Apache Tajo - zapytania SQL
W tym rozdziale wyjaśniono następujące ważne zapytania.
- Predicates
- Explain
- Join
Przejdźmy dalej i wykonajmy zapytania.
Predykaty
Predykat jest wyrażeniem używanym do obliczania wartości prawda / fałsz i NIEZNANY. Predykaty są używane w warunku wyszukiwania klauzul WHERE i HAVING oraz w innych konstrukcjach, w których wymagana jest wartość logiczna.
Predykat IN
Określa, czy wartość wyrażenia do przetestowania pasuje do dowolnej wartości w podzapytaniu lub na liście. Podzapytanie to zwykła instrukcja SELECT, która ma zestaw wyników składający się z jednej kolumny i co najmniej jednego wiersza. Ta kolumna lub wszystkie wyrażenia na liście muszą mieć ten sam typ danych co testowane wyrażenie.
Syntax
IN::=
<expression to test> [NOT] IN (<subquery>)
| (<expression1>,...)Query
select id,name,address from mytable where id in(2,3,4);Result
Powyższe zapytanie wygeneruje następujący wynik.
id, name, address
-------------------------------
2, Amit, 12 old street
3, Bob, 10 cross street
4, David, 15 express avenueZapytanie zwraca rekordy z mytable dla uczniów id 2, 3 i 4.
Query
select id,name,address from mytable where id not in(2,3,4);Result
Powyższe zapytanie wygeneruje następujący wynik.
id, name, address
-------------------------------
1, Adam, 23 new street
5, Esha, 20 garden street
6, Ganga, 25 north street
7, Jack, 2 park street
8, Leena, 24 south street
9, Mary, 5 west street
10, Peter, 16 park avenuePowyższe zapytanie zwraca rekordy z mytable gdzie uczniowie nie są w 2,3 i 4.
Podobnie jak Predicate
Predykat LIKE porównuje ciąg określony w pierwszym wyrażeniu w celu obliczenia wartości ciągu, która jest określana jako wartość do przetestowania, ze wzorcem zdefiniowanym w drugim wyrażeniu w celu obliczenia wartości ciągu.
Wzorzec może zawierać dowolną kombinację symboli wieloznacznych, takich jak -
Symbol podkreślenia (_), którego można użyć zamiast dowolnego pojedynczego znaku w testowanej wartości.
Znak procentu (%), który zastępuje dowolny ciąg zera lub więcej znaków w testowanej wartości.
Syntax
LIKE::=
<expression for calculating the string value>
[NOT] LIKE
<expression for calculating the string value>
[ESCAPE <symbol>]Query
select * from mytable where name like ‘A%';Result
Powyższe zapytanie wygeneruje następujący wynik.
id, name, address, age, mark
-------------------------------
1, Adam, 23 new street, 12, 90
2, Amit, 12 old street, 13, 95Zapytanie zwraca rekordy z mytable tych uczniów, których imiona zaczynają się na literę „A”.
Query
select * from mytable where name like ‘_a%';Result
Powyższe zapytanie wygeneruje następujący wynik.
id, name, address, age, mark
——————————————————————————————————————-
4, David, 15 express avenue, 12, 85
6, Ganga, 25 north street, 12, 55
7, Jack, 2 park street, 12, 60
9, Mary, 5 west street, 12, 75Zapytanie zwraca rekordy z mytable tych uczniów, których imiona zaczynają się od „a” jako drugiego znaku.
Używanie wartości NULL w warunkach wyszukiwania
Zrozummy teraz, jak używać wartości NULL w warunkach wyszukiwania.
Syntax
Predicate
IS [NOT] NULLQuery
select name from mytable where name is not null;Result
Powyższe zapytanie wygeneruje następujący wynik.
name
-------------------------------
Adam
Amit
Bob
David
Esha
Ganga
Jack
Leena
Mary
Peter
(10 rows, 0.076 sec, 163 B selected)Tutaj wynik jest prawdziwy, więc zwraca wszystkie nazwy z tabeli.
Query
Sprawdźmy teraz zapytanie z warunkiem NULL.
default> select name from mytable where name is null;Result
Powyższe zapytanie wygeneruje następujący wynik.
name
-------------------------------
(0 rows, 0.068 sec, 0 B selected)Wyjaśnić
Explainsłuży do uzyskania planu wykonania zapytania. Przedstawia logiczny i globalny plan wykonania instrukcji.
Zapytanie dotyczące planu logicznego
explain select * from mytable;
explain
-------------------------------
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}Result
Powyższe zapytanie wygeneruje następujący wynik.

Wynik zapytania przedstawia logiczny format planu dla danej tabeli. Plan logiczny zwraca następujące trzy wyniki -
- Lista docelowa
- Nasz schemat
- W schemacie
Zapytanie dotyczące planu globalnego
explain global select * from mytable;
explain
-------------------------------
-------------------------------------------------------------------------------
Execution Block Graph (TERMINAL - eb_0000000000000_0000_000002)
-------------------------------------------------------------------------------
|-eb_0000000000000_0000_000002
|-eb_0000000000000_0000_000001
-------------------------------------------------------------------------------
Order of Execution
-------------------------------------------------------------------------------
1: eb_0000000000000_0000_000001
2: eb_0000000000000_0000_000002
-------------------------------------------------------------------------------
=======================================================
Block Id: eb_0000000000000_0000_000001 [ROOT]
=======================================================
SCAN(0) on default.mytable
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT),default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=======================================================
Block Id: eb_0000000000000_0000_000002 [TERMINAL]
=======================================================
(24 rows, 0.065 sec, 0 B selected)Result
Powyższe zapytanie wygeneruje następujący wynik.

Tutaj plan globalny pokazuje identyfikator bloku wykonania, kolejność wykonywania i informacje o nim.
Łączy
Łączenia SQL służą do łączenia wierszy z dwóch lub więcej tabel. Poniżej przedstawiono różne typy połączeń SQL -
- Połączenie wewnętrzne
- {LEFT | PRAWO | FULL} OUTER JOIN
- Łączenie krzyżowe
- Dołącz do siebie
- Połączenie naturalne
Aby wykonać operacje łączenia, rozważ poniższe dwie tabele.
Tabela 1 - Klienci
| ID | Nazwa | Adres | Wiek |
|---|---|---|---|
| 1 | Klient 1 | 23 Old Street | 21 |
| 2 | Klient 2 | 12 New Street | 23 |
| 3 | Klient 3 | 10 Express Avenue | 22 |
| 4 | Klient 4 | 15 Express Avenue | 22 |
| 5 | Klient 5 | 20 Garden Street | 33 |
| 6 | Klient 6 | 21 North Street | 25 |
Table2 - customer_order
| ID | Identyfikator zamówienia | Emp Id |
|---|---|---|
| 1 | 1 | 101 |
| 2 | 2 | 102 |
| 3 | 3 | 103 |
| 4 | 4 | 104 |
| 5 | 5 | 105 |
Przejdźmy teraz i wykonajmy operacje łączenia SQL na dwóch powyższych tabelach.
Połączenie wewnętrzne
Sprzężenie wewnętrzne wybiera wszystkie wiersze z obu tabel, gdy istnieje zgodność między kolumnami w obu tabelach.
Syntax
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;Query
default> select c.age,c1.empid from customers c inner join customer_order c1 on c.id = c1.id;Result
Powyższe zapytanie wygeneruje następujący wynik.
age, empid
-------------------------------
21, 101
23, 102
22, 103
22, 104
33, 105Zapytanie dopasowuje pięć wierszy z obu tabel. W związku z tym zwraca wiek dopasowanych wierszy z pierwszej tabeli.
Lewe połączenie zewnętrzne
Lewe sprzężenie zewnętrzne zachowuje wszystkie wiersze „lewej” tabeli, niezależnie od tego, czy istnieje wiersz, który pasuje do „prawej” tabeli, czy nie.
Query
select c.name,c1.empid from customers c left outer join customer_order c1 on c.id = c1.id;Result
Powyższe zapytanie wygeneruje następujący wynik.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105
customer6,W tym przypadku lewe sprzężenie zewnętrzne zwraca wiersze kolumn nazw z tabeli klientów (po lewej) i wiersze dopasowane do kolumn empid z tabeli customer_order (po prawej).
Prawe połączenie zewnętrzne
Prawe sprzężenie zewnętrzne zachowuje wszystkie wiersze „prawej” tabeli, niezależnie od tego, czy istnieje wiersz, który pasuje do „lewej” tabeli.
Query
select c.name,c1.empid from customers c right outer join customer_order c1 on c.id = c1.id;Result
Powyższe zapytanie wygeneruje następujący wynik.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105W tym przypadku prawe sprzężenie zewnętrzne zwraca empid wiersze z tabeli customer_order (po prawej) i wiersze zgodne z kolumną nazwy z tabeli klientów.
Pełne połączenie zewnętrzne
Pełne łączenie zewnętrzne zachowuje wszystkie wiersze z lewej i prawej tabeli.
Query
select * from customers c full outer join customer_order c1 on c.id = c1.id;Result
Powyższe zapytanie wygeneruje następujący wynik.

Zapytanie zwraca wszystkie pasujące i niepasujące wiersze zarówno z tabel customer, jak i customer_order.
Łączenie krzyżowe
Zwraca iloczyn kartezjański zestawów rekordów z dwóch lub więcej połączonych tabel.
Syntax
SELECT * FROM table1 CROSS JOIN table2;Query
select orderid,name,address from customers,customer_order;Result
Powyższe zapytanie wygeneruje następujący wynik.
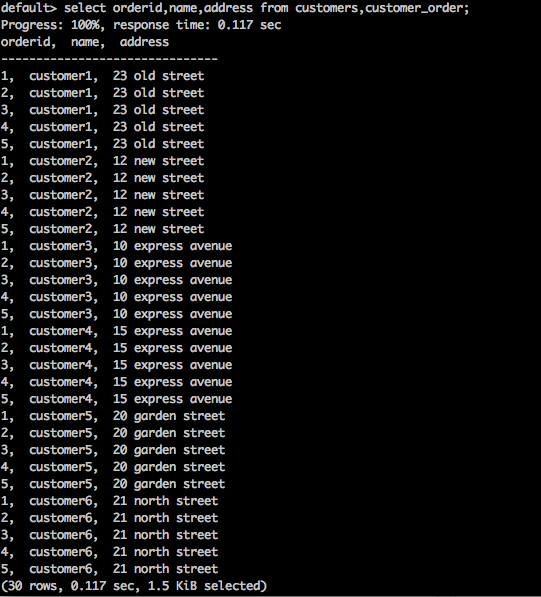
Powyższe zapytanie zwraca iloczyn kartezjański tabeli.
Połączenie naturalne
Naturalne łączenie nie używa żadnego operatora porównania. Nie łączy się w sposób, w jaki robi to produkt kartezjański. Możemy wykonać sprzężenie naturalne tylko wtedy, gdy istnieje co najmniej jeden wspólny atrybut, który istnieje między dwiema relacjami.
Syntax
SELECT * FROM table1 NATURAL JOIN table2;Query
select * from customers natural join customer_order;Result
Powyższe zapytanie wygeneruje następujący wynik.

Tutaj istnieje jeden wspólny identyfikator kolumny, który istnieje między dwiema tabelami. Korzystając z tej wspólnej kolumny, plikNatural Join łączy oba stoły.
Dołącz do siebie
SQL SELF JOIN służy do łączenia tabeli ze sobą, tak jakby była to dwie tabele, tymczasowo zmieniając nazwę przynajmniej jednej tabeli w instrukcji SQL.
Syntax
SELECT a.column_name, b.column_name...
FROM table1 a, table1 b
WHERE a.common_filed = b.common_fieldQuery
default> select c.id,c1.name from customers c, customers c1 where c.id = c1.id;Result
Powyższe zapytanie wygeneruje następujący wynik.
id, name
-------------------------------
1, customer1
2, customer2
3, customer3
4, customer4
5, customer5
6, customer6Zapytanie łączy ze sobą tabelę klientów.