MS SQL Server - Szybki przewodnik
W tym rozdziale przedstawiono SQL Server, omówiono jego użycie, zalety, wersje i składniki.
Co to jest SQL Server?
Jest to oprogramowanie opracowane przez firmę Microsoft, które jest realizowane na podstawie specyfikacji RDBMS.
Jest to również ORDBMS.
To zależy od platformy.
Jest to zarówno GUI, jak i oprogramowanie oparte na poleceniach.
Obsługuje język SQL (SEQUEL), który jest produktem IBM, nieproceduralną, wspólną bazą danych i językiem niewrażliwym na wielkość liter.
Wykorzystanie SQL Server
- Tworzenie baz danych.
- Aby utrzymać bazy danych.
- Analiza danych za pomocą usług SQL Server Analysis Services (SSAS).
- Generowanie raportów za pośrednictwem usług SQL Server Reporting Services (SSRS).
- Wykonywanie operacji ETL za pośrednictwem usług SQL Server Integration Services (SSIS).
Wersje SQL Server
| Wersja | Rok | Kryptonim |
|---|---|---|
| 6.0 | 1995 | SQL95 |
| 6.5 | 1996 | Hydra |
| 7.0 | 1998 | Sfinks |
| 8,0 (2000) | 2000 | Shiloh |
| 9,0 (2005) | 2005 | Yukon |
| 10, 0 (2008) | 2008 | Katmai |
| 10,5 (2008 R2) | 2010 | Kilimandżaro |
| 11, 0 (2012) | 2012 | Denali |
| 12 (2014) | 2014 | Hekaton (początkowo), SQL 14 (obecnie) |
Składniki SQL Server
SQL Server działa w architekturze klient-serwer, dlatego obsługuje dwa typy komponentów - (a) Stacja robocza i (b) Serwer.
Workstation componentssą instalowane na każdym urządzeniu / maszynie operatora SQL Server. To tylko interfejsy do interakcji z komponentami serwera. Przykład: SSMS, SSCM, Profiler, BIDS, SQLEM itp.
Server componentssą instalowane na scentralizowanym serwerze. To są usługi. Przykład: SQL Server, SQL Server Agent, SSIS, SSAS, SSRS, przeglądarka SQL, wyszukiwanie pełnotekstowe SQL Server itp.
Wystąpienie programu SQL Server
- Instancja to instalacja programu SQL Server.
- Instancja to dokładna kopia tego samego oprogramowania.
- Jeśli zainstalujemy „n” razy, zostanie utworzonych „n” instancji.
- Istnieją dwa typy instancji w SQL Server a) Domyślne b) Nazwane.
- Tylko jedna domyślna instancja będzie obsługiwana na jednym serwerze.
- Na jednym serwerze będzie obsługiwanych wiele nazwanych wystąpień.
- Domyślna instancja przyjmie nazwę serwera jako nazwę instancji.
- Domyślna nazwa usługi wystąpienia to MSSQLSERVER.
- 16 instancji będzie obsługiwanych w wersji 2000.
- 50 instancji będzie obsługiwanych w wersjach 2005 i nowszych.
Zalety instancji
- Aby zainstalować różne wersje na jednym komputerze.
- Aby obniżyć koszty.
- Aby oddzielnie utrzymywać środowiska produkcyjne, programistyczne i testowe.
- Aby zmniejszyć tymczasowe problemy z bazą danych.
- Oddzielenie uprawnień bezpieczeństwa.
- Aby utrzymać serwer rezerwowy.
SQL Server jest dostępny w różnych wersjach. W tym rozdziale wymieniono wiele wydań wraz z ich funkcjami.
Enterprise - To jest najwyższej klasy edycja z pełnym zestawem funkcji.
Standard - Ma mniej funkcji niż Enterprise, gdy nie ma wymagań dotyczących zaawansowanych funkcji.
Workgroup - Jest to odpowiednie dla zdalnych biur większej firmy.
Web - To jest przeznaczone dla aplikacji internetowych.
Developer- Jest to podobne do Enterprise, ale licencjonowane tylko dla jednego użytkownika na potrzeby programowania, testowania i demonstracji. Można go łatwo zaktualizować do wersji Enterprise bez ponownej instalacji.
Express- To jest bezpłatna baza danych na poziomie podstawowym. Może wykorzystywać tylko 1 procesor i 1 GB pamięci, maksymalny rozmiar bazy danych to 10 GB.
Compact- Jest to bezpłatna wbudowana baza danych do tworzenia aplikacji mobilnych. Maksymalny rozmiar bazy danych to 4 GB.
Datacenter- Główną zmianą w nowym SQL Server 2008 R2 jest Datacenter Edition. Edycja Datacenter nie ma ograniczeń pamięci i oferuje obsługę ponad 25 instancji.
Business Intelligence - Business Intelligence Edition to nowe wprowadzenie w SQL Server 2012. Ta edycja zawiera wszystkie funkcje w wersji Standard i obsługę zaawansowanych funkcji BI, takich jak Power View i PowerPivot, ale nie obsługuje zaawansowanych funkcji dostępności, takich jak AlwaysOn Availability Groups i inne operacje online.
Enterprise Evaluation- SQL Server Evaluation Edition to świetny sposób na uzyskanie w pełni funkcjonalnej i bezpłatnej instancji SQL Server do nauki i tworzenia rozwiązań. Ta edycja ma wbudowaną ważność 6 miesięcy od momentu jej zainstalowania.
| 2005 | 2008 | 2008 R2 | 2012 | 2014 |
|---|---|---|---|---|
| Przedsiębiorstwo | tak | tak | tak | tak |
| Standard | tak | tak | tak | tak |
| Deweloper | tak | tak | tak | tak |
| Grupa robocza | tak | tak | Nie | Nie |
| Wygraj Compact Edition - Mobile | tak | tak | tak | tak |
| Ocena przedsiębiorstwa | tak | tak | tak | tak |
| Wyrazić | tak | tak | tak | tak |
| Sieć | tak | tak | tak | |
| Centrum danych | Nie | Nie | ||
| Business Intelligence | tak |
SQL Server obsługuje dwa typy instalacji -
- Standalone
- Oparty na klastrze
Czeki
- Sprawdź dostęp RDP do serwera.
- Sprawdź bit systemu operacyjnego, IP, domenę serwera.
- Sprawdź, czy Twoje konto jest w grupie administratorów, aby uruchomić plik setup.exe.
- Lokalizacja oprogramowania.
Wymagania
- Która wersja, wydanie, SP i poprawka, jeśli istnieje.
- Konta usług dla silnika bazy danych, agenta, SSAS, SSIS, SSRS, jeśli istnieją.
- Nazwana nazwa instancji, jeśli istnieje.
- Lokalizacja plików binarnych, systemu, baz danych użytkowników.
- Tryb uwierzytelniania.
- Ustawienie sortowania.
- Lista funkcji.
Wymagania wstępne na rok 2005
- Skonfiguruj pliki pomocnicze.
- .NET Framework 2.0.
- Natywny klient SQL Server.
Wymagania wstępne na lata 2008 i 2008R2
- Skonfiguruj pliki pomocnicze.
- .net Framework 3.5 z dodatkiem SP1.
- Natywny klient SQL Server.
- Instalator Windows 4.5 / nowsza wersja.
Wymagania wstępne na lata 2012 i 2014
- Skonfiguruj pliki pomocnicze.
- .NET Framework 4.0.
- Natywny klient SQL Server.
- Instalator Windows 4.5 / nowsza wersja.
- Windows PowerShell 2.0.
Kroki instalacji
Step 1 - Pobierz wersję ewaluacyjną z http://www.microsoft.com/download/en/details.aspx?id=29066
Po pobraniu oprogramowania następujące pliki będą dostępne w zależności od opcji pobierania (wersja 32- lub 64-bitowa).
ENU \ x86 \ SQLFULL_x86_ENU_Core.box
ENU \ x86 \ SQLFULL_x86_ENU_Install.exe
ENU \ x86 \ SQLFULL_x86_ENU_Lang.box
OR
ENU \ x86 \ SQLFULL_x64_ENU_Core.box
ENU \ x86 \ SQLFULL_x64_ENU_Install.exe
ENU \ x86 \ SQLFULL_x64_ENU_Lang.box
Note - X86 (32-bitowy) i X64 (64-bitowy)
Step 2 - Kliknij dwukrotnie plik „SQLFULL_x86_ENU_Install.exe” lub „SQLFULL_x64_ENU_Install.exe”, aby wyodrębnić pliki wymagane do instalacji odpowiednio w folderze „SQLFULL_x86_ENU” lub „SQLFULL_x86_ENU”.
Step 3 - Kliknij folder „SQLFULL_x86_ENU” lub „SQLFULL_x64_ENU_Install.exe” i dwukrotnie kliknij aplikację „SETUP”.
Dla zrozumienia użyliśmy tutaj oprogramowania SQLFULL_x64_ENU_Install.exe.
Step 4 - Po kliknięciu aplikacji „konfiguracja” otworzy się następujący ekran.

Step 5 - Kliknij opcję Instalacja, która znajduje się po lewej stronie powyższego ekranu.

Step 6- Kliknij pierwszą opcję po prawej stronie widoczną na powyższym ekranie. Otworzy się następujący ekran.

Step 7 - Kliknij OK i pojawi się następujący ekran.
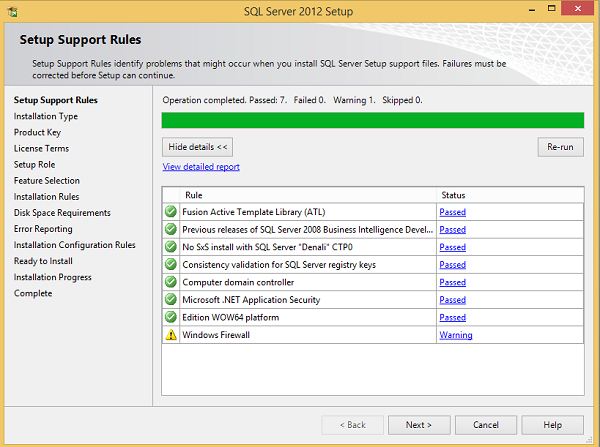
Step 8 - Kliknij Dalej, aby wyświetlić następujący ekran.

Step 9 - Pamiętaj, aby sprawdzić wybór klucza produktu i kliknij przycisk Dalej.

Step 10 - Zaznacz pole wyboru, aby zaakceptować opcję licencji i kliknij Dalej.

Step 11 - Wybierz opcję instalacji funkcji programu SQL Server i kliknij przycisk Dalej.

Step 12 - Zaznacz pole wyboru Usługi silnika bazy danych i kliknij Dalej.
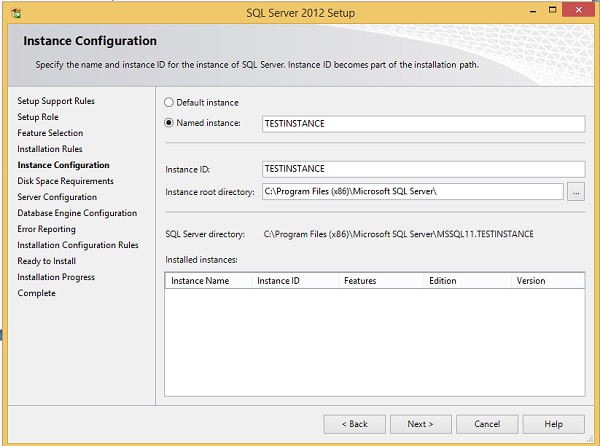
Step 13 - Wprowadź nazwaną instancję (tutaj użyłem TestInstance) i kliknij Dalej.

Step 14 - Kliknij Dalej na powyższym ekranie, a pojawi się następujący ekran.

Step 15 - Wybierz nazwy kont usług i typy uruchamiania dla wyżej wymienionych usług i kliknij Sortowanie.

Step 16 - Upewnij się, że zaznaczono prawidłowy wybór sortowania i kliknij przycisk Dalej.

Step 17 - Upewnij się, że zaznaczono wybór trybu uwierzytelniania i administratorów, a następnie kliknij opcję Katalogi danych.
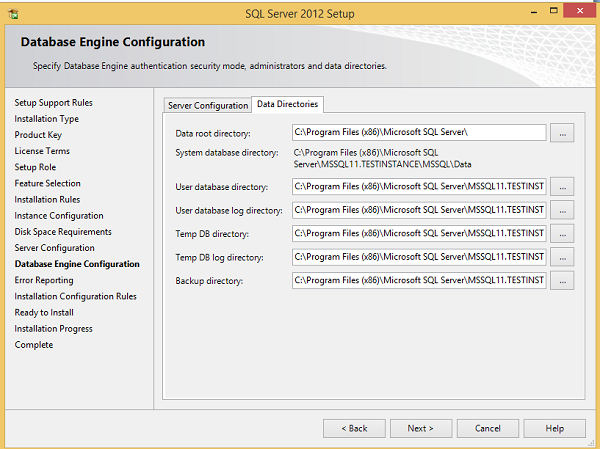
Step 18- Upewnij się, że wybrałeś powyższe lokalizacje katalogu i kliknij Dalej. Pojawi się następujący ekran.

Step 19 - Kliknij Dalej na powyższym ekranie.

Step 20 - Kliknij Dalej na powyższym ekranie, aby wyświetlić następujący ekran.

Step 21 - Upewnij się, że powyższy wybór jest poprawny i kliknij Zainstaluj.
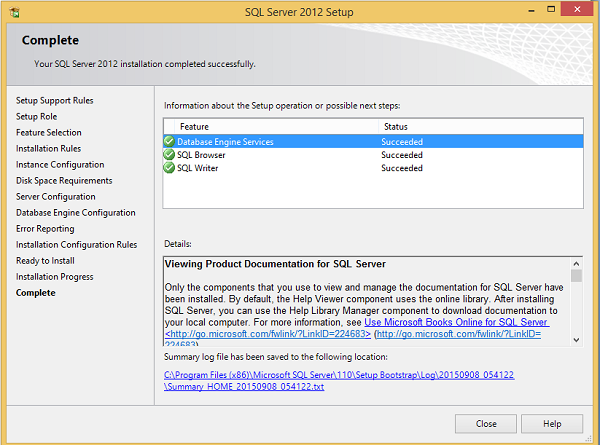
Instalacja powiodła się, jak pokazano na powyższym ekranie. Kliknij Zamknij, aby zakończyć.
Podzieliliśmy architekturę SQL Server na następujące części, aby ułatwić zrozumienie -
- Ogólna architektura
- Architektura pamięci
- Architektura plików danych
- Architektura plików dziennika
Architektura ogólna
Client - Gdzie zainicjowano żądanie.
Query - Zapytanie SQL, które jest językiem wysokiego poziomu.
Logical Units - Słowa kluczowe, wyrażenia i operatory itp.
N/W Packets - Kod związany z siecią.
Protocols - W SQL Server mamy 4 protokoły.
Pamięć współdzielona (do połączeń lokalnych i rozwiązywania problemów).
Nazwane potoki (dla połączeń w sieci LAN).
TCP / IP (dla połączeń, które są w łączności WAN).
VIA-Virtual Interface Adapter (wymaga specjalnego sprzętu do skonfigurowania przez dostawcę, a także wycofany z wersji SQL 2012).
Server - Gdzie zainstalowano usługi SQL i znajdują się bazy danych.
Relational Engine- To tutaj odbędzie się prawdziwa egzekucja. Zawiera parser zapytań, optymalizator zapytań i moduł wykonawczy zapytań.
Query Parser (Command Parser) and Compiler (Translator) - Spowoduje to sprawdzenie składni zapytania i przekonwertowanie zapytania na język maszynowy.
Query Optimizer - Przygotuje plan wykonania jako dane wyjściowe, przyjmując zapytania, statystyki i drzewo Algebrizera jako dane wejściowe.
Execution Plan - To jest jak mapa drogowa, która zawiera kolejność wszystkich kroków do wykonania w ramach wykonywania zapytania.
Query Executor - Tutaj zapytanie zostanie wykonane krok po kroku przy pomocy planu wykonania, a także skontaktujemy się z silnikiem pamięci masowej.
Storage Engine - Odpowiada za przechowywanie i odzyskiwanie danych w systemie pamięci masowej (dysk, SAN itp.), Manipulowanie danymi, blokowanie i zarządzanie transakcjami.
SQL OS- Znajduje się między komputerem głównym (systemem operacyjnym Windows) a serwerem SQL. Wszystkie czynności wykonywane na silniku bazy danych są obsługiwane przez system operacyjny SQL. SQL OS zapewnia różne usługi systemu operacyjnego, takie jak zarządzanie pamięcią z pulą buforów, bufor dziennika i wykrywanie zakleszczeń przy użyciu struktury blokowania i blokowania.
Checkpoint Process- Punkt kontrolny to wewnętrzny proces, który zapisuje wszystkie brudne strony (zmodyfikowane strony) z pamięci podręcznej bufora na dysk fizyczny. Oprócz tego zapisuje również rekordy dziennika z bufora dziennika do pliku fizycznego. Zapisywanie brudnych stron z pamięci podręcznej bufora do pliku danych jest również nazywane utwardzaniem brudnych stron.
Jest to proces dedykowany, uruchamiany automatycznie przez SQL Server w określonych odstępach czasu. SQL Server uruchamia proces punktu kontrolnego indywidualnie dla każdej bazy danych. Checkpoint pomaga skrócić czas przywracania programu SQL Server w przypadku nieoczekiwanego zamknięcia lub awarii systemu \ Awaria.
Punkty kontrolne w SQL Server
W SQL Server 2012 istnieją cztery typy checkpoints -
Automatic - Jest to najczęstszy punkt kontrolny, który działa jako proces w tle, aby upewnić się, że baza danych SQL Server może zostać odzyskana w czasie określonym w opcji Okres odzyskiwania - opcja konfiguracji serwera.
Indirect- Jest to nowość w programie SQL Server 2012. Działa również w tle, ale w celu spełnienia określonego przez użytkownika docelowego czasu odzyskiwania dla określonej bazy danych, w której skonfigurowano tę opcję. Po wybraniu Target_Recovery_Time dla danej bazy danych, spowoduje to zastąpienie interwału odzyskiwania określonego dla serwera i uniknięcie automatycznego punktu kontrolnego w takiej bazie danych.
Manual- Ta instrukcja działa jak każda inna instrukcja T-SQL, po wydaniu polecenia punktu kontrolnego będzie działać do końca. Ręczny punkt kontrolny działa tylko dla bieżącej bazy danych. Możesz również określić Checkpoint_Duration, który jest opcjonalny - ten czas trwania określa czas, w którym chcesz zakończyć punkt kontrolny.
Internal- Jako użytkownik nie możesz kontrolować wewnętrznego punktu kontrolnego. Wydane na określone operacje, takie jak
Shutdown inicjuje operację punktu kontrolnego na wszystkich bazach danych, z wyjątkiem sytuacji, gdy shutdown nie jest czysty (shutdown with nowait).
Jeśli model odzyskiwania zostanie zmieniony z Full \ Bulk-logged na Simple.
Podczas wykonywania kopii zapasowej bazy danych.
Jeśli Twoja baza danych jest w prostym modelu odzyskiwania, proces punktu kontrolnego jest wykonywany automatycznie, gdy dziennik zapełni się w 70% lub w oparciu o opcję serwera - okres odzyskiwania.
Polecenie Alter database w celu dodania lub usunięcia pliku data \ log również inicjuje punkt kontrolny.
Punkt kontrolny ma również miejsce, gdy model odzyskiwania bazy danych jest rejestrowany zbiorczo i wykonywana jest minimalnie zarejestrowana operacja.
Tworzenie migawki bazy danych.
Lazy Writer Process- Leniwy program zapisujący będzie wypychał brudne strony na dysk z zupełnie innego powodu, ponieważ musi zwolnić pamięć w puli buforów. Dzieje się tak, gdy serwer SQL znajduje się pod presją pamięci. O ile mi wiadomo, jest to kontrolowane przez wewnętrzny proces i nie ma na to żadnego ustawienia.
Serwer SQL stale monitoruje użycie pamięci, aby ocenić rywalizację o zasoby (lub dostępność); jego zadaniem jest upewnienie się, że przez cały czas dostępna jest pewna ilość wolnego miejsca. W ramach tego procesu, gdy zauważy jakąkolwiek rywalizację o zasoby, wyzwala program Lazy Writer, aby zwolnić niektóre strony w pamięci, zapisując brudne strony na dysk. Wykorzystuje algorytm LRU, który decyduje, które strony mają zostać zrzucone na dysk.
Jeśli program Lazy Writer jest zawsze aktywny, może to wskazywać na wąskie gardło pamięci.
Architektura pamięci
Oto niektóre z najistotniejszych cech architektury pamięci.
Jednym z głównych celów projektowych całego oprogramowania bazodanowego jest zminimalizowanie operacji we / wy dysku, ponieważ odczyty i zapisy na dysku należą do operacji wymagających największej ilości zasobów.
Pamięć w systemie Windows można wywołać za pomocą wirtualnej przestrzeni adresowej, współdzielonej przez tryb jądra (tryb systemu operacyjnego) i tryb użytkownika (aplikacja taka jak SQL Server).
„Przestrzeń adresowa użytkownika” programu SQL Server jest podzielona na dwa regiony: MemToLeave i Pula buforów.
Rozmiar MemToLeave (MTL) i puli buforów (BPool) jest określany przez SQL Server podczas uruchamiania.
Buffer managementjest kluczowym elementem w osiąganiu wysokiej wydajności we / wy. Komponent zarządzania buforami składa się z dwóch mechanizmów: menedżera buforów do uzyskiwania dostępu do stron bazy danych i ich aktualizowania oraz puli buforów do zmniejszania operacji we / wy pliku bazy danych.
Pula buforów jest dalej podzielona na wiele sekcji. Najważniejsze z nich to pamięć podręczna bufora (nazywana również pamięcią podręczną danych) i pamięć podręczna procedur.Buffer cacheprzechowuje strony danych w pamięci, dzięki czemu często używane dane można pobrać z pamięci podręcznej. Alternatywą byłoby odczytywanie stron danych z dysku. Odczytywanie stron danych z pamięci podręcznej optymalizuje wydajność, minimalizując liczbę wymaganych operacji we / wy, które są z natury wolniejsze niż pobieranie danych z pamięci.
Procedure cacheutrzymuje procedury składowane i plany wykonywania zapytań, aby zminimalizować liczbę generowanych planów zapytań. Możesz uzyskać informacje o rozmiarze i aktywności w pamięci podręcznej procedur za pomocą instrukcji DBCC PROCCACHE.
Inne części puli buforów obejmują -
System level data structures - Przechowuje dane poziomu instancji SQL Server dotyczące baz danych i blokad.
Log cache - Zarezerwowane do czytania i zapisywania stron dziennika transakcji.
Connection context- Każde połączenie z instancją ma niewielki obszar pamięci do zapisywania aktualnego stanu połączenia. Informacje te obejmują procedury składowane i parametry funkcji zdefiniowanych przez użytkownika, pozycje kursorów i nie tylko.
Stack space - Windows przydziela miejsce na stosie dla każdego wątku uruchomionego przez SQL Server.
Architektura plików danych
Architektura pliku danych składa się z następujących składników -
Grupy plików
Pliki baz danych można grupować w grupy plików do celów alokacji i administrowania. Żaden plik nie może być członkiem więcej niż jednej grupy plików. Pliki dziennika nigdy nie są częścią grupy plików. Przestrzeń dziennika jest zarządzana oddzielnie od przestrzeni danych.
Istnieją dwa typy grup plików w SQL Server, podstawowe i zdefiniowane przez użytkownika. Podstawowa grupa plików zawiera podstawowy plik danych i wszystkie inne pliki, które nie zostały specjalnie przypisane do innej grupy plików. Wszystkie strony tabel systemowych są przydzielone w podstawowej grupie plików. Grupy plików zdefiniowane przez użytkownika to dowolne grupy plików określone za pomocą słowa kluczowego file group w instrukcji tworzenia bazy danych lub zmiany bazy danych.
Jedna grupa plików w każdej bazie danych działa jako domyślna grupa plików. Gdy SQL Server przydziela stronę do tabeli lub indeksu, dla którego nie określono grupy plików podczas ich tworzenia, strony są przydzielane z domyślnej grupy plików. Aby przełączyć domyślną grupę plików z jednej grupy plików na inną, powinna mieć stałą rolę db_owner.
Domyślnie podstawową grupą plików jest domyślna grupa plików. Użytkownik powinien mieć stałą rolę db_owner w bazie danych, aby samodzielnie tworzyć kopie zapasowe plików i grup plików.
Akta
Bazy danych mają trzy typy plików - podstawowy plik danych, dodatkowy plik danych i plik dziennika. Podstawowy plik danych jest punktem początkowym bazy danych i wskazuje na inne pliki w bazie danych.
Każda baza danych ma jeden podstawowy plik danych. Możemy podać dowolne rozszerzenie dla podstawowego pliku danych, ale zalecanym rozszerzeniem jest.mdf. Dodatkowy plik danych to plik inny niż podstawowy plik danych w tej bazie danych. Niektóre bazy danych mogą mieć wiele pomocniczych plików danych. Niektóre bazy danych mogą nie mieć ani jednego dodatkowego pliku danych. Zalecane rozszerzenie dla dodatkowego pliku danych to.ndf.
Pliki dziennika zawierają wszystkie informacje dziennika używane do odzyskiwania bazy danych. Baza danych musi mieć co najmniej jeden plik dziennika. Możemy mieć wiele plików dziennika dla jednej bazy danych. Zalecane rozszerzenie pliku dziennika to.ldf.
Lokalizacja wszystkich plików w bazie danych jest rejestrowana zarówno w bazie danych master, jak i w pliku podstawowym bazy danych. W większości przypadków aparat bazy danych korzysta z lokalizacji pliku z bazy danych master.
Pliki mają dwie nazwy - logiczną i fizyczną. Nazwa logiczna jest używana w odniesieniu do pliku we wszystkich instrukcjach T-SQL. Nazwa fizyczna to nazwa_pliku_OS, musi być zgodna z zasadami systemu operacyjnego. Pliki danych i dziennika można umieszczać w systemach plików FAT lub NTFS, ale nie można ich umieszczać w systemach plików skompresowanych. W jednej bazie danych może znajdować się do 32767 plików.
Zakresy
Zakresy to podstawowa jednostka, w której miejsce jest przydzielane tabelom i indeksom. Zasięg to 8 sąsiadujących ze sobą stron lub 64 KB. SQL Server ma dwa typy zakresów - jednolite i mieszane. Jednolite zakresy składają się tylko z jednego obiektu. Zakresy mieszane są współdzielone przez maksymalnie osiem obiektów.
Strony
Jest to podstawowa jednostka przechowywania danych w MS SQL Server. Rozmiar strony to 8 KB. Początkiem każdej strony jest 96-bajtowy nagłówek służący do przechowywania informacji systemowych, takich jak typ strony, ilość wolnego miejsca na stronie i identyfikator obiektu będącego właścicielem strony. W SQL Server istnieje 9 typów stron danych.
Data - Wiersze danych zawierające wszystkie dane z wyjątkiem danych tekstowych, tekstowych i graficznych.
Index - Wpisy indeksu.
Text\Image - Dane tekstowe, graficzne i ntext.
GAM - Informacje o przydzielonych zakresach.
SGAM - Informacje o przydzielonych zakresach na poziomie systemu.
Page Free Space (PFS) - Informacje o wolnym miejscu dostępnym na stronach.
Index Allocation Map (IAM) - Informacje o zakresach używanych przez tabelę lub indeks.
Bulk Changed Map (BCM) - Informacje o zakresach zmodyfikowanych przez operacje zbiorcze od ostatniej kopii zapasowej instrukcji dziennika.
Differential Changed Map (DCM) - Informacje o zakresach, które zmieniły się od czasu ostatniej instrukcji kopii zapasowej bazy danych.
Architektura pliku dziennika
Dziennik transakcji programu SQL Server działa logicznie tak, jakby dziennik transakcji był ciągiem rekordów dziennika. Każdy rekord dziennika jest identyfikowany przez numer sekwencji dziennika (LSN). Każdy rekord dziennika zawiera identyfikator transakcji, do której należy.
Rekordy dziennika modyfikacji danych rejestrują albo wykonaną operację logiczną, albo rejestrują obrazy przed i po zmodyfikowanych danych. Obraz przed jest kopią danych przed wykonaniem operacji; obraz wtórny jest kopią danych po wykonaniu operacji.
Kroki umożliwiające odzyskanie operacji zależą od typu rekordu dziennika -
- Logiczna operacja zarejestrowana.
- Aby wycofać operację logiczną do przodu, operacja jest wykonywana ponownie.
- Aby wycofać operację logiczną, wykonywana jest odwrotna operacja logiczna.
- Rejestracja obrazu przed i po.
- Aby przewinąć operację do przodu, stosowany jest obraz po.
- Aby cofnąć operację, stosowany jest obraz sprzed.
W dzienniku transakcji rejestrowane są różne typy operacji. Te operacje obejmują -
Początek i koniec każdej transakcji.
Każda modyfikacja danych (wstawianie, aktualizowanie lub usuwanie). Obejmuje to zmiany wprowadzone przez procedury składowane w systemie lub instrukcje języka definicji danych (DDL) w dowolnej tabeli, w tym tabelach systemowych.
Każdy zakres i alokacja stron lub usunięcie alokacji.
Tworzenie lub usuwanie tabeli lub indeksu.
Operacje wycofywania zmian są również rejestrowane. Każda transakcja rezerwuje miejsce w dzienniku transakcji, aby upewnić się, że istnieje wystarczająca ilość miejsca w dzienniku do obsługi wycofywania spowodowanego jawną instrukcją wycofania lub napotkaniem błędu. To zarezerwowane miejsce jest zwalniane po zakończeniu transakcji.
Sekcja pliku dziennika z pierwszego rekordu dziennika, która musi istnieć, aby pomyślnie przywrócić całą bazę danych do ostatniego zapisanego rekordu dziennika, nazywana jest aktywną częścią dziennika lub dziennikiem aktywnym. To jest sekcja dziennika wymagana do pełnego odzyskania bazy danych. Żadna część aktywnego dziennika nie może nigdy zostać obcięta. LSN tego pierwszego rekordu dziennika jest nazywany minimalnym LSN odzyskiwania (Min LSN).
Aparat bazy danych programu SQL Server dzieli każdy fizyczny plik dziennika wewnętrznie na kilka wirtualnych plików dziennika. Pliki dziennika wirtualnego nie mają stałego rozmiaru i nie ma ustalonej liczby wirtualnych plików dziennika dla fizycznego pliku dziennika.
Aparat baz danych dynamicznie wybiera rozmiar wirtualnych plików dziennika podczas tworzenia lub rozszerzania plików dziennika. Aparat baz danych próbuje zachować niewielką liczbę plików wirtualnych. Administratorzy nie mogą konfigurować ani ustawiać rozmiaru ani liczby wirtualnych plików dziennika. Jedyny przypadek, w którym wirtualne pliki dziennika wpływają na wydajność systemu, to sytuacja, gdy fizyczne pliki dziennika są zdefiniowane przez mały rozmiar i wartości growth_increment.
Wartość rozmiaru to początkowy rozmiar pliku dziennika, a wartość growth_increment to ilość miejsca dodawana do pliku za każdym razem, gdy wymagane jest nowe miejsce. Jeśli pliki dziennika osiągną duży rozmiar z powodu wielu małych przyrostów, będą miały wiele wirtualnych plików dziennika. Może to spowolnić uruchamianie bazy danych, a także rejestrować operacje tworzenia kopii zapasowych i przywracania.
Zalecamy przypisanie plikom dziennika wartości rozmiaru zbliżonej do wymaganego rozmiaru końcowego, a także stosunkowo dużej wartości growth_increment. SQL Server używa dziennika zapisu z wyprzedzeniem (WAL), który gwarantuje, że żadne modyfikacje danych nie zostaną zapisane na dysku przed zapisaniem skojarzonego rekordu dziennika na dysk. To zachowuje właściwości ACID transakcji.
SQL Server Management Studio to komponent stacji roboczej \ narzędzie klienta, które zostanie zainstalowane, jeśli wybierzemy komponent stacji roboczej w krokach instalacji. Pozwala to na łączenie się z serwerem SQL i zarządzanie nim z poziomu interfejsu graficznego zamiast używania wiersza poleceń.
Aby połączyć się ze zdalną instancją serwera SQL, będziesz potrzebować tego lub podobnego oprogramowania. Jest używany przez administratorów, programistów, testerów itp.
Następujące metody służą do otwierania programu SQL Server Management Studio.
Pierwsza metoda
Start → Wszystkie programy → MS SQL Server 2012 → SQL Server Management Studio
Druga metoda
Przejdź do Uruchom i wpisz SQLWB (dla wersji 2005) SSMS (dla wersji 2008 i nowszych). Następnie kliknij Enter.
SQL Server Management Studio zostanie otwarte, jak pokazano na poniższej migawce, w dowolnej z powyższych metod.

Login to proste poświadczenie dostępu do SQL Server. Na przykład podajesz swoją nazwę użytkownika i hasło podczas logowania się do systemu Windows lub nawet do konta e-mail. Ta nazwa użytkownika i hasło tworzą poświadczenia. Dlatego poświadczenia to po prostu nazwa użytkownika i hasło.
SQL Server umożliwia cztery typy logowania -
- Logowanie oparte na poświadczeniach systemu Windows.
- Login specyficzny dla SQL Server.
- Login odwzorowany na certyfikat.
- Login odwzorowany na klucz asymetryczny.
W tym samouczku interesują nas logowania oparte na poświadczeniach systemu Windows i loginy specyficzne dla SQL Server.
Loginy oparte na poświadczeniach systemu Windows umożliwiają logowanie do programu SQL Server przy użyciu nazwy użytkownika i hasła systemu Windows. Jeśli chcesz utworzyć własne poświadczenia (nazwa użytkownika i hasło), możesz utworzyć login specyficzny dla SQL Server.
Aby utworzyć, zmienić lub usunąć login SQL Server, możesz zastosować jedną z dwóch metod:
- Korzystanie z programu SQL Server Management Studio.
- Korzystanie z instrukcji T-SQL.
Do utworzenia Loginu używane są następujące metody -
Pierwsza metoda - użycie programu SQL Server Management Studio
Step 1 - Po nawiązaniu połączenia z wystąpieniem SQL Server, rozwiń folder logowania, jak pokazano na poniższej migawce.

Step 2 - Kliknij prawym przyciskiem myszy Logins, a następnie kliknij Newlogin, a otworzy się następujący ekran.

Step 3 - Wypełnij kolumny Nazwa logowania, Hasło i Potwierdź hasło, jak pokazano na powyższym ekranie, a następnie kliknij OK.
Logowanie zostanie utworzone, jak pokazano na poniższym obrazku.

Druga metoda - użycie skryptu T-SQL
Create login yourloginname with password='yourpassword'Aby utworzyć nazwę logowania z TestLogin i hasłem „P @ ssword”, uruchom poniższe zapytanie.
Create login TestLogin with password='P@ssword'Baza danych to zbiór obiektów, takich jak tabela, widok, procedura składowana, funkcja, wyzwalacz itp.
W MS SQL Server dostępne są dwa typy baz danych.
- Systemowe bazy danych
- Bazy danych użytkowników
Systemowe bazy danych
Systemowe bazy danych są tworzone automatycznie podczas instalacji MS SQL Server. Poniżej znajduje się lista systemowych baz danych -
- Master
- Model
- MSDB
- Tempdb
- Zasoby (wprowadzone w wersji 2005)
- Dystrybucja (tylko funkcja jest do replikacji)
Bazy danych użytkowników
Bazy danych użytkowników są tworzone przez użytkowników (administratorów, programistów i testerów, którzy mają dostęp do tworzenia baz danych).
Do tworzenia bazy danych użytkowników używane są następujące metody.
Metoda 1 - użycie skryptu T-SQL lub przywrócenie bazy danych
Poniżej przedstawiono podstawową składnię tworzenia bazy danych w MS SQL Server.
Create database <yourdatabasename>LUB
Restore Database <Your database name> from disk = '<Backup file location + file name>Przykład
Aby utworzyć bazę danych o nazwie „Testdb”, uruchom następujące zapytanie.
Create database TestdbLUB
Restore database Testdb from disk = 'D:\Backup\Testdb_full_backup.bak'Note - D: \ kopia zapasowa to lokalizacja pliku kopii zapasowej, a Testdb_full_backup.bak to nazwa pliku kopii zapasowej
Metoda 2 - użycie programu SQL Server Management Studio
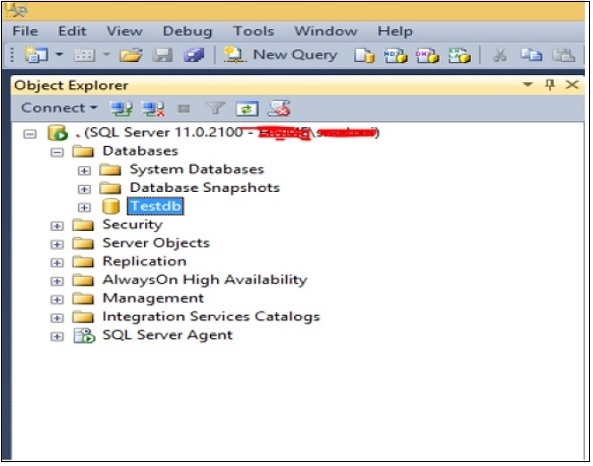
Połącz się z wystąpieniem SQL Server i kliknij prawym przyciskiem myszy folder baz danych. Kliknij nową bazę danych, a pojawi się następujący ekran.

Wpisz w pole nazwy bazy danych nazwę swojej bazy danych (przykład: aby utworzyć bazę danych o nazwie „Testdb”) i kliknij OK. Baza danych Testdb zostanie utworzona, jak pokazano na poniższej migawce.
Wybierz bazę danych na podstawie swojej akcji, zanim zaczniesz stosować którąkolwiek z poniższych metod.
Metoda 1 - użycie programu SQL Server Management Studio
Przykład
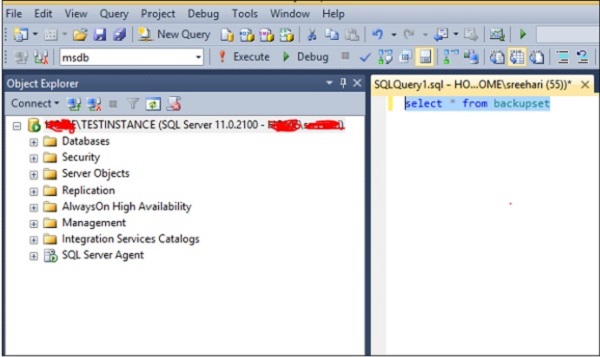
Aby uruchomić zapytanie w celu wybrania historii kopii zapasowych w bazie danych o nazwie „msdb”, wybierz bazę danych msdb, jak pokazano na poniższej migawce.
Metoda 2 - użycie skryptu T-SQL
Use <your database name>Przykład
Aby uruchomić zapytanie w celu wybrania historii kopii zapasowych w bazie danych o nazwie „msdb”, wybierz bazę danych msdb, wykonując następujące zapytanie.
Exec use msdbZapytanie otworzy bazę danych msdb. Możesz wykonać następujące zapytanie, aby wybrać historię kopii zapasowych.
Select * from backupsetAby usunąć bazę danych z MS SQL Server, użyj polecenia drop database. W tym celu można zastosować dwie metody.
Metoda 1 - użycie skryptu T-SQL
Poniżej przedstawiono podstawową składnię usuwania bazy danych z MS SQL Server.
Drop database <your database name>Przykład
Aby usunąć nazwę bazy danych „Testdb”, uruchom następujące zapytanie.
Drop database TestdbMetoda 2 - Korzystanie z MS SQL Server Management Studio
Połącz się z SQL Server i kliknij prawym przyciskiem myszy bazę danych, którą chcesz usunąć. Kliknij polecenie usuń, a pojawi się następujący ekran.

Kliknij OK, aby usunąć bazę danych (w tym przykładzie nazwa to Testdb, jak pokazano na powyższym ekranie) z MS SQL Server.
Backupjest kopią danych / bazy danych itp. Tworzenie kopii zapasowej bazy danych MS SQL Server jest niezbędne do ochrony danych. Kopie zapasowe MS SQL Server są głównie trzy typy - pełne lub bazodanowe, różnicowe lub przyrostowe oraz transakcje lub dzienniki.
Kopię zapasową bazy danych można wykonać jedną z następujących dwóch metod.
Metoda 1 - użycie T-SQL
Pełny typ
Backup database <Your database name> to disk = '<Backup file location + file name>'Typ różnicowy
Backup database <Your database name> to
disk = '<Backup file location + file name>' with differentialTyp dziennika
Backup log <Your database name> to disk = '<Backup file location + file name>'Przykład
Następujące polecenie jest używane do pełnej kopii zapasowej bazy danych o nazwie „TestDB” w lokalizacji „D: \” z nazwą pliku kopii zapasowej „TestDB_Full.bak”
Backup database TestDB to disk = 'D:\TestDB_Full.bak'Następujące polecenie jest używane do różnicowej bazy danych kopii zapasowych o nazwie „TestDB” w lokalizacji „D: \” z nazwą pliku kopii zapasowej „TestDB_diff.bak”
Backup database TestDB to disk = 'D:\TestDB_diff.bak' with differentialNastępujące polecenie jest używane dla bazy danych kopii zapasowej dziennika o nazwie „TestDB” w lokalizacji „D: \” z nazwą pliku kopii zapasowej „TestDB_log.trn”
Backup log TestDB to disk = 'D:\TestDB_log.trn'Metoda 2 - Korzystanie z programu SSMS (SQL SERVER Management Studio)
Step 1 - Połącz się z instancją bazy danych o nazwie „TESTINSTANCE” i rozwiń folder baz danych, jak pokazano na poniższej migawce.

Step 2- Kliknij prawym przyciskiem myszy bazę danych „TestDB” i wybierz zadania. Kliknij opcję Kopia zapasowa, a pojawi się następujący ekran.

Step 3- Wybierz typ kopii zapasowej (Full \ diff \ log) i sprawdź ścieżkę docelową, w której zostanie utworzony plik kopii zapasowej. Wybierz opcje w lewym górnym rogu, aby zobaczyć następujący ekran.

Step 4 - Kliknij OK, aby utworzyć pełną kopię zapasową bazy danych „TestDB”, jak pokazano na poniższej migawce.


Restoringto proces kopiowania danych z kopii zapasowej i stosowania do danych zarejestrowanych transakcji. Przywracanie jest tym, co robisz z kopiami zapasowymi. Weź plik kopii zapasowej i zamień go z powrotem w bazę danych.
Opcję Przywróć bazę danych można wykonać za pomocą jednej z następujących dwóch metod.
Metoda 1 - T-SQL
Składnia
Restore database <Your database name> from disk = '<Backup file location + file name>'Przykład
Następujące polecenie służy do przywracania bazy danych o nazwie „TestDB” z nazwą pliku kopii zapasowej „TestDB_Full.bak”, która jest dostępna w lokalizacji „D: \” w przypadku nadpisywania istniejącej bazy danych.
Restore database TestDB from disk = ' D:\TestDB_Full.bak' with replaceJeśli tworzysz nową bazę danych za pomocą tego polecenia przywracania i nie ma podobnej ścieżki danych, plików dziennika na serwerze docelowym, użyj opcji przenoszenia, takiej jak poniższa komenda.
Upewnij się, że ścieżka D: \ Data istnieje, tak jak została użyta w poniższym poleceniu dla plików danych i dziennika.
RESTORE DATABASE TestDB FROM DISK = 'D:\ TestDB_Full.bak' WITH MOVE 'TestDB' TO
'D:\Data\TestDB.mdf', MOVE 'TestDB_Log' TO 'D:\Data\TestDB_Log.ldf'Metoda 2 - SSMS (SQL SERVER Management Studio)
Step 1- Połącz się z instancją bazy danych o nazwie „TESTINSTANCE” i kliknij prawym przyciskiem myszy folder baz danych. Kliknij opcję Przywróć bazę danych, jak pokazano na poniższej migawce.

Step 2 - Wybierz przycisk opcji urządzenia i kliknij elipsę, aby wybrać plik kopii zapasowej, jak pokazano na poniższej migawce.
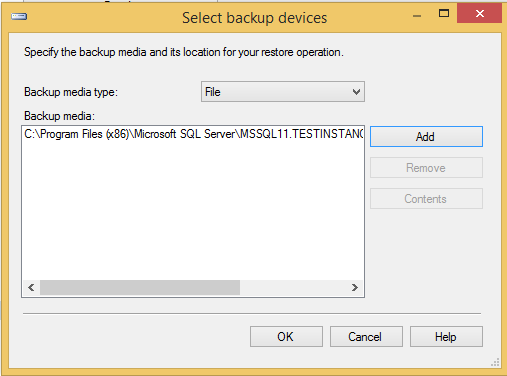
Step 3 - Kliknij OK i pojawi się następujący ekran.

Step 4 - Wybierz opcję Pliki, która znajduje się w lewym górnym rogu, jak pokazano na poniższej migawce.

Step 5 - Wybierz Opcje w lewym górnym rogu i kliknij OK, aby przywrócić bazę danych „TestDB”, jak pokazano na poniższej migawce.

Użytkownik oznacza konto w bazie danych MS SQL Server, które jest używane do uzyskiwania dostępu do bazy danych.
Użytkowników można tworzyć za pomocą jednej z następujących dwóch metod.
Metoda 1 - użycie T-SQL
Składnia
Create user <username> for login <loginname>Przykład
Aby utworzyć nazwę użytkownika „TestUser” z mapowaniem na nazwę logowania „TestLogin” w bazie danych TestDB, uruchom następujące zapytanie.
create user TestUser for login TestLoginGdzie „TestLogin” to nazwa logowania, która została utworzona podczas tworzenia Loginu
Metoda 2 - Korzystanie z programu SSMS (SQL Server Management Studio)
Note - Najpierw musimy stworzyć login z dowolną nazwą przed utworzeniem konta użytkownika.
Użyjmy nazwy logowania o nazwie „TestLogin”.
Step 1- Podłącz SQL Server i rozwiń folder baz danych. Następnie rozwiń bazę danych o nazwie „TestDB”, w której utworzymy konto użytkownika i rozwiniemy folder bezpieczeństwa. Kliknij prawym przyciskiem myszy użytkowników i kliknij nowego użytkownika, aby wyświetlić następujący ekran.

Step 2 - Wpisz „TestUser” w polu nazwy użytkownika i kliknij elipsę, aby wybrać nazwę logowania o nazwie „TestLogin”, jak pokazano na poniższej migawce.

Step 3- Kliknij OK, aby wyświetlić nazwę logowania. Ponownie kliknij OK, aby utworzyć użytkownika „TestUser”, jak pokazano na poniższej migawce.

Permissionsodnoszą się do zasad regulujących poziomy dostępu zleceniodawców do papierów wartościowych. Możesz nadawać, cofać i odmawiać uprawnień w MS SQL Server.
Aby przypisać uprawnienia, można użyć jednej z dwóch poniższych metod.
Metoda 1 - użycie T-SQL
Składnia
Use <database name>
Grant <permission name> on <object name> to <username\principle>Przykład
Aby przypisać uprawnienie do wyboru użytkownikowi o nazwie „TestUser” w obiekcie o nazwie „TestTable” w bazie danych „TestDB”, uruchom następujące zapytanie.
USE TestDB
GO
Grant select on TestTable to TestUserMetoda 2 - Korzystanie z programu SSMS (SQL Server Management Studio)
Step 1 - Połącz się z instancją i rozwiń foldery, jak pokazano na poniższej migawce.

Step 2- Kliknij prawym przyciskiem myszy TestUser i kliknij Właściwości. Pojawi się następujący ekran.
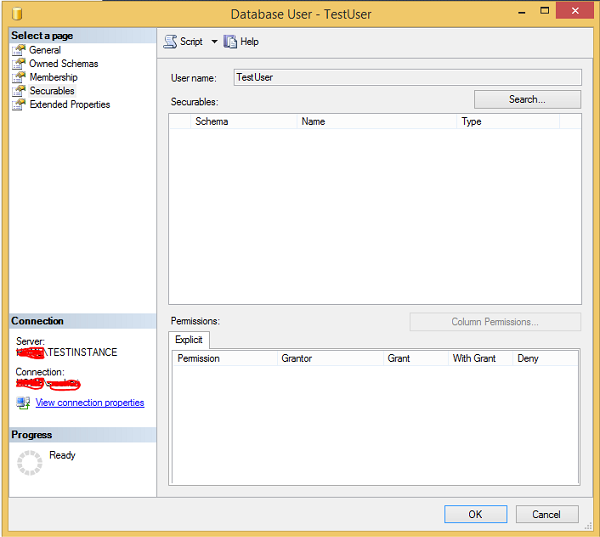
Step 3Kliknij Wyszukaj i wybierz określone opcje. Kliknij Typy obiektów, wybierz tabele i kliknij Przeglądaj. Wybierz „TestTable” i kliknij OK. Pojawi się następujący ekran.

Step 4 Zaznacz pole wyboru dla kolumny Przyznaj w obszarze Wybierz uprawnienia i kliknij przycisk OK, jak pokazano na powyższej migawce.

Step 5Wybierz uprawnienie do „TestTable” bazy danych TestDB przyznane „TestUser”. Kliknij OK.
Monitorowanie polega na sprawdzaniu stanu bazy danych, ustawień, którymi może być nazwa właściciela, nazwy plików, rozmiary plików, harmonogramy tworzenia kopii zapasowych itp.
Bazy danych SQL Server mogą być monitorowane głównie przez SQL Server Management Studio lub T-SQL, a także mogą być monitorowane różnymi metodami, takimi jak tworzenie zadań agenta i konfigurowanie poczty bazy danych, narzędzi innych firm itp.
Stan bazy danych można sprawdzić, czy jest w trybie online lub w jakimkolwiek innym stanie, jak pokazano na poniższej migawce.

Jak na powyższym ekranie, wszystkie bazy danych mają status „Online”. Jeśli jakakolwiek baza danych jest w jakimkolwiek innym stanie, ten stan zostanie pokazany tak, jak pokazano na poniższej migawce.

MS SQL Server zapewnia następujące dwie usługi, które są niezbędne do tworzenia i konserwacji baz danych. Wyświetlane są również inne usługi dodatkowe dostępne do różnych celów.
- SQL Server
- Agent programu SQL Server
Inne usługi
- Przeglądarka SQL Server
- Wyszukiwanie pełnotekstowe programu SQL Server
- Usługi integracji programu SQL Server
- Usługi SQL Server Reporting Services
- Usługi SQL Server Analysis Services
Z powyższych usług można skorzystać w następujący sposób.
Uruchom usługi
Aby uruchomić dowolną z usług, można użyć jednej z następujących dwóch metod.
Metoda 1 - Services.msc
Step 1- Przejdź do Uruchom, wpisz services.msc i kliknij OK. Pojawi się następujący ekran.

Step 2- Aby uruchomić usługę, kliknij prawym przyciskiem myszy usługę, kliknij przycisk Start. Usługi zostaną uruchomione, jak pokazano na poniższej migawce.

Metoda 2 - Menedżer konfiguracji programu SQL Server
Step 1 - Otwórz menedżera konfiguracji, korzystając z następującego procesu.
Start → Wszystkie programy → MS SQL Server 2012 → Narzędzia konfiguracyjne → Menedżer konfiguracji SQL Server.

Step 2- Wybierz nazwę usługi, kliknij prawym przyciskiem myszy i kliknij opcję Start. Usługi zostaną uruchomione, jak pokazano na poniższej migawce.

Zatrzymaj usługi
Aby zatrzymać dowolną z usług, można użyć jednej z następujących trzech metod.
Metoda 1 - Services.msc
Step 1- Przejdź do Uruchom, wpisz services.msc i kliknij OK. Pojawi się następujący ekran.

Step 2- Aby zatrzymać usługi, kliknij prawym przyciskiem myszy usługę i kliknij Zatrzymaj. Wybrana usługa zostanie zatrzymana, jak pokazano na poniższej migawce.

Metoda 2 - Menedżer konfiguracji programu SQL Server
Step 1 - Otwórz menedżera konfiguracji, korzystając z następującego procesu.
Start → Wszystkie programy → MS SQL Server 2012 → Narzędzia konfiguracyjne → Menedżer konfiguracji SQL Server.

Step 2- Wybierz nazwę usługi, kliknij prawym przyciskiem myszy i kliknij opcję Zatrzymaj. Wybrana usługa zostanie zatrzymana, jak pokazano na poniższej migawce.

Metoda 3 - SSMS (SQL Server Management Studio)
Step 1 - Połącz się z instancją, jak pokazano na poniższej migawce.

Step 2- Kliknij prawym przyciskiem myszy nazwę instancji i kliknij opcję Zatrzymaj. Pojawi się następujący ekran.

Step 3 - Kliknij przycisk Tak, a otworzy się następujący ekran.

Step 4- Kliknij opcję Tak na powyższym ekranie, aby zatrzymać usługę agenta SQL Server. Usługi zostaną zatrzymane, jak pokazano na poniższym zrzucie ekranu.

Uwaga
Nie możemy użyć metody SQL Server Management Studio do uruchomienia usług, ponieważ nie można nawiązać połączenia z powodu stanu usług już zatrzymanych.
Nie możemy wykluczyć zatrzymania usługi agenta usługi SQL podczas zatrzymywania usługi SQL Server, ponieważ usługa SQL Server Agent Service jest usługą zależną.
Wysoka dostępność (HA) to rozwiązanie \ proces \ technologia, które umożliwia całodobową dostępność aplikacji \ bazy danych w przypadku planowanych lub nieplanowanych przestojów.
Głównie jest pięć opcji w MS SQL Server, aby osiągnąć \ skonfigurować rozwiązanie wysokiej dostępności dla baz danych.
Replikacja
Dane źródłowe zostaną skopiowane do miejsca docelowego za pośrednictwem agentów replikacji (zadań). Technologia na poziomie obiektu.
Terminologia
- Wydawca jest serwerem źródłowym.
- Dystrybutor jest opcjonalny i przechowuje replikowane dane dla subskrybenta.
- Subskrybent jest serwerem docelowym.
Wysyłka dziennika
Dane źródłowe zostaną skopiowane do miejsca docelowego za pośrednictwem zadań tworzenia kopii zapasowych dziennika transakcji. Technologia na poziomie bazy danych.
Terminologia
- Serwer główny to serwer źródłowy.
- Serwer pomocniczy to serwer docelowy.
- Serwer monitorowania jest opcjonalny i będzie monitorowany na podstawie statusu wysyłki dziennika.
Dublowanie
Podstawowe dane zostaną skopiowane do drugorzędnych na podstawie transakcji sieciowych za pomocą dublowania punktu końcowego i numeru portu. Technologia na poziomie bazy danych.
Terminologia
- Głównym serwerem jest serwer źródłowy.
- Serwer kopii dystrybucyjnych jest serwerem docelowym.
- Serwer świadka jest opcjonalny i służy do automatycznego przełączania awaryjnego.
Grupowanie
Dane będą przechowywane we współdzielonej lokalizacji, z której korzystają zarówno serwery podstawowe, jak i pomocnicze w zależności od dostępności serwera. Technologia na poziomie instancji. W przypadku udostępnionego magazynu wymagana jest konfiguracja usługi klastrowania systemu Windows.
Terminologia
- Węzeł aktywny to miejsce, w którym działają usługi SQL.
- Węzeł pasywny to miejsce, w którym usługi SQL nie są uruchomione.
Grupy dostępności AlwaysON
Podstawowe dane zostaną skopiowane do drugorzędnych na podstawie transakcji sieciowych. Grupa technologii na poziomie bazy danych. Wymagana jest konfiguracja usługi Windows Clustering bez współdzielonego magazynu.
Terminologia
- Replika podstawowa to serwer źródłowy.
- Replika pomocnicza to serwer docelowy.
Poniżej przedstawiono kroki konfiguracji technologii HA (dublowanie i wysyłanie dziennika) z wyjątkiem klastrowania, grup dostępności AlwaysON i replikacji.
Step 1 - Wykonaj jedną pełną i jedną kopię zapasową w dzienniku T źródłowej bazy danych.
Przykład
Aby skonfigurować tworzenie kopii lustrzanych \ wysyłanie dzienników dla bazy danych „TestDB” w „TESTINSTANCE” jako podstawowe i „DEVINSTANCE” jako pomocnicze serwery SQL, napisz następujące zapytanie, aby wykonać pełne i T-logowe kopie zapasowe na serwerze źródłowym (TESTINSTANCE).
Połącz się z serwerem SQL „TESTINSTANCE” i otwórz nową kwerendę, napisz następujący kod i wykonaj, jak pokazano na poniższym zrzucie ekranu.
Backup database TestDB to disk = 'D:\testdb_full.bak'
GO
Backup log TestDB to disk = 'D:\testdb_log.trn'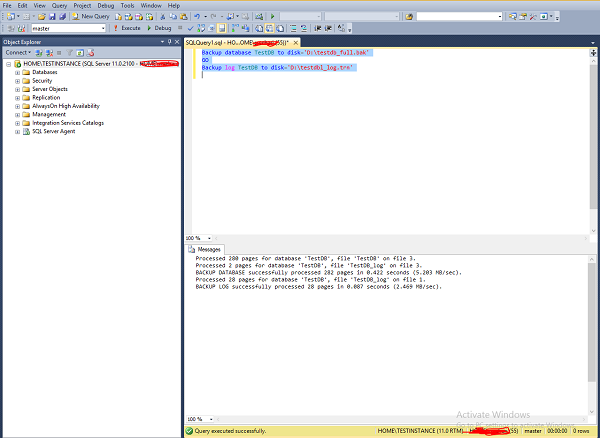
Step 2 - Skopiuj pliki kopii zapasowej na serwer docelowy.
W tym przypadku mamy zainstalowany tylko jeden serwer fizyczny i dwie instancje SQL Server, stąd nie ma potrzeby kopiowania, ale jeśli dwie instancje SQL Server znajdują się na innym serwerze fizycznym, musimy skopiować następujące dwa pliki do dowolnej lokalizacji serwer pomocniczy, na którym jest zainstalowana instancja „DEVINSTANCE”.

Step 3 - Przywróć bazę danych z plikami kopii zapasowych na serwerze docelowym z opcją „norecovery”.
Przykład
Połącz się z serwerem SQL „DEVINSTANCE” i otwórz nowe zapytanie. Napisz następujący kod, aby odtworzyć bazę danych o nazwie „TestDB”, która jest tą samą nazwą podstawowej bazy danych („TestDB”) dla dublowania bazy danych. Możemy jednak podać inną nazwę konfiguracji wysyłania dziennika. W tym przypadku użyjmy nazwy bazy danych „TestDB”. Użyj opcji „norecovery”, aby przywrócić dwa (pełne pliki kopii zapasowych i pliki kopii zapasowej T-log).
Restore database TestDB from disk = 'D:\TestDB_full.bak'
with move 'TestDB' to 'D:\DATA\TestDB_DR.mdf',
move 'TestDB_log' to 'D:\DATA\TestDB_log_DR.ldf',
norecovery
GO
Restore database TestDB from disk = 'D:\TestDB_log.trn' with norecovery
Odśwież folder baz danych na serwerze „DEVINSTANCE”, aby zobaczyć przywróconą bazę danych „TestDB” ze stanem przywracania, jak pokazano na poniższej migawce.
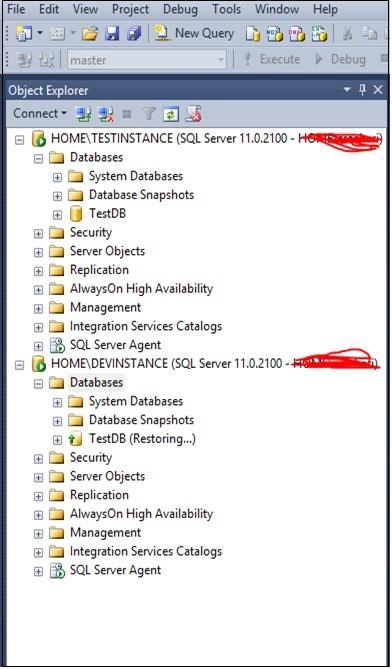
Step 4 - Skonfiguruj HA (wysyłanie dziennika, dublowanie) zgodnie z wymaganiami, jak pokazano na poniższej migawce.
Przykład
Kliknij prawym przyciskiem myszy bazę danych „TestDB” serwera SQL „TESTINSTANCE”, która jest podstawowym serwerem, i kliknij opcję Właściwości. Pojawi się następujący ekran.

Step 5 - Wybierz opcję o nazwie „Mirroring” lub „Transaction Log Shipping”, które są zaznaczone na czerwono, jak pokazano na powyższym ekranie, zgodnie z wymaganiami i postępuj zgodnie z instrukcjami kreatora prowadzonymi przez sam system, aby zakończyć konfigurację.
Report jest wyświetlanym komponentem.
Stosowanie
Raport jest zasadniczo używany do dwóch celów - wewnętrznych operacji firmy i zewnętrznych operacji firmy.
Usługi raportowania
Jest to usługa służąca do tworzenia i publikowania różnego rodzaju raportów.
Poniżej przedstawiono trzy wymagania niezbędne do opracowania dowolnego raportu.
- Proces biznesowy
- Layout
- Query\Procedure\View
BIDS (Business Intelligence Studio do 2008 R2) i SSDT (SQL Server Data Tools od 2012) to środowisko do tworzenia raportów.
Poniżej przedstawiono kroki otwierania środowiska BIDS \ SSDT w celu tworzenia raportów.
Step 1- Otwórz BIDS \ SSDT na podstawie wersji z grupy programów Microsoft SQL Server. Pojawi się następujący ekran. W tym przypadku otworzył się SSDT.
Step 2- Przejdź do pliku w lewym górnym rogu na powyższym zrzucie ekranu. Kliknij Nowy i wybierz projekt. Otworzy się następujący ekran.

Step 3 - Na powyższym ekranie wybierz usługi raportowania w obszarze Business Intelligence w lewym górnym rogu, jak pokazano na poniższym zrzucie ekranu.

Step 4 - Na powyższym ekranie wybierz kreator projektu serwera raportów (poprowadzi Cię krok po kroku przez kreatory) lub projekt serwera raportów (będzie używany do wybierania niestandardowych ustawień) w zależności od wymagań dotyczących opracowania raportu.
Plan wykonania zostanie wygenerowany przez optymalizator zapytań przy pomocy statystyk i drzewa Algebrizer \ procesor. Jest wynikiem działania Optymalizatora zapytań i mówi, jak wykonać \ wykonać pracę \ wymaganie.
Istnieją dwa różne plany wykonania - szacowane i rzeczywiste.
Estimated execution plan wskazuje widok optymalizatora.
Actual execution plan wskazuje, co wykonało zapytanie i jak zostało wykonane.
Plany wykonania są przechowywane w pamięci zwanej pamięcią podręczną planów, dzięki czemu można je ponownie wykorzystać. Każdy plan jest przechowywany raz, chyba że optymalizator zdecyduje o równoległości wykonywania zapytania.
W SQL Server dostępne są trzy różne formaty planów wykonania - plany graficzne, plany tekstowe i plany XML.
SHOWPLAN to uprawnienie wymagane od użytkownika, który chce zobaczyć plan wykonania.
Przykład 1
Poniżej przedstawiono procedurę przeglądania szacunkowego planu wykonania.
Step 1- Połącz się z instancją SQL Server. W tym przypadku „TESTINSTANCE” jest nazwą instancji, jak pokazano na poniższej migawce.

Step 2- Kliknij opcję New Query na powyższym ekranie i wpisz następujące zapytanie. Przed napisaniem zapytania wybierz nazwę bazy danych. W tym przypadku „TestDB” to nazwa bazy danych.
Select * from StudentTable
Step 3 - Kliknij symbol, który jest podświetlony na czerwono w ramce na powyższym ekranie, aby wyświetlić szacowany plan wykonania, jak pokazano na poniższym zrzucie ekranu.

Step 4- Umieść kursor myszy na skanie tabeli, który jest drugim symbolem nad czerwoną ramką na powyższym ekranie, aby wyświetlić szczegółowo szacowany plan wykonania. Pojawi się następujący zrzut ekranu.

Przykład 2
Poniżej przedstawiono procedurę przeglądania rzeczywistego planu wykonania.
Step 1Połącz się z wystąpieniem SQL Server. W tym przypadku „TESTINSTANCE” jest nazwą instancji.

Step 2- Kliknij opcję New Query widoczną na powyższym ekranie i napisz następujące zapytanie. Przed napisaniem zapytania wybierz nazwę bazy danych. W tym przypadku „TestDB” to nazwa bazy danych.
Select * from StudentTable
Step 3 - Kliknij symbol, który jest podświetlony na czerwono w ramce na powyższym ekranie, a następnie wykonaj zapytanie, aby wyświetlić rzeczywisty plan wykonania wraz z wynikiem zapytania, jak pokazano na poniższym zrzucie ekranu.

Step 4- Umieść kursor myszy na skanie tabeli, który jest drugim symbolem nad czerwoną ramką na ekranie, aby wyświetlić szczegółowy plan wykonania. Pojawi się następujący zrzut ekranu.

Step 5 - Kliknij Wyniki w lewym górnym rogu na powyższym ekranie, aby wyświetlić następujący ekran.

Ta usługa służy do wykonywania operacji ETL (ekstrakcji, transformacji i ładowania danych) oraz operacji administracyjnych. BIDS (Business Intelligence Studio do 2008 R2) i SSDT (SQL Server Data Tools od 2012) to środowiska do tworzenia pakietów.
Podstawowa architektura SSIS
Rozwiązanie (zbiór projektów) ---> Projekt (zbiór pakietów) ---> Pakiet (zbiór zadań dla operacji ETL i administratora)
W obszarze Pakiet dostępne są następujące składniki -
- Przepływ kontroli (kontenery i zadania)
- Przepływ danych (źródło, transformacje, miejsca docelowe)
- Obsługa zdarzeń (wysyłanie wiadomości, e-maili)
- Eksplorator pakietów (jeden widok dla wszystkich w pakiecie)
- Parametry (interakcja z użytkownikiem)
Oto kroki, aby otworzyć BIDS \ SSDT.
Step 1- Otwórz BIDS \ SSDT na podstawie wersji z grupy programów Microsoft SQL Server. Pojawi się następujący ekran.
Step 2- Powyższy ekran pokazuje, że SSDT zostało otwarte. Przejdź do pliku w lewym górnym rogu na powyższym obrazku i kliknij Nowy. Wybierz projekt i otworzy się następujący ekran.

Step 3 - Wybierz Usługi integracji w obszarze Business Intelligence w lewym górnym rogu ekranu powyżej, aby wyświetlić następujący ekran.

Step 4 - Na powyższym ekranie wybierz Integration Services Project lub Integration Services Import Project Wizard w zależności od wymagań dotyczących opracowania / utworzenia pakietu.
Ta usługa służy do analizy ogromnych ilości danych i ma zastosowanie do decyzji biznesowych. Służy również do tworzenia dwu- lub wielowymiarowych modeli biznesowych.
W wersji SQL Server 2000 nosi nazwę MSAS (Microsoft Analysis Services).
Od SQL Server 2005 nosi nazwę SSAS (SQL Server Analysis Services).
Tryby
Istnieją dwa tryby - tryb macierzysty (tryb serwera SQL) i tryb współdzielenia punktów.
Modele
Istnieją dwa modele - model tabelaryczny (do analizy zespołowej i osobistej) i model wielowymiarowy (do analizy korporacyjnej).
BIDS (Business Intelligence Studio do 2008 R2) i SSDT (SQL Server Data Tools od 2012) to środowiska do pracy z SSAS.
Step 1- Otwórz BIDS \ SSDT na podstawie wersji z grupy programów Microsoft SQL Server. Pojawi się następujący ekran.

Step 2- Powyższy ekran pokazuje, że SSDT zostało otwarte. Przejdź do pliku w lewym górnym rogu na powyższym obrazku i kliknij Nowy. Wybierz projekt i otworzy się następujący ekran.

Step 3- Wybierz usługi Analysis Services na powyższym ekranie w obszarze Business Intelligence, jak widać w lewym górnym rogu. Pojawi się następujący ekran.
Step 4 - Na powyższym ekranie wybierz dowolną opcję z pięciu wymienionych w zależności od wymagań dotyczących pracy z usługami analitycznymi.