Git - podstawowe pojęcia
System kontroli wersji
Version Control System (VCS) to oprogramowanie, które pomaga programistom współpracować i utrzymywać pełną historię ich pracy.
Poniżej wymienione są funkcje VCS -
- Umożliwia programistom jednoczesną pracę.
- Nie pozwala na wzajemne nadpisywanie zmian.
- Zachowuje historię każdej wersji.
Poniżej znajdują się typy VCS -
- Scentralizowany system kontroli wersji (CVCS).
- Rozproszony / zdecentralizowany system kontroli wersji (DVCS).
W tym rozdziale skoncentrujemy się tylko na rozproszonym systemie kontroli wersji, a zwłaszcza na Gicie. Git podlega rozproszonemu systemowi kontroli wersji.
Rozproszony system kontroli wersji
Scentralizowany system kontroli wersji (CVCS) wykorzystuje centralny serwer do przechowywania wszystkich plików i umożliwia współpracę zespołową. Jednak główną wadą CVCS jest pojedynczy punkt awarii, tj. Awaria serwera centralnego. Niestety, jeśli centralny serwer przestanie działać na godzinę, to w ciągu tej godziny nikt nie może w ogóle współpracować. A nawet w najgorszym przypadku, jeśli dysk serwera centralnego ulegnie uszkodzeniu i nie zostanie wykonana właściwa kopia zapasowa, stracisz całą historię projektu. Tutaj pojawia się rozproszony system kontroli wersji (DVCS).
Klienci DVCS nie tylko pobierają najnowszą migawkę katalogu, ale także w pełni odzwierciedlają repozytorium. Jeśli serwer ulegnie awarii, repozytorium dowolnego klienta można skopiować z powrotem na serwer, aby je przywrócić. Każde zamówienie to pełna kopia zapasowa repozytorium. Git nie opiera się na serwerze centralnym, dlatego możesz wykonywać wiele operacji w trybie offline. Możesz zatwierdzać zmiany, tworzyć gałęzie, przeglądać dzienniki i wykonywać inne operacje w trybie offline. Połączenie sieciowe jest potrzebne tylko do publikowania zmian i przyjmowania najnowszych zmian.
Zalety Git
Darmowe i otwarte źródło
Git jest udostępniany na licencji open source GPL. Jest dostępny bezpłatnie w Internecie. Możesz użyć Git do zarządzania projektami nieruchomości bez płacenia ani grosza. Ponieważ jest to oprogramowanie typu open source, możesz pobrać jego kod źródłowy, a także wprowadzić zmiany zgodnie z własnymi wymaganiami.
Szybki i mały
Ponieważ większość operacji jest wykonywana lokalnie, daje to ogromne korzyści pod względem szybkości. Git nie polega na centralnym serwerze; dlatego nie ma potrzeby interakcji ze zdalnym serwerem przy każdej operacji. Podstawowa część Git została napisana w C, co pozwala uniknąć narzutów czasu wykonywania związanych z innymi językami wysokiego poziomu. Chociaż Git odzwierciedla całe repozytorium, rozmiar danych po stronie klienta jest niewielki. To ilustruje skuteczność Gita w kompresji i przechowywaniu danych po stronie klienta.
Niejawna kopia zapasowa
Szanse na utratę danych są bardzo rzadkie, gdy istnieje wiele ich kopii. Dane obecne po dowolnej stronie klienta odzwierciedlają repozytorium, dzięki czemu można je wykorzystać w przypadku awarii lub uszkodzenia dysku.
Bezpieczeństwo
Git używa wspólnej kryptograficznej funkcji skrótu zwanej bezpieczną funkcją skrótu (SHA1) do nazywania i identyfikowania obiektów w swojej bazie danych. Każdy plik i zatwierdzenie jest sumowane i pobierane na podstawie sumy kontrolnej w momencie wyewidencjonowania. Oznacza to, że nie można zmienić pliku, daty i komunikatu zatwierdzenia oraz innych danych z bazy danych Git bez znajomości Gita.
Nie potrzeba potężnego sprzętu
W przypadku CVCS centralny serwer musi być wystarczająco wydajny, aby obsługiwać żądania całego zespołu. W przypadku mniejszych zespołów nie stanowi to problemu, ale wraz ze wzrostem wielkości zespołu ograniczenia sprzętowe serwera mogą stanowić wąskie gardło wydajności. W przypadku DVCS programiści nie współpracują z serwerem, chyba że muszą wypychać lub pobierać zmiany. Cała ciężka praca odbywa się po stronie klienta, więc sprzęt serwera może być naprawdę bardzo prosty.
Łatwiejsze rozgałęzianie
CVCS korzysta z taniego mechanizmu kopiowania, jeśli utworzymy nową gałąź, to skopiuje wszystkie kody do nowej gałęzi, więc jest to czasochłonne i mało wydajne. Ponadto usuwanie i łączenie oddziałów w CVCS jest skomplikowane i czasochłonne. Ale zarządzanie oddziałami za pomocą Gita jest bardzo proste. Tworzenie, usuwanie i łączenie gałęzi zajmuje tylko kilka sekund.
Terminologie DVCS
Repozytorium lokalne
Każde narzędzie VCS zapewnia prywatne miejsce pracy jako kopię roboczą. Deweloperzy wprowadzają zmiany w swoim prywatnym miejscu pracy, a po zatwierdzeniu zmiany te stają się częścią repozytorium. Git idzie o krok dalej, udostępniając prywatną kopię całego repozytorium. Użytkownicy mogą wykonywać wiele operacji w tym repozytorium, takich jak dodawanie pliku, usuwanie pliku, zmiana nazwy pliku, przenoszenie pliku, zatwierdzanie zmian i wiele innych.
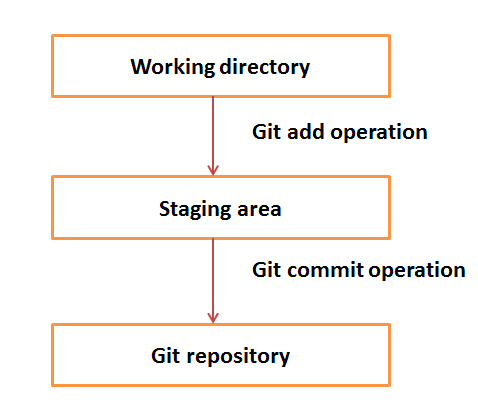
Katalog roboczy i strefa przejściowa lub indeks
Katalog roboczy to miejsce, w którym wypisywane są pliki. W innych CVCS programiści zazwyczaj dokonują modyfikacji i wysyłają zmiany bezpośrednio do repozytorium. Ale Git używa innej strategii. Git nie śledzi każdego zmodyfikowanego pliku. Za każdym razem, gdy wykonujesz operację, Git szuka plików znajdujących się w obszarze przejściowym. Do zatwierdzenia są brane pod uwagę tylko te pliki, które znajdują się w obszarze pomostowym, a nie wszystkie zmodyfikowane pliki.
Zobaczmy podstawowy przepływ pracy w Git.
Step 1 - Modyfikujesz plik z katalogu roboczego.
Step 2 - Dodajesz te pliki do obszaru przemieszczania.
Step 3- Wykonujesz operację zatwierdzenia, która przenosi pliki z obszaru przemieszczania. Po operacji wypychania trwale zapisuje zmiany w repozytorium Git.
Załóżmy, że zmodyfikowałeś dwa pliki, a mianowicie „sort.c” i „search.c” i chcesz mieć dwa różne zatwierdzenia dla każdej operacji. Możesz dodać jeden plik do obszaru przemieszczania i zatwierdzić. Po pierwszym zatwierdzeniu powtórz tę samą procedurę dla innego pliku.
# First commit
[bash]$ git add sort.c
# adds file to the staging area
[bash]$ git commit –m “Added sort operation”
# Second commit
[bash]$ git add search.c
# adds file to the staging area
[bash]$ git commit –m “Added search operation”Bloby
Blob oznacza Binary Large Object. Każda wersja pliku jest reprezentowana przez obiekt BLOB. Obiekt BLOB przechowuje dane pliku, ale nie zawiera żadnych metadanych dotyczących pliku. Jest to plik binarny, który w bazie danych Git nosi nazwę skrótu SHA1 tego pliku. W Gicie pliki nie są adresowane za pomocą nazw. Wszystko jest zaadresowane merytorycznie.
Drzewa
Drzewo to obiekt, który reprezentuje katalog. Przechowuje obiekty blob, a także inne podkatalogi. Drzewo to plik binarny, który przechowuje odniesienia do obiektów blob i drzew, które są również nazywane jakoSHA1 skrót obiektu drzewa.
Commits
Commit przechowuje bieżący stan repozytorium. Zatwierdzenie jest również nazwane przezSHA1haszysz. Obiekt zatwierdzenia można traktować jako węzeł połączonej listy. Każdy obiekt zatwierdzenia ma wskaźnik do nadrzędnego obiektu zatwierdzenia. Z danego zatwierdzenia możesz cofnąć się, patrząc na wskaźnik nadrzędny, aby wyświetlić historię zatwierdzenia. Jeśli zatwierdzenie ma wiele zatwierdzeń nadrzędnych, to konkretne zatwierdzenie zostało utworzone przez połączenie dwóch gałęzi.
Gałęzie
Gałęzie służą do stworzenia kolejnej linii rozwoju. Domyślnie Git ma gałąź główną, która jest taka sama jak trunk w Subversion. Zwykle gałąź jest tworzona do pracy nad nową funkcją. Po zakończeniu funkcji jest ona ponownie scalana z gałęzią główną i usuwamy gałąź. Do każdej gałęzi odwołuje się HEAD, który wskazuje na najnowsze zatwierdzenie w gałęzi. Za każdym razem, gdy dokonujesz zatwierdzenia, HEAD jest aktualizowany najnowszym zatwierdzeniem.
Tagi
Znacznik przypisuje znaczącą nazwę z określoną wersją w repozytorium. Tagi są bardzo podobne do gałęzi, ale różnica polega na tym, że tagi są niezmienne. Oznacza to, że tag to gałąź, której nikt nie zamierza modyfikować. Po utworzeniu znacznika dla konkretnego zatwierdzenia, nawet jeśli utworzysz nowe zatwierdzenie, nie zostanie on zaktualizowany. Zwykle programiści tworzą tagi dla wydań produktów.
Klonuj
Operacja klonowania tworzy instancję repozytorium. Operacja klonowania nie tylko pobiera kopię roboczą, ale także odzwierciedla całe repozytorium. Użytkownicy mogą wykonywać wiele operacji w tym repozytorium lokalnym. Jedyny przypadek, w którym zaangażowana jest sieć, ma miejsce, gdy instancje repozytorium są synchronizowane.
Ciągnąć
Operacja ściągania kopiuje zmiany ze zdalnego wystąpienia repozytorium do lokalnego. Operacja ściągania służy do synchronizacji między dwoma wystąpieniami repozytorium. To jest to samo, co operacja aktualizacji w Subversion.
Pchać
Operacja wypychania kopiuje zmiany z instancji repozytorium lokalnego do instancji zdalnej. Służy do trwałego przechowywania zmian w repozytorium Git. To jest to samo, co operacja zatwierdzenia w Subversion.
GŁOWA
HEAD to wskaźnik, który zawsze wskazuje na najnowsze zatwierdzenie w gałęzi. Za każdym razem, gdy dokonujesz zatwierdzenia, HEAD jest aktualizowany najnowszym zatwierdzeniem. Główki gałęzi są przechowywane w.git/refs/heads/ informator.
[CentOS]$ ls -1 .git/refs/heads/
master
[CentOS]$ cat .git/refs/heads/master
570837e7d58fa4bccd86cb575d884502188b0c49Rewizja
Wersja reprezentuje wersję kodu źródłowego. Zmiany w Git są reprezentowane przez zatwierdzenia. Te zatwierdzenia są identyfikowane przezSHA1 bezpieczne skróty.
URL
URL reprezentuje lokalizację repozytorium Git. Adres URL Gita jest przechowywany w pliku konfiguracyjnym.
[tom@CentOS tom_repo]$ pwd
/home/tom/tom_repo
[tom@CentOS tom_repo]$ cat .git/config
[core]
repositoryformatversion = 0
filemode = true
bare = false
logallrefupdates = true
[remote "origin"]
url = [email protected]:project.git
fetch = +refs/heads/*:refs/remotes/origin/*