MapReduce - wprowadzenie
MapReduce to model programowania do pisania aplikacji, które mogą przetwarzać duże zbiory danych równolegle na wielu węzłach. MapReduce zapewnia możliwości analityczne do analizowania ogromnych ilości złożonych danych.
Co to jest Big Data?
Big Data to zbiór dużych zbiorów danych, których nie można przetwarzać przy użyciu tradycyjnych technik obliczeniowych. Na przykład ilość danych potrzebnych Facebookowi lub YouTube do codziennego gromadzenia i zarządzania może należeć do kategorii Big Data. Jednak Big Data to nie tylko skala i objętość, ale obejmuje również jeden lub więcej z następujących aspektów - prędkość, różnorodność, objętość i złożoność.
Dlaczego MapReduce?
Tradycyjne systemy korporacyjne mają zwykle scentralizowany serwer do przechowywania i przetwarzania danych. Poniższa ilustracja przedstawia schematyczny widok tradycyjnego systemu przedsiębiorstwa. Tradycyjny model z pewnością nie nadaje się do przetwarzania dużych ilości skalowalnych danych i nie może być dostosowany do standardowych serwerów baz danych. Co więcej, scentralizowany system tworzy zbyt duże wąskie gardło podczas jednoczesnego przetwarzania wielu plików.

Google rozwiązało ten problem z wąskim gardłem za pomocą algorytmu o nazwie MapReduce. MapReduce dzieli zadanie na małe części i przypisuje je do wielu komputerów. Później wyniki są gromadzone w jednym miejscu i integrowane w celu utworzenia zestawu danych wyników.

Jak działa MapReduce?
Algorytm MapReduce zawiera dwa ważne zadania, a mianowicie Mapowanie i Zmniejszanie.
Zadanie mapy pobiera zestaw danych i konwertuje go na inny zestaw danych, w którym poszczególne elementy są dzielone na krotki (pary klucz-wartość).
Zadanie Reduce pobiera dane wyjściowe z mapy jako dane wejściowe i łączy te krotki danych (pary klucz-wartość) w mniejszy zestaw krotek.
Zadanie redukcji jest zawsze wykonywane po utworzeniu mapy.
Przyjrzyjmy się teraz bliżej każdej z faz i spróbujmy zrozumieć ich znaczenie.
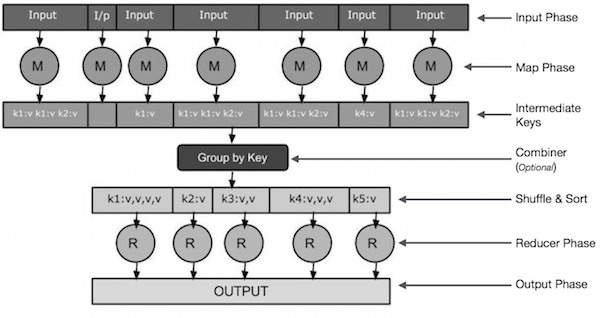
Input Phase - Tutaj mamy czytnik rekordów, który tłumaczy każdy rekord w pliku wejściowym i wysyła przeanalizowane dane do programu odwzorowującego w postaci par klucz-wartość.
Map - Map to funkcja zdefiniowana przez użytkownika, która pobiera serię par klucz-wartość i przetwarza każdą z nich, aby wygenerować zero lub więcej par klucz-wartość.
Intermediate Keys - Pary klucz-wartość generowane przez program odwzorowujący nazywane są kluczami pośrednimi.
Combiner- Sumator jest rodzajem lokalnego reduktora, który grupuje podobne dane z fazy mapy w możliwe do zidentyfikowania zbiory. Pobiera klucze pośrednie z programu odwzorowującego jako dane wejściowe i stosuje kod zdefiniowany przez użytkownika w celu agregacji wartości w małym zakresie jednego programu odwzorowującego. Nie jest częścią głównego algorytmu MapReduce; jest to opcjonalne.
Shuffle and Sort- Zadanie Reducer rozpoczyna się od kroku Shuffle and Sort. Pobiera zgrupowane pary klucz-wartość na komputer lokalny, na którym działa reduktor. Poszczególne pary klucz-wartość są sortowane według klucza w większą listę danych. Lista danych grupuje równoważne klucze razem, dzięki czemu ich wartości można łatwo iterować w zadaniu reduktora.
Reducer- Reducer pobiera pogrupowane sparowane dane klucz-wartość jako dane wejściowe i uruchamia funkcję Reduktora na każdym z nich. Tutaj dane mogą być agregowane, filtrowane i łączone na wiele sposobów, a to wymaga szerokiego zakresu przetwarzania. Po zakończeniu wykonywania daje zero lub więcej par klucz-wartość do ostatniego kroku.
Output Phase - W fazie wyjściowej mamy program formatujący dane wyjściowe, który tłumaczy końcowe pary klucz-wartość z funkcji Reducer i zapisuje je do pliku za pomocą programu do zapisywania rekordów.
Spróbujmy zrozumieć dwa zadania Map & f Reduce za pomocą małego diagramu -

MapReduce-Example
Weźmy przykład ze świata rzeczywistego, aby zrozumieć moc MapReduce. Twitter otrzymuje około 500 milionów tweetów dziennie, co daje prawie 3000 tweetów na sekundę. Poniższa ilustracja pokazuje, jak głośnik wysokotonowy zarządza swoimi tweetami za pomocą MapReduce.
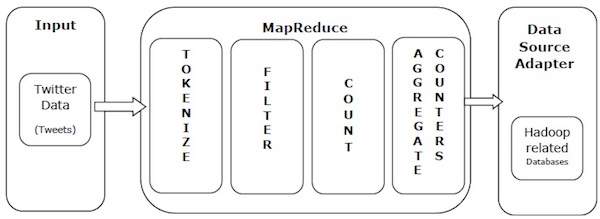
Jak pokazano na ilustracji, algorytm MapReduce wykonuje następujące czynności -
Tokenize - Tokenizuje tweety na mapy tokenów i zapisuje je jako pary klucz-wartość.
Filter - Filtruje niechciane słowa z map tokenów i zapisuje przefiltrowane mapy jako pary klucz-wartość.
Count - Generuje licznik żetonów na słowo.
Aggregate Counters - Przygotowuje agregat podobnych wartości liczników w małe możliwe do zarządzania jednostki.