포 토폴로지 및 아키텍처 스타일에 대한 선호 옵션을 고려하여 관련 기술을 식별합니다. 기술 선택은 조직 정책, 인프라 제한, 리소스 기술 등에 따라 결정됩니다.
주요 문제 또는 주요 핫스팟
애플리케이션을 설계하는 동안 핫스팟은 실수가 가장 자주 발생하는 영역입니다. 품질 속성 및 교차 우려 사항을 기반으로 주요 문제를 식별합니다. 잠재적 인 문제에는 새로운 기술의 출현과 중요한 비즈니스 요구 사항이 포함됩니다.
품질 속성은 런타임 동작, 시스템 디자인 및 사용자 경험에 영향을 미치는 아키텍처의 전반적인 기능입니다. 크로스 커팅 문제는 모든 레이어, 구성 요소 및 계층에 적용될 수있는 디자인의 특징입니다.
이는 또한 영향력이 큰 설계 실수가 가장 자주 발생하는 영역이기도합니다. 교차 문제의 예로는 인증 및 권한 부여, 통신, 구성 관리, 예외 관리 및 유효성 검사 등이 있습니다.
후보 솔루션
주요 핫스팟을 정의한 후 초기 기준 아키텍처 또는 첫 번째 상위 수준 디자인을 구축 한 다음 세부 정보를 입력하여 후보 아키텍처를 생성합니다.
후보 아키텍처에는 애플리케이션 유형, 배포 아키텍처, 아키텍처 스타일, 기술 선택, 품질 속성 및 교차 문제가 포함됩니다. 후보 아키텍처가 개선 된 경우 새로운 후보 아키텍처를 만들고 테스트 할 수있는 기준이 될 수 있습니다.
주기를 반복하고 설계를 개선하기 전에 이미 정의 된 주요 시나리오 및 요구 사항에 대해 후보 솔루션 설계를 검증합니다.
아키텍처 스파이크를 사용하여 설계의 특정 영역을 발견하거나 새로운 개념을 검증 할 수 있습니다. 아키텍처 스파이크는 특정 설계 경로의 실행 가능성을 결정하고 위험을 줄이며 다양한 접근 방식의 실행 가능성을 신속하게 결정하는 설계 프로토 타입입니다. 주요 시나리오 및 핫스팟에 대해 아키텍처 스파이크를 테스트합니다.
아키텍처 검토
아키텍처 검토는 실수 비용을 줄이고 가능한 한 빨리 아키텍처 문제를 찾아 수정하기위한 가장 중요한 작업입니다. 이는 프로젝트 비용과 프로젝트 실패 가능성을 줄이는 잘 확립되고 비용 효율적인 방법입니다.
시나리오 기반 평가는 비즈니스 관점에서 가장 중요하고 아키텍처에 가장 큰 영향을 미치는 시나리오에 초점을 맞춘 아키텍처 설계를 검토하는 지배적 인 방법입니다. 다음은 일반적인 검토 방법입니다.
소프트웨어 아키텍처 분석 방법 (SAAM)
원래는 수정 가능성을 평가하기 위해 설계되었지만 나중에 품질 속성과 관련하여 아키텍처를 검토하기 위해 확장되었습니다.
아키텍처 트레이드 오프 분석 방법 (ATAM)
품질 속성 요구 사항과 관련하여 아키텍처 결정을 검토하고 특정 품질 목표를 얼마나 잘 충족하는지 검토하는 세련되고 개선 된 SAAM 버전입니다.
ADR (Active Design Review)
일반적인 검토를 수행하는 대신 한 번에 일련의 문제 또는 아키텍처의 개별 섹션에 더 집중하는 불완전하거나 진행중인 아키텍처에 가장 적합합니다.
중간 디자인 (ARID)에 대한 적극적인 검토
진행중인 아키텍처 검토의 ADR 측면과 일련의 문제에 초점을 맞추고, 품질 속성에 초점을 맞춘 시나리오 기반 검토의 ATAM 및 SAAM 접근 방식을 결합합니다.
비용 편익 분석 방법 (CBAM)
아키텍처 결정의 비용, 이점 및 일정에 미치는 영향을 분석하는 데 중점을 둡니다.
아키텍처 수준 수정 가능성 분석 (ALMA)
비즈니스 정보 시스템 (BIS)에 대한 아키텍처 수정 가능성을 평가합니다.
가족 아키텍처 평가 방법 (FAAM)
상호 운용성과 확장 성을 위해 정보 시스템 제품군 아키텍처를 추정합니다.
아키텍처 디자인 전달
아키텍처 설계를 완료 한 후에는 개발 팀, 시스템 관리자, 운영자, 비즈니스 소유자 및 기타 이해 관계자를 포함하는 다른 이해 관계자들에게 설계를 전달해야합니다.
다른 사람에게 아키텍처를 설명하는 다음과 같은 잘 알려진 방법이 있습니다. −
4 + 1 모델
이 접근 방식은 전체 아키텍처에 대한 다섯 가지보기를 사용합니다. 그중 네 가지 견해 (logical view, 그만큼 process view, 그만큼 physical view, 그리고 development view) 다른 접근 방식의 아키텍처를 설명합니다. 다섯 번째보기는 소프트웨어의 시나리오 및 사용 사례를 보여줍니다. 이해 관계자는 특히 관심이있는 아키텍처의 기능을 볼 수 있습니다.
아키텍처 설명 언어 (ADL)
이 접근 방식은 시스템 구현 전에 소프트웨어 아키텍처를 설명하는 데 사용됩니다. 동작, 프로토콜 및 커넥터와 같은 문제를 해결합니다.
ADL의 가장 큰 장점은 설계를 공식적으로 사용하기 전에 아키텍처의 완전성, 일관성, 모호성 및 성능을 분석 할 수 있다는 것입니다.
애자일 모델링
이 접근 방식은 "표현보다 콘텐츠가 더 중요하다"는 개념을 따릅니다. 생성 된 모델이 간단하고 이해하기 쉬우 며 충분히 정확하고 상세하며 일관성이 있는지 확인합니다.
애자일 모델 문서는 특정 고객을 대상으로하고 해당 고객의 작업 노력을 수행합니다. 문서의 단순성은 아티팩트 모델링에 이해 관계자의 적극적인 참여를 보장합니다.
IEEE 1471
IEEE 1471은 ANSI / IEEE 1471-2000,“소프트웨어 집약적 시스템의 아키텍처 설명을위한 권장 사례”로 알려진 표준의 축약 이름입니다. IEEE 1471은 아키텍처 설명의 내용을 향상시켜 특히 컨텍스트,보기 및 관점에 특정 의미를 부여합니다.
통합 모델링 언어 (UML)
이 접근 방식은 시스템 모델의 세 가지보기를 나타냅니다. 그만큼functional requirements view (사용 사례를 포함하여 사용자 관점에서 본 시스템의 기능적 요구 사항) the static structural view(클래스 다이어그램을 포함한 객체, 속성, 관계 및 작업); 그리고dynamic behavior view (오브젝트 간의 협업 및 시퀀스, 활동 및 상태 다이어그램을 포함한 오브젝트의 내부 상태 변경).