Konfigurowanie projektu
W tym rozdziale szczegółowo poznamy proces tworzenia projektu w celu wykonania regresji logistycznej w Pythonie.
Instalowanie Jupyter
Będziemy używać Jupyter - jednej z najczęściej używanych platform do uczenia maszynowego. Jeśli nie masz zainstalowanego Jupytera na swoim komputerze, pobierz go stąd . Aby zainstalować, możesz postępować zgodnie z instrukcjami na ich stronie, aby zainstalować platformę. Jak sugeruje witryna, możesz preferować użycieAnaconda Distributionktóry jest dostarczany wraz z Pythonem i wieloma powszechnie używanymi pakietami Pythona do obliczeń naukowych i nauki o danych. Zmniejszy to potrzebę instalowania tych pakietów indywidualnie.
Po pomyślnej instalacji Jupytera rozpocznij nowy projekt, twój ekran na tym etapie wyglądałby tak, jakby był gotowy do zaakceptowania twojego kodu.
Teraz zmień nazwę projektu z Untitled1 to “Logistic Regression” klikając nazwę tytułu i edytując ją.
Najpierw zaimportujemy kilka pakietów Pythona, których będziemy potrzebować w naszym kodzie.
Importowanie pakietów Pythona
W tym celu wpisz lub wytnij i wklej następujący kod w edytorze kodu -
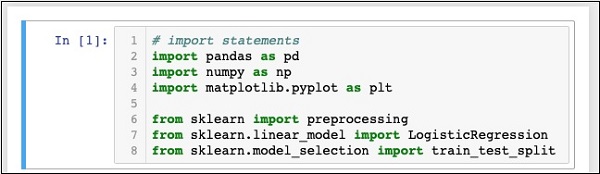
In [1]: # import statements
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import preprocessing
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_splitTwój Notebook na tym etapie powinien wyglądać następująco -
Uruchom kod, klikając plik Runprzycisk. Jeśli nie zostaną wygenerowane żadne błędy, pomyślnie zainstalowałeś Jupyter i jesteś teraz gotowy do dalszej części rozwoju.
Pierwsze trzy instrukcje importu importują pandy, pakiety numpy i matplotlib.pyplot w naszym projekcie. Następne trzy instrukcje importują określone moduły ze sklearn.
Naszym kolejnym zadaniem jest pobranie danych wymaganych dla naszego projektu. Dowiemy się tego w następnym rozdziale.