Sqoop-소개
전통적인 애플리케이션 관리 시스템, 즉 RDBMS를 사용하는 관계형 데이터베이스와 애플리케이션의 상호 작용은 빅 데이터를 생성하는 소스 중 하나입니다. RDBMS에서 생성 된 이러한 빅 데이터는 관계형에 저장됩니다.Database Servers 관계형 데이터베이스 구조에서.
Hadoop 생태계의 MapReduce, Hive, HBase, Cassandra, Pig 등과 같은 빅 데이터 스토리지 및 분석기가 등장했을 때, 그 안에 상주하는 빅 데이터를 가져오고 내보내기 위해 관계형 데이터베이스 서버와 상호 작용하는 도구가 필요했습니다. 여기에서 Sqoop은 관계형 데이터베이스 서버와 Hadoop의 HDFS 간의 실행 가능한 상호 작용을 제공하기 위해 Hadoop 에코 시스템의 한 자리를 차지합니다.
Sqoop − "SQL에서 Hadoop으로, Hadoop에서 SQL로"
Sqoop은 Hadoop과 관계형 데이터베이스 서버간에 데이터를 전송하도록 설계된 도구입니다. MySQL, Oracle과 같은 관계형 데이터베이스에서 Hadoop HDFS로 데이터를 가져오고 Hadoop 파일 시스템에서 관계형 데이터베이스로 내보내는 데 사용됩니다. Apache Software Foundation에서 제공합니다.
Sqoop은 어떻게 작동합니까?
다음 이미지는 Sqoop의 워크 플로를 설명합니다.
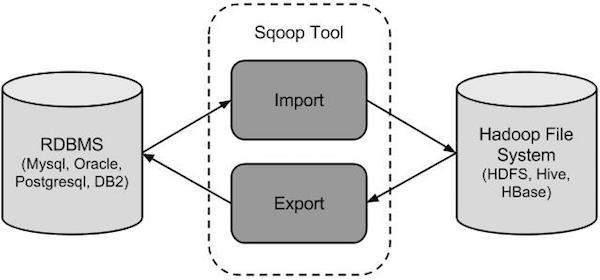
Sqoop 가져 오기
가져 오기 도구는 RDBMS에서 HDFS로 개별 테이블을 가져옵니다. 테이블의 각 행은 HDFS에서 레코드로 처리됩니다. 모든 레코드는 텍스트 파일의 텍스트 데이터 또는 Avro 및 Sequence 파일의 이진 데이터로 저장됩니다.
Sqoop 내보내기
내보내기 도구는 HDFS에서 RDBMS로 파일 세트를 다시 내 보냅니다. Sqoop에 대한 입력으로 제공된 파일에는 테이블의 행이라고하는 레코드가 포함됩니다. 이를 읽고 레코드 세트로 구문 분석하고 사용자 지정 구분 기호로 구분합니다.