Caffe2 - Szybki przewodnik
W ostatnich latach Deep Learning stał się dużym trendem w uczeniu maszynowym. Z powodzeniem zastosowano go do rozwiązywania wcześniej nierozwiązywalnych problemów w programie Vision, Speech Recognition and Natural Language Processing(NLP). Istnieje wiele innych dziedzin, w których jest stosowane uczenie głębokie i które wykazały swoją przydatność.
Caffe (Convolutional Architecture for Fast Feature Embedding) to platforma uczenia głębokiego opracowana w Berkeley Vision and Learning Center (BVLC). Projekt Caffe został stworzony przez Yangqing Jia podczas jego doktoratu. na University of California - Berkeley. Caffe zapewnia łatwy sposób eksperymentowania z głębokim uczeniem się. Jest napisany w C ++ i zapewnia powiązania dlaPython i Matlab.
Obsługuje wiele różnych typów architektur głębokiego uczenia, takich jak CNN (Konwolucyjna sieć neuronowa), LSTM(Pamięć długoterminowa) i FC (w pełni połączone). Obsługuje GPU, dzięki czemu idealnie nadaje się do środowisk produkcyjnych, w których występują głębokie sieci neuronowe. Obsługuje również biblioteki jądra oparte na procesorach, takie jakNVIDIA, Biblioteka CUDA Deep Neural Network (cuDNN) i Intel Math Kernel Library (Intel MKL).
W kwietniu 2017 r. Firma Facebook z siedzibą w USA ogłosiła Caffe2, która obejmuje teraz RNN (Recurrent Neural Networks), aw marcu 2018 r. Caffe2 została połączona z PyTorch. Twórcy Caffe2 i członkowie społeczności stworzyli modele rozwiązywania różnych problemów. Modele te są dostępne publicznie jako modele wstępnie przeszkolone. Caffe2 pomaga twórcom w korzystaniu z tych modeli i tworzeniu własnej sieci do prognozowania zbioru danych.
Zanim przejdziemy do szczegółów Caffe2, zrozummy różnicę między machine learning i deep learning. Jest to konieczne, aby zrozumieć, w jaki sposób modele są tworzone i używane w Caffe2.
Machine Learning v / s Deep Learning
W każdym algorytmie uczenia maszynowego, czy to tradycyjnym, czy też opartym na uczeniu głębokim, wybór funkcji w zestawie danych odgrywa niezwykle ważną rolę w uzyskaniu pożądanej dokładności przewidywania. W tradycyjnych technikach uczenia maszynowegofeature selectionodbywa się głównie na podstawie ludzkiej inspekcji, oceny i głębokiej wiedzy dziedzinowej. Czasami możesz zwrócić się o pomoc do kilku przetestowanych algorytmów wyboru funkcji.
Na poniższym rysunku przedstawiono tradycyjny przepływ uczenia maszynowego -

W uczeniu głębokim wybór funkcji jest automatyczny i jest częścią samego algorytmu uczenia głębokiego. Pokazuje to poniższy rysunek -

W algorytmach głębokiego uczenia się feature engineeringodbywa się automatycznie. Ogólnie rzecz biorąc, inżynieria funkcji jest czasochłonna i wymaga dobrej wiedzy w tej dziedzinie. Aby zaimplementować automatyczne wyodrębnianie funkcji, algorytmy głębokiego uczenia zwykle wymagają ogromnej ilości danych, więc jeśli masz tylko tysiące i dziesiątki tysięcy punktów danych, technika głębokiego uczenia może nie przynieść zadowalających wyników.
W przypadku większych danych algorytmy głębokiego uczenia dają lepsze wyniki w porównaniu z tradycyjnymi algorytmami ML z dodatkową zaletą polegającą na mniejszej lub zerowej inżynierii funkcji.
Teraz, gdy masz już wgląd w głębokie uczenie się, przyjrzyjmy się, czym jest Caffe.
Szkolenie CNN
Poznajmy proces szkolenia CNN w zakresie klasyfikowania obrazów. Proces składa się z następujących kroków -
Data Preparation- Na tym etapie wyśrodkowujemy obrazy i zmieniamy ich rozmiar, aby wszystkie obrazy do szkolenia i testowania miały ten sam rozmiar. Odbywa się to zwykle poprzez uruchomienie małego skryptu w Pythonie na danych obrazu.
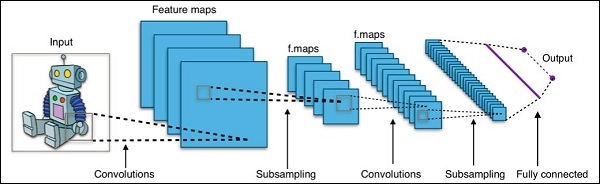
Model Definition- Na tym etapie definiujemy architekturę CNN. Konfiguracja jest przechowywana w.pb (protobuf)plik. Typową architekturę CNN przedstawiono na poniższym rysunku.
Solver Definition- Definiujemy plik konfiguracyjny solvera. Solver przeprowadza optymalizację modelu.
Model Training- Używamy wbudowanego narzędzia Caffe do trenowania modelu. Szkolenie może zająć dużo czasu i zużycie procesora. Po zakończeniu szkolenia Caffe przechowuje model w pliku, którego można później użyć na danych testowych i ostatecznym wdrożeniu na potrzeby prognoz.
Co nowego w Caffe2
W Caffe2 można znaleźć wiele gotowych do użycia wstępnie wytrenowanych modeli, a także dość często korzystać z wkładu społeczności w nowe modele i algorytmy. Tworzone modele można łatwo skalować w górę, korzystając z mocy GPU w chmurze, a także można je sprowadzić do użycia mas na urządzeniach mobilnych dzięki bibliotekom wieloplatformowym.
Ulepszenia wprowadzone w Caffe2 w porównaniu z Caffe można podsumować w następujący sposób -
- Wdrożenie mobilne
- Nowa obsługa sprzętu
- Wsparcie dla rozproszonych szkoleń na dużą skalę
- Obliczenia kwantowe
- Test stresu na Facebooku
Wstępnie wytrenowany model demonstracyjny
Witryna Berkeley Vision and Learning Center (BVLC) zawiera prezentacje ich wstępnie przeszkolonych sieci. Jedna taka sieć klasyfikacji obrazów jest dostępna pod podanym tutaj linkiemhttps://caffe2.ai/docs/learn-more#null__caffe-neural-network-for-image-classification i jest przedstawione na poniższym zrzucie ekranu.
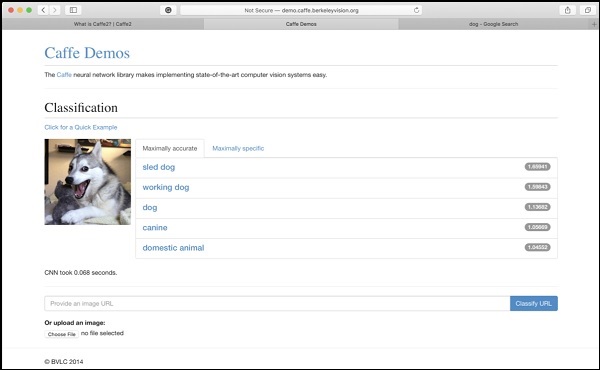
Na zrzucie ekranu wizerunek psa jest klasyfikowany i oznaczany zgodnie z dokładnością przewidywania. Mówi też, że wystarczyło0.068 secondsdo klasyfikacji obrazu. Możesz wypróbować wybrany przez siebie obraz, podając adres URL obrazu lub przesyłając sam obraz w opcjach podanych na dole ekranu.
Teraz, gdy masz wystarczająco dużo wglądu w możliwości Caffe2, czas na samodzielne eksperymentowanie z Caffe2. Aby użyć wstępnie wytrenowanych modeli lub opracować modele we własnym kodzie Pythona, musisz najpierw zainstalować Caffe2 na swoim komputerze.
Na stronie instalacyjnej witryny Caffe2 dostępnej pod linkiem https://caffe2.ai/docs/getting-started.html zobaczysz następujące informacje, aby wybrać platformę i typ instalacji.

Jak widać na powyższym zrzucie ekranu, Caffe2 obsługuje kilka popularnych platform, w tym mobilne.
Teraz zrozumiemy kroki dla MacOS installation na którym testowane są wszystkie projekty w tym samouczku.
Instalacja MacOS
Instalacja może być czterech typów, jak podano poniżej -
- Gotowe pliki binarne
- Kompiluj ze źródła
- Obrazy platformy Docker
- Cloud
W zależności od preferencji wybierz dowolny z powyższych jako typ instalacji. Instrukcje podane tutaj są zgodne z witryną instalacyjną Caffe2 dlapre-built binaries. Używa Anacondy doJupyter environment. Wykonaj następujące polecenie w wierszu polecenia konsoli
pip install torch_nightly -f
https://download.pytorch.org/whl/nightly/cpu/torch_nightly.htmlOprócz powyższego będziesz potrzebować kilku bibliotek innych firm, które są instalowane za pomocą następujących poleceń -
conda install -c anaconda setuptools
conda install -c conda-forge graphviz
conda install -c conda-forge hypothesis
conda install -c conda-forge ipython
conda install -c conda-forge jupyter
conda install -c conda-forge matplotlib
conda install -c anaconda notebook
conda install -c anaconda pydot
conda install -c conda-forge python-nvd3
conda install -c anaconda pyyaml
conda install -c anaconda requests
conda install -c anaconda scikit-image
conda install -c anaconda scipyNiektóre samouczki na stronie Caffe2 wymagają również instalacji zeromq, który jest instalowany za pomocą następującego polecenia -
conda install -c anaconda zeromqInstalacja w systemie Windows / Linux
Wykonaj następujące polecenie w wierszu polecenia konsoli -
conda install -c pytorch pytorch-nightly-cpuJak pewnie zauważyłeś, do korzystania z powyższej instalacji potrzebujesz Anacondy. Będziesz musiał zainstalować dodatkowe pakiety, jak określono wMacOS installation.
Testowanie instalacji
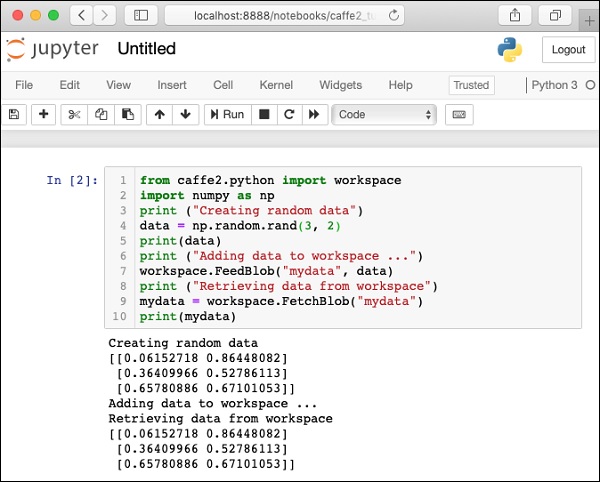
Aby przetestować instalację, poniżej znajduje się mały skrypt Pythona, który można wyciąć i wkleić w projekcie Juypter i wykonać.
from caffe2.python import workspace
import numpy as np
print ("Creating random data")
data = np.random.rand(3, 2)
print(data)
print ("Adding data to workspace ...")
workspace.FeedBlob("mydata", data)
print ("Retrieving data from workspace")
mydata = workspace.FetchBlob("mydata")
print(mydata)Po wykonaniu powyższego kodu powinieneś zobaczyć następujące dane wyjściowe -
Creating random data
[[0.06152718 0.86448082]
[0.36409966 0.52786113]
[0.65780886 0.67101053]]
Adding data to workspace ...
Retrieving data from workspace
[[0.06152718 0.86448082]
[0.36409966 0.52786113]
[0.65780886 0.67101053]]Zrzut ekranu strony testowej instalacji jest pokazany tutaj w celu szybkiego odniesienia -
Teraz, gdy zainstalowałeś Caffe2 na swoim komputerze, przejdź do instalacji aplikacji samouczków.
Instalacja samouczka
Pobierz źródło samouczków za pomocą następującego polecenia na konsoli -
git clone --recursive https://github.com/caffe2/tutorials caffe2_tutorialsPo zakończeniu pobierania znajdziesz kilka projektów Pythona w caffe2_tutorialsfolder w katalogu instalacyjnym. Zrzut ekranu tego folderu jest udostępniony do szybkiego przejrzenia.
/Users/yourusername/caffe2_tutorials
Możesz otworzyć niektóre z tych samouczków, aby zobaczyć, co Caffe2 codewygląda jak. Kolejne dwa projekty opisane w tym samouczku są w dużej mierze oparte na przykładach pokazanych powyżej.
Nadszedł czas, aby wykonać własne kodowanie w Pythonie. Zrozummy, jak używać wstępnie wytrenowanego modelu z Caffe2. Później nauczysz się tworzyć własną trywialną sieć neuronową do treningu na własnym zestawie danych.
Zanim nauczysz się używać wstępnie wytrenowanego modelu w aplikacji Python, najpierw sprawdźmy, czy modele są zainstalowane na Twoim komputerze i są dostępne za pośrednictwem kodu Pythona.
Podczas instalowania Caffe2 wstępnie wytrenowane modele są kopiowane do folderu instalacyjnego. Na komputerze z instalacją Anaconda modele te są dostępne w następującym folderze.
anaconda3/lib/python3.7/site-packages/caffe2/python/modelsSprawdź folder instalacyjny na swoim komputerze, aby sprawdzić obecność tych modeli. Możesz spróbować załadować te modele z folderu instalacyjnego za pomocą następującego krótkiego skryptu w języku Python -
CAFFE_MODELS = os.path.expanduser("/anaconda3/lib/python3.7/site-packages/caffe2/python/models")
INIT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'init_net.pb')
PREDICT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'predict_net.pb')
print(INIT_NET)
print(PREDICT_NET)Po pomyślnym uruchomieniu skryptu zobaczysz następujące dane wyjściowe -
/anaconda3/lib/python3.7/site-packages/caffe2/python/models/squeezenet/init_net.pb
/anaconda3/lib/python3.7/site-packages/caffe2/python/models/squeezenet/predict_net.pbPotwierdza to, że squeezenet moduł jest zainstalowany na twoim komputerze i jest dostępny dla twojego kodu.
Teraz możesz napisać własny kod Pythona do klasyfikacji obrazów przy użyciu Caffe2 squeezenet wstępnie przeszkolony moduł.
W tej lekcji nauczysz się używać wstępnie wytrenowanego modelu do wykrywania obiektów na danym obrazie. Będziesz używaćsqueezenet wstępnie wyszkolony moduł, który z dużą dokładnością wykrywa i klasyfikuje obiekty na danym obrazie.
Otwórz nowy Juypter notebook i postępuj zgodnie z instrukcjami, aby opracować tę aplikację do klasyfikacji obrazów.
Importowanie bibliotek
Najpierw importujemy wymagane pakiety za pomocą poniższego kodu -
from caffe2.proto import caffe2_pb2
from caffe2.python import core, workspace, models
import numpy as np
import skimage.io
import skimage.transform
from matplotlib import pyplot
import os
import urllib.request as urllib2
import operatorNastępnie skonfigurowaliśmy kilka variables -
INPUT_IMAGE_SIZE = 227
mean = 128Obrazy używane do treningu będą oczywiście miały różne rozmiary. Wszystkie te obrazy muszą zostać przekonwertowane na stały rozmiar, aby zapewnić dokładne szkolenie. Podobnie obrazy testowe i obraz, który chcesz przewidzieć w środowisku produkcyjnym, również muszą zostać przekonwertowane na rozmiar, taki sam jak używany podczas treningu. W ten sposób tworzymy zmienną powyżej o nazwieINPUT_IMAGE_SIZE mający wartość 227. Dlatego przekonwertujemy wszystkie nasze obrazy do rozmiaru227x227 przed użyciem w naszym klasyfikatorze.
Deklarujemy również zmienną o nazwie mean mający wartość 128, który jest później używany do poprawy wyników klasyfikacji.
Następnie opracujemy dwie funkcje do przetwarzania obrazu.
Przetwarzanie obrazu
Przetwarzanie obrazu składa się z dwóch etapów. Pierwsza to zmiana rozmiaru obrazu, a druga to centralne przycięcie obrazu. W tych dwóch krokach napiszemy dwie funkcje do zmiany rozmiaru i kadrowania.
Zmiana rozmiaru obrazu
Najpierw napiszemy funkcję do zmiany rozmiaru obrazu. Jak wspomniano wcześniej, zmienimy rozmiar obrazu na227x227. Zdefiniujmy więc funkcjęresize w następujący sposób -
def resize(img, input_height, input_width):Współczynnik kształtu obrazu uzyskujemy, dzieląc szerokość przez wysokość.
original_aspect = img.shape[1]/float(img.shape[0])Jeśli współczynnik proporcji jest większy niż 1, oznacza to, że obraz jest szeroki, to znaczy w trybie poziomym. Teraz dostosowujemy wysokość obrazu i zwracamy obraz o zmienionym rozmiarze, używając następującego kodu -
if(original_aspect>1):
new_height = int(original_aspect * input_height)
return skimage.transform.resize(img, (input_width,
new_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)Jeśli współczynnik proporcji to less than 1, to wskazuje portrait mode. Teraz dostosowujemy szerokość za pomocą następującego kodu -
if(original_aspect<1):
new_width = int(input_width/original_aspect)
return skimage.transform.resize(img, (new_width,
input_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)Jeśli współczynnik proporcji jest równy 1, nie dokonujemy żadnych regulacji wysokości / szerokości.
if(original_aspect == 1):
return skimage.transform.resize(img, (input_width,
input_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)Pełny kod funkcji jest podany poniżej w celu szybkiego odniesienia -
def resize(img, input_height, input_width):
original_aspect = img.shape[1]/float(img.shape[0])
if(original_aspect>1):
new_height = int(original_aspect * input_height)
return skimage.transform.resize(img, (input_width,
new_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)
if(original_aspect<1):
new_width = int(input_width/original_aspect)
return skimage.transform.resize(img, (new_width,
input_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)
if(original_aspect == 1):
return skimage.transform.resize(img, (input_width,
input_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)Napiszemy teraz funkcję przycinania obrazu wokół jego środka.
Kadrowanie obrazu
Deklarujemy crop_image działają w następujący sposób -
def crop_image(img,cropx,cropy):Wyodrębniamy wymiary obrazu za pomocą następującego stwierdzenia -
y,x,c = img.shapeTworzymy nowy punkt początkowy dla obrazu, używając następujących dwóch wierszy kodu -
startx = x//2-(cropx//2)
starty = y//2-(cropy//2)Na koniec zwracamy przycięty obraz, tworząc obiekt obrazu o nowych wymiarach -
return img[starty:starty+cropy,startx:startx+cropx]Cały kod funkcji jest podany poniżej w celu szybkiego odniesienia -
def crop_image(img,cropx,cropy):
y,x,c = img.shape
startx = x//2-(cropx//2)
starty = y//2-(cropy//2)
return img[starty:starty+cropy,startx:startx+cropx]Teraz napiszemy kod do testowania tych funkcji.
Przetwarzanie obrazu
Najpierw skopiuj plik obrazu do images podfolder w katalogu projektu. tree.jpgplik jest kopiowany w projekcie. Poniższy kod Pythona ładuje obraz i wyświetla go na konsoli -
img = skimage.img_as_float(skimage.io.imread("images/tree.jpg")).astype(np.float32)
print("Original Image Shape: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Original image')Dane wyjściowe są następujące -
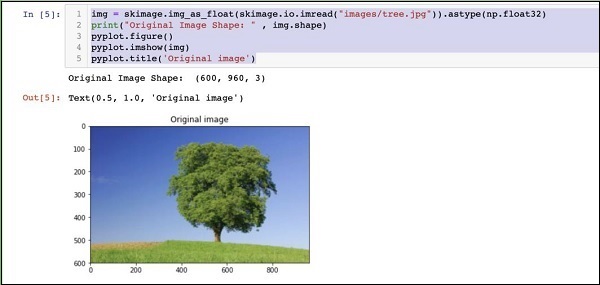
Zwróć uwagę, że rozmiar oryginalnego obrazu to 600 x 960. Musimy zmienić rozmiar tego do naszej specyfikacji227 x 227. Wołanie naszego wcześniej zdefiniowanegoresizefunkcja wykonuje tę pracę.
img = resize(img, INPUT_IMAGE_SIZE, INPUT_IMAGE_SIZE)
print("Image Shape after resizing: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Resized image')Wynik jest taki, jak podano poniżej -
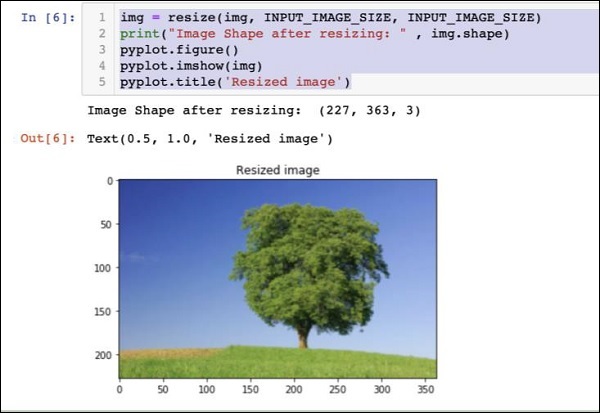
Zwróć uwagę, że teraz rozmiar obrazu to 227 x 363. Musimy to przyciąć227 x 227dla końcowego kanału do naszego algorytmu. W tym celu nazywamy wcześniej zdefiniowaną funkcję crop.
img = crop_image(img, INPUT_IMAGE_SIZE, INPUT_IMAGE_SIZE)
print("Image Shape after cropping: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Center Cropped')Poniżej wymienione jest wyjście kodu -
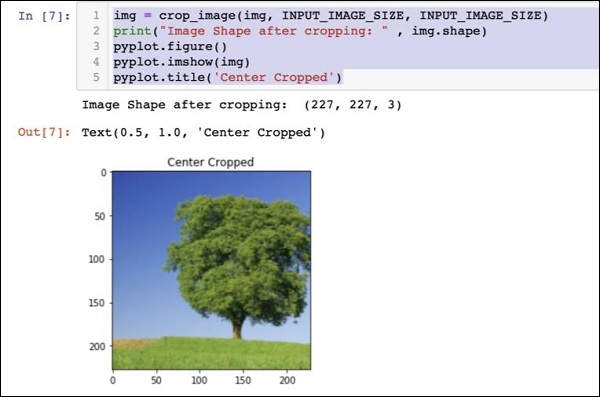
W tym momencie obraz ma rozmiar 227 x 227i jest gotowy do dalszej obróbki. Teraz zamieniamy osie obrazu, aby wyodrębnić trzy kolory do trzech różnych stref.
img = img.swapaxes(1, 2).swapaxes(0, 1)
print("CHW Image Shape: " , img.shape)Poniżej podano wynik -
CHW Image Shape: (3, 227, 227)Zauważ, że ostatnia oś stała się teraz pierwszym wymiarem w szyku. Teraz wykreślimy trzy kanały za pomocą następującego kodu -
pyplot.figure()
for i in range(3):
pyplot.subplot(1, 3, i+1)
pyplot.imshow(img[i])
pyplot.axis('off')
pyplot.title('RGB channel %d' % (i+1))Dane wyjściowe podano poniżej -

Na koniec wykonujemy dodatkowe przetwarzanie obrazu, takie jak konwersja Red Green Blue do Blue Green Red (RGB to BGR), usuwając średnią dla lepszych wyników i dodając oś wielkości partii przy użyciu następujących trzech wierszy kodu -
# convert RGB --> BGR
img = img[(2, 1, 0), :, :]
# remove mean
img = img * 255 - mean
# add batch size axis
img = img[np.newaxis, :, :, :].astype(np.float32)W tym momencie Twój obraz jest w formacie NCHW formati jest gotowy do wprowadzenia do naszej sieci. Następnie załadujemy nasze wstępnie wytrenowane pliki modelu i przekażemy do niego powyższy obraz w celu przewidywania.
Przewidywanie obiektów w przetworzonym obrazie
Najpierw konfigurujemy ścieżki dla init i predict sieci zdefiniowane we wstępnie wytrenowanych modelach Caffe.
Ustawianie ścieżek do plików modelu
Pamiętaj z naszej wcześniejszej dyskusji, że wszystkie wstępnie wyszkolone modele są zainstalowane w modelsteczka. Skonfigurowaliśmy ścieżkę do tego folderu w następujący sposób -
CAFFE_MODELS = os.path.expanduser("/anaconda3/lib/python3.7/site-packages/caffe2/python/models")Ustanowiliśmy ścieżkę do init_net protobuf pliku squeezenet model w następujący sposób -
INIT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'init_net.pb')W podobny sposób utworzyliśmy ścieżkę do predict_net protobuf w następujący sposób -
PREDICT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'predict_net.pb')Drukujemy dwie ścieżki do celów diagnostycznych -
print(INIT_NET)
print(PREDICT_NET)Powyższy kod wraz z danymi wyjściowymi jest podany tutaj w celu szybkiego odniesienia -
CAFFE_MODELS = os.path.expanduser("/anaconda3/lib/python3.7/site-packages/caffe2/python/models")
INIT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'init_net.pb')
PREDICT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'predict_net.pb')
print(INIT_NET)
print(PREDICT_NET)Dane wyjściowe są wymienione poniżej -
/anaconda3/lib/python3.7/site-packages/caffe2/python/models/squeezenet/init_net.pb
/anaconda3/lib/python3.7/site-packages/caffe2/python/models/squeezenet/predict_net.pbNastępnie utworzymy predyktor.
Tworzenie Predictora
Czytamy pliki modelu, korzystając z następujących dwóch instrukcji -
with open(INIT_NET, "rb") as f:
init_net = f.read()
with open(PREDICT_NET, "rb") as f:
predict_net = f.read()Predykator jest tworzony przez przekazanie wskaźników do dwóch plików jako parametrów do pliku Predictor funkcjonować.
p = workspace.Predictor(init_net, predict_net)Plik pobiekt jest predyktorem używanym do przewidywania obiektów na dowolnym podanym obrazie. Zauważ, że każdy obraz wejściowy musi być w formacie NCHW, tak jak to zrobiliśmy wcześniej w naszymtree.jpg plik.
Przewidywanie obiektów
Przewidywanie obiektów na danym obrazku jest trywialne - wystarczy wykonać jedną linię polecenia. Nazywamyrun metoda na predictor obiekt do wykrycia obiektu na danym obrazie.
results = p.run({'data': img})Wyniki prognozy są teraz dostępne w results obiekt, który konwertujemy na tablicę dla naszej czytelności.
results = np.asarray(results)Wydrukuj wymiary tablicy dla zrozumienia, używając następującej instrukcji -
print("results shape: ", results.shape)Wyjście jest jak pokazano poniżej -
results shape: (1, 1, 1000, 1, 1)Teraz usuniemy niepotrzebną oś -
preds = np.squeeze(results)Najwyższe orzeczenie można teraz pobrać, biorąc rozszerzenie max wartość w preds szyk.
curr_pred, curr_conf = max(enumerate(preds), key=operator.itemgetter(1))
print("Prediction: ", curr_pred)
print("Confidence: ", curr_conf)Dane wyjściowe są następujące -
Prediction: 984
Confidence: 0.89235985Jak widać, model przewidział obiekt z wartością indeksu 984 z 89%pewność siebie. Indeks 984 nie ma dla nas większego sensu w zrozumieniu, jaki rodzaj obiektu jest wykrywany. Musimy uzyskać ujednoliconą nazwę obiektu za pomocą jego wartości indeksu. Rodzaj obiektów, które model rozpoznaje wraz z odpowiadającymi im wartościami indeksu, jest dostępny w repozytorium github.
Teraz zobaczymy, jak pobrać nazwę naszego obiektu o wartości indeksu 984.
Wynik usztywniający
Tworzymy obiekt URL do repozytorium github w następujący sposób -
codes = "https://gist.githubusercontent.com/aaronmarkham/cd3a6b6ac0
71eca6f7b4a6e40e6038aa/raw/9edb4038a37da6b5a44c3b5bc52e448ff09bfe5b/alexnet_codes"Przeczytaliśmy zawartość adresu URL -
response = urllib2.urlopen(codes)Odpowiedź będzie zawierała listę wszystkich kodów i ich opisy. Poniżej przedstawiono kilka wierszy odpowiedzi, aby zrozumieć, co zawiera -
5: 'electric ray, crampfish, numbfish, torpedo',
6: 'stingray',
7: 'cock',
8: 'hen',
9: 'ostrich, Struthio camelus',
10: 'brambling, Fringilla montifringilla',Teraz iterujemy całą tablicę, aby zlokalizować nasz pożądany kod 984 za pomocą pliku for pętla w następujący sposób -
for line in response:
mystring = line.decode('ascii')
code, result = mystring.partition(":")[::2]
code = code.strip()
result = result.replace("'", "")
if (code == str(curr_pred)):
name = result.split(",")[0][1:]
print("Model predicts", name, "with", curr_conf, "confidence")Po uruchomieniu kodu zobaczysz następujące dane wyjściowe -
Model predicts rapeseed with 0.89235985 confidenceMożesz teraz wypróbować model na innym zdjęciu.
Przewidywanie innego obrazu
Aby przewidzieć inny obraz, po prostu skopiuj plik obrazu do pliku imagesfolder katalogu twojego projektu. To jest katalog, w którym nasz wcześniejszy pliktree.jpgplik jest przechowywany. Zmień nazwę pliku obrazu w kodzie. Wymagana jest tylko jedna zmiana, jak pokazano poniżej
img = skimage.img_as_float(skimage.io.imread("images/pretzel.jpg")).astype(np.float32)Oryginalny obraz i wynik prognozy pokazano poniżej -

Dane wyjściowe są wymienione poniżej -
Model predicts pretzel with 0.99999976 confidenceJak widać, wstępnie wytrenowany model jest w stanie wykryć obiekty na danym obrazie z dużą dokładnością.
Pełne źródło
Pełne źródło powyższego kodu, które używa wstępnie wytrenowanego modelu do wykrywania obiektów na danym obrazie, jest wymienione tutaj dla szybkiego odniesienia -
def crop_image(img,cropx,cropy):
y,x,c = img.shape
startx = x//2-(cropx//2)
starty = y//2-(cropy//2)
return img[starty:starty+cropy,startx:startx+cropx]
img = skimage.img_as_float(skimage.io.imread("images/pretzel.jpg")).astype(np.float32)
print("Original Image Shape: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Original image')
img = resize(img, INPUT_IMAGE_SIZE, INPUT_IMAGE_SIZE)
print("Image Shape after resizing: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Resized image')
img = crop_image(img, INPUT_IMAGE_SIZE, INPUT_IMAGE_SIZE)
print("Image Shape after cropping: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Center Cropped')
img = img.swapaxes(1, 2).swapaxes(0, 1)
print("CHW Image Shape: " , img.shape)
pyplot.figure()
for i in range(3):
pyplot.subplot(1, 3, i+1)
pyplot.imshow(img[i])
pyplot.axis('off')
pyplot.title('RGB channel %d' % (i+1))
# convert RGB --> BGR
img = img[(2, 1, 0), :, :]
# remove mean
img = img * 255 - mean
# add batch size axis
img = img[np.newaxis, :, :, :].astype(np.float32)
CAFFE_MODELS = os.path.expanduser("/anaconda3/lib/python3.7/site-packages/caffe2/python/models")
INIT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'init_net.pb')
PREDICT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'predict_net.pb')
print(INIT_NET)
print(PREDICT_NET)
with open(INIT_NET, "rb") as f:
init_net = f.read()
with open(PREDICT_NET, "rb") as f:
predict_net = f.read()
p = workspace.Predictor(init_net, predict_net)
results = p.run({'data': img})
results = np.asarray(results)
print("results shape: ", results.shape)
preds = np.squeeze(results)
curr_pred, curr_conf = max(enumerate(preds), key=operator.itemgetter(1))
print("Prediction: ", curr_pred)
print("Confidence: ", curr_conf)
codes = "https://gist.githubusercontent.com/aaronmarkham/cd3a6b6ac071eca6f7b4a6e40e6038aa/raw/9edb4038a37da6b5a44c3b5bc52e448ff09bfe5b/alexnet_codes"
response = urllib2.urlopen(codes)
for line in response:
mystring = line.decode('ascii')
code, result = mystring.partition(":")[::2]
code = code.strip()
result = result.replace("'", "")
if (code == str(curr_pred)):
name = result.split(",")[0][1:]
print("Model predicts", name, "with", curr_conf, "confidence")W tym czasie wiesz, jak używać wstępnie wytrenowanego modelu do wykonywania prognoz w zbiorze danych.
Następnie dowiesz się, jak zdefiniować swój neural network (NN) architektury w Caffe2i trenuj je na swoim zbiorze danych. Dowiemy się teraz, jak utworzyć trywialny jednowarstwowy NN.
W tej lekcji nauczysz się definiować plik single layer neural network (NN)w Caffe2 i uruchom go na losowo wygenerowanym zbiorze danych. Napiszemy kod przedstawiający graficznie architekturę sieci, dane wejściowe i wyjściowe drukowania, wagi i wartości odchylenia. Aby zrozumieć tę lekcję, musisz się z nią zapoznaćneural network architectures, jego terms i mathematics używane w nich.
Architektura sieci
Rozważmy, że chcemy zbudować pojedynczą warstwę NN, jak pokazano na poniższym rysunku -

Matematycznie ta sieć jest reprezentowana przez następujący kod Pythona -
Y = X * W^T + bGdzie X, W, b są tensorami i Yjest wyjściem. Wypełnimy wszystkie trzy tensory pewnymi przypadkowymi danymi, uruchomimy sieć i zbadamy plikYwynik. Aby zdefiniować sieć i tensory, Caffe2 udostępnia kilkaOperator Funkcje.
Operatory Caffe2
W Caffe2 Operatorjest podstawową jednostką obliczeniową. The Caffe2Operator przedstawia się następująco.
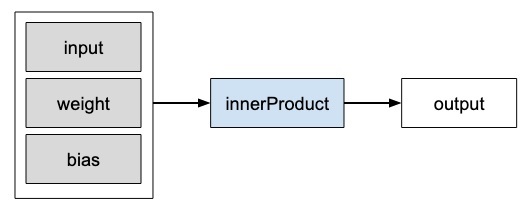
Caffe2 zawiera wyczerpującą listę operatorów. Dla sieci, którą aktualnie projektujemy, użyjemy operatora o nazwie FC, który oblicza wynik przekazania wektora wejściowegoX w w pełni połączoną sieć z dwuwymiarową macierzą wag W i jednowymiarowy wektor odchylenia b. Innymi słowy, oblicza następujące równanie matematyczne
Y = X * W^T + bGdzie X ma wymiary (M x k), W ma wymiary (n x k) i b jest (1 x n). WyjścieY będzie mieć wymiar (M x n), gdzie M to wielkość partii.
Dla wektorów X i W, użyjemy GaussianFilloperator do tworzenia losowych danych. Do generowania wartości odchyleniab, użyjemy ConstantFill operator.
Przejdziemy teraz do zdefiniowania naszej sieci.
Tworzenie sieci
Przede wszystkim zaimportuj wymagane pakiety -
from caffe2.python import core, workspaceNastępnie określ sieć, dzwoniąc core.Net w następujący sposób -
net = core.Net("SingleLayerFC")Nazwa sieci jest określona jako SingleLayerFC. W tym momencie tworzony jest obiekt sieciowy o nazwie net. Na razie nie zawiera żadnych warstw.
Tworzenie tensorów
Utworzymy teraz trzy wektory wymagane przez naszą sieć. Najpierw utworzymy tensor X przez wywołanieGaussianFill operator w następujący sposób -
X = net.GaussianFill([], ["X"], mean=0.0, std=1.0, shape=[2, 3], run_once=0)Plik X wektor ma wymiary 2 x 3 ze średnią wartością danych 0,0 i odchyleniem standardowym wynoszącym 1.0.
Podobnie my tworzymy W tensor w następujący sposób -
W = net.GaussianFill([], ["W"], mean=0.0, std=1.0, shape=[5, 3], run_once=0)Plik W wektor ma rozmiar 5 x 3.
Wreszcie tworzymy stronniczość b matryca o rozmiarze 5.
b = net.ConstantFill([], ["b"], shape=[5,], value=1.0, run_once=0)Teraz najważniejsza część kodu, czyli definiowanie samej sieci.
Definiowanie sieci
Definiujemy sieć w poniższej instrukcji Pythona -
Y = X.FC([W, b], ["Y"])Nazywamy FC operator danych wejściowych X. Wagi są określone wWi stronniczość w b. Wynik jestY. Alternatywnie możesz utworzyć sieć za pomocą poniższej instrukcji Pythona, która jest bardziej szczegółowa.
Y = net.FC([X, W, b], ["Y"])W tym momencie sieć jest po prostu tworzona. Dopóki przynajmniej raz nie uruchomimy sieci, nie będzie ona zawierała żadnych danych. Przed uruchomieniem sieci zbadamy jej architekturę.
Drukowanie architektury sieci
Caffe2 definiuje architekturę sieci w pliku JSON, który można sprawdzić, wywołując metodę Proto na utworzonym net obiekt.
print (net.Proto())Daje to następujący wynik -
name: "SingleLayerFC"
op {
output: "X"
name: ""
type: "GaussianFill"
arg {
name: "mean"
f: 0.0
}
arg {
name: "std"
f: 1.0
}
arg {
name: "shape"
ints: 2
ints: 3
}
arg {
name: "run_once"
i: 0
}
}
op {
output: "W"
name: ""
type: "GaussianFill"
arg {
name: "mean"
f: 0.0
}
arg {
name: "std"
f: 1.0
}
arg {
name: "shape"
ints: 5
ints: 3
}
arg {
name: "run_once"
i: 0
}
}
op {
output: "b"
name: ""
type: "ConstantFill"
arg {
name: "shape"
ints: 5
}
arg {
name: "value"
f: 1.0
}
arg {
name: "run_once"
i: 0
}
}
op {
input: "X"
input: "W"
input: "b"
output: "Y"
name: ""
type: "FC"
}Jak widać na powyższej liście, najpierw definiuje operatory X, W i b. Przeanalizujmy definicjęWjako przykład. TypW jest określony jako GausianFill. Plikmean jest zdefiniowany jako float 0.0, odchylenie standardowe określa się jako zmiennoprzecinkowe 1.0i shape jest 5 x 3.
op {
output: "W"
name: "" type: "GaussianFill"
arg {
name: "mean"
f: 0.0
}
arg {
name: "std"
f: 1.0
}
arg {
name: "shape"
ints: 5
ints: 3
}
...
}Sprawdź definicje X i bdla własnego zrozumienia. Na koniec przyjrzyjmy się definicji naszej sieci jednowarstwowej, która została tutaj odtworzona
op {
input: "X"
input: "W"
input: "b"
output: "Y"
name: ""
type: "FC"
}Tutaj typ sieci to FC (W pełni połączony) z X, W, b jako wejścia i Yjest wyjściem. Ta definicja sieci jest zbyt szczegółowa i w przypadku dużych sieci badanie jej zawartości będzie nudne. Na szczęście Caffe2 zapewnia graficzną reprezentację utworzonych sieci.
Graficzna reprezentacja sieci
Aby uzyskać graficzną reprezentację sieci, uruchom następujący fragment kodu, który jest zasadniczo tylko dwoma wierszami kodu Pythona.
from caffe2.python import net_drawer
from IPython import display
graph = net_drawer.GetPydotGraph(net, rankdir="LR")
display.Image(graph.create_png(), width=800)Po uruchomieniu kodu zobaczysz następujące dane wyjściowe -
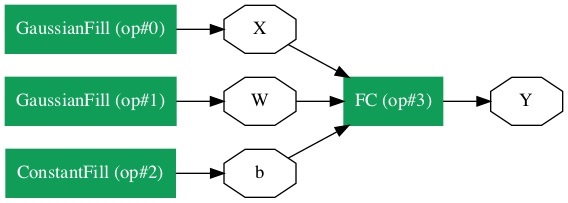
W przypadku dużych sieci reprezentacja graficzna staje się niezwykle przydatna w wizualizacji i debugowaniu błędów definicji sieci.
Wreszcie nadszedł czas, aby uruchomić sieć.
Uruchomiona sieć
Uruchamiasz sieć, dzwoniąc pod numer RunNetOnce metoda na workspace obiekt -
workspace.RunNetOnce(net)Po jednorazowym uruchomieniu sieci wszystkie nasze dane, które są generowane losowo, zostaną utworzone, wprowadzone do sieci i utworzone zostaną dane wyjściowe. Nazywa się tensory, które powstają po uruchomieniu sieciblobsw Caffe2. Obszar roboczy składa się zblobstworzysz i przechowujesz w pamięci. Jest to dość podobne do Matlab.
Po uruchomieniu sieci możesz sprawdzić plik blobs że obszar roboczy zawiera następujące elementy print Komenda
print("Blobs in the workspace: {}".format(workspace.Blobs()))Zobaczysz następujący wynik -
Blobs in the workspace: ['W', 'X', 'Y', 'b']Zwróć uwagę, że obszar roboczy składa się z trzech wejściowych obiektów blob - X, W i b. Zawiera również wyjściowy obiekt BLOB o nazwieY. Przeanalizujmy teraz zawartość tych plamek.
for name in workspace.Blobs():
print("{}:\n{}".format(name, workspace.FetchBlob(name)))Zobaczysz następujący wynik -
W:
[[ 1.0426593 0.15479846 0.25635982]
[-2.2461145 1.4581774 0.16827184]
[-0.12009818 0.30771437 0.00791338]
[ 1.2274994 -0.903331 -0.68799865]
[ 0.30834186 -0.53060573 0.88776857]]
X:
[[ 1.6588869e+00 1.5279824e+00 1.1889904e+00]
[ 6.7048723e-01 -9.7490678e-04 2.5114202e-01]]
Y:
[[ 3.2709925 -0.297907 1.2803618 0.837985 1.7562964]
[ 1.7633215 -0.4651525 0.9211631 1.6511179 1.4302125]]
b:
[1. 1. 1. 1. 1.]Zauważ, że dane na twoim komputerze lub w rzeczywistości przy każdym uruchomieniu sieci byłyby inne, ponieważ wszystkie wejścia są tworzone losowo. Teraz pomyślnie zdefiniowałeś sieć i uruchomiłeś ją na swoim komputerze.
W poprzedniej lekcji nauczyłeś się tworzyć trywialną sieć i nauczyłeś się, jak ją wykonywać i analizować wyniki. Proces tworzenia złożonych sieci jest podobny do procesu opisanego powyżej. Caffe2 zapewnia ogromny zestaw operatorów do tworzenia złożonych architektur. Zachęcamy do przejrzenia dokumentacji Caffe2 w celu znalezienia listy operatorów. Po zapoznaniu się z przeznaczeniem różnych operatorów będziesz w stanie tworzyć złożone sieci i szkolić je. Do szkolenia sieci Caffe2 udostępnia kilkapredefined computation units- to operatorzy. Będziesz musiał wybrać odpowiednich operatorów do przeszkolenia sieci pod kątem problemu, który próbujesz rozwiązać.
Gdy sieć zostanie odpowiednio przeszkolona, możesz zapisać ją w pliku modelu podobnym do wstępnie wytrenowanych plików modeli, których używałeś wcześniej. Te wyszkolone modele można wnieść do repozytorium Caffe2 z korzyścią dla innych użytkowników. Możesz też po prostu umieścić wyszkolony model na własny użytek produkcyjny.
Podsumowanie
Caffe2, który jest platformą uczenia głębokiego, umożliwia eksperymentowanie z kilkoma rodzajami sieci neuronowych w celu przewidywania danych. Witryna Caffe2 zapewnia wiele wstępnie wytrenowanych modeli. Nauczyłeś się używać jednego z wstępnie wytrenowanych modeli do klasyfikowania obiektów na danym obrazie. Nauczyłeś się również definiować wybraną architekturę sieci neuronowej. Takie sieci niestandardowe można trenować przy użyciu wielu predefiniowanych operatorów w Caffe. Wytrenowany model jest przechowywany w pliku, który można przenieść do środowiska produkcyjnego.