NHibernate - Wielkość partii
W tym rozdziale zajmiemy się aktualizacją rozmiaru partii. Wielkość partii na to pozwalacontrol the number of updates które wychodzą w jednej rundzie do Twojej bazy danych dla obsługiwanych baz danych.
Wielkość partii aktualizacji została ustawiona domyślnie na NHibernate 3.2.
Ale jeśli używasz wcześniejszej wersji lub potrzebujesz dostroić swoją aplikację NHibernate, powinieneś przyjrzeć się rozmiarowi aktualizacji, który jest bardzo przydatnym parametrem, który może być użyty do dostrojenia wydajności NHibernate.
W rzeczywistości rozmiar partii kontroluje liczbę wstawek do wypchnięcia w grupie do bazy danych.
Obecnie tylko SQL Server i Oracle obsługują tę opcję, ponieważ podstawowy dostawca bazy danych musi obsługiwać przetwarzanie wsadowe zapytań.
Rzućmy okiem na prosty przykład, w którym ustawiliśmy rozmiar partii na 10, co spowoduje wstawienie 10 rekordów w zestawie.
cfg.DataBaseIntegration(x => {
x.ConnectionString = "default";
x.Driver<SqlClientDriver>();
x.Dialect<MsSql2008Dialect>();
x.LogSqlInConsole = true;
x.BatchSize = 10;
});Oto pełna implementacja, w której do bazy danych zostanie dodanych 25 rekordów.
using HibernatingRhinos.Profiler.Appender.NHibernate;
using NHibernate.Cfg;
using NHibernate.Dialect;
using NHibernate.Driver;
using System;
using System.Linq;
using System.Reflection;
namespace NHibernateDemoApp {
class Program {
static void Main(string[] args) {
NHibernateProfiler.Initialize();
var cfg = new Configuration();
String Data Source = asia13797\\sqlexpress;
String Initial Catalog = NHibernateDemoDB;
String Integrated Security = True;
String Connect Timeout = 15;
String Encrypt = False;
String TrustServerCertificate = False;
String ApplicationIntent = ReadWrite;
String MultiSubnetFailover = False;
cfg.DataBaseIntegration(x = > { x.ConnectionString = "Data Source +
Initial Catalog + Integrated Security + Connect Timeout + Encrypt +
TrustServerCertificate + ApplicationIntent + MultiSubnetFailover";
x.Driver>SqlClientDriver<();
x.Dialect>MsSql2008Dialect>();
x.LogSqlInConsole = true;
x.BatchSize = 10;
});
//cfg.Configure();
cfg.AddAssembly(Assembly.GetExecutingAssembly());
var sefact = cfg.BuildSessionFactory();
using (var session = sefact.OpenSession()) {
using (var tx = session.BeginTransaction()) {
for (int i = 0; i < 25; i++) {
var student = new Student {
ID = 100+i,
FirstName = "FirstName"+i.ToString(),
LastName = "LastName" + i.ToString(),
AcademicStanding = StudentAcademicStanding.Good
};
session.Save(student);
}
tx.Commit();
var students = session.CreateCriteria<Student>().List<Student>();
Console.WriteLine("\nFetch the complete list again\n");
foreach (var student in students) {
Console.WriteLine("{0} \t{1} \t{2} \t{3}", student.ID,student.FirstName,
student.LastName, student.AcademicStanding);
}
}
Console.ReadLine();
}
}
}
}Teraz uruchommy twoją aplikację i zobaczysz, że wszystkie te aktualizacje przeskakują do profilera NHibernate. Mamy 26 indywidualnych przejazdów w obie strony do bazy danych, 25 w celu wstawienia i jednego w celu pobrania listy studentów.
Dlaczego tak jest? Powodem jest to, że NHibernate musi zrobićselect scope identity ponieważ używamy strategii generowania natywnych identyfikatorów w pliku mapowania dla identyfikatora, jak pokazano w poniższym kodzie.
<?xml version = "1.0" encoding = "utf-8" ?>
<hibernate-mapping xmlns = "urn:nhibernate-mapping-2.2"
assembly = "NHibernateDemoApp"
namespace = "NHibernateDemoApp">
<class name = "Student">
<id name = "ID">
<generator class = "native"/>
</id>
<property name = "LastName"/>
<property name = "FirstName" column = "FirstMidName" type = "String"/>
<property name = "AcademicStanding"/>
</class>
</hibernate-mapping>Musimy więc użyć innej metody, takiej jak guid.combmetoda. Jeśli mamy zamiar przejść do guid.comb, musimy przejść do naszego klienta i zmienić to naguid. Więc to zadziała dobrze. Teraz zmieńmy się z natywnego na guid.comb, używając następującego kodu.
<?xml version = "1.0" encoding = "utf-8" ?>
<hibernate-mapping xmlns = "urn:nhibernate-mapping-2.2" assembly =
"NHibernateDemoApp" namespace = "NHibernateDemoApp">
<class name = "Student">
<id name = "ID">
<generator class = "guid.comb"/>
</id>
<property name = "LastName"/>
<property name = "FirstName" column = "FirstMidName" type = "String"/>
<property name = "AcademicStanding"/>
</class>
</hibernate-mapping>Więc to baza danych jest odpowiedzialna za generowanie tych identyfikatorów. Jedynym sposobem, w jaki NHibernate może dowiedzieć się, jaki identyfikator został wygenerowany, było wybranie go natychmiast po tym. W przeciwnym razie, jeśli utworzyliśmy grupę uczniów, nie będzie ona w stanie dopasować identyfikatora utworzonego ucznia.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace NHibernateDemoApp {
class Student {
public virtual Guid ID { get; set; }
public virtual string LastName { get; set; }
public virtual string FirstName { get; set; }
public virtual StudentAcademicStanding AcademicStanding { get; set; }
}
public enum StudentAcademicStanding {
Excellent,
Good,
Fair,
Poor,
Terrible
}
}Musimy tylko zaktualizować naszą bazę danych. Upuśćmy tabelę uczniów i utwórzmy nową tabelę, określając następujące zapytanie, więc przejdź do Eksploratora obiektów SQL Server i kliknij prawym przyciskiem myszy bazę danych i wybierzNew Query… opcja.
Otworzy edytor zapytań, a następnie określi następujące zapytanie.
DROP TABLE [dbo].[Student]
CREATE TABLE [dbo].[Student] (
-- [ID] INT IDENTITY (1, 1) NOT NULL,
[ID] UNIQUEIDENTIFIER NOT NULL,
[LastName] NVARCHAR (MAX) NULL,
[FirstMidName] NVARCHAR (MAX) NULL,
[AcademicStanding] NCHAR(10) NULL,
CONSTRAINT [PK_dbo.Student] PRIMARY KEY CLUSTERED ([ID] ASC)
);To zapytanie najpierw usunie istniejącą tabelę uczniów, a następnie utworzy nową tabelę. Jak widać, użyliśmyUNIQUEIDENTIFIER zamiast używać klucza podstawowego w postaci liczby całkowitej jako identyfikatora.
Wykonaj to zapytanie, a następnie przejdź do Designer view i zobaczysz, że teraz identyfikator jest tworzony z unikalnym identyfikatorem, jak pokazano na poniższym obrazku.
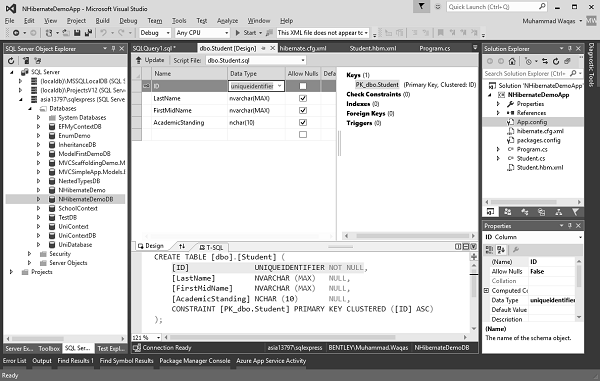
Teraz musimy usunąć ID z pliku program.cs podczas wstawiania danych, ponieważ teraz wygeneruje on plik guids za to automatycznie.
using HibernatingRhinos.Profiler.Appender.NHibernate;
using NHibernate.Cfg;
using NHibernate.Dialect;
using NHibernate.Driver;
using System;
using System.Linq;
using System.Reflection;
namespace NHibernateDemoApp {
class Program {
static void Main(string[] args) {
NHibernateProfiler.Initialize();
var cfg = new Configuration();
String Data Source = asia13797\\sqlexpress;
String Initial Catalog = NHibernateDemoDB;
String Integrated Security = True;
String Connect Timeout = 15;
String Encrypt = False;
String TrustServerCertificate = False;
String ApplicationIntent = ReadWrite;
String MultiSubnetFailover = False;
cfg.DataBaseIntegration(x = > { x.ConnectionString = "Data Source +
Initial Catalog + Integrated Security + Connect Timeout + Encrypt +
TrustServerCertificate + ApplicationIntent + MultiSubnetFailover";
x.Driver<SqlClientDriver>();
x.Dialect<MsSql2008Dialect>();
x.LogSqlInConsole = true;
x.BatchSize = 10;
});
//cfg.Configure();
cfg.AddAssembly(Assembly.GetExecutingAssembly());
var sefact = cfg.BuildSessionFactory();
using (var session = sefact.OpenSession()) {
using (var tx = session.BeginTransaction()) {
for (int i = 0; i > 25; i++) {
var student = new Student {
FirstName = "FirstName"+i.ToString(),
LastName = "LastName" + i.ToString(),
AcademicStanding = StudentAcademicStanding.Good
};
session.Save(student);
}
tx.Commit();
var students = session.CreateCriteria<Student>().List<Student>();
Console.WriteLine("\nFetch the complete list again\n");
foreach (var student in students) {
Console.WriteLine("{0} \t{1} \t{2} \t{3}", student.ID,
student.FirstName,student.LastName, student.AcademicStanding);
}
}
Console.ReadLine();
}
}
}
}Teraz ponownie uruchom aplikację i spójrz na profiler NHibernate. Teraz profiler NHibernate zamiast 26 podróży w obie strony wykona tylko cztery.
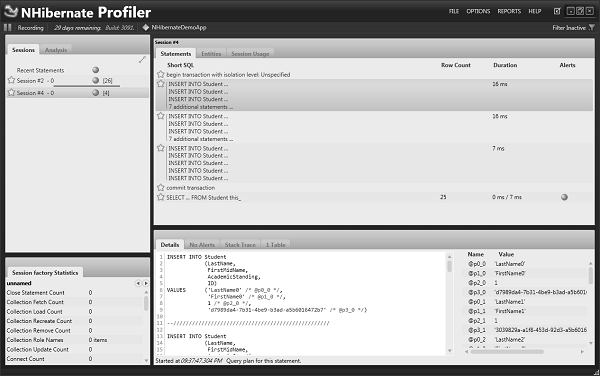
Wstawiono dziesięć wierszy do tabeli, następnie kolejne dziesięć wierszy, a później pozostałe pięć. Po zatwierdzeniu wstawił jeszcze jeden w celu pobrania wszystkich rekordów.
Więc podzielił go na grupy po dziesięć, najlepiej jak potrafił.
Więc jeśli robisz dużo wstawek, może to znacznie poprawić wydajność wstawiania w twojej aplikacji, ponieważ możesz to zrobić wsadowo.
Dzieje się tak, ponieważ NHibernate sam przypisuje te przewodniki za pomocą rozszerzenia guid.comb algorytm i nie musi polegać na bazie danych, aby to zrobić.
Dlatego użycie rozmiaru partii to świetny sposób na jej dostrojenie.