Krótki przewodnik po C ++
C ++ to statycznie wpisywany, skompilowany język programowania ogólnego przeznaczenia, z rozróżnianiem wielkości liter i dowolnego typu, który obsługuje programowanie proceduralne, obiektowe i ogólne.
C ++ jest uważany za plik middle-level język, ponieważ zawiera połączenie cech języka wysokiego i niskiego poziomu.
C ++ został opracowany przez Bjarne Stroustrup począwszy od 1979 roku w Bell Labs w Murray Hill w stanie New Jersey, jako rozszerzenie języka C i pierwotnie nazwany C z Classes, ale później został przemianowany na C ++ w 1983.
C ++ jest nadzbiorem języka C i praktycznie każdy legalny program w C jest legalnym programem w C ++.
Note - Mówi się, że język programowania używa wpisywania statycznego, gdy sprawdzanie typów jest wykonywane w czasie kompilacji, w przeciwieństwie do czasu wykonywania.
Programowanie obiektowe
C ++ w pełni obsługuje programowanie obiektowe, w tym cztery filary programowania obiektowego -
- Encapsulation
- Ukrywanie danych
- Inheritance
- Polymorphism
Biblioteki standardowe
Standardowy C ++ składa się z trzech ważnych części -
Podstawowy język zawierający wszystkie elementy konstrukcyjne, w tym zmienne, typy danych i literały itp.
Biblioteka standardowa C ++ oferująca bogaty zestaw funkcji manipulujących plikami, ciągami znaków itp.
Biblioteka szablonów standardowych (STL) zapewniająca bogaty zestaw metod manipulujących strukturami danych itp.
Standard ANSI
Standard ANSI jest próbą zapewnienia przenośności języka C ++; ten kod, który napiszesz dla kompilatora Microsoftu, skompiluje się bez błędów, używając kompilatora na komputerze Mac, UNIX, Windows Box lub Alpha.
Standard ANSI był stabilny od jakiegoś czasu, a wszyscy główni producenci kompilatorów C ++ obsługują standard ANSI.
Nauka C ++
Najważniejszą rzeczą podczas nauki C ++ jest skupienie się na pojęciach.
Celem nauki języka programowania jest stać się lepszym programistą; to znaczy bardziej efektywnie projektować i wdrażać nowe systemy oraz konserwować stare.
C ++ obsługuje różne style programowania. Możesz pisać w stylu Fortran, C, Smalltalk itp. W dowolnym języku. Każdy styl może skutecznie osiągnąć swoje cele, zachowując czas działania i wydajność przestrzeni.
Zastosowanie C ++
C ++ jest używany przez setki tysięcy programistów praktycznie w każdej domenie aplikacji.
C ++ jest często używany do pisania sterowników urządzeń i innego oprogramowania, które polega na bezpośredniej manipulacji sprzętem w warunkach ograniczeń czasu rzeczywistego.
C ++ jest szeroko stosowany w nauczaniu i badaniach, ponieważ jest wystarczająco czysty, aby skutecznie nauczać podstawowych pojęć.
Każdy, kto korzystał z Apple Macintosh lub PC z systemem Windows, pośrednio używał C ++, ponieważ podstawowe interfejsy użytkownika tych systemów są napisane w C ++.
Konfiguracja środowiska lokalnego
Jeśli nadal chcesz skonfigurować swoje środowisko dla C ++, musisz mieć na swoim komputerze następujące dwa programy.
Edytor tekstu
Będzie to użyte do wpisania twojego programu. Przykłady kilku edytorów obejmują Notatnik Windows, polecenie edycji systemu operacyjnego, Brief, Epsilon, EMACS i vim lub vi.
Nazwa i wersja edytora tekstu mogą się różnić w różnych systemach operacyjnych. Na przykład Notatnik będzie używany w systemie Windows, a vim lub vi może być używany w systemie Windows, a także w systemie Linux lub UNIX.
Pliki tworzone za pomocą edytora nazywane są plikami źródłowymi, aw przypadku języka C ++ zwykle mają one rozszerzenie .cpp, .cp lub .c.
Aby rozpocząć programowanie w C ++, powinien istnieć edytor tekstu.
Kompilator C ++
To jest rzeczywisty kompilator C ++, który zostanie użyty do skompilowania twojego kodu źródłowego do końcowego programu wykonywalnego.
Większość kompilatorów C ++ nie obchodzi, jakie rozszerzenie nadasz swojemu kodowi źródłowemu, ale jeśli nie określisz inaczej, wiele z nich będzie domyślnie używać .cpp.
Najczęściej używanym i darmowym kompilatorem jest kompilator GNU C / C ++, w przeciwnym razie możesz mieć kompilatory albo z HP, albo z Solaris, jeśli masz odpowiedni system operacyjny.
Instalowanie kompilatora GNU C / C ++
Instalacja w systemie UNIX / Linux
Jeśli używasz Linux or UNIX następnie sprawdź, czy GCC jest zainstalowane w twoim systemie, wprowadzając następujące polecenie z wiersza poleceń -
$ g++ -vJeśli zainstalowałeś GCC, powinien wydrukować komunikat taki jak następujący -
Using built-in specs.
Target: i386-redhat-linux
Configured with: ../configure --prefix=/usr .......
Thread model: posix
gcc version 4.1.2 20080704 (Red Hat 4.1.2-46)Jeśli GCC nie jest zainstalowane, będziesz musiał zainstalować go samodzielnie, korzystając ze szczegółowych instrukcji dostępnych pod adresem https://gcc.gnu.org/install/
Instalacja w systemie Mac OS X
Jeśli używasz Mac OS X, najłatwiejszym sposobem uzyskania GCC jest pobranie środowiska programistycznego Xcode ze strony Apple i wykonanie prostych instrukcji instalacji.
Xcode jest obecnie dostępny pod adresem developer.apple.com/technologies/tools/ .
Instalacja systemu Windows
Aby zainstalować GCC w systemie Windows, musisz zainstalować MinGW. Aby zainstalować MinGW, przejdź do strony domowej MinGW, www.mingw.org , i kliknij łącze do strony pobierania MinGW. Pobierz najnowszą wersję programu instalacyjnego MinGW o nazwie MinGW- <wersja> .exe.
Podczas instalacji MinGW, musisz przynajmniej zainstalować gcc-core, gcc-g ++, binutils i środowisko wykonawcze MinGW, ale możesz chcieć zainstalować więcej.
Dodaj podkatalog bin twojej instalacji MinGW do twojego PATH zmienną środowiskową, aby można było określić te narzędzia w wierszu poleceń za pomocą ich prostych nazw.
Po zakończeniu instalacji będziesz mógł uruchomić gcc, g ++, ar, ranlib, dlltool i kilka innych narzędzi GNU z wiersza poleceń systemu Windows.
Kiedy rozważamy program w C ++, można go zdefiniować jako zbiór obiektów, które komunikują się poprzez wywoływanie swoich metod. Przyjrzyjmy się teraz pokrótce, co oznaczają klasa, obiekt, metody i zmienne natychmiastowe.
Object- Przedmioty mają stany i zachowania. Przykład: Pies ma stany - maść, imię, rasę, a także zachowania - merdanie, szczekanie, jedzenie. Obiekt jest instancją klasy.
Class - Klasę można zdefiniować jako szablon / plan, który opisuje zachowania / stany, które obiekt tego typu obsługuje.
Methods- Metoda to w zasadzie zachowanie. Klasa może zawierać wiele metod. Dzieje się tak w metodach, w których zapisuje się logikę, manipuluje się danymi i wykonuje wszystkie akcje.
Instance Variables- Każdy obiekt ma swój unikalny zestaw zmiennych instancji. Stan obiektu jest tworzony przez wartości przypisane do tych zmiennych instancji.
Struktura programu C ++
Spójrzmy na prosty kod, który wypisuje słowa Hello World .
#include <iostream>
using namespace std;
// main() is where program execution begins.
int main() {
cout << "Hello World"; // prints Hello World
return 0;
}Spójrzmy na różne części powyższego programu -
Język C ++ definiuje kilka nagłówków, które zawierają informacje, które są albo konieczne, albo przydatne dla twojego programu. W przypadku tego programu plik header<iostream> jest potrzebne.
Linia using namespace std;informuje kompilator, aby używał przestrzeni nazw std. Przestrzenie nazw są stosunkowo nowym dodatkiem do C ++.
Następna linia ”// main() is where program execution begins.'to jednowierszowy komentarz dostępny w C ++. Komentarze jednowierszowe zaczynają się od // i kończą na końcu linii.
Linia int main() jest główną funkcją, od której rozpoczyna się wykonywanie programu.
Następna linia cout << "Hello World"; powoduje wyświetlenie na ekranie komunikatu „Hello World”.
Następna linia return 0; kończy funkcję main () i powoduje, że zwraca ona wartość 0 do procesu wywołującego.
Skompiluj i uruchom program w C ++
Spójrzmy, jak zapisać plik, skompilować i uruchomić program. Postępuj zgodnie z instrukcjami podanymi poniżej -
Otwórz edytor tekstu i dodaj kod jak powyżej.
Zapisz plik jako: hello.cpp
Otwórz wiersz polecenia i przejdź do katalogu, w którym zapisałeś plik.
Wpisz „g ++ hello.cpp” i naciśnij klawisz Enter, aby skompilować kod. Jeśli w kodzie nie ma błędów, wiersz polecenia przeniesie Cię do następnej linii i wygeneruje plik wykonywalny a.out.
Teraz wpisz „a.out”, aby uruchomić program.
Będziesz mógł zobaczyć napis „Hello World” w oknie.
$ g++ hello.cpp
$ ./a.out
Hello WorldUpewnij się, że w ścieżce znajduje się g ++ i że uruchamiasz go w katalogu zawierającym plik hello.cpp.
Możesz skompilować programy C / C ++ używając makefile. Aby uzyskać więcej informacji, zapoznaj się z naszym 'Samouczkiem Makefile' .
Średniki i bloki w C ++
W C ++ średnik jest zakończeniem instrukcji. Oznacza to, że każda instrukcja musi być zakończona średnikiem. Wskazuje koniec jednej logicznej jednostki.
Na przykład poniżej znajdują się trzy różne stwierdzenia -
x = y;
y = y + 1;
add(x, y);Blok to zestaw logicznie połączonych instrukcji, które są otoczone nawiasami otwierającymi i zamykającymi. Na przykład -
{
cout << "Hello World"; // prints Hello World
return 0;
}C ++ nie rozpoznaje końca wiersza jako terminatora. Z tego powodu nie ma znaczenia, gdzie umieścisz oświadczenie w wierszu. Na przykład -
x = y;
y = y + 1;
add(x, y);jest taki sam jak
x = y; y = y + 1; add(x, y);Identyfikatory C ++
Identyfikator C ++ to nazwa używana do identyfikowania zmiennej, funkcji, klasy, modułu lub dowolnego innego elementu zdefiniowanego przez użytkownika. Identyfikator zaczyna się od litery od A do Z lub od a do z lub znaku podkreślenia (_), po którym następuje zero lub więcej liter, podkreślników i cyfr (od 0 do 9).
C ++ nie zezwala na znaki interpunkcyjne, takie jak @, $ i% w identyfikatorach. C ++ to język programowania uwzględniający wielkość liter. A zatem,Manpower i manpower to dwa różne identyfikatory w C ++.
Oto kilka przykładów akceptowanych identyfikatorów -
mohd zara abc move_name a_123
myname50 _temp j a23b9 retValSłowa kluczowe C ++
Poniższa lista przedstawia zarezerwowane słowa w C ++. Te zarezerwowane słowa nie mogą być używane jako stałe, zmienne ani żadne inne nazwy identyfikatorów.
| jako M | jeszcze | Nowy | to |
| automatyczny | enum | operator | rzucać |
| bool | wyraźny | prywatny | prawdziwe |
| przerwa | eksport | chroniony | próbować |
| walizka | zewnętrzny | publiczny | typedef |
| łapać | fałszywy | zarejestrować | typid |
| zwęglać | pływak | reinterpret_cast | Wpisz imię |
| klasa | dla | powrót | unia |
| konst | przyjaciel | krótki | niepodpisany |
| const_cast | iść do | podpisany | za pomocą |
| kontyntynuj | gdyby | rozmiar | wirtualny |
| domyślna | inline | statyczny | unieważnić |
| usunąć | int | static_cast | lotny |
| zrobić | długo | struct | wchar_t |
| podwójnie | zmienny | przełącznik | podczas |
| dynamic_cast | przestrzeń nazw | szablon |
Trygrafy
Kilka znaków ma alternatywną reprezentację, zwaną sekwencją trygrafów. Trygraf to trzyznakowy ciąg, który reprezentuje pojedynczy znak, a sekwencja zawsze zaczyna się od dwóch znaków zapytania.
Trygrafy są rozwijane wszędzie tam, gdzie się pojawią, w tym w literałach łańcuchowych i literałach znakowych, w komentarzach i dyrektywach preprocesora.
Poniżej przedstawiono najczęściej używane sekwencje trygrafów -
| Trigraph | Zastąpienie |
|---|---|
| ?? = | # |
| ?? / | \ |
| ?? ' | ^ |
| ?? ( | [ |
| ??) | ] |
| ??! | | |
| ?? < | { |
| ??> | } |
| ?? - | ~ |
Wszystkie kompilatory nie obsługują trójgrafów i nie zaleca się ich używania ze względu na ich zagmatwany charakter.
Białe spacje w C ++
Linia zawierająca tylko białe znaki, być może z komentarzem, jest nazywana pustą linią, a kompilator C ++ całkowicie ją ignoruje.
Białe znaki to termin używany w C ++ do opisu spacji, tabulatorów, znaków nowej linii i komentarzy. Biała spacja oddziela jedną część instrukcji od drugiej i umożliwia kompilatorowi określenie, gdzie kończy się jeden element instrukcji, taki jak int, a zaczyna następny element.
Oświadczenie 1
int age;W powyższej instrukcji musi znajdować się co najmniej jeden znak odstępu (zwykle spacja) między int a age, aby kompilator mógł je rozróżnić.
Oświadczenie 2
fruit = apples + oranges; // Get the total fruitW powyższym zdaniu 2 nie są wymagane żadne białe znaki między owocami a = lub między = a jabłkami, chociaż możesz je dołączyć, jeśli chcesz, aby były czytelne.
Komentarze do programów to wyjaśnienia, które można umieścić w kodzie C ++. Te komentarze pomagają każdemu czytać kod źródłowy. Wszystkie języki programowania pozwalają na jakąś formę komentarzy.
C ++ obsługuje komentarze jednowierszowe i wielowierszowe. Wszystkie znaki dostępne w komentarzach są ignorowane przez kompilator C ++.
Komentarze w C ++ zaczynają się od / * i kończą na * /. Na przykład -
/* This is a comment */
/* C++ comments can also
* span multiple lines
*/Komentarz może również zaczynać się od // i sięgać do końca wiersza. Na przykład -
#include <iostream>
using namespace std;
main() {
cout << "Hello World"; // prints Hello World
return 0;
}Gdy powyższy kod zostanie skompilowany, zignoruje // prints Hello World a końcowy plik wykonywalny zwróci następujący wynik -
Hello WorldW komentarzu / * i * / znaki // nie mają specjalnego znaczenia. W // komentarzu / * i * / nie mają specjalnego znaczenia. W ten sposób można „zagnieździć” jeden rodzaj komentarza w innym rodzaju. Na przykład -
/* Comment out printing of Hello World:
cout << "Hello World"; // prints Hello World
*/Pisząc program w dowolnym języku, musisz używać różnych zmiennych do przechowywania różnych informacji. Zmienne to nic innego jak zarezerwowane miejsca w pamięci do przechowywania wartości. Oznacza to, że kiedy tworzysz zmienną, rezerwujesz trochę miejsca w pamięci.
Możesz chcieć przechowywać informacje o różnych typach danych, takich jak znak, szeroki znak, liczba całkowita, zmiennoprzecinkowa, podwójna zmiennoprzecinkowa, boolean itp. Na podstawie typu danych zmiennej system operacyjny przydziela pamięć i decyduje, co może być przechowywane w zarezerwowana pamięć.
Prymitywne typy wbudowane
C ++ oferuje programiście bogaty asortyment wbudowanych i zdefiniowanych przez użytkownika typów danych. Poniższa tabela zawiera listę siedmiu podstawowych typów danych C ++ -
| Rodzaj | Słowo kluczowe |
|---|---|
| Boolean | bool |
| Postać | zwęglać |
| Liczba całkowita | int |
| Punkt zmiennoprzecinkowy | pływak |
| Podwójny zmiennoprzecinkowy | podwójnie |
| Bezwartościowy | unieważnić |
| Szeroki charakter | wchar_t |
Kilka podstawowych typów można modyfikować za pomocą jednego lub więcej z tych modyfikatorów typu -
- signed
- unsigned
- short
- long
Poniższa tabela pokazuje typ zmiennej, ile pamięci zajmuje przechowywanie wartości w pamięci oraz jaka jest maksymalna i minimalna wartość jaka może być przechowywana w tego typu zmiennych.
| Rodzaj | Typowa szerokość bitu | Typowy zakres |
|---|---|---|
| zwęglać | 1 bajt | -127 do 127 lub 0 do 255 |
| unsigned char | 1 bajt | Od 0 do 255 |
| podpisany char | 1 bajt | -127 do 127 |
| int | 4 bajty | Od -2147483648 do 2147483647 |
| unsigned int | 4 bajty | 0 do 4294967295 |
| podpisany int | 4 bajty | Od -2147483648 do 2147483647 |
| krótki int | 2 bajty | -32768 do 32767 |
| unsigned short int | 2 bajty | 0 do 65 535 |
| podpisany krótki int | 2 bajty | -32768 do 32767 |
| długi int | 8 bajtów | -2 147 483 648 do 2 147 483 647 |
| podpisany długi int | 8 bajtów | tak samo jak long int |
| unsigned long int | 8 bajtów | Od 0 do 4 294 967 295 |
| długi długi int | 8 bajtów | - (2 ^ 63) do (2 ^ 63) -1 |
| unsigned long long int | 8 bajtów | Od 0 do 18 446 744 073 709 551 615 |
| pływak | 4 bajty | |
| podwójnie | 8 bajtów | |
| długie podwójne | 12 bajtów | |
| wchar_t | 2 lub 4 bajty | 1 szeroki znak |
Rozmiar zmiennych może różnić się od przedstawionych w powyższej tabeli, w zależności od kompilatora i używanego komputera.
Poniżej znajduje się przykład, który zapewni prawidłowy rozmiar różnych typów danych na komputerze.
#include <iostream>
using namespace std;
int main() {
cout << "Size of char : " << sizeof(char) << endl;
cout << "Size of int : " << sizeof(int) << endl;
cout << "Size of short int : " << sizeof(short int) << endl;
cout << "Size of long int : " << sizeof(long int) << endl;
cout << "Size of float : " << sizeof(float) << endl;
cout << "Size of double : " << sizeof(double) << endl;
cout << "Size of wchar_t : " << sizeof(wchar_t) << endl;
return 0;
}W tym przykładzie zastosowano endl, który wstawia znak nowego wiersza po każdym wierszu, a operator << służy do przekazywania wielu wartości na ekran. Używamy równieżsizeof() operator, aby uzyskać rozmiar różnych typów danych.
Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik, który może się różnić w zależności od maszyny -
Size of char : 1
Size of int : 4
Size of short int : 2
Size of long int : 4
Size of float : 4
Size of double : 8
Size of wchar_t : 4deklaracje typedef
Możesz utworzyć nową nazwę dla istniejącego typu za pomocą typedef. Poniżej znajduje się prosta składnia definiowania nowego typu przy użyciu typedef -
typedef type newname;Na przykład poniższy fragment mówi kompilatorowi, że stopy to inna nazwa dla int -
typedef int feet;Teraz poniższa deklaracja jest całkowicie poprawna i tworzy zmienną całkowitą o nazwie odległość -
feet distance;Wyliczone typy
Typ wyliczeniowy deklaruje opcjonalną nazwę typu i zestaw zer lub więcej identyfikatorów, które mogą być używane jako wartości typu. Każdy moduł wyliczający jest stałą, której typem jest wyliczenie.
Utworzenie wyliczenia wymaga użycia słowa kluczowego enum. Ogólna postać typu wyliczenia to -
enum enum-name { list of names } var-list;W tym przypadku nazwa-wyliczenia jest nazwą typu wyliczenia. Lista nazw jest oddzielona przecinkami.
Na przykład poniższy kod definiuje wyliczenie kolorów zwanych kolorami i zmienną c typu color. Wreszcie c otrzymuje wartość „niebieski”.
enum color { red, green, blue } c;
c = blue;Domyślnie pierwsze imię ma wartość 0, drugie imię ma wartość 1, trzecie ma wartość 2 i tak dalej. Ale możesz nadać nazwę, konkretną wartość, dodając inicjator. Na przykład w poniższym wyliczeniugreen będzie mieć wartość 5.
enum color { red, green = 5, blue };Tutaj, blue będzie mieć wartość 6, ponieważ każda nazwa będzie o jeden większa niż ta, która ją poprzedza.
Zmienna zapewnia nam nazwane miejsce do przechowywania, którym nasze programy mogą manipulować. Każda zmienna w C ++ ma określony typ, który określa rozmiar i układ pamięci zmiennej; zakres wartości, które mogą być przechowywane w tej pamięci; oraz zestaw operacji, które można zastosować do zmiennej.
Nazwa zmiennej może składać się z liter, cyfr i znaku podkreślenia. Musi zaczynać się od litery lub podkreślenia. Wielkie i małe litery są różne, ponieważ C ++ rozróżnia wielkość liter -
Istnieją następujące podstawowe typy zmiennych w C ++, jak wyjaśniono w ostatnim rozdziale -
| Sr.No | Typ i opis |
|---|---|
| 1 | bool Przechowuje wartość true lub false. |
| 2 | char Zwykle pojedynczy oktet (jeden bajt). To jest typ całkowity. |
| 3 | int Najbardziej naturalny rozmiar liczby całkowitej dla maszyny. |
| 4 | float Wartość zmiennoprzecinkowa o pojedynczej precyzji. |
| 5 | double Wartość zmiennoprzecinkowa podwójnej precyzji. |
| 6 | void Reprezentuje brak typu. |
| 7 | wchar_t Szeroki typ znaków. |
C ++ pozwala także na definiowanie różnych innych typów zmiennych, które omówimy w kolejnych rozdziałach, np Enumeration, Pointer, Array, Reference, Data structures, i Classes.
W poniższej sekcji opisano, jak definiować, deklarować i używać różnych typów zmiennych.
Definicja zmiennej w C ++
Definicja zmiennej informuje kompilator, gdzie i ile pamięci ma utworzyć dla zmiennej. Definicja zmiennej określa typ danych i zawiera listę co najmniej jednej zmiennej tego typu w następujący sposób -
type variable_list;Tutaj, type musi być prawidłowym typem danych C ++, w tym char, w_char, int, float, double, bool lub dowolny obiekt zdefiniowany przez użytkownika itp. oraz variable_listmoże składać się z jednej lub więcej nazw identyfikatorów oddzielonych przecinkami. Tutaj pokazano kilka ważnych deklaracji -
int i, j, k;
char c, ch;
float f, salary;
double d;Linia int i, j, k;zarówno deklaruje, jak i definiuje zmienne i, j oraz k; co instruuje kompilator, aby utworzył zmienne o nazwach i, j oraz k typu int.
Zmienne można zainicjować (przypisać wartość początkową) w ich deklaracji. Inicjator składa się ze znaku równości, po którym następuje stałe wyrażenie w następujący sposób -
type variable_name = value;Oto kilka przykładów:
extern int d = 3, f = 5; // declaration of d and f.
int d = 3, f = 5; // definition and initializing d and f.
byte z = 22; // definition and initializes z.
char x = 'x'; // the variable x has the value 'x'.Definicja bez inicjalizatora: zmienne ze statycznym czasem trwania są niejawnie inicjowane wartością NULL (wszystkie bajty mają wartość 0); początkowa wartość wszystkich innych zmiennych jest niezdefiniowana.
Deklaracja zmiennej w C ++
Deklaracja zmiennej zapewnia kompilatorowi, że istnieje jedna zmienna o podanym typie i nazwie, dzięki czemu kompilator przechodzi do dalszej kompilacji bez konieczności posiadania pełnych szczegółów na temat zmiennej. Deklaracja zmiennej ma swoje znaczenie tylko w momencie kompilacji, kompilator potrzebuje rzeczywistej definicji zmiennej w momencie linkowania programu.
Deklaracja zmiennej jest przydatna, gdy używasz wielu plików i definiujesz swoją zmienną w jednym z plików, który będzie dostępny w momencie łączenia programu. Będziesz używaćexternsłowo kluczowe, aby zadeklarować zmienną w dowolnym miejscu. Chociaż możesz deklarować zmienną wiele razy w swoim programie C ++, ale można ją zdefiniować tylko raz w pliku, funkcji lub bloku kodu.
Przykład
Wypróbuj poniższy przykład, w którym zmienna została zadeklarowana u góry, ale została zdefiniowana w funkcji głównej -
#include <iostream>
using namespace std;
// Variable declaration:
extern int a, b;
extern int c;
extern float f;
int main () {
// Variable definition:
int a, b;
int c;
float f;
// actual initialization
a = 10;
b = 20;
c = a + b;
cout << c << endl ;
f = 70.0/3.0;
cout << f << endl ;
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
30
23.3333Ta sama koncepcja dotyczy deklaracji funkcji, gdzie podajesz nazwę funkcji w momencie jej deklaracji, a jej rzeczywistą definicję można podać gdziekolwiek indziej. Na przykład -
// function declaration
int func();
int main() {
// function call
int i = func();
}
// function definition
int func() {
return 0;
}Lvalues i Rvalues
W C ++ istnieją dwa rodzaje wyrażeń -
lvalue- Wyrażenia odnoszące się do miejsca w pamięci nazywane są wyrażeniem „l-wartość”. Wartość l może pojawić się jako lewa lub prawa strona przypisania.
rvalue- Termin rvalue odnosi się do wartości danych przechowywanych pod jakimś adresem w pamięci. Wartość r to wyrażenie, któremu nie można przypisać wartości, co oznacza, że wartość r może pojawić się po prawej, ale nie po lewej stronie przypisania.
Zmienne to lvalues, więc mogą pojawiać się po lewej stronie przydziału. Literały numeryczne są wartościami r, więc nie można ich przypisywać i nie mogą pojawiać się po lewej stronie. Poniżej znajduje się prawidłowe oświadczenie -
int g = 20;Ale poniższa instrukcja nie jest prawidłową instrukcją i spowodowałaby błąd w czasie kompilacji -
10 = 20;Zakres to region programu i ogólnie mówiąc istnieją trzy miejsca, w których można zadeklarować zmienne -
Wewnątrz funkcji lub bloku, który nazywa się zmiennymi lokalnymi,
W definicji parametrów funkcji nazywamy parametrami formalnymi.
Poza wszystkimi funkcjami nazywanymi zmiennymi globalnymi.
Co to jest funkcja i jej parametr dowiemy się w kolejnych rozdziałach. Tutaj wyjaśnijmy, czym są zmienne lokalne i globalne.
Zmienne lokalne
Zmienne zadeklarowane wewnątrz funkcji lub bloku są zmiennymi lokalnymi. Mogą być używane tylko przez instrukcje, które znajdują się wewnątrz tej funkcji lub bloku kodu. Zmienne lokalne nie są znane z funkcji innych niż ich własne. Poniżej znajduje się przykład z użyciem zmiennych lokalnych -
#include <iostream>
using namespace std;
int main () {
// Local variable declaration:
int a, b;
int c;
// actual initialization
a = 10;
b = 20;
c = a + b;
cout << c;
return 0;
}Zmienne globalne
Zmienne globalne są definiowane poza wszystkimi funkcjami, zwykle w górnej części programu. Zmienne globalne zachowają swoją wartość przez cały okres istnienia programu.
Dostęp do zmiennej globalnej można uzyskać za pomocą dowolnej funkcji. Oznacza to, że zmienna globalna jest dostępna do użycia w całym programie po jej zadeklarowaniu. Poniżej znajduje się przykład z użyciem zmiennych globalnych i lokalnych -
#include <iostream>
using namespace std;
// Global variable declaration:
int g;
int main () {
// Local variable declaration:
int a, b;
// actual initialization
a = 10;
b = 20;
g = a + b;
cout << g;
return 0;
}Program może mieć taką samą nazwę dla zmiennych lokalnych i globalnych, ale wartość zmiennej lokalnej wewnątrz funkcji będzie miała pierwszeństwo. Na przykład -
#include <iostream>
using namespace std;
// Global variable declaration:
int g = 20;
int main () {
// Local variable declaration:
int g = 10;
cout << g;
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
10Inicjalizacja zmiennych lokalnych i globalnych
Gdy zdefiniowana jest zmienna lokalna, nie jest inicjalizowana przez system, należy ją zainicjować samodzielnie. Zmienne globalne są inicjowane automatycznie przez system po ich zdefiniowaniu w następujący sposób -
| Typ danych | Inicjator |
|---|---|
| int | 0 |
| zwęglać | '\ 0' |
| pływak | 0 |
| podwójnie | 0 |
| wskaźnik | ZERO |
Dobrą praktyką programistyczną jest prawidłowe inicjowanie zmiennych, w przeciwnym razie czasami program dałby nieoczekiwany wynik.
Stałe odnoszą się do stałych wartości, których program nie może zmienić i są wywoływane literals.
Stałe mogą mieć dowolny z podstawowych typów danych i można je podzielić na liczby całkowite, liczby zmiennoprzecinkowe, znaki, ciągi znaków i wartości logiczne.
Ponownie, stałe są traktowane tak jak zwykłe zmienne, z tym wyjątkiem, że ich wartości nie mogą być modyfikowane po ich definicji.
Literały całkowite
Literał liczby całkowitej może być stałą dziesiętną, ósemkową lub szesnastkową. Prefiks określa podstawę lub podstawę: 0x lub 0X dla szesnastkowej, 0 dla ósemkowej i nic dla dziesiętnej.
Literał liczby całkowitej może również mieć sufiks będący kombinacją U i L, odpowiednio dla unsigned i long. Sufiks może być pisany wielką lub małą literą i może mieć dowolną kolejność.
Oto kilka przykładów literałów całkowitych -
212 // Legal
215u // Legal
0xFeeL // Legal
078 // Illegal: 8 is not an octal digit
032UU // Illegal: cannot repeat a suffixPoniżej znajdują się inne przykłady różnych typów literałów całkowitych -
85 // decimal
0213 // octal
0x4b // hexadecimal
30 // int
30u // unsigned int
30l // long
30ul // unsigned longLiterały zmiennoprzecinkowe
Literał zmiennoprzecinkowy ma część całkowitą, przecinek dziesiętny, część ułamkową i część wykładniczą. Literały zmiennoprzecinkowe można przedstawiać w postaci dziesiętnej lub wykładniczej.
Przedstawiając przy użyciu postaci dziesiętnej, należy uwzględnić kropkę dziesiętną, wykładnik lub jedno i drugie, a podczas przedstawiania w postaci wykładniczej należy uwzględnić część całkowitą, część ułamkową lub oba te elementy. Podpisany wykładnik jest wprowadzany przez e lub E.
Oto kilka przykładów literałów zmiennoprzecinkowych -
3.14159 // Legal
314159E-5L // Legal
510E // Illegal: incomplete exponent
210f // Illegal: no decimal or exponent
.e55 // Illegal: missing integer or fractionLiterały logiczne
Istnieją dwa literały Boolean i są one częścią standardowych słów kluczowych C ++ -
Wartość true reprezentujące prawdę.
Wartość false reprezentujące fałsz.
Nie powinieneś brać pod uwagę wartości true równej 1 i wartości fałszu równej 0.
Literały postaci
Literały znakowe są ujęte w pojedyncze cudzysłowy. Jeśli literał zaczyna się od L (tylko wielkie litery), jest to literał szerokiego znaku (np. L'x ') i powinien być przechowywany wwchar_trodzaj zmiennej. W przeciwnym razie jest to wąski literał znakowy (np. „X”) i może być przechowywany w prostej zmiennej typuchar rodzaj.
Literał znakowy może być zwykłym znakiem (np. „X”), sekwencją ucieczki (np. „\ T”) lub znakiem uniwersalnym (np. „\ U02C0”).
W C ++ są pewne znaki poprzedzone odwrotnym ukośnikiem, które będą miały specjalne znaczenie i są używane do reprezentowania jak nowa linia (\ n) lub tabulacja (\ t). Tutaj masz listę niektórych takich kodów sekwencji ucieczki -
| Sekwencja ewakuacyjna | Znaczenie |
|---|---|
| \\ | \ postać |
| \ ' | ' postać |
| \ " | " postać |
| \? | ? postać |
| \za | Alert lub dzwonek |
| \b | Backspace |
| \fa | Form feed |
| \ n | Nowa linia |
| \ r | Powrót karetki |
| \ t | Zakładka pozioma |
| \ v | Zakładka pionowa |
| \ ooo | Liczba ósemkowa składająca się z jednej do trzech cyfr |
| \ xhh. . . | Liczba szesnastkowa składająca się z jednej lub więcej cyfr |
Poniżej znajduje się przykład pokazujący kilka znaków sekwencji sterującej -
#include <iostream>
using namespace std;
int main() {
cout << "Hello\tWorld\n\n";
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Hello WorldLiterały strunowe
Literały łańcuchowe są ujęte w podwójne cudzysłowy. Ciąg zawiera znaki podobne do literałów znakowych: zwykłe znaki, sekwencje ucieczki i znaki uniwersalne.
Możesz podzielić długi wiersz na wiele wierszy za pomocą literałów łańcuchowych i oddzielić je odstępami.
Oto kilka przykładów literałów ciągów. Wszystkie trzy formy są identycznymi ciągami.
"hello, dear"
"hello, \
dear"
"hello, " "d" "ear"Definiowanie stałych
Istnieją dwa proste sposoby definiowania stałych w C ++ -
Za pomocą #define preprocesor.
Za pomocą const słowo kluczowe.
#Define Preprocessor
Poniżej znajduje się formularz użycia #define preprocesora do zdefiniowania stałej -
#define identifier valuePoniższy przykład wyjaśnia to szczegółowo -
#include <iostream>
using namespace std;
#define LENGTH 10
#define WIDTH 5
#define NEWLINE '\n'
int main() {
int area;
area = LENGTH * WIDTH;
cout << area;
cout << NEWLINE;
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
50Słowo kluczowe const
Możesz użyć const prefiks do deklarowania stałych o określonym typie w następujący sposób -
const type variable = value;Poniższy przykład wyjaśnia to szczegółowo -
#include <iostream>
using namespace std;
int main() {
const int LENGTH = 10;
const int WIDTH = 5;
const char NEWLINE = '\n';
int area;
area = LENGTH * WIDTH;
cout << area;
cout << NEWLINE;
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
50Zauważ, że dobrą praktyką programistyczną jest definiowanie stałych WIELKIMI LITERAMI.
C ++ zezwala na char, int, i doubletypy danych, które mają poprzedzać modyfikatory. Modyfikator służy do zmiany znaczenia typu podstawowego, aby bardziej precyzyjnie odpowiadał potrzebom różnych sytuacji.
Modyfikatory typu danych są wymienione tutaj -
- signed
- unsigned
- long
- short
Modyfikatory signed, unsigned, long, i shortmożna zastosować do bazowych typów całkowitych. Dodatkowo,signed i unsigned można zastosować do char, i long można zastosować do podwójnego.
Modyfikatory signed i unsigned może być również używany jako przedrostek do long lub shortmodyfikatory. Na przykład,unsigned long int.
C ++ pozwala na skróconą notację do deklarowania unsigned, short, lub longliczby całkowite. Możesz po prostu użyć tego słowaunsigned, short, lub long, bez int. To automatycznie sugerujeint. Na przykład poniższe dwie instrukcje deklarują zmienne całkowite bez znaku.
unsigned x;
unsigned int y;Aby zrozumieć różnicę między sposobem interpretacji modyfikatorów liczb całkowitych ze znakiem i bez znaku w języku C ++, należy uruchomić następujący krótki program -
#include <iostream>
using namespace std;
/* This program shows the difference between
* signed and unsigned integers.
*/
int main() {
short int i; // a signed short integer
short unsigned int j; // an unsigned short integer
j = 50000;
i = j;
cout << i << " " << j;
return 0;
}Kiedy ten program jest uruchomiony, następuje wyjście -
-15536 50000Powyższy wynik jest taki, że wzorzec bitowy reprezentujący 50 000 jako krótką liczbę całkowitą bez znaku jest interpretowany jako -15 536 przez skrót.
Kwalifikatory typu w C ++
Kwalifikatory typu zapewniają dodatkowe informacje o zmiennych, które poprzedzają.
| Sr.No | Kwalifikator i znaczenie |
|---|---|
| 1 | const Obiekty typu const nie może zostać zmieniony przez program podczas wykonywania. |
| 2 | volatile Modyfikator volatile informuje kompilator, że wartość zmiennej może zostać zmieniona w sposób, który nie został wyraźnie określony przez program. |
| 3 | restrict Wskaźnik kwalifikowany przez restrictjest początkowo jedynym sposobem dostępu do obiektu, na który wskazuje. Tylko C99 dodaje nowy kwalifikator typu o nazwie ogranicz. |
Klasa pamięci definiuje zakres (widoczność) i czas życia zmiennych i / lub funkcji w programie C ++. Te specyfikatory poprzedzają typ, który modyfikują. Istnieją następujące klasy pamięci, których można używać w programie C ++
- auto
- register
- static
- extern
- mutable
Auto Storage Class
Plik auto klasa pamięci to domyślna klasa pamięci dla wszystkich zmiennych lokalnych.
{
int mount;
auto int month;
}Powyższy przykład definiuje dwie zmienne z tą samą klasą pamięci, auto może być używane tylko w funkcjach, tj. Zmienne lokalne.
Register Storage Class
Plik registerklasa pamięci służy do definiowania zmiennych lokalnych, które powinny być przechowywane w rejestrze zamiast w pamięci RAM. Oznacza to, że zmienna ma maksymalny rozmiar równy rozmiarowi rejestru (zwykle jedno słowo) i nie może mieć zastosowanego do niej jednoargumentowego operatora „&” (ponieważ nie ma miejsca w pamięci).
{
register int miles;
}Rejestr powinien być używany tylko dla zmiennych, które wymagają szybkiego dostępu, takich jak liczniki. Należy również zauważyć, że zdefiniowanie „rejestru” nie oznacza, że zmienna będzie przechowywana w rejestrze. Oznacza to, że MOŻE być przechowywany w rejestrze w zależności od ograniczeń sprzętowych i wdrożeniowych.
Statyczna klasa magazynu
Plik staticstorage class instruuje kompilator, aby utrzymywał lokalną zmienną w czasie życia programu, zamiast tworzyć i niszczyć ją za każdym razem, gdy wchodzi i wychodzi poza zakres. Dlatego uczynienie zmiennych lokalnych statycznymi pozwala im zachować ich wartości między wywołaniami funkcji.
Modyfikator statyczny można również zastosować do zmiennych globalnych. Gdy to jest zrobione, powoduje to, że zakres tej zmiennej jest ograniczony do pliku, w którym jest zadeklarowana.
W C ++, kiedy static jest używane na składowej danych klasy, powoduje to, że tylko jedna kopia tego elementu członkowskiego jest współużytkowana przez wszystkie obiekty tej klasy.
#include <iostream>
// Function declaration
void func(void);
static int count = 10; /* Global variable */
main() {
while(count--) {
func();
}
return 0;
}
// Function definition
void func( void ) {
static int i = 5; // local static variable
i++;
std::cout << "i is " << i ;
std::cout << " and count is " << count << std::endl;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
i is 6 and count is 9
i is 7 and count is 8
i is 8 and count is 7
i is 9 and count is 6
i is 10 and count is 5
i is 11 and count is 4
i is 12 and count is 3
i is 13 and count is 2
i is 14 and count is 1
i is 15 and count is 0Zewnętrzna klasa pamięci
Plik externklasa pamięci służy do podania odniesienia do zmiennej globalnej, która jest widoczna dla WSZYSTKICH plików programu. Gdy używasz „extern”, zmienna nie może zostać zainicjowana, ponieważ wszystko, co robi, to wskazanie nazwy zmiennej w uprzednio zdefiniowanym miejscu przechowywania.
Jeśli masz wiele plików i zdefiniujesz globalną zmienną lub funkcję, która będzie używana również w innych plikach, to extern zostanie użyty w innym pliku, aby podać odniesienie do zdefiniowanej zmiennej lub funkcji. Dla zrozumienia extern służy do deklarowania zmiennej globalnej lub funkcji w innym pliku.
Modyfikator extern jest najczęściej używany, gdy istnieją dwa lub więcej plików współużytkujących te same zmienne globalne lub funkcje, jak wyjaśniono poniżej.
Pierwszy plik: main.cpp
#include <iostream>
int count ;
extern void write_extern();
main() {
count = 5;
write_extern();
}Drugi plik: support.cpp
#include <iostream>
extern int count;
void write_extern(void) {
std::cout << "Count is " << count << std::endl;
}Tutaj słowo kluczowe extern jest używane do zadeklarowania licznika w innym pliku. Teraz skompiluj te dwa pliki w następujący sposób -
$g++ main.cpp support.cpp -o writeTo wyprodukuje write wykonywalny program, spróbuj wykonać write i sprawdź wynik w następujący sposób -
$./write
5Zmienna klasa pamięci
Plik mutableSpecifier ma zastosowanie tylko do obiektów klas, które zostaną omówione w dalszej części tego samouczka. Pozwala elementowi obiektu przesłonić stałą funkcję składową. Oznacza to, że zmienny element członkowski może być modyfikowany przez stałą funkcję składową.
Operator to symbol, który mówi kompilatorowi, aby wykonał określone operacje matematyczne lub logiczne. C ++ jest bogaty we wbudowane operatory i udostępnia następujące typy operatorów -
- Operatory arytmetyczne
- Operatorzy relacyjni
- Operatory logiczne
- Operatory bitowe
- Operatory przypisania
- Różne operatory
W tym rozdziale przeanalizujemy kolejno operatory arytmetyczne, relacyjne, logiczne, bitowe, przypisania i inne.
Operatory arytmetyczne
Istnieją następujące operatory arytmetyczne obsługiwane przez język C ++ -
Załóżmy, że zmienna A zawiera 10, a zmienna B 20, a następnie -
Pokaż przykłady
| Operator | Opis | Przykład |
|---|---|---|
| + | Dodaje dwa operandy | A + B da 30 |
| - | Odejmuje drugi operand od pierwszego | A - B da -10 |
| * | Mnoży oba operandy | A * B da 200 |
| / | Dzieli licznik przez de-licznik | B / A da 2 |
| % | Operator modułu i reszta po dzieleniu całkowitoliczbowym | B% A da 0 |
| ++ | Operator inkrementacji , zwiększa wartość całkowitą o jeden | A ++ da 11 |
| - | Operator zmniejszania, zmniejsza wartość całkowitą o jeden | A-- da 9 |
Operatorzy relacyjni
Istnieją następujące operatory relacyjne obsługiwane przez język C ++
Załóżmy, że zmienna A zawiera 10, a zmienna B 20, a następnie -
Pokaż przykłady
| Operator | Opis | Przykład |
|---|---|---|
| == | Sprawdza, czy wartości dwóch operandów są równe, czy nie, jeśli tak, warunek staje się prawdziwy. | (A == B) nie jest prawdą. |
| ! = | Sprawdza, czy wartości dwóch operandów są równe, czy nie, jeśli wartości nie są równe, warunek staje się prawdziwy. | (A! = B) jest prawdą. |
| > | Sprawdza, czy wartość lewego operandu jest większa niż wartość prawego operandu, jeśli tak, warunek staje się prawdziwy. | (A> B) nie jest prawdą. |
| < | Sprawdza, czy wartość lewego operandu jest mniejsza niż wartość prawego operandu. Jeśli tak, warunek staje się prawdziwy. | (A <B) jest prawdą. |
| > = | Sprawdza, czy wartość lewego operandu jest większa lub równa wartości prawego operandu, jeśli tak, warunek staje się prawdziwy. | (A> = B) nie jest prawdą. |
| <= | Sprawdza, czy wartość lewego operandu jest mniejsza lub równa wartości prawego operandu, jeśli tak, warunek staje się prawdziwy. | (A <= B) jest prawdą. |
Operatory logiczne
Istnieją następujące operatory logiczne obsługiwane przez język C ++.
Załóżmy, że zmienna A zawiera 1, a zmienna B 0, a następnie -
Pokaż przykłady
| Operator | Opis | Przykład |
|---|---|---|
| && | Nazywany operatorem logicznym AND. Jeśli oba operandy są niezerowe, warunek staje się prawdziwy. | (A && B) jest fałszem. |
| || | Nazywany operatorem logicznym OR. Jeśli którykolwiek z dwóch operandów jest niezerowy, warunek staje się prawdziwy. | (A || B) jest prawdą. |
| ! | Nazywany operatorem logicznym NOT. Służy do odwracania stanu logicznego operandu. Jeśli warunek jest spełniony, operator logiczny NIE spowoduje fałsz. | ! (A && B) jest prawdą. |
Operatory bitowe
Operator bitowy działa na bitach i wykonuje operacje bit po bicie. Tabele prawdy dla &, | i ^ są następujące -
| p | q | p & q | p | q | p ^ q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
Załóżmy, że A = 60; i B = 13; teraz w formacie binarnym będą wyglądać następująco -
A = 0011 1100
B = 0000 1101
-----------------
A&B = 0000 1100
A | B = 0011 1101
A ^ B = 0011 0001
~ A = 1100 0011
W poniższej tabeli wymieniono operatory bitowe obsługiwane przez język C ++. Załóżmy, że zmienna A zawiera 60, a zmienna B 13, a następnie -
Pokaż przykłady
| Operator | Opis | Przykład |
|---|---|---|
| & | Operator binarny AND kopiuje trochę do wyniku, jeśli istnieje w obu operandach. | (A i B) dadzą 12, czyli 0000 1100 |
| | | Operator binarny OR kopiuje bit, jeśli istnieje w którymkolwiek operandzie. | (A | B) da 61, czyli 0011 1101 |
| ^ | Binarny operator XOR kopiuje bit, jeśli jest ustawiony w jednym operandzie, ale nie w obu. | (A ^ B) da 49, czyli 0011 0001 |
| ~ | Operator dopełniacza binarnego jest jednoargumentowy i powoduje „odwracanie” bitów. | (~ A) da -61, czyli 1100 0011 w postaci uzupełnienia do 2 ze względu na liczbę binarną ze znakiem. |
| << | Binarny operator przesunięcia w lewo. Wartość lewych operandów jest przesuwana w lewo o liczbę bitów określoną przez prawy operand. | << 2 da 240, czyli 1111 0000 |
| >> | Binarny operator przesunięcia w prawo. Wartość lewego operandu jest przesuwana w prawo o liczbę bitów określoną przez prawy operand. | >> 2 da 15, czyli 0000 1111 |
Operatory przypisania
Istnieją następujące operatory przypisania obsługiwane przez język C ++ -
Pokaż przykłady
| Operator | Opis | Przykład |
|---|---|---|
| = | Prosty operator przypisania, przypisuje wartości z operandów po prawej stronie do argumentów po lewej stronie. | C = A + B przypisze wartość A + B do C. |
| + = | Dodaj operator przypisania AND, dodaje prawy operand do lewego operandu i przypisuje wynik do lewego operandu. | C + = A jest równoważne C = C + A |
| - = | Operator odejmowania AND przypisania, Odejmuje prawy operand od lewego operandu i przypisuje wynik do lewego operandu. | C - = A jest równoważne C = C - A |
| * = | Operator mnożenia AND przypisania, Mnoży prawy operand przez lewy operand i przypisuje wynik do lewego operandu. | C * = A jest równoważne C = C * A |
| / = | Dzielenie AND operator przypisania, dzieli lewy operand z prawym operandem i przypisuje wynik do lewego operandu. | C / = A jest równoważne C = C / A |
| % = | Operator przypisania modułu AND, pobiera moduł przy użyciu dwóch operandów i przypisuje wynik do lewego operandu. | C% = A jest równoważne C = C% A |
| << = | Operator przesunięcia w lewo AND przypisania. | C << = 2 to to samo, co C = C << 2 |
| >> = | Operator prawego przesunięcia AND przypisania. | C >> = 2 to to samo, co C = C >> 2 |
| & = | Operator przypisania bitowego AND. | C & = 2 to to samo, co C = C & 2 |
| ^ = | Bitowe wykluczające OR i operator przypisania. | C ^ = 2 to to samo, co C = C ^ 2 |
| | = | Bitowy operator OR i przypisanie. | C | = 2 to to samo, co C = C | 2 |
Różne operatory
W poniższej tabeli wymieniono inne operatory obsługiwane w języku C ++.
| Sr.No | Operator i opis |
|---|---|
| 1 | sizeof Operator sizeof zwraca rozmiar zmiennej. Na przykład sizeof (a), gdzie „a” jest liczbą całkowitą i zwróci 4. |
| 2 | Condition ? X : Y Operator warunkowy (?) . Jeśli warunek jest prawdziwy, zwraca wartość X, w przeciwnym razie zwraca wartość Y. |
| 3 | , Operator przecinka powoduje wykonanie sekwencji operacji. Wartość całego wyrażenia z przecinkiem jest wartością ostatniego wyrażenia na liście oddzielonej przecinkami. |
| 4 | . (dot) and -> (arrow) Operatory składowe służą do odwoływania się do poszczególnych elementów członkowskich klas, struktur i unii. |
| 5 | Cast Operatory rzutowania konwertują jeden typ danych na inny. Na przykład int (2,2000) zwróci wartość 2. |
| 6 | & Operator wskaźnika & zwraca adres zmiennej. Na przykład & a; poda rzeczywisty adres zmiennej. |
| 7 | * Operator wskaźnika * jest wskaźnikiem do zmiennej. Na przykład * var; wskaże na zmienną var. |
Pierwszeństwo operatorów w C ++
Pierwszeństwo operatorów określa grupowanie terminów w wyrażeniu. Ma to wpływ na sposób oceny wyrażenia. Niektórzy operatorzy mają wyższy priorytet niż inni; na przykład operator mnożenia ma wyższy priorytet niż operator dodawania -
Na przykład x = 7 + 3 * 2; tutaj x ma przypisane 13, a nie 20, ponieważ operator * ma wyższy priorytet niż +, więc najpierw jest mnożony przez 3 * 2, a następnie sumowany do 7.
Tutaj operatory o najwyższym priorytecie pojawiają się na górze tabeli, a operatory o najniższym priorytecie - na dole. W wyrażeniu najpierw zostaną ocenione operatory o wyższym priorytecie.
Pokaż przykłady
| Kategoria | Operator | Łączność |
|---|---|---|
| Przyrostek | () [] ->. ++ - - | Z lewej na prawą |
| Jednoargumentowe | + -! ~ ++ - - (typ) * & sizeof | Od prawej do lewej |
| Mnożny | * /% | Z lewej na prawą |
| Przyłączeniowy | + - | Z lewej na prawą |
| Zmiana | << >> | Z lewej na prawą |
| Relacyjny | <<=>> = | Z lewej na prawą |
| Równość | ==! = | Z lewej na prawą |
| Bitowe AND | & | Z lewej na prawą |
| Bitowe XOR | ^ | Z lewej na prawą |
| Bitowe OR | | | Z lewej na prawą |
| Logiczne AND | && | Z lewej na prawą |
| Logiczne LUB | || | Z lewej na prawą |
| Warunkowy | ?: | Od prawej do lewej |
| Zadanie | = + = - = * = / =% = >> = << = & = ^ = | = | Od prawej do lewej |
| Przecinek | , | Z lewej na prawą |
Może zaistnieć sytuacja, gdy trzeba będzie kilkakrotnie wykonać blok kodu. Ogólnie instrukcje są wykonywane sekwencyjnie: pierwsza instrukcja funkcji jest wykonywana jako pierwsza, po niej następuje druga i tak dalej.
Języki programowania zapewniają różne struktury kontrolne, które pozwalają na bardziej skomplikowane ścieżki wykonywania.
Instrukcja pętli pozwala nam wykonać instrukcję lub grupę instrukcji wiele razy, a następująca po niej jest ogólna instrukcja pętli w większości języków programowania -
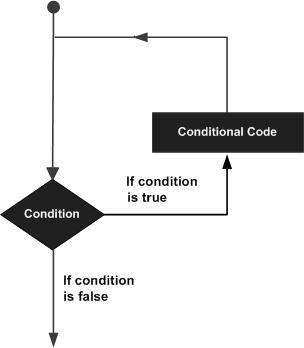
Język programowania C ++ zapewnia następujący typ pętli do obsługi wymagań dotyczących pętli.
| Sr.No | Typ i opis pętli |
|---|---|
| 1 | pętla while Powtarza instrukcję lub grupę instrukcji, gdy dany warunek jest prawdziwy. Testuje warunek przed wykonaniem treści pętli. |
| 2 | dla pętli Wykonuje sekwencję instrukcji wiele razy i skraca kod zarządzający zmienną pętli. |
| 3 | zrobić ... pętla while Podobnie jak instrukcja „while”, z tą różnicą, że testuje warunek na końcu treści pętli. |
| 4 | pętle zagnieżdżone Możesz użyć jednej lub więcej pętli wewnątrz dowolnej innej pętli „while”, „for” lub „do..while”. |
Instrukcje sterowania pętlą
Instrukcje sterujące pętlą zmieniają wykonanie z jego normalnej sekwencji. Gdy wykonanie opuszcza zakres, wszystkie automatyczne obiekty utworzone w tym zakresie są niszczone.
C ++ obsługuje następujące instrukcje sterujące.
| Sr.No | Oświadczenie i opis kontroli |
|---|---|
| 1 | instrukcja break Kończy loop lub switch instrukcja i przekazuje wykonanie do instrukcji bezpośrednio po pętli lub przełączniku. |
| 2 | kontynuuj oświadczenie Powoduje, że pętla pomija pozostałą część swojego ciała i natychmiast ponownie testuje swój stan przed ponownym powtórzeniem. |
| 3 | instrukcja goto Przekazuje kontrolę do oznaczonej instrukcji. Chociaż nie jest zalecane używanie w programie instrukcji goto. |
Nieskończona pętla
Pętla staje się nieskończoną pętlą, jeśli warunek nigdy nie staje się fałszywy. Plikforpętla jest tradycyjnie używana do tego celu. Ponieważ żadne z trzech wyrażeń tworzących pętlę „for” nie jest wymagane, można utworzyć nieskończoną pętlę, pozostawiając puste wyrażenie warunkowe.
#include <iostream>
using namespace std;
int main () {
for( ; ; ) {
printf("This loop will run forever.\n");
}
return 0;
}W przypadku braku wyrażenia warunkowego przyjmuje się, że jest ono prawdziwe. Możesz mieć wyrażenie inicjujące i inkrementujące, ale programiści C ++ częściej używają konstrukcji „for (;;)” do oznaczenia nieskończonej pętli.
NOTE - Możesz zakończyć nieskończoną pętlę, naciskając klawisze Ctrl + C.
Struktury decyzyjne wymagają, aby programista określił jeden lub więcej warunków, które mają być ocenione lub przetestowane przez program, wraz z instrukcją lub instrukcjami, które mają zostać wykonane, jeśli warunek zostanie określony jako prawdziwy, i opcjonalnie inne instrukcje do wykonania, jeśli warunek jest zdeterminowany, aby być fałszywy.
Poniżej przedstawiono ogólną formę typowej struktury podejmowania decyzji występującej w większości języków programowania -
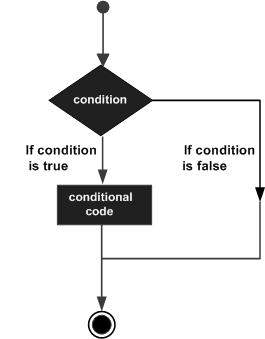
Język programowania C ++ udostępnia następujące typy instrukcji decyzyjnych.
| Sr.No | Oświadczenie i opis |
|---|---|
| 1 | jeśli oświadczenie Instrukcja „if” składa się z wyrażenia logicznego, po którym następuje co najmniej jedna instrukcja. |
| 2 | if ... else oświadczenie Po instrukcji „if” może następować opcjonalna instrukcja „else”, która jest wykonywana, gdy wyrażenie boolowskie ma wartość fałsz. |
| 3 | instrukcja przełączania Instrukcja „switch” umożliwia testowanie zmiennej pod kątem równości względem listy wartości. |
| 4 | zagnieżdżone instrukcje if Możesz użyć jednej instrukcji „if” lub „else if” wewnątrz innych instrukcji „if” lub „else if”. |
| 5 | zagnieżdżone instrukcje przełączające Możesz użyć jednej instrukcji „switch” wewnątrz innych instrukcji „switch”. |
The? : Operator
Omówiliśmy operator warunkowy „? : ” W poprzednim rozdziale, który można zastąpićif...elsesprawozdania. Ma następującą ogólną postać -
Exp1 ? Exp2 : Exp3;Exp1, Exp2 i Exp3 to wyrażenia. Zwróć uwagę na użycie i położenie okrężnicy.
Wartość „?” wyrażenie jest określane w następujący sposób: Exp1 jest oceniane. Jeśli to prawda, to Exp2 jest obliczane i staje się wartością całego „?” wyrażenie. Jeśli Exp1 ma wartość false, to Exp3 jest oceniane, a jego wartość staje się wartością wyrażenia.
Funkcja to grupa instrukcji, które razem wykonują zadanie. Każdy program w C ++ ma przynajmniej jedną funkcję, którą jestmain(), a wszystkie najbardziej trywialne programy mogą definiować dodatkowe funkcje.
Możesz podzielić swój kod na osobne funkcje. To, w jaki sposób podzielisz swój kod na różne funkcje, zależy od Ciebie, ale logicznie podział jest zwykle taki, że każda funkcja wykonuje określone zadanie.
Funkcja declarationinformuje kompilator o nazwie funkcji, typie zwracanym i parametrach. Funkcjadefinition dostarcza rzeczywistą treść funkcji.
Biblioteka standardowa C ++ zapewnia wiele wbudowanych funkcji, które program może wywołać. Na przykład functionstrcat() aby połączyć dwa ciągi, function memcpy() aby skopiować jedną lokalizację pamięci do innej lokalizacji i wiele innych funkcji.
Funkcja jest znana pod różnymi nazwami, takimi jak metoda, podprogram, procedura itp.
Definiowanie funkcji
Ogólna postać definicji funkcji C ++ jest następująca -
return_type function_name( parameter list ) {
body of the function
}Definicja funkcji C ++ składa się z nagłówka funkcji i jej treści. Oto wszystkie części funkcji -
Return Type- Funkcja może zwrócić wartość. Plikreturn_typejest typem danych wartości zwracanej przez funkcję. Niektóre funkcje wykonują żądane operacje bez zwracania wartości. W tym przypadku return_type jest słowem kluczowymvoid.
Function Name- To jest rzeczywista nazwa funkcji. Nazwa funkcji i lista parametrów razem tworzą podpis funkcji.
Parameters- Parametr działa jak symbol zastępczy. Gdy funkcja jest wywoływana, przekazujesz wartość do parametru. Ta wartość jest określana jako rzeczywisty parametr lub argument. Lista parametrów odnosi się do typu, kolejności i liczby parametrów funkcji. Parametry są opcjonalne; to znaczy funkcja może nie zawierać żadnych parametrów.
Function Body - Treść funkcji zawiera zbiór instrukcji, które definiują, co robi funkcja.
Przykład
Poniżej znajduje się kod źródłowy funkcji o nazwie max(). Ta funkcja przyjmuje dwa parametry num1 i num2 i zwraca największy z nich -
// function returning the max between two numbers
int max(int num1, int num2) {
// local variable declaration
int result;
if (num1 > num2)
result = num1;
else
result = num2;
return result;
}Deklaracje funkcji
Funkcja declarationinformuje kompilator o nazwie funkcji i sposobie wywołania funkcji. Rzeczywistą treść funkcji można zdefiniować oddzielnie.
Deklaracja funkcji składa się z następujących części -
return_type function_name( parameter list );Dla wyżej zdefiniowanej funkcji max (), poniżej znajduje się deklaracja funkcji -
int max(int num1, int num2);Nazwy parametrów nie są ważne w deklaracji funkcji tylko ich typ jest wymagany, więc poniżej znajduje się również poprawna deklaracja -
int max(int, int);Deklaracja funkcji jest wymagana, gdy definiujesz funkcję w jednym pliku źródłowym i wywołujesz tę funkcję w innym pliku. W takim przypadku powinieneś zadeklarować funkcję na początku pliku wywołującego funkcję.
Wywołanie funkcji
Tworząc funkcję w C ++, podajesz definicję tego, co ta funkcja ma robić. Aby użyć funkcji, będziesz musiał wywołać lub wywołać tę funkcję.
Gdy program wywołuje funkcję, sterowanie programem jest przekazywane do wywoływanej funkcji. Wywołana funkcja wykonuje określone zadanie i po wykonaniu jej instrukcji return lub po osiągnięciu zamykającego nawiasu zamykającego funkcję zwraca sterowanie programem z powrotem do programu głównego.
Aby wywołać funkcję, wystarczy przekazać wymagane parametry wraz z nazwą funkcji, a jeśli funkcja zwraca wartość, można ją zapisać. Na przykład -
#include <iostream>
using namespace std;
// function declaration
int max(int num1, int num2);
int main () {
// local variable declaration:
int a = 100;
int b = 200;
int ret;
// calling a function to get max value.
ret = max(a, b);
cout << "Max value is : " << ret << endl;
return 0;
}
// function returning the max between two numbers
int max(int num1, int num2) {
// local variable declaration
int result;
if (num1 > num2)
result = num1;
else
result = num2;
return result;
}Zachowałem funkcję max () wraz z funkcją main () i skompilowałem kod źródłowy. Podczas uruchamiania końcowego pliku wykonywalnego dałoby to następujący wynik -
Max value is : 200Argumenty funkcji
Jeśli funkcja ma używać argumentów, musi zadeklarować zmienne, które akceptują wartości argumentów. Te zmienne nazywane sąformal parameters funkcji.
Parametry formalne zachowują się jak inne zmienne lokalne wewnątrz funkcji i są tworzone po wejściu do funkcji i niszczone po zakończeniu.
Podczas wywoływania funkcji istnieją dwa sposoby przekazywania argumentów do funkcji -
| Sr.No | Typ i opis połączenia |
|---|---|
| 1 | Zadzwoń według wartości Ta metoda kopiuje rzeczywistą wartość argumentu do parametru formalnego funkcji. W tym przypadku zmiany wprowadzone w parametrze wewnątrz funkcji nie mają wpływu na argument. |
| 2 | Zadzwoń przez wskaźnik Ta metoda kopiuje adres argumentu do parametru formalnego. Wewnątrz funkcji adres służy do uzyskania dostępu do rzeczywistego argumentu użytego w wywołaniu. Oznacza to, że zmiany wprowadzone w parametrze wpływają na argument. |
| 3 | Zadzwoń przez numer referencyjny Ta metoda kopiuje odwołanie do argumentu do parametru formalnego. Wewnątrz funkcji odwołanie służy do uzyskania dostępu do rzeczywistego argumentu użytego w wywołaniu. Oznacza to, że zmiany wprowadzone w parametrze wpływają na argument. |
Domyślnie C ++ używa call by valueprzekazywać argumenty. Generalnie oznacza to, że kod wewnątrz funkcji nie może zmieniać argumentów użytych do wywołania funkcji i powyższego przykładu podczas wywoływania funkcji max () używającej tej samej metody.
Domyślne wartości parametrów
Podczas definiowania funkcji można określić wartość domyślną dla każdego z ostatnich parametrów. Ta wartość zostanie użyta, jeśli odpowiadający jej argument pozostanie pusty podczas wywoływania funkcji.
Odbywa się to poprzez użycie operatora przypisania i przypisanie wartości argumentom w definicji funkcji. Jeśli wartość tego parametru nie jest przekazywana podczas wywoływania funkcji, używana jest domyślna podana wartość, ale jeśli wartość jest określona, ta wartość domyślna jest ignorowana, a zamiast niej używana jest przekazana wartość. Rozważmy następujący przykład -
#include <iostream>
using namespace std;
int sum(int a, int b = 20) {
int result;
result = a + b;
return (result);
}
int main () {
// local variable declaration:
int a = 100;
int b = 200;
int result;
// calling a function to add the values.
result = sum(a, b);
cout << "Total value is :" << result << endl;
// calling a function again as follows.
result = sum(a);
cout << "Total value is :" << result << endl;
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Total value is :300
Total value is :120Zwykle, gdy pracujemy z Numbers, używamy prymitywnych typów danych, takich jak int, short, long, float i double itd. Typy liczbowe, ich możliwe wartości i zakresy liczb zostały wyjaśnione podczas omawiania typów danych w języku C ++.
Definiowanie liczb w C ++
Zdefiniowałeś już liczby w różnych przykładach podanych w poprzednich rozdziałach. Oto kolejny skonsolidowany przykład definiujący różne typy liczb w C ++ -
#include <iostream>
using namespace std;
int main () {
// number definition:
short s;
int i;
long l;
float f;
double d;
// number assignments;
s = 10;
i = 1000;
l = 1000000;
f = 230.47;
d = 30949.374;
// number printing;
cout << "short s :" << s << endl;
cout << "int i :" << i << endl;
cout << "long l :" << l << endl;
cout << "float f :" << f << endl;
cout << "double d :" << d << endl;
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
short s :10
int i :1000
long l :1000000
float f :230.47
double d :30949.4Operacje matematyczne w C ++
Oprócz różnych funkcji, które możesz tworzyć, C ++ zawiera również przydatne funkcje, których możesz użyć. Te funkcje są dostępne w standardowych bibliotekach C i C ++ i są wywoływanebuilt-inFunkcje. Są to funkcje, które można włączyć do programu, a następnie użyć.
C ++ ma bogaty zestaw operacji matematycznych, które można wykonać na różnych liczbach. Poniższa tabela zawiera listę przydatnych wbudowanych funkcji matematycznych dostępnych w C ++.
Aby skorzystać z tych funkcji, musisz dołączyć plik nagłówkowy matematyki <cmath>.
| Sr.No | Funkcja i cel |
|---|---|
| 1 | double cos(double); Ta funkcja przyjmuje kąt (jako podwójny) i zwraca cosinus. |
| 2 | double sin(double); Ta funkcja przyjmuje kąt (jako podwójny) i zwraca sinus. |
| 3 | double tan(double); Ta funkcja przyjmuje kąt (jako podwójny) i zwraca styczną. |
| 4 | double log(double); Ta funkcja przyjmuje liczbę i zwraca logarytm naturalny tej liczby. |
| 5 | double pow(double, double); Pierwsza to liczba, którą chcesz podbić, a druga to moc, którą chcesz podbić |
| 6 | double hypot(double, double); Jeśli przekażesz tej funkcji długość dwóch boków trójkąta prostokątnego, zwróci ona długość przeciwprostokątnej. |
| 7 | double sqrt(double); Przekazujesz tej funkcji liczbę, która daje pierwiastek kwadratowy. |
| 8 | int abs(int); Ta funkcja zwraca wartość bezwzględną przekazanej do niej liczby całkowitej. |
| 9 | double fabs(double); Ta funkcja zwraca wartość bezwzględną dowolnej przekazanej do niej liczby dziesiętnej. |
| 10 | double floor(double); Znajduje liczbę całkowitą, która jest mniejsza lub równa przekazanemu argumentowi. |
Poniżej znajduje się prosty przykład pokazujący kilka operacji matematycznych -
#include <iostream>
#include <cmath>
using namespace std;
int main () {
// number definition:
short s = 10;
int i = -1000;
long l = 100000;
float f = 230.47;
double d = 200.374;
// mathematical operations;
cout << "sin(d) :" << sin(d) << endl;
cout << "abs(i) :" << abs(i) << endl;
cout << "floor(d) :" << floor(d) << endl;
cout << "sqrt(f) :" << sqrt(f) << endl;
cout << "pow( d, 2) :" << pow(d, 2) << endl;
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
sign(d) :-0.634939
abs(i) :1000
floor(d) :200
sqrt(f) :15.1812
pow( d, 2 ) :40149.7Losowe liczby w C ++
Istnieje wiele przypadków, w których będziesz chciał wygenerować liczbę losową. Istnieją dwie funkcje, które musisz wiedzieć o generowaniu liczb losowych. Pierwsza torand(), ta funkcja zwróci tylko liczbę pseudolosową. Aby to naprawić, najpierw wywołaj pliksrand() funkcjonować.
Poniżej znajduje się prosty przykład generowania kilku liczb losowych. Ten przykład wykorzystujetime() funkcja, aby uzyskać liczbę sekund czasu systemowego, aby losowo zapełnić funkcję rand () -
#include <iostream>
#include <ctime>
#include <cstdlib>
using namespace std;
int main () {
int i,j;
// set the seed
srand( (unsigned)time( NULL ) );
/* generate 10 random numbers. */
for( i = 0; i < 10; i++ ) {
// generate actual random number
j = rand();
cout <<" Random Number : " << j << endl;
}
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Random Number : 1748144778
Random Number : 630873888
Random Number : 2134540646
Random Number : 219404170
Random Number : 902129458
Random Number : 920445370
Random Number : 1319072661
Random Number : 257938873
Random Number : 1256201101
Random Number : 580322989C ++ zapewnia strukturę danych, the array, który przechowuje sekwencyjną kolekcję elementów tego samego typu o stałym rozmiarze. Tablica jest używana do przechowywania kolekcji danych, ale często bardziej przydatne jest myślenie o tablicy jako o zbiorze zmiennych tego samego typu.
Zamiast deklarować pojedyncze zmienne, takie jak liczba0, liczba1, ... i liczba99, deklarujesz jedną zmienną tablicową, taką jak liczby, i używasz liczb [0], liczb [1] i ..., liczb [99] do reprezentowania indywidualne zmienne. Dostęp do określonego elementu w tablicy uzyskuje się za pomocą indeksu.
Wszystkie tablice składają się z ciągłych lokalizacji pamięci. Najniższy adres odpowiada pierwszemu elementowi, a najwyższy adres ostatniemu elementowi.
Deklarowanie tablic
Aby zadeklarować tablicę w C ++, programista określa typ elementów i liczbę elementów wymaganych przez tablicę w następujący sposób -
type arrayName [ arraySize ];Nazywa się to tablicą jednowymiarową. PlikarraySize musi być stałą liczbą całkowitą większą od zera i typemoże być dowolnym poprawnym typem danych C ++. Na przykład, aby zadeklarować 10-elementową tablicę o nazwie balance typu double, użyj tej instrukcji -
double balance[10];Inicjowanie tablic
Możesz zainicjować elementy tablicy w C ++ pojedynczo lub za pomocą pojedynczej instrukcji w następujący sposób -
double balance[5] = {1000.0, 2.0, 3.4, 17.0, 50.0};Liczba wartości w nawiasach klamrowych {} nie może być większa niż liczba elementów, które zadeklarujemy dla tablicy w nawiasach kwadratowych []. Poniżej znajduje się przykład przypisywania pojedynczego elementu tablicy -
Jeśli pominiesz rozmiar tablicy, zostanie utworzona tablica wystarczająco duża, aby pomieścić inicjalizację. Dlatego jeśli napiszesz -
double balance[] = {1000.0, 2.0, 3.4, 17.0, 50.0};Utworzysz dokładnie taką samą tablicę, jak w poprzednim przykładzie.
balance[4] = 50.0;Powyższe oświadczenie przypisuje numer elementu 5 th w tablicy wartość 50.0. Tablica z 4- tym indeksem będzie piątym , czyli ostatnim elementem, ponieważ wszystkie tablice mają 0 jako indeks pierwszego elementu, który jest również nazywany indeksem bazowym. Poniżej znajduje się obrazkowa reprezentacja tej samej tablicy, którą omówiliśmy powyżej -

Dostęp do elementów tablicy
Dostęp do elementu uzyskuje się poprzez indeksowanie nazwy tablicy. Odbywa się to poprzez umieszczenie indeksu elementu w nawiasach kwadratowych po nazwie tablicy. Na przykład -
double salary = balance[9];Powyższe stwierdzenie zajmie 10 th element z tablicy i przypisać wartość do zmiennej wynagrodzenia. Poniżej znajduje się przykład, który będzie wykorzystywał wszystkie wyżej wymienione trzy koncepcje, a mianowicie. deklaracja, przypisanie i dostęp do tablic -
#include <iostream>
using namespace std;
#include <iomanip>
using std::setw;
int main () {
int n[ 10 ]; // n is an array of 10 integers
// initialize elements of array n to 0
for ( int i = 0; i < 10; i++ ) {
n[ i ] = i + 100; // set element at location i to i + 100
}
cout << "Element" << setw( 13 ) << "Value" << endl;
// output each array element's value
for ( int j = 0; j < 10; j++ ) {
cout << setw( 7 )<< j << setw( 13 ) << n[ j ] << endl;
}
return 0;
}Ten program korzysta z setw()funkcję formatowania danych wyjściowych. Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Element Value
0 100
1 101
2 102
3 103
4 104
5 105
6 106
7 107
8 108
9 109Tablice w C ++
Tablice są ważne dla C ++ i powinny wymagać dużo więcej szczegółów. Oto kilka ważnych pojęć, które powinny być jasne dla programisty C ++:
| Sr.No | Koncepcja i opis |
|---|---|
| 1 | Tablice wielowymiarowe C ++ obsługuje tablice wielowymiarowe. Najprostszą formą tablicy wielowymiarowej jest tablica dwuwymiarowa. |
| 2 | Wskaźnik do tablicy Możesz wygenerować wskaźnik do pierwszego elementu tablicy, po prostu określając nazwę tablicy, bez żadnego indeksu. |
| 3 | Przekazywanie tablic do funkcji Możesz przekazać do funkcji wskaźnik do tablicy, podając nazwę tablicy bez indeksu. |
| 4 | Zwróć tablicę z funkcji C ++ umożliwia funkcji zwracanie tablicy. |
C ++ udostępnia następujące dwa typy reprezentacji ciągów -
- Ciąg znaków w stylu C.
- Typ klasy ciągu wprowadzony w standardowym języku C ++.
Ciąg znaków w stylu C.
Ciąg znaków w stylu C pochodzi z języka C i nadal jest obsługiwany w C ++. Ten ciąg jest w rzeczywistości jednowymiarową tablicą znaków zakończoną znakiemnullznak „\ 0”. Zatem ciąg zakończony znakiem null zawiera znaki, które składają się na ciąg, po którym następuje znaknull.
Następująca deklaracja i inicjalizacja tworzą ciąg składający się ze słowa „Hello”. Aby przechowywać znak null na końcu tablicy, rozmiar tablicy znaków zawierającej ciąg jest o jeden większy niż liczba znaków w słowie „Hello”.
char greeting[6] = {'H', 'e', 'l', 'l', 'o', '\0'};Jeśli zastosujesz się do zasady inicjalizacji tablicy, możesz napisać powyższą instrukcję w następujący sposób -
char greeting[] = "Hello";Poniżej znajduje się prezentacja pamięci powyżej zdefiniowanego ciągu w C / C ++ -

W rzeczywistości nie umieszcza się znaku null na końcu stałej łańcuchowej. Kompilator C ++ automatycznie umieszcza znak „\ 0” na końcu ciągu podczas inicjowania tablicy. Spróbujmy wydrukować powyższy ciąg -
#include <iostream>
using namespace std;
int main () {
char greeting[6] = {'H', 'e', 'l', 'l', 'o', '\0'};
cout << "Greeting message: ";
cout << greeting << endl;
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Greeting message: HelloC ++ obsługuje szeroką gamę funkcji, które obsługują ciągi zakończone znakiem null -
| Sr.No | Funkcja i cel |
|---|---|
| 1 | strcpy(s1, s2); Kopiuje ciąg s2 do łańcucha s1. |
| 2 | strcat(s1, s2); Łączy ciąg s2 z końcem łańcucha s1. |
| 3 | strlen(s1); Zwraca długość łańcucha s1. |
| 4 | strcmp(s1, s2); Zwraca 0, jeśli s1 i s2 są takie same; mniej niż 0, jeśli s1 <s2; większe niż 0, jeśli s1> s2. |
| 5 | strchr(s1, ch); Zwraca wskaźnik do pierwszego wystąpienia znaku ch w ciągu s1. |
| 6 | strstr(s1, s2); Zwraca wskaźnik do pierwszego wystąpienia ciągu s2 w ciągu s1. |
Poniższy przykład wykorzystuje kilka z wyżej wymienionych funkcji -
#include <iostream>
#include <cstring>
using namespace std;
int main () {
char str1[10] = "Hello";
char str2[10] = "World";
char str3[10];
int len ;
// copy str1 into str3
strcpy( str3, str1);
cout << "strcpy( str3, str1) : " << str3 << endl;
// concatenates str1 and str2
strcat( str1, str2);
cout << "strcat( str1, str2): " << str1 << endl;
// total lenghth of str1 after concatenation
len = strlen(str1);
cout << "strlen(str1) : " << len << endl;
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje wynik w następujący sposób -
strcpy( str3, str1) : Hello
strcat( str1, str2): HelloWorld
strlen(str1) : 10Klasa String w C ++
Standardowa biblioteka C ++ udostępnia plik stringklasa obsługująca wszystkie wymienione powyżej operacje, dodatkowo znacznie większa funkcjonalność. Sprawdźmy następujący przykład -
#include <iostream>
#include <string>
using namespace std;
int main () {
string str1 = "Hello";
string str2 = "World";
string str3;
int len ;
// copy str1 into str3
str3 = str1;
cout << "str3 : " << str3 << endl;
// concatenates str1 and str2
str3 = str1 + str2;
cout << "str1 + str2 : " << str3 << endl;
// total length of str3 after concatenation
len = str3.size();
cout << "str3.size() : " << len << endl;
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje wynik w następujący sposób -
str3 : Hello
str1 + str2 : HelloWorld
str3.size() : 10Wskaźniki C ++ są łatwe i przyjemne do nauczenia. Niektóre zadania C ++ są łatwiejsze do wykonania za pomocą wskaźników, a innych zadań C ++, takich jak dynamiczna alokacja pamięci, nie można wykonać bez nich.
Jak wiadomo, każda zmienna jest miejscem w pamięci, a każda lokalizacja pamięci ma zdefiniowany adres, do którego można uzyskać dostęp za pomocą operatora ampersand (&), który oznacza adres w pamięci. Rozważ następujące, które spowodują wydrukowanie adresu zdefiniowanych zmiennych -
#include <iostream>
using namespace std;
int main () {
int var1;
char var2[10];
cout << "Address of var1 variable: ";
cout << &var1 << endl;
cout << "Address of var2 variable: ";
cout << &var2 << endl;
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Address of var1 variable: 0xbfebd5c0
Address of var2 variable: 0xbfebd5b6Co to są wskaźniki?
ZA pointerjest zmienną, której wartością jest adres innej zmiennej. Jak w przypadku każdej zmiennej lub stałej, przed rozpoczęciem pracy należy zadeklarować wskaźnik. Ogólną postacią deklaracji zmiennej wskaźnikowej jest -
type *var-name;Tutaj, typejest typem bazowym wskaźnika; musi to być prawidłowy typ C ++ ivar-namejest nazwą zmiennej wskaźnika. Gwiazdka użyta do zadeklarowania wskaźnika to ta sama gwiazdka, której używasz do mnożenia. Jednak w tej instrukcji gwiazdka jest używana do oznaczania zmiennej jako wskaźnika. Poniżej znajduje się prawidłowa deklaracja wskaźnika -
int *ip; // pointer to an integer
double *dp; // pointer to a double
float *fp; // pointer to a float
char *ch // pointer to characterRzeczywisty typ danych wartości wszystkich wskaźników, niezależnie od tego, czy są to liczby całkowite, zmiennoprzecinkowe, znakowe, czy inne, jest taki sam, długa liczba szesnastkowa, która reprezentuje adres pamięci. Jedyną różnicą między wskaźnikami różnych typów danych jest typ danych zmiennej lub stałej, na którą wskazuje wskaźnik.
Używanie wskaźników w C ++
Jest kilka ważnych operacji, które będziemy wykonywać bardzo często ze wskaźnikami. (a) Definiujemy zmienną wskaźnikową. (b) Przypisz adres zmiennej do wskaźnika. (c)Na koniec uzyskaj dostęp do wartości pod adresem dostępnym w zmiennej wskaźnika. Odbywa się to za pomocą jednoargumentowego operatora *, który zwraca wartość zmiennej znajdującej się pod adresem określonym przez jej operand. Poniższy przykład wykorzystuje te operacje -
#include <iostream>
using namespace std;
int main () {
int var = 20; // actual variable declaration.
int *ip; // pointer variable
ip = &var; // store address of var in pointer variable
cout << "Value of var variable: ";
cout << var << endl;
// print the address stored in ip pointer variable
cout << "Address stored in ip variable: ";
cout << ip << endl;
// access the value at the address available in pointer
cout << "Value of *ip variable: ";
cout << *ip << endl;
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje wynik w następujący sposób -
Value of var variable: 20
Address stored in ip variable: 0xbfc601ac
Value of *ip variable: 20Wskaźniki w C ++
Wskaźniki mają wiele, ale łatwych koncepcji i są bardzo ważne w programowaniu w C ++. Istnieje kilka ważnych pojęć dotyczących wskaźników, które powinny być jasne dla programisty C ++:
| Sr.No | Koncepcja i opis |
|---|---|
| 1 | Puste wskaźniki C ++ obsługuje wskaźnik zerowy, który jest stałą o wartości zero zdefiniowaną w kilku standardowych bibliotekach. |
| 2 | Arytmetyka wskaźników Istnieją cztery operatory arytmetyczne, których można używać na wskaźnikach: ++, -, +, - |
| 3 | Wskaźniki a tablice Istnieje ścisły związek między wskaźnikami a tablicami. |
| 4 | Tablica wskaźników Możesz zdefiniować tablice do przechowywania wielu wskaźników. |
| 5 | Wskaźnik do wskaźnika C ++ pozwala mieć wskaźnik na wskaźniku i tak dalej. |
| 6 | Przekazywanie wskaźników do funkcji Przekazywanie argumentu przez odwołanie lub przez adres umożliwia zmianę przekazanego argumentu w funkcji wywołującej przez wywoływaną funkcję. |
| 7 | Zwróć wskaźnik z funkcji C ++ umożliwia funkcji zwracanie wskaźnika do zmiennej lokalnej, zmiennej statycznej i dynamicznie przydzielanej pamięci. |
Zmienna odniesienia to alias, czyli inna nazwa już istniejącej zmiennej. Po zainicjowaniu odwołania ze zmienną można użyć nazwy zmiennej lub nazwy odwołania do odniesienia się do zmiennej.
Odniesienia a wskaźniki
Odnośniki są często mylone ze wskaźnikami, ale trzy główne różnice między odniesieniami a wskaźnikami to:
Nie możesz mieć odniesień NULL. Zawsze musisz mieć możliwość założenia, że odniesienie jest połączone z legalnym elementem pamięci.
Po zainicjowaniu odwołania do obiektu nie można go zmienić tak, aby odwoływał się do innego obiektu. W dowolnym momencie można wskazać inny obiekt.
Podczas tworzenia odwołania należy zainicjować. Wskaźniki można zainicjować w dowolnym momencie.
Tworzenie referencji w C ++
Pomyśl o nazwie zmiennej jak o etykiecie dołączonej do lokalizacji zmiennej w pamięci. Możesz wtedy myśleć o odwołaniu jako o drugiej etykiecie dołączonej do tego miejsca w pamięci. Dlatego można uzyskać dostęp do zawartości zmiennej poprzez oryginalną nazwę zmiennej lub odwołanie. Załóżmy na przykład, że mamy następujący przykład -
int i = 17;Możemy zadeklarować zmienne referencyjne dla i w następujący sposób.
int& r = i;Przeczytaj & w tych deklaracjach jako reference. Zatem odczytaj pierwszą deklarację jako „r jest odwołaniem w postaci liczby całkowitej zainicjowanej na i”, a drugą deklarację jako „s jest odwołaniem podwójnym zainicjowanym w d.”. Poniższy przykład wykorzystuje odwołania do int i double -
#include <iostream>
using namespace std;
int main () {
// declare simple variables
int i;
double d;
// declare reference variables
int& r = i;
double& s = d;
i = 5;
cout << "Value of i : " << i << endl;
cout << "Value of i reference : " << r << endl;
d = 11.7;
cout << "Value of d : " << d << endl;
cout << "Value of d reference : " << s << endl;
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany razem, daje następujący wynik -
Value of i : 5
Value of i reference : 5
Value of d : 11.7
Value of d reference : 11.7Odnośniki są zwykle używane w przypadku list argumentów funkcji i wartości zwracanych przez funkcję. Oto dwa ważne tematy związane z referencjami C ++, które powinny być jasne dla programisty C ++ -
| Sr.No | Koncepcja i opis |
|---|---|
| 1 | Odniesienia jako parametry C ++ obsługuje przekazywanie odwołań jako parametrów funkcji bezpieczniej niż parametry. |
| 2 | Odniesienie jako wartość zwracana Możesz zwrócić odwołanie z funkcji C ++, tak jak każdy inny typ danych. |
Biblioteka standardowa C ++ nie zapewnia prawidłowego typu daty. C ++ dziedziczy struktury i funkcje do manipulacji datą i godziną z C. Aby uzyskać dostęp do funkcji i struktur związanych z datą i godziną, musiałbyś dołączyć plik nagłówkowy <ctime> do swojego programu C ++.
Istnieją cztery typy związane z czasem: clock_t, time_t, size_t, i tm. Typy - clock_t, size_t i time_t mogą reprezentować czas i datę systemową jako pewnego rodzaju liczby całkowite.
Typ konstrukcji tm przechowuje datę i godzinę w postaci struktury C zawierającej następujące elementy -
struct tm {
int tm_sec; // seconds of minutes from 0 to 61
int tm_min; // minutes of hour from 0 to 59
int tm_hour; // hours of day from 0 to 24
int tm_mday; // day of month from 1 to 31
int tm_mon; // month of year from 0 to 11
int tm_year; // year since 1900
int tm_wday; // days since sunday
int tm_yday; // days since January 1st
int tm_isdst; // hours of daylight savings time
}Poniżej przedstawiamy najważniejsze funkcje, z których korzystamy podczas pracy z datą i czasem w C lub C ++. Wszystkie te funkcje są częścią standardowej biblioteki C i C ++ i możesz sprawdzić ich szczegóły, korzystając z odniesienia do standardowej biblioteki C ++ podanej poniżej.
| Sr.No | Funkcja i cel |
|---|---|
| 1 | time_t time(time_t *time); Zwraca bieżący czas kalendarzowy systemu w liczbie sekund, które upłynęły od 1 stycznia 1970 r. Jeśli system nie ma czasu, zwracane jest .1. |
| 2 | char *ctime(const time_t *time); Zwraca wskaźnik do ciągu w postaci dzień miesiąc rok godziny: minuty: sekundy rok \ n \ 0 . |
| 3 | struct tm *localtime(const time_t *time); To zwraca wskaźnik do tm struktura reprezentująca czas lokalny. |
| 4 | clock_t clock(void); Zwraca wartość przybliżającą czas działania programu wywołującego. Wartość 0,1 jest zwracana, jeśli czas nie jest dostępny. |
| 5 | char * asctime ( const struct tm * time ); Zwraca wskaźnik do ciągu zawierającego informacje przechowywane w strukturze wskazywanej przez czas przekonwertowany na postać: dzień miesiąc data godziny: minuty: sekundy rok \ n \ 0 |
| 6 | struct tm *gmtime(const time_t *time); To zwraca wskaźnik do czasu w postaci struktury tm. Czas jest przedstawiony w uniwersalnym czasie koordynowanym (UTC), który jest zasadniczo czasem Greenwich (GMT). |
| 7 | time_t mktime(struct tm *time); Zwraca kalendarzowy odpowiednik czasu znalezionego w strukturze wskazywanej przez czas. |
| 8 | double difftime ( time_t time2, time_t time1 ); Ta funkcja oblicza różnicę w sekundach między time1 a time2. |
| 9 | size_t strftime(); Ta funkcja może służyć do formatowania daty i godziny w określonym formacie. |
Bieżąca data i godzina
Załóżmy, że chcesz pobrać bieżącą datę i godzinę systemową jako czas lokalny lub uniwersalny czas koordynowany (UTC). Oto przykład, jak osiągnąć to samo -
#include <iostream>
#include <ctime>
using namespace std;
int main() {
// current date/time based on current system
time_t now = time(0);
// convert now to string form
char* dt = ctime(&now);
cout << "The local date and time is: " << dt << endl;
// convert now to tm struct for UTC
tm *gmtm = gmtime(&now);
dt = asctime(gmtm);
cout << "The UTC date and time is:"<< dt << endl;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
The local date and time is: Sat Jan 8 20:07:41 2011
The UTC date and time is:Sun Jan 9 03:07:41 2011Formatowanie czasu przy użyciu struct tm
Plik tmstruktura jest bardzo ważna podczas pracy z datą i godziną w C lub C ++. Ta struktura zawiera datę i godzinę w postaci struktury C, jak wspomniano powyżej. Większość funkcji związanych z czasem wykorzystuje strukturę tm. Poniżej znajduje się przykład wykorzystujący różne funkcje związane z datą i godziną oraz strukturę tm -
Używając struktury w tym rozdziale, zakładam, że masz podstawową wiedzę na temat struktury C i jak uzyskać dostęp do elementów struktury za pomocą operatora strzałki ->.
#include <iostream>
#include <ctime>
using namespace std;
int main() {
// current date/time based on current system
time_t now = time(0);
cout << "Number of sec since January 1,1970 is:: " << now << endl;
tm *ltm = localtime(&now);
// print various components of tm structure.
cout << "Year:" << 1900 + ltm->tm_year<<endl;
cout << "Month: "<< 1 + ltm->tm_mon<< endl;
cout << "Day: "<< ltm->tm_mday << endl;
cout << "Time: "<< 5+ltm->tm_hour << ":";
cout << 30+ltm->tm_min << ":";
cout << ltm->tm_sec << endl;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Number of sec since January 1,1970 is:: 1588485717
Year:2020
Month: 5
Day: 3
Time: 11:31:57Biblioteki w standardzie C ++ zapewniają obszerny zestaw funkcji wejścia / wyjścia, które zobaczymy w kolejnych rozdziałach. W tym rozdziale omówiono podstawowe i najczęściej używane operacje we / wy wymagane do programowania w C ++.
C ++ I / O występuje w strumieniach, które są sekwencjami bajtów. Jeśli bajty przepływają z urządzenia takiego jak klawiatura, napęd dyskowy lub połączenie sieciowe itp. Do pamięci głównej, nazywa się toinput operation a jeśli bajty przepływają z pamięci głównej do urządzenia takiego jak ekran wyświetlacza, drukarka, napęd dyskowy lub połączenie sieciowe itp., nazywa się to output operation.
Pliki nagłówkowe biblioteki I / O
Istnieją następujące pliki nagłówkowe ważne dla programów C ++ -
| Sr.No | Plik nagłówkowy, funkcja i opis |
|---|---|
| 1 | <iostream> Ten plik definiuje cin, cout, cerr i clog obiekty, które odpowiadają odpowiednio standardowemu strumieniowi wejściowemu, standardowemu strumieniowi wyjściowemu, niebuforowanemu standardowemu strumieniowi błędów i zbuforowanemu standardowemu strumieniowi błędów. |
| 2 | <iomanip> Ten plik deklaruje usługi przydatne do wykonywania sformatowanych operacji we / wy z tak zwanymi parametrycznymi manipulatorami strumieni, takimi jak setw i setprecision. |
| 3 | <fstream> Ten plik deklaruje usługi do kontrolowanego przez użytkownika przetwarzania plików. Omówimy to szczegółowo w rozdziale dotyczącym plików i strumieni. |
Standardowy strumień wyjściowy (cout)
Predefiniowany obiekt cout jest przykładem ostreamklasa. Mówi się, że obiekt cout jest „podłączony” do standardowego urządzenia wyjściowego, którym jest zwykle ekran wyświetlacza. Plikcout jest używany w połączeniu z operatorem wstawiania strumienia, który jest zapisywany jako <<, które są dwoma znakami mniejszymi niż, jak pokazano w poniższym przykładzie.
#include <iostream>
using namespace std;
int main() {
char str[] = "Hello C++";
cout << "Value of str is : " << str << endl;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Value of str is : Hello C++Kompilator C ++ określa również typ danych wyjściowych zmiennej i wybiera odpowiedni operator wstawiania strumienia, aby wyświetlić wartość. Operator << jest przeciążony, aby wyprowadzać elementy danych wbudowanych typów integer, float, double, stringi i wartości wskaźnika.
Operator wstawiania << może być używany więcej niż raz w jednej instrukcji, jak pokazano powyżej i endl służy do dodania nowej linii na końcu linii.
Standardowy strumień wejściowy (cin)
Predefiniowany obiekt cin jest przykładem istreamklasa. Mówi się, że obiekt cin jest podłączony do standardowego urządzenia wejściowego, którym jest zwykle klawiatura. Plikcin jest używany w połączeniu z operatorem wyodrębniania strumienia, który jest zapisywany jako >>, czyli dwa znaki większe niż znaki, jak pokazano w poniższym przykładzie.
#include <iostream>
using namespace std;
int main() {
char name[50];
cout << "Please enter your name: ";
cin >> name;
cout << "Your name is: " << name << endl;
}Gdy powyższy kod zostanie skompilowany i wykonany, wyświetli się monit o wprowadzenie nazwy. Wprowadzasz wartość, a następnie naciskasz Enter, aby zobaczyć następujący wynik -
Please enter your name: cplusplus
Your name is: cplusplusKompilator C ++ określa również typ danych wprowadzanej wartości i wybiera odpowiedni operator wyodrębniania strumienia, aby wyodrębnić wartość i zapisać ją w danych zmiennych.
Operator wyodrębniania strumienia >> może być używany więcej niż raz w jednej instrukcji. Aby zażądać więcej niż jednego odniesienia, możesz użyć następującego -
cin >> name >> age;Będzie to równoważne z następującymi dwoma stwierdzeniami -
cin >> name;
cin >> age;Standardowy strumień błędów (cerr)
Predefiniowany obiekt cerr jest przykładem ostreamklasa. Mówi się, że obiekt cerr jest dołączony do standardowego urządzenia błędu, które jest jednocześnie ekranem, ale obiektemcerr nie jest buforowany i każde wstawienie strumienia do cerr powoduje natychmiastowe wyświetlenie jego danych wyjściowych.
Plik cerr jest również używany w połączeniu z operatorem wstawiania strumienia, jak pokazano w poniższym przykładzie.
#include <iostream>
using namespace std;
int main() {
char str[] = "Unable to read....";
cerr << "Error message : " << str << endl;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Error message : Unable to read....Standardowy strumień dziennika (zatkanie)
Predefiniowany obiekt clog jest przykładem ostreamklasa. Mówi się, że obiekt zatykający jest przymocowany do standardowego urządzenia błędu, które jest jednocześnie ekranem, ale obiektemclogjest buforowany. Oznacza to, że każde włożenie do zatkania może spowodować zatrzymanie wyjścia w buforze do czasu jego zapełnienia lub opróżnienia bufora.
Plik clog jest również używany w połączeniu z operatorem wstawiania strumienia, jak pokazano w poniższym przykładzie.
#include <iostream>
using namespace std;
int main() {
char str[] = "Unable to read....";
clog << "Error message : " << str << endl;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Error message : Unable to read....Nie byłbyś w stanie zobaczyć żadnej różnicy w cout, cerr i clog z tymi małymi przykładami, ale podczas pisania i wykonywania dużych programów różnica staje się oczywista. Dlatego dobrą praktyką jest wyświetlanie komunikatów o błędach za pomocą strumienia cerr, a podczas wyświetlania innych komunikatów dziennika należy używać clog.
Tablice C / C ++ umożliwiają definiowanie zmiennych, które łączą kilka elementów danych tego samego rodzaju, ale structure to inny typ danych zdefiniowany przez użytkownika, który umożliwia łączenie elementów danych różnych typów.
Struktury są używane do reprezentowania rekordów, przypuśćmy, że chcesz śledzić swoje książki w bibliotece. Możesz chcieć śledzić następujące atrybuty dotyczące każdej książki -
- Title
- Author
- Subject
- Identyfikator książki
Definiowanie struktury
Aby zdefiniować strukturę, należy użyć instrukcji struct. Instrukcja struct definiuje nowy typ danych, z więcej niż jednym składnikiem, dla twojego programu. Format instrukcji struct jest następujący -
struct [structure tag] {
member definition;
member definition;
...
member definition;
} [one or more structure variables];Plik structure tagjest opcjonalna, a każda definicja elementu jest zwykłą definicją zmiennej, na przykład int i; lub float f; lub jakąkolwiek inną prawidłową definicję zmiennej. Na końcu definicji struktury, przed ostatnim średnikiem, można określić jedną lub więcej zmiennych strukturalnych, ale jest to opcjonalne. Oto sposób, w jaki można zadeklarować strukturę książki -
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
} book;Dostęp do członków struktury
Aby uzyskać dostęp do dowolnego elementu członkowskiego struktury, używamy rozszerzenia member access operator (.). Operator dostępu do elementu jest zakodowany jako okres między nazwą zmiennej strukturalnej a elementem struktury, do którego chcemy uzyskać dostęp. Użyłbyśstructsłowo kluczowe do definiowania zmiennych typu konstrukcji. Poniżej znajduje się przykład wyjaśniający użycie struktury -
#include <iostream>
#include <cstring>
using namespace std;
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
};
int main() {
struct Books Book1; // Declare Book1 of type Book
struct Books Book2; // Declare Book2 of type Book
// book 1 specification
strcpy( Book1.title, "Learn C++ Programming");
strcpy( Book1.author, "Chand Miyan");
strcpy( Book1.subject, "C++ Programming");
Book1.book_id = 6495407;
// book 2 specification
strcpy( Book2.title, "Telecom Billing");
strcpy( Book2.author, "Yakit Singha");
strcpy( Book2.subject, "Telecom");
Book2.book_id = 6495700;
// Print Book1 info
cout << "Book 1 title : " << Book1.title <<endl;
cout << "Book 1 author : " << Book1.author <<endl;
cout << "Book 1 subject : " << Book1.subject <<endl;
cout << "Book 1 id : " << Book1.book_id <<endl;
// Print Book2 info
cout << "Book 2 title : " << Book2.title <<endl;
cout << "Book 2 author : " << Book2.author <<endl;
cout << "Book 2 subject : " << Book2.subject <<endl;
cout << "Book 2 id : " << Book2.book_id <<endl;
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Book 1 title : Learn C++ Programming
Book 1 author : Chand Miyan
Book 1 subject : C++ Programming
Book 1 id : 6495407
Book 2 title : Telecom Billing
Book 2 author : Yakit Singha
Book 2 subject : Telecom
Book 2 id : 6495700Struktury jako argumenty funkcji
Możesz przekazać strukturę jako argument funkcji w bardzo podobny sposób, jak przekazujesz dowolną inną zmienną lub wskaźnik. Dostęp do zmiennych strukturalnych uzyskasz w podobny sposób, jak w powyższym przykładzie -
#include <iostream>
#include <cstring>
using namespace std;
void printBook( struct Books book );
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
};
int main() {
struct Books Book1; // Declare Book1 of type Book
struct Books Book2; // Declare Book2 of type Book
// book 1 specification
strcpy( Book1.title, "Learn C++ Programming");
strcpy( Book1.author, "Chand Miyan");
strcpy( Book1.subject, "C++ Programming");
Book1.book_id = 6495407;
// book 2 specification
strcpy( Book2.title, "Telecom Billing");
strcpy( Book2.author, "Yakit Singha");
strcpy( Book2.subject, "Telecom");
Book2.book_id = 6495700;
// Print Book1 info
printBook( Book1 );
// Print Book2 info
printBook( Book2 );
return 0;
}
void printBook( struct Books book ) {
cout << "Book title : " << book.title <<endl;
cout << "Book author : " << book.author <<endl;
cout << "Book subject : " << book.subject <<endl;
cout << "Book id : " << book.book_id <<endl;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Book title : Learn C++ Programming
Book author : Chand Miyan
Book subject : C++ Programming
Book id : 6495407
Book title : Telecom Billing
Book author : Yakit Singha
Book subject : Telecom
Book id : 6495700Wskaźniki do struktur
Możesz zdefiniować wskaźniki do struktur w bardzo podobny sposób, jak definiujesz wskaźnik do dowolnej innej zmiennej w następujący sposób -
struct Books *struct_pointer;Teraz możesz zapisać adres zmiennej strukturalnej w zdefiniowanej powyżej zmiennej wskaźnikowej. Aby znaleźć adres zmiennej strukturalnej, umieść operator & przed nazwą struktury w następujący sposób -
struct_pointer = &Book1;Aby uzyskać dostęp do elementów struktury za pomocą wskaźnika do tej struktury, należy użyć operatora -> w następujący sposób -
struct_pointer->title;Napiszmy ponownie powyższy przykład za pomocą wskaźnika struktury, mam nadzieję, że będzie to łatwe do zrozumienia koncepcji -
#include <iostream>
#include <cstring>
using namespace std;
void printBook( struct Books *book );
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
};
int main() {
struct Books Book1; // Declare Book1 of type Book
struct Books Book2; // Declare Book2 of type Book
// Book 1 specification
strcpy( Book1.title, "Learn C++ Programming");
strcpy( Book1.author, "Chand Miyan");
strcpy( Book1.subject, "C++ Programming");
Book1.book_id = 6495407;
// Book 2 specification
strcpy( Book2.title, "Telecom Billing");
strcpy( Book2.author, "Yakit Singha");
strcpy( Book2.subject, "Telecom");
Book2.book_id = 6495700;
// Print Book1 info, passing address of structure
printBook( &Book1 );
// Print Book1 info, passing address of structure
printBook( &Book2 );
return 0;
}
// This function accept pointer to structure as parameter.
void printBook( struct Books *book ) {
cout << "Book title : " << book->title <<endl;
cout << "Book author : " << book->author <<endl;
cout << "Book subject : " << book->subject <<endl;
cout << "Book id : " << book->book_id <<endl;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Book title : Learn C++ Programming
Book author : Chand Miyan
Book subject : C++ Programming
Book id : 6495407
Book title : Telecom Billing
Book author : Yakit Singha
Book subject : Telecom
Book id : 6495700Słowo kluczowe typedef
Istnieje łatwiejszy sposób definiowania struktur lub tworzenie typów „aliasów”. Na przykład -
typedef struct {
char title[50];
char author[50];
char subject[100];
int book_id;
} Books;Teraz możesz używać Książek bezpośrednio do definiowania zmiennych typu Książki bez użycia słowa kluczowego struct. Oto przykład -
Books Book1, Book2;Możesz użyć typedef słowo kluczowe dla niestruktur, a także następujące -
typedef long int *pint32;
pint32 x, y, z;x, y i z są wskaźnikami do długich liczb całkowitych.
Głównym celem programowania w C ++ jest dodanie orientacji obiektowej do języka programowania C, a klasy są centralną cechą C ++, która obsługuje programowanie obiektowe i są często nazywane typami zdefiniowanymi przez użytkownika.
Klasa służy do określania formy obiektu i łączy reprezentację danych i metody manipulowania tymi danymi w jeden zgrabny pakiet. Dane i funkcje w klasie nazywane są członkami klasy.
Definicje klas C ++
Definiując klasę, definiujesz plan dla typu danych. W rzeczywistości nie definiuje to żadnych danych, ale definiuje, co oznacza nazwa klasy, czyli z czego będzie się składał obiekt klasy i jakie operacje można wykonać na takim obiekcie.
Definicja klasy zaczyna się od słowa kluczowego classpo którym następuje nazwa klasy; i treść klasy, ujęta w nawiasy klamrowe. Po definicji klasy należy umieścić średnik lub listę deklaracji. Na przykład zdefiniowaliśmy typ danych Box za pomocą słowa kluczowegoclass w następujący sposób -
class Box {
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};Słowo kluczowe publicokreśla atrybuty dostępu członków klasy, która po nim następuje. Dostęp do publicznego członka można uzyskać spoza klasy w dowolnym miejscu w zakresie obiektu klasy. Możesz również określić członków klasy jakoprivate lub protected które omówimy w podrozdziale.
Zdefiniuj obiekty C ++
Klasa zapewnia plany obiektów, więc zasadniczo obiekt jest tworzony z klasy. Deklarujemy obiekty klasy z dokładnie takim samym rodzajem deklaracji, jak deklarujemy zmienne typu podstawowego. Następujące instrukcje deklarują dwa obiekty klasy Box -
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type BoxOba obiekty Box1 i Box2 będą miały własną kopię członków danych.
Dostęp do członków danych
Dostęp do publicznych członków danych obiektów klasy można uzyskać za pomocą operatora bezpośredniego dostępu do elementu członkowskiego (.). Wypróbujmy następujący przykład, aby wyjaśnić sprawę -
#include <iostream>
using namespace std;
class Box {
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
int main() {
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
Box1.height = 5.0;
Box1.length = 6.0;
Box1.breadth = 7.0;
// box 2 specification
Box2.height = 10.0;
Box2.length = 12.0;
Box2.breadth = 13.0;
// volume of box 1
volume = Box1.height * Box1.length * Box1.breadth;
cout << "Volume of Box1 : " << volume <<endl;
// volume of box 2
volume = Box2.height * Box2.length * Box2.breadth;
cout << "Volume of Box2 : " << volume <<endl;
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Volume of Box1 : 210
Volume of Box2 : 1560Należy zauważyć, że nie można uzyskać bezpośredniego dostępu do członków prywatnych i chronionych za pomocą operatora bezpośredniego dostępu do członków (.). Dowiemy się, jak można uzyskać dostęp do prywatnych i chronionych członków.
Klasy i obiekty w szczegółach
Jak dotąd masz bardzo podstawowe pojęcie o klasach i obiektach C ++. Istnieją dalsze interesujące koncepcje związane z klasami i obiektami C ++, które omówimy w różnych podsekcjach wymienionych poniżej -
| Sr.No | Koncepcja i opis |
|---|---|
| 1 | Funkcje składowe klasy Funkcja składowa klasy to funkcja, która ma swoją definicję lub swój prototyp w definicji klasy, jak każda inna zmienna. |
| 2 | Modyfikatory dostępu do klas Członka klasy można zdefiniować jako publiczny, prywatny lub chroniony. Domyślnie członkowie zostaną uznani za prywatnych. |
| 3 | Konstruktor i niszczyciel Konstruktor klasy to specjalna funkcja w klasie, która jest wywoływana, gdy tworzony jest nowy obiekt tej klasy. Destruktor to także specjalna funkcja, która jest wywoływana po usunięciu utworzonego obiektu. |
| 4 | Copy Constructor Konstruktor kopiujący to konstruktor, który tworzy obiekt inicjalizując go obiektem tej samej klasy, który został utworzony wcześniej. |
| 5 | Funkcje przyjaciół ZA friend funkcja ma pełny dostęp do prywatnych i chronionych członków klasy. |
| 6 | Funkcje wbudowane W przypadku funkcji wbudowanej kompilator próbuje rozwinąć kod w treści funkcji zamiast wywołania funkcji. |
| 7 | ten wskaźnik Każdy obiekt ma specjalny wskaźnik this co wskazuje na sam obiekt. |
| 8 | Wskaźnik do klas C ++ Wskaźnik do klasy jest wykonywany dokładnie w taki sam sposób, jak wskaźnik do struktury. W rzeczywistości klasa jest po prostu strukturą zawierającą funkcje. |
| 9 | Statyczne składowe klasy Zarówno elementy członkowskie danych, jak i elementy członkowskie funkcji klasy można zadeklarować jako statyczne. |
Jedną z najważniejszych koncepcji programowania obiektowego jest dziedziczenie. Dziedziczenie pozwala nam zdefiniować klasę pod względem innej klasy, co ułatwia tworzenie i utrzymywanie aplikacji. Daje to również możliwość ponownego wykorzystania funkcjonalności kodu i szybkiego czasu implementacji.
Tworząc klasę, zamiast pisać zupełnie nowe składowe danych i funkcje składowe, programista może wyznaczyć, że nowa klasa powinna dziedziczyć składowe istniejącej klasy. Ta istniejąca klasa nosi nazwębase class, a nowa klasa jest nazywana derived klasa.
Idea dziedziczenia implementuje is azwiązek. Na przykład, ssak IS-A zwierzę, pies IS-A ssak, stąd też pies IS-A zwierzę i tak dalej.
Klasy bazowe i pochodne
Klasa może pochodzić z więcej niż jednej klasy, co oznacza, że może dziedziczyć dane i funkcje z wielu klas bazowych. Aby zdefiniować klasę pochodną, używamy listy pochodnych klas, aby określić klasy bazowe. Lista pochodnych klas zawiera nazwę jednej lub więcej klas bazowych i ma postać -
class derived-class: access-specifier base-classGdzie specyfikator dostępu jest jednym z public, protected, lub private, a klasa bazowa to nazwa wcześniej zdefiniowanej klasy. Jeśli specyfikator dostępu nie jest używany, domyślnie jest prywatny.
Rozważ klasę bazową Shape i jej klasa pochodna Rectangle w następujący sposób -
#include <iostream>
using namespace std;
// Base class
class Shape {
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
protected:
int width;
int height;
};
// Derived class
class Rectangle: public Shape {
public:
int getArea() {
return (width * height);
}
};
int main(void) {
Rectangle Rect;
Rect.setWidth(5);
Rect.setHeight(7);
// Print the area of the object.
cout << "Total area: " << Rect.getArea() << endl;
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Total area: 35Kontrola dostępu i dziedziczenie
Klasa pochodna może uzyskać dostęp do wszystkich nieprywatnych elementów członkowskich swojej klasy bazowej. W związku z tym elementy członkowskie klasy bazowej, które nie powinny być dostępne dla funkcji składowych klas pochodnych, powinny być zadeklarowane jako prywatne w klasie bazowej.
Możemy podsumować różne typy dostępu według - kto może uzyskać do nich dostęp w następujący sposób -
| Dostęp | publiczny | chroniony | prywatny |
|---|---|---|---|
| Sama klasa | tak | tak | tak |
| Klasy pochodne | tak | tak | Nie |
| Zajęcia pozalekcyjne | tak | Nie | Nie |
Klasa pochodna dziedziczy wszystkie metody klasy bazowej z następującymi wyjątkami -
- Konstruktory, destruktory i konstruktory kopiujące klasy bazowej.
- Przeciążone operatory klasy bazowej.
- Zaprzyjaźnione funkcje klasy bazowej.
Rodzaj dziedziczenia
Podczas wyprowadzania klasy z klasy bazowej, klasa bazowa może być dziedziczona za pośrednictwem public, protected lub privatedziedzictwo. Typ dziedziczenia jest określony przez specyfikator dostępu, jak wyjaśniono powyżej.
Rzadko używamy protected lub private dziedziczenie, ale publicdziedziczenie jest powszechnie stosowane. Podczas korzystania z innego rodzaju dziedziczenia obowiązują następujące zasady -
Public Inheritance - Wyprowadzając klasę z pliku public klasa bazowa, public stają się członkami klasy bazowej public członkowie klasy pochodnej i protected stają się członkami klasy bazowej protectedczłonkowie klasy pochodnej. Klasa bazowaprivate elementy członkowskie nigdy nie są dostępne bezpośrednio z klasy pochodnej, ale można uzyskać do nich dostęp za pośrednictwem wywołań do public i protected członkowie klasy bazowej.
Protected Inheritance - W przypadku wyprowadzenia z pliku protected klasa bazowa, public i protected stają się członkami klasy bazowej protected członkowie klasy pochodnej.
Private Inheritance - W przypadku wyprowadzenia z pliku private klasa bazowa, public i protected stają się członkami klasy bazowej private członkowie klasy pochodnej.
Dziedziczenie wielokrotne
Klasa C ++ może dziedziczyć elementy członkowskie z więcej niż jednej klasy, a oto rozszerzona składnia -
class derived-class: access baseA, access baseB....Gdzie dostęp jest jednym z public, protected, lub privatei zostaną podane dla każdej klasy bazowej i zostaną oddzielone przecinkiem, jak pokazano powyżej. Wypróbujmy następujący przykład -
#include <iostream>
using namespace std;
// Base class Shape
class Shape {
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
protected:
int width;
int height;
};
// Base class PaintCost
class PaintCost {
public:
int getCost(int area) {
return area * 70;
}
};
// Derived class
class Rectangle: public Shape, public PaintCost {
public:
int getArea() {
return (width * height);
}
};
int main(void) {
Rectangle Rect;
int area;
Rect.setWidth(5);
Rect.setHeight(7);
area = Rect.getArea();
// Print the area of the object.
cout << "Total area: " << Rect.getArea() << endl;
// Print the total cost of painting
cout << "Total paint cost: $" << Rect.getCost(area) << endl;
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Total area: 35
Total paint cost: $2450C ++ umożliwia określenie więcej niż jednej definicji dla function imię lub nazwisko operator w tym samym zakresie, który jest nazywany function overloading i operator overloading odpowiednio.
Deklaracja przeciążona to deklaracja, która jest zadeklarowana z taką samą nazwą jak poprzednio zadeklarowana deklaracja w tym samym zakresie, z tą różnicą, że obie deklaracje mają różne argumenty i oczywiście inną definicję (implementację).
Kiedy dzwonisz do przeciążonego pliku function lub operator, kompilator określa najbardziej odpowiednią definicję do użycia, porównując typy argumentów, których użyłeś do wywołania funkcji lub operatora z typami parametrów określonymi w definicjach. Wywoływany jest proces wyboru najbardziej odpowiedniej przeciążonej funkcji lub operatoraoverload resolution.
Przeciążanie funkcji w C ++
Możesz mieć wiele definicji dla tej samej nazwy funkcji w tym samym zakresie. Definicja funkcji musi różnić się od siebie typami i / lub liczbą argumentów na liście argumentów. Nie można przeciążać deklaracji funkcji, które różnią się tylko zwracanym typem.
Poniżej znajduje się przykład, w którym ta sama funkcja print() jest używany do drukowania różnych typów danych -
#include <iostream>
using namespace std;
class printData {
public:
void print(int i) {
cout << "Printing int: " << i << endl;
}
void print(double f) {
cout << "Printing float: " << f << endl;
}
void print(char* c) {
cout << "Printing character: " << c << endl;
}
};
int main(void) {
printData pd;
// Call print to print integer
pd.print(5);
// Call print to print float
pd.print(500.263);
// Call print to print character
pd.print("Hello C++");
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Printing int: 5
Printing float: 500.263
Printing character: Hello C++Przeciążanie operatorów w C ++
Możesz ponownie zdefiniować lub przeciążać większość wbudowanych operatorów dostępnych w C ++. Dlatego programista może również używać operatorów z typami zdefiniowanymi przez użytkownika.
Przeciążone operatory to funkcje o specjalnych nazwach: słowo kluczowe „operator”, po którym następuje symbol definiowanego operatora. Podobnie jak każda inna funkcja, przeciążony operator ma typ zwracany i listę parametrów.
Box operator+(const Box&);deklaruje operator dodawania, którego można użyć adddwa obiekty Box i zwraca ostateczny obiekt Box. Większość przeciążonych operatorów można zdefiniować jako zwykłe funkcje niebędące składowymi lub jako funkcje składowe klasy. W przypadku zdefiniowania powyższej funkcji jako funkcji niebędącej składową klasy, musielibyśmy przekazać dwa argumenty dla każdego operandu w następujący sposób -
Box operator+(const Box&, const Box&);Poniżej znajduje się przykład pokazujący koncepcję operatora nad ładowaniem przy użyciu funkcji składowej. Tutaj obiekt jest przekazywany jako argument, którego właściwości będą dostępne przy użyciu tego obiektu, do obiektu, który wywoła ten operator można uzyskać dostęp za pomocąthis operator, jak wyjaśniono poniżej -
#include <iostream>
using namespace std;
class Box {
public:
double getVolume(void) {
return length * breadth * height;
}
void setLength( double len ) {
length = len;
}
void setBreadth( double bre ) {
breadth = bre;
}
void setHeight( double hei ) {
height = hei;
}
// Overload + operator to add two Box objects.
Box operator+(const Box& b) {
Box box;
box.length = this->length + b.length;
box.breadth = this->breadth + b.breadth;
box.height = this->height + b.height;
return box;
}
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
// Main function for the program
int main() {
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type Box
Box Box3; // Declare Box3 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
Box1.setLength(6.0);
Box1.setBreadth(7.0);
Box1.setHeight(5.0);
// box 2 specification
Box2.setLength(12.0);
Box2.setBreadth(13.0);
Box2.setHeight(10.0);
// volume of box 1
volume = Box1.getVolume();
cout << "Volume of Box1 : " << volume <<endl;
// volume of box 2
volume = Box2.getVolume();
cout << "Volume of Box2 : " << volume <<endl;
// Add two object as follows:
Box3 = Box1 + Box2;
// volume of box 3
volume = Box3.getVolume();
cout << "Volume of Box3 : " << volume <<endl;
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Volume of Box1 : 210
Volume of Box2 : 1560
Volume of Box3 : 5400Przeciążalne / nieprzeciążalne Operatory
Poniżej znajduje się lista operatorów, które mogą być przeciążone -
| + | - | * | / | % | ^ |
| & | | | ~ | ! | , | = |
| < | > | <= | > = | ++ | - |
| << | >> | == | ! = | && | || |
| + = | - = | / = | % = | ^ = | & = |
| | = | * = | << = | >> = | [] | () |
| -> | -> * | Nowy | Nowy [] | usunąć | usunąć [] |
Poniżej znajduje się lista operatorów, których nie można przeciążać -
| :: | . * | . | ?: |
Przykłady przeciążania operatorów
Oto różne przykłady przeciążania operatorów, które pomogą Ci zrozumieć tę koncepcję.
| Sr.No | Operatory i przykład |
|---|---|
| 1 | Przeciążanie operatorów jednoargumentowych |
| 2 | Przeciążanie operatorów binarnych |
| 3 | Przeciążanie operatorów relacyjnych |
| 4 | Przeciążenie operatorów wejścia / wyjścia |
| 5 | ++ i - Przeciążanie operatorów |
| 6 | Przeciążanie operatorów przypisania |
| 7 | Funkcja wywołania () Przeciążanie operatora |
| 8 | Przeciążanie operatora subscripting [] |
| 9 | Operator dostępu do składowej klasy -> Przeciążanie |
Słowo polymorphismoznacza posiadanie wielu form. Zwykle polimorfizm występuje, gdy istnieje hierarchia klas i są one powiązane dziedziczeniem.
Polimorfizm C ++ oznacza, że wywołanie funkcji składowej spowoduje wykonanie innej funkcji w zależności od typu obiektu, który wywołuje funkcję.
Rozważmy następujący przykład, w którym klasa bazowa została wyprowadzona przez inne dwie klasy -
#include <iostream>
using namespace std;
class Shape {
protected:
int width, height;
public:
Shape( int a = 0, int b = 0){
width = a;
height = b;
}
int area() {
cout << "Parent class area :" <<endl;
return 0;
}
};
class Rectangle: public Shape {
public:
Rectangle( int a = 0, int b = 0):Shape(a, b) { }
int area () {
cout << "Rectangle class area :" <<endl;
return (width * height);
}
};
class Triangle: public Shape {
public:
Triangle( int a = 0, int b = 0):Shape(a, b) { }
int area () {
cout << "Triangle class area :" <<endl;
return (width * height / 2);
}
};
// Main function for the program
int main() {
Shape *shape;
Rectangle rec(10,7);
Triangle tri(10,5);
// store the address of Rectangle
shape = &rec;
// call rectangle area.
shape->area();
// store the address of Triangle
shape = &tri;
// call triangle area.
shape->area();
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Parent class area :
Parent class area :Przyczyną nieprawidłowego wyniku jest to, że wywołanie funkcji area () jest ustawiane raz przez kompilator jako wersja zdefiniowana w klasie bazowej. To się nazywastatic resolution wywołania funkcji lub static linkage- wywołanie funkcji jest naprawiane przed wykonaniem programu. Jest to również czasami nazywaneearly binding ponieważ funkcja area () jest ustawiana podczas kompilacji programu.
Ale teraz dokonajmy niewielkiej modyfikacji w naszym programie i poprzedźmy deklarację area () w klasie Shape słowem kluczowym virtual żeby wyglądało tak -
class Shape {
protected:
int width, height;
public:
Shape( int a = 0, int b = 0) {
width = a;
height = b;
}
virtual int area() {
cout << "Parent class area :" <<endl;
return 0;
}
};Po tej niewielkiej modyfikacji, gdy poprzedni kod przykładowy jest kompilowany i wykonywany, daje następujący wynik -
Rectangle class area
Triangle class areaTym razem kompilator patrzy na zawartość wskaźnika zamiast na jego typ. Stąd, ponieważ adresy obiektów klas tri i rec są przechowywane w kształcie *, wywoływana jest odpowiednia funkcja area ().
Jak widać, każda z klas potomnych ma oddzielną implementację dla funkcji area (). Oto jakpolymorphismjest powszechnie używany. Masz różne klasy z funkcją o tej samej nazwie, a nawet z tymi samymi parametrami, ale z różnymi implementacjami.
Funkcja wirtualna
ZA virtual funkcja to funkcja w klasie bazowej zadeklarowana za pomocą słowa kluczowego virtual. Zdefiniowanie w klasie bazowej funkcji wirtualnej z inną wersją w klasie pochodnej sygnalizuje kompilatorowi, że nie chcemy statycznego powiązania dla tej funkcji.
To, czego chcemy, to wybór funkcji, która ma zostać wywołana w dowolnym punkcie programu, aby była oparta na rodzaju obiektu, dla którego jest wywoływana. Ten rodzaj operacji jest określany jakodynamic linkagelub late binding.
Czyste funkcje wirtualne
Możliwe, że chcesz zawrzeć wirtualną funkcję w klasie bazowej, aby można ją było przedefiniować w klasie pochodnej, aby pasowała do obiektów tej klasy, ale nie ma sensownej definicji, którą możesz podać dla funkcji w klasie bazowej .
Możemy zmienić obszar funkcji wirtualnej () w klasie bazowej na następującą -
class Shape {
protected:
int width, height;
public:
Shape(int a = 0, int b = 0) {
width = a;
height = b;
}
// pure virtual function
virtual int area() = 0;
};= 0 mówi kompilatorowi, że funkcja nie ma treści i powyżej zostanie wywołana funkcja wirtualna pure virtual function.
Abstrakcja danych odnosi się do dostarczania tylko niezbędnych informacji światu zewnętrznemu i ukrywania ich podstawowych szczegółów, tj. Reprezentowania potrzebnych informacji w programie bez przedstawiania szczegółów.
Abstrakcja danych to technika programowania (i projektowania) polegająca na oddzieleniu interfejsu i implementacji.
Weźmy jeden przykład z życia telewizora, który można włączać i wyłączać, zmieniać kanał, regulować głośność i dodawać zewnętrzne komponenty, takie jak głośniki, magnetowidy i odtwarzacze DVD, ALE nie znasz jego wewnętrznych szczegółów, które to znaczy, że nie wiesz, jak odbiera sygnały drogą radiową lub kablową, jak je tłumaczy, a na koniec wyświetla je na ekranie.
Można więc powiedzieć, że telewizor wyraźnie oddziela swoją wewnętrzną implementację od zewnętrznego interfejsu i można bawić się jego interfejsami, takimi jak przycisk zasilania, zmieniacz kanałów i regulacja głośności, bez znajomości jego elementów wewnętrznych.
W C ++ klasy zapewniają świetny poziom data abstraction. Dostarczają one światu zewnętrznemu wystarczających metod publicznych do zabawy z funkcjonalnością obiektu i manipulowania danymi obiektu, tj. Stanu bez faktycznej wiedzy, w jaki sposób klasa została zaimplementowana wewnętrznie.
Na przykład Twój program może wywołać plik sort()nie wiedząc, jakiego algorytmu faktycznie używa funkcja do sortowania podanych wartości. W rzeczywistości podstawowa implementacja funkcji sortowania może zmieniać się między wydaniami biblioteki i tak długo, jak interfejs pozostaje taki sam, wywołanie funkcji będzie nadal działać.
W C ++ używamy classesaby zdefiniować własne abstrakcyjne typy danych (ADT). Możesz użyćcout przedmiot klasy ostream przesyłać dane na standardowe wyjście w ten sposób -
#include <iostream>
using namespace std;
int main() {
cout << "Hello C++" <<endl;
return 0;
}Tutaj nie musisz rozumieć, jak to zrobić coutwyświetla tekst na ekranie użytkownika. Musisz znać tylko interfejs publiczny, a podstawowa implementacja „cout” może ulec zmianie.
Etykiety dostępu wymuszają abstrakcję
W C ++ używamy etykiet dostępu do definiowania abstrakcyjnego interfejsu do klasy. Klasa może zawierać zero lub więcej etykiet dostępu -
Członkowie zdefiniowani za pomocą etykiety publicznej są dostępni dla wszystkich części programu. Widok typu abstrakcji danych jest definiowany przez jego publicznych członków.
Elementy członkowskie zdefiniowane z etykietą prywatną nie są dostępne dla kodu używającego tej klasy. Sekcje prywatne ukrywają implementację przed kodem używającym typu.
Nie ma ograniczeń co do częstotliwości wyświetlania etykiety dostępu. Każda etykieta dostępu określa poziom dostępu kolejnych definicji elementów członkowskich. Określony poziom dostępu obowiązuje do momentu napotkania następnej etykiety dostępu lub wyświetlenia prawego zamykającego nawiasu klamrowego treści klasy.
Korzyści z abstrakcji danych
Abstrakcja danych zapewnia dwie ważne zalety -
Elementy wewnętrzne klas są chronione przed nieumyślnymi błędami na poziomie użytkownika, które mogą uszkodzić stan obiektu.
Implementacja klasy może ewoluować w czasie w odpowiedzi na zmieniające się wymagania lub raporty o błędach bez konieczności zmiany kodu na poziomie użytkownika.
Definiując członków danych tylko w prywatnej części klasy, autor klasy może dowolnie wprowadzać zmiany w danych. Jeśli implementacja się zmieni, wystarczy zbadać tylko kod klasy, aby zobaczyć, jaki wpływ może mieć zmiana. Jeśli dane są publiczne, każda funkcja, która ma bezpośredni dostęp do elementów składowych danych starej reprezentacji, może zostać uszkodzona.
Przykład abstrakcji danych
Każdy program C ++, w którym zaimplementujesz klasę z publicznymi i prywatnymi elementami członkowskimi, jest przykładem abstrakcji danych. Rozważmy następujący przykład -
#include <iostream>
using namespace std;
class Adder {
public:
// constructor
Adder(int i = 0) {
total = i;
}
// interface to outside world
void addNum(int number) {
total += number;
}
// interface to outside world
int getTotal() {
return total;
};
private:
// hidden data from outside world
int total;
};
int main() {
Adder a;
a.addNum(10);
a.addNum(20);
a.addNum(30);
cout << "Total " << a.getTotal() <<endl;
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Total 60Powyższa klasa dodaje liczby do siebie i zwraca sumę. Członkowie publiczni -addNum i getTotalto interfejsy do świata zewnętrznego i użytkownik musi je znać, aby używać tej klasy. Członek prywatnytotal jest czymś, o czym użytkownik nie musi wiedzieć, ale jest potrzebne do prawidłowego działania klasy.
Projektowanie strategii
Abstrakcja rozdziela kod na interfejs i implementację. Dlatego podczas projektowania komponentu należy zachować niezależność interfejsu od implementacji, aby w przypadku zmiany podstawowej implementacji interfejs pozostał nienaruszony.
W takim przypadku jakiekolwiek programy używają tych interfejsów, nie będzie to miało wpływu i wymagałoby jedynie ponownej kompilacji z najnowszą implementacją.
Wszystkie programy w języku C ++ składają się z następujących dwóch podstawowych elementów -
Program statements (code) - To jest część programu, która wykonuje czynności i nazywa się je funkcjami.
Program data - Dane to informacje o programie, na które mają wpływ funkcje programu.
Hermetyzacja to koncepcja programowania zorientowanego obiektowo, która wiąże ze sobą dane i funkcje, które manipulują danymi, i która chroni zarówno przed zewnętrznymi zakłóceniami, jak i nadużyciami. Hermetyzacja danych doprowadziła do powstania ważnej koncepcji OOPdata hiding.
Data encapsulation jest mechanizmem łączenia danych i funkcji, które z nich korzystają oraz data abstraction to mechanizm ujawniania tylko interfejsów i ukrywania szczegółów implementacji przed użytkownikiem.
C ++ obsługuje właściwości hermetyzacji i ukrywania danych poprzez tworzenie typów zdefiniowanych przez użytkownika, tzw classes. Sprawdziliśmy już, że klasa może zawieraćprivate, protected i publicczłonków. Domyślnie wszystkie elementy zdefiniowane w klasie są prywatne. Na przykład -
class Box {
public:
double getVolume(void) {
return length * breadth * height;
}
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};Zmienne długość, szerokość i wysokość to private. Oznacza to, że dostęp do nich mają tylko inni członkowie klasy Box, a nie inna część programu. Jest to jeden ze sposobów osiągnięcia hermetyzacji.
Tworzyć części klasy public (tj. dostępne dla innych części twojego programu), musisz zadeklarować je po publicsłowo kluczowe. Wszystkie zmienne lub funkcje zdefiniowane po publicznym specyfikatorze są dostępne dla wszystkich innych funkcji w programie.
Zaprzyjaźnienie jednej klasy z inną ujawnia szczegóły implementacji i zmniejsza hermetyzację. Ideałem jest, aby jak najwięcej szczegółów każdej klasy było ukryte przed wszystkimi innymi klasami.
Przykład enkapsulacji danych
Każdy program w C ++, w którym zaimplementowano klasę z publicznymi i prywatnymi elementami członkowskimi, jest przykładem enkapsulacji i abstrakcji danych. Rozważmy następujący przykład -
#include <iostream>
using namespace std;
class Adder {
public:
// constructor
Adder(int i = 0) {
total = i;
}
// interface to outside world
void addNum(int number) {
total += number;
}
// interface to outside world
int getTotal() {
return total;
};
private:
// hidden data from outside world
int total;
};
int main() {
Adder a;
a.addNum(10);
a.addNum(20);
a.addNum(30);
cout << "Total " << a.getTotal() <<endl;
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Total 60Powyższa klasa dodaje liczby do siebie i zwraca sumę. Członkowie publiczniaddNum i getTotal to interfejsy do świata zewnętrznego i użytkownik musi je znać, aby używać tej klasy. Członek prywatnytotal jest czymś, co jest ukryte przed światem zewnętrznym, ale jest potrzebne klasie do prawidłowego działania.
Projektowanie strategii
Większość z nas nauczyła się domyślnie ustawiać członków klasy jako prywatnych, chyba że naprawdę musimy ich ujawniać. Po prostu dobrzeencapsulation.
Jest to stosowane najczęściej do członków danych, ale dotyczy w równym stopniu wszystkich członków, w tym funkcji wirtualnych.
Interfejs opisuje zachowanie lub możliwości klasy C ++ bez angażowania się w konkretną implementację tej klasy.
Interfejsy C ++ są implementowane przy użyciu abstract classes i tych klas abstrakcyjnych nie należy mylić z abstrakcją danych, która jest koncepcją oddzielenia szczegółów implementacji od powiązanych danych.
Klasa staje się abstrakcyjna, deklarując co najmniej jedną z jej funkcji jako pure virtualfunkcjonować. Czystą funkcję wirtualną określa się przez umieszczenie w jej deklaracji „= 0” w następujący sposób -
class Box {
public:
// pure virtual function
virtual double getVolume() = 0;
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};Celem abstract class(często określane jako ABC) ma na celu zapewnienie odpowiedniej klasy bazowej, z której inne klasy mogą dziedziczyć. Klasy abstrakcyjne nie mogą służyć do tworzenia instancji obiektów i służą tylko jako plikinterface. Próba utworzenia wystąpienia obiektu klasy abstrakcyjnej powoduje błąd kompilacji.
Tak więc, jeśli trzeba utworzyć instancję podklasy ABC, musi zaimplementować każdą z funkcji wirtualnych, co oznacza, że obsługuje interfejs zadeklarowany przez ABC. Niepowodzenie zastąpienia czystej funkcji wirtualnej w klasie pochodnej, a następnie próba utworzenia instancji obiektów tej klasy jest błędem kompilacji.
Klasy, których można użyć do tworzenia instancji obiektów, są wywoływane concrete classes.
Przykład klasy abstrakcyjnej
Rozważmy następujący przykład, w którym klasa nadrzędna udostępnia interfejs do klasy bazowej w celu zaimplementowania funkcji o nazwie getArea() -
#include <iostream>
using namespace std;
// Base class
class Shape {
public:
// pure virtual function providing interface framework.
virtual int getArea() = 0;
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
protected:
int width;
int height;
};
// Derived classes
class Rectangle: public Shape {
public:
int getArea() {
return (width * height);
}
};
class Triangle: public Shape {
public:
int getArea() {
return (width * height)/2;
}
};
int main(void) {
Rectangle Rect;
Triangle Tri;
Rect.setWidth(5);
Rect.setHeight(7);
// Print the area of the object.
cout << "Total Rectangle area: " << Rect.getArea() << endl;
Tri.setWidth(5);
Tri.setHeight(7);
// Print the area of the object.
cout << "Total Triangle area: " << Tri.getArea() << endl;
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Total Rectangle area: 35
Total Triangle area: 17Możesz zobaczyć, jak klasa abstrakcyjna zdefiniowała interfejs za pomocą metody getArea (), a dwie inne klasy zaimplementowały tę samą funkcję, ale z innym algorytmem obliczania obszaru specyficznego dla kształtu.
Projektowanie strategii
System zorientowany obiektowo może używać abstrakcyjnej klasy bazowej, aby zapewnić wspólny i znormalizowany interfejs odpowiedni dla wszystkich aplikacji zewnętrznych. Następnie, poprzez dziedziczenie z tej abstrakcyjnej klasy bazowej, tworzone są klasy pochodne, które działają podobnie.
Możliwości (tj. Funkcje publiczne) oferowane przez aplikacje zewnętrzne są dostarczane jako czyste funkcje wirtualne w abstrakcyjnej klasie bazowej. Implementacje tych czystych funkcji wirtualnych są dostarczane w klasach pochodnych, które odpowiadają określonym typom aplikacji.
Architektura ta umożliwia również łatwe dodawanie nowych aplikacji do systemu, nawet po zdefiniowaniu systemu.
Do tej pory używaliśmy iostream biblioteka standardowa, która udostępnia cin i cout metody odczytu odpowiednio ze standardowego wejścia i zapisu na standardowe wyjście.
Ten samouczek nauczy Cię, jak czytać i pisać z pliku. Wymaga to innej standardowej biblioteki C ++ o nazwiefstream, który definiuje trzy nowe typy danych -
| Sr.No | Typ i opis danych |
|---|---|
| 1 | ofstream Ten typ danych reprezentuje strumień pliku wyjściowego i służy do tworzenia plików i zapisywania informacji w plikach. |
| 2 | ifstream Ten typ danych reprezentuje strumień pliku wejściowego i służy do odczytywania informacji z plików. |
| 3 | fstream Ten typ danych ogólnie reprezentuje strumień plików i ma możliwości zarówno ofstream, jak i ifstream, co oznacza, że może tworzyć pliki, zapisywać informacje do plików i odczytywać informacje z plików. |
Aby wykonać przetwarzanie plików w C ++, pliki nagłówkowe <iostream> i <fstream> muszą być zawarte w pliku źródłowym C ++.
Otwieranie pliku
Plik musi zostać otwarty, zanim będzie można go odczytać lub zapisać. Zarównoofstream lub fstreamobiekt może służyć do otwierania pliku do zapisu. Obiekt ifstream służy do otwierania pliku tylko do odczytu.
Poniżej znajduje się standardowa składnia funkcji open (), która jest składnikiem obiektów fstream, ifstream i ofstream.
void open(const char *filename, ios::openmode mode);Tutaj pierwszy argument określa nazwę i lokalizację pliku, który ma zostać otwarty, a drugi argument pliku open() funkcja członkowska definiuje tryb, w którym plik powinien zostać otwarty.
| Sr.No | Flaga trybu i opis |
|---|---|
| 1 | ios::app Tryb dołączania. Wszystkie dane wyjściowe do tego pliku mają być dołączone na końcu. |
| 2 | ios::ate Otwórz plik do wyjścia i przenieś kontrolkę odczytu / zapisu na koniec pliku. |
| 3 | ios::in Otwórz plik do odczytu. |
| 4 | ios::out Otwórz plik do zapisu. |
| 5 | ios::trunc Jeśli plik już istnieje, jego zawartość zostanie obcięta przed otwarciem pliku. |
Możesz połączyć dwie lub więcej z tych wartości za pomocą ORje razem. Na przykład, jeśli chcesz otworzyć plik w trybie do zapisu i chcesz go obciąć w przypadku, gdy już istnieje, następująca będzie składnia -
ofstream outfile;
outfile.open("file.dat", ios::out | ios::trunc );W podobny sposób możesz otworzyć plik do odczytu i zapisu w następujący sposób -
fstream afile;
afile.open("file.dat", ios::out | ios::in );Zamykanie pliku
Kiedy program w C ++ kończy pracę, automatycznie opróżnia wszystkie strumienie, zwalnia całą przydzieloną pamięć i zamyka wszystkie otwarte pliki. Ale zawsze jest dobrą praktyką, aby programista zamknął wszystkie otwarte pliki przed zakończeniem programu.
Poniżej znajduje się standardowa składnia funkcji close (), która jest składnikiem obiektów fstream, ifstream i ofstream.
void close();Zapisywanie do pliku
Podczas programowania w C ++ zapisujesz informacje do pliku z programu za pomocą operatora wstawiania strumienia (<<), tak samo jak używasz tego operatora do wyświetlania informacji na ekranie. Jedyna różnica polega na tym, że używasz plikuofstream lub fstream obiekt zamiast cout obiekt.
Czytanie z pliku
Wczytujesz informacje z pliku do programu za pomocą operatora wyodrębniania strumienia (>>), tak jak używasz tego operatora do wprowadzania informacji z klawiatury. Jedyna różnica polega na tym, że używasz plikuifstream lub fstream obiekt zamiast cin obiekt.
Przykład odczytu i zapisu
Poniżej znajduje się program C ++, który otwiera plik w trybie odczytu i zapisu. Po zapisaniu informacji wprowadzonych przez użytkownika do pliku o nazwie afile.dat, program odczytuje informacje z pliku i wyświetla je na ekranie -
#include <fstream>
#include <iostream>
using namespace std;
int main () {
char data[100];
// open a file in write mode.
ofstream outfile;
outfile.open("afile.dat");
cout << "Writing to the file" << endl;
cout << "Enter your name: ";
cin.getline(data, 100);
// write inputted data into the file.
outfile << data << endl;
cout << "Enter your age: ";
cin >> data;
cin.ignore();
// again write inputted data into the file.
outfile << data << endl;
// close the opened file.
outfile.close();
// open a file in read mode.
ifstream infile;
infile.open("afile.dat");
cout << "Reading from the file" << endl;
infile >> data;
// write the data at the screen.
cout << data << endl;
// again read the data from the file and display it.
infile >> data;
cout << data << endl;
// close the opened file.
infile.close();
return 0;
}Gdy powyższy kod jest kompilowany i wykonywany, generuje następujące przykładowe dane wejściowe i wyjściowe -
$./a.out
Writing to the file
Enter your name: Zara
Enter your age: 9
Reading from the file
Zara
9Powyższe przykłady wykorzystują dodatkowe funkcje z obiektu cin, takie jak funkcja getline () do odczytywania linii z zewnątrz i funkcja ignore () do ignorowania dodatkowych znaków pozostawionych przez poprzednią instrukcję read.
Wskaźniki pozycji pliku
Obie istream i ostreamudostępniają funkcje składowe do zmiany położenia wskaźnika pozycji pliku. Te funkcje członkowskie toseekg („szukaj”) dla istream i seekp („seek put”) dla ostream.
Argumentem funkcji seekg i seekp jest zwykle długa liczba całkowita. Można podać drugi argument, aby wskazać kierunek wyszukiwania. Kierunek wyszukiwania może byćios::beg (domyślnie) do pozycjonowania względem początku strumienia, ios::cur do pozycjonowania względem aktualnej pozycji w strumieniu lub ios::end do pozycjonowania względem końca strumienia.
Wskaźnik pozycji pliku jest wartością całkowitą, która określa lokalizację w pliku jako liczbę bajtów od początkowej lokalizacji pliku. Oto kilka przykładów pozycjonowania wskaźnika pozycji pliku „pobierz” -
// position to the nth byte of fileObject (assumes ios::beg)
fileObject.seekg( n );
// position n bytes forward in fileObject
fileObject.seekg( n, ios::cur );
// position n bytes back from end of fileObject
fileObject.seekg( n, ios::end );
// position at end of fileObject
fileObject.seekg( 0, ios::end );Wyjątkiem jest problem, który pojawia się podczas wykonywania programu. Wyjątek C ++ jest odpowiedzią na wyjątkowe okoliczności, które pojawiają się podczas działania programu, na przykład próbę podzielenia przez zero.
Wyjątki umożliwiają przekazanie kontroli z jednej części programu do drugiej. Obsługa wyjątków w C ++ jest oparta na trzech słowach kluczowych:try, catch, i throw.
throw- Program zgłasza wyjątek, gdy pojawia się problem. Odbywa się to za pomocą plikuthrow słowo kluczowe.
catch- Program przechwytuje wyjątek z obsługą wyjątków w miejscu programu, w którym chcesz obsłużyć problem. Plikcatch słowo kluczowe wskazuje na przechwycenie wyjątku.
try - A tryblok identyfikuje blok kodu, dla którego zostaną aktywowane określone wyjątki. Po nim następuje jeden lub więcej bloków catch.
Zakładając, że blok zgłosi wyjątek, metoda przechwytuje wyjątek przy użyciu kombinacji try i catchsłowa kluczowe. Blok try / catch jest umieszczany wokół kodu, który może generować wyjątek. Kod w bloku try / catch jest nazywany kodem chronionym, a składnia użycia try / catch jest następująca:
try {
// protected code
} catch( ExceptionName e1 ) {
// catch block
} catch( ExceptionName e2 ) {
// catch block
} catch( ExceptionName eN ) {
// catch block
}Możesz wymienić wiele catch instrukcje, aby wychwycić różne typy wyjątków w przypadku, gdy plik try block wywołuje więcej niż jeden wyjątek w różnych sytuacjach.
Rzucanie wyjątków
Wyjątki można zgłaszać w dowolnym miejscu w bloku kodu przy użyciu throwkomunikat. Operand instrukcji throw określa typ wyjątku i może być dowolnym wyrażeniem, a typ wyniku wyrażenia określa typ zgłoszonego wyjątku.
Poniżej znajduje się przykład zgłaszania wyjątku, gdy występuje warunek dzielenia przez zero -
double division(int a, int b) {
if( b == 0 ) {
throw "Division by zero condition!";
}
return (a/b);
}Łapanie wyjątków
Plik catch blok następujący po tryblok wyłapuje każdy wyjątek. Możesz określić typ wyjątku, który chcesz przechwycić, i jest to określone przez deklarację wyjątku, która pojawia się w nawiasach po słowie kluczowym catch.
try {
// protected code
} catch( ExceptionName e ) {
// code to handle ExceptionName exception
}Powyższy kod złapie wyjątek ExceptionNamerodzaj. Jeśli chcesz określić, że blok catch powinien obsługiwać każdy typ wyjątku, który jest generowany w bloku try, musisz umieścić wielokropek, ..., między nawiasami otaczającymi deklarację wyjątku w następujący sposób -
try {
// protected code
} catch(...) {
// code to handle any exception
}Poniżej znajduje się przykład, który rzuca wyjątek dzielenia przez zero i przechwytujemy go w bloku catch.
#include <iostream>
using namespace std;
double division(int a, int b) {
if( b == 0 ) {
throw "Division by zero condition!";
}
return (a/b);
}
int main () {
int x = 50;
int y = 0;
double z = 0;
try {
z = division(x, y);
cout << z << endl;
} catch (const char* msg) {
cerr << msg << endl;
}
return 0;
}Ponieważ zgłaszamy wyjątek typu const char*, więc przechwytując ten wyjątek, musimy użyć const char * w bloku catch. Jeśli skompilujemy i uruchomimy powyższy kod, otrzymamy następujący wynik -
Division by zero condition!Wyjątki standardowe języka C ++
C ++ zawiera listę standardowych wyjątków zdefiniowanych w <exception>których możemy używać w naszych programach. Są one ułożone w hierarchię klas nadrzędnych i podrzędnych pokazaną poniżej -
Oto krótki opis każdego wyjątku wymienionego w powyższej hierarchii -
| Sr.No | Wyjątek i opis |
|---|---|
| 1 | std::exception Wyjątek i klasa nadrzędna wszystkich standardowych wyjątków C ++. |
| 2 | std::bad_alloc Może to zostać rzucone przez new. |
| 3 | std::bad_cast Może to zostać rzucone przez dynamic_cast. |
| 4 | std::bad_exception Jest to przydatne urządzenie do obsługi nieoczekiwanych wyjątków w programie C ++. |
| 5 | std::bad_typeid Może to zostać rzucone przez typeid. |
| 6 | std::logic_error Wyjątek, który teoretycznie można wykryć czytając kod. |
| 7 | std::domain_error Jest to wyjątek zgłaszany, gdy używana jest matematycznie nieprawidłowa domena. |
| 8 | std::invalid_argument Jest to generowane z powodu nieprawidłowych argumentów. |
| 9 | std::length_error Jest to generowane, gdy tworzony jest zbyt duży std :: string. |
| 10 | std::out_of_range Można to wywołać metodą „at”, na przykład std :: vector i std :: bitset <> :: operator [] (). |
| 11 | std::runtime_error Wyjątek, którego teoretycznie nie można wykryć, odczytując kod. |
| 12 | std::overflow_error Jest to generowane, jeśli wystąpi przepełnienie matematyczne. |
| 13 | std::range_error Dzieje się tak, gdy próbujesz zapisać wartość, która jest poza zakresem. |
| 14 | std::underflow_error Jest to generowane, jeśli występuje niedomiar matematyczny. |
Zdefiniuj nowe wyjątki
Możesz zdefiniować własne wyjątki, dziedzicząc i zastępując exceptionfunkcjonalność klasy. Poniżej znajduje się przykład, który pokazuje, jak można użyć klasy std :: wyjątek do zaimplementowania własnego wyjątku w standardowy sposób -
#include <iostream>
#include <exception>
using namespace std;
struct MyException : public exception {
const char * what () const throw () {
return "C++ Exception";
}
};
int main() {
try {
throw MyException();
} catch(MyException& e) {
std::cout << "MyException caught" << std::endl;
std::cout << e.what() << std::endl;
} catch(std::exception& e) {
//Other errors
}
}Dałoby to następujący wynik -
MyException caught
C++ ExceptionTutaj, what()jest metodą publiczną udostępnianą przez klasę wyjątków i została nadpisana przez wszystkie podrzędne klasy wyjątków. To zwraca przyczynę wyjątku.
Dobre zrozumienie tego, jak naprawdę działa pamięć dynamiczna w C ++, jest niezbędne, aby zostać dobrym programistą C ++. Pamięć w programie w C ++ jest podzielona na dwie części -
The stack - Wszystkie zmienne zadeklarowane wewnątrz funkcji zajmą pamięć ze stosu.
The heap - Jest to nieużywana pamięć programu i może być używana do dynamicznego przydzielania pamięci podczas działania programu.
Często zdarza się, że nie wiesz z góry, ile pamięci będziesz potrzebować do przechowywania określonych informacji w określonej zmiennej, a rozmiar wymaganej pamięci można określić w czasie wykonywania.
Możesz przydzielić pamięć w czasie wykonywania w stercie dla zmiennej danego typu za pomocą specjalnego operatora w C ++, który zwraca adres przydzielonego miejsca. Ten operator nazywa sięnew operator.
Jeśli nie potrzebujesz już dynamicznie przydzielanej pamięci, możesz użyć delete operator, który usuwa alokację pamięci, która została wcześniej przydzielona przez nowego operatora.
nowe i usuń Operatory
Do użycia jest następująca ogólna składnia new operator do dynamicznego przydzielania pamięci dla dowolnego typu danych.
new data-type;Tutaj, data-typemoże być dowolnym wbudowanym typem danych, w tym tablicą lub dowolnym typem danych zdefiniowanym przez użytkownika, w tym klasą lub strukturą. Zacznijmy od wbudowanych typów danych. Na przykład możemy zdefiniować wskaźnik do wpisania double, a następnie zażądać przydzielenia pamięci w czasie wykonywania. Możemy to zrobić za pomocąnew operator z następującymi instrukcjami -
double* pvalue = NULL; // Pointer initialized with null
pvalue = new double; // Request memory for the variablePamięć mogła nie zostać przydzielona pomyślnie, jeśli wolny magazyn został wykorzystany. Dlatego dobrą praktyką jest sprawdzenie, czy nowy operator zwraca wskaźnik NULL i podjęcie odpowiednich działań, jak poniżej -
double* pvalue = NULL;
if( !(pvalue = new double )) {
cout << "Error: out of memory." <<endl;
exit(1);
}Plik malloc()funkcja z C, nadal istnieje w C ++, ale zaleca się unikanie funkcji malloc (). Główną zaletą new w porównaniu z malloc () jest to, że new nie tylko alokuje pamięć, ale konstruuje obiekty, co jest głównym celem C ++.
W dowolnym momencie, gdy uznasz, że zmienna, która została przydzielona dynamicznie, nie jest już potrzebna, możesz zwolnić zajmowaną przez nią pamięć w wolnym magazynie za pomocą operatora „usuń” w następujący sposób -
delete pvalue; // Release memory pointed to by pvalueUmieśćmy powyższe pojęcia i stwórzmy następujący przykład, aby pokazać, jak działają `` nowy '' i `` usuń '' -
#include <iostream>
using namespace std;
int main () {
double* pvalue = NULL; // Pointer initialized with null
pvalue = new double; // Request memory for the variable
*pvalue = 29494.99; // Store value at allocated address
cout << "Value of pvalue : " << *pvalue << endl;
delete pvalue; // free up the memory.
return 0;
}Jeśli skompilujemy i uruchomimy powyższy kod, otrzymamy następujący wynik -
Value of pvalue : 29495Dynamiczne przydzielanie pamięci dla tablic
Zastanów się, czy chcesz przydzielić pamięć na tablicę znaków, tj. Ciąg 20 znaków. Używając tej samej składni, której używaliśmy powyżej, możemy przydzielać pamięć dynamicznie, jak pokazano poniżej.
char* pvalue = NULL; // Pointer initialized with null
pvalue = new char[20]; // Request memory for the variableAby usunąć tablicę, którą właśnie utworzyliśmy, instrukcja wyglądałaby następująco:
delete [] pvalue; // Delete array pointed to by pvalueZgodnie z podobną ogólną składnią operatora new, możesz przydzielić wielowymiarową tablicę w następujący sposób -
double** pvalue = NULL; // Pointer initialized with null
pvalue = new double [3][4]; // Allocate memory for a 3x4 arrayJednak składnia zwolnienia pamięci dla tablicy wielowymiarowej pozostanie taka sama jak powyżej -
delete [] pvalue; // Delete array pointed to by pvalueDynamiczne przydzielanie pamięci dla obiektów
Obiekty nie różnią się od prostych typów danych. Na przykład rozważmy następujący kod, w którym zamierzamy użyć tablicy obiektów, aby wyjaśnić pojęcie -
#include <iostream>
using namespace std;
class Box {
public:
Box() {
cout << "Constructor called!" <<endl;
}
~Box() {
cout << "Destructor called!" <<endl;
}
};
int main() {
Box* myBoxArray = new Box[4];
delete [] myBoxArray; // Delete array
return 0;
}Gdybyś miał zaalokować tablicę czterech obiektów Box, konstruktor Simple zostałby wywołany cztery razy i podobnie podczas usuwania tych obiektów, destruktor również będzie wywoływany tyle samo razy.
Jeśli skompilujemy i uruchomimy powyższy kod, otrzymamy następujący wynik -
Constructor called!
Constructor called!
Constructor called!
Constructor called!
Destructor called!
Destructor called!
Destructor called!
Destructor called!Rozważmy sytuację, gdy mamy dwie osoby o tym samym imieniu, Zara, w tej samej klasie. Ilekroć potrzebujemy ich definitywnie rozróżnić, musielibyśmy użyć dodatkowych informacji wraz z ich imieniem, jak np. Okolica, jeśli mieszkają w innym rejonie, nazwisko matki lub ojca itp.
Taka sama sytuacja może wystąpić w twoich aplikacjach C ++. Na przykład, możesz pisać kod, który ma funkcję o nazwie xyz () i jest dostępna inna biblioteka, która również ma tę samą funkcję xyz (). Teraz kompilator nie może dowiedzieć się, do której wersji funkcji xyz () odwołujesz się w kodzie.
ZA namespacejest zaprojektowany, aby przezwyciężyć tę trudność i jest używany jako dodatkowe informacje do rozróżniania podobnych funkcji, klas, zmiennych itp. o tej samej nazwie dostępnej w różnych bibliotekach. Korzystając z przestrzeni nazw, można zdefiniować kontekst, w którym są definiowane nazwy. W istocie przestrzeń nazw definiuje zakres.
Definiowanie przestrzeni nazw
Definicja przestrzeni nazw zaczyna się od słowa kluczowego namespace po którym następuje nazwa przestrzeni nazw w następujący sposób -
namespace namespace_name {
// code declarations
}Aby wywołać wersję funkcji lub zmiennej z włączoną przestrzenią nazw, dodaj przed (: :) nazwę przestrzeni nazw w następujący sposób -
name::code; // code could be variable or function.Zobaczmy, jak przestrzeń nazw obejmuje jednostki, w tym zmienne i funkcje -
#include <iostream>
using namespace std;
// first name space
namespace first_space {
void func() {
cout << "Inside first_space" << endl;
}
}
// second name space
namespace second_space {
void func() {
cout << "Inside second_space" << endl;
}
}
int main () {
// Calls function from first name space.
first_space::func();
// Calls function from second name space.
second_space::func();
return 0;
}Jeśli skompilujemy i uruchomimy powyższy kod, otrzymamy następujący wynik -
Inside first_space
Inside second_spaceDyrektywa using
Możesz również uniknąć poprzedzania przestrzeni nazw rozszerzeniem using namespacedyrektywa. Ta dyrektywa mówi kompilatorowi, że kolejny kod używa nazw w określonej przestrzeni nazw. Przestrzeń nazw jest zatem implikowana dla następującego kodu -
#include <iostream>
using namespace std;
// first name space
namespace first_space {
void func() {
cout << "Inside first_space" << endl;
}
}
// second name space
namespace second_space {
void func() {
cout << "Inside second_space" << endl;
}
}
using namespace first_space;
int main () {
// This calls function from first name space.
func();
return 0;
}Jeśli skompilujemy i uruchomimy powyższy kod, otrzymamy następujący wynik -
Inside first_spaceDyrektywa „using” może być również używana do odwoływania się do konkretnego elementu w przestrzeni nazw. Na przykład, jeśli jedyną częścią standardowej przestrzeni nazw, której zamierzasz użyć, jest cout, możesz odnieść się do niej w następujący sposób -
using std::cout;Kolejny kod może odwoływać się do cout bez poprzedzania przestrzeni nazw, ale inne elementy w std przestrzeń nazw nadal będzie musiała być jawna w następujący sposób -
#include <iostream>
using std::cout;
int main () {
cout << "std::endl is used with std!" << std::endl;
return 0;
}Jeśli skompilujemy i uruchomimy powyższy kod, otrzymamy następujący wynik -
std::endl is used with std!Nazwy wprowadzone w usingdyrektywy są zgodne z normalnymi zasadami zakresu. Nazwa jest widoczna z punktuusingdyrektywy do końca zakresu, w jakim dyrektywa się znajduje. Elementy o tej samej nazwie zdefiniowanej w zakresie zewnętrznym są ukryte.
Nieciągłe przestrzenie nazw
Przestrzeń nazw może być zdefiniowana w kilku częściach, dlatego przestrzeń nazw składa się z sumy jej oddzielnie zdefiniowanych części. Oddzielne części przestrzeni nazw można rozłożyć na wiele plików.
Tak więc, jeśli jedna część przestrzeni nazw wymaga nazwy zdefiniowanej w innym pliku, ta nazwa musi być nadal zadeklarowana. Pisanie następującej definicji przestrzeni nazw albo definiuje nową przestrzeń nazw, albo dodaje nowe elementy do istniejącej -
namespace namespace_name {
// code declarations
}Zagnieżdżone przestrzenie nazw
Przestrzenie nazw mogą być zagnieżdżane, gdzie można zdefiniować jedną przestrzeń nazw w innej przestrzeni nazw w następujący sposób -
namespace namespace_name1 {
// code declarations
namespace namespace_name2 {
// code declarations
}
}Dostęp do członków zagnieżdżonej przestrzeni nazw można uzyskać za pomocą operatorów rozpoznawania w następujący sposób -
// to access members of namespace_name2
using namespace namespace_name1::namespace_name2;
// to access members of namespace:name1
using namespace namespace_name1;W powyższych instrukcjach, jeśli używasz namespace_name1, to udostępni elementy namespace_name2 w zakresie w następujący sposób -
#include <iostream>
using namespace std;
// first name space
namespace first_space {
void func() {
cout << "Inside first_space" << endl;
}
// second name space
namespace second_space {
void func() {
cout << "Inside second_space" << endl;
}
}
}
using namespace first_space::second_space;
int main () {
// This calls function from second name space.
func();
return 0;
}Jeśli skompilujemy i uruchomimy powyższy kod, otrzymamy następujący wynik -
Inside second_spaceSzablony są podstawą programowania ogólnego, które polega na pisaniu kodu w sposób niezależny od określonego typu.
Szablon jest planem lub formułą służącą do tworzenia ogólnej klasy lub funkcji. Kontenery bibliotek, takie jak iteratory i algorytmy, są przykładami programowania ogólnego i zostały opracowane przy użyciu koncepcji szablonu.
Istnieje jedna definicja każdego kontenera, na przykład vector, ale możemy zdefiniować wiele różnych rodzajów wektorów, na przykład vector <int> lub vector <string>.
Możesz używać szablonów do definiowania funkcji i klas, zobaczmy, jak one działają -
Szablon funkcji
Ogólną postać definicji funkcji szablonu pokazano tutaj -
template <class type> ret-type func-name(parameter list) {
// body of function
}W tym przypadku typ jest nazwą zastępczą dla typu danych używanego przez funkcję. Tej nazwy można używać w definicji funkcji.
Poniżej znajduje się przykład szablonu funkcji, który zwraca maksymalnie dwie wartości -
#include <iostream>
#include <string>
using namespace std;
template <typename T>
inline T const& Max (T const& a, T const& b) {
return a < b ? b:a;
}
int main () {
int i = 39;
int j = 20;
cout << "Max(i, j): " << Max(i, j) << endl;
double f1 = 13.5;
double f2 = 20.7;
cout << "Max(f1, f2): " << Max(f1, f2) << endl;
string s1 = "Hello";
string s2 = "World";
cout << "Max(s1, s2): " << Max(s1, s2) << endl;
return 0;
}Jeśli skompilujemy i uruchomimy powyższy kod, otrzymamy następujący wynik -
Max(i, j): 39
Max(f1, f2): 20.7
Max(s1, s2): WorldSzablon klasy
Tak jak możemy definiować szablony funkcji, możemy również definiować szablony klas. Ogólna forma deklaracji klasy ogólnej jest pokazana tutaj -
template <class type> class class-name {
.
.
.
}Tutaj, typeto nazwa typu symbolu zastępczego, która zostanie określona podczas tworzenia wystąpienia klasy. Możesz zdefiniować więcej niż jeden ogólny typ danych, używając listy oddzielonej przecinkami.
Poniżej znajduje się przykład definiowania klasy Stack <> i implementowania ogólnych metod do wypychania i zdejmowania elementów ze stosu -
#include <iostream>
#include <vector>
#include <cstdlib>
#include <string>
#include <stdexcept>
using namespace std;
template <class T>
class Stack {
private:
vector<T> elems; // elements
public:
void push(T const&); // push element
void pop(); // pop element
T top() const; // return top element
bool empty() const { // return true if empty.
return elems.empty();
}
};
template <class T>
void Stack<T>::push (T const& elem) {
// append copy of passed element
elems.push_back(elem);
}
template <class T>
void Stack<T>::pop () {
if (elems.empty()) {
throw out_of_range("Stack<>::pop(): empty stack");
}
// remove last element
elems.pop_back();
}
template <class T>
T Stack<T>::top () const {
if (elems.empty()) {
throw out_of_range("Stack<>::top(): empty stack");
}
// return copy of last element
return elems.back();
}
int main() {
try {
Stack<int> intStack; // stack of ints
Stack<string> stringStack; // stack of strings
// manipulate int stack
intStack.push(7);
cout << intStack.top() <<endl;
// manipulate string stack
stringStack.push("hello");
cout << stringStack.top() << std::endl;
stringStack.pop();
stringStack.pop();
} catch (exception const& ex) {
cerr << "Exception: " << ex.what() <<endl;
return -1;
}
}Jeśli skompilujemy i uruchomimy powyższy kod, otrzymamy następujący wynik -
7
hello
Exception: Stack<>::pop(): empty stackPreprocesory to dyrektywy, które przekazują kompilatorowi instrukcje dotyczące wstępnego przetworzenia informacji przed rozpoczęciem właściwej kompilacji.
Wszystkie dyrektywy preprocesora zaczynają się od #, a przed dyrektywą preprocesora w wierszu mogą pojawić się tylko znaki odstępu. Dyrektywy preprocesora nie są instrukcjami C ++, więc nie kończą się średnikiem (;).
Widziałeś już #includedyrektywy we wszystkich przykładach. To makro służy do dołączania pliku nagłówkowego do pliku źródłowego.
Istnieje wiele dyrektyw preprocesora obsługiwanych przez C ++, takich jak #include, #define, #if, #else, #line itp. Zobaczmy ważne dyrektywy -
#Define Preprocessor
Dyrektywa #define preprocesora tworzy symboliczne stałe. Symboliczna stała nazywana jest amacro a ogólna forma dyrektywy to -
#define macro-name replacement-textKiedy ta linia pojawi się w pliku, wszystkie kolejne wystąpienia makra w tym pliku zostaną zastąpione tekstem zastępczym przed skompilowaniem programu. Na przykład -
#include <iostream>
using namespace std;
#define PI 3.14159
int main () {
cout << "Value of PI :" << PI << endl;
return 0;
}Teraz wykonajmy wstępne przetwarzanie tego kodu, aby zobaczyć wynik, zakładając, że mamy plik kodu źródłowego. Skompilujmy go więc z opcją -E i przekierujmy wynik do test.p. Teraz, jeśli zaznaczysz test.p, będzie on zawierał wiele informacji, a na dole znajdziesz wartość zamienioną w następujący sposób -
$gcc -E test.cpp > test.p
...
int main () {
cout << "Value of PI :" << 3.14159 << endl;
return 0;
}Makra podobne do funkcji
Możesz użyć #define, aby zdefiniować makro, które będzie przyjmować argument w następujący sposób -
#include <iostream>
using namespace std;
#define MIN(a,b) (((a)<(b)) ? a : b)
int main () {
int i, j;
i = 100;
j = 30;
cout <<"The minimum is " << MIN(i, j) << endl;
return 0;
}Jeśli skompilujemy i uruchomimy powyższy kod, otrzymamy następujący wynik -
The minimum is 30Kompilacja warunkowa
Istnieje kilka dyrektyw, których można użyć do kompilacji wybranych fragmentów kodu źródłowego programu. Ten proces nazywa się kompilacją warunkową.
Konstrukcja preprocesora warunkowego jest podobna do struktury selekcji „if”. Rozważmy następujący kod preprocesora -
#ifndef NULL
#define NULL 0
#endifMożesz skompilować program do celów debugowania. Możesz także włączyć lub wyłączyć debugowanie za pomocą jednego makra w następujący sposób -
#ifdef DEBUG
cerr <<"Variable x = " << x << endl;
#endifTo powoduje cerrinstrukcja do wkompilowania w programie, jeśli stała symboliczna DEBUG została zdefiniowana przed dyrektywą #ifdef DEBUG. Możesz użyć instrukcji #if 0, aby skomentować część programu w następujący sposób -
#if 0
code prevented from compiling
#endifWypróbujmy następujący przykład -
#include <iostream>
using namespace std;
#define DEBUG
#define MIN(a,b) (((a)<(b)) ? a : b)
int main () {
int i, j;
i = 100;
j = 30;
#ifdef DEBUG
cerr <<"Trace: Inside main function" << endl;
#endif
#if 0
/* This is commented part */
cout << MKSTR(HELLO C++) << endl;
#endif
cout <<"The minimum is " << MIN(i, j) << endl;
#ifdef DEBUG
cerr <<"Trace: Coming out of main function" << endl;
#endif
return 0;
}Jeśli skompilujemy i uruchomimy powyższy kod, otrzymamy następujący wynik -
The minimum is 30
Trace: Inside main function
Trace: Coming out of main functionOperatory # i ##
Operatory preprocesorów # i ## są dostępne w językach C ++ i ANSI / ISO C. Operator # powoduje, że token zastępujący tekst jest konwertowany na ciąg znaków otoczony cudzysłowami.
Rozważ następującą definicję makra -
#include <iostream>
using namespace std;
#define MKSTR( x ) #x
int main () {
cout << MKSTR(HELLO C++) << endl;
return 0;
}Jeśli skompilujemy i uruchomimy powyższy kod, otrzymamy następujący wynik -
HELLO C++Zobaczmy, jak to działało. Łatwo zrozumieć, że preprocesor C ++ zmienia linię -
cout << MKSTR(HELLO C++) << endl;Powyższa linia zostanie zamieniona w następującą linię -
cout << "HELLO C++" << endl;Operator ## służy do łączenia dwóch tokenów. Oto przykład -
#define CONCAT( x, y ) x ## yGdy w programie pojawi się CONCAT, jego argumenty są łączone i używane do zastąpienia makra. Na przykład CONCAT (HELLO, C ++) jest zastępowane w programie przez „HELLO C ++” w następujący sposób.
#include <iostream>
using namespace std;
#define concat(a, b) a ## b
int main() {
int xy = 100;
cout << concat(x, y);
return 0;
}Jeśli skompilujemy i uruchomimy powyższy kod, otrzymamy następujący wynik -
100Zobaczmy, jak to działało. Łatwo zrozumieć, że preprocesor C ++ przekształca -
cout << concat(x, y);Powyższa linia zostanie przekształcona w następującą linię -
cout << xy;Wstępnie zdefiniowane makra C ++
C ++ udostępnia szereg wstępnie zdefiniowanych makr wymienionych poniżej -
| Sr.No | Makro i opis |
|---|---|
| 1 | __LINE__ Zawiera bieżący numer wiersza programu w momencie jego kompilacji. |
| 2 | __FILE__ Zawiera aktualną nazwę pliku programu podczas kompilacji. |
| 3 | __DATE__ Zawiera ciąg w postaci miesiąc / dzień / rok, który jest datą tłumaczenia pliku źródłowego na kod wynikowy. |
| 4 | __TIME__ Zawiera ciąg w postaci godzina: minuta: sekunda, czyli czas, w którym program został skompilowany. |
Zobaczmy przykład dla wszystkich powyższych makr -
#include <iostream>
using namespace std;
int main () {
cout << "Value of __LINE__ : " << __LINE__ << endl;
cout << "Value of __FILE__ : " << __FILE__ << endl;
cout << "Value of __DATE__ : " << __DATE__ << endl;
cout << "Value of __TIME__ : " << __TIME__ << endl;
return 0;
}Jeśli skompilujemy i uruchomimy powyższy kod, otrzymamy następujący wynik -
Value of __LINE__ : 6
Value of __FILE__ : test.cpp
Value of __DATE__ : Feb 28 2011
Value of __TIME__ : 18:52:48Sygnały to przerwania dostarczane do procesu przez system operacyjny, które mogą zakończyć program przedwcześnie. Możesz generować przerwania, naciskając Ctrl + C w systemie UNIX, LINUX, Mac OS X lub Windows.
Istnieją sygnały, których program nie może wychwycić, ale jest następująca lista sygnałów, które można przechwycić w programie i na ich podstawie podjąć odpowiednie działania. Sygnały te są zdefiniowane w pliku nagłówkowym C ++ <csignal>.
| Sr.No | Sygnał i opis |
|---|---|
| 1 | SIGABRT Nieprawidłowe zakończenie programu, na przykład wywołanie abort. |
| 2 | SIGFPE Błędna operacja arytmetyczna, taka jak dzielenie przez zero lub operacja powodująca przepełnienie. |
| 3 | SIGILL Wykrycie niedozwolonej instrukcji. |
| 4 | SIGINT Otrzymanie interaktywnego sygnału uwagi. |
| 5 | SIGSEGV Nieprawidłowy dostęp do pamięci. |
| 6 | SIGTERM Żądanie zakończenia wysłane do programu. |
Funkcja signal ()
Biblioteka obsługi sygnałów C ++ zapewnia funkcje signaldo łapania nieoczekiwanych wydarzeń. Poniżej znajduje się składnia funkcji signal () -
void (*signal (int sig, void (*func)(int)))(int);Upraszczając, ta funkcja otrzymuje dwa argumenty: pierwszy argument jako liczbę całkowitą, która reprezentuje numer sygnału, a drugi argument jako wskaźnik do funkcji obsługi sygnału.
Napiszmy prosty program w C ++, w którym złapiemy sygnał SIGINT za pomocą funkcji signal (). Jakikolwiek sygnał chcesz złapać w swoim programie, musisz zarejestrować ten sygnał za pomocąsignalfunkcji i skojarz ją z obsługą sygnału. Przeanalizuj następujący przykład -
#include <iostream>
#include <csignal>
using namespace std;
void signalHandler( int signum ) {
cout << "Interrupt signal (" << signum << ") received.\n";
// cleanup and close up stuff here
// terminate program
exit(signum);
}
int main () {
// register signal SIGINT and signal handler
signal(SIGINT, signalHandler);
while(1) {
cout << "Going to sleep...." << endl;
sleep(1);
}
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Going to sleep....
Going to sleep....
Going to sleep....Teraz naciśnij Ctrl + c, aby przerwać program, a zobaczysz, że twój program złapie sygnał i wyjdzie, drukując coś w następujący sposób -
Going to sleep....
Going to sleep....
Going to sleep....
Interrupt signal (2) received.Funkcja raise ()
Możesz generować sygnały według funkcji raise(), który przyjmuje jako argument liczbę całkowitą sygnału i ma następującą składnię.
int raise (signal sig);Tutaj, sigto numer sygnału do wysłania dowolnego z sygnałów: SIGINT, SIGABRT, SIGFPE, SIGILL, SIGSEGV, SIGTERM, SIGHUP. Poniżej znajduje się przykład, w którym wewnętrznie podnosimy sygnał za pomocą funkcji raise () w następujący sposób -
#include <iostream>
#include <csignal>
using namespace std;
void signalHandler( int signum ) {
cout << "Interrupt signal (" << signum << ") received.\n";
// cleanup and close up stuff here
// terminate program
exit(signum);
}
int main () {
int i = 0;
// register signal SIGINT and signal handler
signal(SIGINT, signalHandler);
while(++i) {
cout << "Going to sleep...." << endl;
if( i == 3 ) {
raise( SIGINT);
}
sleep(1);
}
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik i pojawia się automatycznie -
Going to sleep....
Going to sleep....
Going to sleep....
Interrupt signal (2) received.Wielowątkowość to wyspecjalizowana forma wielozadaniowości, a wielozadaniowość to funkcja, która umożliwia komputerowi jednoczesne uruchamianie dwóch lub więcej programów. Ogólnie rzecz biorąc, istnieją dwa typy wielozadaniowości: oparte na procesach i wątkach.
Wielozadaniowość oparta na procesach obsługuje równoczesne wykonywanie programów. Wielozadaniowość oparta na wątkach polega na współbieżnym wykonywaniu elementów tego samego programu.
Program wielowątkowy zawiera dwie lub więcej części, które mogą działać równolegle. Każda część takiego programu nazywana jest wątkiem, a każdy wątek definiuje oddzielną ścieżkę wykonania.
C ++ nie zawiera żadnej wbudowanej obsługi aplikacji wielowątkowych. Zamiast tego, aby zapewnić tę funkcję, całkowicie polega na systemie operacyjnym.
W tym samouczku założono, że pracujesz w systemie Linux i zamierzamy napisać wielowątkowy program w języku C ++ przy użyciu POSIX. POSIX Threads lub Pthreads dostarcza API, które jest dostępne w wielu systemach POSIX podobnych do Uniksa, takich jak FreeBSD, NetBSD, GNU / Linux, Mac OS X i Solaris.
Tworzenie wątków
Następująca procedura służy do tworzenia wątku POSIX -
#include <pthread.h>
pthread_create (thread, attr, start_routine, arg)Tutaj, pthread_createtworzy nowy wątek i czyni go wykonywalnym. Tę procedurę można wywołać dowolną liczbę razy z dowolnego miejsca w kodzie. Oto opis parametrów -
| Sr.No | Parametr i opis |
|---|---|
| 1 | thread Nieprzezroczysty, unikalny identyfikator nowego wątku zwracany przez podprogram. |
| 2 | attr Nieprzezroczysty obiekt atrybutu, którego można użyć do ustawienia atrybutów wątku. Możesz określić obiekt atrybutów wątku lub NULL dla wartości domyślnych. |
| 3 | start_routine Procedura C ++, którą wątek wykona po utworzeniu. |
| 4 | arg Pojedynczy argument, który można przekazać do procedury start_routine. Musi być przekazywany przez odwołanie jako rzutowanie wskaźnika typu void. Można użyć NULL, jeśli nie ma być przekazany żaden argument. |
Maksymalna liczba wątków, które mogą zostać utworzone przez proces, zależy od implementacji. Po utworzeniu wątki są równorzędne i mogą tworzyć inne wątki. Nie ma domniemanej hierarchii ani zależności między wątkami.
Kończenie wątków
Istnieje następująca procedura, której używamy do zakończenia wątku POSIX -
#include <pthread.h>
pthread_exit (status)Tutaj pthread_exitsłuży do jawnego opuszczania wątku. Zwykle procedura pthread_exit () jest wywoływana po zakończeniu pracy wątku i nie musi już istnieć.
Jeśli main () zakończy działanie przed utworzonymi przez siebie wątkami i zakończy działanie za pomocą pthread_exit (), pozostałe wątki będą nadal wykonywać. W przeciwnym razie zostaną automatycznie zakończone po zakończeniu funkcji main ().
Example
Ten prosty przykładowy kod tworzy 5 wątków za pomocą procedury pthread_create (). Każdy wątek drukuje napis „Hello World!” wiadomości, a następnie kończy się wywołaniem pthread_exit ().
#include <iostream>
#include <cstdlib>
#include <pthread.h>
using namespace std;
#define NUM_THREADS 5
void *PrintHello(void *threadid) {
long tid;
tid = (long)threadid;
cout << "Hello World! Thread ID, " << tid << endl;
pthread_exit(NULL);
}
int main () {
pthread_t threads[NUM_THREADS];
int rc;
int i;
for( i = 0; i < NUM_THREADS; i++ ) {
cout << "main() : creating thread, " << i << endl;
rc = pthread_create(&threads[i], NULL, PrintHello, (void *)i);
if (rc) {
cout << "Error:unable to create thread," << rc << endl;
exit(-1);
}
}
pthread_exit(NULL);
}Skompiluj następujący program przy użyciu biblioteki -lpthread w następujący sposób -
$gcc test.cpp -lpthreadTeraz uruchom program, który daje następujący wynik -
main() : creating thread, 0
main() : creating thread, 1
main() : creating thread, 2
main() : creating thread, 3
main() : creating thread, 4
Hello World! Thread ID, 0
Hello World! Thread ID, 1
Hello World! Thread ID, 2
Hello World! Thread ID, 3
Hello World! Thread ID, 4Przekazywanie argumentów do wątków
Ten przykład pokazuje, jak przekazać wiele argumentów za pośrednictwem struktury. W wywołaniu zwrotnym wątku można przekazać dowolny typ danych, ponieważ wskazuje on na void, jak wyjaśniono w poniższym przykładzie -
#include <iostream>
#include <cstdlib>
#include <pthread.h>
using namespace std;
#define NUM_THREADS 5
struct thread_data {
int thread_id;
char *message;
};
void *PrintHello(void *threadarg) {
struct thread_data *my_data;
my_data = (struct thread_data *) threadarg;
cout << "Thread ID : " << my_data->thread_id ;
cout << " Message : " << my_data->message << endl;
pthread_exit(NULL);
}
int main () {
pthread_t threads[NUM_THREADS];
struct thread_data td[NUM_THREADS];
int rc;
int i;
for( i = 0; i < NUM_THREADS; i++ ) {
cout <<"main() : creating thread, " << i << endl;
td[i].thread_id = i;
td[i].message = "This is message";
rc = pthread_create(&threads[i], NULL, PrintHello, (void *)&td[i]);
if (rc) {
cout << "Error:unable to create thread," << rc << endl;
exit(-1);
}
}
pthread_exit(NULL);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
main() : creating thread, 0
main() : creating thread, 1
main() : creating thread, 2
main() : creating thread, 3
main() : creating thread, 4
Thread ID : 3 Message : This is message
Thread ID : 2 Message : This is message
Thread ID : 0 Message : This is message
Thread ID : 1 Message : This is message
Thread ID : 4 Message : This is messageŁączenie i odłączanie wątków
Istnieją dwie procedury, których możemy użyć do łączenia lub odłączania wątków -
pthread_join (threadid, status)
pthread_detach (threadid)Podprocedura pthread_join () blokuje wątek wywołujący do momentu zakończenia określonego wątku „threadid”. Podczas tworzenia wątku jeden z jego atrybutów określa, czy można go łączyć, czy odłączać. Można łączyć tylko wątki utworzone jako możliwe do dołączenia. Jeśli wątek zostanie utworzony jako odłączony, nigdy nie można go połączyć.
W tym przykładzie pokazano, jak czekać na zakończenie wątku przy użyciu procedury łączenia Pthread.
#include <iostream>
#include <cstdlib>
#include <pthread.h>
#include <unistd.h>
using namespace std;
#define NUM_THREADS 5
void *wait(void *t) {
int i;
long tid;
tid = (long)t;
sleep(1);
cout << "Sleeping in thread " << endl;
cout << "Thread with id : " << tid << " ...exiting " << endl;
pthread_exit(NULL);
}
int main () {
int rc;
int i;
pthread_t threads[NUM_THREADS];
pthread_attr_t attr;
void *status;
// Initialize and set thread joinable
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_JOINABLE);
for( i = 0; i < NUM_THREADS; i++ ) {
cout << "main() : creating thread, " << i << endl;
rc = pthread_create(&threads[i], &attr, wait, (void *)i );
if (rc) {
cout << "Error:unable to create thread," << rc << endl;
exit(-1);
}
}
// free attribute and wait for the other threads
pthread_attr_destroy(&attr);
for( i = 0; i < NUM_THREADS; i++ ) {
rc = pthread_join(threads[i], &status);
if (rc) {
cout << "Error:unable to join," << rc << endl;
exit(-1);
}
cout << "Main: completed thread id :" << i ;
cout << " exiting with status :" << status << endl;
}
cout << "Main: program exiting." << endl;
pthread_exit(NULL);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
main() : creating thread, 0
main() : creating thread, 1
main() : creating thread, 2
main() : creating thread, 3
main() : creating thread, 4
Sleeping in thread
Thread with id : 0 .... exiting
Sleeping in thread
Thread with id : 1 .... exiting
Sleeping in thread
Thread with id : 2 .... exiting
Sleeping in thread
Thread with id : 3 .... exiting
Sleeping in thread
Thread with id : 4 .... exiting
Main: completed thread id :0 exiting with status :0
Main: completed thread id :1 exiting with status :0
Main: completed thread id :2 exiting with status :0
Main: completed thread id :3 exiting with status :0
Main: completed thread id :4 exiting with status :0
Main: program exiting.Co to jest CGI?
Common Gateway Interface (CGI) to zestaw standardów definiujących sposób wymiany informacji między serwerem WWW a niestandardowym skryptem.
Specyfikacje CGI są obecnie utrzymywane przez NCSA, a NCSA definiuje CGI w następujący sposób:
Interfejs Common Gateway Interface (CGI) jest standardem dla zewnętrznych programów bram do łączenia się z serwerami informacyjnymi, takimi jak serwery HTTP.
Obecna wersja to CGI / 1.1, a CGI / 1.2 jest w trakcie opracowywania.
Przeglądanie sieci
Aby zrozumieć koncepcję CGI, zobaczmy, co się dzieje, gdy klikamy hiperłącze w celu przeglądania określonej strony internetowej lub adresu URL.
Twoja przeglądarka kontaktuje się z serwerem HTTP i żąda adresu URL, tj. Nazwa pliku.
Serwer WWW przeanalizuje adres URL i poszuka nazwy pliku. Jeśli znajdzie żądany plik, serwer sieciowy wysyła ten plik z powrotem do przeglądarki, w przeciwnym razie wysyła komunikat o błędzie wskazujący, że zażądałeś niewłaściwego pliku.
Przeglądarka internetowa pobiera odpowiedź z serwera WWW i wyświetla otrzymany plik lub komunikat o błędzie na podstawie otrzymanej odpowiedzi.
Możliwe jest jednak skonfigurowanie serwera HTTP w taki sposób, aby za każdym razem, gdy zażądano pliku w określonym katalogu, plik ten nie był odsyłany; zamiast tego jest wykonywany jako program, a dane wyjściowe programu są wysyłane z powrotem do przeglądarki w celu wyświetlenia.
Common Gateway Interface (CGI) to standardowy protokół umożliwiający aplikacjom (zwanym programami CGI lub skryptami CGI) interakcję z serwerami sieci Web i klientami. Te programy CGI mogą być napisane w Pythonie, PERL, Shell, C lub C ++ itp.
Diagram architektury CGI
Poniższy prosty program przedstawia prostą architekturę CGI -
Konfiguracja serwera WWW
Przed przystąpieniem do programowania CGI upewnij się, że serwer WWW obsługuje CGI i jest skonfigurowany do obsługi programów CGI. Wszystkie programy CGI, które mają być wykonywane przez serwer HTTP, są przechowywane we wstępnie skonfigurowanym katalogu. Ten katalog nazywa się katalogiem CGI i zgodnie z konwencją nosi nazwę / var / www / cgi-bin. Zgodnie z konwencją pliki CGI będą miały rozszerzenie jako.cgi, chociaż są wykonywalne w C ++.
Domyślnie serwer sieciowy Apache jest skonfigurowany do uruchamiania programów CGI w / var / www / cgi-bin. Jeśli chcesz określić inny katalog do uruchamiania skryptów CGI, możesz zmodyfikować następującą sekcję w pliku httpd.conf -
<Directory "/var/www/cgi-bin">
AllowOverride None
Options ExecCGI
Order allow,deny
Allow from all
</Directory>
<Directory "/var/www/cgi-bin">
Options All
</Directory>Tutaj zakładam, że masz poprawnie uruchomiony serwer sieciowy i możesz uruchomić dowolny inny program CGI, taki jak Perl lub Shell itp.
Pierwszy program CGI
Rozważ następującą zawartość programu w języku C ++ -
#include <iostream>
using namespace std;
int main () {
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Hello World - First CGI Program</title>\n";
cout << "</head>\n";
cout << "<body>\n";
cout << "<h2>Hello World! This is my first CGI program</h2>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Skompiluj powyższy kod i nazwij plik wykonywalny jako cplusplus.cgi. Ten plik jest przechowywany w katalogu / var / www / cgi-bin i ma następującą zawartość. Przed uruchomieniem programu CGI upewnij się, że masz zmianę trybu pliku za pomocąchmod 755 cplusplus.cgi Polecenie UNIX, aby uczynić plik wykonywalnym.
Mój pierwszy program CGI
Powyższy program w C ++ jest prostym programem, który zapisuje swoje wyjście do pliku STDOUT, np. Screen. Dostępna jest jedna ważna i dodatkowa funkcja, czyli drukowanie w pierwszej liniiContent-type:text/html\r\n\r\n. Ta linia jest wysyłana z powrotem do przeglądarki i określa typ zawartości, która ma być wyświetlana na ekranie przeglądarki. Teraz musisz zrozumieć podstawową koncepcję CGI i możesz pisać wiele skomplikowanych programów CGI w języku Python. Program C ++ CGI może współdziałać z dowolnym innym systemem zewnętrznym, takim jak RDBMS, w celu wymiany informacji.
Nagłówek HTTP
Linia Content-type:text/html\r\n\r\nto część nagłówka HTTP, która jest wysyłana do przeglądarki w celu zrozumienia treści. Cały nagłówek HTTP będzie miał następującą postać -
HTTP Field Name: Field Content
For Example
Content-type: text/html\r\n\r\nIstnieje kilka innych ważnych nagłówków HTTP, których będziesz często używać w programowaniu CGI.
| Sr.No | Nagłówek i opis |
|---|---|
| 1 | Content-type: Ciąg MIME określający format zwracanego pliku. Przykład: Typ treści: tekst / html. |
| 2 | Expires: Date Data utraty informacji. Powinno to być używane przez przeglądarkę, aby zdecydować, kiedy strona wymaga odświeżenia. Prawidłowy ciąg daty powinien mieć format 01 Jan 1998 12:00:00 GMT. |
| 3 | Location: URL Adres URL, który powinien zostać zwrócony zamiast żądanego adresu URL. Możesz użyć tego pola, aby przekierować żądanie do dowolnego pliku. |
| 4 | Last-modified: Date Data ostatniej modyfikacji zasobu. |
| 5 | Content-length: N Długość zwracanych danych w bajtach. Przeglądarka używa tej wartości do raportowania szacowanego czasu pobierania pliku. |
| 6 | Set-Cookie: String Ustaw plik cookie przekazany przez ciąg . |
Zmienne środowiskowe CGI
Cały program CGI będzie miał dostęp do następujących zmiennych środowiskowych. Te zmienne odgrywają ważną rolę podczas pisania dowolnego programu CGI.
| Sr.No | Nazwa i opis zmiennej |
|---|---|
| 1 | CONTENT_TYPE Typ danych treści używany, gdy klient wysyła załączoną zawartość do serwera. Na przykład przesyłanie plików itp. |
| 2 | CONTENT_LENGTH Długość informacji o zapytaniu, które są dostępne tylko dla żądań POST. |
| 3 | HTTP_COOKIE Zwraca ustawione pliki cookie w postaci pary klucz-wartość. |
| 4 | HTTP_USER_AGENT Pole nagłówka żądania agenta użytkownika zawiera informacje o kliencie użytkownika, który wysłał żądanie. Jest to nazwa przeglądarki internetowej. |
| 5 | PATH_INFO Ścieżka do skryptu CGI. |
| 6 | QUERY_STRING Informacje zakodowane w adresie URL, które są wysyłane z żądaniem metody GET. |
| 7 | REMOTE_ADDR Adres IP zdalnego hosta wysyłającego żądanie. Może to być przydatne do logowania lub do celów uwierzytelniania. |
| 8 | REMOTE_HOST W pełni kwalifikowana nazwa hosta wysyłającego żądanie. Jeśli te informacje nie są dostępne, można użyć REMOTE_ADDR do uzyskania adresu IR. |
| 9 | REQUEST_METHOD Metoda użyta do wysłania żądania. Najpopularniejsze metody to GET i POST. |
| 10 | SCRIPT_FILENAME Pełna ścieżka do skryptu CGI. |
| 11 | SCRIPT_NAME Nazwa skryptu CGI. |
| 12 | SERVER_NAME Nazwa hosta lub adres IP serwera. |
| 13 | SERVER_SOFTWARE Nazwa i wersja oprogramowania, na którym działa serwer. |
Oto mały program CGI do wyszczególnienia wszystkich zmiennych CGI.
#include <iostream>
#include <stdlib.h>
using namespace std;
const string ENV[ 24 ] = {
"COMSPEC", "DOCUMENT_ROOT", "GATEWAY_INTERFACE",
"HTTP_ACCEPT", "HTTP_ACCEPT_ENCODING",
"HTTP_ACCEPT_LANGUAGE", "HTTP_CONNECTION",
"HTTP_HOST", "HTTP_USER_AGENT", "PATH",
"QUERY_STRING", "REMOTE_ADDR", "REMOTE_PORT",
"REQUEST_METHOD", "REQUEST_URI", "SCRIPT_FILENAME",
"SCRIPT_NAME", "SERVER_ADDR", "SERVER_ADMIN",
"SERVER_NAME","SERVER_PORT","SERVER_PROTOCOL",
"SERVER_SIGNATURE","SERVER_SOFTWARE" };
int main () {
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>CGI Environment Variables</title>\n";
cout << "</head>\n";
cout << "<body>\n";
cout << "<table border = \"0\" cellspacing = \"2\">";
for ( int i = 0; i < 24; i++ ) {
cout << "<tr><td>" << ENV[ i ] << "</td><td>";
// attempt to retrieve value of environment variable
char *value = getenv( ENV[ i ].c_str() );
if ( value != 0 ) {
cout << value;
} else {
cout << "Environment variable does not exist.";
}
cout << "</td></tr>\n";
}
cout << "</table><\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Biblioteka C ++ CGI
Aby uzyskać prawdziwe przykłady, musiałbyś wykonać wiele operacji w programie CGI. Istnieje biblioteka CGI napisana dla programu C ++, którą można pobrać z ftp://ftp.gnu.org/gnu/cgicc/ i postępować zgodnie z instrukcjami, aby zainstalować bibliotekę -
$tar xzf cgicc-X.X.X.tar.gz
$cd cgicc-X.X.X/ $./configure --prefix=/usr
$make $make installMożesz sprawdzić powiązaną dokumentację dostępną w 'C ++ CGI Lib Documentation .
Metody GET i POST
Musiałeś spotkać się z wieloma sytuacjami, w których musisz przekazać pewne informacje z przeglądarki na serwer WWW, a ostatecznie do programu CGI. Przeglądarka najczęściej używa dwóch metod przekazywania tych informacji do serwera WWW. Te metody to metoda GET i metoda POST.
Przekazywanie informacji metodą GET
Metoda GET wysyła zakodowane informacje o użytkowniku dołączone do żądania strony. Strona i zakodowane informacje są oddzielone znakiem? znak w następujący sposób -
http://www.test.com/cgi-bin/cpp.cgi?key1=value1&key2=value2Metoda GET jest domyślną metodą przekazywania informacji z przeglądarki do serwera WWW i tworzy długi ciąg, który pojawia się w polu Lokalizacja: przeglądarki. Nigdy nie używaj metody GET, jeśli masz hasło lub inne poufne informacje do przekazania na serwer. Metoda GET ma ograniczenie rozmiaru i można przekazać do 1024 znaków w ciągu żądania.
W przypadku korzystania z metody GET informacje są przekazywane przy użyciu nagłówka http QUERY_STRING i będą dostępne w programie CGI za pośrednictwem zmiennej środowiskowej QUERY_STRING.
Możesz przekazywać informacje, po prostu łącząc pary klucz i wartość wraz z dowolnym adresem URL lub możesz użyć tagów HTML <FORM>, aby przekazać informacje metodą GET.
Prosty przykład adresu URL: metoda pobierania
Oto prosty adres URL, który przekazuje dwie wartości do programu hello_get.py przy użyciu metody GET.
/cgi-bin/cpp_get.cgi?first_name=ZARA&last_name=ALIPoniżej znajduje się program do wygenerowania cpp_get.cgiProgram CGI do obsługi danych wejściowych podawanych przez przeglądarkę internetową. Będziemy używać biblioteki C ++ CGI, która bardzo ułatwia dostęp do przekazywanych informacji -
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc formData;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Using GET and POST Methods</title>\n";
cout << "</head>\n";
cout << "<body>\n";
form_iterator fi = formData.getElement("first_name");
if( !fi->isEmpty() && fi != (*formData).end()) {
cout << "First name: " << **fi << endl;
} else {
cout << "No text entered for first name" << endl;
}
cout << "<br/>\n";
fi = formData.getElement("last_name");
if( !fi->isEmpty() &&fi != (*formData).end()) {
cout << "Last name: " << **fi << endl;
} else {
cout << "No text entered for last name" << endl;
}
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Teraz skompiluj powyższy program w następujący sposób -
$g++ -o cpp_get.cgi cpp_get.cpp -lcgiccWygeneruj cpp_get.cgi i umieść go w katalogu CGI i spróbuj uzyskać dostęp za pomocą następującego linku -
/cgi-bin/cpp_get.cgi?first_name=ZARA&last_name=ALIDałoby to następujący wynik -
First name: ZARA
Last name: ALIProsty przykład FORMULARZA: GET Method
Oto prosty przykład, który przekazuje dwie wartości za pomocą HTML FORM i przycisku przesyłania. Będziemy używać tego samego skryptu CGI cpp_get.cgi do obsługi tego wejścia.
<form action = "/cgi-bin/cpp_get.cgi" method = "get">
First Name: <input type = "text" name = "first_name"> <br />
Last Name: <input type = "text" name = "last_name" />
<input type = "submit" value = "Submit" />
</form>Oto rzeczywisty wynik powyższego formularza. Wpisz Imię i Nazwisko, a następnie kliknij przycisk Prześlij, aby zobaczyć wynik.
Przekazywanie informacji metodą POST
Generalnie bardziej niezawodną metodą przekazywania informacji do programu CGI jest metoda POST. Spowoduje to pakowanie informacji dokładnie w taki sam sposób, jak metody GET, ale zamiast wysyłać je jako ciąg tekstowy po znaku? w adresie URL wysyła go jako oddzielną wiadomość. Ta wiadomość pojawia się w skrypcie CGI w postaci standardowego wejścia.
Ten sam program cpp_get.cgi obsługuje również metodę POST. Weźmy ten sam przykład co powyżej, który przekazuje dwie wartości za pomocą HTML FORM i przycisku przesyłania, ale tym razem z metodą POST w następujący sposób -
<form action = "/cgi-bin/cpp_get.cgi" method = "post">
First Name: <input type = "text" name = "first_name"><br />
Last Name: <input type = "text" name = "last_name" />
<input type = "submit" value = "Submit" />
</form>Oto rzeczywisty wynik powyższego formularza. Wpisz Imię i Nazwisko, a następnie kliknij przycisk Prześlij, aby zobaczyć wynik.
Przekazywanie danych pola wyboru do programu CGI
Pola wyboru są używane, gdy wymagane jest wybranie więcej niż jednej opcji.
Oto przykładowy kod HTML formularza z dwoma polami wyboru -
<form action = "/cgi-bin/cpp_checkbox.cgi" method = "POST" target = "_blank">
<input type = "checkbox" name = "maths" value = "on" /> Maths
<input type = "checkbox" name = "physics" value = "on" /> Physics
<input type = "submit" value = "Select Subject" />
</form>Wynikiem tego kodu jest następująca postać -
Poniżej znajduje się program w C ++, który wygeneruje skrypt cpp_checkbox.cgi do obsługi danych wprowadzanych przez przeglądarkę internetową za pomocą przycisku checkbox.
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc formData;
bool maths_flag, physics_flag;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Checkbox Data to CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
maths_flag = formData.queryCheckbox("maths");
if( maths_flag ) {
cout << "Maths Flag: ON " << endl;
} else {
cout << "Maths Flag: OFF " << endl;
}
cout << "<br/>\n";
physics_flag = formData.queryCheckbox("physics");
if( physics_flag ) {
cout << "Physics Flag: ON " << endl;
} else {
cout << "Physics Flag: OFF " << endl;
}
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Przekazywanie danych przycisku radiowego do programu CGI
Przyciski radiowe są używane, gdy wymagana jest tylko jedna opcja.
Oto przykład kodu HTML dla formularza z dwoma przyciskami opcji -
<form action = "/cgi-bin/cpp_radiobutton.cgi" method = "post" target = "_blank">
<input type = "radio" name = "subject" value = "maths" checked = "checked"/> Maths
<input type = "radio" name = "subject" value = "physics" /> Physics
<input type = "submit" value = "Select Subject" />
</form>Wynikiem tego kodu jest następująca postać -
Poniżej znajduje się program C ++, który wygeneruje skrypt cpp_radiobutton.cgi do obsługi danych wprowadzanych przez przeglądarkę internetową za pomocą przycisków opcji.
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc formData;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Radio Button Data to CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
form_iterator fi = formData.getElement("subject");
if( !fi->isEmpty() && fi != (*formData).end()) {
cout << "Radio box selected: " << **fi << endl;
}
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Przekazywanie danych obszaru tekstowego do programu CGI
Element TEXTAREA jest używany, gdy tekst wielowierszowy ma zostać przesłany do programu CGI.
Oto przykładowy kod HTML dla formularza z polem TEXTAREA -
<form action = "/cgi-bin/cpp_textarea.cgi" method = "post" target = "_blank">
<textarea name = "textcontent" cols = "40" rows = "4">
Type your text here...
</textarea>
<input type = "submit" value = "Submit" />
</form>Wynikiem tego kodu jest następująca postać -
Poniżej znajduje się program w C ++, który wygeneruje skrypt cpp_textarea.cgi do obsługi danych wprowadzanych przez przeglądarkę internetową poprzez obszar tekstowy.
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc formData;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Text Area Data to CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
form_iterator fi = formData.getElement("textcontent");
if( !fi->isEmpty() && fi != (*formData).end()) {
cout << "Text Content: " << **fi << endl;
} else {
cout << "No text entered" << endl;
}
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Przekazywanie danych z rozwijanej skrzynki do programu CGI
Rozwijane okno jest używane, gdy mamy wiele dostępnych opcji, ale tylko jedna lub dwie zostaną wybrane.
Oto przykładowy kod HTML dla formularza z jednym rozwijanym oknem -
<form action = "/cgi-bin/cpp_dropdown.cgi" method = "post" target = "_blank">
<select name = "dropdown">
<option value = "Maths" selected>Maths</option>
<option value = "Physics">Physics</option>
</select>
<input type = "submit" value = "Submit"/>
</form>Wynikiem tego kodu jest następująca postać -
Poniżej znajduje się program w C ++, który wygeneruje skrypt cpp_dropdown.cgi do obsługi danych wejściowych podawanych przez przeglądarkę internetową za pośrednictwem rozwijanej listy.
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc formData;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Drop Down Box Data to CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
form_iterator fi = formData.getElement("dropdown");
if( !fi->isEmpty() && fi != (*formData).end()) {
cout << "Value Selected: " << **fi << endl;
}
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Korzystanie z plików cookie w CGI
Protokół HTTP jest protokołem bezstanowym. Jednak w przypadku komercyjnej witryny internetowej wymagane jest przechowywanie informacji o sesjach między różnymi stronami. Na przykład rejestracja jednego użytkownika kończy się po wypełnieniu wielu stron. Ale jak zachować informacje o sesji użytkownika na wszystkich stronach internetowych.
W wielu sytuacjach używanie plików cookie jest najskuteczniejszą metodą zapamiętywania i śledzenia preferencji, zakupów, prowizji i innych informacji wymaganych dla lepszych wrażeń odwiedzających lub statystyk witryny.
Jak to działa
Twój serwer wysyła pewne dane do przeglądarki odwiedzającego w formie pliku cookie. Przeglądarka może zaakceptować plik cookie. Jeśli tak, jest przechowywany jako zwykły zapis tekstowy na dysku twardym gościa. Teraz, gdy użytkownik przejdzie na inną stronę w Twojej witrynie, plik cookie jest dostępny do pobrania. Po odzyskaniu serwer wie / pamięta, co zostało zapisane.
Pliki cookie to zapis danych w postaci zwykłego tekstu składający się z 5 pól o zmiennej długości -
Expires- Pokazuje datę wygaśnięcia pliku cookie. Jeśli jest puste, plik cookie wygaśnie, gdy odwiedzający zamknie przeglądarkę.
Domain - Wyświetla nazwę domeny Twojej witryny.
Path- Pokazuje ścieżkę do katalogu lub strony internetowej, która ustawiła plik cookie. To może być puste, jeśli chcesz pobrać plik cookie z dowolnego katalogu lub strony.
Secure- Jeśli to pole zawiera słowo „bezpieczny”, plik cookie można pobrać tylko z bezpiecznego serwera. Jeśli to pole jest puste, takie ograniczenie nie istnieje.
Name = Value - Pliki cookie są ustawiane i pobierane w postaci par klucza i wartości.
Konfiguracja plików cookie
Wysyłanie plików cookie do przeglądarki jest bardzo łatwe. Te pliki cookie będą wysyłane wraz z nagłówkiem HTTP przed zapisaniem typu zawartości. Zakładając, że chcesz ustawić identyfikator użytkownika i hasło jako pliki cookie. Więc ustawienia plików cookie będą wykonywane w następujący sposób
#include <iostream>
using namespace std;
int main () {
cout << "Set-Cookie:UserID = XYZ;\r\n";
cout << "Set-Cookie:Password = XYZ123;\r\n";
cout << "Set-Cookie:Domain = www.tutorialspoint.com;\r\n";
cout << "Set-Cookie:Path = /perl;\n";
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Cookies in CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
cout << "Setting cookies" << endl;
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Na podstawie tego przykładu musisz wiedzieć, jak ustawić pliki cookie. UżywamySet-Cookie Nagłówek HTTP do ustawiania plików cookie.
W tym przypadku opcjonalne jest ustawienie atrybutów plików cookie, takich jak Wygasa, Domena i Ścieżka. Warto zauważyć, że pliki cookie są ustawiane przed wysłaniem magicznej linii"Content-type:text/html\r\n\r\n.
Skompiluj powyższy program, aby utworzyć setcookies.cgi, i spróbuj ustawić pliki cookie za pomocą poniższego linku. Ustawi cztery pliki cookie na Twoim komputerze -
/cgi-bin/setcookies.cgi
Pobieranie plików cookie
Pobranie wszystkich ustawionych plików cookie jest łatwe. Pliki cookie są przechowywane w zmiennej środowiskowej CGI HTTP_COOKIE i będą miały następującą postać.
key1 = value1; key2 = value2; key3 = value3....Oto przykład pobierania plików cookie.
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc cgi;
const_cookie_iterator cci;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Cookies in CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
cout << "<table border = \"0\" cellspacing = \"2\">";
// get environment variables
const CgiEnvironment& env = cgi.getEnvironment();
for( cci = env.getCookieList().begin();
cci != env.getCookieList().end();
++cci ) {
cout << "<tr><td>" << cci->getName() << "</td><td>";
cout << cci->getValue();
cout << "</td></tr>\n";
}
cout << "</table><\n";
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Teraz skompiluj powyższy program, aby utworzyć getcookies.cgi i spróbuj uzyskać listę wszystkich plików cookie dostępnych na twoim komputerze -
/cgi-bin/getcookies.cgi
Spowoduje to wyświetlenie listy wszystkich czterech plików cookie ustawionych w poprzedniej sekcji i wszystkich innych plików cookie ustawionych na Twoim komputerze -
UserID XYZ
Password XYZ123
Domain www.tutorialspoint.com
Path /perlPrzykład przesyłania plików
Aby przesłać plik, formularz HTML musi mieć atrybut enctype ustawiony na multipart/form-data. Znacznik wejściowy z typem pliku utworzy przycisk „Przeglądaj”.
<html>
<body>
<form enctype = "multipart/form-data" action = "/cgi-bin/cpp_uploadfile.cgi"
method = "post">
<p>File: <input type = "file" name = "userfile" /></p>
<p><input type = "submit" value = "Upload" /></p>
</form>
</body>
</html>Wynikiem tego kodu jest następująca postać -
Note- Powyższy przykład został celowo wyłączony, aby uniemożliwić ludziom przesyłanie plików na nasz serwer. Ale możesz wypróbować powyższy kod na swoim serwerze.
Oto scenariusz cpp_uploadfile.cpp do obsługi przesyłania plików -
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc cgi;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>File Upload in CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
// get list of files to be uploaded
const_file_iterator file = cgi.getFile("userfile");
if(file != cgi.getFiles().end()) {
// send data type at cout.
cout << HTTPContentHeader(file->getDataType());
// write content at cout.
file->writeToStream(cout);
}
cout << "<File uploaded successfully>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Powyższy przykład służy do pisania treści pod adresem cout stream, ale możesz otworzyć strumień plików i zapisać zawartość przesłanego pliku w pliku w wybranej lokalizacji.
Mam nadzieję, że podobał Ci się ten samouczek. Jeśli tak, prześlij nam swoją opinię.