Apache Presto - szybki przewodnik
Analityka danych to proces analizy surowych danych w celu zebrania odpowiednich informacji w celu lepszego podejmowania decyzji. Jest używany przede wszystkim w wielu organizacjach do podejmowania decyzji biznesowych. Cóż, analiza dużych zbiorów danych obejmuje dużą ilość danych, a proces ten jest dość złożony, dlatego firmy stosują różne strategie.
Na przykład Facebook jest jedną z wiodących firm zajmujących się hurtowniami danych i największą na świecie. Dane hurtowni Facebooka są przechowywane w Hadoop na potrzeby obliczeń na dużą skalę. Później, gdy dane w hurtowni rozrosły się do petabajtów, zdecydowali się opracować nowy system z niewielkimi opóźnieniami. W roku 2012 członkowie zespołu Facebooka zaprojektowali“Presto” do interaktywnej analizy zapytań, która działałaby szybko nawet z petabajtami danych.
Co to jest Apache Presto?
Apache Presto to rozproszony silnik równoległego wykonywania zapytań, zoptymalizowany pod kątem małych opóźnień i interaktywnej analizy zapytań. Presto z łatwością wykonuje zapytania i skaluje bez przestojów, nawet z gigabajtów do petabajtów.
Pojedyncze zapytanie Presto może przetwarzać dane z wielu źródeł, takich jak HDFS, MySQL, Cassandra, Hive i wiele innych źródeł danych. Presto jest zbudowany w Javie i łatwo integruje się z innymi komponentami infrastruktury danych. Presto to potężne narzędzie, które wdrażają wiodące firmy, takie jak Airbnb, DropBox, Groupon i Netflix.
Presto - funkcje
Presto zawiera następujące funkcje -
- Prosta i rozszerzalna architektura.
- Wtykowe złącza - Presto obsługuje wtykowe złącza w celu dostarczania metadanych i danych do zapytań.
- Wykonywanie potokowe - pozwala uniknąć niepotrzebnych opóźnień we / wy.
- Funkcje zdefiniowane przez użytkownika - analitycy mogą tworzyć niestandardowe funkcje zdefiniowane przez użytkownika w celu łatwej migracji.
- Wektoryzowane przetwarzanie kolumnowe.
Presto - korzyści
Oto lista korzyści, które oferuje Apache Presto -
- Specjalistyczne operacje SQL
- Łatwy w instalacji i debugowaniu
- Prosta abstrakcja pamięci masowej
- Szybko skaluje dane w petabajtach z małym opóźnieniem
Presto - Aplikacje
Presto obsługuje większość dzisiejszych najlepszych aplikacji przemysłowych. Rzućmy okiem na niektóre z godnych uwagi aplikacji.
Facebook- Facebook zbudował Presto na potrzeby analizy danych. Presto z łatwością skaluje dużą prędkość danych.
Teradata- Teradata zapewnia kompleksowe rozwiązania w zakresie analityki Big Data i hurtowni danych. Wkład Teradata w Presto ułatwia większej liczbie firm realizację wszystkich potrzeb analitycznych.
Airbnb- Presto jest integralną częścią infrastruktury danych Airbnb. Cóż, setki pracowników każdego dnia wykonują zapytania dotyczące tej technologii.
Dlaczego Presto?
Presto obsługuje standardowy ANSI SQL, co bardzo ułatwia pracę analitykom danych i programistom. Chociaż jest zbudowany w Javie, pozwala uniknąć typowych problemów z kodem Java związanych z alokacją pamięci i usuwaniem elementów bezużytecznych. Presto ma architekturę złącza, która jest przyjazna dla Hadoop. Umożliwia łatwe podłączanie systemów plików.
Presto działa na wielu dystrybucjach Hadoop. Ponadto Presto może nawiązać kontakt z platformą Hadoop, aby wysyłać zapytania do Cassandry, relacyjnych baz danych lub innych magazynów danych. Ta wieloplatformowa funkcja analityczna umożliwia użytkownikom Presto wydobycie maksymalnej wartości biznesowej od gigabajtów do petabajtów danych.
Architektura Presto jest prawie podobna do klasycznej architektury DBMS MPP (masowo równoległe przetwarzanie). Poniższy diagram ilustruje architekturę Presto.

Powyższy schemat składa się z różnych elementów. Poniższa tabela szczegółowo opisuje każdy z elementów.
| S.Nr | Opis podzespołu |
|---|---|
| 1. | Client Klient (Presto CLI) przesyła instrukcje SQL do koordynatora w celu uzyskania wyniku. |
| 2. | Coordinator Koordynator to główny demon. Koordynator najpierw analizuje zapytania SQL, a następnie analizuje i planuje wykonanie zapytania. Harmonogram wykonuje potok, przypisuje pracę do najbliższego węzła i monitoruje postęp. |
| 3. | Connector Wtyczki pamięci masowej nazywane są łącznikami. Hive, HBase, MySQL, Cassandra i wiele innych działają jako łączniki; w przeciwnym razie możesz również zaimplementować niestandardowy. Łącznik udostępnia metadane i dane do zapytań. Koordynator używa łącznika, aby uzyskać metadane do tworzenia planu kwerend. |
| 4. | Worker Koordynator przydziela zadania do węzłów roboczych. Pracownicy pobierają rzeczywiste dane z łącznika. Na koniec węzeł roboczy dostarcza klientowi wynik. |
Presto - przepływ pracy
Presto to system rozproszony działający w klastrze węzłów. Rozproszony silnik zapytań Presto jest zoptymalizowany pod kątem interaktywnej analizy i obsługuje standard ANSI SQL, w tym złożone zapytania, agregacje, sprzężenia i funkcje okien. Architektura Presto jest prosta i rozszerzalna. Klient Presto (CLI) przesyła instrukcje SQL do głównego koordynatora demona.
Harmonogram łączy się za pośrednictwem potoku wykonywania. Planista przydziela pracę do węzłów, które są najbliżej danych i monitoruje postęp. Koordynator przydziela zadanie do wielu węzłów roboczych, a na końcu węzeł roboczy dostarcza wynik z powrotem do klienta. Klient pobiera dane z procesu wyjściowego. Elastyczność to kluczowy projekt. Wtykowe łączniki, takie jak Hive, HBase, MySQL itp., Zapewniają metadane i dane do zapytań. Presto zostało zaprojektowane z „prostą abstrakcją pamięci”, która ułatwia udostępnianie możliwości zapytań SQL w odniesieniu do różnych rodzajów źródeł danych.
Model wykonania
Presto obsługuje niestandardowy mechanizm zapytań i wykonywania z operatorami zaprojektowanymi do obsługi semantyki SQL. Oprócz ulepszonego planowania, całe przetwarzanie odbywa się w pamięci i jest przesyłane potokowo przez sieć między różnymi etapami. Pozwala to uniknąć niepotrzebnych opóźnień we / wy.
W tym rozdziale wyjaśniono, jak zainstalować Presto na komputerze. Przejdźmy przez podstawowe wymagania Presto,
- Linux lub Mac OS
- Java w wersji 8
Teraz kontynuujmy następujące kroki, aby zainstalować Presto na twoim komputerze.
Weryfikacja instalacji Java
Mamy nadzieję, że już zainstalowałeś Javę w wersji 8 na swoim komputerze, więc po prostu zweryfikuj ją za pomocą następującego polecenia.
$ java -versionJeśli Java została pomyślnie zainstalowana na twoim komputerze, możesz zobaczyć wersję zainstalowanej Javy. Jeśli Java nie jest zainstalowana, wykonaj kolejne kroki, aby zainstalować Javę 8 na swoim komputerze.
Pobierz JDK. Pobierz najnowszą wersję JDK, odwiedzając poniższe łącze.
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Najnowsza wersja to JDK 8u 92, a plik to „jdk-8u92-linux-x64.tar.gz”. Pobierz plik na swój komputer.
Następnie wypakuj pliki i przejdź do określonego katalogu.
Następnie ustaw alternatywy dla języka Java. Wreszcie Java zostanie zainstalowana na twoim komputerze.
Instalacja Apache Presto
Pobierz najnowszą wersję Presto, odwiedzając poniższe łącze,
https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.149/
Teraz najnowsza wersja „presto-server-0.149.tar.gz” zostanie pobrana na twój komputer.
Wyodrębnij pliki tar
Wyodrębnij plik tar plik za pomocą następującego polecenia -
$ tar -zxf presto-server-0.149.tar.gz
$ cd presto-server-0.149Ustawienia konfiguracji
Utwórz katalog „data”
Utwórz katalog danych poza katalogiem instalacyjnym, który będzie używany do przechowywania dzienników, metadanych itp., Aby można go było łatwo zachować podczas aktualizacji Presto. Jest definiowany za pomocą następującego kodu -
$ cd
$ mkdir dataAby wyświetlić ścieżkę, w której się znajduje, użyj polecenia „pwd”. Ta lokalizacja zostanie przypisana w następnym pliku node.properties.
Utwórz katalog „etc”
Utwórz katalog etc w katalogu instalacyjnym Presto, używając następującego kodu -
$ cd presto-server-0.149
$ mkdir etcW tym katalogu będą przechowywane pliki konfiguracyjne. Utwórzmy każdy plik po kolei.
Właściwości węzła
Plik właściwości węzła Presto zawiera konfigurację środowiska specyficzną dla każdego węzła. Jest tworzony w katalogu etc (etc / node.properties) przy użyciu następującego kodu -
$ cd etc
$ vi node.properties
node.environment = production
node.id = ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir = /Users/../workspace/PrestoPo wprowadzeniu wszystkich zmian zapisz plik i zamknij terminal. Tutajnode.data jest ścieżką lokalizacji wyżej utworzonego katalogu danych. node.id reprezentuje unikalny identyfikator każdego węzła.
Konfiguracja JVM
Utwórz plik „jvm.config” w katalogu etc (etc / jvm.config). Ten plik zawiera listę opcji wiersza poleceń używanych do uruchamiania wirtualnej maszyny języka Java.
$ cd etc
$ vi jvm.config
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize = 32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:OnOutOfMemoryError = kill -9 %pPo wprowadzeniu wszystkich zmian zapisz plik i zamknij terminal.
Właściwości konfiguracji
Utwórz plik „config.properties” w katalogu etc (etc / config.properties). Ten plik zawiera konfigurację serwera Presto. Jeśli konfigurujesz pojedynczą maszynę do testowania, serwer Presto może działać tylko jako proces koordynacji zdefiniowany przy użyciu następującego kodu -
$ cd etc
$ vi config.properties
coordinator = true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = http://localhost:8080Tutaj,
coordinator - węzeł główny.
node-scheduler.include-coordinator - Umożliwia planowanie pracy koordynatora.
http-server.http.port - Określa port dla serwera HTTP.
query.max-memory=5GB - Maksymalna ilość pamięci rozproszonej.
query.max-memory-per-node=1GB - Maksymalna ilość pamięci na węzeł.
discovery-server.enabled - Presto używa usługi Discovery, aby znaleźć wszystkie węzły w klastrze.
discovery.uri - URI do serwera Discovery.
Jeśli konfigurujesz serwer Presto na wielu komputerach, Presto będzie działał zarówno jako proces koordynacyjny, jak i roboczy. Użyj tego ustawienia konfiguracji, aby przetestować serwer Presto na wielu komputerach.
Konfiguracja dla koordynatora
$ cd etc
$ vi config.properties
coordinator = true
node-scheduler.include-coordinator = false
http-server.http.port = 8080
query.max-memory = 50GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = http://localhost:8080Konfiguracja dla pracownika
$ cd etc
$ vi config.properties
coordinator = false
http-server.http.port = 8080
query.max-memory = 50GB
query.max-memory-per-node = 1GB
discovery.uri = http://localhost:8080Właściwości dziennika
Utwórz plik „log.properties” w katalogu etc (etc / log.properties). Ten plik zawiera minimalny poziom dziennika dla nazwanych hierarchii programów rejestrujących. Jest definiowany za pomocą następującego kodu -
$ cd etc
$ vi log.properties
com.facebook.presto = INFOZapisz plik i zamknij terminal. Tutaj używane są cztery poziomy dziennika, takie jak DEBUG, INFO, WARN i ERROR. Domyślny poziom dziennika to INFO.
Właściwości katalogu
Utwórz katalog „katalog” w katalogu etc (etc / catalog). Będzie to używane do montowania danych. Na przykład createetc/catalog/jmx.properties z następującą zawartością, aby zamontować plik jmx connector jako katalog jmx -
$ cd etc
$ mkdir catalog $ cd catalog
$ vi jmx.properties
connector.name = jmxUruchom Presto
Presto można uruchomić za pomocą następującego polecenia,
$ bin/launcher startWtedy zobaczysz odpowiedź podobną do tej,
Started as 840Uruchom Presto
Aby uruchomić serwer Presto, użyj następującego polecenia -
$ bin/launcher runPo pomyślnym uruchomieniu serwera Presto, możesz znaleźć pliki dziennika w katalogu „var / log”.
launcher.log - Ten dziennik jest tworzony przez program uruchamiający i jest połączony ze strumieniami stdout i stderr serwera.
server.log - To jest główny plik dziennika używany przez Presto.
http-request.log - żądanie HTTP odebrane przez serwer.
Do tej pory pomyślnie zainstalowałeś ustawienia konfiguracyjne Presto na swoim komputerze. Kontynuujmy kroki instalacji Presto CLI.
Zainstaluj Presto CLI
Presto CLI zapewnia opartą na terminalu interaktywną powłokę do uruchamiania zapytań.
Pobierz Presto CLI, odwiedzając poniższe łącze,
https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.149/
Teraz na twoim komputerze zostanie zainstalowany plik „presto-cli-0.149-executable.jar”.
Uruchom CLI
Po pobraniu presto-cli skopiuj go do lokalizacji, z której chcesz go uruchomić. Ta lokalizacja może być dowolnym węzłem, który ma dostęp sieciowy do koordynatora. Najpierw zmień nazwę pliku Jar na Presto. Następnie uczyń go wykonywalnym za pomocąchmod + x polecenie przy użyciu następującego kodu -
$ mv presto-cli-0.149-executable.jar presto
$ chmod +x prestoTeraz uruchom CLI za pomocą następującego polecenia,
./presto --server localhost:8080 --catalog jmx --schema default
Here jmx(Java Management Extension) refers to catalog and default referes to schema.Zobaczysz następującą odpowiedź,
presto:default>Teraz wpisz polecenie „jps” na swoim terminalu, a zobaczysz działające demony.
Zatrzymaj Presto
Po wykonaniu wszystkich uruchomień możesz zatrzymać serwer presto za pomocą następującego polecenia -
$ bin/launcher stopW tym rozdziale omówiono ustawienia konfiguracji Presto.
Presto Verifier
Weryfikator Presto może być używany do testowania Presto względem innej bazy danych (takiej jak MySQL) lub do testowania dwóch klastrów Presto względem siebie.
Utwórz bazę danych w MySQL
Otwórz serwer MySQL i utwórz bazę danych za pomocą następującego polecenia.
create database testTeraz utworzyłeś „testową” bazę danych na serwerze. Utwórz tabelę i załaduj ją za pomocą następującego zapytania.
CREATE TABLE verifier_queries(
id INT NOT NULL AUTO_INCREMENT,
suite VARCHAR(256) NOT NULL,
name VARCHAR(256),
test_catalog VARCHAR(256) NOT NULL,
test_schema VARCHAR(256) NOT NULL,
test_prequeries TEXT,
test_query TEXT NOT NULL,
test_postqueries TEXT,
test_username VARCHAR(256) NOT NULL default 'verifier-test',
test_password VARCHAR(256),
control_catalog VARCHAR(256) NOT NULL,
control_schema VARCHAR(256) NOT NULL,
control_prequeries TEXT,
control_query TEXT NOT NULL,
control_postqueries TEXT,
control_username VARCHAR(256) NOT NULL default 'verifier-test',
control_password VARCHAR(256),
session_properties_json TEXT,
PRIMARY KEY (id)
);Dodaj ustawienia konfiguracji
Utwórz plik właściwości, aby skonfigurować weryfikator -
$ vi config.properties
suite = mysuite
query-database = jdbc:mysql://localhost:3306/tutorials?user=root&password=pwd
control.gateway = jdbc:presto://localhost:8080
test.gateway = jdbc:presto://localhost:8080
thread-count = 1Tutaj, w query-database wprowadź następujące dane - nazwę bazy danych mysql, nazwę użytkownika i hasło.
Pobierz plik JAR
Pobierz plik jar weryfikatora Presto, odwiedzając poniższy link,
https://repo1.maven.org/maven2/com/facebook/presto/presto-verifier/0.149/
Teraz wersja “presto-verifier-0.149-executable.jar” jest pobierany na twój komputer.
Wykonaj JAR
Uruchom plik JAR za pomocą następującego polecenia,
$ mv presto-verifier-0.149-executable.jar verifier
$ chmod+x verifierUruchom weryfikator
Uruchom weryfikator za pomocą następującego polecenia,
$ ./verifier config.propertiesUtwórz tabelę
Stwórzmy prostą tabelę w formacie “test” baza danych za pomocą następującego zapytania.
create table product(id int not null, name varchar(50))Wypełnij tabelę
Po utworzeniu tabeli wstaw dwa rekordy za pomocą następującego zapytania,
insert into product values(1,’Phone')
insert into product values(2,’Television’)Uruchom zapytanie weryfikatora
Wykonaj następujące przykładowe zapytanie w terminalu weryfikatora (./verifier config.propeties), aby sprawdzić wynik weryfikatora.
Przykładowe zapytanie
insert into verifier_queries (suite, test_catalog, test_schema, test_query,
control_catalog, control_schema, control_query) values
('mysuite', 'mysql', 'default', 'select * from mysql.test.product',
'mysql', 'default', 'select * from mysql.test.product');Tutaj, select * from mysql.test.product zapytanie dotyczy katalogu mysql, test to nazwa bazy danych i productto nazwa tabeli. W ten sposób możesz uzyskać dostęp do łącznika mysql za pomocą serwera Presto.
Tutaj dwa takie same zapytania wybierające są testowane ze sobą, aby zobaczyć wydajność. Podobnie możesz uruchomić inne zapytania, aby przetestować wyniki wydajności. Możesz także podłączyć dwa klastry Presto, aby sprawdzić wyniki wydajności.
W tym rozdziale omówimy narzędzia administracyjne używane w Presto. Zacznijmy od interfejsu internetowego Presto.
Interfejs sieciowy
Presto zapewnia interfejs sieciowy do monitorowania zapytań i zarządzania nimi. Można uzyskać do niego dostęp z numeru portu określonego we właściwościach konfiguracyjnych koordynatora.
Uruchom serwer Presto i Presto CLI. Następnie możesz uzyskać dostęp do interfejsu internetowego z następującego adresu URL -http://localhost:8080/
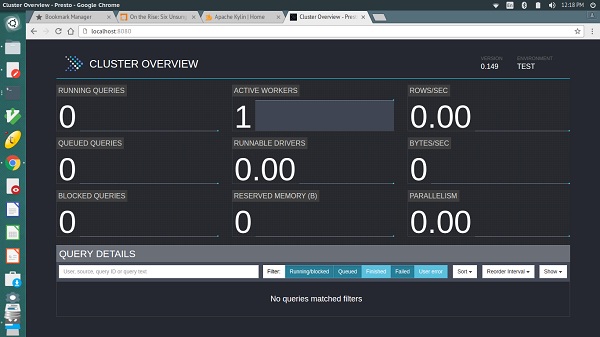
Wynik będzie podobny do powyższego ekranu.
Tutaj strona główna zawiera listę zapytań wraz z informacjami, takimi jak unikalny identyfikator zapytania, tekst zapytania, stan zapytania, procent ukończenia, nazwa użytkownika i źródło, z którego pochodzi to zapytanie. Najnowsze zapytania są uruchamiane jako pierwsze, a następnie zapytania zakończone lub nieukończone są wyświetlane na dole.
Dostrajanie wydajności w Presto
Jeśli w klastrze Presto występują jakiekolwiek problemy związane z wydajnością, zmień domyślne ustawienia konfiguracji na następujące ustawienia.
Właściwości konfiguracji
task. info -refresh-max-wait - Zmniejsza obciążenie pracą koordynatora.
task.max-worker-threads - Dzieli proces i przypisuje do każdego węzła roboczego.
distributed-joins-enabled - Sprzężenia rozproszone oparte na skrótach.
node-scheduler.network-topology - Ustawia topologię sieci na harmonogram.
Ustawienia JVM
Zmień domyślne ustawienia maszyny JVM na następujące ustawienia. Będzie to pomocne przy diagnozowaniu problemów z usuwaniem elementów bezużytecznych.
-XX:+PrintGCApplicationConcurrentTime
-XX:+PrintGCApplicationStoppedTime
-XX:+PrintGCCause
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-XX:+PrintGCDetails
-XX:+PrintReferenceGC
-XX:+PrintClassHistogramAfterFullGC
-XX:+PrintClassHistogramBeforeFullGC
-XX:PrintFLSStatistics = 2
-XX:+PrintAdaptiveSizePolicy
-XX:+PrintSafepointStatistics
-XX:PrintSafepointStatisticsCount = 1W tym rozdziale omówimy, jak tworzyć i wykonywać zapytania w Presto. Przejdźmy przez obsługiwane przez Presto podstawowe typy danych.
Podstawowe typy danych
W poniższej tabeli opisano podstawowe typy danych Presto.
| S.Nr | Typ danych i opis |
|---|---|
| 1. | VARCHAR Dane znakowe o zmiennej długości |
| 2. | BIGINT 64-bitowa liczba całkowita ze znakiem |
| 3. | DOUBLE 64-bitowa zmiennoprzecinkowa wartość podwójnej precyzji |
| 4. | DECIMAL Liczba dziesiętna o stałej precyzji. Na przykład DECIMAL (10,3) - 10 to precyzja, tj. Całkowita liczba cyfr, a 3 to wartość skali reprezentowana jako punkt ułamkowy. Skala jest opcjonalna, a wartość domyślna to 0 |
| 5. | BOOLEAN Wartości logiczne prawda i fałsz |
| 6. | VARBINARY Dane binarne o zmiennej długości |
| 7. | JSON Dane JSON |
| 8. | DATE Typ danych daty reprezentowany jako rok-miesiąc-dzień |
| 9. | TIME, TIMESTAMP, TIMESTAMP with TIME ZONE TIME - pora dnia (godzina-min-sek-milisekunda) TIMESTAMP - data i godzina TIMESTAMP z TIME ZONE - Data i godzina ze strefą czasową od wartości |
| 10. | INTERVAL Rozciągaj lub rozszerzaj typy danych daty i godziny |
| 11. | ARRAY Tablica danego typu komponentu. Na przykład ARRAY [5,7] |
| 12. | MAP Mapa między podanymi typami komponentów. Na przykład MAP (ARRAY ['jeden', 'dwa'], ARRAY [5,7]) |
| 13. | ROW Struktura wierszy składająca się z nazwanych pól |
Presto - operatorzy
Operatory Presto są wymienione w poniższej tabeli.
| S.Nr | Operator i opis |
|---|---|
| 1. | Operator arytmetyczny Presto obsługuje operatory arytmetyczne, takie jak +, -, *, /,% |
| 2. | Operator relacyjny <,>, <=,> =, =, <> |
| 3. | Operator logiczny I LUB NIE |
| 4. | Operator zakresu Operator zakresu służy do testowania wartości w określonym zakresie. Presto obsługuje POMIĘDZY, JEST ZEROWE, NIE JEST ZEROWE, WIELKIE i NAJMNIEJ |
| 5. | Operator dziesiętny Binarny operator arytmetyczny dziesiętny wykonuje binarną operację arytmetyczną dla typu dziesiętnego Jednoargumentowy operator dziesiętny - operator przeprowadza negację |
| 6. | Operator łańcuchowy Plik ‘||’ operator wykonuje konkatenację ciągów |
| 7. | Operator daty i czasu Wykonuje arytmetyczne dodawanie i odejmowanie typów danych typu data i godzina |
| 8. | Operator tablicy Operator indeksu [] - dostęp do elementu tablicy Operator konkatenacji || - konkatenuje tablicę z tablicą lub elementem tego samego typu |
| 9. | Operator mapy Map subscript operator [] - pobranie wartości odpowiadającej danemu kluczowi z mapy |
Do tej pory omawialiśmy uruchamianie kilku prostych podstawowych zapytań w Presto. W tym rozdziale omówimy ważne funkcje SQL.
Funkcje matematyczne
Funkcje matematyczne działają na formułach matematycznych. Poniższa tabela szczegółowo opisuje listę funkcji.
| S.No. | Opis funkcji |
|---|---|
| 1. | abs (x) Zwraca wartość bezwzględną x |
| 2. | cbrt (x) Zwraca pierwiastek sześcienny z x |
| 3. | sufit (x) Zwraca x wartość zaokrąglona w górę do najbliższej liczby całkowitej |
| 4. | ceil(x) Alias dla sufitu (x) |
| 5. | stopnie (x) Zwraca wartość stopnia dla x |
| 6. | dawny) Zwraca podwójną wartość liczby Eulera |
| 7. | exp(x) Zwraca wartość wykładnika dla liczby Eulera |
| 8. | piętro (x) Zwroty x zaokrąglone w dół do najbliższej liczby całkowitej |
| 9. | from_base(string,radix) Zwraca wartość ciągu interpretowaną jako podstawową liczbę |
| 10. | ln(x) Zwraca logarytm naturalny z x |
| 11. | log2 (x) Zwraca logarytm o podstawie 2 z x |
| 12. | log10(x) Zwraca logarytm o podstawie 10 x |
| 13. | log(x,y) Zwraca podstawę y logarytm x |
| 14. | mod (rzecz., m.) Zwraca moduł (resztę) n podzielony przez m |
| 15. | pi() Zwraca wartość pi. Wynik zostanie zwrócony jako podwójna wartość |
| 16. | moc (x, p) Zwraca potęgę wartości ‘p’ do x wartość |
| 17. | pow(x,p) Alias dla władzy (x, p) |
| 18. | radiany (x) przekształca kąt x w radianach stopni |
| 19. | rand() Alias dla radianów () |
| 20. | losowy() Zwraca wartość pseudolosową |
| 21. | rand(n) Alias dla random () |
| 22. | okrągły (x) Zwraca zaokrągloną wartość x |
| 23. | round(x,d) x wartość zaokrąglona dla ‘d’ miejsca dziesiętne |
| 24. | sign(x) Zwraca funkcję signum x, tj. 0, jeśli argumentem jest 0 1, jeśli argument jest większy niż 0 -1, jeśli argument jest mniejszy niż 0 W przypadku argumentów podwójnych funkcja dodatkowo zwraca - NaN, jeśli argumentem jest NaN 1, jeśli argumentem jest + Nieskończoność -1, jeśli argumentem jest -Infinity |
| 25. | sqrt (x) Zwraca pierwiastek kwadratowy z x |
| 26. | to_base (x; podstawa) Typ zwrotu to łucznik. Wynik jest zwracany jako podstawa dlax |
| 27. | obetnij (x) Obcina wartość dla x |
| 28. | width_bucket (x, bound1, bound2, n) Zwraca numer przedziału x określone granice bound1 i bound2 oraz n liczba segmentów |
| 29. | width_bucket (x, bins) Zwraca numer przedziału x zgodnie z przedziałami określonymi przez przedziały tablicy |
Funkcje trygonometryczne
Argumenty funkcji trygonometrycznych są przedstawiane jako radiany (). Poniższa tabela zawiera listę funkcji.
| S.Nr | Funkcje i opis |
|---|---|
| 1. | acos (x) Zwraca odwrotną wartość cosinusa (x) |
| 2. | asin(x) Zwraca odwrotną wartość sinusa (x) |
| 3. | atan(x) Zwraca odwrotną wartość stycznej (x) |
| 4. | atan2 (y, x) Zwraca odwrotną wartość stycznej (y / x) |
| 5. | cos(x) Zwraca cosinus (x) |
| 6. | cosh (x) Zwraca hiperboliczną wartość cosinusa (x) |
| 7. | sin (x) Zwraca wartość sinusa (x) |
| 8. | tan(x) Zwraca wartość styczną (x) |
| 9. | tanh(x) Zwraca hiperboliczną wartość styczną (x) |
Funkcje bitowe
W poniższej tabeli wymieniono funkcje bitowe.
| S.Nr | Funkcje i opis |
|---|---|
| 1. | bit_count (x, bity) Policz liczbę bitów |
| 2. | bitwise_and (x, y) Wykonaj operację bitową AND na dwóch bitach, x i y |
| 3. | bitwise_or (x, y) Operacja bitowa OR między dwoma bitami x, y |
| 4. | bitwise_not (x) Bitwise Not operacja dla bitu x |
| 5. | bitwise_xor (x, y) Operacja XOR dla bitów x, y |
Funkcje łańcuchowe
Poniższa tabela zawiera listę funkcji ciągów.
| S.Nr | Funkcje i opis |
|---|---|
| 1. | concat (ciąg1, ..., ciągN) Połącz podane ciągi |
| 2. | długość (ciąg) Zwraca długość podanego ciągu |
| 3. | dolny (ciąg) Zwraca format małych liter dla ciągu |
| 4. | górny (ciąg) Zwraca format wielkich liter dla podanego ciągu |
| 5. | lpad (string, size, padstring) Lewe wypełnienie dla danego ciągu |
| 6. | ltrim (ciąg) Usuwa wiodące białe znaki z ciągu |
| 7. | replace (ciąg, szukaj, zamień) Zastępuje wartość ciągu |
| 8. | reverse (ciąg) Odwraca operację wykonaną dla ciągu |
| 9. | rpad (string, size, padstring) Prawe wypełnienie dla danego ciągu |
| 10. | rtrim (ciąg) Usuwa końcowe białe znaki z ciągu |
| 11. | split (ciąg, separator) Dzieli ciąg na separatorze i zwraca tablicę o maksymalnym rozmiarze |
| 12. | split_part (ciąg, separator, indeks) Dzieli ciąg na separatorze i zwraca indeks pola |
| 13. | strpos (ciąg, podciąg) Zwraca pozycję początkową podciągu w ciągu |
| 14. | substr (ciąg, początek) Zwraca podciąg dla podanego ciągu |
| 15. | substr (ciąg, początek, długość) Zwraca podciąg dla podanego ciągu o określonej długości |
| 16. | przycinanie (ciąg) Usuwa początkowy i końcowy biały znak z ciągu |
Funkcje daty i czasu
Poniższa tabela zawiera listę funkcji daty i godziny.
| S.Nr | Funkcje i opis |
|---|---|
| 1. | bieżąca data Zwraca bieżącą datę |
| 2. | Obecny czas Zwraca aktualny czas |
| 3. | current_timestamp Zwraca bieżący znacznik czasu |
| 4. | current_timezone () Zwraca bieżącą strefę czasową |
| 5. | teraz() Zwraca bieżącą datę, sygnaturę czasową ze strefą czasową |
| 6. | czas lokalny Zwraca czas lokalny |
| 7. | localtimestamp Zwraca lokalny znacznik czasu |
Funkcje wyrażeń regularnych
W poniższej tabeli wymieniono funkcje wyrażeń regularnych.
| S.Nr | Funkcje i opis |
|---|---|
| 1. | regexp_extract_all (ciąg, wzorzec) Zwraca ciąg dopasowany przez wyrażenie regularne dla wzorca |
| 2. | regexp_extract_all (ciąg, wzorzec, grupa) Zwraca ciąg dopasowany przez wyrażenie regularne dla wzorca i grupy |
| 3. | regexp_extract (ciąg, wzorzec) Zwraca pierwszy podciąg dopasowany przez wyrażenie regularne dla wzorca |
| 4. | regexp_extract (ciąg, wzorzec, grupa) Zwraca pierwszy podciąg dopasowany przez wyrażenie regularne dla wzorca i grupy |
| 5. | regexp_like (ciąg, wzorzec) Zwraca ciąg pasujący do wzorca. Jeśli zwracany jest ciąg, wartość będzie true, w przeciwnym razie false |
| 6. | regexp_replace (ciąg, wzorzec) Zastępuje wystąpienie ciągu dopasowanego do wyrażenia wzorcem |
| 7. | regexp_replace (ciąg, wzorzec, zamiana) Zastąp wystąpienie ciągu dopasowanego do wyrażenia wzorcem i zamiennikiem |
| 8. | regexp_split (ciąg, wzorzec) Dzieli wyrażenie regularne dla danego wzorca |
Funkcje JSON
W poniższej tabeli wymieniono funkcje JSON.
| S.Nr | Funkcje i opis |
|---|---|
| 1. | json_array_contains (json, wartość) Sprawdź, czy wartość istnieje w tablicy JSON. Jeśli wartość istnieje, zwróci true, w przeciwnym razie false |
| 2. | json_array_get (json_array, indeks) Pobierz element indeksu w tablicy JSON |
| 3. | json_array_length (json) Zwraca długość w tablicy json |
| 4. | json_format (json) Zwraca format struktury JSON |
| 5. | json_parse (ciąg) Analizuje ciąg jako plik json |
| 6. | json_size (json, json_path) Zwraca rozmiar wartości |
Funkcje URL
Poniższa tabela zawiera listę funkcji adresów URL.
| S.Nr | Funkcje i opis |
|---|---|
| 1. | url_extract_host (url) Zwraca hosta adresu URL |
| 2. | url_extract_path (adres URL) Zwraca ścieżkę adresu URL |
| 3. | url_extract_port (adres URL) Zwraca port adresu URL |
| 4. | url_extract_protocol (url) Zwraca protokół adresu URL |
| 5. | url_extract_query (url) Zwraca ciąg zapytania adresu URL |
Funkcje agregujące
W poniższej tabeli wymieniono funkcje agregujące.
| S.Nr | Funkcje i opis |
|---|---|
| 1. | avg(x) Zwraca średnią dla podanej wartości |
| 2. | min (x, n) Zwraca minimalną wartość z dwóch wartości |
| 3. | max (x, n) Zwraca maksymalną wartość z dwóch wartości |
| 4. | suma (x) Zwraca sumę wartości |
| 5. | liczyć(*) Zwraca liczbę wierszy wejściowych |
| 6. | liczyć (x) Zwraca liczbę wartości wejściowych |
| 7. | suma kontrolna (x) Zwraca sumę kontrolną dla x |
| 8. | arbitralny (x) Zwraca dowolną wartość dla x |
Funkcje koloru
Poniższa tabela zawiera listę funkcji koloru.
| S.Nr | Funkcje i opis |
|---|---|
| 1. | bar (x, szerokość) Renderuje pojedynczy pasek przy użyciu rgb low_color i high_color |
| 2. | bar (x, width, low_color, high_color) Renderuje pojedynczy pasek o określonej szerokości |
| 3. | kolor (ciąg) Zwraca wartość koloru dla wprowadzonego ciągu |
| 4. | render (x, kolor) Renderuje wartość x przy użyciu określonego koloru przy użyciu kodów kolorów ANSI |
| 5. | render (b) Akceptuje wartość logiczną b i renderuje zieloną prawdę lub czerwoną fałsz za pomocą kodów kolorów ANSI |
| 6. | rgb(red, green, blue) Zwraca wartość koloru przechwytującą wartość RGB trzech wartości kolorów składowych dostarczonych jako parametry int z zakresu od 0 do 255 |
Funkcje tablicowe
Poniższa tabela zawiera listę funkcji Array.
| S.Nr | Funkcje i opis |
|---|---|
| 1. | tablica_max (x) Znajduje maksymalny element w tablicy |
| 2. | tablica_min (x) Znajduje element min w tablicy |
| 3. | array_sort (x) Sortuje elementy w tablicy |
| 4. | array_remove (x, element) Usuwa określony element z tablicy |
| 5. | concat (x, y) Łączy dwie tablice |
| 6. | zawiera (x, element) Znajduje podane elementy w tablicy. Prawda zostanie zwrócona, jeśli jest obecna, w przeciwnym razie false |
| 7. | array_position (x, element) Znajdź pozycję danego elementu w tablicy |
| 8. | array_intersect (x, y) Wykonuje przecięcie między dwiema tablicami |
| 9. | element_at (tablica, indeks) Zwraca pozycję elementu tablicy |
| 10. | plasterek (x, początek, długość) Tnie elementy tablicy o określonej długości |
Funkcje Teradata
Poniższa tabela zawiera listę funkcji Teradata.
| S.Nr | Funkcje i opis |
|---|---|
| 1. | indeks (ciąg, podciąg) Zwraca indeks ciągu z podanym podciągiem |
| 2. | substring (ciąg, początek) Zwraca podłańcuch podanego ciągu. Tutaj możesz określić indeks początkowy |
| 3. | podciąg (ciąg, początek, długość) Zwraca podciąg podanego ciągu dla określonego indeksu początkowego i długości łańcucha |
Łącznik MySQL służy do wysyłania zapytań do zewnętrznej bazy danych MySQL.
Wymagania wstępne
Instalacja serwera MySQL.
Ustawienia konfiguracji
Mamy nadzieję, że zainstalowałeś serwer mysql na swoim komputerze. Aby włączyć właściwości mysql na serwerze Presto, musisz utworzyć plik“mysql.properties” w “etc/catalog”informator. Wydaj następujące polecenie, aby utworzyć plik mysql.properties.
$ cd etc $ cd catalog
$ vi mysql.properties
connector.name = mysql
connection-url = jdbc:mysql://localhost:3306
connection-user = root
connection-password = pwdZapisz plik i zamknij terminal. W powyższym pliku musisz wpisać swoje hasło mysql w polu hasło połączenia.
Utwórz bazę danych na serwerze MySQL
Otwórz serwer MySQL i utwórz bazę danych za pomocą następującego polecenia.
create database tutorialsUtworzyłeś już bazę danych „tutoriali” na serwerze. Aby włączyć typ bazy danych, użyj polecenia „użyj samouczków” w oknie zapytania.
Utwórz tabelę
Utwórzmy prostą tabelę w bazie danych „tutoriali”.
create table author(auth_id int not null, auth_name varchar(50),topic varchar(100))Wypełnij tabelę
Po utworzeniu tabeli wstaw trzy rekordy, używając następującego zapytania.
insert into author values(1,'Doug Cutting','Hadoop')
insert into author values(2,’James Gosling','java')
insert into author values(3,'Dennis Ritchie’,'C')Wybierz Rekordy
Aby pobrać wszystkie rekordy, wpisz następujące zapytanie.
Pytanie
select * from authorWynik
auth_id auth_name topic
1 Doug Cutting Hadoop
2 James Gosling java
3 Dennis Ritchie CW tej chwili odpytywałeś dane za pomocą serwera MySQL. Połączmy wtyczkę pamięci masowej MySQL z serwerem Presto.
Połącz Presto CLI
Wpisz następujące polecenie, aby podłączyć wtyczkę MySql do Presto CLI.
./presto --server localhost:8080 --catalog mysql --schema tutorialsOtrzymasz następującą odpowiedź.
presto:tutorials>Tutaj “tutorials” odnosi się do schematu na serwerze mysql.
Schematy list
Aby wyświetlić listę wszystkich schematów w mysql, wpisz następujące zapytanie na serwerze Presto.
Pytanie
presto:tutorials> show schemas from mysql;Wynik
Schema
--------------------
information_schema
performance_schema
sys
tutorialsNa podstawie tego wyniku możemy wywnioskować, że pierwsze trzy schematy są zdefiniowane wcześniej, a ostatni jako utworzony samodzielnie.
Lista tabel ze schematu
Następujące zapytanie wyświetla wszystkie tabele w schemacie samouczków.
Pytanie
presto:tutorials> show tables from mysql.tutorials;Wynik
Table
--------
authorStworzyliśmy tylko jedną tabelę w tym schemacie. Jeśli utworzyłeś wiele tabel, wyświetli listę wszystkich tabel.
Opisz tabelę
Aby opisać pola tabeli, wpisz następujące zapytanie.
Pytanie
presto:tutorials> describe mysql.tutorials.author;Wynik
Column | Type | Comment
-----------+--------------+---------
auth_id | integer |
auth_name | varchar(50) |
topic | varchar(100) |Pokaż kolumny z tabeli
Pytanie
presto:tutorials> show columns from mysql.tutorials.author;Wynik
Column | Type | Comment
-----------+--------------+---------
auth_id | integer |
auth_name | varchar(50) |
topic | varchar(100) |Dostęp do rekordów tabeli
Aby pobrać wszystkie rekordy z tabeli mysql, wyślij następujące zapytanie.
Pytanie
presto:tutorials> select * from mysql.tutorials.author;Wynik
auth_id | auth_name | topic
---------+----------------+--------
1 | Doug Cutting | Hadoop
2 | James Gosling | java
3 | Dennis Ritchie | CZ tego wyniku możesz pobrać rekordy serwera mysql w Presto.
Utwórz tabelę, używając jako polecenia
Łącznik MySQL nie obsługuje zapytania tworzenia tabeli, ale możesz utworzyć tabelę za pomocą polecenia.
Pytanie
presto:tutorials> create table mysql.tutorials.sample as
select * from mysql.tutorials.author;Wynik
CREATE TABLE: 3 rowsNie możesz wstawiać wierszy bezpośrednio, ponieważ ten łącznik ma pewne ograniczenia. Nie obsługuje następujących zapytań -
- create
- insert
- update
- delete
- drop
Aby wyświetlić rekordy w nowo utworzonej tabeli, wpisz następujące zapytanie.
Pytanie
presto:tutorials> select * from mysql.tutorials.sample;Wynik
auth_id | auth_name | topic
---------+----------------+--------
1 | Doug Cutting | Hadoop
2 | James Gosling | java
3 | Dennis Ritchie | CJava Management Extensions (JMX) udostępnia informacje o wirtualnej maszynie języka Java i oprogramowaniu działającym w JVM. Łącznik JMX służy do wysyłania zapytań o informacje JMX na serwerze Presto.
Jak już włączyliśmy “jmx.properties” plik w ramach “etc/catalog”informator. Teraz podłącz Perst CLI, aby włączyć wtyczkę JMX.
Presto CLI
Pytanie
$ ./presto --server localhost:8080 --catalog jmx --schema jmxWynik
Otrzymasz następującą odpowiedź.
presto:jmx>Schemat JMX
Aby wyświetlić listę wszystkich schematów w „jmx”, wpisz następujące zapytanie.
Pytanie
presto:jmx> show schemas from jmx;Wynik
Schema
--------------------
information_schema
currentPokaż tabele
Aby wyświetlić tabele w „bieżącym” schemacie, użyj następującego polecenia.
Zapytanie 1
presto:jmx> show tables from jmx.current;Wynik
Table
------------------------------------------------------------------------------
com.facebook.presto.execution.scheduler:name = nodescheduler
com.facebook.presto.execution:name = queryexecution
com.facebook.presto.execution:name = querymanager
com.facebook.presto.execution:name = remotetaskfactory
com.facebook.presto.execution:name = taskexecutor
com.facebook.presto.execution:name = taskmanager
com.facebook.presto.execution:type = queryqueue,name = global,expansion = global
………………
……………….Zapytanie 2
presto:jmx> select * from jmx.current.”java.lang:type = compilation";Wynik
node | compilationtimemonitoringsupported | name | objectname | totalcompilationti
--------------------------------------+------------------------------------+--------------------------------+----------------------------+-------------------
ffffffff-ffff-ffff-ffff-ffffffffffff | true | HotSpot 64-Bit Tiered Compilers | java.lang:type=Compilation | 1276Zapytanie 3
presto:jmx> select * from jmx.current."com.facebook.presto.server:name = taskresource";Wynik
node | readfromoutputbuffertime.alltime.count
| readfromoutputbuffertime.alltime.max | readfromoutputbuffertime.alltime.maxer
--------------------------------------+---------------------------------------+--------------------------------------+---------------------------------------
ffffffff-ffff-ffff-ffff-ffffffffffff | 92.0 | 1.009106149 |Łącznik Hive umożliwia wykonywanie zapytań dotyczących danych przechowywanych w hurtowni danych Hive.
Wymagania wstępne
- Hadoop
- Hive
Mamy nadzieję, że zainstalowałeś Hadoop i Hive na swoim komputerze. Uruchom wszystkie usługi pojedynczo w nowym terminalu. Następnie uruchom metastore gałęzi, używając następującego polecenia:
hive --service metastorePresto używa usługi metastore Hive, aby uzyskać szczegółowe informacje o tabeli ula.
Ustawienia konfiguracji
Utwórz plik “hive.properties” pod “etc/catalog”informator. Użyj następującego polecenia.
$ cd etc $ cd catalog
$ vi hive.properties
connector.name = hive-cdh4
hive.metastore.uri = thrift://localhost:9083Po wprowadzeniu wszystkich zmian zapisz plik i zamknij terminal.
Utwórz bazę danych
Utwórz bazę danych w programie Hive przy użyciu następującego zapytania -
Pytanie
hive> CREATE SCHEMA tutorials;Po utworzeniu bazy danych możesz ją zweryfikować za pomocą “show databases” Komenda.
Utwórz tabelę
Utwórz tabelę to instrukcja używana do tworzenia tabeli w gałęzi. Na przykład użyj następującego zapytania.
hive> create table author(auth_id int, auth_name varchar(50),
topic varchar(100) STORED AS SEQUENCEFILE;Wypełnij tabelę
Poniższe zapytanie służy do wstawiania rekordów do tabeli gałęzi.
hive> insert into table author values (1,’ Doug Cutting’,Hadoop),
(2,’ James Gosling’,java),(3,’ Dennis Ritchie’,C);Uruchom Presto CLI
Możesz uruchomić Presto CLI, aby połączyć wtyczkę magazynu Hive za pomocą następującego polecenia.
$ ./presto --server localhost:8080 --catalog hive —schema tutorials;Otrzymasz następującą odpowiedź.
presto:tutorials >Schematy list
Aby wyświetlić listę wszystkich schematów w łączniku Hive, wpisz następujące polecenie.
Pytanie
presto:tutorials > show schemas from hive;Wynik
default
tutorialsTabele list
Aby wyświetlić listę wszystkich tabel w schemacie „samouczków”, użyj następującego zapytania.
Pytanie
presto:tutorials > show tables from hive.tutorials;Wynik
authorPobierz tabelę
Poniższe zapytanie służy do pobierania wszystkich rekordów z tabeli ula.
Pytanie
presto:tutorials > select * from hive.tutorials.author;Wynik
auth_id | auth_name | topic
---------+----------------+--------
1 | Doug Cutting | Hadoop
2 | James Gosling | java
3 | Dennis Ritchie | CKafka Connector for Presto umożliwia dostęp do danych z Apache Kafka przy użyciu Presto.
Wymagania wstępne
Pobierz i zainstaluj najnowszą wersję następujących projektów Apache.
- Apache ZooKeeper
- Apache Kafka
Uruchom ZooKeeper
Uruchom serwer ZooKeeper za pomocą następującego polecenia.
$ bin/zookeeper-server-start.sh config/zookeeper.propertiesTeraz ZooKeeper uruchamia port 2181.
Uruchom Kafkę
Uruchom Kafkę w innym terminalu, używając następującego polecenia.
$ bin/kafka-server-start.sh config/server.propertiesPo uruchomieniu kafka używa numeru portu 9092.
Dane TPCH
Pobierz pliki tpch-kafka
$ curl -o kafka-tpch
https://repo1.maven.org/maven2/de/softwareforge/kafka_tpch_0811/1.0/kafka_tpch_
0811-1.0.shTeraz pobrałeś moduł ładujący z centrali Maven za pomocą powyższego polecenia. Otrzymasz podobną odpowiedź, jak poniżej.
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- 0:00:01 --:--:-- 0
5 21.6M 5 1279k 0 0 83898 0 0:04:30 0:00:15 0:04:15 129k
6 21.6M 6 1407k 0 0 86656 0 0:04:21 0:00:16 0:04:05 131k
24 21.6M 24 5439k 0 0 124k 0 0:02:57 0:00:43 0:02:14 175k
24 21.6M 24 5439k 0 0 124k 0 0:02:58 0:00:43 0:02:15 160k
25 21.6M 25 5736k 0 0 128k 0 0:02:52 0:00:44 0:02:08 181k
………………………..Następnie uczyń go wykonywalnym za pomocą następującego polecenia,
$ chmod 755 kafka-tpchUruchom tpch-kafka
Uruchom program kafka-tpch, aby wstępnie załadować kilka tematów z danymi tpch, używając następującego polecenia.
Pytanie
$ ./kafka-tpch load --brokers localhost:9092 --prefix tpch. --tpch-type tinyWynik
2016-07-13T16:15:52.083+0530 INFO main io.airlift.log.Logging Logging
to stderr
2016-07-13T16:15:52.124+0530 INFO main de.softwareforge.kafka.LoadCommand
Processing tables: [customer, orders, lineitem, part, partsupp, supplier,
nation, region]
2016-07-13T16:15:52.834+0530 INFO pool-1-thread-1
de.softwareforge.kafka.LoadCommand Loading table 'customer' into topic 'tpch.customer'...
2016-07-13T16:15:52.834+0530 INFO pool-1-thread-2
de.softwareforge.kafka.LoadCommand Loading table 'orders' into topic 'tpch.orders'...
2016-07-13T16:15:52.834+0530 INFO pool-1-thread-3
de.softwareforge.kafka.LoadCommand Loading table 'lineitem' into topic 'tpch.lineitem'...
2016-07-13T16:15:52.834+0530 INFO pool-1-thread-4
de.softwareforge.kafka.LoadCommand Loading table 'part' into topic 'tpch.part'...
………………………
……………………….Teraz tablice klientów, zamówień, dostawców Kafki są ładowane za pomocą tpch.
Dodaj ustawienia konfiguracji
Dodajmy następujące ustawienia konfiguracji łącznika Kafka na serwerze Presto.
connector.name = kafka
kafka.nodes = localhost:9092
kafka.table-names = tpch.customer,tpch.orders,tpch.lineitem,tpch.part,tpch.partsupp,
tpch.supplier,tpch.nation,tpch.region
kafka.hide-internal-columns = falseW powyższej konfiguracji tabele Kafki są ładowane za pomocą programu Kafka-tpch.
Uruchom Presto CLI
Uruchom Presto CLI za pomocą następującego polecenia,
$ ./presto --server localhost:8080 --catalog kafka —schema tpch;Tutaj “tpch" jest schematem dla łącznika Kafka i otrzymasz następującą odpowiedź.
presto:tpch>Tabele list
Następujące zapytanie wyświetla wszystkie tabele w “tpch” schemat.
Pytanie
presto:tpch> show tables;Wynik
Table
----------
customer
lineitem
nation
orders
part
partsupp
region
supplierOpisz tabelę klientów
Następujące zapytanie opisuje “customer” stół.
Pytanie
presto:tpch> describe customer;Wynik
Column | Type | Comment
-------------------+---------+---------------------------------------------
_partition_id | bigint | Partition Id
_partition_offset | bigint | Offset for the message within the partition
_segment_start | bigint | Segment start offset
_segment_end | bigint | Segment end offset
_segment_count | bigint | Running message count per segment
_key | varchar | Key text
_key_corrupt | boolean | Key data is corrupt
_key_length | bigint | Total number of key bytes
_message | varchar | Message text
_message_corrupt | boolean | Message data is corrupt
_message_length | bigint | Total number of message bytesInterfejs JDBC Presto jest używany do uzyskiwania dostępu do aplikacji Java.
Wymagania wstępne
Zainstaluj presto-jdbc-0.150.jar
Możesz pobrać plik jar JDBC, odwiedzając poniższy link,
https://repo1.maven.org/maven2/com/facebook/presto/presto-jdbc/0.150/
Po pobraniu pliku jar dodaj go do ścieżki klasy aplikacji Java.
Utwórz prostą aplikację
Stwórzmy prostą aplikację java wykorzystującą interfejs JDBC.
Kodowanie - PrestoJdbcSample.java
import java.sql.*;
import com.facebook.presto.jdbc.PrestoDriver;
//import presto jdbc driver packages here.
public class PrestoJdbcSample {
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
try {
Class.forName("com.facebook.presto.jdbc.PrestoDriver");
connection = DriverManager.getConnection(
"jdbc:presto://localhost:8080/mysql/tutorials", "tutorials", “");
//connect mysql server tutorials database here
statement = connection.createStatement();
String sql;
sql = "select auth_id, auth_name from mysql.tutorials.author”;
//select mysql table author table two columns
ResultSet resultSet = statement.executeQuery(sql);
while(resultSet.next()){
int id = resultSet.getInt("auth_id");
String name = resultSet.getString(“auth_name");
System.out.print("ID: " + id + ";\nName: " + name + "\n");
}
resultSet.close();
statement.close();
connection.close();
}catch(SQLException sqlException){
sqlException.printStackTrace();
}catch(Exception exception){
exception.printStackTrace();
}
}
}Zapisz plik i zamknij aplikację. Teraz uruchom serwer Presto w jednym terminalu i otwórz nowy terminal, aby skompilować i wykonać wynik. Oto kroki -
Kompilacja
~/Workspace/presto/presto-jdbc $ javac -cp presto-jdbc-0.149.jar PrestoJdbcSample.javaWykonanie
~/Workspace/presto/presto-jdbc $ java -cp .:presto-jdbc-0.149.jar PrestoJdbcSampleWynik
INFO: Logging initialized @146ms
ID: 1;
Name: Doug Cutting
ID: 2;
Name: James Gosling
ID: 3;
Name: Dennis RitchieUtwórz projekt Maven, aby opracować niestandardową funkcję Presto.
SimpleFunctionsFactory.java
Utwórz klasę SimpleFunctionsFactory, aby zaimplementować interfejs FunctionFactory.
package com.tutorialspoint.simple.functions;
import com.facebook.presto.metadata.FunctionFactory;
import com.facebook.presto.metadata.FunctionListBuilder;
import com.facebook.presto.metadata.SqlFunction;
import com.facebook.presto.spi.type.TypeManager;
import java.util.List;
public class SimpleFunctionFactory implements FunctionFactory {
private final TypeManager typeManager;
public SimpleFunctionFactory(TypeManager typeManager) {
this.typeManager = typeManager;
}
@Override
public List<SqlFunction> listFunctions() {
return new FunctionListBuilder(typeManager)
.scalar(SimpleFunctions.class)
.getFunctions();
}
}SimpleFunctionsPlugin.java
Utwórz klasę SimpleFunctionsPlugin, aby zaimplementować interfejs wtyczki.
package com.tutorialspoint.simple.functions;
import com.facebook.presto.metadata.FunctionFactory;
import com.facebook.presto.spi.Plugin;
import com.facebook.presto.spi.type.TypeManager;
import com.google.common.collect.ImmutableList;
import javax.inject.Inject;
import java.util.List;
import static java.util.Objects.requireNonNull;
public class SimpleFunctionsPlugin implements Plugin {
private TypeManager typeManager;
@Inject
public void setTypeManager(TypeManager typeManager) {
this.typeManager = requireNonNull(typeManager, "typeManager is null”);
//Inject TypeManager class here
}
@Override
public <T> List<T> getServices(Class<T> type){
if (type == FunctionFactory.class) {
return ImmutableList.of(type.cast(new SimpleFunctionFactory(typeManager)));
}
return ImmutableList.of();
}
}Dodaj plik zasobów
Utwórz plik zasobów określony w pakiecie implementacyjnym.
(com.tutorialspoint.simple.functions.SimpleFunctionsPlugin)Teraz przejdź do lokalizacji pliku zasobów @ / path / to / resource /
Następnie dodaj zmiany,
com.facebook.presto.spi.Pluginpom.xml
Dodaj następujące zależności do pliku pom.xml.
<?xml version = "1.0"?>
<project xmlns = "http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.tutorialspoint.simple.functions</groupId>
<artifactId>presto-simple-functions</artifactId>
<packaging>jar</packaging>
<version>1.0</version>
<name>presto-simple-functions</name>
<description>Simple test functions for Presto</description>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>com.facebook.presto</groupId>
<artifactId>presto-spi</artifactId>
<version>0.149</version>
</dependency>
<dependency>
<groupId>com.facebook.presto</groupId>
<artifactId>presto-main</artifactId>
<version>0.149</version>
</dependency>
<dependency>
<groupId>javax.inject</groupId>
<artifactId>javax.inject</artifactId>
<version>1</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>
</dependencies>
<build>
<finalName>presto-simple-functions</finalName>
<plugins>
<!-- Make this jar executable -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.3.2</version>
</plugin>
</plugins>
</build>
</project>SimpleFunctions.java
Utwórz klasę SimpleFunctions przy użyciu atrybutów Presto.
package com.tutorialspoint.simple.functions;
import com.facebook.presto.operator.Description;
import com.facebook.presto.operator.scalar.ScalarFunction;
import com.facebook.presto.operator.scalar.StringFunctions;
import com.facebook.presto.spi.type.StandardTypes;
import com.facebook.presto.type.LiteralParameters;
import com.facebook.presto.type.SqlType;
public final class SimpleFunctions {
private SimpleFunctions() {
}
@Description("Returns summation of two numbers")
@ScalarFunction(“mysum")
//function name
@SqlType(StandardTypes.BIGINT)
public static long sum(@SqlType(StandardTypes.BIGINT) long num1,
@SqlType(StandardTypes.BIGINT) long num2) {
return num1 + num2;
}
}Po utworzeniu aplikacji skompiluj i uruchom aplikację. Spowoduje to utworzenie pliku JAR. Skopiuj plik i przenieś plik JAR do docelowego katalogu wtyczek serwera Presto.
Kompilacja
mvn compileWykonanie
mvn packageTeraz zrestartuj serwer Presto i podłącz klienta Presto. Następnie wykonaj aplikację funkcji niestandardowej, jak wyjaśniono poniżej,
$ ./presto --catalog mysql --schema defaultPytanie
presto:default> select mysum(10,10);Wynik
_col0
-------
20