Keras - przewidywanie szeregów czasowych przy użyciu LSTM RNN
W tym rozdziale napiszemy prosty RNN oparty na pamięci długoterminowej (LSTM), aby przeprowadzić analizę sekwencji. Sekwencja to zestaw wartości, w których każda wartość odpowiada określonemu wystąpieniu czasu. Rozważmy prosty przykład czytania zdania. Czytanie i rozumienie zdania polega na przeczytaniu słowa w określonej kolejności i próbie zrozumienia każdego słowa i jego znaczenia w danym kontekście, a na koniec zrozumieniu zdania w pozytywnym lub negatywnym odczuciu.
Tutaj słowa są traktowane jako wartości, a pierwsza wartość odpowiada pierwszemu słowu, druga wartość odpowiada drugiemu słowu itd., A kolejność będzie ściśle zachowana. Sequence Analysis jest często używany w przetwarzaniu języka naturalnego do znalezienia analizy sentymentu danego tekstu.
Stwórzmy model LSTM, aby przeanalizować recenzje filmów IMDB i znaleźć ich pozytywne / negatywne opinie.
Model analizy sekwencji można przedstawić jak poniżej -
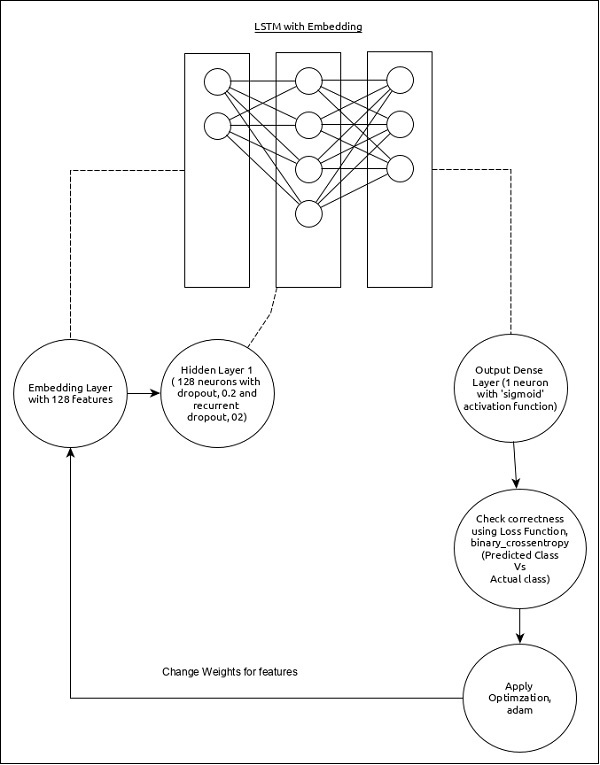
Podstawowe cechy modelu są następujące -
Warstwa wejściowa wykorzystująca warstwę osadzania z 128 funkcjami.
Pierwsza warstwa, Dense, składa się ze 128 jednostek z normalnym spadkiem i powtarzającym się spadkiem ustawionym na 0,2.
Warstwa wyjściowa, Gęsta, składa się z 1 jednostki i funkcji aktywacji „sigmoidalnej”.
Posługiwać się binary_crossentropy jako funkcja straty.
Posługiwać się adam jako optymalizator.
Posługiwać się accuracy jako metryki.
Użyj 32 jako wielkości partii.
Użyj 15 jako epok.
Użyj 80 jako maksymalnej długości słowa.
Użyj 2000 jako maksymalnej liczby słów w zdaniu.
Krok 1: Zaimportuj moduły
Zaimportujmy niezbędne moduły.
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Embedding
from keras.layers import LSTM
from keras.datasets import imdbKrok 2: Załaduj dane
Zaimportujmy zestaw danych imdb.
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words = 2000)Tutaj,
imdbto zbiór danych dostarczony przez Keras. Reprezentuje zbiór filmów i ich recenzje.
num_words reprezentują maksymalną liczbę słów w recenzji.
Krok 3: Przetwórz dane
Zmieńmy zbiór danych zgodnie z naszym modelem, aby można go było wprowadzić do naszego modelu. Dane można zmienić za pomocą poniższego kodu -
x_train = sequence.pad_sequences(x_train, maxlen=80)
x_test = sequence.pad_sequences(x_test, maxlen=80)Tutaj,
sequence.pad_sequences przekonwertować listę danych wejściowych na kształt, (data) na tablicę kształtów 2D NumPy (data, timesteps). Zasadniczo dodaje koncepcję timesteps do podanych danych. Generuje timesteps długości,maxlen.
Krok 4: Utwórz model
Stwórzmy rzeczywisty model.
model = Sequential()
model.add(Embedding(2000, 128))
model.add(LSTM(128, dropout = 0.2, recurrent_dropout = 0.2))
model.add(Dense(1, activation = 'sigmoid'))Tutaj,
Użyliśmy Embedding layerjako warstwę wejściową, a następnie dodano warstwę LSTM. Wreszcie aDense layer jest używana jako warstwa wyjściowa.
Krok 5: Skompiluj model
Skompilujmy model wykorzystując wybraną funkcję straty, optymalizator i metryki.
model.compile(loss = 'binary_crossentropy',
optimizer = 'adam', metrics = ['accuracy'])Krok 6: Wytrenuj model
L Przećwiczmy model przy użyciu fit() metoda.
model.fit(
x_train, y_train,
batch_size = 32,
epochs = 15,
validation_data = (x_test, y_test)
)Uruchomienie aplikacji spowoduje wyświetlenie poniższych informacji -
Epoch 1/15 2019-09-24 01:19:01.151247: I
tensorflow/core/platform/cpu_feature_guard.cc:142]
Your CPU supports instructions that this
TensorFlow binary was not co mpiled to use: AVX2
25000/25000 [==============================] - 101s 4ms/step - loss: 0.4707
- acc: 0.7716 - val_loss: 0.3769 - val_acc: 0.8349 Epoch 2/15
25000/25000 [==============================] - 95s 4ms/step - loss: 0.3058
- acc: 0.8756 - val_loss: 0.3763 - val_acc: 0.8350 Epoch 3/15
25000/25000 [==============================] - 91s 4ms/step - loss: 0.2100
- acc: 0.9178 - val_loss: 0.5065 - val_acc: 0.8110 Epoch 4/15
25000/25000 [==============================] - 90s 4ms/step - loss: 0.1394
- acc: 0.9495 - val_loss: 0.6046 - val_acc: 0.8146 Epoch 5/15
25000/25000 [==============================] - 90s 4ms/step - loss: 0.0973
- acc: 0.9652 - val_loss: 0.5969 - val_acc: 0.8147 Epoch 6/15
25000/25000 [==============================] - 98s 4ms/step - loss: 0.0759
- acc: 0.9730 - val_loss: 0.6368 - val_acc: 0.8208 Epoch 7/15
25000/25000 [==============================] - 95s 4ms/step - loss: 0.0578
- acc: 0.9811 - val_loss: 0.6657 - val_acc: 0.8184 Epoch 8/15
25000/25000 [==============================] - 97s 4ms/step - loss: 0.0448
- acc: 0.9850 - val_loss: 0.7452 - val_acc: 0.8136 Epoch 9/15
25000/25000 [==============================] - 95s 4ms/step - loss: 0.0324
- acc: 0.9894 - val_loss: 0.7616 - val_acc: 0.8162Epoch 10/15
25000/25000 [==============================] - 100s 4ms/step - loss: 0.0247
- acc: 0.9922 - val_loss: 0.9654 - val_acc: 0.8148 Epoch 11/15
25000/25000 [==============================] - 99s 4ms/step - loss: 0.0169
- acc: 0.9946 - val_loss: 1.0013 - val_acc: 0.8104 Epoch 12/15
25000/25000 [==============================] - 90s 4ms/step - loss: 0.0154
- acc: 0.9948 - val_loss: 1.0316 - val_acc: 0.8100 Epoch 13/15
25000/25000 [==============================] - 89s 4ms/step - loss: 0.0113
- acc: 0.9963 - val_loss: 1.1138 - val_acc: 0.8108 Epoch 14/15
25000/25000 [==============================] - 89s 4ms/step - loss: 0.0106
- acc: 0.9971 - val_loss: 1.0538 - val_acc: 0.8102 Epoch 15/15
25000/25000 [==============================] - 89s 4ms/step - loss: 0.0090
- acc: 0.9972 - val_loss: 1.1453 - val_acc: 0.8129
25000/25000 [==============================] - 10s 390us/stepKrok 7 - Oceń model
Oceńmy model na podstawie danych testowych.
score, acc = model.evaluate(x_test, y_test, batch_size = 32)
print('Test score:', score)
print('Test accuracy:', acc)Wykonanie powyższego kodu spowoduje wyświetlenie poniższych informacji -
Test score: 1.145306069601178
Test accuracy: 0.81292