Lucene - Pierwsza aplikacja
W tym rozdziale nauczymy się programowania w Lucene Framework. Zanim zaczniesz pisać swój pierwszy przykład przy użyciu frameworka Lucene, musisz upewnić się, że poprawnie skonfigurowałeś środowisko Lucene, jak wyjaśniono w samouczku Lucene - Konfiguracja środowiska . Zaleca się posiadanie praktycznej wiedzy na temat Eclipse IDE.
Przejdźmy teraz do napisania prostej aplikacji wyszukującej, która wydrukuje liczbę znalezionych wyników wyszukiwania. Zobaczymy również listę indeksów utworzonych podczas tego procesu.
Krok 1 - Utwórz projekt Java
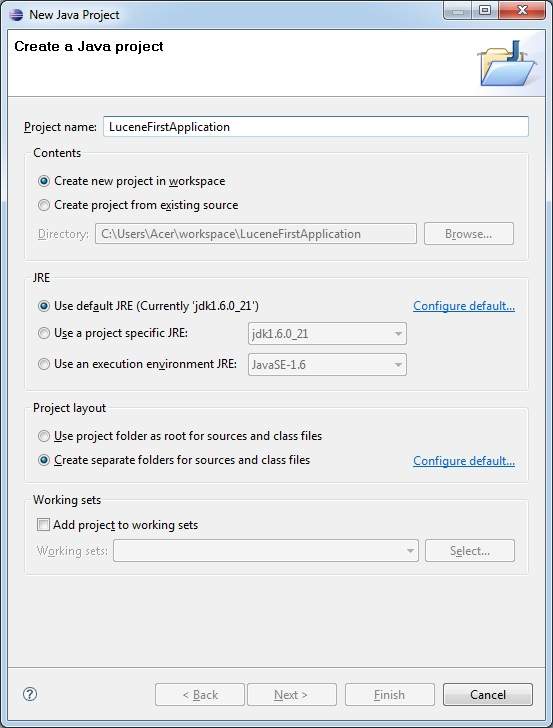
Pierwszym krokiem jest stworzenie prostego projektu Java przy użyciu Eclipse IDE. Postępuj zgodnie z opcjąFile > New -> Project i na koniec wybierz Java Projectkreator z listy kreatorów. Teraz nazwij swój projekt jakoLuceneFirstApplication używając okna kreatora w następujący sposób -
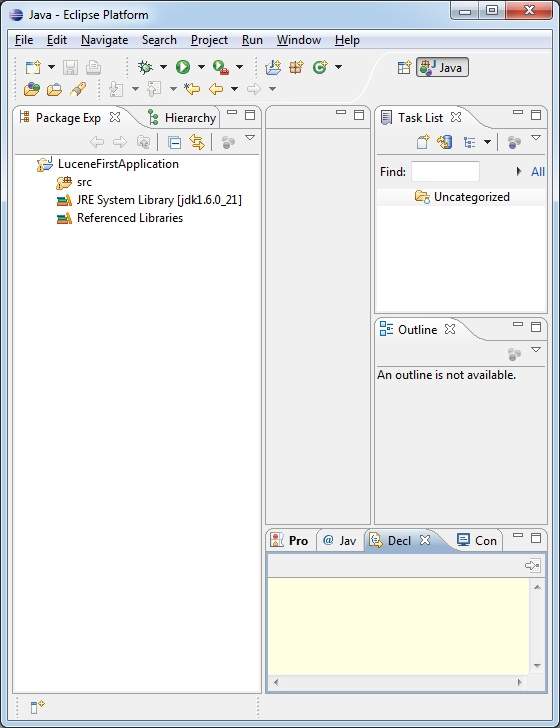
Po pomyślnym utworzeniu projektu będziesz mieć następującą zawartość w swoim Project Explorer -
Krok 2 - Dodaj wymagane biblioteki
Dodajmy teraz do naszego projektu bibliotekę rdzeniową Lucene Framework. Aby to zrobić, kliknij prawym przyciskiem myszy nazwę swojego projektuLuceneFirstApplication a następnie skorzystaj z opcji dostępnej w menu kontekstowym: Build Path -> Configure Build Path aby wyświetlić okno ścieżki budowania języka Java w następujący sposób -

Teraz użyj Add External JARs przycisk dostępny pod Libraries aby dodać następujący podstawowy plik JAR z katalogu instalacyjnego Lucene -
- lucene-core-3.6.2
Krok 3 - Utwórz pliki źródłowe
Utwórzmy teraz rzeczywiste pliki źródłowe w ramach LuceneFirstApplicationprojekt. Najpierw musimy utworzyć pakiet o nazwiecom.tutorialspoint.lucene. Aby to zrobić, kliknij prawym przyciskiem myszy src w sekcji eksploratora pakietów i postępuj zgodnie z opcją: New -> Package.
Następnie stworzymy LuceneTester.java i inne klasy java w ramach com.tutorialspoint.lucene pakiet.
LuceneConstants.java
Ta klasa jest używana do dostarczania różnych stałych do użycia w przykładowej aplikacji.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}TextFileFilter.java
Ta klasa jest używana jako .txt file filtr.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}Indexer.java
Ta klasa jest używana do indeksowania surowych danych, dzięki czemu można je przeszukiwać za pomocą biblioteki Lucene.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
//create the indexer
writer = new IndexWriter(indexDirectory,
new StandardAnalyzer(Version.LUCENE_36),true,
IndexWriter.MaxFieldLength.UNLIMITED);
}
public void close() throws CorruptIndexException, IOException {
writer.close();
}
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new Field(LuceneConstants.CONTENTS, new FileReader(file));
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),Field.Store.YES,Field.Index.NOT_ANALYZED);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),Field.Store.YES,Field.Index.NOT_ANALYZED);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException {
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.numDocs();
}
}Searcher.java
Ta klasa jest używana do przeszukiwania indeksów utworzonych przez indeksatora w celu przeszukania żądanej zawartości.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Searcher {
IndexSearcher indexSearcher;
QueryParser queryParser;
Query query;
public Searcher(String indexDirectoryPath)
throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
public void close() throws IOException {
indexSearcher.close();
}
}LuceneTester.java
Ta klasa jest używana do testowania możliwości indeksowania i wyszukiwania biblioteki lucene.
package com.tutorialspoint.lucene;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Indexer indexer;
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
tester.search("Mohan");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException {
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
System.out.println(numIndexed+" File indexed, time taken: "
+(endTime-startTime)+" ms");
}
private void search(String searchQuery) throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
TopDocs hits = searcher.search(searchQuery);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime));
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "
+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
}Krok 4 - Tworzenie katalogu Data & Index
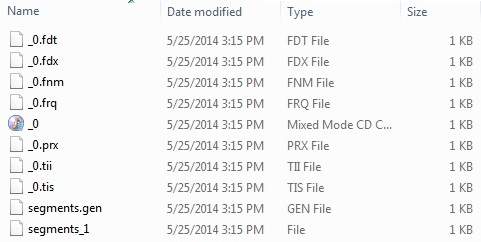
Użyliśmy 10 plików tekstowych z plików record1.txt do record10.txt zawierających nazwiska i inne dane uczniów i umieściliśmy je w katalogu E:\Lucene\Data. Dane testowe . Ścieżka katalogu indeksu powinna zostać utworzona jakoE:\Lucene\Index. Po uruchomieniu tego programu możesz zobaczyć listę plików indeksu utworzonych w tym folderze.
Krok 5 - Uruchomienie programu
Po utworzeniu źródła, surowych danych, katalogu danych i katalogu indeksu, jesteś gotowy do kompilacji i uruchomienia programu. Aby to zrobić, zachowajLuceneTester.Java aktywna jest karta pliku i użyj rozszerzenia Run opcja dostępna w Eclipse IDE lub użyj Ctrl + F11 skompilować i uruchomić LuceneTesterpodanie. Jeśli aplikacja zostanie pomyślnie uruchomiona, wydrukuje następujący komunikat w konsoli Eclipse IDE -
Indexing E:\Lucene\Data\record1.txt
Indexing E:\Lucene\Data\record10.txt
Indexing E:\Lucene\Data\record2.txt
Indexing E:\Lucene\Data\record3.txt
Indexing E:\Lucene\Data\record4.txt
Indexing E:\Lucene\Data\record5.txt
Indexing E:\Lucene\Data\record6.txt
Indexing E:\Lucene\Data\record7.txt
Indexing E:\Lucene\Data\record8.txt
Indexing E:\Lucene\Data\record9.txt
10 File indexed, time taken: 109 ms
1 documents found. Time :0
File: E:\Lucene\Data\record4.txtPo pomyślnym uruchomieniu programu będziesz mieć następującą zawartość w swoim index directory -