Logstash - Szybki przewodnik
Logstash to narzędzie oparte na wzorcach filtrów / potoków do gromadzenia, przetwarzania i generowania dzienników lub zdarzeń. Pomaga w centralizacji i dokonywaniu analizy dzienników i zdarzeń z różnych źródeł w czasie rzeczywistym.
Logstash jest napisany w języku programowania JRuby, który działa na JVM, więc możesz uruchomić Logstash na różnych platformach. Zbiera różne typy danych, takie jak dzienniki, pakiety, zdarzenia, transakcje, dane znacznika czasu itp., Z prawie każdego rodzaju źródła. Źródłem danych mogą być dane społecznościowe, handel elektroniczny, artykuły z wiadomościami, CRM, dane gier, trendy w sieci, dane finansowe, internet rzeczy, urządzenia mobilne itp.
Ogólne funkcje Logstash
Ogólne cechy Logstash są następujące -
Logstash może zbierać dane z różnych źródeł i wysyłać do wielu miejsc docelowych.
Logstash może obsługiwać wszystkie typy danych rejestrowania, takie jak dzienniki Apache, dzienniki zdarzeń systemu Windows, dane przez protokoły sieciowe, dane ze standardowego wejścia i wiele innych.
Logstash może również obsługiwać żądania HTTP i dane odpowiedzi.
Logstash zapewnia różnorodne filtry, które pomagają użytkownikowi znaleźć więcej znaczenia w danych poprzez ich analizę i przekształcanie.
Logstash może być również używany do obsługi danych z czujników w internecie rzeczy.
Logstash jest oprogramowaniem typu open source i jest dostępny na licencji Apache w wersji 2.0.
Kluczowe koncepcje Logstash
Kluczowe koncepcje Logstash są następujące -
Obiekt zdarzenia
Jest to główny obiekt w Logstash, który hermetyzuje przepływ danych w potoku Logstash. Logstash używa tego obiektu do przechowywania danych wejściowych i dodawania dodatkowych pól utworzonych na etapie filtrowania.
Logstash oferuje programistom Event API do manipulowania zdarzeniami. W tym samouczku to zdarzenie jest określane różnymi nazwami, takimi jak zdarzenie rejestrowania danych, zdarzenie dziennika, dane dziennika, dane dziennika wejściowego, dane dziennika wyjściowego itp.
Rurociąg
Obejmuje etapy przepływu danych w Logstash od wejścia do wyjścia. Dane wejściowe są wprowadzane do potoku i przetwarzane w formie zdarzenia. Następnie wysyła do miejsca docelowego w pożądanym formacie użytkownika lub systemu końcowego.
Wejście
Jest to pierwszy etap potoku Logstash, który służy do pobierania danych w Logstash do dalszego przetwarzania. Logstash oferuje różne wtyczki do pobierania danych z różnych platform. Niektóre z najczęściej używanych wtyczek to - File, Syslog, Redis i Beats.
Filtr
To środkowy etap Logstash, w którym odbywa się faktyczna obróbka zdarzeń. Deweloper może użyć wstępnie zdefiniowanych wzorców Regex autorstwa Logstash do tworzenia sekwencji do rozróżniania pól w zdarzeniach i kryteriów akceptowanych zdarzeń wejściowych.
Logstash oferuje różne wtyczki, które pomagają programistom analizować i przekształcać zdarzenia w pożądaną strukturę. Niektóre z najczęściej używanych wtyczek filtrów to - Grok, Mutate, Drop, Clone i Geoip.
Wynik
Jest to ostatni etap potoku Logstash, w którym zdarzenia wyjściowe można sformatować do struktury wymaganej przez systemy docelowe. Na koniec wysyła zdarzenie wyjściowe po zakończeniu przetwarzania do miejsca docelowego za pomocą wtyczek. Niektóre z najczęściej używanych wtyczek to - Elasticsearch, File, Graphite, Statsd itp.
Zalety Logstash
Poniższe punkty wyjaśniają różne zalety Logstash.
Logstash oferuje sekwencje wzorców regex do identyfikowania i analizowania różnych pól w dowolnym zdarzeniu wejściowym.
Logstash obsługuje różne serwery internetowe i źródła danych do wyodrębniania danych logowania.
Logstash zapewnia wiele wtyczek do analizowania i przekształcania danych logowania do dowolnego formatu pożądanego przez użytkownika.
Logstash jest scentralizowany, co ułatwia przetwarzanie i zbieranie danych z różnych serwerów.
Logstash obsługuje wiele baz danych, protokołów sieciowych i innych usług jako docelowe źródło zdarzeń rejestrowania.
Logstash używa protokołu HTTP, który umożliwia użytkownikowi aktualizację wersji Elasticsearch bez konieczności uaktualniania Logstash w trybie blokady.
Wady Logstash
Poniższe punkty wyjaśniają różne wady Logstash.
Logstash wykorzystuje protokół http, co negatywnie wpływa na przetwarzanie danych logowania.
Praca z Logstash może być czasami nieco skomplikowana, ponieważ wymaga dobrego zrozumienia i analizy wejściowych danych logowania.
Wtyczki filtrów nie są ogólne, więc użytkownik może potrzebować znaleźć poprawną sekwencję wzorców, aby uniknąć błędów podczas analizowania.
W następnym rozdziale zrozumiemy, czym jest stos ELK i jak pomaga Logstash.
ELK oznacza Elasticsearch, Logstash, i Kibana. W stosie ELK Logstash wyodrębnia dane logowania lub inne zdarzenia z różnych źródeł wejściowych. Przetwarza zdarzenia, a później przechowuje je w Elasticsearch. Kibana to interfejs sieciowy, który uzyskuje dostęp do danych logowania z Elasticsearch i wizualizuje je.
Logstash i Elasticsearch
Logstash udostępnia wtyczkę Elasticsearch wejściową i wyjściową do odczytywania i zapisywania zdarzeń dziennika w Elasticsearch. Elasticsearch jako miejsce docelowe danych wyjściowych jest również zalecane przez firmę Elasticsearch ze względu na jego zgodność z Kibaną. Logstash wysyła dane do Elasticsearch przez protokół http.
Elasticsearch zapewnia funkcję przesyłania zbiorczego, która pomaga przesyłać dane z różnych źródeł lub instancji Logstash do scentralizowanego silnika Elasticsearch. ELK ma następujące zalety w porównaniu z innymi rozwiązaniami DevOps -
Stos ELK jest łatwiejszy w zarządzaniu i można go skalować w celu obsługi petabajtów zdarzeń.
Architektura stosu ELK jest bardzo elastyczna i zapewnia integrację z Hadoop. Hadoop jest używany głównie do celów archiwalnych. Logstash może być bezpośrednio połączony z Hadoop przy użyciu flume, a Elasticsearch udostępnia łącznik o nazwiees-hadoop aby połączyć się z Hadoop.
Całkowity koszt posiadania ELK jest znacznie niższy niż jego alternatyw.
Logstash i Kibana
Kibana nie współdziała z Logstash bezpośrednio, ale za pośrednictwem źródła danych, którym jest Elasticsearch w stosie ELK. Logstash zbiera dane z każdego źródła, a Elasticsearch analizuje je z bardzo dużą szybkością, a następnie Kibana dostarcza przydatne informacje o tych danych.
Kibana to internetowe narzędzie do wizualizacji, które pomaga programistom i innym osobom analizować różnice w dużej liczbie zdarzeń zbieranych przez Logstash w silniku Elasticsearch. Ta wizualizacja ułatwia przewidywanie lub obserwowanie zmian trendów błędów lub innych znaczących zdarzeń źródła wejściowego.
Aby zainstalować Logstash w systemie, powinniśmy wykonać kroki podane poniżej -
Step 1- Sprawdź wersję oprogramowania Java zainstalowaną na komputerze; powinna to być Java 8, ponieważ nie jest ona zgodna z Javą 9. Możesz to sprawdzić przez -
W systemie operacyjnym Windows (OS) (za pomocą wiersza polecenia) -
> java -versionW systemie UNIX (przy użyciu terminala) -
$ echo $JAVA_HOMEStep 2 - Pobierz Logstash z -
https://www.elastic.co/downloads/logstash.
W przypadku systemu operacyjnego Windows pobierz plik ZIP.
W przypadku systemu operacyjnego UNIX pobierz plik TAR.
W przypadku systemu operacyjnego Debian pobierz plik DEB.
W przypadku Red Hat i innych dystrybucji Linuksa pobierz plik RPN.
Narzędzia APT i Yum mogą być również używane do instalowania Logstash w wielu dystrybucjach Linuksa.
Step 3- Proces instalacji Logstash jest bardzo łatwy. Zobaczmy, jak możesz zainstalować Logstash na różnych platformach.
Note - Nie umieszczaj spacji ani dwukropka w folderze instalacyjnym.
Windows OS - Rozpakuj pakiet zip, a Logstash zostanie zainstalowany.
UNIX OS - Rozpakuj plik tar w dowolnej lokalizacji, a Logstash zostanie zainstalowany.
$tar –xvf logstash-5.0.2.tar.gzUsing APT utility for Linux OS −
- Pobierz i zainstaluj publiczny klucz podpisu -
$ wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -- Zapisz definicję repozytorium -
$ echo "deb https://artifacts.elastic.co/packages/5.x/apt stable main" | sudo
tee -a /etc/apt/sources.list.d/elastic-5.x.list- Uruchom aktualizację -
$ sudo apt-get update- Teraz możesz zainstalować za pomocą następującego polecenia -
$ sudo apt-get install logstashUsing YUM utility for Debian Linux OS -
- Pobierz i zainstaluj publiczny klucz podpisu -
$ rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchDodaj następujący tekst do pliku z przyrostkiem .repo w katalogu o „/etc/yum.repos.d/”. Na przykład,logstash.repo
[logstash-5.x]
name = Elastic repository for 5.x packages
baseurl = https://artifacts.elastic.co/packages/5.x/yum
gpgcheck = 1
gpgkey = https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled = 1
autorefresh = 1
type = rpm-md- Możesz teraz zainstalować Logstash za pomocą następującego polecenia -
$ sudo yum install logstashStep 4- Przejdź do katalogu domowego Logstash. Wewnątrz folderu bin uruchom plikelasticsearch.batplik w przypadku okien lub możesz zrobić to samo za pomocą wiersza poleceń i terminala. W systemie UNIX uruchom plik Logstash.
Musimy określić źródło wejściowe, źródło wyjściowe i opcjonalne filtry. Aby zweryfikować instalację, można uruchomić ją z podstawową konfiguracją, używając standardowego strumienia wejściowego (stdin) jako źródła wejściowego i standardowego strumienia wyjściowego (stdout) jako źródła wyjściowego. Możesz określić konfigurację w wierszu poleceń również za pomocą–e opcja.
In Windows −
> cd logstash-5.0.1/bin
> Logstash -e 'input { stdin { } } output { stdout {} }'In Linux −
$ cd logstash-5.0.1/bin
$ ./logstash -e 'input { stdin { } } output { stdout {} }'Note- w przypadku okien może pojawić się błąd informujący, że JAVA_HOME nie jest ustawiony. W tym celu ustaw go w zmiennych środowiskowych na „C: \ Program Files \ Java \ jre1.8.0_111” lub lokalizację, w której zainstalowałeś java.
Step 5 - Domyślne porty interfejsu sieciowego Logstash to od 9600 do 9700, które są zdefiniowane w logstash-5.0.1\config\logstash.yml jako http.port i odbierze pierwszy dostępny port w podanym zakresie.
Możemy sprawdzić, czy serwer Logstash jest uruchomiony i działa, przeglądając http://localhost:9600lub jeśli port jest inny, a następnie sprawdź wiersz polecenia lub terminal. Przypisany port widzimy jako „Pomyślnie uruchomiono punkt końcowy interfejsu API Logstash {: port ⇒ 9600}. Zwróci obiekt JSON, który zawiera informacje o zainstalowanym Logstash w następujący sposób -
{
"host":"manu-PC",
"version":"5.0.1",
"http_address":"127.0.0.1:9600",
"build_date":"2016-11-11T22:28:04+00:00",
"build_sha":"2d8d6263dd09417793f2a0c6d5ee702063b5fada",
"build_snapshot":false
}W tym rozdziale omówimy wewnętrzną architekturę i różne komponenty Logstash.
Architektura usługi Logstash
Logstash przetwarza logi z różnych serwerów i źródeł danych i zachowuje się jak nadawca. Spedytorzy są wykorzystywani do zbierania dzienników, które są instalowane w każdym źródle wejściowym. Brokerzy lubiąRedis, Kafka lub RabbitMQ są buforami do przechowywania danych dla indeksatorów, może istnieć więcej niż jeden broker w przypadku awarii.
Indeksatory lubią Lucenesą używane do indeksowania dzienników w celu uzyskania lepszej wydajności wyszukiwania, a następnie dane wyjściowe są przechowywane w usłudze Elasticsearch lub w innym miejscu docelowym. Dane w pamięci wyjściowej są dostępne dla Kibany i innych programów do wizualizacji.
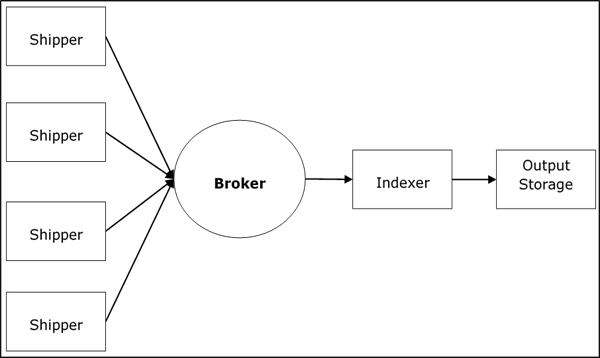
Architektura wewnętrzna Logstash
Potok Logstash składa się z trzech komponentów Input, Filters i Output. Część wejściowa jest odpowiedzialna za określenie i dostęp do źródła danych wejściowych, takiego jak folder dziennikaApache Tomcat Server.
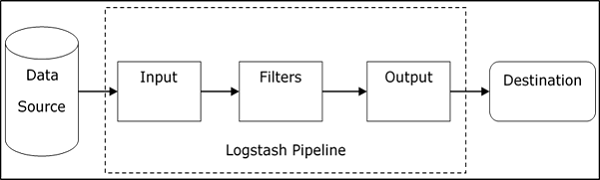
Przykład wyjaśniający potok Logstash
Plik konfiguracyjny Logstash zawiera szczegółowe informacje o trzech składnikach Logstash. W tym przypadku tworzymy nazwę pliku o nazwieLogstash.conf.
Poniższa konfiguracja przechwytuje dane z dziennika wejściowego „inlog.log” i zapisuje je w dzienniku wyjściowym „outlog.log” bez żadnych filtrów.
Logstash.conf
Plik konfiguracyjny Logstash po prostu kopiuje dane z pliku inlog.log plik za pomocą wtyczki wejściowej i opróżnia dane dziennika do outlog.log plik za pomocą wtyczki wyjściowej.
input {
file {
path => "C:/tpwork/logstash/bin/log/inlog.log"
}
}
output {
file {
path => "C:/tpwork/logstash/bin/log/outlog.log"
}
}Uruchom Logstash
Logstash używa –f możliwość określenia pliku konfiguracyjnego.
C:\logstash\bin> logstash –f logstash.confinlog.log
Poniższy blok kodu przedstawia dane dziennika wejściowego.
Hello tutorialspoint.comoutlog.log
Dane wyjściowe Logstash zawierają dane wejściowe w polu komunikatu. Logstash dodaje również inne pola do danych wyjściowych, takie jak sygnatura czasowa, ścieżka źródła danych wejściowych, wersja, host i tagi.
{
"path":"C:/tpwork/logstash/bin/log/inlog1.log",
"@timestamp":"2016-12-13T02:28:38.763Z",
"@version":"1", "host":"Dell-PC",
"message":" Hello tutorialspoint.com", "tags":[]
}Jak możesz, dane wyjściowe Logstash zawierają więcej niż dane dostarczane przez dziennik wejściowy. Dane wyjściowe zawierają ścieżkę źródłową, znacznik czasu, wersję, nazwę hosta i znacznik, które są używane do reprezentowania dodatkowych komunikatów, takich jak błędy.
Możemy wykorzystać filtry do przetwarzania danych i uczynienia ich przydatnymi dla naszych potrzeb. W następnym przykładzie używamy filtra do pobierania danych, który ogranicza dane wyjściowe tylko do danych z czasownikiem takim jak GET lub POST, po którym następujeUnique Resource Identifier.
Logstash.conf
W tej konfiguracji Logstash dodajemy filtr o nazwie grokaby odfiltrować dane wejściowe. Zdarzenie dziennika wejściowego, które jest zgodne z dziennikiem wejściowym sekwencji wzorców, dociera do miejsca docelowego tylko z błędem. Logstash dodaje tag o nazwie „_grokparsefailure” do zdarzeń wyjściowych, który nie jest zgodny z sekwencją wzorca filtru grok.
Logstash oferuje wiele wbudowanych wzorców regex do analizowania popularnych dzienników serwera, takich jak Apache. Wzorzec użyty tutaj wymaga czasownika takiego jak get, post itp., Po którym następuje jednolity identyfikator zasobu.
input {
file {
path => "C:/tpwork/logstash/bin/log/inlog2.log"
}
}
filter {
grok {
match => {"message" => "%{WORD:verb} %{URIPATHPARAM:uri}"}
}
}
output {
file {
path => "C:/tpwork/logstash/bin/log/outlog2.log"
}
}Uruchom Logstash
Możemy uruchomić Logstash za pomocą następującego polecenia.
C:\logstash\bin> logstash –f Logstash.confinlog2.log
Nasz plik wejściowy zawiera dwa zdarzenia oddzielone domyślnym separatorem, tj. Nowym ogranicznikiem linii. Pierwsze zdarzenie pasuje do wzorca określonego w GROk, a drugie nie.
GET /tutorialspoint/Logstash
Input 1234outlog2.log
Widzimy, że drugie zdarzenie wyjściowe zawiera tag „_grokparsefailure”, ponieważ nie pasuje do wzorca filtru grok. Użytkownik może również usunąć te niedopasowane zdarzenia w danych wyjściowych przy użyciu‘if’ warunek we wtyczce wyjściowej.
{
"path":"C:/tpwork/logstash/bin/log/inlog2.log",
"@timestamp":"2016-12-13T02:47:10.352Z","@version":"1","host":"Dell-PC","verb":"GET",
"message":"GET /tutorialspoint/logstash", "uri":"/tutorialspoint/logstash", "tags":[]
}
{
"path":"C:/tpwork/logstash/bin/log/inlog2.log",
"@timestamp":"2016-12-13T02:48:12.418Z", "@version":"1", "host":"Dell-PC",
"message":"t 1234\r", "tags":["_grokparsefailure"]
}Dzienniki z różnych serwerów lub źródeł danych są gromadzone przez spedytorów. Nadawca to instancja Logstash zainstalowana na serwerze, która uzyskuje dostęp do dzienników serwera i wysyła je do określonej lokalizacji wyjściowej.
Głównie wysyła dane wyjściowe do Elasticsearch w celu przechowywania. Logstash pobiera dane wejściowe z następujących źródeł -
- STDIN
- Syslog
- Files
- TCP/UDP
- Dzienniki zdarzeń Microsoft Windows
- Websocket
- Zeromq
- Dostosowane rozszerzenia
Zbieranie dzienników za pomocą serwera Apache Tomcat 7
W tym przykładzie zbieramy dzienniki serwera Apache Tomcat 7 zainstalowanego w systemie Windows za pomocą wtyczki do wprowadzania plików i wysyłamy je do innego dziennika.
logstash.conf
Tutaj Logstash jest skonfigurowany tak, aby uzyskać dostęp do dziennika dostępu Apache Tomcat 7 zainstalowanego lokalnie. Wzorzec wyrażenia regularnego jest używany podczas ustawiania ścieżki wtyczki pliku w celu pobrania danych z pliku dziennika. Zawiera „access” w swojej nazwie i dodaje typ Apache, który pomaga w odróżnieniu zdarzeń Apache od innych w scentralizowanym źródle docelowym. Na koniec zdarzenia wyjściowe zostaną pokazane w output.log.
input {
file {
path => "C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/*access*"
type => "apache"
}
}
output {
file {
path => "C:/tpwork/logstash/bin/log/output.log"
}
}Uruchom Logstash
Możemy uruchomić Logstash za pomocą następującego polecenia.
C:\logstash\bin> logstash –f Logstash.confDziennik Apache Tomcat
Uzyskaj dostęp do serwera Apache Tomcat i jego aplikacji internetowych (http://localhost:8080) do generowania dzienników. Zaktualizowane dane w dziennikach są odczytywane przez Logstash w czasie rzeczywistym i przechowywane w pliku output.log, jak określono w pliku konfiguracyjnym.
Apache Tomcat generuje nowy plik dziennika dostępu zgodnie z datą i rejestruje w nim zdarzenia dostępu. W naszym przypadku był to localhost_access_log.2016-12-24.txt w plikulogs katalog Apache Tomcat.
0:0:0:0:0:0:0:1 - - [
25/Dec/2016:18:37:00 +0800] "GET / HTTP/1.1" 200 11418
0:0:0:0:0:0:0:1 - munish [
25/Dec/2016:18:37:02 +0800] "GET /manager/html HTTP/1.1" 200 17472
0:0:0:0:0:0:0:1 - - [
25/Dec/2016:18:37:08 +0800] "GET /docs/ HTTP/1.1" 200 19373
0:0:0:0:0:0:0:1 - - [
25/Dec/2016:18:37:10 +0800] "GET /docs/introduction.html HTTP/1.1" 200 15399output.log
Możesz zobaczyć w zdarzeniach wyjściowych, pole typu jest dodane, a zdarzenie jest obecne w polu wiadomości.
{
"path":"C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/
localhost_access_log.2016-12-25.txt",
"@timestamp":"2016-12-25T10:37:00.363Z","@version":"1","host":"Dell-PC",
"message":"0:0:0:0:0:0:0:1 - - [25/Dec/2016:18:37:00 +0800] \"GET /
HTTP/1.1\" 200 11418\r","type":"apache","tags":[]
}
{
"path":"C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/
localhost_access_log.2016-12-25.txt","@timestamp":"2016-12-25T10:37:10.407Z",
"@version":"1","host":"Dell-PC",
"message":"0:0:0:0:0:0:0:1 - munish [25/Dec/2016:18:37:02 +0800] \"GET /
manager/html HTTP/1.1\" 200 17472\r","type":"apache","tags":[]
}
{
"path":"C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/
localhost_access_log.2016-12-25.txt","@timestamp":"2016-12-25T10:37:10.407Z",
"@version":"1","host":"Dell-PC",
"message":"0:0:0:0:0:0:0:1 - - [25/Dec/2016:18:37:08 +0800] \"GET /docs/
HTTP/1.1\" 200 19373\r","type":"apache","tags":[]
}
{
"path":"C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/
localhost_access_log.2016-12-25.txt","@timestamp":"2016-12-25T10:37:20.436Z",
"@version":"1","host":"Dell-PC",
"message":"0:0:0:0:0:0:0:1 - - [25/Dec/2016:18:37:10 +0800] \"GET /docs/
introduction.html HTTP/1.1\" 200 15399\r","type":"apache","tags":[]
}Zbieranie dzienników za pomocą wtyczki STDIN
W tej sekcji omówimy kolejny przykład zbierania dzienników przy użyciu STDIN Plugin.
logstash.conf
Jest to bardzo prosty przykład, w którym Logstash odczytuje zdarzenia wprowadzone przez użytkownika na standardowe wejście. W naszym przypadku jest to wiersz poleceń, który przechowuje zdarzenia w pliku output.log.
input {
stdin{}
}
output {
file {
path => "C:/tpwork/logstash/bin/log/output.log"
}
}Uruchom Logstash
Możemy uruchomić Logstash za pomocą następującego polecenia.
C:\logstash\bin> logstash –f Logstash.confWpisz następujący tekst w wierszu polecenia -
Użytkownik wprowadził następujące dwie linie. Logstash oddziela zdarzenia według ustawienia separatora, a jego domyślną wartością jest „\ n”. Użytkownik może zmienić, zmieniając wartość separatora we wtyczce pliku.
Tutorialspoint.com welcomes you
Simply easy learningoutput.log
Poniższy blok kodu przedstawia dane dziennika wyjściowego.
{
"@timestamp":"2016-12-25T11:41:16.518Z","@version":"1","host":"Dell-PC",
"message":"tutrialspoint.com welcomes you\r","tags":[]
}
{
"@timestamp":"2016-12-25T11:41:53.396Z","@version":"1","host":"Dell-PC",
"message":"simply easy learning\r","tags":[]
}Logstash obsługuje szeroką gamę dzienników z różnych źródeł. Działa ze znanymi źródłami, jak wyjaśniono poniżej.
Zbierz dzienniki z Metrics
Zdarzenia systemowe i inne czynności związane z czasem są rejestrowane w metrykach. Logstash może uzyskać dostęp do dziennika z metryk systemowych i przetwarzać je za pomocą filtrów. Pomaga to pokazać użytkownikowi transmisję wydarzeń na żywo w dostosowany sposób. Metryki są przepłukiwane zgodnie zflush_interval settingmetryk filtru i domyślnie; jest ustawiony na 5 sekund.
Śledzimy metryki testowe generowane przez Logstash, zbierając i analizując zdarzenia przebiegające przez Logstash i pokazując transmisję na żywo w wierszu polecenia.
logstash.conf
Ta konfiguracja zawiera wtyczkę generatora, która jest oferowana przez Logstash do testowania metryk i ustawia ustawienie typu na „wygenerowane” do analizy. W fazie filtrowania przetwarzamy tylko wiersze z wygenerowanym typem za pomocą instrukcji „if”. Następnie wtyczka metryki zlicza pole określone w ustawieniach licznika. Wtyczka metryk opróżnia liczbę co 5 sekund określonych w plikuflush_interval.
Na koniec wyślij zdarzenia filtru na standardowe wyjście, takie jak wiersz polecenia, używając rozszerzenia codec plugindo formatowania. Wtyczka Codec używa wartości [ events ] [ rate_1m ] do wyświetlania zdarzeń na sekundę w 1-minutowym przesuwanym oknie.
input {
generator {
type => "generated"
}
}
filter {
if [type] == "generated" {
metrics {
meter => "events"
add_tag => "metric"
}
}
}
output {
# only emit events with the 'metric' tag
if "metric" in [tags] {
stdout {
codec => line { format => "rate: %{[events][rate_1m]}"
}
}
}Uruchom Logstash
Możemy uruchomić Logstash za pomocą następującego polecenia.
>logsaths –f logstash.confstdout (wiersz polecenia)
rate: 1308.4
rate: 1308.4
rate: 1368.654529135342
rate: 1416.4796003951449
rate: 1464.974293984808
rate: 1523.3119444107458
rate: 1564.1602979542715
rate: 1610.6496496890895
rate: 1645.2184750334154
rate: 1688.7768007612485
rate: 1714.652283095914
rate: 1752.5150680019278
rate: 1785.9432934744932
rate: 1806.912181962126
rate: 1836.0070454626025
rate: 1849.5669494173826
rate: 1871.3814756851832
rate: 1883.3443123790712
rate: 1906.4879113216743
rate: 1925.9420717997118
rate: 1934.166137658981
rate: 1954.3176526556897
rate: 1957.0107444542625Zbierz dzienniki z serwera internetowego
Serwery internetowe generują dużą liczbę dzienników dotyczących dostępu użytkowników i błędów. Logstash pomaga wyodrębnić dzienniki z różnych serwerów za pomocą wtyczek wejściowych i przechowywać je w scentralizowanej lokalizacji.
Wyodrębniamy dane z stderr logs lokalnego serwera Apache Tomcat i przechowując go w pliku output.log.
logstash.conf
Ten plik konfiguracyjny Logstash nakazuje Logstash odczytywanie dzienników błędów Apache i dodawanie tagu o nazwie „apache-error”. Możemy po prostu wysłać go do output.log za pomocą wtyczki wyjściowej pliku.
input {
file {
path => "C:/Program Files/Apache Software Foundation/Tomcat 7.0 /logs/*stderr*"
type => "apache-error"
}
}
output {
file {
path => "C:/tpwork/logstash/bin/log/output.log"
}
}Uruchom Logstash
Możemy uruchomić Logstash za pomocą następującego polecenia.
>Logstash –f Logstash.confPrzykład dziennika wejściowego
To jest próbka stderr log, który generuje, gdy zdarzenia serwera występują w Apache Tomcat.
C: \ Program Files \ Apache Software Foundation \ Tomcat 7.0 \ logs \ tomcat7-stderr.2016-12-25.log
Dec 25, 2016 7:05:14 PM org.apache.coyote.AbstractProtocol start
INFO: Starting ProtocolHandler ["http-bio-9999"]
Dec 25, 2016 7:05:14 PM org.apache.coyote.AbstractProtocol start
INFO: Starting ProtocolHandler ["ajp-bio-8009"]
Dec 25, 2016 7:05:14 PM org.apache.catalina.startup.Catalina start
INFO: Server startup in 823 msoutput.log
{
"path":"C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/
tomcat7-stderr.2016-12-25.log","@timestamp":"2016-12-25T11:05:27.045Z",
"@version":"1","host":"Dell-PC",
"message":"Dec 25, 2016 7:05:14 PM org.apache.coyote.AbstractProtocol start\r",
"type":"apache-error","tags":[]
}
{
"path":"C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/
tomcat7-stderr.2016-12-25.log","@timestamp":"2016-12-25T11:05:27.045Z",
"@version":"1","host":"Dell-PC",
"message":"INFO: Starting ProtocolHandler [
\"ajp-bio-8009\"]\r","type":"apache-error","tags":[]
}
{
"path":"C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/
tomcat7-stderr.2016-12-25.log","@timestamp":"2016-12-25T11:05:27.045Z",
"@version":"1","host":"Dell-PC",
"message":"Dec 25, 2016 7:05:14 PM org.apache.catalina.startup.Catalina start\r",
"type":"apache-error","tags":[]
}
{
"path":"C:/Program Files/Apache Software Foundation/Tomcat 7.0/logs/
tomcat7-stderr.2016-12-25.log","@timestamp":"2016-12-25T11:05:27.045Z",
"@version":"1","host":"Dell-PC",
"message":"INFO: Server startup in 823 ms\r","type":"apache-error","tags":[]
}Zbierz dzienniki ze źródeł danych
Na początek pozwól nam zrozumieć, jak skonfigurować MySQL do logowania. Dodaj następujące wierszemy.ini file serwera bazy danych MySQL w [mysqld].
W systemie Windows znajduje się w katalogu instalacyjnym MySQL, który znajduje się w -
C:\wamp\bin\mysql\mysql5.7.11W systemie UNIX można go znaleźć w - /etc/mysql/my.cnf
general_log_file = "C:/wamp/logs/queries.log"
general_log = 1logstash.conf
W tym pliku konfiguracyjnym wtyczka pliku służy do odczytywania dziennika MySQL i zapisywania go w ouput.log.
input {
file {
path => "C:/wamp/logs/queries.log"
}
}
output {
file {
path => "C:/tpwork/logstash/bin/log/output.log"
}
}queries.log
Jest to dziennik generowany przez zapytania wykonywane w bazie danych MySQL.
2016-12-25T13:05:36.854619Z 2 Query select * from test1_users
2016-12-25T13:05:51.822475Z 2 Query select count(*) from users
2016-12-25T13:05:59.998942Z 2 Query select count(*) from test1_usersoutput.log
{
"path":"C:/wamp/logs/queries.log","@timestamp":"2016-12-25T13:05:37.905Z",
"@version":"1","host":"Dell-PC",
"message":"2016-12-25T13:05:36.854619Z 2 Query\tselect * from test1_users",
"tags":[]
}
{
"path":"C:/wamp/logs/queries.log","@timestamp":"2016-12-25T13:05:51.938Z",
"@version":"1","host":"Dell-PC",
"message":"2016-12-25T13:05:51.822475Z 2 Query\tselect count(*) from users",
"tags":[]
}
{
"path":"C:/wamp/logs/queries.log","@timestamp":"2016-12-25T13:06:00.950Z",
"@version":"1","host":"Dell-PC",
"message":"2016-12-25T13:05:59.998942Z 2 Query\tselect count(*) from test1_users",
"tags":[]
}Logstash odbiera dzienniki za pomocą wtyczek wejściowych, a następnie używa wtyczek filtrów do analizowania i przekształcania danych. Analiza i transformacja logów są wykonywane zgodnie z systemami obecnymi w miejscu docelowym wyjścia. Logstash analizuje dane logowania i przekazuje tylko wymagane pola. Później pola te są przekształcane w kompatybilną i zrozumiałą formę systemu docelowego.
Jak analizować dzienniki?
Parsowanie dzienników odbywa się za pomocą rozszerzenia GROK (Graficzna reprezentacja wiedzy) wzorce i można je znaleźć na Github -
https://github.com/elastic/logstash/tree/v1.4.2/patterns.
Logstash dopasowuje dane dzienników z określonym wzorcem GROK lub sekwencją wzorców do analizowania dzienników, np. „% {COMBINEDAPACHELOG}”, który jest powszechnie używany w dziennikach Apache.
Przeanalizowane dane są bardziej uporządkowane i łatwe do przeszukiwania i wykonywania zapytań. Logstash wyszukuje określone wzorce GROK w dziennikach wejściowych i wyodrębnia pasujące wiersze z dzienników. Możesz użyć debugera GROK, aby przetestować swoje wzorce GROK.
Składnia wzorca GROK to% {SYNTAX: SEMANTIC}. Filtr Logstash GROK jest zapisany w postaci -
%{PATTERN:FieldName}
Tutaj PATTERN reprezentuje wzorzec GROK, a nazwa pola to nazwa pola, które reprezentuje przeanalizowane dane w wyniku.
Na przykład za pomocą debugera online GROK https://grokdebug.herokuapp.com/
Wejście
Przykładowy wiersz błędu w dzienniku -
[Wed Dec 07 21:54:54.048805 2016] [:error] [pid 1234:tid 3456829102]
[client 192.168.1.1:25007] JSP Notice: Undefined index: abc in
/home/manu/tpworks/tutorialspoint.com/index.jsp on line 11Sekwencja wzorców GROK
Ta sekwencja wzorca GROK jest zgodna ze zdarzeniem dziennika, które składa się ze znacznika czasu, po którym następuje poziom dziennika, identyfikator procesu, identyfikator transakcji i komunikat o błędzie.
\[(%{DAY:day} %{MONTH:month} %{MONTHDAY} %{TIME} %{YEAR})\] \[.*:%{LOGLEVEL:loglevel}\]
\[pid %{NUMBER:pid}:tid %{NUMBER:tid}\] \[client %{IP:clientip}:.*\]
%{GREEDYDATA:errormsg}wynik
Dane wyjściowe są w formacie JSON.
{
"day": [
"Wed"
],
"month": [
"Dec"
],
"loglevel": [
"error"
],
"pid": [
"1234"
],
"tid": [
"3456829102"
],
"clientip": [
"192.168.1.1"
],
"errormsg": [
"JSP Notice: Undefined index: abc in
/home/manu/tpworks/tutorialspoint.com/index.jsp on line 11"
]
}Logstash używa filtrów w środku potoku między wejściem a wyjściem. Filtry miar Logstash manipulują i tworzą zdarzenia, takie jakApache-Access. Wiele wtyczek filtrów używanych do zarządzania zdarzeniami w Logstash. Tutaj, na przykładzieLogstash Aggregate Filter, filtrujemy czas trwania każdej transakcji SQL w bazie danych i obliczamy łączny czas.
Instalowanie wtyczki Aggregate Filter
Instalowanie wtyczki Aggregate Filter za pomocą narzędzia Logstash-plugin. Wtyczka Logstash to plik wsadowy dla systemu Windows w formaciebin folder w Logstash.
>logstash-plugin install logstash-filter-aggregatelogstash.conf
W tej konfiguracji można zobaczyć trzy instrukcje „if” dla Initializing, Incrementing, i generating całkowity czas trwania transakcji, tj sql_duration. Wtyczka agregująca służy do dodawania sql_duration, obecnego w każdym zdarzeniu dziennika wejściowego.
input {
file {
path => "C:/tpwork/logstash/bin/log/input.log"
}
}
filter {
grok {
match => [
"message", "%{LOGLEVEL:loglevel} -
%{NOTSPACE:taskid} - %{NOTSPACE:logger} -
%{WORD:label}( - %{INT:duration:int})?"
]
}
if [logger] == "TRANSACTION_START" {
aggregate {
task_id => "%{taskid}"
code => "map['sql_duration'] = 0"
map_action => "create"
}
}
if [logger] == "SQL" {
aggregate {
task_id => "%{taskid}"
code => "map['sql_duration'] ||= 0 ;
map['sql_duration'] += event.get('duration')"
}
}
if [logger] == "TRANSACTION_END" {
aggregate {
task_id => "%{taskid}"
code => "event.set('sql_duration', map['sql_duration'])"
end_of_task => true
timeout => 120
}
}
}
output {
file {
path => "C:/tpwork/logstash/bin/log/output.log"
}
}Uruchom Logstash
Możemy uruchomić Logstash za pomocą następującego polecenia.
>logstash –f logstash.confinput.log
Poniższy blok kodu przedstawia dane dziennika wejściowego.
INFO - 48566 - TRANSACTION_START - start
INFO - 48566 - SQL - transaction1 - 320
INFO - 48566 - SQL - transaction1 - 200
INFO - 48566 - TRANSACTION_END - endoutput.log
Jak określono w pliku konfiguracyjnym, ostatnia instrukcja „if”, w której znajduje się program rejestrujący - TRANSACTION_END, która drukuje całkowity czas transakcji lub sql_duration. Zostało to zaznaczone na żółto w pliku output.log.
{
"path":"C:/tpwork/logstash/bin/log/input.log","@timestamp": "2016-12-22T19:04:37.214Z",
"loglevel":"INFO","logger":"TRANSACTION_START","@version": "1","host":"wcnlab-PC",
"message":"8566 - TRANSACTION_START - start\r","tags":[]
}
{
"duration":320,"path":"C:/tpwork/logstash/bin/log/input.log",
"@timestamp":"2016-12-22T19:04:38.366Z","loglevel":"INFO","logger":"SQL",
"@version":"1","host":"wcnlab-PC","label":"transaction1",
"message":" INFO - 48566 - SQL - transaction1 - 320\r","taskid":"48566","tags":[]
}
{
"duration":200,"path":"C:/tpwork/logstash/bin/log/input.log",
"@timestamp":"2016-12-22T19:04:38.373Z","loglevel":"INFO","logger":"SQL",
"@version":"1","host":"wcnlab-PC","label":"transaction1",
"message":" INFO - 48566 - SQL - transaction1 - 200\r","taskid":"48566","tags":[]
}
{
"sql_duration":520,"path":"C:/tpwork/logstash/bin/log/input.log",
"@timestamp":"2016-12-22T19:04:38.380Z","loglevel":"INFO","logger":"TRANSACTION_END",
"@version":"1","host":"wcnlab-PC","label":"end",
"message":" INFO - 48566 - TRANSACTION_END - end\r","taskid":"48566","tags":[]
}Logstash oferuje różne wtyczki do przekształcania przeanalizowanego dziennika. Te wtyczki mogąAdd, Delete, i Update pola w dziennikach dla lepszego zrozumienia i wykonywania zapytań w systemach wyjściowych.
Używamy Mutate Plugin aby dodać nazwę użytkownika pola w każdym wierszu dziennika wejściowego.
Zainstaluj wtyczkę Mutate Filter
Aby zainstalować wtyczkę mutate filter; możemy użyć następującego polecenia.
>Logstash-plugin install Logstash-filter-mutatelogstash.conf
W tym pliku konfiguracyjnym wtyczka Mutate jest dodawana po wtyczce Aggregate w celu dodania nowego pola.
input {
file {
path => "C:/tpwork/logstash/bin/log/input.log"
}
}
filter {
grok {
match => [ "message", "%{LOGLEVEL:loglevel} -
%{NOTSPACE:taskid} - %{NOTSPACE:logger} -
%{WORD:label}( - %{INT:duration:int})?" ]
}
if [logger] == "TRANSACTION_START" {
aggregate {
task_id => "%{taskid}"
code => "map['sql_duration'] = 0"
map_action => "create"
}
}
if [logger] == "SQL" {
aggregate {
task_id => "%{taskid}"
code => "map['sql_duration'] ||= 0 ;
map['sql_duration'] += event.get('duration')"
}
}
if [logger] == "TRANSACTION_END" {
aggregate {
task_id => "%{taskid}"
code => "event.set('sql_duration', map['sql_duration'])"
end_of_task => true
timeout => 120
}
}
mutate {
add_field => {"user" => "tutorialspoint.com"}
}
}
output {
file {
path => "C:/tpwork/logstash/bin/log/output.log"
}
}Uruchom Logstash
Możemy uruchomić Logstash za pomocą następującego polecenia.
>logstash –f logstash.confinput.log
Poniższy blok kodu przedstawia dane dziennika wejściowego.
INFO - 48566 - TRANSACTION_START - start
INFO - 48566 - SQL - transaction1 - 320
INFO - 48566 - SQL - transaction1 - 200
INFO - 48566 - TRANSACTION_END - endoutput.log
Możesz zobaczyć, że w zdarzeniach wyjściowych jest nowe pole o nazwie „użytkownik”.
{
"path":"C:/tpwork/logstash/bin/log/input.log",
"@timestamp":"2016-12-25T19:55:37.383Z",
"@version":"1",
"host":"wcnlab-PC",
"message":"NFO - 48566 - TRANSACTION_START - start\r",
"user":"tutorialspoint.com","tags":["_grokparsefailure"]
}
{
"duration":320,"path":"C:/tpwork/logstash/bin/log/input.log",
"@timestamp":"2016-12-25T19:55:37.383Z","loglevel":"INFO","logger":"SQL",
"@version":"1","host":"wcnlab-PC","label":"transaction1",
"message":" INFO - 48566 - SQL - transaction1 - 320\r",
"user":"tutorialspoint.com","taskid":"48566","tags":[]
}
{
"duration":200,"path":"C:/tpwork/logstash/bin/log/input.log",
"@timestamp":"2016-12-25T19:55:37.399Z","loglevel":"INFO",
"logger":"SQL","@version":"1","host":"wcnlab-PC","label":"transaction1",
"message":" INFO - 48566 - SQL - transaction1 - 200\r",
"user":"tutorialspoint.com","taskid":"48566","tags":[]
}
{
"sql_duration":520,"path":"C:/tpwork/logstash/bin/log/input.log",
"@timestamp":"2016-12-25T19:55:37.399Z","loglevel":"INFO",
"logger":"TRANSACTION_END","@version":"1","host":"wcnlab-PC","label":"end",
"message":" INFO - 48566 - TRANSACTION_END - end\r",
"user":"tutorialspoint.com","taskid":"48566","tags":[]
}Dane wyjściowe to ostatni etap potoku Logstash, który wysyła dane filtru z dzienników wejściowych do określonego miejsca docelowego. Logstash oferuje wiele wtyczek wyjściowych do przechowywania przefiltrowanych zdarzeń dziennika w różnych różnych mechanizmach przechowywania i wyszukiwania.
Przechowywanie dzienników
Logstash może przechowywać przefiltrowane dzienniki w pliku File, Elasticsearch Engine, stdout, AWS CloudWatch, itp. Protokoły sieciowe, takie jak TCP, UDP, Websocket może być również używany w Logstash do przesyłania zdarzeń dziennika do zdalnych systemów pamięci masowej.
W stosie ELK użytkownicy używają silnika Elasticsearch do przechowywania zdarzeń dziennika. Tutaj, w poniższym przykładzie, wygenerujemy zdarzenia dziennika dla lokalnego silnika Elasticsearch.
Instalowanie wtyczki Elasticsearch Output
Możemy zainstalować wtyczkę wyjściową Elasticsearch za pomocą następującego polecenia.
>logstash-plugin install Logstash-output-elasticsearchlogstash.conf
Ten plik konfiguracyjny zawiera wtyczkę Elasticsearch, która przechowuje zdarzenie wyjściowe w Elasticsearch zainstalowanym lokalnie.
input {
file {
path => "C:/tpwork/logstash/bin/log/input.log"
}
}
filter {
grok {
match => [ "message", "%{LOGLEVEL:loglevel} -
%{NOTSPACE:taskid} - %{NOTSPACE:logger} -
%{WORD:label}( - %{INT:duration:int})?" ]
}
if [logger] == "TRANSACTION_START" {
aggregate {
task_id => "%{taskid}"
code => "map['sql_duration'] = 0"
map_action => "create"
}
}
if [logger] == "SQL" {
aggregate {
task_id => "%{taskid}"
code => "map['sql_duration'] ||= 0 ;
map['sql_duration'] += event.get('duration')"
}
}
if [logger] == "TRANSACTION_END" {
aggregate {
task_id => "%{taskid}"
code => "event.set('sql_duration', map['sql_duration'])"
end_of_task => true
timeout => 120
}
}
mutate {
add_field => {"user" => "tutorialspoint.com"}
}
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
}
}Input.log
Poniższy blok kodu przedstawia dane dziennika wejściowego.
INFO - 48566 - TRANSACTION_START - start
INFO - 48566 - SQL - transaction1 - 320
INFO - 48566 - SQL - transaction1 - 200
INFO - 48566 - TRANSACTION_END - endUruchom Elasticsearch na Localhost
Aby uruchomić Elasticsearch na hoście lokalnym, należy użyć następującego polecenia.
C:\elasticsearch\bin> elasticsearchGdy Elasticsearch jest gotowy, możesz to sprawdzić, wpisując następujący adres URL w przeglądarce.
http://localhost:9200/
Odpowiedź
Poniższy blok kodu przedstawia odpowiedź Elasticsearch na hoście lokalnym.
{
"name" : "Doctor Dorcas",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "2.1.1",
"build_hash" : "40e2c53a6b6c2972b3d13846e450e66f4375bd71",
"build_timestamp" : "2015-12-15T13:05:55Z",
"build_snapshot" : false,
"lucene_version" : "5.3.1"
},
"tagline" : "You Know, for Search"
}Note - Aby uzyskać więcej informacji na temat Elasticsearch, kliknij poniższe łącze.
https://www.tutorialspoint.com/elasticsearch/index.html
Teraz uruchom Logstash z wyżej wymienionym Logstash.conf
>Logstash –f Logstash.confPo wklejeniu powyższego tekstu do dziennika wyjściowego, tekst ten zostanie zapisany w Elasticsearch przez Logstash. Możesz sprawdzić zapisane dane, wpisując następujący adres URL w przeglądarce.
http://localhost:9200/logstash-2017.01.01/_search?pretty
Odpowiedź
Są to dane w formacie JSON przechowywane w indeksie Logstash-2017.01.01.
{
"took" : 20,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 10,
"max_score" : 1.0,
"hits" : [ {
"_index" : "logstash-2017.01.01",
"_type" : "logs",
"_id" : "AVlZ9vF8hshdrGm02KOs",
"_score" : 1.0,
"_source":{
"duration":200,"path":"C:/tpwork/logstash/bin/log/input.log",
"@timestamp":"2017-01-01T12:17:49.140Z","loglevel":"INFO",
"logger":"SQL","@version":"1","host":"wcnlab-PC",
"label":"transaction1",
"message":" INFO - 48566 - SQL - transaction1 - 200\r",
"user":"tutorialspoint.com","taskid":"48566","tags":[]
}
},
{
"_index" : "logstash-2017.01.01",
"_type" : "logs",
"_id" : "AVlZ9vF8hshdrGm02KOt",
"_score" : 1.0,
"_source":{
"sql_duration":520,"path":"C:/tpwork/logstash/bin/log/input.log",
"@timestamp":"2017-01-01T12:17:49.145Z","loglevel":"INFO",
"logger":"TRANSACTION_END","@version":"1","host":"wcnlab-PC",
"label":"end",
"message":" INFO - 48566 - TRANSACTION_END - end\r",
"user":"tutorialspoint.com","taskid":"48566","tags":[]
}
}
}
}Logstash zapewnia wiele wtyczek do obsługi różnych magazynów danych lub wyszukiwarek. Zdarzenia wyjściowe dzienników mogą być wysyłane do pliku wyjściowego, standardowego wyjścia lub wyszukiwarki, takiej jak Elasticsearch. Istnieją trzy typy obsługiwanych danych wyjściowych w Logstash, którymi są:
- Wyjście standardowe
- Plik wyjściowy
- Wyjście zerowe
Omówmy teraz szczegółowo każdą z nich.
Standardowe wyjście (standardowe wyjście)
Służy do generowania przefiltrowanych zdarzeń dziennika jako strumienia danych do interfejsu wiersza poleceń. Oto przykład generowania całkowitego czasu trwania transakcji bazy danych na standardowe wyjście.
logstash.conf
Ten plik konfiguracyjny zawiera wtyczkę wyjściową stdout, która zapisuje całkowity czas_sql_duration na standardowe wyjście.
input {
file {
path => "C:/tpwork/logstash/bin/log/input.log"
}
}
filter {
grok {
match => [
"message", "%{LOGLEVEL:loglevel} - %{NOTSPACE:taskid}
- %{NOTSPACE:logger} - %{WORD:label}( - %{INT:duration:int})?"
]
}
if [logger] == "TRANSACTION_START" {
aggregate {
task_id => "%{taskid}"
code => "map['sql_duration'] = 0"
map_action => "create"
}
}
if [logger] == "SQL" {
aggregate {
task_id => "%{taskid}"
code => "map['sql_duration'] ||= 0 ;
map['sql_duration'] += event.get('duration')"
}
}
if [logger] == "TRANSACTION_END" {
aggregate {
task_id => "%{taskid}"
code => "event.set('sql_duration', map['sql_duration'])"
end_of_task => true
timeout => 120
}
}
}
output {
if [logger] == "TRANSACTION_END" {
stdout {
codec => line{format => "%{sql_duration}"}
}
}
}Note - Zainstaluj filtr kruszywa, jeśli nie został jeszcze zainstalowany.
>logstash-plugin install Logstash-filter-aggregateUruchom Logstash
Możemy uruchomić Logstash za pomocą następującego polecenia.
>logstash –f logsatsh.confInput.log
Poniższy blok kodu przedstawia dane dziennika wejściowego.
INFO - 48566 - TRANSACTION_START - start
INFO - 48566 - SQL - transaction1 - 320
INFO - 48566 - SQL - transaction1 - 200
INFO - 48566 - TRANSACTION_END – endstdout (będzie to wiersz poleceń w systemie Windows lub terminal w systemie UNIX)
To jest całkowity czas trwania_sql 320 + 200 = 520.
520Plik wyjściowy
Logstash może również przechowywać zdarzenia dziennika filtrów w pliku wyjściowym. Skorzystamy z powyższego przykładu i zapiszemy wynik w pliku zamiast STDOUT.
logstash.conf
Ten plik konfiguracyjny Logstash bezpośrednio Logstash przechowuje całkowity sql_duration w wyjściowym pliku dziennika.
input {
file {
path => "C:/tpwork/logstash/bin/log/input1.log"
}
}
filter {
grok {
match => [
"message", "%{LOGLEVEL:loglevel} - %{NOTSPACE:taskid} -
%{NOTSPACE:logger} - %{WORD:label}( - %{INT:duration:int})?"
]
}
if [logger] == "TRANSACTION_START" {
aggregate {
task_id => "%{taskid}"
code => "map['sql_duration'] = 0"
map_action => "create"
}
}
if [logger] == "SQL" {
aggregate {
task_id => "%{taskid}"
code => "map['sql_duration'] ||= 0 ;
map['sql_duration'] += event.get('duration')"
}
}
if [logger] == "TRANSACTION_END" {
aggregate {
task_id => "%{taskid}"
code => "event.set('sql_duration', map['sql_duration'])"
end_of_task => true
timeout => 120
}
}
}
output {
if [logger] == "TRANSACTION_END" {
file {
path => "C:/tpwork/logstash/bin/log/output.log"
codec => line{format => "%{sql_duration}"}
}
}
}Uruchom logstash
Możemy uruchomić Logstash za pomocą następującego polecenia.
>logstash –f logsatsh.confinput.log
Poniższy blok kodu przedstawia dane dziennika wejściowego.
INFO - 48566 - TRANSACTION_START - start
INFO - 48566 - SQL - transaction1 - 320
INFO - 48566 - SQL - transaction1 - 200
INFO - 48566 - TRANSACTION_END – endoutput.log
Poniższy blok kodu przedstawia dane dziennika wyjściowego.
520Wyjście zerowe
Jest to specjalna wtyczka wyjściowa, która służy do analizowania wydajności wtyczek wejściowych i filtrujących.
Logstash oferuje różne wtyczki dla wszystkich trzech etapów potoku (wejście, filtr i wyjście). Te wtyczki pomagają użytkownikowi przechwytywać dzienniki z różnych źródeł, takich jak serwery internetowe, bazy danych, protokoły sieciowe itp.
Po przechwyceniu Logstash może przeanalizować i przekształcić dane w znaczące informacje zgodnie z wymaganiami użytkownika. Wreszcie Logstash może wysyłać lub przechowywać te znaczące informacje do różnych źródeł docelowych, takich jak Elasticsearch, AWS Cloudwatch itp.
Wtyczki wejściowe
Wtyczki wejściowe w Logstash pomagają użytkownikowi wyodrębniać i odbierać logi z różnych źródeł. Składnia korzystania z wtyczki wejściowej jest następująca -
Input {
Plugin name {
Setting 1……
Setting 2……..
}
}Możesz pobrać wtyczkę wejściową za pomocą następującego polecenia -
>Logstash-plugin install Logstash-input-<plugin name>Narzędzie Logstash-plugin jest obecne w bin folderkatalogu instalacyjnego Logstash. Poniższa tabela zawiera listę wtyczek wejściowych oferowanych przez Logstash.
| Sr.No. | Nazwa i opis wtyczki |
|---|---|
| 1 | beats Aby uzyskać dane logowania lub zdarzenia z platformy elastycznej beats. |
| 2 | cloudwatch Aby wyodrębnić zdarzenia z CloudWatch, oferty API firmy Amazon Web Services. |
| 3 | couchdb_changes Zdarzenia z identyfikatora URI _chages z couchdb wysłane przy użyciu tej wtyczki. |
| 4 | drupal_dblog Aby wyodrębnić dane logowania strażnika drupala z włączonym DBLog. |
| 5 | Elasticsearch Aby pobrać wyniki zapytań wykonanych w klastrze Elasticsearch. |
| 6 | eventlog Aby pobrać zdarzenia z dziennika zdarzeń systemu Windows. |
| 7 | exec Aby uzyskać dane wyjściowe polecenia powłoki jako dane wejściowe w Logstash. |
| 8 | file Aby pobrać zdarzenia z pliku wejściowego. Jest to przydatne, gdy Logstash jest lokalnie instalowany ze źródłem wejściowym i ma dostęp do dzienników źródła wejściowego. |
| 9 | generator Służy do celów testowych, co tworzy zdarzenia losowe. |
| 10 | github Przechwytuje zdarzenia z webhooka GitHub. |
| 11 | graphite Aby uzyskać dane metryczne z narzędzia do monitorowania grafitu. |
| 12 | heartbeat Jest również używany do testowania i wytwarza zdarzenia przypominające bicie serca |
| 13 | http Do zbierania zdarzeń z dziennika za pośrednictwem dwóch protokołów sieciowych, a są to http i https. |
| 14 | http_poller Służy do dekodowania danych wyjściowych interfejsu API HTTP do zdarzenia. |
| 15 | jdbc Konwertuje transakcje JDBC na zdarzenie w Logstash. |
| 16 | jmx Aby wyodrębnić metryki ze zdalnych aplikacji Java przy użyciu JMX. |
| 17 | log4j Przechwytywanie zdarzeń z obiektu socketAppender w Log4j przez gniazdo TCP. |
| 18 | rss Do danych wyjściowych narzędzi wiersza poleceń jako zdarzenie wejściowe w Logstash. |
| 19 | tcp Przechwytuje zdarzenia przez gniazdo TCP. |
| 20 | Zbieraj zdarzenia z Twittera streaming API. |
| 21 | unix Zbieraj zdarzenia przez gniazdo UNIX. |
| 22 | websocket Przechwytuj zdarzenia przez protokół WebSocket. |
| 23 | xmpp Odczytuje zdarzenia przez protokoły Jabber / xmpp. |
Ustawienia wtyczki
Wszystkie wtyczki mają swoje specyficzne ustawienia, które pomagają określić ważne pola, takie jak Port, Ścieżka itp., We wtyczce. Omówimy ustawienia niektórych wtyczek wejściowych.
Plik
Ta wtyczka wejściowa służy do wyodrębniania zdarzeń bezpośrednio z dziennika lub plików tekstowych obecnych w źródle wejściowym. Działa podobnie do polecenia tail w systemie UNIX i zapisuje ostatni kursor odczytu i odczytuje tylko nowe dodane dane z pliku wejściowego, ale można to zmienić za pomocą ustawienia star_position. Poniżej przedstawiono ustawienia tej wtyczki wejściowej.
| Nazwa ustawienia | Domyślna wartość | Opis |
|---|---|---|
| Dodaj pole | {} | Dołącz nowe pole do zdarzenia wejściowego. |
| close_older | 3600 | Pliki, których czas ostatniego odczytu (w sekundach) jest dłuższy niż określony w tej wtyczce, są zamykane. |
| kodek | "Równina" | Służy do dekodowania danych przed wejściem do potoku Logstash. |
| ogranicznik | „\ N” | Służy do określenia nowego ogranicznika linii. |
| Discover_interval | 15 | Jest to odstęp czasu (w sekundach) między wykryciem nowych plików w określonej ścieżce. |
| enable_metric | prawdziwe | Służy do włączania lub wyłączania raportowania i zbierania danych dla określonej wtyczki. |
| wykluczać | Służy do określenia nazwy pliku lub wzorców, które powinny być wykluczone z wtyczki wejściowej. | |
| ID | Aby określić unikalną tożsamość dla tej instancji wtyczki. | |
| max_open_files | Określa maksymalną liczbę plików wejściowych przez Logstash w dowolnym momencie. | |
| ścieżka | Określ ścieżkę do plików i może zawierać wzorce dla nazwy pliku. | |
| pozycja startowa | "koniec" | Możesz zmienić na „początek”, jeśli chcesz; początkowo Logstash powinien rozpocząć odczytywanie plików od początku, a nie tylko nowego zdarzenia dziennika. |
| start_interval | 1 | Określa przedział czasu w sekundach, po którym Logstash sprawdza zmodyfikowane pliki. |
| tagi | Aby dodać dodatkowe informacje, takie jak Logstash, dodaje „_grokparsefailure” do tagów, gdy jakiekolwiek zdarzenie dziennika nie spełnia określonego filtru grok. | |
| rodzaj | Jest to specjalne pole, które można dodać do zdarzenia wejściowego i jest przydatne w filtrach i kibanie. |
Elasticsearch
Ta konkretna wtyczka służy do odczytywania wyników zapytań wyszukiwania w klastrze Elasticsearch. Poniżej znajdują się ustawienia używane w tej wtyczce -
| Nazwa ustawienia | Domyślna wartość | Opis |
|---|---|---|
| Dodaj pole | {} | Podobnie jak w przypadku wtyczki pliku, służy do dołączania pola w zdarzeniu wejściowym. |
| ca_file | Służy do określenia ścieżki do pliku urzędu certyfikacji SSL. | |
| kodek | "Równina" | Służy do dekodowania zdarzeń wejściowych z Elasticsearch przed wejściem do potoku Logstash. |
| docinfo | "fałszywy" | Możesz zmienić to na true, jeśli chcesz wyodrębnić dodatkowe informacje, takie jak indeks, typ i identyfikator z silnika Elasticsearch. |
| docinfo_fields | [„_index”, „_type”, „_id”] | Możesz usunąć dowolne pole, którego nie chcesz w swoim Logstash. |
| enable_metric | prawdziwe | Służy do włączania lub wyłączania raportowania i zbierania danych dla tej instancji wtyczki. |
| zastępy niebieskie | Służy do określania adresów wszystkich silników elastycznego wyszukiwania, które będą źródłem wejściowym tego wystąpienia Logstash. Składnia to host: port lub IP: port. | |
| ID | Służy do nadania unikalnego numeru identyfikacyjnego tej konkretnej instancji wtyczki wejściowej. | |
| indeks | „logstash- *” | Służy do określenia nazwy indeksu lub wzorca, który Logstash będzie monitorował przez Logstash pod kątem danych wejściowych. |
| hasło | Do celów uwierzytelniania. | |
| pytanie | „{\" sort \ ": [\" _ doc \ "]}" | Zapytanie o wykonanie. |
| ssl | fałszywy | Włącz lub wyłącz bezpieczną warstwę gniazda. |
| tagi | Aby dodać dodatkowe informacje w zdarzeniach wejściowych. | |
| rodzaj | Służy do klasyfikowania formularzy wejściowych, aby można było łatwo przeszukać wszystkie zdarzenia wejściowe na późniejszych etapach. | |
| użytkownik | Do celów autentycznych. |
Dziennik zdarzeń
Ta wtyczka wejściowa odczytuje dane z win32 API serwerów Windows. Poniżej znajdują się ustawienia tej wtyczki -
| Nazwa ustawienia | Domyślna wartość | Opis |
|---|---|---|
| Dodaj pole | {} | Podobnie jak w przypadku wtyczki pliku, służy do dołączania pola w zdarzeniu wejściowym |
| kodek | "Równina" | Służy do dekodowania zdarzeń wejściowych z okien; przed wejściem do potoku Logstash |
| plik dziennika | [„Aplikacja”, „Bezpieczeństwo”, „System”] | Zdarzenia wymagane w wejściowym pliku dziennika |
| interwał | 1000 | Jest wyrażony w milisekundach i określa odstęp czasu między dwoma kolejnymi sprawdzeniami nowych dzienników zdarzeń |
| tagi | Aby dodać dodatkowe informacje w zdarzeniach wejściowych | |
| rodzaj | Służy do klasyfikowania danych wejściowych z określonych wtyczek do danego typu, dzięki czemu w późniejszych etapach będzie można łatwo przeszukać wszystkie zdarzenia wejściowe |
Świergot
Ta wtyczka wejściowa służy do zbierania danych z Twittera z jego Streaming API. W poniższej tabeli opisano ustawienia tej wtyczki.
| Nazwa ustawienia | Domyślna wartość | Opis |
|---|---|---|
| Dodaj pole | {} | Podobnie jak w przypadku wtyczki pliku, służy do dołączania pola w zdarzeniu wejściowym |
| kodek | "Równina" | Służy do dekodowania zdarzeń wejściowych z okien; przed wejściem do potoku Logstash |
| Klucz klienta | Zawiera klucz klienta aplikacji Twitter. Aby uzyskać więcej informacji, odwiedźhttps://dev.twitter.com/apps/new | |
| tajemnica_konsumenta | Zawiera tajny klucz klienta aplikacji twitter. Aby uzyskać więcej informacji, odwiedźhttps://dev.twitter.com/apps/new | |
| enable_metric | prawdziwe | Służy do włączania lub wyłączania raportowania i zbierania danych dla tej instancji wtyczki |
| następuje | Określa identyfikatory użytkowników oddzielone przecinkami, a LogStash sprawdza status tych użytkowników na Twitterze. Aby uzyskać więcej informacji, odwiedź https://dev.twitter.com |
|
| full_tweet | fałszywy | Możesz zmienić to na true, jeśli chcesz, aby Logstash odczytywał pełny zwrot obiektu z Twittera API |
| ID | Służy do nadania unikalnego numeru identyfikacyjnego tej konkretnej instancji wtyczki wejściowej | |
| ignore_retweets | Fałszywy | Możesz zmienić ustawienie true, aby ignorować retweety w wejściowym kanale Twittera |
| słowa kluczowe | Jest to tablica słów kluczowych, które należy śledzić w kanale wejściowym Twittera | |
| język | Definiuje język tweetów wymaganych przez LogStash z wejściowego kanału Twittera. To tablica identyfikatorów, która definiuje konkretny język na Twitterze | |
| lokalizacje | Aby odfiltrować tweety z kanału wejściowego zgodnie z określoną lokalizacją. To jest tablica, która zawiera długość i szerokość geograficzną lokalizacji | |
| oauth_token | Jest to pole wymagane, które zawiera token użytkownika oauth. Aby uzyskać więcej informacji, odwiedź poniższy linkhttps://dev.twitter.com/apps | |
| oauth_token_secret | Jest to pole wymagane, które zawiera tajny token użytkownika oauth. Aby uzyskać więcej informacji, odwiedź poniższy linkhttps://dev.twitter.com/apps | |
| tagi | Aby dodać dodatkowe informacje w zdarzeniach wejściowych | |
| rodzaj | Służy do klasyfikowania danych wejściowych z określonych wtyczek do danego typu, dzięki czemu w późniejszych etapach będzie można łatwo przeszukać wszystkie zdarzenia wejściowe |
TCP
TCP jest używany do pobierania zdarzeń przez gniazdo TCP; może czytać z połączeń użytkownika lub serwera, który jest określony w ustawieniach trybu. Poniższa tabela opisuje ustawienia tej wtyczki -
| Nazwa ustawienia | Domyślna wartość | Opis |
|---|---|---|
| Dodaj pole | {} | Podobnie jak w przypadku wtyczki pliku, służy do dołączania pola w zdarzeniu wejściowym |
| kodek | "Równina" | Służy do dekodowania zdarzeń wejściowych z okien; przed wejściem do potoku Logstash |
| enable_metric | prawdziwe | Służy do włączania lub wyłączania raportowania i zbierania danych dla tej instancji wtyczki |
| gospodarz | „0.0.0.0” | Adres systemu operacyjnego serwera, od którego zależy klient |
| ID | Zawiera klucz klienta aplikacji Twitter | |
| tryb | "serwer" | Służy do określenia źródła wejściowego serwera lub klienta. |
| Port | Określa numer portu | |
| ssl_cert | Służy do określenia ścieżki certyfikatu SSL | |
| ssl_enable | fałszywy | Włącz lub wyłącz SSL |
| ssl_key | Aby określić ścieżkę do pliku kluczy SSL | |
| tagi | Aby dodać dodatkowe informacje w zdarzeniach wejściowych | |
| rodzaj | Służy do klasyfikowania danych wejściowych z określonych wtyczek do danego typu, dzięki czemu w późniejszych etapach będzie można łatwo przeszukać wszystkie zdarzenia wejściowe |
Logstash - wtyczki wyjściowe
Logstash obsługuje różne źródła wyjściowe i różne technologie, takie jak baza danych, plik, e-mail, standardowe wyjście itp.
Składnia korzystania z wtyczki wyjściowej jest następująca -
output {
Plugin name {
Setting 1……
Setting 2……..
}
}Możesz pobrać wtyczkę wyjściową za pomocą następującego polecenia -
>logstash-plugin install logstash-output-<plugin name>Plik Logstash-plugin utilityznajduje się w folderze bin katalogu instalacyjnego Logstash. W poniższej tabeli opisano wtyczki wyjściowe oferowane przez Logstash.
| Sr.No. | Nazwa i opis wtyczki |
|---|---|
| 1 | CloudWatch Ta wtyczka służy do wysyłania zagregowanych danych metrycznych do CloudWatch usług internetowych Amazon. |
| 2 | csv Służy do zapisywania zdarzeń wyjściowych w sposób oddzielony przecinkami. |
| 3 | Elasticsearch Służy do przechowywania dzienników wyjściowych w indeksie Elasticsearch. |
| 4 | Służy do wysyłania wiadomości e-mail z powiadomieniem, gdy dane wyjściowe są generowane. Użytkownik może dodać informacje o wynikach w wiadomości e-mail. |
| 5 | exec Służy do uruchomienia polecenia, które pasuje do zdarzenia wyjściowego. |
| 6 | ganglia Skręca metryki do Gmonda z Gangili. |
| 7 | gelf Służy do generowania wyników dla Graylog2 w formacie GELF. |
| 8 | google_bigquery Wysyła zdarzenia do Google BigQuery. |
| 9 | google_cloud_storage Przechowuje zdarzenia wyjściowe w Google Cloud Storage. |
| 10 | graphite Służy do przechowywania zdarzeń wyjściowych w Graphite. |
| 11 | graphtastic Służy do zapisywania metryk wyjściowych w systemie Windows. |
| 12 | hipchat Służy do przechowywania zdarzeń dziennika wyjściowego w HipChat. |
| 13 | http Służy do wysyłania wyjściowych zdarzeń dziennika do punktów końcowych http lub https. |
| 14 | influxdb Służy do przechowywania zdarzenia wyjściowego w InfluxDB. |
| 15 | irc Służy do zapisywania zdarzeń wyjściowych do IRC. |
| 16 | mongodb Przechowuje dane wyjściowe w MongoDB. |
| 17 | nagios Służy do powiadamiania Nagiosa o wynikach kontroli pasywnej. |
| 18 | nagios_nsca Służy do powiadamiania Nagiosa o wynikach kontroli pasywnej za pośrednictwem protokołu NSCA. |
| 19 | opentsdb Przechowuje zdarzenia wyjściowe Logstash w OpenTSDB. |
| 20 | pipe Przesyła strumieniowo zdarzenia wyjściowe do standardowego wejścia innego programu. |
| 21 | rackspace Służy do wysyłania zdarzeń z dziennika wyjściowego do usługi kolejki w Rackspace Cloud. |
| 22 | redis Używa polecenia rpush, aby wysłać wyjściowe dane rejestrowania do kolejki Redis. |
| 23 | riak Służy do przechowywania zdarzeń wyjściowych w rozproszonej parze klucz / wartość Riak. |
| 24 | s3 Przechowuje wyjściowe dane logowania w usłudze Amazon Simple Storage Service. |
| 25 | sns Służy do wysyłania zdarzeń wyjściowych do usługi Simple Notification Service firmy Amazon. |
| 26 | solr_http Indeksuje i przechowuje wyjściowe dane logowania w Solr. |
| 27 | sps Służy do wysyłania zdarzeń do usługi Simple Queue Service w AWS. |
| 28 | statsd Służy do wysyłania danych metryk do demona sieciowego statsd. |
| 29 | stdout Służy do wyświetlania zdarzeń wyjściowych na standardowym wyjściu CLI, takim jak wiersz polecenia. |
| 30 | syslog Służy do wysyłania zdarzeń wyjściowych do serwera syslog. |
| 31 | tcp Służy do wysyłania zdarzeń wyjściowych do gniazda TCP. |
| 32 | udp Służy do przesyłania zdarzeń wyjściowych przez UDP. |
| 33 | websocket Służy do przekazywania zdarzeń wyjściowych przez protokół WebSocket. |
| 34 | xmpp Służy do przesyłania zdarzeń wyjściowych przez protokół XMPP. |
Wszystkie wtyczki mają swoje specyficzne ustawienia, które pomagają określić ważne pola, takie jak Port, Ścieżka itp., We wtyczce. Omówimy ustawienia niektórych wtyczek wyjściowych.
Elasticsearch
Wtyczka wyjścia Elasticsearch umożliwia Logstash przechowywanie danych wyjściowych w określonych klastrach silnika Elasticsearch. Jest to jeden ze słynnych wyborów użytkowników, ponieważ znajduje się w pakiecie ELK Stack i dlatego zapewnia kompleksowe rozwiązania dla Devops. W poniższej tabeli opisano ustawienia tej wtyczki wyjściowej.
| Nazwa ustawienia | Domyślna wartość | Opis |
|---|---|---|
| akcja | indeks | Służy do definiowania akcji wykonywanej w silniku Elasticsearch. Inne wartości tych ustawień to usuń, utwórz, zaktualizuj itp. |
| cacert | Zawiera ścieżkę do pliku z rozszerzeniem .cer lub .pem do weryfikacji certyfikatu serwera. | |
| kodek | "Równina" | Służy do kodowania wyjściowych danych rejestrowania przed wysłaniem ich do źródła docelowego. |
| doc_as_upset | fałszywy | To ustawienie jest używane w przypadku akcji aktualizacji. Tworzy dokument w silniku Elasticsearch, jeśli identyfikator dokumentu nie jest określony we wtyczce wyjściowej. |
| typ dokumentu | Służy do przechowywania zdarzeń tego samego typu w tym samym typie dokumentu. Jeśli nie zostanie określony, typ zdarzenia jest używany do tego samego. | |
| flush_size | 500 | Służy do poprawy wydajności przesyłania zbiorczego w Elasticsearch |
| zastępy niebieskie | [„127.0.0.1”] | Jest to tablica adresów docelowych dla wyjściowych danych logowania |
| idle_flush_time | 1 | Określa limit czasu (sekundę) między dwoma rzutami, Logstash wymusza spłukiwanie po upływie określonego limitu czasu w tym ustawieniu |
| indeks | „logstash -% {+ RRRR.MM.dd}” | Służy do określenia indeksu silnika Elasticsearch |
| manage_temlpate | prawdziwe | Służy do zastosowania domyślnego szablonu w Elasticsearch |
| rodzic | zero | Służy do określenia identyfikatora dokumentu nadrzędnego w Elasticsearch |
| hasło | Służy do uwierzytelniania żądania w bezpiecznym klastrze w Elasticsearch | |
| ścieżka | Służy do określenia ścieżki HTTP Elasticsearch. | |
| rurociąg | zero | Służy do ustawiania potoku pozyskiwania, który użytkownik chce wykonać dla zdarzenia |
| pełnomocnik | Służy do określenia serwera proxy HTTP | |
| retry_initial_interval | 2 | Służy do ustawiania początkowego odstępu czasu (w sekundach) między próbami zbiorczymi. Zwiększa się dwukrotnie po każdej ponownej próbie, aż osiągnie wartość retry_max_interval |
| retry_max_interval | 64 | Służy do ustawiania maksymalnego odstępu czasu dla retry_initial_interval |
| retry_on_conflict | 1 | Jest to liczba ponownych prób aktualizacji dokumentu przez Elasticsearch |
| ssl | Aby włączyć lub wyłączyć SSL / TLS zabezpieczony przez Elasticsearch | |
| szablon | Zawiera ścieżkę do dostosowanego szablonu w Elasticsearch | |
| nazwa_szablonu | „logstash” | Służy do nazwania szablonu w Elasticsearch |
| koniec czasu | 60 | Jest to limit czasu dla żądań sieciowych do Elasticsearch |
| upert | „” | Aktualizuje dokument lub jeśli identyfikator_dokumentu nie istnieje, tworzy nowy dokument w Elasticsearch |
| użytkownik | Zawiera użytkownika do uwierzytelnienia żądania Logstash w bezpiecznym klastrze Elasticsearch |
Wtyczka do wysyłania wiadomości e-mail służy do powiadamiania użytkownika, gdy Logstash generuje dane wyjściowe. W poniższej tabeli opisano ustawienia tej wtyczki.
| Nazwa ustawienia | Domyślna wartość | Opis |
|---|---|---|
| adres | "Lokalny Gospodarz" | Jest to adres serwera pocztowego |
| załączniki | [] | Zawiera nazwy i lokalizacje załączonych plików |
| ciało | „” | Zawiera treść wiadomości e-mail i powinien być zwykłym tekstem |
| cc | Zawiera adresy e-mail oddzielone przecinkami jako kopię zapasową wiadomości e-mail | |
| kodek | "Równina" | Służy do kodowania wyjściowych danych rejestrowania przed wysłaniem ich do źródła docelowego. |
| Typ zawartości | "text / html; charset = UTF-8" | Służy do typu treści wiadomości e-mail |
| odpluskwić | fałszywy | Służy do wykonywania przekazywania poczty w trybie debugowania |
| domena | "Lokalny Gospodarz" | Służy do ustawienia domeny do wysyłania wiadomości e-mail |
| od | „[email protected]” | Służy do określenia adresu e-mail nadawcy |
| htmlbody | „” | Służy do określenia treści wiadomości e-mail w formacie html |
| hasło | Służy do uwierzytelniania na serwerze poczty | |
| Port | 25 | Służy do określenia portu do komunikacji z serwerem pocztowym |
| odpowiedzieć do | Służy do określenia identyfikatora e-mail dla pola odpowiedzi na wiadomość e-mail | |
| Przedmiot | „” | Zawiera temat wiadomości e-mail |
| use_tls | fałszywy | Włącz lub wyłącz TSL do komunikacji z serwerem poczty |
| Nazwa Użytkownika | Zawiera nazwę użytkownika do uwierzytelnienia na serwerze | |
| przez | „Smtp” | Określa metody wysyłania wiadomości e-mail przez Logstash |
Http
To ustawienie służy do wysyłania zdarzeń wyjściowych za pośrednictwem protokołu HTTP do miejsca docelowego. Ta wtyczka ma następujące ustawienia -
| Nazwa ustawienia | Domyślna wartość | Opis |
|---|---|---|
| automatic_retries | 1 | Służy do ustawiania liczby ponownych prób żądania HTTP przez logstash |
| cacert | Zawiera ścieżkę do pliku służącego do weryfikacji certyfikatu serwera | |
| kodek | "Równina" | Służy do kodowania wyjściowych danych rejestrowania przed wysłaniem ich do źródła docelowego. |
| Typ zawartości | I określa typ treści żądania http wysyłanego do serwera docelowego | |
| ciasteczka | prawdziwe | Służy do włączania lub wyłączania plików cookie |
| format | „json” | Służy do ustawiania formatu treści żądania http |
| nagłówki | Zawiera informacje o nagłówku http | |
| http_method | „” | Służy do określenia metody http używanej w żądaniu przez logstash, a wartościami mogą być "put", "post", "patch", "delete", "get", "head" |
| Limit czasu żądania | 60 | Służy do uwierzytelniania na serwerze poczty |
| url | Jest to wymagane ustawienie dla tej wtyczki, aby określić punkt końcowy http lub https |
stdout
Wtyczka wyjścia stdout służy do zapisywania zdarzeń wyjściowych na standardowym wyjściu interfejsu wiersza poleceń. Jest to wiersz poleceń w systemie Windows i terminalu w systemie UNIX. Ta wtyczka ma następujące ustawienia -
| Nazwa ustawienia | Domyślna wartość | Opis |
|---|---|---|
| kodek | "Równina" | Służy do kodowania wyjściowych danych rejestrowania przed wysłaniem ich do źródła docelowego. |
| pracownicy | 1 | Służy do określenia liczby pracowników dla wyniku |
statsd
Jest to demon sieciowy używany do wysyłania danych macierzy przez UDP do usług zaplecza docelowego. Jest to wiersz poleceń w systemie Windows i terminalu w systemie UNIX. Ta wtyczka ma następujące ustawienia -
| Nazwa ustawienia | Domyślna wartość | Opis |
|---|---|---|
| kodek | "Równina" | Służy do kodowania wyjściowych danych rejestrowania przed wysłaniem ich do źródła docelowego. |
| liczyć | {} | Służy do definiowania liczby, która ma być używana w metrykach |
| ubytek | [] | Służy do określania nazw metryk dekrementacji |
| gospodarz | "Lokalny Gospodarz" | Zawiera adres serwera statsd |
| przyrost | [] | Służy do określania nazw metryk przyrostu |
| Port | 8125 | Zawiera port serwera statsd |
| próbna stawka | 1 | Służy do określenia częstotliwości próbkowania metryki |
| nadawca | "%{gospodarz}" | Określa nazwę nadawcy |
| zestaw | {} | Służy do określenia metryki zestawu |
| wyczucie czasu | {} | Służy do określenia metryki czasu |
| pracownicy | 1 | Służy do określenia liczby pracowników dla wyniku |
Filtruj wtyczki
Logstash obsługuje różne wtyczki filtrów do analizowania i przekształcania dzienników wejściowych w bardziej uporządkowany i łatwy do przeszukiwania format.
Składnia korzystania z wtyczki filtru jest następująca -
filter {
Plugin name {
Setting 1……
Setting 2……..
}
}Możesz pobrać wtyczkę filtra, używając następującego polecenia -
>logstash-plugin install logstash-filter-<plugin name>Narzędzie Logstash-plugin znajduje się w folderze bin katalogu instalacyjnego Logstash. W poniższej tabeli opisano wtyczki wyjściowe oferowane przez Logstash.
| Sr.No. | Nazwa i opis wtyczki |
|---|---|
| 1 | aggregate Ta wtyczka zbiera lub agreguje dane z różnych wydarzeń tego samego typu i przetwarza je w zdarzeniu końcowym |
| 2 | alter Pozwala użytkownikowi na zmianę pola zdarzeń dziennika, których nie obsługuje filtr mutacji |
| 3 | anonymize Służy do zastępowania wartości pól spójnym hashem |
| 4 | cipher Służy do szyfrowania zdarzeń wyjściowych przed zapisaniem ich w źródle docelowym |
| 5 | clone Służy do tworzenia duplikatów zdarzeń wyjściowych w Logstash |
| 6 | collate Łączy zdarzenia z różnych dzienników według ich czasu lub liczby |
| 7 | csv Ta wtyczka analizuje dane z dzienników wejściowych zgodnie z separatorem |
| 8 | date Analizuje daty z pól w zdarzeniu i ustawia je jako sygnaturę czasową zdarzenia |
| 9 | dissect Ta wtyczka pomaga użytkownikowi wyodrębnić pola z nieustrukturyzowanych danych i ułatwia filtrowi Grok ich prawidłowe przeanalizowanie |
| 10 | drop Służy do odrzucania wszystkich zdarzeń tego samego typu lub innego podobieństwa |
| 11 | elapsed Służy do obliczania czasu między zdarzeniami początkowymi i końcowymi |
| 12 | Elasticsearch Służy do kopiowania pól z poprzednich zdarzeń dziennika obecnych w Elasticsearch do bieżącego w Logstash |
| 13 | extractnumbers Służy do wyodrębniania liczby z ciągów znaków w dzienniku zdarzeń |
| 14 | geoip Dodaje pole do zdarzenia, które zawiera szerokość i długość geograficzną lokalizacji adresu IP obecnego w zdarzeniu dziennika |
| 15 | grok Jest to powszechnie używana wtyczka filtrująca do analizowania zdarzenia w celu pobrania pól |
| 16 | i18n Usuwa znaki specjalne ze zdarzenia zapisanego w dzienniku |
| 17 | json Służy do tworzenia strukturalnego obiektu Json w przypadku zdarzenia lub w określonym polu zdarzenia |
| 18 | kv Ta wtyczka jest przydatna do parowania par klucz-wartość w danych logowania |
| 19 | metrics Służy do agregowania danych, takich jak zliczanie czasu trwania każdego zdarzenia |
| 20 | multiline Jest to również jedna z powszechnie używanych wtyczek filtrujących, która pomaga użytkownikowi w przypadku konwersji wielowierszowych danych logowania na pojedyncze zdarzenie. |
| 21 | mutate Ta wtyczka służy do zmiany nazwy, usuwania, zastępowania i modyfikowania pól w wydarzeniach |
| 22 | range Służyło do porównywania wartości liczbowych pól w zdarzeniach z oczekiwanym zakresem i długością łańcucha w zakresie. |
| 23 | ruby Służy do uruchamiania dowolnego kodu Rubiego |
| 24 | sleep To sprawia, że Logstash śpi przez określony czas |
| 25 | split Służy do dzielenia pola zdarzenia i umieszczania wszystkich podzielonych wartości w klonach tego zdarzenia |
| 26 | xml Służy do tworzenia zdarzeń poprzez parowanie danych XML obecnych w dziennikach |
Wtyczki kodeków
Wtyczki kodeków mogą być częścią wtyczek wejściowych lub wyjściowych. Te wtyczki służą do zmiany lub formatowania prezentacji danych logowania. Logstash oferuje wiele wtyczek kodeków, a te są następujące -
| Sr.No. | Nazwa i opis wtyczki |
|---|---|
| 1 | avro Ta wtyczka koduje serializację zdarzeń Logstash do danych avro lub dekoduje rekordy avro do zdarzeń Logstash |
| 2 | cloudfront Ta wtyczka odczytuje zakodowane dane z AWS Cloudfront |
| 3 | cloudtrail Ta wtyczka służy do odczytu danych z AWS cloudtrail |
| 4 | collectd Odczytuje dane z protokołu binarnego o nazwie zbierane przez UDP |
| 5 | compress_spooler Służy do kompresji zdarzeń dziennika w Logstash do zbuforowanych partii |
| 6 | dots Służy do śledzenia wydajności przez ustawienie kropki dla każdego zdarzenia na standardowe wyjście |
| 7 | es_bulk Służy do konwersji danych zbiorczych z Elasticsearch na zdarzenia Logstash, w tym metadane Elasticsearch |
| 8 | graphite Ten kodek wczytuje dane z grafitu na zdarzenia i zamienia zdarzenie na rekordy w formacie grafitowym |
| 9 | gzip_lines Ta wtyczka jest używana do obsługi danych zakodowanych w formacie gzip |
| 10 | json Służy do konwertowania pojedynczego elementu w tablicy Json na pojedyncze zdarzenie Logstash |
| 11 | json_lines Służy do obsługi danych Json z ogranicznikiem nowego wiersza |
| 12 | line Wtyczka odczyta i zapisze zdarzenie w pojedynczym trybie na żywo, co oznacza, że po separatorze nowej linii pojawi się nowe wydarzenie |
| 13 | multiline Służy do konwersji wielowierszowych danych logowania na pojedyncze zdarzenie |
| 14 | netflow Ta wtyczka służy do konwersji danych nertflow v5 / v9 na zdarzenia logstash |
| 15 | nmap Analizuje dane wynikowe nmap do formatu XML |
| 16 | plain This reads text without delimiters |
| 17 | rubydebug This plugin will write the output Logstash events using Ruby awesome print library |
Build Your Own Plugin
You can also create your own Plugins in Logstash, which suites your requirements. The Logstash-plugin utility is used to create custom Plugins. Here, we will create a filter plugin, which will add a custom message in the events.
Generate the Base Structure
A user can generate the necessary files by using the generate option of the logstash-plugin utility or it is also available on the GitHub.
>logstash-plugin generate --type filter --name myfilter --path c:/tpwork/logstash/libHere, type option is used to specify the plugin is either Input, Output or Filter. In this example, we are creating a filter plugin named myfilter. The path option is used to specify the path, where you want your plugin directory to be created. After executing the above mentioned command, you will see that a directory structure is created.
Develop the Plugin
You can find the code file of the plugin in the \lib\logstash\filters folder in the plugin directory. The file extension will be .rb.
In our case, the code file was located inside the following path −
C:\tpwork\logstash\lib\logstash-filter-myfilter\lib\logstash\filters\myfilter.rbWe change the message to − default ⇒ "Hi, You are learning this on tutorialspoint.com" and save the file.
Install the Plugin
To install this plugin, the Gemfile of Logstash need to be modified. You can find this file in the installation directory of Logstash. In our case, it will be in C:\tpwork\logstash. Edit this file using any text editor and add the following text in it.
gem "logstash-filter-myfilter",:path => "C:/tpwork/logstash/lib/logstash-filter-myfilter"In the above command, we specify the name of the plugin along with where we can find it for installation. Then, run the Logstash-plugin utility to install this plugin.
>logstash-plugin install --no-verifyTesting
Here, we are adding myfilter in one of the previous examples −
logstash.conf
This Logstash config file contains myfilter in the filter section after the grok filter plugin.
input {
file {
path => "C:/tpwork/logstash/bin/log/input1.log"
}
}
filter {
grok {
match => [
"message", "%{LOGLEVEL:loglevel} - %{NOTSPACE:taskid} -
%{NOTSPACE:logger} - %{WORD:label}( - %{INT:duration:int})?" ]
}
myfilter{}
}
output {
file {
path => "C:/tpwork/logstash/bin/log/output1.log"
codec => rubydebug
}
}Run logstash
We can run Logstash by using the following command.
>logstash –f logsatsh.confinput.log
The following code block shows the input log data.
INFO - 48566 - TRANSACTION_START - startoutput.log
The following code block shows the output log data.
{
"path" => "C:/tpwork/logstash/bin/log/input.log",
"@timestamp" => 2017-01-07T06:25:25.484Z,
"loglevel" => "INFO",
"logger" => "TRANSACTION_END",
"@version" => "1",
"host" => "Dell-PC",
"label" => "end",
"message" => "Hi, You are learning this on tutorialspoint.com",
"taskid" => "48566",
"tags" => []
}Publish it on Logstash
A developer can also publish his/her custom plugin to Logstash by uploading it on the github and following the standardized steps defined by the Elasticsearch Company.
Please refer the following URL for more information on publishing −
https://www.elastic.co/guide/en/logstash/current/contributing-to-logstash.html
Logstash offers APIs to monitor its performance. These monitoring APIs extract runtime metrics about Logstash.
Node Info API
This API is used to get the information about the nodes of Logstash. It returns the information of the OS, Logstash pipeline and JVM in JSON format.
You can extract the information by sending a get request to Logstash using the following URL −
GET http://localhost:9600/_node?prettyResponse
Following would be the response of the Node Info API.
{
"host" : "Dell-PC",
"version" : "5.0.1",
"http_address" : "127.0.0.1:9600",
"pipeline" : {
"workers" : 4,
"batch_size" : 125,
"batch_delay" : 5,
"config_reload_automatic" : false,
"config_reload_interval" : 3
},
"os" : {
"name" : "Windows 7",
"arch" : "x86",
"version" : "6.1",
"available_processors" : 4
},
"jvm" : {
"pid" : 312,
"version" : "1.8.0_111",
"vm_name" : "Java HotSpot(TM) Client VM",
"vm_version" : "1.8.0_111",
"vm_vendor" : "Oracle Corporation",
"start_time_in_millis" : 1483770315412,
"mem" : {
"heap_init_in_bytes" : 16777216,
"heap_max_in_bytes" : 1046937600,
"non_heap_init_in_bytes" : 163840,
"non_heap_max_in_bytes" : 0
},
"gc_collectors" : [ "ParNew", "ConcurrentMarkSweep" ]
}
}You can also get the specific information of Pipeline, OS and JVM, by just adding their names in the URL.
GET http://localhost:9600/_node/os?pretty
GET http://localhost:9600/_node/pipeline?pretty
GET http://localhost:9600/_node/jvm?prettyPlugins Info API
This API is used to get the information about the installed plugins in the Logstash. You can retrieve this information by sending a get request to the URL mentioned below −
GET http://localhost:9600/_node/plugins?prettyResponse
Following would be the response of the Plugins Info API.
{
"host" : "Dell-PC",
"version" : "5.0.1",
"http_address" : "127.0.0.1:9600",
"total" : 95,
"plugins" : [ {
"name" : "logstash-codec-collectd",
"version" : "3.0.2"
},
{
"name" : "logstash-codec-dots",
"version" : "3.0.2"
},
{
"name" : "logstash-codec-edn",
"version" : "3.0.2"
},
{
"name" : "logstash-codec-edn_lines",
"version" : "3.0.2"
},
............
}Node Stats API
This API is used to extract the statistics of the Logstash (Memory, Process, JVM, Pipeline) in JSON objects. You can retrieve this information by sending a get request to the URLS mentioned below −
GET http://localhost:9600/_node/stats/?pretty
GET http://localhost:9600/_node/stats/process?pretty
GET http://localhost:9600/_node/stats/jvm?pretty
GET http://localhost:9600/_node/stats/pipeline?prettyHot Threads API
This API retrieves the information about the hot threads in Logstash. Hot threads are the java threads, which has high CPU usage and run longer than then normal execution time. You can retrieve this information by sending a get request to the URL mentioned below −
GET http://localhost:9600/_node/hot_threads?prettyA user can use the following URL to get the response in a form that is more readable.
GET http://localhost:9600/_node/hot_threads?human = trueIn this chapter, we will discuss the security and monitoring aspects of Logstash.
Monitoring
Logstash is a very good tool to monitor the servers and services in production environments. Applications in production environment produces different kinds of log data like access Logs, Error Logs, etc. Logstash can count or analyze the number of errors, accesses or other events using filter plugins. This analysis and counting can be used for monitoring different servers and their services.
Logstash offers plugins like HTTP Poller to monitor the website status monitoring. Here, we are monitoring a website named mysite hosted on a local Apache Tomcat Server.
logstash.conf
In this config file, the http_poller plugin is used to hit the site specified in the plugin after a time interval specified in interval setting. Finally, it writes the status of the site to a standard output.
input {
http_poller {
urls => {
site => "http://localhost:8080/mysite"
}
request_timeout => 20
interval => 30
metadata_target => "http_poller_metadata"
}
}
output {
if [http_poller_metadata][code] == 200 {
stdout {
codec => line{format => "%{http_poller_metadata[response_message]}"}
}
}
if [http_poller_metadata][code] != 200 {
stdout {
codec => line{format => "down"}
}
}
}Run logstash
We can run Logstash with the following command.
>logstash –f logstash.confstdout
If the site is up, then the output will be −
OkIf we stop the site by using the Manager App of Tomcat, the output will change to −
downSecurity
Logstash provides plenty of features for secure communication with external systems and supports authentication mechanism. All Logstash plugins support authentication and encryption over HTTP connections.
Security with HTTP protocol
There are settings like user and password for authentication purposes in various plugins offered by Logstash like in the Elasticsearch plugin.
elasticsearch {
user => <username>
password => <password>
}The other authentication is PKI (public key infrastructure) for Elasticsearch. The developer needs to define two settings in the Elasticsearch output plugin to enable the PKI authentication.
elasticsearch {
keystore => <string_value>
keystore_password => <password>
}In the HTTPS protocol, a developer can use the authority’s certificate for SSL/TLS.
elasticsearch {
ssl => true
cacert => <path to .pem file>
}Security with Transport Protocol
To use the transport protocol with Elasticsearch, users need to set protocol setting to transport. This avoids un-marshalling of JSON objects and leads to more efficiency.
The basic authentication is same as performed in http protocol in Elasticsearch output protocol.
elasticsearch {
protocol => “transport”
user => <username>
password => <password>
}The PKI authentication also needs the SSL sets to be true with other settings in the Elasticsearch output protocol −
elasticsearch {
protocol => “transport”
ssl => true
keystore => <string_value>
keystore_password => <password>
}Finally, the SSL security requires a little with more settings than other security methods in communication.
elasticsearch {
ssl => true
ssl => true
keystore => <string_value>
keystore_password => <password>
truststore =>
truststore_password => <password> }
Other Security Benefits from Logstash
Logstash can help input system sources to prevent against attacks like denial of service attacks. The monitoring of logs and analyzing the different events in those logs can help system administrators to check the variation in the incoming connections and errors. These analyses can help to see if the attack is happening or going to happen on the servers.
Other products of the Elasticsearch Company such as x-pack and filebeat provides some functionality to communicate securely with Logstash.