SQLAlchemy-퀵 가이드
SQLAlchemy는 널리 사용되는 SQL 툴킷이며 Object Relational Mapper. 작성되었습니다Python응용 프로그램 개발자에게 SQL의 모든 기능과 유연성을 제공합니다. 이것은open source 과 cross-platform software MIT 라이센스로 출시되었습니다.
SQLAlchemy는 객체 관계형 매퍼 (ORM)로 유명합니다.이를 사용하여 클래스를 데이터베이스에 매핑 할 수 있으므로 객체 모델과 데이터베이스 스키마가 처음부터 명확하게 분리 된 방식으로 개발 될 수 있습니다.
SQL 데이터베이스의 크기와 성능이 중요 해짐에 따라 개체 컬렉션처럼 작동하지 않습니다. 반면에 객체 컬렉션의 추상화가 중요 해짐에 따라 테이블 및 행처럼 작동하지 않습니다. SQLAlchemy는 이러한 원칙을 모두 수용하는 것을 목표로합니다.
이러한 이유로, 그것은 data mapper pattern (like Hibernate) rather than the active record pattern used by a number of other ORMs. 데이터베이스와 SQL은 SQLAlchemy를 사용하여 다른 관점에서 볼 수 있습니다.
Michael Bayer는 SQLAlchemy의 원저자입니다. 초기 버전은 2006 년 2 월에 출시되었습니다. 최신 버전은 1.2.7로 번호가 매겨져 있으며 2018 년 4 월에 출시되었습니다.
ORM은 무엇입니까?
ORM (Object Relational Mapping)은 객체 지향 프로그래밍 언어에서 호환되지 않는 유형 시스템간에 데이터를 변환하는 프로그래밍 기술입니다. 일반적으로 Python과 같은 객체 지향 (OO) 언어에서 사용되는 유형 시스템에는 비 스칼라 유형이 포함됩니다. 이는 정수 및 문자열과 같은 기본 유형으로 표현 될 수 없습니다. 따라서 OO 프로그래머는 백엔드 데이터베이스와 상호 작용하기 위해 스칼라 데이터의 개체를 변환해야합니다. 그러나 Oracle, MySQL 등과 같은 대부분의 데이터베이스 제품에서 데이터 유형은 기본입니다.
ORM 시스템에서 각 클래스는 기본 데이터베이스의 테이블에 매핑됩니다. 지루한 데이터베이스 인터페이스 코드를 직접 작성하는 대신 ORM이 이러한 문제를 처리하는 동시에 시스템 논리 프로그래밍에 집중할 수 있습니다.
SQLAlchemy-환경 설정
SQLAlchemy를 사용하는 데 필요한 환경 설정에 대해 논의하겠습니다.
SQLAlchemy를 설치하려면 2.7 이상의 Python 버전이 필요합니다. 설치하는 가장 쉬운 방법은 Python 패키지 관리자를 사용하는 것입니다.pip. 이 유틸리티는 Python의 표준 배포와 함께 번들로 제공됩니다.
pip install sqlalchemy위의 명령을 사용하여 latest released versionpython.org 에서 SQLAlchemy를 제거 하고 시스템에 설치합니다.
아나콘다 Python 배포의 경우 SQLAlchemy는 다음 위치에서 설치할 수 있습니다. conda terminal 아래 명령을 사용하여-
conda install -c anaconda sqlalchemy아래 소스 코드에서 SQLAlchemy를 설치할 수도 있습니다.
python setup.py installSQLAlchemy는 특정 데이터베이스 용으로 구축 된 DBAPI 구현과 함께 작동하도록 설계되었습니다. 방언 시스템을 사용하여 다양한 유형의 DBAPI 구현 및 데이터베이스와 통신합니다. 모든 언어를 사용하려면 적절한 DBAPI 드라이버가 설치되어 있어야합니다.
다음은 포함 된 방언입니다-
- Firebird
- 마이크로 소프트 SQL 서버
- MySQL
- Oracle
- PostgreSQL
- SQLite
- Sybase
SQLAlchemy가 제대로 설치되었는지 확인하고 버전을 확인하려면 Python 프롬프트에 다음 명령을 입력하십시오.
>>> import sqlalchemy
>>>sqlalchemy.__version__
'1.2.7'SQLAlchemy 핵심에는 다음이 포함됩니다. SQL rendering engine, DBAPI integration, transaction integration, 및 schema description services. SQLAlchemy 코어는 SQL Expression Language를 사용하여schema-centric usage 패러다임 SQLAlchemy ORM은 domain-centric mode of usage.
SQL Expression Language는 Python 구조를 사용하여 관계형 데이터베이스 구조 및 표현식을 나타내는 시스템을 제공합니다. 그것은 표현 언어의 응용 사용의 예인 높은 수준의 추상화 된 사용 패턴을 제시하는 ORM과는 달리 의견없이 관계형 데이터베이스의 원시 구조를 직접적으로 표현하는 시스템을 제시합니다.
Expression Language는 SQLAlchemy의 핵심 구성 요소 중 하나입니다. 이를 통해 프로그래머는 Python 코드에서 SQL 문을 지정하고보다 복잡한 쿼리에서 직접 사용할 수 있습니다. 표현식 언어는 백엔드와 독립적이며 원시 SQL의 모든 측면을 포괄적으로 다룹니다. SQLAlchemy의 다른 구성 요소보다 원시 SQL에 더 가깝습니다.
Expression Language는 관계형 데이터베이스의 기본 구조를 직접 나타냅니다. ORM은 Expression 언어를 기반으로하기 때문에 일반적인 Python 데이터베이스 응용 프로그램은 두 가지를 중복 사용했을 수 있습니다. 응용 프로그램은 응용 프로그램 개념을 개별 데이터베이스 쿼리로 변환하는 자체 시스템을 정의해야하지만 표현식 언어 만 사용할 수 있습니다.
표현 언어의 문은 SQLAlchemy 엔진에 의해 해당 원시 SQL 쿼리로 변환됩니다. 이제 엔진을 생성하고 도움을 받아 다양한 SQL 쿼리를 실행하는 방법을 배웁니다.
이전 장에서 SQLAlchemy의 표현 언어에 대해 논의했습니다. 이제 데이터베이스 연결과 관련된 단계를 진행하겠습니다.
엔진 클래스는 Pool and Dialect together 데이터베이스 소스 제공 connectivity and behavior. Engine 클래스의 개체는 다음을 사용하여 인스턴스화됩니다.create_engine() 함수.
create_engine () 함수는 데이터베이스를 하나의 인수로 사용합니다. 데이터베이스는 어디에도 정의 할 필요가 없습니다. 표준 호출 양식은 URL을 첫 번째 위치 인수, 일반적으로 데이터베이스 언어 및 연결 인수를 나타내는 문자열로 보내야합니다. 아래의 코드를 사용하여 데이터베이스를 생성 할 수 있습니다.
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///college.db', echo = True)에 대한 MySQL database, 아래 명령을 사용하십시오-
engine = create_engine("mysql://user:pwd@localhost/college",echo = True)구체적으로 언급하기 위해 DB-API 연결에 사용되는 URL string 다음과 같은 형식을 취합니다-
dialect[+driver]://user:password@host/dbname예를 들어, PyMySQL driver with MySQL, 다음 명령을 사용하십시오-
mysql+pymysql://<username>:<password>@<host>/<dbname>그만큼 echo flagPython의 표준 로깅 모듈을 통해 수행되는 SQLAlchemy 로깅을 설정하는 바로 가기입니다. 다음 장에서는 생성 된 모든 SQL에 대해 알아 봅니다. 자세한 출력을 숨기려면 echo 속성을 다음과 같이 설정하십시오.None. create_engine () 함수에 대한 다른 인수는 언어별로 다를 수 있습니다.
create_engine () 함수는 Engine object. Engine 클래스의 몇 가지 중요한 방법은 다음과 같습니다.
| Sr. 아니. | 방법 및 설명 |
|---|---|
| 1 | connect() 연결 개체를 반환합니다. |
| 2 | execute() SQL 문 구성을 실행합니다. |
| 삼 | begin() 트랜잭션이 설정된 연결을 제공하는 컨텍스트 관리자를 반환합니다. 작업이 성공하면 트랜잭션이 커밋되고 그렇지 않으면 롤백됩니다. |
| 4 | dispose() 엔진에서 사용하는 연결 풀을 삭제합니다. |
| 5 | driver() 엔진에서 사용중인 방언의 드라이버 이름 |
| 6 | table_names() 데이터베이스에서 사용 가능한 모든 테이블 이름 목록을 반환합니다. |
| 7 | transaction() 트랜잭션 경계 내에서 주어진 함수를 실행합니다. |
이제 테이블 생성 기능을 사용하는 방법에 대해 설명하겠습니다.
SQL 표현식 언어는 테이블 열에 대해 표현식을 구성합니다. SQLAlchemy Column 개체는column 차례로 표시되는 데이터베이스 테이블에서 Tableobject. 메타 데이터에는 인덱스, 뷰, 트리거 등과 같은 테이블 및 관련 개체의 정의가 포함됩니다.
따라서 SQLAlchemy Metadata의 MetaData 클래스 개체는 Table 개체 및 관련 스키마 구성의 모음입니다. 여기에는 Engine 또는 Connection에 대한 선택적 바인딩뿐만 아니라 Table 개체 컬렉션도 포함됩니다.
from sqlalchemy import MetaData
meta = MetaData()MetaData 클래스의 생성자는 기본적으로 바인딩 및 스키마 매개 변수를 가질 수 있습니다. None.
다음으로 위의 메타 데이터 카탈로그 내에서 테이블을 모두 정의합니다. the Table construct, 일반 SQL CREATE TABLE 문과 유사합니다.
Table 클래스의 객체는 데이터베이스의 해당 테이블을 나타냅니다. 생성자는 다음 매개 변수를 사용합니다.
| 이름 | 테이블의 이름 |
|---|---|
| 메타 데이터 | 이 테이블을 보유 할 MetaData 객체 |
| 열 | 열 클래스의 하나 이상의 개체 |
열 개체는 column 안에 database table. 생성자는 이름, 유형 및 primary_key, autoincrement 및 기타 제약과 같은 기타 매개 변수를 사용합니다.
SQLAlchemy는 Python 데이터를 여기에 정의 된 최상의 일반 열 데이터 형식과 일치시킵니다. 일반 데이터 유형 중 일부는-
- BigInteger
- Boolean
- Date
- DateTime
- Float
- Integer
- Numeric
- SmallInteger
- String
- Text
- Time
만들려면 students table 대학 데이터베이스에서 다음 스 니펫을 사용하십시오-
from sqlalchemy import Table, Column, Integer, String, MetaData
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)create_all () 함수는 엔진 개체를 사용하여 정의 된 모든 테이블 개체를 만들고 메타 데이터에 정보를 저장합니다.
meta.create_all(engine)student 테이블이있는 SQLite 데이터베이스 college.db를 만드는 완전한 코드가 아래에 제공됩니다.
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
meta.create_all(engine)create_engine () 함수의 echo 속성이 True, 콘솔은 다음과 같이 테이블 생성을위한 실제 SQL 쿼리를 표시합니다.
CREATE TABLE students (
id INTEGER NOT NULL,
name VARCHAR,
lastname VARCHAR,
PRIMARY KEY (id)
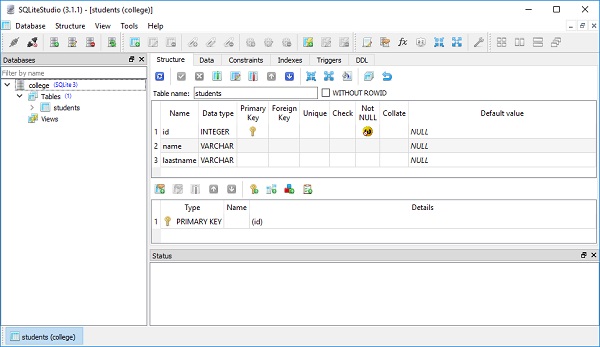
)college.db는 현재 작업 디렉토리에 생성됩니다. 학생 테이블이 생성되었는지 확인하려면 다음과 같은 SQLite GUI 도구를 사용하여 데이터베이스를 열 수 있습니다.SQLiteStudio.
아래 이미지는 데이터베이스에 생성 된 학생 테이블을 보여줍니다-
이 장에서는 SQL 표현식과 그 기능에 대해 간략하게 설명합니다.
SQL 표현식은 대상 테이블 오브젝트에 상대적인 해당 메소드를 사용하여 구성됩니다. 예를 들어 INSERT 문은 다음과 같이 insert () 메서드를 실행하여 생성됩니다.
ins = students.insert()위 방법의 결과는 다음을 사용하여 확인할 수있는 삽입 객체입니다. str()함수. 아래 코드는 학생 ID, 이름, 성과 같은 세부 정보를 삽입합니다.
'INSERT INTO students (id, name, lastname) VALUES (:id, :name, :lastname)'특정 필드에 값을 삽입 할 수 있습니다. values()개체를 삽입하는 방법. 동일한 코드는 다음과 같습니다.
>>> ins = users.insert().values(name = 'Karan')
>>> str(ins)
'INSERT INTO users (name) VALUES (:name)'Python 콘솔에 에코 된 SQL은 실제 값 (이 경우 'Karan')을 표시하지 않습니다. 대신 SQLALchemy는 명령문의 컴파일 된 형태로 표시되는 바인드 매개 변수를 생성합니다.
ins.compile().params
{'name': 'Karan'}마찬가지로 update(), delete() 과 select()UPDATE, DELETE 및 SELECT 표현식을 각각 작성하십시오. 우리는 이후 장에서 그것들에 대해 배울 것입니다.
이전 장에서 SQL 표현식을 배웠습니다. 이 장에서 우리는 이러한 표현의 실행을 살펴볼 것입니다.
결과 SQL 표현식을 실행하려면 다음을 수행해야합니다. obtain a connection object representing an actively checked out DBAPI connection resource 그리고 feed the expression object 아래 코드와 같이.
conn = engine.connect()다음 insert () 객체는 execute () 메서드에 사용할 수 있습니다-
ins = students.insert().values(name = 'Ravi', lastname = 'Kapoor')
result = conn.execute(ins)콘솔은 아래와 같이 SQL 표현식의 실행 결과를 보여줍니다-
INSERT INTO students (name, lastname) VALUES (?, ?)
('Ravi', 'Kapoor')
COMMIT다음은 SQLAlchemy의 핵심 기술을 사용하여 INSERT 쿼리의 실행을 보여주는 전체 스 니펫입니다.
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
ins = students.insert()
ins = students.insert().values(name = 'Ravi', lastname = 'Kapoor')
conn = engine.connect()
result = conn.execute(ins)결과는 아래 스크린 샷과 같이 SQLite Studio를 사용하여 데이터베이스를 열어 확인할 수 있습니다.

결과 변수는 ResultProxy 로 알려져 있습니다. object. DBAPI 커서 개체와 유사합니다. 다음을 사용하여 진술에서 생성 된 기본 키 값에 대한 정보를 얻을 수 있습니다.ResultProxy.inserted_primary_key 아래와 같이-
result.inserted_primary_key
[1]DBAPI의 execute many () 메소드를 사용하여 많은 삽입을 발행하려면 삽입 할 고유 한 매개 변수 세트를 각각 포함하는 사전 목록을 보낼 수 있습니다.
conn.execute(students.insert(), [
{'name':'Rajiv', 'lastname' : 'Khanna'},
{'name':'Komal','lastname' : 'Bhandari'},
{'name':'Abdul','lastname' : 'Sattar'},
{'name':'Priya','lastname' : 'Rajhans'},
])이것은 다음 그림과 같이 테이블의 데이터보기에 반영됩니다.
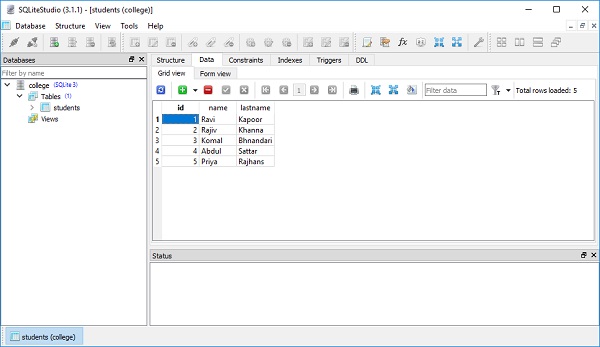
이 장에서는 테이블 개체에서 행을 선택하는 개념에 대해 설명합니다.
테이블 객체의 select () 메서드를 사용하면 construct SELECT expression.
s = students.select()선택 개체는 다음과 같이 변환됩니다. SELECT query by str(s) function 아래와 같이-
'SELECT students.id, students.name, students.lastname FROM students'이 선택 객체를 아래 코드와 같이 연결 객체의 execute () 메서드에 대한 매개 변수로 사용할 수 있습니다.
result = conn.execute(s)위의 명령문이 실행되면 Python 쉘은 동등한 SQL 표현식을 따라 에코합니다.
SELECT students.id, students.name, students.lastname
FROM students결과 변수는 DBAPI의 커서와 동일합니다. 이제 다음을 사용하여 레코드를 가져올 수 있습니다.fetchone() method.
row = result.fetchone()테이블에서 선택한 모든 행은 for loop 아래와 같이-
for row in result:
print (row)학생 테이블의 모든 행을 인쇄하는 전체 코드는 다음과 같습니다.
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
s = students.select()
conn = engine.connect()
result = conn.execute(s)
for row in result:
print (row)Python 셸에 표시된 출력은 다음과 같습니다.
(1, 'Ravi', 'Kapoor')
(2, 'Rajiv', 'Khanna')
(3, 'Komal', 'Bhandari')
(4, 'Abdul', 'Sattar')
(5, 'Priya', 'Rajhans')SELECT 쿼리의 WHERE 절은 다음을 사용하여 적용 할 수 있습니다. Select.where(). 예를 들어, ID가> 2 인 행을 표시하려면
s = students.select().where(students.c.id>2)
result = conn.execute(s)
for row in result:
print (row)여기 c attribute is an alias for column. 다음 출력은 쉘에 표시됩니다-
(3, 'Komal', 'Bhandari')
(4, 'Abdul', 'Sattar')
(5, 'Priya', 'Rajhans')여기서는 sqlalchemy.sql 모듈의 select () 함수를 통해서도 select 객체를 얻을 수 있다는 점에 유의해야합니다. select () 함수에는 테이블 객체가 인수로 필요합니다.
from sqlalchemy.sql import select
s = select([users])
result = conn.execute(s)SQLAlchemy를 사용하면 SQL이 이미 알려져 있고 동적 기능을 지원하기 위해 명령문이 강력하게 필요하지 않은 경우에만 문자열을 사용할 수 있습니다. text () 구조는 대부분 변경되지 않은 상태로 데이터베이스에 전달되는 텍스트 문을 작성하는 데 사용됩니다.
그것은 새로운 TextClause, 아래 코드와 같이 직접 텍스트 SQL 문자열을 나타냅니다.
from sqlalchemy import text
t = text("SELECT * FROM students")
result = connection.execute(t)이점들 text() 일반 문자열을 통해 제공됩니다-
- 바인드 매개 변수에 대한 백엔드 중립 지원
- 문별 실행 옵션
- 결과 열 입력 동작
text () 함수에는 명명 된 콜론 형식의 Bound 매개 변수가 필요합니다. 데이터베이스 백엔드에 관계없이 일관성이 있습니다. 매개 변수에 대한 값을 보내려면 추가 인수로 execute () 메서드에 전달합니다.
다음 예제는 텍스트 SQL에서 바인딩 된 매개 변수를 사용합니다-
from sqlalchemy.sql import text
s = text("select students.name, students.lastname from students where students.name between :x and :y")
conn.execute(s, x = 'A', y = 'L').fetchall()text () 함수는 다음과 같이 SQL 표현식을 구성합니다.
select students.name, students.lastname from students where students.name between ? and ?x = 'A'및 y = 'L'의 값이 매개 변수로 전달됩니다. 결과는 'A'와 'L'사이의 이름을 가진 행 목록입니다-
[('Komal', 'Bhandari'), ('Abdul', 'Sattar')]text () 구조는 TextClause.bindparams () 메서드를 사용하여 미리 설정된 바인딩 된 값을 지원합니다. 매개 변수는 다음과 같이 명시 적으로 입력 할 수도 있습니다.
stmt = text("SELECT * FROM students WHERE students.name BETWEEN :x AND :y")
stmt = stmt.bindparams(
bindparam("x", type_= String),
bindparam("y", type_= String)
)
result = conn.execute(stmt, {"x": "A", "y": "L"})
The text() function also be produces fragments of SQL within a select() object that
accepts text() objects as an arguments. The “geometry” of the statement is provided by
select() construct , and the textual content by text() construct. We can build a statement
without the need to refer to any pre-established Table metadata.
from sqlalchemy.sql import select
s = select([text("students.name, students.lastname from students")]).where(text("students.name between :x and :y"))
conn.execute(s, x = 'A', y = 'L').fetchall()당신은 또한 사용할 수 있습니다 and_() text () 함수의 도움으로 생성 된 WHERE 절에서 여러 조건을 결합하는 함수.
from sqlalchemy import and_
from sqlalchemy.sql import select
s = select([text("* from students")]) \
.where(
and_(
text("students.name between :x and :y"),
text("students.id>2")
)
)
conn.execute(s, x = 'A', y = 'L').fetchall()위의 코드는 ID가 2보다 큰 "A"와 "L"사이의 이름을 가진 행을 가져옵니다. 코드의 출력은 다음과 같습니다.
[(3, 'Komal', 'Bhandari'), (4, 'Abdul', 'Sattar')]SQL의 별칭은 "SELECT * FROM table1 AS a"라고 말할 때마다 발생하는 테이블 또는 SELECT 문의 "이름이 변경된"버전에 해당합니다. AS는 테이블의 새 이름을 만듭니다. 별칭을 사용하면 고유 한 이름으로 모든 테이블 또는 하위 쿼리를 참조 할 수 있습니다.
테이블의 경우 FROM 절에서 동일한 테이블의 이름을 여러 번 지정할 수 있습니다. 이 이름에 상대적으로 참조 할 수 있도록 명령문으로 표시되는 열에 대한 상위 이름을 제공합니다.
SQLAlchemy에서 Table, select () 구문 또는 기타 선택 가능한 개체는 다음을 사용하여 별칭으로 변환 할 수 있습니다. From Clause.alias()메서드는 Alias 구문을 생성합니다. sqlalchemy.sql 모듈의 alias () 함수는 일반적으로 AS 키워드를 사용하는 SQL 문 내의 모든 테이블 또는 하위 선택에 적용되는 별칭을 나타냅니다.
from sqlalchemy.sql import alias
st = students.alias("a")이 별칭은 이제 학생 테이블을 참조하기 위해 select () 구조에서 사용할 수 있습니다.
s = select([st]).where(st.c.id>2)이것은 다음과 같이 SQL 표현식으로 변환됩니다-
SELECT a.id, a.name, a.lastname FROM students AS a WHERE a.id > 2이제 연결 개체의 execute () 메서드를 사용하여이 SQL 쿼리를 실행할 수 있습니다. 완전한 코드는 다음과 같습니다.
from sqlalchemy.sql import alias, select
st = students.alias("a")
s = select([st]).where(st.c.id > 2)
conn.execute(s).fetchall()위의 코드 줄이 실행되면 다음과 같은 출력이 생성됩니다.
[(3, 'Komal', 'Bhandari'), (4, 'Abdul', 'Sattar'), (5, 'Priya', 'Rajhans')]그만큼 update() 대상 테이블 객체의 메소드는 동등한 UPDATE SQL 표현식을 구성합니다.
table.update().where(conditions).values(SET expressions)그만큼 values()결과 업데이트 개체의 메서드는 UPDATE의 SET 조건을 지정하는 데 사용됩니다. None으로 남겨두면 SET 조건은 명령문의 실행 및 / 또는 컴파일 중에 명령문에 전달 된 매개 변수에서 결정됩니다.
where 절은 UPDATE 문의 WHERE 조건을 설명하는 선택적 표현식입니다.
다음 코드 스 니펫은 학생 테이블에서 '성'열의 값을 'Khanna'에서 'Kapoor'로 변경합니다.
stmt = students.update().where(students.c.lastname == 'Khanna').values(lastname = 'Kapoor')stmt 객체는 다음과 같이 번역되는 업데이트 객체입니다.
'UPDATE students SET lastname = :lastname WHERE students.lastname = :lastname_1'바인딩 된 매개 변수 lastname_1 때 대체됩니다 execute()메소드가 호출됩니다. 전체 업데이트 코드는 다음과 같습니다.
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students',
meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
conn = engine.connect()
stmt=students.update().where(students.c.lastname=='Khanna').values(lastname='Kapoor')
conn.execute(stmt)
s = students.select()
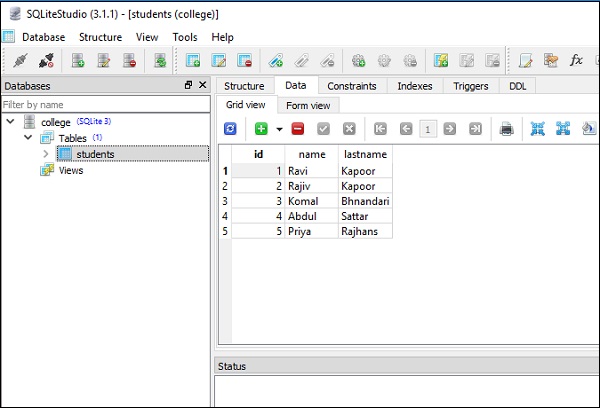
conn.execute(s).fetchall()위의 코드는 주어진 스크린 샷에서와 같이 업데이트 작업의 효과를 보여주는 두 번째 행과 함께 다음 출력을 표시합니다.
[
(1, 'Ravi', 'Kapoor'),
(2, 'Rajiv', 'Kapoor'),
(3, 'Komal', 'Bhandari'),
(4, 'Abdul', 'Sattar'),
(5, 'Priya', 'Rajhans')
]
유사한 기능은 다음을 사용하여 얻을 수도 있습니다. update() 아래와 같이 sqlalchemy.sql.expression 모듈의 함수-
from sqlalchemy.sql.expression import update
stmt = update(students).where(students.c.lastname == 'Khanna').values(lastname = 'Kapoor')이전 장에서 우리는 Update표현이 그렇습니다. 다음으로 배울 표현은Delete.
삭제 작업은 다음 문과 같이 대상 테이블 객체에서 delete () 메서드를 실행하여 수행 할 수 있습니다.
stmt = students.delete()학생 테이블의 경우 위 코드 줄은 다음과 같이 SQL 표현식을 구성합니다.
'DELETE FROM students'그러나 이것은 student 테이블의 모든 행을 삭제합니다. 일반적으로 DELETE 쿼리는 WHERE 절에 지정된 논리 식과 연결됩니다. 다음 문은 매개 변수-
stmt = students.delete().where(students.c.id > 2)결과 SQL 표현식에는 명령문이 실행될 때 런타임에 대체되는 바인딩 된 매개 변수가 있습니다.
'DELETE FROM students WHERE students.id > :id_1'다음 코드 예제는 성이 'Khanna'인 students 테이블에서 해당 행을 삭제합니다.
from sqlalchemy.sql.expression import update
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
conn = engine.connect()
stmt = students.delete().where(students.c.lastname == 'Khanna')
conn.execute(stmt)
s = students.select()
conn.execute(s).fetchall()결과를 확인하려면 SQLiteStudio에서 학생 테이블의 데이터보기를 새로 고칩니다.
RDBMS의 중요한 기능 중 하나는 테이블 간의 관계를 설정하는 것입니다. SELECT, UPDATE 및 DELETE와 같은 SQL 작업은 관련 테이블에서 수행 할 수 있습니다. 이 섹션에서는 SQLAlchemy를 사용하는 이러한 작업에 대해 설명합니다.
이를 위해 SQLite 데이터베이스 (college.db)에 두 개의 테이블이 생성됩니다. student 테이블은 이전 섹션에서 제공된 것과 동일한 구조를 갖습니다. 주소 테이블에는st_id 매핑되는 열 id column in students table 외래 키 제약 사용.
다음 코드는 college.db에 두 개의 테이블을 생성합니다-
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey
engine = create_engine('sqlite:///college.db', echo=True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer, ForeignKey('students.id')),
Column('postal_add', String),
Column('email_add', String))
meta.create_all(engine)위의 코드는 아래와 같이 학생 및 주소 테이블에 대한 CREATE TABLE 쿼리로 변환됩니다.
CREATE TABLE students (
id INTEGER NOT NULL,
name VARCHAR,
lastname VARCHAR,
PRIMARY KEY (id)
)
CREATE TABLE addresses (
id INTEGER NOT NULL,
st_id INTEGER,
postal_add VARCHAR,
email_add VARCHAR,
PRIMARY KEY (id),
FOREIGN KEY(st_id) REFERENCES students (id)
)다음 스크린 샷은 위의 코드를 매우 명확하게 보여줍니다.
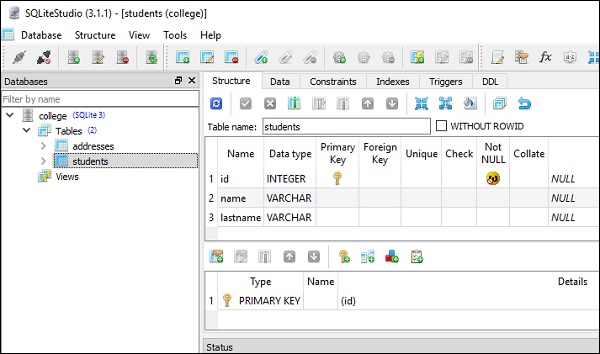
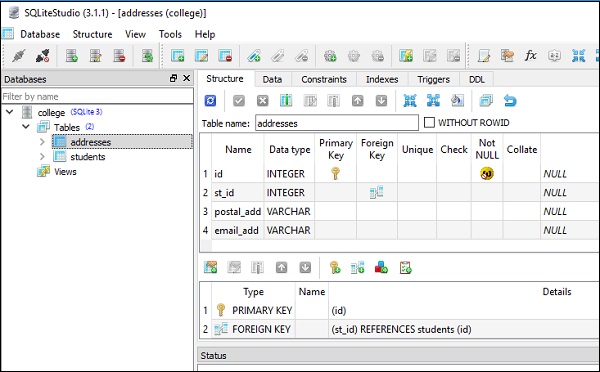
이 테이블은 다음을 실행하여 데이터로 채워집니다. insert() method테이블 개체의. 학생 테이블에 5 개의 행을 삽입하려면 아래 코드를 사용할 수 있습니다.
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
conn.execute(students.insert(), [
{'name':'Ravi', 'lastname':'Kapoor'},
{'name':'Rajiv', 'lastname' : 'Khanna'},
{'name':'Komal','lastname' : 'Bhandari'},
{'name':'Abdul','lastname' : 'Sattar'},
{'name':'Priya','lastname' : 'Rajhans'},
])Rows 다음 코드의 도움으로 주소 테이블에 추가됩니다-
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer),
Column('postal_add', String),
Column('email_add', String)
)
conn.execute(addresses.insert(), [
{'st_id':1, 'postal_add':'Shivajinagar Pune', 'email_add':'[email protected]'},
{'st_id':1, 'postal_add':'ChurchGate Mumbai', 'email_add':'[email protected]'},
{'st_id':3, 'postal_add':'Jubilee Hills Hyderabad', 'email_add':'[email protected]'},
{'st_id':5, 'postal_add':'MG Road Bangaluru', 'email_add':'[email protected]'},
{'st_id':2, 'postal_add':'Cannought Place new Delhi', 'email_add':'[email protected]'},
])address 테이블의 st_id 열은 students 테이블의 id 열을 참조합니다. 이제이 관계를 사용하여 두 테이블에서 데이터를 가져올 수 있습니다. 우리는 가져오고 싶다name 과 lastname 주소 테이블의 st_id에 해당하는 학생 테이블에서.
from sqlalchemy.sql import select
s = select([students, addresses]).where(students.c.id == addresses.c.st_id)
result = conn.execute(s)
for row in result:
print (row)선택 객체는 공통 관계에서 두 테이블을 결합하는 다음 SQL 표현식으로 효과적으로 변환됩니다.
SELECT students.id,
students.name,
students.lastname,
addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM students, addresses
WHERE students.id = addresses.st_id이것은 다음과 같이 두 테이블에서 해당 데이터를 추출하는 출력을 생성합니다.
(1, 'Ravi', 'Kapoor', 1, 1, 'Shivajinagar Pune', '[email protected]')
(1, 'Ravi', 'Kapoor', 2, 1, 'ChurchGate Mumbai', '[email protected]')
(3, 'Komal', 'Bhandari', 3, 3, 'Jubilee Hills Hyderabad', '[email protected]')
(5, 'Priya', 'Rajhans', 4, 5, 'MG Road Bangaluru', '[email protected]')
(2, 'Rajiv', 'Khanna', 5, 2, 'Cannought Place new Delhi', '[email protected]')이전 장에서 여러 테이블을 사용하는 방법에 대해 논의했습니다. 그래서 우리는 한 단계 더 나아가서multiple table updates 이 챕터에서는.
SQLAlchemy의 테이블 객체를 사용하면 update () 메서드의 WHERE 절에 둘 이상의 테이블을 지정할 수 있습니다. PostgreSQL 및 Microsoft SQL Server는 여러 테이블을 참조하는 UPDATE 문을 지원합니다. 이것은 구현“UPDATE FROM”한 번에 하나의 테이블을 업데이트하는 구문. 그러나 추가 테이블은 WHERE 절의 추가 "FROM"절에서 직접 참조 할 수 있습니다. 다음 코드 줄은 개념을 설명합니다.multiple table updates 분명히.
stmt = students.update().\
values({
students.c.name:'xyz',
addresses.c.email_add:'[email protected]'
}).\
where(students.c.id == addresses.c.id)업데이트 개체는 다음 UPDATE 쿼리와 동일합니다-
UPDATE students
SET email_add = :addresses_email_add, name = :name
FROM addresses
WHERE students.id = addresses.idMySQL 방언에 관한 한, 아래에 주어진 것처럼 쉼표로 구분 된 단일 UPDATE 문에 여러 테이블을 포함 할 수 있습니다.
stmt = students.update().\
values(name = 'xyz').\
where(students.c.id == addresses.c.id)다음 코드는 결과 UPDATE 쿼리를 묘사합니다-
'UPDATE students SET name = :name
FROM addresses
WHERE students.id = addresses.id'그러나 SQLite 방언은 UPDATE 내에서 다중 테이블 기준을 지원하지 않으며 다음 오류를 표시합니다.
NotImplementedError: This backend does not support multiple-table criteria within UPDATE원시 SQL의 UPDATE 쿼리에는 SET 절이 있습니다. 이는 원래 Table 객체에 제공된 열 순서를 사용하여 update () 구성에 의해 렌더링됩니다. 따라서 특정 열이있는 특정 UPDATE 문은 매번 동일하게 렌더링됩니다. 매개 변수 자체는 Python 사전 키로 Update.values () 메서드에 전달되므로 다른 고정 된 순서를 사용할 수 없습니다.
어떤 경우에는 SET 절에서 렌더링되는 매개 변수의 순서가 중요합니다. MySQL에서 열 값에 대한 업데이트 제공은 다른 열 값의 업데이트를 기반으로합니다.
다음 진술의 결과-
UPDATE table1 SET x = y + 10, y = 20-와는 다른 결과가 나타납니다.
UPDATE table1 SET y = 20, x = y + 10MySQL의 SET 절은 행 기준이 아닌 값 기준으로 평가됩니다. 이를 위해preserve_parameter_order사용. 2- 튜플의 파이썬 목록은Update.values() 방법-
stmt = table1.update(preserve_parameter_order = True).\
values([(table1.c.y, 20), (table1.c.x, table1.c.y + 10)])List 객체는 정렬된다는 점을 제외하고 사전과 유사합니다. 이렇게하면 "y"열의 SET 절이 먼저 렌더링 된 다음 "x"열의 SET 절이 렌더링됩니다.
이 장에서는 Multiple Table Updates 기능을 사용하는 것과 유사한 Multiple Table Deletes 표현식을 살펴 보겠습니다.
많은 DBMS 방언에서 DELETE 문의 WHERE 절에서 하나 이상의 테이블을 참조 할 수 있습니다. PG 및 MySQL의 경우 "DELETE USING"구문이 사용됩니다. SQL Server의 경우 "DELETE FROM"식을 사용하면 둘 이상의 테이블을 참조합니다. SQLAlchemydelete() 구문은 다음과 같이 WHERE 절에 여러 테이블을 지정하여 이러한 모드를 모두 암시 적으로 지원합니다.
stmt = users.delete().\
where(users.c.id == addresses.c.id).\
where(addresses.c.email_address.startswith('xyz%'))
conn.execute(stmt)PostgreSQL 백엔드에서 위 명령문의 결과 SQL은 다음과 같이 렌더링됩니다.
DELETE FROM users USING addresses
WHERE users.id = addresses.id
AND (addresses.email_address LIKE %(email_address_1)s || '%%')이 메서드가이 동작을 지원하지 않는 데이터베이스와 함께 사용되는 경우 컴파일러는 NotImplementedError를 발생시킵니다.
이 장에서는 SQLAlchemy에서 조인을 사용하는 방법을 배웁니다.
조인의 효과는 두 개의 테이블을 columns clause 아니면 그 where clauseselect () 구조의. 이제 join () 및 outerjoin () 메서드를 사용합니다.
The join() method returns a join object from one table object to another.
join(right, onclause = None, isouter = False, full = False)The functions of the parameters mentioned in the above code are as follows −
right − the right side of the join; this is any Table object
onclause − a SQL expression representing the ON clause of the join. If left at None, it attempts to join the two tables based on a foreign key relationship
isouter − if True, renders a LEFT OUTER JOIN, instead of JOIN
full − if True, renders a FULL OUTER JOIN, instead of LEFT OUTER JOIN
For example, following use of join() method will automatically result in join based on the foreign key.
>>> print(students.join(addresses))This is equivalent to following SQL expression −
students JOIN addresses ON students.id = addresses.st_idYou can explicitly mention joining criteria as follows −
j = students.join(addresses, students.c.id == addresses.c.st_id)If we now build the below select construct using this join as −
stmt = select([students]).select_from(j)This will result in following SQL expression −
SELECT students.id, students.name, students.lastname
FROM students JOIN addresses ON students.id = addresses.st_idIf this statement is executed using the connection representing engine, data belonging to selected columns will be displayed. The complete code is as follows −
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer,ForeignKey('students.id')),
Column('postal_add', String),
Column('email_add', String)
)
from sqlalchemy import join
from sqlalchemy.sql import select
j = students.join(addresses, students.c.id == addresses.c.st_id)
stmt = select([students]).select_from(j)
result = conn.execute(stmt)
result.fetchall()The following is the output of the above code −
[
(1, 'Ravi', 'Kapoor'),
(1, 'Ravi', 'Kapoor'),
(3, 'Komal', 'Bhandari'),
(5, 'Priya', 'Rajhans'),
(2, 'Rajiv', 'Khanna')
]Conjunctions are functions in SQLAlchemy module that implement relational operators used in WHERE clause of SQL expressions. The operators AND, OR, NOT, etc., are used to form a compound expression combining two individual logical expressions. A simple example of using AND in SELECT statement is as follows −
SELECT * from EMPLOYEE WHERE salary>10000 AND age>30SQLAlchemy functions and_(), or_() and not_() respectively implement AND, OR and NOT operators.
and_() function
It produces a conjunction of expressions joined by AND. An example is given below for better understanding −
from sqlalchemy import and_
print(
and_(
students.c.name == 'Ravi',
students.c.id <3
)
)This translates to −
students.name = :name_1 AND students.id < :id_1To use and_() in a select() construct on a students table, use the following line of code −
stmt = select([students]).where(and_(students.c.name == 'Ravi', students.c.id <3))SELECT statement of the following nature will be constructed −
SELECT students.id,
students.name,
students.lastname
FROM students
WHERE students.name = :name_1 AND students.id < :id_1The complete code that displays output of the above SELECT query is as follows −
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey, select
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
from sqlalchemy import and_, or_
stmt = select([students]).where(and_(students.c.name == 'Ravi', students.c.id <3))
result = conn.execute(stmt)
print (result.fetchall())Following row will be selected assuming that students table is populated with data used in previous example −
[(1, 'Ravi', 'Kapoor')]or_() function
It produces conjunction of expressions joined by OR. We shall replace the stmt object in the above example with the following one using or_()
stmt = select([students]).where(or_(students.c.name == 'Ravi', students.c.id <3))Which will be effectively equivalent to following SELECT query −
SELECT students.id,
students.name,
students.lastname
FROM students
WHERE students.name = :name_1
OR students.id < :id_1Once you make the substitution and run the above code, the result will be two rows falling in the OR condition −
[(1, 'Ravi', 'Kapoor'),
(2, 'Rajiv', 'Khanna')]asc() function
It produces an ascending ORDER BY clause. The function takes the column to apply the function as a parameter.
from sqlalchemy import asc
stmt = select([students]).order_by(asc(students.c.name))The statement implements following SQL expression −
SELECT students.id,
students.name,
students.lastname
FROM students
ORDER BY students.name ASCFollowing code lists out all records in students table in ascending order of name column −
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey, select
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
from sqlalchemy import asc
stmt = select([students]).order_by(asc(students.c.name))
result = conn.execute(stmt)
for row in result:
print (row)Above code produces following output −
(4, 'Abdul', 'Sattar')
(3, 'Komal', 'Bhandari')
(5, 'Priya', 'Rajhans')
(2, 'Rajiv', 'Khanna')
(1, 'Ravi', 'Kapoor')desc() function
Similarly desc() function produces descending ORDER BY clause as follows −
from sqlalchemy import desc
stmt = select([students]).order_by(desc(students.c.lastname))The equivalent SQL expression is −
SELECT students.id,
students.name,
students.lastname
FROM students
ORDER BY students.lastname DESCAnd the output for the above lines of code is −
(4, 'Abdul', 'Sattar')
(5, 'Priya', 'Rajhans')
(2, 'Rajiv', 'Khanna')
(1, 'Ravi', 'Kapoor')
(3, 'Komal', 'Bhandari')between() function
It produces a BETWEEN predicate clause. This is generally used to validate if value of a certain column falls between a range. For example, following code selects rows for which id column is between 2 and 4 −
from sqlalchemy import between
stmt = select([students]).where(between(students.c.id,2,4))
print (stmt)The resulting SQL expression resembles −
SELECT students.id,
students.name,
students.lastname
FROM students
WHERE students.id
BETWEEN :id_1 AND :id_2and the result is as follows −
(2, 'Rajiv', 'Khanna')
(3, 'Komal', 'Bhandari')
(4, 'Abdul', 'Sattar')Some of the important functions used in SQLAlchemy are discussed in this chapter.
Standard SQL has recommended many functions which are implemented by most dialects. They return a single value based on the arguments passed to it. Some SQL functions take columns as arguments whereas some are generic. Thefunc keyword in SQLAlchemy API is used to generate these functions.
In SQL, now() is a generic function. Following statements renders the now() function using func −
from sqlalchemy.sql import func
result = conn.execute(select([func.now()]))
print (result.fetchone())Sample result of above code may be as shown below −
(datetime.datetime(2018, 6, 16, 6, 4, 40),)On the other hand, count() function which returns number of rows selected from a table, is rendered by following usage of func −
from sqlalchemy.sql import func
result = conn.execute(select([func.count(students.c.id)]))
print (result.fetchone())From the above code, count of number of rows in students table will be fetched.
Some built-in SQL functions are demonstrated using Employee table with following data −
| 신분증 | 이름 | 점수 |
|---|---|---|
| 1 | 카말 | 56 |
| 2 | 페르난데스 | 85 |
| 삼 | 수닐 | 62 |
| 4 | Bhaskar | 76 |
max () 함수는 다음과 같이 SQLAlchemy에서 func를 사용하여 구현되며 결과적으로 총 최대 마크 수는 85입니다.
from sqlalchemy.sql import func
result = conn.execute(select([func.max(employee.c.marks)]))
print (result.fetchone())마찬가지로, 최소 마크인 56을 반환하는 min () 함수는 다음 코드에 의해 렌더링됩니다.
from sqlalchemy.sql import func
result = conn.execute(select([func.min(employee.c.marks)]))
print (result.fetchone())따라서 AVG () 함수는 아래 코드를 사용하여 구현할 수도 있습니다.
from sqlalchemy.sql import func
result = conn.execute(select([func.avg(employee.c.marks)]))
print (result.fetchone())
Functions are normally used in the columns clause of a select statement.
They can also be given label as well as a type. A label to function allows the result
to be targeted in a result row based on a string name, and a type is required when
you need result-set processing to occur.from sqlalchemy.sql import func
result = conn.execute(select([func.max(students.c.lastname).label('Name')]))
print (result.fetchone())지난 장에서 우리는 max (), min (), count () 등과 같은 다양한 함수에 대해 배웠습니다. 여기서 우리는 집합 연산과 그 용도에 대해 배울 것입니다.
UNION 및 INTERSECT와 같은 집합 연산은 표준 SQL 및 대부분의 언어에서 지원됩니다. SQLAlchemy는 다음 기능을 사용하여 구현합니다.
노동 조합()
둘 이상의 SELECT 문의 결과를 결합하는 동안 UNION은 결과 집합에서 중복을 제거합니다. 두 테이블에서 열 수와 데이터 유형이 동일해야합니다.
union () 함수는 여러 테이블에서 CompoundSelect 객체를 반환합니다. 다음 예제는 그 사용을 보여줍니다-
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, union
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer),
Column('postal_add', String),
Column('email_add', String)
)
u = union(addresses.select().where(addresses.c.email_add.like('%@gmail.com addresses.select().where(addresses.c.email_add.like('%@yahoo.com'))))
result = conn.execute(u)
result.fetchall()통합 구조는 다음 SQL 표현식으로 변환됩니다.
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? UNION SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ?주소 테이블에서 다음 행은 통합 작업을 나타냅니다.
[
(1, 1, 'Shivajinagar Pune', '[email protected]'),
(2, 1, 'ChurchGate Mumbai', '[email protected]'),
(3, 3, 'Jubilee Hills Hyderabad', '[email protected]'),
(4, 5, 'MG Road Bangaluru', '[email protected]')
]union_all ()
UNION ALL 작업은 중복 항목을 제거 할 수 없으며 결과 집합의 데이터를 정렬 할 수 없습니다. 예를 들어 위 쿼리에서 UNION은 UNION ALL로 대체되어 효과를 확인합니다.
u = union_all(addresses.select().where(addresses.c.email_add.like('%@gmail.com')), addresses.select().where(addresses.c.email_add.like('%@yahoo.com')))해당 SQL 표현식은 다음과 같습니다.
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? UNION ALL SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ?외_()
SQL EXCEPT절 / 연산자는 두 개의 SELECT 문을 결합하고 두 번째 SELECT 문에서 반환하지 않는 첫 번째 SELECT 문에서 행을 반환하는 데 사용됩니다. except_ () 함수는 EXCEPT 절이있는 SELECT 표현식을 생성합니다.
다음 예에서 except_ () 함수는 email_add 필드에 'gmail.com'이있는 주소 테이블의 레코드 만 반환하지만 postal_add 필드의 일부로 'Pune'이있는 레코드는 제외합니다.
u = except_(addresses.select().where(addresses.c.email_add.like('%@gmail.com')), addresses.select().where(addresses.c.postal_add.like('%Pune')))위 코드의 결과는 다음 SQL 표현식입니다.
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? EXCEPT SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.postal_add LIKE ?주소 테이블에 이전 예제에서 사용 된 데이터가 포함되어 있다고 가정하면 다음과 같은 출력이 표시됩니다.
[(2, 1, 'ChurchGate Mumbai', '[email protected]'),
(3, 3, 'Jubilee Hills Hyderabad', '[email protected]')]intersect ()
INTERSECT 연산자를 사용하여 SQL은 두 SELECT 문의 공통 행을 표시합니다. intersect () 함수는이 동작을 구현합니다.
다음 예제에서 두 개의 SELECT 구문은 intersect () 함수에 대한 매개 변수입니다. 하나는 email_add 열의 일부로 'gmail.com'을 포함하는 행을 반환하고 다른 하나는 postal_add 열의 일부로 'Pune'이있는 행을 반환합니다. 결과는 두 결과 집합의 공통 행이됩니다.
u = intersect(addresses.select().where(addresses.c.email_add.like('%@gmail.com')), addresses.select().where(addresses.c.postal_add.like('%Pune')))실제로 이것은 다음 SQL 문과 동일합니다.
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? INTERSECT SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.postal_add LIKE ?두 개의 바인딩 된 매개 변수 '% gmail.com'과 '% Pune'은 아래와 같이 주소 테이블의 원본 데이터에서 단일 행을 생성합니다.
[(1, 1, 'Shivajinagar Pune', '[email protected]')]SQLAlchemy의 Object Relational Mapper API의 주요 목적은 사용자 정의 Python 클래스를 데이터베이스 테이블과 연결하고 해당 클래스의 개체를 해당 테이블의 행과 쉽게 연결하는 것입니다. 개체 및 행의 상태 변경은 서로 동 기적으로 일치합니다. SQLAlchemy를 사용하면 사용자 정의 클래스 및 정의 된 관계 측면에서 데이터베이스 쿼리를 표현할 수 있습니다.
ORM은 SQL 표현식 언어 위에 구성됩니다. 높은 수준의 추상적 인 사용 패턴입니다. 실제로 ORM은 Expression Language의 적용 용도입니다.
Object Relational Mapper만을 사용하여 성공적인 애플리케이션을 구축 할 수 있지만, ORM으로 구축 된 애플리케이션은 특정 데이터베이스 상호 작용이 필요한 경우 직접 Expression Language를 사용할 수 있습니다.
매핑 선언
우선 create_engine () 함수를 호출하여 나중에 SQL 작업을 수행하는 데 사용되는 엔진 개체를 설정합니다. 이 함수에는 두 개의 인수가 있습니다. 하나는 데이터베이스 이름이고 다른 하나는 True로 설정하면 활동 로그를 생성하는 에코 매개 변수입니다. 존재하지 않는 경우 데이터베이스가 생성됩니다. 다음 예에서는 SQLite 데이터베이스가 생성됩니다.
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)Engine은 Engine.execute () 또는 Engine.connect ()와 같은 메서드가 호출 될 때 데이터베이스에 대한 실제 DBAPI 연결을 설정합니다. 그런 다음 엔진을 직접 사용하지 않는 SQLORM을 내보내는 데 사용됩니다. 대신 ORM에서 배후에서 사용됩니다.
ORM의 경우 구성 프로세스는 데이터베이스 테이블을 설명하고 해당 테이블에 매핑 될 클래스를 정의하여 시작됩니다. SQLAlchemy에서는이 두 작업이 함께 수행됩니다. 이것은 선언 시스템을 사용하여 수행됩니다. 생성 된 클래스에는 매핑 된 실제 데이터베이스 테이블을 설명하는 지시문이 포함됩니다.
기본 클래스는 선언 시스템에 클래스 및 매핑 된 테이블의 카탈로그를 저장합니다. 이를 선언적 기본 클래스라고합니다. 일반적으로 일반적으로 가져온 모듈에는이베이스의 인스턴스가 하나만 있습니다. declarative_base () 함수는 기본 클래스를 만드는 데 사용됩니다. 이 함수는 sqlalchemy.ext.declarative 모듈에 정의되어 있습니다.
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()일단 기본 클래스가 선언되면 그 관점에서 매핑 된 클래스를 원하는만큼 정의 할 수 있습니다. 다음 코드는 고객의 클래스를 정의합니다. 여기에는 매핑 할 테이블과 그 안에있는 열의 이름과 데이터 유형이 포함됩니다.
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)Declarative의 클래스에는 __tablename__ 속성 및 하나 이상의 Column기본 키의 일부입니다. 선언적은 모든Column 특수 Python 접근자가있는 객체 descriptors. 이 프로세스는 SQL 컨텍스트에서 테이블을 참조하는 수단을 제공하고 데이터베이스에서 열 값을 유지하고로드 할 수 있도록하는 도구로 알려져 있습니다.
일반 Python 클래스와 같은이 매핑 된 클래스에는 요구 사항에 따라 속성과 메서드가 있습니다.
선언적 시스템의 클래스에 대한 정보를 테이블 메타 데이터라고합니다. SQLAlchemy는 Table 개체를 사용하여 Declarative에서 만든 특정 테이블에 대한이 정보를 나타냅니다. Table 개체는 사양에 따라 생성되며 Mapper 개체를 구성하여 클래스와 연결됩니다. 이 매퍼 객체는 직접 사용되지 않고 매핑 된 클래스와 테이블 간의 인터페이스로 내부적으로 사용됩니다.
각 Table 개체는 MetaData라고하는 더 큰 컬렉션의 구성원이며이 개체는 .metadata선언적 기본 클래스의 속성. 그만큼MetaData.create_all()방법은 데이터베이스 연결의 소스로 엔진을 전달하는 것입니다. 아직 생성되지 않은 모든 테이블에 대해 CREATE TABLE 문을 데이터베이스에 발급합니다.
Base.metadata.create_all(engine)데이터베이스와 테이블을 생성하고 Python 클래스를 매핑하는 완전한 스크립트는 다음과 같습니다.
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key=True)
name = Column(String)
address = Column(String)
email = Column(String)
Base.metadata.create_all(engine)실행되면 Python 콘솔은 실행중인 SQL 표현식에 따라 에코됩니다.
CREATE TABLE customers (
id INTEGER NOT NULL,
name VARCHAR,
address VARCHAR,
email VARCHAR,
PRIMARY KEY (id)
)SQLiteStudio 그래픽 도구를 사용하여 Sales.db를 열면 위에서 언급 한 구조로 내부 고객 테이블이 표시됩니다.

데이터베이스와 상호 작용하기 위해서는 핸들을 얻어야합니다. 세션 개체는 데이터베이스에 대한 핸들입니다. 세션 클래스는 이전에 생성 된 엔진 객체에 바인딩 된 구성 가능한 세션 팩토리 메서드 인 sessionmaker ()를 사용하여 정의됩니다.
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)세션 객체는 다음과 같이 기본 생성자를 사용하여 설정됩니다.
session = Session()자주 요구되는 세션 수업 방법 중 일부는 다음과 같습니다.
| Sr. 아니. | 방법 및 설명 |
|---|---|
| 1 | begin() 이 세션에서 트랜잭션을 시작합니다. |
| 2 | add() 세션에 개체를 배치합니다. 그 상태는 다음 플러시 작업시 데이터베이스에 유지됩니다. |
| 삼 | add_all() 세션에 개체 컬렉션을 추가합니다. |
| 4 | commit() 진행중인 모든 항목과 모든 트랜잭션을 플러시합니다. |
| 5 | delete() 거래를 삭제 된 것으로 표시 |
| 6 | execute() SQL 표현식을 실행합니다. |
| 7 | expire() 인스턴스의 속성을 오래된 것으로 표시 |
| 8 | flush() 모든 개체 변경 사항을 데이터베이스에 플러시합니다. |
| 9 | invalidate() 연결 무효화를 사용하여 세션을 닫습니다. |
| 10 | rollback() 진행중인 현재 트랜잭션을 롤백합니다. |
| 11 | close() 모든 항목을 지우고 진행중인 트랜잭션을 종료하여 현재 세션을 닫습니다. |
SQLAlchemy ORM의 이전 장에서 매핑을 선언하고 세션을 만드는 방법을 배웠습니다. 이 장에서는 테이블에 객체를 추가하는 방법을 배웁니다.
customers 테이블에 매핑 된 Customer 클래스를 선언했습니다. 이 클래스의 객체를 선언하고 세션 객체의 add () 메소드로 테이블에 지속적으로 추가해야합니다.
c1 = Sales(name = 'Ravi Kumar', address = 'Station Road Nanded', email = '[email protected]')
session.add(c1)이 트랜잭션은 commit () 메서드를 사용하여 동일한 트랜잭션이 플러시 될 때까지 보류 중입니다.
session.commit()다음은 고객 테이블에 레코드를 추가하는 완전한 스크립트입니다-
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key=True)
name = Column(String)
address = Column(String)
email = Column(String)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
c1 = Customers(name = 'Ravi Kumar', address = 'Station Road Nanded', email = '[email protected]')
session.add(c1)
session.commit()여러 레코드를 추가하려면 다음을 사용할 수 있습니다. add_all() 세션 클래스의 메소드.
session.add_all([
Customers(name = 'Komal Pande', address = 'Koti, Hyderabad', email = '[email protected]'),
Customers(name = 'Rajender Nath', address = 'Sector 40, Gurgaon', email = '[email protected]'),
Customers(name = 'S.M.Krishna', address = 'Budhwar Peth, Pune', email = '[email protected]')]
)
session.commit()SQLiteStudio의 테이블보기는 레코드가 고객 테이블에 지속적으로 추가되었음을 보여줍니다. 다음 이미지는 결과를 보여줍니다-
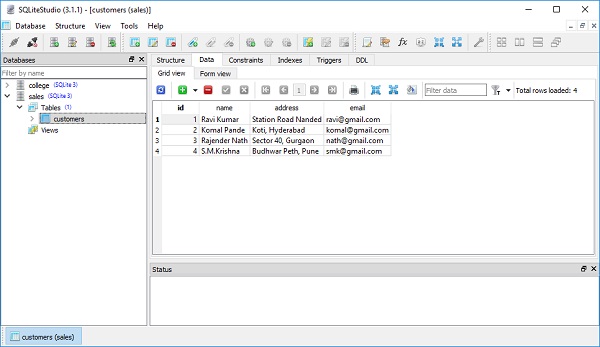
SQLAlchemy ORM에 의해 생성 된 모든 SELECT 문은 Query 개체에 의해 생성됩니다. 생성 인터페이스를 제공하므로 연속적인 호출은 새로운 쿼리 개체를 반환합니다.이 개체는 추가 기준 및 관련 옵션과 함께 전자의 복사본입니다.
Query 객체는 처음에 다음과 같이 Session의 query () 메소드를 사용하여 생성됩니다.
q = session.query(mapped class)다음 진술은 위의 주어진 진술과 동일합니다-
q = Query(mappedClass, session)쿼리 객체에는 객체 목록 형식으로 결과 집합을 반환하는 all () 메서드가 있습니다. 고객 테이블에서 실행하면-
result = session.query(Customers).all()이 명령문은 다음 SQL 표현식과 효과적으로 동일합니다.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers결과 개체는 기본 고객 테이블의 모든 레코드를 얻기 위해 아래와 같이 For 루프를 사용하여 순회 할 수 있습니다. 다음은 Customers 테이블의 모든 레코드를 표시하는 완전한 코드입니다.
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
result = session.query(Customers).all()
for row in result:
print ("Name: ",row.name, "Address:",row.address, "Email:",row.email)Python 콘솔은 다음과 같이 레코드 목록을 보여줍니다.
Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
Name: Komal Pande Address: Koti, Hyderabad Email: [email protected]
Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]Query 객체에는 다음과 같은 유용한 방법이 있습니다.
| Sr. 아니. | 방법 및 설명 |
|---|---|
| 1 | add_columns() 리턴 될 결과 열 목록에 하나 이상의 열 표현식을 추가합니다. |
| 2 | add_entity() 반환 될 결과 열 목록에 매핑 된 엔터티를 추가합니다. |
| 삼 | count() 이 쿼리가 반환 할 행 수를 반환합니다. |
| 4 | delete() 대량 삭제 쿼리를 수행합니다. 이 쿼리와 일치하는 행을 데이터베이스에서 삭제합니다. |
| 5 | distinct() 쿼리에 DISTINCT 절을 적용하고 새로 결과 쿼리를 반환합니다. |
| 6 | filter() SQL 표현식을 사용하여 주어진 필터링 기준을이 쿼리의 사본에 적용합니다. |
| 7 | first() 이 쿼리의 첫 번째 결과를 반환하거나 결과에 행이 포함되지 않은 경우 None을 반환합니다. |
| 8 | get() 소유 세션의 ID 맵에 대한 직접 액세스를 제공하는 주어진 기본 키 식별자를 기반으로 인스턴스를 반환합니다. |
| 9 | group_by() 하나 이상의 GROUP BY 기준을 쿼리에 적용하고 새로 결과 쿼리를 반환합니다. |
| 10 | join() 이 쿼리 개체의 기준에 대해 SQL JOIN을 만들고 생성하여 적용하여 새로 결과 쿼리를 반환합니다. |
| 11 | one() 정확히 하나의 결과를 반환하거나 예외를 발생시킵니다. |
| 12 | order_by() 하나 이상의 ORDER BY 기준을 쿼리에 적용하고 새로 결과 쿼리를 반환합니다. |
| 13 | update() 대량 업데이트 쿼리를 수행하고 데이터베이스에서이 쿼리와 일치하는 행을 업데이트합니다. |
이 장에서는 원하는 값으로 테이블을 수정하거나 업데이트하는 방법을 알아 봅니다.
객체의 특정 속성 데이터를 수정하려면 새 값을 할당하고 변경 사항을 커밋하여 변경 사항을 영구적으로 만들어야합니다.
ID = 2 인 Customers 테이블에서 기본 키 식별자를 가진 테이블에서 객체를 가져 오겠습니다. 세션의 get () 메소드를 다음과 같이 사용할 수 있습니다.
x = session.query(Customers).get(2)아래 주어진 코드로 선택된 객체의 내용을 표시 할 수 있습니다.
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)고객 테이블에서 다음 출력이 표시되어야합니다.
Name: Komal Pande Address: Koti, Hyderabad Email: [email protected]이제 아래와 같이 새 값을 할당하여 주소 필드를 업데이트해야합니다.
x.address = 'Banjara Hills Secunderabad'
session.commit()변경 사항은 데이터베이스에 지속적으로 반영됩니다. 이제 다음을 사용하여 테이블의 첫 번째 행에 해당하는 객체를 가져옵니다.first() method 다음과 같이-
x = session.query(Customers).first()이것은 다음 SQL 표현식을 실행합니다-
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
LIMIT ? OFFSET ?바인딩 된 매개 변수는 각각 LIMIT = 1 및 OFFSET = 0이되며 이는 첫 번째 행이 선택됨을 의미합니다.
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)이제 첫 번째 행을 표시하는 위 코드의 출력은 다음과 같습니다.
Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]이제 이름 속성을 변경하고 아래 코드를 사용하여 내용을 표시합니다.
x.name = 'Ravi Shrivastava'
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)위 코드의 출력은-
Name: Ravi Shrivastava Address: Station Road Nanded Email: [email protected]변경 사항이 표시 되더라도 커밋되지 않습니다. 다음을 사용하여 이전 영구 위치를 유지할 수 있습니다.rollback() method 아래 코드로.
session.rollback()
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)첫 번째 레코드의 원본 내용이 표시됩니다.
대량 업데이트의 경우 Query 객체의 update () 메서드를 사용합니다. 접두사 '미스터'를 붙여 보겠습니다. 각 행에 이름을 지정합니다 (ID = 2 제외). 해당 update () 문은 다음과 같습니다.
session.query(Customers).filter(Customers.id! = 2).
update({Customers.name:"Mr."+Customers.name}, synchronize_session = False)The update() method requires two parameters as follows −
키가 업데이트 될 속성이고 값이 속성의 새 내용 인 키-값 사전입니다.
세션에서 속성을 업데이트하는 전략을 언급하는 동기화 _ 세션 속성. 유효한 값은 false입니다. 세션을 동기화하지 않는 경우 fetch : 업데이트 전에 선택 쿼리를 수행하여 업데이트 쿼리와 일치하는 개체를 찾습니다. 및 평가 : 세션의 개체에 대한 기준을 평가합니다.
테이블의 4 개 행 중 3 개 행에 'Mr.'접두사가 붙습니다. 그러나 변경 사항은 커밋되지 않으므로 SQLiteStudio의 테이블보기에 반영되지 않습니다. 세션을 커밋 할 때만 새로 고쳐집니다.
이 장에서는 코드와 함께 필터 및 특정 필터 작업을 적용하는 방법에 대해 설명합니다.
Query 객체로 표현되는 Resultset은 filter () 메서드를 사용하여 특정 기준을 따를 수 있습니다. 필터 방식의 일반적인 사용법은 다음과 같습니다.
session.query(class).filter(criteria)다음 예에서 Customers 테이블에 대한 SELECT 쿼리로 얻은 결과 집합은 (ID> 2)-
result = session.query(Customers).filter(Customers.id>2)이 문은 다음 SQL 표현식으로 번역됩니다-
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id > ?바인딩 된 매개 변수 (?)가 2로 주어 지므로 ID column> 2 인 행만 표시됩니다. 전체 코드는 다음과 같습니다.
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
result = session.query(Customers).filter(Customers.id>2)
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)Python 콘솔에 표시되는 출력은 다음과 같습니다.
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
ID: 4 Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]이제 각각의 코드와 출력을 사용하여 필터 작업을 배웁니다.
같음
사용되는 일반적인 연산자는 ==이며 동등성을 확인하는 기준을 적용합니다.
result = session.query(Customers).filter(Customers.id == 2)
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)SQLAlchemy는 다음 SQL 표현식을 보냅니다-
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id = ?위 코드의 출력은 다음과 같습니다.
ID: 2 Name: Komal Pande Address: Banjara Hills Secunderabad Email: [email protected]같지 않음
같지 않음에 사용되는 연산자는! =이며 같지 않음 기준을 제공합니다.
result = session.query(Customers).filter(Customers.id! = 2)
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)결과 SQL 표현식은 다음과 같습니다.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id != ?위 코드 줄의 출력은 다음과 같습니다.
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
ID: 4 Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]처럼
like () 메서드 자체는 SELECT 표현식의 WHERE 절에 대한 LIKE 기준을 생성합니다.
result = session.query(Customers).filter(Customers.name.like('Ra%'))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)위의 SQLAlchemy 코드는 다음 SQL 표현식과 동일합니다.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name LIKE ?그리고 위 코드의 출력은-
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]에
이 연산자는 열 값이 목록의 항목 모음에 속하는지 여부를 확인합니다. in_ () 메소드로 제공됩니다.
result = session.query(Customers).filter(Customers.id.in_([1,3]))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)여기에서 SQLite 엔진에 의해 평가되는 SQL 표현식은 다음과 같습니다.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id IN (?, ?)위 코드의 출력은 다음과 같습니다.
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]과
이 접속사는 다음 중 하나에 의해 생성됩니다. putting multiple commas separated criteria in the filter or using and_() method 아래와 같이-
result = session.query(Customers).filter(Customers.id>2, Customers.name.like('Ra%'))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)from sqlalchemy import and_
result = session.query(Customers).filter(and_(Customers.id>2, Customers.name.like('Ra%')))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)위의 두 접근 방식 모두 비슷한 SQL 표현식을 생성합니다.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id > ? AND customers.name LIKE ?위 코드 줄의 출력은 다음과 같습니다.
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]또는
이 접속은 다음에 의해 구현됩니다. or_() method.
from sqlalchemy import or_
result = session.query(Customers).filter(or_(Customers.id>2, Customers.name.like('Ra%')))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)결과적으로 SQLite 엔진은 동일한 SQL 표현식을 따릅니다.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id > ? OR customers.name LIKE ?위 코드의 출력은 다음과 같습니다.
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
ID: 4 Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]SQL을 즉시 실행하고로드 된 데이터베이스 결과를 포함하는 값을 반환하는 Query 개체의 메서드가 많이 있습니다.
다음은 목록과 스칼라를 반환하는 간단한 요약입니다.
모두()
목록을 반환합니다. 다음은 all () 함수에 대한 코드 줄입니다.
session.query(Customers).all()Python 콘솔은 다음과 같은 SQL 표현식을 표시합니다.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers먼저()
한도를 적용하고 첫 번째 결과를 스칼라로 반환합니다.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
LIMIT ? OFFSET ?LIMIT의 바운드 매개 변수는 1이고 OFFSET의 경우 0입니다.
하나()
이 명령은 모든 행을 완전히 페치하고 결과에 정확히 하나의 객체 ID 또는 복합 행이 없으면 오류가 발생합니다.
session.query(Customers).one()여러 행이 발견되면-
MultipleResultsFound: Multiple rows were found for one()행을 찾을 수 없음-
NoResultFound: No row was found for one()one () 메서드는 "항목을 찾을 수 없음"과 "여러 항목을 찾을 수 없음"을 다르게 처리 할 것으로 예상되는 시스템에 유용합니다.
스칼라()
one () 메서드를 호출하고 성공하면 다음과 같이 행의 첫 번째 열을 반환합니다.
session.query(Customers).filter(Customers.id == 3).scalar()이것은 다음 SQL 문을 생성합니다-
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id = ?앞서 text () 함수를 사용한 텍스트 SQL은 SQLAlchemy의 핵심 표현 언어 관점에서 설명했습니다. 이제 우리는 ORM 관점에서 논의 할 것입니다.
리터럴 문자열은 text () 구문과 함께 사용을 지정하여 Query 객체와 함께 유연하게 사용할 수 있습니다. 대부분의 적용 가능한 방법이이를 받아들입니다. 예를 들어, filter () 및 order_by ().
아래 주어진 예에서 filter () 메서드는 문자열 "id <3"을 WHERE id <3으로 변환합니다.
from sqlalchemy import text
for cust in session.query(Customers).filter(text("id<3")):
print(cust.name)생성 된 원시 SQL 표현식은 아래 설명 된 코드를 사용하여 필터를 WHERE 절로 변환 한 것을 보여줍니다.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE id<3Customers 테이블의 샘플 데이터에서 두 행이 선택되고 이름 열이 다음과 같이 인쇄됩니다.
Ravi Kumar
Komal Pande문자열 기반 SQL로 바인드 매개 변수를 지정하려면 콜론을 사용하고 값을 지정하려면 params () 메소드를 사용하십시오.
cust = session.query(Customers).filter(text("id = :value")).params(value = 1).one()Python 콘솔에 표시되는 효과적인 SQL은 다음과 같습니다.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE id = ?완전한 문자열 기반 명령문을 사용하려면 완전한 명령문을 나타내는 text () 구조를 from_statement ()에 전달할 수 있습니다.
session.query(Customers).from_statement(text("SELECT * FROM customers")).all()위 코드의 결과는 아래와 같이 기본 SELECT 문이됩니다.
SELECT * FROM customers분명히 고객 테이블의 모든 레코드가 선택됩니다.
text () 구조를 사용하면 텍스트 SQL을 Core 또는 ORM 매핑 된 열 표현식에 위치 적으로 연결할 수 있습니다. 열 표현식을 위치 인수로 TextClause.columns () 메서드에 전달하여이를 달성 할 수 있습니다.
stmt = text("SELECT name, id, name, address, email FROM customers")
stmt = stmt.columns(Customers.id, Customers.name)
session.query(Customers.id, Customers.name).from_statement(stmt).all()SQLite 엔진이 위 코드에서 생성 된 다음 표현식을 실행하더라도 모든 행의 ID 및 이름 열은 text () 메서드의 모든 열을 보여줍니다.
SELECT name, id, name, address, email FROM customers이 세션에서는 데이터베이스에 이미있는 테이블과 관련된 다른 테이블을 만드는 방법에 대해 설명합니다. 고객 테이블에는 고객의 마스터 데이터가 포함됩니다. 이제 고객에게 속한 모든 송장을 포함 할 수있는 송장 테이블을 만들어야합니다. 이것은 일대 다 관계의 경우입니다.
선언적을 사용하여 매핑 된 클래스 인 송장과 함께이 테이블을 정의합니다.
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
class Invoice(Base):
__tablename__ = 'invoices'
id = Column(Integer, primary_key = True)
custid = Column(Integer, ForeignKey('customers.id'))
invno = Column(Integer)
amount = Column(Integer)
customer = relationship("Customer", back_populates = "invoices")
Customer.invoices = relationship("Invoice", order_by = Invoice.id, back_populates = "customer")
Base.metadata.create_all(engine)다음과 같이 SQLite 엔진에 CREATE TABLE 쿼리를 보냅니다.
CREATE TABLE invoices (
id INTEGER NOT NULL,
custid INTEGER,
invno INTEGER,
amount INTEGER,
PRIMARY KEY (id),
FOREIGN KEY(custid) REFERENCES customers (id)
)SQLiteStudio 도구를 사용하여 sales.db에 새 테이블이 생성되었는지 확인할 수 있습니다.
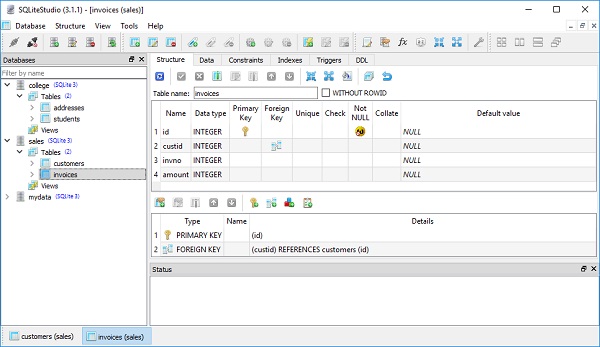
Invoices 클래스는 custid 속성에 ForeignKey 구성을 적용합니다. 이 지시문은이 열의 값이 customers 테이블의 id 열에있는 값으로 제한되어야 함을 나타냅니다. 이것은 관계형 데이터베이스의 핵심 기능이며 연결되지 않은 테이블 컬렉션을 풍부한 중첩 관계를 갖도록 변환하는 "접착제"입니다.
relationship ()이라고하는 두 번째 지시문은 ORM에 Invoice.customer 속성을 사용하여 Invoice 클래스가 Customer 클래스에 연결되어야 함을 알려줍니다. relationship ()은 두 테이블 간의 외래 키 관계를 사용하여이 연결의 특성을 결정하고 다대 일인지 확인합니다.
추가 relationship () 지시문은 Customer.invoices 속성 아래의 Customer 매핑 된 클래스에 배치됩니다. 매개 변수 relationship.back_populates는 보완 속성 이름을 참조하도록 지정되므로 각 relationship ()은 반대로 표현 된 것과 동일한 관계에 대해 지능적인 결정을 내릴 수 있습니다. 한쪽에서 Invoices.customer는 Invoices 인스턴스를 나타내고 다른 쪽에서 Customer.invoices는 Customers 인스턴스의 목록을 나타냅니다.
관계 함수는 SQLAlchemy ORM 패키지의 Relationship API의 일부입니다. 두 개의 매핑 된 클래스 간의 관계를 제공합니다. 이것은 상위-하위 또는 연관 테이블 관계에 해당합니다.
다음은 발견 된 기본 관계 패턴입니다-
일대 다
일대 다 관계는 자식 테이블의 외래 키를 사용하여 부모를 나타냅니다. 그런 다음 child가 나타내는 항목 모음을 참조하여 parent에 관계 ()가 지정됩니다. relationship.back_populates 매개 변수는 일대 다에서 양방향 관계를 설정하는 데 사용됩니다. 여기서 "역"쪽은 다 대일입니다.
다 대일
반면 다 대일 관계는 상위 테이블에 외래 키를 배치하여 하위를 참조합니다. relationship ()은 새로운 스칼라 보유 속성이 생성되는 부모에서 선언됩니다. 여기서 다시 relationship.back_populates 매개 변수가 양방향 동작에 사용됩니다.
1-1
일대일 관계는 본질적으로 양방향 관계입니다. uselist 플래그는 관계의 "다"쪽에서 컬렉션 대신 스칼라 속성의 배치를 나타냅니다. 일대 다를 일대일 유형의 관계로 변환하려면 uselist 매개 변수를 false로 설정하십시오.
다 대다
다 대다 관계는 외래 키로 속성을 정의하여 두 클래스와 관련된 연관 테이블을 추가하여 설정됩니다. relationship ()에 대한 보조 인수로 표시됩니다. 일반적으로 Table은 선언적 기본 클래스와 연결된 MetaData 개체를 사용하므로 ForeignKey 지시문은 연결할 원격 테이블을 찾을 수 있습니다. 각 relationship ()에 대한 relationship.back_populates 매개 변수는 양방향 관계를 설정합니다. 관계의 양쪽에는 컬렉션이 포함됩니다.
이 장에서는 SQLAlchemy ORM의 관련 개체에 중점을 둡니다.
이제 Customer 개체를 만들 때 빈 송장 컬렉션이 Python List 형식으로 표시됩니다.
c1 = Customer(name = "Gopal Krishna", address = "Bank Street Hydarebad", email = "[email protected]")c1.invoices의 청구서 속성은 빈 목록이됩니다. 목록에서 항목을 다음과 같이 할당 할 수 있습니다.
c1.invoices = [Invoice(invno = 10, amount = 15000), Invoice(invno = 14, amount = 3850)]다음과 같이 Session 객체를 사용하여이 객체를 데이터베이스에 커밋합니다.
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
session.add(c1)
session.commit()이것은 자동으로 고객 및 송장 테이블에 대한 INSERT 쿼리를 생성합니다-
INSERT INTO customers (name, address, email) VALUES (?, ?, ?)
('Gopal Krishna', 'Bank Street Hydarebad', '[email protected]')
INSERT INTO invoices (custid, invno, amount) VALUES (?, ?, ?)
(2, 10, 15000)
INSERT INTO invoices (custid, invno, amount) VALUES (?, ?, ?)
(2, 14, 3850)이제 SQLiteStudio의 테이블보기에서 고객 테이블과 송장 테이블의 내용을 살펴 보겠습니다.

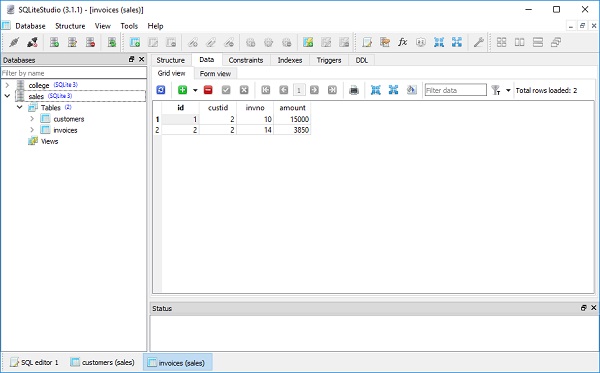
아래 명령을 사용하여 생성자 자체에서 송장의 매핑 된 속성을 제공하여 Customer 객체를 생성 할 수 있습니다.
c2 = [
Customer(
name = "Govind Pant",
address = "Gulmandi Aurangabad",
email = "[email protected]",
invoices = [Invoice(invno = 3, amount = 10000),
Invoice(invno = 4, amount = 5000)]
)
]또는 아래와 같이 세션 객체의 add_all () 함수를 사용하여 추가 할 객체 목록-
rows = [
Customer(
name = "Govind Kala",
address = "Gulmandi Aurangabad",
email = "[email protected]",
invoices = [Invoice(invno = 7, amount = 12000), Invoice(invno = 8, amount = 18500)]),
Customer(
name = "Abdul Rahman",
address = "Rohtak",
email = "[email protected]",
invoices = [Invoice(invno = 9, amount = 15000),
Invoice(invno = 11, amount = 6000)
])
]
session.add_all(rows)
session.commit()이제 두 개의 테이블이 있으므로 두 테이블에 대해 동시에 쿼리를 만드는 방법을 살펴 보겠습니다. Customer와 Invoice 간의 단순한 암시 적 조인을 구성하기 위해 Query.filter ()를 사용하여 관련 열을 서로 동일시 할 수 있습니다. 아래에서는이 방법을 사용하여 고객 및 송장 엔터티를 한 번에로드합니다.
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
for c, i in session.query(Customer, Invoice).filter(Customer.id == Invoice.custid).all():
print ("ID: {} Name: {} Invoice No: {} Amount: {}".format(c.id,c.name, i.invno, i.amount))SQLAlchemy가 내 보낸 SQL 표현식은 다음과 같습니다.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email, invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM customers, invoices
WHERE customers.id = invoices.custid그리고 위의 코드 줄의 결과는 다음과 같습니다.
ID: 2 Name: Gopal Krishna Invoice No: 10 Amount: 15000
ID: 2 Name: Gopal Krishna Invoice No: 14 Amount: 3850
ID: 3 Name: Govind Pant Invoice No: 3 Amount: 10000
ID: 3 Name: Govind Pant Invoice No: 4 Amount: 5000
ID: 4 Name: Govind Kala Invoice No: 7 Amount: 12000
ID: 4 Name: Govind Kala Invoice No: 8 Amount: 8500
ID: 5 Name: Abdul Rahman Invoice No: 9 Amount: 15000
ID: 5 Name: Abdul Rahman Invoice No: 11 Amount: 6000실제 SQL JOIN 구문은 다음과 같이 Query.join () 메서드를 사용하여 쉽게 얻을 수 있습니다.
session.query(Customer).join(Invoice).filter(Invoice.amount == 8500).all()조인에 대한 SQL 표현식이 콘솔에 표시됩니다.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers JOIN invoices ON customers.id = invoices.custid
WHERE invoices.amount = ?for 루프를 사용하여 결과를 반복 할 수 있습니다.
result = session.query(Customer).join(Invoice).filter(Invoice.amount == 8500)
for row in result:
for inv in row.invoices:
print (row.id, row.name, inv.invno, inv.amount)8500을 bind 매개 변수로 사용하면 다음과 같은 출력이 표시됩니다.
4 Govind Kala 8 8500Query.join ()은 이러한 테이블 사이에 외래 키가 하나만 있기 때문에 이러한 테이블을 조인하는 방법을 알고 있습니다. 외래 키가 없거나 더 많은 외래 키가 없으면 Query.join ()은 다음 형식 중 하나를 사용할 때 더 잘 작동합니다.
| query.join (인보이스, id == Address.custid) | 명시 적 조건 |
| query.join (Customer.invoices) | 왼쪽에서 오른쪽으로 관계 지정 |
| query.join (Invoice, Customer.invoices) | 동일, 명시 적 대상 포함 |
| query.join ( 'invoices') | 동일, 문자열 사용 |
마찬가지로 outerjoin () 함수를 사용하여 왼쪽 외부 조인을 수행 할 수 있습니다.
query.outerjoin(Customer.invoices)subquery () 메서드는 별칭에 포함 된 SELECT 문을 나타내는 SQL 식을 생성합니다.
from sqlalchemy.sql import func
stmt = session.query(
Invoice.custid, func.count('*').label('invoice_count')
).group_by(Invoice.custid).subquery()stmt 객체는 아래와 같이 SQL 문을 포함합니다-
SELECT invoices.custid, count(:count_1) AS invoice_count FROM invoices GROUP BY invoices.custid진술이 있으면 Table 구조처럼 작동합니다. 명령문의 열은 아래 코드와 같이 c라는 속성을 통해 액세스 할 수 있습니다.
for u, count in session.query(Customer, stmt.c.invoice_count).outerjoin(stmt, Customer.id == stmt.c.custid).order_by(Customer.id):
print(u.name, count)위의 for 루프는 다음과 같이 이름 별 인보이스 개수를 표시합니다.
Arjun Pandit None
Gopal Krishna 2
Govind Pant 2
Govind Kala 2
Abdul Rahman 2이 장에서는 관계를 기반으로하는 연산자에 대해 설명합니다.
__eq __ ()
위의 연산자는 다 대일 "같음"비교입니다. 이 연산자에 대한 코드 줄은 다음과 같습니다.
s = session.query(Customer).filter(Invoice.invno.__eq__(12))위의 코드 줄에 해당하는 SQL 쿼리는 다음과 같습니다.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers, invoices
WHERE invoices.invno = ?__ne __ ()
이 연산자는 다 대일 "같지 않음"비교입니다. 이 연산자에 대한 코드 줄은 다음과 같습니다.
s = session.query(Customer).filter(Invoice.custid.__ne__(2))위의 코드 줄에 해당하는 SQL 쿼리는 다음과 같습니다.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers, invoices
WHERE invoices.custid != ?contains ()
이 연산자는 일대 다 컬렉션에 사용되며 다음은 contains ()에 대한 코드입니다.
s = session.query(Invoice).filter(Invoice.invno.contains([3,4,5]))위의 코드 줄에 해당하는 SQL 쿼리는 다음과 같습니다.
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE (invoices.invno LIKE '%' + ? || '%')어떤()
any () 연산자는 아래와 같이 컬렉션에 사용됩니다.
s = session.query(Customer).filter(Customer.invoices.any(Invoice.invno==11))위의 코드 줄에 해당하는 SQL 쿼리는 다음과 같습니다.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE EXISTS (
SELECT 1
FROM invoices
WHERE customers.id = invoices.custid
AND invoices.invno = ?)has ()
이 연산자는 다음과 같이 스칼라 참조에 사용됩니다-
s = session.query(Invoice).filter(Invoice.customer.has(name = 'Arjun Pandit'))위의 코드 줄에 해당하는 SQL 쿼리는 다음과 같습니다.
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE EXISTS (
SELECT 1
FROM customers
WHERE customers.id = invoices.custid
AND customers.name = ?)빠른로드는 쿼리 수를 줄입니다. SQLAlchemy는 쿼리에 추가 지침을 제공하는 쿼리 옵션을 통해 호출되는 즉시로드 기능을 제공합니다. 이러한 옵션은 Query.options () 메서드를 통해 다양한 속성을로드하는 방법을 결정합니다.
하위 쿼리로드
Customer.invoices가 열심히로드되기를 바랍니다. orm.subqueryload () 옵션은 방금로드 된 결과와 관련된 컬렉션을 완전히로드하는 두 번째 SELECT 문을 제공합니다. "subquery"라는 이름을 사용하면 쿼리를 통해 직접 SELECT 문이 구성되고 관련 테이블에 대한 SELECT에 하위 쿼리로 재사용되고 포함됩니다.
from sqlalchemy.orm import subqueryload
c1 = session.query(Customer).options(subqueryload(Customer.invoices)).filter_by(name = 'Govind Pant').one()결과적으로 다음 두 SQL 표현식이 생성됩니다.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name = ?
('Govind Pant',)
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount, anon_1.customers_id
AS anon_1_customers_id
FROM (
SELECT customers.id
AS customers_id
FROM customers
WHERE customers.name = ?)
AS anon_1
JOIN invoices
ON anon_1.customers_id = invoices.custid
ORDER BY anon_1.customers_id, invoices.id 2018-06-25 18:24:47,479
INFO sqlalchemy.engine.base.Engine ('Govind Pant',)두 테이블의 데이터에 액세스하려면 아래 프로그램을 사용할 수 있습니다.
print (c1.name, c1.address, c1.email)
for x in c1.invoices:
print ("Invoice no : {}, Amount : {}".format(x.invno, x.amount))위 프로그램의 출력은 다음과 같습니다.
Govind Pant Gulmandi Aurangabad [email protected]
Invoice no : 3, Amount : 10000
Invoice no : 4, Amount : 5000결합 된 부하
다른 함수는 orm.joinedload ()입니다. 이것은 LEFT OUTER JOIN을 방출합니다. 리드 개체와 관련 개체 또는 컬렉션이 한 단계로로드됩니다.
from sqlalchemy.orm import joinedload
c1 = session.query(Customer).options(joinedload(Customer.invoices)).filter_by(name='Govind Pant').one()이것은 위와 동일한 출력을 제공하는 다음 표현식을 방출합니다.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email, invoices_1.id
AS invoices_1_id, invoices_1.custid
AS invoices_1_custid, invoices_1.invno
AS invoices_1_invno, invoices_1.amount
AS invoices_1_amount
FROM customers
LEFT OUTER JOIN invoices
AS invoices_1
ON customers.id = invoices_1.custid
WHERE customers.name = ? ORDER BY invoices_1.id
('Govind Pant',)OUTER JOIN은 두 개의 행을 생성했지만 Customer 인스턴스 하나를 반환합니다. 쿼리는 개체 ID를 기반으로 "고유 한"전략을 반환 된 엔터티에 적용하기 때문입니다. 조인 된 즉시로드는 쿼리 결과에 영향을주지 않고 적용 할 수 있습니다.
subqueryload ()는 관련 컬렉션을로드하는 데 더 적합하고 joinload ()는 다 대일 관계에 더 적합합니다.
단일 테이블에서 삭제 작업을 수행하는 것은 쉽습니다. 세션에서 매핑 된 클래스의 개체를 삭제하고 작업을 커밋하기 만하면됩니다. 그러나 여러 관련 테이블에 대한 삭제 작업은 약간 까다 롭습니다.
sales.db 데이터베이스에서 Customer 및 Invoice 클래스는 일대 다 유형의 관계로 고객 및 송장 테이블에 매핑됩니다. Customer 개체를 삭제하고 결과를 확인합니다.
빠른 참조로, 아래는 고객 및 송장 클래스의 정의입니다-
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
class Invoice(Base):
__tablename__ = 'invoices'
id = Column(Integer, primary_key = True)
custid = Column(Integer, ForeignKey('customers.id'))
invno = Column(Integer)
amount = Column(Integer)
customer = relationship("Customer", back_populates = "invoices")
Customer.invoices = relationship("Invoice", order_by = Invoice.id, back_populates = "customer")세션을 설정하고 아래 프로그램을 사용하여 기본 ID로 쿼리하여 Customer 개체를 얻습니다.
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
session = Session()
x = session.query(Customer).get(2)샘플 테이블에서 x.name은 'Gopal Krishna'입니다. 세션에서이 x를 삭제하고이 이름의 발생 횟수를 계산해 보겠습니다.
session.delete(x)
session.query(Customer).filter_by(name = 'Gopal Krishna').count()결과 SQL 표현식은 0을 반환합니다.
SELECT count(*)
AS count_1
FROM (
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name = ?)
AS anon_1('Gopal Krishna',) 0그러나 x의 관련 송장 개체는 여전히 있습니다. 다음 코드로 확인할 수 있습니다.
session.query(Invoice).filter(Invoice.invno.in_([10,14])).count()여기서 10과 14는 고객 Gopal Krishna의 송장 번호입니다. 위 쿼리의 결과는 2로 관련 개체가 삭제되지 않았 음을 의미합니다.
SELECT count(*)
AS count_1
FROM (
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE invoices.invno IN (?, ?))
AS anon_1(10, 14) 2이는 SQLAlchemy가 캐스케이드 삭제를 가정하지 않기 때문입니다. 삭제 명령을 내려야합니다.
동작을 변경하기 위해 User.addresses 관계에 계단식 옵션을 구성합니다. 진행중인 세션을 닫고 new declarative_base ()를 사용하고 User 클래스를 다시 선언하여 캐스케이드 구성을 포함한 주소 관계를 추가하겠습니다.
관계 함수의 캐스케이드 속성은 세션 작업이 부모에서 자식으로 "캐스케이드"되어야하는 방법을 결정하는 쉼표로 구분 된 캐스케이드 규칙 목록입니다. 기본적으로 False이며 "save-update, merge"를 의미합니다.
사용 가능한 캐스케이드는 다음과 같습니다.
- save-update
- merge
- expunge
- delete
- delete-orphan
- refresh-expire
자주 사용되는 옵션은 "all, delete-orphan"으로 관련 개체가 모든 경우에 부모 개체와 함께 따라야하며 연결 해제시 삭제되어야 함을 나타냅니다.
따라서 재 선언 된 고객 클래스는 다음과 같습니다.
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
invoices = relationship(
"Invoice",
order_by = Invoice.id,
back_populates = "customer",
cascade = "all,
delete, delete-orphan"
)아래 프로그램을 사용하여 Gopal Krishna 이름으로 고객을 삭제하고 관련 송장 개체 수를 확인하겠습니다.
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
x = session.query(Customer).get(2)
session.delete(x)
session.query(Customer).filter_by(name = 'Gopal Krishna').count()
session.query(Invoice).filter(Invoice.invno.in_([10,14])).count()위의 스크립트에 의해 생성 된 다음 SQL과 함께 카운트는 이제 0입니다.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id = ?
(2,)
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE ? = invoices.custid
ORDER BY invoices.id (2,)
DELETE FROM invoices
WHERE invoices.id = ? ((1,), (2,))
DELETE FROM customers
WHERE customers.id = ? (2,)
SELECT count(*)
AS count_1
FROM (
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name = ?)
AS anon_1('Gopal Krishna',)
SELECT count(*)
AS count_1
FROM (
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE invoices.invno IN (?, ?))
AS anon_1(10, 14)
0Many to Many relationship두 테이블 사이에 연결 테이블을 추가하여 각 테이블의 기본 키에서 하나씩 두 개의 외래 키를 갖도록합니다. 또한, 두 테이블에 매핑되는 클래스에는 relationship () 함수의 보조 속성으로 할당 된 다른 연관 테이블의 개체 모음이있는 속성이 있습니다.
이를 위해 부서와 직원이라는 두 개의 테이블이있는 SQLite 데이터베이스 (mycollege.db)를 생성합니다. 여기에서는 직원이 둘 이상의 부서에 속해 있고 부서에 둘 이상의 직원이 있다고 가정합니다. 이것은 다 대다 관계를 구성합니다.
부서 및 직원 테이블에 매핑 된 Employee 및 Department 클래스의 정의는 다음과 같습니다.
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine('sqlite:///mycollege.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Department(Base):
__tablename__ = 'department'
id = Column(Integer, primary_key = True)
name = Column(String)
employees = relationship('Employee', secondary = 'link')
class Employee(Base):
__tablename__ = 'employee'
id = Column(Integer, primary_key = True)
name = Column(String)
departments = relationship(Department,secondary='link')이제 Link 클래스를 정의합니다. 링크 테이블에 연결되며 부서 및 직원 테이블의 기본 키를 각각 참조하는 department_id 및 employee_id 속성을 포함합니다.
class Link(Base):
__tablename__ = 'link'
department_id = Column(
Integer,
ForeignKey('department.id'),
primary_key = True)
employee_id = Column(
Integer,
ForeignKey('employee.id'),
primary_key = True)여기서 Department 클래스에는 Employee 클래스와 관련된 직원 속성이 있음을 유의해야합니다. 관계 함수의 보조 속성에는 값으로 링크가 할당됩니다.
마찬가지로 Employee 클래스에는 Department 클래스와 관련된 부서 속성이 있습니다. 관계 함수의 보조 속성에는 값으로 링크가 할당됩니다.
이 세 테이블은 모두 다음 명령문이 실행될 때 생성됩니다.
Base.metadata.create_all(engine)Python 콘솔은 다음 CREATE TABLE 쿼리를 내 보냅니다.
CREATE TABLE department (
id INTEGER NOT NULL,
name VARCHAR,
PRIMARY KEY (id)
)
CREATE TABLE employee (
id INTEGER NOT NULL,
name VARCHAR,
PRIMARY KEY (id)
)
CREATE TABLE link (
department_id INTEGER NOT NULL,
employee_id INTEGER NOT NULL,
PRIMARY KEY (department_id, employee_id),
FOREIGN KEY(department_id) REFERENCES department (id),
FOREIGN KEY(employee_id) REFERENCES employee (id)
)아래 스크린 샷과 같이 SQLiteStudio를 사용하여 mycollege.db를 열어 확인할 수 있습니다.
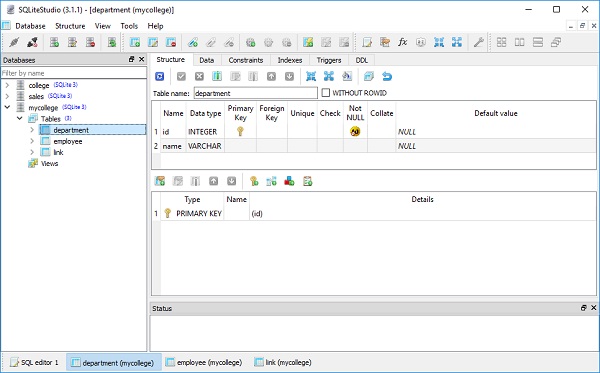
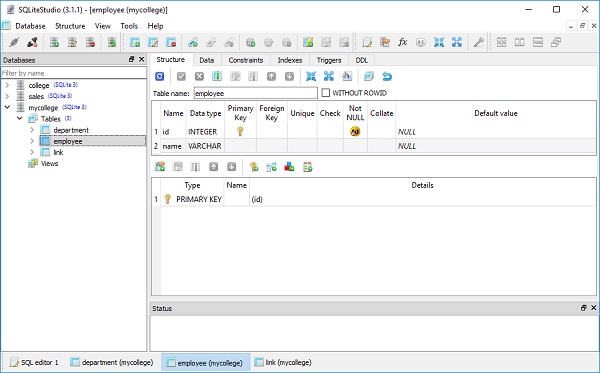
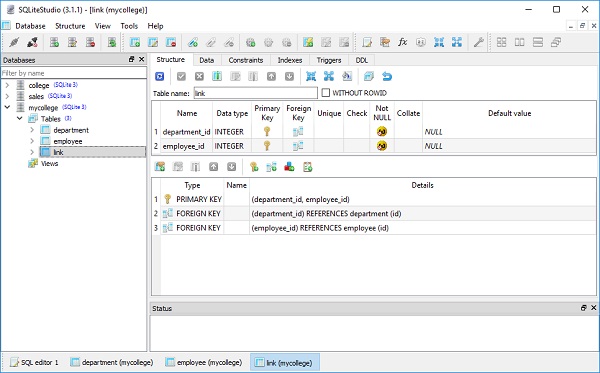
다음으로 Department 클래스의 세 개체와 Employee 클래스의 세 개체를 아래와 같이 만듭니다.
d1 = Department(name = "Accounts")
d2 = Department(name = "Sales")
d3 = Department(name = "Marketing")
e1 = Employee(name = "John")
e2 = Employee(name = "Tony")
e3 = Employee(name = "Graham")각 테이블에는 append () 메서드가있는 컬렉션 속성이 있습니다. Employee 개체를 Department 개체의 Employees 컬렉션에 추가 할 수 있습니다. 마찬가지로 Employee 개체의 부서 컬렉션 속성에 Department 개체를 추가 할 수 있습니다.
e1.departments.append(d1)
e2.departments.append(d3)
d1.employees.append(e3)
d2.employees.append(e2)
d3.employees.append(e1)
e3.departments.append(d2)이제해야 할 일은 세션 개체를 설정하고 모든 개체를 여기에 추가하고 아래와 같이 변경 사항을 커밋하는 것입니다.
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
session.add(e1)
session.add(e2)
session.add(d1)
session.add(d2)
session.add(d3)
session.add(e3)
session.commit()다음 SQL 문은 Python 콘솔에서 생성됩니다.
INSERT INTO department (name) VALUES (?) ('Accounts',)
INSERT INTO department (name) VALUES (?) ('Sales',)
INSERT INTO department (name) VALUES (?) ('Marketing',)
INSERT INTO employee (name) VALUES (?) ('John',)
INSERT INTO employee (name) VALUES (?) ('Graham',)
INSERT INTO employee (name) VALUES (?) ('Tony',)
INSERT INTO link (department_id, employee_id) VALUES (?, ?) ((1, 2), (3, 1), (2, 3))
INSERT INTO link (department_id, employee_id) VALUES (?, ?) ((1, 1), (2, 2), (3, 3))위 작업의 효과를 확인하려면 SQLiteStudio를 사용하고 부서, 직원 및 링크 테이블에서 데이터를 봅니다.
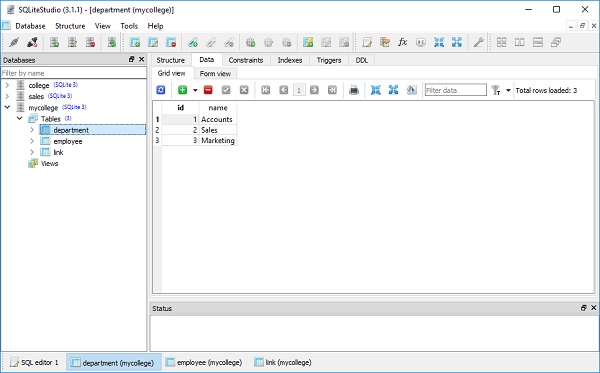
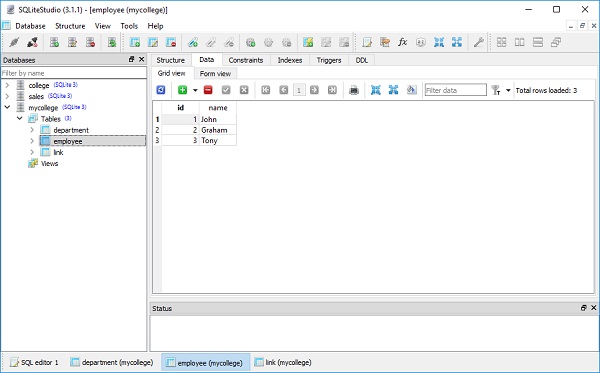
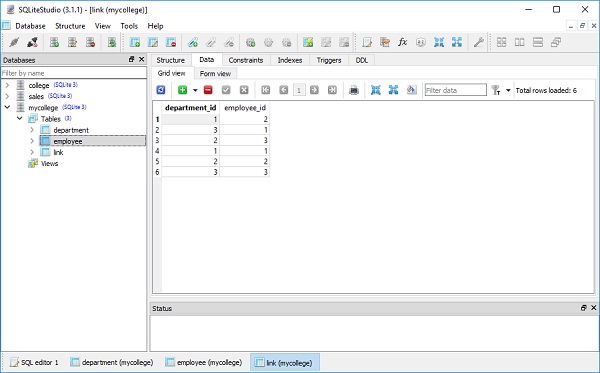
데이터를 표시하려면 다음 쿼리 문을 실행하십시오.
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
for x in session.query( Department, Employee).filter(Link.department_id == Department.id,
Link.employee_id == Employee.id).order_by(Link.department_id).all():
print ("Department: {} Name: {}".format(x.Department.name, x.Employee.name))예제에서 채워진 데이터에 따라 출력은 다음과 같이 표시됩니다.
Department: Accounts Name: John
Department: Accounts Name: Graham
Department: Sales Name: Graham
Department: Sales Name: Tony
Department: Marketing Name: John
Department: Marketing Name: TonySQLAlchemy는 방언 시스템을 사용하여 다양한 유형의 데이터베이스와 통신합니다. 각 데이터베이스에는 해당 DBAPI 래퍼가 있습니다. 모든 언어를 사용하려면 적절한 DBAPI 드라이버가 설치되어 있어야합니다.
다음 방언은 SQLAlchemy API에 포함되어 있습니다-
- Firebird
- 마이크로 소프트 SQL 서버
- MySQL
- Oracle
- PostgreSQL
- SQL
- Sybase
URL을 기반으로하는 Engine 객체는 create_engine () 함수에 의해 생성됩니다. 이러한 URL에는 사용자 이름, 암호, 호스트 이름 및 데이터베이스 이름이 포함될 수 있습니다. 추가 구성을위한 선택적 키워드 인수가있을 수 있습니다. 어떤 경우에는 파일 경로가 허용되고 다른 경우에는 "데이터 소스 이름"이 "호스트"및 "데이터베이스"부분을 대체합니다. 데이터베이스 URL의 일반적인 형식은 다음과 같습니다.
dialect+driver://username:password@host:port/databasePostgreSQL
PostgreSQL 언어는 psycopg2기본 DBAPI로. pg8000은 아래와 같이 순수 Python 대체품으로도 제공됩니다.
# default
engine = create_engine('postgresql://scott:tiger@localhost/mydatabase')
# psycopg2
engine = create_engine('postgresql+psycopg2://scott:tiger@localhost/mydatabase')
# pg8000
engine = create_engine('postgresql+pg8000://scott:tiger@localhost/mydatabase')MySQL
MySQL 방언은 mysql-python기본 DBAPI로. 다음과 같이 MySQL-connector-python과 같은 많은 MySQL DBAPI를 사용할 수 있습니다.
# default
engine = create_engine('mysql://scott:tiger@localhost/foo')
# mysql-python
engine = create_engine('mysql+mysqldb://scott:tiger@localhost/foo')
# MySQL-connector-python
engine = create_engine('mysql+mysqlconnector://scott:tiger@localhost/foo')신탁
Oracle 방언은 cx_oracle 다음과 같이 기본 DBAPI로-
engine = create_engine('oracle://scott:[email protected]:1521/sidname')
engine = create_engine('oracle+cx_oracle://scott:tiger@tnsname')마이크로 소프트 SQL 서버
SQL Server 언어는 pyodbc기본 DBAPI로. pymssql도 사용할 수 있습니다.
# pyodbc
engine = create_engine('mssql+pyodbc://scott:tiger@mydsn')
# pymssql
engine = create_engine('mssql+pymssql://scott:tiger@hostname:port/dbname')SQLite
SQLite는 Python 내장 모듈을 사용하여 파일 기반 데이터베이스에 연결합니다. sqlite3기본적으로. SQLite가 로컬 파일에 연결되면 URL 형식이 약간 다릅니다. URL의 "파일"부분은 데이터베이스의 파일 이름입니다. 상대 파일 경로의 경우 아래와 같이 세 개의 슬래시가 필요합니다.
engine = create_engine('sqlite:///foo.db')그리고 절대 파일 경로의 경우 아래에 주어진 것처럼 세 개의 슬래시 뒤에 절대 경로가옵니다.
engine = create_engine('sqlite:///C:\\path\\to\\foo.db')SQLite : memory : database를 사용하려면 아래와 같이 빈 URL을 지정하십시오.
engine = create_engine('sqlite://')결론
이 자습서의 첫 번째 부분에서는 Expression Language를 사용하여 SQL 문을 실행하는 방법을 배웠습니다. 식 언어는 Python 코드에 SQL 구문을 포함합니다. 두 번째 부분에서는 SQLAlchemy의 개체 관계 매핑 기능에 대해 설명했습니다. ORM API는 SQL 테이블을 Python 클래스와 매핑합니다.