Talend-Hadoop 분산 파일 시스템
이 장에서는 Talend가 Hadoop 분산 파일 시스템에서 작동하는 방식에 대해 자세히 알아 보겠습니다.
설정 및 전제 조건
HDFS로 Talend를 진행하기 전에이 목적을 위해 충족되어야하는 설정 및 전제 조건에 대해 배워야합니다.
여기서는 가상 박스에서 Cloudera 빠른 시작 5.10 VM을 실행하고 있습니다. 이 VM에서 호스트 전용 네트워크를 사용해야합니다.
호스트 전용 네트워크 IP : 192.168.56.101

cloudera 관리자에서도 동일한 호스트를 실행해야합니다.

이제 Windows 시스템에서 c : \ Windows \ System32 \ Drivers \ etc \ hosts로 이동하여 아래와 같이 메모장을 사용하여이 파일을 편집합니다.

마찬가지로 cloudera 빠른 시작 VM에서 아래와 같이 / etc / hosts 파일을 편집합니다.
sudo gedit /etc/hosts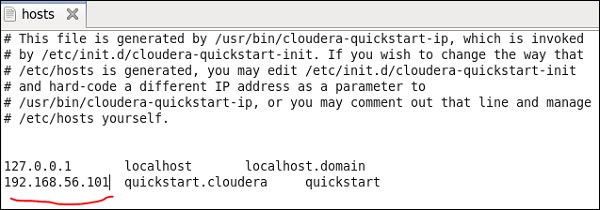
Hadoop 연결 설정
저장소 패널에서 메타 데이터로 이동하십시오. Hadoop 클러스터를 마우스 오른쪽 버튼으로 클릭하고 새 클러스터를 만듭니다. 이 Hadoop 클러스터 연결의 이름, 목적 및 설명을 제공하십시오.
다음을 클릭하십시오.

cloudera로 배포를 선택하고 사용중인 버전을 선택하십시오. 구성 검색 옵션을 선택하고 다음을 클릭합니다.

아래와 같이 관리자 자격 증명 (포트, 사용자 이름, 암호가있는 URI)을 입력하고 연결을 클릭합니다. 세부 정보가 정확하면 검색된 클러스터 아래에 Cloudera QuickStart가 표시됩니다.
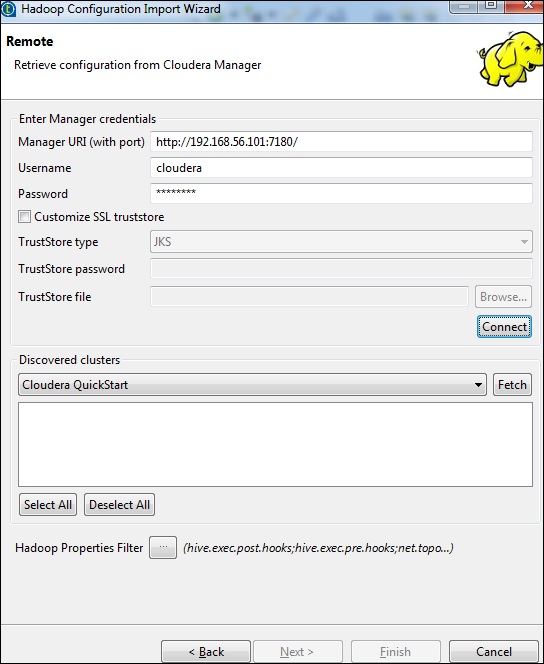
가져 오기를 클릭합니다. HDFS, YARN, HBASE, HIVE에 대한 모든 연결 및 구성을 가져옵니다.
모두를 선택하고 마침을 클릭합니다.

모든 연결 매개 변수가 자동으로 채워집니다. 사용자 이름에 cloudera를 언급하고 마침을 클릭합니다.

이것으로 Hadoop 클러스터에 성공적으로 연결되었습니다.

HDFS에 연결
이 작업에서는 HDFS에있는 모든 디렉토리와 파일을 나열합니다.
먼저 작업을 생성 한 다음 여기에 HDFS 구성 요소를 추가합니다. 작업 디자인을 마우스 오른쪽 버튼으로 클릭하고 새 작업 인 hadoopjob을 만듭니다.
이제 팔레트에서 tHDFSConnection 및 tHDFSList의 두 구성 요소를 추가합니다. tHDFSConnection을 마우스 오른쪽 버튼으로 클릭하고 'OnSubJobOk'트리거를 사용하여이 두 구성 요소를 연결합니다.
이제 두 가지 talend hdfs 구성 요소를 구성하십시오.

tHDFSConnection에서 속성 유형으로 리포지토리를 선택하고 이전에 생성 한 Hadoop cloudera 클러스터를 선택합니다. 이 구성 요소에 필요한 모든 세부 정보가 자동으로 채워집니다.

tHDFSList에서 "기존 연결 사용"을 선택하고 구성 요소 목록에서 구성한 tHDFSConnection을 선택합니다.
HDFS 디렉토리 옵션에서 HDFS의 홈 경로를 지정하고 오른쪽의 찾아보기 버튼을 클릭합니다.

위에서 언급 한 구성으로 제대로 연결을 설정했다면 아래와 같은 창이 나타납니다. HDFS 홈에있는 모든 디렉토리와 파일을 나열합니다.

cloudera에서 HDFS를 확인하여이를 확인할 수 있습니다.

HDFS에서 파일 읽기
이 섹션에서는 Talend의 HDFS에서 파일을 읽는 방법을 이해하겠습니다. 이 목적으로 새 작업을 만들 수 있지만 여기서는 기존 작업을 사용합니다.
팔레트에서 디자이너 창으로 tHDFSConnection, tHDFSInput 및 tLogRow의 세 가지 구성 요소를 끌어서 놓습니다.
tHDFSConnection을 마우스 오른쪽 버튼으로 클릭하고 'OnSubJobOk'트리거를 사용하여 tHDFSInput 구성 요소를 연결합니다.
tHDFSInput을 마우스 오른쪽 버튼으로 클릭하고 기본 링크를 tLogRow로 드래그합니다.

tHDFSConnection은 이전과 유사한 구성을 갖습니다. tHDFSInput에서 "기존 연결 사용"을 선택하고 구성 요소 목록에서 tHDFSConnection을 선택합니다.
파일 이름에서 읽으려는 파일의 HDFS 경로를 제공하십시오. 여기서는 간단한 텍스트 파일을 읽고 있으므로 파일 유형은 텍스트 파일입니다. 마찬가지로 입력에 따라 아래에 언급 된대로 행 구분 기호, 필드 구분 기호 및 헤더 세부 정보를 입력합니다. 마지막으로 스키마 편집 버튼을 클릭합니다.

파일에 일반 텍스트 만 있기 때문에 문자열 유형의 열 하나만 추가합니다. 이제 확인을 클릭하십시오.
Note − 입력에 서로 다른 유형의 여러 열이있는 경우 여기에서 그에 따라 스키마를 언급해야합니다.

tLogRow 구성 요소에서 스키마 편집의 열 동기화를 클릭합니다.
출력물을 인쇄 할 모드를 선택하십시오.

마지막으로 실행을 클릭하여 작업을 실행합니다.
HDFS 파일 읽기에 성공하면 다음 출력을 볼 수 있습니다.

HDFS에 파일 쓰기
Talend에서 HDFS에서 파일을 작성하는 방법을 살펴 보겠습니다. 팔레트에서 디자이너 창으로 tHDFSConnection, tFileInputDelimited 및 tHDFSOutput의 3 가지 구성 요소를 끌어서 놓습니다.
tHDFSConnection을 마우스 오른쪽 버튼으로 클릭하고 'OnSubJobOk'트리거를 사용하여 tFileInputDelimited 구성 요소를 연결합니다.
tFileInputDelimited를 마우스 오른쪽 버튼으로 클릭하고 기본 링크를 tHDFSOutput으로 드래그합니다.

tHDFSConnection은 이전과 유사한 구성을 갖습니다.
이제 tFileInputDelimited에서 File name / Stream 옵션에 입력 파일의 경로를 지정합니다. 여기서는 csv 파일을 입력으로 사용하므로 필드 구분 기호는 ","입니다.
입력 파일에 따라 머리글, 바닥 글, 제한을 선택합니다. HDFS에 처음 3 개 행만 쓰기 때문에 1 행에 열 이름이 포함되고 제한이 3이기 때문에 여기서 헤더는 1입니다.
이제 스키마 편집을 클릭하십시오.
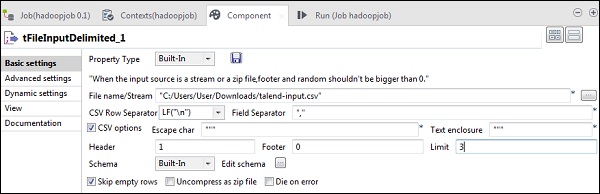
이제 입력 파일에 따라 스키마를 정의하십시오. 입력 파일에는 아래와 같이 3 개의 열이 있습니다.

tHDFSOutput 구성 요소에서 열 동기화를 클릭합니다. 그런 다음 기존 연결 사용에서 tHDFSConnection을 선택합니다. 또한 파일 이름에 파일을 작성할 HDFS 경로를 지정하십시오.
파일 유형은 텍스트 파일, Action은 "create", 행 구분 기호는 "\ n", 필드 구분 기호는 ";"입니다.

마지막으로 실행을 클릭하여 작업을 실행합니다. 작업이 성공적으로 실행되면 파일이 HDFS에 있는지 확인하십시오.

작업에서 언급 한 출력 경로로 다음 hdfs 명령을 실행합니다.
hdfs dfs -cat /input/talendwriteHDFS 쓰기에 성공하면 다음 출력이 표시됩니다.
