Modelowanie i symulacja - szybki przewodnik
Modellingjest procesem reprezentacji modelu, który obejmuje jego budowę i działanie. Model ten jest podobny do rzeczywistego systemu, który pomaga analitykowi przewidzieć skutki zmian w systemie. Innymi słowy, modelowanie to tworzenie modelu, który reprezentuje system wraz z jego właściwościami. To czynność budowania modelu.
Simulationsystemu to działanie modelu pod względem czasu lub przestrzeni, które pomaga analizować wydajność istniejącego lub proponowanego systemu. Innymi słowy, symulacja to proces wykorzystania modelu do badania wydajności systemu. Jest to czynność wykorzystania modelu do symulacji.
Historia symulacji
Historyczna perspektywa symulacji została wyliczona w porządku chronologicznym.
1940 - Metoda nazwana „Monte Carlo” została opracowana przez naukowców (John von Neumann, Stanislaw Ulan, Edward Teller, Herman Kahn) i fizyków pracujących nad projektem na Manhattanie, mającym na celu badanie rozpraszania neutronów.
1960 - Opracowano pierwsze języki symulacji specjalnego przeznaczenia, takie jak SIMSCRIPT autorstwa Harry'ego Markowitza w RAND Corporation.
1970 - W tym okresie rozpoczęto badania nad matematycznymi podstawami symulacji.
1980 - W tym okresie opracowano oprogramowanie symulacyjne dla komputerów PC, graficzne interfejsy użytkownika i programowanie obiektowe.
1990 - W tym okresie opracowano symulację internetową, fantazyjną animowaną grafikę, optymalizację opartą na symulacji, metody Monte Carlo z łańcuchem Markowa.
Tworzenie modeli symulacyjnych
Modele symulacyjne składają się z następujących komponentów: jednostki systemowe, zmienne wejściowe, miary wydajności i zależności funkcjonalne. Poniżej przedstawiono kroki niezbędne do opracowania modelu symulacyjnego.
Step 1 - Zidentyfikuj problem w istniejącym systemie lub ustal wymagania dla proponowanego systemu.
Step 2 - Zaprojektuj problem, biorąc pod uwagę istniejące czynniki i ograniczenia systemu.
Step 3 - Zbierz i rozpocznij przetwarzanie danych systemowych, obserwując jego wydajność i wynik.
Step 4 - Opracuj model za pomocą diagramów sieciowych i zweryfikuj go za pomocą różnych technik weryfikacyjnych.
Step 5 - Sprawdź poprawność modelu, porównując jego działanie w różnych warunkach z rzeczywistym systemem.
Step 6 - Utwórz dokument dotyczący modelu do wykorzystania w przyszłości, który zawiera cele, założenia, zmienne wejściowe i szczegółowe wyniki.
Step 7 - Wybierz odpowiedni projekt eksperymentalny zgodnie z wymaganiami.
Step 8 - Wprowadź warunki doświadczalne w modelu i obserwuj wynik.
Wykonywanie analizy symulacji
Poniżej przedstawiono kroki umożliwiające wykonanie analizy symulacyjnej.
Step 1 - Przygotuj opis problemu.
Step 2- Wybierz zmienne wejściowe i utwórz encje do procesu symulacji. Istnieją dwa rodzaje zmiennych - zmienne decyzyjne i zmienne niekontrolowane. Zmienne decyzyjne są kontrolowane przez programistę, podczas gdy zmiennymi niekontrolowanymi są zmienne losowe.
Step 3 - Utwórz ograniczenia dla zmiennych decyzyjnych, przypisując je do procesu symulacji.
Step 4 - Określ zmienne wyjściowe.
Step 5 - Zbierz dane z rzeczywistego systemu, aby wprowadzić je do symulacji.
Step 6 - Opracuj schemat blokowy przedstawiający postęp procesu symulacji.
Step 7 - Wybierz odpowiednie oprogramowanie do symulacji, aby uruchomić model.
Step 8 - Zweryfikuj model symulacyjny, porównując jego wynik z systemem czasu rzeczywistego.
Step 9 - Przeprowadź eksperyment na modelu, zmieniając wartości zmiennych, aby znaleźć najlepsze rozwiązanie.
Step 10 - Na koniec zastosuj te wyniki do systemu czasu rzeczywistego.
Modelowanie i symulacja ─ Zalety
Oto zalety korzystania z modelowania i symulacji -
Easy to understand - Pozwala zrozumieć, jak system naprawdę działa bez pracy w systemach czasu rzeczywistego.
Easy to test - Pozwala na dokonywanie zmian w systemie i ich wpływ na wyjście bez pracy w systemach czasu rzeczywistego.
Easy to upgrade - Pozwala określić wymagania systemowe poprzez zastosowanie różnych konfiguracji.
Easy to identifying constraints - Pozwala na analizę wąskich gardeł, które powodują opóźnienia w procesie pracy, informacji itp.
Easy to diagnose problems- Niektóre systemy są tak złożone, że nie jest łatwo zrozumieć ich interakcję na raz. Jednak modelowanie i symulacja pozwala zrozumieć wszystkie interakcje i przeanalizować ich wpływ. Ponadto można badać nowe zasady, operacje i procedury bez wpływu na rzeczywisty system.
Modelowanie i symulacja ─ Wady
Poniżej przedstawiono wady korzystania z modelowania i symulacji -
Projektowanie modelu to sztuka, która wymaga wiedzy dziedzinowej, szkolenia i doświadczenia.
Operacje są wykonywane w systemie przy użyciu liczby losowej, stąd trudno przewidzieć wynik.
Symulacja wymaga siły roboczej i jest procesem czasochłonnym.
Wyniki symulacji są trudne do przetłumaczenia. To wymaga od ekspertów zrozumienia.
Proces symulacji jest kosztowny.
Modelowanie i symulacja ─ Obszary zastosowań
Modelowanie i symulacja można zastosować w następujących obszarach - zastosowania wojskowe, szkolenia i wsparcie, projektowanie półprzewodników, telekomunikacja, projekty i prezentacje inżynierii lądowej oraz modele e-biznesu.
Dodatkowo służy do badania wewnętrznej struktury złożonego systemu, takiego jak system biologiczny. Jest używany podczas optymalizacji projektu systemu, takiego jak algorytm routingu, linia montażowa itp. Służy do testowania nowych projektów i polityk. Służy do weryfikacji rozwiązań analitycznych.
W tym rozdziale omówimy różne koncepcje i klasyfikację modelowania.
Modele i wydarzenia
Poniżej przedstawiono podstawowe koncepcje modelowania i symulacji.
Object jest bytem istniejącym w prawdziwym świecie w celu zbadania zachowania modelu.
Base Model jest hipotetycznym wyjaśnieniem właściwości obiektu i jego zachowania, które obowiązuje w całym modelu.
System jest wyartykułowanym przedmiotem w określonych warunkach, który istnieje w świecie rzeczywistym.
Experimental Framesłuży do badania systemu w świecie rzeczywistym, np. warunków eksperymentalnych, aspektów, celów itp. Podstawowa ramka eksperymentalna składa się z dwóch zestawów zmiennych - zmiennych wejściowych ramki i zmiennych wyjściowych ramki, które pasują do terminali systemu lub modelu. Zmienna wejściowa Frame jest odpowiedzialna za dopasowanie danych wejściowych zastosowanych do systemu lub modelu. Zmienna wyjściowa Frame jest odpowiedzialna za dopasowanie wartości wyjściowych do systemu lub modelu.
Lumped Model jest dokładnym wyjaśnieniem systemu, który jest zgodny z określonymi warunkami danej ramy eksperymentu.
Verificationto proces porównywania dwóch lub więcej pozycji w celu zapewnienia ich dokładności. W modelowaniu i symulacji weryfikację można przeprowadzić, porównując spójność programu symulacyjnego i modelu skupionego, aby zapewnić ich wydajność. Istnieje kilka sposobów przeprowadzania procesu walidacji, które omówimy w osobnym rozdziale.
Validationto proces porównywania dwóch wyników. W modelowaniu i symulacji walidacja jest przeprowadzana poprzez porównanie pomiarów eksperymentalnych z wynikami symulacji w kontekście ramy eksperymentu. Model jest nieprawidłowy, jeśli wyniki są niezgodne. Istnieje wiele sposobów przeprowadzania procesu walidacji, które omówimy w osobnym rozdziale.
Zmienne stanu systemu
Zmienne stanu systemu to zbiór danych wymaganych do zdefiniowania procesu wewnętrznego w systemie w danym momencie.
W discrete-event model, zmienne stanu systemu pozostają stałe w przedziałach czasu, a wartości zmieniają się w określonych punktach zwanych czasami zdarzeń.
W continuous-event model, zmienne stanu systemu są definiowane przez wyniki równań różniczkowych, których wartość zmienia się w sposób ciągły w czasie.
Poniżej przedstawiono niektóre zmienne stanu systemu -
Entities & Attributes- Jednostka reprezentuje obiekt, którego wartość może być statyczna lub dynamiczna, w zależności od procesu z innymi jednostkami. Atrybuty to wartości lokalne używane przez jednostkę.
Resources- Zasób to jednostka, która jednocześnie świadczy usługi jednej lub większej liczbie dynamicznych jednostek. Jednostka dynamiczna może zażądać jednej lub więcej jednostek zasobu; jeśli zostanie przyjęta, jednostka może użyć zasobu i zwolnić po zakończeniu. W przypadku odrzucenia jednostka może dołączyć do kolejki.
Lists- Listy są używane do reprezentowania kolejek używanych przez jednostki i zasoby. W zależności od procesu istnieją różne możliwości tworzenia kolejek, takich jak LIFO, FIFO itp.
Delay - Jest to czas nieokreślony, spowodowany pewną kombinacją warunków systemowych.
Klasyfikacja modeli
System można podzielić na następujące kategorie.
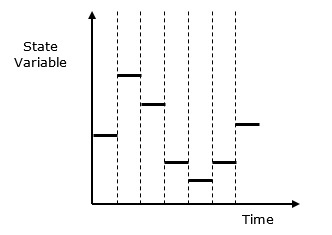
Discrete-Event Simulation Model- W tym modelu wartości zmiennych stanu zmieniają się tylko w niektórych dyskretnych punktach w czasie, w których występują zdarzenia. Zdarzenia będą miały miejsce tylko w określonym czasie i z opóźnieniami.
Stochastic vs. Deterministic Systems - Na układy stochastyczne nie ma wpływu losowość, a ich wynik nie jest zmienną losową, podczas gdy na układy deterministyczne wpływa losowość, a ich wynik jest zmienną losową.
Static vs. Dynamic Simulation- Symulacja statyczna obejmuje modele, na które nie ma wpływu czas. Na przykład: Model Monte Carlo. Symulacja dynamiczna obejmuje modele, na które wpływa czas.
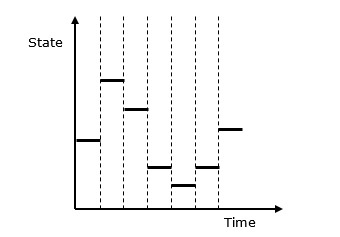
Discrete vs. Continuous Systems- Na system dyskretny wpływają zmiany stanu zmiennych w dyskretnym momencie. Jego zachowanie przedstawiono na poniższej reprezentacji graficznej.
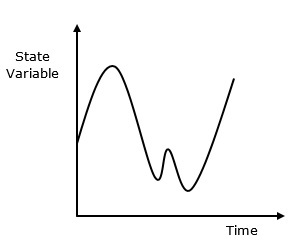
Na system ciągły wpływa zmienna stanu, która zmienia się w sposób ciągły w funkcji czasu. Jego zachowanie przedstawiono na poniższej reprezentacji graficznej.
Proces modelowania
Proces modelowania obejmuje następujące kroki.
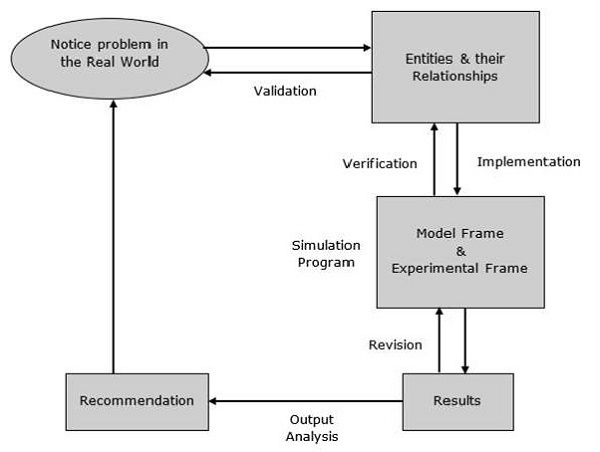
Step 1- Zbadaj problem. Na tym etapie musimy zrozumieć problem i odpowiednio dobrać jego klasyfikację, np. Deterministyczną lub stochastyczną.
Step 2- Zaprojektuj model. Na tym etapie musimy wykonać następujące proste zadania, które pomogą nam zaprojektować model -
Zbieraj dane zgodnie z zachowaniem systemu i przyszłymi wymaganiami.
Przeanalizuj cechy systemu, jego założenia i niezbędne działania, które należy podjąć, aby model odniósł sukces.
Określ nazwy zmiennych, funkcje, ich jednostki, relacje i ich zastosowania używane w modelu.
Rozwiąż model za pomocą odpowiedniej techniki i zweryfikuj wynik metodami weryfikacyjnymi. Następnie sprawdź wynik.
Przygotuj raport zawierający wyniki, interpretacje, wnioski i sugestie.
Step 3- Podaj zalecenia po zakończeniu całego procesu związanego z modelem. Obejmuje inwestycje, zasoby, algorytmy, techniki itp.
Jednym z prawdziwych problemów, z którymi boryka się analityk symulacji, jest walidacja modelu. Model symulacyjny jest ważny tylko wtedy, gdy model jest dokładną reprezentacją rzeczywistego systemu, w przeciwnym razie jest nieważny.
Walidacja i weryfikacja to dwa kroki w każdym projekcie symulacyjnym, mające na celu walidację modelu.
Validationto proces porównywania dwóch wyników. W tym procesie musimy porównać reprezentację modelu konceptualnego z rzeczywistym systemem. Jeśli porównanie jest prawdziwe, to jest poprawne, w przeciwnym razie nieważne.
Verificationto proces porównywania dwóch lub więcej wyników w celu zapewnienia ich dokładności. W tym procesie musimy porównać implementację modelu i powiązane z nim dane z opisem koncepcyjnym i specyfikacjami dewelopera.

Techniki weryfikacji i walidacji
Istnieją różne techniki służące do przeprowadzania weryfikacji i walidacji modelu symulacyjnego. Oto niektóre z typowych technik -
Techniki wykonywania weryfikacji modelu symulacyjnego
Poniżej przedstawiono sposoby przeprowadzania weryfikacji modelu symulacyjnego -
Wykorzystując umiejętności programowania do pisania i debugowania programu w podprogramach.
Korzystając z zasad „Strukturalny przewodnik”, w których więcej niż jedna osoba ma czytać program.
Śledzenie wyników pośrednich i porównywanie ich z obserwowanymi wynikami.
Sprawdzając wynik modelu symulacyjnego przy użyciu różnych kombinacji danych wejściowych.
Porównując ostateczny wynik symulacji z wynikami analitycznymi.
Techniki przeprowadzania walidacji modelu symulacyjnego
Step 1- Zaprojektuj model o wysokiej trafności. Można to osiągnąć, wykonując następujące czynności -
- Model należy omówić z ekspertami systemowymi podczas projektowania.
- Model musi współdziałać z klientem przez cały proces.
- Wyjście musi być nadzorowane przez ekspertów systemowych.
Step 2- Przetestuj model na podstawie założeń. Można to osiągnąć poprzez zastosowanie danych założeń do modelu i testowanie go ilościowo. Wrażliwą analizę można również przeprowadzić w celu zaobserwowania wpływu zmiany wyniku w przypadku wprowadzenia znaczących zmian w danych wejściowych.
Step 3- Określić reprezentatywny wynik modelu symulacyjnego. Można to osiągnąć, wykonując następujące czynności -
Określ, jak blisko jest wynik symulacji z rzeczywistym wyjściem systemu.
Porównanie można przeprowadzić za pomocą testu Turinga. Prezentuje dane w formacie systemowym, co może być wyjaśnione tylko przez ekspertów.
Do porównania wyników modelu z rzeczywistymi wynikami systemu można zastosować metodę statystyczną.
Porównanie danych modelu z danymi rzeczywistymi
Po opracowaniu modelu musimy przeprowadzić porównanie jego danych wyjściowych z rzeczywistymi danymi systemu. Poniżej przedstawiono dwa podejścia do wykonania tego porównania.
Walidacja istniejącego systemu
W tym podejściu używamy rzeczywistych danych wejściowych modelu, aby porównać jego dane wyjściowe z danymi wejściowymi ze świata rzeczywistego rzeczywistego systemu. Ten proces walidacji jest prosty, jednak może powodować pewne trudności podczas przeprowadzania, na przykład jeśli wynik ma być porównany ze średnią długością, czasem oczekiwania, czasem bezczynności itp., Można go porównać za pomocą testów statystycznych i testowania hipotez. Niektóre z testów statystycznych to test chi-kwadrat, test Kołmogorowa-Smirnowa, test Cramera-von Misesa i test momentów.
Walidacja modelu po raz pierwszy
Rozważmy, że musimy opisać proponowany system, który obecnie nie istnieje ani nie istniał w przeszłości. Dlatego nie ma dostępnych danych historycznych, z którymi można by porównać jego wyniki. Dlatego musimy zastosować hipotetyczny system oparty na założeniach. Przestrzeganie przydatnych wskazówek pomoże uczynić go wydajnym.
Subsystem Validity- Sam model może nie mieć żadnego istniejącego systemu, z którym można by go porównać, ale może składać się ze znanego podsystemu. Każdą z tych trafności można przetestować oddzielnie.
Internal Validity - Model o wysokim stopniu wariancji wewnętrznej zostanie odrzucony jako system stochastyczny o dużej wariancji ze względu na procesy wewnętrzne, który będzie ukrywał zmiany w wyniku wynikające ze zmian wejściowych.
Sensitivity Analysis - Dostarcza informacji o wrażliwym parametrze w systemie, na który musimy zwrócić większą uwagę.
Face Validity - Gdy model działa na przeciwnych logikach, to należy go odrzucić, nawet jeśli zachowuje się jak rzeczywisty system.
W systemach dyskretnych zmiany stanu systemu są nieciągłe, a każda zmiana stanu systemu nazywana jest event. Model używany w symulacji systemu dyskretnego zawiera zestaw liczb reprezentujących stan systemu, zwany jakostate descriptor. W tym rozdziale dowiemy się również o symulacji kolejek, która jest bardzo ważnym aspektem w symulacji dyskretnych zdarzeń wraz z symulacją systemu podziału czasu.
Poniżej przedstawiono graficzną reprezentację zachowania symulacji systemu dyskretnego.
Symulacja dyskretnych zdarzeń ─ Kluczowe cechy
Symulacja zdarzeń dyskretnych jest zazwyczaj przeprowadzana za pomocą oprogramowania zaprojektowanego w językach programowania wysokiego poziomu, takich jak Pascal, C ++ lub dowolnym specjalistycznym języku symulacji. Oto pięć kluczowych funkcji -
Entities - Są to reprezentacje rzeczywistych elementów, takich jak części maszyn.
Relationships - Oznacza łączenie podmiotów razem.
Simulation Executive - Odpowiada za kontrolowanie czasu wyprzedzenia i wykonywanie dyskretnych zdarzeń.
Random Number Generator - Pomaga symulować różne dane wchodzące do modelu symulacyjnego.
Results & Statistics - Sprawdza model i dostarcza miary wydajności.
Reprezentacja wykresu czasu
Każdy system zależy od parametru czasu. W reprezentacji graficznej jest określany jako czas zegarowy lub licznik czasu i początkowo jest ustawiony na zero. Czas jest aktualizowany na podstawie następujących dwóch czynników -
Time Slicing - Jest to czas określony przez model dla każdego wydarzenia, aż do braku jakiegokolwiek wydarzenia.
Next Event- Jest to zdarzenie zdefiniowane przez model dla następnego zdarzenia, które ma zostać wykonane zamiast przedziału czasu. Jest bardziej wydajny niż podział czasu.
Symulacja systemu kolejkowego
Kolejka to połączenie wszystkich podmiotów w obsługiwanym systemie i tych, które czekają na swoją kolej.
Parametry
Poniżej znajduje się lista parametrów używanych w systemie kolejkowania.
| Symbol | Opis |
|---|---|
| λ | Oznacza wskaźnik przybycia, który jest liczbą przyjazdów na sekundę |
| Ts | Oznacza średni czas obsługi dla każdego przyjazdu z wyłączeniem czasu oczekiwania w kolejce |
| σTs | Oznacza odchylenie standardowe czasu obsługi |
| ρ | Oznacza wykorzystanie czasu serwera, zarówno gdy był bezczynny, jak i zajęty |
| u | Oznacza natężenie ruchu |
| r | Oznacza średnią pozycji w systemie |
| R | Oznacza całkowitą liczbę elementów w systemie |
| Tr | Oznacza średni czas elementu w systemie |
| TR | Oznacza całkowity czas elementu w systemie |
| σr | Oznacza odchylenie standardowe r |
| σTr | Oznacza odchylenie standardowe Tr |
| w | Oznacza średnią liczbę pozycji oczekujących w kolejce |
| σw | Oznacza odchylenie standardowe w |
| Tw | Oznacza średni czas oczekiwania wszystkich pozycji |
| Td | Oznacza średni czas oczekiwania pozycji oczekujących w kolejce |
| N | Oznacza liczbę serwerów w systemie |
| mx (y) | Oznacza y ty percentyl co oznacza, że wartość Y, poniżej której występuje x y procent |
Pojedyncza kolejka serwera
To najprostszy system kolejkowy przedstawiony na poniższym rysunku. Centralnym elementem systemu jest serwer obsługujący podłączone urządzenia lub przedmioty. Elementy żądają obsłużenia systemu, jeśli serwer jest bezczynny. Następnie jest obsługiwany natychmiast, w przeciwnym razie dołącza do kolejki oczekujących. Po wykonaniu zadania przez serwer element wyjeżdża.
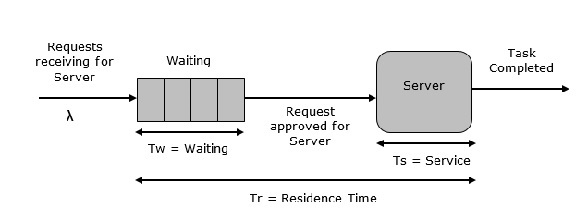
Kolejka na wielu serwerach
Jak sama nazwa wskazuje, system składa się z wielu serwerów i wspólnej kolejki dla wszystkich pozycji. Gdy jakikolwiek element żąda od serwera, jest przydzielany, jeśli przynajmniej jeden serwer jest dostępny. W przeciwnym razie kolejka zaczyna się uruchamiać, dopóki serwer nie będzie wolny. W tym systemie zakładamy, że wszystkie serwery są identyczne, tj. Nie ma różnicy, który serwer jest wybrany dla której pozycji.
Istnieje wyjątek dotyczący użytkowania. PozwolićN być identycznymi serwerami ρto wykorzystanie każdego serwera. RozważaćNρbyć utylizacją całego systemu; wtedy maksymalne wykorzystanie wynosiN*100%, a maksymalna wielkość wejściowa wynosi -
$ λmax = \ frac {\ text {N}} {\ text {T} s} $

Relacje w kolejce
W poniższej tabeli przedstawiono kilka podstawowych relacji kolejkowania.
| Ogólne warunki | Pojedynczy serwer | Wiele serwerów |
|---|---|---|
| r = λTr Wzór Little'a | ρ = λTs | ρ = λTs / N |
| w = λTw Wzór Little'a | r = w + ρ | u = λTs = ρN |
| Tr = Tw + Ts | r = w + Nρ |
Symulacja systemu podziału czasu
System współdzielenia czasu jest zaprojektowany w taki sposób, że każdy użytkownik wykorzystuje niewielką część czasu współdzielonego w systemie, co powoduje, że wielu użytkowników współdzieli system jednocześnie. Przełączanie każdego użytkownika jest tak szybkie, że każdy użytkownik ma ochotę korzystać z własnego systemu. Opiera się na koncepcji planowania procesora i programowania wieloprogramowego, w którym wiele zasobów można efektywnie wykorzystać, wykonując jednocześnie wiele zadań w systemie.
Example - System symulacji SimOS.
Został zaprojektowany przez Uniwersytet Stanforda w celu badania złożonych projektów sprzętu komputerowego, analizowania wydajności aplikacji i badania systemów operacyjnych. SimOS zawiera programową symulację wszystkich komponentów sprzętowych współczesnych systemów komputerowych, tj. Procesorów, jednostek zarządzania pamięcią (MMU), pamięci podręcznych itp.
System ciągły to taki, w którym ważne działania systemu kończą się płynnie bez żadnych opóźnień, tj. Bez kolejki zdarzeń, bez sortowania symulacji czasu itp. Kiedy system ciągły jest modelowany matematycznie, jego zmienne reprezentujące atrybuty są kontrolowane przez funkcje ciągłe. .
Co to jest symulacja ciągła?
Symulacja ciągła to rodzaj symulacji, w którym zmienne stanu zmieniają się w sposób ciągły w czasie. Poniżej przedstawiono graficzne przedstawienie jego zachowania.

Dlaczego warto korzystać z symulacji ciągłej?
Musimy skorzystać z symulacji ciągłej, ponieważ zależy ona od równań różniczkowych różnych parametrów związanych z układem i znanych nam ich szacunkowych wyników.
Obszary zastosowań
Ciągła symulacja jest stosowana w następujących sektorach. W inżynierii lądowej przy budowie nasypów zaporowych i konstrukcji tuneli. W zastosowaniach wojskowych do symulacji trajektorii pocisku, symulacji szkolenia samolotów myśliwskich oraz projektowania i testowania inteligentnego sterownika dla pojazdów podwodnych.
W logistyce przy projektowaniu płatnych dróg, analizie przepływu pasażerów na terminalu lotniska i proaktywnej ocenie rozkładu lotów. W rozwoju biznesowym w zakresie planowania rozwoju produktów, planowania zarządzania personelem i analizy badań rynkowych.
Symulacja Monte Carlo to skomputeryzowana technika matematyczna służąca do generowania danych z losowych próbek na podstawie pewnego znanego rozkładu dla eksperymentów numerycznych. Metoda ta jest stosowana do ilościowej analizy ryzyka i problemów decyzyjnych. Metodę tę stosują specjaliści o różnych profilach, takich jak finanse, zarządzanie projektami, energia, produkcja, inżynieria, badania i rozwój, ubezpieczenia, ropa i gaz, transport itp.
Metodę tę po raz pierwszy zastosowali naukowcy pracujący nad bombą atomową w 1940 roku. Metodę tę można zastosować w sytuacjach, w których musimy dokonać oszacowania i niepewnych decyzji, takich jak prognozy pogody.
Symulacja Monte Carlo ─ Ważne cechy
Oto trzy ważne cechy metody Monte-Carlo:
- Jego wynik musi generować losowe próbki.
- Jego dystrybucja wejściowa musi być znana.
- Jego wynik należy poznać podczas wykonywania eksperymentu.
Symulacja Monte Carlo ─ Zalety
- Łatwe do wdrożenia.
- Zapewnia statystyczne próbkowanie do eksperymentów numerycznych przy użyciu komputera.
- Zapewnia przybliżone rozwiązanie problemów matematycznych.
- Może być stosowany zarówno do problemów stochastycznych, jak i deterministycznych.
Symulacja Monte Carlo ─ Wady
Czasochłonne, ponieważ istnieje potrzeba wygenerowania dużej liczby próbkowania, aby uzyskać żądany wynik.
Wyniki tej metody są jedynie przybliżeniem prawdziwych wartości, a nie dokładnością.
Metoda symulacji Monte Carlo ─ Diagram przepływu
Poniższa ilustracja przedstawia uogólniony schemat blokowy symulacji Monte Carlo.

Celem bazy danych w Modelowaniu i symulacji jest zapewnienie reprezentacji danych i ich relacji do celów analizy i testowania. Pierwszy model danych został wprowadzony w 1980 roku przez Edgara Codda. Poniżej przedstawiono najważniejsze cechy modelu.
Baza danych to zbiór różnych obiektów danych, które definiują informacje i ich relacje.
Reguły służą do definiowania ograniczeń danych w obiektach.
Operacje można zastosować do obiektów w celu pobrania informacji.
Początkowo modelowanie danych opierało się na koncepcji encji i relacji, w których encje są typami informacji danych, a relacje reprezentują powiązania między podmiotami.
Najnowszą koncepcją modelowania danych jest projekt zorientowany obiektowo, w którym jednostki są reprezentowane jako klasy, które są używane jako szablony w programowaniu komputerowym. Klasa mająca swoją nazwę, atrybuty, ograniczenia i relacje z obiektami innych klas.
Jego podstawowa reprezentacja wygląda następująco -
Reprezentacja danych
Reprezentacja danych dotyczących wydarzeń
Zdarzenie symulacyjne ma swoje atrybuty, takie jak nazwa zdarzenia i skojarzona z nim informacja o czasie. Reprezentuje wykonanie dostarczonej symulacji przy użyciu zestawu danych wejściowych skojarzonych z parametrem pliku wejściowego i zapewnia jej wynik w postaci zestawu danych wyjściowych przechowywanych w wielu plikach powiązanych z plikami danych.
Reprezentacja danych dla plików wejściowych
Każdy proces symulacji wymaga innego zestawu danych wejściowych i powiązanych z nimi wartości parametrów, które są reprezentowane w pliku danych wejściowych. Plik wejściowy jest powiązany z oprogramowaniem przetwarzającym symulację. Model danych reprezentuje pliki, do których istnieją odniesienia, poprzez powiązanie z plikiem danych.
Reprezentacja danych dla plików wyjściowych
Po zakończeniu procesu symulacji generowane są różne pliki wyjściowe, a każdy plik wyjściowy jest reprezentowany jako plik danych. Każdy plik ma swoją nazwę, opis i uniwersalny czynnik. Plik danych jest podzielony na dwa pliki. Pierwszy plik zawiera wartości liczbowe, a drugi plik zawiera opisowe informacje o zawartości pliku liczbowego.
Sieci neuronowe w modelowaniu i symulacji
Sieć neuronowa to gałąź sztucznej inteligencji. Sieć neuronowa to sieć wielu procesorów nazywanych jednostkami, z których każda ma swoją małą pamięć lokalną. Każda jednostka jest połączona jednokierunkowymi kanałami komunikacyjnymi nazywanymi połączeniami, które przenoszą dane numeryczne. Każda jednostka działa tylko na swoich lokalnych danych i na wejściach, które otrzymuje z połączeń.
Historia
Historyczna perspektywa symulacji została wyliczona w porządku chronologicznym.
Pierwszy model neuronowy został opracowany w 1940 przez McCulloch & Pitts.
W 1949Donald Hebb napisał książkę „Organizacja zachowań”, w której wskazał na pojęcie neuronów.
W 1950wraz z rozwojem komputerów stało się możliwe stworzenie modelu na podstawie tych teorii. Dokonały tego laboratoria badawcze IBM. Jednak wysiłek się nie powiódł, a późniejsze próby zakończyły się sukcesem.
W 1959Bernard Widrow i Marcian Hoff opracowali modele o nazwach ADALINE i MADALINE. Te modele mają wiele ADAptive LINear Elements. MADALINE była pierwszą siecią neuronową, która została zastosowana do rozwiązania problemu w świecie rzeczywistym.
W 1962model perceptronu został opracowany przez Rosenblatta, mając możliwość rozwiązywania prostych problemów klasyfikacji wzorców.
W 1969Minsky i Papert przedstawili matematyczny dowód ograniczeń modelu perceptronowego w obliczeniach. Mówiono, że model perceptronu nie może rozwiązać problemu X-OR. Takie wady doprowadziły do tymczasowego zaniku sieci neuronowych.
W 1982John Hopfield z Caltech przedstawił swoje pomysły na papierze Narodowej Akademii Nauk, aby stworzyć maszyny wykorzystujące linie dwukierunkowe. Wcześniej używano linii jednokierunkowych.
Gdy zawiodły tradycyjne techniki sztucznej inteligencji wykorzystujące metody symboliczne, pojawia się potrzeba wykorzystania sieci neuronowych. Sieci neuronowe mają swoje techniki masowego paralelizmu, które zapewniają moc obliczeniową potrzebną do rozwiązania takich problemów.
Obszary zastosowań
Sieć neuronowa może być używana w maszynach do syntezy mowy, do rozpoznawania wzorców, do wykrywania problemów diagnostycznych, w robotycznych tablicach kontrolnych i sprzęcie medycznym.
Rozmyty zestaw w modelowaniu i symulacji
Jak wspomniano wcześniej, każdy proces ciągłej symulacji zależy od równań różniczkowych i ich parametrów, takich jak a, b, c, d> 0. Generalnie szacunki punktowe są obliczane i wykorzystywane w modelu. Czasami jednak szacunki te są niepewne, więc potrzebujemy liczb rozmytych w równaniach różniczkowych, które zapewniają oszacowania nieznanych parametrów.
Co to jest zestaw rozmyty?
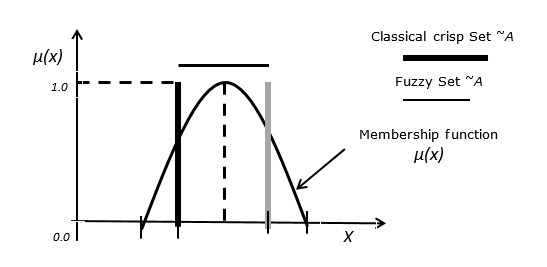
W zestawie klasycznym element albo należy do zbioru, albo nie. Zbiory rozmyte definiuje się w kategoriach zbiorów klasycznychX jako -
A = {(x, μA (x)) | x ∈ X}
Case 1 - Funkcja μA(x) ma następujące właściwości -
∀x ∈ X μA (x) ≥ 0
sup x ∈ X {μA (x)} = 1
Case 2 - Niech rozmyty zestaw B być zdefiniowane jako A = {(3, 0.3), (4, 0.7), (5, 1), (6, 0.4)}, to jego standardowa notacja rozmyta jest zapisywana jako A = {0.3/3, 0.7/4, 1/5, 0.4/6}
Żadna wartość z zerową oceną członkostwa nie pojawia się w wyrażeniu zestawu.
Case 3 - Związek między zbiorem rozmytym a klasycznym zbiorem wyrazistym.
Poniższy rysunek przedstawia zależność między zestawem rozmytym a klasycznym zbiorem wyrazistym.