Spring Batch-아키텍처
다음은 Spring Batch 아키텍처의 다이어그램 표현입니다. 그림에 표시된 것처럼 아키텍처에는 세 가지 주요 구성 요소가 있습니다.Application, Batch Core, 및 Batch Infrastructure.
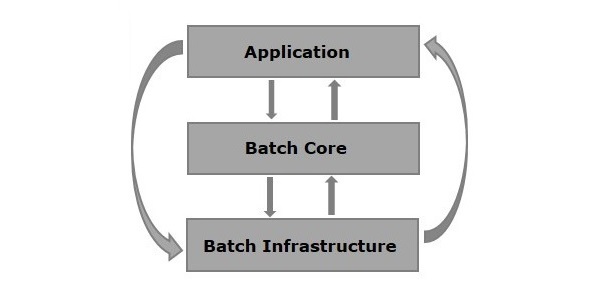
Application −이 컴포넌트는 Spring Batch 프레임 워크를 사용하여 작성한 모든 작업과 코드를 포함합니다.
Batch Core −이 구성 요소에는 배치 작업을 제어하고 시작하는 데 필요한 모든 API 클래스가 포함되어 있습니다.
Batch Infrastructure −이 구성 요소에는 애플리케이션과 Batch 핵심 구성 요소 모두에서 사용하는 리더, 작성자 및 서비스가 포함됩니다.
Spring Batch의 구성 요소
다음 그림은 Spring Batch의 다양한 구성 요소와 서로 연결되는 방식을 보여줍니다.
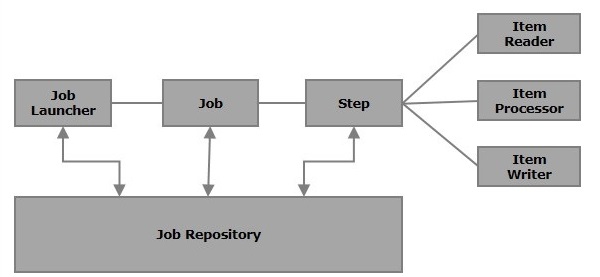
일
Spring Batch 애플리케이션에서 작업은 실행될 배치 프로세스입니다. 중단없이 처음부터 끝까지 실행됩니다. 이 작업은 단계로 더 나뉩니다 (또는 작업에 단계가 포함됨).
XML 파일 또는 Java 클래스를 사용하여 Spring Batch에서 작업을 구성합니다. 다음은 Spring Batch에서 Job의 XML 구성입니다.
<job id = "jobid">
<step id = "step1" next = "step2"/>
<step id = "step2" next = "step3"/>
<step id = "step3"/>
</job>배치 작업은 <job> </ job> 태그 내에 구성됩니다. 이름이 지정된 속성이 있습니다.id. 이러한 태그 내에서 단계의 정의와 순서를 정의합니다.
Restartable − 일반적으로 작업이 실행 중이고 다시 시작하려고 할 때 restart다시 시작됩니다. 이를 방지하려면restartable 가치 false 아래 그림과 같이.
<job id = "jobid" restartable = "false" >
</job>단계
ㅏ step 작업 (해당 부분)을 정의하고 실행하는 데 필요한 정보를 포함하는 작업의 독립적 인 부분입니다.
다이어그램에 지정된대로 각 단계는 ItemReader, ItemProcessor (선택 사항) 및 ItemWriter로 구성됩니다. A job may contain one or more steps.
독자, 작가 및 프로세서
안 item reader 특정 소스에서 Spring Batch 애플리케이션으로 데이터를 읽는 반면 item writer Spring Batch 애플리케이션의 데이터를 특정 대상에 씁니다.
안 Item processor스프링 배치로 읽은 데이터를 처리하는 처리 코드를 포함하는 클래스입니다. 응용 프로그램이 읽는 경우"n" 그러면 프로세서의 코드가 각 레코드에서 실행됩니다.
독자와 작가가 주어지지 않으면 taskletSpringBatch의 프로세서 역할을합니다. 단일 작업 만 처리합니다. 예를 들어, MySQL 데이터베이스에서 데이터를 읽고 처리하고 파일 (플랫)에 쓰는 간단한 단계로 작업을 작성하는 경우 다음 단계를 사용합니다.
ㅏ reader MySQL 데이터베이스에서 읽습니다.
ㅏ writer 플랫 파일에 기록합니다.
ㅏ custom processor 우리가 원하는대로 데이터를 처리합니다.
<job id = "helloWorldJob">
<step id = "step1">
<tasklet>
<chunk reader = "mysqlReader" writer = "fileWriter"
processor = "CustomitemProcessor" ></chunk>
</tasklet>
</step>
</ job>Spring Batch는 긴 목록을 제공합니다. readers 과 writers. 이러한 사전 정의 된 클래스를 사용하여 이에 대한 빈을 정의 할 수 있습니다. 우리는 논의 할 것이다readers 과 writers 다음 장에서 자세히 설명합니다.
JobRepository
Spring Batch의 Job 저장소는 JobLauncher, Job 및 Step 구현을위한 CRUD (Create, Retrieve, Update 및 Delete) 작업을 제공합니다. 아래와 같이 XML 파일에 작업 저장소를 정의합니다.
<job-repository id = "jobRepository"/>이외에 id, 더 많은 옵션 (선택 사항)을 사용할 수 있습니다. 다음은 모든 옵션과 기본값이있는 작업 저장소의 구성입니다.
<job-repository id = "jobRepository"
data-source = "dataSource"
transaction-manager = "transactionManager"
isolation-level-for-create = "SERIALIZABLE"
table-prefix = "BATCH_"
max-varchar-length = "1000"/>In-Memory Repository − Spring Batch의 도메인 객체를 데이터베이스에 저장하지 않으려는 경우 아래와 같이 jobRepository의 인 메모리 버전을 구성 할 수 있습니다.
<bean id = "jobRepository"
class = "org.springframework.batch.core.repository.support.MapJobRepositoryFactoryBean ">
<property name = "transactionManager" ref = "transactionManager"/>
</bean>JobLauncher
JobLauncher는 Spring Batch 작업을 given set of parameters. SampleJoblauncher 구현하는 클래스입니다 JobLauncher상호 작용. 다음은 JobLauncher의 구성입니다.
<bean id = "jobLauncher"
class = "org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name = "jobRepository" ref = "jobRepository" />
</bean>JobInstance
ㅏ JobInstance작업의 논리적 실행을 나타냅니다. 작업을 실행할 때 생성됩니다. 각 작업 인스턴스는 작업 이름과 실행 중에 전달되는 매개 변수로 구분됩니다.
JobInstance 실행이 실패하면 동일한 JobInstance를 다시 실행할 수 있습니다. 따라서 각 JobInstance는 여러 작업 실행을 가질 수 있습니다.
JobExecution 및 StepExecution
JobExecution 및 StepExecution은 작업 / 단계의 실행을 나타냅니다. 여기에는 시작 시간 (작업 / 단계), 종료 시간 (작업 / 단계)과 같은 작업 / 단계의 실행 정보가 포함됩니다.