Eksploracja danych - szybki przewodnik
W przemyśle informacyjnym dostępnych jest ogromna ilość danych. Dane te są bezużyteczne, dopóki nie zostaną przekształcone w przydatne informacje. Konieczne jest przeanalizowanie tej ogromnej ilości danych i wydobycie z nich przydatnych informacji.
Wydobywanie informacji nie jest jedynym procesem, jaki musimy wykonać; eksploracja danych obejmuje również inne procesy, takie jak czyszczenie danych, integracja danych, transformacja danych, eksploracja danych, ocena wzorców i prezentacja danych. Po zakończeniu wszystkich tych procesów moglibyśmy wykorzystać te informacje w wielu zastosowaniach, takich jak wykrywanie oszustw, analiza rynku, kontrola produkcji, badanie naukowe itp.
Co to jest eksploracja danych?
Data Mining definiuje się jako wydobywanie informacji z ogromnych zbiorów danych. Innymi słowy, możemy powiedzieć, że eksploracja danych to procedura wydobywania wiedzy z danych. Uzyskane w ten sposób informacje lub wiedzę można wykorzystać do dowolnej z następujących aplikacji:
- Analiza rynku
- Wykrywanie oszustw
- Utrzymanie klienta
- Kontrola produkcji
- Eksploracja nauki
Aplikacje Data Mining
Eksploracja danych jest bardzo przydatna w następujących domenach -
- Analiza rynku i zarządzanie
- Analiza korporacyjna i zarządzanie ryzykiem
- Wykrywanie oszustw
Oprócz tego eksploracja danych może być również wykorzystywana w obszarach kontroli produkcji, zatrzymywania klientów, eksploracji nauki, sportu, astrologii i pomocy w surfowaniu po Internecie.
Analiza rynku i zarządzanie
Poniżej wymieniono różne obszary rynku, na których wykorzystuje się eksplorację danych -
Customer Profiling - Eksploracja danych pomaga określić, jacy ludzie kupują jakie produkty.
Identifying Customer Requirements- Eksploracja danych pomaga w identyfikacji najlepszych produktów dla różnych klientów. Wykorzystuje prognozy, aby znaleźć czynniki, które mogą przyciągnąć nowych klientów.
Cross Market Analysis - Eksploracja danych wykonuje powiązania / korelacje między sprzedażą produktów.
Target Marketing - Eksploracja danych pomaga znaleźć klastry modelowych klientów, którzy mają te same cechy, takie jak zainteresowania, nawyki związane z wydawaniem pieniędzy, dochody itp.
Determining Customer purchasing pattern - Eksploracja danych pomaga w określeniu wzorca zakupów klientów.
Providing Summary Information - Eksploracja danych zapewnia nam różne wielowymiarowe raporty podsumowujące.
Analiza korporacyjna i zarządzanie ryzykiem
Eksploracja danych jest stosowana w następujących obszarach sektora korporacyjnego -
Finance Planning and Asset Evaluation - Obejmuje analizę i prognozowanie przepływów pieniężnych, analizę roszczeń warunkowych w celu oceny aktywów.
Resource Planning - Polega na podsumowaniu i porównaniu zasobów i wydatków.
Competition - Polega na monitorowaniu konkurencji i kierunków rynkowych.
Wykrywanie oszustw
Eksploracja danych jest również wykorzystywana w dziedzinie usług kart kredytowych i telekomunikacji do wykrywania oszustw. W przypadku oszukańczych rozmów telefonicznych pomaga znaleźć cel połączenia, czas trwania połączenia, porę dnia lub tygodnia itp. Analizuje również wzorce odbiegające od oczekiwanych norm.
Eksploracja danych zajmuje się rodzajami wzorców, które można wydobyć. Ze względu na rodzaj danych do wydobycia istnieją dwie kategorie funkcji związanych z Data Mining -
- Descriptive
- Klasyfikacja i przewidywanie
Funkcja opisowa
Funkcja opisowa zajmuje się ogólnymi właściwościami danych w bazie danych. Oto lista funkcji opisowych -
- Opis klasy / koncepcji
- Wydobywanie częstych wzorców
- Górnictwo zrzeszeń
- Wydobywanie korelacji
- Wydobywanie klastrów
Opis klasy / koncepcji
Klasa / koncepcja odnosi się do danych, które mają być powiązane z klasami lub koncepcjami. Na przykład w firmie klasy towarów do sprzedaży obejmują komputery i drukarki, a koncepcje klientów obejmują dużych wydatków i wydatków budżetowych. Takie opisy klasy lub pojęcia nazywane są opisami klas / koncepcji. Opisy te można uzyskać na dwa następujące sposoby -
Data Characterization- Dotyczy to podsumowania danych z badanej klasy. Ta badana klasa jest nazywana klasą docelową.
Data Discrimination - Odnosi się do mapowania lub klasyfikacji klasy z pewną predefiniowaną grupą lub klasą.
Wydobywanie częstych wzorców
Częste wzorce to te wzorce, które często występują w danych transakcyjnych. Oto lista rodzajów częstych wzorców -
Frequent Item Set - Odnosi się do zestawu elementów, które często występują razem, na przykład mleko i chleb.
Frequent Subsequence - Po sekwencji często występujących wzorców, takich jak kupowanie aparatu, następuje karta pamięci.
Frequent Sub Structure - Podstruktura odnosi się do różnych form strukturalnych, takich jak grafy, drzewa lub kraty, które można łączyć ze zbiorami elementów lub podciągami.
Górnictwo Stowarzyszenia
Powiązania są używane w sprzedaży detalicznej do identyfikacji wzorców, które są często kupowane razem. Proces ten odnosi się do procesu odkrywania relacji między danymi i określania reguł asocjacji.
Na przykład sprzedawca detaliczny generuje regułę asocjacyjną, która pokazuje, że 70% przypadków mleka jest sprzedawanych z chlebem, a tylko 30% przypadków ciastek jest sprzedawanych z chlebem.
Wydobywanie korelacji
Jest to rodzaj dodatkowej analizy przeprowadzanej w celu odkrycia interesujących korelacji statystycznych między parami skojarzonych atrybutów i wartości lub między dwoma zestawami pozycji w celu przeanalizowania, czy mają one na siebie pozytywny, negatywny lub żaden wpływ.
Wydobywanie klastrów
Klaster odnosi się do grupy podobnych obiektów. Analiza skupień odnosi się do tworzenia grup obiektów, które są do siebie bardzo podobne, ale bardzo różnią się od obiektów w innych skupieniach.
Klasyfikacja i przewidywanie
Klasyfikacja to proces znajdowania modelu opisującego klasy danych lub pojęcia. Celem jest umożliwienie wykorzystania tego modelu do przewidywania klasy obiektów, których etykieta jest nieznana. Ten wyprowadzony model jest oparty na analizie zbiorów danych uczących. Wyprowadzony model można przedstawić w następujących postaciach -
- Zasady klasyfikacji (IF-THEN)
- Drzewa decyzyjne
- Wzory matematyczne
- Sieci neuronowe
Lista funkcji zaangażowanych w te procesy jest następująca -
Classification- Przewiduje klasę obiektów, których etykieta jest nieznana. Jego celem jest znalezienie modelu pochodnego, który opisuje i rozróżnia klasy danych lub pojęcia. Model pochodny jest oparty na zbiorze analiz danych uczących, tj. Obiekcie danych, którego etykieta klasy jest dobrze znana.
Prediction- Służy do przewidywania brakujących lub niedostępnych wartości danych liczbowych zamiast etykiet klas. Analiza regresji jest zwykle używana do przewidywania. Prognozowanie można również wykorzystać do identyfikacji trendów dystrybucji na podstawie dostępnych danych.
Outlier Analysis - Wartości odstające można zdefiniować jako obiekty danych, które nie są zgodne z ogólnym zachowaniem lub modelem dostępnych danych.
Evolution Analysis - Analiza ewolucji odnosi się do opisu i modelowych prawidłowości lub trendów dla obiektów, których zachowanie zmienia się w czasie.
Prymitywy zadania eksploracji danych
- Możemy określić zadanie eksploracji danych w postaci zapytania eksploracyjnego.
- To zapytanie jest wprowadzane do systemu.
- Zapytanie eksploracyjne jest zdefiniowane w kategoriach podstawowych zadań eksploracji danych.
Note- Te prymitywy pozwalają nam komunikować się w sposób interaktywny z systemem data mining. Oto lista prymitywów zadań eksploracji danych -
- Zestaw danych dotyczących zadania do wydobycia.
- Rodzaj wiedzy do wydobycia.
- Wiedza podstawowa do wykorzystania w procesie odkrywania.
- Interesujące miary i progi oceny wzorców.
- Reprezentacja do wizualizacji odkrytych wzorców.
Zestaw danych dotyczących zadania do wydobycia
To jest część bazy danych, którą interesuje się użytkownik. Ta część obejmuje:
- Atrybuty bazy danych
- Interesujące wymiary hurtowni danych
Rodzaj wiedzy do wydobycia
Odnosi się do rodzaju funkcji do wykonania. Te funkcje to -
- Characterization
- Discrimination
- Analiza asocjacji i korelacji
- Classification
- Prediction
- Clustering
- Analiza wartości odstających
- Analiza ewolucji
Wiedza podstawowa
Podstawowa wiedza pozwala na wydobywanie danych na wielu poziomach abstrakcji. Na przykład hierarchie pojęć są jedną z wiedzy podstawowej, która umożliwia wydobywanie danych na wielu poziomach abstrakcji.
Interesujące miary i progi oceny wzorców
Służy do oceny wzorców odkrytych w procesie odkrywania wiedzy. Istnieją różne interesujące miary dla różnych rodzajów wiedzy.
Reprezentacja do wizualizacji odkrytych wzorców
Odnosi się to do formy, w jakiej mają być wyświetlane odkryte wzorce. Te reprezentacje mogą obejmować następujące elementy. -
- Rules
- Tables
- Charts
- Graphs
- Drzewa decyzyjne
- Cubes
Eksploracja danych nie jest łatwym zadaniem, ponieważ wykorzystywane algorytmy mogą być bardzo złożone, a dane nie zawsze są dostępne w jednym miejscu. Musi być zintegrowany z różnych heterogenicznych źródeł danych. Te czynniki również powodują pewne problemy. W tym samouczku omówimy główne problemy dotyczące -
- Metodologia wydobycia i interakcja użytkownika
- Problemy z wydajnością
- Zagadnienia dotyczące różnych typów danych
Poniższy diagram przedstawia główne problemy.

Metodyka wyszukiwania i problemy z interakcją z użytkownikiem
Odnosi się do następujących rodzajów problemów -
Mining different kinds of knowledge in databases- Różni użytkownicy mogą być zainteresowani różnymi rodzajami wiedzy. Dlatego konieczne jest, aby eksploracja danych obejmowała szeroki zakres zadań związanych z odkrywaniem wiedzy.
Interactive mining of knowledge at multiple levels of abstraction - Proces eksploracji danych musi być interaktywny, ponieważ umożliwia użytkownikom skoncentrowanie się na wyszukiwaniu wzorców, dostarczaniu i udoskonalaniu żądań eksploracji danych w oparciu o zwrócone wyniki.
Incorporation of background knowledge- Aby pokierować procesem odkrywania i wyrazić odkryte wzorce, można wykorzystać wiedzę podstawową. Wiedza podstawowa może być wykorzystana do wyrażenia odkrytych wzorców nie tylko w zwięzłych terminach, ale na wielu poziomach abstrakcji.
Data mining query languages and ad hoc data mining - Język zapytań Data Mining, który pozwala użytkownikowi opisywać zadania eksploracji ad hoc, powinien być zintegrowany z językiem zapytań hurtowni danych i zoptymalizowany pod kątem wydajnej i elastycznej eksploracji danych.
Presentation and visualization of data mining results- Po odkryciu wzorców należy je wyrazić w językach wysokiego poziomu i przedstawiać wizualnie. Przedstawienia te powinny być łatwo zrozumiałe.
Handling noisy or incomplete data- Metody czyszczenia danych są wymagane do obsługi szumu i niekompletnych obiektów podczas eksploracji prawidłowości danych. Jeśli nie ma metod czyszczenia danych, dokładność wykrytych wzorców będzie niska.
Pattern evaluation - Odkryte wzorce powinny być interesujące, ponieważ albo reprezentują wiedzę powszechną, albo brak im nowości.
Problemy z wydajnością
Mogą wystąpić problemy związane z wydajnością, takie jak:
Efficiency and scalability of data mining algorithms - Aby skutecznie wydobywać informacje z ogromnych ilości danych w bazach danych, algorytm eksploracji danych musi być wydajny i skalowalny.
Parallel, distributed, and incremental mining algorithms- Czynniki takie jak ogromny rozmiar baz danych, szeroka dystrybucja danych i złożoność metod eksploracji danych motywują rozwój równoległych i rozproszonych algorytmów eksploracji danych. Algorytmy te dzielą dane na partycje, które są dalej równolegle przetwarzane. Następnie wyniki z partycji są scalane. Algorytmy przyrostowe aktualizują bazy danych bez ponownego wydobywania danych od zera.
Zagadnienia dotyczące różnych typów danych
Handling of relational and complex types of data - Baza danych może zawierać złożone obiekty danych, obiekty danych multimedialnych, dane przestrzenne, dane czasowe itp. Nie jest możliwe, aby jeden system mógł wydobywać wszystkie tego rodzaju dane.
Mining information from heterogeneous databases and global information systems- Dane są dostępne w różnych źródłach danych w sieci LAN lub WAN. Te źródła danych mogą być ustrukturyzowane, częściowo ustrukturyzowane lub nieustrukturyzowane. Dlatego wydobywanie z nich wiedzy stanowi wyzwanie dla eksploracji danych.
Hurtownia danych
Hurtownia danych wykazuje następujące cechy wspierające proces podejmowania decyzji przez kierownictwo:
Subject Oriented- Hurtownia danych jest zorientowana tematycznie, ponieważ dostarcza nam informacji na dany temat, a nie bieżących działań organizacji. Przedmiotami tymi mogą być produkty, klienci, dostawcy, sprzedaż, przychody itp. Hurtownia danych nie koncentruje się na bieżącej działalności, a raczej na modelowaniu i analizie danych w celu podejmowania decyzji.
Integrated - Hurtownia danych jest zbudowana poprzez integrację danych z heterogenicznych źródeł, takich jak relacyjne bazy danych, pliki płaskie itp. Integracja ta usprawnia efektywną analizę danych.
Time Variant- Dane gromadzone w hurtowni danych są identyfikowane z określonym przedziałem czasu. Dane w hurtowni danych dostarczają informacji z historycznego punktu widzenia.
Non-volatile- Nieulotna oznacza, że poprzednie dane nie są usuwane po dodaniu do nich nowych danych. Hurtownia danych jest oddzielona od operacyjnej bazy danych, dlatego częste zmiany w operacyjnej bazie danych nie są odzwierciedlane w hurtowni danych.
Magazyn danych
Hurtownie danych to proces tworzenia i użytkowania hurtowni danych. Hurtownia danych jest budowana poprzez integrację danych z wielu heterogenicznych źródeł. Obsługuje raportowanie analityczne, zapytania ustrukturyzowane i / lub ad hoc oraz podejmowanie decyzji.
Hurtownia danych obejmuje czyszczenie danych, integrację danych i konsolidację danych. Aby zintegrować heterogeniczne bazy danych, mamy dwa podejścia -
- Podejście oparte na zapytaniach
- Zaktualizuj podejście sterowane
Podejście oparte na zapytaniach
Jest to tradycyjne podejście do integracji heterogenicznych baz danych. To podejście jest używane do tworzenia opakowań i integratorów na podstawie wielu heterogenicznych baz danych. Ci integratorzy są również znani jako mediatorzy.
Proces podejścia opartego na zapytaniach
Gdy zapytanie jest wysyłane po stronie klienta, słownik metadanych tłumaczy zapytanie na zapytania, odpowiednie dla danej heterogenicznej witryny.
Teraz te zapytania są mapowane i wysyłane do lokalnego procesora zapytań.
Wyniki z heterogenicznych witryn są integrowane w globalnym zestawie odpowiedzi.
Niedogodności
To podejście ma następujące wady -
Podejście oparte na zapytaniach wymaga złożonych procesów integracji i filtrowania.
Jest to bardzo nieefektywne i bardzo kosztowne w przypadku częstych zapytań.
Takie podejście jest kosztowne w przypadku zapytań wymagających agregacji.
Podejście oparte na aktualizacji
Dzisiejsze systemy hurtowni danych stosują podejście oparte na aktualizacjach, a nie tradycyjne podejście omówione wcześniej. W podejściu opartym na aktualizacjach informacje z wielu heterogenicznych źródeł są z wyprzedzeniem integrowane i przechowywane w magazynie. Te informacje są dostępne do bezpośredniego wyszukiwania i analizy.
Zalety
Takie podejście ma następujące zalety -
Takie podejście zapewnia wysoką wydajność.
Dane mogą być kopiowane, przetwarzane, integrowane, opisywane, podsumowywane i restrukturyzowane z wyprzedzeniem w semantycznym magazynie danych.
Przetwarzanie zapytań nie wymaga interfejsu z przetwarzaniem w źródłach lokalnych.
Od hurtowni danych (OLAP) do eksploracji danych (OLAM)
Online Analytical Mining integruje się z Online Analytical Processing z eksploracją danych i wiedzą w wielowymiarowych bazach danych. Oto diagram przedstawiający integrację OLAP i OLAM -

Znaczenie OLAM
OLAM jest ważny z następujących powodów -
High quality of data in data warehouses- Narzędzia do eksploracji danych są wymagane do pracy na zintegrowanych, spójnych i oczyszczonych danych. Te kroki są bardzo kosztowne w przypadku wstępnego przetwarzania danych. Hurtownie danych zbudowane w ramach takiego wstępnego przetwarzania są cennymi źródłami wysokiej jakości danych dla OLAP i data mining.
Available information processing infrastructure surrounding data warehouses - Infrastruktura przetwarzania informacji odnosi się do dostępu, integracji, konsolidacji i transformacji wielu heterogenicznych baz danych, dostępu do sieci i obiektów usługowych, narzędzi do raportowania i analizy OLAP.
OLAP−based exploratory data analysis- Eksploracyjna analiza danych jest wymagana do efektywnej eksploracji danych. OLAM zapewnia funkcję eksploracji danych na różnych podzbiorach danych i na różnych poziomach abstrakcji.
Online selection of data mining functions - Integracja OLAP z wieloma funkcjami eksploracji danych i eksploracją analityczną online zapewnia użytkownikom elastyczność wyboru żądanych funkcji eksploracji danych i dynamicznej wymiany zadań eksploracji danych.
Eksploracja danych
Eksploracja danych jest definiowana jako wydobywanie informacji z ogromnego zestawu danych. Innymi słowy, możemy powiedzieć, że eksploracja danych polega na wydobywaniu wiedzy z danych. Tych informacji można użyć do dowolnej z następujących aplikacji -
- Analiza rynku
- Wykrywanie oszustw
- Utrzymanie klienta
- Kontrola produkcji
- Eksploracja nauki
Silnik wyszukiwania danych
Silnik eksploracji danych jest bardzo istotny dla systemu eksploracji danych. Składa się z zestawu modułów funkcjonalnych, które wykonują następujące funkcje -
- Characterization
- Analiza asocjacji i korelacji
- Classification
- Prediction
- Analiza skupień
- Analiza wartości odstających
- Analiza ewolucji
Baza wiedzy
To jest wiedza domeny. Wiedza ta jest wykorzystywana do kierowania wyszukiwaniem lub oceniania ciekawości uzyskanych wzorców.
Odkrywanie wiedzy
Niektórzy ludzie traktują eksplorację danych tak samo, jak odkrywanie wiedzy, podczas gdy inni postrzegają eksplorację danych jako niezbędny krok w procesie odkrywania wiedzy. Oto lista kroków związanych z procesem odkrywania wiedzy -
- Czyszczenie danych
- Integracja danych
- Wybór danych
- Transformacja danych
- Eksploracja danych
- Ocena wzoru
- Prezentacja wiedzy
Interfejs użytkownika
Interfejs użytkownika to moduł systemu data mining, który pomaga w komunikacji pomiędzy użytkownikami a systemem data mining. Interfejs użytkownika umożliwia następujące funkcje -
- Wejdź w interakcję z systemem, określając zadanie zapytania eksploracyjnego.
- Dostarczanie informacji pomagających w zawężeniu wyszukiwania.
- Wydobywanie w oparciu o pośrednie wyniki eksploracji danych.
- Przeglądaj bazy danych i schematy lub struktury danych hurtowni danych.
- Oceń wykopane wzorce.
- Wizualizuj wzory w różnych formach.
Integracja danych
Integracja danych to technika wstępnego przetwarzania danych, która łączy dane z wielu heterogenicznych źródeł danych w spójny magazyn danych. Integracja danych może wiązać się z niespójnymi danymi i dlatego wymaga czyszczenia danych.
Czyszczenie danych
Czyszczenie danych to technika stosowana do usuwania zaszumionych danych i korygowania niespójności danych. Czyszczenie danych obejmuje transformacje mające na celu poprawienie nieprawidłowych danych. Czyszczenie danych jest wykonywane jako etap wstępnego przetwarzania danych podczas przygotowywania danych do hurtowni danych.
Wybór danych
Wybór danych to proces, w którym dane istotne dla zadania analizy są pobierane z bazy danych. Czasami transformacja i konsolidacja danych jest przeprowadzana przed procesem selekcji danych.
Klastry
Klaster odnosi się do grupy podobnych obiektów. Analiza skupień odnosi się do tworzenia grup obiektów, które są do siebie bardzo podobne, ale bardzo różnią się od obiektów w innych skupieniach.
Transformacja danych
Na tym etapie dane są przekształcane lub konsolidowane do postaci odpowiednich do eksploracji, poprzez wykonywanie operacji podsumowania lub agregacji.
Co to jest odkrywanie wiedzy?
Niektórzy ludzie nie odróżniają eksploracji danych od odkrywania wiedzy, podczas gdy inni postrzegają eksplorację danych jako zasadniczy krok w procesie odkrywania wiedzy. Oto lista kroków związanych z procesem odkrywania wiedzy -
Data Cleaning - Na tym etapie szum i niespójne dane są usuwane.
Data Integration - Na tym etapie łączy się wiele źródeł danych.
Data Selection - Na tym etapie dane istotne dla zadania analizy są pobierane z bazy danych.
Data Transformation - Na tym etapie dane są przekształcane lub konsolidowane do postaci odpowiednich do eksploracji poprzez wykonywanie operacji podsumowania lub agregacji.
Data Mining - Na tym etapie stosowane są inteligentne metody w celu wyodrębnienia wzorców danych.
Pattern Evaluation - Na tym etapie oceniane są wzorce danych.
Knowledge Presentation - Na tym etapie reprezentowana jest wiedza.
Poniższy diagram przedstawia proces odkrywania wiedzy -

Dostępnych jest wiele różnych systemów eksploracji danych. Systemy eksploracji danych mogą integrować techniki z następujących:
- Analiza danych przestrzennych
- Wyszukiwanie informacji
- Rozpoznawanie wzorców
- Analiza obrazu
- Przetwarzanie sygnałów
- Grafika komputerowa
- Technologia internetowa
- Business
- Bioinformatics
Klasyfikacja systemów wyszukiwania danych
System eksploracji danych można sklasyfikować według następujących kryteriów -
- Technologia baz danych
- Statistics
- Nauczanie maszynowe
- Informatyka
- Visualization
- Inne dyscypliny

Oprócz tego system eksploracji danych można również sklasyfikować na podstawie rodzaju (a) wydobywanych baz danych, (b) wydobywanej wiedzy, (c) wykorzystywanych technik oraz (d) dostosowywanych aplikacji.
Klasyfikacja na podstawie wydobytych baz danych
System eksploracji danych możemy sklasyfikować według rodzaju wydobywanych baz danych. System baz danych można klasyfikować według różnych kryteriów, takich jak modele danych, typy danych itp. System eksploracji danych można odpowiednio sklasyfikować.
Na przykład, jeśli sklasyfikujemy bazę danych zgodnie z modelem danych, możemy mieć system relacyjny, transakcyjny, obiektowo-relacyjny lub hurtowni danych.
Klasyfikacja na podstawie rodzaju wydobywanej wiedzy
System eksploracji danych możemy sklasyfikować według rodzaju wydobywanej wiedzy. Oznacza to, że system data mining jest klasyfikowany na podstawie funkcjonalności takich jak:
- Characterization
- Discrimination
- Analiza asocjacji i korelacji
- Classification
- Prediction
- Analiza wartości odstających
- Analiza ewolucji
Klasyfikacja oparta na zastosowanych technikach
System eksploracji danych możemy sklasyfikować według rodzaju zastosowanych technik. Możemy opisać te techniki w zależności od stopnia interakcji użytkownika lub zastosowanych metod analizy.
Klasyfikacja na podstawie dostosowanych aplikacji
System eksploracji danych możemy sklasyfikować zgodnie z dostosowanymi aplikacjami. Te aplikacje są następujące -
- Finance
- Telecommunications
- DNA
- Rynki akcji
Integracja systemu Data Mining z systemem DB / DW
Jeśli system eksploracji danych nie jest zintegrowany z bazą danych lub hurtownią danych, nie będzie systemu, z którym można by się komunikować. Ten schemat jest znany jako schemat niepowiązania. W tym schemacie główny nacisk położono na projekt eksploracji danych oraz na opracowanie wydajnych i skutecznych algorytmów eksploracji dostępnych zestawów danych.
Lista schematów integracji jest następująca -
No Coupling- W tym schemacie system eksploracji danych nie wykorzystuje żadnej z funkcji bazy danych ani hurtowni danych. Pobiera dane z określonego źródła i przetwarza je za pomocą niektórych algorytmów eksploracji danych. Wynik eksploracji danych jest przechowywany w innym pliku.
Loose Coupling- W tym schemacie system eksploracji danych może wykorzystywać niektóre funkcje systemu bazodanowego i hurtowni danych. Pobiera dane z respiratora danych zarządzanego przez te systemy i wykonuje eksplorację danych na tych danych. Następnie przechowuje wynik wyszukiwania w pliku lub w wyznaczonym miejscu w bazie danych lub w hurtowni danych.
Semi−tight Coupling - W tym schemacie system data mining jest połączony z bazą danych lub systemem hurtowni danych, a ponadto w bazie danych można zapewnić wydajne implementacje kilku prymitywów eksploracji danych.
Tight coupling- W tym schemacie łączenia system eksploracji danych jest płynnie zintegrowany z bazą danych lub systemem hurtowni danych. Podsystem eksploracji danych jest traktowany jako jeden z funkcjonalnych elementów systemu informatycznego.
Data Mining Query Language (DMQL) został zaproponowany przez Han, Fu, Wang i in. dla systemu data mining DBMiner. Język zapytań Data Mining jest w rzeczywistości oparty na Structured Query Language (SQL). Języki zapytań eksploracji danych mogą być zaprojektowane do obsługi eksploracji danych ad hoc i interaktywnej. Ten DMQL udostępnia polecenia do określania prymitywów. DMQL może również współpracować z bazami danych i hurtowniami danych. DMQL może służyć do definiowania zadań eksploracji danych. W szczególności badamy, jak definiować hurtownie danych i składnice danych w DMQL.
Składnia specyfikacji danych istotnych dla zadania
Oto składnia DMQL do określania danych istotnych dla zadania -
use database database_name
or
use data warehouse data_warehouse_name
in relevance to att_or_dim_list
from relation(s)/cube(s) [where condition]
order by order_list
group by grouping_listSkładnia określania rodzaju wiedzy
Tutaj omówimy składnię charakteryzacji, dyskryminacji, skojarzeń, klasyfikacji i przewidywania.
Charakteryzacja
Składnia charakteryzacji to -
mine characteristics [as pattern_name]
analyze {measure(s) }Klauzula analizy określa zagregowane miary, takie jak count, sum lub count%.
Na przykład -
Description describing customer purchasing habits.
mine characteristics as customerPurchasing
analyze count%Dyskryminacja
Składnia Dyskryminacji to -
mine comparison [as {pattern_name]}
For {target_class } where {t arget_condition }
{versus {contrast_class_i }
where {contrast_condition_i}}
analyze {measure(s) }Na przykład użytkownik może zdefiniować osoby, które dużo wydają, jako klientów, którzy kupują przedmioty, które kosztują $100 or more on an average; and budget spenders as customers who purchase items at less than $Średnio 100. Wydobywanie dyskryminacyjnych opisów dla klientów z każdej z tych kategorii można określić w DMQL jako -
mine comparison as purchaseGroups
for bigSpenders where avg(I.price) ≥$100 versus budgetSpenders where avg(I.price)< $100
analyze countStowarzyszenie
Składnia asocjacji to -
mine associations [ as {pattern_name} ]
{matching {metapattern} }Na przykład -
mine associations as buyingHabits
matching P(X:customer,W) ^ Q(X,Y) ≥ buys(X,Z)gdzie X jest kluczem do relacji z klientami; P i Q są zmiennymi predykatowymi; a W, Y i Z są zmiennymi obiektowymi.
Klasyfikacja
Składnia klasyfikacji to -
mine classification [as pattern_name]
analyze classifying_attribute_or_dimensionNa przykład, aby wydobyć wzorce, klasyfikując rating kredytowy klienta, w którym klasy są określone przez atrybut Credit_rating, a moja klasyfikacja jest określana jako classifyCustomerCreditRating.
analyze credit_ratingPrognoza
Składnia przewidywania to -
mine prediction [as pattern_name]
analyze prediction_attribute_or_dimension
{set {attribute_or_dimension_i= value_i}}Składnia specyfikacji hierarchii pojęć
Aby określić hierarchie pojęć, użyj następującej składni -
use hierarchy <hierarchy> for <attribute_or_dimension>Używamy różnych składni do definiowania różnych typów hierarchii, takich jak -
-schema hierarchies
define hierarchy time_hierarchy on date as [date,month quarter,year]
-
set-grouping hierarchies
define hierarchy age_hierarchy for age on customer as
level1: {young, middle_aged, senior} < level0: all
level2: {20, ..., 39} < level1: young
level3: {40, ..., 59} < level1: middle_aged
level4: {60, ..., 89} < level1: senior
-operation-derived hierarchies
define hierarchy age_hierarchy for age on customer as
{age_category(1), ..., age_category(5)}
:= cluster(default, age, 5) < all(age)
-rule-based hierarchies
define hierarchy profit_margin_hierarchy on item as
level_1: low_profit_margin < level_0: all
if (price - cost)< $50 level_1: medium-profit_margin < level_0: all if ((price - cost) > $50) and ((price - cost) ≤ $250))
level_1: high_profit_margin < level_0: allSkładnia specyfikacji miar ciekawości
Interesujące miary i progi użytkownik może określić stwierdzeniem -
with <interest_measure_name> threshold = threshold_valueNa przykład -
with support threshold = 0.05
with confidence threshold = 0.7Składnia prezentacji wzoru i specyfikacji wizualizacji
Mamy składnię, która pozwala użytkownikom określić sposób wyświetlania wykrytych wzorców w jednej lub kilku formach.
display as <result_form>Na przykład -
display as tablePełna specyfikacja DMQL
Jako menadżer rynku w firmie chciałbyś scharakteryzować zwyczaje zakupowe klientów, którzy mogą kupować produkty w cenie nie niższej niż 100 USD; ze względu na wiek klienta, rodzaj zakupionego przedmiotu oraz miejsce zakupu. Chciałbyś wiedzieć, jaki procent klientów ma tę cechę. W szczególności interesują Cię tylko zakupy dokonane w Kanadzie i opłacone kartą kredytową American Express. Chciałbyś zobaczyć wynikowe opisy w formie tabeli.
use database AllElectronics_db
use hierarchy location_hierarchy for B.address
mine characteristics as customerPurchasing
analyze count%
in relevance to C.age,I.type,I.place_made
from customer C, item I, purchase P, items_sold S, branch B
where I.item_ID = S.item_ID and P.cust_ID = C.cust_ID and
P.method_paid = "AmEx" and B.address = "Canada" and I.price ≥ 100
with noise threshold = 5%
display as tableStandaryzacja języków wyszukiwania danych
Standaryzacja języków eksploracji danych będzie służyć następującym celom -
Pomaga w systematycznym opracowywaniu rozwiązań do eksploracji danych.
Poprawia współdziałanie wielu systemów i funkcji eksploracji danych.
Promuje edukację i szybkie uczenie się.
Promuje wykorzystanie systemów eksploracji danych w przemyśle i społeczeństwie.
Istnieją dwie formy analizy danych, które można wykorzystać do wyodrębnienia modeli opisujących ważne klasy lub do przewidywania przyszłych trendów danych. Te dwie formy są następujące -
- Classification
- Prediction
Modele klasyfikacyjne przewidują kategoryczne etykiety klas; a modele predykcyjne przewidują funkcje o wartościach ciągłych. Na przykład, możemy zbudować model klasyfikacyjny, aby sklasyfikować wnioski o pożyczkę bankową jako bezpieczne lub ryzykowne, albo model prognozujący, aby przewidzieć wydatki potencjalnych klientów na sprzęt komputerowy w dolarach, biorąc pod uwagę ich dochody i zawód.
Co to jest klasyfikacja?
Poniżej znajdują się przykłady przypadków, w których zadaniem analizy danych jest Klasyfikacja -
Pracownik banku chce przeanalizować dane, aby wiedzieć, który klient (wnioskodawca kredytowy) jest ryzykowny lub który jest bezpieczny.
Menedżer ds. Marketingu w firmie musi przeanalizować klienta o określonym profilu, który kupi nowy komputer.
W obu powyższych przykładach model lub klasyfikator jest konstruowany w celu przewidywania etykiet jakościowych. Etykiety te są ryzykowne lub bezpieczne dla danych wniosków o pożyczkę oraz tak lub nie dla danych marketingowych.
Co to jest przewidywanie?
Poniżej znajdują się przykłady przypadków, w których zadanie analizy danych to Prognoza -
Załóżmy, że menedżer ds. Marketingu musi przewidzieć, ile dany klient wyda podczas sprzedaży w swojej firmie. W tym przykładzie przeszkadza nam przewidzenie wartości liczbowej. Dlatego zadanie analizy danych jest przykładem predykcji numerycznej. W takim przypadku zostanie skonstruowany model lub predyktor, który przewiduje funkcję o wartościach ciągłych lub wartości uporządkowanej.
Note - Analiza regresji to metodologia statystyczna, która jest najczęściej używana do prognozowania numerycznego.
Jak działa klasyfikacja?
Z pomocą omawianego powyżej wniosku kredytowego, zrozummy, jak działa klasyfikacja. Proces klasyfikacji danych obejmuje dwa etapy -
- Budowanie klasyfikatora lub modelu
- Używanie klasyfikatora do klasyfikacji
Budowanie klasyfikatora lub modelu
Ten krok to etap uczenia się lub faza uczenia się.
Na tym etapie algorytmy klasyfikacji budują klasyfikator.
Klasyfikator jest zbudowany z zestawu uczącego składającego się z krotek bazy danych i powiązanych z nimi etykiet klas.
Każda krotka, która stanowi zbiór uczący, jest określana jako kategoria lub klasa. Te krotki mogą być również nazywane punktami próbki, obiektu lub danych.

Używanie klasyfikatora do klasyfikacji
Na tym etapie klasyfikator służy do klasyfikacji. Tutaj dane testowe są wykorzystywane do oszacowania dokładności reguł klasyfikacji. Reguły klasyfikacji można zastosować do nowych krotek danych, jeśli dokładność zostanie uznana za akceptowalną.

Problemy z klasyfikacją i prognozowaniem
Głównym problemem jest przygotowanie danych do klasyfikacji i prognozowania. Przygotowanie danych obejmuje następujące czynności -
Data Cleaning- Czyszczenie danych polega na usunięciu szumu i leczeniu brakujących wartości. Szum jest usuwany przez zastosowanie technik wygładzania, a problem brakujących wartości jest rozwiązany poprzez zastąpienie brakującej wartości najczęściej występującą wartością dla tego atrybutu.
Relevance Analysis- Baza danych może mieć również nieistotne atrybuty. Analiza korelacji służy do określenia, czy jakiekolwiek dwa podane atrybuty są powiązane.
Data Transformation and reduction - Dane można przekształcić za pomocą jednej z następujących metod.
Normalization- Dane są przekształcane przy użyciu normalizacji. Normalizacja polega na skalowaniu wszystkich wartości danego atrybutu, tak aby mieściły się w małym określonym zakresie. Normalizacja jest stosowana, gdy na etapie uczenia się używane są sieci neuronowe lub metody obejmujące pomiary.
Generalization- Dane można również przekształcić poprzez uogólnienie ich na wyższą koncepcję. W tym celu możemy wykorzystać hierarchie pojęć.
Note - Dane można również zmniejszyć innymi metodami, takimi jak transformacja falkowa, binning, analiza histogramu i grupowanie.
Porównanie metod klasyfikacji i predykcji
Oto kryteria porównania metod klasyfikacji i prognozowania -
Accuracy- Dokładność klasyfikatora odnosi się do zdolności klasyfikatora. Przewiduje poprawnie etykietę klasy, a dokładność predyktora odnosi się do tego, jak dobrze dany predyktor może odgadnąć wartość przewidywanego atrybutu dla nowych danych.
Speed - Odnosi się to do kosztu obliczeniowego generowania i używania klasyfikatora lub predyktora.
Robustness - Odnosi się do zdolności klasyfikatora lub predyktora do dokonywania poprawnych prognoz na podstawie podanych zaszumionych danych.
Scalability- Skalowalność odnosi się do zdolności do efektywnego konstruowania klasyfikatora lub predyktora; biorąc pod uwagę dużą ilość danych.
Interpretability - Odnosi się do tego, w jakim stopniu klasyfikator lub predyktor rozumie.
Drzewo decyzyjne to struktura zawierająca węzeł główny, gałęzie i węzły liści. Każdy węzeł wewnętrzny oznacza test atrybutu, każda gałąź oznacza wynik testu, a każdy węzeł liścia posiada etykietę klasy. Najwyższym węzłem w drzewie jest węzeł główny.
Poniższe drzewo decyzyjne dotyczy koncepcji komputer_kup, które wskazuje, czy klient w firmie prawdopodobnie kupi komputer, czy nie. Każdy węzeł wewnętrzny reprezentuje test atrybutu. Każdy węzeł liścia reprezentuje klasę.

Korzyści z posiadania drzewa decyzyjnego są następujące:
- Nie wymaga znajomości domeny.
- Łatwo to pojąć.
- Etapy uczenia się i klasyfikacji w drzewie decyzyjnym są proste i szybkie.
Algorytm indukcji drzewa decyzyjnego
Badacz maszyn o nazwisku J. Ross Quinlan w 1980 roku opracował algorytm drzewa decyzyjnego znany jako ID3 (Iterative Dichotomiser). Później przedstawił C4.5, który był następcą ID3. ID3 i C4.5 przyjmują chciwe podejście. W tym algorytmie nie ma cofania; drzewa są zbudowane w sposób rekurencyjny z góry na dół, dziel i zwyciężaj.
Generating a decision tree form training tuples of data partition D
Algorithm : Generate_decision_tree
Input:
Data partition, D, which is a set of training tuples
and their associated class labels.
attribute_list, the set of candidate attributes.
Attribute selection method, a procedure to determine the
splitting criterion that best partitions that the data
tuples into individual classes. This criterion includes a
splitting_attribute and either a splitting point or splitting subset.
Output:
A Decision Tree
Method
create a node N;
if tuples in D are all of the same class, C then
return N as leaf node labeled with class C;
if attribute_list is empty then
return N as leaf node with labeled
with majority class in D;|| majority voting
apply attribute_selection_method(D, attribute_list)
to find the best splitting_criterion;
label node N with splitting_criterion;
if splitting_attribute is discrete-valued and
multiway splits allowed then // no restricted to binary trees
attribute_list = splitting attribute; // remove splitting attribute
for each outcome j of splitting criterion
// partition the tuples and grow subtrees for each partition
let Dj be the set of data tuples in D satisfying outcome j; // a partition
if Dj is empty then
attach a leaf labeled with the majority
class in D to node N;
else
attach the node returned by Generate
decision tree(Dj, attribute list) to node N;
end for
return N;Przycinanie drzew
Przycinanie drzew jest wykonywane w celu usunięcia anomalii w danych uczących spowodowanych szumem lub wartościami odstającymi. Przycinane drzewa są mniejsze i mniej złożone.
Podejścia do przycinania drzew
Istnieją dwa sposoby przycinania drzewa -
Pre-pruning - Drzewo jest przycinane przez wcześniejsze zatrzymanie jego budowy.
Post-pruning - To podejście usuwa poddrzewo z w pełni rozwiniętego drzewa.
Złożoność kosztów
Złożoność kosztów jest mierzona za pomocą następujących dwóch parametrów -
- Liczba liści na drzewie i
- Wskaźnik błędów drzewa.
Klasyfikacja bayesowska oparta jest na twierdzeniu Bayesa. Klasyfikatory bayesowskie to klasyfikatory statystyczne. Klasyfikatory bayesowskie mogą przewidywać prawdopodobieństwa przynależności do klas, takie jak prawdopodobieństwo, że dana krotka należy do określonej klasy.
Twierdzenie Baye'a
Twierdzenie Bayesa nosi imię Thomasa Bayesa. Istnieją dwa rodzaje prawdopodobieństw -
- Prawdopodobieństwo późniejsze [P (H / X)]
- Wcześniejsze prawdopodobieństwo [P (H)]
gdzie X to krotka danych, a H to pewna hipoteza.
Zgodnie z twierdzeniem Bayesa,
Bayesian Belief Network
Sieci przekonań bayesowskich określają wspólne rozkłady prawdopodobieństwa warunkowego. Są również znane jako sieci przekonań, sieci bayesowskie lub sieci probabilistyczne.
Sieć przekonań umożliwia definiowanie warunkowych niezależności klas między podzbiorami zmiennych.
Zapewnia graficzny model związku przyczynowego, na podstawie którego można przeprowadzić naukę.
Do klasyfikacji możemy użyć wyszkolonej sieci bayesowskiej.
Istnieją dwa komponenty, które definiują sieć przekonań bayesowskich:
- Skierowany graf acykliczny
- Zestaw tablic prawdopodobieństwa warunkowego
Skierowany wykres acykliczny
- Każdy węzeł na skierowanym acyklicznym grafie reprezentuje zmienną losową.
- Te zmienne mogą mieć wartość dyskretną lub ciągłą.
- Te zmienne mogą odpowiadać faktycznemu atrybutowi podanemu w danych.
Reprezentacja ukierunkowanego grafu acyklicznego
Poniższy diagram przedstawia skierowany acykliczny wykres dla sześciu zmiennych boolowskich.

Łuk na diagramie umożliwia przedstawienie wiedzy przyczynowej. Na przykład na raka płuc ma wpływ historia raka płuc w rodzinie, a także to, czy dana osoba jest palaczem. Warto zauważyć, że zmienna PositiveXray jest niezależna od tego, czy pacjent ma raka płuc w wywiadzie rodzinnym lub czy pacjent jest palaczem, biorąc pod uwagę, że wiemy, że pacjent ma raka płuc.
Warunkowa tabela prawdopodobieństwa
Tabela prawdopodobieństwa warunkowego dla wartości zmiennej LungCancer (LC) pokazująca każdą możliwą kombinację wartości jej węzłów macierzystych, FamilyHistory (FH) i Smoker (S) jest następująca -

IF-THEN Reguły
Klasyfikator oparty na regułach korzysta z zestawu reguł IF-THEN do klasyfikacji. Regułę możemy wyrazić w następujący sposób:
Rozważmy regułę R1,
R1: IF age = youth AND student = yes
THEN buy_computer = yesPoints to remember −
Nazywa się część JEŻELI reguły rule antecedent lub precondition.
Nazywa się TO część reguły rule consequent.
Poprzednia część warunku składa się z co najmniej jednego testu atrybutów, a testy te są logicznie połączone operatorem AND.
Następna część składa się z przewidywania klas.
Note - Możemy również napisać regułę R1 w następujący sposób -
R1: (age = youth) ^ (student = yes))(buys computer = yes)Jeśli warunek jest spełniony dla danej krotki, to poprzednik jest spełniony.
Wyodrębnianie reguł
Tutaj dowiemy się, jak zbudować klasyfikator oparty na regułach, wyodrębniając reguły IF-THEN z drzewa decyzyjnego.
Points to remember −
Aby wyodrębnić regułę z drzewa decyzyjnego -
Dla każdej ścieżki od katalogu głównego do węzła-liścia tworzona jest jedna reguła.
Aby utworzyć poprzednik reguły, każde kryterium podziału jest logicznie połączone operatorem AND.
Węzeł liścia zawiera prognozę klasy, tworząc następnik reguły.
Indukcja reguł z wykorzystaniem algorytmu pokrycia sekwencyjnego
Algorytm pokrycia sekwencyjnego może być użyty do wyodrębnienia reguł IF-THEN z danych uczących. Nie wymagamy najpierw generowania drzewa decyzyjnego. W tym algorytmie każda reguła dla danej klasy obejmuje wiele krotek tej klasy.
Niektóre z sekwencyjnych algorytmów pokrycia to AQ, CN2 i RIPPER. Zgodnie z ogólną strategią, zasady są uczone pojedynczo. Za każdym razem, gdy reguły są uczone, krotka objęta regułą jest usuwana, a proces jest kontynuowany przez pozostałe krotki. Dzieje się tak, ponieważ ścieżka do każdego liścia w drzewie decyzyjnym odpowiada regule.
Note - Indukcja drzewa decyzyjnego może być traktowana jako uczenie się zestawu reguł jednocześnie.
Poniżej przedstawiono algorytm uczenia sekwencyjnego, w którym reguły są uczone dla jednej klasy na raz. Ucząc się reguły z klasy Ci, chcemy, aby reguła obejmowała wszystkie krotki tylko z klasy C i nie obejmowała żadnej krotki z żadnej innej klasy.
Algorithm: Sequential Covering
Input:
D, a data set class-labeled tuples,
Att_vals, the set of all attributes and their possible values.
Output: A Set of IF-THEN rules.
Method:
Rule_set={ }; // initial set of rules learned is empty
for each class c do
repeat
Rule = Learn_One_Rule(D, Att_valls, c);
remove tuples covered by Rule form D;
until termination condition;
Rule_set=Rule_set+Rule; // add a new rule to rule-set
end for
return Rule_Set;Przycinanie reguł
Reguła jest przycinana z następującego powodu -
Ocena jakości dokonywana jest na oryginalnym zestawie danych szkoleniowych. Reguła może działać dobrze na danych uczących, ale gorzej na kolejnych danych. Dlatego wymagane jest przycinanie reguł.
Reguła jest przycinana przez usunięcie spojówki. Reguła R jest przycinana, jeśli przycięta wersja R ma wyższą jakość niż to, co zostało ocenione na niezależnym zestawie krotek.
FOLIA to jedna z prostych i skutecznych metod przycinania reguł. Dla danej reguły R,
gdzie pos i neg to odpowiednio liczba dodatnich krotek pokrytych przez R.
Note- Ta wartość będzie rosła wraz z dokładnością R na zestawie do przycinania. Stąd, jeśli wartość FOIL_Prune jest wyższa dla przyciętej wersji R, to przycinamy R.
Tutaj omówimy inne metody klasyfikacji, takie jak algorytmy genetyczne, podejście przybliżone i podejście rozmyte.
Algorytmy genetyczne
Idea algorytmu genetycznego wywodzi się z naturalnej ewolucji. W algorytmie genetycznym przede wszystkim tworzona jest populacja początkowa. Ta początkowa populacja składa się z losowo generowanych reguł. Każdą regułę możemy przedstawić za pomocą ciągu bitów.
Na przykład w danym zbiorze uczącym próbki są opisane przez dwa atrybuty boolowskie, takie jak A1 i A2. Ten podany zestaw treningowy zawiera dwie klasy, takie jak C1 i C2.
Możemy zakodować regułę IF A1 AND NOT A2 THEN C2 w ciąg bitowy 100. W tej reprezentacji bitowej dwa skrajne lewe bity reprezentują odpowiednio atrybut A1 i A2.
Podobnie zasada IF NOT A1 AND NOT A2 THEN C1 można zakodować jako 001.
Note- Jeśli atrybut ma wartości K, gdzie K> 2, możemy użyć bitów K do zakodowania wartości atrybutów. Klasy są również kodowane w ten sam sposób.
Punkty do zapamiętania -
Opierając się na pojęciu przetrwania najlepiej przystosowanych, tworzy się nowa populacja, która składa się z najsilniejszych reguł w obecnej populacji oraz wartości potomnych tych reguł.
Przydatność reguły ocenia się na podstawie jej dokładności klasyfikacji na zbiorze próbek szkoleniowych.
Operatory genetyczne, takie jak krzyżowanie i mutacja, są stosowane do tworzenia potomstwa.
W przypadku krzyżowania podciąg z pary reguł jest zamieniany w celu utworzenia nowej pary reguł.
W przypadku mutacji losowo wybrane bity w łańcuchu reguły są odwracane.
Podejście zgrubne
Możemy użyć przybliżonego podejścia, aby odkryć strukturalną zależność w nieprecyzyjnych i zaszumionych danych.
Note- To podejście można zastosować tylko do atrybutów o wartościach dyskretnych. Dlatego atrybuty o wartościach ciągłych muszą być dyskretyzowane przed ich użyciem.
Teoria zbiorów przybliżonych opiera się na ustaleniu klas równoważności w ramach danych uczących. Krotki tworzące klasę równoważności są nierozróżnialne. Oznacza to, że próbki są identyczne pod względem atrybutów opisujących dane.
W danych rzeczywistych istnieją klasy, których nie można rozróżnić pod względem dostępnych atrybutów. Możemy użyć przybliżonych zestawów doroughly zdefiniować takie klasy.
Dla danej klasy C przybliżona definicja zbioru jest aproksymowana przez dwa zbiory w następujący sposób -
Lower Approximation of C - Niższe przybliżenie C składa się ze wszystkich krotek danych, które na podstawie znajomości atrybutu z pewnością należą do klasy C.
Upper Approximation of C - Górne przybliżenie C składa się ze wszystkich krotek, których w oparciu o znajomość atrybutów nie można opisać jako nienależących do C.
Poniższy diagram przedstawia przybliżenie górne i dolne klasy C -

Podejścia do zbioru rozmytego
Teoria zbiorów rozmytych jest również nazywana teorią możliwości. Teoria ta została zaproponowana przez Lotfi Zadeh w 1965 roku jako alternatywa dlatwo-value logic i probability theory. Ta teoria pozwala nam pracować na wysokim poziomie abstrakcji. Zapewnia nam również środki do radzenia sobie z nieprecyzyjnymi pomiarami danych.
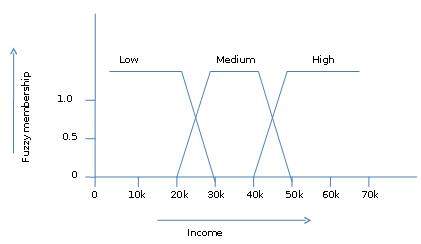
Teoria zbiorów rozmytych pozwala nam również radzić sobie z niejasnymi lub niedokładnymi faktami. Na przykład przynależność do zbioru o wysokich dochodach jest dokładna (np$50,000 is high then what about $49 000 i 48 000 USD). W przeciwieństwie do tradycyjnego zbioru CRISP, w którym element należy do S lub jego uzupełnienia, ale w teorii zbiorów rozmytych element może należeć do więcej niż jednego zbioru rozmytego.
Na przykład wartość dochodu 49 000 USD należy do średnich i dużych zbiorów rozmytych, ale w różnym stopniu. Rozmyty zapis zbioru dla tej wartości dochodu jest następujący -
mmedium_income($49k)=0.15 and mhigh_income($49k)=0.96gdzie „m” jest funkcją przynależności, która operuje na rozmytych zbiorach odpowiednio medium_income i high_income. Ten zapis można przedstawić schematycznie w następujący sposób -
Klaster to grupa obiektów należących do tej samej klasy. Innymi słowy, podobne obiekty są zgrupowane w jednym klastrze, a niepodobne obiekty są zgrupowane w innym klastrze.
Co to jest klastrowanie?
Klastrowanie to proces tworzenia grupy abstrakcyjnych obiektów w klasy podobnych obiektów.
Points to Remember
Klaster obiektów danych można traktować jako jedną grupę.
Podczas analizy skupień najpierw dzielimy zestaw danych na grupy na podstawie podobieństwa danych, a następnie przypisujemy etykiety do grup.
Główną zaletą łączenia w klastry nad klasyfikacją jest to, że można go dostosować do zmian i pomóc w wyodrębnieniu przydatnych cech, które odróżniają różne grupy.
Zastosowania analizy skupień
Analiza skupień jest szeroko stosowana w wielu zastosowaniach, takich jak badania rynku, rozpoznawanie wzorców, analiza danych i przetwarzanie obrazu.
Tworzenie klastrów może również pomóc marketerom odkryć odrębne grupy w ich bazie klientów. Mogą scharakteryzować swoje grupy klientów na podstawie wzorców zakupowych.
W dziedzinie biologii można go wykorzystać do wyprowadzenia taksonomii roślin i zwierząt, kategoryzacji genów o podobnych funkcjach i uzyskania wglądu w struktury właściwe dla populacji.
Tworzenie klastrów pomaga również w identyfikacji obszarów o podobnym użytkowaniu gruntów w bazie danych obserwacji Ziemi. Pomaga również w identyfikacji grup domów w mieście według typu domu, wartości i położenia geograficznego.
Klastrowanie pomaga również w klasyfikowaniu dokumentów w sieci WWW w celu wyszukiwania informacji.
Grupowanie jest również wykorzystywane w aplikacjach do wykrywania wartości odstających, takich jak wykrywanie oszustw związanych z kartami kredytowymi.
Jako funkcja eksploracji danych analiza skupień służy jako narzędzie do uzyskania wglądu w dystrybucję danych w celu obserwacji cech każdego klastra.
Wymagania klastrowania w eksploracji danych
Poniższe punkty rzucają światło na to, dlaczego klastrowanie jest wymagane w eksploracji danych -
Scalability - Potrzebujemy wysoce skalowalnych algorytmów klastrowania, aby radzić sobie z dużymi bazami danych.
Ability to deal with different kinds of attributes - Algorytmy powinny mieć możliwość zastosowania do dowolnego rodzaju danych, takich jak dane oparte na przedziałach (numeryczne), dane jakościowe i binarne.
Discovery of clusters with attribute shape- Algorytm grupowania powinien być zdolny do wykrywania skupień o dowolnym kształcie. Nie powinny być ograniczone jedynie do miar odległości, które mają tendencję do znajdowania sferycznych skupisk o małych rozmiarach.
High dimensionality - Algorytm grupowania powinien być w stanie obsłużyć nie tylko dane niskowymiarowe, ale także przestrzeń wielowymiarową.
Ability to deal with noisy data- Bazy danych zawierają zaszumione, brakujące lub błędne dane. Niektóre algorytmy są wrażliwe na takie dane i mogą prowadzić do niskiej jakości klastrów.
Interpretability - Wyniki grupowania powinny być możliwe do interpretacji, zrozumiałe i użyteczne.
Metody grupowania
Metody grupowania można podzielić na następujące kategorie -
- Metoda partycjonowania
- Metoda hierarchiczna
- Metoda oparta na gęstości
- Metoda siatkowa
- Metoda oparta na modelu
- Metoda oparta na ograniczeniach
Metoda partycjonowania
Załóżmy, że mamy bazę danych „n” obiektów, a metoda partycjonowania tworzy partycję „k” danych. Każda partycja będzie reprezentować klaster i k ≤ n. Oznacza to, że sklasyfikuje dane na k grup, które spełniają następujące wymagania -
Każda grupa zawiera co najmniej jeden obiekt.
Każdy obiekt musi należeć do dokładnie jednej grupy.
Points to remember −
Dla danej liczby partycji (powiedzmy k) metoda partycjonowania utworzy początkowe partycjonowanie.
Następnie wykorzystuje iteracyjną technikę relokacji, aby ulepszyć partycjonowanie poprzez przenoszenie obiektów z jednej grupy do drugiej.
Metody hierarchiczne
Ta metoda tworzy hierarchiczną dekompozycję danego zestawu obiektów danych. Możemy sklasyfikować metody hierarchiczne na podstawie tego, jak powstaje hierarchiczna dekompozycja. Istnieją dwa podejścia -
- Podejście aglomeracyjne
- Podejście dzielące
Podejście aglomeracyjne
Podejście to jest również znane jako podejście oddolne. W tym miejscu zaczynamy od tego, że każdy obiekt tworzy oddzielną grupę. Ciągle łączy obiekty lub grupy, które są blisko siebie. Robi to tak długo, aż wszystkie grupy zostaną połączone w jedną lub do momentu spełnienia warunku zakończenia.
Podejście dzielące
To podejście jest również znane jako podejście odgórne. W tym miejscu zaczynamy od wszystkich obiektów w tym samym klastrze. W ciągłej iteracji klaster jest dzielony na mniejsze klastry. Jest wyłączony, dopóki każdy obiekt w jednym klastrze lub warunek zakończenia nie zostanie spełniony. Ta metoda jest sztywna, tj. Po zakończeniu scalania lub dzielenia nie można go nigdy cofnąć.
Podejścia do poprawy jakości hierarchicznego grupowania
Oto dwa podejścia stosowane w celu poprawy jakości hierarchicznego grupowania:
Przeprowadź dokładną analizę powiązań obiektów na każdym hierarchicznym partycjonowaniu.
Zintegruj hierarchiczną aglomerację, najpierw używając hierarchicznego algorytmu aglomeracyjnego do grupowania obiektów w mikro-klastry, a następnie wykonując makro-klastry na mikro-klastrach.
Metoda oparta na gęstości
Ta metoda opiera się na pojęciu gęstości. Podstawową ideą jest kontynuowanie wzrostu danego klastra tak długo, jak długo gęstość w sąsiedztwie przekroczy pewien próg, tj. Dla każdego punktu danych w obrębie danego klastra promień danego klastra musi zawierać co najmniej minimalną liczbę punktów.
Metoda oparta na siatce
W tym przypadku obiekty razem tworzą siatkę. Przestrzeń obiektów jest kwantowana do skończonej liczby komórek, które tworzą strukturę siatki.
Advantages
Główną zaletą tej metody jest szybki czas przetwarzania.
Zależy to tylko od liczby komórek w każdym wymiarze w kwantowanej przestrzeni.
Metody oparte na modelach
W tej metodzie zakłada się hipotezę modelu dla każdego klastra, aby znaleźć najlepsze dopasowanie danych do danego modelu. Ta metoda lokalizuje klastry poprzez grupowanie funkcji gęstości. Odzwierciedla rozkład przestrzenny punktów danych.
Ta metoda zapewnia również sposób automatycznego określania liczby klastrów na podstawie standardowych statystyk, z uwzględnieniem wartości odstających lub szumu. W związku z tym zapewnia solidne metody grupowania.
Metoda oparta na ograniczeniach
W tej metodzie grupowanie jest wykonywane przez wprowadzenie ograniczeń zorientowanych na użytkownika lub aplikację. Ograniczenie odnosi się do oczekiwań użytkownika lub właściwości pożądanych wyników grupowania. Ograniczenia zapewniają nam interaktywny sposób komunikacji z procesem klastrowania. Ograniczenia mogą być określane przez użytkownika lub wymagania aplikacji.
Bazy tekstowe zawierają ogromne zbiory dokumentów. Gromadzą te informacje z kilku źródeł, takich jak artykuły informacyjne, książki, biblioteki cyfrowe, wiadomości e-mail, strony internetowe itp. W związku ze wzrostem ilości informacji tekstowe bazy danych szybko się rozrastają. W wielu bazach danych tekstowych dane są częściowo ustrukturyzowane.
Na przykład dokument może zawierać kilka pól ustrukturyzowanych, takich jak tytuł, autor, data_publikowania itp. Jednak wraz z danymi strukturalnymi dokument zawiera również niestrukturalne składniki tekstowe, takie jak streszczenie i treść. Nie wiedząc, co może znajdować się w dokumentach, trudno jest sformułować skuteczne zapytania do analizy i wydobywania przydatnych informacji z danych. Użytkownicy potrzebują narzędzi do porównywania dokumentów i oceniania ich ważności i trafności. Dlatego eksploracja tekstu stała się popularna i istotnym tematem w eksploracji danych.
Wyszukiwanie informacji
Wyszukiwanie informacji zajmuje się wyszukiwaniem informacji z dużej liczby dokumentów tekstowych. Niektóre systemy baz danych zwykle nie występują w systemach wyszukiwania informacji, ponieważ oba obsługują różne rodzaje danych. Przykłady systemu wyszukiwania informacji obejmują -
- System katalogów bibliotecznych online
- Systemy zarządzania dokumentami online
- Systemy wyszukiwania internetowego itp.
Note- Głównym problemem w systemie wyszukiwania informacji jest zlokalizowanie odpowiednich dokumentów w zbiorze dokumentów na podstawie zapytania użytkownika. Tego rodzaju zapytanie użytkownika składa się z kilku słów kluczowych opisujących potrzebę informacyjną.
W przypadku takich problemów z wyszukiwaniem użytkownik przejmuje inicjatywę, aby wyciągnąć odpowiednie informacje ze zbioru. Jest to właściwe, gdy użytkownik ma doraźną potrzebę informacyjną, tj. Potrzebę krótkoterminową. Ale jeśli użytkownik ma długoterminowe zapotrzebowanie na informacje, wówczas system wyszukiwania może również przejąć inicjatywę, aby przekazać użytkownikowi nowo otrzymaną informację.
Ten rodzaj dostępu do informacji nazywa się filtrowaniem informacji. Odpowiednie systemy są znane jako systemy filtrujące lub systemy rekomendujące.
Podstawowe pomiary wyszukiwania tekstu
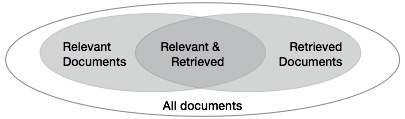
Musimy sprawdzić poprawność systemu, gdy pobiera szereg dokumentów na podstawie danych wejściowych użytkownika. Niech zbiór dokumentów związanych z zapytaniem będzie oznaczony jako {Relevant}, a zbiór pobranych dokumentów jako {Retrieved}. Zbiór dokumentów, które są istotne i pobrane, można oznaczyć jako {Relevant} ∩ {Retrieved}. Można to przedstawić w postaci diagramu Venna w następujący sposób -
Istnieją trzy podstawowe miary oceny jakości wyszukiwania tekstu -
- Precision
- Recall
- F-score
Precyzja
Precyzja to odsetek pobranych dokumentów, które są w rzeczywistości istotne dla zapytania. Precyzja może być zdefiniowana jako -
Precision= |{Relevant} ∩ {Retrieved}| / |{Retrieved}|Odwołanie
Odwołaj to procent dokumentów, które są istotne dla zapytania i zostały faktycznie pobrane. Wycofanie definiuje się jako -
Recall = |{Relevant} ∩ {Retrieved}| / |{Relevant}|Wynik F.
Wynik F to powszechnie stosowany kompromis. System wyszukiwania informacji często wymaga kompromisu dla precyzji lub odwrotnie. Wynik F jest definiowany jako średnia harmoniczna przypomnienia lub precyzji w następujący sposób -
F-score = recall x precision / (recall + precision) / 2Sieć WWW zawiera ogromne ilości informacji, które stanowią bogate źródło do eksploracji danych.
Wyzwania w Web Mining
Sieć stwarza wielkie wyzwania w zakresie odkrywania zasobów i wiedzy na podstawie następujących obserwacji:
The web is too huge- Rozmiar sieci jest bardzo duży i szybko rośnie. Wygląda na to, że sieć jest zbyt rozległa, aby można było przechowywać dane i eksplorować dane.
Complexity of Web pages- Strony internetowe nie mają ujednolicającej struktury. Są bardzo złożone w porównaniu z tradycyjnym dokumentem tekstowym. W cyfrowej bibliotece sieci znajduje się ogromna ilość dokumentów. Te biblioteki nie są uporządkowane według żadnej określonej kolejności sortowania.
Web is dynamic information source- Informacje w sieci są szybko aktualizowane. Dane, takie jak wiadomości, giełdy, pogoda, sport, zakupy itp. Są regularnie aktualizowane.
Diversity of user communities- Społeczność użytkowników w sieci szybko się rozwija. Ci użytkownicy mają różne pochodzenie, zainteresowania i cele użytkowania. Istnieje ponad 100 milionów stacji roboczych podłączonych do Internetu i wciąż szybko rośnie.
Relevancy of Information - Uważa się, że dana osoba jest na ogół zainteresowana tylko niewielką częścią sieci, podczas gdy pozostała część sieci zawiera informacje, które nie są istotne dla użytkownika i mogą spowodować utratę pożądanych wyników.
Struktura układu strony WWW wyszukiwania
Podstawowa struktura strony internetowej oparta jest na modelu Document Object Model (DOM). Struktura DOM odnosi się do struktury podobnej do drzewa, w której znacznik HTML na stronie odpowiada węzłowi w drzewie DOM. Możemy posegmentować stronę internetową za pomocą predefiniowanych tagów w HTML. Składnia HTML jest elastyczna, dlatego strony internetowe nie są zgodne ze specyfikacjami W3C. Nieprzestrzeganie specyfikacji W3C może spowodować błąd w strukturze drzewa DOM.
Struktura DOM została początkowo wprowadzona do prezentacji w przeglądarce, a nie do opisu semantycznej struktury strony internetowej. Struktura DOM nie może poprawnie zidentyfikować relacji semantycznej między różnymi częściami strony internetowej.
Segmentacja stron oparta na wizji (VIPS)
Celem VIPS jest wyodrębnienie struktury semantycznej strony internetowej na podstawie jej wizualnej prezentacji.
Taka struktura semantyczna odpowiada strukturze drzewa. W tym drzewie każdy węzeł odpowiada blokowi.
Do każdego węzła przypisywana jest wartość. Ta wartość nazywa się stopniem spójności. Ta wartość jest przypisywana, aby wskazać spójną zawartość w bloku na podstawie percepcji wizualnej.
Algorytm VIPS najpierw wyodrębnia wszystkie odpowiednie bloki z drzewa HTML DOM. Następnie znajduje separatory między tymi blokami.
Separatory odnoszą się do poziomych lub pionowych linii na stronie internetowej, które wizualnie przecinają się bez bloków.
Na podstawie tych bloków konstruowana jest semantyka strony internetowej.
Poniższy rysunek przedstawia procedurę algorytmu VIPS -

Eksploracja danych jest szeroko stosowana w różnych obszarach. Obecnie dostępnych jest wiele komercyjnych systemów eksploracji danych, a jednak istnieje wiele wyzwań w tej dziedzinie. W tym samouczku omówimy aplikacje i trendy w eksploracji danych.
Aplikacje Data Mining
Oto lista obszarów, w których eksploracja danych jest szeroko stosowana -
- Analiza danych finansowych
- Branży detalicznej
- Przemysł telekomunikacyjny
- Analiza danych biologicznych
- Inne zastosowania naukowe
- Wykrywanie wtargnięcia
Analiza danych finansowych
Dane finansowe w branży bankowej i finansowej są generalnie wiarygodne i wysokiej jakości, co ułatwia ich systematyczną analizę i eksplorację. Oto niektóre z typowych przypadków -
Projektowanie i budowa hurtowni danych do wielowymiarowej analizy danych i eksploracji danych.
Przewidywanie spłaty kredytu i analiza polityki kredytowej klientów.
Klasyfikacja i grupowanie klientów na potrzeby marketingu ukierunkowanego.
Wykrywanie prania pieniędzy i innych przestępstw finansowych.
Branży detalicznej
Data Mining ma świetne zastosowanie w handlu detalicznym, ponieważ gromadzi duże ilości danych dotyczących sprzedaży, historii zakupów klientów, transportu towarów, konsumpcji i usług. Jest naturalne, że ilość gromadzonych danych będzie nadal szybko rosła ze względu na rosnącą łatwość, dostępność i popularność sieci.
Eksploracja danych w handlu detalicznym pomaga w identyfikacji wzorców i trendów zakupowych klientów, które prowadzą do poprawy jakości obsługi klienta oraz dobrego utrzymania i satysfakcji klienta. Oto lista przykładów eksploracji danych w branży detalicznej -
Projektowanie i budowa hurtowni danych w oparciu o korzyści płynące z eksploracji danych.
Wielowymiarowa analiza sprzedaży, klientów, produktów, czasu i regionu.
Analiza efektywności kampanii sprzedażowych.
Utrzymanie klienta.
Rekomendacja produktu i porównanie pozycji.
Przemysł telekomunikacyjny
Obecnie branża telekomunikacyjna jest jedną z najbardziej rozwijających się gałęzi przemysłu, oferującą różne usługi, takie jak faks, pager, telefon komórkowy, komunikator internetowy, obrazy, poczta e-mail, transmisja danych internetowych itp. Ze względu na rozwój nowych technologii komputerowych i komunikacyjnych, przemysł telekomunikacyjny szybko się rozwija. To jest powód, dla którego eksploracja danych stała się bardzo ważna, aby pomóc i zrozumieć biznes.
Eksploracja danych w branży telekomunikacyjnej pomaga w identyfikacji wzorców telekomunikacyjnych, wyłapaniu oszukańczych działań, lepszym wykorzystaniu zasobów i poprawie jakości usług. Oto lista przykładów, dla których eksploracja danych usprawnia usługi telekomunikacyjne -
Wielowymiarowa analiza danych telekomunikacyjnych.
Nieuczciwa analiza wzorców.
Identyfikacja nietypowych wzorów.
Wielowymiarowa analiza asocjacyjna i sekwencyjna.
Usługi telefonii komórkowej.
Wykorzystanie narzędzi wizualizacyjnych w analizie danych telekomunikacyjnych.
Analiza danych biologicznych
W ostatnim czasie zaobserwowaliśmy ogromny rozwój w dziedzinie biologii, takiej jak genomika, proteomika, genomika funkcjonalna i badania biomedyczne. Eksploracja danych biologicznych jest bardzo ważną częścią bioinformatyki. Poniżej przedstawiono aspekty, w których eksploracja danych przyczynia się do analizy danych biologicznych -
Integracja semantyczna heterogenicznych, rozproszonych genomicznych i proteomicznych baz danych.
Dopasowanie, indeksowanie, wyszukiwanie podobieństw i analiza porównawcza wielu sekwencji nukleotydowych.
Odkrycie wzorców strukturalnych i analiza sieci genetycznych i szlaków białkowych.
Analiza skojarzeń i ścieżek.
Narzędzia wizualizacyjne w analizie danych genetycznych.
Inne zastosowania naukowe
Aplikacje omówione powyżej mają tendencję do obsługi stosunkowo małych i jednorodnych zbiorów danych, dla których odpowiednie są techniki statystyczne. Ogromna ilość danych została zebrana z dziedzin naukowych, takich jak nauki o Ziemi, astronomia itp. Duża ilość zbiorów danych jest generowana z powodu szybkich symulacji numerycznych w różnych dziedzinach, takich jak modelowanie klimatu i ekosystemów, inżynieria chemiczna, dynamika płynów itp. . Poniżej przedstawiono zastosowania eksploracji danych w dziedzinie zastosowań naukowych -
- Hurtownie danych i wstępne przetwarzanie danych.
- Eksploracja oparta na grafach.
- Wizualizacja i wiedza dziedzinowa.
Wykrywanie wtargnięcia
Włamanie odnosi się do wszelkiego rodzaju działań, które zagrażają integralności, poufności lub dostępności zasobów sieciowych. W tym świecie łączności bezpieczeństwo stało się głównym problemem. Zwiększone wykorzystanie Internetu oraz dostępność narzędzi i sztuczek do włamań i ataków spowodowały, że wykrywanie włamań stało się krytycznym elementem administracji sieci. Oto lista obszarów, w których można zastosować technologię eksploracji danych do wykrywania włamań -
Opracowanie algorytmu eksploracji danych do wykrywania włamań.
Analiza asocjacji i korelacji, agregacja pomagająca wybrać i zbudować rozróżniające atrybuty.
Analiza danych Stream.
Rozproszone eksploracja danych.
Narzędzia do wizualizacji i zapytań.
Produkty systemu wyszukiwania danych
Istnieje wiele produktów związanych z systemami eksploracji danych i aplikacji do eksploracji danych specyficznych dla domeny. Nowe systemy i aplikacje eksploracji danych są dodawane do poprzednich systemów. Podejmowane są również wysiłki w celu standaryzacji języków eksploracji danych.
Wybór systemu eksploracji danych
Wybór systemu eksploracji danych zależy od następujących funkcji -
Data Types- System eksploracji danych może obsługiwać sformatowany tekst, dane oparte na rekordach i dane relacyjne. Dane mogą być również w postaci tekstu ASCII, danych z relacyjnej bazy danych lub danych z hurtowni danych. Dlatego powinniśmy sprawdzić, jaki dokładny format obsługuje system data mining.
System Issues- Musimy wziąć pod uwagę kompatybilność systemu eksploracji danych z różnymi systemami operacyjnymi. Jeden system eksploracji danych może działać tylko na jednym systemie operacyjnym lub na kilku. Istnieją również systemy eksploracji danych, które zapewniają interfejsy użytkownika oparte na sieci Web i umożliwiają wprowadzanie danych XML.
Data Sources- Źródła danych odnoszą się do formatów danych, w których będzie działał system eksploracji danych. Niektóre systemy eksploracji danych mogą działać tylko na plikach tekstowych ASCII, podczas gdy inne na wielu źródłach relacyjnych. System eksploracji danych powinien również obsługiwać połączenia ODBC lub OLE DB dla połączeń ODBC.
Data Mining functions and methodologies - Istnieją systemy eksploracji danych, które zapewniają tylko jedną funkcję eksploracji danych, taką jak klasyfikacja, podczas gdy niektóre zapewniają wiele funkcji eksploracji danych, takich jak opis koncepcji, analiza OLAP oparta na odkryciach, eksploracja skojarzeń, analiza powiązań, analiza statystyczna, klasyfikacja, przewidywanie, grupowanie, analiza wartości odstających, wyszukiwanie podobieństw itp.
Coupling data mining with databases or data warehouse systems- Systemy Data Mining muszą być połączone z bazą danych lub systemem hurtowni danych. Połączone komponenty są zintegrowane w jednolite środowisko przetwarzania informacji. Oto typy sprzęgieł wymienione poniżej -
- Bez sprzężenia
- Luźne powiązanie
- Złącze półciskowe
- Ciasne połączenie
Scalability - W eksploracji danych występują dwa problemy ze skalowalnością -
Row (Database size) Scalability- System eksploracji danych jest uważany za skalowalny wierszami, gdy liczba lub wiersze są powiększane 10 razy. Wykonanie zapytania nie zajmuje więcej niż 10 razy.
Column (Dimension) Salability - System eksploracji danych jest uważany za skalowalny kolumnowo, jeśli czas wykonywania zapytania eksploracyjnego zwiększa się liniowo wraz z liczbą kolumn.
Visualization Tools - Wizualizację w eksploracji danych można podzielić na następujące kategorie -
- Wizualizacja danych
- Wizualizacja wyników wydobycia
- Wizualizacja procesu wydobywczego
- Wizualna eksploracja danych
Data Mining query language and graphical user interface- Łatwy w użyciu graficzny interfejs użytkownika jest ważny dla promowania interaktywnej eksploracji danych prowadzonej przez użytkownika. W przeciwieństwie do systemów relacyjnych baz danych, systemy eksploracji danych nie współużytkują bazowego języka zapytań eksploracji danych.
Trendy w eksploracji danych
Koncepcje eksploracji danych wciąż ewoluują, a oto najnowsze trendy, które widzimy w tej dziedzinie -
Eksploracja aplikacji.
Skalowalne i interaktywne metody eksploracji danych.
Integracja data mining z systemami baz danych, systemami hurtowni danych i systemami baz danych webowych.
S Standaryzacja języka zapytań eksploracji danych.
Wizualna eksploracja danych.
Nowe metody eksploracji złożonych typów danych.
Eksploracja danych biologicznych.
Eksploracja danych i inżynieria oprogramowania.
Eksploracja sieci.
Rozproszone eksploracja danych.
Eksploracja danych w czasie rzeczywistym.
Eksploracja danych z wielu baz danych.
Ochrona prywatności i bezpieczeństwo informacji w eksploracji danych.
Teoretyczne podstawy eksploracji danych
Teoretyczne podstawy eksploracji danych obejmują następujące pojęcia -
Data Reduction- Podstawową ideą tej teorii jest zmniejszenie reprezentacji danych, która zamienia dokładność na szybkość w odpowiedzi na potrzebę uzyskania szybkich przybliżonych odpowiedzi na zapytania w bardzo dużych bazach danych. Niektóre techniki redukcji danych są następujące:
Rozkład według wartości osobliwych
Wavelets
Regression
Modele liniowo-logarytmiczne
Histograms
Clustering
Sampling
Budowa drzew indeksowych
Data Compression - Podstawową ideą tej teorii jest kompresja danych poprzez kodowanie w następujący sposób -
Bits
Zasady stowarzyszenia
Drzewa decyzyjne
Clusters
Pattern Discovery- Podstawową ideą tej teorii jest odkrycie wzorców występujących w bazie danych. Oto obszary, które składają się na tę teorię -
Nauczanie maszynowe
Sieć neuronowa
Stowarzyszenie Górnictwo
Sekwencyjne dopasowywanie wzorców
Clustering
Probability Theory- Ta teoria jest oparta na teorii statystycznej. Podstawową ideą tej teorii jest odkrycie wspólnych rozkładów prawdopodobieństwa zmiennych losowych.
Probability Theory - Zgodnie z tą teorią eksploracja danych znajduje wzorce, które są interesujące tylko na tyle, na ile można je wykorzystać w procesie decyzyjnym jakiegoś przedsiębiorstwa.
Microeconomic View- Zgodnie z tą teorią schemat bazy danych składa się z danych i wzorców przechowywanych w bazie danych. Dlatego eksploracja danych jest zadaniem przeprowadzania indukcji w bazach danych.
Inductive databases- Oprócz technik zorientowanych na bazy danych dostępne są techniki statystyczne do analizy danych. Techniki te można również zastosować do danych naukowych i danych z nauk ekonomicznych i społecznych.
Eksploracja danych statystycznych
Niektóre z technik wyszukiwania danych statystycznych są następujące:
Regression- Metody regresji są używane do przewidywania wartości zmiennej odpowiedzi na podstawie co najmniej jednej zmiennej predykcyjnej, gdzie zmienne są numeryczne. Poniżej wymienione są formy regresji -
Linear
Multiple
Weighted
Polynomial
Nonparametric
Robust
Generalized Linear Models - Uogólniony model liniowy obejmuje -
Regresja logistyczna
Regresja Poissona
Uogólnienie modelu umożliwia powiązanie jakościowej zmiennej odpowiedzi ze zbiorem predyktorów w sposób podobny do modelowania numerycznej zmiennej odpowiedzi za pomocą regresji liniowej.
Analysis of Variance - Ta technika analizuje -
Dane eksperymentalne dla dwóch lub więcej populacji opisanych liczbową zmienną odpowiedzi.
Jedna lub więcej zmiennych kategorialnych (czynników).
Mixed-effect Models- Te modele są używane do analizy danych zgrupowanych. Modele te opisują związek między zmienną odpowiedzi a pewnymi współzmiennymi w danych pogrupowanych według jednego lub większej liczby czynników.
Factor Analysis- Analiza czynnikowa służy do przewidywania jakościowej zmiennej odpowiedzi. Ta metoda zakłada, że zmienne niezależne mają wielowymiarowy rozkład normalny.
Time Series Analysis - Poniżej przedstawiono metody analizy danych szeregów czasowych -
Metody autoregresji.
Jednowymiarowe modelowanie ARIMA (AutoRegressive Integrated Moving Average).
Modelowanie szeregów czasowych z długą pamięcią.
Wizualne wyszukiwanie danych
Visual Data Mining wykorzystuje techniki wizualizacji danych i / lub wiedzy do wykrywania ukrytej wiedzy z dużych zbiorów danych. Wizualną eksplorację danych można postrzegać jako integrację następujących dyscyplin -
Wizualizacja danych
Eksploracja danych
Wizualna eksploracja danych jest ściśle związana z następującymi -
Grafika komputerowa
Systemy multimedialne
Interakcja człowiek-komputer
Rozpoznawanie wzorców
Obliczenia o wysokiej wydajności
Generalnie wizualizację danych i eksplorację danych można zintegrować na następujące sposoby -
Data Visualization - Dane w bazie danych lub hurtowni danych można przeglądać w kilku wizualnych formach, które są wymienione poniżej -
Boxplots
Kostki 3-D
Wykresy dystrybucji danych
Curves
Surfaces
Wykresy linków itp.
Data Mining Result Visualization- Wizualizacja wyników eksploracji danych to prezentacja wyników eksploracji danych w formie wizualnej. Te wizualne formy mogą być rozproszonymi wykresami, wykresami pudełkowymi itp.
Data Mining Process Visualization- Wizualizacja procesu eksploracji danych przedstawia kilka procesów eksploracji danych. Pozwala użytkownikom zobaczyć, w jaki sposób dane są wydobywane. Pozwala również użytkownikom zobaczyć, z jakiej bazy danych lub hurtowni danych dane są czyszczone, integrowane, wstępnie przetwarzane i wydobywane.
Eksploracja danych audio
Eksploracja danych audio wykorzystuje sygnały audio do wskazania wzorców danych lub cech wyników eksploracji danych. Przekształcając wzory w dźwięki i zadumy, możemy słuchać wysokości i melodii zamiast oglądać obrazy, aby zidentyfikować coś interesującego.
Eksploracja danych i wspólne filtrowanie
W dzisiejszych czasach konsumenci podczas zakupów napotykają na różnorodne towary i usługi. Podczas transakcji z klientami na żywo, System Polecający pomaga konsumentowi poprzez rekomendacje produktów. Podejście oparte na filtrowaniu opartym na współpracy jest zwykle używane do polecania produktów klientom. Te rekomendacje są oparte na opiniach innych klientów.