Apache MXNet - pakiety Python
W tym rozdziale dowiemy się o pakietach Pythona dostępnych w Apache MXNet.
Ważne pakiety MXNet Python
MXNet ma następujące ważne pakiety Pythona, które będziemy omawiać jeden po drugim -
Autograd (automatyczne różnicowanie)
NDArray
KVStore
Gluon
Visualization
Najpierw zacznijmy od Autograd Pakiet Pythona dla Apache MXNet.
Autograd
Autograd oznacza automatic differentiationsłuży do wstecznej propagacji gradientów z miernika strat z powrotem do każdego z parametrów. Wraz z wsteczną propagacją wykorzystuje dynamiczne podejście programistyczne do wydajnego obliczania gradientów. Nazywa się to również automatycznym różnicowaniem w trybie odwrotnym. Technika ta jest bardzo skuteczna w sytuacjach „fan-in”, w których wiele parametrów wpływa na jeden miernik strat.
Co to są gradienty?
Gradienty są podstawą procesu uczenia sieci neuronowej. Zasadniczo mówią nam, jak zmienić parametry sieci, aby poprawić jej wydajność.
Jak wiemy, sieci neuronowe (NN) składają się z operatorów, takich jak sumy, iloczyn, zwoje, itp. Operatory te do obliczeń wykorzystują takie parametry, jak wagi w jądrach splotów. Powinniśmy być zmuszeni znaleźć optymalne wartości dla tych parametrów, a gradienty wskazują nam drogę i prowadzą do rozwiązania.
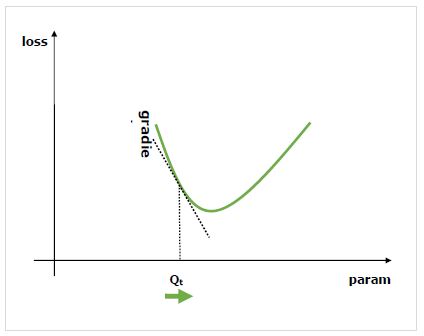
Interesuje nas wpływ zmiany parametru na wydajność sieci, a gradienty mówią nam, o ile dana zmienna rośnie lub maleje, gdy zmieniamy zmienną, od której zależy. Wydajność jest zwykle definiowana za pomocą miernika strat, który staramy się zminimalizować. Na przykład w przypadku regresji możemy spróbować zminimalizowaćL2 strata między naszymi przewidywaniami a dokładną wartością, podczas gdy w przypadku klasyfikacji możemy zminimalizować cross-entropy loss.
Po obliczeniu gradientu każdego parametru w odniesieniu do straty możemy użyć optymalizatora, takiego jak stochastyczne zejście gradientowe.
Jak obliczyć gradienty?
Mamy następujące opcje obliczania gradientów -
Symbolic Differentiation- Pierwsza opcja to Zróżnicowanie symboliczne, które oblicza formuły dla każdego gradientu. Wadą tej metody jest to, że szybko prowadzi ona do niewiarygodnie długich formuł, ponieważ sieć pogłębia się, a operatorzy stają się bardziej złożeni.
Finite Differencing- Inną opcją jest użycie różnicowania skończonego, które wypróbuje niewielkie różnice w każdym parametrze i zobacz, jak reaguje miernik strat. Wadą tej metody jest to, że byłaby kosztowna obliczeniowo i może mieć słabą dokładność numeryczną.
Automatic differentiation- Rozwiązaniem wad powyższych metod jest użycie automatycznego różnicowania do wstecznej propagacji gradientów z miernika strat z powrotem do każdego z parametrów. Propagacja umożliwia nam dynamiczne podejście programistyczne do wydajnego obliczania gradientów. Ta metoda jest również nazywana automatycznym różnicowaniem w trybie odwrotnym.
Automatyczne różnicowanie (autograd)
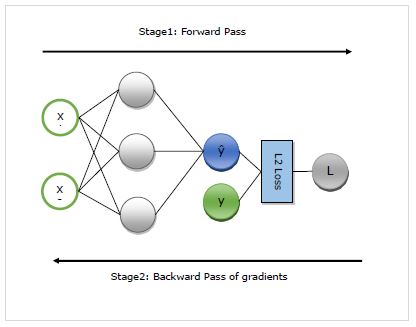
Tutaj szczegółowo zrozumiemy działanie autogradu. Zasadniczo działa w dwóch etapach -
Stage 1 - Ten etap się nazywa ‘Forward Pass’treningu. Jak sama nazwa wskazuje, na tym etapie tworzy zapis operatora wykorzystywanego przez sieć do prognozowania i obliczania miernika strat.
Stage 2 - Ten etap się nazywa ‘Backward Pass’treningu. Jak sama nazwa wskazuje, na tym etapie działa wstecz na tym rekordzie. Cofając się, ocenia częściowe pochodne każdego operatora, aż do parametru sieci.
Zalety autogradu
Oto zalety korzystania z automatycznego różnicowania (autograd) -
Flexible- Elastyczność, jaką daje nam przy definiowaniu naszej sieci, jest jedną z ogromnych zalet korzystania z autogradu. Możemy zmieniać operacje w każdej iteracji. Nazywa się to grafami dynamicznymi, które są znacznie bardziej złożone do implementacji w strukturach wymagających grafu statycznego. Autograd, nawet w takich przypadkach, nadal będzie w stanie poprawnie odwrócić gradienty.
Automatic- Autograd jest automatyczny, tzn. Załatwia za Ciebie zawiłości procedury wstecznej propagacji. Musimy tylko określić, jakie gradienty chcemy obliczyć.
Efficient - Autogard bardzo sprawnie oblicza gradienty.
Can use native Python control flow operators- Możemy użyć natywnych operatorów przepływu sterowania w Pythonie, takich jak if condition i while loop. Autograd nadal będzie w stanie efektywnie i poprawnie odwracać gradienty.
Korzystanie z autograd w MXNet Gluon
Tutaj, na przykładzie, zobaczymy, jak możemy wykorzystać autograd w MXNet Gluon.
Przykład implementacji
W poniższym przykładzie zaimplementujemy model regresji mający dwie warstwy. Po wdrożeniu za pomocą programu autograd automatycznie obliczymy gradient ubytku w odniesieniu do każdego z parametrów wagi -
Najpierw zaimportuj autogrard i inne wymagane pakiety w następujący sposób -
from mxnet import autograd
import mxnet as mx
from mxnet.gluon.nn import HybridSequential, Dense
from mxnet.gluon.loss import L2LossTeraz musimy zdefiniować sieć w następujący sposób -
N_net = HybridSequential()
N_net.add(Dense(units=3))
N_net.add(Dense(units=1))
N_net.initialize()Teraz musimy zdefiniować stratę w następujący sposób -
loss_function = L2Loss()Następnie musimy utworzyć fikcyjne dane w następujący sposób -
x = mx.nd.array([[0.5, 0.9]])
y = mx.nd.array([[1.5]])Teraz jesteśmy gotowi do pierwszego przejścia przez sieć. Chcemy, aby autograd zapisywał wykres obliczeniowy, abyśmy mogli obliczyć gradienty. W tym celu musimy uruchomić kod sieciowy w zakresieautograd.record kontekst w następujący sposób -
with autograd.record():
y_hat = N_net(x)
loss = loss_function(y_hat, y)Teraz jesteśmy gotowi na przejście wstecz, które zaczynamy od wywołania metody wstecznej na ilości będącej przedmiotem zainteresowania. Wartością interesującą w naszym przykładzie jest strata, ponieważ próbujemy obliczyć gradient strat w odniesieniu do parametrów -
loss.backward()Teraz mamy gradienty dla każdego parametru sieci, które będą używane przez optymalizator do aktualizacji wartości parametru w celu poprawy wydajności. Sprawdźmy gradienty pierwszej warstwy w następujący sposób -
N_net[0].weight.grad()Output
Wynik jest następujący -
[[-0.00470527 -0.00846948]
[-0.03640365 -0.06552657]
[ 0.00800354 0.01440637]]
<NDArray 3x2 @cpu(0)>Kompletny przykład wdrożenia
Poniżej podano pełny przykład realizacji.
from mxnet import autograd
import mxnet as mx
from mxnet.gluon.nn import HybridSequential, Dense
from mxnet.gluon.loss import L2Loss
N_net = HybridSequential()
N_net.add(Dense(units=3))
N_net.add(Dense(units=1))
N_net.initialize()
loss_function = L2Loss()
x = mx.nd.array([[0.5, 0.9]])
y = mx.nd.array([[1.5]])
with autograd.record():
y_hat = N_net(x)
loss = loss_function(y_hat, y)
loss.backward()
N_net[0].weight.grad()