XML DOM - szybki przewodnik
Plik Document Object Model (DOM) to standard W3C. Definiuje standard dostępu do dokumentów, takich jak HTML i XML.
Definicja DOM według W3C to -
Document Object Model (DOM) to interfejs programowania aplikacji (API) dla dokumentów HTML i XML. Definiuje logiczną strukturę dokumentów oraz sposób uzyskiwania dostępu do dokumentu i manipulowania nim.
DOM definiuje obiekty i właściwości oraz metody (interfejs) umożliwiające dostęp do wszystkich elementów XML. Jest podzielony na 3 różne części / poziomy -
Core DOM - standardowy model dla dowolnego dokumentu strukturalnego
XML DOM - standardowy model dokumentów XML
HTML DOM - standardowy model dokumentów HTML
XML DOM to standardowy model obiektowy dla XML. Dokumenty XML mają hierarchię jednostek informacyjnych zwanych węzłami ; DOM jest standardowym interfejsem programistycznym opisującym te węzły i relacje między nimi.
Ponieważ XML DOM zapewnia również interfejs API, który umożliwia programistom dodawanie, edytowanie, przenoszenie lub usuwanie węzłów w dowolnym punkcie drzewa w celu utworzenia aplikacji.
Poniżej znajduje się diagram struktury DOM. Diagram przedstawia, że parser ocenia dokument XML jako strukturę DOM, przechodząc przez każdy węzeł.
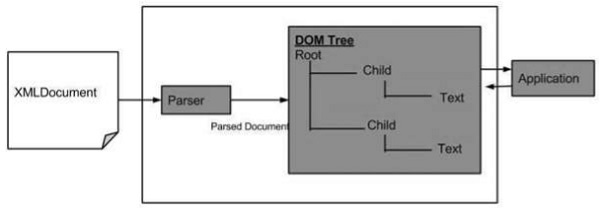
Zalety XML DOM
Oto zalety XML DOM.
XML DOM jest niezależny od języka i platformy.
XML DOM jest traversable - Informacje w XML DOM są zorganizowane w hierarchię, która umożliwia programiście poruszanie się po hierarchii w poszukiwaniu określonych informacji.
XML DOM jest modifiable - Ma charakter dynamiczny, zapewniając programiście możliwość dodawania, edytowania, przenoszenia lub usuwania węzłów w dowolnym punkcie drzewa.
Wady XML DOM
Zużywa więcej pamięci (jeśli struktura XML jest duża), ponieważ raz napisany program pozostaje w pamięci przez cały czas, dopóki nie zostanie jawnie usunięty.
Ze względu na duże wykorzystanie pamięci, jej prędkość operacyjna w porównaniu do SAX jest wolniejsza.
Teraz, gdy wiemy, co oznacza DOM, zobaczmy, czym jest struktura DOM. Dokument DOM to zbiór węzłów lub fragmentów informacji zorganizowanych w hierarchię. Niektóre typy węzłów mogą mieć węzły potomne różnych typów, a inne są węzłami-liśćmi, które nie mogą mieć nic pod sobą w strukturze dokumentu. Poniżej znajduje się lista typów węzłów wraz z listą typów węzłów, które mogą mieć jako dzieci -
Document - Element (maksymalnie jeden), ProcessingInstrukcja, Komentarz, Typ dokumentu (maksymalnie jeden)
DocumentFragment - Element, ProcessingInstrukcja, Komentarz, Tekst, CDATASection, EntityReference
EntityReference - Element, ProcessingInstrukcja, Komentarz, Tekst, CDATASection, EntityReference
Element - Element, tekst, komentarz, ProcessingInstruction, CDATASection, EntityReference
Attr - Text, EntityReference
ProcessingInstruction - Żadnych dzieci
Comment - Żadnych dzieci
Text - Żadnych dzieci
CDATASection - Żadnych dzieci
Entity - Element, ProcessingInstrukcja, Komentarz, Tekst, CDATASection, EntityReference
Notation - Żadnych dzieci
Przykład
Rozważmy reprezentację DOM następującego dokumentu XML node.xml.
<?xml version = "1.0"?>
<Company>
<Employee category = "technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
</Employee>
<Employee category = "non-technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
</Employee>
</Company>Model obiektu dokumentu powyższego dokumentu XML wyglądałby następująco -

Z powyższego schematu możemy wywnioskować -
Węzeł obiekt może mieć tylko jeden rodzic węzła obiektu. Zajmuje to pozycję ponad wszystkimi węzłami. Oto Firma .
Węzeł nadrzędny może mieć wiele węzłów nazwał dziecko węzły. Te węzły potomne mogą mieć dodatkowe węzły zwane węzłami atrybutów . W powyższym przykładzie mamy dwa węzły atrybutów: Techniczny i Nietechniczny . Atrybut węzeł nie jest w rzeczywistości dzieckiem węzła elementu, ale nadal jest z nim związane.
Te węzły podrzędne z kolei mogą mieć wiele węzłów podrzędnych. Tekst w węzłach nazywany jest węzłem tekstowym .
Obiekty węzłów na tym samym poziomie nazywane są rodzeństwem.
DOM identyfikuje -
obiekty reprezentujące interfejs i manipulujące dokumentem.
relacje między obiektami i interfejsami.
W tym rozdziale zajmiemy się węzłami XML DOM . Każdy XML DOM zawiera informacje w hierarchicznych jednostkach zwanych węzłami, a DOM opisuje te węzły i relacje między nimi.
Typy węzłów
Poniższy schemat blokowy przedstawia wszystkie typy węzłów -
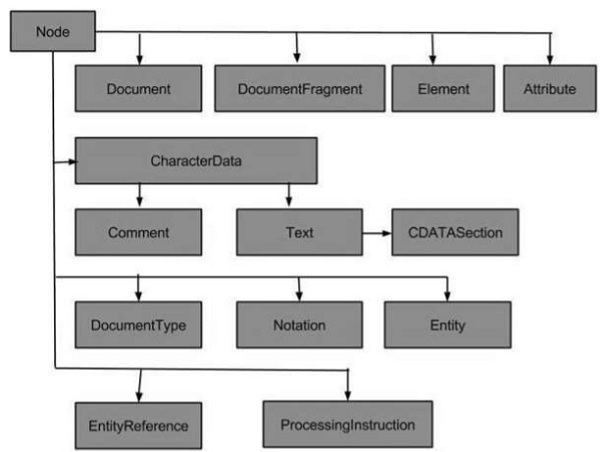
Najpopularniejsze typy węzłów w XML to -
Document Node- Pełna struktura dokumentu XML to węzeł dokumentu .
Element Node- Każdy element XML jest węzłem elementu . Jest to również jedyny typ węzła, który może mieć atrybuty.
Attribute Node- Każdy atrybut jest uważany za węzeł atrybutu . Zawiera informacje o węźle elementu, ale w rzeczywistości nie jest uważany za element podrzędny elementu.
Text Node- Teksty dokumentu są traktowane jako węzeł tekstowy . Może zawierać więcej informacji lub tylko odstępy.
Niektóre mniej popularne typy węzłów to -
CData Node- Ten węzeł zawiera informacje, które nie powinny być analizowane przez parser. Zamiast tego należy go po prostu przekazać jako zwykły tekst.
Comment Node - Ten węzeł zawiera informacje o danych i jest zwykle ignorowany przez aplikację.
Processing Instructions Node - Ten węzeł zawiera informacje przeznaczone specjalnie dla aplikacji.
Document Fragments Node
Entities Node
Entity reference nodes
Notations Node
W tym rozdziale zajmiemy się drzewem węzłów XML DOM . W dokumencie XML informacje są utrzymywane w strukturze hierarchicznej; ta hierarchiczna struktura jest nazywana drzewem węzłów . Ta hierarchia umożliwia programiście poruszanie się po drzewie w poszukiwaniu określonych informacji, dzięki czemu węzły mają dostęp. Zawartość tych węzłów można następnie zaktualizować.
Struktura drzewa węzłów zaczyna się od elementu głównego i rozciąga się na elementy potomne aż do najniższego poziomu.
Przykład
Poniższy przykład demonstruje prosty dokument XML, którego drzewo węzłów jest strukturą pokazaną na poniższym diagramie -
<?xml version = "1.0"?>
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
</Employee>
</Company>Jak widać na powyższym przykładzie, którego obrazowa reprezentacja (jego DOM) jest taka, jak pokazano poniżej -
Najwyższy węzeł drzewa to root. Plikrootwęzeł to <Firma>, który z kolei zawiera dwa węzły <Pracownik>. Te węzły są nazywane węzłami podrzędnymi.
Węzeł podrzędny <Employee> węzła głównego <Company>, z kolei składa się z własnego węzła podrzędnego (<FirstName>, <LastName>, <ContactNo>).
Dwa węzły podrzędne, <Pracownik>, mają wartości atrybutów Techniczne i Nietechniczne, nazywane są węzłami atrybutów .
Tekst w każdym węźle nazywany jest węzłem tekstowym .
XML DOM - Metody
DOM jako API zawiera interfejsy, które reprezentują różne typy informacji, które można znaleźć w dokumencie XML, takie jak elementy i tekst. Te interfejsy obejmują metody i właściwości niezbędne do pracy z tymi obiektami. Właściwości definiują charakterystykę węzła, podczas gdy metody umożliwiają manipulowanie węzłami.
Poniższa tabela zawiera listę klas DOM i interfejsów -
| S.No. | Interfejs i opis |
|---|---|
| 1 | DOMImplementation Udostępnia szereg metod wykonywania operacji, które są niezależne od poszczególnych instancji modelu obiektowego dokumentu. |
| 2 | DocumentFragment Jest to „lekki” lub „minimalny” obiekt dokumentu i (jako nadklasa dokumentu) zakotwicza drzewo XML / HTML w pełnoprawnym dokumencie. |
| 3 | Document Reprezentuje węzeł najwyższego poziomu dokumentu XML, który zapewnia dostęp do wszystkich węzłów w dokumencie, w tym do elementu głównego. |
| 4 | Node Reprezentuje węzeł XML. |
| 5 | NodeList Reprezentuje listę obiektów węzła tylko do odczytu . |
| 6 | NamedNodeMap Reprezentuje kolekcje węzłów, do których można uzyskać dostęp za pomocą nazwy. |
| 7 | Data Rozszerza Node o zestaw atrybutów i metod dostępu do danych znakowych w DOM. |
| 8 | Attribute Reprezentuje atrybut w obiekcie Element. |
| 9 | Element Reprezentuje węzeł elementu. Pochodzi z Node. |
| 10 | Text Reprezentuje węzeł tekstowy. Pochodzi z CharacterData. |
| 11 | Comment Reprezentuje węzeł komentarza. Pochodzi z CharacterData. |
| 12 | ProcessingInstruction Stanowi „instrukcję przetwarzania”. Jest używany w XML jako sposób na przechowywanie informacji specyficznych dla procesora w tekście dokumentu. |
| 13 | CDATA Section Reprezentuje sekcję CDATA. Pochodzi z tekstu. |
| 14 | Entity Reprezentuje jednostkę. Pochodzi z Node. |
| 15 | EntityReference To reprezentuje odniesienie do jednostki w drzewie. Pochodzi z Node. |
Będziemy omawiać metody i właściwości każdego z powyższych interfejsów w odpowiednich rozdziałach.
W tym rozdziale zajmiemy się ładowaniem i analizowaniem XML .
Aby opisać interfejsy dostarczane przez API, W3C używa abstrakcyjnego języka zwanego Interface Definition Language (IDL). Zaletą korzystania z IDL jest to, że programista uczy się korzystania z DOM ze swoim ulubionym językiem i może łatwo przełączyć się na inny język.
Wadą jest to, że ponieważ jest abstrakcyjny, IDL nie może być używany bezpośrednio przez programistów WWW. Ze względu na różnice między językami programowania muszą mieć mapowanie - lub powiązanie - między abstrakcyjnymi interfejsami a ich konkretnymi językami. DOM został odwzorowany na języki programowania, takie jak Javascript, JScript, Java, C, C ++, PLSQL, Python i Perl.
W następnych sekcjach i rozdziałach będziemy używać Javascript jako języka programowania do ładowania pliku XML.
Parser
Parser jest aplikacja, która służy do analizowania dokumentu, w naszym przypadku dokumentu XML i zrobić coś konkretnego z informacjami. Niektóre parsery oparte na DOM są wymienione w poniższej tabeli -
| S.Nr | Parser i opis |
|---|---|
| 1 | JAXP Sun Microsystem's Java API for XML Parsing (JAXP) |
| 2 | XML4J IBM Parser XML dla Java (XML4J) |
| 3 | msxml Parser XML firmy Microsoft (msxml) w wersji 2.0 jest wbudowany w Internet Explorer 5.5 |
| 4 | 4DOM 4DOM to parser dla języka programowania Python |
| 5 | XML::DOM XML :: DOM to moduł Perla do manipulowania dokumentami XML za pomocą Perla |
| 6 | Xerces Parser Java Xerces Apache |
W interfejsie API opartym na drzewie, takim jak DOM, parser przegląda plik XML i tworzy odpowiadające mu obiekty DOM. Następnie możesz przechodzić po strukturze DOM w tę iz powrotem.
Ładowanie i analizowanie XML
Podczas ładowania dokumentu XML zawartość XML może przybierać dwie formy -
- Bezpośrednio jako plik XML
- Jako ciąg XML
Treść jako plik XML
Poniższy przykład pokazuje, jak ładować dane XML ( node.xml ) przy użyciu Ajax i Javascript, gdy zawartość XML jest odbierana jako plik XML. Tutaj funkcja Ajax pobiera zawartość pliku xml i przechowuje ją w XML DOM. Po utworzeniu obiektu DOM jest on następnie analizowany.
<!DOCTYPE html>
<html>
<body>
<div>
<b>FirstName:</b> <span id = "FirstName"></span><br>
<b>LastName:</b> <span id = "LastName"></span><br>
<b>ContactNo:</b> <span id = "ContactNo"></span><br>
<b>Email:</b> <span id = "Email"></span>
</div>
<script>
//if browser supports XMLHttpRequest
if (window.XMLHttpRequest) { // Create an instance of XMLHttpRequest object.
code for IE7+, Firefox, Chrome, Opera, Safari xmlhttp = new XMLHttpRequest();
} else { // code for IE6, IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
// sets and sends the request for calling "node.xml"
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
// sets and returns the content as XML DOM
xmlDoc = xmlhttp.responseXML;
//parsing the DOM object
document.getElementById("FirstName").innerHTML =
xmlDoc.getElementsByTagName("FirstName")[0].childNodes[0].nodeValue;
document.getElementById("LastName").innerHTML =
xmlDoc.getElementsByTagName("LastName")[0].childNodes[0].nodeValue;
document.getElementById("ContactNo").innerHTML =
xmlDoc.getElementsByTagName("ContactNo")[0].childNodes[0].nodeValue;
document.getElementById("Email").innerHTML =
xmlDoc.getElementsByTagName("Email")[0].childNodes[0].nodeValue;
</script>
</body>
</html>node.xml
<Company>
<Employee category = "Technical" id = "firstelement">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>[email protected]</Email>
</Employee>
</Company>Większość szczegółów kodu znajduje się w kodzie skryptu.
Internet Explorer używa ActiveXObject („Microsoft.XMLHTTP”) do tworzenia instancji obiektu XMLHttpRequest, inne przeglądarki używają metody XMLHttpRequest () .
responseXML przekształca zawartość XML bezpośrednio w XML DOM.
Gdy zawartość XML zostanie przekształcona w JavaScript XML DOM, możesz uzyskać dostęp do dowolnego elementu XML za pomocą metod i właściwości JS DOM. Użyliśmy właściwości DOM takie jak childNodes , nodeValue i metod, takich jak getElementsById DOM (Id) getElementsByTagName (tags_name).
Wykonanie
Zapisz ten plik jako loadingexample.html i otwórz go w przeglądarce. Otrzymasz następujący wynik -

Treść jako ciąg XML
Poniższy przykład pokazuje, jak ładować dane XML za pomocą Ajax i Javascript, gdy zawartość XML jest odbierana jako plik XML. Tutaj funkcja Ajax pobiera zawartość pliku xml i przechowuje ją w XML DOM. Po utworzeniu obiektu DOM jest on następnie analizowany.
<!DOCTYPE html>
<html>
<head>
<script>
// loads the xml string in a dom object
function loadXMLString(t) { // for non IE browsers
if (window.DOMParser) {
// create an instance for xml dom object parser = new DOMParser();
xmlDoc = parser.parseFromString(t,"text/xml");
}
// code for IE
else { // create an instance for xml dom object
xmlDoc = new ActiveXObject("Microsoft.XMLDOM");
xmlDoc.async = false;
xmlDoc.loadXML(t);
}
return xmlDoc;
}
</script>
</head>
<body>
<script>
// a variable with the string
var text = "<Employee>";
text = text+"<FirstName>Tanmay</FirstName>";
text = text+"<LastName>Patil</LastName>";
text = text+"<ContactNo>1234567890</ContactNo>";
text = text+"<Email>[email protected]</Email>";
text = text+"</Employee>";
// calls the loadXMLString() with "text" function and store the xml dom in a variable
var xmlDoc = loadXMLString(text);
//parsing the DOM object
y = xmlDoc.documentElement.childNodes;
for (i = 0;i<y.length;i++) {
document.write(y[i].childNodes[0].nodeValue);
document.write("<br>");
}
</script>
</body>
</html>Większość szczegółów kodu znajduje się w kodzie skryptu.
Internet Explorer używa ActiveXObject („Microsoft.XMLDOM”) do ładowania danych XML do obiektu DOM, inne przeglądarki używają funkcji DOMParser () i metody parseFromString (text, 'text / xml') .
Zmienna tekst zawiera ciąg z zawartością XML.
Po przekształceniu treści XML w JavaScript XML DOM, można uzyskać dostęp do dowolnego elementu XML za pomocą metod i właściwości JS DOM. Użyliśmy właściwości DOM takie jak childNodes , nodeValue .
Wykonanie
Zapisz ten plik jako loadingexample.html i otwórz go w przeglądarce. Zobaczysz następujący wynik -

Teraz, gdy widzieliśmy, jak treść XML przekształca się w JavaScript XML DOM, możesz teraz uzyskać dostęp do dowolnego elementu XML za pomocą metod XML DOM.
W tym rozdziale omówimy przechodzenie przez XML DOM. W poprzednim rozdziale przestudiowaliśmy, jak załadować dokument XML i parsować otrzymany w ten sposób obiekt DOM. Przez ten przeanalizowany obiekt DOM można przejść. Przechodzenie to proces, w którym pętle są wykonywane w sposób systematyczny, poprzez przechodzenie przez każdy element krok po kroku w drzewie węzłów.
Przykład
Poniższy przykład (traverse_example.htm) przedstawia przechodzenie przez DOM. Tutaj przechodzimy przez każdy węzeł podrzędny elementu <Employee>.
<!DOCTYPE html>
<html>
<style>
table,th,td {
border:1px solid black;
border-collapse:collapse
}
</style>
<body>
<div id = "ajax_xml"></div>
<script>
//if browser supports XMLHttpRequest
if (window.XMLHttpRequest) {// Create an instance of XMLHttpRequest object.
code for IE7+, Firefox, Chrome, Opera, Safari
var xmlhttp = new XMLHttpRequest();
} else {// code for IE6, IE5
var xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
// sets and sends the request for calling "node.xml"
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
// sets and returns the content as XML DOM
var xml_dom = xmlhttp.responseXML;
// this variable stores the code of the html table
var html_tab = '<table id = "id_tabel" align = "center">
<tr>
<th>Employee Category</th>
<th>FirstName</th>
<th>LastName</th>
<th>ContactNo</th>
<th>Email</th>
</tr>';
var arr_employees = xml_dom.getElementsByTagName("Employee");
// traverses the "arr_employees" array
for(var i = 0; i<arr_employees.length; i++) {
var employee_cat = arr_employees[i].getAttribute('category');
// gets the value of 'category' element of current "Element" tag
// gets the value of first child-node of 'FirstName'
// element of current "Employee" tag
var employee_firstName =
arr_employees[i].getElementsByTagName('FirstName')[0].childNodes[0].nodeValue;
// gets the value of first child-node of 'LastName'
// element of current "Employee" tag
var employee_lastName =
arr_employees[i].getElementsByTagName('LastName')[0].childNodes[0].nodeValue;
// gets the value of first child-node of 'ContactNo'
// element of current "Employee" tag
var employee_contactno =
arr_employees[i].getElementsByTagName('ContactNo')[0].childNodes[0].nodeValue;
// gets the value of first child-node of 'Email'
// element of current "Employee" tag
var employee_email =
arr_employees[i].getElementsByTagName('Email')[0].childNodes[0].nodeValue;
// adds the values in the html table
html_tab += '<tr>
<td>'+ employee_cat+ '</td>
<td>'+ employee_firstName+ '</td>
<td>'+ employee_lastName+ '</td>
<td>'+ employee_contactno+ '</td>
<td>'+ employee_email+ '</td>
</tr>';
}
html_tab += '</table>';
// adds the html table in a html tag, with id = "ajax_xml"
document.getElementById('ajax_xml').innerHTML = html_tab;
</script>
</body>
</html>Ten kod ładuje plik node.xml .
Treść XML jest przekształcana w obiekt XML DOM JavaScript.
Tablicę elementów (z tagiem Element) uzyskuje się za pomocą metody getElementsByTagName ().
Następnie przechodzimy przez tę tablicę i wyświetlamy wartości węzłów potomnych w tabeli.
Wykonanie
Zapisz ten plik jako traverse_example.html na ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). Otrzymasz następujący wynik -

Do tej pory studiowaliśmy strukturę DOM, jak ładować i analizować obiekt XML DOM oraz przechodzić przez obiekty DOM. Tutaj zobaczymy, jak możemy nawigować między węzłami w obiekcie DOM. XML DOM składa się z różnych właściwości węzłów, które pomagają nam poruszać się po węzłach, takich jak -
- parentNode
- childNodes
- firstChild
- lastChild
- nextSibling
- previousSibling
Poniżej znajduje się diagram drzewa węzłów pokazujący jego relacje z innymi węzłami.
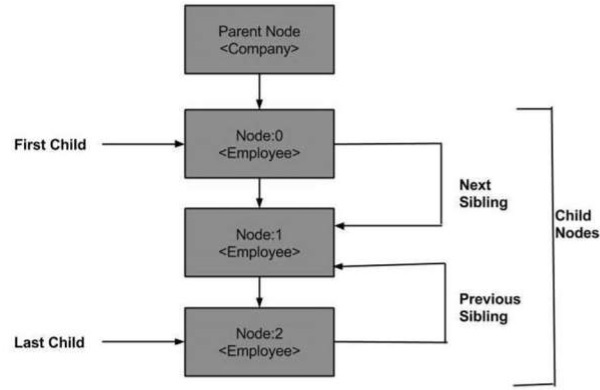
DOM - węzeł nadrzędny
Ta właściwość określa węzeł nadrzędny jako obiekt węzłowy.
Przykład
Poniższy przykład (navigate_example.htm) analizuje dokument XML ( node.xml ) do obiektu XML DOM. Następnie obiekt DOM jest nawigowany do węzła nadrzędnego przez węzeł podrzędny -
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
var y = xmlDoc.getElementsByTagName("Employee")[0];
document.write(y.parentNode.nodeName);
</script>
</body>
</html>Jak widać w powyższym przykładzie, węzeł podrzędny Pracownik przechodzi do swojego węzła nadrzędnego.
Wykonanie
Zapisz ten plik jako navigate_example.html na ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). Na wyjściu otrzymujemy węzeł macierzysty Pracownik , czyli Firma .
Pierworodny
Ta właściwość jest typu Node i reprezentuje pierwsze imię potomne obecne w NodeList.
Przykład
Poniższy przykład (first_node_example.htm) analizuje dokument XML ( node.xml ) do obiektu XML DOM, a następnie przechodzi do pierwszego węzła podrzędnego obecnego w obiekcie DOM.
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_firstChild(p) {
a = p.firstChild;
while (a.nodeType != 1) {
a = a.nextSibling;
}
return a;
}
var firstchild = get_firstChild(xmlDoc.getElementsByTagName("Employee")[0]);
document.write(firstchild.nodeName);
</script>
</body>
</html>Funkcja get_firstChild (p) służy do unikania pustych węzłów. Pomaga pobrać element firstChild z listy węzłów.
x = get_firstChild(xmlDoc.getElementsByTagName("Employee")[0])pobiera pierwszy węzeł podrzędny dla nazwy tagu Employee .
Wykonanie
Zapisz ten plik jako first_node_example.htm w ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). Na wyjściu otrzymujemy pierwszy węzeł potomny pracownika, czyli FirstName .
Ostatnie dziecko
Ta właściwość jest typu Node i reprezentuje ostatnie imię potomne obecne w NodeList.
Przykład
Poniższy przykład (last_node_example.htm) analizuje dokument XML ( node.xml ) do obiektu XML DOM, a następnie przechodzi do ostatniego węzła podrzędnego obecnego w obiekcie xml DOM.
<!DOCTYPE html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_lastChild(p) {
a = p.lastChild;
while (a.nodeType != 1){
a = a.previousSibling;
}
return a;
}
var lastchild = get_lastChild(xmlDoc.getElementsByTagName("Employee")[0]);
document.write(lastchild.nodeName);
</script>
</body>
</html>Wykonanie
Zapisz ten plik jako last_node_example.htm na ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). Na wyjściu otrzymujemy ostatni węzeł potomny pracownika, tj . Email .
Następne rodzeństwo
Ta właściwość jest typu Node i reprezentuje następne dziecko, tj. Następny element podrzędny określonego elementu potomnego znajdujący się w NodeList.
Przykład
Poniższy przykład (nextSibling_example.htm) analizuje dokument XML ( node.xml ) do obiektu XML DOM, który prowadzi natychmiast do następnego węzła obecnego w dokumencie xml.
<!DOCTYPE html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
}
else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_nextSibling(p) {
a = p.nextSibling;
while (a.nodeType != 1) {
a = a.nextSibling;
}
return a;
}
var nextsibling = get_nextSibling(xmlDoc.getElementsByTagName("FirstName")[0]);
document.write(nextsibling.nodeName);
</script>
</body>
</html>Wykonanie
Zapisz ten plik jako nextSibling_example.htm na ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). W danych wyjściowych otrzymujemy następny węzeł siostrzany FirstName, tj . LastName .
Poprzednie rodzeństwo
Ta właściwość jest typu Node i reprezentuje poprzednie dziecko, tj. Poprzednie elementy równorzędne określonego elementu podrzędnego znajdującego się w NodeList.
Przykład
Poniższy przykład (previoussibling_example.htm) analizuje dokument XML ( node.xml ) do obiektu XML DOM, a następnie przechodzi do węzła przed ostatnim węzłem podrzędnym obecnym w dokumencie xml.
<!DOCTYPE html>
<body>
<script>
if (window.XMLHttpRequest)
{
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_previousSibling(p) {
a = p.previousSibling;
while (a.nodeType != 1) {
a = a.previousSibling;
}
return a;
}
prevsibling = get_previousSibling(xmlDoc.getElementsByTagName("Email")[0]);
document.write(prevsibling.nodeName);
</script>
</body>
</html>Wykonanie
Zapisz ten plik jako previoussibling_example.htm na ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). Na wyjściu otrzymujemy poprzedni węzeł siostrzany Email, tj . ContactNo .
W tym rozdziale zbadamy, jak uzyskać dostęp do węzłów XML DOM, które są uważane za jednostki informacyjne dokumentu XML. Struktura węzłów XML DOM umożliwia programiście poruszanie się po drzewie w poszukiwaniu określonych informacji i jednoczesny dostęp do nich.
Dostęp do węzłów
Poniżej przedstawiono trzy sposoby uzyskiwania dostępu do węzłów -
Korzystając z getElementsByTagName () metoda
Przez pętlę lub przechodzenie przez drzewo węzłów
Poruszając się po drzewie węzłów, używając relacji węzłów
getElementsByTagName ()
Ta metoda umożliwia dostęp do informacji o węźle poprzez określenie nazwy węzła. Umożliwia również dostęp do informacji o liście węzłów i długości listy węzłów.
Składnia
Metoda getElementByTagName () ma następującą składnię -
node.getElementByTagName("tagname");Gdzie,
węzeł - jest węzłem dokumentu.
zmienna - przechowuje nazwę węzła, którego wartość chcesz pobrać.
Przykład
Poniżej znajduje się prosty program, który ilustruje użycie metody getElementByTagName.
<!DOCTYPE html>
<html>
<body>
<div>
<b>FirstName:</b> <span id = "FirstName"></span><br>
<b>LastName:</b> <span id = "LastName"></span><br>
<b>Category:</b> <span id = "Employee"></span><br>
</div>
<script>
if (window.XMLHttpRequest) {// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp = new XMLHttpRequest();
} else {// code for IE6, IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
document.getElementById("FirstName").innerHTML =
xmlDoc.getElementsByTagName("FirstName")[0].childNodes[0].nodeValue;
document.getElementById("LastName").innerHTML =
xmlDoc.getElementsByTagName("LastName")[0].childNodes[0].nodeValue;
document.getElementById("Employee").innerHTML =
xmlDoc.getElementsByTagName("Employee")[0].attributes[0].nodeValue;
</script>
</body>
</html>W powyższym przykładzie uzyskujemy dostęp do informacji o węzłach FirstName , LastName i Employee .
xmlDoc.getElementsByTagName ("FirstName") [0] .childNodes [0] .nodeValue; Ta linia uzyskuje dostęp do wartości węzła podrzędnego FirstName przy użyciu metody getElementByTagName ().
xmlDoc.getElementsByTagName ("Pracownik") [0] .attributes [0] .nodeValue; Ten wiersz uzyskuje dostęp do wartości atrybutu metody Employee getElementByTagName ().
Przechodzenie przez węzły
Jest to omówione w rozdziale Przechodzenie przez DOM z przykładami.
Nawigacja przez węzły
Jest to omówione w rozdziale Nawigacja DOM z przykładami.
W tym rozdziale nauczymy się, jak uzyskać wartość węzła obiektu XML DOM. Dokumenty XML mają hierarchię jednostek informacyjnych zwanych węzłami. Obiekt Node ma właściwość nodeValue , która zwraca wartość elementu.
W kolejnych sekcjach omówimy -
Pobieranie wartości węzła elementu
Pobieranie wartości atrybutu węzła
Plik node.xml użyty we wszystkich poniższych przykładach wygląda jak poniżej -
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>[email protected]</Email>
</Employee>
</Company>Uzyskaj wartość węzła
Metoda getElementsByTagName () zwraca NodeList wszystkich elementów w kolejności dokumentu z podaną nazwą znacznika.
Przykład
Poniższy przykład (getnode_example.htm) analizuje dokument XML ( node.xml ) do obiektu XML DOM i wyodrębnia wartość węzła węzła potomnego Firstname (indeks na 0) -
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else{
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
x = xmlDoc.getElementsByTagName('FirstName')[0]
y = x.childNodes[0];
document.write(y.nodeValue);
</script>
</body>
</html>Wykonanie
Zapisz ten plik jako getnode_example.htm na ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). Na wyjściu otrzymujemy wartość węzła jako Tanmay .
Uzyskaj wartość atrybutu
Atrybuty są częścią elementów węzła XML. Element węzła może mieć wiele unikalnych atrybutów. Atrybut zawiera więcej informacji o elementach węzłów XML. Mówiąc dokładniej, określają one właściwości elementów węzła. Atrybut XML jest zawsze parą nazwa-wartość. Ta wartość atrybutu nazywana jest węzłem atrybutu .
Metoda getAttribute () pobiera wartość atrybutu na podstawie nazwy elementu.
Przykład
Poniższy przykład (get_attribute_example.htm) analizuje dokument XML ( node.xml ) do obiektu XML DOM i wyodrębnia wartość atrybutu kategorii Pracownik (indeks na 2) -
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
x = xmlDoc.getElementsByTagName('Employee')[2];
document.write(x.getAttribute('category'));
</script>
</body>
</html>Wykonanie
Zapisz ten plik jako get_attribute_example.htm na ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). W wyniku otrzymujemy wartość atrybutu jako Zarządzanie .
W tym rozdziale nauczymy się, jak zmieniać wartości węzłów w obiekcie XML DOM. Wartość węzła można zmienić w następujący sposób -
var value = node.nodeValue;Jeśli węzeł jest Atrybut wówczas wartość zmiennej będzie wartością atrybutu; jeśli węzeł jest węzłem tekstowym , będzie to zawartość tekstowa; jeśli węzeł to element będzie zerowy .
Poniższe sekcje przedstawiają ustawienia wartości węzłów dla każdego typu węzła (atrybut, węzeł tekstowy i element).
Plik node.xml użyty we wszystkich poniższych przykładach wygląda jak poniżej -
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>[email protected]</Email>
</Employee>
</Company>Zmień wartość węzła tekstowego
Kiedy mówimy o wartości zmiany elementu Node, mamy na myśli edycję zawartości tekstowej elementu (który jest również nazywany węzłem tekstowym ). Poniższy przykład pokazuje, jak zmienić węzeł tekstowy elementu.
Przykład
Poniższy przykład (set_text_node_example.htm) analizuje dokument XML ( node.xml ) do obiektu XML DOM i zmienia wartość węzła tekstowego elementu. W takim przypadku wyślij wiadomość e-mail każdego pracownika na adres [email protected] i wydrukuj wartości.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("Email");
for(i = 0;i<x.length;i++) {
x[i].childNodes[0].nodeValue = "[email protected]";
document.write(i+');
document.write(x[i].childNodes[0].nodeValue);
document.write('<br>');
}
</script>
</body>
</html>Wykonanie
Zapisz ten plik jako set_text_node_example.htm na ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). Otrzymasz następujący wynik -
0) [email protected]
1) [email protected]
2) [email protected]Zmień wartość węzła atrybutu
Poniższy przykład ilustruje sposób zmiany węzła atrybutu elementu.
Przykład
Poniższy przykład (set_attribute_example.htm) analizuje dokument XML ( node.xml ) do obiektu XML DOM i zmienia wartość węzła atrybutu elementu. W tym przypadku kategoria każdego pracownika do odpowiednio admin-0, admin-1, admin-2 i wydrukowanie wartości.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("Employee");
for(i = 0 ;i<x.length;i++){
newcategory = x[i].getAttributeNode('category');
newcategory.nodeValue = "admin-"+i;
document.write(i+');
document.write(x[i].getAttributeNode('category').nodeValue);
document.write('<br>');
}
</script>
</body>
</html>Wykonanie
Zapisz ten plik jako set_node_attribute_example.htm w ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). Wynik byłby taki jak poniżej -
0) admin-0
1) admin-1
2) admin-2W tym rozdziale omówimy, jak tworzyć nowe węzły przy użyciu kilku metod obiektu dokumentu. Te metody zapewniają zakres tworzenia nowego węzła elementu, węzła tekstowego, węzła komentarza, węzła sekcji CDATA i węzła atrybutów . Jeśli nowo utworzony węzeł już istnieje w obiekcie elementu, zostanie zastąpiony nowym. Poniższe sekcje pokazują to na przykładach.
Utwórz nowy węzeł Element
Metoda createElement () tworzy nowy węzeł elementu. Jeśli nowo utworzony węzeł elementu istnieje w obiekcie elementu, jest zastępowany nowym.
Składnia
Składnia użycia metody createElement () jest następująca -
var_name = xmldoc.createElement("tagname");Gdzie,
nazwa_zmiennej - to nazwa zmiennej zdefiniowanej przez użytkownika, która przechowuje nazwę nowego elementu.
("zmienna") - jest to nazwa tworzonego węzła elementu.
Przykład
Poniższy przykład (createnewelement_example.htm) analizuje dokument XML ( node.xml ) do obiektu XML DOM i tworzy nowy element węzeł PhoneNo w dokumencie XML.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
new_element = xmlDoc.createElement("PhoneNo");
x = xmlDoc.getElementsByTagName("FirstName")[0];
x.appendChild(new_element);
document.write(x.getElementsByTagName("PhoneNo")[0].nodeName);
</script>
</body>
</html>new_element = xmlDoc.createElement ("PhoneNo"); tworzy nowy węzeł elementu <PhoneNo>
x.appendChild (nowy_element); x zawiera nazwę określonego węzła podrzędnego <FirstName>, do którego dołączany jest nowy węzeł elementu.
Wykonanie
Zapisz ten plik jako createnewelement_example.htm na ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). W wyniku otrzymujemy wartość atrybutu jako PhoneNo .
Utwórz nowy węzeł tekstowy
Metoda createTextNode () tworzy nowy węzeł tekstowy.
Składnia
Składnia do użycia funkcji createTextNode () jest następująca -
var_name = xmldoc.createTextNode("tagname");Gdzie,
nazwa_zmiennej - jest to nazwa zmiennej zdefiniowanej przez użytkownika, która przechowuje nazwę nowego węzła tekstowego.
("zmienna") - w nawiasie podano nazwę tworzonego węzła tekstowego.
Przykład
Poniższy przykład (createtextnode_example.htm) analizuje dokument XML ( node.xml ) do obiektu XML DOM i tworzy nowy węzeł tekstowy Im nowy węzeł tekstowy w dokumencie XML.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_e = xmlDoc.createElement("PhoneNo");
create_t = xmlDoc.createTextNode("Im new text node");
create_e.appendChild(create_t);
x = xmlDoc.getElementsByTagName("Employee")[0];
x.appendChild(create_e);
document.write(" PhoneNO: ");
document.write(x.getElementsByTagName("PhoneNo")[0].childNodes[0].nodeValue);
</script>
</body>
</html>Szczegóły powyższego kodu są jak poniżej -
create_e = xmlDoc.createElement ("PhoneNo"); tworzy nowy element < PhoneNo >.
create_t = xmlDoc.createTextNode ("Jestem nowym węzłem tekstowym"); tworzy nowy węzeł tekstowy „Im nowy węzeł tekstowy” .
x.appendChild (create_e); węzeł tekstowy „Im nowy węzeł tekstowy” jest dołączany do elementu < PhoneNo >.
document.write (x.getElementsByTagName ("PhoneNo") [0] .childNodes [0] .nodeValue); zapisuje nową wartość węzła tekstowego do elementu <PhoneNo>.
Wykonanie
Zapisz ten plik jako createtextnode_example.htm na ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). Na wyjściu otrzymujemy wartość atrybutu jako np. PhoneNO: Im nowy węzeł tekstowy .
Utwórz nowy węzeł komentarza
Metoda createComment () tworzy nowy węzeł komentarza. W programie zawarto węzeł komentarza w celu ułatwienia zrozumienia funkcjonalności kodu.
Składnia
Składnia do użycia funkcji createComment () jest następująca -
var_name = xmldoc.createComment("tagname");Gdzie,
nazwa_zmiennej - jest nazwą zmiennej zdefiniowanej przez użytkownika, która zawiera nazwę nowego węzła komentarza.
("zmienna") - jest nazwą tworzonego węzła komentarza.
Przykład
Poniższy przykład (createcommentnode_example.htm) analizuje dokument XML ( node.xml ) do obiektu XML DOM i tworzy nowy węzeł komentarza „Firma jest węzłem nadrzędnym” w dokumencie XML.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
}
else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_comment = xmlDoc.createComment("Company is the parent node");
x = xmlDoc.getElementsByTagName("Company")[0];
x.appendChild(create_comment);
document.write(x.lastChild.nodeValue);
</script>
</body>
</html>W powyższym przykładzie -
create_comment = xmlDoc.createComment ("Firma jest węzłem nadrzędnym") creates a specified comment line.
x.appendChild (create_comment) W tym wierszu „x” przechowuje nazwę elementu <Firma>, do którego dołączony jest wiersz komentarza.
Wykonanie
Zapisz ten plik jako createcommentnode_example.htm na ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). W danych wyjściowych otrzymujemy wartość atrybutu, ponieważ firma jest węzłem nadrzędnym .
Utwórz nowy węzeł sekcji CDATA
Metoda createCDATASection () tworzy nowy węzeł sekcji CDATA. Jeśli nowo utworzony węzeł sekcji CDATA istnieje w obiekcie elementu, jest zastępowany przez nowy.
Składnia
Składnia do użycia createCDATASection () jest następująca -
var_name = xmldoc.createCDATASection("tagname");Gdzie,
nazwa_zmiennej - jest nazwą zmiennej zdefiniowanej przez użytkownika, która przechowuje nazwę nowego węzła sekcji CDATA.
("zmienna") - to nazwa tworzonego węzła sekcji CDATA.
Przykład
Poniższy przykład (createcdatanode_example.htm) analizuje dokument XML ( node.xml ) do obiektu XML DOM i tworzy nowy węzeł sekcji CDATA „Utwórz przykład CDATA” w dokumencie XML.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
}
else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_CDATA = xmlDoc.createCDATASection("Create CDATA Example");
x = xmlDoc.getElementsByTagName("Employee")[0];
x.appendChild(create_CDATA);
document.write(x.lastChild.nodeValue);
</script>
</body>
</html>W powyższym przykładzie -
create_CDATA = xmlDoc.createCDATASection ("Utwórz przykład CDATA") tworzy nowy węzeł sekcji CDATA, "Utwórz przykład CDATA"
x.appendChild (create_CDATA) tutaj, x przechowuje określony element <Employee> indeksowany na 0, do którego jest dołączana wartość węzła CDATA.
Wykonanie
Zapisz ten plik jako createcdatanode_example.htm na ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). W danych wyjściowych otrzymujemy wartość atrybutu jako przykład utworzenia CDATA .
Utwórz nowy węzeł atrybutów
Aby utworzyć nowy węzeł atrybutu, używana jest metoda setAttributeNode () . Jeśli nowo utworzony węzeł atrybutu istnieje w obiekcie elementu, jest zastępowany nowym.
Składnia
Składnia użycia metody createElement () jest następująca -
var_name = xmldoc.createAttribute("tagname");Gdzie,
nazwa_zmiennej - to nazwa zmiennej zdefiniowanej przez użytkownika, która przechowuje nazwę nowego węzła atrybutu.
("zmienna") - jest nazwą tworzonego węzła atrybutu.
Przykład
Poniższy przykład (createattributenode_example.htm) analizuje dokument XML ( node.xml ) do obiektu XML DOM i tworzy nową sekcję węzła atrybutów w dokumencie XML.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_a = xmlDoc.createAttribute("section");
create_a.nodeValue = "A";
x = xmlDoc.getElementsByTagName("Employee");
x[0].setAttributeNode(create_a);
document.write("New Attribute: ");
document.write(x[0].getAttribute("section"));
</script>
</body>
</html>W powyższym przykładzie -
create_a = xmlDoc.createAttribute ("Category") tworzy atrybut o nazwie <section>.
create_a.nodeValue = "Management" tworzy wartość "A" dla atrybutu <section>.
x [0] .setAttributeNode (create_a) ta wartość atrybutu jest ustawiona na element węzła <Employee> indeksowany na 0.
W tym rozdziale omówimy węzły istniejącego elementu. Zapewnia środki do -
dołącz nowe węzły podrzędne przed lub po istniejących węzłach podrzędnych
wstaw dane w węźle tekstowym
dodaj węzeł atrybutu
Do dodawania / dołączania węzłów do elementu w modelu DOM można użyć następujących metod -
- appendChild()
- insertBefore()
- insertData()
appendChild ()
Metoda appendChild () dodaje nowy węzeł podrzędny po istniejącym węźle podrzędnym.
Składnia
Składnia metody appendChild () jest następująca -
Node appendChild(Node newChild) throws DOMExceptionGdzie,
newChild - jest węzłem do dodania
Ta metoda zwraca dodany węzeł .
Przykład
Poniższy przykład (appendchildnode_example.htm) analizuje dokument XML ( node.xml ) do obiektu XML DOM i dołącza nowy podrzędny PhoneNo do elementu <FirstName>.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_e = xmlDoc.createElement("PhoneNo");
x = xmlDoc.getElementsByTagName("FirstName")[0];
x.appendChild(create_e);
document.write(x.getElementsByTagName("PhoneNo")[0].nodeName);
</script>
</body>
</html>W powyższym przykładzie -
za pomocą metody createElement () tworzony jest nowy element PhoneNo .
Nowy element PhoneNo jest dodawany do elementu FirstName przy użyciu metody appendChild ().
Wykonanie
Zapisz ten plik jako appendchildnode_example.htm na ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). W wyniku otrzymujemy wartość atrybutu jako PhoneNo .
insertBefore ()
Metoda insertBefore () wstawia nowe węzły podrzędne przed określonymi węzłami podrzędnymi.
Składnia
Składnia metody insertBefore () jest następująca -
Node insertBefore(Node newChild, Node refChild) throws DOMExceptionGdzie,
newChild - jest węzłem do wstawienia
refChild - Jest węzłem odniesienia, tj. węzłem, przed którym należy wstawić nowy węzeł.
Ta metoda zwraca wstawiany węzeł .
Przykład
Poniższy przykład (insertnodebefore_example.htm) analizuje dokument XML ( node.xml ) do obiektu XML DOM i wstawia nowy podrzędny adres e-mail przed określonym elementem <Email>.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_e = xmlDoc.createElement("Email");
x = xmlDoc.documentElement;
y = xmlDoc.getElementsByTagName("Email");
document.write("No of Email elements before inserting was: " + y.length);
document.write("<br>");
x.insertBefore(create_e,y[3]);
y=xmlDoc.getElementsByTagName("Email");
document.write("No of Email elements after inserting is: " + y.length);
</script>
</body>
</html>W powyższym przykładzie -
za pomocą metody createElement () tworzony jest nowy element Email .
Nowy element Email jest dodawany przed elementem Email przy pomocy metody insertBefore ().
y.length podaje całkowitą liczbę elementów dodanych przed i po nowym elemencie.
Wykonanie
Zapisz ten plik jako insertnodebefore_example.htm na ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). Otrzymamy następujący wynik -
No of Email elements before inserting was: 3
No of Email elements after inserting is: 4insertData ()
Metoda insertData () wstawia ciąg o określonym 16-bitowym przesunięciu jednostki.
Składnia
Funkcja insertData () ma następującą składnię -
void insertData(int offset, java.lang.String arg) throws DOMExceptionGdzie,
offset - jest przesunięciem znaku, w którym należy wstawić.
arg - to słowo kluczowe do wstawiania danych. Obejmuje dwa parametry offset i string w nawiasach oddzielone przecinkiem.
Przykład
Poniższy przykład (addtext_example.htm) analizuje dokument XML („ node.xml ”) do obiektu XML DOM i wstawia nowe dane MiddleName w określonej pozycji do elementu <FirstName>.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("FirstName")[0].childNodes[0];
document.write(x.nodeValue);
x.insertData(6,"MiddleName");
document.write("<br>");
document.write(x.nodeValue);
</script>
</body>
</html>x.insertData(6,"MiddleName");- Tutaj x przechowuje nazwę podanej nazwy dziecka, tj. <FirstName>. Następnie wstawiamy do tego węzła tekstowego dane „MiddleName”, zaczynając od pozycji 6.
Wykonanie
Zapisz ten plik jako addtext_example.htm na ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). W wyniku otrzymamy:
Tanmay
TanmayMiddleNameW tym rozdziale zajmiemy się operacją zamiany węzła w obiekcie XML DOM. Jak wiemy, wszystko w DOM jest utrzymywane w hierarchicznej jednostce informacyjnej znanej jako węzeł, a zastępujący węzeł zapewnia inny sposób aktualizacji tych określonych węzłów lub węzła tekstowego.
Poniżej przedstawiono dwie metody zastępowania węzłów.
- replaceChild()
- replaceData()
replaceChild ()
Metoda replaceChild () zastępuje określony węzeł nowym węzłem.
Składnia
Funkcja insertData () ma następującą składnię -
Node replaceChild(Node newChild, Node oldChild) throws DOMExceptionGdzie,
newChild - to nowy węzeł do umieszczenia na liście potomków .
oldChild - to zastępowany węzeł na liście.
Ta metoda zwraca zastąpiony węzeł.
Przykład
Poniższy przykład (replaceenode_example.htm) analizuje dokument XML ( node.xml ) do obiektu XML DOM i zastępuje określony węzeł <FirstName> nowym węzłem <Name>.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.documentElement;
z = xmlDoc.getElementsByTagName("FirstName");
document.write("<b>Content of FirstName element before replace operation</b><br>");
for (i=0;i<z.length;i++) {
document.write(z[i].childNodes[0].nodeValue);
document.write("<br>");
}
//create a Employee element, FirstName element and a text node
newNode = xmlDoc.createElement("Employee");
newTitle = xmlDoc.createElement("Name");
newText = xmlDoc.createTextNode("MS Dhoni");
//add the text node to the title node,
newTitle.appendChild(newText);
//add the title node to the book node
newNode.appendChild(newTitle);
y = xmlDoc.getElementsByTagName("Employee")[0]
//replace the first book node with the new node
x.replaceChild(newNode,y);
z = xmlDoc.getElementsByTagName("FirstName");
document.write("<b>Content of FirstName element after replace operation</b><br>");
for (i = 0;i<z.length;i++) {
document.write(z[i].childNodes[0].nodeValue);
document.write("<br>");
}
</script>
</body>
</html>Wykonanie
Zapisz ten plik jako replaceenode_example.htm na ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). Otrzymamy dane wyjściowe, jak pokazano poniżej -
Content of FirstName element before replace operation
Tanmay
Taniya
Tanisha
Content of FirstName element after replace operation
Taniya
TanishareplaceData ()
Metoda replaceData () zastępuje znaki zaczynające się od określonego 16-bitowego przesunięcia jednostki określonym ciągiem.
Składnia
Funkcja replaceData () ma następującą składnię -
void replaceData(int offset, int count, java.lang.String arg) throws DOMExceptionGdzie
offset - to przesunięcie, od którego należy rozpocząć zastępowanie.
count - to liczba jednostek 16-bitowych do zastąpienia. Jeśli suma przesunięcia i liczby przekracza długość, wówczas wszystkie 16-bitowe jednostki do końca danych są zastępowane.
arg - DOMString, którym należy zastąpić zakres.
Przykład
Poniższy przykład ( replaceata_example.htm ) analizuje dokument XML ( node.xml ) do obiektu XML DOM i zastępuje go.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("ContactNo")[0].childNodes[0];
document.write("<b>ContactNo before replace operation:</b> "+x.nodeValue);
x.replaceData(1,5,"9999999");
document.write("<br>");
document.write("<b>ContactNo after replace operation:</b> "+x.nodeValue);
</script>
</body>
</html>W powyższym przykładzie -
x.replaceData (2, 3, "999"); - Tutaj x przechowuje tekst podanego elementu <ContactNo>, którego tekst jest zastępowany nowym tekstem „9999999” , począwszy od pozycji 1 do długości 5 .
Wykonanie
Zapisz ten plik jako replacedata_example.htm na ścieżce serwera (ten plik i node.xml powinny znajdować się na tej samej ścieżce na serwerze). Otrzymamy dane wyjściowe, jak pokazano poniżej -
ContactNo before replace operation: 1234567890
ContactNo after replace operation: 199999997890W tym rozdziale zajmiemy się operacją XML DOM Remove Node . Operacja usuwania węzła usuwa określony węzeł z dokumentu. Ta operacja może zostać zaimplementowana w celu usunięcia węzłów, takich jak węzeł tekstowy, węzeł elementu lub węzeł atrybutów.
Poniżej przedstawiono metody używane do usuwania węzłów -
removeChild()
removeAttribute()
removeChild ()
Metoda removeChild () usuwa węzeł potomny wskazany przez oldChild z listy dzieci i zwraca go. Usunięcie węzła podrzędnego jest równoznaczne z usunięciem węzła tekstowego. Dlatego usunięcie węzła potomnego powoduje usunięcie skojarzonego z nim węzła tekstowego.
Składnia
Składnia użycia removeChild () jest następująca -
Node removeChild(Node oldChild) throws DOMExceptionGdzie,
oldChild - to usuwany węzeł.
Ta metoda zwraca usunięty węzeł.
Przykład - Usuń bieżący węzeł
Poniższy przykład (removecurrentnode_example.htm) analizuje dokument XML ( node.xml ) do obiektu XML DOM i usuwa określony węzeł <ContactNo> z węzła nadrzędnego.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
document.write("<b>Before remove operation, total ContactNo elements: </b>");
document.write(xmlDoc.getElementsByTagName("ContactNo").length);
document.write("<br>");
x = xmlDoc.getElementsByTagName("ContactNo")[0];
x.parentNode.removeChild(x);
document.write("<b>After remove operation, total ContactNo elements: </b>");
document.write(xmlDoc.getElementsByTagName("ContactNo").length);
</script>
</body>
</html>W powyższym przykładzie -
x = xmlDoc.getElementsByTagName ("ContactNo") [0] pobiera element <ContactNo> indeksowany na 0.
x.parentNode.removeChild (x); usuwa element <ContactNo> indeksowany na 0 z węzła nadrzędnego.
Wykonanie
Zapisz ten plik jako removecurrentnode_example.htm na ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). Otrzymujemy następujący wynik -
Before remove operation, total ContactNo elements: 3
After remove operation, total ContactNo elements: 2Przykład - Usuń węzeł tekstowy
Poniższy przykład (removetextNode_example.htm) analizuje dokument XML ( node.xml ) do obiektu XML DOM i usuwa określony węzeł potomny <FirstName>.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("FirstName")[0];
document.write("<b>Text node of child node before removal is:</b> ");
document.write(x.childNodes.length);
document.write("<br>");
y = x.childNodes[0];
x.removeChild(y);
document.write("<b>Text node of child node after removal is:</b> ");
document.write(x.childNodes.length);
</script>
</body>
</html>W powyższym przykładzie -
x = xmlDoc.getElementsByTagName ("FirstName") [0]; - pobiera pierwszy element <FirstName> do x indeksowanego na 0.
y = x.childNodes [0]; - w tej linii y zawiera węzeł potomny do usunięcia.
x.removeChild (y); - usuwa określony węzeł podrzędny.
Wykonanie
Zapisz ten plik jako removetextNode_example.htm na ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). Otrzymujemy następujący wynik -
Text node of child node before removal is: 1
Text node of child node after removal is: 0removeAttribute ()
Metoda removeAttribute () usuwa atrybut elementu według nazwy.
Składnia
Składnia do użycia removeAttribute () jest następująca -
void removeAttribute(java.lang.String name) throws DOMExceptionGdzie,
name - to nazwa atrybutu do usunięcia.
Przykład
Poniższy przykład (removeelementattribute_example.htm) analizuje dokument XML ( node.xml ) do obiektu XML DOM i usuwa określony węzeł atrybutu.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName('Employee');
document.write(x[1].getAttribute('category'));
document.write("<br>");
x[1].removeAttribute('category');
document.write(x[1].getAttribute('category'));
</script>
</body>
</html>W powyższym przykładzie -
document.write (x [1] .getAttribute ('category')); - wywoływana jest wartość kategorii atrybutu indeksowana na 1 pozycji.
x [1] .removeAttribute ('kategoria'); - usuwa wartość atrybutu.
Wykonanie
Zapisz ten plik jako removeelementattribute_example.htm w ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). Otrzymujemy następujący wynik -
Non-Technical
nullW tym rozdziale omówimy działanie Clone Node na obiekcie XML DOM. Operacja klonowania węzła służy do tworzenia zduplikowanej kopii określonego węzła. CloneNode () jest używany do tej operacji.
cloneNode ()
Ta metoda zwraca duplikat tego węzła, tj. Służy jako ogólny konstruktor kopiujący dla węzłów. Zduplikowany węzeł nie ma elementu nadrzędnego (parentNode ma wartość null) ani danych użytkownika.
Składnia
Metoda cloneNode () ma następującą składnię -
Node cloneNode(boolean deep)deep - jeśli prawda, rekurencyjnie klonuje poddrzewo w określonym węźle; jeśli fałsz, klonuj tylko sam węzeł (i jego atrybuty, jeśli jest elementem).
Ta metoda zwraca zduplikowany węzeł.
Przykład
Poniższy przykład (clonenode_example.htm) analizuje dokument XML ( node.xml ) do obiektu XML DOM i tworzy głęboką kopię pierwszego elementu pracownika .
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName('Employee')[0];
clone_node = x.cloneNode(true);
xmlDoc.documentElement.appendChild(clone_node);
firstname = xmlDoc.getElementsByTagName("FirstName");
lastname = xmlDoc.getElementsByTagName("LastName");
contact = xmlDoc.getElementsByTagName("ContactNo");
email = xmlDoc.getElementsByTagName("Email");
for (i = 0;i < firstname.length;i++) {
document.write(firstname[i].childNodes[0].nodeValue+'
'+lastname[i].childNodes[0].nodeValue+',
'+contact[i].childNodes[0].nodeValue+', '+email[i].childNodes[0].nodeValue);
document.write("<br>");
}
</script>
</body>
</html>Jak widać w powyższym przykładzie, ustawiliśmy parametr cloneNode () na true . Stąd każdy element podrzędny w elemencie Employee jest kopiowany lub klonowany.
Wykonanie
Zapisz ten plik jako clonenode_example.htm na ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). Otrzymamy dane wyjściowe, jak pokazano poniżej -
Tanmay Patil, 1234567890, [email protected]
Taniya Mishra, 1234667898, [email protected]
Tanisha Sharma, 1234562350, [email protected]
Tanmay Patil, 1234567890, [email protected]Zauważysz, że pierwszy element Employee został całkowicie sklonowany.
Interfejs węzła jest podstawowym typem danych dla całego modelu obiektu dokumentu. Węzeł służy do reprezentowania pojedynczego elementu XML w całym drzewie dokumentu.
Węzeł może być dowolnego typu, który jest węzłem atrybutów, węzłem tekstowym lub dowolnym innym węzłem. Atrybuty nodeName, nodeValue i atrybuty są zawarte jako mechanizm uzyskiwania informacji o węźle bez rzutowania w dół do określonego interfejsu pochodnego.
Atrybuty
Poniższa tabela zawiera listę atrybutów obiektu Node -
| Atrybut | Rodzaj | Opis |
|---|---|---|
| atrybuty | NamedNodeMap | Jest to NamedNodeMap typu zawierającego atrybuty tego węzła (jeśli jest to Element) lub null w innym przypadku. To zostało usunięte. Sprawdź specyfikacje |
| baseURI | DOMString | Służy do określenia bezwzględnego podstawowego identyfikatora URI węzła. |
| childNodes | NodeList | Jest to lista NodeList zawierająca wszystkie elementy podrzędne tego węzła. Jeśli nie ma elementów podrzędnych, jest to lista węzłów nie zawierająca węzłów. |
| pierworodny | Węzeł | Określa pierwsze dziecko węzła. |
| ostatnie dziecko | Węzeł | Określa ostatnie dziecko węzła. |
| localName | DOMString | Służy do określenia nazwy lokalnej części węzła. To zostało usunięte. Sprawdź specyfikacje . |
| namespaceURI | DOMString | Określa identyfikator URI przestrzeni nazw węzła. To zostało usunięte. Sprawdź specyfikacje |
| nextSibling | Węzeł | Zwraca węzeł bezpośrednio następujący po tym węźle. Jeśli nie ma takiego węzła, zwraca wartość null. |
| nodeName | DOMString | Nazwa tego węzła, w zależności od jego typu. |
| nodeType | unsigned short | Jest to kod reprezentujący typ obiektu bazowego. |
| nodeValue | DOMString | Służy do określenia wartości węzła w zależności od ich typów. |
| ownerDocument | Dokument | Określa obiekt Document powiązany z węzłem. |
| parentNode | Węzeł | Ta właściwość określa węzeł nadrzędny węzła. |
| prefiks | DOMString | Ta właściwość zwraca prefiks przestrzeni nazw węzła. To zostało usunięte. Sprawdź specyfikacje |
| previousSibling | Węzeł | Określa węzeł bezpośrednio poprzedzający bieżący węzeł. |
| textContent | DOMString | Określa tekstową zawartość węzła. |
Typy węzłów
Poniżej wymieniliśmy typy węzłów -
- ELEMENT_NODE
- ATTRIBUTE_NODE
- ENTITY_NODE
- ENTITY_REFERENCE_NODE
- DOCUMENT_FRAGMENT_NODE
- TEXT_NODE
- CDATA_SECTION_NODE
- COMMENT_NODE
- PROCESSING_INSTRUCTION_NODE
- DOCUMENT_NODE
- DOCUMENT_TYPE_NODE
- NOTATION_NODE
Metody
Poniższa tabela zawiera listę różnych metod obiektów węzłów -
| S.No. | Metoda i opis |
|---|---|
| 1 | appendChild (węzeł newChild) Ta metoda dodaje węzeł po ostatnim węźle podrzędnym określonego węzła elementu. Zwraca dodany węzeł. |
| 2 | cloneNode (boolean deep) Ta metoda służy do tworzenia zduplikowanego węzła, gdy jest zastępowany w klasie pochodnej. Zwraca zduplikowany węzeł. |
| 3 | compareDocumentPosition (Node other) Ta metoda służy do porównywania pozycji bieżącego węzła z określonym węzłem zgodnie z kolejnością dokumentów. Zwraca bez znaku krótkie położenie węzła względem węzła odniesienia. |
| 4 | getFeature(DOMString feature, DOMString version) Zwraca obiekt DOM, który implementuje wyspecjalizowane interfejsy API określonej funkcji i wersji, jeśli takie istnieją, lub null, jeśli nie ma żadnego obiektu. To zostało usunięte. Sprawdź specyfikacje . |
| 5 | getUserData(DOMString key) Pobiera obiekt skojarzony z kluczem w tym węźle. Obiekt musi najpierw zostać ustawiony na ten węzeł, wywołując metodę setUserData z tym samym kluczem. Zwraca DOMUserData skojarzony z podanym kluczem w tym węźle lub null, jeśli nie było żadnego. To zostało usunięte. Sprawdź specyfikacje . |
| 6 | hasAttributes() Zwraca czy ten węzeł (jeśli jest elementem) ma atrybuty, czy nie. Zwraca wartość true, jeśli dowolny atrybut jest obecny w określonym węźle, w przeciwnym razie zwraca wartość false . To zostało usunięte. Sprawdź specyfikacje . |
| 7 | hasChildNodes () Zwraca, czy ten węzeł ma dzieci. Ta metoda zwraca wartość true, jeśli bieżący węzeł ma węzły podrzędne, w przeciwnym razie false . |
| 8 | insertBefore (Node newChild, Node refChild) Ta metoda służy do wstawiania nowego węzła jako elementu podrzędnego tego węzła, bezpośrednio przed istniejącym węzłem podrzędnym tego węzła. Zwraca wstawiany węzeł. |
| 9 | isDefaultNamespace (DOMString namespaceURI) Ta metoda przyjmuje identyfikator URI przestrzeni nazw jako argument i zwraca wartość logiczną z wartością true, jeśli przestrzeń nazw jest domyślną przestrzenią nazw w danym węźle lub false, jeśli nie. |
| 10 | isEqualNode (węzeł arg) Ta metoda sprawdza, czy dwa węzły są równe. Zwraca true, jeśli węzły są równe, false w przeciwnym razie. |
| 11 | isSameNode(Node other) Ta metoda zwraca, czy bieżący węzeł jest tym samym węzłem, co podany. Zwraca true, jeśli węzły są takie same, false w przeciwnym razie. To zostało usunięte. Sprawdź specyfikacje . |
| 12 | isSupported(DOMString feature, DOMString version) Ta metoda zwraca, czy określony moduł DOM jest obsługiwany przez bieżący węzeł. Zwraca wartość true, jeśli określona funkcja jest obsługiwana w tym węźle, w przeciwnym razie wartość false . To zostało usunięte. Sprawdź specyfikacje . |
| 13 | lookupNamespaceURI (prefiks DOMString) Ta metoda pobiera identyfikator URI przestrzeni nazw skojarzonej z prefiksem przestrzeni nazw. |
| 14 | lookupPrefix (DOMString namespaceURI) Ta metoda zwraca najbliższy prefiks zdefiniowany w bieżącej przestrzeni nazw dla identyfikatora URI przestrzeni nazw. Zwraca skojarzony prefiks przestrzeni nazw, jeśli został znaleziony, lub null, jeśli żaden nie zostanie znaleziony. |
| 15 | normalizować() Normalizacja dodaje wszystkie węzły tekstowe, w tym węzły atrybutów, które definiują normalną formę, w której struktura węzłów, które zawierają elementy, komentarze, instrukcje przetwarzania, sekcje CDATA i odniesienia do jednostek, oddziela węzły tekstowe, tj. Ani sąsiednie węzły tekstowe, ani puste węzły tekstowe. |
| 16 | removeChild (węzeł oldChild) Ta metoda służy do usuwania określonego węzła podrzędnego z bieżącego węzła. Zwraca usunięty węzeł. |
| 17 | replaceChild (węzeł newChild, węzeł oldChild) Ta metoda służy do zastąpienia starego węzła podrzędnego nowym węzłem. Zwraca to zastąpiony węzeł. |
| 18 | setUserData(DOMString key, DOMUserData data, UserDataHandler handler) Ta metoda wiąże obiekt z kluczem w tym węźle. Obiekt można później pobrać z tego węzła, wywołując metodę getUserData z tym samym kluczem. Zwraca to DOMUserData poprzednio skojarzone z danym kluczem w tym węźle. To zostało usunięte. Sprawdź specyfikacje . |
Obiekt NodeList określa abstrakcję uporządkowanej kolekcji węzłów. Elementy w NodeList są dostępne za pośrednictwem indeksu całkowitego, zaczynając od 0.
Atrybuty
Poniższa tabela zawiera listę atrybutów obiektu NodeList -
| Atrybut | Rodzaj | Opis |
|---|---|---|
| długość | unsigned long | Podaje liczbę węzłów na liście węzłów. |
Metody
Poniżej przedstawiono jedyną metodę obiektu NodeList.
| S.No. | Metoda i opis |
|---|---|
| 1 | pozycja() Zwraca indeksowany element kolekcji. Jeśli indeks jest większy lub równy liczbie węzłów na liście, zwraca wartość null. |
Obiekt NamedNodeMap służy do reprezentowania kolekcji węzłów, do których można uzyskać dostęp za pomocą nazwy.
Atrybuty
Poniższa tabela zawiera listę właściwości obiektu NamedNodeMap.
| Atrybut | Rodzaj | Opis |
|---|---|---|
| długość | unsigned long | Podaje liczbę węzłów na tej mapie. Zakres prawidłowych indeksów węzłów podrzędnych wynosi od 0 do długości -1 włącznie. |
Metody
W poniższej tabeli wymieniono metody obiektu NamedNodeMap .
| S.No. | Metody i opis |
|---|---|
| 1 | getNamedItem () Pobiera węzeł określony przez nazwę. |
| 2 | getNamedItemNS () Pobiera węzeł określony przez nazwę lokalną i identyfikator URI przestrzeni nazw. |
| 3 | pozycja () Zwraca indeksowany element na mapie. Jeśli indeks jest większy lub równy liczbie węzłów w tej mapie, zwraca wartość null. |
| 4 | removeNamedItem () Usuwa węzeł określony przez nazwę. |
| 5 | removeNamedItemNS () Usuwa węzeł określony przez lokalną nazwę i identyfikator URI przestrzeni nazw. |
| 6 | setNamedItem () Dodaje węzeł przy użyciu jego atrybutu nodeName . Jeśli węzeł o tej nazwie jest już obecny na tej mapie, zostanie zastąpiony nowym. |
| 7 | setNamedItemNS () Dodaje węzeł przy użyciu jego przestrzeni nazwURI i localName . Jeśli węzeł z tym identyfikatorem URI przestrzeni nazw i tą nazwą lokalną jest już obecny w tej mapie, jest zastępowany nową. Samo zastąpienie węzła nie daje żadnego efektu. |
Obiekt DOMImplementation zapewnia szereg metod wykonywania operacji, które są niezależne od poszczególnych instancji modelu obiektowego dokumentu.
Metody
Poniższa tabela zawiera listę metod obiektu DOMImplementation -
| S.No. | Metoda i opis |
|---|---|
| 1 | createDocument (namespaceURI, QualifiedName, doctype) Tworzy obiekt DOM Document określonego typu wraz z elementem dokumentu. |
| 2 | createDocumentType (QualifiedName, publicId, systemId) Tworzy pusty węzeł DocumentType . |
| 3 | getFeature(feature, version) Ta metoda zwraca wyspecjalizowany obiekt, który implementuje wyspecjalizowane interfejsy API określonej funkcji i wersji. To zostało usunięte. Sprawdź specyfikacje . |
| 4 | hasFeature (funkcja, wersja) Ta metoda sprawdza, czy implementacja DOM implementuje określoną funkcję i wersję. |
Obiekty DocumentType są kluczem do dostępu do danych dokumentu, aw dokumencie atrybut doctype może mieć wartość null lub wartość obiektu DocumentType. Te obiekty DocumentType działają jako interfejs dla jednostek opisanych dla dokumentu XML.
Atrybuty
Poniższa tabela zawiera listę atrybutów obiektu DocumentType -
| Atrybut | Rodzaj | Opis |
|---|---|---|
| Nazwa | DOMString | Zwraca nazwę DTD, która jest zapisywana bezpośrednio obok słowa kluczowego! DOCTYPE. |
| podmioty | NamedNodeMap | Zwraca obiekt NamedNodeMap zawierający ogólne encje, zarówno zewnętrzne, jak i wewnętrzne, zadeklarowane w DTD. |
| notacje | NamedNodeMap | Zwraca NamedNodeMap zawierającą notacje zadeklarowane w DTD. |
| internalSubset | DOMString | Zwraca wewnętrzny podzbiór jako ciąg lub null, jeśli nie ma żadnego. To zostało usunięte. Sprawdź specyfikacje . |
| publicId | DOMString | Zwraca publiczny identyfikator podzbioru zewnętrznego. |
| systemId | DOMString | Zwraca identyfikator systemu zewnętrznego podzbioru. Może to być bezwzględny identyfikator URI lub nie. |
Metody
DocumentType dziedziczy metody ze swojego elementu nadrzędnego, Node , i implementuje interfejs ChildNode .
ProcessingInstruction podaje informacje specyficzne dla aplikacji, które są zwykle zawarte w sekcji prologu dokumentu XML.
Instrukcje przetwarzania (PI) mogą służyć do przekazywania informacji do aplikacji. Punkty PI mogą pojawiać się w dowolnym miejscu dokumentu poza znacznikami. Mogą pojawić się w prologu, w tym w definicji typu dokumentu (DTD), w treści tekstowej lub po dokumencie.
PI zaczyna się od specjalnego znacznika <? i kończy się na ?>. Przetwarzanie treści kończy się natychmiast po napisie?> napotkano.
Atrybuty
Poniższa tabela zawiera listę atrybutów obiektu ProcessingInstruction -
| Atrybut | Rodzaj | Opis |
|---|---|---|
| dane | DOMString | Jest to znak opisujący informacje, które aplikacja ma przetworzyć bezpośrednio poprzedzający znak?>. |
| cel | DOMString | Identyfikuje aplikację, do której skierowana jest instrukcja lub dane. |
Interfejs jednostki reprezentuje znaną jednostkę w dokumencie XML, przeanalizowaną lub nie przeanalizowaną. NodeName atrybut, który jest dziedziczony od węzła zawiera nazwę podmiotu.
Obiekt Entity nie ma żadnego węzła nadrzędnego, a wszystkie jego następcze węzły są tylko do odczytu.
Atrybuty
Poniższa tabela zawiera listę atrybutów obiektu Entity -
| Atrybut | Rodzaj | Opis |
|---|---|---|
| inputEncoding | DOMString | Określa kodowanie używane przez zewnętrzną analizowaną jednostkę. Jego wartość jest null, jeśli jest to jednostka z wewnętrznego podzbioru lub jeśli nie jest znana. |
| notationName | DOMString | W przypadku nieprzeanalizowanych jednostek podaje nazwę notacji, a jej wartość jest pusta dla przeanalizowanych jednostek. |
| publicId | DOMString | Podaje nazwę publicznego identyfikatora związanego z jednostką. |
| systemId | DOMString | Podaje nazwę identyfikatora systemu związanego z jednostką. |
| xmlEncoding | DOMString | Daje kodowanie xml zawarte jako część deklaracji tekstu dla zewnętrznej analizowanej jednostki, w przeciwnym razie null. |
| xmlVersion | DOMString | Daje wersję XML dołączoną jako część deklaracji tekstowej dla zewnętrznej analizowanej jednostki, w przeciwnym razie null. |
Obiekty EntityReference to ogólne odniesienia do encji, które są wstawiane do dokumentu XML, zapewniając zakres w celu zastąpienia tekstu. Obiekt EntityReference nie działa w przypadku wstępnie zdefiniowanych jednostek, ponieważ uważa się, że są one rozszerzane przez HTML lub procesor XML.
Ten interfejs nie ma własnych właściwości ani metod, ale dziedziczy po Node .
W tym rozdziale zajmiemy się obiektem XML DOM Notation . Właściwość obiektu notation zapewnia zakres rozpoznawania formatu elementów z atrybutem notacji, określoną instrukcją przetwarzania lub danymi innymi niż XML. Właściwości i metody obiektu węzła można wykonać na obiekcie Notation, ponieważ jest on również traktowany jako węzeł.
Ten obiekt dziedziczy metody i właściwości z Node . Jego nodeName jest nazwą notacji. Nie ma rodzica.
Atrybuty
Poniższa tabela zawiera listę atrybutów obiektu Notation -
| Atrybut | Rodzaj | Opis |
|---|---|---|
| publicID | DOMString | Podaje nazwę publicznego identyfikatora związanego z zapisem. |
| identyfikator systemowy | DOMString | Podaje nazwę identyfikatora systemu związanego z zapisem. |
Elementy XML można zdefiniować jako bloki konstrukcyjne XML. Elementy mogą zachowywać się jak kontenery zawierające tekst, elementy, atrybuty, obiekty multimedialne lub wszystkie te elementy. Za każdym razem, gdy parser analizuje dokument XML pod kątem jego poprawnego sformułowania, analizator przechodzi przez węzeł elementu. Węzeł elementu zawiera tekst, który jest nazywany węzłem tekstowym.
Obiekt Element dziedziczy właściwości i metody obiektu Node, ponieważ obiekt element jest również uważany za Node. Oprócz właściwości i metod obiektu węzła ma następujące właściwości i metody.
Nieruchomości
Poniższa tabela zawiera listę atrybutów obiektu Element -
| Atrybut | Rodzaj | Opis |
|---|---|---|
| Nazwa znacznika | DOMString | Podaje nazwę tagu dla określonego elementu. |
| schemaTypeInfo | TypeInfo | Reprezentuje informacje o typie skojarzone z tym elementem. To zostało usunięte. Sprawdź specyfikacje . |
Metody
Poniższa tabela zawiera listę metod obiektów elementu -
| Metody | Rodzaj | Opis |
|---|---|---|
| getAttribute () | DOMString | Pobiera wartość atrybutu, jeśli istnieje dla określonego elementu. |
| getAttributeNS () | DOMString | Pobiera wartość atrybutu na podstawie nazwy lokalnej i identyfikatora URI przestrzeni nazw. |
| getAttributeNode () | Attr | Pobiera nazwę węzła atrybutu z bieżącego elementu. |
| getAttributeNodeNS () | Attr | Pobiera węzeł Attr według nazwy lokalnej i identyfikatora URI przestrzeni nazw. |
| getElementsByTagName () | NodeList | Zwraca listę węzłów wszystkich elementów podrzędnych o podanej nazwie znacznika w kolejności dokumentu. |
| getElementsByTagNameNS () | NodeList | Zwraca NodeList wszystkich elementów podrzędnych z podaną nazwą lokalną i identyfikatorem URI przestrzeni nazw w kolejności dokumentu. |
| hasAttribute () | boolean | Zwraca wartość true, gdy atrybut o podanej nazwie jest określony w tym elemencie lub ma wartość domyślną, w przeciwnym razie false. |
| hasAttributeNS () | boolean | Zwraca wartość true, gdy atrybut o danej nazwie lokalnej i identyfikatorze URI przestrzeni nazw jest określony w tym elemencie lub ma wartość domyślną, w przeciwnym razie ma wartość false. |
| removeAttribute () | Brak wartości zwracanej | Usuwa atrybut według nazwy. |
| removeAttributeNS | Brak wartości zwracanej | Usuwa atrybut według nazwy lokalnej i identyfikatora URI przestrzeni nazw. |
| removeAttributeNode () | Attr | Określony węzeł atrybutu jest usuwany z elementu. |
| setAttribute () | Brak wartości zwracanej | Ustawia nową wartość atrybutu dla istniejącego elementu. |
| setAttributeNS () | Brak wartości zwracanej | Dodaje nowy atrybut. Jeśli atrybut o tej samej nazwie lokalnej i identyfikatorze URI przestrzeni nazw jest już obecny w elemencie, jego prefiks jest zmieniany tak, aby był częścią przedrostka QualifiedName, a jego wartość jest zmieniana na parametr value. |
| setAttributeNode () | Attr | Ustawia nowy węzeł atrybutu na istniejący element. |
| setAttributeNodeNS | Attr | Dodaje nowy atrybut. Jeśli atrybut z tą nazwą lokalną i tym identyfikatorem URI przestrzeni nazw jest już obecny w elemencie, jest zastępowany nowym. |
| setIdAttribute | Brak wartości zwracanej | Jeśli parametr isId ma wartość true, ta metoda deklaruje określony atrybut jako atrybut identyfikatora określony przez użytkownika. To zostało usunięte. Sprawdź specyfikacje . |
| setIdAttributeNS | Brak wartości zwracanej | Jeśli parametr isId ma wartość true, ta metoda deklaruje określony atrybut jako atrybut identyfikatora określony przez użytkownika. To zostało usunięte. Sprawdź specyfikacje . |
Interfejs Attr reprezentuje atrybut w obiekcie Element. Zazwyczaj dopuszczalne wartości atrybutu są zdefiniowane w schemacie skojarzonym z dokumentem. Obiekty Attr nie są uważane za część drzewa dokumentu, ponieważ nie są w rzeczywistości węzłami potomnymi elementu, który opisują. Dlatego dla węzłów podrzędnych parentNode , previousSibling i nextSibling wartość atrybutu jest równa null .
Atrybuty
Poniższa tabela zawiera listę atrybutów obiektu Attribute -
| Atrybut | Rodzaj | Opis |
|---|---|---|
| Nazwa | DOMString | To daje nazwę atrybutu. |
| określony | boolean | Jest to wartość logiczna, która zwraca prawdę, jeśli wartość atrybutu istnieje w dokumencie. |
| wartość | DOMString | Zwraca wartość atrybutu. |
| ownerElement | Element | Daje węzeł, z którym powiązany jest atrybut, lub null, jeśli atrybut nie jest używany. |
| isId | boolean | Zwraca, czy atrybut jest typu ID (tzn. Zawiera identyfikator elementu właściciela), czy nie. |
W tym rozdziale zajmiemy się obiektem XML DOM CDATASection . Tekst obecny w dokumencie XML jest analizowany lub nieanalizowany w zależności od tego, co jest zadeklarowane. Jeśli tekst jest zadeklarowany jako Parse Character Data (PCDATA), jest on analizowany przez parser w celu konwersji dokumentu XML na obiekt XML DOM. Z drugiej strony, jeśli tekst jest zadeklarowany jako nieprzetworzone dane znakowe (CDATA), tekst zawarty w nim nie jest analizowany przez parser XML. Nie są one traktowane jako znaczniki i nie powodują rozszerzenia jednostek.
Celem użycia obiektu CDATASection jest uniknięcie bloków tekstu zawierających znaki, które w innym przypadku byłyby traktowane jako znaczniki. "]]>", jest to jedyny separator rozpoznawany w sekcji CDATA, który kończy sekcję CDATA.
Atrybut CharacterData.data zawiera tekst zawarty w sekcji CDATA. Ten interfejs dziedziczy interfejs CharatcterData poprzez interfejs tekstowy .
Dla obiektu CDATASection nie zdefiniowano żadnych metod ani atrybutów. Tylko bezpośrednio implementuje interfejs tekstowy .
W tym rozdziale zajmiemy się obiektem Comment . Komentarze są dodawane jako uwagi lub wiersze w celu zrozumienia celu kodu XML. Komentarze mogą służyć do dołączania powiązanych linków, informacji i terminów. Mogą pojawić się w dowolnym miejscu kodu XML.
Interfejs komentarza dziedziczy interfejs CharacterData reprezentujący treść komentarza.
Składnia
Komentarz XML ma następującą składnię -
<!-------Your comment----->Komentarz zaczyna się od <! - i kończy na ->. Możesz dodawać notatki tekstowe jako komentarze między znakami. Nie możesz zagnieżdżać jednego komentarza w drugim.
Dla obiektu Comment nie zdefiniowano żadnych metod ani atrybutów. Dziedziczy te ze swojego rodzica, CharacterData , i pośrednio te z Node .
Obiekt XMLHttpRequest ustanawia medium między stroną klienta a serwerem strony internetowej, które może być używane przez wiele języków skryptowych, takich jak JavaScript, JScript, VBScript i inne przeglądarki internetowe, do przesyłania i manipulowania danymi XML.
Za pomocą obiektu XMLHttpRequest można aktualizować część strony WWW bez przeładowywania całej strony, żądać i odbierać dane z serwera po załadowaniu strony i wysyłać dane na serwer.
Składnia
Obiekt XMLHttpRequest można wstawiać w następujący sposób -
xmlhttp = new XMLHttpRequest();Aby obsłużyć wszystkie przeglądarki, w tym IE5 i IE6, sprawdź, czy przeglądarka obsługuje obiekt XMLHttpRequest, jak poniżej -
if(window.XMLHttpRequest) // for Firefox, IE7+, Opera, Safari, ... {
xmlHttp = new XMLHttpRequest();
} else if(window.ActiveXObject) // for Internet Explorer 5 or 6 {
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
}Przykłady ładowania pliku XML za pomocą obiektu XMLHttpRequest można znaleźć tutaj
Metody
Poniższa tabela zawiera listę metod obiektu XMLHttpRequest -
| S.No. | Metoda i opis |
|---|---|
| 1 | abort() Kończy bieżące żądanie. |
| 2 | getAllResponseHeaders() Zwraca wszystkie nagłówki odpowiedzi jako ciąg lub wartość null, jeśli nie otrzymano żadnej odpowiedzi. |
| 3 | getResponseHeader() Zwraca ciąg zawierający tekst określonego nagłówka lub wartość null, jeśli odpowiedź nie została jeszcze odebrana lub nagłówek nie istnieje w odpowiedzi. |
| 4 | open(method,url,async,uname,pswd) Jest używany w połączeniu z metodą Send w celu wysłania żądania do serwera. Metoda open określa następujące parametry -
|
| 5 | send(string) Służy do wysyłania żądania działającego w koniugacji z metodą Open. |
| 6 | setRequestHeader() Nagłówek zawiera parę etykieta / wartość, do której wysyłane jest żądanie. |
Atrybuty
Poniższa tabela zawiera listę atrybutów obiektu XMLHttpRequest -
| S.No. | Atrybut i opis |
|---|---|
| 1 | onreadystatechange Jest to właściwość oparta na zdarzeniach, która jest włączana przy każdej zmianie stanu. |
| 2 | readyState Opisuje obecny stan obiektu XMLHttpRequest. Istnieje pięć możliwych stanów właściwości readyState -
|
| 3 | responseText Ta właściwość jest używana, gdy odpowiedź z serwera jest plikiem tekstowym. |
| 4 | responseXML Ta właściwość jest używana, gdy odpowiedź z serwera jest plikiem XML. |
| 5 | status Podaje stan obiektu żądania HTTP jako liczbę. Na przykład „404” lub „200”. |
| 6 | statusText Podaje stan obiektu żądania HTTP jako ciąg. Na przykład „Nie znaleziono” lub „OK”. |
Przykłady
Zawartość node.xml jest jak poniżej -
<?xml version = "1.0"?>
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>[email protected]</Email>
</Employee>
</Company>Pobierz określone informacje o pliku zasobów
Poniższy przykład demonstruje, jak pobrać określone informacje z pliku zasobów za pomocą metody getResponseHeader () i właściwości readState .
<!DOCTYPE html>
<html>
<head>
<meta http-equiv = "content-type" content = "text/html; charset = iso-8859-2" />
<script>
function loadXMLDoc() {
var xmlHttp = null;
if(window.XMLHttpRequest) // for Firefox, IE7+, Opera, Safari, ... {
xmlHttp = new XMLHttpRequest();
}
else if(window.ActiveXObject) // for Internet Explorer 5 or 6 {
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
}
return xmlHttp;
}
function makerequest(serverPage, myDiv) {
var request = loadXMLDoc();
request.open("GET", serverPage);
request.send(null);
request.onreadystatechange = function() {
if (request.readyState == 4) {
document.getElementById(myDiv).innerHTML = request.getResponseHeader("Content-length");
}
}
}
</script>
</head>
<body>
<button type = "button" onclick="makerequest('/dom/node.xml', 'ID')">Click me to get the specific ResponseHeader</button>
<div id = "ID">Specific header information is returned.</div>
</body>
</html>Wykonanie
Zapisz ten plik jako elementattribute_removeAttributeNS.htm w ścieżce serwera (ten plik i node_ns.xml powinny znajdować się w tej samej ścieżce na serwerze). Otrzymamy dane wyjściowe, jak pokazano poniżej -
Before removing the attributeNS: en
After removing the attributeNS: nullPobierz informacje nagłówka pliku zasobów
Poniższy przykład ilustruje sposób pobierania informacji nagłówka pliku zasobów przy użyciu metody getAllResponseHeaders() korzystanie z nieruchomości readyState.
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="content-type" content="text/html; charset=iso-8859-2" />
<script>
function loadXMLDoc() {
var xmlHttp = null;
if(window.XMLHttpRequest) // for Firefox, IE7+, Opera, Safari, ... {
xmlHttp = new XMLHttpRequest();
} else if(window.ActiveXObject) // for Internet Explorer 5 or 6 {
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
}
return xmlHttp;
}
function makerequest(serverPage, myDiv) {
var request = loadXMLDoc();
request.open("GET", serverPage);
request.send(null);
request.onreadystatechange = function() {
if (request.readyState == 4) {
document.getElementById(myDiv).innerHTML = request.getAllResponseHeaders();
}
}
}
</script>
</head>
<body>
<button type = "button" onclick = "makerequest('/dom/node.xml', 'ID')">
Click me to load the AllResponseHeaders</button>
<div id = "ID"></div>
</body>
</html>Wykonanie
Zapisz ten plik jako http_allheader.html na ścieżce serwera (ten plik i node.xml powinny znajdować się w tej samej ścieżce na serwerze). Otrzymamy dane wyjściowe, jak pokazano poniżej (w zależności od przeglądarki) -
Date: Sat, 27 Sep 2014 07:48:07 GMT Server: Apache Last-Modified:
Wed, 03 Sep 2014 06:35:30 GMT Etag: "464bf9-2af-50223713b8a60" Accept-Ranges: bytes Vary: Accept-Encoding,User-Agent
Content-Encoding: gzip Content-Length: 256 Content-Type: text/xmlDOMException oznacza nieprawidłowe zdarzenie dzieje, gdy stosuje się sposób lub właściwości.
Nieruchomości
Poniższa tabela zawiera listę właściwości obiektu DOMException
| S.No. | Właściwość i opis |
|---|---|
| 1 | name Zwraca DOMString, który zawiera jeden z ciągów znaków powiązanych ze stałą błędu (jak pokazano w poniższej tabeli). |
Typy błędów
| S.No. | Typ i opis |
|---|---|
| 1 | IndexSizeError Indeks nie mieści się w dozwolonym zakresie. Na przykład może to zostać wyrzucone przez obiekt Range. (Starsza wartość kodu: 1 i starsza nazwa stałej: INDEX_SIZE_ERR) |
| 2 | HierarchyRequestError Hierarchia drzewa węzłów jest nieprawidłowa. (Starsza wartość kodu: 3 i starsza nazwa stałej: HIERARCHY_REQUEST_ERR) |
| 3 | WrongDocumentError Obiekt znajduje się w złym dokumencie. (Starsza wartość kodu: 4 i starsza nazwa stałej: WRONG_DOCUMENT_ERR) |
| 4 | InvalidCharacterError Ciąg zawiera nieprawidłowe znaki. (Starsza wartość kodu: 5 i starsza nazwa stałej: INVALID_CHARACTER_ERR) |
| 5 | NoModificationAllowedError Obiekt nie może być modyfikowany. (Starsza wartość kodu: 7 i starsza nazwa stałej: NO_MODIFICATION_ALLOWED_ERR) |
| 6 | NotFoundError Nie można tu znaleźć obiektu. (Starsza wartość kodu: 8 i starsza nazwa stałej: NOT_FOUND_ERR) |
| 7 | NotSupportedError Operacja nie jest obsługiwana. (Starsza wartość kodu: 9 i starsza nazwa stałej: NOT_SUPPORTED_ERR) |
| 8 | InvalidStateError Obiekt jest w nieprawidłowym stanie. (Starsza wartość kodu: 11 i starsza nazwa stałej: INVALID_STATE_ERR) |
| 9 | SyntaxError Ciąg nie pasuje do oczekiwanego wzorca. (Starsza wartość kodu: 12 i starsza nazwa stałej: SYNTAX_ERR) |
| 10 | InvalidModificationError Obiekt nie może być w ten sposób modyfikowany. (Starsza wartość kodu: 13 i starsza nazwa stałej: INVALID_MODIFICATION_ERR) |
| 11 | NamespaceError Operacja nie jest dozwolona przez przestrzenie nazw w XML. (Starsza wartość kodu: 14 i starsza nazwa stałej: NAMESPACE_ERR) |
| 12 | InvalidAccessError Obiekt nie obsługuje operacji lub argumentu. (Starsza wartość kodu: 15 i starsza nazwa stałej: INVALID_ACCESS_ERR) |
| 13 | TypeMismatchError Typ obiektu nie odpowiada oczekiwanemu typowi. (Starsza wartość kodu: 17 i starsza nazwa stałej: TYPE_MISMATCH_ERR) Ta wartość jest przestarzała, wyjątek JavaScript TypeError jest teraz zgłaszany zamiast DOMException o tej wartości. |
| 14 | SecurityError Operacja jest niebezpieczna. (Starsza wartość kodu: 18 i starsza nazwa stałej: SECURITY_ERR) |
| 15 | NetworkError Wystąpił błąd sieci. (Starsza wartość kodu: 19 i starsza nazwa stałej: NETWORK_ERR) |
| 16 | AbortError Operacja została przerwana. (Starsza wartość kodu: 20 i starsza nazwa stałej: ABORT_ERR) |
| 17 | URLMismatchError Podany adres URL nie pasuje do innego adresu URL. (Starsza wartość kodu: 21 i starsza nazwa stałej: URL_MISMATCH_ERR) |
| 18 | QuotaExceededError Limit został przekroczony. (Starsza wartość kodu: 22 i starsza nazwa stałej: QUOTA_EXCEEDED_ERR) |
| 19 | TimeoutError Upłynął czas operacji. (Starsza wartość kodu: 23 i starsza nazwa stałej: TIMEOUT_ERR) |
| 20 | InvalidNodeTypeError Węzeł jest nieprawidłowy lub ma nieprawidłowego przodka dla tej operacji. (Starsza wartość kodu: 24 i starsza nazwa stałej: INVALID_NODE_TYPE_ERR) |
| 21 | DataCloneError Nie można sklonować obiektu. (Starsza wartość kodu: 25 i starsza nazwa stałej: DATA_CLONE_ERR) |
| 22 | EncodingError Operacja kodowania, będąca kodowaniem lub dekodowaniem, nie powiodła się (brak starszej wartości kodu i stałej nazwy). |
| 23 | NotReadableError Operacja odczytu wejścia / wyjścia nie powiodła się (brak starszej wartości kodu i stałej nazwy). |
Przykład
Poniższy przykład pokazuje, jak użycie źle sformułowanego dokumentu XML powoduje wyjątek DOMException.
Zawartość error.xml jest jak poniżej -
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?>
<Company id = "companyid">
<Employee category = "Technical" id = "firstelement" type = "text/html">
<FirstName>Tanmay</first>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>[email protected]</Email>
</Employee>
</Company>Poniższy przykład demonstruje użycie atrybutu name -
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
try {
xmlDoc = loadXMLDoc("/dom/error.xml");
var node = xmlDoc.getElementsByTagName("to").item(0);
var refnode = node.nextSibling;
var newnode = xmlDoc.createTextNode('That is why you fail.');
node.insertBefore(newnode, refnode);
} catch(err) {
document.write(err.name);
}
</script>
</body>
</html>Wykonanie
Zapisz ten plik jako domexcption_name.html na ścieżce serwera (ten plik i error.xml powinny znajdować się w tej samej ścieżce na serwerze). Otrzymamy dane wyjściowe, jak pokazano poniżej -
TypeError