Apache Spark - programowanie podstawowe
Podstawą całego projektu jest Spark Core. Zapewnia rozproszone przydzielanie zadań, planowanie i podstawowe funkcje we / wy. Spark używa wyspecjalizowanej podstawowej struktury danych znanej jako RDD (Resilient Distributed Datasets), która jest logiczną kolekcją danych podzielonych na partycje między maszynami. RDD można tworzyć na dwa sposoby; jeden polega na tworzeniu odniesień do zbiorów danych w zewnętrznych systemach pamięci masowej, a po drugie polega na zastosowaniu przekształceń (np. mapa, filtr, reduktor, łączenie) na istniejących RDD.
Abstrakcja RDD jest udostępniana za pośrednictwem interfejsu API zintegrowanego z językiem. Upraszcza to złożoność programowania, ponieważ sposób, w jaki aplikacje manipulują RDD, jest podobny do manipulowania lokalnymi zbiorami danych.
Spark Shell
Spark zapewnia interaktywną powłokę - potężne narzędzie do interaktywnej analizy danych. Jest dostępny w języku Scala lub Python. Podstawową abstrakcją Sparka jest rozproszona kolekcja elementów o nazwie Resilient Distributed Dataset (RDD). Pliki RDD można tworzyć z formatów wejściowych Hadoop (takich jak pliki HDFS) lub przekształcając inne pliki RDD.
Otwórz Spark Shell
Następujące polecenie służy do otwierania powłoki Spark.
$ spark-shellUtwórz prosty RDD
Stwórzmy prosty RDD z pliku tekstowego. Użyj następującego polecenia, aby utworzyć prosty RDD.
scala> val inputfile = sc.textFile(“input.txt”)Dane wyjściowe dla powyższego polecenia to
inputfile: org.apache.spark.rdd.RDD[String] = input.txt MappedRDD[1] at textFile at <console>:12Spark RDD API wprowadza kilka Transformations i kilka Actions manipulować RDD.
Transformacje RDD
Transformacje RDD zwracają wskaźnik do nowego RDD i pozwalają tworzyć zależności między RDD. Każdy RDD w łańcuchu zależności (String of Dependencies) ma funkcję obliczania swoich danych i ma wskaźnik (zależność) do swojego nadrzędnego RDD.
Spark jest leniwy, więc nic nie zostanie wykonane, chyba że wywołasz jakąś transformację lub akcję, która wyzwoli tworzenie i wykonywanie zadań. Spójrz na poniższy fragment przykładu z liczbą słów.
Dlatego transformacja RDD nie jest zbiorem danych, ale jest krokiem w programie (może to być jedyny krok), który mówi Sparkowi, jak uzyskać dane i co z nimi zrobić.
Poniżej podano listę przekształceń RDD.
| S.Nr | Transformacje i znaczenie |
|---|---|
| 1 | map(func) Zwraca nowy rozproszony zestaw danych utworzony przez przekazanie każdego elementu źródła przez funkcję func. |
| 2 | filter(func) Zwraca nowy zestaw danych utworzony przez wybranie tych elementów źródła, w którym func zwraca prawdę. |
| 3 | flatMap(func) Podobny do map, ale każdy element wejściowy może być odwzorowany na 0 lub więcej elementów wyjściowych (więc func powinien zwracać Seq, a nie pojedynczy element). |
| 4 | mapPartitions(func) Podobny do map, ale działa osobno na każdej partycji (bloku) RDD, więc func musi być typu Iterator <T> ⇒ Iterator <U>, gdy działa na RDD typu T. |
| 5 | mapPartitionsWithIndex(func) Podobny do mapowania partycji, ale zapewnia również func z wartością całkowitą reprezentującą indeks partycji, więc func musi być typu (Int, Iterator <T>) ⇒ Iterator <U>, gdy działa na RDD typu T. |
| 6 | sample(withReplacement, fraction, seed) Próbka a fraction danych, z zastąpieniem lub bez, przy użyciu danego ziarna generatora liczb losowych. |
| 7 | union(otherDataset) Zwraca nowy zestaw danych, który zawiera sumę elementów w źródłowym zestawie danych i argument. |
| 8 | intersection(otherDataset) Zwraca nowy RDD, który zawiera przecięcie elementów w źródłowym zbiorze danych i argument. |
| 9 | distinct([numTasks]) Zwraca nowy zestaw danych zawierający różne elementy źródłowego zestawu danych. |
| 10 | groupByKey([numTasks]) W przypadku wywołania zestawu danych składającego się z (K, V) par, zwraca zestaw danych składający się z (K, Iterable <V>) par. Note - W przypadku grupowania w celu wykonania agregacji (takiej jak suma lub średnia) dla każdego klucza, użycie funkcji redukujByKey lub agregatuByKey zapewni znacznie lepszą wydajność. |
| 11 | reduceByKey(func, [numTasks]) Wywołany na zbiorze danych z (K, V) par zwraca zestaw danych z (K, V) par gdzie wartości dla każdego klucza są agregowane przy użyciu danego zmniejszenia funkcji func , który musi być typu (V, V) ⇒ V Podobnie jak w przypadku groupByKey, liczbę zadań redukcji można konfigurować za pomocą opcjonalnego drugiego argumentu. |
| 12 | aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) Po wywołaniu na zestawie danych zawierającym (K, V) par, zwraca zestaw danych składający się z (K, U) par, w których wartości dla każdego klucza są agregowane przy użyciu podanych funkcji łączenia i neutralnej wartości „zero”. Zezwala na zagregowany typ wartości inny niż typ wartości wejściowej, unikając niepotrzebnych alokacji. Podobnie jak w przypadku groupByKey, liczbę zadań redukcji można konfigurować za pomocą opcjonalnego drugiego argumentu. |
| 13 | sortByKey([ascending], [numTasks]) W przypadku wywołania zestawu danych zawierającego (K, V) par, w którym K implementuje uporządkowane, zwraca zestaw danych składający się z (K, V) par posortowanych według kluczy w porządku rosnącym lub malejącym, zgodnie z argumentem rosnącym logicznym. |
| 14 | join(otherDataset, [numTasks]) W przypadku wywołania zestawów danych typu (K, V) i (K, W) zwraca zestaw danych (K, (V, W)) par ze wszystkimi parami elementów dla każdego klucza. Łączenia zewnętrzne są obsługiwane przez leftOuterJoin, rightOuterJoin i fullOuterJoin. |
| 15 | cogroup(otherDataset, [numTasks]) W przypadku wywołania na zestawach danych typu (K, V) i (K, W) zwraca zestaw danych obejmujący (K, (Iterable <V>, Iterable <W>)) krotek. Ta operacja jest również nazywana grupą z. |
| 16 | cartesian(otherDataset) W przypadku wywołania w zestawach danych typu T i U zwraca zestaw danych składający się z (T, U) par (wszystkie pary elementów). |
| 17 | pipe(command, [envVars]) Prześlij każdą partycję RDD poleceniem powłoki, np. Skryptem Perla lub basha. Elementy RDD są zapisywane na stdin procesu, a linie wyprowadzane na jego standardowe wyjście są zwracane jako RDD łańcuchów. |
| 18 | coalesce(numPartitions) Zmniejsz liczbę partycji w RDD do numPartitions. Przydatne do wydajniejszego wykonywania operacji po odfiltrowaniu dużego zbioru danych. |
| 19 | repartition(numPartitions) Przetasuj losowo dane w RDD, aby utworzyć więcej lub mniej partycji i zrównoważyć je między nimi. To zawsze tasuje wszystkie dane w sieci. |
| 20 | repartitionAndSortWithinPartitions(partitioner) Podziel RDD na partycje zgodnie z podanym partycjonatorem i, w ramach każdej wynikowej partycji, posortuj rekordy według ich kluczy. Jest to bardziej wydajne niż wywołanie podziału na partycje, a następnie sortowanie w ramach każdej partycji, ponieważ może zepchnąć sortowanie w dół do mechanizmu tasowania. |
działania
Poniższa tabela zawiera listę akcji, które zwracają wartości.
| S.Nr | Działanie i znaczenie |
|---|---|
| 1 | reduce(func) Agreguj elementy zestawu danych za pomocą funkcji func(który przyjmuje dwa argumenty i zwraca jeden). Funkcja powinna być przemienna i asocjacyjna, aby można ją było poprawnie obliczyć równolegle. |
| 2 | collect() Zwraca wszystkie elementy zestawu danych jako tablicę w programie sterownika. Zwykle jest to przydatne po filtrze lub innej operacji, która zwraca wystarczająco mały podzbiór danych. |
| 3 | count() Zwraca liczbę elementów w zbiorze danych. |
| 4 | first() Zwraca pierwszy element zbioru danych (podobnie do take (1)). |
| 5 | take(n) Zwraca tablicę z pierwszą n elementy zbioru danych. |
| 6 | takeSample (withReplacement,num, [seed]) Zwraca tablicę z losową próbką num elementy zbioru danych, z wymianą lub bez, opcjonalnie z wstępnym określeniem ziarna generatora liczb losowych. |
| 7 | takeOrdered(n, [ordering]) Zwraca pierwszy n elementy RDD przy użyciu ich naturalnej kolejności lub niestandardowego komparatora. |
| 8 | saveAsTextFile(path) Zapisuje elementy zbioru danych jako plik tekstowy (lub zestaw plików tekstowych) w podanym katalogu w lokalnym systemie plików, HDFS lub dowolnym innym systemie plików obsługiwanym przez Hadoop. Spark wywołuje toString dla każdego elementu, aby przekonwertować go na wiersz tekstu w pliku. |
| 9 | saveAsSequenceFile(path) (Java and Scala) Zapisuje elementy zestawu danych jako Hadoop SequenceFile w podanej ścieżce w lokalnym systemie plików, HDFS lub dowolnym innym systemie plików obsługiwanym przez Hadoop. Jest to dostępne na RDD par klucz-wartość, które implementują interfejs Hadoop Writable. W Scali jest również dostępny dla typów, które są niejawnie konwertowane na Writable (Spark obejmuje konwersje dla typów podstawowych, takich jak Int, Double, String itp.). |
| 10 | saveAsObjectFile(path) (Java and Scala) Zapisuje elementy zestawu danych w prostym formacie przy użyciu serializacji Java, który można następnie załadować za pomocą SparkContext.objectFile (). |
| 11 | countByKey() Dostępne tylko w RDD typu (K, V). Zwraca wartość mieszania (K, Int) par z liczbą każdego klucza. |
| 12 | foreach(func) Uruchamia funkcję funcna każdym elemencie zbioru danych. Zwykle dzieje się tak w przypadku skutków ubocznych, takich jak aktualizacja akumulatora lub interakcja z zewnętrznymi systemami pamięci masowej. Note- modyfikowanie zmiennych innych niż akumulatory poza foreach () może spowodować nieokreślone zachowanie. Aby uzyskać więcej informacji, zobacz Omówienie zamknięć. |
Programowanie z RDD
Zobaczmy implementacje kilku transformacji RDD i akcji w programowaniu RDD na przykładzie.
Przykład
Rozważ przykład liczenia słów - liczy każde słowo występujące w dokumencie. Rozważ poniższy tekst jako dane wejściowe i zostanie zapisany jako plikinput.txt plik w katalogu domowym.
input.txt - plik wejściowy.
people are not as beautiful as they look,
as they walk or as they talk.
they are only as beautiful as they love,
as they care as they share.Postępuj zgodnie z procedurą podaną poniżej, aby wykonać podany przykład.
Otwórz Spark-Shell
Następujące polecenie służy do otwierania powłoki iskrowej. Generalnie iskrę buduje się przy użyciu Scali. Dlatego program Spark działa w środowisku Scala.
$ spark-shellJeśli powłoka Spark otworzy się pomyślnie, znajdziesz następujące dane wyjściowe. Spójrz na ostatni wiersz danych wyjściowych „Kontekst Spark dostępny jako sc” oznacza, że kontener Spark jest automatycznie tworzony jako obiekt kontekstu Spark o nazwiesc. Przed rozpoczęciem pierwszego kroku programu należy utworzyć obiekt SparkContext.
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>Utwórz RDD
Najpierw musimy odczytać plik wejściowy za pomocą Spark-Scala API i utworzyć RDD.
Poniższe polecenie służy do odczytu pliku z podanej lokalizacji. Tutaj tworzony jest nowy RDD z nazwą pliku wejściowego. Ciąg podany jako argument w metodzie textFile („”) jest ścieżką bezwzględną dla nazwy pliku wejściowego. Jeśli jednak podana jest tylko nazwa pliku, oznacza to, że plik wejściowy znajduje się w bieżącej lokalizacji.
scala> val inputfile = sc.textFile("input.txt")Wykonaj transformację liczby słów
Naszym celem jest policzenie słów w pliku. Utwórz płaską mapę, aby podzielić każdy wiersz na słowa (flatMap(line ⇒ line.split(“ ”)).
Następnie przeczytaj każde słowo jako klucz z wartością ‘1’ (<klucz, wartość> = <słowo, 1>) przy użyciu funkcji mapy (map(word ⇒ (word, 1)).
Na koniec zredukuj te klucze, dodając wartości podobnych kluczy (reduceByKey(_+_)).
Następujące polecenie służy do wykonywania logiki liczenia słów. Po wykonaniu tego nie znajdziesz żadnych wyników, ponieważ to nie jest akcja, to jest transformacja; wskazanie nowego RDD lub wskazanie Sparkowi, co zrobić z podanymi danymi)
scala> val counts = inputfile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_);Aktualny RDD
Podczas pracy z RDD, jeśli chcesz wiedzieć o aktualnym RDD, użyj następującego polecenia. Pokaże ci opis aktualnego RDD i jego zależności do debugowania.
scala> counts.toDebugStringBuforowanie transformacji
Możesz oznaczyć RDD do utrwalenia używając na nim metod persist () lub cache (). Gdy zostanie obliczony po raz pierwszy w akcji, zostanie zachowany w pamięci węzłów. Użyj następującego polecenia, aby zapisać transformacje pośrednie w pamięci.
scala> counts.cache()Wykonanie akcji
Zastosowanie akcji, podobnie jak zapisanie wszystkich przekształceń, powoduje powstanie pliku tekstowego. Argument String metody saveAsTextFile („”) to bezwzględna ścieżka do folderu wyjściowego. Wypróbuj następujące polecenie, aby zapisać dane wyjściowe w pliku tekstowym. W poniższym przykładzie folder „output” znajduje się w bieżącej lokalizacji.
scala> counts.saveAsTextFile("output")Sprawdzanie wyników
Otwórz inny terminal, aby przejść do katalogu domowego (gdzie iskra jest wykonywana w drugim terminalu). Użyj następujących poleceń, aby sprawdzić katalog wyjściowy.
[hadoop@localhost ~]$ cd output/
[hadoop@localhost output]$ ls -1
part-00000
part-00001
_SUCCESSPoniższe polecenie służy do wyświetlania danych wyjściowych z Part-00000 akta.
[hadoop@localhost output]$ cat part-00000Wynik
(people,1)
(are,2)
(not,1)
(as,8)
(beautiful,2)
(they, 7)
(look,1)Poniższe polecenie służy do wyświetlania danych wyjściowych z Part-00001 akta.
[hadoop@localhost output]$ cat part-00001Wynik
(walk, 1)
(or, 1)
(talk, 1)
(only, 1)
(love, 1)
(care, 1)
(share, 1)ONZ nie ustaje w przechowywaniu
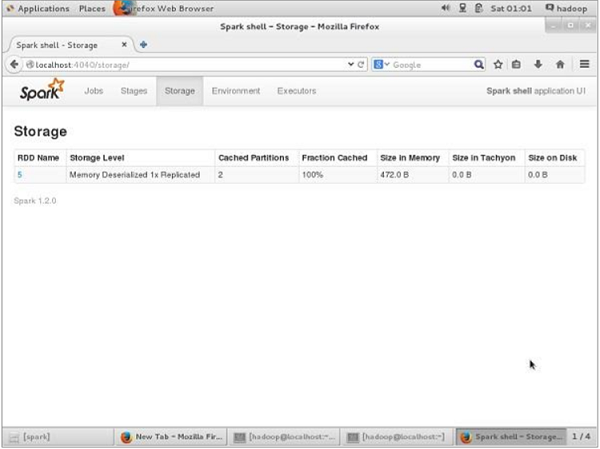
Jeśli chcesz zobaczyć przestrzeń dyskową używaną przez tę aplikację przed cofnięciem się, użyj następującego adresu URL w przeglądarce.
http://localhost:4040Zobaczysz następujący ekran, który pokazuje przestrzeń dyskową używaną przez aplikację, która działa w powłoce Spark.

Jeśli chcesz cofnąć utrwalenie przestrzeni dyskowej określonego RDD, użyj następującego polecenia.
Scala> counts.unpersist()Zobaczysz dane wyjściowe w następujący sposób -
15/06/27 00:57:33 INFO ShuffledRDD: Removing RDD 9 from persistence list
15/06/27 00:57:33 INFO BlockManager: Removing RDD 9
15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_1
15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_1 of size 480 dropped from memory (free 280061810)
15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_0
15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_0 of size 296 dropped from memory (free 280062106)
res7: cou.type = ShuffledRDD[9] at reduceByKey at <console>:14Aby zweryfikować przestrzeń dyskową w przeglądarce, użyj następującego adresu URL.
http://localhost:4040/Pojawi się następujący ekran. Pokazuje przestrzeń dyskową używaną przez aplikację, która działa w powłoce Spark.