Przetwarzanie dyskursu w języku naturalnym
Najtrudniejszym problemem AI jest przetwarzanie języka naturalnego przez komputery lub innymi słowy przetwarzanie języka naturalnego jest najtrudniejszym problemem sztucznej inteligencji. Jeśli mówimy o głównych problemach w NLP, to jednym z głównych problemów w NLP jest przetwarzanie dyskursu - budowanie teorii i modeli tego, jak wypowiedzi łączą się w formęcoherent discourse. W rzeczywistości język zawsze składa się z kolokowanych, uporządkowanych i spójnych grup zdań, a nie pojedynczych i niepowiązanych zdań, takich jak filmy. Te spójne grupy zdań nazywane są dyskursem.
Pojęcie spójności
Spójność i struktura dyskursu są ze sobą powiązane na wiele sposobów. Spójność, wraz z właściwością dobrego tekstu, służy do oceny jakości wyjściowej systemu generowania języka naturalnego. Powstaje pytanie, co to znaczy, że tekst jest spójny? Załóżmy, że zebraliśmy jedno zdanie z każdej strony gazety, czy będzie to dyskurs? Oczywiście nie. Dzieje się tak, ponieważ zdania te nie wykazują spójności. Spójny dyskurs musi mieć następujące właściwości -
Relacja koherencyjna między wypowiedziami
Dyskurs byłby spójny, gdyby zawierał znaczące powiązania między swoimi wypowiedziami. Ta własność nazywa się relacją koherencji. Na przykład musi istnieć jakieś wyjaśnienie, które uzasadnia związek między wypowiedziami.
Relacje między podmiotami
Kolejną właściwością, która czyni dyskurs spójnym, jest to, że musi istnieć pewien rodzaj relacji z podmiotami. Taki rodzaj spójności nazywany jest koherencją opartą na encji.
Struktura dyskursu
Ważnym pytaniem dotyczącym dyskursu jest to, jaką strukturę musi mieć dyskurs. Odpowiedź na to pytanie zależy od segmentacji, jaką zastosowaliśmy w dyskursie. Segmentacje dyskursu można zdefiniować jako określenie typów struktur dla dużego dyskursu. Wdrożenie segmentacji dyskursu jest dość trudne, ale jest bardzo ważneinformation retrieval, text summarization and information extraction rodzaj aplikacji.
Algorytmy segmentacji dyskursu
W tej sekcji dowiemy się o algorytmach segmentacji dyskursu. Algorytmy opisano poniżej -
Nienadzorowana segmentacja dyskursu
Klasa nienadzorowanej segmentacji dyskursu jest często reprezentowana jako segmentacja liniowa. Na przykładzie możemy zrozumieć zadanie segmentacji liniowej. W tym przykładzie zadaniem jest podzielenie tekstu na jednostki składające się z wielu akapitów; Jednostki reprezentują fragment tekstu oryginalnego. Algorytmy te są zależne od spójności, którą można zdefiniować jako użycie pewnych narzędzi językowych do powiązania ze sobą jednostek tekstowych. Z drugiej strony spójność leksykonu to spójność, na którą wskazuje relacja między dwoma lub więcej wyrazami w dwóch jednostkach, jak na przykład użycie synonimów.
Nadzorowana segmentacja dyskursu
Wcześniejsza metoda nie ma żadnych ręcznie oznaczonych granic segmentów. Z drugiej strony, nadzorowana segmentacja dyskursu musi mieć dane treningowe oznaczone granicami. Uzyskanie tego samego jest bardzo łatwe. W nadzorowanej segmentacji dyskursu znacznik dyskursu lub słowa-wskazówki odgrywają ważną rolę. Znacznik dyskursu lub słowo sygnalizacyjne to słowo lub fraza, która sygnalizuje strukturę dyskursu. Te znaczniki dyskursu są specyficzne dla domeny.
Spójność tekstu
Powtórzenie leksykalne jest sposobem na znalezienie struktury w dyskursie, ale nie spełnia wymogu bycia dyskursem spójnym. Aby osiągnąć spójny dyskurs, musimy skupić się na relacjach koherencyjnych w konkretnych. Jak wiemy, relacja koherencji określa możliwy związek między wypowiedziami w dyskursie. Hebb zaproponował następujące relacje:
Mamy dwa terminy S0 i S1 aby przedstawić znaczenie dwóch powiązanych zdań -
Wynik
Wynika z tego, że stan potwierdził terminem S0 może spowodować stan twierdzony przez S1. Na przykład dwa stwierdzenia pokazują wynik związku: Ram został złapany w ogień. Jego skóra płonęła.
Wyjaśnienie
Wynika z tego, że państwo twierdziło S1 może spowodować stan twierdzony przez S0. Na przykład dwa stwierdzenia pokazują związek - Ram walczył z przyjacielem Shyama. Był pijany.
Równolegle
Wywodzi p (a1, a2,…) z twierdzenia o S0 i p (b1, b2,…) z asercji S1. Tutaj ai i bi są podobne dla wszystkich i. Na przykład dwa stwierdzenia są równoległe - samochód szukał Ram. Shyam chciał pieniędzy.
Opracowanie
Wyprowadza to samo zdanie P z obu stwierdzeń - S0 i S1Na przykład dwa stwierdzenia pokazują rozwinięcie relacji: Ram pochodził z Chandigarh. Shyam pochodził z Kerali.
Okazja
Dzieje się tak, gdy zmianę stanu można wywnioskować z twierdzenia S0, z którego można wywnioskować stan końcowy S1i wzajemnie. Na przykład, te dwa stwierdzenia pokazują relację: Ram podniósł książkę. Dał go Shyamowi.
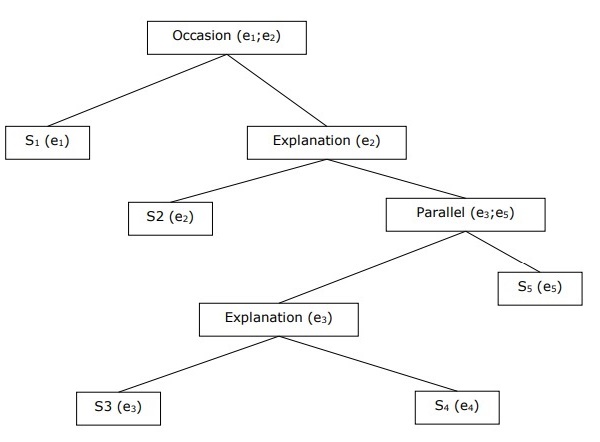
Budowanie hierarchicznej struktury dyskursu
Spójność całego dyskursu można rozpatrywać także poprzez hierarchiczną strukturę relacji koherencji. Na przykład następujący fragment można przedstawić jako strukturę hierarchiczną -
S1 - Ram poszedł do banku, aby zdeponować pieniądze.
S2 - Następnie pojechał pociągiem do sklepu z ubraniami Shyama.
S3 - Chciał kupić jakieś ubrania.
S4 - Nie ma nowych ciuchów na imprezę.
S5 - Chciał też porozmawiać z Shyamem na temat jego zdrowia
Rozdzielczość odniesienia
Interpretacja zdań z dowolnego dyskursu jest kolejnym ważnym zadaniem i aby to osiągnąć, musimy wiedzieć, o kim lub o jakiej jednostce się mówi. Tutaj odniesienie do interpretacji jest kluczowym elementem.Referencemożna zdefiniować jako wyrażenie językowe oznaczające jednostkę lub osobę. Na przykład we fragmencie Ram , menadżer banku ABC , zobaczył swojego przyjaciela Shyama w sklepie. On udał się z nim spotkać, wyrażenia językowe takie jak Ram, His, że są odniesienia.
Z tej samej uwagi, reference resolution można zdefiniować jako zadanie określenia, do jakich podmiotów odnosi się dane wyrażenie językowe.
Terminologia stosowana w rozdzielczości odniesienia
W rozdzielczości referencyjnej używamy następujących terminów -
Referring expression- Wyrażenie w języku naturalnym używane do wykonywania odniesienia nazywa się wyrażeniem odsyłającym. Na przykład fragment użyty powyżej jest wyrażeniem odsyłającym.
Referent- To podmiot, o którym mowa. Na przykład w ostatnim podanym przykładzie Ram jest desygnatem.
Corefer- Kiedy dwa wyrażenia są używane w celu odniesienia się do tej samej jednostki, nazywane są one corefers. Na przykład,Ram i he są koreferami.
Antecedent- Termin ma licencję na używanie innego terminu. Na przykład,Ram jest poprzednikiem odniesienia he.
Anaphora & Anaphoric- Można to zdefiniować jako odniesienie do podmiotu, który został wcześniej wprowadzony do zdania. A wyrażenie odnoszące się do niego nazywa się anaforą.
Discourse model - Model zawierający reprezentacje podmiotów, o których mowa w dyskursie oraz relację, w jaką są zaangażowane.
Typy wyrażeń odsyłających
Przyjrzyjmy się teraz różnym typom wyrażeń odsyłających. Poniżej opisano pięć typów wyrażeń odsyłających:
Zwroty rzeczownikowe nieokreślone
Tego rodzaju odniesienie reprezentuje byty, które są nowe dla słuchacza w kontekście dyskursu. Na przykład - w zdaniu, które pewnego dnia Ram chodził po okolicy, by przynieść mu jedzenie - niektóre są nieokreślonym odniesieniem.
Zdania rzeczownikowe określone
W przeciwieństwie do powyższego, tego rodzaju odniesienie reprezentuje byty, które nie są nowe lub nie są identyfikowalne dla słuchacza w kontekście dyskursu. Na przykład w zdaniu - czytałem „The Times of India” - „The Times of India” jest wyraźnym odniesieniem.
Zaimki
Jest to forma określonego odniesienia. Na przykład Ram śmiał się tak głośno, jak tylko potrafił. Słowohe reprezentuje wyrażenie odwołujące się do zaimka.
Demonstracje
Te demonstrują i zachowują się inaczej niż proste zaimki określone. Na przykład this and that są zaimkami wskazującymi.
Nazwy
To najprostszy rodzaj wyrażenia odsyłającego. Może to być również nazwisko osoby, nazwa organizacji i lokalizacja. Na przykład w powyższych przykładach Ram jest wyrażeniem sędziującym nazwę.
Zadania dotyczące rozwiązywania problemów
Poniżej opisano dwa zadania związane z rozdzielczością odniesienia.
Rozdzielczość koreferencji
Jest to zadanie znalezienia wyrażeń odsyłających w tekście, które odnoszą się do tego samego bytu. Mówiąc najprościej, jest to zadanie znalezienia wyrażeń korelacyjnych. Zestaw wyrażeń współzależnych nazywany jest łańcuchem korelacji. Na przykład - On, Chief Manager i His - są to wyrażenia odnoszące się w pierwszym fragmencie podane jako przykład.
Ograniczenie rozdzielczości koreferencji
W języku angielskim głównym problemem przy rozwiązywaniu koreferencji jest zaimek it. Powodem tego jest to, że zaimek ma wiele zastosowań. Na przykład może odnosić się podobnie jak on i ona. Zaimek odnosi się również do rzeczy, które nie odnoszą się do konkretnych rzeczy. Na przykład pada deszcz. To jest naprawdę dobre.
Rozdzielczość zaimkowa anafory
W przeciwieństwie do rozwiązania koreferencji, rozdzielczość anafory zaimkowej można zdefiniować jako zadanie znalezienia poprzednika dla pojedynczego zaimka. Na przykład, zaimek jest jego, a zadaniem rozwiązania anafory zaimkowej jest znalezienie słowa Ram, ponieważ Ram jest poprzednikiem.