TIKA-퀵 가이드
Apache Tika 란 무엇입니까?
Apache Tika는 다양한 파일 형식에서 문서 유형 감지 및 콘텐츠 추출에 사용되는 라이브러리입니다.
내부적으로 Tika는 기존의 다양한 문서 파서 및 문서 유형 감지 기술을 사용하여 데이터를 감지하고 추출합니다.
Tika를 사용하면 스프레드 시트, 텍스트 문서, 이미지, PDF 및 멀티미디어 입력 형식과 같은 다양한 유형의 문서에서 구조화 된 텍스트와 메타 데이터를 어느 정도까지 추출하는 범용 유형 감지기 및 콘텐츠 추출기를 개발할 수 있습니다.
Tika는 다양한 파일 형식을 구문 분석하기위한 단일 일반 API를 제공합니다. 각 문서 유형에 대해 기존의 특수 파서 라이브러리를 사용합니다.
이러한 모든 파서 라이브러리는 다음과 같은 단일 인터페이스로 캡슐화됩니다. Parser interface.

왜 Tika?
filext.com에 따르면 콘텐츠 유형은 약 15,000 ~ 51,000 개이며이 숫자는 날로 증가하고 있습니다. 데이터는 텍스트 문서, 엑셀 스프레드 시트, PDF, 이미지 및 멀티미디어 파일과 같은 다양한 형식으로 저장되고 있습니다. 따라서 검색 엔진 및 콘텐츠 관리 시스템과 같은 응용 프로그램은 이러한 문서 유형에서 데이터를 쉽게 추출하기 위해 추가 지원이 필요합니다. Apache Tika는 여러 파일 형식에서 데이터를 찾고 추출하는 일반 API를 제공하여 이러한 목적을 수행합니다.
Apache Tika 애플리케이션
Apache Tika를 사용하는 다양한 애플리케이션이 있습니다. 여기에서는 Apache Tika에 크게 의존하는 몇 가지 주요 애플리케이션에 대해 설명합니다.
검색 엔진
Tika는 디지털 문서의 텍스트 콘텐츠를 인덱싱하기 위해 검색 엔진을 개발하는 동안 널리 사용됩니다.
검색 엔진은 웹에서 정보 및 색인화 된 문서를 검색하도록 설계된 정보 처리 시스템입니다.
크롤러는 일부 인덱싱 기술을 사용하여 인덱싱 할 문서를 가져 오기 위해 웹을 통해 크롤링하는 검색 엔진의 중요한 구성 요소입니다. 그 후 크롤러는 이러한 색인화 된 문서를 추출 구성 요소로 전송합니다.
추출 구성 요소의 임무는 문서에서 텍스트와 메타 데이터를 추출하는 것입니다. 이러한 추출 된 콘텐츠와 메타 데이터는 검색 엔진에 매우 유용합니다. 이 추출 구성 요소에는 Tika가 포함되어 있습니다.
추출 된 콘텐츠는 검색 인덱스를 작성하는 데 사용하는 검색 엔진의 인덱서로 전달됩니다. 이 외에도 검색 엔진은 추출 된 콘텐츠를 다른 여러 방법으로도 사용합니다.

문서 분석
인공 지능 분야에는 의미 론적 수준에서 문서를 자동으로 분석하고 모든 종류의 데이터를 추출하는 특정 도구가 있습니다.
이러한 응용 프로그램에서 문서는 문서의 추출 된 내용에서 눈에 띄는 용어를 기준으로 분류됩니다.
이러한 도구는 콘텐츠 추출에 Tika를 사용하여 일반 텍스트에서 디지털 문서에 이르기까지 다양한 문서를 분석합니다.
디지털 자산 관리
일부 조직에서는 DAM (디지털 자산 관리)이라는 특수 응용 프로그램을 사용하여 사진, 전자 책, 그림, 음악 및 비디오와 같은 디지털 자산을 관리합니다.
이러한 애플리케이션은 문서 유형 감지기 및 메타 데이터 추출기의 도움을 받아 다양한 문서를 분류합니다.
내용 분석
Amazon과 같은 웹 사이트는 자신의 관심사에 따라 웹 사이트의 새로 출시 된 콘텐츠를 개별 사용자에게 추천합니다. 이를 위해 이러한 웹 사이트는machine learning techniques또는 Facebook과 같은 소셜 미디어 웹 사이트의 도움을 받아 사용자의 좋아요 및 관심사와 같은 필수 정보를 추출합니다. 이렇게 수집 된 정보는 html 태그 또는 추가 콘텐츠 유형 감지 및 추출이 필요한 기타 형식의 형태입니다.
문서의 콘텐츠 분석을 위해 다음과 같은 기계 학습 기술을 구현하는 기술이 있습니다. UIMA 과 Mahout. 이러한 기술은 문서의 데이터를 클러스터링하고 분석하는 데 유용합니다.
Apache Mahout클라우드 컴퓨팅 플랫폼 인 Apache Hadoop에서 ML 알고리즘을 제공하는 프레임 워크입니다. Mahout은 특정 클러스터링 및 필터링 기술을 따라 아키텍처를 제공합니다. 이 아키텍처를 따르면 프로그래머는 다양한 텍스트 및 메타 데이터 조합을 사용하여 권장 사항을 생성하는 자체 ML 알고리즘을 작성할 수 있습니다. 이러한 알고리즘에 입력을 제공하기 위해 최신 버전의 Mahout은 Tika를 사용하여 바이너리 콘텐츠에서 텍스트와 메타 데이터를 추출합니다.
Apache UIMA다양한 프로그래밍 언어를 분석 및 처리하고 UIMA 주석을 생성합니다. 내부적으로 Tika Annotator를 사용하여 문서 텍스트와 메타 데이터를 추출합니다.
역사
| 년 | 개발 |
|---|---|
| 2006 년 | Tika의 아이디어는 Lucene 프로젝트 관리위원회에서 시작되었습니다. |
| 2006 년 | Tika의 개념과 Jackrabbit 프로젝트에서의 유용성에 대해 논의했습니다. |
| 2007 년 | Tika는 Apache 인큐베이터에 들어갔습니다. |
| 2008 년 | 버전 0.1과 0.2가 출시되었고 Tika는 인큐베이터에서 Lucene 하위 프로젝트로 졸업했습니다. |
| 2009 년 | 버전 0.3, 0.4 및 0.5가 출시되었습니다. |
| 2010 년 | 버전 0.6과 0.7이 출시되었고 Tika는 최상위 수준의 Apache 프로젝트로 나아갔습니다. |
| 2011 년 | Tika 1.0이 발표되었고 Tika "Tika in Action"도 같은 해에 발표되었습니다. |
Tika의 애플리케이션 레벨 아키텍처
응용 프로그램 프로그래머는 Tika를 응용 프로그램에 쉽게 통합 할 수 있습니다. Tika는 사용자 친화적 인 명령 줄 인터페이스와 GUI를 제공합니다.
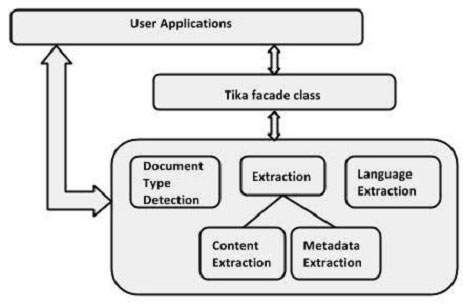
이 장에서는 Tika 아키텍처를 구성하는 4 가지 중요한 모듈에 대해 설명합니다. 다음 그림은 4 개의 모듈과 함께 Tika의 아키텍처를 보여줍니다.
- 언어 감지 메커니즘.
- MIME 감지 메커니즘.
- 파서 인터페이스.
- Tika Facade 클래스.

언어 감지 메커니즘
텍스트 문서가 Tika에 전달 될 때마다 작성된 언어를 감지합니다. 언어 주석이없는 문서를 받아들이고 언어를 감지하여 문서의 메타 데이터에 해당 정보를 추가합니다.
언어 식별을 지원하기 위해 Tika에는 Language Identifier 패키지에 org.apache.tika.language, 그리고 주어진 텍스트에서 언어를 감지하기위한 알고리즘을 포함하는 언어 식별 저장소. Tika는 언어 감지를 위해 내부적으로 N-gram 알고리즘을 사용합니다.
MIME 감지 메커니즘
Tika는 MIME 표준에 따라 문서 유형을 감지 할 수 있습니다. Tika의 기본 MIME 유형 감지는 org.apache.tika.mime.mimeTypes를 사용하여 수행됩니다 . 대부분의 콘텐츠 유형 감지에 org.apache.tika.detect.Detector 인터페이스를 사용합니다 .
내부적으로 Tika는 파일 글롭, 콘텐츠 유형 힌트, 매직 바이트, 문자 인코딩 및 기타 여러 기술과 같은 여러 기술을 사용합니다.
파서 인터페이스
org.apache.tika.parser의 파서 인터페이스는 Tika에서 문서를 파싱하기위한 핵심 인터페이스입니다. 이 인터페이스는 문서에서 텍스트와 메타 데이터를 추출하고 파서 플러그인을 작성하려는 외부 사용자를 위해 요약합니다.
개별 문서 유형에 따라 다른 구체적인 파서 클래스를 사용하여 Tika는 많은 문서 형식을 지원합니다. 이러한 형식 별 클래스는 파서 논리를 직접 구현하거나 외부 파서 라이브러리를 사용하여 다양한 문서 형식을 지원합니다.
티카 파사드 클래스
Tika 파사드 클래스를 사용하는 것은 자바에서 Tika를 호출하는 가장 간단하고 직접적인 방법이며 파사드 디자인 패턴을 따릅니다. Tika API의 org.apache.tika 패키지에서 Tika 파사드 클래스를 찾을 수 있습니다.
기본 사용 사례를 구현함으로써 Tika는 조경 중개인 역할을합니다. MIME 감지 메커니즘, 파서 인터페이스 및 언어 감지 메커니즘과 같은 Tika 라이브러리의 기본 복잡성을 추상화하고 사용자에게 사용하기위한 간단한 인터페이스를 제공합니다.
Tika의 특징
Unified parser Interface− Tika는 단일 파서 인터페이스 내에서 모든 타사 파서 라이브러리를 캡슐화합니다. 이 기능으로 인해 사용자는 적합한 파서 라이브러리를 선택하는 부담에서 벗어나 발생한 파일 유형에 따라 사용합니다.
Low memory usage− Tika는 메모리 리소스를 덜 소비하므로 Java 애플리케이션에 쉽게 포함 할 수 있습니다. 모바일 PDA와 같은 리소스가 적은 플랫폼에서 실행되는 애플리케이션 내에서 Tika를 사용할 수도 있습니다.
Fast processing − 빠른 콘텐츠 감지 및 애플리케이션에서 추출을 기대할 수 있습니다.
Flexible metadata − Tika는 파일을 설명하는 데 사용되는 모든 메타 데이터 모델을 이해합니다.
Parser integration − Tika는 단일 애플리케이션에서 각 문서 유형에 사용할 수있는 다양한 파서 라이브러리를 사용할 수 있습니다.
MIME type detection − Tika는 MIME 표준에 포함 된 모든 미디어 유형에서 콘텐츠를 감지하고 추출 할 수 있습니다.
Language detection − Tika에는 언어 식별 기능이 포함되어 있으므로 다국어 웹 사이트의 언어 유형에 따라 문서에서 사용할 수 있습니다.
Tika의 기능
Tika는 다양한 기능을 지원합니다-
- 문서 유형 감지
- 콘텐츠 추출
- 메타 데이터 추출
- 언어 감지
문서 유형 감지
Tika는 다양한 감지 기술을 사용하고 주어진 문서의 유형을 감지합니다.

콘텐츠 추출
Tika에는 다양한 문서 형식의 내용을 구문 분석하고 추출 할 수있는 파서 라이브러리가 있습니다. 문서 유형을 감지 한 후 파서 저장소에서 적절한 파서를 선택하고 문서를 전달합니다. Tika의 다른 클래스에는 다른 문서 형식을 구문 분석하는 방법이 있습니다.

메타 데이터 추출
콘텐츠와 함께 Tika는 콘텐츠 추출과 동일한 절차로 문서의 메타 데이터를 추출합니다. 일부 문서 유형의 경우 Tika에는 메타 데이터를 추출하는 클래스가 있습니다.

언어 감지
내부적으로 Tika는 다음과 같은 알고리즘을 따릅니다. n-gram주어진 문서에서 콘텐츠의 언어를 감지합니다. Tika는 다음과 같은 수업에 의존합니다.Languageidentifier 과 Profiler 언어 식별을 위해.

이 장에서는 Windows 및 Linux에서 Apache Tika를 설정하는 프로세스를 안내합니다. Apache Tika를 설치하는 동안 사용자 관리가 필요합니다.
시스템 요구 사항
| JDK | Java SE 2 JDK 1.6 이상 |
| 기억 | 1GB RAM (권장) |
| 디스크 공간 | 최소 요구 사항 없음 |
| 운영 체제 버전 | Windows XP 이상, Linux |
1 단계 : Java 설치 확인
Java 설치를 확인하려면 콘솔을 열고 다음을 실행하십시오. java 명령.
| OS | 직무 | 명령 |
|---|---|---|
| 윈도우 | 명령 콘솔 열기 | \> java –version |
| 리눅스 | 명령 터미널 열기 | $ java –version |
시스템에 Java가 제대로 설치되어 있으면 작업중인 플랫폼에 따라 다음 출력 중 하나가 표시됩니다.
| OS | 산출 |
|---|---|
| 윈도우 | 자바 버전 '1.7.0_60'
Java (TM) SE 런타임 환경 (빌드 1.7.0_60-b19) Java Hotspot (TM) 64 비트 서버 VM (빌드 24.60-b09, 혼합 모드) |
| Lunix | 자바 버전 "1.7.0_25" JDK 런타임 환경 열기 (rhel-2.3.10.4.el6_4-x86_64) JDK 64 비트 서버 VM 열기 (빌드 23.7-b01, 혼합 모드) |
이 튜토리얼을 진행하기 전에이 튜토리얼의 독자가 시스템에 Java 1.7.0_60을 설치했다고 가정합니다.
Java SDK가없는 경우 현재 버전을 https://www.oracle.com/technetwork/java/javase/downloads/index.html and have it installed.
2 단계 : Java 환경 설정
시스템에 Java가 설치된 기본 디렉토리 위치를 가리 키도록 JAVA_HOME 환경 변수를 설정하십시오. 예를 들면
| OS | 산출 |
|---|---|
| 윈도우 | 환경 변수 JAVA_HOME을 C : \ ProgramFiles \ java \ jdk1.7.0_60으로 설정합니다. |
| 리눅스 | 내보내기 JAVA_HOME = / usr / local / java-current |
Java 컴파일러 위치의 전체 경로를 시스템 경로에 추가하십시오.
| OS | 산출 |
|---|---|
| 윈도우 | 문자열을 추가하십시오. C : \ Program Files \ Java \ jdk1.7.0_60 \ bin을 시스템 변수 PATH의 끝에 추가합니다. |
| 리눅스 | 내보내기 경로 = $ PATH : $ JAVA_HOME / bin / |
위에서 설명한대로 명령 프롬프트에서 명령 java-version을 확인하십시오.
3 단계 : Apache Tika 환경 설정
프로그래머는 다음을 사용하여 Apache Tika를 환경에 통합 할 수 있습니다.
- 명령 줄,
- Tika API,
- Tika의 명령 줄 인터페이스 (CLI),
- Tika의 GUI (그래픽 사용자 인터페이스) 또는
- 소스 코드.
이러한 접근 방식을 사용하려면 먼저 Tika의 소스 코드를 다운로드해야합니다.
Tika의 소스 코드는 https://Tika.apache.org/download.html, 두 개의 링크를 찾을 수 있습니다-
apache-tika-1.6-src.zip − Tika의 소스 코드가 포함되어 있으며
Tika -app-1.6.jar − Tika 애플리케이션이 포함 된 jar 파일입니다.
이 두 파일을 다운로드하십시오. Tika 공식 웹 사이트의 스냅 샷은 아래와 같습니다.
파일을 다운로드 한 후 jar 파일의 클래스 경로를 설정하십시오. tika-app-1.6.jar. 아래 표에 표시된대로 jar 파일의 전체 경로를 추가하십시오.
| OS | 산출 |
|---|---|
| 윈도우 | 사용자 환경 변수 CLASSPATH에 문자열“C : \ jars \ Tika-app-1.6.jar”을 추가합니다. |
| 리눅스 | 내보내기 CLASSPATH = $ CLASSPATH − /usr/share/jars/Tika-app-1.6.tar − |
Apache는 Eclipse를 사용하는 GUI (Graphical User Interface) 애플리케이션 인 Tika 애플리케이션을 제공합니다.
Eclipse를 사용한 Tika-Maven 빌드
Eclipse를 열고 새 프로젝트를 만듭니다.
Eclipse에 Maven이없는 경우 주어진 단계에 따라 설정하십시오.
https://wiki.eclipse.org/M2E_updatesite_and_gittags 링크를 엽니 다 . m2e 플러그인 릴리스가 표 형식으로 제공됩니다.
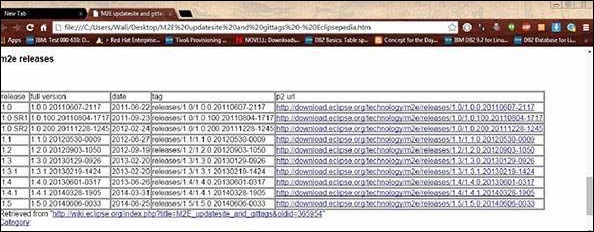
최신 버전을 선택하고 p2 url 열에 URL 경로를 저장하십시오.
이제 eclipse를 다시 방문하고 메뉴 모음에서 Help, 선택 Install New Software 드롭 다운 메뉴에서

클릭 Add버튼을 클릭하고 원하는 이름을 입력합니다. 이제 저장된 URL을Location 들.
이전 단계에서 선택한 이름으로 새 플러그인이 추가됩니다. 앞에있는 확인란을 선택하고 Next.

설치를 진행하십시오. 완료되면 Eclipse를 다시 시작하십시오.
이제 프로젝트를 마우스 오른쪽 버튼으로 클릭하고 configure 옵션, 선택 convert to maven project.
새 pom을 만드는 새 마법사가 나타납니다. 그룹 ID를 org.apache.tika로 입력하고 최신 버전의 Tika를 입력하고packaging 항아리로 클릭하고 Finish.
Maven 프로젝트가 성공적으로 설치되고 프로젝트가 Maven으로 변환됩니다. 이제 pom.xml 파일을 구성해야합니다.
XML 파일 구성
Tika maven 종속성 가져 오기https://mvnrepository.com/artifact/org.apache.tika
아래는 Apache Tika의 완전한 Maven 종속성입니다.
<dependency>
<groupId>org.apache.Tika</groupId>
<artifactId>Tika-core</artifactId>
<version>1.6</version>
<groupId>org.apache.Tika</groupId>
<artifactId> Tika-parsers</artifactId>
<version> 1.6</version>
<groupId> org.apache.Tika</groupId>
<artifactId>Tika</artifactId>
<version>1.6</version>
<groupId>org.apache.Tika</groupId>
< artifactId>Tika-serialization</artifactId>
< version>1.6< /version>
< groupId>org.apache.Tika< /groupId>
< artifactId>Tika-app< /artifactId>
< version>1.6< /version>
<groupId>org.apache.Tika</groupId>
<artifactId>Tika-bundle</artifactId>
<version>1.6</version>
</dependency>사용자는 Tika 파사드 클래스를 사용하여 애플리케이션에 Tika를 포함 할 수 있습니다. Tika의 모든 기능을 탐색하는 방법이 있습니다. 파사드 클래스이기 때문에 Tika는 기능 뒤에있는 복잡성을 추상화합니다. 이 외에도 사용자는 응용 프로그램에서 다양한 클래스의 Tika를 사용할 수도 있습니다.
티카 클래스 (외관)
이것은 Tika 라이브러리에서 가장 눈에 띄는 클래스이며 외관 디자인 패턴을 따릅니다. 따라서 모든 내부 구현을 추상화하고 Tika 기능에 액세스하는 간단한 방법을 제공합니다. 다음 표에는이 클래스의 생성자와 해당 설명이 나열되어 있습니다.
package − org.apache.tika
class − 티카
| Sr. 아니. | 생성자 및 설명 |
|---|---|
| 1 | Tika () 기본 구성을 사용하고 Tika 클래스를 구성합니다. |
| 2 | Tika (Detector detector) 감지기 인스턴스를 매개 변수로 받아 Tika 파사드를 생성합니다. |
| 삼 | Tika (Detector detector, Parser parser) 감지기 및 파서 인스턴스를 매개 변수로 받아 Tika 파사드를 만듭니다. |
| 4 | Tika (Detector detector, Parser parser, Translator translator) 감지기, 파서 및 변환기 인스턴스를 매개 변수로 받아 Tika 파사드를 만듭니다. |
| 5 | Tika (TikaConfig config) TikaConfig 클래스의 객체를 매개 변수로 받아 Tika 파사드를 생성합니다. |
방법 및 설명
다음은 Tika 파사드 클래스의 중요한 방법입니다-
| Sr. 아니. | 방법 및 설명 |
|---|---|
| 1 | 구문 분석ToString (File 파일) 이 메서드와 모든 변형은 매개 변수로 전달 된 파일을 구문 분석하고 추출 된 텍스트 콘텐츠를 문자열 형식으로 반환합니다. 기본적으로이 문자열 매개 변수의 길이는 제한됩니다. |
| 2 | int getMaxStringLength () parseToString 메서드가 반환하는 문자열의 최대 길이를 반환합니다. |
| 삼 | 빈 setMaxStringLength (int maxStringLength) parseToString 메서드에서 반환하는 문자열의 최대 길이를 설정합니다. |
| 4 | 리더 parse (File 파일) 이 메소드와 모든 변형은 매개 변수로 전달 된 파일을 구문 분석하고 추출 된 텍스트 콘텐츠를 java.io.reader 객체 형식으로 반환합니다. |
| 5 | 끈 detect (InputStream 흐름, Metadata 메타 데이터) 이 메소드와 모든 변형은 InputStream 객체와 Metadata 객체를 매개 변수로 받아들이고, 주어진 문서의 유형을 감지하고, 문서 유형 이름을 String 객체로 반환합니다. 이 방법은 Tika가 사용하는 탐지 메커니즘을 추상화합니다. |
| 6 | 끈 translate (InputStream 본문, String 대상 언어) 이 메서드와 모든 변형은 InputStream 객체와 텍스트를 번역 할 언어를 나타내는 String을 받아들이고, 주어진 텍스트를 원하는 언어로 번역하여 소스 언어를 자동 감지하려고 시도합니다. |
파서 인터페이스
이것은 Tika 패키지의 모든 파서 클래스에 의해 구현되는 인터페이스입니다.
package − org.apache.tika.parser
Interface − 파서
방법 및 설명
다음은 Tika Parser 인터페이스의 중요한 방법입니다.
| Sr. 아니. | 방법 및 설명 |
|---|---|
| 1 | parse (InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context) 이 메서드는 주어진 문서를 XHTML 및 SAX 이벤트 시퀀스로 구문 분석합니다. 구문 분석 후 추출 된 문서 콘텐츠를 ContentHandler 클래스의 개체에 배치하고 메타 데이터를 Metadata 클래스의 개체에 배치합니다. |
메타 데이터 클래스
이 클래스는 CreativeCommons, Geographic, HttpHeaders, Message, MSOffice, ClimateForcast, TIFF, TikaMetadataKeys, TikaMimeKeys, Serializable과 같은 다양한 인터페이스를 구현하여 다양한 데이터 모델을 지원합니다. 다음 표에는이 클래스의 생성자 및 메서드와 해당 설명이 나와 있습니다.
package − org.apache.tika.metadata
class − 메타 데이터
| Sr. 아니. | 생성자 및 설명 |
|---|---|
| 1 | Metadata() 비어있는 새 메타 데이터를 생성합니다. |
| Sr. 아니. | 방법 및 설명 |
|---|---|
| 1 | add (Property property, String value) 주어진 문서에 메타 데이터 속성 / 값 매핑을 추가합니다. 이 함수를 사용하여 값을 속성으로 설정할 수 있습니다. |
| 2 | add (String name, String value) 주어진 문서에 메타 데이터 속성 / 값 매핑을 추가합니다. 이 방법을 사용하여 문서의 기존 메타 데이터에 새 이름 값을 설정할 수 있습니다. |
| 삼 | String get (Property property) 주어진 메타 데이터 속성의 값 (있는 경우)을 반환합니다. |
| 4 | String get (String name) 주어진 메타 데이터 이름의 값 (있는 경우)을 반환합니다. |
| 5 | Date getDate (Property property) Date 메타 데이터 속성의 값을 반환합니다. |
| 6 | String[] getValues (Property property) 메타 데이터 속성의 모든 값을 반환합니다. |
| 7 | String[] getValues (String name) 주어진 메타 데이터 이름의 모든 값을 반환합니다. |
| 8 | String[] names() 메타 데이터 개체에있는 메타 데이터 요소의 모든 이름을 반환합니다. |
| 9 | set (Property property, Date date) 주어진 메타 데이터 속성의 날짜 값을 설정합니다. |
| 10 | set(Property property, String[] values) 메타 데이터 속성에 여러 값을 설정합니다. |
언어 식별자 클래스
이 클래스는 주어진 콘텐츠의 언어를 식별합니다. 다음 표는이 클래스의 생성자를 설명과 함께 나열합니다.
package − org.apache.tika.language
class − 언어 식별자
| Sr. 아니. | 생성자 및 설명 |
|---|---|
| 1 | LanguageIdentifier (LanguageProfile profile) 언어 식별자를 인스턴스화합니다. 여기에서 LanguageProfile 객체를 매개 변수로 전달해야합니다. |
| 2 | LanguageIdentifier (String content) 이 생성자는 텍스트 콘텐츠에서 문자열을 전달하여 언어 식별자를 인스턴스화 할 수 있습니다. |
| Sr. 아니. | 방법 및 설명 |
|---|---|
| 1 | String getLanguage () 현재 LanguageIdentifier 객체에 제공된 언어를 반환합니다. |
Tika에서 지원하는 파일 형식
다음 표는 Tika가 지원하는 파일 형식을 보여줍니다.
| 파일 형식 | 패키지 라이브러리 | Tika 클래스 |
|---|---|---|
| XML | org.apache.tika.parser.xml | XMLParser |
| HTML | org.apache.tika.parser.html 및 Tagsoup 라이브러리를 사용합니다. | HtmlParser |
| MS-Office 복합 문서 Ole2 ~ 2007 ooxml 2007 이후 | org.apache.tika.parser.microsoft org.apache.tika.parser.microsoft.ooxml이며 Apache Poi 라이브러리를 사용합니다. |
OfficeParser (ole2) OOXMLParser (ooxml) |
| OpenDocument 형식 openoffice | org.apache.tika.parser.odf | OpenOfficeParser |
| 휴대용 문서 형식 (PDF) | org.apache.tika.parser.pdf 및이 패키지는 Apache PdfBox 라이브러리를 사용합니다. | PDFParser |
| 전자 출판 형식 (디지털 도서) | org.apache.tika.parser.epub | EpubParser |
| 서식있는 텍스트 형식 | org.apache.tika.parser.rtf | RTFParser |
| 압축 및 패키징 형식 | org.apache.tika.parser.pkg 및이 패키지는 공통 압축 라이브러리를 사용합니다. | PackageParser 및 CompressorParser 및 해당 하위 클래스 |
| 텍스트 형식 | org.apache.tika.parser.txt | TXTParser |
| 피드 및 신디케이션 형식 | org.apache.tika.parser.feed | FeedParser |
| 오디오 형식 | org.apache.tika.parser.audio 및 org.apache.tika.parser.mp3 | AudioParser MidiParser Mp3- for mp3parser |
| 이미지 파서 | org.apache.tika.parser.jpeg | JpegParser-for jpeg 이미지 |
| 비디오 형식 | org.apache.tika.parser.mp4 및 org.apache.tika.parser.video이 파서는 내부적으로 단순 알고리즘을 사용하여 플래시 비디오 형식을 구문 분석합니다. | Mp4parser FlvParser |
| Java 클래스 파일 및 jar 파일 | org.apache.tika.parser.asm | ClassParser CompressorParser |
| Mobxformat (이메일 메시지) | org.apache.tika.parser.mbox | MobXParser |
| CAD 형식 | org.apache.tika.parser.dwg | DWGParser |
| 글꼴 형식 | org.apache.tika.parser.font | TrueTypeParser |
| 실행 가능한 프로그램 및 라이브러리 | org.apache.tika.parser.executable | ExecutableParser |
MIME 표준
MIME (Multipurpose Internet Mail Extensions) 표준은 문서 유형을 식별하는 데 가장 적합한 표준입니다. 이러한 표준에 대한 지식은 내부 상호 작용 중에 브라우저에 도움이됩니다.
브라우저는 미디어 파일을 발견 할 때마다 해당 콘텐츠를 표시하기 위해 사용할 수있는 호환 소프트웨어를 선택합니다. 특정 미디어 파일을 실행하는 데 적합한 응용 프로그램이없는 경우 사용자에게 적합한 플러그인 소프트웨어를 얻을 것을 권장합니다.
Tika의 유형 감지
Tika는 MIME에서 제공되는 모든 인터넷 미디어 문서 유형을 지원합니다. 파일이 Tika를 통해 전달 될 때마다 파일과 문서 유형을 감지합니다. 미디어 유형을 감지하기 위해 Tika는 내부적으로 다음 메커니즘을 사용합니다.
파일 확장자
파일 확장자를 확인하는 것은 파일 형식을 감지하는 데 가장 간단하고 널리 사용되는 방법입니다. 많은 응용 프로그램과 운영 체제가 이러한 확장을 지원합니다. 다음은 몇 가지 알려진 파일 형식의 확장자입니다.
| 파일 이름 | 연장 |
|---|---|
| 영상 | .jpg |
| 오디오 | .mp3 |
| 자바 아카이브 파일 | .항아리 |
| 자바 클래스 파일 | .수업 |
콘텐츠 유형 힌트
데이터베이스에서 파일을 검색하거나 다른 문서에 첨부 할 때마다 파일의 이름이나 확장자가 손실 될 수 있습니다. 이러한 경우 파일과 함께 제공되는 메타 데이터는 파일 확장자를 감지하는 데 사용됩니다.
매직 바이트
파일의 원시 바이트를 관찰하면 각 파일에 대해 고유 한 문자 패턴을 찾을 수 있습니다. 일부 파일에는 다음과 같은 특수 바이트 접두사가 있습니다.magic bytes 파일 유형을 식별하기 위해 특별히 만들어져 파일에 포함 된 것
예를 들어 Java 파일에서 CA FE BA BE (16 진수 형식)를, pdf 파일에서 % PDF (ASCII 형식)를 찾을 수 있습니다. Tika는이 정보를 사용하여 파일의 미디어 유형을 식별합니다.
문자 인코딩
일반 텍스트가있는 파일은 다양한 유형의 문자 인코딩을 사용하여 인코딩됩니다. 여기서 주된 과제는 파일에 사용 된 문자 인코딩 유형을 식별하는 것입니다. Tika는 다음과 같은 문자 인코딩 기술을 따릅니다.Bom markers 과 Byte Frequencies 일반 텍스트 콘텐츠에서 사용하는 인코딩 시스템을 식별합니다.
XML 루트 문자
XML 문서를 감지하기 위해 Tika는 xml 문서를 구문 분석하고 파일의 실제 미디어 유형을 찾을 수있는 루트 요소, 네임 스페이스 및 참조 된 스키마와 같은 정보를 추출합니다.
Facade 클래스를 사용한 유형 감지
그만큼 detect()파사드 클래스의 메소드는 문서 유형을 감지하는 데 사용됩니다. 이 메서드는 파일을 입력으로받습니다. 아래는 Tika 파사드 클래스를 사용한 문서 유형 감지를위한 예제 프로그램입니다.
import java.io.File;
import org.apache.tika.Tika;
public class Typedetection {
public static void main(String[] args) throws Exception {
//assume example.mp3 is in your current directory
File file = new File("example.mp3");//
//Instantiating tika facade class
Tika tika = new Tika();
//detecting the file type using detect method
String filetype = tika.detect(file);
System.out.println(filetype);
}
}위 코드를 TypeDetection.java로 저장하고 다음 명령을 사용하여 명령 프롬프트에서 실행하십시오.
javac TypeDetection.java
java TypeDetection
audio/mpegTika는 다양한 파서 라이브러리를 사용하여 주어진 파서에서 콘텐츠를 추출합니다. 주어진 문서 유형을 추출하기위한 올바른 파서를 선택합니다.
문서를 파싱하기 위해 일반적으로 Tika 파사드 클래스의 parseToString () 메서드가 사용됩니다. 다음은 구문 분석 프로세스와 관련된 단계이며 Tika ParsertoString () 메서드에 의해 추상화됩니다.

파싱 프로세스 추상화-
처음에 우리가 문서를 Tika에 전달할 때 그것은 그것과 함께 사용 가능한 적절한 유형 감지 메커니즘을 사용하고 문서 유형을 감지합니다.
문서 유형이 알려지면 파서 저장소에서 적합한 파서를 선택합니다. 파서 저장소에는 외부 라이브러리를 사용하는 클래스가 포함되어 있습니다.
그런 다음 문서가 전달되어 콘텐츠를 구문 분석하고 텍스트를 추출하며 읽을 수없는 형식에 대한 예외를 throw 할 파서를 선택합니다.
Tika를 사용한 콘텐츠 추출
다음은 Tika 파사드 클래스를 사용하여 파일에서 텍스트를 추출하는 프로그램입니다.
import java.io.File;
import java.io.IOException;
import org.apache.tika.Tika;
import org.apache.tika.exception.TikaException;
import org.xml.sax.SAXException;
public class TikaExtraction {
public static void main(final String[] args) throws IOException, TikaException {
//Assume sample.txt is in your current directory
File file = new File("sample.txt");
//Instantiating Tika facade class
Tika tika = new Tika();
String filecontent = tika.parseToString(file);
System.out.println("Extracted Content: " + filecontent);
}
}위의 코드를 TikaExtraction.java로 저장하고 명령 프롬프트에서 실행하십시오.
javac TikaExtraction.java
java TikaExtraction다음은 sample.txt의 내용입니다.
Hi students welcome to tutorialspoint다음과 같은 출력을 제공합니다.
Extracted Content: Hi students welcome to tutorialspoint파서 인터페이스를 사용한 콘텐츠 추출
Tika의 파서 패키지는 텍스트 문서를 파싱 할 수있는 몇 가지 인터페이스와 클래스를 제공합니다. 다음은 블록 다이어그램입니다.org.apache.tika.parser 꾸러미.

pdf 파서, Mp3Passer, OfficeParser 등 여러 파서 클래스를 사용하여 각 문서를 개별적으로 구문 분석 할 수 있습니다. 이러한 모든 클래스는 파서 인터페이스를 구현합니다.
CompositeParser
주어진 다이어그램은 Tika의 범용 파서 클래스를 보여줍니다. CompositeParser 과 AutoDetectParser. CompositeParser 클래스는 복합 디자인 패턴을 따르므로 파서 인스턴스 그룹을 단일 파서로 사용할 수 있습니다. CompositeParser 클래스는 또한 파서 인터페이스를 구현하는 모든 클래스에 대한 액세스를 허용합니다.
AutoDetectParser
이것은 CompositeParser의 하위 클래스이며 자동 유형 감지를 제공합니다. 이 기능을 사용하여 AutoDetectParser는 복합 방법론을 사용하여 들어오는 문서를 적절한 파서 클래스로 자동으로 보냅니다.
parse () 메서드
parseToString ()과 함께 파서 인터페이스의 parse () 메서드를 사용할 수도 있습니다. 이 메서드의 프로토 타입은 다음과 같습니다.
parse(InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context)다음 표는 매개 변수로 허용하는 4 개의 오브젝트를 나열합니다.
| Sr. 아니. | 개체 및 설명 |
|---|---|
| 1 | InputStream stream 파일 내용을 포함하는 모든 Inputstream 개체 |
| 2 | ContentHandler handler Tika는 문서를 XHTML 컨텐츠로이 핸들러에 전달한 후 SAX API를 사용하여 문서를 처리합니다. 문서 내용의 효율적인 후 처리를 제공합니다. |
| 삼 | Metadata metadata The metadata object is used both as a source and a target of document metadata. |
| 4 | ParseContext context This object is used in cases where the client application wants to customize the parsing process. |
Example
Given below is an example that shows how the parse() method is used.
Step 1 −
To use the parse() method of the parser interface, instantiate any of the classes providing the implementation for this interface.
There are individual parser classes such as PDFParser, OfficeParser, XMLParser, etc. You can use any of these individual document parsers. Alternatively, you can use either CompositeParser or AutoDetectParser that uses all the parser classes internally and extracts the contents of a document using a suitable parser.
Parser parser = new AutoDetectParser();
(or)
Parser parser = new CompositeParser();
(or)
object of any individual parsers given in Tika LibraryStep 2 −
Create a handler class object. Given below are the three content handlers −
| Sr.No. | Class & Description |
|---|---|
| 1 | BodyContentHandler This class picks the body part of the XHTML output and writes that content to the output writer or output stream. Then it redirects the XHTML content to another content handler instance. |
| 2 | LinkContentHandler This class detects and picks all the H-Ref tags of the XHTML document and forwards those for the use of tools like web crawlers. |
| 3 | TeeContentHandler This class helps in using multiple tools simultaneously. |
Since our target is to extract the text contents from a document, instantiate BodyContentHandler as shown below −
BodyContentHandler handler = new BodyContentHandler( );Step 3 −
Create the Metadata object as shown below −
Metadata metadata = new Metadata();Step 4 −
Create any of the input stream objects, and pass your file that should be extracted to it.
FileInputstream
Instantiate a file object by passing the file path as parameter and pass this object to the FileInputStream class constructor.
Note − The path passed to the file object should not contain spaces.
The problem with these input stream classes is that they don’t support random access reads, which is required to process some file formats efficiently. To resolve this problem, Tika provides TikaInputStream.
File file = new File(filepath)
FileInputStream inputstream = new FileInputStream(file);
(or)
InputStream stream = TikaInputStream.get(new File(filename));Step 5 −
Create a parse context object as shown below −
ParseContext context =new ParseContext();Step 6 −
Instantiate the parser object, invoke the parse method, and pass all the objects required, as shown in the prototype below −
parser.parse(inputstream, handler, metadata, context);Given below is the program for content extraction using the parser interface −
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class ParserExtraction {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//Assume sample.txt is in your current directory
File file = new File("sample.txt");
//parse method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
//parsing the file
parser.parse(inputstream, handler, metadata, context);
System.out.println("File content : " + Handler.toString());
}
}Save the above code as ParserExtraction.java and run it from the command prompt −
javac ParserExtraction.java
java ParserExtractionGiven below is the content of sample.txt
Hi students welcome to tutorialspointIf you execute the above program, it will give you the following output −
File content : Hi students welcome to tutorialspointBesides content, Tika also extracts the metadata from a file. Metadata is nothing but the additional information supplied with a file. If we consider an audio file, the artist name, album name, title comes under metadata.
XMP Standards
The Extensible Metadata Platform (XMP) is a standard for processing and storing information related to the content of a file. It was created by Adobe Systems Inc. XMP provides standards for defining, creating, and processing of metadata. You can embed this standard into several file formats such as PDF, JPEG, JPEG, GIF, jpg, HTML etc.
Property Class
Tika uses the Property class to follow XMP property definition. It provides the PropertyType and ValueType enums to capture the name and value of a metadata.
Metadata Class
This class implements various interfaces such as ClimateForcast, CativeCommons, Geographic, TIFF etc. to provide support for various metadata models. In addition, this class provides various methods to extract the content from a file.
Metadata Names
We can extract the list of all metadata names of a file from its metadata object using the method names(). It returns all the names as a string array. Using the name of the metadata, we can get the value using the get() method. It takes a metadata name and returns a value associated with it.
String[] metadaNames = metadata.names();
String value = metadata.get(name);Extracting Metadata using Parse Method
Whenever we parse a file using parse(), we pass an empty metadata object as one of the parameters. This method extracts the metadata of the given file (if that file contains any), and places them in the metadata object. Therefore, after parsing the file using parse(), we can extract the metadata from that object.
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata(); //empty metadata object
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
parser.parse(inputstream, handler, metadata, context);
// now this metadata object contains the extracted metadata of the given file.
metadata.metadata.names();Given below is the complete program to extract metadata from a text file.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class GetMetadata {
public static void main(final String[] args) throws IOException, TikaException {
//Assume that boy.jpg is in your current directory
File file = new File("boy.jpg");
//Parser method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
parser.parse(inputstream, handler, metadata, context);
System.out.println(handler.toString());
//getting the list of all meta data elements
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Save the above code as GetMetadata.java and run it from the command prompt using the following commands −
javac GetMetadata .java
java GetMetadataGiven below is the snapshot of boy.jpg

If you execute the above program, it will give you the following output −
X-Parsed-By: org.apache.tika.parser.DefaultParser
Resolution Units: inch
Compression Type: Baseline
Data Precision: 8 bits
Number of Components: 3
tiff:ImageLength: 3000
Component 2: Cb component: Quantization table 1, Sampling factors 1 horiz/1 vert
Component 1: Y component: Quantization table 0, Sampling factors 2 horiz/2 vert
Image Height: 3000 pixels
X Resolution: 300 dots
Original Transmission Reference:
53616c7465645f5f2368da84ca932841b336ac1a49edb1a93fae938b8db2cb3ec9cc4dc28d7383f1
Image Width: 4000 pixels
IPTC-NAA record: 92 bytes binary data
Component 3: Cr component: Quantization table 1, Sampling factors 1 horiz/1 vert
tiff:BitsPerSample: 8
Application Record Version: 4
tiff:ImageWidth: 4000
Content-Type: image/jpeg
Y Resolution: 300 dotsWe can also get our desired metadata values.
Adding New Metadata Values
We can add new metadata values using the add() method of the metadata class. Given below is the syntax of this method. Here we are adding the author name.
metadata.add(“author”,”Tutorials point”);The Metadata class has predefined properties including the properties inherited from classes like ClimateForcast, CativeCommons, Geographic, etc., to support various data models. Shown below is the usage of the SOFTWARE data type inherited from the TIFF interface implemented by Tika to follow XMP metadata standards for TIFF image formats.
metadata.add(Metadata.SOFTWARE,"ms paint");Given below is the complete program that demonstrates how to add metadata values to a given file. Here the list of the metadata elements is displayed in the output so that you can observe the change in the list after adding new values.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Arrays;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class AddMetadata {
public static void main(final String[] args) throws IOException, SAXException, TikaException {
//create a file object and assume sample.txt is in your current directory
File file = new File("Example.txt");
//Parser method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
//parsing the document
parser.parse(inputstream, handler, metadata, context);
//list of meta data elements before adding new elements
System.out.println( " metadata elements :" +Arrays.toString(metadata.names()));
//adding new meta data name value pair
metadata.add("Author","Tutorials Point");
System.out.println(" metadata name value pair is successfully added");
//printing all the meta data elements after adding new elements
System.out.println("Here is the list of all the metadata
elements after adding new elements");
System.out.println( Arrays.toString(metadata.names()));
}
}위 코드를 AddMetadata.java 클래스로 저장하고 명령 프롬프트에서 실행하십시오.
javac AddMetadata .java
java AddMetadata다음은 Example.txt의 내용입니다.
Hi students welcome to tutorialspoint위의 프로그램을 실행하면 다음과 같은 결과가 나옵니다.
metadata elements of the given file :
[Content-Encoding, Content-Type]
enter the number of metadata name value pairs to be added 1
enter metadata1name:
Author enter metadata1value:
Tutorials point metadata name value pair is successfully added
Here is the list of all the metadata elements after adding new elements
[Content-Encoding, Author, Content-Type]기존 메타 데이터 요소에 값 설정
set () 메서드를 사용하여 기존 메타 데이터 요소에 값을 설정할 수 있습니다. set () 메서드를 사용하여 날짜 속성을 설정하는 구문은 다음과 같습니다.
metadata.set(Metadata.DATE, new Date());set () 메서드를 사용하여 속성에 여러 값을 설정할 수도 있습니다. set () 메서드를 사용하여 Author 속성에 여러 값을 설정하는 구문은 다음과 같습니다.
metadata.set(Metadata.AUTHOR, "ram ,raheem ,robin ");아래에 set () 메서드를 보여주는 완전한 프로그램이 있습니다.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Date;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class SetMetadata {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//Create a file object and assume example.txt is in your current directory
File file = new File("example.txt");
//parameters of parse() method
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
//Parsing the given file
parser.parse(inputstream, handler, metadata, context);
//list of meta data elements elements
System.out.println( " metadata elements and values of the given file :");
String[] metadataNamesb4 = metadata.names();
for(String name : metadataNamesb4) {
System.out.println(name + ": " + metadata.get(name));
}
//setting date meta data
metadata.set(Metadata.DATE, new Date());
//setting multiple values to author property
metadata.set(Metadata.AUTHOR, "ram ,raheem ,robin ");
//printing all the meta data elements with new elements
System.out.println("List of all the metadata elements after adding new elements ");
String[] metadataNamesafter = metadata.names();
for(String name : metadataNamesafter) {
System.out.println(name + ": " + metadata.get(name));
}
}
}위 코드를 SetMetadata.java로 저장하고 명령 프롬프트에서 실행하십시오.
javac SetMetadata.java
java SetMetadata다음은 example.txt의 내용입니다.
Hi students welcome to tutorialspoint위의 프로그램을 실행하면 다음과 같은 결과가 나옵니다. 출력에서 새로 추가 된 메타 데이터 요소를 관찰 할 수 있습니다.
metadata elements and values of the given file :
Content-Encoding: ISO-8859-1
Content-Type: text/plain; charset = ISO-8859-1
Here is the list of all the metadata elements after adding new elements
date: 2014-09-24T07:01:32Z
Content-Encoding: ISO-8859-1
Author: ram, raheem, robin
Content-Type: text/plain; charset = ISO-8859-1언어 감지의 필요성
다국어 웹 사이트에서 작성된 언어를 기반으로 문서를 분류하려면 언어 감지 도구가 필요합니다. 이 도구는 언어 주석 (메타 데이터)이없는 문서를 허용하고 언어를 감지하여 문서의 메타 데이터에 해당 정보를 추가해야합니다.
코퍼스 프로파일 링을위한 알고리즘
코퍼스는 무엇입니까?
문서의 언어를 감지하기 위해 언어 프로필이 구성되고 알려진 언어의 프로필과 비교됩니다. 이러한 알려진 언어의 텍스트 세트를corpus.
말뭉치는 실제 상황에서 언어가 사용되는 방식을 설명하는 서면 언어 텍스트 모음입니다.
코퍼스는 도서, 성적 증명서 및 인터넷과 같은 기타 데이터 리소스에서 개발됩니다. 말뭉치의 정확성은 우리가 말뭉치를 구성하는 데 사용하는 프로파일 링 알고리즘에 따라 다릅니다.
프로파일 링 알고리즘이란?
언어를 감지하는 일반적인 방법은 사전을 사용하는 것입니다. 주어진 텍스트에 사용 된 단어는 사전에있는 단어와 일치합니다.
언어에서 사용되는 일반적인 단어 목록은 특정 언어 (예 : 기사)를 감지하는 데 가장 간단하고 효과적인 말뭉치입니다. a, an, the 영어로.
단어 집합을 말뭉치로 사용
단어 집합을 사용하여 두 말뭉치 사이의 거리를 찾기 위해 간단한 알고리즘을 구성합니다. 이는 일치하는 단어의 빈도 차이의 합과 같습니다.
이러한 알고리즘에는 다음과 같은 문제가 있습니다.
일치하는 단어의 빈도가 매우 적기 때문에 알고리즘은 문장이 적은 작은 텍스트에서는 효율적으로 작동하지 않습니다. 정확한 일치를 위해 많은 텍스트가 필요합니다.
복합 문장이있는 언어와 공백이나 구두점과 같은 단어 구분선이없는 언어의 경우 단어 경계를 감지 할 수 없습니다.
단어 집합을 말뭉치로 사용하는 데있어 이러한 어려움으로 인해 개별 문자 또는 문자 그룹이 고려됩니다.
문자 집합을 말뭉치로 사용
언어에서 일반적으로 사용되는 문자는 한정되어 있기 때문에 문자가 아닌 단어 빈도를 기반으로 알고리즘을 적용하기 쉽습니다. 이 알고리즘은 하나 또는 매우 적은 언어에서 사용되는 특정 문자 집합의 경우 더 잘 작동합니다.
이 알고리즘은 다음과 같은 단점이 있습니다.
비슷한 문자 빈도를 가진 두 언어를 구별하는 것은 어렵습니다.
여러 언어에서 사용하는 문자 집합 (말뭉치)의 도움으로 언어를 구체적으로 식별하는 특정 도구 나 알고리즘은 없습니다.
N- 그램 알고리즘
위에서 언급 한 단점은 말뭉치를 프로파일 링하기 위해 주어진 길이의 문자 시퀀스를 사용하는 새로운 접근 방식을 야기했습니다. 이러한 문자 시퀀스를 일반적으로 N- 그램이라고하며 여기서 N은 문자 시퀀스의 길이를 나타냅니다.
N-gram 알고리즘은 특히 영어와 같은 유럽 언어의 경우 언어 감지를위한 효과적인 접근 방식입니다.
이 알고리즘은 짧은 텍스트에서 잘 작동합니다.
더 매력적인 기능을 가진 다국어 문서에서 여러 언어를 감지하는 고급 언어 프로파일 링 알고리즘이 있지만 Tika는 대부분의 실제 상황에 적합하기 때문에 3 그램 알고리즘을 사용합니다.
Tika의 언어 감지
ISO 639-1에 의해 표준화 된 184 개 표준 언어 중 Tika는 18 개 언어를 감지 할 수 있습니다. Tika의 언어 감지는getLanguage() 의 방법 LanguageIdentifier수업. 이 메서드는 언어의 코드 이름을 문자열 형식으로 반환합니다. 다음은 Tika가 감지 한 18 개의 언어 코드 쌍 목록입니다.
| da-덴마크어 | de— 독일어 | et-에스토니아어 | el-그리스어 |
| en— 영어 | es-스페인어 | fi-핀란드어 | fr-프랑스어 |
| hu-헝가리어 | is-아이슬란드 어 | it— 이탈리아어 | nl-네덜란드어 |
| no-노르웨이어 | pl-폴란드어 | pt-포르투갈어 | ru-러시아어 |
| sv-스웨덴어 | th— 태국 |
인스턴스화하는 동안 LanguageIdentifier 클래스에서 추출 할 콘텐츠의 문자열 형식을 전달하거나 LanguageProfile 클래스 개체.
LanguageIdentifier object = new LanguageIdentifier(“this is english”);다음은 Tika에서 언어 감지를위한 예제 프로그램입니다.
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.language.LanguageIdentifier;
import org.xml.sax.SAXException;
public class LanguageDetection {
public static void main(String args[])throws IOException, SAXException, TikaException {
LanguageIdentifier identifier = new LanguageIdentifier("this is english ");
String language = identifier.getLanguage();
System.out.println("Language of the given content is : " + language);
}
}위 코드를 다른 이름으로 저장 LanguageDetection.java 다음 명령을 사용하여 명령 프롬프트에서 실행하십시오-
javac LanguageDetection.java
java LanguageDetection위의 프로그램을 실행하면 다음과 같은 출력이 나옵니다.
Language of the given content is : en문서의 언어 감지
주어진 문서의 언어를 감지하려면 parse () 메서드를 사용하여 구문 분석해야합니다. parse () 메서드는 내용을 구문 분석하고 인수 중 하나로 전달 된 핸들러 객체에 저장합니다. 핸들러 객체의 문자열 형식을LanguageIdentifier 아래와 같이 클래스-
parser.parse(inputstream, handler, metadata, context);
LanguageIdentifier object = new LanguageIdentifier(handler.toString());다음은 주어진 문서의 언어를 감지하는 방법을 보여주는 완전한 프로그램입니다.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.apache.tika.language.*;
import org.xml.sax.SAXException;
public class DocumentLanguageDetection {
public static void main(final String[] args) throws IOException, SAXException, TikaException {
//Instantiating a file object
File file = new File("Example.txt");
//Parser method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream content = new FileInputStream(file);
//Parsing the given document
parser.parse(content, handler, metadata, new ParseContext());
LanguageIdentifier object = new LanguageIdentifier(handler.toString());
System.out.println("Language name :" + object.getLanguage());
}
}위 코드를 SetMetadata.java로 저장하고 명령 프롬프트에서 실행하십시오.
javac SetMetadata.java
java SetMetadata다음은 Example.txt의 내용입니다.
Hi students welcome to tutorialspoint위의 프로그램을 실행하면 다음과 같은 결과가 나옵니다.
Language name :enTika jar와 함께 Tika는 그래픽 사용자 인터페이스 애플리케이션 (GUI) 및 명령 줄 인터페이스 (CLI) 애플리케이션을 제공합니다. 다른 Java 애플리케이션과 마찬가지로 명령 프롬프트에서 Tika 애플리케이션을 실행할 수 있습니다.
그래픽 사용자 인터페이스 (GUI)
Tika는 다음 링크에서 소스 코드와 함께 jar 파일을 제공합니다. https://tika.apache.org/download.html.
두 파일을 모두 다운로드하고 jar 파일의 클래스 경로를 설정하십시오.
소스 코드 zip 폴더를 추출하고 tika-app 폴더를 엽니 다.
“tika-1.6 \ tika-app \ src \ main \ java \ org \ apache \ Tika \ gui”의 압축을 푼 폴더에 두 개의 클래스 파일이 있습니다. ParsingTransferHandler.java 과 TikaGUI.java.
두 클래스 파일을 모두 컴파일하고 TikaGUI.java 클래스 파일을 실행하면 다음 창이 열립니다.

이제 Tika GUI를 사용하는 방법을 살펴 보겠습니다.
GUI에서 열기를 클릭하고 추출 할 파일을 찾아서 선택하거나 창의 공백으로 끕니다.
Tika는 파일의 내용을 추출하여 다섯 가지 형식으로 표시합니다. 메타 데이터, 서식있는 텍스트, 일반 텍스트, 주요 콘텐츠 및 구조화 된 텍스트. 원하는 형식을 선택할 수 있습니다.
같은 방법으로“tika-1.6 \ tikaapp \ src \ main \ java \ org \ apache \ tika \ cli”폴더에서도 CLI 클래스를 찾을 수 있습니다.
다음 그림은 Tika가 할 수있는 작업을 보여줍니다. GUI에 이미지를 드롭하면 Tika는 메타 데이터를 추출하여 표시합니다.
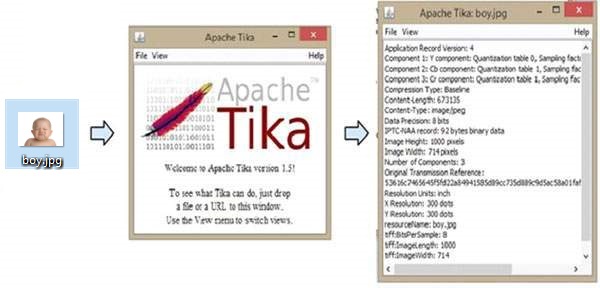
다음은 PDF에서 콘텐츠와 메타 데이터를 추출하는 프로그램입니다.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.pdf.PDFParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class PdfParse {
public static void main(final String[] args) throws IOException,TikaException {
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("Example.pdf"));
ParseContext pcontext = new ParseContext();
//parsing the document using PDF parser
PDFParser pdfparser = new PDFParser();
pdfparser.parse(inputstream, handler, metadata,pcontext);
//getting the content of the document
System.out.println("Contents of the PDF :" + handler.toString());
//getting metadata of the document
System.out.println("Metadata of the PDF:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name+ " : " + metadata.get(name));
}
}
}위 코드를 다른 이름으로 저장 PdfParse.java, 다음 명령을 사용하여 명령 프롬프트에서 컴파일하십시오-
javac PdfParse.java
java PdfParse아래는 example.pdf의 스냅 샷입니다.

우리가 전달하는 PDF에는 다음과 같은 속성이 있습니다.

프로그램을 컴파일하면 아래와 같이 출력됩니다.
Output −
Contents of the PDF:
Apache Tika is a framework for content type detection and content extraction
which was designed by Apache software foundation. It detects and extracts metadata
and structured text content from different types of documents such as spreadsheets,
text documents, images or PDFs including audio or video input formats to certain extent.
Metadata of the PDF:
dcterms:modified : 2014-09-28T12:31:16Z
meta:creation-date : 2014-09-28T12:31:16Z
meta:save-date : 2014-09-28T12:31:16Z
dc:creator : Krishna Kasyap
pdf:PDFVersion : 1.5
Last-Modified : 2014-09-28T12:31:16Z
Author : Krishna Kasyap
dcterms:created : 2014-09-28T12:31:16Z
date : 2014-09-28T12:31:16Z
modified : 2014-09-28T12:31:16Z
creator : Krishna Kasyap
xmpTPg:NPages : 1
Creation-Date : 2014-09-28T12:31:16Z
pdf:encrypted : false
meta:author : Krishna Kasyap
created : Sun Sep 28 05:31:16 PDT 2014
dc:format : application/pdf; version = 1.5
producer : Microsoft® Word 2013
Content-Type : application/pdf
xmp:CreatorTool : Microsoft® Word 2013
Last-Save-Date : 2014-09-28T12:31:16Z다음은 ODF (Open Office Document Format)에서 콘텐츠와 메타 데이터를 추출하는 프로그램입니다.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.odf.OpenDocumentParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class OpenDocumentParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example_open_document_presentation.odp"));
ParseContext pcontext = new ParseContext();
//Open Document Parser
OpenDocumentParser openofficeparser = new OpenDocumentParser ();
openofficeparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}위 코드를 다른 이름으로 저장 OpenDocumentParse.java, 다음 명령을 사용하여 명령 프롬프트에서 컴파일하십시오-
javac OpenDocumentParse.java
java OpenDocumentParse아래는 example_open_document_presentation.odp 파일의 스냅 샷입니다.

이 문서에는 다음과 같은 속성이 있습니다.
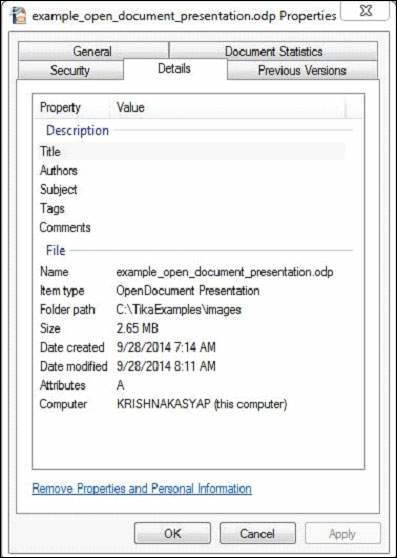
프로그램을 컴파일하면 다음과 같은 출력이 표시됩니다.
Output −
Contents of the document:
Apache Tika
Apache Tika is a framework for content type detection and content extraction which was designed
by Apache software foundation. It detects and extracts metadata and structured text content from
different types of documents such as spreadsheets, text documents, images or PDFs including audio
or video input formats to certain extent.
Metadata of the document:
editing-cycles: 4
meta:creation-date: 2009-04-16T11:32:32.86
dcterms:modified: 2014-09-28T07:46:13.03
meta:save-date: 2014-09-28T07:46:13.03
Last-Modified: 2014-09-28T07:46:13.03
dcterms:created: 2009-04-16T11:32:32.86
date: 2014-09-28T07:46:13.03
modified: 2014-09-28T07:46:13.03
nbObject: 36
Edit-Time: PT32M6S
Creation-Date: 2009-04-16T11:32:32.86
Object-Count: 36
meta:object-count: 36
generator: OpenOffice/4.1.0$Win32 OpenOffice.org_project/410m18$Build-9764
Content-Type: application/vnd.oasis.opendocument.presentation
Last-Save-Date: 2014-09-28T07:46:13.03다음은 Microsoft Office 문서에서 콘텐츠와 메타 데이터를 추출하는 프로그램입니다.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.microsoft.ooxml.OOXMLParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class MSExcelParse {
public static void main(final String[] args) throws IOException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example_msExcel.xlsx"));
ParseContext pcontext = new ParseContext();
//OOXml parser
OOXMLParser msofficeparser = new OOXMLParser ();
msofficeparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}위 코드를 다른 이름으로 저장 MSExelParse.java, 다음 명령을 사용하여 명령 프롬프트에서 컴파일하십시오-
javac MSExcelParse.java
java MSExcelParse여기에서는 다음 샘플 Excel 파일을 전달합니다.
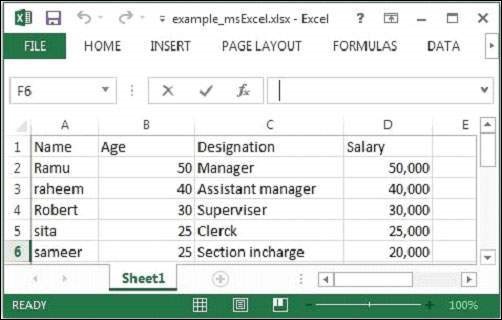
주어진 Excel 파일에는 다음과 같은 속성이 있습니다.

위의 프로그램을 실행하면 다음과 같은 결과가 나옵니다.
Output −
Contents of the document:
Sheet1
Name Age Designation Salary
Ramu 50 Manager 50,000
Raheem 40 Assistant manager 40,000
Robert 30 Superviser 30,000
sita 25 Clerk 25,000
sameer 25 Section in-charge 20,000
Metadata of the document:
meta:creation-date: 2006-09-16T00:00:00Z
dcterms:modified: 2014-09-28T15:18:41Z
meta:save-date: 2014-09-28T15:18:41Z
Application-Name: Microsoft Excel
extended-properties:Company:
dcterms:created: 2006-09-16T00:00:00Z
Last-Modified: 2014-09-28T15:18:41Z
Application-Version: 15.0300
date: 2014-09-28T15:18:41Z
publisher:
modified: 2014-09-28T15:18:41Z
Creation-Date: 2006-09-16T00:00:00Z
extended-properties:AppVersion: 15.0300
protected: false
dc:publisher:
extended-properties:Application: Microsoft Excel
Content-Type: application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
Last-Save-Date: 2014-09-28T15:18:41Z다음은 텍스트 문서에서 콘텐츠와 메타 데이터를 추출하는 프로그램입니다.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.sax.BodyContentHandler;
import org.apache.tika.parser.txt.TXTParser;
import org.xml.sax.SAXException;
public class TextParser {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.txt"));
ParseContext pcontext=new ParseContext();
//Text document parser
TXTParser TexTParser = new TXTParser();
TexTParser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}위 코드를 다른 이름으로 저장 TextParser.java, 다음 명령을 사용하여 명령 프롬프트에서 컴파일하십시오-
javac TextParser.java
java TextParser다음은 sample.txt 파일의 스냅 샷입니다.
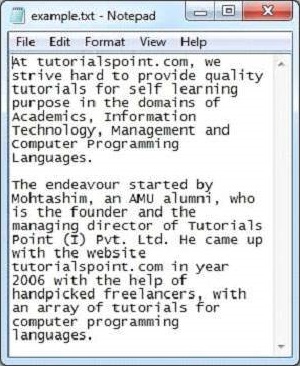
텍스트 문서에는 다음과 같은 속성이 있습니다.

위의 프로그램을 실행하면 다음과 같은 결과가 나옵니다.
Output −
Contents of the document:
At tutorialspoint.com, we strive hard to provide quality tutorials for self-learning
purpose in the domains of Academics, Information Technology, Management and Computer
Programming Languages.
The endeavour started by Mohtashim, an AMU alumni, who is the founder and the managing
director of Tutorials Point (I) Pvt. Ltd. He came up with the website tutorialspoint.com
in year 2006 with the help of handpicked freelancers, with an array of tutorials for
computer programming languages.
Metadata of the document:
Content-Encoding: windows-1252
Content-Type: text/plain; charset = windows-1252다음은 HTML 문서에서 콘텐츠와 메타 데이터를 추출하는 프로그램입니다.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.html.HtmlParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class HtmlParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.html"));
ParseContext pcontext = new ParseContext();
//Html parser
HtmlParser htmlparser = new HtmlParser();
htmlparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}위 코드를 다른 이름으로 저장 HtmlParse.java, 다음 명령을 사용하여 명령 프롬프트에서 컴파일하십시오-
javac HtmlParse.java
java HtmlParse다음은 example.txt 파일의 스냅 샷입니다.
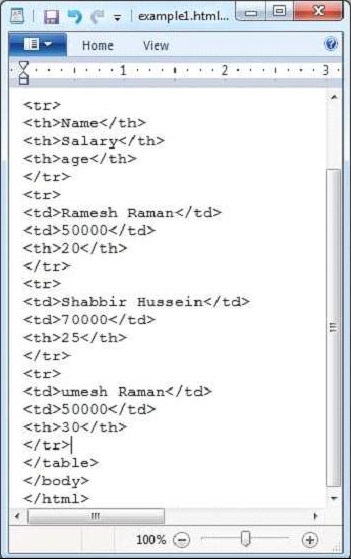
HTML 문서에는 다음과 같은 속성이 있습니다.

위의 프로그램을 실행하면 다음과 같은 결과가 나옵니다.
Output −
Contents of the document:
Name Salary age
Ramesh Raman 50000 20
Shabbir Hussein 70000 25
Umesh Raman 50000 30
Somesh 50000 35
Metadata of the document:
title: HTML Table Header
Content-Encoding: windows-1252
Content-Type: text/html; charset = windows-1252
dc:title: HTML Table Header다음은 XML 문서에서 콘텐츠와 메타 데이터를 추출하는 프로그램입니다.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.xml.XMLParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class XmlParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("pom.xml"));
ParseContext pcontext = new ParseContext();
//Xml parser
XMLParser xmlparser = new XMLParser();
xmlparser.parse(inputstream, handler, metadata, pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}위 코드를 다른 이름으로 저장 XmlParse.java, 다음 명령을 사용하여 명령 프롬프트에서 컴파일하십시오-
javac XmlParse.java
java XmlParse아래는 example.xml 파일의 스냅 샷입니다.
이 문서에는 다음과 같은 속성이 있습니다.

위의 프로그램을 실행하면 다음과 같은 결과가 나옵니다.
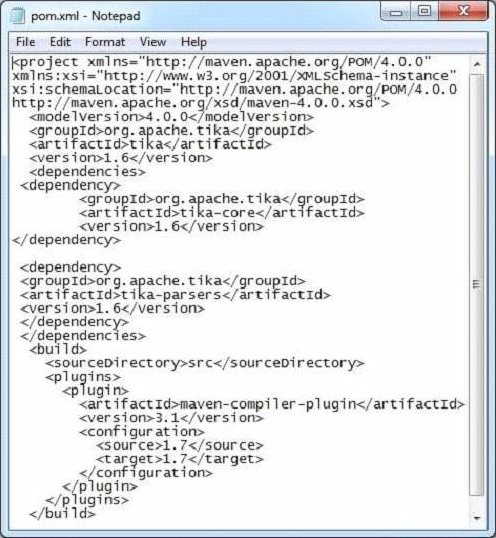
Output −
Contents of the document:
4.0.0
org.apache.tika
tika
1.6
org.apache.tika
tika-core
1.6
org.apache.tika
tika-parsers
1.6
src
maven-compiler-plugin
3.1
1.7
1.7
Metadata of the document:
Content-Type: application/xml다음은 .class 파일에서 콘텐츠와 메타 데이터를 추출하는 프로그램입니다.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.asm.ClassParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class JavaClassParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("Example.class"));
ParseContext pcontext = new ParseContext();
//Html parser
ClassParser ClassParser = new ClassParser();
ClassParser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}위 코드를 다른 이름으로 저장 JavaClassParse.java, 다음 명령을 사용하여 명령 프롬프트에서 컴파일하십시오-
javac JavaClassParse.java
java JavaClassParse아래에 주어진 스냅 샷은 Example.java 컴파일 후 Example.class를 생성합니다.

Example.class 파일에는 다음과 같은 속성이 있습니다-
위의 프로그램을 실행하면 다음과 같은 출력이 나옵니다.
Output −
Contents of the document:
package tutorialspoint.tika.examples;
public synchronized class Example {
public void Example();
public static void main(String[]);
}
Metadata of the document:
title: Example
resourceName: Example.class
dc:title: Example다음은 Java 아카이브 (jar) 파일에서 컨텐츠와 메타 데이터를 추출하는 프로그램입니다.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.sax.BodyContentHandler;
import org.apache.tika.parser.pkg.PackageParser;
import org.xml.sax.SAXException;
public class PackageParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("Example.jar"));
ParseContext pcontext = new ParseContext();
//Package parser
PackageParser packageparser = new PackageParser();
packageparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document: " + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}위 코드를 다른 이름으로 저장 PackageParse.java, 다음 명령을 사용하여 명령 프롬프트에서 컴파일하십시오-
javac PackageParse.java
java PackageParse아래는 패키지 내부에있는 Example.java의 스냅 샷입니다.

jar 파일에는 다음과 같은 속성이 있습니다.

위의 프로그램을 실행하면 다음과 같은 결과가 나옵니다.
Output −
Contents of the document:
META-INF/MANIFEST.MF
tutorialspoint/tika/examples/Example.class
Metadata of the document:
Content-Type: application/zip다음은 JPEG 이미지에서 콘텐츠와 메타 데이터를 추출하는 프로그램입니다.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.jpeg.JpegParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class JpegParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("boy.jpg"));
ParseContext pcontext = new ParseContext();
//Jpeg Parse
JpegParser JpegParser = new JpegParser();
JpegParser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}위 코드를 다른 이름으로 저장 JpegParse.java, 다음 명령을 사용하여 명령 프롬프트에서 컴파일하십시오-
javac JpegParse.java
java JpegParse다음은 Example.jpeg의 스냅 샷입니다-

JPEG 파일에는 다음과 같은 속성이 있습니다.
프로그램을 실행하면 다음과 같은 출력이 표시됩니다.
Output −
Contents of the document:
Meta data of the document:
Resolution Units: inch
Compression Type: Baseline
Data Precision: 8 bits
Number of Components: 3
tiff:ImageLength: 3000
Component 2: Cb component: Quantization table 1, Sampling factors 1 horiz/1 vert
Component 1: Y component: Quantization table 0, Sampling factors 2 horiz/2 vert
Image Height: 3000 pixels
X Resolution: 300 dots
Original Transmission Reference: 53616c7465645f5f2368da84ca932841b336ac1a49edb1a93fae938b8db2cb3ec9cc4dc28d7383f1
Image Width: 4000 pixels
IPTC-NAA record: 92 bytes binary data
Component 3: Cr component: Quantization table 1, Sampling factors 1 horiz/1 vert
tiff:BitsPerSample: 8
Application Record Version: 4
tiff:ImageWidth: 4000
Y Resolution: 300 dots다음은 mp4 파일에서 콘텐츠와 메타 데이터를 추출하는 프로그램입니다.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.mp4.MP4Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class Mp4Parse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.mp4"));
ParseContext pcontext = new ParseContext();
//Html parser
MP4Parser MP4Parser = new MP4Parser();
MP4Parser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document: :" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}위 코드를 JpegParse.java로 저장하고 다음 명령을 사용하여 명령 프롬프트에서 컴파일하십시오.
javac Mp4Parse.java
java Mp4Parse다음은 Example.mp4 파일의 속성 스냅 샷입니다.

위의 프로그램을 실행하면 다음과 같은 출력이 나타납니다.
Output −
Contents of the document:
Metadata of the document:
dcterms:modified: 2014-01-06T12:10:27Z
meta:creation-date: 1904-01-01T00:00:00Z
meta:save-date: 2014-01-06T12:10:27Z
Last-Modified: 2014-01-06T12:10:27Z
dcterms:created: 1904-01-01T00:00:00Z
date: 2014-01-06T12:10:27Z
tiff:ImageLength: 360
modified: 2014-01-06T12:10:27Z
Creation-Date: 1904-01-01T00:00:00Z
tiff:ImageWidth: 640
Content-Type: video/mp4
Last-Save-Date: 2014-01-06T12:10:27Z다음은 mp3 파일에서 콘텐츠와 메타 데이터를 추출하는 프로그램입니다.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.mp3.LyricsHandler;
import org.apache.tika.parser.mp3.Mp3Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class Mp3Parse {
public static void main(final String[] args) throws Exception, IOException, SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.mp3"));
ParseContext pcontext = new ParseContext();
//Mp3 parser
Mp3Parser Mp3Parser = new Mp3Parser();
Mp3Parser.parse(inputstream, handler, metadata, pcontext);
LyricsHandler lyrics = new LyricsHandler(inputstream,handler);
while(lyrics.hasLyrics()) {
System.out.println(lyrics.toString());
}
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}위 코드를 다른 이름으로 저장 JpegParse.java, 다음 명령을 사용하여 명령 프롬프트에서 컴파일하십시오-
javac Mp3Parse.java
java Mp3ParseExample.mp3 파일에는 다음과 같은 속성이 있습니다.
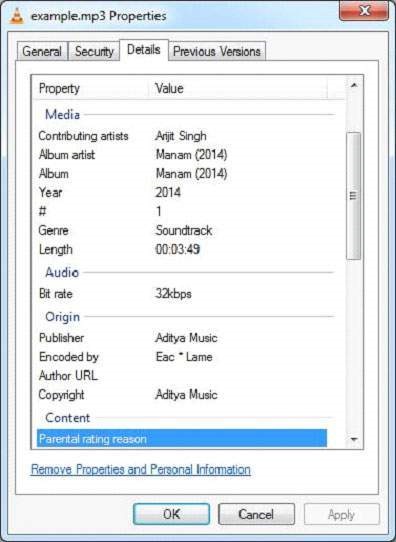
프로그램을 실행하면 다음과 같은 출력이 나타납니다. 주어진 파일에 가사가있는 경우 애플리케이션은 출력과 함께이를 캡처하고 표시합니다.
Output −
Contents of the document:
Kanulanu Thaake
Arijit Singh
Manam (2014), track 01/06
2014
Soundtrack
30171.65
eng -
DRGM
Arijit Singh
Manam (2014), track 01/06
2014
Soundtrack
30171.65
eng -
DRGM
Metadata of the document:
xmpDM:releaseDate: 2014
xmpDM:duration: 30171.650390625
xmpDM:audioChannelType: Stereo
dc:creator: Arijit Singh
xmpDM:album: Manam (2014)
Author: Arijit Singh
xmpDM:artist: Arijit Singh
channels: 2
xmpDM:audioSampleRate: 44100
xmpDM:logComment: eng -
DRGM
xmpDM:trackNumber: 01/06
version: MPEG 3 Layer III Version 1
creator: Arijit Singh
xmpDM:composer: Music : Anoop Rubens | Lyrics : Vanamali
xmpDM:audioCompressor: MP3
title: Kanulanu Thaake
samplerate: 44100
meta:author: Arijit Singh
xmpDM:genre: Soundtrack
Content-Type: audio/mpeg
xmpDM:albumArtist: Manam (2014)
dc:title: Kanulanu Thaake