KDB + - Szybki przewodnik
To jest kompletna instrukcja kdb+z systemów kx, skierowany przede wszystkim do osób uczących się samodzielnie. kdb +, wprowadzony w 2003 r., to nowa generacja bazy danych kdb, która służy do przechwytywania, analizowania, porównywania i przechowywania danych.
System kdb + zawiera dwa następujące komponenty -
KDB+ - baza danych (k database plus)
Q - język programowania do pracy z kdb +
Obie kdb+ i q są zapisane k programming language (taki sam jak q ale mniej czytelne).
tło
Kdb + / q powstał jako mało znany język akademicki, ale z biegiem lat stopniowo poprawiał swoją przyjazność dla użytkownika.
APL (1964, język programowania)
A+ (1988, zmodyfikowany APL autorstwa Arthura Whitneya)
K (1993, ostra wersja A +, opracowana przez A.Whitneya)
Kdb (1998, baza danych oparta na kolumnach w pamięci)
Kdb+/q (2003, język q - bardziej czytelna wersja k)
Dlaczego i gdzie używać KDB +
Czemu? - Jeśli potrzebujesz jednego rozwiązania do danych w czasie rzeczywistym z analityką, powinieneś rozważyć kdb +. Kdb + przechowuje bazę danych jako zwykłe pliki natywne, więc nie ma żadnych specjalnych wymagań dotyczących sprzętu i architektury pamięci. Warto zaznaczyć, że baza danych to tylko zbiór plików, więc Twoja praca administracyjna nie będzie trudna.
Gdzie używać KDB +?- Łatwo policzyć, które banki inwestycyjne NIE używają kdb +, ponieważ większość z nich używa obecnie lub planuje przejście z konwencjonalnych baz danych na kdb +. Ponieważ ilość danych rośnie z dnia na dzień, potrzebujemy systemu, który może obsługiwać ogromne ilości danych. KDB + spełnia ten wymóg. KDB + nie tylko przechowuje ogromną ilość danych, ale także analizuje je w czasie rzeczywistym.
Pierwsze kroki
Mając na tyle dużo informacji, przejdźmy teraz do omówienia i nauczmy się, jak skonfigurować środowisko dla KDB +. Zaczniemy od tego, jak pobrać i zainstalować KDB +.
Pobieranie i instalowanie KDB +
Bezpłatną 32-bitową wersję KDB + z wszystkimi funkcjami wersji 64-bitowej można pobrać z witryny http://kx.com/software-download.php
Zgadzam się z umową licencyjną, wybierz system operacyjny (dostępny dla wszystkich głównych systemów operacyjnych). W przypadku systemu operacyjnego Windows najnowsza wersja to 3.2. Pobierz najnowszą wersję. Po rozpakowaniu otrzymasz nazwę folderu“windows” a wewnątrz folderu Windows otrzymasz kolejny folder “q”. Skopiuj całośćq folder na dysk c: /.
Otwórz terminal Uruchom, wpisz lokalizację, w której przechowujesz plik qteczka; będzie wyglądać jak „c: /q/w32/q.exe”. Po naciśnięciu Enter otrzymasz nową konsolę w następujący sposób -
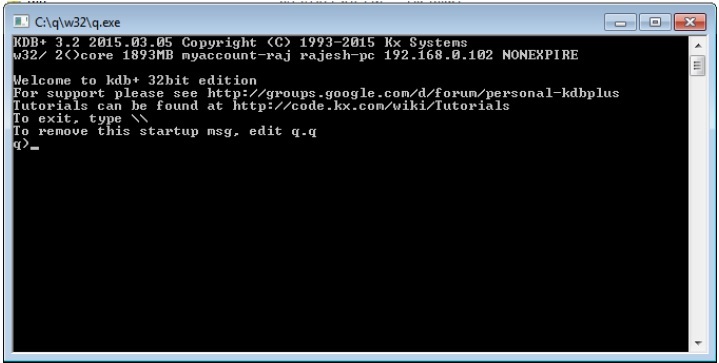
W pierwszym wierszu można zobaczyć numer wersji 3.2 i datę wydania 2015.03.05
Układ katalogów
Wersja próbna / bezpłatna jest zwykle instalowana w katalogach,
For linux/Mac −
~/q / main q directory (under the user’s home)
~/q/l32 / location of linux 32-bit executable
~/q/m32 / Location of mac 32-bit executableFor Windows −
c:/q / Main q directory
c:/q/w32/ / Location of windows 32-bit executableExample Files −
Po pobraniu kdb + struktura katalogów na platformie Windows wyglądałaby następująco -
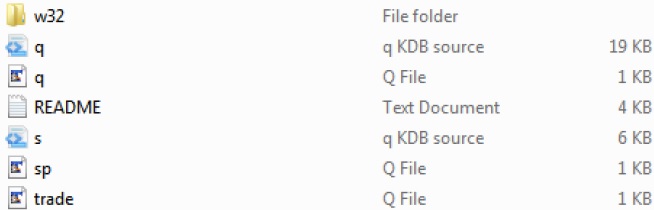
W powyższej strukturze katalogów trade.q i sp.q to przykładowe pliki, których możemy użyć jako punktu odniesienia.
Kdb + to wysokowydajna baza danych o dużej objętości, zaprojektowana od samego początku do obsługi ogromnych ilości danych. Jest w pełni 64-bitowy i ma wbudowane przetwarzanie wielordzeniowe i wielowątkowość. Ta sama architektura jest używana do danych w czasie rzeczywistym i danych historycznych. Baza danych zawiera własny, zaawansowany język zapytań,q, więc analizy można przeprowadzać bezpośrednio na danych.
kdb+tick to architektura, która umożliwia przechwytywanie, przetwarzanie i przeszukiwanie danych historycznych i w czasie rzeczywistym.
Architektura Kdb + / tick
Poniższa ilustracja przedstawia ogólny zarys typowej architektury Kdb + / tick, po którym następuje krótkie wyjaśnienie różnych składników i przepływu danych.
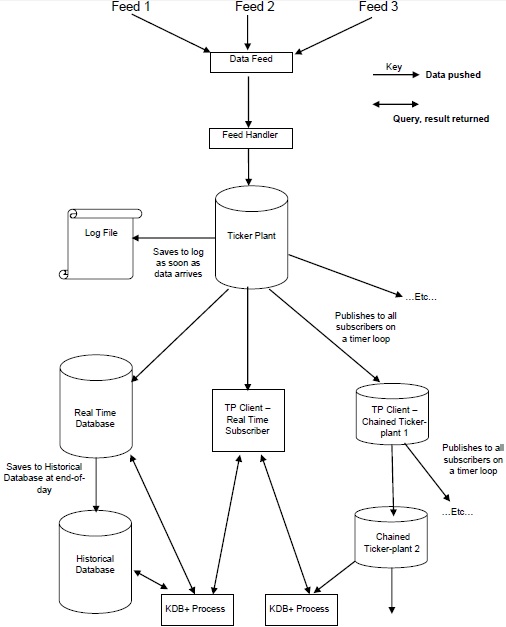
Plik Data Feeds to dane szeregów czasowych, które są głównie dostarczane przez dostawców danych, takich jak Reuters, Bloomberg, lub bezpośrednio z giełd.
Aby uzyskać odpowiednie dane, dane z pliku danych są analizowane przez feed handler.
Gdy dane zostaną przeanalizowane przez program obsługi kanału, trafiają do pliku ticker-plant.
Aby odzyskać dane z jakiejkolwiek awarii, ticker-plant najpierw aktualizuje / przechowuje nowe dane w pliku dziennika, a następnie aktualizuje własne tabele.
Po zaktualizowaniu wewnętrznych tabel i plików dziennika, dane pętli czasu są w sposób ciągły przesyłane / publikowane do bazy danych czasu rzeczywistego i wszystkich połączonych abonentów, którzy zażądali danych.
Pod koniec dnia roboczego plik dziennika jest usuwany, tworzony jest nowy, a baza danych czasu rzeczywistego jest zapisywana w bazie danych historycznych. Po zapisaniu wszystkich danych w historycznej bazie danych baza danych czasu rzeczywistego czyści swoje tabele.
Komponenty architektury Kdb + Tick
Źródła danych
Źródłami danych mogą być dowolne dane rynkowe lub inne dane szeregów czasowych. Traktuj źródła danych jako nieprzetworzone dane wejściowe do programu obsługi kanału. Kanały mogą pochodzić bezpośrednio z giełdy (dane przesyłane strumieniowo na żywo), od dostawców wiadomości / danych, takich jak Thomson-Reuters, Bloomberg lub inne agencje zewnętrzne.
Feed Handler
Program obsługi kanału konwertuje strumień danych na format odpowiedni do zapisu w kdb +. Jest podłączony do źródła danych i pobiera i konwertuje dane z formatu specyficznego dla kanału na komunikat Kdb +, który jest publikowany w procesie ticker-plant. Zwykle program obsługi paszy służy do wykonywania następujących operacji -
- Przechwytuj dane zgodnie z zestawem reguł.
- Przetłumacz (/ wzbogacaj) te dane z jednego formatu na inny.
- Złap najnowsze wartości.
Ticker Plant
Ticker Plant jest najważniejszym elementem architektury KDB +. Jest to zakład ticker, z którym połączona jest baza danych czasu rzeczywistego lub bezpośrednio abonenci (klienci) w celu uzyskania dostępu do danych finansowych. Działa wpublish and subscribemechanizm. Po uzyskaniu subskrypcji (licencji) definiowana jest (rutynowo) publikacja od wydawcy (zakładka ticker). Wykonuje następujące operacje -
Odbiera dane z modułu obsługi kanału.
Natychmiast po otrzymaniu danych przez zakład tickera przechowuje kopię jako plik dziennika i aktualizuje go, gdy fabryka notowań otrzyma jakąkolwiek aktualizację, aby w przypadku jakiejkolwiek awarii nie doszło do utraty danych.
Klienci (abonent w czasie rzeczywistym) mogą bezpośrednio subskrybować zakład ticker.
Pod koniec każdego dnia roboczego, tj. Gdy baza danych czasu rzeczywistego otrzyma ostatnią wiadomość, przechowuje wszystkie dzisiejsze dane w bazie danych historycznych i przekazuje je wszystkim subskrybentom, którzy zapisali się na dzisiejsze dane. Następnie resetuje wszystkie swoje tabele. Plik dziennika jest również usuwany, gdy dane są przechowywane w historycznej bazie danych lub innym bezpośrednio powiązanym abonencie bazy danych czasu rzeczywistego (rtdb).
W rezultacie fabryka tickerów, baza danych czasu rzeczywistego i baza danych historycznych działają 24 godziny na dobę, 7 dni w tygodniu.
Ponieważ zakład-ticker jest aplikacją Kdb +, jego tabele można przeszukiwać za pomocą qjak każda inna baza danych Kdb +. Wszyscy klienci systemu ticker powinni mieć dostęp do bazy danych tylko jako subskrybenci.
Baza danych czasu rzeczywistego
Baza danych czasu rzeczywistego (rdb) przechowuje dzisiejsze dane. Jest bezpośrednio połączony z zakładem giełdowym. Zwykle byłby przechowywany w pamięci w godzinach rynkowych (dzień) i zapisywany do historycznej bazy danych (hdb) pod koniec dnia. Ponieważ dane (dane rdb) są przechowywane w pamięci, przetwarzanie jest niezwykle szybkie.
Ponieważ kdb + zaleca, aby rozmiar pamięci RAM był cztery lub więcej razy większy od oczekiwanego rozmiaru danych dziennie, zapytanie uruchamiane na rdb jest bardzo szybkie i zapewnia doskonałą wydajność. Ponieważ baza danych czasu rzeczywistego zawiera tylko dzisiejsze dane, kolumna daty (parametr) nie jest wymagana.
Na przykład możemy mieć zapytania rdb, takie jak,
select from trade where sym = `ibm
OR
select from trade where sym = `ibm, price > 100Historyczna baza danych
Jeśli musimy obliczyć szacunki firmy, musimy mieć dostępne jej dane historyczne. Historyczna baza danych (HDB) zawiera dane o transakcjach przeprowadzonych w przeszłości. Rekord każdego nowego dnia był dodawany do hdb pod koniec dnia. Duże tabele na dysku twardym są albo przechowywane rozproszone (każda kolumna jest przechowywana we własnym pliku), albo są przechowywane na partycjach według danych czasowych. Również niektóre bardzo duże bazy danych mogą być dalej partycjonowane przy użyciupar.txt (plik).
Te strategie przechowywania (podzielone, podzielone na partycje itp.) Są wydajne podczas wyszukiwania lub uzyskiwania dostępu do danych z dużej tabeli.
Historyczną bazę danych można również wykorzystać do celów raportowania wewnętrznego i zewnętrznego, tj. Do celów analitycznych. Na przykład, przypuśćmy, że chcemy uzyskać transakcje firmy IBM na określony dzień z nazwy tabeli transakcji (lub dowolnej), musimy napisać zapytanie w następujący sposób -
thisday: 2014.10.12
select from trade where date = thisday, sym =`ibmNote - Napiszemy wszystkie takie zapytania, gdy uzyskamy przegląd q język.
Kdb + ma wbudowany język programowania, znany jako q. Zawiera nadzbiór standardowego SQL, który jest rozszerzony o analizę szeregów czasowych i oferuje wiele zalet w porównaniu ze standardową wersją. Każdy, kto zna SQL, może się nauczyćq w ciągu kilku dni i móc szybko pisać własne zapytania ad hoc.
Uruchamianie środowiska „q”
Aby rozpocząć korzystanie z kdb +, musisz uruchomić qsesja. Istnieją trzy sposoby, aby rozpocząćq sesja -
Po prostu wpisz „c: /q/w32/q.exe” w terminalu uruchamiania.
Uruchom terminal poleceń MS-DOS i wpisz q.
Skopiuj plik q.exe plik do „C: \ Windows \ System32” i na terminalu uruchamiania, po prostu wpisz „q”.
Tutaj zakładamy, że pracujesz na platformie Windows.
Typy danych
Poniższa tabela zawiera listę obsługiwanych typów danych -
| Nazwa | Przykład | Zwęglać | Rodzaj | Rozmiar |
|---|---|---|---|---|
| boolean | 1b | b | 1 | 1 |
| bajt | 0xff | x | 4 | 1 |
| krótki | 23h | godz | 5 | 2 |
| int | 23i | ja | 6 | 4 |
| długo | 23j | jot | 7 | 8 |
| real | 2.3e | mi | 8 | 4 |
| pływak | 2.3f | fa | 9 | 8 |
| zwęglać | "za" | do | 10 | 1 |
| varchar | `ab | s | 11 | * |
| miesiąc | 2003.03m | m | 13 | 4 |
| data | 2015.03.17T18: 01: 40.134 | z | 15 | 8 |
| minuta | 08:31 | u | 17 | 4 |
| druga | 08:31:53 | v | 18 | 4 |
| czas | 18: 03: 18.521 | t | 19 | 4 |
| enum | `u $` b, gdzie u: `a`b | * | 20 | 4 |
Tworzenie atomów i list
Atomy to pojedyncze byty, np. Pojedyncza liczba, znak lub symbol. W powyższej tabeli (dla różnych typów danych) wszystkie obsługiwane typy danych to atomy. Lista to sekwencja atomów lub innych typów, w tym listy.
Przekazanie atomu dowolnego typu do funkcji typu monadycznego (tj. Funkcji jednoargumentowej) zwróci wartość ujemną, tj. –n, podczas gdy przekazanie prostej listy tych atomów do funkcji typu zwróci wartość dodatnią n.
Przykład 1 - Tworzenie atomu i listy
/ Note that the comments begin with a slash “ / ” and cause the parser
/ to ignore everything up to the end of the line.
x: `mohan / `mohan is a symbol, assigned to a variable x
type x / let’s check the type of x
-11h / -ve sign, because it’s single element.
y: (`abc;`bca;`cab) / list of three symbols, y is the variable name.
type y
11h / +ve sign, as it contain list of atoms (symbol).
y1: (`abc`bca`cab) / another way of writing y, please note NO semicolon
y2: (`$”symbols may have interior blanks”) / string to symbol conversion
y[0] / return `abc
y 0 / same as y[0], also returns `abc
y 0 2 / returns `abc`cab, same as does y[0 2]
z: (`abc; 10 20 30; (`a`b); 9.9 8.8 7.7) / List of different types,
z 2 0 / returns (`a`b; `abc),
z[2;0] / return `a. first element of z[2]
x: “Hello World!” / list of character, a string
x 4 0 / returns “oH” i.e. 4th and 0th(first)
elementCzęsto wymagana jest zmiana typu danych niektórych danych z jednego typu na inny. Standardową funkcją rzutowania jest „$”dyadic operator.
Trzy podejścia są używane do rzutowania z jednego typu na inny (z wyjątkiem stringów) -
- Określ żądany typ danych, podając jego nazwę symbolu
- Określ żądany typ danych za pomocą jego znaku
- Określ żądany typ danych za pomocą krótkiej wartości.
Rzutowanie liczb całkowitych na zmiennoprzecinkowe
W poniższym przykładzie rzutowania liczb całkowitych na zmiennoprzecinkowe wszystkie trzy różne sposoby rzutowania są równoważne -
q)a:9 18 27
q)$[`float;a] / Specify desired data type by its symbol name, 1st way
9 18 27f
q)$["f";a] / Specify desired data type by its character, 2nd way
9 18 27f
q)$[9h;a] / Specify desired data type by its short value, 3rd way
9 18 27fSprawdź, czy wszystkie trzy operacje są równoważne,
q)($[`float;a]~$["f";a]) and ($[`float;a] ~ $[9h;a])
1bRzutowanie łańcuchów na symbole
Rzutowanie ciągu znaków na symbole i odwrotnie działa nieco inaczej. Sprawdźmy to na przykładzie -
q)b: ("Hello";"World";"HelloWorld") / define a list of strings
q)b
"Hello"
"World"
"HelloWorld"
q)c: `$b / this is how to cast strings to symbols
q)c / Now c is a list of symbols
`Hello`World`HelloWorldPróba rzutowania ciągów na symbole przy użyciu słów kluczowych `symbol lub 11h zakończy się niepowodzeniem z błędem typu -
q)b
"Hello"
"World"
"HelloWorld"
q)`symbol$b
'type
q)11h$b
'typeRzutowanie łańcuchów na symbole niebędące symbolami
Rzutowanie ciągów na typ danych inny niż symbol odbywa się w następujący sposób -
q)b:900 / b contain single atomic integer
q)c:string b / convert this integer atom to string “900”
q)c
"900"
q)`int $ c / converting string to integer will return the
/ ASCII equivalent of the character “9”, “0” and
/ “0” to produce the list of integer 57, 48 and
/ 48.
57 48 48i
q)6h $ c / Same as above 57 48 48i q)"i" $ c / Same a above
57 48 48i
q)"I" $ c
900iZatem rzutowanie całego ciągu (listy znaków) na pojedynczy atom typu danych x wymaga od nas określenia dużej litery reprezentującej typ danych x jako pierwszy argument do $operator. Jeśli określisz typ danychx w inny sposób powoduje to, że rzutowanie jest stosowane do każdego znaku ciągu.
Plik q język ma wiele różnych sposobów przedstawiania i manipulowania danymi czasowymi, takimi jak godziny i daty.
Data
Data w kdb + jest wewnętrznie przechowywana jako całkowita liczba dni od naszej daty odniesienia to 01 stycznia 2000. Data po tej dacie jest wewnętrznie przechowywana jako liczba dodatnia, a data przed nią jest określana jako liczba ujemna.
Domyślnie data jest zapisywana w formacie „RRRR.MM.DD”
q)x:2015.01.22 / This is how we write 22nd Jan 2015
q)`int$x / Number of days since 2000.01.01 5500i q)`year$x / Extracting year from the date
2015i
q)x.year / Another way of extracting year
2015i
q)`mm$x / Extracting month from the date 1i q)x.mm / Another way of extracting month 1i q)`dd$x / Extracting day from the date
22i
q)x.dd / Another way of extracting day
22iArithmetic and logical operations można wykonać bezpośrednio na datach.
q)x+1 / Add one day
2015.01.23
q)x-7 / Subtract 7 days
2015.01.151 stycznia 2000 roku wypadł w sobotę. Dlatego każda sobota w historii lub w przyszłości podzielona przez 7 dałaby resztę 0, w niedzielę 1, w poniedziałek 2.
Day mod 7
Saturday 0
Sunday 1
Monday 2
Tuesday 3
Wednesday 4
Thursday 5
Friday 6Czasy
Czas jest wewnętrznie przechowywany jako całkowita liczba milisekund od wybicia o północy. Godzina jest zapisywana w formacie GG: MM: SS.MSS
q)tt1: 03:30:00.000 / tt1 store the time 03:30 AM
q)tt1
03:30:00.000
q)`int$tt1 / Number of milliseconds in 3.5 hours 12600000i q)`hh$tt1 / Extract the hour component from time
3i
q)tt1.hh
3i
q)`mm$tt1 / Extract the minute component from time 30i q)tt1.mm 30i q)`ss$tt1 / Extract the second component from time
0i
q)tt1.ss
0iPodobnie jak w przypadku dat, arytmetyka może być wykonywana bezpośrednio na czasach.
Datetimes
Data i godzina to połączenie daty i godziny, oddzielone znakiem „T”, jak w standardowym formacie ISO. Wartość data-godzina przechowuje ułamkową liczbę dni od północy 1 stycznia 2000 r.
q)dt:2012.12.20T04:54:59:000 / 04:54.59 AM on 20thDec2012
q)type dt
-15h
q)dt
2012.12.20T04:54:59.000
9
q)`float$dt
4737.205Podstawową ułamkową liczbę dni można uzyskać, rzucając na float.
Listy to podstawowe elementy składowe q language, więc dokładne zrozumienie list jest bardzo ważne. Lista to po prostu uporządkowany zbiór atomów (pierwiastków atomowych) i inne listy (grupa jednego lub więcej atomów).
Rodzaje list
ZA general listzamyka swoje elementy w pasujących nawiasach i oddziela je średnikami. Na przykład -
(9;8;7) or ("a"; "b"; "c") or (-10.0; 3.1415e; `abcd; "r")Jeśli lista zawiera atomy tego samego typu, jest nazywana uniform list. W przeciwnym razie jest znany jakogeneral list (typ mieszany).
Liczyć
Liczbę pozycji na liście możemy uzyskać poprzez jej liczbę.
q)l1:(-10.0;3.1415e;`abcd;"r") / Assigning variable name to general list
q)count l1 / Calculating number of items in the list l1
4Przykłady prostej listy
q)h:(1h;2h;255h) / Simple Integer List
q)h
1 2 255h
q)f:(123.4567;9876.543;98.7) / Simple Floating Point List
q)f
123.4567 9876.543 98.7
q)b:(0b;1b;0b;1b;1b) / Simple Binary Lists
q)b
01011b
q)symbols:(`Life;`Is;`Beautiful) / Simple Symbols List
q)symbols
`Life`Is`Beautiful
q)chars:("h";"e";"l";"l";"o";" ";"w";"o";"r";"l";"d")
/ Simple char lists and Strings.
q)chars
"hello world"**Note − A simple list of char is called a string.
Lista zawiera atomy lub listy. To create a single item listużywamy -
q)singleton:enlist 42
q)singleton
,42To distinguish between an atom and the equivalent singletonsprawdź znak ich typu.
q)signum type 42
-1i
q)signum type enlist 42
1iLista jest uporządkowana od lewej do prawej według pozycji jej elementów. Przesunięcie elementu od początku listy nazywa się jegoindex. Tak więc pierwsza pozycja ma indeks 0, druga pozycja (jeśli istnieje) ma indeks 1 itd. Lista licznikówn ma domenę indeksu od 0 do n–1.
Notacja indeksowa
Biorąc pod uwagę listę L, pozycja w indeksie i jest dostępny przez L[i]. Nazywa się pobieranie elementu według jego indeksuitem indexing. Na przykład,
q)L:(99;98.7e;`b;`abc;"z")
q)L[0]
99
q)L[1]
98.7e
q)L[4]
"zPrzypisanie indeksowane
Pozycje na liście można również przypisywać poprzez indeksowanie elementów. A zatem,
q)L1:9 8 7
q)L1[2]:66 / Indexed assignment into a simple list
/ enforces strict type matching.
q)L1
9 8 66Listy ze zmiennych
q)l1:(9;8;40;200)
q)l2:(1 4 3; `abc`xyz)
q)l:(l1;l2) / combining the two list l1 and l2
q)l
9 8 40 200
(1 4 3;`abc`xyz)Dołączanie do list
Najczęstszą operacją na dwóch listach jest ich połączenie w celu utworzenia większej listy. Dokładniej, operator łączenia (,) dołącza prawy operand na końcu lewego operandu i zwraca wynik. Akceptuje atom w każdym argumencie.
q)1,2 3 4
1 2 3 4
q)1 2 3, 4.4 5.6 / If the arguments are not of uniform type,
/ the result is a general list.
1
2
3
4.4
5.6Zagnieżdżanie
Złożoność danych jest budowana przy użyciu list jako elementów list.
Głębokość
Liczba poziomów zagnieżdżenia listy nazywana jest jej głębokością. Atomy mają głębokość 0, a proste listy mają głębokość 1.
q)l1:(9;8;(99;88))
q)count l1
3Oto lista głębokości 3 z dwoma elementami -
q)l5
9
(90;180;900 1800 2700 3600)
q)count l5
2
q)count l5[1]
3Indeksowanie na głębokości
Możliwe jest indeksowanie bezpośrednio do pozycji zagnieżdżonej listy.
Repeated Item Indexing
Pobieranie elementu za pośrednictwem pojedynczego indeksu zawsze powoduje pobranie elementu znajdującego się najwyżej z zagnieżdżonej listy.
q)L:(1;(100;200;(300;400;500;600)))
q)L[0]
1
q)L[1]
100
200
300 400 500 600Ponieważ wynik L[1] sama jest listą, możemy pobrać jej elementy za pomocą jednego indeksu.
q)L[1][2]
300 400 500 600Możemy powtórzyć pojedyncze indeksowanie jeszcze raz, aby pobrać element z najbardziej wewnętrznej zagnieżdżonej listy.
q)L[1][2][0]
300Możesz to przeczytać jako:
Pobierz element o indeksie 1 od L i z niego pobierz element o indeksie 2, a następnie pobierz element o indeksie 0.
Notation for Indexing at Depth
Istnieje alternatywna notacja do wielokrotnego indeksowania elementów listy zagnieżdżonej. Ostatnie pobranie można również zapisać jako:
q)L[1;2;0]
300Przypisywanie za pomocą indeksu działa również na głębokości.
q)L[1;2;1]:900
q)L
1
(100;200;300 900 500 600)Indeksy Elided
Eliding Indices for a General List
q)L:((1 2 3; 4 5 6 7); (`a`b`c;`d`e`f`g;`0`1`2);("good";"morning"))
q)L
(1 2 3;4 5 6 7)
(`a`b`c;`d`e`f`g;`0`1`2)
("good";"morning")
q)L[;1;]
4 5 6 7
`d`e`f`g
"morning"
q)L[;;2]
3 6
`c`f`2
"or"Interpret L[;1;] as,
Pobierz wszystkie elementy z drugiej pozycji każdej listy na najwyższym poziomie.
Interpret L[;;2] as,
Pobierz elementy na trzeciej pozycji dla każdej listy na drugim poziomie.
Słowniki są rozszerzeniem list, które stanowią podstawę tworzenia tabel. W terminologii matematycznej słownik tworzy rozszerzenie
„Domena → zakres”
lub ogólnie (krótko) tworzy
„Klucz → wartość”
związek między elementami.
Słownik to uporządkowany zbiór par klucz-wartość, który jest z grubsza równoważny z tablicą skrótów. Słownik to odwzorowanie zdefiniowane przez jawne powiązanie we / wy między listą domen a listą zakresów za pośrednictwem korespondencji pozycyjnej. Tworzenie słownika używa prymitywu „xkey” (!)
ListOfDomain ! ListOfRangeNajbardziej podstawowy słownik odwzorowuje prostą listę na prostą listę.
| Wejście (I) | Wyjście (O) |
|---|---|
| Imię | John |
| `Wiek | 36 |
| `` Seks | „M” |
| Waga | 60.3 |
q)d:`Name`Age`Sex`Weight!(`John;36;"M";60.3) / Create a dictionary d
q)d
Name | `John
Age | 36
Sex | "M"
Weight | 60.3
q)count d / To get the number of rows in a dictionary.
4
q)key d / The function key returns the domain
`Name`Age`Sex`Weight
q)value d / The function value returns the range.
`John
36
"M"
60.3
q)cols d / The function cols also returns the domain.
`Name`Age`Sex`WeightWyszukaj
Nazywa się wyszukiwanie słownika wartości wyjściowej odpowiadającej wartości wejściowej looking up wejście.
q)d[`Name] / Accessing the value of domain `Name
`John
q)d[`Name`Sex] / extended item-wise to a simple list of keys
`John
"M"Wyszukaj za pomocą Verb @
q)d1:`one`two`three!9 18 27
q)d1[`two]
18
q)d1@`two
18Operacje na słownikach
Amend and Upsert
Podobnie jak w przypadku list, elementy słownika mogą być modyfikowane poprzez przypisanie indeksowane.
d:`Name`Age`Sex`Weight! (`John;36;"M";60.3)
/ A dictionary d
q)d[`Age]:35 / Assigning new value to key Age
q)d
/ New value assigned to key Age in d
Name | `John
Age | 35
Sex | "M"
Weight | 60.3Słowniki można rozszerzać poprzez przypisywanie indeksów.
q)d[`Height]:"182 Ft"
q)d
Name | `John
Age | 35
Sex | "M"
Weight | 60.3
Height | "182 Ft"Wyszukiwanie wsteczne z funkcją Find (?)
Operator find (?) Służy do wyszukiwania wstecznego poprzez mapowanie zakresu elementów na jego element domeny.
q)d2:`x`y`z!99 88 77
q)d2?77
`zW przypadku, gdy elementy listy nie są unikatowe, rozszerzenie find zwraca mapowanie pierwszego elementu z listy domen.
Usuwanie wpisów
Aby usunąć wpis ze słownika, rozszerzenie delete ( _ ) functionjest używany. Lewy operand (_) to słownik, a prawy operand to wartość klucza.
q)d2:`x`y`z!99 88 77
q)d2 _`z
x| 99
y| 88Jeśli pierwszy operand jest zmienną, po lewej stronie _ jest wymagany odstęp.
q)`x`y _ d2 / Deleting multiple entries
z| 77Słowniki kolumnowe
Podstawą tworzenia tabel są słowniki kolumnowe. Rozważmy następujący przykład -
q)scores: `name`id!(`John`Jenny`Jonathan;9 18 27)
/ Dictionary scores
q)scores[`name] / The values for the name column are
`John`Jenny`Jonathan
q)scores.name / Retrieving the values for a column in a
/ column dictionary using dot notation.
`John`Jenny`Jonathan
q)scores[`name][1] / Values in row 1 of the name column
`Jenny
q)scores[`id][2] / Values in row 2 of the id column is
27Odwracanie słownika
Efektem netto odwrócenia słownika kolumn jest po prostu odwrócenie kolejności indeksów. Jest to logicznie równoważne transpozycji wierszy i kolumn.
Odwróć słownik kolumn
Transpozycja słownika jest uzyskiwana przez zastosowanie jednoargumentowego operatora odwracania. Spójrz na następujący przykład -
q)scores
name | John Jenny Jonathan
id | 9 18 27
q)flip scores
name id
---------------
John 9
Jenny 18
Jonathan 27Odwrócenie słownika odwróconej kolumny
Jeśli transponujesz słownik dwukrotnie, otrzymasz oryginalny słownik,
q)scores ~ flip flip scores
1bTabele są sercem kdb +. Tabela to zbiór nazwanych kolumn zaimplementowany jako słownik.q tables są zorientowane na kolumny.
Tworzenie tabel
Tabele są tworzone przy użyciu następującej składni -
q)trade:([]time:();sym:();price:();size:())
q)trade
time sym price size
-------------------W powyższym przykładzie nie określiliśmy typu każdej kolumny. Zostanie to ustawione przez pierwsze wstawienie do tabeli.
Innym sposobem możemy określić typ kolumny podczas inicjalizacji -
q)trade:([]time:`time$();sym:`$();price:`float$();size:`int$())Lub możemy również zdefiniować niepuste tabele -
q)trade:([]sym:(`a`b);price:(1 2))
q)trade
sym price
-------------
a 1
b 2Jeśli w nawiasach kwadratowych nie ma kolumn, jak w przykładach powyżej, w tabeli jest unkeyed.
Stworzyć keyed tablewstawiamy kolumnę (y) klucza w nawiasach kwadratowych.
q)trade:([sym:`$()]time:`time$();price:`float$();size:`int$())
q)trade
sym | time price size
----- | ---------------Można również zdefiniować typy kolumn, ustawiając wartości jako puste listy różnych typów -
q)trade:([]time:0#0Nt;sym:0#`;price:0#0n;size:0#0N)Pobieranie informacji o tabeli
Stwórzmy tabelę handlową -
trade: ([]sym:`ibm`msft`apple`samsung;mcap:2000 4000 9000 6000;ex:`nasdaq`nasdaq`DAX`Dow)
q)cols trade / column names of a table
`sym`mcap`ex
q)trade.sym / Retrieves the value of column sym
`ibm`msft`apple`samsung
q)show meta trade / Get the meta data of a table trade.
c | t f a
----- | -----
Sym | s
Mcap | j
ex | sKlucze podstawowe i tabele z kluczami
Tabela z kluczami
Tabela z kluczami to słownik, który odwzorowuje każdy wiersz w tabeli unikatowych kluczy na odpowiadający mu wiersz w tabeli wartości. Weźmy przykład -
val:flip `name`id!(`John`Jenny`Jonathan;9 18 27)
/ a flip dictionary create table val
id:flip (enlist `eid)!enlist 99 198 297
/ flip dictionary, having single column eidTeraz utwórz prostą tabelę z kluczami zawierającą eid jako klucz,
q)valid: id ! val
q)valid / table name valid, having key as eid
eid | name id
--- | ---------------
99 | John 9
198 | Jenny 18
297 | Jonathan 27Klucz obcy
ZA foreign key definiuje mapowanie z wierszy tabeli, w której jest zdefiniowane, do wierszy tabeli z odpowiednim primary key.
Klucze obce zapewniają referential integrity. Innymi słowy, próba wstawienia wartości klucza obcego, której nie ma w kluczu podstawowym, zakończy się niepowodzeniem.
Rozważ następujące przykłady. W pierwszym przykładzie jawnie zdefiniujemy klucz obcy podczas inicjalizacji. W drugim przykładzie użyjemy ścigania klucza obcego, który nie zakłada żadnego wcześniejszego związku między dwiema tabelami.
Example 1 − Define foreign key on initialization
q)sector:([sym:`SAMSUNG`HSBC`JPMC`APPLE]ex:`N`CME`DAQ`N;MC:1000 2000 3000 4000)
q)tab:([]sym:`sector$`HSBC`APPLE`APPLE`APPLE`HSBC`JPMC;price:6?9f)
q)show meta tab
c | t f a
------ | ----------
sym | s sector
price | f
q)show select from tab where sym.ex=`N
sym price
----------------
APPLE 4.65382
APPLE 4.643817
APPLE 3.659978Example 2 − no pre-defined relationship between tables
sector: ([symb:`IBM`MSFT`HSBC]ex:`N`CME`N;MC:1000 2000 3000)
tab:([]sym:`IBM`MSFT`MSFT`HSBC`HSBC;price:5?9f)Aby użyć ścigania klucza obcego, musimy utworzyć tabelę, aby wprowadzić klucz do sektora.
q)show update mc:(sector([]symb:sym))[`MC] from tab
sym price mc
--------------------------
IBM 7.065297 1000
MSFT 4.812387 2000
MSFT 6.400545 2000
HSBC 3.704373 3000
HSBC 4.438651 3000Notacja ogólna dla predefiniowanego klucza obcego -
wybierz ab z c, gdzie a to klucz obcy (sym), b to a
pole w tabeli kluczy podstawowych (ind), c to
tabela kluczy obcych (handel)
Manipulowanie tabelami
Utwórzmy jedną tabelę handlową i sprawdźmy wynik innego wyrażenia tabeli -
q)trade:([]sym:5?`ibm`msft`hsbc`samsung;price:5?(303.00*3+1);size:5?(900*5);time:5?(.z.T-365))
q)trade
sym price size time
-----------------------------------------
msft 743.8592 3162 02:32:17.036
msft 641.7307 2917 01:44:56.936
hsbc 838.2311 1492 00:25:23.210
samsung 278.3498 1983 00:29:38.945
ibm 838.6471 4006 07:24:26.842Przyjrzyjmy się teraz instrukcjom używanym do manipulowania tabelami przy użyciu q język.
Wybierz
Składnia używająca pliku Select oświadczenie jest następujące -
select [columns] [by columns] from table [where clause]Weźmy teraz przykład, aby zademonstrować, jak używać instrukcji Select -
q)/ select expression example
q)select sym,price,size by time from trade where size > 2000
time | sym price size
------------- | -----------------------
01:44:56.936 | msft 641.7307 2917
02:32:17.036 | msft 743.8592 3162
07:24:26.842 | ibm 838.6471 4006Wstawić
Składnia używająca pliku Insert oświadczenie jest następujące -
`tablename insert (values)
Insert[`tablename; values]Weźmy teraz przykład, aby zademonstrować, jak używać instrukcji Wstaw -
q)/ Insert expression example
q)`trade insert (`hsbc`apple;302.0 730.40;3020 3012;09:30:17.00409:15:00.000)
5 6
q)trade
sym price size time
------------------------------------------
msft 743.8592 3162 02:32:17.036
msft 641.7307 2917 01:44:56.936
hsbc 838.2311 1492 00:25:23.210
samsung 278.3498 1983 00:29:38.945
ibm 838.6471 4006 07:24:26.842
hsbc 302 3020 09:30:17.004
apple 730.4 3012 09:15:00.000
q)/Insert another value
q)insert[`trade;(`samsung;302.0; 3333;10:30:00.000]
']
q)insert[`trade;(`samsung;302.0; 3333;10:30:00.000)]
,7
q)trade
sym price size time
----------------------------------------
msft 743.8592 3162 02:32:17.036
msft 641.7307 2917 01:44:56.936
hsbc 838.2311 1492 00:25:23.210
samsung 278.3498 1983 00:29:38.945
ibm 838.6471 4006 07:24:26.842
hsbc 302 3020 09:30:17.004
apple 730.4 3012 09:15:00.000
samsung 302 3333 10:30:00.000Usunąć
Składnia używająca pliku Delete oświadczenie jest następujące -
delete columns from table
delete from table where clauseWeźmy teraz przykład, aby zademonstrować, jak używać instrukcji Delete -
q)/Delete expression example
q)delete price from trade
sym size time
-------------------------------
msft 3162 02:32:17.036
msft 2917 01:44:56.936
hsbc 1492 00:25:23.210
samsung 1983 00:29:38.945
ibm 4006 07:24:26.842
hsbc 3020 09:30:17.004
apple 3012 09:15:00.000
samsung 3333 10:30:00.000
q)delete from trade where price > 3000
sym price size time
-------------------------------------------
msft 743.8592 3162 02:32:17.036
msft 641.7307 2917 01:44:56.936
hsbc 838.2311 1492 00:25:23.210
samsung 278.3498 1983 00:29:38.945
ibm 838.6471 4006 07:24:26.842
hsbc 302 3020 09:30:17.004
apple 730.4 3012 09:15:00.000
samsung 302 3333 10:30:00.000
q)delete from trade where price > 500
sym price size time
-----------------------------------------
samsung 278.3498 1983 00:29:38.945
hsbc 302 3020 09:30:17.004
samsung 302 3333 10:30:00.000Aktualizacja
Składnia używająca pliku Update oświadczenie jest następujące -
update column: newValue from table where ….Użyj następującej składni, aby zaktualizować format / typ danych kolumny za pomocą funkcji rzutowania -
update column:newValue from `table where …Weźmy teraz przykład, aby zademonstrować, jak używać Update oświadczenie -
q)/Update expression example
q)update size:9000 from trade where price > 600
sym price size time
------------------------------------------
msft 743.8592 9000 02:32:17.036
msft 641.7307 9000 01:44:56.936
hsbc 838.2311 9000 00:25:23.210
samsung 278.3498 1983 00:29:38.945
ibm 838.6471 9000 07:24:26.842
hsbc 302 3020 09:30:17.004
apple 730.4 9000 09:15:00.000
samsung 302 3333 10:30:00.000
q)/Update the datatype of a column using the cast function
q)meta trade
c | t f a
----- | --------
sym | s
price| f
size | j
time | t
q)update size:`float$size from trade sym price size time ------------------------------------------ msft 743.8592 3162 02:32:17.036 msft 641.7307 2917 01:44:56.936 hsbc 838.2311 1492 00:25:23.210 samsung 278.3498 1983 00:29:38.945 ibm 838.6471 4006 07:24:26.842 hsbc 302 3020 09:30:17.004 apple 730.4 3012 09:15:00.000 samsung 302 3333 10:30:00.000 q)/ Above statement will not update the size column datatype permanently q)meta trade c | t f a ------ | -------- sym | s price | f size | j time | t q)/to make changes in the trade table permanently, we have do q)update size:`float$size from `trade
`trade
q)meta trade
c | t f a
------ | --------
sym | s
price | f
size | f
time | tKdb + ma rzeczowniki, czasowniki i przysłówki. Wszystkie obiekty i funkcje danych sąnouns. Verbs popraw czytelność, zmniejszając liczbę nawiasów kwadratowych i nawiasów w wyrażeniach. Adverbsmodyfikowanie funkcji i czasowników dwupargumentowych w celu uzyskania nowych, pokrewnych czasowników. Nazywane są funkcje tworzone przez przysłówkiderived functions lub derived verbs.
Każdy
Przysłówek each, oznaczony przez (`), modyfikuje funkcje diadyczne i czasowniki, aby zastosować je do elementów list zamiast do samych list. Spójrz na następujący przykład -
q)1, (2 3 5) / Join
1 2 3 5
q)1, '( 2 3 4) / Join each
1 2
1 3
1 4Istnieje forma Eachdla funkcji monadycznych, które używają słowa kluczowego „każdy”. Na przykład,
q)reverse ( 1 2 3; "abc") /Reverse
a b c
1 2 3
q)each [reverse] (1 2 3; "abc") /Reverse-Each
3 2 1
c b a
q)'[reverse] ( 1 2 3; "abc")
3 2 1
c b aKażdy lewy i prawy
Istnieją dwa warianty Each dla funkcji diadycznych o nazwie Each-Left (\:) i Each-Right(/ :). Poniższy przykład wyjaśnia, jak ich używać.
q)x: 9 18 27 36
q)y:10 20 30 40
q)x,y / join
9 18 27 36 10 20 30 40
q)x,'y / each
9 10
18 20
27 30
36 40
q)x: 9 18 27 36
q)y:10 20 30 40
q)x,y / join
9 18 27 36 10 20 30 40
q)x,'y / each, will return a list of pairs
9 10
18 20
27 30
36 40
q)x, \:y / each left, returns a list of each element
/ from x with all of y
9 10 20 30 40
18 10 20 30 40
27 10 20 30 40
36 10 20 30 40
q)x,/:y / each right, returns a list of all the x with
/ each element of y
9 18 27 36 10
9 18 27 36 20
9 18 27 36 30
9 18 27 36 40
q)1 _x / drop the first element
18 27 36
q)-2_y / drop the last two element
10 20
q) / Combine each left and each right to be a
/ cross-product (cartesian product)
q)x,/:\:y
9 10 9 20 9 30 9 40
18 10 18 20 18 30 18 40
27 10 27 20 27 30 27 40
36 10 36 20 36 30 36 40W qjęzyka mamy różne rodzaje sprzężeń w oparciu o dostarczone tabele wejściowe i pożądany przez nas rodzaj połączonych tabel. Łączenie łączy dane z dwóch tabel. Oprócz pogoni za kluczem obcym istnieją cztery inne sposoby dołączania do tabel -
- Proste łączenie
- Jak dołączyć
- Lewe połączenie
- Dołącz do Unii
Tutaj, w tym rozdziale, omówimy szczegółowo każde z tych połączeń.
Proste łączenie
Łączenie proste to najbardziej podstawowy typ łączenia, wykonywany przecinkiem „,”. W tym przypadku dwie tabele muszą byćtype conformanttj. obie tabele mają taką samą liczbę kolumn w tej samej kolejności i ten sam klucz.
table1,:table2 / table1 is assigned the value of table2Możemy użyć łączenia przecinkiem-każde dla tabel o tej samej długości, aby łączyć na boki. Tutaj można wprowadzić klucz do jednej z tabel,
Table1, `Table2Asof Join (aj)
Jest to najpotężniejsze łączenie, które jest używane do uzyskania wartości pola w jednej tabeli w czasie w innej tabeli. Zwykle służy do uzyskania dominującej oferty i zapytania w momencie każdej transakcji.
Ogólny format
aj[joinColumns;tbl1;tbl2]Na przykład,
aj[`sym`time;trade;quote]Przykład
q)tab1:([]a:(1 2 3 4);b:(2 3 4 5);d:(6 7 8 9))
q)tab2:([]a:(2 3 4);b:(3 4 5); c:( 4 5 6))
q)show aj[`a`b;tab1;tab2]
a b d c
-------------
1 2 6
2 3 7 4
3 4 8 5
4 5 9 6Łączenie lewe (lj)
Jest to specjalny przypadek aj, w którym drugi argument jest tabelą z kluczem, a pierwszy argument zawiera kolumny klucza prawego argumentu.
Ogólny format
table1 lj Keyed-tablePrzykład
q)/Left join- syntax table1 lj table2 or lj[table1;table2]
q)tab1:([]a:(1 2 3 4);b:(2 3 4 5);d:(6 7 8 9))
q)tab2:([a:(2 3 4);b:(3 4 5)]; c:( 4 5 6))
q)show lj[tab1;tab2]
a b d c
-------------
1 2 6
2 3 7 4
3 4 8 5
4 5 9 6Union Join (uj)
Pozwala na utworzenie unii dwóch tabel z różnymi schematami. Jest to w zasadzie rozszerzenie prostego łączenia (,)
q)tab1:([]a:(1 2 3 4);b:(2 3 4 5);d:(6 7 8 9))
q)tab2:([]a:(2 3 4);b:(3 4 5); c:( 4 5 6))
q)show uj[tab1;tab2]
a b d c
------------
1 2 6
2 3 7
3 4 8
4 5 9
2 3 4
3 4 5
4 5 6Jeśli używasz uj w tabelach z kluczem, klucze podstawowe muszą być zgodne.
Rodzaje funkcji
Funkcje można klasyfikować na wiele sposobów. Tutaj sklasyfikowaliśmy je na podstawie liczby i typu argumentów, które przyjmują, oraz typu wyniku. Funkcje mogą być,
Atomic - gdzie argumenty są atomowe i dają niepodzielne wyniki
Aggregate - atom z listy
Uniform (list from list)- Rozszerzono pojęcie atomu w odniesieniu do list. Liczba listy argumentów równa się liczbie listy wyników.
Other - jeśli funkcja nie należy do powyższej kategorii.
Nazywa się operacje binarne w matematyce dyadic functionsw q; na przykład „+”. Podobnie wywoływane są operacje jednoargumentowemonadic functions; na przykład „abs” lub „floor”.
Często używane funkcje
Istnieje kilka funkcji często używanych w programie qprogramowanie. Tutaj, w tej sekcji, zobaczymy użycie niektórych popularnych funkcji -
abs
q) abs -9.9 / Absolute value, Negates -ve number & leaves non -ve number
9.9wszystko
q) all 4 5 0 -4 / Logical AND (numeric min), returns the minimum value
0bMax (&), Min (|) i nie (!)
q) /And, Or, and Logical Negation
q) 1b & 1b / And (Max)
1b
q) 1b|0b / Or (Min)
1b
q) not 1b /Logical Negate (Not)
0brosn
q)asc 1 3 5 7 -2 0 4 / Order list ascending, sorted list
/ in ascending order i
s returned
`s#-2 0 1 3 4 5 7
q)/attr - gives the attributes of data, which describe how it's sorted.
`s denotes fully sorted, `u denotes unique and `p and `g are used to
refer to lists with repetition, with `p standing for parted and `g for groupedśr
q)avg 3 4 5 6 7 / Return average of a list of numeric values
5f
q)/Create on trade table
q)trade:([]time:3?(.z.Z-200);sym:3?(`ibm`msft`apple);price:3?99.0;size:3?100)przez
q)/ by - Groups rows in a table at given sym
q)select sum price by sym from trade / find total price for each sym
sym | price
------ | --------
apple | 140.2165
ibm | 16.11385cols
q)cols trade / Lists columns of a table
`time`sym`price`sizeliczyć
q)count (til 9) / Count list, count the elements in a list and
/ return a single int value 9Port
q)\p 9999 / assign port number
q)/csv - This command allows queries in a browser to be exported to
excel by prefixing the query, such as http://localhost:9999/.csv?select from trade where sym =`ibmskaleczenie
q)/ cut - Allows a table or list to be cut at a certain point
q)(1 3 5) cut "abcdefghijkl"
/ the argument is split at 1st, 3rd and 5th letter.
"bc"
"de"
"fghijkl"
q)5 cut "abcdefghijkl" / cut the right arg. Into 5 letters part
/ until its end.
"abcde"
"fghij"
"kl"Usunąć
q)/delete - Delete rows/columns from a table
q)delete price from trade
time sym size
---------------------------------------
2009.06.18T06:04:42.919 apple 36
2009.11.14T12:42:34.653 ibm 12
2009.12.27T17:02:11.518 apple 97Odrębny
q)/distinct - Returns the distinct element of a list
q)distinct 1 2 3 2 3 4 5 2 1 3 / generate unique set of number
1 2 3 4 5zwerbować
q)/enlist - Creates one-item list.
q)enlist 37
,37
q)type 37 / -ve type value
-7h
q)type enlist 37 / +ve type value
7hWypełnij (^)
q)/fill - used with nulls. There are three functions for processing null values.
The dyadic function named fill replaces null values in the right argument with the atomic left argument.
q)100 ^ 3 4 0N 0N -5
3 4 100 100 -5
q)`Hello^`jack`herry``john`
`jack`herry`Hello`john`HelloWypełnienia
q)/fills - fills in nulls with the previous not null value.
q)fills 1 0N 2 0N 0N 2 3 0N -5 0N
1 1 2 2 2 2 3 3 -5 -5Pierwszy
q)/first - returns the first atom of a list
q)first 1 3 34 5 3
1Trzepnięcie
q)/flip - Monadic primitive that applies to lists and associations. It interchange the top two levels of its argument.
q)trade
time sym price size
------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
q)flip trade
time | 2009.06.18T06:04:42.919 2009.11.14T12:42:34.653
2009.12.27T17:02:11.518
sym | apple ibm apple
price | 72.05742 16.11385 68.15909
size | 36 12 97iasc
q)/iasc - Index ascending, return the indices of the ascended sorted list relative to the input list.
q)iasc 5 4 0 3 4 9
2 3 1 4 0 5Idesc
q)/idesc - Index desceding, return the descended sorted list relative to the input list
q)idesc 0 1 3 4
3 2 1 0w
q)/in - In a list, dyadic function used to query list (on the right-handside) about their contents.
q)(2 4) in 1 2 3
10bwstawić
q)/insert - Insert statement, upload new data into a table.
q)insert[`trade;((.z.Z);`samsung;48.35;99)],3
q)trade
time sym price size
------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99klucz
q)/key - three different functions i.e. generate +ve integer number, gives content of a directory or key of a table/dictionary.
q)key 9
0 1 2 3 4 5 6 7 8
q)key `:c:
`$RECYCLE.BIN`Config.Msi`Documents and Settings`Drivers`Geojit`hiberfil.sys`I..niższy
q)/lower - Convert to lower case and floor
q)lower ("JoHn";`HERRY`SYM)
"john"
`herry`symMax i Min (tj. | I &)
q)/Max and Min / a|b and a&b
q)9|7
9
q)9&5
5zero
q)/null - return 1b if the atom is a null else 0b from the argument list
q)null 1 3 3 0N
0001bBrzoskwinia
q)/peach - Parallel each, allows process across slaves
q)foo peach list1 / function foo applied across the slaves named in list1
'list1
q)foo:{x+27}
q)list1:(0 1 2 3 4)
q)foo peach list1 / function foo applied across the slaves named in list1
27 28 29 30 31Poprz
q)/prev - returns the previous element i.e. pushes list forwards
q)prev 0 1 3 4 5 7
0N 0 1 3 4 5Losowy( ?)
q)/random - syntax - n?list, gives random sequences of ints and floats
q)9?5
0 0 4 0 3 2 2 0 1
q)3?9.9
0.2426823 1.674133 3.901671Zburzyć
q)/raze - Flattn a list of lists, removes a layer of indexing from a list of lists. for instance:
q)raze (( 12 3 4; 30 0);("hello";7 8); 1 3 4)
12 3 4
30 0
"hello"
7 8
1
3
4przeczytaj0
q)/read0 - Read in a text file
q)read0 `:c:/q/README.txt / gives the contents of *.txt fileprzeczytaj1
q)/read1 - Read in a q data file
q)read1 `:c:/q/t1
0xff016200630b000500000073796d0074696d6500707269636…odwrócić
q)/reverse - Reverse a list
q)reverse 2 30 29 1 3 4
4 3 1 29 30 2
q)reverse "HelloWorld"
"dlroWolleH"zestaw
q)/set - set value of a variable
q)`x set 9
`x
q)x
9
q)`:c:/q/test12 set trade
`:c:/q/test12
q)get `:c:/q/test12
time sym price size
---------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99ssr
q)/ssr - String search and replace, syntax - ssr["string";searchstring;replaced-with]
q)ssr["HelloWorld";"o";"O"]
"HellOWOrld"strunowy
q)/string - converts to string, converts all types to a string format.
q)string (1 2 3; `abc;"XYZ";0b)
(,"1";,"2";,"3")
"abc"
(,"X";,"Y";,"Z")
,"0"SV
q)/sv - Scalar from vector, performs different tasks dependent on its arguments.
It evaluates the base representation of numbers, which allows us to calculate the number of seconds in a month or convert a length from feet and inches to centimeters.
q)24 60 60 sv 11 30 49
41449 / number of seconds elapsed in a day at 11:30:49system
q)/system - allows a system command to be sent,
q)system "dir *.py"
" Volume in drive C is New Volume"
" Volume Serial Number is 8CD2-05B2"
""
" Directory of C:\\Users\\myaccount-raj"
""
"09/14/2014 06:32 PM 22 hello1.py"
" 1 File(s) 22 bytes"stoły
q)/tables - list all tables
q)tables `
`s#`tab1`tab2`tradeTil
q)/til - Enumerate
q)til 5
0 1 2 3 4trym
q)/trim - Eliminate string spaces
q)trim " John "
"John"vs
q)/vs - Vector from scaler , produces a vector quantity from a scaler quantity
q)"|" vs "20150204|msft|20.45"
"20150204"
"msft"
"20.45"xasc
q)/xasc - Order table ascending, allows a table (right-hand argument) to be sorted such that (left-hand argument) is in ascending order
q)`price xasc trade
time sym price size
----------------------------------------------------------
2009.11.14T12:42:34.653 ibm 16.11385 12
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99
2009.12.27T17:02:11.518 apple 68.15909 97
2009.06.18T06:04:42.919 apple 72.05742 36xcol
q)/xcol - Renames columns of a table
q)`timeNew`symNew xcol trade
timeNew symNew price size
-------------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99xcols
q)/xcols - Reorders the columns of a table,
q)`size`price xcols trade
size price time sym
-----------------------------------------------------------
36 72.05742 2009.06.18T06:04:42.919 apple
12 16.11385 2009.11.14T12:42:34.653 ibm
97 68.15909 2009.12.27T17:02:11.518 apple
99 48.35 2015.04.06T10:03:36.738 samsung
99 48.35 2015.04.06T10:03:47.540 samsung
99 48.35 2015.04.06T10:04:44.844 samsungxdesc
q)/xdesc - Order table descending, allows tables to be sorted such that the left-hand argument is in descending order.
q)`price xdesc trade
time sym price size
-----------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99
2009.11.14T12:42:34.653 ibm 16.11385 12xgroup
q)/xgroup - Creates nested table
q)`x xgroup ([]x:9 18 9 18 27 9 9;y:10 20 10 20 30 40)
'length
q)`x xgroup ([]x:9 18 9 18 27 9 9;y:10 20 10 20 30 40 10)
x | y
---- | -----------
9 | 10 10 40 10
18 | 20 20
27 | ,30xkey
q)/xkey - Set key on table
q)`sym xkey trade
sym | time price size
--------- | -----------------------------------------------
apple | 2009.06.18T06:04:42.919 72.05742 36
ibm | 2009.11.14T12:42:34.653 16.11385 12
apple | 2009.12.27T17:02:11.518 68.15909 97
samsung | 2015.04.06T10:03:36.738 48.35 99
samsung | 2015.04.06T10:03:47.540 48.35 99
samsung | 2015.04.06T10:04:44.844 48.35 99Polecenia systemowe
Polecenia systemowe sterują qśrodowisko. Mają następującą postać -
\cmd [p] where p may be optionalNiektóre z popularnych poleceń systemowych zostały omówione poniżej -
\ a [przestrzeń nazw] - wyświetla listę tabel w podanej przestrzeni nazw
q)/Tables in default namespace
q)\a
,`trade
q)\a .o / table in .o namespace.
,`TI\ b - Wyświetl zależności
q)/ views/dependencies
q)a:: x+y / global assingment
q)b:: x+1
q)\b
`s#`a`b\ B - Oczekujące widoki / zależności
q)/ Pending views/dependencies
q)a::x+1 / a depends on x
q)\B / the dependency is pending
' / the dependency is pending
q)\B
`s#`a`b
q)\b
`s#`a`b
q)b
29
q)a
29
q)\B
`symbol$()\ cd - Zmień katalog
q)/change directory, \cd [name]
q)\cd
"C:\\Users\\myaccount-raj"
q)\cd ../new-account
q)\cd
"C:\\Users\\new-account"\ d - ustawia aktualną przestrzeń nazw
q)/ sets current namespace \d [namespace]
q)\d /default namespace
'
q)\d .o /change to .o
q.o)\d
`.o
q.o)\d . / return to default
q)key ` /lists namespaces other than .z
`q`Q`h`j`o
q)\d .john /change to non-existent namespace
q.john)\d
`.john
q.john)\d .
q)\d
`.\ l - załaduj plik lub katalog z bazy danych
q)/ Load file or directory, \l
q)\l test2.q / loading test2.q which is stored in current path.
ric | date ex openP closeP MCap
----------- | -------------------------------------------------
JPMORGAN | 2008.05.23 SENSEX 18.30185 17.16319 17876
HSBC | 2002.05.21 NIFTY 2.696749 16.58846 26559
JPMORGAN | 2006.09.07 NIFTY 14.15219 20.05624 14557
HSBC | 2010.10.11 SENSEX 7.394497 25.45859 29366
JPMORGAN | 2007.10.02 SENSEX 1.558085 25.61478 20390
ric | date ex openP closeP MCap
---------- | ------------------------------------------------
INFOSYS | 2003.10.30 DOW 21.2342 7.565652 2375
RELIANCE | 2004.08.12 DOW 12.34132 17.68381 4201
SBIN | 2008.02.14 DOW 1.830857 9.006485 15465
INFOSYS | 2009.06.11 HENSENG 19.47664 12.05208 11143
SBIN | 2010.07.05 DOW 18.55637 10.54082 15873\ p - numer portu
q)/ assign port number, \p
q)\p
5001i
q)\p 8888
q)\p
8888i\\ - Wyjście z konsoli q
\\ - exit
Exit form q.Plik qjęzyk programowania ma zestaw bogatych i potężnych wbudowanych funkcji. Wbudowana funkcja może mieć następujące typy -
String function - Pobiera ciąg jako dane wejściowe i zwraca ciąg.
Aggregate function - Pobiera listę jako dane wejściowe i zwraca atom.
Uniform function - Pobiera listę i zwraca listę o tej samej liczbie.
Mathematical function - Pobiera argument numeryczny i zwraca argument numeryczny.
Miscellaneous function - Wszystkie funkcje inne niż wymienione powyżej.
Funkcje łańcuchowe
Like - dopasowywanie wzorców
q)/like is a dyadic, performs pattern matching, return 1b on success else 0b
q)"John" like "J??n"
1b
q)"John My Name" like "J*"
1bltrim - usuwa wiodące spacje
q)/ ltrim - monadic ltrim takes string argument, removes leading blanks
q)ltrim " Rick "
"Rick "rtrim - usuwa końcowe spacje
q)/rtrim - takes string argument, returns the result of removing trailing blanks
q)rtrim " Rick "
" Rick"ss - wyszukiwanie ciągów
q)/ss - string search, perform pattern matching, same as "like" but return the indices of the matches of the pattern in source.
q)"Life is beautiful" ss "i"
1 5 13przycinanie - usuwa początkowe i końcowe spacje
q)/trim - takes string argument, returns the result of removing leading & trailing blanks
q)trim " John "
"John"Funkcje matematyczne
acos - odwrotność cos
q)/acos - inverse of cos, for input between -1 and 1, return float between 0 and pi
q)acos 1
0f
q)acos -1
3.141593
q)acos 0
1.570796cor - podaje korelację
q)/cor - the dyadic takes two numeric lists of same count, returns a correlation between the items of the two arguments
q)27 18 18 9 0 cor 27 36 45 54 63
-0.9707253krzyż - iloczyn kartezjański
q)/cross - takes atoms or lists as arguments and returns their Cartesian product
q)9 18 cross `x`y`z
9 `x
9 `y
9 `z
18 `x
18 `y
18 `zvar - wariancja
q)/var - monadic, takes a scaler or numeric list and returns a float equal to the mathematical variance of the items
q)var 45
0f
q)var 9 18 27 36
101.25wavg
q)/wavg - dyadic, takes two numeric lists of the same count and returns the average of the second argument weighted by the first argument.
q)1 2 3 4 wavg 200 300 400 500
400fFunkcje agregujące
wszystko - i działanie
q)/all - monadic, takes a scaler or list of numeric type and returns the result of & applied across the items.
q)all 0b
0b
q)all 9 18 27 36
1b
q)all 10 20 30
1bDowolne - | operacja
q)/any - monadic, takes scaler or list of numeric type and the return the result of | applied across the items
q)any 20 30 40 50
1b
q)any 20012.02.12 2013.03.11
'20012.02.12prd - iloczyn arytmetyczny
q)/prd - monadic, takes scaler, list, dictionary or table of numeric type and returns the arithmetic product.
q)prd `x`y`z! 10 20 30
6000
q)prd ((1 2; 3 4);(10 20; 30 40))
10 40
90 160Suma - suma arytmetyczna
q)/sum - monadic, takes a scaler, list,dictionary or table of numeric type and returns the arithmetic sum.
q)sum 2 3 4 5 6
20
q)sum (1 2; 4 5)
5 7Jednolite funkcje
Delty - różnica w stosunku do poprzedniej pozycji.
q)/deltas -takes a scalar, list, dictionary or table and returns the difference of each item from its predecessor.
q)deltas 2 3 5 7 9
2 1 2 2 2
q)deltas `x`y`z!9 18 27
x | 9
y | 9
z | 9wypełnia - wypełnia wartość null
q)/fills - takes scalar, list, dictionary or table of numeric type and returns a c copy of the source in which non-null items are propagated forward to fill nulls
q)fills 1 0N 2 0N 4
1 1 2 2 4
q)fills `a`b`c`d! 10 0N 30 0N
a | 10
b | 10
c | 30
d | 30maxs - skumulowane maksimum
q)/maxs - takes scalar, list, dictionary or table and returns the cumulative maximum of the source items.
q)maxs 1 2 4 3 9 13 2
1 2 4 4 9 13 13
q)maxs `a`b`c`d!9 18 0 36
a | 9
b | 18
c | 18
d | 36Różne funkcje
Count - zwracana liczba elementów
q)/count - returns the number of entities in its argument.
q)count 10 30 30
3
q)count (til 9)
9
q)count ([]a:9 18 27;b:1.1 2.2 3.3)
3Distinct - zwraca odrębne jednostki
q)/distinct - monadic, returns the distinct entities in its argument
q)distinct 1 2 3 4 2 3 4 5 6 9
1 2 3 4 5 6 9Z wyjątkiem - element nie występuje w drugim argumencie.
q)/except - takes a simple list (target) as its first argument and returns a list containing the items of target that are not in its second argument
q)1 2 3 4 3 1 except 1
2 3 4 3fill - wypełnij null pierwszym argumentem
q)/fill (^) - takes an atom as its first argument and a list(target) as its second argument and return a list obtained by substituting the first argument for every occurrence of null in target
q)42^ 9 18 0N 27 0N 36
9 18 42 27 42 36
q)";"^"Life is Beautiful"
"Life;is;Beautiful"Zapytania w qsą krótsze i prostsze oraz rozszerzają możliwości sql. Głównym wyrażeniem zapytania jest „wyrażenie wyboru”, które w najprostszej formie wyodrębnia tabele podrzędne, ale może również tworzyć nowe kolumny.
Ogólna forma pliku Select expression wygląda następująco -
Select columns by columns from table where conditions**Note − by & where wyrażenia są opcjonalne, tylko „z wyrażenia” jest obowiązkowe.
Ogólnie składnia będzie wyglądać następująco -
select [a] [by b] from t [where c]
update [a] [by b] from t [where c]Składnia q wyrażenia wyglądają dość podobnie do SQL, ale qwyrażenia są proste i potężne. Równoważne wyrażenie sql dla powyższegoq wyrażenie byłoby następujące -
select [b] [a] from t [where c] [group by b order by b]
update t set [a] [where c]Wszystkie klauzule są wykonywane na kolumnach, a zatem qmoże skorzystać z zamówienia. Ponieważ zapytania Sql nie są oparte na kolejności, nie mogą skorzystać z tej korzyści.
qzapytania relacyjne są na ogół znacznie mniejsze w porównaniu do odpowiadających im zapytań sql. Zapytania uporządkowane i funkcjonalne robią rzeczy, które są trudne w sql.
W historycznej bazie danych kolejność plików whereklauzula jest bardzo ważna, ponieważ wpływa na wydajność zapytania. Plikpartition zmienna (data / miesiąc / dzień) zawsze pojawia się jako pierwsza, po której następuje posortowana i zindeksowana kolumna (zazwyczaj kolumna sym).
Na przykład,
select from table where date in d, sym in sjest znacznie szybszy niż
select from table where sym in s, date in dPodstawowe zapytania
Napiszmy skrypt zapytania w notatniku (jak poniżej), zapiszmy (jako * .q), a następnie załadujmy.
sym:asc`AIG`CITI`CSCO`IBM`MSFT;
ex:"NASDAQ"
dst:`$":c:/q/test/data/"; /database destination @[dst;`sym;:;sym]; n:1000000; trade:([]sym:n?`sym;time:10:30:00.0+til n;price:n?3.3e;size:n?9;ex:n?ex); quote:([]sym:n?`sym;time:10:30:00.0+til n;bid:n?3.3e;ask:n?3.3e;bsize:n?9;asize:n?9;ex:n?ex); {@[;`sym;`p#]`sym xasc x}each`trade`quote; d:2014.08.07 2014.08.08 2014.08.09 2014.08.10 2014.08.11; /Date vector can also be changed by the user dt:{[d;t].[dst;(`$string d;t;`);:;value t]};
d dt/:\:`trade`quote;
Note: Once you run this query, two folders .i.e. "test" and "data" will be created under "c:/q/", and date partition data can be seen inside data folder.Zapytania z ograniczeniami
* Denotes HDB query
Select all IBM trades
select from trade where sym in `IBM*Select all IBM trades on a certain day
thisday: 2014.08.11
select from trade where date=thisday,sym=`IBMSelect all IBM trades with a price > 100
select from trade where sym=`IBM, price > 100.0Select all IBM trades with a price less than or equal to 100
select from trade where sym=`IBM,not price > 100.0*Select all IBM trades between 10.30 and 10.40, in the morning, on a certain date
thisday: 2014.08.11
select from trade where
date = thisday, sym = `IBM, time > 10:30:00.000,time < 10:40:00.000Select all IBM trades in ascending order of price
`price xasc select from trade where sym =`IBM*Select all IBM trades in descending order of price in a certain time frame
`price xdesc select from trade where date within 2014.08.07 2014.08.11, sym =`IBMComposite sort − sort ascending order by sym and then sort the result in descending order of price
`sym xasc `price xdesc select from trade where date = 2014.08.07,size = 5Select all IBM or MSFT trades
select from trade where sym in `IBM`MSFT*Calculate count of all symbols in ascending order within a certain time frame
`numsym xasc select numsym: count i by sym from trade where date within 2014.08.07 2014.08.11*Calculate count of all symbols in descending order within a certain time frame
`numsym xdesc select numsym: count i by sym from trade where date within 2014.08.07 2014.08.11* What is the maximum price of IBM stock within a certain time frame, and when does this first happen?
select time,ask from quote where date within 2014.08.07 2014.08.11,
sym =`IBM, ask = exec first ask from select max ask from quote where
sym =`IBMSelect the last price for each sym in hourly buckets
select last price by hour:time.hh, sym from tradeZapytania z agregacjami
* Calculate vwap (Volume Weighted Average Price) of all symbols
select vwap:size wavg price by sym from trade* Count the number of records (in millions) for a certain month
(select trade:1e-6*count i by date.dd from trade where date.month=2014.08m) + select quote:1e-6*count i by date.dd from quote where date.month=2014.08m* HLOC – Daily High, Low, Open and Close for CSCO in a certain month
select high:max price,low:min price,open:first price,close:last price by date.dd from trade where date.month=2014.08m,sym =`CSCO* Daily Vwap for CSCO in a certain month
select vwap:size wavg price by date.dd from trade where date.month = 2014.08m ,sym = `CSCO* Calculate the hourly mean, variance and standard deviation of the price for AIG
select mean:avg price, variance:var price, stdDev:dev price by date, hour:time.hh from trade where sym = `AIGSelect the price range in hourly buckets
select range:max[price] – min price by date,sym,hour:time.hh from trade* Daily Spread (average bid-ask) for CSCO in a certain month
select spread:avg bid-ask by date.dd from quote where date.month = 2014.08m, sym = `CSCO* Daily Traded Values for all syms in a certain month
select dtv:sum size by date,sym from trade where date.month = 2014.08mExtract a 5 minute vwap for CSCO
select size wavg price by 5 xbar time.minute from trade where sym = `CSCO* Extract 10 minute bars for CSCO
select high:max price,low:min price,close:last price by date, 10 xbar time.minute from trade where sym = `CSCO* Find the times when the price exceeds 100 basis points (100e-4) over the last price for CSCO for a certain day
select time from trade where date = 2014.08.11,sym = `CSCO,price > 1.01*last price* Full Day Price and Volume for MSFT in 1 Minute Intervals for the last date in the database
select last price,last size by time.minute from trade where date = last date, sym = `MSFTKDB + umożliwia jednemu procesowi komunikację z innym procesem poprzez komunikację międzyprocesową. Procesy Kdb + mogą łączyć się z dowolnym innym kdb + na tym samym komputerze, w tej samej sieci lub nawet zdalnie. Musimy tylko określić port, a klienci będą mogli rozmawiać z tym portem. Każdyq proces może komunikować się z każdym innym q tak długo, jak jest dostępny w sieci i nasłuchuje połączeń.
proces serwera nasłuchuje połączeń i przetwarza wszelkie żądania
proces klienta inicjuje połączenie i wysyła polecenia do wykonania
Klient i serwer mogą znajdować się na tym samym komputerze lub na różnych komputerach. Proces może być zarówno klientem, jak i serwerem.
Komunikacja może być,
Synchronous (poczekaj na zwrot wyniku)
Asynchronous (bez czekania i brak wyników)
Zainicjuj serwer
ZA q serwer jest inicjowany poprzez określenie portu nasłuchiwania,
q –p 5001 / command line
\p 5001 / session commandUchwyt komunikacyjny
Uchwyt komunikacyjny to symbol zaczynający się od „:” i mający postać -
`:[server]:port-numberPrzykład
`::5001 / server and client on same machine
`:jack:5001 / server on machine jack
`:192.168.0.156 / server on specific IP address
`:www.myfx.com:5001 / server at www.myfx.comAby rozpocząć połączenie, używamy funkcji „hopen”, która zwraca uchwyt połączenia będący liczbą całkowitą. Ten uchwyt jest używany do wszystkich kolejnych żądań klientów. Na przykład -
q)h:hopen `::5001
q)h"til 5"
0 1 2 3 4
q)hclose hWiadomości synchroniczne i asynchroniczne
Gdy już mamy uchwyt, możemy wysłać wiadomość synchronicznie lub asynchronicznie.
Synchronous Message- Po wysłaniu wiadomości czeka na i zwraca wynik. Jego format jest następujący -
handle “message”Asynchronous Message- Po wysłaniu wiadomości natychmiast rozpocznij przetwarzanie następnej instrukcji bez konieczności czekania i zwracania wyniku. Jego format jest następujący -
neg[handle] “message”Komunikaty wymagające odpowiedzi, na przykład wywołania funkcji lub instrukcje wyboru, będą normalnie używać formy synchronicznej; podczas gdy komunikaty, które nie muszą zwracać danych wyjściowych, na przykład wstawianie aktualizacji do tabeli, będą asynchroniczne.
Kiedy q proces łączy się z innym qproces poprzez komunikację między procesami, jest przetwarzany przez programy obsługi komunikatów. Te programy obsługi komunikatów mają zachowanie domyślne. Na przykład w przypadku synchronicznej obsługi wiadomości program obsługi zwraca wartość zapytania. W tym przypadku procedura obsługi synchronicznej to.z.pg, które możemy zastąpić zgodnie z wymaganiami.
Procesy Kdb + mają kilka predefiniowanych programów obsługi komunikatów. Programy obsługi komunikatów są ważne przy konfigurowaniu bazy danych. Niektóre z zastosowań obejmują -
Logging - Rejestruj przychodzące wiadomości (pomocne w przypadku krytycznego błędu),
Security- Zezwalaj / nie zezwalaj na dostęp do bazy danych, niektórych wywołań funkcji itp. W oparciu o nazwę użytkownika / adres IP. Pomaga w zapewnieniu dostępu tylko upoważnionym abonentom.
Handle connections/disconnections z innych procesów.
Predefiniowane programy obsługi wiadomości
Poniżej omówiono niektóre z predefiniowanych programów obsługi komunikatów.
.z.pg
Jest to synchroniczna obsługa wiadomości (proces get). Ta funkcja jest wywoływana automatycznie po odebraniu wiadomości synchronizacji w instancji kdb +.
Parametr to wywołanie ciągu / funkcji do wykonania, tj. Przekazana wiadomość. Domyślnie jest zdefiniowany w następujący sposób -
.z.pg: {value x} / simply execute the message
received but we can overwrite it to
give any customized result.
.z.pg : {handle::.z.w;value x} / this will store the remote handle
.z.pg : {show .z.w;value x} / this will show the remote handle.z.ps
Jest to asynchroniczna obsługa komunikatów (zestaw procesów). Jest to równoważny program obsługi dla komunikatów asynchronicznych. Parametr to wywołanie ciągu / funkcji do wykonania. Domyślnie jest zdefiniowany jako,
.z.pg : {value x} / Can be overriden for a customized action.Poniżej znajduje się dostosowana obsługa komunikatów dla komunikatów asynchronicznych, w przypadku których używaliśmy chronionego wykonania,
.z.pg: {@[value; x; errhandler x]}Tutaj errhandler to funkcja używana w przypadku nieoczekiwanego błędu.
.z.po []
Jest to otwarta procedura obsługi połączenia (proces otwierania). Jest wykonywany, gdy zdalny proces otwiera połączenie. Aby zobaczyć uchwyt podczas otwierania połączenia z procesem, możemy zdefiniować plik .z.po jako,
.z.po : {Show “Connection opened by” , string h: .z.h}.z.pc []
Jest to program obsługi bliskiego połączenia (proces zamykania). Jest wywoływana, gdy połączenie jest zamknięte. Możemy stworzyć własną procedurę zamykania, która może zresetować uchwyt połączenia globalnego do 0 i wydać polecenie ustawiania licznika czasu na uruchomienie (wykonanie) co 3 sekundy (3000 milisekund).
.z.pc : { h::0; value “\\t 3000”}Program obsługi licznika czasu (.z.ts) próbuje ponownie otworzyć połączenie. Jeśli się powiedzie, wyłącza stoper.
.z.ts : { h:: hopen `::5001; if [h>0; value “\\t 0”] }.z.pi []
PI oznacza wejście procesowe. Wzywa się do dowolnego rodzaju danych wejściowych. Może być używany do obsługi danych wejściowych konsoli lub klienta zdalnego. Używając .z.pi [], można sprawdzić poprawność danych wejściowych konsoli lub zastąpić domyślny ekran. Ponadto może być używany do wszelkiego rodzaju operacji logowania.
q).z.pi
'.z.pi
q).z.pi:{">", .Q.s value x}
q)5+4
>9
q)30+42
>72
q)30*2
>60
q)\x .z.pi
>q)
q)5+4
9.z.pw
Jest to moduł obsługi połączenia walidacji (uwierzytelnianie użytkownika). Dodaje dodatkowe wywołanie zwrotne, gdy otwierane jest połączenie do sesji kdb +. Jest wywoływana po sprawdzeniach –u / -U i przed .z.po (port otwarty).
.z.pw : {[user_id;passwd] 1b}Wejścia są userid (symbol) i password (tekst).
Listy, słowniki lub kolumny tabeli mogą mieć przypisane do nich atrybuty. Atrybuty narzucają określone właściwości na liście. Niektóre atrybuty mogą zniknąć po modyfikacji.
Typy atrybutów
Posortowano (s #)
`s # oznacza, że lista jest posortowana w porządku rosnącym. Jeśli lista jest jawnie posortowana według asc (lub xasc), automatycznie będzie miała ustawiony atrybut sortowania.
q)L1: asc 40 30 20 50 9 4
q)L1
`s#4 9 20 30 40 50Lista, o której wiadomo, że jest posortowana, może również mieć jawnie ustawiony atrybut. Q sprawdzi, czy lista jest posortowana, a jeśli nie, plik s-fail zostanie wyrzucony błąd.
q)L2:30 40 24 30 2
q)`s#L2
's-failPosortowany atrybut zostanie utracony po nieposortowanym dołączeniu.
Rozstał się (`p #)
`p # oznacza, że lista jest podzielona i identyczne pozycje są przechowywane w sposób ciągły.
Zakres to int lub temporal type posiadające bazową wartość int, taką jak lata, miesiące, dni itp. Możesz również podzielić symbol, pod warunkiem, że jest wyliczony.
Zastosowanie atrybutu parted powoduje utworzenie słownika indeksu, który odwzorowuje każdą unikatową wartość wyjściową na pozycję jej pierwszego wystąpienia. Kiedy lista jest rozdzielana, wyszukiwanie jest znacznie szybsze, ponieważ wyszukiwanie liniowe jest zastępowane wyszukiwaniem z użyciem tablicy z haszowaniem.
q)L:`p# 99 88 77 1 2 3
q)L
`p#99 88 77 1 2 3
q)L,:3
q)L
99 88 77 1 2 3 3Note −
Atrybut parted nie jest zachowywany w ramach operacji na liście, nawet jeśli operacja zachowuje partycjonowanie.
Atrybut rozdzielony należy brać pod uwagę, gdy liczba podmiotów sięga miliarda, a większość partycji ma znaczną wielkość, tj. Występuje znaczna liczba powtórzeń.
Zgrupowane (`g #)
`g # oznacza, że lista jest zgrupowana. Tworzy się i utrzymuje wewnętrzny słownik, który odwzorowuje każdy unikalny element na każdy z jego indeksów, co wymaga znacznej przestrzeni dyskowej. Aby uzyskać listę długościL zawierający u unikalne rozmiary s, to będzie (L × 4) + (u × s) bajtów.
Grupowanie można zastosować do listy, gdy nie można poczynić żadnych innych założeń dotyczących jej struktury.
Atrybut można zastosować do dowolnych wpisanych list. Jest utrzymywany przy dołączaniu, ale tracony przy usuwaniu.
q)L: `g# 1 2 3 4 5 4 2 3 1 4 5 6
q)L
`g#1 2 3 4 5 4 2 3 1 4 5 6
q)L,:9
q)L
`g#1 2 3 4 5 4 2 3 1 4 5 6 9
q)L _:2
q)L
1 2 4 5 4 2 3 1 4 5 6 9Unikalne (`#u)
Zastosowanie unikalnego atrybutu (`u #) do listy wskazuje, że pozycje na liście są różne. Świadomość, że elementy listy są wyjątkowe, dramatycznie przyspieszadistinct i pozwala q aby wcześniej przeprowadzić pewne porównania.
Gdy lista jest oznaczona jako unikalna, dla każdej pozycji na liście tworzona jest wewnętrzna mapa skrótów. Operacje na liście muszą zachować niepowtarzalność, w przeciwnym razie atrybut zostanie utracony.
q)LU:`u#`MSFT`SAMSUNG`APPLE
q)LU
`u#`MSFT`SAMSUNG`APPLE
q)LU,:`IBM /Uniqueness preserved
q)LU
`u#`MSFT`SAMSUNG`APPLE`IBM
q)LU,:`SAMSUNG / Attribute lost
q)LU
`MSFT`SAMSUNG`APPLE`IBM`SAMSUNGNote −
`u # jest zachowywane w konkatenacjach, które zachowują wyjątkowość. Jest tracony w przypadku usunięć i nieunikalnych konkatenacji.
Przeszukiwanie list `u # odbywa się za pomocą funkcji skrótu.
Usuwanie atrybutów
Atrybuty można usunąć, stosując `` #.
Stosowanie atrybutów
Trzy formaty stosowania atrybutów to -
L: `s# 14 2 3 3 9/ Określ podczas tworzenia listy
@[ `.; `L ; `s#]/ Funkcjonalne, tzn. Do listy zmiennych L
/ w domyślnej przestrzeni nazw (tj.)
/ posortowany atrybut s #
Update `s#time from `tab
/ Zaktualizuj tabelę (kartę), aby zastosować
/ atrybut.
Zastosujmy powyższe trzy różne formaty z przykładami.
q)/ set the attribute during creation
q)L:`s# 3 4 9 10 23 84 90
q)/apply the attribute to existing list data
q)L1: 9 18 27 36 42 54
q)@[`.;`L1;`s#]
`.
q)L1 / check
`s#9 18 27 36 42 54
q)@[`.;`L1;`#] / clear attribute
`.
q)L1
9 18 27 36 42 54
q)/update a table to apply the attribute
q)t: ([] sym:`ibm`msft`samsung; mcap:9000 18000 27000)
q)t:([]time:09:00 09:30 10:00t;sym:`ibm`msft`samsung; mcap:9000 18000 27000)
q)t
time sym mcap
---------------------------------
09:00:00.000 ibm 9000
09:30:00.000 msft 18000
10:00:00.000 samsung 27000
q)update `s#time from `t
`t
q)meta t / check it was applied
c | t f a
------ | -----
time | t s
sym | s
mcap | j
Above we can see that the attribute column in meta table results shows the time column is sorted (`s#).Zapytania funkcjonalne (dynamiczne) pozwalają na określenie nazw kolumn jako symboli dla typowych kolumn Q-sql select / exec / delete. Jest to bardzo przydatne, gdy chcemy dynamicznie określać nazwy kolumn.
Formy funkcjonalne to -
?[t;c;b;a] / for select
![t;c;b;a] / for updategdzie
t jest stołem;
a jest słownikiem agregatów;
bfraza oboczna; i
c to lista ograniczeń.
Uwaga -
Wszystko q podmioty w a, b, i c muszą być przywoływane przez nazwę, czyli jako symbole zawierające nazwy jednostek.
Składniowe formy wyboru i aktualizacji są analizowane do ich równoważnych form funkcjonalnych przez q tłumacza, więc nie ma różnicy w wydajności między tymi dwoma formami.
Funkcjonalny wybór
Poniższy blok kodu pokazuje, jak używać functional select -
q)t:([]n:`ibm`msft`samsung`apple;p:40 38 45 54)
q)t
n p
-------------------
ibm 40
msft 38
samsung 45
apple 54
q)select m:max p,s:sum p by name:n from t where p>36, n in `ibm`msft`apple
name | m s
------ | ---------
apple | 54 54
ibm | 40 40
msft | 38 38Przykład 1
Zacznijmy od najłatwiejszego przypadku, funkcjonalnej wersji “select from t” będzie wyglądać jak -
q)?[t;();0b;()] / select from t
n p
-----------------
ibm 40
msft 38
samsung 45
apple 54Przykład 2
W poniższym przykładzie używamy funkcji enlist do tworzenia singletonów, aby upewnić się, że odpowiednie jednostki są listami.
q)wherecon: enlist (>;`p;40)
q)?[`t;wherecon;0b;()] / select from t where p > 40
n p
----------------
samsung 45
apple 54Przykład 3
q)groupby: enlist[`p] ! enlist `p
q)selcols: enlist [`n]!enlist `n
q)?[ `t;(); groupby;selcols] / select n by p from t
p | n
----- | -------
38 | msft
40 | ibm
45 | samsung
54 | appleFunkcjonalny Exec
Funkcjonalna forma exec jest uproszczoną formą select.
q)?[t;();();`n] / exec n from t (functional form of exec)
`ibm`msft`samsung`apple
q)?[t;();`n;`p] / exec p by n from t (functional exec)
apple | 54
ibm | 40
msft | 38
samsung | 45Aktualizacja funkcjonalna
Funkcjonalna forma aktualizacji jest całkowicie analogiczna do tej z select. W poniższym przykładzie użycie enlist polega na utworzeniu singletonów, aby upewnić się, że jednostki wejściowe są listami.
q)c:enlist (>;`p;0)
q)b: (enlist `n)!enlist `n
q)a: (enlist `p) ! enlist (max;`p)
q)![t;c;b;a]
n p
-------------
ibm 40
msft 38
samsung 45
apple 54Funkcjonalne usuwanie
Usuwanie funkcjonalne to uproszczona forma aktualizacji funkcjonalnej. Jego składnia jest następująca -
![t;c;0b;a] / t is a table, c is a list of where constraints, a is a
/ list of column namesWeźmy teraz przykład, aby pokazać, jak działa usuwanie funkcjonalne -
q)![t; enlist (=;`p; 40); 0b;`symbol$()]
/ delete from t where p = 40
n p
---------------
msft 38
samsung 45
apple 54W tym rozdziale nauczymy się, jak operować na słownikach, a następnie na tabelach. Zacznijmy od słowników -
q)d:`u`v`x`y`z! 9 18 27 36 45 / Creating a dictionary d
q)/ key of this dictionary (d) is given by
q)key d
`u`v`x`y`z
q)/and the value by
q)value d
9 18 27 36 45
q)/a specific value
q)d`x
27
q)d[`x]
27
q)/values can be manipulated by using the arithmetic operator +-*% as,
q)45 + d[`x`y]
72 81Jeśli trzeba zmienić wartości słownikowe, to wyrażenie zmiany może mieć postać -
q)@[`d;`z;*;9]
`d
q)d
u | 9
v | 18
x | 27
y | 36
q)/Example, table tab
q)tab:([]sym:`;time:0#0nt;price:0n;size:0N)
q)n:10;sym:`IBM`SAMSUNG`APPLE`MSFT
q)insert[`tab;(n?sym;("t"$.z.Z);n?100.0;n?100)]
0 1 2 3 4 5 6 7 8 9
q)`time xasc `tab
`tab
q)/ to get particular column from table tab
q)tab[`size]
12 10 1 90 73 90 43 90 84 63
q)tab[`size]+9
21 19 10 99 82 99 52 99 93 72
z | 405
q)/Example table tab
q)tab:([]sym:`;time:0#0nt;price:0n;size:0N)
q)n:10;sym:`IBM`SAMSUNG`APPLE`MSFT
q)insert[`tab;(n?sym;("t"$.z.Z);n?100.0;n?100)] 0 1 2 3 4 5 6 7 8 9 q)`time xasc `tab `tab q)/ to get particular column from table tab q)tab[`size] 12 10 1 90 73 90 43 90 84 63 q)tab[`size]+9 21 19 10 99 82 99 52 99 93 72 q)/Example table tab q)tab:([]sym:`;time:0#0nt;price:0n;size:0N) q)n:10;sym:`IBM`SAMSUNG`APPLE`MSFT q)insert[`tab;(n?sym;("t"$.z.Z);n?100.0;n?100)]
0 1 2 3 4 5 6 7 8 9
q)`time xasc `tab
`tab
q)/ to get particular column from table tab
q)tab[`size]
12 10 1 90 73 90 43 90 84 63
q)tab[`size]+9
21 19 10 99 82 99 52 99 93 72
q)/We can also use the @ amend too
q)@[tab;`price;-;2]
sym time price size
--------------------------------------------
APPLE 11:16:39.779 6.388858 12
MSFT 11:16:39.779 17.59907 10
IBM 11:16:39.779 35.5638 1
SAMSUNG 11:16:39.779 59.37452 90
APPLE 11:16:39.779 50.94808 73
SAMSUNG 11:16:39.779 67.16099 90
APPLE 11:16:39.779 20.96615 43
SAMSUNG 11:16:39.779 67.19531 90
IBM 11:16:39.779 45.07883 84
IBM 11:16:39.779 61.46716 63
q)/if the table is keyed
q)tab1:`sym xkey tab[0 1 2 3 4]
q)tab1
sym | time price size
--------- | ----------------------------------
APPLE | 11:16:39.779 8.388858 12
MSFT | 11:16:39.779 19.59907 10
IBM | 11:16:39.779 37.5638 1
SAMSUNG | 11:16:39.779 61.37452 90
APPLE | 11:16:39.779 52.94808 73
q)/To work on specific column, try this
q){tab1[x]`size} each sym
1 90 12 10
q)(0!tab1)`size
12 10 1 90 73
q)/once we got unkeyed table, manipulation is easy
q)2+ (0!tab1)`size
14 12 3 92 75Dane na dysku twardym (zwane również historyczną bazą danych) można zapisać w trzech różnych formatach - płaskie pliki, tabele podzielone i tabele podzielone na partycje. Tutaj dowiemy się, jak używać tych trzech formatów do zapisywania danych.
Plik płaski
Płaskie pliki są w pełni ładowane do pamięci, dlatego ich rozmiar (zużycie pamięci) powinien być niewielki. Tabele są zapisywane na dysku w całości w jednym pliku (więc rozmiar ma znaczenie).
Funkcje używane do manipulowania tymi tabelami to set/get -
`:path_to_file/filename set tablenameWeźmy przykład, aby pokazać, jak to działa -
q)tables `.
`s#`t`tab`tab1
q)`:c:/q/w32/tab1_test set tab1
`:c:/q/w32/tab1_testW środowisku Windows płaskie pliki są zapisywane w lokalizacji - C:\q\w32
Pobierz płaski plik z dysku (historyczna baza danych) i użyj rozszerzenia get polecenie w następujący sposób -
q)tab2: get `:c:/q/w32/tab1_test
q)tab2
sym | time price size
--------- | -------------------------------
APPLE | 11:16:39.779 8.388858 12
MSFT | 11:16:39.779 19.59907 10
IBM | 11:16:39.779 37.5638 1
SAMSUNG | 11:16:39.779 61.37452 90
APPLE | 11:16:39.779 52.94808 73Tworzona jest nowa tabela tab2 z zawartością przechowywaną w tab1_test plik.
Stoły rozłożone
Jeśli w tabeli jest za dużo kolumn, to przechowujemy takie tabele w formacie splay, czyli zapisujemy je na dysku w katalogu. W katalogu każda kolumna jest zapisywana w oddzielnym pliku pod tą samą nazwą co nazwa kolumny. Każda kolumna jest zapisywana jako lista odpowiedniego typu w pliku binarnym kdb +.
Zapisywanie tabeli w formacie rozłożonym jest bardzo przydatne, gdy musimy często uzyskiwać dostęp tylko do kilku kolumn z wielu kolumn. Katalog podzielonej tabeli zawiera.d plik binarny zawierający kolejność kolumn.
Podobnie jak w przypadku pliku płaskiego, tabelę można zapisać jako rozłożoną przy użyciu rozszerzenia setKomenda. Aby zapisać tabelę jako rozdzieloną, ścieżka pliku powinna kończyć się luzem -
`:path_to_filename/filename/ set tablenameDo czytania rozłożonej tabeli możemy użyć get funkcja -
tablename: get `:path_to_file/filenameNote - Aby tabela została zapisana jako rozłożona, powinna być pozbawiona klucza i wyliczona.
W środowisku Windows struktura plików będzie wyglądać następująco -
Tabele podzielone
Tabele podzielone na partycje zapewniają skuteczny sposób zarządzania ogromnymi tabelami zawierającymi znaczne ilości danych. Tabele podzielone na partycje to tabele podzielone na więcej partycji (katalogów).
Wewnątrz każdej partycji tabela będzie miała swój własny katalog o strukturze tabeli podzielonej. Tabele można podzielić na dzień / miesiąc / rok, aby zapewnić optymalny dostęp do ich zawartości.
Aby uzyskać zawartość tabeli podzielonej na partycje, użyj następującego bloku kodu -
q)get `:c:/q/data/2000.01.13 // “get” command used, sample folder
quote| +`sym`time`bid`ask`bsize`asize`ex!(`p#`sym!0 0 0 0 0 0 0 0 0 0 0
0 0 0….
trade| +`sym`time`price`size`ex!(`p#`sym!0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 ….Spróbujmy uzyskać zawartość tabeli handlowej -
q)get `:c:/q/data/2000.01.13/trade
sym time price size ex
--------------------------------------------------
0 09:30:00.496 0.4092016 7 T
0 09:30:00.501 1.428629 4 N
0 09:30:00.707 0.5647834 6 T
0 09:30:00.781 1.590509 5 T
0 09:30:00.848 2.242627 3 A
0 09:30:00.860 2.277041 8 T
0 09:30:00.931 0.8044885 8 A
0 09:30:01.197 1.344031 2 A
0 09:30:01.337 1.875 3 A
0 09:30:01.399 2.187723 7 ANote - Tryb partycjonowany jest odpowiedni dla tabel zawierających miliony rekordów dziennie (tj. Dane szeregów czasowych)
Plik sym
Plik sym jest plikiem binarnym kdb + zawierającym listę symboli ze wszystkich tabel podzielonych i podzielonych na partycje. Można go czytać,
get `:symplik par.txt (opcjonalnie)
Jest to plik konfiguracyjny używany, gdy partycje są rozmieszczone w kilku katalogach / dyskach i zawierają ścieżki do partycji dyskowych.
.Q.en
.Q.enjest funkcją dwójkową, która pomaga w dzieleniu tabeli przez wyliczenie kolumny symboli. Jest to szczególnie przydatne, gdy mamy do czynienia z historyczną bazą danych (podzieloną, partycjonowaną itp.). -
.Q.en[`:directory;table]gdzie directory jest katalogiem domowym historycznej bazy danych, gdzie sym file znajduje się i table to tabela do wyliczenia.
Ręczne wyliczanie tabel nie jest wymagane, aby zapisać je jako tabele rozdzielone, ponieważ zostanie to zrobione przez -
.Q.en[`:directory_where_symbol_file_stored]table_name.Q.dpft
Plik .Q.dpftfunkcja pomaga w tworzeniu podzielonych i posegmentowanych tabel. Jest to zaawansowana forma.Q.en, ponieważ nie tylko rozdziela tabelę, ale także tworzy tabelę partycji.
W programie używane są cztery argumenty .Q.dpft -
symboliczny uchwyt pliku bazy danych, w której chcemy utworzyć partycję,
q wartość danych, którymi podzielimy tabelę,
nazwa pola, z którym ma zostać zastosowany atrybut parted (`p #) (zwykle` sym), a
nazwa tabeli.
Weźmy przykład, aby zobaczyć, jak to działa -
q)tab:([]sym:5?`msft`hsbc`samsung`ibm;time:5?(09:30:30);price:5?30.25)
q).Q.dpft[`:c:/q/;2014.08.24;`sym;`tab]
`tab
q)delete tab from `
'type
q)delete tab from `/
'type
q)delete tab from .
'type
q)delete tab from `.
`.
q)tab
'tabUsunęliśmy tabelę tabz pamięci. Załadujmy teraz go z bazy danych
q)\l c:/q/2014.08.24/
q)\a
,`tab
q)tab
sym time price
-------------------------------
hsbc 07:38:13 15.64201
hsbc 07:21:05 5.387037
msft 06:16:58 11.88076
msft 08:09:26 12.30159
samsung 04:57:56 15.60838.Q.chk
.Q.chk jest funkcją monadyczną, której pojedynczym parametrem jest symboliczny uchwyt pliku katalogu głównego. W razie potrzeby tworzy puste tabele w partycji, badając podkatalogi każdej partycji w katalogu głównym.
.Q.chk `:directorygdzie directory jest katalogiem domowym historycznej bazy danych.